Коэффициент корреляции Спирмена. Ранжирование данных онлайн
Онлайн калькулятор: Коэффициент корреляции Спирмена
Калькулятор ниже вычисляет коэффициент ранговой корреляции Спирмена между двумя случайными величинами. Теоретическая часть, чтобы не отвлекаться от калькулятора, традиционно размещается под ним.
addimport_exportmode_editdeleteИзменения случайных величин
Размер страницы: 5102050100chevron_leftchevron_rightДля разделения полей можно использовать один из этих символов: Tab, ";" или "," Пример: -50.5;-50.5
Точность вычисленияЗнаков после запятой: 4
Коэффициент корреляции Спирмена
Сохранить share extension
Метод расчета коэффициента ранговой корреляции Спирмена на самом деле описывается очень просто. Это тот же самый Коэффициент корреляции Пирсона, только рассчитанный не для самих результатов измерений случайных величин, а для их ранговых значений.
То есть,
Осталось только разобраться, что такое ранговые значения и для чего все это нужно.
Если элементы вариационного ряда расположить в порядке возрастания или убывания, то рангом элемента будет являться его номер в этом упорядоченном ряду.
Например, пусть у нас есть вариационный ряд {17,26,5,14,21}. Отсортируем его элементы в порядке убывания {26,21,17,14,5}. 26 имеет ранг 1, 21 — ранг 2 и т.д. Вариационный ряд ранговых значений будет выглядеть следующим образом {3,1,5,4,2}.
То есть, при расчете коэффициента Спирмена исходные вариационные ряды преобразуются в вариационные ряды ранговых значений, после чего к ним применяется формула Пирсона.
Есть одна тонкость — ранг повторяющихся значений берется как среднее из рангов. То есть для ряда {17, 15, 14, 15} ряд ранговых значений будет выглядеть как {1, 2.5, 4, 2.5}, так как первый элемент равный 15 имеет ранг 2, а второй — ранг 3, и .
Если же повторяющихся значений нет, то есть все значения ранговых рядов — числа из диапазона от 1 до n, формулу Пирсона можно упростить доНу и кстати, эта формула чаще всего и приводится как формула расчета коэффицента Спирмена.
В чем же суть перехода от самих значений к их ранговым значениям?А суть в том, что исследуя корреляцию ранговых значений можно установить насколько хорошо зависимость двух переменных описывается монотонной функцией.
Знак коэффициента указывает на направление связи между переменными. Если знак положительный, то значения Y имеют тенденцию увеличиваться при увеличении значений X; если знак отрицательный, то значения Y имеют тенденцию уменьшаться при увеличении значений X. Если коэффициент равен 0, то никакой тенденции нет. Если же коэффициент равен 1 или -1, то зависимость между X и Y имеет вид монотонной функции — то есть, при увеличении X, Y также увеличивается, либо наоборот, при увеличении X, Y уменьшается.
То есть, в отличие от коэффициента корреляции Пирсона, который может выявить только линейную зависимость одной переменной от другой, коэффициент корреляции Спирмена может выявить монотонную зависимость, там, где непосредственная линейная связь не выявляется.
Поясню на примере. Предположим, что мы исследуем функцию y=10/x.У нас есть следующие результаты измерений X и Y{{1,10}, {5,2}, {10,1}, {20,0.5}, {100,0.1}}Для этих данных коэффициент корреляции Пирсона равен -0.4686, то есть связь слабая либо отсутствует. А вот коэффициент корреляции Спирмена строго равен -1, что как бы намекает исследователю, что Y имеет строгую отрицательную монотонную зависимость от X.
planetcalc.ru
11 практических SEO выводов на основе анализа 1 миллиона поисковых результатов Гугл
Сегодня у нас перевод крупного исследования от Брайна Дина, автора блога Беклинко. Данный анализ позволит вам узнать корреляцию между известными поисковыми факторами ранжирования в гугл и характеристиками документов находящихся в топе поисковых результатов. Рекомендую запастись чаем и ознакомиться с ними:)
Недавно мы проанализировали 1 миллион результатов поиска Google, чтобы ответить на вопрос:
какие факторы коррелируют с высокими позициями в поисковой выдаче?
Мы рассмотрели контент, обратные ссылки и даже скорость загрузки сайта.
С помощью Эрика Ван Баскирка и наших партнеров по предоставлению данных 1 мы обнаружили интересные результаты.
И сегодня я собираюсь поделиться с вами тем, что мы нашли.
Краткое изложение наших основных выводов
- Обратные ссылки остаются чрезвычайно важным фактором ранжирования в Google. Мы обнаружили, что число доменов, ссылающихся на страницу, коррелирует с ранжированием больше, чем любой другой фактор.
- Наши данные также показывают, что общий авторитет ссылок на сайт (измерено с помощью Ahrefs Domain Rating) значительно влияет на ранжирование.
- Мы обнаружили, что контент, получивший оценку «тематически релевантный» («topically relevant») (по оценкам MarketMuse), по результатам поисковой выдачи значительно превосходит контент, который недостаточно глубоко охватывает тему. Поэтому публикация контента, раскрывающего одну тему, может способствовать увеличению ранжирования.
- На основании анализа данных поисковой выдачи от SEMRush мы обнаружили, что более длинный текст, как правило, ранжируется выше в результатах поиска Google. Средняя длина текста страниц на первой странице результатов поиска составляет 1890 слов.
- Протокол https имел достаточно сильную корреляцию с попаданием на первую страницу выдачи. И это неудивительно, так как Google подтвердил, что HTTPS является сигналом ранжирования.
- Несмотря на ажиотаж вокруг микроразметки Schema, наши данные показывают, что ее использование не коррелирует с более высоким ранжированием.
- Контент, имеющий по меньшей мере одно изображение, обошел контент без изображений. Тем не менее, мы не обнаружили, что добавление дополнительных картинок может влиять на ранжирование.
- Мы нашли очень незначительную взаимосвязь между оптимизацией ключевых слов в теге Title и ранжированием. Эта корреляция была намного меньше, чем мы ожидали, что может свидетельствовать о переходе Google к семантическому поиску.
- Скорость загрузки сайта имеет значение. На основе данных от Alexa, страницы сайтов, имеющих высокую скорость загрузки, получают более высокие позиции по сравнению со страницами медленно загружающихся сайтов.
- Несмотря на многочисленные обновления алгоритма Penguin, анкорный текст с точным соответствием оказывает сильное влияние на ранжирование.
- Используя данные SimilarWeb, мы обнаружили, что низкий показатель отказов коррелирует с более высокими позициями сайта в выдаче Google.
Ниже предоставлены подробные данные и информация о наших выводах.
Количество ссылающихся доменов имеет очень сильное влияние на ранжирование
Возможно, Вы слышали о том, что получение обратных ссылок с одного и того же домена уменьшает их эффективность.
Другими словами, лучше получить 10 ссылок с 10 разных сайтов, чем 10 ссылок с одного домена.
Согласно нашему анализу, это соответствует действительности. Мы обнаружили, что разнообразие доменов существенно влияет на ранжирование.
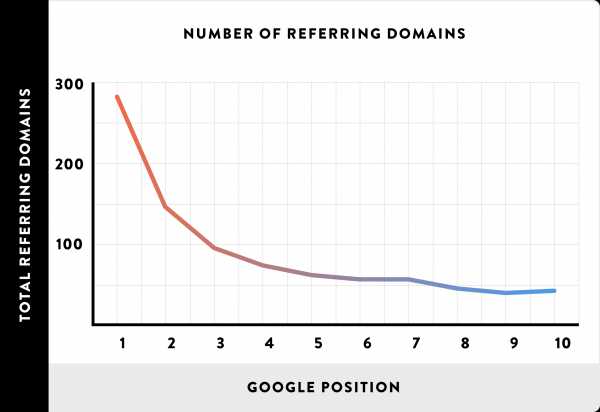
Google «хочет» видеть, что несколько разных сайтов одобрило Вашу страницу. И чем больше доменов сослалось на Вас, тем больше одобрения Вы получаете в глазах Google.
На самом деле число уникальных ссылающихся доменов было сильнейшим фактором, оказывающим влияние на ранжирование, в нашем исследовании.
Вывод: получение ссылок от различных групп доменов является чрезвычайно важным для SEO.
Авторитетные домены, как правило, имеют более высокие позиции в результатах поиска Google
Мы обнаружили, что общий авторитет всех ссылок сайта (измеренный с помощью Ahrefs Domain Rating) сильно связан с ранжированием в Google:
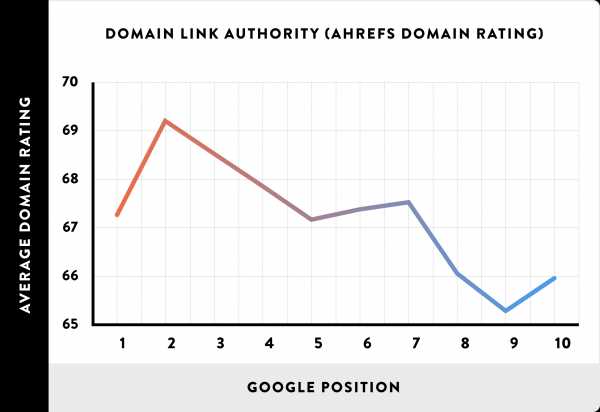
На самом деле общий авторитет сайта имеет большую связь с ранжированием, чем авторитет страницы.
Другими словами, домен, на котором находится страница, гораздо важнее, чем сама страница.
Вывод: увеличение количества ссылок на Ваш сайт может улучшить ранжирование других страниц сайта.
Публикация глубоко раскрывающего ту или иную тему контента может повысить ранжирование сайта
В самом начале развития SEO, Google определял тему страницы, по ключевым словам, появляющихся на ней.
Если ключевое слово появилось на странице X количество раз, Google определял, что страница была об этом ключевом слове. Сегодня, во многом благодаря алгоритму Колибри (Hummingbird), Google понимает тему каждой страницы.
К примеру, когда Вы ищите «кто был режиссером назад в будущее»…

…Google не ищет страницы, которые содержат ключевое слово «кто был режиссером назад в будущее»…
Вместо этого он понимает смысл вопроса и дает ответ:

Как и следовало ожидать, это заметно сказывается на том, как мы оптимизируем контент для SEO. В теории Google должен предпочитать контент, который глубоко охватывает одну тему.
Но соответствуют ли данные этому предложению?
Чтобы ответить на этот вопрос, мы использовали MarketMuse для анализа 10 тыс. адресов из набора данных для анализа «Тематического траста».
И мы обнаружили, что контент, глубоко раскрывающий указанную тему, ранжировался выше, чем более поверхностный.
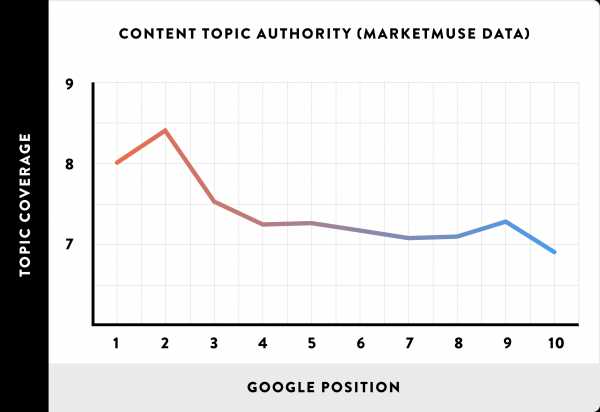
Это интересно. Но как написать контент, который Google будет считать исчерпывающим?
Давайте рассмотрим два примера из нашей подборки данных, чтобы понять это.
Во-первых, у нас есть статья из Daily Press о карте развлечений (Fun Card) для Busch Gardens:

На этой странице есть много традиционных метрик, использование которых приводит к попаданию на первую страницу рейтинга. Например, мы видим ключевое слово в теге заголовка и тег h2. Также домен (Dailypress.com) имеет очень высокий траст (64 балла, согласно Ahrefs Domain Rating).
Тем не менее, эта страница занимает только 10-е место по ключевому слову «Busch Gardens fun card».

Такая низкая позиция отчасти объясняется тем фактом, что контент страницы имеет очень низкий балл по показателю Тематического траста (Topical Authority).
Во-вторых, у нас есть другая страница — о приготовлении Балийского соуса сатай.
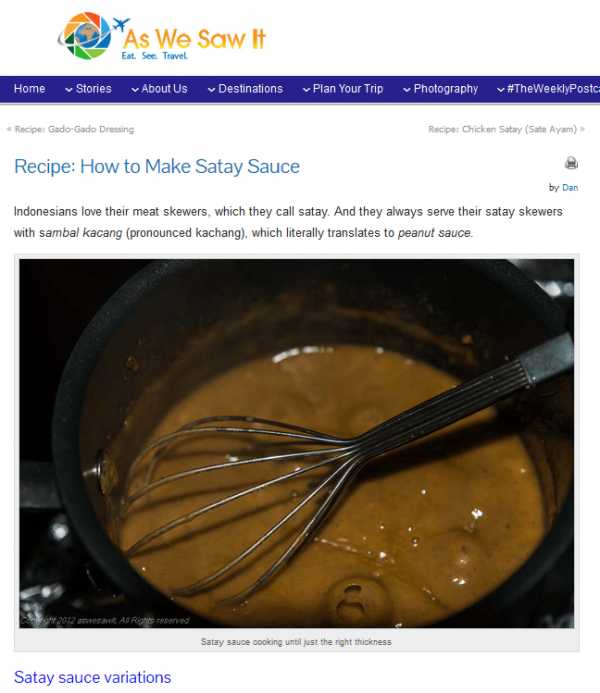
На этой странице можно найти массу информации о соусе сатай, а именно историю появления соуса сатай в Индонезии, как его используют, сам рецепт и даже пищевую ценность.И хотя на этой странице не используется термин «индонезийский соус сатай», она достаточно высоко ранжируется по этому ключевому слову:
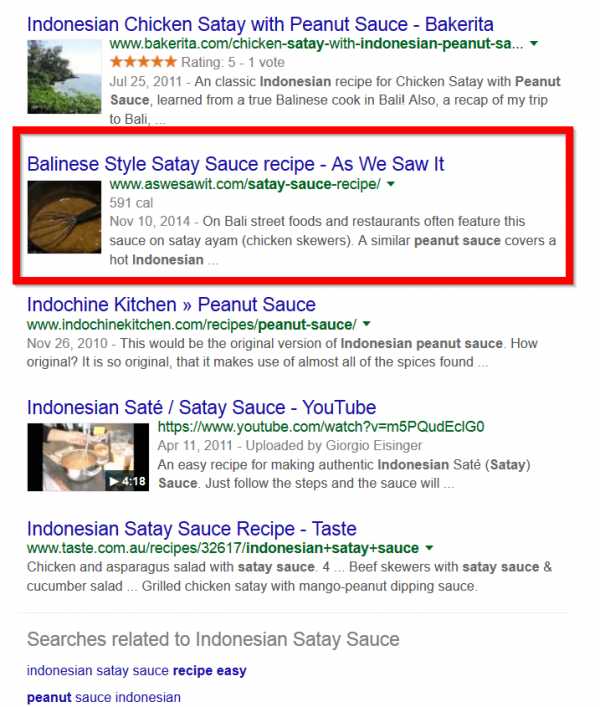
Частично это может объясняться тем, что страница имеет высокий балл по Тематическому траста по запросу «индонезийский соус сатай».
Вывод: Написание контента, полно раскрывающего ту или иную тему, может помочь получить более высокое ранжирование в Google.
Более объемный контент в результатах поиска Google ранжируется выше, чем короткие статьи
Правда ли, что длинный контент опережает короткие посты, состоящие из 200 слов?
Мы обратились к нашим данным, чтобы выяснить это.
После удаления из наших данных отклоняющихся значений (страницы с контентом менее 51 и более 9999 слов) мы обнаружили, что страницы с объемным контентом ранжируются намного лучше, чем страницы с контентом небольшого объема.
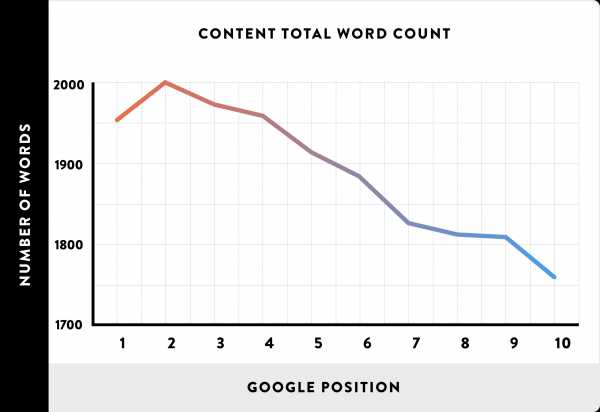
Таким образом, среднее количество слов на первой странице результатов поиска Google составляет 1890 слов.
Предыдущие исследования факторов ранжирования в поисковых системах показали, что более объемный контент лучше работает в Google.
Эта корреляция может быть обусловлена тем, что более объемным контентом значительно чаще делятся в социальных сетях.
Также преимущество объемного контента может отражать лишь тот факт, что владельцы сайтов заботятся о публикации качественного контента. Так как это исследование посвящено корреляции, мы не можем сказать, почему объемный контент лучше ранжируется.
Однако если Вы соедините нашу информацию со своей собственной, Вы увидите полную картину, которая покажет, что использование объемного контента лучше для SЕО.
Вывод: Объемный контент лучше ранжируется в результатах поиска Google, чем короткий. Среднее количество слов на первой странице результатов поиска Google – 1890 слов.
HTTPS умеренно коррелирует с более высоким ранжированием
В прошлом году Google призывал веб-мастеров сменить протокол сайтов на защищенный HTTPS. Они даже назвали HTTPS «сигналом ранжирования«.
Что говорят об этом наши данные?
Хотя эта корреляция не была очень сильной, мы обнаружили, что наличие HTTPS коррелирует с высокими позициями сайта на первой странице выдачи Google.
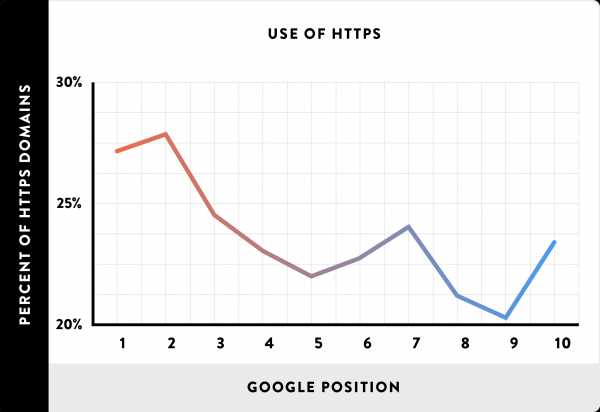
Означает ли это, что нужно уже сегодня переходить на https? Очевидно, решение остается за вами. Следует отметить, что перенос сайта на HTTPS — это сложный процесс, который может привести к серьезным техническим проблемам.
Прежде чем Вы сделаете переход на HTTPS, изучите это руководство от Google.
Вывод: Так как корреляция между HTTPS и ранжированием не так уж сильна, и ввиду того, что смена протокола является достаточно ресурсоемкой задачей, мы не рекомендуем реализовывать эти изменения исключительно ради SЕО. Но при запуске нового сайта лучше иметь HTTPS с самого начала.
Корреляция между разметкой Schema и ранжированием отсутствует
Ранее было много шума вокруг разметки Schema и SEO.
Теория звучит примерно так:
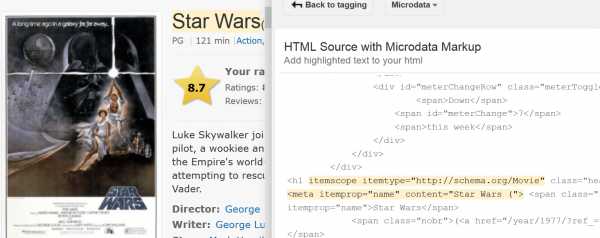
разметка Schema позволяет поисковым системам лучше понимать, о чем Ваш контент. Это понимание подтолкнет их к тому, чтобы показывать Ваш сайт большему количеству людей.
Например, Вы можете использовать тег структурированных данных <name>. Тем самым Вы даете Google понять, что когда Вы используете словосочетание «Звездные войны», Вы имеете в виду оригинальное название фильма, а не франшизу в целом:
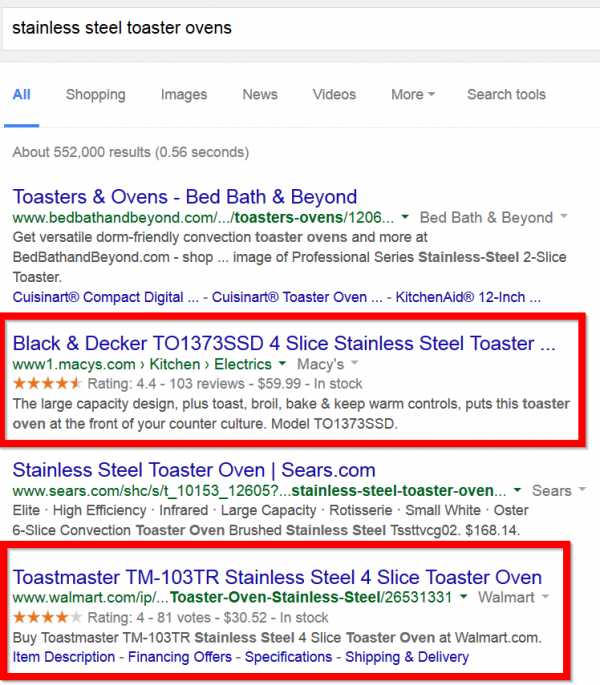
Или Вы можете использовать Schema.org, чтобы показать рейтинг продуктов на своем коммерческом сайте:
Все эти вещи должны помогать вам в ранжировании. Работник компании Google Джон Мюллер намекнул, что в будущем они, возможно, будут использовать структурированные данные в качестве сигнала ранжирования.
Однако согласно нашему анализу, наличие на сайте структурированной информации не имеет никакого отношения к ранжированию в Google.
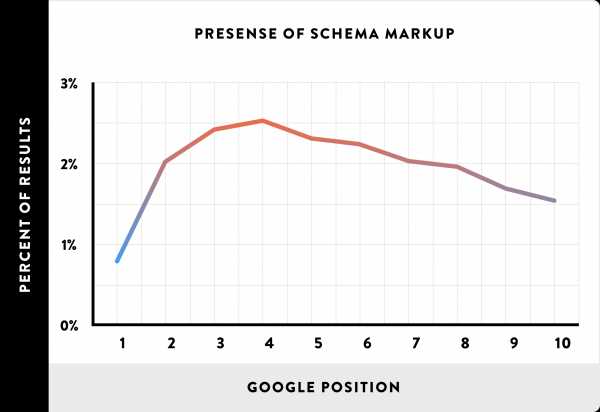
Вывод: Не стесняйтесь использовать структурированные данные на сайте. Но не ждите, что это скажется на ранжировании.
Более короткие URL-адреса лучше ранжируются, чем длинные
Обычно я рекомендую людям использовать короткие URL-адреса для лучшей оптимизации страницы.
Почему?
Есть две причины:
Во-первых, короткий URL-адрес, например, backlinko.com/my-post, проще для понимания Google, чем backlinko.com/1/12/2016/blog/category/this-is-the-title-of-my-blog-post.
По словам сотрудника компании Google Мэта Каттса, после 5 слов в Вашем URL:
«алгоритм [Google] придает меньше веса этим словам».
И наши данные подтверждают эффективность использования более коротких URL-адресов.
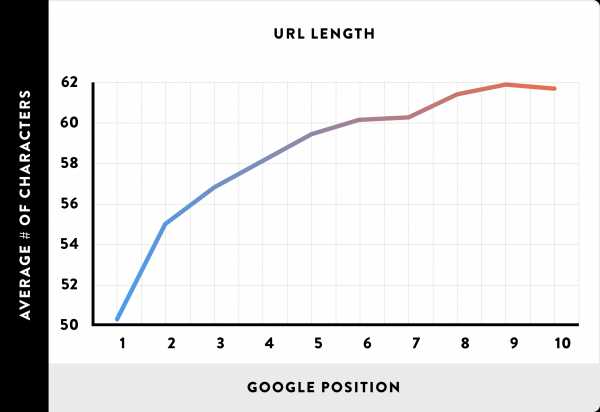
К счастью, это будет не сложно реализовать на практике. Всякий раз, когда Вы публикуете новый контент, делайте URL-адрес коротким и привлекательным.
Если Вы используете WordPress, то можно установить постоянную структуру на «post name»:
После этого, когда Вы пишете пост, редактируйте URL, чтобы включить несколько слов:
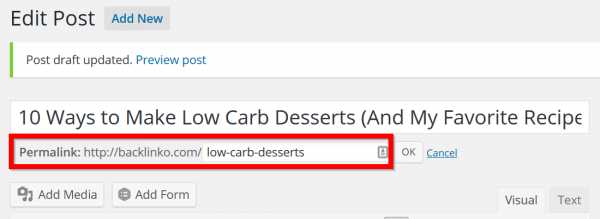
Предупреждение: убедитесь в том, что новая опция будет применяться только к будущим постам. Если изменятся адреса старых страниц, это может привести к возникновению серьезных проблем с SЕО.
Например, URL-адрес моего поста 21 Actionable SEO Techniques You Can Use Right Now (21 действенная SЕО-техника, которую можно использовать прямо сейчас) представляет собой просто ключевое слово:
Во-вторых, длинный URL-адрес, как правило, указывает на страницу, которая находится в нескольких кликах от главной. Это обычно означает, что данная страница обладает меньшим весом и авторитетностью, что в свою очередь ведет к более низким позициям в выдаче.
Например, этот URL-адрес продукта iPad на BestBuy.com представляет собой страницу, которая сильно удалена от авторитетной главной страницы:
Вывод: Используйте короткие URL-адреса, когда это возможно, поскольку они могут дать Google лучшее представление о реальном содержании страницы.
Контент, содержащий как минимум одно изображение, ранжируется выше, чем контент без изображений (но увеличение числа картинок не влияет на позиции)
Исследования показали, что контент, богатый изображениями, генерируют больше просмотров и им чаще делятся в социальных сетях.
Это говорит о том, что добавление графики в контент может способствовать росту репостов, которые должны повысить ранжирование в Google.
Для измерения влияния изображений на ранжирование мы смотрели на наличие или отсутствие картинок в теле страницы (другими словами, в контенте страницы).
Согласно нашим данным, использование по меньшей мере одного изображения в контенте значительно лучше, чем отсутствие изображений вообще.

Тем не менее, когда мы исследовали связь между общим числом изображений и позициями в выдаче, мы не нашли никакой корреляции.
Это говорит о том, что когда дело доходит до использования изображений и ранжирования, существует точка убывающей значимости.
Вывод: использование одного изображения явно лучше, чем их полное отсутствие. Но большое количество изображений, по-видимому, не влияет на поисковое ранжирование.
Использование (точного) ключевого слова в теге заголовка страницы имеет небольшую корреляцию с ранжированием
С первых дней появления поисковых систем тег заголовка был наиболее важным элементом SЕО на странице.
Поскольку тег заголовка предоставляет пользователям (и поисковой системе) обзор темы Вашей страницы, слова, которые появляются в нем, уже давно имеют значительное влияние на ранжирование.
Тем не менее, мы хотели выяснить, уменьшилось ли значение заголовка после перехода Google к семантическому поиску.
Мы обнаружили, что использование ключевых слов в теге заголовка все еще немного коррелирует с ранжированием. Тем не менее, эта взаимосвязь меньше, чем мы ожидали.
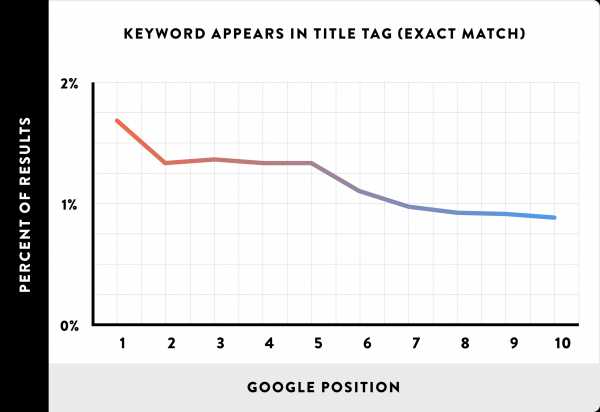
Это свидетельствует о том, что Google не нужно видеть точное ключевое слово в теге заголовка, чтобы распознать тему страницы.
Например, вот шесть лучших результатов по ключевому слову «list building».
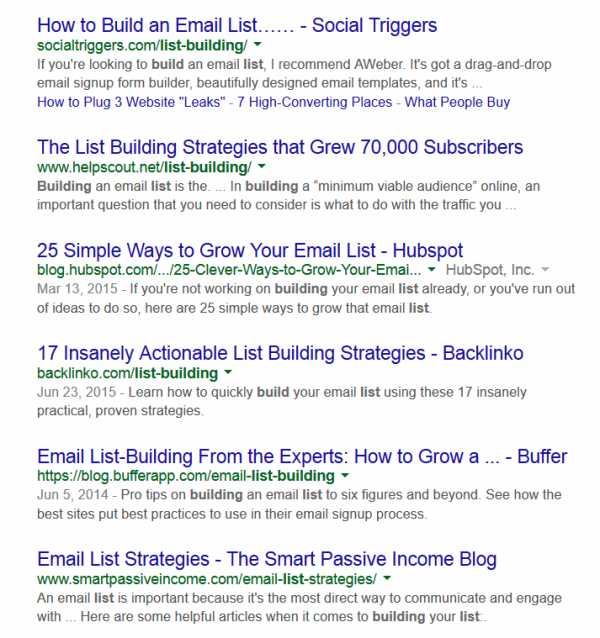
Обратите внимание на то, что три из шести лучших результатов (включая результат #1) не содержат точное ключевое слово «list building» в теге заголовка.
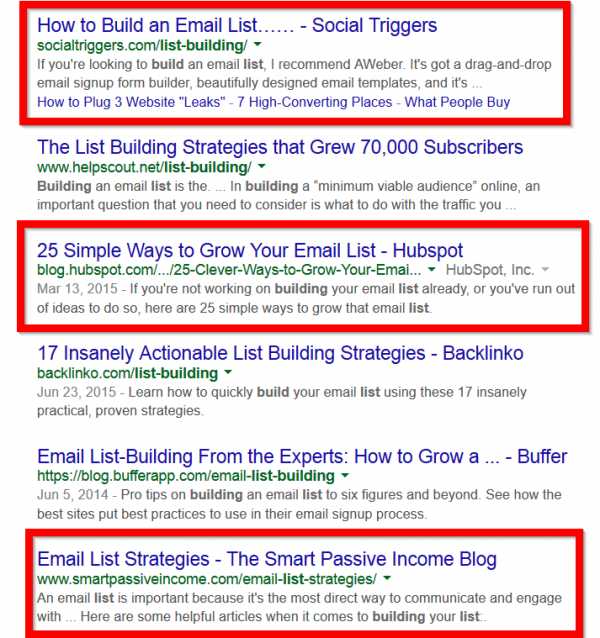
Это является отражением перехода Google от использования точного вхождения ключевого слова к семантическому поиску.
Вывод: Добавление ключевого слова в тег заголовка может помочь при ранжировании по этому запросу. Однако вследствие перехода к семантическому поиску результаты не кажутся такими же значительными, как раньше.
Страницы сайтов, имеющих высокую скорость загрузки, ранжируются выше страниц на более медленных сайтах
Начиная с 2010 года, Google использует скорость загрузки сайта в качестве официального сигнала ранжирования.
Но нам было интересно:
насколько сильно скорость загрузки сайта влияет на ранжирование?
Мы использовали скорость домена Alexa, чтобы проанализировать среднее время загрузки 1 миллиона доменов из нашего набора данных. Иными словами, мы не измеряли напрямую скорость загрузки отдельных страниц сайтов в выборке. Мы просто анализировали среднюю скорость загрузки всего домена.
И мы обнаружили сильную корреляцию между скоростью загрузки сайта и ранжированием в Google:
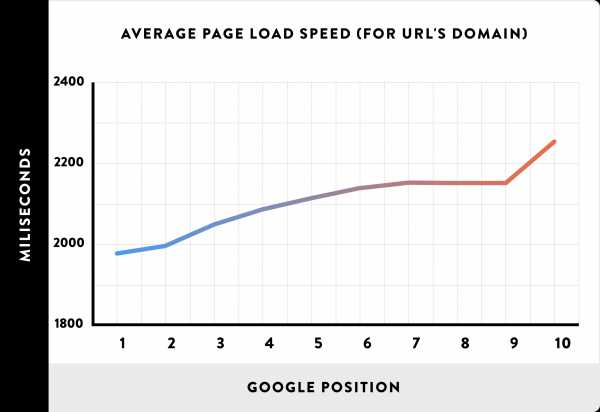
Опять же, это просто корреляция. Может ли быть так, что владельцы сайтов, оптимизирующие их скорость, также проводят его SEO оптимизацию? Конечно.
Но наличие быстро загружающегося сайта определенно не повредит SEO продвижению. Так что есть смысл ускорить загрузку.
Вывод: быстро загружаемые сайты, вероятнее всего, будут лучше ранжироваться в Google.
Больше обратных ссылок — выше позиции в выдаче
Было много суеты вокруг новых сигналов ранжирования (таких, как социальные сигналы), которые сегодня используются поисковыми системами. Многие даже считают, что обратные ссылки стали менее важными.
Нам было интересно узнать, по-прежнему ли Google использует огромное количество обратных ссылок в качестве алгоритмического сигнала ранжирования.
Чтобы измерить это, мы использовали Ahrefs API для определения общего количества обратных ссылок, указывающих на каждую страницу из нашей базы.
Мы обнаружили, что страницы с наибольшим количеством обратных ссылок лучше всего ранжируются в Google.
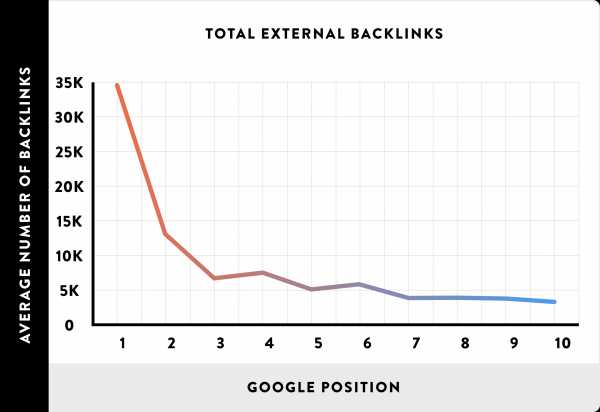
Даже несмотря на то, что Google продолжает обновлять свой алгоритм, обратные ссылки остаются критическим сигналом ранжирования.
Вывод: страницы с большим числом обратных ссылок ранжируются выше, чем страницы с меньшим их количеством.
Ранжирование страницы тесно связано с общим ссылочным авторитетом страницы
В дополнение к общему количеству обратных ссылок, мы хотели ответить на вопрос:
влияет ли общий авторитет страницы на ранжирование?
Большинство SEO-специалистов соглашаются с тем, что качество обратных ссылок так же важно, как и их количество.
Другими словами, лучше получить одну ссылку с авторитетной страницы, чем 100 ссылок со 100 некачественных страниц.
И наши данные подтверждают это:

Согласно измерениям авторитетности ссылок, выполненного Ahrefs (рейтинг URL-адресов), страницы с авторитетными обратными ссылками ранжируются выше, чем страницы с небольшим авторитетом. Однако эта корреляция не так сильна, как влияние общего числа ссылающихся доменов.
Вывод: общая авторитетность ссылок оказывает влияние на ранжирование.
Точное соответствие анкорного текста ключевым словам значительно коррелирует с ранжированием
Поскольку компания Google выпустила в 2012 году обновление алгоритма Пингвин, многие SEO-специалисты советовали избегать использования обратных ссылок с точным соответствием анкорного текста по ключевому слову. Однако несколько исследований ранжирования в поисковых системах выявили, что анкорный текст все еще важен.
Именно поэтому мы хотели выявить, является ли до сих пор анкорный текст важным сигналом ранжирования.
Наши исследования показали, что точное совпадение анкорного текста сильно коррелирует с ранжированием.
В самом начале развития SЕО построение обратных ссылок с точным соответствием анкорного текста было очень эффективно. Например, если Вы хотите ранжироваться по ключевому слову «online flower delivery», нужно убедиться в том, что анкорный текст выглядят так:
Однако Google положил конец этой практике, начиная с выхода обновления алгоритма Пингвин. По этой причине мы не рекомендуем использовать в анкорном тексте ссылки с точным соответствием ключевому слову, несмотря на то, что это оказывает сильное влияние на ранжирование.
Вывод: обратные ссылки с анкорами с точным соответствием четко коррелируют с ранжированием. Однако из-за риска попадания под фильтр мы не рекомендуем использовать их как тактику SEO.
Низкий показатель отказов имеет сильную связь с высокими позициями сайта в поисковой выдаче Google
Многие SЕО-специалисты считают, что Google использует сигналы, связанные со взаимодействием с пользователем (например, показатель отказов, время нахождения на сайте и процент возвратов в выдачу) в качестве факторов ранжирования.
Чтобы проверить эту теорию, мы взяли 100000 сайтов из нашей группы и проанализировали их в SimilarWeb.
В частности мы проанализировали три сигнала взаимодействия с пользователем: показатель отказов, время нахождения на сайте и процент возвратов в выдачу.
Мы обнаружили, что сайты с низким средним показателем отказов сильно коррелируют с высокими позициями.
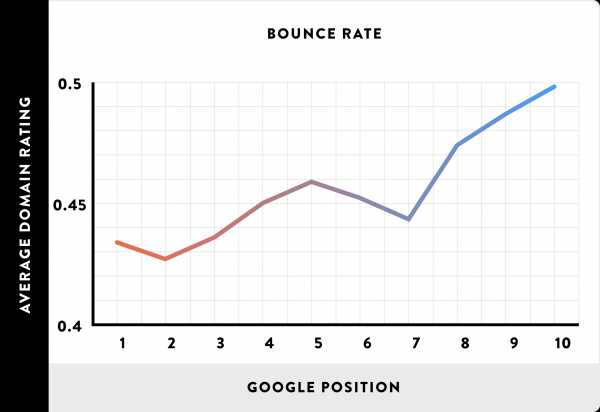
Пожалуйста, имейте в виду, что мы не утверждаем, что низкие показатели отказов гарантирует более высокое ранжирование.
Google может использовать показатель отказов как сигнал ранжирования (хотя ранее они отрицали это). Или, возможно, качественный контент делает людей более вовлеченными. Поэтому низкий показатель отказов — это побочный продукт высококачественного контента, который Google измеряет.
Опять же, так как это лишь корреляционное исследование, данную связь сложно выявить наверняка.
Вывод: Google может использовать показатель отказов как сигнал ранжирования. Или это может быть случай корреляции, когда корреляция не подразумевает причинно-следственной связи.
Заключение
Выражаем особую благодарность нашим партнерам: SEMRush, Ahrefs, MarketMuse и SimilarWeb, благодаря которым это исследование стало возможным.
Я также хочу поблагодарить Эрика Ван Баскирка из ClickStream (руководитель проекта), Зака Рассела (ведущий разработчик) и Ци Чжао (ведущий специалист по обработке и анализу данных) за их вклад.
Если Вы хотите узнать больше о том, как мы собирали и анализировали данные, вот ссылка на наши методы исследования.
Теперь я бы хотел услышать от Вас: какие выводы удивили вас (или не удивили)? Или, может быть, у Вас есть вопросы касательно чего-то в нашем исследовании.
Оставьте комментарий и дайте нам знать об этом.
Игорь Рудник Руководитель referr.ru. В интернет-маркетинге 7+ лет. Докладчик профильных конференций поделиться с друзьямиreferr.ru
Машинное обучение ранжированию, 15 мая 2009 — Обучение в Яндексе
Данные
В рамках конкурса «Интернет-математика» мы распространяем реальные таблицы оценок, которые используются для подбора формулы ранжирования Яндекса. Таблицы содержат уже посчитанные и нормализованные признаки пар «запрос-документ», а также оценки релевантности, сделанные асессорами (оценщиками качества поиска) Яндекса. Таблицы не содержат оригинальных запросов и ссылок на оригинальные документы, не описана семантика признаков (признаки просто пронумерованы). Примеры признаков, участвующих в таблице, – tf*idf, PageRank, длина запроса в словах.
Данные разбиты на два файла – обучающее множество (imat2009_learning.txt) и множество для оценки (imat2009_test.txt). Файл с обучающим множеством содержит 97 290 строк, которые соответствуют 9 124 запросам. Множество для оценки (115 643 строки) делится на часть для предварительной публичной оценки (первые 21 103 строки) и часть для финальной оценки (остальные строки). Данные разбиты так: 45% – обучение, 10% – публичная оценка, 45% – финальная оценка. Каждая строка файлов данных соответствует паре «запрос-документ». Все признаки либо бинарные – принимают значения из {0, 1}, либо непрерывные. Значения непрерывных признаков нормированы на интервал [0, 1]. Каждой паре «запрос-документ» соответствуют значения 245 признаков. Данные представлены в формате, готовом для загрузки в SVMlight в режиме построения регрессии. Если значение признака равно 0, то он опускается. В комментариях в конце каждой строки указан идентификатор запроса. Файл с обучающей выборкой содержит оценку релевантности, значения из диапазона [0, 4] (4 – «высокая релевантность», 0 – «нерелевантно»).
Формат файла с обучающим множеством:
<line> .=. <relevance> <feature>:<value> <feature>:<value> ... <feature>:<value> # <queryid> <relevance> .=. <float> <feature> .=. <integer> <value> .=. <float> <queryid> .=. <integer>Оценка
Полученные от участников оценки релевантности документов ранжируются внутри каждого запроса по убыванию, причем в случае одинаковых значений выше ранжируется документ с худшей оценкой асессора.По ранжированному списку на основании оценок асессеров вычисляется метрика качества. Метрикой качества ранжирования в рамках конкурса является Discounted Cumulative Gain (DCG), усредненный по всем запросам. Мы используем такую формулу для вычисления DCG:
Результаты
Результат выполнения конкурсного задания – это файл, содержащий ровно 115 643 строки. В каждой строке записано число (полученная оценка релевантости), соответствующее строке файла множества для оценки. Первые 21 103 строки используются для предварительной публичной оценки, остальные будут использованы для финальной оценки при подведении итогов конкурса. По результатам предварительной публичной оценки формируется текущий рейтинг решений. Каждая команда может многократно подавать файл с результатами вплоть до окончания приема результатов, но не чаще, чем один раз в 10 минут. После окончания приема результатов вычисляется финальная оценка – значение метрики по второй части множества для оценки. На основании финальной оценки подводятся итоги конкурса и объявляются победители.
academy.yandex.ru