Релевантность — это что такое? Факторы, влияющие на релевантность страницы. Факторы релевантности яндекса
Релевантность и ранжирование
Релевантность и ранжирование это стандартные и понятные термины для всех вебмастеров которые присутствуют в почти во всех публикациях по теме SEO. А начинающим вебмастерам хочется сказать ничего сложного в них нет со временем они станут для вас очевидными. По ним поисковые системы выстраивают иерархию сайтов в выдаче и находят документы максимально соответствующие запросам пользователей.
Релевантность и ранжирование.
 Релевантность это мера (если ее можно так назвать) соответствия одного к другому. В поисковиках это соответствие применяется к веб-страницам исходя из поисковых запросов пользователей. Чем больше соответствует содержание веб-страницы к запросу пользователя тем ближе она к первым местам выдачи (выше позиция — лучше ранжирование т.е. ранжирование это сортировка страниц в поисковой выдаче).
Релевантность это мера (если ее можно так назвать) соответствия одного к другому. В поисковиках это соответствие применяется к веб-страницам исходя из поисковых запросов пользователей. Чем больше соответствует содержание веб-страницы к запросу пользователя тем ближе она к первым местам выдачи (выше позиция — лучше ранжирование т.е. ранжирование это сортировка страниц в поисковой выдаче).
Не знаю как у вас (пишите в комментариях обсудим) а у меня есть вывод из всего вышесказанного: «SEO оптимизация это работа над искусственным повышением релевантности веб-страницы запросу для лучшего ранжирования поисковыми системами.»
Все просто идем в Яндекс или Google (а лучше и в Яндекс и в Google) выбираем запросы, которые пользуются наибольшей популярностью и делаем страницы сайта более релевантными этим запросам, чем страницы находящиеся в ТОПе.
Но не думайте, что только релевантность страниц влияет на лучшее ранжирование в поисковой выдаче. Поисковые системы учитывают множество факторов (про некоторые мы даже не знаем) влияющих при формировании выдачи. Некоторые из них нам знакомы:
1. Внутренние факторы. Поисковые системы анализируют контент расположенный на странице, ее структуру, верстку и заспамленность ключевиками.
2. Внешние факторы. Поисковики учитывают ссылочную массу, текст ссылок, количество и качество сайтов доноров, и их траст.
3. Поведенческие факторы. Поисковые машины оценивают то, как ведут себя пользователи в выдаче и дальнейшее поведение на сайте.
Ранжирование производится, основываясь на соответствие веб-страниц введеным пользователями запросам. Пользователям нет дела до того какие сайты будут занимать первые строчки выдачи им главное найти ответы на интересующие вопросы.
Поисковые системы это те же сайты в интернете (ну может не совсем простые как наши) а значит им тоже нужны, посетители. Это их прибыль, которая измеряется миллионами долларов. А как поисковики могут привлечь посетителей? Максимально релевантными страницами поисковым запросам пользователей, которые найдут искомую информацию, останутся довольными работой поисковика и в следующий раз за ответами придут сюда же.
Поисковики заинтересованы в том, что бы удержать имеющуюся аудиторию и расширить ее. Ведь от этого зависят их заработки, а SEO оптимизаторы отбирают у них часть этой прибыли. И поисковые системы будут бороться с оптимизаторами вводя все новые алгоритмы ранжирования.
Как поисковики рассчитывают релевантность?

Яндекс пользуется формулой ранжирования, которая называется MatrixNet она основана на системе обучения машин. Алгоритму подают оценки на вход которые сделали специальные люди (асессоры) а он свою очередь из этого строит формулу.
Асессорами выносятся оценки определенным сайтам по определенным запросам. Алгоритм начинаем подробно изучать сайты, которые асессоры пометили как плохие и хорошие. И основываясь на этих метках сам определяет факторы для их ранжирования. Далее он использует данную формулу в масштабах всей сети.
Яндекс использует для регионов России, стран СНГ и Турции отдельные формулы. Алгоритмы работают в автоматическом режиме, но иногда применяются полуавтоматические и ручные режимы, для корректировки релевантности в поисковой выдаче.
Какие алгоритмы использует Google пока для нас является тайной. По обрывкам информации становится понятно, что Google пользуется ручной формулой ранжирования, так как результаты автоматического ранжирования бывают непредсказуемыми (этим грешит Яндекс). Для разных стран Google использует разные формулы ранжирования.
Факторы ранжирования в поисковиках.
Внутренние факторы:
1. Текстовое ранжирование. Соответствие текста запросу.
2. Качество контента. Грамотность текста и естественность.2.1. Уникальность контента.2.2. Вторичность контента.2.3. Естественность контента.2.4. Ненормативная лексика и адалт.
3. Свойства сайта. Присутствие ключевых слов в имени домена, количество страниц и возраст сайта и домена.3.1. Возраст сайта.3.2. Формат страницы.3.3 Присутствие ключевиков в Url.3.4. Всплывающие баннеры.3.5. Плохие Ip адреса и доменные зоны.
Внешние факторы:
1. Статические факторы.
2. Динамические факторы.
3. Поведенческие факторы.3.1. Кликабельность сайта в результатах поиска.3.2. Статистика посещаемости.3.3. Поведение пользователей на сайте.
Региональные факторы.
1. Правильная доменная зона.
2. Присвоение сайту региона.
3. Употребление региона в текстах и анкорах ссылок.
4. Получение внешних ссылок с одного региона.
5. Добавление на страницы сайта адреса, индекса и телефона региона.
Запросные факторы. Нч, сч, вч и коммерческие (навигационные, транзакционные и т.д.)
Социальные сигналы. Ссылки, лайки и репосты из соцсетей.
mustic.ru
Релевантность и ранжирование. Основные их факторы.

Каждый вебмастер создавая свой сайт, хочет продвинуть его страницы на верхние позиции в поиске. Некоторые хотят донести свою мысль большому количеству посетителей, другие хотят получить доход с контекстной рекламы. Без достижения страницами ТОПа выдачи бессмысленно создавать и содержать свой сайт.
В связи с большим количеством создаваемых сайтов, поисковые системы должны постоянно совершенствовать алгоритмы ранжирования страниц, дабы они отвечали всем потребностям пользователей.
К сожалению, для оптимизаторов и вебмастеров остается неведомым большинство алгоритмов ранжирования. Тем не менее, известны основные правила составления поисковой выдачи и это уже дает возможность улучшать свой сайт.
Релевантность и ее роль в ранжировании сайта.
В работе основных поисковых систем Яндекс и Google ранжирование и релевантность – это основополагающие понятия. Высокая популярность этих систем и обусловлена тем, что пользователям выдаются результаты релевантные запросу. Релевантность означает «соответствие».
В СЕО релевантность – это степень соответствия контента страницы заданному запросу.
Ранжирование сайта.
Теперь давайте разберемся с ранжированием сайта. Ранжирование выполняется поисковыми системами для распределения страниц в поисковой выдаче.
В начале эры поисковых систем ранжирования как такового и не было. Вебмастеры просто «набивали» тексты страниц, ключевыми словами не сильно волнуясь о качестве самого контента. Большое количество ключевых фраз обеспечивали рост позиций сайта в поисковой выдаче.
На сегодняшний день ситуация изменилась. Сегодня ключевые слова играют уже не ту роль, которые они играли ранее. И каждая поисковая система старается обеспечить своих пользователей качественным контентом, а не набором ключевых фраз.
Поисковым системам выгодно выводить качественный контент на первые места в поисковых системах, дабы удерживать своих пользователей. И это верно, ведь на первых местах должны быть качественные ресурсы.
Что касается поисковой системы Яндекс, то ранжирование поисковой выдачи заключается в релевантности страницы. Для определения релевантности существует функция с множеством переменных. Переменными в данном случае выступают факторы.
Факторов, которые влияют на релевантность несколько сотен, поэтому учесть все при оптимизации контента практически невозможно. А вот учесть основные факторы, влияющие на релевантность – вполне возможно.
Основные факторы ранжирования
Как говорилось выше, общее количество факторов может быть около 200. Все они учитываются неравномерно. Их распределение зависит от тематики сайта, направленности, региона и т.д.
Предлагаем ознакомиться с основными факторами, влияющими на ранжирование поисковой выдачи Яндекса.
Внутренние факторы
Сюда входят всевозможные оценки структуры сайта и страницы:
- соответствие текста поисковому запросу;
- наличие ошибок различного вида;
- качество контента, степень оптимизации сайта и отдельных страниц;
- валидность CSS и HTML.
Внешние факторы
Сюда входят всевозможные внешние факторы:
1. Внешние ссылки. Ссылки с анкором на ваш сайт с другого, более авторитетного ресурса. В последнее время часто появляется информация об отмене ссылочного ранжирования, однако это коснется только коммерческих сайтов.
2. Факторы, не зависящие от поискового запроса. Сюда можно отнести показатели ТИЦ и траста сайта.
3. Поведенческие факторы. Это далеко не второстепенный фактор, влияющий на место сайта в поисковой выдаче. Позаботьтесь об улучшении поведенческих факторов для улучшения позиций сайта.
4. Доступность сайта и скорость работы. Эти параметры в большинстве случаев зависит от хостера. Если сайт часто не будет доступен, то вы потеряете много посетителей. Скорость работы также сильно влияет на поведенческие факторы, которые в свою очередь влияют на место в поиске.
5. Социальные сигналы. Этот фактор уже начинает оказывать небольшое влияние на ранжирование сайта, но вскоре он может оказывать чуть ли не решающее влияние на ранжирование сайта в поисковой выдаче.
Это далеко не полный список факторов влияющих на ранжирование сайта в поисковой выдаче. Учитывать все – невозможно, если использовать хотя-бы эти факторы, то можно добиться высоких позиций сайта в поисковой выдаче. Вышеперечисленные факторы относятся к Яндексу, но для Google также можно их применять.
Коммерческие факторы
В 2013 году Яндекс опубликовал отчет об изменении поискового алгоритма, введении коммерческой релевантности, частичной отмене ссылочного ранжирования. Данное заявление вызвало немало критических отзывов и существенно повлияло на дальнейшее направление развития сео-рынка. В 2015 году Яндекс заявил о полной отмене влияния внешних ссылок на ранжирование сайтов коммерческой тематики.
Что такое коммерческая релевантность?
Аналитические системы Яндекс установили, что поведение пользователей варьируется от сайта к сайту. Эксперты ПС провели ряд исследований для определения, что привлекает, а что отталкивает пользователей, что побуждает посетителя к определенному действию, а на каких сайтах пользователи бездействуют. Результатом исследования стала выборка параметров, которые легли в основу формулы ранжирования:
- Доверие
- Дизайн
- Качество сервиса
- Юзабилити
- возможность оставить комментарии и прочее
Выделенные параметры назвали одним обобщающим термином – коммерческая релевантность.

Дело осталось за малым, научить машину качественно оценивать данные параметры. На то время маховиком ранжирования поисковой выдачи Яндекс уже управляла система Матрикснет - первая система, поддающаяся обучению.
Эксперты Яндекса понимали, что единственно возможный способ научить машину понимать человека – включить человеческий фактор в механизм оценки сайтов. Для этого Яндекс набирает и обучает команду асессоров (оценщиков сайтов).
Для того чтобы исключить «шум», асессоры оценивают каждый ресурс по четко заданной схеме. Каждый весомый критерий оценивается по индивидуальной шкале (спам/плохо, удовлетворительно, хорошо, отлично), что обеспечивает объективность оценки каждой функции и характеристики сайта. Полученная асессорская оценка отправляется в центр Матрикснет, где данные используются в сложной формуле ранжирования.

Основная цель оценки коммерческой релевантности – сделать поисковую выборку по коммерческим запросам максимально очищенной от спама, а также объективно ранжировать сайты по коммерческим запросам, которые формируют достаточно высоко конкурентную среду.
Повторив действия асессоров, можно узнать уровень коммерческой релевантности ресурса. Понять и устранить причины, мешающие сайту подняться в ТОП
Весь процесс асессорской оценки условно разделяется на два этапа: определение тематической релевантности и собственно оценка факторов коммерческой релевантности. Каждой оценке соответствует числовое значение. Так мнение человека приобретает численную форму.
Для простоты понимания Яндекс приводит упрощенный вид формулы коммерческой релевантности:
Коммерческая релевантность = ассортимент* (2 доверия+дизайн+юзабельность+2качества сервиса)
В этой формуле Яндекс применяет удваивающий коэффициент для параметров доверие пользователей и качества сервиса. Аналитики ПС полагают, что именно эти факторы в значительной степени определяют вероятность посещения сайта пользователями и совершения необходимого действия (заказа, звонка, покупки). Однако Яндекс сообщает, что формула гораздо сложнее, в ней участвует намного большее количество параметров, с разными весовыми коэффициентами.
Мы провели исследование и включили в развернутую оценку коммерческих факторов максимум параметров, оказывающих влияние на пользователя и принимающихся во внимание поисковыми системами. В список вошли такие параметры как:
- детальная контактная информация
- страницы компании в социальных сетях
- отсутствие рекламы
- ассортимент продукции
- качественно заполненные карточки товаров
- соответствие заголовка страницы ее тематическому содержанию
- читабельность и понятность информации
- выбор способов доставки и оплаты
- работа службы поддержки клиентов
- наличие онлайн-консультанта
- скидки и акционные предложения
и многие другие.
Конечная формула ранжирования поисковой выдачи в Яндекс выглядит следующим образом:
Релевантность сайта запросу = Тематическая релевантность + α коммерческой релевантности, где α – весовой коэффициент.
Коммерческая релевантность входит как один из главных параметров в общую формулу ранжирования Яндекса, а значит повысив уровень коммерческих факторов сайта, ресурс существенно улучшает свои позиции в поисковой выдаче.
getgoodrank.ru
определение и факторы на нее влияющие

И вновь приветствую вас, читатели блога int-net-partner.ru. Сегодняшняя статья будет полезна начинающим вебмастерам и оптимизаторам, которые только знакомятся с базовыми понятиями. Вы узнаете о том, что такое релевантность и как она влияет на результаты поиска.
В представленных, на первый взгляд непонятных, терминах нет ничего сложного. Как не трудно было догадаться, они касаются построения иерархии сайтов в поисковых системах в зависимости от запроса пользователя. Чтобы разобраться в этих вопросах, сначала стоит понять, что такое ранжирование и релевантность.
data-ad-client="ca-pub-8243622403449707"data-ad-slot="1319308473"data-ad-format="auto">
Релевантность информации представляет собой степень соответствия какого-то объекта определенному признаку. Также это касается соответствия запроса пользователя и виртуальной страницы (веб страницы,документа), найденного в качестве ответа. Чем больше соответствует запрос содержанию веб страницы ресурса, тем на более высоких позициях он будет находиться в поисковой выдаче, то есть лучше ранжироваться.
Таким образом, SEO оптимизация — это способы искусственного повышения той самой релевантности любой страницы вашего сайта к определенному конкретному запросу. Подробно об этом я писал здесь.Как же можно искусственно повысить релевантность страницы сайта? Механизм очень прост. Для начала подбирается список наиболее часто задаваемых в поисковых системах фраз, запросов. Далее предпринимаются меры, чтобы определенные страницы вашего ресурса стали более релевантным и вышли на первые места поисковой выдачи.
Существуют определенные группы факторов, влияющих на выдачу. Рассмотрим и их:
- Внутренние. Они зависят в первую очередь от структуры сайта, его контента, правильности верстки, заспамленности ключевиками (ключевыми словами)
- Внешние. Во внимание берутся тексты ссылок, которые ведут на Ваш ресурс, их качество и количество. А также траст вашего сайта.
- Поведенческие факторы. Идет оценка поведения пользователей в поисковой выдаче и на самом Интернет-ресурсе. Поисковики хотят узнать насколько определенная страница ресурса отвечает запросам пользователей.
Из всего сказанного можно сделать вывод о том, что ранжирование в выдаче зависит от соответствия определенного веб-документа запросу, введенному пользователем.
Чем же поисковая система может привлечь посетителя? Максимально точным определением релевантности текста (веб-страниц) в Топе по запросу пользователя. Если это будет выполнено, то следовательно, ранжирование будет более точным, и пользователь найдёт то, что ему надо и останется довольным.
Поэтому в борьбе за посетителей оптимизаторам необходимо придумывать максимально точные ответы на заданные вопросы. В этом отличным помощником может быть статистика поисковых запросов Яндекса и Гугла. Владеть информацией — значит быть впереди своих конкурентов.
Ну а что же или кто мешает Яндексу, Гуглу и другим поисковым системам правильно оценивать релевантность поиска информации? Собственно, ответ прост. Это оптимизаторы, которые действуют благодаря принципам SEO. Правильная оптимизация позволяет делать страницы любого ресурса более релевантными.
И все это благодаря использованию ключевых слов, запросов, покупке внешних ссылок с нужными анкорами. И, разумеется, поисковых программ такой расклад не устраивает. Следовательно, борьба с нестандартными методами повышения релевантности будет всегда актуальна, так как пользователь может получить не совсем релевантный запрос.
Существует формулы определения релевантности. Наверняка они будут интересны начинающим вебмастерам.
Поисковая система Яндекс работает по формуле ранжирования сайта, основанной на системе машинного обучения MatrixNet. Построением той или иной формулы занимается алгоритм, в котором есть оценки, сделанные специальными людьми. Они занимаются тем, что выносят оценки сайтам по тем или иным запросам. Ранжирование данных впоследствии осуществляется благодаря разнообразным оценкам.
А теперь, что касается Гугл. Информации об использовании формул практически нет. Остается делать только догадки. Результаты выдачи порой бывают непредсказуемыми. Скорее всего, Гугл использует ручную форму ранжирования.
Факторы ранжирования в поисковиках

Известны и основные факторы ранжирования в популярных поисковиках (Яндекс и Гугл):
1. Внутренние факторы делятся на несколько категорий:
- Текстовое ранжирование. Это касается того, насколько текст того или иного документа соответствует заданному запросу пользователя.
- Качество контента, помещенного на ресурс. Рассматривается грамотность текста, его уникальность и естественность.
В этом пункте я думаю всё понятно, кроме естественности текста. При определении естественности контента используется метод математической лингвистики. Поисковик сопоставляет количество вхождений той или иной части речи со средним значением всей базы документов. Таким образом исключается неестественность контента, если вы пытались повысить релевантность, путём увеличения количества ключевых слов.
Также следует добавить, что вы можете легко схлопотать фильтр, если у на сайте присутствует ненормативная или адалт лексика.
- Свойства самого сайта. Имеется ввиду возраст ресурса, наличие ключевых слов в названии домена, количество веб документов, формат документа, всплывающие баннеры, качество доменной зоны.
- Возраст сайта — здесь имеется в виду возраст Интернет — ресурса, с момента попадания в индекс поисковых систем, а также возраст веб страницы, релевантность которой оценивает поисковик. На самом деле это очень и очень важный фактор. В Интернете на эту тему множество статей написано. Вот Яндекс, например, не даёт пробиться сайтам по тем или иным конкурентным запросам, если их возраст менее года. У Гугла на этот счёт предусмотрен фильтр "песочница". Говорят сайт начинает хорошо ранжироваться примерно через три года.
- Формат документа — рекомендуется продвигать документы формата html, они лучше всего ранжируются нежели документы других форматов.
- Ключевые слова — наличие ключевых слов в URL-адресе Интернет — ресурса. Есть вероятность попадания под фильтр поисковых систем.
- Всплывающие баннеры — приводит к пессимизации (из-за вычитания значения релевантности, происходит понижение в позициях) Интернет — ресурса.
- Качество доменной зоны — например, регистрация в заспамленной доменной зоне или покупка бесплатного или дешёвого хостинга, на IP — адресе которого весит множество откровенных ГС, или на вас было зарегистрировано несколько ГС и вы зарегистрировали, наконец-то, СДЛ, то ранжирование будет занижено и хороших позиций сайта не ждите.
2. Внешние факторы ранжирования. Делятся они всего на две категории:
- Статические факторы. Это, прежде всего, касается тех факторов, которые не зависят от того, по какому запросу поисковик обязан определить релевантность того или иного документа. Это тИЦ, Page Rank и тому подобные.
- Динамические факторы (ссылочное ранжирование). Речь идет о том, насколько релевантны тексты ссылок, ведущие на данную статью (страницу), тому запросу, который интересует пользователя (который посетитель вводит в поиске).
- Пользовательские и поведенческие факторы. Это группа факторов, которые учитывают, как ведет себя тот или ной пользователь на анализируемом сайте. К таким факторам обычно относят:
- Кликабельность ресурса (CTR). Это, пожалуй, самый важный фактор. Он определяет заинтересованность пользователей конкретным ресурсом, а также оказывает влияние на попадание в топ, ИМХО.
- Статистика посещаемости. Учёт источников трафика на сайт ( кто и откуда пришёл к вам на страницу сайта).
- Поведение пользователей на странице ресурса. Пользователи могут долгое время оставаться на страницах ресурса или же мгновенно закрывать сайт. Также учитывается количество переходов с одной страницы на другую (внутренние переходы) и другое. Могут делаться отдельные выборки посетителей по тому или иному запросу, по конкретному региону. Но это уже подробности, нам главное суть уловить.
- Региональные факторы. Здесь основной упор делается на определение регионов, в которых тот или иной ресурс становится популярным.
- Запросные факторы. Для информационных и коммерческих запросов могут использоваться разные формулы расчета релевантности.
Вот вы и узнали о том, что такое релевантность и ранжирование, теперь эти вопросы не застану врасплох.
Пока-пока!
P.S.
Как вам статья? Рекомендую получать свежие статьи блога на e-mail, чтобы не пропустить много новой интересной информации!
С уважением, Александр Сергиенко
int-net-partner.ru
Релевантность — это что такое? Факторы, влияющие на релевантность страницы | yurbol.ru
В этой статье речь пойдет о релевантности страниц сайта. Не буду писать умными словами, а объясню определение релевантности по-простому, чтобы каждому было понятно. Релевантность-это максимальное соответствие документа заданному поисковому запросу пользователя. По релевантности можно судить о работе поисковых систем. Если пользователь задал поисковой запрос в какой-либо поисковой системе, и поиск выдал результаты, где нету того ответа на вопрос ,который искал пользователь, то явно поисковик работает плохо. Из всех поисковиков, я лично ставлю на первое место Google а потом Яндекс, именно в этих ПС я получаю наиболее точные ответы ответы.
Содержание статьи
Отчего же зависит релевантность?
У ПС есть свой алгоритм расчета релевантности.Конечно, у каждой ПС он разный, но принцип работы алгоритма у всех одинаков с небольшими отличиями, так сказать фишками, которые есть у каждого, чтобы хоть чем-то отличаться от своих конкурентов. К сожалению точно неизвестно на 100% по каким именно критериям идет расчет релевантности , так как каждый поисковик это хранит в секрете, но основной принцип работы этого алгоритма известен благодаря экспериментам сеошников и конференциям где представители поисковой системы рассказывали некоторые факторы расчета релевантности.
- Сперва из базы отбираются страницы, где часто встречается заданный пользователям запрос.
- Потом отсеиваются сайты за которыми были замечены методы использования черного seo (клоакинг, дорвеи,и т.д) и площадки которые находятся под различными фильтрами.
- Далее отсеиваются документы, где нету четкой информации для пользователя.
- Потом идут вход внутренние факторы.
К внутренним факторам относятся следующие:
- Частота поискового запроса в тексте. Алгоритм отбирает документы, на которых наиболее часто встречаются слова и точные вхождения из заданного запроса. В народе этот фактор прозвали плотностью ключевых слов. У каждого поисковика эта цифра разная. Но скажу следующие- главное не переборщить. Оптимальный вариант плотности ключа в тексте не больше 2%. Если сделаете больше, то возможен фильтр за переспам ключами в тексте. Так что держите плотность ключа в районе 1.5-2%. Ну а точные вхождения употребляйте на 1000 знаков текста 1 раз, если запрос СЧ или ВЧ, если НЧ, то можно на всю статью употребить один раз. Это оптимальный вариант, не навредит вашим страница и сделает их более релевантными;
- Месторасположение слов в заголовках. Здесь имеется в виду то, что желательно ключи и точные вхождения, которые вы продвигаете употребить в самом начале заголовка (h2) и в теге Title. Чем ближе ключи к началу, тем выше будет релевантность ;
- Близость ключей и точных вхождений к началу страницы. Поисковые роботы при сканировании документа идут с самого начала и в самый конец. Если продвигаемые ключи и точные вхождения будут в самом начале текста, то роботы их заметят намного раньше, и возможно выдадут страницу выше в выдаче;
- Наличие ключевых слов в тегах h3-h4, Description,Keywords. Не будет лишнем, если вы употребите ключи в тексте в тегах h3-h4. Про h2 я писал выше, это заголовок , а теги h3-h4 это добавочные, также показывают значимые ключи в тексте поисковикам. Про Description,Keywords точно не скажу, так как многие говорят, что ПС уже их не учитывает при расчете;
- Наличие в тексте синонимов ключевых слов. Старайтесь в тексте употреблять синонимы ключей по которым продвигается документ. Поисковики стали учитывать этот фактор довольно сильно при расчете релевантности;
Внешние факторы
Наличие обратных ссылок на продвигаемую страницу. Если ,к примеру, на мою страницу будет много ссылаться сайтов, то значит пользователям мой текст помог найти ответ и они этой информацией делятся с другими. ПС эти ссылки видят и учитывают при расчете релевантности. Раньше только одними ссылками можно было загнать продвигаемую страницу в ТОП, не прибегая к внутренним факторам. Люди покупали кучу ссылок на продвигаемый запрос. Кто больше купил, тот и в ТОП. Но поисковики со временем просекли эту хитрость, так как в ТОП выходили тексты, которые не были максимально релевантны, и пользователи не находили то, что искали. Получалось то, что выдача была нерелевантна, а в ТОПЕ находился один мусор. Сейчас ПС уже ссылки не так сильно учитывают как раньше. Да и если просекут, что ссылки покупные ,а не естественные, то документ не только вылетит из ТОПА, но еще можно получить на сайт фильтр. Поэтому те, кто до сих пор продвигаются ссылками маскируются, не прибегают к сервисам, где продают временные ссылки, закупаются только вечными, проставленным в ручную в статьях, а не программами в сайдбаре и футоре. Яндекс так вообще отказался от учета ссылок по коммерческим запросам в Регионе Москве, но по остальным регионам и информационным сайтам ссылки еще работают, хоть и не так сильно как раньше.
Поведенческие факторы
Поведенческие факторы также играют большую роль . К примеру, вы пробились в ТОП за счет внутренних и внешних факторов и к вам пошел посетитель из поиска, но пользователь не находит у вас то что он искал и быстро закрывает страницу в и обратно возвращается в поиск с таким же запросам. В этом случаи ваша страница долго в ТОП не пробудет. Поисковики это видят, и понимают, что на вашей странице нету ничего полезного. Поэтому, нужно сделать так, чтобы по запросу который вы продвигаете, пользователь нашел то, что искал.
Авторитетность сайта
Как ни странно, но чем старше ресурс, чем выше у него внешние факторы, тем выше документы этого сайта будут оказываться в ТОП. К примеру, есть два сайта. Одному два года, а другому 5 месяцев. Допустим что внешние факторы (ссылочная масса) у обоих сайтов одинаковая но у сайта которому 5 месяцев выше внутренние факторы и поведенческие . Но все ровно сайт которому 2 года, будет выше в ТОП в 80% случаев, чем ресурс с 5 месяцами жизни. А все потому, что здесь играет роль возраст. Чем больше возраст, тем авторитетнее сайт в глазах ПС. Поисковики доверяют больше ресурсу который живет уже не первый год, нежели молодому сайту.Чтобы обойти в поиске так сказать старичков, нужно чтобы вы обходили их по внутренним,внешним и ПФ, и имели возраст хотя бы один год. А до этих пор, вы будете брать только огрызки, весь траф будут собирать старички, так как ПС уважают возраст, и придают страницам сайтов с большим возрастом большую релевантность.
Заключение
Ну вот в принципе и все, что я хотел рассказать про релевантность. Конечно, это не все факторы, их намного больше, но факторы которые я перечислил, имеют наиболее значимый вес.
yurbol.ru
как не загубить оптимизацию под длинный хвост ключей
Cеошная общественность бурно обсуждает новый алгоритм Яндекса Баден-Баден. Не особо продуктивное занятие, на мой взгляд. Слишком мало времени прошло. Вряд ли у кого-то накопились достоверные наблюдения по хорошей выборке пострадавших сайтов. Тем более наивно ждать эффективную методику снятия. Да что там, пока даже неизвестно, включен ли алгоритм на полную мощность.
Ясно только одно: оптимизацию теперь нужно делать еще аккуратнее и тщательнее. Поэтому нелишне будет разобраться в достаточно редко упоминаемом факторе текстовой релевантности – YMW. Он основан на размере минимального куска текста, включающего максимальное количество встречающихся в документе слов запроса.
Статья Александра Сафронова “Тестирование простой ранжирующей формулы”
В публикации описана формула ранжирования, разработанная сотрудниками Яндекса для экспериментальной оценки отдельных факторов. Среди них – в первую очередь хорошо знакомые оптимизаторам вариации BM25 а также пара метрик, оценивающих близость слов запроса.
Вот описание одной из них – YMW:

Впали в уныние от нагромождения формул? Напрасно! Разобраться не так сложно. Внимательно читаем легенду:

Вторая же часть формулы представляет поправку на тот случай, если в тексте документа содержатся не все слова запроса. Она оперирует понятием “вес слова”. IDF (inverse document frequency) – оценка частоты встречаемости слова во всей базе документов в поисковой системе. Эта величина используется во многих других факторах текстовой релевантности.
Теперь опустим конкретные знаки действий и логарифмы, просто отметим, какие параметры увеличивают итоговую оценку, а какие уменьшают.
- Минимальный размер “окна” в котором встречаются все слова запроса – находится в знаменателе дроби. Чем он меньше, тем выше значение фактора.
- Количество слов запроса, встречающиеся в документе – вычитаются из знаменателя. Чем больше, тем выше значение фактора.
Видите? От всей сложной формулы остается всего два параметра, специфичных для рассматриваемого фактора. Чуть ниже будет еще более наглядное объяснение, а пока проясним важный вопрос:
Стоит ли вообще учитывать этот фактор?
Рассматриваемая статья достаточно старая, выпущена еще в 2010 году. Тем не менее, я считаю, что по крайней мере общие тенденции, выделенные выше, остаются актуальными. Вот несколько причин:
- Судя по свежему докладу об устройстве поиска Яндекса, статья описывает вполне актуальные подходы к тестированию новых факторов ранжирования (вторая часть публикации).
- Фактор упоминается в ТЗ на SEO-текст сравнительно редко. Поэтому поисковым системам не было нужды его отбрасывать под давлением оптимизаторов. Вообще он актуален для длинных запросов, под которые редко продвигают специально.
- Группировка слов запроса в пределах абзаца-двух характерна для качественного профессионального контента. Очевидно, что слова, связанные с конкретной темой будут сами по себе тянуться друг к другу: их связывает общая мысль.
- В той же статье указан фактор “кучности”. То есть близость слов – это реально важный фактор, поисковик пытается “зацепить” его разными способами.
Думаю, достаточно. Переходим к самому интересному – практике и выводам.
Как неосторожный оптимизатор может уменьшить релевантность текста
Если мы имеем дело со страницами, которые не претендуют на другие ключи, кроме вставленных в title, то фактор не будет особо значим. Ясно, что в этом случае мы получим очень маленькое “окно” – сам title. А вот если мы хотим сэкономить на создании страниц и одной статьей охватить десяток-другой среднечастотников и сотни их мелких НЧ-расширений – то учитывать YMW необходимо.
Сначала пример как делать НЕ надо (заодно буквально в картинках разберем суть фактора).
Допустим, у нас есть статья, в которой упомянут определенный ключевик:

Потом до нее дотянулись шаловливые ручки оптимизатора и он решил расширить семантику а также напичкать текст модными LSI-словами. Загнал запросы в сервис генерации ТЗ, вытащил уйму расширений и тематичных слов. Отдал копирайтеру. Копирайтер не заморачиваясь дописал лишний абзац, куда густо натыкал затребованные термины. На выходе получилось это:

Все что надо – упомянуто. Ура?
Не совсем. Давайте прикинем YMW для “запрос из трех слов + расширение 1” до и после доработки. Смотрим сделанный выше вывод из формулы: чем меньше размер “окна” содержащего все слова запроса и чем больше слов из запроса встречается в документе – тем сильнее оценка фактора.
До:
- размер окна, включающего все слова: 3 (они просто идут вместе).
- число слов: 3 из 4
После:
Окно резко выросло!
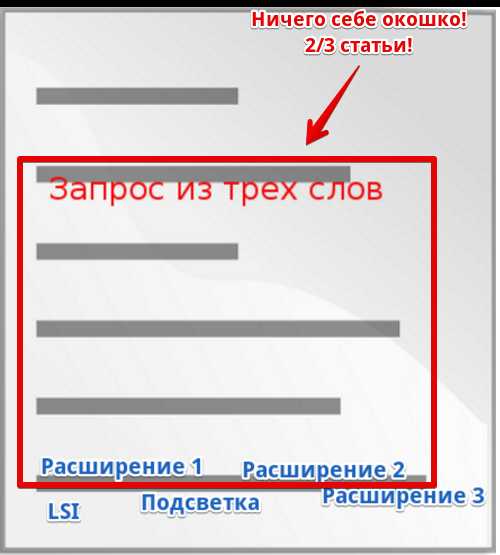
То есть мы что-то добавили к итоговой оценке YMW за счет вхождения всех слов запроса и одновременно убавили, сделав окно огромным. Итоговое значение при этом могло упасть. Оцените порядок цифр в знаменателе первой дроби: для первого случая это (3 – 3 + α) а во втором что-то вроде (500 – 4 + α).
Конечно, другие факторы при этом могут сыграть в плюс (вхождение всех слов запроса – сильный сигнал). Но полного эффекта, который могло бы дать расширение семантики мы не получим.
Заметьте кстати: негативное влияние бездумного добавления ключей прослеживается на примере даже простого фактора ранжирования, без привлечения факторов антиспама.
Выводы
- Фактор YMW имеет смысл учитывать в текстовой оптимизации. Особенно с учетом резко негативного отношения поисковых систем к традиционным методикам, опирающимся на число вхождений.
- При продвижении под кластер ключей необходимо следить за близостью ключевых слов и расширений запроса в пределах страницы. Принцип максимального сокращения межсловных расстояний нужно применять не только к основным ключевым словам. Требуется проектировать страницу так, чтобы ему соответствовал весь набор поисковых фраз, включая микро-НЧ, предусмотреть которые невозможно.
- Добавление на страницу связанной лексики без учета расположения основных ключей не даст полного эффекта.
- Для оптимизации под длинный хвост в отношении YMW лучше всего подходят тексты с четкой структурой, разбитые заголовками на небольшие блоки. При этом каждый блок должен быть посвящен раскрытию конкретной под-темы и содержать максимум лексики, которая с ней связана. Нежелательна ситуация, когда запрос используется в одном блоке, а важное расширение в другом.
Поделиться
Твитнуть
Поделиться
Отправить
Плюсануть
alexeytrudov.com
| 1. Примерный алгоритм определения релевантности документа запросу. Довольно часто, особенно от людей, недавно занявшихся поисковой оптимизацией, приходится слышать просьбу раскрыть "волшебную формулу", с помощью которой можно добиться хороших позиций в поисковых системах. Как частный случай можно привести также вопрос о плотности ключевых слов на странице (с точностью до сотых долей процента), необходимый для попадания на первые строчки выдачи. Сразу же хочу предупредить вас - таких формул и магических цифр нет. Не правы и те, кто считает алгоритмы поисковых систем абсолютно недоступными "простым смертным". Да, действительно, эти алгоритмы никогда не будут раскрыты во всех тонкостях, потому как слишком много желающих делать "идеальные" странички и занимать первые места в поисковиках, зачастую ухудшая тем самым качество поиска, т.е. выдаваемой пользователю информации. Однако, основные принципы работы алгоритмов ранжирования документов всё же известны, и прежде чем начать рассказывать о каждом из факторов, оказывающем влияние на релевантность документов запросам, мне хотелось бы ознакомить вас с обобщенной формулой, аппроксимирующей формулы ранжирования, используемые четверкой наиболее популярных в Рунете поисковых машин (Яндекс, Рамблер, Апорт и Google). Повторяю, что это не есть конкретная формула, используемая в поисковых машинах, это лишь сильно укрупненная формула, приближенно описывающая процесс определения релевантности документа запросу. Вот она: Rа(x)=(m*Tа(x)+p*Lа(x))* F(PRa),где: Rа(x) - итоговое соответствие документа а запросу x, Tа(x) - релевантность текста (кода) документа а запросу x, Lа(x) - релевантность текста ссылок с других документов на документ а запросу x, PRа - показатель авторитетности страницы а, константа относительно х, F(PRa) - монотонно неубывающая функция, причем F(0)=1, можно допустить, что F(PRa) = (1+q*PRа), m, p, q - некие коэффициенты.Конечно же, эта формула даёт очень общее представление об алгоритмах ранжирования документов в результатах поиска и даже может вызвать недоумённый вопрос - "почему же, если все поисковики пользуются подобным алгоритмом, результаты в них зачастую сильно различаются?". Как говорится, "дело в деталях". Любой из этих показателей является функцией от других, которые могут учитываться или нет поисковой системой, причём каждый из этих показателей имеет свой "вес", а точнее коэффициент, различный для каждого конкретного поисковика. Также влияние могут оказывать собственные ресурсы поисковых систем, прежде всего их каталоги. Обо всём этом мы и будем говорить далее, а сейчас хочу обратить внимание лишь на то, что итоговое положение сайта в результатах поиска зависит от 3-х основных составляющих:
Вот с этого "показателя авторитетности" мы и начнём более подробно рассматривать факторы, влияющие на релевантность документов запросам. 2. Факторы, не зависящие от запроса (статические). Если выразиться точнее - фактор, который в общем случае имеет название показатель авторитетности или ранг документа. В нашей формуле он обозначается как PRa. В рассматриваемых поисковых машинах он именуется по-разному, однако все они при его расчете используют алгоритмы, учитывающие гиперссылки между документами. Эти алгоритмы являются, по сути, модификациями алгоритма PageRank, придуманного в свое время двумя американскими аспирантами Сергеем Брином и Ларри Пейджем, основавшими в последствии поисковую машину Google. PageRank в Google С ростом объёма информации в интернете вообще и информации, индексируемой поисковыми системами в частности, перед разработчиками поисковиков встала серьёзная проблема - количество одинаково релевантных запросу документов было велико, и корректно ранжировать их в результатах поиска становилось всё сложнее. К тому же алгоритмы ранжирования, разработанные для контролируемых коллекций документов, оказались беззащитны перед простейшими способами воздействия на них, когда для обеспечения хорошего результата достаточно было просто скопировать структуру расположения ключевых слов из текста хорошо ранжируемого по этому запросу документа. Появилась необходимость разделять информацию на более и менее достоверную, учитывать "важность" или "авторитетность" ресурсов, предоставляющих её. Как это сделать? Лучше всего на основе данных о популярности страницы у пользователей, например посещаемости. Но тогда потребуется устанавливать какой-либо счётчик на каждую страницу. Такой вариант для глобального поиска не подходит. Тогда в качестве критерия была выбрана теоретическая посещаемость страницы. Была разработана модель, эмулирующая движение пользователя по документам сети путем перехода по ссылкам с документа на документ, подразумевающая, что пользователь с равной долей вероятности перейдет по любой из ссылок, содержащихся в документе, который он в данный момент просматривает. Следовательно, вероятность пользователя попасть на конкретный документ будет зависит от количества ссылок на него с других документов и от того, насколько вероятно нахождение пользователя на одном из ссылающихся документов и сколько исходящих ссылок содержит этот ссылающийся документ. Эта вероятность и была принята за показатель авторитетности или ранг страницы (PageRank): где PRa - PageRank рассматриваемой страницы, d - коэффициент затухания (означает вероятность того, что пользователь, зашедший на страницу, перейдет по одной из ссылок, содержащейся на этой странице, а не прекратит путешествие по сети, обычно устанавливается равным 0,85), PRi - PageRank i-й страницы, ссылающейся на страницу а, Ci - общее число ссылок на i-й странице.Одним из распространенных заблуждение является то, что можно вычислить PageRank по этой формуле для отдельно взятого документа, используя известные значения PageRank для ссылающихся на него документов. Так делать нельзя. Чтобы вычислить PageRank какого-либо документа надо составить систему N линейных уравнений данного вида для каждого из документа из поисковой базы, где N - количество документов в поисковой базе. Причем, для выполнения условия, что сумма значений PageRank для всех документов (т.е. вероятность того, что пользователь находится на любой из страниц) равна 1, к свободный члену (1 - d) в каждом уравнении добавляют множитель 1/N. Эта система будет содержать N неизвестных. Решив ее, получим значения PageRank для каждого документа, известного поисковой машине. В поисковой базе крупнейших поисковых машин содержится огромное количество документов. Несмотря на то, что матрица, соответствующая системе уравнений будет сильно разрежена, численное решение этой системы требует огромных вычислительных мощностей. Поэтому поисковая система должна постараться максимально упростить процесс расчета, вводя некоторые допущения. Вот эти конкретные особенности реализации классической формулы PageRank, увы, составляют коммерческую тайну поисковых машин. Нормированное значение PageRank для конкретного документа, загруженного в браузер, можно узнать, скачав и установив Google ToolBar - специальную панель инструментов для работы с этим поисковиком. ВИЦ в Яндексе В Яндексе аналогичная PageRank величина, обозначающая количественное представление "авторитетности" страницы и называемая "взвешенный индекс цитирования" - ВИЦ, была введена весной 2001 года. Как говорили сами представители Яндекса, ВИЦ высчитывается на основе классического алгоритма PageRank "с точностью до деталей реализации". До осени 2002 года ВИЦ можно было посмотреть с помощью Яндекс-Бара, специальной панели инструментов. В нем отражался ВИЦ главной страницы с точностью до сотых. Теперь в этом индикаторе отображается значение тИЦ, совсем другого показателя, использующегося для ранжирования ресурсов в каталоге Яндекса, и узнать значение ВИЦ не представляется возможным. ИЦ в Апорте Апорт в 1999 г. первым из отечественных поисковых систем стал использовать для ранжирования документов модификацию классического алгоритма PageRank. Показатель авторитетности документа имеет название "Индекс Цитирования" - ИЦ (также представители Апорта называют его в своих документах как Page Rank, так и взвешенный индекс цитирования). Самым кардинальным отличием от классического PageRank в Апорте является то, что пре расчёте ИЦ документа им учитывается всего одна, "лучшая" ссылка со всех страниц домена второго уровня. "Лучшей" считается та ссылка, которая передаёт наибольший вес документу. Индексом цитирования сайта (он же Site Rank), использующегося для ранжирования сайтов в каталоге Апорта, считается наибольший индекс цитирования из всех страниц сайта. Значение ИЦ можно узнать только для сайтов, зарегистрированных в каталоге, в соответствующей ему категории. Коэффициент популярности в Рамблере. С осени 2002 года поисковая машина стала рассчитывать для каждого документа коэффициент популярности. Вот что сказано на сайте Рамблера об этом коэффициенте: "Данный коэффициент, как и алгоритм PageRank, основан на учете гиперссылок между страницами сети, однако наша реализация дополнительно использует данные о реальной посещаемости страниц, полученные от счетчика Top100. Дело в том, что "классические" ссылочные алгоритмы фактически учитывают мнение только одной категории пользователей сети - web-мастеров. Действительно, если большому количеству web-мастеров нравится тот или иной ресурс, они размещают на него ссылки. Обычные пользователи, как правило, созданием страниц и сайтов не занимаются, и поэтому учесть их мнение оказывается невозможно. Счетчик Top100 как раз и предназначен для того, чтобы сделать коэффициент популярности более справедливым". Однако, судя по всему, в последнее время данные о посещаемости документов, полученные от счетчика Top100, оказывают все меньшее и меньшее влияние на коэффициент популярности, так как счетчик не в состоянии противостоять массовым накруткам, практикуемым владельцами некоторых сайтов. Соответственно, все большее значение приобретает составляющая, вычисляемая на основе учета гиперссылок между страницами сети. Необходимо, заметить, что некоторые документы и даже целые сайты в поисковых машинах могут по той или иной причине исключаться из процесса расчета ранга документа, на который они ссылаются. Так, например, в Яндексе для этих целей существует так называемый "непот-фильтр", который накладывается на ресурсы, находящиеся на бесплатных хостингах, но не описанные в Яндекс-каталоге, ресурсы со свободным размещением ссылок (например, гостевые книги, доски объявлений), сайты, размещающие на своих страницах ссылки, невидимые пользователю и т.п. Резюмируя вышесказанное, можно сказать, что для повышения ранга страницы необходимо работать над тем, чтобы как можно большее количество документов сети ссылалось на него. Делать это можно различными способами - с помощью обмена ссылками с другими сайтами, регистраций в каталогах и различных тематических ресурсах и т.д. Идеальный способ - сделать свой сайт настолько уникальным и интересным, чтобы владельцы других ресурсов сами считали необходимым поставить ссылку на него. Не следует также забывать, что при расчете ранга документа учитываются как внешние, так и внутренние ссылки. Поэтому грамотная перелинковка документов внутри сайта позволяет повысить ранг самых важных из них с точки зрения содержащейся информации. Наиболее важные в этом смысле документы обязательно должны иметь ссылку с главной страницы сайта, которая, как правило, имеет максимальный ранг среди всех страниц сайта вследствие того, что на нее указывает большинство внешних ссылок на сайт. 3. Факторы, зависящие от запроса (динамические). Внутренние динамические факторы. Внутренние динамические факторы (в нашей формуле они используются при вычислении составляющей Tа(x)) гораздо более легки в понимании, чем показатели авторитетности, хотя бы потому, что доступны для просмотра любому пользователю. Они легко могут быть изменены владельцем ресурса с целью достижения нужных позиций в результатах поиска. Именно поэтому в настоящее время соответствие кода страницы запросу является, пожалуй, наименее слабым фактором в алгоритмах ранжирования поисковых систем, и достичь хороших результатов в ранжировании по серьезным запросам, основываясь только на работе с внутренними факторами, практически невозможно. Я не случайно сказал именно "кода страницы" потому, что помимо собственно текста к внутренним факторам относятся также элементы форматирования текста и служебные тэги. Итак, по порядку. Непосредственно текст страницы оценивается поисковой системой по двум основным характеристикам: расположение искомого текста на странице и частота встречаемости слова из запроса в документе по сравнению с другими словами. Что касается расположения текста на странице, то больший вес имеют слова, расположенные ближе к началу документа и предложения. Ведь считается, что в начале чаще располагается важная информация. Также особенно ценится поисковиками "точное вхождение" искомой фразы в текст документа для запросов из нескольких слов, т.е. текст, идентичный запросу, с сохранением порядка слов в запросе. В этой связи хочется отметить вот ещё что. Несмотря на то, что поиск по стоп-словам, к которым относятся, в основном, предлоги, союзы, частицы и междометия, не производится, при ранжировании документов они всё же используются, что может очень серьёзно повлиять на выдачу. Сравните запросы из 2-х слов с союзом "и" между ними, например "бумага и картон" и "бумага картон". Тоже можно сказать и о морфологии запроса, предпочтительно, чтобы слова из запроса в тексте были в той же форме, что и в самом запросе. Особенно это касается Рамблера. Для Google это имеет принципиальное значение, так как русской морфологии он не поддерживает. Кстати, у Рамблера есть ещё одна интересная особенность - этот поисковик считает знаки пунктуации словами. Запятая между двумя словами становится третьим словом. Относительно частоты употребления слов в документе сказано немало. Часто от новичков приходится слышать вопрос об "идеальной" плотности ключевых слов с точностью до сотых процента. Существуют рекомендации об использовании ключевого слова на странице в пределах 3-7%. Однако, точные цифры не известны. Считается что, страница со слишком часто встречающимся словом запроса может посчитаться спамом, и ее позиция в результатах поиска может быть автоматически понижена. Это утверждение довольно спорно. Ведь если на странице всего 3 слова и запрос содержит эти же 3, то плотность составит 100% - однако такие страницы прекрасно находятся в поиске. Гораздо более вероятно, что существуют некие пороговые значения, после достижения которых дальнейшее увеличение частоты не влияет на релевантность документа. Представители Апорта, например, определенно говорили о наличии в их поисковой системе подобного порогового значения. Лично я при употреблении слов на странице руководствуюсь, прежде всего, понятием разумности - пользователю должно быть удобно читать текст - и ни разу не высчитывал эту величину для своих сайтов и сайтов конкурентов. Кстати, не следует забывать и о том, что поисковые машины накладывают ограничения на индексируемый объем документа. Так, Google индексирует только первые 101 килобайт, Рамблер - 200 килобат, Апорт - 128 килобайт. По Яндексу у меня такой информации, к сожалению, нет, но, я думаю, что и у него имеется ограничение на индексируемый объем документа примерно в пределах 100-200 килобайт. Элементы форматирования текста. К таковым относятся заголовки(<h2>, ..., <h6>), а также тэги <strong>, <em>, <b>, <i>. Если некоторая часть текста выделяется, значит, с точки зрения поисковой системы, в этой части содержится более важная информация, следовательно, документ посвящён этой теме и более релевантен запросу, если слова из него, содержатся в выделенном тексте. Поэтому использование этих тэгов в документе желательно, но в разумных количествах. Не стоит забывать, что они используются именно для выделения в пределах одного документа, и слишком частое их использование для различных слов уже не даст такого эффекта. Если весь текст страницы представить заголовком, <h2> например, то это будет равносильно не использованию этого тэга вообще. Добавлю, что Апортом тэги <i> и <em> игнорируются. Служебные тэги. Ранее мета-тэги keywords и description активно использовались многими поисковыми машинами. Но в связи с тем, что их содержимое не видно пользователю, они стали действенным инструментом для обмана поисковых систем, что привело к тому, что в настоящее время эти мета-тэги либо вообще не учитываются поисковыми системами, либо влияние их мизерно по сравнению с другими факторами. Рамблер и Google при ранжировании документов их игнорируют вообще. Однако, Google использует содержимое мета-тега description при построении сниппетов - фрагментов текста, содержащих слова из запроса, выдаваемых рядом со ссылкой на документ в результатах поиска. Апорт единственный использует мета-тег description, но, судя по всему, он имеет очень небольшой вес по сравнению с другими внутренними факторами. Из тега keywords берутся, по словам представителей Апорта, только 16 слов, причём учитывается только одно вхождение слова, даже если его нет в тексте страницы. На сайте Яндекса указано, что он учитывает первые 50 слов из тега keywords при условии что это слово присутствует в тексте страницы но, повторюсь, эффект от его использования крайне мал. Мета-тег description в расчёте релевантности страницы запросу в Яндексе не участвует, но до двухсот первых символов из него в некоторых случаях может выводиться в результатах поиска как первая часть аннотации к ссылке. Поэтому я бы рекомендовал использовать в теге description текст, описывающий краткое содержание документа - это может стать дополнительным аргументом для принятия пользователем решения перейти на ваш сайт по ссылке с результатов поиска. Пожалуй, наибольший эффект из страничных факторов даёт применение тэга title - заголовка страницы. Причём использовать в нём можно даже слова, которые не содержатся в тексте страницы - это тоже даёт эффект, хотя и меньший, но в некоторых случаях это оправдано. К тексту внутри этого тэга применимы те же понятия, что и для текста документа вообще: больший вес имеют слова, расположенные ближе к началу, очень эффективно точное вхождение искомой фразы. Судя по информации представленной на сайтах Яндекса и Апорта, эти поисковые машины не учитывают частоту вхождения слов из запроса в этом теге, а только факт их присутствия. Следует иметь в виду, что нецелесообразно делать очень длинные теги title, так как поисковые машины могут накладывать ограничение на длину индексируемой части этого тега. Старайтесь использовать не более 20-25 слов. Атрибут alt тега img. Необходимо упомянуть ещё об одном атрибуте, используемом некоторыми поисковыми системами при ранжировании. Это атрибут alt тэга img - текстовый комментарий к изображениям. Rambler учитывает не более 8 слов из него при ранжировании, возможно, приравнивая по значимости к тексту страницы. Этим свойством можно пользоваться при оптимизации страниц. Для Яндекса и Апорта же этот атрибут имеет значение только при поиске по картинкам, а при ранжировании документов в основном поиске не используется. Нами ставились некоторые эксперименты по продвижению через картинки сайтов и их результаты, мягко говоря, нас не удовлетворили - переходов на сайты по картинкам практически не наблюдалось. Google учитывает содержимое этого атрибута только для изображений, являющихся ссылками. Часто приходится слышать вопросы о том, учитывается ли при ранжировании содержимое атрибута title тега а. Так вот, на данный момент, ни одной из четырех рассматриваемых в этой статье поисковых машин при ранжировании содержимое этого атрибута не учитывается. Таким образом, общие рекомендации по оптимизации кода страницы можно свести к следующим мероприятиям:
Однако, используя эти рекомендации, не забывайте, что текст документа должен быть удобен для чтения и восприятия пользователем. Не стоит чрезмерно пичкать его ключевыми фразами в надежде повысить их концентрацию. Эффект, который это может принести, несоизмеримо мал по сравнению с риском потерять пользователя, пришедшего на страницу, из-за того, что ему неудобно или неприятно воспринимать ее содержимое. Зачастую, бывает достаточно того, чтобы конкретная ключевая фраза хотя бы один раз встречалась в тексте документа. Дальнейшее повышение релевантности документа этому запросу можно проводить за счет воздействия на внешние факторы, влияющие на ранжирование. Внешние динамические факторы (ссылочное ранжирование). Ссылочное ранжирование, или поиск по лексике ссылок, является, пожалуй, самым интересным из критериев, оказывающих влияние на ранжирование документов в результатах поиска. Именно ссылочное ранжирование является причиной многих скандалов вокруг поисковых систем, связанных с выдачей поисковыми системами известных сайтов в ответ на запросы по оскорбительным, нецензурным или близким к таковым выражениям. Среди "пострадавших", например, сайты Microsoft, Александра Лукашенко и "Союза Правых Сил". Именно результаты действия ссылочного ранжирования вызывают у людей, далёких от оптимизации, стандартный вопрос: "почему мне выдаётся страница, на которой нет ни одного слова из запроса?" Итак, давайте разберёмся. Ссылочное ранжирование - влияние текста ссылок на документ на релевантность этого документа запросу. То есть если слова из запроса встречаются в тексте ссылки на документ с друго документа, то это повышает его релевантность данному запросу. При введении этого фактора ранжирования в алгоритм поисковой системы разработчики руководствовались тем соображением, что если кто-то ссылается на страницу каким-либо текстом, то значит с большой долей вероятности можно быть уверенным, что эта информация содержится на странице и чем больше таких ссылок, тем выше эта вероятность. А если страница, на которую ссылаются, популярна у многих пользователей, т.е. "авторитетна"? Тогда соответствие содержания страницы тексту ссылки должно быть ещё более вероятным - авторитетный сайт "плохого" не порекомендует. Значит, логично ввести зависимость от показателей "авторитетности" страницы. Рассмотрим переменную Lа(x) из первой формулы: где PRi - показатель авторитетности страницы i, константа относительно запроса х, f(PRi) - некая неубывающая функция от PRi, для простоты можно принять ее линейной, т.е. f(PRi) = k*PRi, где k - некий коэффициент, Lаi(x) - релевантность запросу x ссылок со страницы i на страницу а, если в тексте ссылки нет ни одного слова из запроса, то Lаi(x) = 0. Максимальное значение функция Lаi(x) принимает, если в тексте ссылки встречается точное вхождение поисковой фразы.Вернёмся к нашей первой формуле: Rа(x)=(m*Tа(x)+p*Lа(x))* F(PRa)Из неё видно, что на величину итогового соответствия кода страницы запросу Rа(x) оказывает влияние произведение величин Lа(x) и F(PRa).Таким образом, величина эффекта от ссылочного ранжирования на релевантность страницы запросу напрямую зависит от 3-х параметров:
Зачастую, при анализе позиций сайта в выдаче бывает трудно выделить влияние именно ссылочного ранжирования. Однако хорошо виден его эффект в "крайних" случаях, т.е. когда влияние остальных факторов крайне мало. Случай первый, примеры которого я приводил, начиная рассказывать о ссылочном ранжировании (случаи с сайтами Microsoft, Лукашенко, Союза Правых Сил). Тогда эти ресурсы появились на высоких позициях по определенным запросам в поиске за счёт нескольких текстовых ссылок с форумов, домашних страничек или гостевых книг. В данном случае подобного текста не было на страницах, влияние внутренние динамические факторы не могли оказать, т.е. Tа(x) = 0; ранг ссылающихся страниц с релевантным запросу текстами ссылок был близок к нулю, т.е. значение Lа(x) довольно мало; однако, за счет довольно высокого собственного ранга документа, на которую ведёт ссылка, а, следовательно, довольно высокого значения функции F(PRa), получившееся в итоге значение Rа(x) было достаточно для того, чтобы данный документ был лидером выдачи. Соответственно, несколько ссылок с искомым текстом, ведущие на страницу с большим собственным рангом, могут дать очень существенный эффект. Для борьбы с подобным эффектом поисковые машины вводят ограничение на функцию f(PRi): f(PRi) = 0, если PRi < M,где М - константа, некое пороговое значение. То есть ссылки с документом с довольно низким рангом не учитываются при ссылочном ранжировании. Подобное ограничение, вполне возможно, действует во всех рассматриваемых в данной статье поисковиках. Также поисковые машины могут накладывать по той или иной причине ограничения на отдельные документы и даже сайты и вовсе не учитывать ссылки с них при ссылочном ранжировании, также как и при расчете ранга документов, на которые они ссылаются ("непот-фильтр" в Яндексе, "PR-пенальти" в Google)Другой крайний случай - это когда на страницу без искомого текста и небольшим рангом ссылается текстом страница с рангом высоким. В этом случае внутренние динамические факторы влияния не оказывают, т.е. Tа(x) = 0; "авторитетность" страницы, на которую ссылаются, мала, поэтому влияния практически не оказывает, т.е. F(PRa) имеет значение близкое к 1; ранг документа ссылающегося на данный документ текстом, релевантным запросу, очень высока, т.е. значение Lа(x) довольно велико. В итоге страница, получившая такую ссылку может получить неплохое значение Rа(x) и занять высокие позиции в результатах поиска по запросам запросам, слова из которых содержатся в тексте ссылки. Особо хочу пояснить один момент, из-за которого ссылочное ранжирование в плане повышения релевантности документа запросу намного привлекательнее внутренних факторов. Дело в том, что функция Tа(x), зависящая от внутренних факторов имеет максимум, достигаемый при некотором "идеальном" наборе своих параметров (каждый из которых у конкретного поисковика свой). Функция ссылочного ранжирования Lа(x), в отличие от фунции Tа(x), такого экстремума не имеет, так как любое появление новой содержащей ключевую фразу ссылки на страницу, будет увеличивать ее значение. Поэтому время и силы, которые можно затратить для нахождения идеального набора значений для внутренних факторов (который, кстати, может довольно часто изменяться вследствие действий администраций поисковых машин, постоянно работающих над "улучшением качества поиска"), что по сути является сложной задачей многокритериальной оптимизации, лучше с гораздо большей эффективностью потратить на организацию новых ссылок на страницы сайта с текстами, содержащим необходимые ключевые слова. Очень важным моментом, о котором, однако, часто забывают, является то, что ссылочное ранжирование работает и внутри одного домена. Хотя, возможно, и с некоторыми понижающими коэффициентами. Иногда приходиться сталкиваться с заблуждением, что ссылочное ранжирование должно поднимать релевантность любой из страниц сайта в выдаче по запросу, текст которого содержится в запросе. Это не так. Ссылочное ранжирование действует на конкретные страницы - те, на которые указывают ссылки. Это была общая теория. Рассмотрим особенности реализации ссылочного ранжирования в конкретных поисковых машинах. Рамблер был последней из рассматриваемых нами поисковых машин, которая ввела учет ссылочного ранжирования. Это произошло весной 2003 года, и механизм его реализации пока мало изучен. Апорт, как мы уже говорили, учитывает не более одной ссылки с каждого домена второго уровня. Особенностью является тот факт, что в зависимости от запроса алгоритм может использовать различные ссылки. Google учитывает не более 8 первых слов из текста ссылки, причём предлоги и междометия тоже будут считаться словами. Также хочу напомнить, что Google не учитывает морфологию. Вторая же отличительная особенность Google состоит в использовании им атрибута alt тэга img в качестве текста ссылки, если таковой является картинка. Хочу сразу предупредить вас о последствиях использования однопиксельных картинок с непустым значением атрибута alt для воздействия на ссылочное ранжирование - это считается поисковым спамом и наказывается. Яндекс ограничения на длину ссылки, по нашим наблюдениям, не накладывает, но у него есть другие ограничения по учету текста ссылок при ссылочном ранжировании. Во-первых, как я уже говорил, существует "непот-фильтр", ссылки со страниц, на которые он установлен, учитываться не будут. Во-вторых, кроме порога, накладываемого на ранг документа, существует ещё один, не менее интересный порог, о котором говорил руководитель отдела поисковых систем Яндекса Илья Сегалович. При вычислении релевантности ссылок на страницу запросу вычисляется соотношение между количеством ссылок с релевантным запросу текстом к общему количеству ссылок на страницу. И если это соотношение ниже определённого порогового значения, то эти ссылки не учитываются. Подобная ситуация исправляется обычно небольшим количеством новых ссылок с точным вхождением текста запроса. Причины введения этого ограничения понятны. Если из 100 опрошенных 99 человек сказали, что видят на картинке морковку, а 1 - арбуз, то вряд ли стоит доверять его мнению. И последнее. Документы, найденные за счёт лексики ссылок и не имеющие на странице слов запроса, в результатах поиска вместо обычной подписи "строгое соответствие" обозначаются "найдено по ссылке". И если при этом не выводится описание из Яндекс-Каталога, то тут же вы увидите и надпись "текст ссылок:" со сниппетами (выдержками) из текста ссылок на страницу. Остаётся добавить, что для того, чтобы добиться хороших результатов в ранжировании по средне- и высококонкурентным запросам использование ссылочного ранжирования обязательно. И основная проблема для оптимизатора - при работе по установке внешних ссылок на страницы своего сайта, о которой говорилось в разделе, посвяще |
hostinglist.moy.su