Как оптимизировать производительность большой базы в postgresql? Postgresql оптимизация
Как оптимизировать производительность большой базы в postgresql? — Toster.ru
95% запросов к базе будут на выборку данных, приблизительно равномерно по частоте размазаны тривиальные селекты и join нескольких таблиц со сложными условиями. Данные приблизительно равнометно запрашиваются из разных таблиц.5% запросов будут на запись небольших объемов данных.
Вопрос в том, как лучше оптимизировать все под такую задачу, вариант просто положить в БД данные и минимальный тюнинг СУБД не дают нужной производительности.
Сразу на ум приходит несколько вариантов.
Первый вариант это ограничиться просто вдумчивым тюнингом СУБД. К счастью, на офф сайте документации достаточно (например, тут wiki.postgresql.org/wiki/Performance_Optimization). Но тут остаются вопросы по тому насколько СУБД сможет использовать все ресурсы, и не будет ли проблем с долгим "прогревом".
Второй вариант обусловлен тем, что вся база поместится в оперативную память. Можно примонтировать оперативку и настроить соответствующим образом табличное пространство.Но тогда возникает вопрос стабильности и согласованности данных, ведь память то энергозависимая. Как вариант, можно предусмотреть репликацию с такой же БД на харде,или единую точку входа для прикладного ПО, которая будет отправлять все запросы в обе базы.
Третий вариант обусловлен тем, что большая часть запросов на чтение. Разделить аппаратные ресурсы на несколько реплик БД и соответствующим образом организовать запросы на чтение/запись.
Партицирование просьба не предлагать, это и так отдельный кусок базы, которые далее нецелесообразно отделять.
Понятное дело, что все варианты будут проверяться, эмулироваться нагрузка на машину в разных вариантах и тд, что бы определить наиболее оптимальный.
Хотелось бы услышать советы, если кто-то занимался решением подобных задач. Возможно, есть еще варианты или как-то можно развить эти, или кто-то в подобных вопросах уже напарывался на грабли.То есть буду благодарен любым подсказкам по этому вопросу.Мануалам по данной теме буду то же благодарен, если они не с первых страниц гугла)Спасибо.
toster.ru
Оптимизация PostgreSQL для быстрого тестирования Безопасный SQL
Во-первых, всегда используйте последнюю версию PostgreSQL. Улучшения производительности всегда наступают, поэтому вы, вероятно, тратите свое время, если настраиваете старую версию. Например, PostgreSQL 9.2 значительно улучшает скорость TRUNCATE и, конечно же, добавляет только сканирование по индексу. Всегда следует соблюдать даже незначительные выпуски; см. политику версий .
Этикет
НЕ помещайте табличное пространство в RAMdisk или другое не долговременное хранилище .
Если вы потеряете табличное пространство, вся база данных может быть повреждена и трудна в использовании без существенной работы. Для этого очень мало преимуществ по сравнению с просто использованием таблиц UNLOGGED и наличием большого количества ОЗУ для кеша.
Если вам действительно нужна система на основе ramdisk, initdb новый кластер в ramdisk, initdb новый экземпляр PostgreSQL в ramdisk, так что у вас есть полностью одноразовый экземпляр PostgreSQL.
Конфигурация сервера PostgreSQL
При тестировании вы можете настроить свой сервер на не долговечную, но более быструю работу .
Это одно из допустимых применений для настройки fsync=off в PostgreSQL. Этот параметр в значительной степени говорит PostgreSQL о том, что он не беспокоится о заказанной записи или какой-либо другой неприятной информации, защищающей целостность данных и безопасности при сбое, предоставляя ему разрешение полностью уничтожать ваши данные, если вы потеряете электроэнергию или потерпите крах ОС.
Излишне говорить, что вы никогда не должны включать fsync=off в производство, если вы не используете Pg в качестве временной базы данных для данных, которые вы можете повторно генерировать из других источников. Если и только если вы делаете, чтобы отключить fsync, вы также можете отключить full_page_writes , так как тогда оно больше не работает. Помните, что fsync=off и full_page_writes применяются на уровне кластера , поэтому они влияют на все базы данных в вашем экземпляре PostgreSQL.
Для использования в производстве вы можете использовать synchronous_commit=off и установить commit_delay , так как вы получите много таких же преимуществ, как fsync=off без риска гибели данных. У вас есть небольшое окно потери последних данных, если вы включите асинхронную фиксацию – но это все.
Если у вас есть возможность слегка изменить DDL, вы также можете использовать таблицы UNLOGGED в Pg 9.1+, чтобы полностью исключить ведение журнала WAL и получить реальное ускорение скорости за счет UNLOGGED таблиц при сбое сервера. Не существует опции конфигурации, чтобы сделать все таблицы не включенными, она должна быть установлена во время CREATE TABLE . В дополнение к тому, чтобы быть хорошим для тестирования, это удобно, если у вас есть таблицы, заполненные сгенерированными или несущественными данными в базе данных, которые в остальном содержат вещи, которые вам нужны, чтобы быть в безопасности.
Проверьте свои журналы и посмотрите, получаете ли вы предупреждения о слишком большом количестве контрольных точек. Если да, вы должны увеличить свои контрольные точки . Вы также можете настроить свою контрольную точку_completion_target, чтобы сгладить записи.
Настройте shared_buffers в соответствии с вашей рабочей нагрузкой. Это зависит от ОС, зависит от того, что еще происходит с вашей машиной, и требует некоторых проб и ошибок. По умолчанию они крайне консервативны. Возможно, вам потребуется увеличить максимальный размер общей памяти ОС, если вы увеличите количество shared_buffers на PostgreSQL 9.2 и ниже; 9.3 и выше изменили, как они используют общую память, чтобы этого избежать.
Если вы используете только пару подключений, которые выполняют большую работу, увеличьте work_mem чтобы дать им больше оперативной памяти для сортировки и т. Д. Помните, что слишком высокий параметр work_mem может вызвать проблемы с памятью, сортировать не для каждого соединения, поэтому один запрос может иметь много вложенных ролей. Вам действительно нужно увеличить work_mem если вы можете увидеть сортировку, пролитую на диск в EXPLAIN или войти в систему с параметром log_temp_files (рекомендуется), но более высокое значение также может позволить Pg выбрать более разумные планы.
Как сказал еще один плакат, целесообразно поместить xlog и основные таблицы / индексы на отдельные жесткие диски, если это возможно. Отдельные разделы довольно бессмысленны, вам действительно нужны отдельные диски. Это разделение имеет гораздо меньшую выгоду, если вы работаете с fsync=off и почти нет, если используете таблицы UNLOGGED .
Наконец, настройте свои запросы. Убедитесь, что ваши random_page_cost и seq_page_cost отражают производительность вашей системы, убедитесь, что ваш файл effective_cache_size верен и т. Д. Используйте EXPLAIN (BUFFERS, ANALYZE) чтобы изучить отдельные планы запросов и включить модуль auto_explain чтобы сообщать обо всех медленных запросах. Вы часто можете улучшить производительность запросов, просто создав соответствующий индекс или изменив параметры затрат.
AFAIK нет возможности установить всю базу данных или кластер как UNLOGGED . Было бы интересно уметь это делать. Рассмотрите вопрос о списке рассылки PostgreSQL.
Настройка хост-системы
Есть определенная настройка, которую вы можете сделать и на уровне операционной системы. Главное, что вы, возможно, захотите сделать, – убедить операционную систему не нагнетать записи на диск агрессивно, так как вам действительно все равно, когда / если они попадают на диск.
В Linux вы можете управлять этим с помощью настроек dirty_* подсистемы виртуальной памяти , таких как dirty_writeback_centisecs .
Единственная проблема с настройкой параметров обратной пересылки – слишком слабая, так это то, что флеш какой-либо другой программы может привести к потере всех накопленных буферов PostgreSQL, вызывая большие киоски, а все блокирует запись. Вы можете облегчить это, запустив PostgreSQL в другой файловой системе, но некоторые флеши могут быть уровнями уровня на уровне устройства или всего уровня хоста, а не на уровне файловой системы, поэтому вы не можете полагаться на это.
Эта настройка действительно требует игры с настройками, чтобы увидеть, что лучше всего подходит для вашей рабочей нагрузки.
В более новых ядрах вы можете убедиться, что vm.zone_reclaim_mode установлен на ноль, так как это может вызвать серьезные проблемы с производительностью с системами NUMA (большинство систем в наши дни) из-за взаимодействия с тем, как PostgreSQL управляет shared_buffers .
Настройка запросов и рабочей нагрузки
Это вещи, для которых требуются изменения кода; они могут вас не устраивать. Некоторые из них могут быть применены.
Если вы не участвуете в работе над большими транзакциями, начните. Многие небольшие транзакции стоят дорого, поэтому вы должны готовить материал, когда это возможно и практично. Если вы используете async commit, это менее важно, но все же рекомендуется.
По возможности используйте временные таблицы. Они не генерируют WAL-трафик, поэтому они намного быстрее для вставок и обновлений. Иногда стоит засыпать кучу данных в временную таблицу, манипулируя ею, но вам нужно, а затем сделать INSERT INTO ... SELECT ... чтобы скопировать ее в финальную таблицу. Обратите внимание, что временные таблицы относятся к сеансу; если ваш сеанс заканчивается или вы теряете свое соединение, тогда временная таблица исчезает, и никакое другое соединение не может видеть содержимое временной таблицы (ов) сеанса.
Если вы используете PostgreSQL 9.1 или новее, вы можете использовать таблицы UNLOGGED для данных, которые вы можете потерять, например состояния сеанса. Они видны на разных сеансах и сохраняются между соединениями. Они усекаются, если сервер отключается нечисто, поэтому они не могут использоваться ни для чего, что невозможно воссоздать, но они отлично подходят для кэшей, материализованных представлений, таблиц состояний и т. Д.
В общем, не DELETE FROM blah; , Используйте TRUNCATE TABLE blah; вместо; это намного быстрее, когда вы сбрасываете все строки в таблице. Усекайте многие таблицы одним вызовом TRUNCATE если сможете. Если вы делаете много TRUNCATES маленьких таблиц снова и снова, см .: Postgresql Скорость усечения
Если у вас нет индексов на внешних ключах, DELETE с участием первичных ключей, на которые ссылаются эти внешние ключи, будет ужасно медленным. Не забудьте создать такие индексы, если вы когда-либо ожидали DELETE из ссылочной таблицы (таблиц). Индексы не требуются для TRUNCATE .
Не создавайте индексы, которые вам не нужны. Каждый индекс имеет стоимость обслуживания. Попытайтесь использовать минимальный набор индексов и позволить сканирование растровых индексов сочетать их, а не поддерживать слишком много огромных, дорогостоящих многоколоночных индексов. Если требуются индексы, сначала попробуйте заполнить таблицу, а затем создайте индексы в конце.
аппаратные средства
Наличие достаточного количества оперативной памяти для хранения всей базы данных – это огромная победа, если вы можете управлять ею.
Если у вас недостаточно ОЗУ, тем быстрее вы сможете получить лучшее хранилище. Даже дешевый SSD делает огромную разницу в ржавчине. Не доверяйте дешевым SSD для производства, хотя они часто не являются аварийными и могут съесть ваши данные.
Обучение
Книга Грега Смита, PostgreSQL 9.0 Высокая производительность остается актуальной, несмотря на несколько более старую версию. Это должно быть полезной ссылкой.
Присоединитесь к списку рассылки PostgreSQL и следуйте за ним.
Чтение:
- Настройка сервера PostgreSQL – Викитека PostgreSQL
- Количество подключений к базе данных – Wiki PostgreSQL
sql.fliplinux.com
Производительность запросов в PostgreSQL – шаг за шагом / Блог компании Конференции Олега Бунина (Онтико) / Хабр

Илья Космодемьянский ( hydrobiont )
Для начала сразу пару слов о том, о чем пойдет речь. Во-первых, что такое оптимизация запросов? Люди редко формулируют и, бывает так, что часто недооценивают понимание того, что они делают. Можно пытаться ускорить какой-то конкретный запрос, но это не обязательно будет оптимизацией. Мы немного на эту тему потеоретизируем, потом поговорим о том, с какого конца к этому вопросу подходить, когда начинать оптимизировать, как это делать, и как понять, что какой-то запрос или набор запросов никак нельзя оптимизировать – такие случаи тоже бывают, и тогда нужно просто переделывать. Как ни странно, я почти не буду приводить примеров того, как запросы оптимизировать, потому что даже 100 примеров не приблизят нас к разгадке.В качестве эпиграфа к докладу я хотел бы привести цитату из академика Крылова, который в свое время строил корабли, цитате этой уже более 100 лет, однако ничего не поменялось.

Основная проблема с базами данных (БД) в том, что: или в БД лежит что-то ненужное, или не лежит чего-то нужного, или же имеет место какой-то неправильный подход к ее эксплуатации. В принципе, мы можем поставить какой-то супер-пупер RAID-контроллер с огромным кэшем, супер-дорогие SSD диски, но если мы не будем включать голову, то результат будет плачевным.
Что значит «оптимизировать запросы»? Как правило, у вас такой задачи не возникает. Проблема обычно заключается в том, что «все плохо!». Мы пишем наш замечательный проект, все работает, все довольны, но в какой-то момент заказали чуть больше рекламы, пришло чуть больше пользователей, и все упало. Потому что, когда разрабатывают проект быстро, обычно используют «рельсы», «джанго» и т.п. и пишут «в лоб» – важно быстрее дать продукт. Это на самом деле правильно, т.к. никому не нужен идеально «вылизанный» проект, который не работает. Дальше нужно понять, что происходит. Эти медленные запросы, которые мы хотим оптимизировать, – это просто такой интерфейс, который выдает наружу, что вот это тормозит, но причина запросто может быть в чем-то другом. Может быть плохое «железо», может быть ненастроенная база, и в этот момент начинать с оптимизации запросов, в принципе, не стоит. Сначала надо посмотреть, что происходит с БД.
Бывают просто грубые ошибки в настройке БД и до того, как они будут исправлены, оптимизировать запросы бесполезно, потому что bottleneck в другом месте. Например, если речь о Postgres’е, у вас может быть отключен autovacuum. Почему-то люди это иногда делают (этого ни в коем случае делать нельзя!), но когда он отключен, у вас очень большая фрагментация таблицы. Легко может быть таблица на 100 тыс. записей размером с таблицу в 1 млрд. записей. Естественно, любые запросы к ней будут медленнее, чем вы ожидаете. Поэтому сначала нужно БД настроить, проверить, что все хорошо работает.
Еще одна частая ошибка, когда 1000 worker ‘ов Postgres’а работают, потому что очень много подключений от приложения, и нет никакого Connection Broker’а. Надо понимать, что если у вас 500 connection’ов, то у вас должно быть 500 ядер на сервере, на котором вы работаете. В противном случае эти connection’ы будут друг другу мешать и будут все время проводить в ожидании. Когда вы эти глупости исправили (их может быть довольно много, но основных – 5-10 штук – правильные настройки памяти, диска, autovacuum...), вы можете переходить к оптимизации запросов. И только тогда. Не надо пытаться оптимизировать то, что еще вы только делаете.
Каков алгоритм, т.е. как подходить к оптимизации запросов? Во-первых, надо проверить настройки, во-вторых, каким-то способом отобрать те запросы, которые вы будете оптимизировать (это важный момент!), и, собственно, оптимизировать их. После того, как вы самые медленные запросы «вылечили», они стали быстрее, у вас немедленно появляются новые медленные запросы, потому что старый топ уступил им место. В результате вы постепенно, шаг за шагом повторяя этот алгоритм, избавляетесь от медленных запросов. Все просто.

Очень важный момент – знать, какие запросы оптимизировать? Если вы будете оптимизировать все подряд, то есть шанс не угадать, какие из запросов являются самыми проблемными. Вы просто потратите много времени и с большой вероятностью не доберетесь до нужных задач. Поэтому запросы нужно оптимизировать по мере поступления проблем. Посмотрите, где работать перестало, стало медленно и плохо – вот этот кусок и оптимизируйте. Если у вас есть что-то, что редко используется, не надо этого трогать, не тратьте время.
По отобранному топу берутся запросы, и смотрится, что с ними можно сделать. Для этого, особенно в версии 9.4, правильный способ – использовать EXTENSION pg_stat_statements, который все это делает «на лету» в онлайне, и можно на все это посмотреть.
Давайте разберемся с этим детально.

По адресу внизу страницы – наши pg-utils, которые доступны в свободном доступе, можно скачать и воспользоваться. В папке лежит некая обвязка вокруг стандартного контриба pg_stat_statements, который позволяет генерить вот такие отчеты за сутки работы на БД, и мы можем посмотреть, что там происходило. Видим, соответственно, некий топ запросов, каким-то образом ранжированный.
Нам важно знать, что есть первая позиция, вторая (обычно их еще десяток), и мы видим, что по каким-то параметрам у нас некий запрос выходит на первое место – он занимает, например, 24% нагрузки базы. Это довольно много и это надо как-то оптимизировать. Вы смотрите на запрос и думаете: «А сколько он денег проекту приносит?». Если он приносит проекту очень много денег, то пусть даже половину нагрузки отъедает, а если он денег не приносит, а отъедает половину ресурсов – это плохо, с этим надо что-то сделать. Таким образом, вы смотрите на топ запросов за предыдущий день и размышляете, что с этим делать.
Хорошей практикой у нас считается, когда есть команда разработчиков, которая делает что-то на проекте, и раз в сутки по cron'у такой отчет приходит всем DBA, всем разработчикам, всем админам.
Что такое медленный запрос? Во-первых, это запрос, который имеется в топе (его надо оптимизировать каким-то образом в любом случае). Но чисто по времени – это всегда некий вопрос. Даже запрос, который будет работать доли миллисекунды, все равно может быть медленным. Например, если этих запросов очень много, и много мелких запросов в итоге подъедают очень большой процент ресурсов базы.
Таким образом, время запроса – вещь относительная, и тут нужно смотреть, насколько часто этот запрос работает. Если это отдача чего-то на Главной странице, и этот запрос занимает 1 секунду, надо понимать, что у вас будет эта секунда и еще плюс оверхед от всего того, что нужно, чтобы сформировать эту страницу. Это значит, что пользователь увидит результат гарантированно медленнее, чем через секунду, и для онлайнового высоконагруженного веба это неприемлемые результаты. Если же запрос у вас для какой-то аналитики гоняется ночью, присылается кому-то асинхронный отчет, то, вероятно, он может себе позволить работать медленно. То есть, всегда надо знать свои данные и всегда думать, сколько времени допустимо, чтобы этот запрос работал. Опять же важен характер нагрузки на базе. Например, у вас есть длинный тяжелый запрос, вы его гоняете в пиковое время, а это запрос для какой-то аналитики, для менеджеров и т.п.
Посмотрите на профиль нагрузки на базу. У вас есть pg_stat_statements, по нему вы можете увидеть, топ медленных запросов, например, с 2х до 4х часов дня, и в это время не гонять длинные аналитические запросы.
Не забываем о том, сколько этот вопрос приносит денег и имеет ли он право занимать много ресурсов БД. Если вы сделали прикольную фичу, которая не зарабатывает для проекта ничего, а этот запрос съедает 50% ресурсов, то значит, вы написали плохой запрос и вам нужно переделать эту идею и даже иногда объяснить менеджеру, почему эта технически очень сложная штука просто съедает ресурсы. Все говорят, мол, хочу, чтобы Золотая Рыбка была у меня на посылках, тем не менее, сервер – он железный, он имеет некие лимиты, и резиново растягивать его нельзя. Люди, которые делают облака, скажут вам, что можно, но я как зануда-админ, скажу, что нельзя.
Где, вообще, могут быть проблемы при исполнении одного конкретного запроса? Во-первых, это может быть передача данных от клиента, и это совершенно не так смешно, как кажется. Следующий слайд демонстрирует, где там может быть «зарыта собака»:

Кто писал на Ruby, использовал всякие хитрые ORM'ы, знает, что вот по этому запросу можно опознать Django. Это фирменный стиль, почерк радиста ни с чем не перепутаешь.
Как вы думаете, какой максимальной длины in-список я видел в своей жизни? Надо считать в гигабайтах! Если не смотреть на то, что делает ваш ORM, то легко может получить несколько гигабайт, и этот запрос никогда не исполнится. Это плохо и означает, что у вас совершенно неоптимальный доступ к данным. Этот запрос плох еще по многим причинам, но основная причина того, что он может быть такой длины, которая в Postgres никогда в жизни не пролезет.
Второй момент – это парсинг. Можно написать очень витиеватый запрос, который просто будет долго парситься. В новой версии Postgres’а, если я не ошибаюсь, будет в EXPLAIN ‘е время парсинга, и можно будет понять, сколько на это уходит времени. Сейчас можно просто сделать EXPLAIN и посмотреть таймингом, соответственно, сколько у нас ушло на исполнение запроса, а сколько – на парсинг.
Потом запрос нужно оптимизировать. И это далеко не такая простая задача, как кажется, потому что оптимизатор – это достаточно сложные алгоритмы. Вот, к примеру, вы хотите сделать Join двух таблиц. Он берет одну таблицу, выбирает метод доступа к нужным данным и при-Join'ивает к ней следующую. Если у вас еще один Join с еще одной таблицей, то сначала он с-Join'ит две, потом с ResultSet’ом с-Join'ит еще одну. Если вы написали запрос, в котором 512 Join'ов, дальше начинается очень интересная «петрушка» с оптимизацией этого всего.
Для перебора того, какой путь Join'ов будет оптимальным, потребуется в зависимости от количества Join'ов n! вариантов плана, среди которых будет вестись отбор. Поэтому, если у вас много Join'ов, то вы сразу понимаете, что сам процесс оптимизации может быть очень и очень длительным.
Далее может быть непосредственно исполнение. Если ваш запрос должен вернуть куда-то 10 Гб данных, сложно рассчитывать на то, что он будет работать миллисекунды. Никаким волшебством его не заставить. Поэтому, если вам нужно отдать много данных, то сразу имейте в виду, что волшебства не бывает. Оно бывает в мире NoSQL, а здесь его нет.
Ну и, возврат результатов. Опять же, если вы несколько гигабайт данных гоняете по сети, то будьте готовы к тому, что это будет медленно, потому что сеть имеет некие ограничения на то, сколько через нее можно пропустить. В таких случаях имеет смысл иногда подумать о том, нужны ли нам все эти результаты? Это очень частая проблема.
Самый главный слайд этой презентации:

Это EXPLAIN.
После того, как вы выделили топ запросов, вы как-то удостоверились, что эти запросы медленные, и хотите с ними что-то сделать, вам нужно прогнать EXPLAIN.
До этого этапа доходят многие, а дальше загвоздка. Люди жалуются: «Ну, мы посмотрели EXPLAIN, и что с ним дальше делать?». Вот это я сейчас вам и расскажу.
На слайде 2 EXPLAIN'а, немного разный синтаксис.
Можно вот так делать: explain (analyze on, buffers on), можно просто написать explain analyze, например.
Важно понимать, что EXPLAIN вам выведет просто план предполагаемый, какой он должен быть. Соответственно, если вы укажете еще и ANALYZE, то этот запрос будет реально исполнен, и будут показаны данные о том, как он был исполнен, т.е. не просто EXPLAIN, а еще какая-то трассировка, собственно говоря, что происходило.
Когда вы отобрали топ медленных запросов, правильно использовать EXPLAIN ANALYZE, потому что у вас может быть выбран неоптимальный план, может быть не собрана статистика и др.
Postgres – супер транзакционная штука, если у вас есть пишущий запрос, вы не хотите, чтобы эти результаты записались, пока вы что-то оптимизируете, говорите: «begin», запускаете запрос (но желательно смотреть, что, вообще, происходит – тяжелый запрос в пиковое время на боевую базу не всегда бывает хорошо), потом говорите «rallback», чтобы у вас эти данные не записались.
Здесь показываются некие цифры, часть которых принадлежит EXPLAIN'у, а часть – ANALYZE'у. Это важные цифры. В EXPLAIN'е есть условные «попугаи» под названием «cost». 1 cost в Postgres‘е по умолчанию – это время, которое затрачивается на извлечение одного блока размером 8 Кб при последовательном sequential scan'е. В принципе, эта величина зависит от машины, поэтому она условная, поэтому это удобно. Если у вас быстрые диски, это будет быстрее, если медленные – медленнее. Важно понимать, что cost=9.54 – это означает, что в 9.54 раза это будет медленнее, чем достать 1 блок размером 8 Кб.
При этом цифр две: первая означает, сколько пройдет времени до момента начала возврата первых результатов, а вторая – это сколько пройдет времени до того, как результат будет возвращен весь. Если вы извлекаете много данных, то первая цифра будет относительно маленькой, а вторая будет достаточно большой. Это актуальное время, сколько это на самом деле заняло. Если по каким-то причинам у вас cost очень маленький, а это время очень большое, значит у вас какие-то проблемы со сбором статистики, нужно проверить, включен ли autovacuum, потому что тот же самый демон autovacuum’а собирает еще и статистику для оптимизатора.
EXPLAIN – это такое дерево, есть нижние варианты, грубо говоря, как достать данные с диска – это скан табличек, скан индексов и т.д.; и более верхние варианты, когда на верх наслаивается какая-то агрегация, Join'ы и т.д. Когда вы смотрите на такой EXPLAIN, задача очень простая:
- понять, насколько быстро он работает, посмотреть на runtime, посмотреть, сколько там чего происходило;
- посмотреть, какой узел этого дерева самый дорогой. Если у вас на нижнем этапе сразу cost достаточно большой, actual time большой, то значит, вам этот кусок и надо оптимизировать. Например, если у вас сканируется таблица целиком, вам может там понадобится сделать индексы. Это то место, которое действительно нужно оптимизировать, на которое нужно смотреть.
Таким образом, вы смотрите на EXPLAIN и находите самые дорогие места. После того, как вы посмотрите на EXPLAIN с полгодика, вы научитесь эти места видеть невооруженным глазом и у вас уже будет в голове набор рецептов, что делать в каком случае. Мы пока не будем их рассматривать подробно.
Какими приемами можно пользоваться? Можно сделать индекс. Идея индекса в том, что это меньший массив данных, который удобно отсканировать, вместо того, чтобы сканировать большую таблицу. Поэтому все программисты любят индексы, любят создать индексы на все случаи жизни и считать, что это поможет. Это неправильно, потому что индекс не бесплатен. Индекс занимает место, при каждой записи в таблицу индекс перестраивается, балансируется, и это все не бесплатно.
Если у вас вся таблица увешана индексами, которые не используются, с большой вероятностью вы можете часть из них снести, и будет быстрее. Тем не менее, если в вашем запросе нужно, например, извлечь половину данных из таблицы, с большой вероятностью ваш индекс не будет использоваться, потому что по индексу имеет смысл спозиционироваться в какое-то достаточно точное место и эти данные достать. Если вам нужно большую «простыню», которая сопоставима по размерам с таблицей, sequential scan самой таблицы будет всегда быстрее, чем index scan, потому что вам будет нужно сначала сделать index scan, потом еще одну операцию – достать данные.
В большинстве случаев оптимизатор в таких вещах не ошибается. Если вы создали индекс и недоумеваете, почему он не используется, то может быть потому, что без индекса будет просто быстрее.
В Postgres’е есть такой параметр – сессионная переменная, enable index scan установить в off или, наоборот, sequential scan установить в off, и вы можете посмотреть – с индексом или без него будет быстрее/медленнее. Оптимизировать так запросы «в бою» я бы не советовал, это очень жесткий «костыль» и очень серьезное ограничение функционала для оптимизатора, но поэкспериментировать, посмотреть – это полезно. Вы сделали запрос, сделали для него индекс, считаете, что он будет работать, отключите sequential scan, оптимизатор будет вынужден выбрать план с индексом, и посмотрите, не получилось ли медленнее, чем то, что Postgres предложил вам сам. В большинстве случаев это именно так.
Далее важно, как написан запрос. Если у нас будет что-то вроде этого – (where counter + 1 = 46) – индекс браться не будет, автоматически Postgres эту операцию сделать не может. Казалось бы, простое сложение, но с тем же успехом можно предложить оптимизатору еще и дифуры порешать. В Postgres’е большое количество типов данных, на них можно определять любые операторы, любые действия, например, алгебраические или др., и оптимизатор должен для всех этих типов знать, как это действие выполнять, а для него это слишком тяжелая задача, это никогда не будет работать.
Следующее – почему, например, Join работает плохо? Это один из важных узлов, его все используют.
Join'ы бывают разных типов, и я говорю не о LEFT, RIGHT, INNER и т.д., а об алгоритмах, как Join'ы выполняются. Postgres имеет три основных алгоритма Join'а, а именно – Nested Loop (название говорит само за себя – мы берем данные из одной таблицы и циклами их Join'им), Hash index (когда одна, чаще маленькая, таблица хэшируется и по этому хэшу Join'ится с другой таблицей) и Merge Join (который тоже очевидно, как работает).
Эти Join'ы не всегда одинаково полезны, оптимизатор может выбрать между ними. Например, у вас Join'ятся две таблицы, оптимизатор выбирает Hash Join, и вы понимаете, что он работает медленно, вас это не устраивает. Имеет смысл посмотреть, а индексированы ли у вас те поля, по которым вы Join'ите? Если у вас эти поля не индексированы, оптимизатор может не выбрать Nested Loop, который здесь очевидно выгоднее. Если вы создадите индекс, оптимизатор выберет Nested Loop, и все будет работать быстро.
Следующий момент – у вас оптимизатор из каких-то соображений выбирает Nested Loop, а вам кажется, что одна таблица очень маленькая, другая – очень большая и Hash Join там был бы очень уместен, потому что маленькую таблицу можно быстро прохэшировать и быстро с ней работать. Посмотрите, сколько у вас work mem'а. т.е. сколько памяти может занять один worker Postgres’а. Если эта таблица хэшируется в, например, 100 Мб, а у вас work mem'а выдано только 30 Мб, то worker будет работать медленно. Если вы добавите work mem'а и хэширование начнет вмещаться в память, оптимизатор выберет правильный Hash Join и будет быстро и хорошо.
Вот такое вот поле для экспериментов, тут надо думать и не стесняться проверять, пробовать и смотреть, что происходит.
Поскольку оптимизировать запросы нужно только «на бою» (потому что на тесте вы никогда не воспроизведете workload настолько же точно), то делать это надо с известной осторожностью.
Пример такой оптимизации:

Я уже показывал этот запрос и очень ругался на него. Одна из причин для такой ругани состоит в том, что, все-таки Postgres не совершенен, он – развивающаяся система, есть в нем какие-то недостатки (сообществу очень нужны разработчики оптимизатора, если вы хотите подконтрибьютить Postgres’у, то можете в эту сторону посмотреть, такие усилия всегда будут очень приветствоваться, потому что есть недоделки). Вот и случай такого длинного массива в WHERE очень распространенный, потому что многие ORM’ы это делают. По идее, Postgres должен как-то хэшировать этот массив и соответственно осуществлять в нем поиск. Вместо этого он его перебирает и получается достаточно противно, время растет очень существенно, и начинаются проблемы.
Посмотрим на EXPLAIN этого дела:

Мы видим, что фильтр без хэша работает плохо, несмотря на то, что имеется Index Scan для того, чтобы что-то сделать и выбрать на массиве, мы заседаем, а он работает максимально плохим образом и все тормозит.
В этой ситуации запрос необходимо переписать, включив воображение. Я уже говорил, что Postgres умеет Hash Join, но не умеет делать хэширование массива. Давайте сконвертируем эту «простыню» таким образом, чтобы результат можно было с-Join'ить. В итоге получится то же самое, только оптимизатор выберет более разумный план.
Можно использовать такую конструкцию VALUES, которая нам все это превратит в ResultSet:

В этой ситуации на самом деле будет Index Scan и Hash Join. Будет произведено хэширование, и запрос довольно существенно ускорится.
Если мы возьмем те же самые запросы, то уже переписанная нормальным образом, она будет так же работать на коротких запросах, но, что самое главное, она будет не хуже работать на больших и длинных списках:

И это достаточно легко переделать.
Это был простой пример того, как, посмотрев на EXPLAIN, можно существенно улучшить производительность тормозного запроса. Это т запрос уйдет из топа, придет новый, его тоже можно будет оптимизировать.
Есть еще одна очень существенная проблема – бывают такие запросы, с которыми нельзя ничего сделать. И первейший из этих запросов –count(*).
Например, есть интернет-сайт, у него – Главная страница, она высоконагруженная, на ней отображаются счетчики. Какую информацию пользователю несет число на счетчике, если это count из таблицы, которая часто обновляется? Число означает, что на тот момент, когда пользователь послал свой запрос, цифра была такая. Обычно пользователю не важно знать эту цифру с высокой точностью, достаточно более-менее приближенно, а чаще, вообще, хватает знания о том, растет число или нет. Если это какой-то финансовый баланс, то можно это делать, но обычно это делается очень редко и не выводится на Главную страницу сайта, чтобы при каждом обращении count гонялся по таблице.
count – он всегда медленный, потому что Postgres, чтобы посчитать количество записей в таблице, всегда сканирует ее целиком и проверяет, актуальна ли эта версия данных или ее уже обновили.
Первый вариант решения этой проблемы – не использовать count'ы. Полезность его сомнительна, а ресурсов он занимает много. Второй момент – можно использовать приближенный count. Есть PG-каталог, из него можно по-select’ить, сколько строк в таблице было на момент последнего analyze'а, когда был произведен последний сбор статистики. Эта приблизительная цифра будет меняться достаточно часто, но при этом запрос по PG-каталогу не стоит практически ничего – это select одного value по условию названия таблицы. Если вы не хотите пускать интернет-юзера базы в PG-каталог, вам ничто не мешает написать хранимую процедуру, сказать ей «security definer» и дать права только на эту процедуру, и интернет-пользователь будет спокойно доставать эти данные без всяких проблем с security.
Следующий запрос-проблема – Join на 300 таблиц. Проблема состоит в том, что будет 300! вариантов, как этот Join сделать. Более того, если вам понадобилось написать Join на 300 таблиц, это значит, что у вас очень плохо с дизайном схемы, что-то очень не продумано, и надо много чего переделывать. В норме Join – это на две, на три таблицы. Иногда на пять, изредка на десять, но это крайние случаи. Когда Join'ов сотни, любой БД станет плохо.
Еще одна проблема – когда клиенту возвращается 1 000 000 строк. Кто долистывал до последней страницы в Google? Часто это бывает? Если вы видите, что онлайновый запрос, результат которого отображается на сайте, по каким-то причинам возвращает 1 млн. строк, задумайтесь – нет ли какой-то ошибки? Может понадобиться 10, 20 строк, может быть, 100, но 1 млн. строк человек не читает. Если у вас столько строк возвращается, это значит, что у вас либо какая-то выгрузка данных, которую можно сделать ночью, можно сделать с помощью дампа, можно еще каким-то способом, либо у вас просто неправильно написан запрос.
Например, вы сгенерили ORM'ом запрос для какай-то листалки, дальше, соответственно, вытаскиваете этот огромный массив, а используете из него реально только 10%. В этой ситуации вам нужно использовать limit и offset и каким-то другим способом определенным окном идти по этим данным и не тянуть их все на клиент, потому что 1 млн. строк – это всегда медленно, и, как правило, это не осмысленно и содержит какую-то логическую ошибку.
Контакты
hydrobiontЭтот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++.Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая HighLoad++ Junior.
habr.com
Тюнинг базы Postgres
Базы данных, как Вы возможно заметили, не ограничиваются на MySQL. Есть и другие! Кто-то выбирает для своих продуктов Postgres, и я этот выбор, в большинстве случаев, поддерживаю и считаю разумным. Для высоконагруженных систем Postgres имеет ряд преимуществ перед конкурентами, но об этом в другой раз.
И так, Вы поставили postgres, у Вас есть приложение (возможно в планах) с определенными требованиями к количеству/размеру таблиц, отношению записи/чтения и т.д. Стандартные настройки, как всегда подходят только для стандартных проектов, а стандартных проектов нет. Поэтому сервер придется настраивать под Ваши требования для обеспечения его оптимальной работы.
Для начала несколько слов о настройках Postgres. Конфигурационный файл обычно лежит по адресу:
/etc/postgresql/8.3/main/postgresql.confЕстественно это пример для версии 8.3. Любые конфигурационные параметры принадлежат к различным уровням, список которых приведен ниже:
- Postmaster — требует перезапуска сервера
- Sighup — требует только сигнала HUP (работающий сервер перезагрузит конфигурационный файл без прекращения работы)
- User — значение может быть установлено в рамках сессии и актуально только внутри этой сессии
- Internal — устанавливает только во время компиляции, т.о. не изменяемо! (Только для справки)
- Backend — значение должно быть установлено до начала сессии
- Superuser — может быть изменено во время работы сервера, но только из под пользователя с правами superuser
Первый пункт выделен, т.к. Вы практически всегда будете сталкиваться именно с такими параметрами.
На что стоит обратить внимание в настройках, и какие значения стоит поменять:
listen_addresses
По умолчанию Postgres принимает соединения только с локальных служб, т.к. слушает интерфейс localhost. Если Вы планируете сетевую подсистему, состоящую из более, чем одного компьютера (Ваш сервер баз данных будет находится на отдельном компьютере), Вам потребуется поменять этот параметр:
listen_addresses = '*'Теперь postgres сможет принимать соединения от удаленных служб по протоколу TCP.
max_connections
Этот параметр определяет максимальное количество одновременных соединений, которые будет обслуживать сервер. В принципе, это число должно определяться исходя из требований к системе. Этот параметр в большей степени влияет на использование ресурсов. Если Вы только стартуете, устанавливайте это значение небольшим (16...32), постепенно увеличивая его (по мере необходимости — такой мерой будет получение ошибок от postgres "too many clients").
Учтите! На поддержку каждого активного клиента, postgres тратит немалое количество ресурсов, и если Вам необходимо добиться производительности в несколько тысяч активных соединений, то стоит использовать менеджеры соединений, например: Pgpool.
shared_buffers
Этот параметр определяет, сколько памяти будет выделяться postgres для кеширования данных. В стандартной поставке значение этого параметра мизерное — для обеспечения совместимости. В практических условиях это значение следует установить в 15..25% от всей доступной оперативной памяти.
effective_cache_size
Этот параметр помогает планировщику postgres определить количество доступной памяти для дискового кеширования. На основе того, доступна память или нет, планировщик будет делать выбор между использованием индексов и использованием сканирования таблицы. Это значение следует устанавливать в 50%...75% всей доступной оперативной памяти, в зависимости от того, сколько памяти доступно для системного кеша. Еще раз — этот параметр не влияет на выделяемые ресурсы — это оценочная информация для планировщика.
checkpoint_segments
На эту настройку стоит обратить внимание, если у Вас происходит немалое количество записей в БД (для высоконагруженных систем это нормальная ситуация). Postgres записывает данные в базу данных порциями (WALL сегменты) — каждая размером в 16Mb. После записи определенного количества таких порций (определяется параметром checkpoint_segments) происходит чекпойнт. Чекпойнт — это набор операций, которые выполняет postgres для гарантии того, что все изменения были записаны в файлы данных (следовательно при сбое, восстановление происходит по последнему чекпойнту). Выполнение чекпоинтов каждые 16Мб может быть весьма ресурсоемким, поэтому это значение следует увеличить хотя бы до 10.
Для случаев с большим количеством записей, стоит увеличивать это значение в рамках от 32 до 256.
work_mem
Важный параметр для запросов, использующих всевозможные сложные выборки и сортировки. Увеличение его позволяет выполнять эти операции в оперативной памяти, что гораздо более эффективно, чем на диске (еще бы). Будьте внимательны! Этот параметр указывает, сколько памяти выделять на каждую подобную операцию! Следовательно, если у Вас 10 активных клиентов и каждый выполняет 1 сложный запрос, то значение в 10Мб для этого параметра скушает 100Мб оперативной памяти. Этот параметр стоит увеличивать, если у Вас большое количество памяти в распоряжении. Для старта следует выставить его в 1Мб.
maintainance_work_mem
Этот параметр определяет количество памяти для различных статистических и управляющих процессов (например вакуумизация). Разработчики рекомендуют выделять 128...256Мб под эти нужды.
wal_buffers
Этот параметр стоит увеличивать в системах с большим количеством записей. Значение в 1Мб рекомендуют разработчики postgres даже для очень больших систем.
synchronous_commit
Обратите особое внимание на этот параметр! Он включает/выключает синхронную запись в лог файлы после каждой транзакции. Это защищает от возможной потери данных. Но это накладывает ограничение на пропускную способность сервера.
Допустим, в Вашей системе не критична потенциально низкая возможность потери небольшого количества изменений при крахе системы. Но жизненно важно обеспечить в несколько раз большую производительность по количеству транзакций в секунду. В этом случае устанавливайте этот параметр в off (отключение синхронной записи).
Самое важное
Производительность Postgres можно значительно поднять, настроим несколько параметров. Убедитесь, что база данных подстроена под конфигурацию Вашего железа.
ruhighload.com
Оптимизация PostgreSQL. Autovacuum – сборка мусора
Таблицы в PostgreSQL представлены в виде страниц, размером 8 КБ, в которых размещены записи. Когда одна страница полностью заполняется записями, к таблице добавляется новая страница. При удалалении записей с помощью DELETE или изменении с помощью UPDATE, место где были старые записи не может быть повторно использовано сразу же.
PostgreSQL как типичный представитель “версионных” СУБД (в противоположность блокирующим) самостоятельно не блокирует при изменении данных таблицы и записи от читающих транзакций (в случае 1С этим занимается сам сервер 1С). Вместо этого создаётся копия изменяемой записи, которая становится видна последующим транзакциям, действующие же продолжают видеть данные, актуальные на начало своей транзакции. А при удалении запись помечается как удаленная, но продолжает занимать физическое пространство.
Как следствие, в таблицах накапливаются устаревшие данные – предыдущие версии измененных записей и удаленные записи. Для того чтобы СУБД могла высвободившееся место использовать, необходимо произвести “сборку мусора” – определить какие из записей больше не используются. Это можно сделать явно SQL-командой VACUUM, либо дождаться когда таблицу обработает автоматический сборщик мусора – AUTOVACUUM. Так же до определенной версии сборка мусора была связана со сбором статистики (планировщик использует данные о количестве записей в таблицах и распределении значений индексированных полей для построения оптимального плана запроса).
Процесс очистки autovacuum, или команда VACUUM, пробегает по изменённым страницам и помечает такое место как свободное, после чего новые записи могут спокойно записываться в это место, то-есть размер файла таблицы физически не уменьшается.
Чтобы максимально уменьшить таблицу в PostgreSQL есть VACUUM FULL или CLUSTER, но оба эти способа требуют exclusively locks на таблицу (блокируют доступ к таблице на время работы, то есть в это время с таблицы нельзя ни читать, ни писать), что далеко не всегда является подходящим решением.
В принципе процедура очистки, autovacuum или VACUUM, все же может сама уменьшить размер таблицы убрав полностью пустые страницы, но только при условии что они находятся в самом конце таблицы.
Сборку мусора безусловно делать необходимо, чтобы таблицы не разрастались и эффективно использовали дисковое пространство, но внезапно начавшаяся уборка мусора дает дополнительную нагрузку на диск и таблицы, что приводит к увеличению времени выполнения запросов.
Есть здесь и свои нюансы – если autovacuum не справляется, например в результате активного изменения большего количества данных или просто из-за плохих настроек, то к таблице будут излишне добавляться новые страницы по мере поступления новых записей. Получается что таблица становится более разряженной в плане плотности записей. Это называется эффектом раздувания таблиц (table bloat).
Полностью отключить autovacuum можно параметром:
autovacuum = off
Так же для работы Autovacuum требуется параметр track_counts = on, в противном случае он работать не будет.
По умолчанию оба параметра включены. На самом деле autovacuum полностью отключить нельзя – даже при autovacuum = off иногда (после большого количества транзакций) autovacuum будет запускаться.
Отключать autovacuum крайне не рекомендуется, иначе имеет смысл самостоятельно запланировать регулярное выполнение команды VACUUM ANALYZE.
Если Autovacuum полностью не отключать, настроить его влияние на выполнение запросов можно следующими параметрами:
autovacuum_max_workers – максимальное количество параллельно запущенных процессов уборки.
autovacuum_naptime – минимальный интервал, реже которого autovacuum не будет запускаться. По умолчанию 1 минута. Можно увеличить, тогда при частых изменениях данных анализ будет выполняться реже.
autovacuum_vacuum_threshold, autovacuum_analyze_threshold – количество измененных или удаленных записей в таблице, необходимых для запуска процесса сборки мусора VACUUM или сбора статистики ANALYZE. По умолчанию по 50.
autovacuum_vacuum_scale_factor, autovacuum_analyze_scale_factor – коэфициент от размера таблицы в записях, добавляемый к autovacuum_vacuum_threshold и autovacuum_analyze_threshold соответственно. Значения по умолчанию 0.2 (т.е. 20% от количества записей) и 0.1 (10%) соответственно.
default_statistics_target – назначает объем статистики, собираемый командой ANALYZE. Значение по умолчанию 100. Большие значения увеличивают время выполнения команды ANALYZE, но позволяют планировщику строить более эффективные планы выполнения запросов. Встречаются рекомендации по увеличению до 300.
Можно управлять производительностью AUTOVACUUM, делая его более длительным но менее нагружающим систему.
vacuum_cost_page_hit – размер “штрафа” за обработку блока, находящегося в shared_buffers. Связан с необходимостью блокировать доступ к буферу. Значение по умолчанию 1
vacuum_cost_page_miss – размер “штрафа” за обработку блока на диске. Связан с блокировкой буфера, поиском данных в буфере, чтении данных с диска. Значение по умолчанию 10
vacuum_cost_page_dirty – размер “штрафа” за модификацию блока. Связан с необходимостью сбросить модифицированные данные на диск. Значение по умолчанию 20
vacuum_cost_limit – максимальный размер “штрафов”, после которых процесс сборки может быть “заморожен” на время vacuum_cost_delay. По умолчанию 200
vacuum_cost_delay – время “заморозки” процесса сборки мусора по достижению vacuum_cost_limit. Значение по умолчанию 0ms
autovacuum_vacuum_cost_delay – время “заморозки” процесса сборки мусора для autovacuum. По умолчанию 20ms. Если установить -1, будет использоваться значение vacuum_cost_delay
autovacuum_vacuum_cost_limit – максимальный размер “штрафа” для autovacuum. Значение по умолчанию -1 – используется значение vacuum_cost_limit
По публикациям использование vacuum_cost_page_hit = 6, vacuum_cost_limit = 100, autovacuum_vacuum_cost_delay = 200ms уменьшает влияние AUTOVACUUM до 80%, но увеличивает время его выполнения втрое.
www.oslogic.ru
Ускорение работы 1С с postgresql и диагностика проблем производительности
Некоторое время назад я настраивал работу 1С предприятия с базой данных postgresql. Во время тестирования столкнулся с проблемой медленной работы некоторых запросов. Хочу поделиться полезной информацией, которая позволит разобраться в таких ситуациях и попытаться ускорить работу и избавиться от узких мест в базе.
Введение
Сервер postgresql настроен по предыдущей статье — Установка и настройка postgresql на debian 8 для работы с 1С. Основные моменты по ускорению работы базы там приведены. Они существенно увеличивают производительность по сравнению с настройками по-умолчанию. В большинстве случаев этого бывает достаточно. Если нет — то у вас уже не типичный случай и надо разбираться более детально.
Проблема, с которой столкнулся я, кроется в особенности работы postgresql и отсутствии оптимизации 1С для работы с этой бд. База данных postgresql, в отличие от mssql, не умеет распараллеливать выполнение одного запроса не несколько ядер процессора. Даже если у вас очень высокопроизводительный сервер с большим числом ядер, вы можете попасть в ситуацию, когда какой-то тяжелый запрос будет очень сильно тормозить, нагружая только одно ядро. Остальные мощности процессора будут простаивать при этом. Увеличение ресурсов сервера никак не поможет вам ускорить работу базы. Она будет всегда спотыкаться на этом запросе.
Параллельное выполнение запросов на нескольких ядрах в postgresql
Я использовал версию postgresql 9.6. Если верить новости — http://www.opennet.ru/opennews/art.shtml?num=43313 в ней добавлена поддержка распараллеливания запросов. Я стал пробовать на практике это распараллеливание. Информации в интернете, к моему сожалению, не так много. Вроде проблема популярная, много где видел вопросов на эту тему. Например, вот тут обсуждают тему использования нескольких ядер процессора для выполнения запроса — http://www.sql.ru/forum/1002408/zadeystvovanie-neskolkih-processorov.
Наиболее популярные рекомендации, это изменить запросы и логику работы приложения с БД, чтобы не попадать в ситуацию, когда возникает один большой запрос, который невозможно разбить и обработать параллельно на нескольких ядрах. Пример такого подхода есть на хабре — https://habrahabr.ru/post/76309/. У меня нет ни должных знаний sql, ни тем более 1С, чтобы на уровне приложения что-то менять. Стал разбираться с возможностями postgresql.
Есть несколько параметров, которые как раз отвечают за параллельную обработку запросов:
max_worker_processes = 16 max_parallel_workers_per_gather = 8 min_parallel_relation_size = 0 parallel_tuple_cost = 0.05 parallel_setup_cost = 1000Их необходимо подбирать под свое количество ядер. В данном случае настройки представлены для 16-ти ядерной системы. Далее необходимо применить скрипт на базе 1С, который позволит оптимизатору постгреса использовать параллельную обработку тех запросов 1С где участвуют текстовые поля (большинство запросов), путём изменения определений функций. Текст скрипта очень длинный, поэтому не привожу его здесь, чтобы не нагружать статью. Качаем его с сайта — postgre.sql.
Запрос необходимо выполнить в базе, которую использует 1С. Для этого можно воспользоваться либо программой pgAdmin, либо напрямую подключиться к базе, через консоль сервера. Опишу второй вариант в подробностях.
Подключаемся к серверу с postgresql по ssh. Заходим под юзером postgres:
# su postgresПереходим в домашний каталог пользователя:
# cdСоздаем файл с запросом, который будем выполнять. В данном случае можете сразу скопировать файл, который скачали ранее, либо создайте вручную и скопируйте в него текст запроса.
# touch postgre.sqlЕсли будете копировать готовый файл, убедитесь, что у пользователя postgres есть доступ к этому файлу.
Подключаемся к серверу бд:
# psql -U postgresПодключаемся к нужной базе данных:
\connect base1cВыполняем sql запрос из файла:
\i postgre.sqlВсе, можно идти проверять. Мы должны были увеличить быстродействие 1С запросов в базе postgresql, разрешив использовать параллельную обработку некоторых запросов. В моем случае это не дало никакого прироста по проблемным запросам. Сама база в целом работала нормально, но спотыкалась на определенных запросах. Разбираемся дальше.
Логирование sql запросов в postgresql
Для того, чтобы разобраться, что же конкретно у нас тормозит, надо посмотреть на сами запросы. Для этого нам нужно включить логирование запросов к базе данных. Запросов будет очень много, нам не нужны все подряд. Сделаем ограничение на логирование только тех запросов, которые выполняются дольше, чем 3 секунды. Для этого рисуем следующие параметры в конфиге БД:
log_destination = 'syslog' syslog_facility = 'LOCAL0' syslog_ident = 'postgres' log_min_duration_statement = 3000 # 3000 мс = 3 секунды log_duration = off log_statement = 'none'И добавляем описание канала для логов LOCAL0 в конфиг rsyslog в файле /etc/rsyslog.conf, в самый конец:
LOCAL0.* -/var/log/postgresql/sql.logЕсли оставить настройки rsyslog в таком виде, то лог запросов будет писаться не только в файл /var/log/postgresql/sql.log, но и в messages, и в syslog. Я не люблю спамить в системные логи, поэтому отключим запись sql логов туда. Добавляем в описание этих лог файлов значение LOCAL0.none. Должно получиться примерно так:
*.*;auth,authpriv.none;LOCAL0.none -/var/log/syslog *.=info;*.=notice;*.=warn;\ auth,authpriv.none;\ cron,daemon.none;\ mail,news.none;\ LOCAL0.none -/var/log/messagesПерезапускаем postgresql и rsyslog:
# systemctl restart postgresql # systemctl restart rsyslogИдем в базу 1С и вызываем свой запрос, который тормозит. Если его выполнение занимает больше, чем 3 секунды, вы увидите текст запроса в лог файле. Можете подольше попользоваться базой, чтобы собрать список запросов для анализа. Запросы 1С настолько громоздкие, что даже просто скопировать их из лога и обработать непростая задача. Воспользуемся для этого специальной программой.
Включение логирования запросов замедляет работу системы. Я рекомендую заниматься диагностикой либо в нерабочее время, либо на тестовой базе и сервере, если есть такая возможность. Для применения настроек базы данных, необходимо перезапускать ее. Это может доставить проблем, если с другими базами сервера кто-то работает. Примите это к сведению.
Анализ запросов postgresql с помощью pgFouine
Устанавливаем pgFouine в debian:
# apt-get install pgfouineЭто старая программа, но для наших целей сойдет. Пользоваться ей очень просто. Я не вдавался в подробности настройки и не смотрел возможные параметры. Мне было достаточно сделать вот так:
# pgfouine -file /var/log/postgresql/sql.log > /root/report.htmlЗабираем файл report.html к себе на компьютер и открываем в браузере. У меня получилось примерно так:
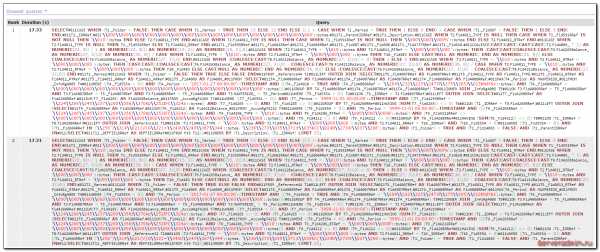
Запрос впечатляет 🙂 Не удивительно, что он тормозит! Сказать, что я был удивлен, это ничего не сказать. Глядя на эти запросы, я понимал, что никакой оптимизации в 1С для работы с postgresql нет. Хотя я очень плохо разбираюсь в sql, знаком поверхностно с синтаксисом, и сам составлял только очень простые запросы. Но даже я вижу, что проблема тормозов в том, что этот запрос просто безобразно огромный. Парсер запроса нахватал в код мусорных символов. В моем случае это символы #011, они присутствую в логе sql.log. Я не знаю, откуда они там берутся, но чтобы получить чистый запрос, их надо убрать. Я скопировал текст запроса в текстовый редактор и сделал замену символов #011 на пробел. В итоге получился синтаксически корректный запрос. В моем случае он выглядит таким образом:
SELECT CASE WHEN (T1._Folder = FALSE) THEN CASE WHEN T1._Marked = TRUE THEN 13 ELSE 12 END ELSE ((-1 + CASE WHEN T1._Marked = TRUE THEN 1 ELSE 0 END) + CASE WHEN (T1._Fld607 = FALSE) THEN 1 ELSE 3 END) END, T1._IDRRef, '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea, T1._ParentIDRRef, T1._Description, CASE WHEN T2.Fld4011_TYPE IS NULL THEN CASE WHEN T1._Fld591RRef IS NOT NULL THEN '\\010'::bytea END ELSE T2.Fld4011_TYPE END, CASE WHEN T2.Fld4011_TYPE IS NULL THEN CASE WHEN T1._Fld591RRef IS NOT NULL THEN '\\000\\000\\000%'::bytea END ELSE T2.Fld4011_RTRef END, CASE WHEN T2.Fld4011_TYPE IS NULL THEN T1._Fld591RRef ELSE T2.Fld4011_RRRef END, T1._Fld595RRef, T1._Fld601RRef, T1._Fld606RRef, T1._Fld607, T1._Fld608, T1._Fld4737RRef, T1._Fld610, COALESCE(CAST(CAST((CAST(CAST((T2.Fld4009_ * 1) AS NUMERIC(22, 8)) / 1 AS NUMERIC(22, 8))) AS NUMERIC(15, 2)) AS NUMERIC(15, 2)),0), CASE WHEN (T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea) THEN (CAST(CAST(COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) AS NUMERIC(35, 8)) / CASE WHEN T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea THEN T10._Fld483 ELSE CAST(NULL AS NUMERIC) END AS NUMERIC(35, 8))) ELSE COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) END, CASE WHEN (COALESCE(CAST(T8.Fld4212Balance_ AS NUMERIC(27, 3)),0) = 0) THEN 1 ELSE 0 END, CASE WHEN (T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea) THEN (CAST(CAST((COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) - COALESCE(CAST(T8.Fld4212Balance_ AS NUMERIC(27, 3)),0)) AS NUMERIC(36, 8)) / CASE WHEN T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea THEN T10._Fld483 ELSE CAST(NULL AS NUMERIC) END AS NUMERIC(36, 8))) ELSE (COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) - COALESCE(CAST(T8.Fld4212Balance_ AS NUMERIC(27, 3)),0)) END, T1._Marked, CASE WHEN (T1._Folder = FALSE) THEN TRUE ELSE FALSE END FROM _Reference44 T1 LEFT OUTER JOIN (SELECT T5._Fld4007RRef AS Fld4007RRef, T5._Fld4011_TYPE AS Fld4011_TYPE, T5._Fld4011_RTRef AS Fld4011_RTRef, T5._Fld4011_RRRef AS Fld4011_RRRef, T5._Fld4009 AS Fld4009_ FROM (SELECT T4._Fld4006RRef AS Fld4006RRef, T4._Fld4007RRef AS Fld4007RRef, T4._Fld4008RRef AS Fld4008RRef, MAX(T4._Period) AS MAXPERIOD_ FROM _InfoRg4005 T4 WHERE ((T4._Fld5554 = 0)) AND (T4._Period <= '2017-01-27 00:00:00'::TIMESTAMP AND (((T4._Fld4010 = TRUE AND (T4._Fld4006RRef = '\\204\\232\\225\\2473l\\375\\305J\\023bNdY&s'::bytea)) AND (T4._Fld4008RRef = '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea)))) GROUP BY T4._Fld4006RRef, T4._Fld4007RRef, T4._Fld4008RRef) T3 INNER JOIN _InfoRg4005 T5 ON T3.Fld4006RRef = T5._Fld4006RRef AND T3.Fld4007RRef = T5._Fld4007RRef AND T3.Fld4008RRef = T5._Fld4008RRef AND T3.MAXPERIOD_ = T5._Period WHERE (T5._Fld5554 = 0)) T2 ON (T1._IDRRef = T2.Fld4007RRef) LEFT OUTER JOIN (SELECT T7._Fld4260RRef AS Fld4260RRef, SUM(T7._Fld4265) AS Fld4265Balance_ FROM _AccumRgT4266 T7 WHERE ((T7._Fld5554 = 0)) AND (T7._Period = '3999-11-01 00:00:00'::TIMESTAMP AND ((T7._Fld4259RRef = '\\224\\206\\245\\237\\200\\356j\\370Kp\\252IFC\\324a'::bytea)) AND (T7._Fld4265 <> 0) AND (T7._Fld4265 <> 0)) GROUP BY T7._Fld4260RRef HAVING (SUM(T7._Fld4265)) <> 0) T6 ON (T1._IDRRef = T6.Fld4260RRef) LEFT OUTER JOIN (SELECT T9._Fld4208RRef AS Fld4208RRef, SUM(T9._Fld4212) AS Fld4212Balance_ FROM _AccumRgT4232 T9 WHERE ((T9._Fld5554 = 0)) AND (T9._Period = '3999-11-01 00:00:00'::TIMESTAMP AND ((((T9._Fld4205RRef = '\\224\\206\\245\\237\\200\\356j\\370Kp\\252IFC\\324a'::bytea) AND (T9._Fld4206_TYPE = '\\010'::bytea AND T9._Fld4206_RTRef = '\\000\\000\\000B'::bytea)) AND (T9._Fld4211RRef <> '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea))) AND (T9._Fld4212 <> 0) AND (T9._Fld4212 <> 0)) GROUP BY T9._Fld4208RRef HAVING (SUM(T9._Fld4212)) <> 0) T8 ON (T1._IDRRef = T8.Fld4208RRef) LEFT OUTER JOIN _Reference32 T10 ON (T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea AND T2.Fld4011_RRRef = T10._IDRRef) AND (T10._Fld5554 = 0) WHERE ((T1._Fld5554 = 0)) AND ((T1._Fld604RRef IN ('\\256")\\314\\021{V}G\\321=\\343U\\243\\367\\344'::bytea, '\\236\\273\\035\\371;t\\035kC{\\024b\\273W\\037\\206'::bytea)) AND (T1._Folder) = TRUE AND (T1._Fld14883 = FALSE) AND (T1._ParentIDRRef IN (SELECT T11._REFFIELDRRef AS REFFIELDRRef FROM tt9 T11))) ORDER BY (T1._Description), (T1._IDRRef) LIMIT 25;Дальше вы можете разбираться со своими запросами, в зависимости от ваших знаний и возможностей. Я не знал, что делать дальше, для решения своей проблемы. Попытался построить карту запроса с помощью EXPLAIN ANALYZE, но не получилось. Запрос использует какие-то временные таблицы, так что просто скопировать и повторить его не получалось. Выходила ошибка, что какой-то таблицы не существует.
В настоящий момент я получил совет на профильном форуме по моей проблеме. Мне сказали, что ситуация известная и достаточно типичная для 1С. Исправлять ее нужно на стороне самой 1С, изменяя код запроса выборки из виртуальных таблиц на запросы из временных таблиц, соединяя их потом с основной. Это уже задача для программиста. Я в самой 1С не разбираюсь вообще.
Заключение
На текущий момент моя проблема не решена, но стало понятно, в каком направлении двигаться и что делать. В принципе, я изначально, когда стал заниматься этой задачей, предполагал, что проблема именно на стороне 1С из-за сложного запроса и отсутствии оптимизации работы 1С именно с postgresql. Я это понял, потому что с mssql таких тормозов никогда наблюдал на базах такого размера. В данном случае объем базы всего 10 гб, она не очень большая. 15 секунд лопатить запрос на такой базе можно только, если этот запрос ужасен. На деле все так и оказалось.
В процессе разбора ситуации приобрел определенный опыт, который постарался зафиксировать в этой статье. Думаю, он пригодится в будущем, как мне, так и другим пользователям. В интернете не нашел хороших статей по анализу производительности постгрес. Пришлось все собирать по крохам в разных статьях, но больше на форумах. С учетом стоимости лицензии mssql, замена ее на postgresql выглядит весьма обоснованной, так что тема актуальна.
Буду рад любым замечаниям и советам в комментариях. Тема для меня новая, но полезная. Хотелось бы разобраться в работе постгрес.
Помогла статья? Есть возможность отблагодарить автора
serveradmin.ru
Автоматическая оптимизация настроек MySQL, PostgreSQL / Блог компании Southbridge / Хабр
Оптимизация настроек всегда дело тонкое и выставить именно те параметры, которые дадут максимальную производительность, зачастую можно только уже в процессе работы приложения, когда уже есть статистика нагрузки и видны узкие места. Но очень полезно сделать и первичную оптимизацию при запуске СУБД. В этом посте рассмотрены пути автоматической оптимизации MySQL и PostgreSQL утилитами mysqltuner и pgtune.MySQL
Для оптимизации mysql существует простая и удобная в использовании утилита mysqltuner. Раздобыть ее в безвозмездное пользование можно на github, а именно тут. Или загрузить одной командой:
wget https://raw.github.com/rackerhacker/MySQLTuner-perl/master/mysqltuner.plПользоваться просто: загружаем mysqltuner.pl на сервер с mysql, ставим права на запуск для файла (или запускаем так: perl mysqltuner.pl), на запрос логина / пароля даем учетку с привилегированными правами и смотрим рекомендации. Рекомендации заносим в конфиг, перезапускаем mysql-server. Или применяем «налету» через консоль mysql, если проект уже запущен и перезапуск нежелателен. Кроме советов по настройкам mysql, утилита так же показывает информацию о индексах в таблицах и фрагментации, если mysql уже какое-то время используется. Про индексы нередко забывают, что сильно повышает потребление ресурсов системы. Простановку индексов лучше поручить тем, кто проектировал структуру базы, но можно и самостоятельно. Для дефрагментации запускаем OPTIMIZE TABLE из консоли mysql, но удобнее сделать для всех таблиц разом через интерфейс типа phpMyAdmin.
По дальнейшей оптимизации в процессе работы проекта уже смотрим по ситуации и увеличиваем нужные параметры. Полезная информация описана моим коллегой в этой статье.
Для большей производительности полезно использовать Percona Server на замену стандартному MySQL Server. О пользе можно судить из графиков производительности. Про Percona Server уже достаточно много статей на Хабре, но в будущем поделюсь и своим опытом использования этой сборки.
PostgreSQL
Для тюнинга настроек PostgreSQL так же существует полезная утилита под названием pgtune.
В отличие от mysqltuner, утилита не дает рекомендаций, а сразу создает конфигурационный файл postgresql.conf с параметрами, оптимальными для системы, на которой запущен PostgreSQL.
Схема использования следующая:
pgtune -i $PGDATA/postgresql.conf -o $PGDATA/postgresql.conf.pgtune
где $PGDATA — путь к директории с конфигом сервера postgresql.conf. На выходе получаем файл postgresql.conf.pgtune, в котором выставлены подобранные утилитой параметры. Эти параметры утилита записывает в конец файла после блока
#------------------------------------------------------------------------------ # pgtune wizard run on YYYY-MM-DD # Based on XXXXXXX KB RAM in the server #------------------------------------------------------------------------------Можно использовать дополнительные параметры, чтобы выставить значения параметров не на основе определенных автоматически характеристик сервера, а по своему усмотрению:
-M или --memory — полный размер ОЗУ на сервере, на основе которого выделяются ресурсы памяти для PostgreSQL; -T или --type — Указывает тип базы данных: DW, OLTP, Web, Mixed, Desktop; -с или --connections — Максимально возможное количество подключений к базе; Если значение не указано, определяется на основе типа базы; -D или --debug — Включает режим отладки в PostgreSQL -S или --settings — Устанавливает к директории, в которойрасположен конфигурационный файл.
После завершения работы утилиты редактируем сгенерированный файл postgresql.conf.pgtune при необходимости (например, выставить нестандартный порт или настроить логирование ), заменяем им конфигурационный файл postgresql.conf и перезапускаем PostgreSQL-server.
Буду рад любым вопросам / замечаниям / дополнениям!
habr.com