29.Оптимизация sql-запросов. Общие сведения. Оптимизация sql
Повышение эффективности MySQL. Оптимизация SQL запросов
Управление индексами, то есть как они создаются и поддерживаются — может значительно повлиять на производительность sql запросов.
Очень часто можно применить следующие оптимизации:
- удалить неиспользуемые индексы
- определить неиспользуемые вообще и неэффективные индексы
- улучшить индексы
- избегать вообще sql запросов!
- упрощать sql запросы
- и магия варианты кеширования
Объединение DDL запросов
Запросы, меняющие структуру данных как правило являются блокирующими таблицу. Исторически, выполнение запроса ALTER требовало создания новой копии таблицы, что может быть очень затратным по времени и по объему данных на диске. Поэтому вместо трех запросов с маленькими альтерами намного выгоднее выполнять один объединенный. Это может сэкономить значительное количество времени на задачах по администрированию баз.
Удаление дублирующихся индексов
Дублирующиеся индексы вредны по двум причинам: все запросы на изменение данных будут медленнее, поскольку выполняется двойная работа для поддержания полноты индекса. Кроме того, это создает лишнюю нагрузку на файловую систему, поскольку размер базы становится большим физически и приводит к увеличение времени создания бэкапов и времени восстановления.
Несколько простых условий могут привести к дублированию индексов. Например, mysql не нужен индекс на полях PRIMARY.
Дублирующий индекс также может существовать, если левая часть одного из индексов полностью совпадает с другим индексом.
Утилита pt-duplicate-key-checker из perkona-toolkit — это простой и быстрый способ проверить свою структуру базы на наличие лишних индексов.
Удаление неиспользуемых индексов
Кроме индексов, которые не используются никогда, поскольку являются дублями, могут быть недублирующиеся индексы, которые просто никогда не используются. Такие индексы влияют также, как и дублирующиеся индексы. В стандартном mysql нет никаких способов определить какие индексы неиспользуются, однако в некоторых версиях есть подобная возможность, например при использовании Google MySQL patch.
В этом патче была введена фишка: SHOW INDEX_STATISTICS.
А в обычном mysql сначала необходимо собрать все используемые sql запросы, прогонять их и смотреть план выполнения, собирать при этом информацию о используемых в каждом случае индексах и сводить это в единую таблицу. В любом случае, это полезный опыт.
Оптимизация индексных полей.
Помимо создания новых индексов для повышения производительности, можно повысить быстродействие через дополнительные оптимизации структуры. В эти оптимизации входит использование специальных данных и типов полей. Профит в данном случае — это меньшая нагрузка на диск и больший объем индексов, который может помещаться в оперативной памяти.
Типы данных
Некоторые типы могут быть заменены безболезненно на текущей существующих базах.
BIGINT vs INT
Когда PRIMARY ключ определён как BIGINT AUTO INCREMENT — как правило нет никаких причин использовать именно его. Тип данных INT UNSIGNED AUTO_INCREMENT может хранить максимум числа до 4294967295. Если у вас реально будет больше записей чем это число, вам скорее всего понадобится другая архитектура.
От такого изменения с BIGINT на INT UNSIGNED каждая строка таблицы начинает занимать в 2 раза меньше места на диске, кроме того с 8 байт до 4 снижается размер, занимаемый PRIMARY ключом.
Это пожалуй одно из самых ощутимых простых улучшений, которые можно делать достаточно безболезненно.
DATETIME vs TIMESTAMP
Тут все просто: timestamp — 4 байта, datetime — 8 байт.
ENUM
По возможности надо использовать, потому что:
- дополнительная проверка целостности данных
- такое поле будет использовать всего 1 байт для хранения 255 уникальных значений
- такие поля удобнее читать :)
Исторически, использование enum полей приводило к зависимости базы от изменений возможных значений в enum. Это был блокирующий DDL запрос. Начиная с версии MySQL 5.1 добавление новых вариантов к enum очень быстрое и не связано с размером таблицы.
NULL vs NOT NULL
Если вы не уверены, что колонка может содержать неопределенное значение (NULL), лучше определять ее как NOT NULL. Индекс на такой колонке будет меньше по размеру и будет легче обрабатываться.
Автоматичесие конвертации типов
Когда вы выбираете тип данных для джойнящихся полей, бывает, что тип данных в поле неопределен. Встроенная конверсия может быть абсолютно лишним оверхедом.
Для целочисленных полей, убедитесь что SIGNED и UNSIGNED совпадают, для переменных типов полей, лишней работой может быть конвертация кодировки при джоине, поэтому их тоже обязательно проверять. Частая проблема это автоконвертация между кодировками latin1 и utf8.
Типы колонок
Некоторые типы данных часто хранятся в неправильных колонках. Изменение типа при этом может привести к более эффективному хранению, особенно когда эти колонки включаются в индекс. Рассмотрим несколько типичных примеров.
IP адрес
IPv4 адрес может храниться в поле INT UNSIGNED, которое займет всего 4 байта. Часто встречается ситуация, когда ip адрес хранят в поле VARCHAR(15), которое занимает 12 байт. Одно это изменение может сократить размер на 2/3. Функции INET_ATON() и INET_NTOA служат для конвертации между строкой с ip адресом и числовым значением.
Для IPv6 адресов, которые все сильнее наступают, важно хранить их 128битное цифровое значение в полях BINARY(16) и не использовать VARCHAR для человекочитаемого формата.
MD5
Хранение md5 полей как CHAR(32) является повсеместной практикой. Если вы используете поле VARCHAR(32) вы еще дополнительно добавляете лишний оверхед длины строки для каждого значения. Однако md5 строка — это шестнадцатиричное значение — и его можно хранить эффективнее используя функции UNHEX() и HEX(). В этом случае данные можно хранить в полях BINARY(16). Такое простое действие снизит размер поля с 32 байт до 16 байт. Подобный принцип можно применять к любым шестнадцатиричным значениям.
Основано на книге Рональда Брэдфорда.
figvam.ru
29.Оптимизация sql-запросов. Общие сведения.
Общее назначение оптимизатора состоит в выборе наиболее эффективной стратегии вычисления реляционного выражения.
Хороший оптимизатор обладает большим объемом полезной информации, которая
пользователю обычно недоступна. Говоря конкретнее, оптимизатор владеет
определенными статистическими данными, в частности акими как: количество значений в
каждом домене; текущее количество значений в каждой базовой переменной-отношении; текущее количество различающихся значений для каждого атрибута в базовой переменной-отношении; количество вхождений каждого значения в каждом из атрибутов и т.п.
Благодаря наличию таких данных оптимизатор способен более точно оценить эффективность любой возможной стратегии реализации конкретного запроса и выбрать наилучшую стратегию реализации запроса.
При изменении статистических показателей базы данных может потребоваться реоптимизация.
Оптимизатор— это программа, которая по определению более "настойчива", чем человек. Оптимизатор способен рассматривать буквально сотни различных стратегий реализации конкретного запроса, в то время как программист едва ли проанализирует более трех-четырех возможных стратегий (по крайней мере, достаточно глубоко).
В оптимизаторе реализованы знания и опыт "лучших из лучших" программистов, в результате чего эти знания и опыт становятся доступными для всех. Это позволяет применять ограниченный набор ресурсов, предоставленный широкому кругу пользователей, наиболее эффективно и экономично.
17.3. Оптимизация запросов
1.Преобразование запроса во внутреннюю форму.
2.Преобразование запроса в каноническую форму.
3.Выбор потенциальных низкоуровневых процедур.
4.Генерация различных вариантов планов вычисления запроса и выбор плана с минимальными затратами.
Перейдем к подробному рассмотрению каждой стадии процесса оптимизации.
Стадия 1. Преобразование запроса во внутреннюю форму
На этой стадии выполняется преобразование запроса в некоторое внутреннее представление, более удобное для машинных манипуляций. В результате из рассмотрения полностью исключаются конструкции сугубо внешнего уровня (например, разнообразные варианты конкретного синтаксиса используемого языка запросов) и готовится почва для последующих стадий оптимизации. Обработка представлений (т.е. процесс замены ссылок на представления выражениями, определяющими соответствующие представления) также выполняется на этом этапе.
Стадия 2. Преобразование запроса в каноническую форму
Чтобы преобразовать результаты выполнения стадии 1 в некоторую эквивалентную, но более эффективную форму, оптимизатор использует определенные и хорошо известные правила преобразования, или законы.
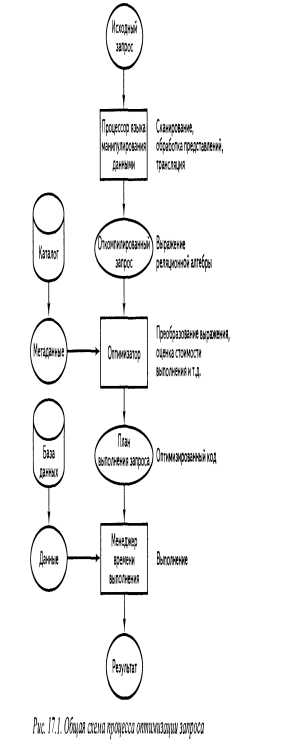 Стадия 3. Выбор потенциальных низкоуровневых процедур
Стадия 3. Выбор потенциальных низкоуровневых процедур
После преобразования внутренней формы запроса в каноническую форму оптимизатор должен решить, как следует выполнять запрос, представленный в этой канонической форме. На данной стадии принимаются во внимание наличие индексов и других путей доступа, статистическое распределение существующих значений данных, физическая кластеризация хранимых данных и т.п. Обратите внимание, что на стадиях 1 и 2 этим аспектам совсем не уделялось внимания.
Основная стратегия состоит в том, чтобы рассматривать выражение запроса как серию низкоуровневых операций (соединения, выборки и т.п.), которые в определенной степени зависят одна от другой.
Для каждой низкоуровневой операции оптимизатор имеет набор низкоуровневых процедур реализации.
С каждой процедурой связана и параметризованная формула стоимости, позволяющая оценить стоимость выполнения процедуры (т.е. уровень затрат, требуемых для ее выполнения). Чаще всего стоимость определяется на основе подсчета количества необходимых дисковых операций ввода-вывода, но некоторые системы учитывают также время использования процессора и другие факторы.
Далее, используя сохраняемую в каталоге информацию о состоянии базы данных (существующие индексы, текущую кардинальность переменных-отношений и т.п.) и сведения о взаимозависимостях, упоминавшихся выше, оптимизатор выбирает одну или несколько процедур-кандидатов для каждой низкоуровневой операции в запросе. Этот процесс обычно называют выбором пути доступа.
Стадия 4. Генерация различных вариантов планов вычисления запроса и выбор плана с минимальными затратами
На последней стадии процесса оптимизации создается набор потенциальных планов запроса, после чего следует выбор лучшего (т.е. наименее дорогого) плана выполнения запроса. Каждый план выполнения строится как комбинация некоторого набора процедур реализации, причем каждой низкоуровневой операции в запросе соответствует одна процедура.
Несомненно, для выбора плана с наименьшей стоимостью необходим метод определения стоимости любого возможного плана. По сути, стоимость плана — это просто сумма стоимостей отдельных процедур, входящих в его состав. Поэтому задача оптимизатора сводится к вычислению формул стоимости для каждой отдельной процедуры. Основная проблема состоит в том, что стоимость выполнения процедуры зависит от размера отношения (или отношений), которое эта процедура обрабатывает. Так как все запросы, за исключением самых простых, требуют создания некоторых промежуточных результатов выполнения, оптимизатор должен суметь оценить размер этих результатов и использовать полученные значения при вычислении формул стоимости. К сожалению, размеры промежуточных наборов данных сильно зависит от конкретных значений хранимых данных, поэтому точная оценка стоимости может оказаться достаточно сложной проблемой.
studfiles.net
sql - Оптимизация запросов T-SQL
Я работаю над некоторыми обновлениями для внутренней системы веб-аналитики, которую мы предоставляем нашим клиентам (в отсутствие предпочтительного поставщика или Google Analytics), и я работаю над следующим запросом:
select path as EntryPage, count(Path) as [Count] from ( /* Sub-query 1 */ select pv2.path from pageviews pv2 inner join ( /* Sub-query 2 */ select pv1.sessionid, min(pv1.created) as created from pageviews pv1 inner join Sessions s1 on pv1.SessionID = s1.SessionID inner join Visitors v1 on s1.VisitorID = v1.VisitorID where pv1.Domain = isnull(@Domain, pv1.Domain) and v1.Campaign = @Campaign group by pv1.sessionid ) t1 on pv2.sessionid = t1.sessionid and pv2.created = t1.created ) t2 group by Path;Я тестировал этот запрос с 2 миллионами строк в таблице PageViews, и для его выполнения требуется около 20 секунд. Я дважды просматриваю кластерное сканирование индекса в плане выполнения, оба раза он попадает в таблицу PageViews. В столбце "Создать" в этой таблице есть кластерный индекс.
Проблема заключается в том, что в обоих случаях она повторяется по всем 2 миллионам строк, что, по моему мнению, является узким местом производительности. Есть ли что-то, что я могу сделать, чтобы предотвратить это, или я в значительной степени максимизирован с точки зрения оптимизации?
Для справки цель запроса - найти первое представление страницы для каждого сеанса.
EDIT: После большого разочарования, несмотря на полученную здесь помощь, я не смог заставить этот запрос работать. Поэтому я решил просто сохранить ссылку на страницу входа (и теперь выйти) в таблице сеансов, что позволяет мне сделать следующее:
select pv.Path, count(*) from PageViews pv inner join Sessions s on pv.SessionID = s.SessionID and pv.PageViewID = s.ExitPage inner join Visitors v on s.VisitorID = v.VisitorID where ( @Domain is null or pv.Domain = @Domain ) and v.Campaign = @Campaign group by pv.Path;Этот запрос выполняется через 3 секунды или меньше. Теперь мне нужно либо обновить страницу входа/выхода в режиме реального времени, когда записи страниц записываются (оптимальное решение), либо периодически запускают пакетное обновление. В любом случае, это решает проблему, но не так, как я предполагал.
Edit Edit: добавление отсутствующего индекса (после очистки от прошлой ночи) уменьшило запрос до нескольких миллисекунд). Woo hoo!
qaru.site
sql - Оптимизация запросов Sql
Всегда убедитесь, что у вас есть индексы в ваших таблицах. Не слишком много и не слишком мало.
Используя sql server 2005, примените включенные столбцы в этих индексах, они помогают искать.
При заказе дорого, если не требуется, зачем сортировать таблицу данных, если она не требуется.
Всегда фильтруйте как можно раньше, если вы сокращаете количество соединений, вызовы функций и т.д., как можно раньше, вы сокращаете время, затрачиваемое на все
- избегать курсоров, если вы можете
- использовать временные таблицы/таблицы vars для фильтрация по возможности
- удаленные запросы будут стоить вам
- запросы с sub выбор в условии where может быть hurtfull
- Функции таблицы могут быть дорогостоящими, если не фильтруют
как всегда, нет жесткого правила, и все должно выполняться на основе запроса.
Всегда создавайте запрос как понятный/читаемый, насколько это возможно, и оптимизируйте, когда это необходимо.
ИЗМЕНИТЬ вопрос:
Таблицы Temp могут использоваться, когда вам нужно добавлять индексы в таблицу temp (вы не можете добавлять индексы в таблицы var, кроме pk). Я в основном использую таблицы var, когда могу, и имею только необходимые поля в них как таковые
DECLARE @Table TABLE( FundID PRIMARY KEY )
я использовал бы это, чтобы заполнить идентификаторы группы фондов, вместо того, чтобы присоединиться к таблицам, которые менее оптимизированы.
Я прочитал несколько статей на днях, и к моему удивлению обнаружил, что таблицы var фактически созданы в tempdb
текст ссылки
Кроме того, я слышал и обнаружил, что таблица UDF может выглядеть как "черный ящик" для планировщика запросов. Еще раз, мы склонны перемещать выборки из функций таблицы в таблицы vars, а затем присоединяться к этим таблицам var. Но, как упоминалось ранее, сначала напишите код, а затем оптимизируйте, когда найдете бутылочные шейки.
Я обнаружил, что CTE могут быть полезны, но также, что, когда уровень рекурсии растет, он может быть очень медленным...
qaru.site