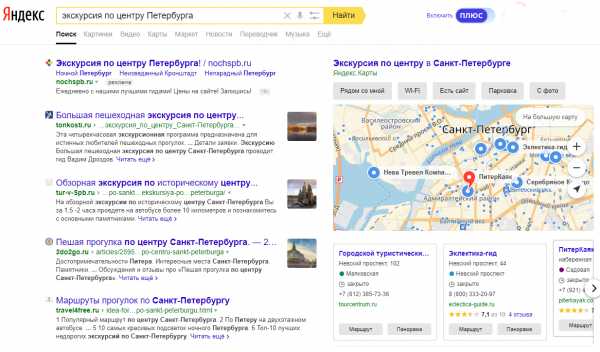
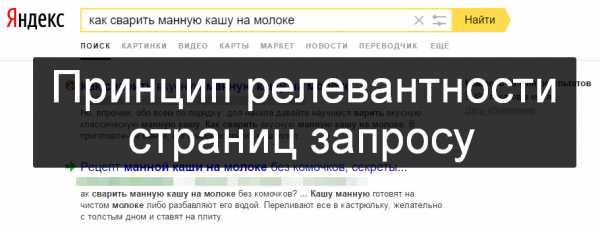
Как настроить релевантность термина на Haystack с помощью Elasticsearch. Python релевантность
Python алгоритмы: Поиск и ранжирование
Все рассматриваемые ниже функции ранжирования возвращают словарь, в котором ключом является идентификатор URL, а значением – числовой ранг. Иногда лучшим считается больший ранг, иногда – меньший. Чтобы сравнивать результаты, получаемые разными методами, необходимо как-то нормализовать их, то есть привести к одному и тому же диапазону и направлению. Функция нормализации принимает на входе словарь идентификаторов и рангов и возвращает новый словарь, в котором идентификаторы те же самые, а ранг находится в диапазоне от 0 до 1. Ранги масштабируются по близости к наилучшему результату, которому всегда припи- сывается ранг 1. От вас требуется лишь передать функции список рангов и указать, какой ранг лучше – меньший или больший:
def normalize_scores(self, scores, smallIsBetter=0): vsmall = 0.00001 # Avoid division by zero errors if smallIsBetter: minscore = min(scores.values()) return {u: float(minscore)/max(vsmall, l) for (u,l) in scores.items()} else: maxscore = max(scores.values()) if maxscore == 0: maxscore = vsmall return {u: float(c)/maxscore for (u,c) in scores.items()} return scores Отлично! Пора заняться весовыми функциями, для которых мы и придумали эту нормализацию.
Весовые функции
Частота слов
Метрика, основанная на частоте слов, ранжирует страницу исходя из того, сколько раз в ней встречаются слова, упомянутые в запросе. Если я выполняю поиск по слову python, то в начале списка скорее получу страницу, где это слово встречается много раз, а не страницу о музыканте, который где-то в конце упомянул, что у него дома живет питон. def frequency_score(self, rows): counts = {row[0]:0 for row in rows} for row in rows: counts[row[0]] += 1 return self.normalize_scores(counts) Чтобы активировать ранжирование документов по частоте слов, измените строку функции get_scored_list, где определяется список weight_functions, следующим образом: weight_functions = [(1.0,self.frequency_score(rows))] Запустите поиск снова и радуйтесь!)Расположение в документе
Еще одна простая метрика для определения релевантности страницы запросу – расположение поисковых слов на странице. Обычно, если страница релевантна поисковому слову, то это слово расположено близко к началу страницы, быть может, даже находится в заголовке. def location_score(self, rows): locations = {} for row in rows: loc = sum(row[1:]) if locations.has_key(row[0]): if loc < locations[row[0]]: locations[row[0]] = loc else: locations[row[0]] = loc return self.normalizescores(locations, smallIsBetter=1)Расстояние между словами
Если запрос содержит несколько слов, то часто бывает полезно ранжировать результаты в зависимости от того, насколько близко друг к другу встречаются поисковые слова. Как правило, вводя запрос из нескольких слов, человек хочет найти документы, в которых эти слова концептуально связаны. Рассматриваемая метрика допускает изменение порядка и наличие дополнительных слов между поисковыми. def distance_score(self, rows): mindistance = {} # Если только 1 слово, любой документ выигрывает if len(rows[0]) <= 2: return {row[0]: 1.0 for row in rows} mindistance = {} for row in rows: dist = sum([abs(row[i]-row[i-1]) for i in xrange(2, len(row))]) if mindistance.has_key(row[0]): if dist < mindistance[row[0]]: mindistance[row[0]] = dist else: mindistance[row[0]] = dist return self.normalize_scores(mindistance, smallIsBetter=1)Использование внешних ссылок на сайт
Все обсуждавшиеся до сих пор метрики ранжирования были основаны на содержимом страницы. Часто результаты можно улучшить, приняв во внимание, что говорят об этой странице другие, а точнее те сайты, на которых размещена ссылка на нее. Особенно это полезно при индексировании страниц сомнительного содержания или таких, которые могли быть созданы спамерами, поскольку маловероятно, что на такие страницы есть ссылки с настоящих сайтов.
Простой подсчет ссылок
Простейший способ работы с внешними ссылками заключается в том, чтобы подсчитать, сколько их ведет на каждую страницу, и использовать результат в качестве метрики. Так обычно оцениваются научные работы; считается, что их значимость тем выше, чем чаще их цитируют. def inbound_link_score(self, rows): unique_urls = {row[0]: 1 for row in rows} inbound_count = {} for url_id in unique_urls: self.cur.execute('select count(*) from link where to_id = %d' % url_id) inbound_count[url_id] = self.cur.fetchone()[0] return self.normalize_scores(inbound_count) Описанный алгоритм трактует все внешние ссылки одинаково, но такой уравнительный подход открывает возможность для манипулирования, поскольку кто угодно может создать несколько сайтов, указывающих на страницу, ранг которой он хочет поднять. Также возможно, что людям более интересны страницы, которые привлекли внимание каких-то популярных сайтов. Далее мы увидим, как придать ссылкам с популярных сайтов больший вес при вычислении ранга страницы.Латентно-семантический анализ и поиск на python / Хабрахабр

Недавно Google объявил, что он переходит от поиска по ключевым словам к полностью семантическому поиску. Не знаю, насколько круты алгоритмы поиска у мировых гигантов, но поиск в маленькой песочнице получается довольно семантическим. Конечно, с поиском по более менее крупным объёмам данных уже не всё так радужно, готовить слова надо очень тщательно, но тем не менее.
Сразу оговорюсь: кому интересна только теория, то отсылаю к очень хорошей статье на хабре, кому не особо интересно знать как все работает, а интересует только продакшн, то он может попробовать неплохую библиотеку для семантического поиска на питоне.
Итак, у нас есть список с десятком документов, по которым мы и будем искать:
titles =[ "Британская полиция знает о местонахождении основателя WikiLeaks", "В суде США начинается процесс против россиянина, рассылавшего спам", "Церемонию вручения Нобелевской премии мира бойкотируют 19 стран", "В Великобритании арестован основатель сайта Wikileaks Джулиан Ассандж", "Украина игнорирует церемонию вручения Нобелевской премии", "Шведский суд отказался рассматривать апелляцию основателя Wikileaks", "НАТО и США разработали планы обороны стран Балтии против России", "Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала", "В Стокгольме и Осло сегодня состоится вручение Нобелевских премий" ]Собственно это входные данные. Теперь нам нужно сделать три подготовительные операции: 1) Удалить разные запятые, точки, двоеточия, если есть html и прочий мусор из текста. 2) Привести все в нижний регистр и удалить все предлоги в, на, за, и тд. 3) Привести слова в нормальную форму, то есть поскольку для поиска слова типа премия, премий и прочее будет разными словами, надо это исправить. 4) Если мы просто хотим найти похожие документы, то можно удалить встречающиеся всего лишь один раз слова — для анализа сходства они бесполезны и будучи удалёнными позволят существенно сэкономить память.
Теперь сам алгоритм, благодаря математическим библиотекам питона тут все довольно просто. 5) Мы составляем матрицу нолей и единиц, соответственно представляющих отсутствие или наличие слова в документе. 6) Выполняем сингулярное разложение этой матрицы, в результате чего получаем три другие матрицы, в которых получим координаты документов и слов в пространстве.
На последнем этапе в упрощённом виде нам остается просто сравнить между собой координаты документов и/или слов: те, которые находятся ближе всего друг к другу и есть нужный результат, те которые подальше соответственно менее релевантны.
Все манипуляции с матрицами мы будем осуществлять с помощью numpy и scipy приводить слова к изначальной форме будем с помощью nltk. Устанавливаем…pip install numpy pip install nltk pip install scipy Если при попытке установить scipy возникнут какие то проблемы (будет требовать установить BLASS) то возможно поможет.apt-get install gfortran libopenblas-dev liblapack-dev
Инициализация класса.
class LSI(object): def __init__(self, stopwords, ignorechars, docs): # все слова которые встречаются в документах, и содержит номера документов в которых встречается каждое слово self.wdict = {} # dictionary - Ключевые слова в матрице слева содержит коды слов self.dictionary = [] # слова которые исключаем из анализа типа и, в, на self.stopwords = stopwords if type(ignorechars) == unicode: ignorechars = ignorechars.encode('utf-8') self.ignorechars = ignorechars # инициализируем сами документы for doc in docs: self.add_doc(doc)Подготовка слов, пополняем словарь, если слово есть в словаре возвращаем его номер, предварительно очищаем от лишних символов и приводим в начальную форму
def dic(self, word, add = False): if type(word) == unicode: word = word.encode('utf-8') # чистим от лишних символом word = word.lower().translate(None, self.ignorechars) word = word.decode('utf-8') # приводим к начальной форме word = stemmer.stem(word) # если слово есть в словаре возвращаем его номер if word in self.dictionary: return self.dictionary.index(word) else: # если нет и стоит флаг автоматически добавлять то пополняем словари возвращвем код слова if add: #self.ready = False self.dictionary.append(word) return len(self.dictionary) - 1 else: return NoneПостроение остальных матриц
def calc(self): """ Вычисление U, S Vt - матриц """ self.U, self.S, self.Vt = svd(self.A)Нормализация веса или важности слов в матрице. Вычисляем важность термина в зависимости от его встречаемости. Например, слово «и» встречается достаточно часто, поэтому это слово будет иметь низкую значимость, а, скажем, слово «США» встречается значительно режем и, соответственно, будет иметь большую значимость. Стандартные обороты речи отсеиваются, а редкие термины остаются.
def TFIDF(self): # всего кол-во слов на документ wordsPerDoc = sum(self.A, axis=0) # сколько документов приходится на слово docsPerWord = sum(asarray(self.A > 0, 'i'), axis=1) rows, cols = self.A.shape for i in range(rows): for j in range(cols): self.A[i,j] = (self.A[i,j] / wordsPerDoc[j]) * log(float(cols) / docsPerWord[i])На этом все, тема довольно обширная, старался как можно лаконичней.
Полезные ссылки
— Краткая теория латентно-семантического поиска (рус.) — gensim — библиотека для ЛСА python — nltk — библиотека для нормализации слов — scikit-learn библиотека для машинного обученияhabr.com
Алгоритм Шинглов — поиск нечетких дубликатов текста
В этой статье я расскажу об алгоритме поиска нечетких дубликатов под названием «Алгоритм Шинглов». А так же реализую данный алгоритм на языке Python.
Почему я решил изучить данный алгоритм? Сам я являюсь SEO-шником, занимаюсь продвижением сайтов и так далее… Соответственно, моя работа заключается в изменении выдачи поисковой системы по определенному запросу. Но проработав более года в этом направлении меня заинтересовала внутренняя часть поисковых систем. Как они борются с поисковым спамом, как ранжируют документы и т.д. Поиск нечетких дубликатов позволяет поисковой системе исключить из выдачи клоны или частично похожие страницы (под словом частично я подразумеваю некоторое значение, при котором в конкретной поисковой системе два документа будут определяться как почти одинаковыми).
Одним из таких алгоритмов является «Алгоритм Шинглов» (шингл на английском означает чешуйка).
Немного теории
Поиск нечетких дубликатов позволяет предположить, являются ли два объекта частично одинаковыми или нет. Под объектом могут пониматься текстовые файлы и другие типы данных. Мы будем работать с текстом, но поняв, как работает алгоритм, вам не составит труда перенести мою реализацию на необходимые вам объекты.
Обратите внимание, задачей не стоит определить абсолютное значение схожести объектов, а так же выделения в каждом из объектов схожих частей. Нам необходимо только предположить, являются ли объекты почти дубликатами или нет.
Где может применяться данный алгоритм?
Как я уже писал выше, он может быть применен в поисковой системе для очистки поисковой выдачи. Так же данный алгоритм может использоваться для кластеризации документов по их схожести.
Почти одинаковый текст
Рассмотрим задачу алгоритма на примере текста. Допустим, мы имеем файл с текстом в 8 абзацев. Делаем его полную копию, а затем переписываем только последний абзац. 7 из 8 абзацев второго файла являются полной копией оригинала.
Другой пример, посложнее. Если мы в копии оригинального текста перепишем каждое 5-6е предложение, то текст по-прежнему будет являться почти дублем.
Представим, что мы имеем большой форум или портал, где контент составляется пользователями. Как показали наблюдения, пользователи имеют привычку заниматься копи-пастом, и кражей контента, лишь немного изменив его. На нашем сайте имеется поисковый механизм. Пользователь вводит какой-либо запрос, и на первых позициях получает десяток текстов, которые отличаются только одним или двумя предложениями. Естественно ему не интересно просматривать их все, и он понимает, что поисковая система работает некорректно.
Поступим логичнее. В поисковой выдаче вместо десятка практически одинаковых документов покажем один из них, например, наиболее релевантный запросу, а ниже дадим ссылочку на список так же найденных страниц, похожих на него.
И таким образом, при наличии множества почти одинакового текста мы распределим его на группы и предоставим пользователю ссылку на эти группы, вместо того, чтобы сваливать все в кучу.
Как работает алгоритм Шинглов?
Итак, мы имеем 2 текста и нам нужно предположить, являются ли они почти дубликатами. Реализация алгоритма подразумевает несколько этапов:
- канонизация текстов;
- разбиение текста на шинглы;
- нахождение контрольных сумм;
- поиск одинаковых подпоследовательностей.
Теперь поконкретнее. В алгоритме шинглов реализовано сравнение контрольных сумм текстов. В своей реализации я использую CRC32, но применимы и другие, например SHA1 или MD5 и т.д. Как известно, контрольные суммы статических функций очень чувствительны к изменениям. Например, контрольные суммы двух следующих текстов будут в корне отличаться:
- Текст: «My war is over.» Контрольная сумма: 1759088479
- Текст: «My war is over!» Контрольная сумма: -127495474
Как сказал Джон Рэмбо: «My war is over». Но сказать он это мог по-разному, громко восклицая или тихо шепча, так и у нас, отличие второй фразы от первой заключается всего лишь в восклицательном знаке в конце фразы, но как видим, контрольные суммы абсолютно разные.
При поиске почти дубликата нас не интересуют всякие там восклицательные знаки, точки, запятые и т.д. Нас интересуют только слова (не союзы, предлоги и т.д., а именно слова).
Следовательно, ставится задача: очистить текст от ненужных нам знаков и слов, которые не несут смысла при сравнении, это и называется «привести текст к канонической форме».
Итак, нам необходимо создать набор символов, которые нужно исключить из обоих текстов, т.е. приведения его к форме, пригодной для нашего сравнения.
Давайте что-нибудь напрограммируем. Допустим, мы имеем два текста, занесем их в 2 переменных: source1 и source2. Нужно их почистить от ненужных символов и слов. Определим наборы стоп-слов и стоп-символов.
stop_symbols = '.,!?:;-\n\r()' stop_words = (u'это', u'как', u'так', u'и', u'в', u'над', u'к', u'до', u'не', u'на', u'но', u'за', u'то', u'с', u'ли', u'а', u'во', u'от', u'со', u'для', u'о', u'же', u'ну', u'вы', u'бы', u'что', u'кто', u'он', u'она')В стоп-символы мы включили знаки препинаний, знаки переноса строки и табуляции. В стоп-лова мы включили союзы, предлоги и прочие слова, которые при сравнении не должны влиять на результат.
Создадим функцию, которая будет производить канонизацию текста:
def canonize(source): stop_symbols = '.,!?:;-\n\r()' stop_words = (u'это', u'как', u'так', u'и', u'в', u'над', u'к', u'до', u'не', u'на', u'но', u'за', u'то', u'с', u'ли', u'а', u'во', u'от', u'со', u'для', u'о', u'же', u'ну', u'вы', u'бы', u'что', u'кто', u'он', u'она') return ( [x for x in [y.strip(stop_symbols) for y in source.lower().split()] if x and (x not in stop_words)] )Функция canonize очищает текст от стоп-символов и стоп-слов, приводит все символы строки к нижнему регистру и возвращает список, оставшихся после чистки слов.
Вообще, приведение текста к единой канонической форме не ограничено действиями, которые я описал. Можно, например, каждое из существительных приводить к единственному числу, именительному падежу и т.д., для этого нужно подключать морфологические анализаторы русского языка (или других языков, где необходимы эти действия).
Итак, тексты у нас очищены от всего лишнего. Теперь необходимо разбить каждый из них на подпоследовательности — шинглы. На практике я применяю подпоследовательности длинной в 10 слов. Из выделенных нами шинглов далее будут находиться контрольные суммы.
Разбиение на шинглы будет происходить внахлест через одно слово, а не встык, т.е., имеем текст:
«Разум дан человеку для того, чтобы он разумно жил, а не для того только, чтобы он понимал, что он неразумно живет.»© В. Г. Белинский
После обработки нашей функцией текст примет следующий вид:
разум дан человеку того чтобы разумно жил того только чтобы понимал неразумно живет
Это и есть каноническая форма. Теперь нужно разбить ее на шинглы длиной в 10 слов. Так как шинглы составляются внахлест, то всего шинглов len(source)-(shingleLen-1), т.е. количество слов в тексте минус длина шинглов плюс 1.
Шинглы будут выглядеть следующим образом:
- Sh2 = разум дан человеку того чтобы разумно жил того только чтобы
- Sh3 = дан человеку того чтобы разумно жил того только чтобы понимал
- Sh4 = человеку того чтобы разумно жил того только чтобы понимал неразумно
- Sh5 = того чтобы разумно жил того только чтобы понимал неразумно живет
Напишем функцию, которая производит разбиение текста на шинглы:
def genshingle(source): shingleLen = 10 #длина шингла out = [] for i in range(len(source)-(shingleLen-1)): out.append (' '.join( [x for x in source[i:i+shingleLen]] ).encode('utf-8')) return outНо так как нас интересую именно контрольные суммы шинглов, то соответственно изменим нашу функцию. Мы будем использовать алгоритм хэширования CRC32, подключим библиотеку binascii, которая содержит в себе нужный нам метод. Измененная функция:
def genshingle(source): import binascii shingleLen = 10 #длина шингла out = [] for i in range(len(source)-(shingleLen-1)): out.append (binascii.crc32(' '.join( [x for x in source[i:i+shingleLen]] ).encode('utf-8'))) return outНаш пример выдаст следующие наборы контрольных сумм:
[1313803605, -1077944445, -2009290115, 1772759749]Таким образом, через наши 2 функции нужно прогнать 2 сравниваемых текста и мы получим 2 множества контрольных сумм шинглов, теперь необходимо найти их пересечения.
def compaire (source1,source2): same = 0 for i in range(len(source1)): if source1[i] in source2: same = same + 1 return same*2/float(len(source1) + len(source2))*100Вот и все, функция нам вернет процент схожести двух текстов.
Скомпонованный код
# -*- coding: UTF-8 -*- if __name__ == '__build__': raise Exception def canonize(source): stop_symbols = '.,!?:;-\n\r()' stop_words = (u'это', u'как', u'так', u'и', u'в', u'над', u'к', u'до', u'не', u'на', u'но', u'за', u'то', u'с', u'ли', u'а', u'во', u'от', u'со', u'для', u'о', u'же', u'ну', u'вы', u'бы', u'что', u'кто', u'он', u'она') return ( [x for x in [y.strip(stop_symbols) for y in source.lower().split()] if x and (x not in stop_words)] ) def genshingle(source): import binascii shingleLen = 10 #длина шингла out = [] for i in range(len(source)-(shingleLen-1)): out.append (binascii.crc32(' '.join( [x for x in source[i:i+shingleLen]] ).encode('utf-8'))) return out def compaire (source1,source2): same = 0 for i in range(len(source1)): if source1[i] in source2: same = same + 1 return same*2/float(len(source1) + len(source2))*100 def main(): text1 = u'' # Текст 1 для сравнения text2 = u'' # Текст 2 для сравнения cmp1 = genshingle(canonize(text1)) cmp2 = genshingle(canonize(text2)) print compaire(cmp1,cmp2) # Start program main()Я показал именно реализацию ядра алгоритма, но его можно дорабатывать до бесконечности, увеличивая его производительность и точность сравнения.
Сам по себе алгоритм достаточно ресурсоемкий, поэтому не помешает для него создать механизм кеширования, который будет особенно актуален для сравнения наборов файлов, чтобы не высчитывать контрольные суммы каждый раз.
Так же, для увеличения производительности при обработке больших объемов текста можно сравнивать не все полученные контрольные суммы, а только те, которые, например, делятся на 25, или любое целое число в пределах от 10 до 40. Как показали тесты, это дает значительный(!) прирост скорости и не сильно уменьшает точность, но только при обработке больших объемов.
Существуют модифицированные версии «Алгоритма шинглов» — «Алгоритм супершинглов» и «Алгоритма мегашинглов», их реализацию я представлю позже.
Скачать алгоритм шинглов на Python.
Материалы по теме:
Спонсор поста: Агентство «Web++» — продвижение и создание сайтов в Волгограде.
Подписаться на обновления блога
www.codeisart.ru
python - Сортировка по релевантности с использованием API YouTube в Python
Я пытаюсь создать проверку рангов YouTube в python. Идея заключается в том, что он ищет на YouTube ключевое слово и проверяет, в какой позиции находится видео.
Единственная проблема заключается в том, что он не возвращает точных результатов. Например, если я ищу "видео для собак", а мое видео - это позиция 3, когда я выполняю поиск на обычном веб-сайте, и API возвращает его в качестве позиции 17. Я думал, что это может быть потому, что он сортирует результаты по-разному (он должен сортировать по релевантность), но я не могу понять, как случайный порядок сортировки.
Если кто-то может оказать какую-либо помощь, даже если он просто укажет на что-то очевидное в моем коде, я был бы очень признателен за это, спасибо за вашу помощь заранее.
Вот мой код:
from apiclient.discovery import build from optparse import OptionParser import time # Set DEVELOPER_KEY to the "API key" value from the "Access" tab of the # Google APIs Console http://code.google.com/apis/console#access # Please ensure that you have enabled the YouTube Data API for your project. DEVELOPER_KEY = "devkey" YOUTUBE_API_SERVICE_NAME = "youtube" YOUTUBE_API_VERSION = "v3" videos = [] channels = [] playlists = [] videoids = [] videoidskeys = {"cat video":"ZBAGEeOms-8", "dog video":"nGeKSiCQkPw", "testing video":"GAyni_fKKLg"} videokeys = videoidskeys.keys() def checkrank(videoid, keyword): time.sleep(6) if __name__ == "__main__": parser = OptionParser() parser.add_option("--q", dest="q", help="Search term", default=keyword) parser.add_option("--max-results", dest="maxResults", help="Max results", default=25) (options, args) = parser.parse_args() youtube = build(YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=DEVELOPER_KEY) search_response = youtube.search().list( q=options.q, part="id,snippet", maxResults=options.maxResults, ).execute() for search_result in search_response.get("items", []): videoids.append(search_result["id"]["videoId"]) count = 0 for videoid1 in videoids: count = count+1 if videoid1 == videoid: return "Keyword: %s - Rank: %s" % (keyword, count) count = 0 for video in videokeys: print checkrank(videoidskeys[video],video)qaru.site
Латентно-семантический анализ и поиск на python

Недавно Google объявил, что он переходит от поиска по ключевым словам к полностью семантическому поиску. Не знаю, насколько круты алгоритмы поиска у мировых гигантов, но поиск в маленькой песочнице получается довольно семантическим. Конечно, с поиском по более менее крупным объёмам данных уже не всё так радужно, готовить слова надо очень тщательно, но тем не менее.
Сразу оговорюсь: кому интересна только голая теория, то отсылаю к очень хорошей статье на хабре, кому не особо интересно знать как все работает, а интересует только продакшн, то он может попробовать неплохую библиотеку для семантического поиска на питоне.
Итак, у нас есть список с десятком документов, по которым мы и будем искать:
titles =[ "Британская полиция знает о местонахождении основателя WikiLeaks", "В суде США начинается процесс против россиянина, рассылавшего спам", "Церемонию вручения Нобелевской премии мира бойкотируют 19 стран", "В Великобритании арестован основатель сайта Wikileaks Джулиан Ассандж", "Украина игнорирует церемонию вручения Нобелевской премии", "Шведский суд отказался рассматривать апелляцию основателя Wikileaks", "НАТО и США разработали планы обороны стран Балтии против России", "Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала", "В Стокгольме и Осло сегодня состоится вручение Нобелевских премий" ]Собственно это входные данные. Теперь нам нужно сделать три подготовительные операции:1) Удалить разные запятые, точки, двоеточия, если есть html и прочий мусор из текста.2) Привести все в нижний регистр и удалить все предлоги в, на, за, и тд.3) Привести слова в нормальную форму, то есть поскольку для поиска слова типа Премия премий и прочее будет разными словами, надо это исправить.4) Если мы просто хотим найти похожие документы, то можно удалить встречающиеся всего лишь один раз слова — для анализа сходства они бесполезны и будучи удалёнными позволят существенно сэкономить память.
Теперь сам алгоритм, благодаря математическим библиотекам питона тут все довольно просто.5) Мы составляем матрицу нолей и единиц, соответственно представляющих отсутствие или наличие слова в документе.6) Выполняем сингулярное разложение этой матрицы, в результате чего получаем три другие матрицы, в которых получим координаты документов и слов в пространстве.
На последнем этапе в упрощённом виде нам остается просто сравнить между собой координаты документов и/или слов: те, которые находятся ближе всего друг к другу и есть нужный результат, те которые подальше соответственно менее релевантны.
Все манипуляции с матрицами мы будем осуществлять с помощью numpy и scipy приводить слова к изначальной форме будем с помощью nltk. Устанавливаем…pip install numpypip install nltkpip install scipyЕсли при попытке установить scipy возникнут какие то проблемы (будет требовать установить BLASS) то возможно поможет.apt-get install gfortran libopenblas-dev liblapack-dev
Инициализация класса.
class LSI(object): def __init__(self, stopwords, ignorechars, docs): # все слова которые встречаются в документах, и содержит номера документов в которых встречается каждое слово self.wdict = {} # dictionary - Ключевые слова в матрице слева содержит коды слов self.dictionary = [] # слова которые исключаем из анализа типа и, в, на self.stopwords = stopwords if type(ignorechars) == unicode: ignorechars = ignorechars.encode('utf-8') self.ignorechars = ignorechars # инициализируем сами документы for doc in docs: self.add_doc(doc)Подготовка слов, пополняем словарь, если слово есть в словаре возвращаем его номер, предварительно очищаем от лишних символов и приводим в начальную форму
def dic(self, word, add = False): if type(word) == unicode: word = word.encode('utf-8') # чистим от лишних символом word = word.lower().translate(None, self.ignorechars) word = word.decode('utf-8') # приводим к начальной форме word = stemmer.stem(word) # если слово есть в словаре возвращаем его номер if word in self.dictionary: return self.dictionary.index(word) else: # если нет и стоит флаг автоматически добавлять то пополняем словари возвращвем код слова if add: #self.ready = False self.dictionary.append(word) return len(self.dictionary) - 1 else: return NoneПостроение исходной матрицы
def build(self): # убираем одиночные слова self.keys = [k for k in self.wdict.keys() if len(self.wdict[k]) > 0] self.keys.sort() # создаём пустую матрицу self.A = zeros([len(self.keys), len(self.docs)]) # наполняем эту матрицу for i, k in enumerate(self.keys): for d in self.wdict[k]: self.A[i,d] += 1Построение остальных матриц
def calc(self): """ Вычисление U, S Vt - матриц """ self.U, self.S, self.Vt = svd(self.A)Нормализация веса или важности слов в матрице. Вычисляем важность термина в зависимости от его встречаемости. Например, слово «и» встречается достаточно часто, поэтому это слово будет иметь низкую значимость, а, скажем, слово «США» встречается значительно режем и, соответственно, будет иметь большую значимость. Стандартные обороты речи отсеиваются, а редкие термины остаются.
def TFIDF(self): # всего кол-во слов на документ wordsPerDoc = sum(self.A, axis=0) # сколько документов приходится на слово docsPerWord = sum(asarray(self.A > 0, 'i'), axis=1) rows, cols = self.A.shape for i in range(rows): for j in range(cols): self.A[i,j] = (self.A[i,j] / wordsPerDoc[j]) * log(float(cols) / docsPerWord[i])Сравнение документов на оси координат и поиск по ним.
def find(self, word): self.prepare() idx = self.dic(word) if not idx: print 'слово невстерчается' return [] if not idx in self.keys: print 'слово отброшено как не имеющее значения которое через stopwords' return [] idx = self.keys.index(idx) print 'word --- ', word, '=', self.dictionary[self.keys[idx]], '.n' # получаем координаты слова wx, wy = (-1 * self.U[:, 1:3])[idx] print 'word {}t{:0.2f}t{:0.2f}t{}n'.format(idx, wx, wy, word) arts = [] xx, yy = -1 * self.Vt[1:3, :] for k, v in enumerate(self.docs): # получаем координаты документа ax, ay = xx[k], yy[k] #вычисляем расстояние между словом и документом dx, dy = float(wx - ax), float(wy - ay) arts.append((k, v, ax, ay, sqrt(dx * dx + dy * dy))) # возвращаем отсортированный по расстоянию список return sorted(arts, key = lambda a: a[4]) Весь код целиком class LSI(object): def __init__(self, stopwords, ignorechars, docs): self.wdict = {} self.dictionary = [] self.stopwords = stopwords if type(ignorechars) == unicode: ignorechars = ignorechars.encode('utf-8') self.ignorechars = ignorechars for doc in docs: self.add_doc(doc) def prepare(self): self.build() self.calc() def dic(self, word, add = False): if type(word) == unicode: word = word.encode('utf-8') word = word.lower().translate(None, self.ignorechars) word = word.decode('utf-8') word = stemmer.stem(word) if word in self.dictionary: return self.dictionary.index(word) else: if add: self.dictionary.append(word) return len(self.dictionary) - 1 else: return None def add_doc(self, doc): words = [self.dic(word, True) for word in doc.lower().split()] self.docs.append(words) for word in words: if word in self.stopwords: continue elif word in self.wdict: self.wdict[word].append(len(self.docs) - 1) else: self.wdict[word] = [len(self.docs) - 1] def build(self): self.keys = [k for k in self.wdict.keys() if len(self.wdict[k]) > 0] self.keys.sort() self.A = zeros([len(self.keys), len(self.docs)]) for i, k in enumerate(self.keys): for d in self.wdict[k]: self.A[i,d] += 1 def calc(self): self.U, self.S, self.Vt = svd(self.A) def TFIDF(self): wordsPerDoc = sum(self.A, axis=0) docsPerWord = sum(asarray(self.A > 0, 'i'), axis=1) rows, cols = self.A.shape for i in range(rows): for j in range(cols): self.A[i,j] = (self.A[i,j] / wordsPerDoc[j]) * log(float(cols) / docsPerWord[i]) def dump_src(self): self.prepare() print 'Здесь представлен расчет матрицы ' for i, row in enumerate(self.A): print self.dictionary[i], row def print_svd(self): self.prepare() print 'Здесь сингулярные значения' print self.S print 'Здесь первые 3 колонки U матрица ' for i, row in enumerate(self.U): print self.dictionary[self.keys[i]], row[0:3] print 'Здесь первые 3 строчки Vt матрица' print -1*self.Vt[0:3, :] def find(self, word): self.prepare() idx = self.dic(word) if not idx: print 'слово невстерчается' return [] if not idx in self.keys: print 'слово отброшено как не имеющее значения которое через stopwords' return [] idx = self.keys.index(idx) print 'word --- ', word, '=', self.dictionary[self.keys[idx]], '.n' # получаем координаты слова wx, wy = (-1 * self.U[:, 1:3])[idx] print 'word {}t{:0.2f}t{:0.2f}t{}n'.format(idx, wx, wy, word) arts = [] xx, yy = -1 * self.Vt[1:3, :] for k, v in enumerate(self.docs): ax, ay = xx[k], yy[k] dx, dy = float(wx - ax), float(wy - ay) arts.append((k, v, ax, ay, sqrt(dx * dx + dy * dy))) return sorted(arts, key = lambda a: a[4])Осталось вызвать приведенный выше код.
docs =[ "Британская полиция знает о местонахождении основателя WikiLeaks", "В суде США США начинается процесс против россиянина, рассылавшего спам", "Церемонию вручения Нобелевской премии мира бойкотируют 19 стран", "В Великобритании арестован основатель сайта Wikileaks Джулиан Ассандж", "Украина игнорирует церемонию вручения Нобелевской премии", "Шведский суд отказался рассматривать апелляцию основателя Wikileaks", "НАТО и США разработали планы обороны стран Балтии против России", "Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала", "В Стокгольме и Осло сегодня состоится вручение Нобелевских премий" ] ignorechars = ''',:'!''' word = "США" lsa = LSI([], ignorechars, docs) lsa.build() lsa.dump_src() lsa.calc() lsa.print_svd() for res in lsa.find(word): print res[0], res[4], res[1], docs[res[0]] lsa.dump_src() британск [ 1. 0. 0. 0. 0. 0. 0. 0. 0.] полиц [ 1. 0. 0. 0. 0. 0. 0. 1. 0.] знает [ 1. 0. 0. 0. 0. 0. 0. 0. 0.] ...В столбцах документы, в строчках термины.
lsa.print_svd() здесь первые 3 колонки U матрица британск [-0.06333698 -0.08969849 0.03023127] полиц [-0.14969793 -0.20853416 0.07106177] знает [-0.06333698 -0.08969849 0.03023127] ... Здесь первые 3 строчки Vt матрица [[ 0.25550481 0.47069418 0.27633104 0.39579252 0.21466192 0.26635401 0.32757769 0.3483847 0.3666749 ] [ 0.34469126 -0.18334417 -0.36995197 0.37444485 -0.29101203 0.27916372 -0.26791709 0.45665895 -0.35715836] [-0.10950444 0.64280654 -0.39672464 -0.1011325 -0.36012511 -0.01213328 0.38644373 -0.14789727 -0.32579232]] for res in lsa.find(word): print res[0], res[4], res[1], docs[res[0]] word 9 (код слова в словаре) -0.17(первая координата слова) 0.46(вторая координата) США (само слово) номер документа в списке | растояние | документ разложеный на коды | сам документ 6 0.127328977215 [35, 36, 9, 37, 38, 39, 23, 40, 12, 41] НАТО и США разработали планы обороны стран Балтии против России 1 0.182108022464 [7, 8, 9, 9, 10, 11, 12, 13, 14, 15] В суде США начинается процесс против россиянина, рассылавшего спам 5 0.649492914495 [31, 8, 32, 33, 34, 5, 6] Шведский суд отказался рассматривать апелляцию основателя Wikileaks 0 0.765573367056 [0, 1, 2, 3, 4, 5, 6] Британская полиция знает о местонахождении основателя WikiLeaks 3 0.779637110377 [7, 24, 25, 5, 26, 6, 27, 28] В Великобритании арестован основатель сайта Wikileaks Джулиан Ассандж 8 0.810477163078 [7, 45, 36, 46, 47, 48, 17, 18, 19] В Стокгольме и Осло сегодня состоится вручение Нобелевских премий 4 0.831319718049 [29, 30, 16, 17, 18, 19] Украина игнорирует церемонию вручения Нобелевской премии 7 0.870710388156 [1, 24, 42, 5, 6, 43, 44, 25] Полиция Великобритании нашла основателя WikiLeaks, но, не арестовала 2 0.88243190531 [16, 17, 18, 19, 20, 21, 22, 23] Церемонию вручения Нобелевской премии мира бойкотируют 19 странНа этом все, тема довольно обширная, старался как можно лаконичней.
Полезные ссылки
— Краткая теория латентно-семантического поиска (рус.)— gensim — библиотека для ЛСА python— nltk — библиотека для нормализации слов
Автор: Alex10
Источник
www.pvsm.ru
python - как использовать "не в" на python, чтобы дать оценку "релевантности" для моего интеллектуального анализа результатов
Я хочу присвоить оценку релевантности (релевантно/не относится) к моему окончательному результату поиска текста и обновить оценку в моей базе данных
вот мой код
#import library import pymysql import nltk from unidecode import unidecode from Sastrawi.StopWordRemover.StopWordRemoverFactory import StopWordRemoverFactory from Sastrawi.Stemmer.StemmerFactory import StemmerFactory import time #define symbols symbols = [',', ':', ')', '(', '-', '[', ']'] symbols = set(symbols) #define stopword factory = StopWordRemoverFactory() stopword = factory.create_stop_word_remover() #define stemmer factory = StemmerFactory() stemmer = factory.create_stemmer() #define relevance relevance = ['gempa'] relevance = set(relevance) R1 = 'Relevan' R2 = 'Tidak Relevan' #Declare Connection conn = pymysql.connect(host='localhost', port='', user='root', passwd='', db='test', use_unicode=True, charset="utf8mb4") cur = conn.cursor() #Get Current Date Time curdatetime = time.strftime("%Y-%m-%d %H:%M:%S") n = 0 #get data from database cur.execute("SELECT text FROM retweet") row = cur.fetchall() for text in row: textfix = unidecode(str(text)).lower() #lower text text_token = (nltk.word_tokenize(str(textfix))) #tokenize text_stop = stopword.remove(str(text_token)) #stopword text_stem = stemmer.stem(str(text_stop)) #stemming print("\n") print(text_stem) if str(text_stem) not in relevance : relevan = R2 elif str(text_stem) in relevance : relevan = R1 n = n + 1 print(relevan) cur.execute("UPDATE retweet SET relevansi=%s WHERE no=%s", (str(relevan), str(n))) conn.commit() cur.close() conn.close()вот моя база данных перед выполнением кода (фокус на № 2 и 4) db1
и результат результат
и моя база данных после выполнения кода db2
и моя точка зрения заключается в том, что я должен давать оценку "релевант", когда текст содержит заданный текст (в данном случае это gempa), и оценка "tidak actualan" не содержит его.
#define relevance relevance = ['gempa'] relevance = set(relevance) R1 = 'Relevan' R2 = 'Tidak Relevan'но мой результат при использовании этого кода, он должен точно совпадать с заданным текстом
if str(text_stem) not in relevance : relevan = R2 elif str(text_stem) in relevance : relevan = R1пожалуйста, любой, кто может решить это, спасибо до
NB: извините за очень длинный пост, я хочу сделать этот вопрос ясным и надеюсь, что этот вопрос ясен для всех, спасибо
qaru.site
python - Как настроить релевантность термина на Haystack с помощью Elasticsearch
Не зная, что вы точно сопоставляете данные и образцы данных, вам будет сложно рассказать вам, почему ваш поиск возвращает слишком много результатов. Тем не менее, я предполагаю, что ваш токенизатор edgengram использует очень маленький начальный размер подстрок вроде 1 или 2. При такой настройке существует много совпадений, например. если у вас есть следующая фраза с начальным размером 1:
a quick brown foxОн будет обозначаться следующим образом:
a q qu qui quick b br bro brow brown f fo foxЧто может вызвать много совпадений для запроса. В качестве решения вы можете использовать другой начальный размер и нечеткий поиск, чтобы найти похожие результаты.
Но сначала укажите свое точное сопоставление данных, образцы данных и свои запросы.
Ниже приведен пример пользовательского бэкэнд. Важнейшей частью являются пользовательские типы в нижней части пользовательской конфигурации и функция build_schema.
Пример пользовательской конфигурации бэкэнда:
HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'myservice.apps.search.search_backends.CustomElasticSearchEngine', 'URL': 'http://127.0.0.1:9200/', 'INDEX_NAME': 'haystack_prod', 'TIMEOUT': 60, }, }Пример Пользовательский бэкэнд:
from django.conf import settings from haystack.backends.elasticsearch_backend import ElasticsearchSearchBackend, ElasticsearchSearchEngine from haystack.fields import NgramField from haystack.models import SearchResult import requests import pyelasticsearch class CustomElasticBackend(ElasticsearchSearchBackend): #DEFAULT_ANALYZER = "snowball" DEFAULT_SETTINGS = { 'settings': { "analysis": { "analyzer": { "ngram_analyzer": { "type": "custom", "tokenizer": "lowercase", "filter": ["haystack_ngram"] }, "edgengram_analyzer": { "type": "custom", "tokenizer": "lowercase", "filter": ["lowercase", "asciifolding", "haystack_edgengram"] }, "full_text": { "type": "custom", "tokenizer": "standard", "filter": ["standard", "lowercase", "asciifolding"] }, "partial_text": { "type": "custom", "tokenizer": "standard", "filter": ["standard", "lowercase", "asciifolding", "text_ngrams"] }, "partial_text_front": { "type": "custom", "tokenizer": "standard", "filter": ["standard", "lowercase", "asciifolding", "text_edgengrams_front"] }, "partial_text_back": { "type": "custom", "tokenizer": "standard", "filter": ["standard", "lowercase", "asciifolding", "text_edgengrams_back"] } }, "tokenizer": { "haystack_ngram_tokenizer": { "type": "nGram", "min_gram": 3, "max_gram": 15, }, "haystack_edgengram_tokenizer": { "type": "edgeNGram", "min_gram": 3, "max_gram": 15, "side": "front" } }, "filter": { "haystack_ngram": { "type": "nGram", "min_gram": 3, "max_gram": 15 }, "haystack_edgengram": { "type": "edgeNGram", "min_gram": 3, "max_gram": 15 }, "text_ngrams": { "type": "nGram", "min_gram": 3, "max_gram": 50 }, "text_edgengrams_front": { "type": "edgeNGram", "side": "front", "min_gram": 3, "max_gram": 50 }, "text_edgengrams_back": { "type": "edgeNGram", "side": "back", "min_gram": 3, "max_gram": 50 } } } } } def makemapping(self, index_fieldname): return { "type": "multi_field", "fields": { index_fieldname: {"type": "string", "analyzer": "partial_text", "include_in_all": True}, "full": {"type": "string", "analyzer": "full_text", "include_in_all": True}, "partial": {"type": "string", "index_analyzer": "partial_text", "search_analyzer": "full_text", "include_in_all": True}, "partial_front": {"type": "string", "index_analyzer": "partial_text_front", "search_analyzer": "full_text", "include_in_all": True}, "partial_back": {"type": "string", "index_analyzer": "partial_text_back", "search_analyzer": "full_text", "include_in_all": True} } } def emailmapping(self, index_fieldname): return { "type": "multi_field", "fields": { index_fieldname: {"type": "string", "analyzer": "standard"}, "keyword": {"type": "string", "analyzer": "keyword", "include_in_all": True}, } } def makequery(self, param): fuzzy_param = param[1:-1] if len(param) > 2 else param query = { "query": { "bool": { "should": [ # TODO: bei fuzzy suche funktionniert die autocompletion nicht {"fuzzy_like_this": {"fields": ["text.full"], "like_text": fuzzy_param, "max_query_terms": 12}}, {"fuzzy": {"text": {"value": fuzzy_param, "min_similarity": 0.6}}}, #{"fuzzy": {"email": fuzzy_param}}, #{"fuzzy": {"first_name": fuzzy_param}}, #{"fuzzy": {"last_name": fuzzy_param}}, # this for the case first name is a CharField #{"match": {"first_name": {"query": param, "boost": 10}}}, #{"match": {"last_name": {"query": param, "boost": 10}}}, # email #{"text": {"first_name": {"boost": 5, "query": param, "type": "phrase"}}}, {"text": {"email": {"boost": 5, "query": param}}}, {"text": {"email.keyword": {"boost": 10, "query": param}}}, {"text": {"contact_email": {"boost": 5, "query": param}}}, {"text": {"contact_email.keyword": {"boost": 10, "query": param}}}, {"text": {"contact_email2": {"boost": 5, "query": param}}}, {"text": {"contact_email2.keyword": {"boost": 10, "query": param}}}, # first_name #{"text": {"first_name": {"boost": 5, "query": param, "type": "phrase"}}}, {"text": {"first_name.partial": {"boost": 5, "query": param}}}, {"text": {"first_name.partial_front": {"boost": 10, "query": param}}}, #{"text": {"first_name.partial_back": {"boost": 4, "query": param}}}, # last_name #{"text": {"last_name": {"boost": 5, "query": param, "type": "phrase"}}}, {"text": {"last_name.partial": {"boost": 5, "query": param}}}, {"text": {"last_name.partial_front": {"boost": 10, "query": param}}}, #{"text": {"last_name.partial_back": {"boost": 4, "query": param}}}, # company #{"text": {"company": {"boost": 5, "query": param, "type": "phrase"}}}, {"text": {"company.partial": {"boost": 5, "query": param}}}, {"text": {"company.partial_front": {"boost": 10, "query": param}}}, #{"text": {"company.partial_back": {"boost": 4, "query": param}}}, # text # ngrams with less accurate results #{"text": {"text": {"boost": 1, "query": param, "type": "phrase"}}}, {"text": {"text.partial": {"boost": 3, "query": param, "type": "phrase"}}}, {"text": {"text.partial_front": {"boost": 5, "query": param, "type": "phrase"}}}, #{"text": {"text.partial_back": {"boost": 5, "query": param, "type": "phrase"}}} ] } }, "size": 100 } return query def search(self, query_string, **kwargs): if len(query_string) == 0: return { 'results': [], 'hits': 0, } if not self.setup_complete: self.setup() search_kwargs = self.build_search_kwargs(query_string, **kwargs) search_kwargs['from'] = kwargs.get('start_offset', 0) order_fields = set() for order in search_kwargs.get('sort', []): for key in order.keys(): order_fields.add(key) geo_sort = '_geo_distance' in order_fields end_offset = kwargs.get('end_offset') start_offset = kwargs.get('start_offset', 0) if end_offset is not None and end_offset > start_offset: search_kwargs['size'] = end_offset - start_offset try: raw_results = self.conn.search(search_kwargs, index=self.index_name, doc_type='modelresult') except (requests.RequestException, pyelasticsearch.ElasticHttpError) as e: if not self.silently_fail: raise self.log.error("Failed to query Elasticsearch using '%s': %s", query_string, e) raw_results = {} return self._process_results(raw_results, highlight=kwargs.get('highlight'), result_class=kwargs.get('result_class', SearchResult), distance_point=kwargs.get('distance_point'), geo_sort=geo_sort) def build_search_kwargs(self, query_string, **kwargs): if True: return self.makequery(query_string) else: # call original super: query = super(CustomElasticBackend, self).build_search_kwargs(query_string, **kwargs) return query def build_schema(self, fields): content_field_name = '' mapping = {} for field_name, field_class in fields.items(): if field_class.field_type == 'nameword': field_mapping = self.makemapping(field_class.index_fieldname) elif field_class.field_type == 'email': field_mapping = self.emailmapping(field_class.index_fieldname) else: field_mapping = { 'boost': field_class.boost, 'index': 'analyzed', 'store': 'yes', 'type': 'string', } if field_class.document is True: content_field_name = field_class.index_fieldname # DRL_FIXME: Perhaps move to something where, if none of these # checks succeed, call a custom method on the form that # returns, per-backend, the right type of storage? if field_class.field_type in ['date', 'datetime']: field_mapping['type'] = 'date' elif field_class.field_type == 'integer': field_mapping['type'] = 'long' elif field_class.field_type == 'float': field_mapping['type'] = 'float' elif field_class.field_type == 'boolean': field_mapping['type'] = 'boolean' elif field_class.field_type == 'ngram': field_mapping['analyzer'] = "ngram_analyzer" elif field_class.field_type == 'edge_ngram': field_mapping['analyzer'] = "edgengram_analyzer" elif field_class.field_type == 'location': field_mapping['type'] = 'geo_point' # The docs claim nothing is needed for multivalue... # if field_class.is_multivalued: # field_data['multi_valued'] = 'true' if field_class.stored is False: field_mapping['store'] = 'no' # Do this last to override `text` fields. if field_class.indexed is False or hasattr(field_class, 'facet_for'): field_mapping['index'] = 'not_analyzed' if field_mapping['type'] == 'string' and field_class.indexed: field_mapping["term_vector"] = "with_positions_offsets" if not hasattr(field_class, 'facet_for') and not field_class.field_type in('ngram', 'edge_ngram'): field_mapping["analyzer"] = "snowball" mapping[field_class.index_fieldname] = field_mapping return (content_field_name, mapping) class CustomElasticSearchEngine(ElasticsearchSearchEngine): backend = CustomElasticBackend class NameWordField(NgramField): field_type = 'nameword' class EmailField(NgramField): field_type = 'email'qaru.site