Регламентные операции на уровне субд для MS SQL Server, Оптимизация работы. Оптимизация ms sql
Регламентные операции на уровне субд для MS SQL Server, Оптимизация работы
Одной из часто встречающихся причин не оптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД. Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы.
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2005.
Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
Обновление статистикОчистка процедурного КЭШаДефрагментация индексовРеиндексация таблиц базы данныхРекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Обновление статистик
MS SQL Server строит план запроса на основании статистической информации о распределении значений в индексах и таблицах. Статистическая информация собирается на основании части (образца) данных и автоматически обновляется при изменении этих данных. Иногда этого оказывается недостаточно для того, что MS SQL Server стабильно строил наиболее оптимальный план выполнения всех запросов.
В этом случае возможно проявление проблем с производительностью запросов. При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальные операции).
Для того, чтобы гарантировать максимально правильную работу оптимизатора MS SQL Server рекомендуется регулярно обновлять статистики базы данных MS SQL.
Для обновления статистик по всем таблицам базы данных необходимо выполнить следующий SQL запрос:
Код SQL exec sp_msforeachtable N'UPDATE STATISTICS ? WITH FULLSCAN'Обновление статистик не приводит к блокировке таблиц, и не будет мешать работе других пользователей. Статистика может обновляться настолько часто, насколько это необходимо. Следует учитывать, что нагрузка на сервер СУБД во время обновления статистик возрастет, что может негативно сказаться на общей производительности системы.
Оптимальная частота обновления статистик зависит от величины и характера нагрузки на систему и определяется экспериментальным путем. Рекомендуется обновлять статистики не реже одного раза в день.
Приведенный выше запрос обновляет статистики для всех таблиц базы данных. В реально работающей системе разные таблицы требуют различной частоты обновления статистик. Путем анализа планов запроса можно установить, какие таблицы больше других нуждаются в частом обновлении статистик, и настроить две (или более) различных регламентных процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит существенно снизить время обновления статистик и влияние процесса обновления статистики на работу системы в целом.
Настройка автоматического обновления статистик (MS SQL 2005)
Запустите MS SQL Server Management Studio и подключитесь к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:
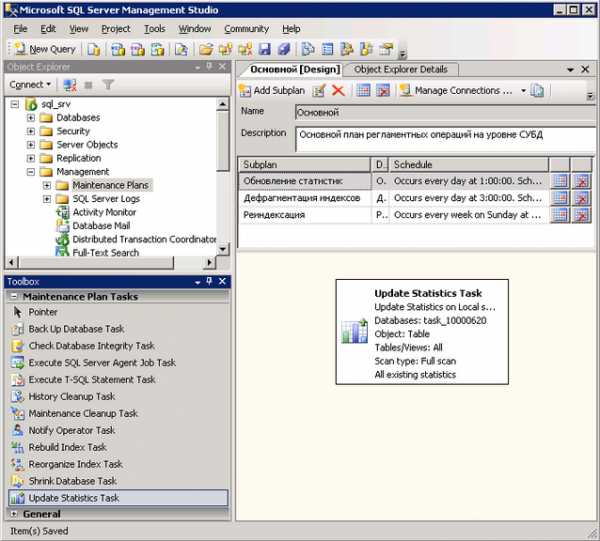
 Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:
Создайте субплан (Add Sublan) и назовите его «Обновление статистик». Добавьте в него задачу Update Statistics Task из панели задач:
Настройте расписание обновления статистик. Рекомендуется обновлять статистики не реже одного раза в день. При необходимости частота обновления статистик может быть увеличена.
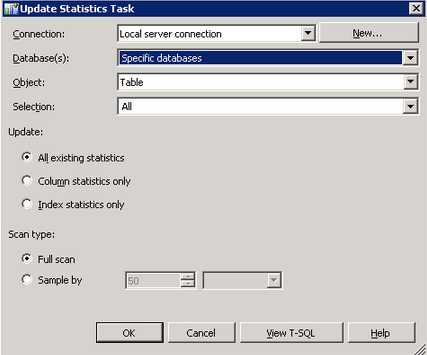
Настройте параметры задачи. Для этого следует два раза кликнуть на задачу в правом нижнем углу окна. В появившейся форме укажите имя базу данных (или несколько баз данных) для которых будет выполняться обновление статистик. Кроме этого вы можете указать для каких таблиц обновлять статистики (если точно неизвестно, какие таблицы требуется указать, то устанавливайте значение All).
Обновление статистик необходимо проводить с включенной опцией Full Scan.
Сохраните созданный план. При наступлении указанного в расписании срока обновление статистик будет запущено автоматически.
Очистка процедурного КЭШа
Оптимизатор MS SQL Server кэширует планы запросов для их повторного выполнения. Это делается для того, чтобы экономить время, затрачиваемое на компиляцию запроса в том случае, если такой же запрос уже выполнялся и его план известен.
Возможна ситуация, при которой MS SQL Server, ориентируясь на устаревшую статистическую информацию, построит неоптимальный план запроса. Этот план будет сохранен в процедурном КЭШе и использован при повторном вызове такого же запроса. Если Вы обновили статистику, но не очистили процедурный кэш, то SQL Server может выбрать старый (неоптимальный) план запроса из КЭШа вместо того, чтобы построить новый (более оптимальный) план.
Таким образом, рекомендуется всегда после обновления статистик очищать содержимое процедурного КЭШа.
Для очистки процедурного КЭШа MS SQL Server необходимо выполнить следующий SQL запрос:
Код SQL DBCC FREEPROCCACHEНастройка очистки процедурного КЭШа
для (MS SQL 2005)
Поскольку процедурный КЭШ необходимо очищать при каждом обновлении статистики, данную операцию рекомендуется добавить в уже созданный субплан «Обновление статистик». Для этого следует открыть субплан и добавить в его схему задачу Execute T-SQL Statement Task. Затем следует соединить задачу Update Statistics Task стрелочкой с новой задачей.
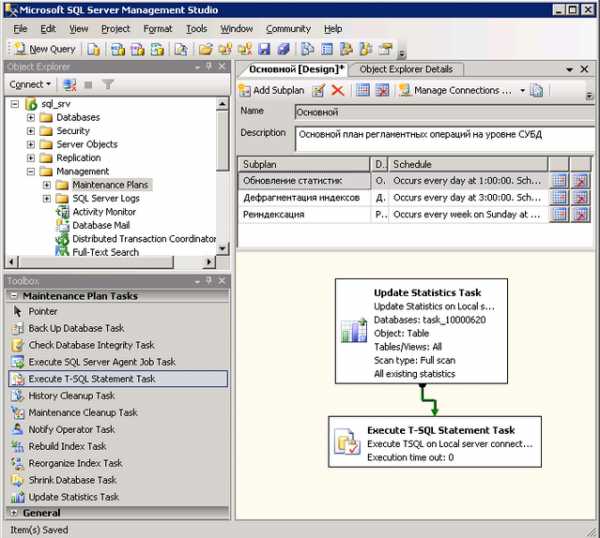
В тексте созданной задачи Execute T-SQL Statement Task следует указать запрос «DBCC FREEPROCCACHE»:
Дефрагментация индексов
При интенсивной работе с таблицами базы данных возникает эффект фрагментации индексов, который может привести к снижению эффективности работы запросов.
Рекомендуется регулярное выполнение дефрагментации индексов. Для дефрагментации всех индексов всех таблиц базы данных необходимо использовать следующий SQL запрос (предварительно подставив имя базы):
Код SQL sp_msforeachtable N'DBCC INDEXDEFRAG (<имя базы данных>, ''?'')'Возможно выполнение дефрагментации для одной или нескольких таблиц, а не для всех таблиц базы данных.
Настройка дефрагментации индексов (MS SQL 2005)
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Reorganize Index Task:
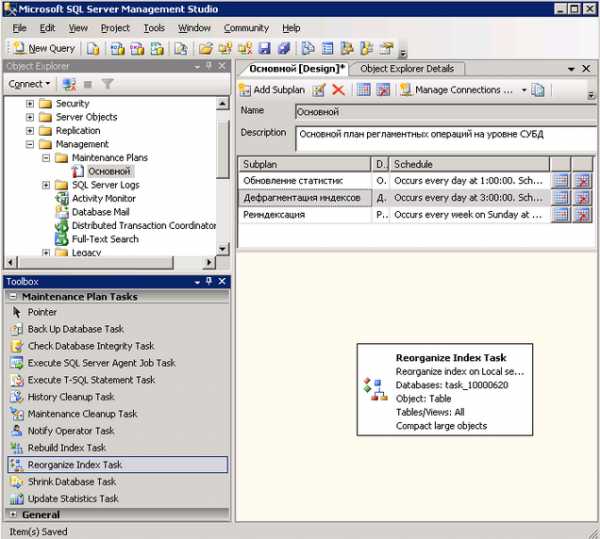
Задайте расписание выполнения для задачи дефрагментации индексов. Рекомендуется выполнять задачу не реже одного раза в неделю, а при высокой изменчивости данных в базе еще чаще – до одного раза в день.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
Реиндексация таблиц включает полное перестроение индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных. Для реиндексации всех таблиц базы данных необходимо выполнить следующий SQL запрос:
Код SQL sp_msforeachtable N'DBCC DBREINDEX (''?'')'Реиндексация таблиц блокирует их на все время своей работы, что может существенно сказаться на работе пользователей. В связи с этим реиндексацию рекомендуется выполнять во время минимальной загрузки системы.
После выполнения реиндексации нет необходимости делать дефрагментацию индексов.
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Rebuild Index Task:
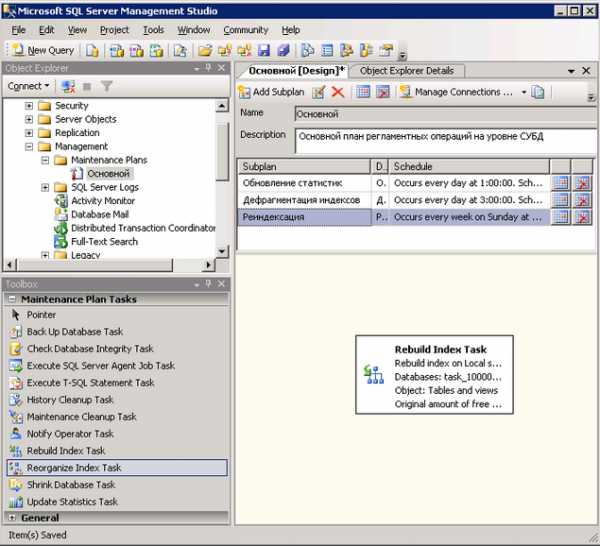
Задайте расписание выполнения для задачи реиндексирования таблиц. Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
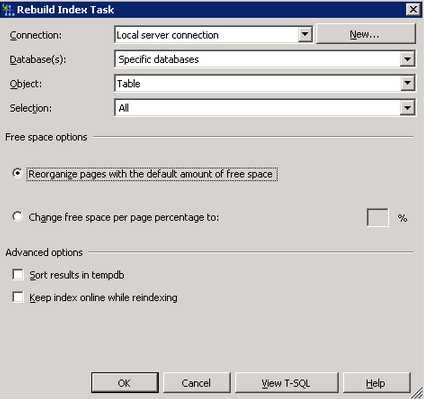
Реиндексация таблиц базы данных
Необходимо осуществлять регулярный контроль выполнения регламентных процедур на уровне СУБД. Ниже приведен пример контроля выполнения плана обслуживания для MS SQL Server 2005.
Откройте созданный вами план обслуживания и выберите из контекстного меню пункт «View History»:
Откроется окно с протоколом выполнения всех заданных регламентных процедур.
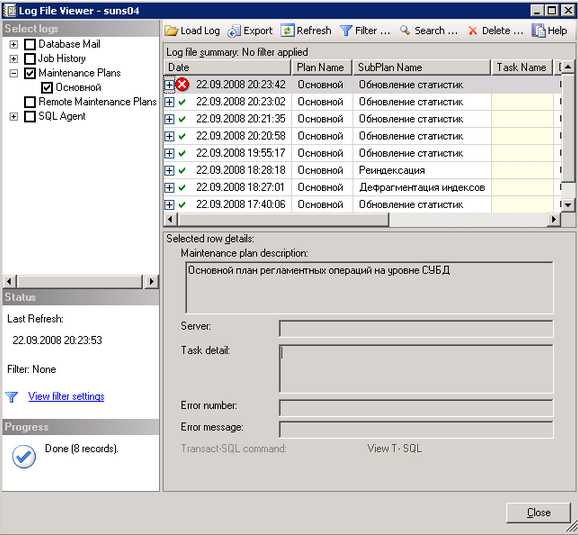
Успешно выполненные задачи и задачи, выполненные с ошибками, будут помечены соответствующими иконками. Для задач, выполненных с ошибками, доступна подробная информация об ошибке.
Источник: Регламентные операции MS SQL Server. Оптимизация работы
helpf.pro
Оптимизация работы на MS SQL
Books OnLine (BOL) так определяет цель оптимизации - "минимизировать время ответа для каждого запроса и максимизировать производительность сервера базы данных путем сокращения сетевого трафика, операций ввода/вывода и загрузки процессора. Эта цель достигается, когда разработчик понимает потребности приложения, логическую и физическую структуру данных, понимает как достигнуть компромисса между конкурирующими запросами различных пользователей". Данная статья посвящена одному из аспектов оптимизации - сокращению времени выполнения операций ввода/вывода.
Значительную часть времени сервер данных тратит на ожидание диска. Самые длительные операции - операции механического перемещения головок к нужным данным и операции чтения/записи этих данных. Как правило, даже незначительное уменьшение времени ожидания диска приводит к существенному росту производительности. BOL рекомендует располагать часто используемые таблицы на независимых дисках. Тогда MS SQL сможет давать разным дискам команды на позиционирование, чтение и запись одновременно. Что позволяет значительно повысить быстродействие сервера в целом.
MS SQL позволяет указать на каком диске располагать те или иные таблицы. Сделать это можно при помощи FileGroups.
Microsoft Axapta не содержит в себе специальных инструментов для работы с FileGroup. FileGroup можно настроить средствами администрирования MS SQL. Аксапта не сопротивляется, не своевольничает и никогда не переопределяет настройки администратора.
Рекомендация: чтобы уменьшить время выполнения дисковых операций, используйте несколько физических дисков. В MS SQL размещайте таблицы и индексы на разных независимых дисках при помощи FileGroup.
На этом совет можно было бы закончить. Дальше будут практические советы для тех, кто только начинает знакомиться с MS SQL. Пошаговую инструкцию начну с создания базы данных. Однако, использовать FileGroup для целей оптимизации можно и на уже существующей базе данных.
Шаг 1. Создание базы данных в MS SQL
Создайте базу данных. Под данные отведите мегабайт 20-30, под журнал транзакций сколько планировалось (для тестов и демонстрационной версии вполне хватит мегабайт 50).
Какой бы размер будущей базы данных вы не планировали, не создавайте на этом шаге DataFile большого размера. В первом файле будут хранится только системные объекты базы данных (описания таблиц, полей, индексов, SQL пользователей и т.п.). Дело в том, что MS SQL не умеет дефрагментировать системные таблицы. Поэтому не рекомендуется держать системные объекты и сами данные вперемешку. На этом шаге создается место как раз для системных объектов, место для прикладных данных будет создаваться позднее. 20-30Mb для системных объектов вполне хватит.
Создание новой базы данных в MS SQL Enterprise Manager
Файл для хранения системных объектов
Нажимайте кнопку OK. MS SQL создаст новую базу данных.
Шаг 2. Создание FileGroups
Откройте свойства созданной базы данных и создайте файловые группы. Стоит создать, по крайней мере, две группы - axData и axDevelop.
В группе axData будут находится все Аксаптовские данные по-умолчанию. Поэтому разместите эту группу на быстром диске.
А в группе axDevelop будут размещаться данные для разработчиков - перекрестные ссылки, индексы по описаниям, поисковые индексы для Enterprise Portal и т.п. Эти данные не являются критичными. К этим данным вряд ли будет обращаться значительное число пользователей. Поэтому их можно разместить на медленном диске или в сети.
Создание файловых групп
Создание файлов
Обратите внимание, что каждый файл данных привязан к определенной файловой группе.
Обратите также внимание, что у файловой группы axData установлена галочка Defaul. Это означает, что все создаваемые таблицы, поля, индексы и т.п. будут автоматически попадать в файловую группу axData. Что и требуется.
Сделать файловую группу группой по-умолчанию можно только после того, как будут созданы файлы. Таким образом шаг 2 выполняется в 3 действия:
- откройте свойства, создайте файловые группы, нажмите ОК;
- откройте свойства, создайте файлы и привяжие их к файловым группам, нажмите ОК;
- откройте свойства, переключите default группу, нажмите ОК.
Шаг 3. Создание новой базы данных в Microsoft Axapta
Проинсталируйте Аксапту, укажите ей только что созданную базу данных. Аксапта запустит мастера, создаст таблицы, поля и индексы в файловой группе по-умолчанию.
Если у вас уже есть база данных, то вы можете оставить большинство таблиц в группе PRIMARY. Ничего плохого не случится. Но если вы озабочены фрагментацией данных, то для всех таблиц стоит изменить файловую группу с PRIMARY на axData.
Шаг 4. Перенос выбранных таблиц в другую файловую группу
Теперь в базе данных таблицы созданы. Все Аксаптовские таблицы и индексы размещаются в группе axData. Пока таблицы пустые. Теперь самое время некоторые таблицы переместить в другую группу.
Прежде всего, надо переместить X-таблицы в файловую группу axDevelop.
Обратите внимание, что у каждой таблицы может быть несколько индексов. Привязка к FileGroup может выполняться для каждого индекса отдельно. Посмотрите на все индексы в выпадающем списке Selected Index и установите для каждого необходимую файловую группу.
Вот список таблиц, которые можно и нужно сразу перенести в файловую группу axDevelop:
- XREFNAMES
- XREFPATHS
- XREFREFERENCES
- XREFTABLERELATION
- XREFTYPEHIERARCHY
- SYSSEARCHNAME (только в Microsoft Axapta 3.0)
- SYSSEARCHPATH (только в Microsoft Axapta 3.0)
- SYSSEARCHREF (только в Microsoft Axapta 3.0)
По ходу работы с Аксаптой, внимательно анализируйте исполняемые запросы и на основании этих данных принимайте решении о размещении дополнительных файловых групп.
Шаг 5. Заполнение данными
После того, как вы создадите в Аксапте перекрестные ссылки, индексы для описаний и хелпов... После того, как загрузите демонстрационные данные или немного поработаете с Аксаптой, вы получите примерно такое распределение данных по файловым группам.
Обратите внимание, что собственно данные занимают не так уж и много места. Собственно данные можно и нужно размещать на самые быстрые диски. Можно и нужно чаще делать резервные копии этих данных. Можно и нужно плотнее заняться параметрами кэширования только для этих данных.
Кроме того, системные объекты MS SQL выделены в отдельную файловую группу и не перемешиваются с прикладными данными. Что дает небольшой, но прирост производительности.
Не останавливайтесь на этом минимальном делении. Анализируйте ваши запросы. Анализируйте использование таблиц. Главный и существенный прирост производительности дает размещение файловых групп на разные диски. Тогда MS SQL может давать команды дискам параллельно, что значительно сокращает время выполнения запросов.
Буду рад Вашим замечаниям и предложениям[email protected], Мазуркин Сергей
axapta.mazzy.ru
Как обеспечить производительность баз данных Microsoft SQL Server, размещаемых в облаке / Блог компании Техносерв / Хабр
Источник
Всем привет! Сегодня хотим поговорить об облачных базах данных, а точнее о тех проактивных и разовых мероприятиях, которые непосредственно обеспечивают их производительность.
Облачные базы данных давно решили вопрос быстрого прироста мощностей и запуска новых баз данных, и сегодня стали практически насущной потребностью компаний любого размера, благодаря переносу задач по администрированию и мониторингу на сторону провайдера.
Мы проделали большую работу, запуская и оптимизируя свою новую услугу облачной базы данных на собственной платформе Техносерв Cloud и, конечно же, столкнулись с рядом проблем и выработали свои подходы к их решению. Сейчас, когда сервис протестирован и работает, мы хотим поделиться с вами своим опытом – уверены, что прочитав этот материал, вы сможете избежать повторения чужих ошибок или откроете для себя что-то новое.
Сегодня бизнесу приходится иметь дело с постоянно растущими объемами данных, поэтому возникла потребность каким-то образом облегчить задачу управления всеми этими огромными информационными массивами. Выход был найден благодаря внедрению платформ облачных вычислений и созданию облачных баз данных.
Согласно расчетам, объемы как структурированных, так и неструктурированных данных возрастают в среднем на 60% в год. До сих пор местом хранения всей этой информации служили традиционные базы данных, но этого оказалось недостаточно, и тогда на помощь пришли облачные технологии. Они избавили пользователей от необходимости выделять под базы данных собственные вычислительные мощности, возложив эту обязанность на провайдеров облачных сервисов. Такой подход оказался чрезвычайно продуктивным в плане повышения производительности и доступности баз данных, а также улучшения их масштабируемости.
В нашей статье мы решили сделать небольшой обзор наиболее оптимальных настроек и механизмов обеспечения производительности баз данных MS SQL Server. Данный список ни в коем случае не является исчерпывающим, поскольку рекомендации разработчиков и «лучшие отраслевые практики» корректируются со временем. Отследить все эти изменения и грамотно реализовать их может только команда профессиональных DBA (администраторов баз данных). Именно таким штатом специалистов располагает поставщик услуг облачных баз данных и, с большей вероятностью, наличием подобной команды не может похвастать большинство заказчиков.
Для обеспечения высокой доступности и высокой производительности БД MS SQL Server, размещаемых в облаке, в соответствии с рекомендациями Microsoft и лучшими практиками, мы проводим нижеследующие мероприятия.
Примечание: Хотя основная часть рекомендаций является общими, их применение на каждом конкретном сервере зависит от очень многих факторов. Поэтому ниже даются ссылки на соответствующие документы Microsoft c более детальной информацией.

Устанавливаем на все MS SQL серверы последние Service Packs / Cumulative Updates / Security Updates:
С 2016 года схема обновлений для Microsoft SQL Server была упрощена — теперь обновления выходят регулярно.
Общая последовательность установки обновлений приведена ниже (все обновления перед установкой на Производственных серверах — первоначально тестируем в Тестовом окружении):
• Устанавливаем последний пакет обновления Service Pack (SP). • Устанавливаем последнее кумулятивное обновление для Service Pack — Cumulative Update (CU). • В случае выхода Security Updates – также их устанавливаем. • В случае проблем ищем и применяем Critical On-Demand (COD) — фикс для их устранения.
Примечание: Хотя Microsoft рекомендует устанавливать последние CU как только они выходят, зачастую большинство компаний устанавливают только последний SP, а CU ставят только в случае, если в состав CU входит фикс для имеющейся на сервере проблемы. Мы согласуем данный процесс с закачиком в соответствии с его внутренними инструкциями, но всегда предлагаем вначале рассмотреть официальные рекомендации Microsoft.
Настраиваем оптимальные параметры использования памяти MS SQL Server и оптимальные параметры MaxDOP:
По умолчанию, MS SQL Server может динамически изменять требования к памяти на основе доступности системных ресурсов. По умолчанию параметр min server memory имеет значение 0, а параметр max server memory — значение 2 147 483 647 MБ. О выборе оптимальных параметров использования памяти MS SQL Server можно прочитать здесь.
Если MS SQL Server работает на многопроцессорном компьютере, он определяет оптимальную степень параллелизма, то есть количество процессоров, задействованных для выполнения одной инструкции, для каждого из планов параллельного выполнения. Для ограничения количества процессоров в плане параллельного выполнения может быть использован параметр max degree of parallelism. О выборе оптимальных параметров MaxDOP можно прочитать здесь.
Используем при необходимости trace flags:
Флаги трассировки в MS SQL Server являются своеобразными «переключателями» поведения сервера с заданного по умолчанию на другое. Информацию о флагах трассировки можно найти здесь.
Оптимизируем настройки базы “TempDB” и других системных баз:
В MS SQL Server входят следующие системные базы данных:
• “master” — в этой БД хранятся все данные системного уровня для экземпляра MS SQL Server; • “msdb” — используется агентом MS SQL Server для планирования предупреждений и задач; • “model” — используется в качестве шаблона для всех баз данных, создаваемых в экземпляре MS SQL Server. Изменение размера, параметров сортировки, модели восстановления и других параметров базы данных model приводит к изменению соответствующих параметров всех баз данных, создаваемых после изменения; • “Resource” — база данных только для чтения. Содержит системные объекты, которые входят в состав MS SQL Server. Системные объекты физически хранятся в базе данных Resource, но логически отображаются в схеме sys любой базы данных; • “TempDB” — рабочее пространство для временных объектов или взаимодействия результирующих наборов.
Рекомендациия для настройки оптимальной производительности базы данных “TempDB” можно найти здесь.
Корректно настраиваем параметры дефолтных расположений дата-файлов/лог-файлов:
Когда новая БД создается в MS SQL Server без явного указания расположения для дата-файла/ов и лог-файла, то MS SQL Server создает эти файлы в дефолтном расположении. Данное дефолтное расположение настраивается при установке MS SQL Server. О настройки параметров дефолтных расположений дата-файлов/лог-файлов можно прочитать здесь.
Используем оптимальные настройки дисковой подсистемы (быстрые накопители SSD, отформатированные с размером кластера 64К):
MS SQL Server имеет свои особенности хранения данных. В связи с этим подготовка дисковой подсистемы как на физическом, так и на логическом уровнях, учитывающие эти особенности, будет оказывать серьезное влияние на производительность. Подробнее об этом можно узнать здесь.
Настраиваем “Мгновенную инициализацию файлов базы данных”:
В MS SQL Server файлы данных могут быть инициализированы мгновенно. Мгновенная инициализация файлов освобождает место на диске, не заполняя пространство нулями. Вместо этого содержимое диска перезаписывается, поскольку в файлы записываются новые данные. Файлы журналов не могут быть инициализированы мгновенно. Подробности – здесь.
Используем разные сетевые интерфейсы для “пользовательской” и для “системной” нагрузок:
Наши сервера имеют несколько сетевых интерфейсов и каждый отдельно взятый интерфейс можно использовать под какую-то выделенную задачу, например, под трафик периодического резервного копирования. Такая конфигурация имеет свои плюсы, например, позволяет максимально жестко разграничить использование интерфейсов под особенности разных задач.

Источник
Проверяем, чтобы параметры “Auto Shrink” и “Auto Close” были выключены:
“Auto Shrink” (Автоматическое сжатие) указывает, что MS SQL Server будет периодически сжимать файлы базы данных (более подробно здесь). “Auto Close” (Автоматическое закрытие) указывает, что база данных будет закрыта после освобождения всех ее ресурсов и отсоединения всех пользователей (более подробно здесь).
Проверяем, чтобы параметры “Auto Create Statistics” и “Auto Update Statistics” были включены:
Если включен параметр “Auto Create Statistics” (Автоматическое создание статистики), то оптимизатор запросов в случае необходимости создает статистику по отдельным столбцам в предикате запроса, чтобы улучшить оценку количества элементов для плана запроса (более подробно здесь).
Если включен параметр “Auto Update Statistics” (Автоматическое обновление статистики), то оптимизатор запросов определяет, когда статистика может оказаться устаревшей, и обновляет ее, если она используется в запросе (более подробно здесь).
Используем при необходимости “Read Committed Snapshot Isolation”:
Термин “Snapshot” («Моментальный снимок») отражает тот факт, что все запросы в транзакции обнаруживают одинаковую версию, или моментальный снимок базы данных, который соответствует состоянию базы данных в момент начала транзакции. Транзакция моментального снимка не требует блокировок базовых строк или страниц данных, что позволяет выполнять другую транзакцию без ее блокировки предыдущей незавершенной транзакцией. Транзакции, изменяющие данные, не блокируют транзакции, в которых происходит чтение данных, а транзакции, считывающие данные, не блокируют транзакции, в которых происходит запись данных, что обычно также наблюдается при использовании уровня изоляции “Read Committed”, заданного по умолчанию в MS SQL Server. Применение такого подхода, предусматривающего отказ от блокировок, способствует значительному снижению вероятности взаимоблокировок в сложных транзакциях.
Включение параметра “Read Committed Snapshot Isolation” обеспечивает доступ к версиям строк из под дефолтного уровня изоляции “Read Committed”. Если параметр “Read Committed Snapshot Isolation” установлен в значение OFF, то для получения доступа к версиям строк потребуется явно задавать уровень изоляции моментального снимка для каждого сеанса (более подробно здесь).
Проверяем, чтобы параметр “Page Verify” была выставлена в “CHECKSUM”:
Если для параметра базы данных “Page Verify” указано значение “CHECKSUM”, то MS SQL Server рассчитывает контрольную сумму для содержимого страницы в целом и сохраняет значение в заголовке страницы при записи страницы на диск. При считывании страницы с диска контрольная сумма вычисляется повторно и сравнивается со значением из заголовка. Это помогает обеспечить высокий уровень целостности данных в файлах (более подробно здесь).
Дата-файл/ы и лог-файл БД размещаем на отдельных физических дисках:
Размещение файлов данных и файлов журнала на одном устройстве может привести к состязанию, что вызовет снижение производительности. Размещение файлов на разных дисках позволяет выполнять операции ввода-вывода для файлов данных и файлов журнала параллельно (более подробно здесь).
Создаем только один лог-файл БД:
Лог-файл используется MS SQL Server последовательно, а не параллельно, и нет никакого выигрыша по производительности иметь несколько лог-файлов (более подробно здесь).
Не допускаем появления фрагментации “Виртуального лог-файла (VLF)” БД:
Лог-файл БД внутренне разделен на разделы, именуемые виртуальными лог-файлами (Virtual Log Files – VLF), и чем выше фрагментация в лог-файле, тем больше число VLF. После того, как число VLF в лог-файле превысит 200, может ухудшиться производительность связанных с лог-файлом операций, таких как чтение лог-файла (скажем, для транзакционной репликации/отката), резервное копирование лог-файла и т.п. (более подробно здесь).
Выбираем корректные начальные размеры дата-файла/ов и лог-файла БД:
При создании базы данных файлы данных следует делать как можно большего размера, в соответствии с наибольшим предполагаемым объемом данных в базе данных. Например, если мы знаем, что сейчас у нас данных будет 50 ГБ, а через полгода добавится еще 50 ГБ, то начальный размер дата-файла лучше сразу сделать равным 100 ГБ (более подробно здесь).
Выбираем корректные параметры “Авто-роста” для дата-файла/ов и лог-файла БД:
Не рекомендуется использовать “Авто-рост” в процентах, так как, если размер файлов БД большой, то сам процесс увеличения базы может вызвать существенное снижение производительности, поэтому более предпочтительным является увеличение базы на фиксированный размер в МБ (более подробно здесь).
Постоянно отслеживаем размеры дата-файла/ов и лог-файла БД и при необходимости проактивно их увеличиваем во время минимальной нагрузки БД:
В производственной системе функцию “Авто-роста” следует использовать только как средство увеличения размера файлов в чрезвычайных обстоятельствах. Не рекомендуется использовать ее для повседневного управления ростом файлов данных БД. Для наблюдения за размерами файлов и их заблаговременного увеличения обычно используют оповещения или программы мониторинга. Это позволяет избежать фрагментации и перенести выполнение этих операций по обслуживанию на часы, когда нагрузка минимальна (более подробно здесь).

Источник
Выполняем проверку целостности данных БД:
Проверяем логическую и физическую целостность всех объектов в базе данных путем выполнения следующих операций (более подробно здесь):
• выполнение инструкции DBCC CHECKALLOC для базы данных; • выполнение инструкции DBCC CHECKTABLE для каждой таблицы и каждого представления в базе данных; • выполнение инструкции DBCC CHECKCATALOG для базы данных; • проверка содержимого каждого индексированного представления в базе данных; • проверка согласованности между файлами и директориями файловой системы и метаданными таблицы на уровне ссылок при хранении данных varbinary(max) в файловой системе с помощью FILESTREAM; • проверка данных компонента Service Broker в базе данных.
Выполняем кастомный index rebuild/reorganize в зависимости от фрагментации индексов:
MS SQL Server автоматически поддерживает состояние индексов при выполнении операций вставки, обновления или удаления в отношении базовых данных. Со временем эти изменения могут привести к тому, что данные в индексе окажутся разбросанными по базе данных (фрагментированными). Фрагментация имеет место в тех случаях, когда в индексах содержатся страницы, для которых логический порядок, основанный на значении ключа, не совпадает с физическим порядком в файле данных. Значительно фрагментированные индексы могут серьезно снижать производительность запросов и служить причиной замедления откликов приложения. Можно устранить фрагментацию путем реорганизации или перестроения индекса (более подробно здесь).
Обновляем статистику:
По умолчанию оптимизатор запросов обновляет статистику по мере необходимости для усовершенствования плана запроса. Обновление статистики гарантирует, что запросы будут компилироваться с актуальной статистикой. Однако обновление статистики вызывает перекомпиляцию запросов. Рекомендуется не обновлять статистику слишком часто, поскольку необходимо найти баланс между выигрышем в производительности за счет усовершенствованных планов запросов и потерей времени на перекомпиляцию запросов. Критерии выбора компромиссного решения зависят от приложения (более подробно здесь).
Не используем никакие “плохие” практики, например, такие как “регулярное сжатие”:
Данные, перемещаемые в процессе сжатия файла, могут быть разбросаны по любым доступным местам в файле. Это вызывает фрагментацию индекса и может увеличить время выполнения запросов, выполняющих поиск в диапазоне индекса (более подробно здесь).
При необходимости организовываем регулярную очистку БД от “старых” данных:
Зачастую компании должны хранить данные в течение какого-то времени, чтобы соответствовать требованиям действующего законодательства и своим внутренним требованиям. После того как данные становятся не нужны – обычно рекомендуется их удалять, что позволяет повысить производительность MS SQL Server и дает возможность более точно предсказывать возможный рост требований к серверному оборудованию (более подробно здесь).

Источник
Определяем лучшую стратегию бэкапирования БД в соответствии с требованиями заказчика по RTO/RPO и лучшими мировыми практиками:
MS SQL Server обеспечивает необходимую защиту важных данных, которые хранятся в базах данных. Чтобы минимизировать риск необратимой потери данных, необходимо регулярно создавать резервные копии баз данных, в которых будут сохраняться производимые изменения данных. Хорошо продуманная стратегия резервного копирования и восстановления защищает базы от потери данных при повреждениях, происходящих из-за различных сбоев (более подробно здесь).
Выполняем регулярное тестовое восстановление бэкапов БД:
Можно сказать, что стратегия восстановления отсутствует, пока резервные копии не протестированы. Очень важно полностью протестировать стратегию резервного копирования для каждой базы данных, восстанавливая копию базы данных в тестовую систему. Необходимо протестировать восстановление каждого типа резервной копии, которую планируется использовать (более подробно здесь).
Always On Failover Cluster Instances:
Экземпляры отказоустойчивой кластеризации AlwaysOn используют функциональные возможности отказоустойчивой кластеризации Windows Server (WSFC) для обеспечения высокого уровня доступности локальных ресурсов за счет избыточности на уровне экземпляра сервера — экземпляра отказоустойчивого кластера (FCI). Экземпляр отказоустойчивого кластера (FCI) является единственным экземпляром MS SQL Server, установленным на всех узлах отказоустойчивой кластеризации Windows Server (WSFC) и, возможно, в нескольких подсетях. Экземпляр отказоустойчивого кластера выглядит в сети как экземпляр MS SQL Server, запущенный на одном компьютере, но экземпляр отказоустойчивого кластера обеспечивает отработку отказа с переходом одного узла WSFC на другой узел, если текущий узел становится недоступным (более подробно здесь).
Always On availability groups:
Группы доступности AlwaysOn — это решение высокой доступности и аварийного восстановления, являющееся альтернативой зеркальному отображению баз данных (“database mirroring”). Группа доступности поддерживает отказоустойчивую среду для набора пользовательских баз данных, известных как базы данных доступности, которые совместно выполняют переход на другой ресурс. Группа доступности поддерживает набор первичных баз данных для чтения/записи и от одного до восьми наборов соответствующих вторичных баз данных. Кроме того, вторичные базы можно сделать доступными только для чтения и/или для некоторых операций резервного копирования (более подробно здесь).
Database mirroring:
Зеркальное отображение базы данных — это решение, нацеленное на повышение доступности базы данных MS SQL Server. Зеркальное отображение каждой базы данных осуществляется отдельно и работает только с теми базами данных, которые используют модель полного восстановления (более подробно здесь).
Log shipping:
MS SQL Server позволяет автоматически отправлять резервные копии журналов транзакций из базы данных-источника экземпляра сервера-источника в одну или более баз данных-получателей других экземпляров сервера-получателя. Резервные копии журналов транзакций применяются к каждой из баз данных-получателей индивидуально (более подробно здесь).
Мониторинг сервера относится к категории жизненно важных мероприятий. Эффективное наблюдение подразумевает регулярное создание моментальных снимков текущей производительности для обнаружения процессов, вызывающих неполадки, и постоянный сбор данных для отслеживания тенденций роста или изменения производительности.

Источник
Постоянная оценка производительности базы данных помогает добиться оптимальной производительности путем минимизации времени ответа и максимального увеличения пропускной способности. Приблизительный сетевой трафик, дисковый ввод-вывод и загрузка ЦП — ключевые факторы, влияющие на производительность. Следует тщательно проанализировать требования приложения, понять логическую и физическую структуру данных, оценить использование базы данных и добиться компромисса между такими конфликтующими нагрузками, как оперативная обработка транзакций (OLTP) и поддержка решений (более подробно здесь).
habr.com
sql - Оптимизация запросов для MS Sql Server 2012
У меня есть таблица, содержащая ~ 5 000 000 строк данных scada, описанных ниже: create table data (o int, m money).
Где: - o - это ПК с кластеризованным индексом на нем. o коэффициент заполнения близок к 100%. o представляет собой дату показания счетчика, можно рассматривать как ось X. - m - десятичное значение, лежащее в пределах области 1..500 и фактическое показание счетчика можно рассматривать как ось Y.
Мне нужно выяснить некоторые закономерности, например, когда, как часто и как долго они происходили.
Пример. Ищите все вхождения m изменяющиеся на область от 500 до 510 пределах 5 единиц (от 1 до 5) o Я запускаю следующий запрос:
select d0.o as tFrom, d1.o as tTo, d1.m - d0.m as dValue from data d0 inner join data d1 on (d1.o = d0.o + 1 or d1.o = d0.o + 2 or d1.o = d0.o + 3 or d1.o = d0.o + 4) and (d1.m - d0.m) between 500 and 510для выполнения запроса требуется 23 секунды.
Предыдущая версия заняла 30 минут (в 90 раз медленнее), мне удалось оптимизировать ее, используя наивный подход, заменив: on (d1.o - d0.o) between 1 and 4 с on (d0.o = d1.o - 1 or d0.o = d1.o - 2 or d0.o = d1.o - 3 or d0.o = d1.o - 4)
Мне ясно, почему это быстрее - с одной стороны, индексированное сканирование столбцов должно быстро развиваться на другом, я могу себе это позволить, поскольку даты дискретны (и я всегда даю 5 минутное время льгот для любой области o, так что за 120 минут это 115..120 регион). Я не могу использовать один и тот же подход с значениями m поскольку они являются интегральными.
Вещи, которые я пробовал до сих пор:
-
Мягкий осколок, применяя where o between @oRegionStart and @oRegionEnd в нижней части моего скрипта. и запускать его в цикле, получая результаты в таблицу temp. Время исполнения - 25 секунд.
-
Жесткий осколок путем разделения данных на ряд физических таблиц. Результат - 2 минуты, без проблем.
-
Используя некоторые предварительно обработанные структуры данных, например:
create table data_change_matrix (o int, dM5Min money, dM5Max money, dM10Min money, dM10Max money... dM{N}Min money, dM{N}Max money)
где N - максимальный уровень, для которого я выполняю анализ. Имея такую таблицу, я мог бы легко написать запрос:
select * from data_change_matrix where dMin5Min between 500 and 510
В результате - он никуда не вышел из-за огромных требований к размеру (5M X ~ 250) и расходов, связанных с обслуживанием, мне нужно поддерживать эту актуальность матрицы, близкую к реальному времени.
- SQL CLR - даже не спрашивайте меня, что пошло не так, как просто не получилось.
Прямо сейчас я не вдохновляюсь и ищу помощь.
В целом - возможно ли приблизиться к мгновенному времени отклика, запускающему такой тип запросов на больших объемах данных?
Все запускаются на MS Sql Server 2012. Не пробовали на сервере MS Sql Server 2014, но с удовольствием сделаем это, если это будет иметь смысл.
Обновление - план выполнения: http://pastebin.com/PkSSGHvH.
Обновление 2 - Хотя мне очень нравится функция LAG, предложенная usr. Интересно, есть ли функция LAG ** S **, позволяющая
выберите o, MIN (LAG ** S ** (o, 4)) over (...) - или какова его кратчайшая реализация в TSL?
Я попробовал что-то очень похожее с помощью SQL CLR и получил его работу, но производительность была ужасной.
qaru.site
MS SQL Server. Оптимизация работы [Статья]
Главная » Новости
Опубликовано: 07.10.2017
Introducing Microsoft SQL Server 2016Предисловие
Платформа 1С:Предприятие 8.x поддерживает работу с несколькими СУБД. Самым используемым является продукт компании Microsoft. Microsoft SQL Server 2014 - Introductory Tutorial
В статье будут рассмотрены распространенные причины неоптимальной работы SQL-сервера и пути их решения на примере MS SQL Server 2008.
Для каждой проблемы будет краткое описание и видеоурок по настройке СУБД для оптимизации работы. Для более подробного описания тех или иных настроек следует обратиться к справочному руководству.По опыту, самыми распространенными причинами неоптимальной работы SQL-сервера являются:
Неактуальная статистика о распределении значений и индексов в таблице базы данных. Устаревание процедурного КЭШа планов запросов. Высокая фрагментация индексов таблиц. Периодическая необходимость в перестроении всех индексов таблиц.Теперь по порядку.
Обновление статистик
MS SQL, как и другие современные СУБД, имеют механизм оптимизации запросов к базе данных на основе собранной статистики распределения значений в таблицах и индексах. Оптимизатор SQL, анализируя собранную статистику, выбирает наиболее эффективный план запроса, исключая нерациональные выборки данных.
Достаточно интенсивная работа с базой данных снижает актуальность собранной статистики что не позволяет оптимизатору создавать оптимальные запросы к БД. Поэтому необходимо проводить обновление статистик. Делается это с помощью следующей команды:
exec sp_msforeachtable N'UPDATE STATISTICS ? WITH FULLSCAN' Наибольшее влияние статистики распределения данных на производительность СУБД можно увидеть с применением вложенных запросов. Если платформа 1С:Предприятие 8.x сформирует запрос к SQL-базе многоуровневой вложенности, плюс к этому еще и соединением двух вложенных запросов, то можно утверждать, что скорость его работы напрямую зависит от актуального состояния собранной статистики. Для поддержки статистик в актуальном состоянии рекомендуется создать регламентное задание, которое будет производить обновление статистик в указанное время. Поскольку данный процесс не блокирует таблицы БД, то его можно запускать практически в любое время. Ниже на видео демонстрируется настройка плана обслуживания по обновлению статистик средствами СУБД MS SQL Server 2008.
MS SQL Server 2008. Обновления статистик
Если возникнет необходимость обновления статистик несколько раз за сутки в связи с режимом работы базы, то рекомендуется разбить этот процесс на несколько частей. Анализ планов запросов позволит определить таблицы, которые нуждаются в частом обновлении статистик, чем остальные. Далее разделить процесс на две задачи: несколько раз в сутки обновлять статистику распределения значений для наиболее используемых таблиц, и раз в сутки для всех остальных.Очистка процедурного КЭШа
SQL-оптимизатор кэширует используемые планы запросов для увеличения быстродействия. Но стоит учитывать, что обновление статистик распределение данных БД может привести к неверным действиям оптимизатора поскольку кэш будет учитывать устаревшую статистику. Поэтому следует очистить процедурный кэш. В дальнейшем, уже на основе обновленной статистики, оптимизатором SQL будет создан новый процедурный кэш. Очистка процедурного кэша осуществляется следующей командой:
balagurs.ru
Оптимизация работы 1C. Настройка сервера MS SQL
Оптимизация работы 1С. Настройка сервера MS SQL
- Включите возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
- Создание базы данных
- Добавление файлов, журналов или данных в существующую базу данных
- Увеличение размера существующего файла (включая операции автоувеличения)
- Восстановление базы данных или файловой группы
Для включения настройки:
- На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc).
- Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей.
- На правой панели дважды кликните Выполнение задач по обслуживанию томов.
- Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server.
- Нажмите кнопку Применить.
- Включите параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Для включения настройки:
- В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc.
- В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows.
- Разверните узлы Настройки безопасности и Локальные политики.
- Выберите папку Назначение прав пользователя.
- Политики будут показаны на панели подробностей.
- На этой панели дважды кликните параметр Блокировка страниц в памяти.
- В диалоговом окне Параметр локальной безопасности — блокировка страниц в памяти выберите «Добавить» пользователя или группу.
- В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server.
- Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server.
- Отключите механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С. Чтобы отключить его только для дисков, нужно:
- Найти в реестре ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TSFairShare\Disk
- Установить значение параметра EnableFairShare в 0
- Отключите сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
- Открыть свойства каталога
- На закладке Общие нажать кнопку Другие
- Снять флаг «Сжимать» содержимое для экономии места на диске.
- Установите параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Дополнительно
- Установить значение параметра равное единице.
- Ограничьте максимальный объем памяти сервера MS SQL Server.
Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Память
- Указать значение параметра Максимальный размер памяти сервера.
- Включите флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Процессоры
- Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок.
- Установите размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
Для установки размера авторасширения необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства нужной базы и выбрать закладку Файлы
- Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
- Разнесите файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски Супер.
Для переноса файлов необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства нужной базы и выбрать закладку Файлы
- Запомнить имена и расположение файлов
- Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
- Поставить флаг Удалить соединения и нажать Ок
- Открыть Проводник и переместить файл данных и файл журнала на нужные носители
- В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
- Нажать кнопку Добавить и указать файл mdf с нового диска
- В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок.
- Вынесите файлы базы TempDB на отдельный диск.
Служебная база данных TempDB используется всеми базами сервера для хранения, промежуточных расчетов, временных таблиц, версий строк при использовании RCSI и многих других вещей. Обычно обращений к этой базе очень много, и если она будет лежать на медленных дисках, это может замедлить работу системы.
Рекомендуется хранить базу TempDB на отдельном диске для повышения производительности работы системы.
Для переноса базы TempDB на отдельный диск необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Создать окно запроса и выполнить скрипт:
| USE master GO ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'Новый_Диск:\Новый_Каталог\tempdb.mdf') GO ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = 'Новый_Диск:\Новый_Каталог\templog.ldf') GO |
- Перезапустить MS SQL Server
- Включите Shared Memory, если сервер 1С расположен на том же компьютере, что и сервер СУБД.
Протокол Shared Memory позволит общаться приложениям через оперативную память, а не через протокол TCP/IP.
Для включения Shared Memory необходимо:
- Запустить диспетчер конфигурации SQL Server.
- Зайти в пункт SQL Native Client – Клиентские протоколы – Общая память – Включено
- Поставить значение Да и нажать Ок.
Протокол Именованные каналы нужно выключить аналогичным образом.
Внимание! Когда все настройки выполнены, необходимо перезапустить службу MS SQL Server
hd.oblakoteka.ru
Оптимизация запросов T-SQL MS SQL Server
Я работаю над некоторыми обновлениями для внутренней системы веб-аналитики, которую мы предоставляем нашим клиентам (в отсутствие предпочтительного поставщика или Google Analytics), и я работаю над следующим запросом:
select path as EntryPage, count(Path) as [Count] from ( /* Sub-query 1 */ select pv2.path from pageviews pv2 inner join ( /* Sub-query 2 */ select pv1.sessionid, min(pv1.created) as created from pageviews pv1 inner join Sessions s1 on pv1.SessionID = s1.SessionID inner join Visitors v1 on s1.VisitorID = v1.VisitorID where pv1.Domain = isnull(@Domain, pv1.Domain) and v1.Campaign = @Campaign group by pv1.sessionid ) t1 on pv2.sessionid = t1.sessionid and pv2.created = t1.created ) t2 group by Path;Я проверил этот запрос с 2 миллионами строк в таблице PageViews, и для запуска требуется около 20 секунд. Я дважды просматриваю кластерное сканирование индекса в плане выполнения, оба раза он попадает в таблицу PageViews. В столбце Создано кластерный индекс.
Проблема в том, что в обоих случаях она, как представляется, перебирает все 2 миллиона строк, что, по моему мнению, является узким местом производительности. Есть ли что-нибудь, что я могу сделать, чтобы предотвратить это, или я в значительной степени максимизирован с точки зрения оптимизации?
Для справки цель запроса – найти первое представление страницы для каждого сеанса.
EDIT: После большого разочарования, несмотря на помощь, полученную здесь, я не мог заставить этот запрос работать. Поэтому я решил просто сохранить ссылку на страницу входа (и теперь выйти) в таблице сеансов, что позволяет мне сделать следующее:
select pv.Path, count(*) from PageViews pv inner join Sessions s on pv.SessionID = s.SessionID and pv.PageViewID = s.ExitPage inner join Visitors v on s.VisitorID = v.VisitorID where ( @Domain is null or pv.Domain = @Domain ) and v.Campaign = @Campaign group by pv.Path; - select pv.Path, count(*) from PageViews pv inner join Sessions s on pv.SessionID = s.SessionID and pv.PageViewID = s.ExitPage inner join Visitors v on s.VisitorID = v.VisitorID where ( @Domain is null or pv.Domain = @Domain ) and v.Campaign = @Campaign group by pv.Path;Этот запрос выполняется через 3 секунды или меньше. Теперь мне нужно либо обновить страницу входа / выхода в режиме реального времени, когда записи страниц записываются (оптимальное решение), либо периодически запускают пакетное обновление. В любом случае, это решает проблему, но не так, как я предполагал.
Редактировать Edit: добавление отсутствующего индекса (после очистки от прошлой ночи) уменьшило запрос до нескольких миллисекунд). Уо!
Solutions Collecting From Web of "Оптимизация запросов T-SQL"
Для начинающих,
where pv1.Domain = isnull(@Domain, pv1.Domain)не будет SARG. Как я помню, вы не можете оптимизировать соответствие функции.
Я вернулся. Чтобы ответить на ваш первый вопрос, вы могли бы просто сделать союз на двух условиях, поскольку они, очевидно, не пересекаются.
Фактически, вы пытаетесь охватить как случай, когда вы предоставляете домен, а где нет. Вам нужны два запроса. Они могут оптимизироваться совершенно по-другому.
Какова природа данных в этих таблицах? Вы находите, что большинство данных вставляются / удаляются регулярно?
Это полная схема для таблиц? В плане запроса отображается другое индексирование. Изменить: Извините, просто прочитайте последнюю строку текста. Я бы предположил, что если таблицы регулярно очищаются / вставляются, вы можете подумать о том, чтобы отбросить кластерный индекс и использовать таблицы в виде кучи таблиц .. просто мысль
Определенно должен помещать некластеризованный индекс (ы) в Кампанию, Домен, как предложил Джон
В вашем внутреннем запросе (pv1) потребуется некластерный индекс (Domain).
Второй запрос (pv2) уже может найти нужные ему строки из-за кластеризованного индекса в Created, но pv1 может возвращать так много строк, что SQL Server решает, что сканирование таблицы происходит быстрее, чем все блокировки, которые необходимо будет выполнить. В качестве pv1-групп в SessionID (и, следовательно, он должен быть упорядочен по SessionID), некластеризованный индекс в SessionID, Созданный и включающий путь должен допускать соединение MERGE. Если нет, вы можете принудительно объединить объединение с помощью «SELECT .. FROM pageviews pv2 INNER MERGE JOIN …»
Два перечисленных выше индекса будут:
CREATE NONCLUSTERED INDEX ncixcampaigndomain ON PageViews (Домен)
CREATE NONCLUSTERED INDEX ncixsessionidcreated ON PageViews (SessionID, Created) INCLUDE (путь)
SELECT sessionid, MIN(created) AS created FROM pageviews pv JOIN visitors v ON pv.visitorid = v.visitorid WHERE v.campaign = @Campaign GROUP BY sessionidтак что вы получите сеансы для кампании. Теперь посмотрим, что вы делаете с этим.
Хорошо, это избавится от вашей группировки:
SELECT campaignid, sessionid, pv.path FROM pageviews pv JOIN visitors v ON pv.visitorid = v.visitorid WHERE v.campaign = @Campaign AND NOT EXISTS ( SELECT 1 FROM pageviews WHERE sessionid = pv.sessionid AND created < pv.created )Продолжить с doofledorf.
Попробуй это:
where (@Domain is null or pv1.Domain = @Domain) and v1.Campaign = @CampaignХорошо, у меня есть несколько предложений
-
Создайте этот закрытый индекс:
create index idx2 on [PageViews]([SessionID], Domain, Created, Path) -
Если вы можете изменить таблицу сеансов так, чтобы она хранила страницу входа, например. EntryPageViewID, вы сможете в значительной степени оптимизировать это.
sqlserver.bilee.com