Ненужные ключевые слова. При оптимизации кода рекомендуется убрать лишние запросы лишний запрос это
Разработчик Bitrix Framework. Инфоблоки
При оптимизации кода рекомендуется убрать лишние запросы. Лишний запрос это:
- запрос в цикле
- запросы, которые добирают данные в цикле
- запрос с неиспользуемыми данными ($arSelect)
Выборка историй изменения элемента осуществляется с помощью метода:
- CIBlockElement::GetList с настроенным фильтром «SHOW_HISTORY» => «Y»
- CIBlockElement::WF_GetLast
- CIBlockElement::WF_GetHistoryList
Переход к добавлению свойств для разделов инфоблока выполняется:
- на закладке «Свойства» страницы редактирования инфоблока
- с помощью ссылки «Добавить пользовательское свойство», расположенной на закладке «Доп. поля» страницы редактирования раздела инфоблока
- на закладке «Свойства» страницы редактирования раздела инфоблока
В чем отличие инфоблоков 2.0 от обычных?
- все значения свойств одного элемента хранятся в одной строке
- используется тип таблиц Innodb вместо MylSAM
- инфоблоки 2.0 хранят свои свойства в отдельной таблице
Если в инфоблоках 2.0 сменен тип свойства, то:
- изменяется тип хранения в самой базе данныхизменяется тип хранения в самой базе данных
- меняется логика интерпретации продуктом значения этого свойств
Параметры информационного блока позволяют:
- управлять выводом свойств инфоблока для публичной части
- управлять правами доступа пользователей к информационному блоку
- указывать пользовательские поля для инфоблоков
- настраивать параметры экспорта в RSS (если экспорт в RSS был разрешен в настройках типа инфоблока)
- определять сайт (или сайты), на котором может быть показан инфоблок
- создавать свойства элементов
- определять URL на страницы со списком всех элементов, разделов и элементов отдельного раздела информационного блока
Преимущества инфоблоков 2.0 проявляются:
- на справочниках с небольшим количеством часто изменяемых свойств
- при использовании составных индексов
- на справочниках с небольшим количеством редко изменяемых свойств
- при использовании инфоблоков 2.0 в качестве товарных предложений
Уровень вложенности разделов экспортируемых в формате CSV инфоблоков задается:
- в настройках модуля Информационные блоки
- в форме настроек экспорта инфоблока в формате CSV
- в настройках Главного модуля
Предположим, что для элементов некоторого инфоблока должны задаваться значения следующих двух свойств: автор и источник. Для этого данные свойства необходимо создать:
- на странице редактирования элементов, для которых будут задаваться значения этих свойств
- на странице настроек соответствующего типа инфоблоков
- на странице настроек соответствующего инфоблока
Флаг IS_FINAL для элемента участвующего в документообороте инфоблока выставляется: Флаг IS_FINAL для элемента участвующего в документообороте инфоблока выставляется:
- методами API Bitrix Framework
- правкой записи в базе данных
С помощью какого метода можно получить свойство элемента?
- CIBlockElement::SetPropertyValues
- CIBlockElement::GetProperty
- CIBlockProperty::Update
Общий порядок работы с инфоблоками при создании сайта
- Создание элементов инфоблока.
- Внимательное продумывание структуры инфоблоков.
- Кастомизация работы компонента под потребности ТЗ и дизайна сайта.
- Создание физической страницы (в случае использования комплексного компонента) или страниц (при использовании простых компонентов) и размещение на ней компонента (компонентов) с последующей настройкой его свойств.
- Создание нужного типа инфоблоков с настройкой параметров.
- Создание самих инфоблоков с настройкой параметров.
- Создание структуры внутри инфоблока.
С помощью каких типов свойств настраивается связь между информационными блоками? С помощью каких типов свойств настраивается связь между информационными блоками?
- привязка к файлу (на сервере)
- привязка к элементам
- привязка к разделам
- привязка к элементам в виде списка
- привязка к элементам по XML_ID
- привязка к элементам с автозаполнением
- привязка к товарам (SKU)
Ненужные запросы при составлении семантического ядра
Исключаем ненужные запросы из семантического ядра
После использования всех возможных методов подбора ключевых слов, Ваше семантическое ядро будет содержать ошибки – ненужные запросы, по которым выполнять продвижение веб-ресурса нецелесообразно. На этом этапе главное не оставить все как есть, а произвести тщательную очистку и убрать из Вашего списка все ненужные ключевые слова.
Как убрать ненужные запросы
Можно произвести чистку вручную. При этом ненужные ключевые слова отсеиваются по признакам:
- Нецелевые. Будут привлекать на Ваш сайт нецелевой трафик – посетителей, приходящих по запросам, которые Вы не можете удовлетворить. Например, если Вы являетесь владельцем дешевого хостела, продвигаясь по запросу «элитные апартаменты», получите много посетителей готовых платить за настоящий комфорт, который Вы им предоставить не сможете. В итоге будет много трафика с минимальной конверсией.
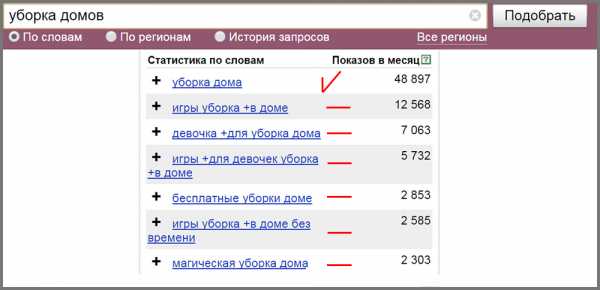
Очень часто подобные ненужные запросы содержат минус-слова (игра, фильм, песня, скачать, он-лайн и т. д.).
- Дорогие. В основном высокочастотные и высококонкурентные, продвижение по которым очень дорогостоящее и длительное. Например, «авто», «сайт», «телефон».
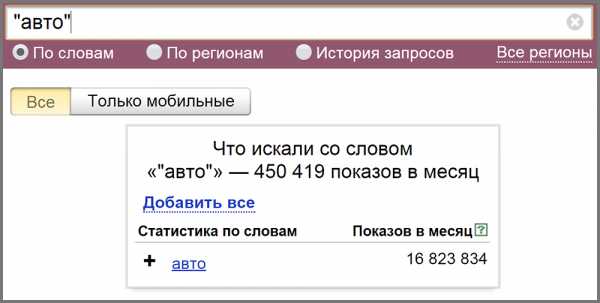
- С опечатками. Яндекс Wordstat без зазрения совести выдает тонны ключевиков с ошибками. Некоторые оптимизаторы их используют эти ненужные ключевые слова в виду их высокой частотности. При этом они совершают две ошибки, не зная что:
- поисковые системы оценивают грамотность текстового контента при ранжировании результатов выдачи; - когда пользователь вбивает в строку поиска запрос с опечатками, поисковик предлагает ему результаты по исправленному запросу.
В итоге, добавляя в семантическое ядро ошибки и опечатки, Вы тем самым создаете не очень качественный контент с точки зрения поисковых систем и тратите лишне время и деньги на продвижение по поисковым запросам, по которым Вас никогда не найдут.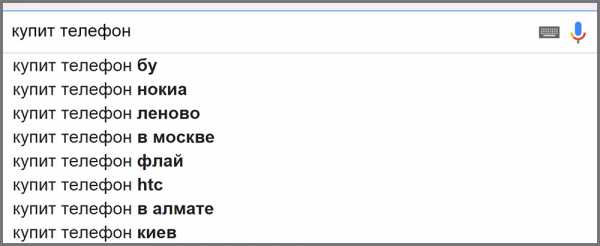
- Не продающие. Это ненужные ключевые слова, которые вполне подходят под тематику Вашего сайта, но продвижение по ним не сможет нужный уровень покупок Ваших товаров или услуг. Поэтому нужно внимательно следить за отсеиванием ключевых фраз, которые в большинстве случаев являются просто информационными.
Как отфильтровать минус-слова
Если список ключевых слов у Вас очень большой, не всегда оказывается по силам качественно его проверить. В таком случае можно использовать специализированные программы вроде Key Collector. Загрузив в нее весь список запросов, программа сможет произвести анализ, на основании которого можно будет отфильтровать ненужные ключевые слова, указав в образовавшихся группах, какие из них содержат минус-слова.
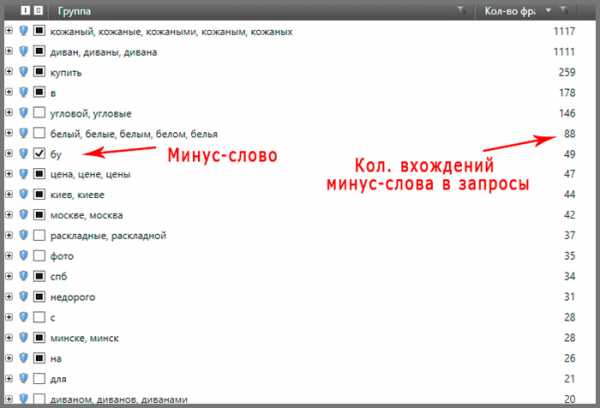
После совершения всех вышеперечисленных действий Ваш сайт наконец-то будет иметь завершенное семантическое ядро. Ошибки и ненужные ключевые слова к этому моменту будут из него удалены. И только от Вашей усидчивости и внимательности будет зависеть качество выполненной работы.
Если материал Вам понравился, не забудьте нажать «Нравится»!
seo-akademiya.com
| SET NAMES utf8; SET time_zone = '+00:00'; SET foreign_key_checks = 0; SET sql_mode = 'NO_AUTO_VALUE_ON_ZERO'; DROP TABLE IF EXISTS `articles`; CREATE TABLE `articles` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `id_user` int(11) NOT NULL, `id_section` int(11) unsigned DEFAULT NULL, `date_add` datetime DEFAULT NULL, `file1` varchar(255) DEFAULT '', `file1caption` varchar(255) NOT NULL, `title_ru` varchar(255) DEFAULT NULL, `title_manual_ru` varchar(255) DEFAULT NULL, `text_small_ru` text, `text_big_ru` mediumtext, `keywords_ru` varchar(255) DEFAULT NULL, `description_ru` varchar(255) DEFAULT NULL, `tags` varchar(255) DEFAULT NULL, `enable` int(1) unsigned DEFAULT NULL, `top_text` varchar(255) NOT NULL, `top_place` tinyint(4) NOT NULL, `status` int(10) unsigned DEFAULT '0', `status2` tinyint(4) NOT NULL, `allow_rating` tinyint(4) NOT NULL DEFAULT '0', `rating_value` float(5,4) NOT NULL DEFAULT '0.0000', `rating_count` int(10) unsigned NOT NULL DEFAULT '0', `viewed` int(11) unsigned DEFAULT '0', `order_id` int(11) NOT NULL DEFAULT '0', `count_comments` smallint(5) unsigned NOT NULL DEFAULT '0', `search_index` longtext NOT NULL, `search_index_title` text NOT NULL, `ph_small` varchar(100) NOT NULL, `ph_title` varchar(250) NOT NULL DEFAULT '', `ph_author` varchar(100) NOT NULL DEFAULT '', `author` varchar(100) NOT NULL DEFAULT '', `mode` tinyint(3) unsigned NOT NULL DEFAULT '0', `rating` int(10) unsigned NOT NULL DEFAULT '0', `source` tinyint(4) NOT NULL DEFAULT '0', `allow_comments` int(11) NOT NULL DEFAULT '1', `regionid` int(11) NOT NULL, `use_on_rss1` tinyint(1) NOT NULL DEFAULT '1', PRIMARY KEY (`id`), KEY `section` (`id_section`), KEY `date_add` (`date_add`), KEY `regionid` (`regionid`), FULLTEXT KEY `search_title` (`title_ru`,`search_index_title`), FULLTEXT KEY `search` (`title_ru`,`text_big_ru`,`search_index`) ) ENGINE=MyISAM DEFAULT CHARSET=cp1251; DROP TABLE IF EXISTS `categories`; CREATE TABLE `categories` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `id_parent` int(11) DEFAULT '0', `file1` varchar(255) DEFAULT '', `title_ru` varchar(255) NOT NULL, `name_ru` varchar(255) DEFAULT NULL, `text_small_ru` text, `text_ru` mediumtext, `description_ru` text, `keywords_ru` text, `status` tinyint(4) DEFAULT '1', `order_id` int(11) NOT NULL DEFAULT '0', `order_id_main` int(11) NOT NULL DEFAULT '0', `allow_news` tinyint(4) DEFAULT '1', `search_index` longtext NOT NULL, `search_index_title` text NOT NULL, PRIMARY KEY (`id`), KEY `id_parent` (`id_parent`), FULLTEXT KEY `search_title` (`title_ru`,`search_index_title`), FULLTEXT KEY `search` (`title_ru`,`text_ru`,`search_index`) ) ENGINE=MyISAM DEFAULT CHARSET=cp1251; |
forundex.ru