.NetBlog - блог о программировании на C# .Net, и других, не мене интересных вещах. Ранжирование sql
Функции ранжирования в MS SQL - .NetBlog
Как вы наверняка знаете, в реляционных базах данных строки в таблице не имеют порядка. Можно, конечно, использовать дополнительные механизмы, например IDENTITY-столбец, но это все равно не поможет вам получить, например, порядок строки в результатах запроса. Для возможности как-то соотносить порядок одних строк с другими и придуманы функции ранжирования. Прежде чем я перейду к рассказу о них, отмечу один важный момент: все ранжирующие функции являются недетерминированными, то есть результат их выполнения каждый раз может быть разным (хотя, на одном и том же наборе данных, один и тот же запрос будет возвращать один и тот же результат).
Итак, собственно, функции ранжирования. Представим, что у нас есть вот такая табличка:
И мы хотим получить порядок строк отсортированных по типу оборудования. Для этого можно использовать функция ROW_NUMBER().SELECT ROW_NUMBER() OVER (ORDER BY PositionType DESC) as RowNumber ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering] В результате выполнения этого запроса мы получим вот такой результат: Как вы заметили, для указания на базе какого столбца будет сделана нумерация в запросе используется конструкция ORDER BY. На больших наборах данных из-за этого может пострадать производительность, но, если порядок следования рядов в результате выдачи вам не важен, то сортировки можно избежать, используя примерно такую конструкцию:SELECT ROW_NUMBER() OVER (ORDER BY (SELECT TOP 1 1 FROM [test].[dbo].[rowNumbering])) as RowNumber ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering]Следующая функция - RANK() более интересна. Она позволяет ранжировать результаты выдачи на основе какого-то столбца. Посмотрите на результат выполнения вот такого запроса:
SELECT RANK() OVER (ORDER BY PositionType DESC) as rnk ,[maker] ,[positionName] ,[positionType] ,[price] FROM [test].[dbo].[rowNumbering] Как видите, все сервера у нас получили ранг равный 1, а модем - ранг равный 4. Почему не 2? Потому что в функции RANK() ранг каждого ряда вычисляется как номер ряда+1. Ряды с одинаковым значением столбца получают одинаковый ранг, а следующий отличающийся - свой порядковый.www.dotnetblog.ru
Функции ранжирования и нумерации в Transact-SQL - ROW_NUMBER, RANK, DENSE_RANK, NTILE | Info-Comp.ru
Изучение Transact-SQL продолжается и на очереди у нас функции ранжирования ROW_NUMBER, RANK, DENSE_RANK и NTILE, сейчас мы узнаем, что делают эти функции и зачем вообще они нужны, все как обычно будем рассматривать на примерах.
В языке Transact-SQL очень много различных функций, конструкций, например, PIVOT или INTERSECT, которые в принципе редко используются, их мы даже в нашем мини справочнике Transact-SQL не указывали, но знать, где и как их можно использовать нужно, так же как и функции ранжирования или их также называют функции нумерации. Поэтому сегодня давайте поговорим именно об этих функция и если говорить конкретно, то это функции: ROW_NUMBER, RANK, DENSE_RANK, NTILE.
И начнем мы, конечно же, с определения, что же вообще это за ранжирующие функции.
Ранжирующие функции в T-SQL
Ранжирующие функции - это функции, которые возвращают значение для каждой строки группы в результирующем наборе данных. На практике они могут быть использованы, например, для простой нумерации списка, составления рейтинга или постраничной выборки.
И для того чтобы лучше усвоить работу и применение этих функций, давайте рассмотрим все их по очереди, и параллельно будем сравнивать их друг с другом, т.е. таким образом, мы еще и узнаем в чем их отличие. Но для того чтобы начать рассматривать примеры, необходимо определится с исходными данными.
Примечание! Для детального изучения языка T-SQL, рекомендую почитать книгу «Путь программиста T-SQL», в ней я подробно, с большим количеством примеров, рассказываю основы программирования на языке T-SQL.
Исходные данные для примеров
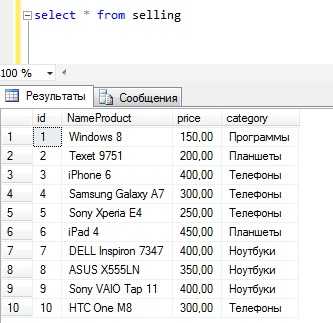
Использовать мы будем MS SQL Server Express 2014, а запросы будем писать в Management Studio Express. В качестве тестовых данных будем использовать таблицу selling, которая будет содержать различные товары (телефоны, планшеты, ноутбуки, программы) с выдуманными ценами.
Наша тестовая таблица
CREATE TABLE [dbo].[selling]( [id] [int] IDENTITY(1,1) NOT NULL, [NameProduct] [varchar](50) NOT NULL, [price] [money] NOT NULL, [category] [varchar](50) NOT NULL ) ON [PRIMARY] GOЗаполним ее тестовыми данными, в итоге получим следующее (для выборки пишем простой запрос select)
ROW_NUMBER
ROW_NUMBER – функция нумерации в Transact-SQL, которая возвращает просто номер строки.
Синтаксис
ROW_NUMBER () OVER ([PARTITION BY столбы группировки] ORDER BY столбец сортировки)
где, partition by - это не обязательное ключевое слово, после которого указывается столбец или столбцы, по которым группировать данные, а order by столбец для сортировки, т.е. по данному столбцу будут отсортированы данные, а потом пронумерованы, он уже обязателен. Сразу скажу, чтобы не возвращаться, что эти ключевые слова относятся ко всем функциям ранжирования, которые мы будем сегодня использовать.
Пример без группировки с сортировкой по цене
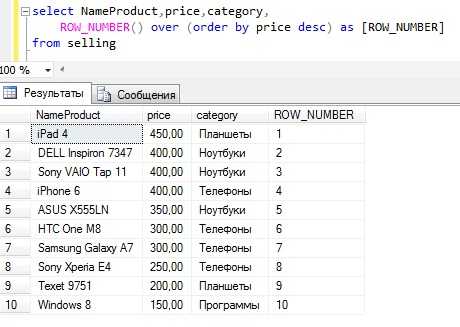
Текст запроса
SELECT NameProduct, price, category, ROW_NUMBER() over (order by price desc) as [ROW_NUMBER] FROM sellingПример с группировкой по категории и с сортировкой по цене

Текст запроса
SELECT NameProduct, price, category, ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART] FROM sellingКак видите, здесь уже нумерация идет в каждой категории.
RANK
RANK – ранжирующая функция, которая возвращает ранг каждой строки. В данном случае, в отличие от row_number(), идет уже анализ значений и в случае нахождения одинаковых, функция возвращает одинаковый ранг с пропуском следующего. Как было уже сказано выше, здесь также можно использовать partition by для группировки и обязательно нужно указывать столбец сортировки в order by.
Пример без группировки с сортировкой по цене и отличие от row_number()

Текст запроса
SELECT NameProduct, price, category, rank() over (order by price desc) [RANK], ROW_NUMBER() over (order by price desc) as [ROW_NUMBER] FROM sellingПример с группировкой по категории и с сортировкой по цене и отличие от row_number()

Текст запроса
SELECT NameProduct, price, category, rank() over (partition by category order by price desc) [RANK], ROW_NUMBER() over (partition by category order by price desc) as [ROW_NUMBER_PART] FROM sellingDENSE_RANK
DENSE_RANK - ранжирующая функция, которая возвращает ранг каждой строки, но в отличие от rank, в случае нахождения одинаковых значений, возвращает ранг без пропуска следующего.
Пример без группировки с сортировкой по цене и отличие от rank() и row_number()

Текст запроса
SELECT NameProduct, price, category, rank() over (order by price desc) [RANK], DENSE_RANK () over (order by price desc) [DENSE_RANK], ROW_NUMBER() over (order by price desc) as [ROW_NUMBER] FROM selling
NTILE
NTILE – функция Transact-SQL, которая делит результирующий набор на группы по определенному столбцу. Количество групп указывается в качестве параметра. В случае если в группах получается не одинаковое количество строк, то в первой группе будет наибольшее количество, например, в нашем случае строк 10 и если мы поделим на три группы, то в первой будет 4 строки, а во второй и третей по 3.
Пример
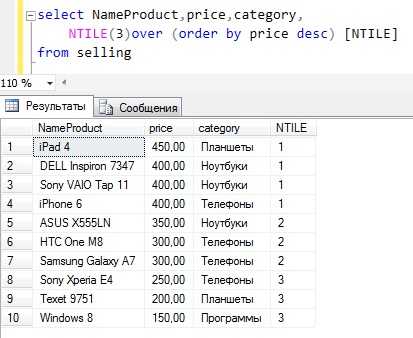
Текст запроса
SELECT NameProduct, price, category, NTILE(3)over (order by price desc) [NTILE] FROM sellingВ заключение давайте приведем пример, в котором мы наглядно увидим различия в работе всех функций, например, вот такой

Текст запроса
SELECT NameProduct, price, category, ROW_NUMBER() over (order by price desc) as [ROW_NUMBER], rank() over (order by price desc) [RANK], DENSE_RANK () over (order by price desc) [DENSE_RANK], NTILE(3)over (order by price desc) [NTILE] FROM sellingПохожие статьи:
info-comp.ru
sql - Если функциональность ранжирования SQL следует рассматривать как "использовать с осторожностью",
Этот вопрос возникает из обсуждения вопроса о том, использовать ли функцию ранжирования SQL или нет в конкретном случае.
Любая общая RDBMS включает в себя некоторые функции ранжирования, то есть язык запросов имеет такие элементы, как TOP n ... ORDER BY key, ROW_NUMBER() OVER (ORDER BY key) или ORDER BY key LIMIT n (обзор).
Они отлично справляются с увеличением производительности, если вы хотите представить только небольшой кусок из огромного количества записей. Но они также вводят серьезную ошибку: если key не является уникальным, результаты не детерминированы. Рассмотрим следующий пример:
users user_id name 1 John 2 Paul 3 George 4 Ringo logins login_id user_id login_date 1 4 2009-08-17 2 1 2009-08-18 3 2 2009-08-19 4 3 2009-08-20Как и ожидалось George, и все выглядит нормально. Но затем новая запись вставляется в таблицу logins:
1 4 2009-08-17 2 1 2009-08-18 3 2 2009-08-19 4 3 2009-08-20 5 4 2009-08-20Что теперь возвращает запрос? Ringo? George? Вы не можете сказать. Насколько я помню, например, MySQL 4.1 возвращает первую физически созданную запись, которая соответствует критериям, т.е. Результат будет George. Но это может варьироваться от версии к версии и от СУБД до СУБД. Что нужно было вернуть? Можно сказать, что Ringo, поскольку он, по-видимому, вошел в последний, но это чистая интерпретация. На мой взгляд, оба должны были быть возвращены, потому что вы не можете однозначно решить из имеющихся данных.
Итак, этот запрос соответствует требованиям:
SELECT users.* FROM logins JOIN users ON logins.user_id = users.user_id AND logins.login_date = ( SELECT max(logins.login_date) FROM logins JOIN users ON logins.user_id = users.user_id)Если вы ищете SO для, например, ROW_NUMBER вы найдете множество решений, предлагающих использовать ранжирование и пропустить, чтобы указать на возможные проблемы.
Вопрос: Какой совет следует дать, если предлагается решение, включающее функции ранжирования?
qaru.site
Используйте Access SQL для группировки ранжирования Безопасный SQL
Как я оцениваю продавцов по # клиентам, сгруппированным по отделам (со связанными галдами)?
Например, учитывая эту таблицу, я хочу создать столбец Rank справа. Как мне это сделать в Access?
Я уже знаю, как сделать простой рейтинг с этим кодом SQL. Но я не знаю, как переделать это, чтобы принять группировку.
Кроме того, для этого есть много ответов, используя функцию Rank () SQL Server, но мне нужно сделать это в Access. Предложения, пожалуйста?
SELECT *, (select count(*) from tbl as tbl2 where tbl.customers > tbl2.customers and tbl.dept = tbl2.dept) + 1 as rank from tblПросто добавьте поле обработки в подзапрос …
Отличное решение с подзапросом! За исключением огромных наборов записей, решение подзапроса становится очень медленным. Лучше (быстрее) использовать Self JOIN, посмотрите на следующее решение: присоединитесь
SELECT tbl1.SalesPerson , count(*) AS Rank FROM tbl AS tbl1 INNER JOIN tbl AS tbl2 ON tbl1.DEPT = tbl2.DEPT AND tbl1.#Customers < tbl2.#Customers GROUP BY tbl1.SalesPersonЯ знаю, что это старая нить. Но так как я провел много времени на очень похожей проблеме, и мне очень помогли первые ответы, приведенные здесь, я хотел бы поделиться тем, что, как мне показалось, было намного быстрее. (Остерегайтесь, это сложнее.)
Сначала создайте другую таблицу под названием «Индивидуализатор». Это будет иметь одно поле, содержащее список чисел 1 через самый высокий ранг, который вам нужен.
Затем создайте модуль VBA и вставьте его в него:
'Global Declarations Section. Option Explicit Global Cntr '************************************************************* ' Function: Qcntr() ' ' Purpose: This function will increment and return a dynamic ' counter. This function should be called from a query. '************************************************************* Function QCntr(x) As Long Cntr = Cntr + 1 QCntr = Cntr End Function '************************************************************** ' Function: SetToZero() ' ' Purpose: This function will reset the global Cntr to 0. This ' function should be called each time before running a query ' containing the Qcntr() function. '************************************************************** Function SetToZero() Cntr = 0 End FunctionСохраните его как Module1.
Затем создайте Query1 следующим образом:
SELECT Table1.Dept, Count(Table1.Salesperson) AS CountOfSalesperson FROM Table1 GROUP BY Table1.Dept;Создайте запрос MakeTable под названием Query2 следующим образом:
SELECT SetToZero() AS Expr1, QCntr([ID]) AS Rank, Query1.Dept, Query1.CountOfSalesperson, Individualizer.ID INTO Qtable1 FROM Query1 INNER JOIN Individualizer ON Query1.CountOfSalesperson >= Individualizer.ID;Создайте еще один запрос MakeTable под названием Query3 следующим образом:
SELECT SetToZero() AS Expr1, QCntr([Identifier]) AS Rank, [Salesperson] & [Dept] & [#Customers] AS Identifier, Table1.Salesperson, Table1.Dept, Table1.[#Customers] INTO Qtable2 FROM Table1;Если у вас есть еще одно поле, которое уникально идентифицирует каждую строку, вам не нужно будет создавать поле Идентификатор.
Запустите Query2 и Query3, чтобы создать таблицы. Создайте четвертый запрос Query4 следующим образом:
SELECT Qtable2.Salesperson, Qtable2.Dept, Qtable2.[#Customers], Qtable1.ID AS Rank FROM Qtable1 INNER JOIN Qtable2 ON Qtable1.Rank = Qtable2.Rank;Query4 возвращает результат, который вы ищете.
Практически вы хотели бы написать функцию VBA для запуска Query2 и Query3, а затем вызвать эту функцию с помощью кнопки, расположенной в удобном месте.
Теперь я знаю, что это звучит смешно сложным для примера, который вы дали. Но в реальной жизни я уверен, что ваш стол сложнее, чем этот. Надеюсь, мои примеры могут быть применены к вашей реальной ситуации. В моей базе данных с более чем 12 000 записей этот метод является FAR самым быстрым (как в: 6 секунд с 12 000 записей по сравнению с более чем 1 минутой с 262 записями, ранжированными по методу подзапроса).
Настоящей тайной для меня был запрос MakeTable, потому что этот метод ранжирования бесполезен, если вы не сразу выводите результаты в таблицу. Но это ограничивает ситуации, к которым он может быть применен.
PS Я забыл упомянуть, что в моей базе данных я не вытягивал результаты непосредственно из таблицы. Записи уже прошли череду запросов и нескольких вычислений, прежде чем они должны были быть ранжированы. Это, вероятно, в значительной степени способствовало огромной разнице в скорости между двумя методами в моей ситуации. Если вы берете записи непосредственно из таблицы, вы можете не заметить почти такое же улучшение.
Вам нужно сделать математику. Обычно я использую комбинацию поля счетчика и поля «смещение». Вы нацеливаетесь на таблицу, которая выглядит так (# Клиент не нужен, но даст вам визуальное представление о том, что вы делаете это правильно):
SalesPerson Dept #Customers Ctr Offset Bill DeptA 20 1 1 Ted DeptA 30 2 1 Jane DeptA 40 3 1 Bill DeptB 50 4 4 Mary DeptB 60 5 4Итак, чтобы дать ранг, вы сделали бы [Ctr] – [Offset] +1 AS Rank
- построить таблицу с SalesPerson , Dept , Ctr и Offset
- вставить в эту таблицу, упорядоченную Dept и #Customers (чтобы все они были правильно отсортированы)
- Обновить Offset чтобы быть MIN(Ctr) , группировка на Dept
- Выполните математический расчет, чтобы определить Rank
- Очистите таблицу, чтобы вы могли снова использовать ее в следующий раз.
Чтобы добавить к этому и любым другим связанным с ними параметрам Access Ranking или Rank Tie Breaker для других версий Access, ранжирование не должно выполняться при запросах кросс-таблицы, если в предложении FROM не содержится таблица, а запрос, который является либо кросс-табличным запросом или запрос, который содержит внутри него в другом месте кросс-таблицу.
Код, упомянутый выше, в котором используется оператор SELECT в статусе SELECT (подзапрос),
"SELECT *, (select count(*) from tbl as tbl2 where tbl.customers > tbl2.customers and tbl.dept = tbl2.dept) + 1 as rank from tbl"не будет работать и всегда будет отказываться от выражения ошибки на части кода, где «tbl.customers> tbl2.customers » не может быть найден.
В моей ситуации в прошлом проекте я ссылался на запрос вместо таблицы, и в рамках этого запроса я ссылался на запрос кросс-таблицы, который таким образом терпел неудачу и вызывал ошибку. Я смог решить это, сначала создав таблицу из запроса кросс-таблицы, и когда я ссылался на вновь созданную таблицу в предложении FROM, она начала работать для меня.
Таким образом, в финале обычно вы можете ссылаться на запрос или таблицу в предложении FROM оператора SELECT, как то, что было ранее описано выше, чтобы сделать ранжирование, но будьте осторожны, если вы ссылаетесь на запрос вместо таблицы, этот запрос должен не содержать быть запросом кросс-таблицы или ссылаться на другой запрос, который является кросс-табличным запросом.
Надеюсь, это поможет кому-то еще, у кого могут возникнуть проблемы с поиском возможной причины, если вам посчастливилось ссылаться на приведенные выше утверждения, и вы не ссылаетесь на таблицу в своем предложении FROM в своем собственном проекте. Кроме того, выполнение подзапросов на псевдонимах с кросс-табличными запросами в Access, вероятно, не является хорошей идеей или лучшей практикой, либо отклоняется от этого, если это возможно.
Если вы сочтете это полезным и хотите, чтобы Access разрешил использование прокручивающейся мыши в редакторе запросов passthru, дайте мне, пожалуйста.
Я обычно выбираю советы и идеи здесь, а иногда и получаю потрясающие вещи от него!
Сегодня (ну, скажем, в течение прошлой недели), я занимался ранжированием данных в Access и, насколько мне мог быть, я не ожидал, что я собираюсь сделать что-то настолько сложное, чтобы взять меня на неделю понять это! Я выбрал titbits с двух основных сайтов:
- https://usefulgyaan.wordpress.com/2013/04/23/ranking-in-ms-access/ (увидела, что умная '> =' часть, а сам присоединяется? Удивительно … это помогло мне построить мое решение из просто один запрос, в отличие от сложного метода, предложенного выше с помощью asight ofMighty (не дискредитируя вас … просто не хотел его пробовать на данный момент, может быть, когда я получаю большие данные, которые, возможно, захочу попробовать и …)
- Прямо здесь, от Пола Аббота выше ('и tbl.dept = tbl2.dept') … Я потерялся после ранжирования, потому что я размещал AND YearID = 1 и т. Д., Тогда ранжирование закончилось бы только для подмножеств, вы догадались, когда YearID = 1! Но у меня было много разных сценариев …
Что ж, я частично рассказал об этом, чтобы поблагодарить упомянутых авторов, потому что то, что я сделал, является для меня одним из самых сложных из ранжирования, которое, я думаю, может помочь вам практически в любой ситуации, и, поскольку я получал пользу от других, я хотел бы поделиться тем, что я надеюсь, может принести пользу и другим.
Простите, что я не могу опубликовать свои таблицы, здесь много связанных таблиц. Я только отправлю запрос, поэтому, если вам нужно, вы можете разработать свои таблицы, чтобы в итоге получить такой запрос. Но вот мой сценарий:
У вас есть ученики в школе. Они проходят класс 1-4, могут быть либо в потоке A или B, либо нет, если класс слишком мал. Каждый из них принимает 4 экзамена (эта часть сейчас не важна), поэтому вы получаете общий балл для моего дела. Вот и все. Да ??
ОК. Позволяет ранжировать их следующим образом:
Мы хотим знать рейтинг
• все учащиеся, которые когда-либо проходили эту школу (лучший ученик)
• все учащиеся в конкретном учебном году (студентка года)
• ученики определенного класса (но помните, что студент прошел все классы, поэтому в основном его / ее звание в каждом из этих классов в разные годы) это обычный рейтинг, который появляется в отчетах
• учащиеся в своих потоках (выше комментариев)
• Я также хотел бы узнать население, против которого мы оценили этого ученика в каждой категории
… все в одной таблице / запросе. Теперь вы понимаете?
(Обычно мне нравится делать столько же «программирования» в базе данных / запросах, чтобы дать мне визуальные эффекты и уменьшить количество кода, который мне потом придется по праву.Я фактически не буду использовать этот запрос в своем приложении :), но давайте мне знать, где и как отправить мои параметры в запрос, из которого он пришел, и какие результаты можно ожидать в моем rdlc)
Не беспокойтесь, вот оно:
SELECT Sc.StudentID, Sc.StudentName, Sc.Mark, (SELECT COUNT(Sch.Mark) FROM [StudentScoreRankTermQ] AS Sch WHERE (Sch.Mark >= Sc.Mark)) AS SchoolRank, (SELECT Count(s.StudentID) FROM StudentScoreRankTermQ AS s) As SchoolTotal, (SELECT COUNT(Yr.Mark) FROM [StudentScoreRankTermQ] AS Yr WHERE (Yr.Mark >= Sc.Mark) AND (Yr.YearID = Sc.YearID) ) AS YearRank, (SELECT COUNT(StudentID) FROM StudentScoreRankTermQ AS Yt WHERE (Yt.YearID = Sc.YearID) ) AS YearTotal, (SELECT COUNT(Cl.Mark) FROM [StudentScoreRankTermQ] AS Cl WHERE (Cl.Mark >= Sc.Mark) AND (Cl.YearID = Sc.YearID) AND (Cl.TermID = Sc.TermID) AND (Cl.ClassID=Sc.ClassID)) AS ClassRank, (SELECT COUNT(StudentID) FROM StudentScoreRankTermQ AS C WHERE (C.YearID = Sc.YearID) AND (C.TermID = Sc.TermID) AND (C.ClassID = Sc.ClassID) ) AS ClassTotal, (SELECT COUNT(Str.Mark) FROM [StudentScoreRankTermQ] AS Str WHERE (Str.Mark >= Sc.Mark) AND (Str.YearID = Sc.YearID) AND (Str.TermID = Sc.TermID) AND (Str.ClassID=Sc.ClassID) AND (Str.StreamID = Sc.StreamID) ) AS StreamRank, (SELECT COUNT(StudentID) FROM StudentScoreRankTermQ AS St WHERE (St.YearID = Sc.YearID) AND (St.TermID = Sc.TermID) AND (St.ClassID = Sc.ClassID) AND (St.StreamID = Sc.StreamID) ) AS StreamTotal, Sc.CalendarYear, Sc.Term, Sc.ClassNo, Sc.Stream, Sc.StreamID, Sc.YearID, Sc.TermID, Sc.ClassID FROM StudentScoreRankTermQ AS Sc ORDER BY Sc.Mark DESC;Вы должны получить что-то вроде этого:
StudentID | StudentName | Марк | SchoolRank | SchoolTotal | YearRank | YearTotal | ClassRank | ClassTotal | StreamRank | StreamTotal | Год | Срок | Класс | Поток
1 | Джейн | 200 | 1 | 20 | 2 | 12 | 1 | 9 | 1 | 5 | 2017 | I | 2 |
2 | Том | 199 | 2 | 20 | 1 | 12 | 3 | 9 | 1 | 4 | 2016 | I | 1 | B
Используйте разделители (|) для восстановления таблицы результатов
Просто идея о таблицах, каждый студент будет связан с классом. Каждый класс относится к годам. Каждый поток относится к классу. Каждый термин относится к году. Каждый экзамен относится к термину и студенту, а также к классу и году; студент может быть в классе 1A в 2016 году и переходит к классу 2b в 2017 году и т. д.
Позвольте мне также добавить, что этот бета-результат, я его недостаточно проверял, и у меня пока нет возможности создать много данных, чтобы увидеть производительность. Мой первый взгляд на это сказал мне, что это хорошо. Поэтому, если вы найдете причины или предупреждения, которые хотите указать на мой путь, пожалуйста, сделайте это в комментариях, чтобы я мог продолжать учиться!
sql.fliplinux.com
sql - Используйте Access SQL для группировки ранжирования
Я обычно выбираю советы и идеи отсюда, а иногда и получаю потрясающие вещи от него!
Сегодня (ну, скажем, в течение прошлой недели), я занимался ранжированием данных в Access и, насколько это было возможно, я не ожидал, что я собираюсь сделать что-то настолько сложное, чтобы принять мне неделю, чтобы понять это! Я выбрал титбит из двух основных сайтов:
- https://usefulgyaan.wordpress.com/2013/04/23/ranking-in-ms-access/ (видно, что умная ' >= часть, а сам присоединяется? Удивительно... это помогло мне построить мое решение из просто один запрос, в отличие от сложного метода, предложенного выше, asonightheMighty (не дискредитируя вас... просто не хотел его проверять на данный момент, может быть, когда я получу большие данные, я мог бы попробовать и это...)
- Прямо здесь, от Пола Аббота выше ('и tbl.dept = tbl2.dept)... Я потерялся после ранжирования, потому что я размещал AND YearID = 1 и т.д., тогда ранжирование закончилось бы только для подмножеств, вы догадались, когда YearID = 1! Но у меня было много разных сценариев...
Хорошо, я дал эту историю частично, чтобы поблагодарить упомянутых авторов, потому что то, что я сделал, для меня является одним из самых сложных из ранжирования, которое, я думаю, может помочь вам практически в любой ситуации, и, поскольку я получал пользу от других, я хотел бы поделиться тем, что, я надеюсь, также принесет пользу другим.
Простите меня, что я не могу опубликовать свои структуры таблиц здесь, много связанных таблиц. Я только отправлю запрос, поэтому, если вам нужно, вы можете разработать свои таблицы, чтобы в итоге получить такой запрос. Но вот мой сценарий:
У вас есть ученики в школе. Они проходят класс 1-4, могут быть либо в потоке A или B, либо нет, если класс слишком мал. Каждый из них принимает 4 экзамена (эта часть сейчас не важна), поэтому вы получаете общий балл для моего дела. Это оно. Да??
Ok. Позволяет ранжировать их следующим образом:
Мы хотим знать рейтинг
• все учащиеся, которые когда-либо проходили эту школу (лучший ученик)
• все учащиеся в конкретном учебном году (студент года)
• учащиеся определенного класса (но помните, что студент прошел через все классы, поэтому в основном его/ее звание в каждом из этих классов в разные годы) это обычное ранжирование, которое появляется в отчетах
• учащиеся в своих потоках (выше комментариев)
• Я также хотел бы знать население, против которого мы оценили этого ученика в каждой категории
... все в одной таблице/запросе. Теперь вы поняли?
(Обычно мне нравится делать как можно больше моего "программирования" в базе данных/запросах, чтобы дать мне визуальные эффекты и уменьшить количество кода, который мне потом придется делать. Я фактически не буду использовать этот запрос в своем приложении:), но это дало мне знать, где и как отправить мои параметры в запрос, из которого он пришел, и какие результаты ожидать в моем rdlc)
Не беспокойтесь, вот оно:
SELECT Sc.StudentID, Sc.StudentName, Sc.Mark, (SELECT COUNT(Sch.Mark) FROM [StudentScoreRankTermQ] AS Sch WHERE (Sch.Mark >= Sc.Mark)) AS SchoolRank, (SELECT Count(s.StudentID) FROM StudentScoreRankTermQ AS s) As SchoolTotal, (SELECT COUNT(Yr.Mark) FROM [StudentScoreRankTermQ] AS Yr WHERE (Yr.Mark >= Sc.Mark) AND (Yr.YearID = Sc.YearID) ) AS YearRank, (SELECT COUNT(StudentID) FROM StudentScoreRankTermQ AS Yt WHERE (Yt.YearID = Sc.YearID) ) AS YearTotal, (SELECT COUNT(Cl.Mark) FROM [StudentScoreRankTermQ] AS Cl WHERE (Cl.Mark >= Sc.Mark) AND (Cl.YearID = Sc.YearID) AND (Cl.TermID = Sc.TermID) AND (Cl.ClassID=Sc.ClassID)) AS ClassRank, (SELECT COUNT(StudentID) FROM StudentScoreRankTermQ AS C WHERE (C.YearID = Sc.YearID) AND (C.TermID = Sc.TermID) AND (C.ClassID = Sc.ClassID) ) AS ClassTotal, (SELECT COUNT(Str.Mark) FROM [StudentScoreRankTermQ] AS Str WHERE (Str.Mark >= Sc.Mark) AND (Str.YearID = Sc.YearID) AND (Str.TermID = Sc.TermID) AND (Str.ClassID=Sc.ClassID) AND (Str.StreamID = Sc.StreamID) ) AS StreamRank, (SELECT COUNT(StudentID) FROM StudentScoreRankTermQ AS St WHERE (St.YearID = Sc.YearID) AND (St.TermID = Sc.TermID) AND (St.ClassID = Sc.ClassID) AND (St.StreamID = Sc.StreamID) ) AS StreamTotal, Sc.CalendarYear, Sc.Term, Sc.ClassNo, Sc.Stream, Sc.StreamID, Sc.YearID, Sc.TermID, Sc.ClassID FROM StudentScoreRankTermQ AS Sc ORDER BY Sc.Mark DESC;Вы должны получить что-то вроде этого:
StudentID | StudentName | Марк | SchoolRank | SchoolTotal | YearRank | YearTotal | ClassRank | ClassTotal | StreamRank | StreamTotal | Год | Срок | Класс | Поток
1 | Джейн | 200 | 1 | 20 | 2 | 12 | 1 | 9 | 1 | 5 | 2017 | я | 2 | А
2 | Том | 199 | 2 | 20 | 1 | 12 | 3 | 9 | 1 | 4 | 2016 | я | 1 | B
Используйте разделители (|) для восстановления таблицы результатов
Просто идея о таблицах, каждый студент будет связан с классом. Каждый класс относится к годам. Каждый поток относится к классу. Каждый термин относится к году. Каждый экзамен относится к термину и студенту, а также к классу и году; студент может быть в классе 1A в 2016 году и переходит к классу 2b в 2017 году и т.д.
Позвольте мне также добавить, что это бета-результат, я его недостаточно проверял, и у меня пока нет возможности создать много данных, чтобы увидеть производительность. Мой первый взгляд на это сказал мне, что это хорошо. Поэтому, если вы найдете причины или предупреждения, которые хотите указать на мой путь, сделайте это в комментариях, чтобы я мог продолжать учиться!
qaru.site
Глава 5. Функции ранжирования.
Очень часто возникает вопрос: «Как получить последнюю добавленную в таблицу строку?». Ответом на вопрос будет "никак", если в таблице не предусмотрен столбец, содержащий дату вставки строки, или не используется последовательная нумерация строк, реализуемая во многих СУБД с помощью столбца с автоинрементируемым значением. Тогда можно выбрать строку с максимальным значением даты или счетчика.
Реляционная модель исходит из того факта, что строки в таблице не имеют порядка, являющегося прямым следствием теоретико-множественного подхода. Вопрос о последней строке имеет смысл только в аспекте выдачи результата выполнения запроса, при этом предполагается некоторая сортировка, которая задается с помощью предложения ORDER BY в операторе SELECT. Если никакая сортировка не задана, то полагаться на то, что порядок вывода строк, полученных при выполнении запроса сегодня, останется таким же и завтра, нельзя, т.к. этот порядок зависит от плана, который выбирает оптимизатор запросов для их выполнения. А план может меняться, и зависит это от многих причин, которые мы здесь опустим.
Теоретически каждая строка запроса обрабатывается независимо от других строк. Однако на практике часто требуется при обработке строки соотносить ее с предыдущими или последующими строками (например, для получения нарастающих итогов), выделять группы строк, обрабатываемые независимо от других и т.д. В ответ на потребности практики в ряде СУБД в языке SQL появились соответствующие конструкции, в частности, функции ранжирования и оконные (аналитические) функции, которые де-юре были зафиксированы в стандарте SQL:2003. В SQL Server ранжирующие функции появились в версии 2005.
5.1. Функция row_number.
Функция ROW_NUMBER, нумерует строки, возвращаемые запросом. С ее помощью можно выполнить более сложное упорядочивание строк в отчете, чем то, которое дает предложение ORDER BY в рамках Стандарта SQL-92.
Используя функцию ROW_NUMBER можно:
задать нумерацию, которая будет отличаться от порядка сортировки строк результирующего набора;
создать "несквозную" нумерацию, т.е. выделить группы из общего множества строк и пронумеровать их отдельно для каждой группы;
использовать одновременно несколько способов нумерации, поскольку, фактически, нумерация не зависит от сортировки строк запроса.
Покажем возможности функции ROW_NUMBER на простых примерах.
Пример 42.
Пронумеровать все блюда из таблицы Блюда в алфавитном порядке. Выполнить сортировку по {Основа, Блюдо}.
SELECT row_number() over(ORDER BY Блюдо) as Номер, Блюдо, Основа
FROM Блюда
WHERE Вид < 2
ORDER BY Основа, Блюдо;
Предложение OVER, с которым используется функция ROW_NUMBER, задает порядок нумерации строк. При этом используется дополнительное предложение ORDER BY, которое не имеет отношения к порядку вывода строк запроса. Если вы посмотрите на результат, то заметите, что порядок строк в результирующем наборе и порядок нумерации не совпадают:
| Результат | ||
| Номер | Блюдо | Основа |
| 7 | Сметана | Молоко |
| 8 | Творог | Молоко |
| 1 | Мясо с гарниром | Мясо |
| 5 | Салат мясной | Мясо |
| 3 | Салат витаминный | Овощи |
| 4 | Салат летний | Овощи |
| 2 | Паштет из рыбы | Рыба |
| 6 | Салат рыбный | Рыба |
А если требуется пронумеровать блюда для каждой основы отдельно? Для этого нам потребуется еще одна конструкция в предложении OVER — PARTITION BY.
Конструкция PARTITION BY задает группы строк, для которых выполняется независимая нумерация. Группа определяется равенством значений в списке столбцов, перечисленных в этой конструкции, у строк, составляющих группу.
Пример 43.
Пронумеровать блюда в рамках каждой основы отдельно.
SELECT row_number() over(partition BY Основа ORDER BY Блюдо) as Номер, Блюдо, Основа
FROM Блюда
WHERE Вид < 2
ORDER BY Основа, Блюдо;
PARTITION BY Основа означает, что блюда с одной основой образуют группу, для которой и выполняется независимая нумерация. В результате получим:
| Результат | ||
| Номер | Блюдо | Основа |
| 1 | Сметана | Молоко |
| 2 | Творог | Молоко |
| 1 | Мясо с гарниром | Мясо |
| 2 | Салат мясной | Мясо |
| 1 | Салат витаминный | Овощи |
| 2 | Салат летний | Овощи |
| 1 | Паштет из рыбы | Рыба |
| 2 | Салат рыбный | Рыба |
Отсутствие конструкции PARTITION BY, как это было в первом примере, означает, что все строки результирующего набора образуют одну единственную группу.
studfiles.net
sql-server - Ранжирование полнотекстового поиска (SQL Server)
В течение последних двух часов я возился со всеми разновидностями полнотекстового поиска SQL Server. Однако я все еще не могу понять, как работает рейтинг. Я столкнулся с несколькими примерами, которые действительно путают меня относительно того, как они выше, чем другие. Например
У меня есть таблица с 5 столбцами + больше, которые не индексируются. Все поля nvarchar.
Я запускаю этот запрос (ну почти.. Я перепечатался с разными именами)
SET @SearchString = REPLACE(@Name, ' ', '*" OR "') --Splits words with an OR between SET @SearchString = '"'+@SearchString+'*"' print @SearchString; SELECT ms.ID, ms.Lastname, ms.DateOfBirth, ms.Aka, ms.Key_TBL.RANK, ms.MiddleName, ms.Firstname FROM View_MemberSearch as ms INNER JOIN CONTAINSTABLE(View_MemberSearch, (ms.LastName, ms.Firstname, ms.MiddleName, ms.Aka, ms.DateOfBirth), @SearchString) AS KEY_TBL ON ms.ID = KEY_TBL.[KEY] WHERE KEY_TBL.RANK > 0 ORDER BY KEY_TBL.RANK DESC;Таким образом, если я ищу 11/05/1964 JOHN JACKSON, я бы получил "11/05/1964" ИЛИ "JOHN *" ИЛИ "JACKSON *" и эти результаты:
ID -- First Name -- Middle Name -- Last Name -- AKA -- Date of Birth -- SQL Server RANK ---------------------------------------------------------------------------------- 1 | DAVE | JOHN | MATHIS | NULL | 11/23/1965 | 192 2 | MARK | JACKSON | GREEN | NULL | 05/29/1998 | 192 3 | JOHN | NULL | JACKSON | NULL | 11/05/1964 | 176 4 | JOE | NULL | JACKSON | NULL | 10/04/1994 | 176Итак, наконец, мой вопрос. Я не вижу, как строки 1 и 2 находятся выше строки 3, и почему строка 3 оценивается так же, как строка 4. Строка 2 должна иметь самый высокий ранг, видя, что строка поиска также совпадает с именем и фамилией как Дата рождения.
Если я изменил OR на AND, я не получу никаких результатов.
qaru.site