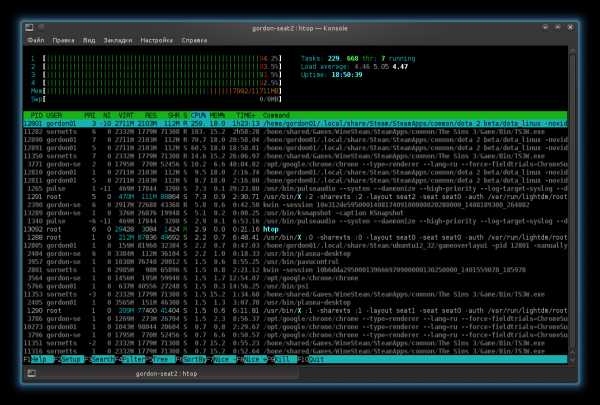
Python: оптимизация или, по крайней мере, свежие идеи для генератора дерева. Python оптимизация
Повышение производительности Python приложений
Повышение производительности Python приложений
Russian translation of the Python Speed - Performance tips article, translated by Anton Vlasenko .
Перевод статьи Python Speed - Performance tips
Автор перевода: Власенко А.П., магистр ДонНТУ
×Внимание!
Данная статья является переводом оригинальной статьи от апреля 2012 года и со временем может потерять актуальность. Дальнейшее обновление статьи на данном ресурсе невозможно, поэтому вы можете исправить или актуализировать данную статью перенеся ее на другой ресурс с условием сохранения ссылки на эту страницу.Эта статья посвящена инструкциям по повышению производительности ваших приложений на Python.
Python существенно изменился с тех пор, как я опубликовал свою первую версию статьи "Быстрый Python" в 1996, а значит некоторые правила могли потерять актуальность. Поэтому я перенес статью в Python wiki, в надежде, что другие помогут мне содержать ее в актуальном состоянии. Всегда проверяйте представленные здесь советы на вашем приложении и на конкретном интерпретаторе Python, который вы собираетесь использовать. Не стоит следовать этим советам вслепую, без проверки, соглашаясь, что один метод быстрее другого. В секции "профилирование" говорится об этом подробно. С тех пор, как была написана оригинальная статья, появились также следующие инструменты: Cython, Pyrex, Psyco, Weave, PyInline, PyPy, которые могут существенно повысить производительность вашего приложения, облегчая процесс преобразования критичного для производительности кода в C или в машинный код.
Предисловие: оптимизируйте то, что требует оптимизации
Не оптимизируйте программу, если производительность является достаточной.
Чтобы узнать, что делает вашу программу медленной, нужно сначала дать приложению выполниться, выдав правильный результат. Если вы решите, что программа выполняется слишком медленно, вы должны профилировать программу, чтобы определить самую медленную её часть. Позаботьтесь о быстром автоматизированном тесте, который должен подтверждать, что будущие оптимизации не сломают вашу программу и не повлияют на правильность ее работы.
- Сделайте приложение.
- Проверьте правильность его работы.
- Профилируйте, если производительность окажется недостаточной.
- Оптимизируйте.
- Повторите шаг 2.
Некоторое базовые оптимизации относятся к хорошему стилю программирования и должны быть выучены по мере изучения языка. В качестве примера - расчеты значений, которые не изменяются в пределах цикла, должны быть вынесены за пределы цикла.
Сортировка
Сортировка списков базовых объектов в Python реализована эффективно. Метод sort() для сортировки списков принимает в качестве дополнительного аргумента функцию, которая может быть использована как признак, используемый во время сортировки. Это достаточно очевидно, но это также можно существенно замедлить ваши сортировки, т. к. эта функция будет вызвана несколько раз. В Python 2.4 рекомендуется использовать аргумент key для встроенной сортировки, который должен быть быстрейшим способом сортировки. Следующие руководство Гвидо ван Россума следует использовать только для более ранних версий Python (до 2.4):
Альтернативный способ ускорить сортировку — создание списка кортежей, где первый элемент — ключ для сортировки, который правильным образом отсортируется используя стандартную сортировку. Второй элемент кортежа — оригинальный список. Это так называемый Schwartzian Transform, также известный как DecorateSortUndecorate(DSU, идиома языка Perl).
Допустим, у вас есть список кортежей, и вы хотите сортировать его по N полю каждого кортежа. Следующая функция выполнит поставленную задачу:
def sortby(somelist, n): nlist = [(x[n], x) for x in somelist] nlist.sort() return [val for (key, val) in nlist]Перезапись списка сортированным также может быть достигнута, повторяя функционал встроенной функции сортировки:
def sortby_inplace(somelist, n): somelist[:] = [(x[n], x) for x in somelist] somelist.sort() somelist[:] = [val for (key, val) in somelist] return somelist Пример использования: >>> somelist = [(1, 2, 'def'), (2, -4, 'ghi'), (3, 6, 'abc')] >>> somelist.sort() >>> somelist [(1, 2, 'def'), (2, -4, 'ghi'), (3, 6, 'abc')] >>> nlist = sortby(somelist, 2) >>> sortby_inplace(somelist, 2) >>> nlist == somelist True >>> nlist = sortby(somelist, 1) >>> sortby_inplace(somelist, 1) >>> nlist == somelist True В Python 2.4 добавлен необязательный параметр key, который существенно упрощает нестандартную сортировку: n = 1 import operator nlist.sort(key=operator.itemgetter(n)) # Используйте sorted() если вы не хотите # перезаписывать существующий список сортированным # sortedlist = sorted(nlist, key=operator.itemgetter(n))Конкатенация строк
Точность и актуальность данной секции подвержена сомнению из-за последних реализаций Python. В CPython 2.5 конкатенация строк реализована очень быстро, однако это может не относиться к другим реализациям.
В Python строки неизменяемые. Этот факт часто вызывает затруднения у новичков. Неизменность строк это одновременно некоторое количество достоинств и недостатков. К достоинствам можно отнести то, что строки могут быть использованы как значения в словарях и отдельные копии строк могут быть связаны с несколькими переменными-ссылками (Python автоматически связывает строки из 1-2 символов). К минусам можно отнести то, что вы не можете просто выполнить запрос “измени все символы 'a' в строке на символы 'б'”. Вместо этого, вы должны создать новую строку с желаемыми свойствами и изменениями. Это постоянное копирование может привести к существенным задержкам в Python приложениях.
Избегайте следующего:
# Так лучше не делать! s = "" for substring in list: s += substringВместо этого используйте s = "".join(list) метод. Предыдущий способ очень распространен и является катастрофической ошибкой при создании огромных строк. Также, если вы генерируете строку по кусочкам, избегайте следующего:
# Так лучше не делать! s = "" for x in list: s += some_function(x) Используйте slist = [some_function(elt) for elt in somelist] s = "".join(slist) # Рекомендованный способ От переводчика: >>> timeit('s = "".join(l)', 's=""; l = ["foo", "bar", "spam"]') 0.3600640296936035 >>> timeit('for sub in l: s+=sub', 's=""; l = ["foo", "bar", "spam"]') 0.857280969619751Избегайте:
out = "<html>" + head + prologue + query + tail + "</html>" # Так лучше не делать!Для улучшения читабельности (никак не влияет на производительность программы, только на вашу, как программиста), используйте словарное описание:
out = "%(head)s%(prologue)s%(query)s%(tail)s" % locals() # Рекомендованный для читабельности способ.Последние два способа должны быть намного быстрее, особенно если через них пропускается огромное количество CGI-запусков, а также более легкими в сопровождении. К тому же, не рекомендованный медленный способ стал еще медленнее в Python 2.0 после добавления возможности перегрузить операторы сравнения. Теперь Python тратит больше времени, чтобы определить как складывать две строки (не забываем, что Python производит поиск методов прямо во время работы программы).
Примечание переводчика:
Для того, чтобы можно было сделать какие-либо выводы, привожу следующий бенчмарк (Python 3.2.3):
>>> timeit('"<html>" + foo + bar + "</html>"', 'foo = "Foo"; bar = "Bar"') 0.44135117530822754 >>> timeit('"<html>%s%s</html>" % (foo, bar)', 'foo = "Foo"; bar = "Bar"') 0.8441739082336426 >>> timeit('out = "<html>" + foo + "<br>" + bar + "</html>"', 'foo = "Foo"; bar = "Bar"') 0.5593209266662598 >>> timeit('out = "<html>%s<br>%s</html>" % (foo, bar)', 'foo = "Foo"; bar = "Bar"') 0.8703830242156982 >>> timeit('out = "<html>" + foo + "<br>" + bar + "<br>" + foo + "<br>" + bar + "</html>"', 'foo = "Foo"; bar = "Bar"') 1.172637939453125 >>> timeit('out = "<html>%s<br>%s<br>%s<br>%s</html>" % (foo, bar, foo, bar)', 'foo = "Foo"; bar = "Bar"') 1.0721790790557861Циклы
Python поддерживает несколько циклических конструкций. Оператор for является наиболее часто используемым. Он проходит циклом по каждому элементу выражения, присваивая каждому элементу переменную цикла. Если тело вашего цикла простое, процессорное время самой функции for может составлять существенную часть общей нагрузки на проведение операции. Именно здесь может пригодиться использование функции map. Функцию map можно представить как перенесение встроенной функции for на язык C. Единственное ограничение – телом цикла должен быть вызов функции. Еще один способ - списочные выражения , они выполняется быстрее, или, как минимум, так же быстро, как цикл map. Наглядный пример. Вместо того, чтобы проходить циклом по каждому элементу списка и переводить весь текст в верхний регистр:
Можно использовать map, чтобы перенести цикл на выполнение из интерпретатора в компилированный C код:
newlist = map(str.upper, oldlist)Списочные выражения также были добавлены в Python 2.0. Они предоставляют более компактный и эффективный способ записи представленного выше примера:
newlist = [s.upper() for s in oldlist]Генераторы были добавлены в Python начиная с версии 2.4. Они функционируют схожим со списочными выражениями или map образом, за исключением того, что они избегают генерации всего списка сразу. Вместо этого, объект-генератор предоставляет возможность выполнять операции пошагово, друг за другом, одновременно загружая в память лишь один объект внутри списка:
Какой метод использовать зависит от используемой версии Python и манипулируемых данных. Гвидо ван Россум написал детальное руководство по оптимизации циклов, с которым обязательно стоит ознакомиться.
Избегание точек [ . ]
Допустим, вы не можете использовать функцию map или списочные выражения, вам остается использовать только for. Пример с циклом for имеет еще один недостаток. Такие операции, как newlist.append и word.upper, являются ссылками на функции, которые определяются каждый раз во время цикла. Оригинальный цикл можно заменить следующим:
upper = str.upper newlist = [] append = newlist.append for word in oldlist: append(upper(word))Эта техника должна использоваться с предельной осторожность. Большие циклы становится труднее поддерживать, т. к. вам придется постоянно проверять код, чтобы понимать, что конкретно значат эти append и upper.
От переводчика:Правила избежания точек относятся и к импорту модулей. В качестве примера:
>>> timeit.timeit ("math.sqrt(4)", 'import math') 0.3284459114074707 >>> timeit.timeit ('sqrt(4)', 'from math import sqrt') 0.25652194023132324Локальные переменные
Последняя возможность ускорить цикл for — использование локальных переменных везде, где это возможно. Если наш пример перевести в функцию, append и upper становятся локальными переменными. Python работает гораздо эффективнее с локальными переменными, чем с глобальными.
def func(): upper = str.upper newlist = [] append = newlist.append for word in oldlist: append(upper(word)) return newlistНа тот момент, когда я начал писать эту статью, я использовал 100MHz Pentium, на котором был запущен BSDI. Я получил следующие значения по времени исполнения при преобразовании списка слов /usr/share/dict/words (38,470 слов на то время) в верхний регистр:
Version Time (seconds) Basic loop 3.47 Eliminate dots 2.45 Local variable & no dots 1.79 Using map function 0.54Инициализация словарей
Представим, что вы создаете словарь для хранения количества встречающихся слов и вы уже разбили ваш текст на список слов. Вы можете использовать для этого нечто вроде:
wdict = {} for word in words: if word not in wdict: wdict[word] = 0 wdict[word] += 1Важно перехватывать только ожидаемое исключение KeyError, чтобы избежать ситуации с перехватом исключения, которое вы на самом деле не сможете обработать. Третий способ становится доступным с выпуском Python 2. Словари теперь поддерживают метод get(), который установит значение по умолчанию, если необходимый ключ не был найден в словаре. Этот способ значительно сокращает цикл:
wdict = {} get = wdict.get for word in words: wdict[word] = get(word, 0) + 1На данный момент все три варианта решения имеют схожую производительности (с разницей не более 10%), более или менее независимо от обрабатываемых данных. Также, если значение, которое хранится в словаре, является объектом или изменяемым списком, вы также можете использовать метод dict.setdefault:
wdict.setdefault(key, []).append(new_element)Вы можете решить, что этот способ исключает производимое дважды обращение к ключу. На самом деле это не так (даже в Python 3), но, как минимум, двойное обращение производится средствами C. Еще одно решение — использование класса defaultdict:
from collections import defaultdict wdict = defaultdict(int) for word in words: wdict[word] += 1Перегрузки от выражений импорта
Операция импорта может быть запущена где угодно в программном коде. Часто бывает полезным размещать их внутри функций, чтобы ограничить их видимость и уменьшить начальное время запуска приложения. Хотя интерпретатор Python оптимизирован, чтобы не производить импорт одного и того же модуля несколько раз, повторный вызов функции импорта может некоторым образом отразиться на производительности. Рассмотрим следующие фрагменты кода (взятые, как мне кажется, у Greg McFarlane):
def doit1(): import string ###### Импорт внутри функции string.lower('Python') for num in range(100000): doit1()Или:
import string ###### Импорт за пределами функции def doit2(): string.lower('Python') for num in range(100000): doit2()Функция doit2 будет работать значительно быстрее, чем doit1, даже не смотря на то, что doit2 обращается к модулю string глобально. Ниже представлена сессия интерпретатора Python 2.3 с модулем timeit, которая показывает, насколько второй способ быстрее первого:
>>> def doit1(): ... import string ... string.lower('Python') ... >>> import string >>> def doit2(): ... string.lower('Python') ... >>> import timeit >>> t = timeit.Timer(setup='from __main__ import doit1', stmt='doit1()') >>> t.timeit() 11.479144930839539 >>> t = timeit.Timer(setup='from __main__ import doit2', stmt='doit2()') >>> t.timeit() 4.6661689281463623Строковые методы были представлены в Python 2.0. Они представляют версию, которая совсем обходится без импортирования и работает еще быстрее:
def doit3(): 'Python'.lower() for num in range(100000): doit3()Наглядное подтверждение:
>>> def doit3(): ... 'Python'.lower() ... >>> t = timeit.Timer(setup='from __main__ import doit3', stmt='doit3()') >>> t.timeit() 2.5606080293655396Имейте в виду, импорт модуля внутри функции может ускорить начальную загрузку модуля, особенно если импортируемый модуль может не понадобиться. Это в общих терминах случай «ленивой» оптимизации — исключение лишней работы - импортирование тяжеловесного модуля только тогда, когда вы уверены, что он точно вам понадобится. Это является существенной оптимизацией только если модуль не будет загружен вовсе (из любого модуля) — если модуль уже был загружен (что является обычным случаем для многих стандартных модулей, таких как string или re), избегание импорта никак не оптимизирует ваш код. Чтобы узнать, какие модули загружены в систему, используйте sys.modules. Хороший способ выполнения «ленивого» импорта:
email = None def parse_email(): global email if email is None: import email ...Таким способом модуль email будет импортирован лишь однажды, при первом вызове parse_email().
Агрегация данных
Затраты на вызов функции в Python относительно высоки, особенно сравнивая с запуском встроенных функций. Это позволяет сделать выводы, что функции, если это возможно, должны сами заниматься агрегацией данных. Рассмотрим пример. Способ 1:
import time x = 0 def doit1(i): global x x = x + i list = range(100000) t = time.time() for i in list: doit1(i) print "%.3f" % (time.time()-t)Способ 2:
import time x = 0 def doit2(list): global x for i in list: x = x + i list = range(100000) t = time.time() doit2(list) print "%.3f" % (time.time()-t)Рассмотрим результаты запуска:
>>> t = time.time() >>> for i in list: ... doit1(i) ... >>> print "%.3f" % (time.time()-t) 0.758 >>> t = time.time() >>> doit2(list) >>> print "%.3f" % (time.time()-t) 0.204Даже написанный на Python, второй способ работает почти в четыре раза быстрее первого. Если бы функция doit была написана на C — разница была бы еще более существенной (заменяя цикл for, написанный на python, циклом for на C, а также с устранением большинства вызовов функций).
Уменьшение частоты выполнения операций
Интерпретатор Python проводит некоторые переодические проверки. В частности, он решает, стоит ли передавать управление другому потоку, или стоит передать управление отложенному вызову (обычно это вызов, установленный обработчиком сигнала). В большинстве случаев он простаивает без работы, и вызов этих проверок каждый цикл интерпретатора может замедлять работу приложения. Существует функция в модуле sys — setcheckinterval, в которой можно указать, через какой промежуток внутренних тактов интерпретатора следует выполнять переодические проверки. По отношению к релизу до 2.3 это значение установлено как 10. В 2.3 значение было увеличено до 100. Если вы не работаете с потоками и вы не расчитываете перехватывать большое количество сигналов, установка высокого значения этого параметра может повысить производительность, иногда значительно.
Python - не C++
А также не Perl, Java, C или Haskell. Будьте аккуратны, когда переносите свои знания из других языков для решения задач в Python. Обычный пример служит отличной демонстрацией:
% timeit.py -s 'x = 47' 'x * 2' 1000000 loops, best of 3: 0.574 usec per loop % timeit.py -s 'x = 47' 'xТеперь рассмотрим похожие программы на C (показан только пример с суммой):
#include int main (int argc, char *argv[]) { int i = 47; int loop; for (loop=0; loopСравним время запуска:
% for prog in mult add shift ; doКак видите, в Python наблюдается заметный прирост производительности, если вы складываете число с самим собой, по сравнению с умножением на два или сдвигом влево на один бит. В языке C, на всех современных архитектурах, все три арифметические операции переносятся в одну и ту же машинную инструкцию, которая тратит на запуск один цикл, поэтому особо не имеет значения, какой способ вы выберите.
Распространенный «тест», который часто проводят новые программисты на Python, переводя распространенную идиому языка Perl
while () { print; }В Python этот код выглядит примерно следующим образом:
import fileinput for line in fileinput.input(): print line,Они используют этот пример чтобы сделать выводы, что Python, должно быть, намного медленнее Perl. Как уже неоднократно отмечали, Python медленнее Perl в некоторых задачах, и быстрее в других. Относительная производительность чаще зависит именно от вашего опыта в обоих языках.
Используйте xrange вместо range
Этот раздел не применим, если вы используете Python 3, где функция range предоставляет итератор над диапазоном заданной длины, и где функция xrange больше не существует. В ранних версиях (до Python 3) имеется два способа получить диапазон чисел: range и xrange. Большинство людей знает о range из-за его очевидного имени, в то время как xrange находится в конце алфавитного указателя и является менее известным.
Функция xrange является генератором, она в общих чертах эквивалентна следующему коду:
def xrange(start, stop=None, step=1): if stop is None: stop = start start = 0 else: stop = int(stop) start = int(start) step = int(step) while startЗа исключением того, что она реализована на чистом C.
Функция xrange имеет свои ограничения. Она работает только с целыми числами. Вы не можете использовать long или float (они будут переконвертированы в int, как показано выше). Тем не менее, она сохраняет много памяти, и если вы не сохраняете генерируемый объект где-либо, то только один объект существует в один момент времени. Разница заключается в следующем: когда вы вызываете функцию range, она создает список, который хранит в себе огромное количество числовых объектов (int, float, long). Все эти объекты создаются одновременно, и все они существуют вместе в один момент времени. Это может быть проблемой, если массив чисел велик. Напротив, xrange не создает числа одновременно — только собственный объект диапазона. Числовые объекты создаются только когда вы обращаетесь к генератору, то есть проходите по нему циклом. Например:
xrange(sys.maxint) # Нет цикла, нет запроса next, поэтому числа не были сгенерированыИменно по этим причинам код выполняется моментально. Если вы запустите таким же образом range, Python заблокируется. Он будет слишком занят нахождением памяти для 9223372036854775807 (для 64-битной архитектуры) числовых объектов, чтобы делать что-либо еще. Скорее всего, процесс завершится исключением MemoryError. В версиях Python до 2.2 xrange поддерживал также быструю проверку на членство (i in xrange(n)), но эти функции были удалены из-за отсутствия применения.
Присваивание функции «на лету»
Скажем, у вас есть функция:
class Test: def check(self,a,b,c): if a == 0: self.str = b*100 else: self.str = c*100 a = Test() def example(): for i in xrange(0,100000): a.check(i,"b","c") import profile profile.run("example()")Скажем, эта функция вызывается откуда-то много раз.
Ваша проверка будет иметь блок проверок if, замедляющий выполнение каждый раз, кроме первого. Можно сделать так:
class Test2: def check(self,a,b,c): self.str = b*100 self.check = self.check_post def check_post(self,a,b,c): self.str = c*100 a = Test2() def example2(): for i in xrange(0,100000): a.check(i,"b","c") import profile profile.run("example2()")Этот пример немного странный, но если оператор if у вас содержит достаточно большое количество условий (или с множеством точек [.]), вы можете избежать его постоянного прохождения, особенно если вы знаете, что условие будет истинным только лишь в первый раз.
Профилирование кода
Первым шагом в оптимизации вашей программы является нахождение ресурсоемких мест. Трудно понять смысл оптимизации кода, который никогда не был запущен, или который уже работает быстро. Я использую два модуля для нахождения ресурсоемких точек моего кода, профилирования и трассировки. В поздних примерах я использую также модуль timeit, который появился в Python 2.3. Ознакомьтесь с отдельной статьей profiling для подробностей (на англ. языке).
Профилирование
Существует несколько профилирующих модулей, включенных в стандартные «батарейки» Python. Использование любого из них для профилирования запуска некоторого набора функций достаточно просто. Допустим, ваша главная функция называется main, не требует входящих аргументов и вы хотите запустить ее под контролем профилирующих модулей. В самом простом виде вы лишь запускаете:
import profile profile.run('main()')Когда функция выполнится, профилирующий модуль распечатает таблицу вызовов функций и времени исполнения. Вывод может быть подкорректирован используя класс Stats, который включен в поставку модуля. Начиная с Python 2.4 профилирование позволяет исследовать также время выполнения встроенных модулей и модулей расширений. Более существенное описание профилирования, используя profile и pstats, может быть найдено по следующей ссылке (на англ.).
Модули cProfile и Hotshot
Начиная с Python 2.2, пакет hotshot представляется как замена для модуля profile, хотя использование cProfile сейчас является более предпочтительным. Основополагающий модуль написан на C, поэтому использование hotshot (или cProfile) должно приводить к гораздо меньшему влиянию на производительность и давать более точную картину того, как ваше приложение работает. Существует также программа hotshotmain.py, которая упрощает запуск вашего приложения под hotshot из командной строки.
Модуль trace
Модуль trace является побочным от profile модулем, который я написал чтобы проводить некоторые низкоуровневые тесты. Он был сильно модифицирован несколькими другими людьми с тех пор, как я выпустил мой изначальный код. В Python 2.0 вы можете найти trace.py в папке Tools/scripts вашего дистрибутива Python. Начиная с версии 2.3 он входит в стандартную библиотеку (папка Lib). Вы можете скопировать его в свою локальную директорию, выставить права на запуск и запустить напрямую. Так можно получить полную трассировочную инфромацию о вашем приложении:
% trace.py -t spam.py eggsВ Python 2.4 запустить его проще — используйте команду python -m trace. Для модуля не существует отдельной документации, но вы можете выполнить команду «pydoc trace» чтобы увидеть внутреннюю документацию.
Визуализация результатов профилирования
RunSnakeRun — GUI утилита от Mike Fletcher'a, которая визуализирует результаты cProfile используя квадратные карты. Вызовы функций и методов могут быть отсортированы по различным критериям, исходный код может отображаться рядом с визуализацией и статистикой вызовов. Пример использования:
runsnake some_profile_dump.profGpof2Dot — утилита, базирующаяся на Python, которая может преобразовывать результаты профилирования в виде графиков, которые могут быть сохранены как PNG или SVG изображения. Типичная сессия профилирования в Python 2.5 выглядит следующим образом (в более старых версиях вам понадобиться использовать сам скрипт, вместо опции -m):
python -m cProfile -o stat.prof MYSCRIPY.PY [ARGS...] python -m pbp.scripts.gprof2dot -f pstats -o stat.dot stat.prof dot -ostat.png -Tpng stat.dotPyCallGraph — модуль Python, который создает графики вызовов для Python приложений. Он генерирует PNG файл, отображающий вызовы функций и их связи с другими вызовами функций, количество вызовов функций и время их исполнения. Пример использования:
pycallgraph scriptname.pymasters.donntu.org
оптимизация или, по крайней мере, свежие идеи для генератора дерева Ru Python
Ниже я подытожил некоторые из наиболее очевидных усилий по оптимизации, не очень сильно затрагивая алгоритм. Все тайминги выполняются с помощью Python 2.6.4 в системе x86-64 для Linux.
Начальное время: 8.3s
Низко висящие фрукты
jellybean уже указал некоторые из них. Простое исправление уже немного улучшает время выполнения. Замена повторных вызовов на Operators.keys() , используя тот же список снова и снова, также экономит некоторое время.
Время: 6,6 с
Использование itertools.count
itertools.count Дэйвом Кирби , просто используя itertools.count также экономит ваше время:
from itertools import count KS = count()Время: 6.2s
Улучшение конструктора
Поскольку вы не устанавливаете все атрибуты Node в ctor, вы можете просто переместить объявления атрибутов в тело класса:
class Node(object): isRoot = False left = None right = None parent = None branch = None seq = 0 def __init__(self, cargo): self.cargo = cargoЭто не изменяет семантику класса, насколько вам известно, поскольку все значения, используемые в теле класса, неизменяемы ( False , None , 0 ), если вам нужны другие значения, сначала прочтите этот ответ на атрибутах класса .
Время: 5.2s
Использование namedtuple
В вашем коде вы больше не меняете дерево выражений, поэтому вы можете использовать объект, который является неизменным. Node также нет никакого поведения, поэтому использование namedtuple – хороший вариант. Это имеет значение, хотя, поскольку parent член должен был быть отброшен на данный момент. Судя по тому, что вы могли бы ввести операторов с более чем двумя аргументами, вам все равно придется заменить left / right на список детей, который будет изменяться снова и позволит создать родительский узел перед всеми дочерними элементами.
from collections import namedtuple Node = namedtuple("Node", ["cargo", "left", "right", "branch", "seq", "isRoot"]) # ... def build_nodes (self, depth = Depth, entry = 1, pparent = None, bbranch = None): r = random.random() if (depth <= 0) or ((r > Ratio) and (not (entry))): this_node = Node( random.choice(Atoms), None, None, bbranch, KS.next(), False) self.thedict[this_node.seq] = this_node return this_node else: this_operator = random.choice(OpKeys) this_node = Node( this_operator, self.build_nodes(entry = 0, depth = depth - 1, pparent = None, bbranch = 'left'), self.build_nodes(entry = 0, depth = depth - 2, pparent = None, bbranch = 'right'), bbranch, KS.next(), bool(entry)) self.thedict[this_node.seq] = this_node return this_nodeЯ сохранил исходное поведение цикла операнда, что уменьшает глубину на каждой итерации. Я не уверен, что это желание, но изменение его увеличивает время выполнения и, следовательно, делает невозможным сравнение.
Конечное время: 4.1s
Куда пойти отсюда
Если вы хотите иметь поддержку для более чем двух операторов и / или поддержки родительского атрибута, используйте что-то в строках следующего кода:
from collections import namedtuple Node = namedtuple("Node", ["cargo", "args", "parent", "branch", "seq", "isRoot"]) def build_nodes (self, depth = Depth, entry = 1, pparent = None, bbranch = None): r = random.random() if (depth <= 0) or ((r > Ratio) and (not (entry))): this_node = Node( random.choice(Atoms), None, pparent, bbranch, KS.next(), False) self.thedict[this_node.seq] = this_node return this_node else: this_operator = random.choice(OpKeys) this_node = Node( this_operator, [], pparent, bbranch, KS.next(), bool(entry)) this_node.args.extend( self.build_nodes(entry = 0, depth = depth - (i + 1), pparent = this_node, bbranch = i) for i in range(Operators[this_operator])) self.thedict[this_node.seq] = this_node return this_nodeЭтот код также уменьшает глубину с позиции оператора.
www.rupython.com
optimization - Оптимизация Python в этом коде?
Во-первых, если вы используете Python 2.x, вы можете получить некоторую скорость, используя xrange() вместо range(). В Python 3.x нет xrange(), но встроенный range() в основном такой же, как xrange().
Затем, если мы идем на скорость, нам нужно написать меньше кода и больше полагаться на встроенные функции Python (написанные на C для скорости).
Вы можете ускорить работу, используя выражение генератора внутри sum(), например:
from itertools import izip def find_best(weights,fields): winner = -1 best = -float('inf') for c in xrange(num_category): score = sum(float(t[0]) * t[1] for t in izip(fields, weights[c])) if score > best: best = score winner = c return winnerПовторяя ту же идею, попробуйте использовать max(), чтобы найти лучший результат. Я думаю, что этот код некрасиво смотреть, но если вы сравниваете его и это достаточно быстро, это может стоить того:
from itertools import izip def find_best(weights, fields): tup = max( ((i, sum(float(t[0]) * t[1] for t in izip(fields, wlist))) for i, wlist in enumerate(weights)), key=lambda t: t[1] ) return tup[0]Тьфу! Но если я не ошибаюсь, это делает то же самое, и он должен много полагаться на машину C на Python. Измерьте его и посмотрите, быстрее ли он.
Итак, мы вызываем max(). Мы даем ему выражение генератора, и оно найдет максимальное значение, возвращаемое из выражения генератора. Но вам нужен индекс наилучшего значения, поэтому выражение генератора возвращает кортеж: индекс и значение веса. Поэтому нам нужно передать выражение генератора в качестве первого аргумента, а второй аргумент должен быть ключевой функцией, которая смотрит на значение веса из кортежа и игнорирует индекс. Поскольку выражение генератора не является единственным аргументом для max(), оно должно быть в parens. Затем он строит кортеж i и рассчитанный вес, рассчитанный тем же самым sum(), который мы использовали выше. Наконец, как только мы вернем кортеж из max(), проиндексируем его, чтобы получить значение индекса, и вернем его.
Мы можем сделать это намного менее уродливым, если вырвать функцию. Это добавляет накладные расходы на вызов функции, но если вы его оцениваете, я буду держать пари, что он не слишком медленный. Кроме того, теперь, когда я думаю об этом, имеет смысл построить список значений fields, предварительно запрограммированных на float; то мы можем использовать это несколько раз. Кроме того, вместо использования izip() для параллельной итерации по двум спискам, просто сделайте итератор и прямо спросите его о значениях. В Python 2.x мы используем функцию метода .next() для запроса значения; в Python 3.x вы должны использовать встроенную функцию next().
def fweight(field_float_list, wlist): f = iter(field_float_list) return sum(f.next() * w for w in wlist) def find_best(weights, fields): flst = [float(x) for x in fields] tup = max( ((i, fweight(flst, wlist)) for i, wlist in enumerate(weights)), key=lambda t: t[1] ) return tup[0]Если значения полей 30K, то предварительная вычисление значений float(), вероятно, будет большой победой скорости.
EDIT: Я пропустил один трюк. Вместо функции lambda я должен был использовать operator.itemgetter() как часть кода в принятом ответе. Кроме того, принятый ответ приурочен, и похоже, что накладные расходы на вызов функции были значительными. Но ответы Numpy были настолько быстрыми, что больше не стоило играть с этим ответом.
Что касается второй части, я не думаю, что ее можно ускорить. Я попробую:
def update_weights(weights,fields,toincrease,todecrease): w_inc = weights[toincrease] w_dec = weights[todecrease] for i, f in enumerated(fields): f = float(f) # see note below w_inc[i] += f w_dec[i] -= fИтак, вместо итерации по xrange() здесь мы просто перебираем значения полей напрямую. У нас есть строка, которая принудительно плавает.
Обратите внимание, что если значения весов уже имеют значение float, нам не нужно принудительно плавать здесь, и мы можем сэкономить время, просто удалив эту строку.
Ваш код индексировал список весов четыре раза: дважды для увеличения, дважды для уменьшения. Этот код делает первый индекс (используя аргумент toincrease или todecrease) только один раз. Для работы += все еще нужно индексировать i. (Моя первая версия пыталась избежать этого с помощью итератора и не работала. Я должен был протестировать перед публикацией, но теперь это исправлено.)
Одна последняя версия: вместо того, чтобы увеличивать и уменьшать значения по мере того, как мы идем, просто используйте списки для создания нового списка со значениями, которые мы хотим:
def update_weights(weights, field_float_list, toincrease, todecrease): f = iter(field_float_list) weights[toincrease] = [x + f.next() for x in weights[toincrease]] f = iter(field_float_list) weights[todecrease] = [x - f.next() for x in weights[todecrease]]Предполагается, что вы уже принудительно использовали все значения полей для float, как показано выше.
Быстрее или медленнее заменить весь список таким образом? Я собираюсь угадать быстрее, но я не уверен. Измерьте и посмотрите!
О, я должен добавить: обратите внимание, что моя версия update_weights(), показанная выше, не возвращает weights. Это связано с тем, что в Python считается хорошей практикой не возвращать значение из функции, которая мутирует структуру данных, просто чтобы убедиться, что никто никогда не путается о том, какие функции выполняют запросы и какие функции меняют вещи.
http://en.wikipedia.org/wiki/Command-query_separation
Измерение меры измерения. Посмотрите, насколько быстрее мои предложения, или нет.
qaru.site
Оптимизация кода в python - Python Скрипты
Привет. Я решал задачку «Покупка футболок», но оказалось, что она работает очень медленно. Причин я не могу понять, так как не слишком хорошо знаю питон. Но одно я понимаю точно, что это странно, так как оно имеет хорошую ассимптотику и не должно долго работать.
n = int(raw_input()) price = [int(value) for value in raw_input().split(' ')] front = [1 << (int(value) - 1) for value in raw_input().split(' ')] back = [1 << (3 + int(value) - 1) for value in raw_input().split(' ')] result = {} for index in range(0, n): if not(front[index] + back[index] in result): result[front[index] + back[index]] = [price[index]] else: result[front[index] + back[index]].append(price[index]) for item in result: result[item] = sorted(result[item]) cust = int(raw_input()) fav = [1 << (int(value) - 1) for value in raw_input().split(' ')] index = 0 for itemCust in fav: minValue = 2000000000 minItem = -1 for item in result: priceValue = result[item] if (item & itemCust != 0 or item & (itemCust << 3) != 0) and len(priceValue) > 0 and priceValue[0] < minValue: minValue = priceValue[0] minItem = item if minItem != -1: result[minItem] = result[minItem][1:] print minValue else: print -1Комментарий по задаче. У нас есть пары чиселок от 1 до 3 (футболки). Есть запросы (покупатели) в виде одной чиселки от 1 до 3, которым важно, чтобы среди пар чиселок (футболок) была хотя бы одна такая же, как и у них.
Для решения мы кидаем все футболки в мапу, кодируя их следующим образом. Каждая футболка — это бит-число из 2х единиц. Первые 3 единицы отвечают первой чиселке из пары. Вторые 3 единицы отвечают второй чиселке из пары.
1 1 --> 100100 (т.е. 1ый бит и (1 + 3)ый бит) 1 2 --> 100010 (т.е. 1ый бит и (2 + 3)ый бит) 3 2 --> 001010 (т.е. 3ий бит и (2 + 3)ый бит)и т.д.
Собственно, для каждого бинарного кода заведём мапу и будем хранить список цен, отсортированных в порядке убывания. После чего переберём всех покупателей поочереди и будем выбирать за 6 шагов самую подходящую футболку.
python-scripts.com
python - Списки Python, оптимизация словаря
Ваша первая программа немного расплывчата. Я предполагаю, что numbers - это список кортежей или что-то еще? Как [(1,2), (3,4), (5,6)]? Если это так, ваша программа довольно хороша, с точки зрения сложности - это O (n). Возможно, вам нужно немного больше решений на основе Pythonic? Самый простой способ очистить это - это присоединиться к вашим условиям:
if i != j and i + j == k:Но это просто повышает удобочитаемость. Я думаю, что это может также добавить дополнительную логическую операцию, поэтому это может быть не оптимизация.
Я не уверен, что вы хотите, чтобы ваша программа вернула первую пару чисел, сумма которых равна k, но если вы хотите, чтобы все пары отвечали этому требованию, вы могли бы написать понимание:
def pairsum(numbers, k): return list(((i, j) for i, j in numbers if i != j and i + j == k))В этом примере я использовал генераторное понимание вместо понимания списка, чтобы сохранить ресурсы - generators - это функции, которые действуют как итераторы, что означает, что они могут экономить память, только предоставляя вам данные, когда вам это нужно. Это называется ленивой итерацией.
Вы также можете использовать фильтр, который является функцией, которая возвращает только элементы из набора, для которого предикат возвращает True. (То есть элементы, которые удовлетворяют определенному требованию.)
import itertools def pairsum(numbers, k): return list(itertools.ifilter(lambda t: t[0] != t[1] and t[0] + t[1] == k, ((i, j) for i, j in numbers)))Но это менее читаемо, на мой взгляд.
Ваша вторая программа может быть оптимизирована с помощью set. Если вы помните из любой дискретной математики, которую вы, возможно, узнали в начальной школе или университете, набор представляет собой набор уникальных элементов - другими словами, набор не имеет повторяющихся элементов.
def dedup(mystring): return set(mystring)Алгоритм поиска уникальных элементов коллекции, как правило, будет O (n ^ 2) во времени, если это O (1) в пространстве - если вы позволяете себе выделять больше памяти, вы можете использовать Двоичное дерево поиска, чтобы уменьшить сложность времени до O (n log n), что, скорее всего, реализовано с помощью наборов Python.
Ваше решение заняло время O (n ^ 2), но также O (n), потому что вы создали новый список, который мог бы, если бы вход был уже строкой только с уникальными элементами, занимал одинаковое пространство - и, для каждого символа в строке, вы повторили вывод. Это, по существу, O (n ^ 2) (хотя я думаю, что это фактически O (n * m), но что угодно). Надеюсь, вы понимаете, почему это так. Прочтите статью дерева двоичного поиска, чтобы узнать, как она улучшает ваш код. Я не хочу снова внедрять его... Год первокурсника был таким изнурительным!
qaru.site
optimization - Оптимизация Python - Qaru
Возможны дальнейшие значительные улучшения.
Следующий файл script демонстрирует их, используя (для краткости) только цикл 4 размера (который занимает более 90% времени).
метод 0: исходный код OP
метод 1: решение Джона Куглемана
метод 2: (1) и перемещение некоторой конкатенации строк из внутренних циклов
метод 3: (2) и поместить код внутри функции - доступ к локальным переменным намного быстрее глобальных переменных. Любой script может это сделать. Многие скрипты должны это делать.
метод 4: (3) и скопируйте строки в списке, затем присоедините их и напишите. Обратите внимание, что это использует память, как вы можете не верить. Мой код не пытается сделать это для всего файла, потому что (127 - 33) ** 4 - это 78M строк. В 32-битном поле это 78 * 4 = 312Mb только для списка (игнорирование неиспользуемой памяти в конце списка), а также 78 * 28 = 2184 Mb для объектов str (sys.getsizeof( "1234" ) 28), плюс 78 * 5 = 390 Мб для результата объединения. Вы просто взорвали свое адресное пространство пользователя, или ваш ulimit, или что-то еще выдувное. Или, если у вас есть 1 ГБ реальной памяти, 128Mb которой был взломан видеодрайвером, но достаточно места для подкачки, у вас есть время для обеда (при запуске конкретной ОС, ужин также).
метод 5: (4) и не запрашивать список о местонахождении его атрибута append 78 миллионов раз: -)
Вот файл script:
import time, sys time_function = time.clock # Windows; time.time may be better on *x ubound, which = map(int, sys.argv[1:3]) t0 = time_function() if which == 0: ### original ### f = open('wl4.txt', 'w') hh = 0 n = 4 for l in range(33, ubound): if n == 1: pass elif n == 2: pass elif n == 3: pass elif n == 4: for s0 in range(33, ubound): for s1 in range(33, ubound): for s2 in range(33,ubound): b = chr(l) + chr(s0) + chr(s1) + chr(s2) + '\n' f.write(b) hh += 1 f.close() elif which == 1: ### John Kugleman ### f = open('wl4.txt', 'w') chars = [chr(c) for c in range(33, ubound)] hh = 0 for l in chars: for s0 in chars: for s1 in chars: for s2 in chars: b = l + s0 + s1 + s2 + '\n' f.write(b) hh += 1 f.close() elif which == 2: ### JohnK, saving + ### f = open('wl4.txt', 'w') chars = [chr(c) for c in range(33, ubound)] hh = 0 for L in chars: # "L" as in "Legible" ;-) for s0 in chars: b0 = L + s0 for s1 in chars: b1 = b0 + s1 for s2 in chars: b = b1 + s2 + '\n' f.write(b) hh += 1 f.close() elif which == 3: ### JohnK, saving +, function ### def which4func(): f = open('wl4.txt', 'w') chars = [chr(c) for c in range(33, ubound)] nwords = 0 for L in chars: for s0 in chars: b0 = L + s0 for s1 in chars: b1 = b0 + s1 for s2 in chars: b = b1 + s2 + '\n' f.write(b) nwords += 1 f.close() return nwords hh = which4func() elif which == 4: ### JohnK, saving +, function, linesep.join() ### def which5func(): f = open('wl4.txt', 'w') chars = [chr(c) for c in range(33, ubound)] nwords = 0 for L in chars: accum = [] for s0 in chars: b0 = L + s0 for s1 in chars: b1 = b0 + s1 for s2 in chars: accum.append(b1 + s2) nwords += len(accum) accum.append("") # so that we get a final newline f.write('\n'.join(accum)) f.close() return nwords hh = which5func() elif which == 5: ### JohnK, saving +, function, linesep.join(), avoid method lookup in loop ### def which5func(): f = open('wl4.txt', 'w') chars = [chr(c) for c in range(33, ubound)] nwords = 0 for L in chars: accum = []; accum_append = accum.append for s0 in chars: b0 = L + s0 for s1 in chars: b1 = b0 + s1 for s2 in chars: accum_append(b1 + s2) nwords += len(accum) accum_append("") # so that we get a final newline f.write('\n'.join(accum)) f.close() return nwords hh = which5func() else: print "Bzzzzzzt!!!" t1 = time_function() print "Method %d made %d words in %.1f seconds" % (which, hh, t1 - t0)Вот несколько результатов:
C:\junk\so>for %w in (0 1 2 3 4 5) do \python26\python wl4.py 127 %w C:\junk\so>\python26\python wl4.py 127 0 Method 0 made 78074896 words in 352.3 seconds C:\junk\so>\python26\python wl4.py 127 1 Method 1 made 78074896 words in 183.9 seconds C:\junk\so>\python26\python wl4.py 127 2 Method 2 made 78074896 words in 157.9 seconds C:\junk\so>\python26\python wl4.py 127 3 Method 3 made 78074896 words in 126.0 seconds C:\junk\so>\python26\python wl4.py 127 4 Method 4 made 78074896 words in 68.3 seconds C:\junk\so>\python26\python wl4.py 127 5 Method 5 made 78074896 words in 60.5 secondsОбновление в ответ на вопросы OP
"" Когда я пытаюсь добавить для циклов, у меня есть ошибка памяти для accum_append.. в чем проблема? ""
Я не знаю, в чем проблема; Я не могу прочитать ваш код на таком расстоянии. Угадайте: если вы пытаетесь выполнить длину == 5, вы, вероятно, получили инициализацию и запись битов accum в неправильном месте, а accum пытается выйти за пределы вашей системной памяти (поскольку я надеялся, что я 'd объяснил ранее).
"" Теперь метод 5 является самым быстрым, но он делает слово tell length 4.. как я могу сделать, сколько я хочу?:) ""
У вас есть два варианта: (1) вы продолжаете использовать вложенные для циклов (2), вы смотрите ответы, которые не используют вложенные для циклов, с указанной динамической длиной.
Методы 4 и 5 получили ускорения с помощью accum, но способ выполнения этого был скроен с точным знанием того, сколько памяти будет использоваться.
Ниже приведены еще 3 метода. 101 - метод tgray без дополнительного использования памяти. 201 - это метод Пола Ханкина (плюс некоторый код для записи в файл), так же как и дополнительное использование памяти. Эти два метода имеют одинаковую скорость и находятся в пределах видимости метода 3 по скорости. Оба они обеспечивают динамическую спецификацию требуемой длины.
Метод 102 - метод tgray с фиксированным буфером 1 Мб - он пытается сэкономить время, уменьшив количество вызовов на f.write()... вы можете поэкспериментировать с размером буфера. Если хотите, вы можете создать ортогональный метод 202. Обратите внимание, что метод tgray использует itertools.product, для которого вам понадобится Python 2.6, тогда как метод Пола Хэнкина использует генераторные выражения, которые были вокруг некоторое время.
elif which == 101: ### tgray, memory-lite version def which201func(): f = open('wl4.txt', 'w') f_write = f.write nwords = 0 chars = map(chr, xrange(33, ubound)) # create a list of characters length = 4 #### length is a variable for x in product(chars, repeat=length): f_write(''.join(x) + '\n') nwords += 1 f.close() return nwords hh = which201func() elif which == 102: ### tgray, memory-lite version, buffered def which202func(): f = open('wl4.txt', 'w') f_write = f.write nwords = 0 chars = map(chr, xrange(33, ubound)) # create a list of characters length = 4 #### length is a variable buffer_size_bytes = 1024 * 1024 buffer_size_words = buffer_size_bytes // (length + 1) words_in_buffer = 0 buffer = []; buffer_append = buffer.append for x in product(chars, repeat=length): words_in_buffer += 1 buffer_append(''.join(x) + '\n') if words_in_buffer >= buffer_size_words: f_write(''.join(buffer)) nwords += words_in_buffer words_in_buffer = 0 del buffer[:] if buffer: f_write(''.join(buffer)) nwords += words_in_buffer f.close() return nwords hh = which202func() elif which == 201: ### Paul Hankin (needed output-to-file code added) def AllWords(n, CHARS=[chr(i) for i in xrange(33, ubound)]): #### n is the required word length if n == 1: return CHARS return (w + c for w in AllWords(n - 1) for c in CHARS) def which301func(): f = open('wl4.txt', 'w') f_write = f.write nwords = 0 for w in AllWords(4): f_write(w + '\n') nwords += 1 f.close() return nwords hh = which301func()qaru.site
optimization - Python: оптимизация или, по крайней мере, свежие идеи для генератора дерева
Ниже я подытожил некоторые из наиболее очевидных усилий по оптимизации, не особо затрагивая алгоритм. Все тайминги выполняются с помощью Python 2.6.4 в системе Linux x86-64.
Начальное время: 8.3s
Низко висящие фрукты
jellybean уже указал некоторые из них. Простое исправление уже немного улучшает время выполнения. Замена повторных вызовов на Operators.keys() с помощью того же списка снова и снова также экономит некоторое время.
Время: 6.6s
Использование itertools.count
Указанный Дэйв Кирби, просто используя itertools.count также сохраняет вы некоторое время:
from itertools import count KS = count()Время: 6.2s
Улучшение конструктора
Поскольку вы не устанавливаете все атрибуты Node в ctor, вы можете просто переместить объявления атрибутов в тело класса:
class Node(object): isRoot = False left = None right = None parent = None branch = None seq = 0 def __init__(self, cargo): self.cargo = cargoЭто не изменяет семантику класса, насколько вам известно, поскольку все значения, используемые в теле класса, неизменяемы (False, None, 0), если вам нужны другие значения, сначала прочитайте этот ответ на атрибуты класса.
Время: 5.2s
Использование namedtuple
В вашем коде вы больше не меняете дерево выражений, поэтому вы можете использовать объект, который является неизменным. Node также не имеет никакого поведения, поэтому использование namedtuple является хорошим вариантом. Это имеет значение, хотя, поскольку член parent должен был быть отброшен на данный момент. Судя по тому, что вы могли бы ввести операторов с более чем двумя аргументами, вам все равно придется заменить left/right на список детей, который будет изменяться снова и позволит создать родительский node перед всеми дочерними элементами.
from collections import namedtuple Node = namedtuple("Node", ["cargo", "left", "right", "branch", "seq", "isRoot"]) # ... def build_nodes (self, depth = Depth, entry = 1, pparent = None, bbranch = None): r = random.random() if (depth <= 0) or ((r > Ratio) and (not (entry))): this_node = Node( random.choice(Atoms), None, None, bbranch, KS.next(), False) self.thedict[this_node.seq] = this_node return this_node else: this_operator = random.choice(OpKeys) this_node = Node( this_operator, self.build_nodes(entry = 0, depth = depth - 1, pparent = None, bbranch = 'left'), self.build_nodes(entry = 0, depth = depth - 2, pparent = None, bbranch = 'right'), bbranch, KS.next(), bool(entry)) self.thedict[this_node.seq] = this_node return this_nodeЯ сохранил исходное поведение цикла операнда, которое уменьшает глубину на каждой итерации. Я не уверен, что это поведение требуется, но его изменение увеличивает время выполнения и, следовательно, делает невозможным сравнение.
Конечное время: 4.1s
Куда пойти отсюда
Если вы хотите иметь поддержку более двух операторов и/или поддержки родительского атрибута, используйте что-то вдоль строк следующего кода:
from collections import namedtuple Node = namedtuple("Node", ["cargo", "args", "parent", "branch", "seq", "isRoot"]) def build_nodes (self, depth = Depth, entry = 1, pparent = None, bbranch = None): r = random.random() if (depth <= 0) or ((r > Ratio) and (not (entry))): this_node = Node( random.choice(Atoms), None, pparent, bbranch, KS.next(), False) self.thedict[this_node.seq] = this_node return this_node else: this_operator = random.choice(OpKeys) this_node = Node( this_operator, [], pparent, bbranch, KS.next(), bool(entry)) this_node.args.extend( self.build_nodes(entry = 0, depth = depth - (i + 1), pparent = this_node, bbranch = i) for i in range(Operators[this_operator])) self.thedict[this_node.seq] = this_node return this_nodeЭтот код также уменьшает глубину с позиции оператора.
qaru.site