Как не допустить грубейших ошибок в роботсе. Роботс тхт для wordpress
составляем правильный роботс для Wordpress и других систем
Содержание статьи
Вы знаете, насколько важна индексация — это основа основ в продвижении сайтов. Потому что если ваш сайт не индексируется, то хрен вы какой трафик из поиска получите. Если он индексируется некорректно — то у вас даже при прочих идеальных условиях будет обрубаться часть трафика. Тут все просто — если вы, например, запретили к индексации папку с изображениями, то у вас почти не будет по ним трафа (хотя многие сознательно идут на такой шаг).
Индексация сайта — это процесс, в ходе которого страницы вашего сайта попадают в Яндекс, Гугл или другой поисковик. И после этого пользователь может найти страницу вашего сайта по какому-нибудь запросу.
Управляете вы такой важной штукой, как индексация, именно посредством файла robots.txt. Начну с азов.
Что такое robots.txt
Robots.txt — файл, который говорит поисковой системе, какие разделы и страницы вашего сайта нужно включать в поиск, а какие — нельзя. Ну то есть он говорит не поисковой системе напрямую, а её роботу, который обходит все сайты интернета. Вот что такое роботс. Этот файл всегда создается в универсальном формате .txt, который сможет открыть даже компьютер вашего деда.
Вот видос от Яндекса:
Основное назначение – контроль за доступом к публикуемой информации. При необходимости определенную информацию можно закрыть для роботов. Стандарт robots был принят в начале 1994 года, но спустя десятилетие продолжает жить.
Использование стандарта осуществляется на добровольной основе владельцами сайтов. Файл должен включать в себя специальные инструкции, на основе которых проводится проверка сайта поисковыми роботами.
Самый простой пример robots:
Данный код открывает весь сайт, структура которого должна быть безупречной.
Зачем закрывают какие-то страницы? Не проще ли открыть всё?
Смотрите — у каждого сайта есть свой лимит, который называется краулинговый бюджет. Это максимальное количество страниц одного конкретного сайта, которое может попасть в индекс. То есть, допустим, у какого-нибудь М-Видео краулинговый бюджет может составлять десять миллионов страниц, а у сайта дяди Вани, который вчера решил продавать огурцы через интернет — всего сотню страниц. Если вы откроете для индексации всё, то в индекс, скорее всего, попадет куча мусора, и с большой вероятностью этот мусор займет в индексе место некоторых нужных страниц. Вот чтобы такой хрени не случилось, и нужен запрет индексации.
Где находится Robots
Robots традиционно загружают в корневой каталог сайта.

Для загрузки текстового файла обычно используется FTP доступ. Некоторые CMS, например WordPress или Joomla, позволяют создавать robots из админпанели.
Для чего нужен этот файл
А вот для чего:
- запрета на индексацию мусора — страниц и разделов, которые не содержат в себе полезный контент;
- разрешение индексации нужных страниц и разделов;
- чтобы давать разные задачи роботам разных поисковиков — то есть, например, Яндексу разрешить индексировать всё, а Рамблеру — ничего;
- можно также задавать роботам разные категории. Заморочиться например вплоть до того, что Гуглу разрешить индексировать только картинки, а Яху — только карту сайта;
- чтобы показать через директиву Host Яндексу, какое у сайта главное зеркало;
- еще некоторые вебмастера запрещают всяким нехорошим парсерам сканировать сайт с помощью этого файла;
То есть большую часть проблем по индексации он решает. Есть конечно помимо роботса еще и такие инструменты, как метатег роботс (не путайте!), заголовок Last-Modified и другие, но это уже для профессионалов и нужны они лишь в особых случаях. Для решения большинства базовых проблем с индексацией хватает манипуляций с роботсом.
Как работают поисковые роботы и как они обрабатывают данный файл
В большинстве случаев, очень упрощенно, они работают так:
- Обходят Интернет;
- Проверяют, какие документы разрешено индексировать, а какие запрещено;
- Включает разрешенные документы в базу;
- Затем уже другие механизмы решают, какие страницы достаточно полезны для включения в индекс.
Вот ссылка на справку Яндекса о работе поисковых роботов, но там все довольно отдаленно описано.
Справка Google свидетельствует: robots – рекомендация. Файл создается для того, чтобы страница не добавлялась в индекс поисковой системы, а не чтобы она не сканировалась поисковыми системами. Гугл позволяет запрещенной странице попасть в индекс, если на нее направляется ссылка внутри ресурса или с внешнего сайта.
По-разному ли Яндекс и Google воспринимают этот файл
Многие прописывают для роботов разных поисковиков разные директивы. Даже если список этих директив ничем не отличается.
Наверное, это для того, чтобы выразить уважение к Господину Поисковику. Как там раньше делали — «великий князь челом бьет… и просит выдать ярлык на княжение». Других соображений по поводу того, зачем разным юзер-агентам прописывают одни и те же директивы, у меня нет, да и вебмастера, так делающие, дать нормальных объяснений своим действиям не могут.
А те, кто может ответить, аргументируют это так: мол, Google не воспринимает директиву Host и поэтому её нужно указывать только для Яндекса, и вот почему, мол, для яндексовского юзер-агента нужны отдельные директивы. Но я скажу так: если какой-то робот не воспринимает какую-то директиву, то он её просто проигнорирует. Так что лично я не вижу смысла указывать одни и те же директивы для разных роботов отдельно. Хотя, отчасти понимаю перестраховщиков.
Чем может грозить неправильно составленный роботс
Некоторые при создании сайта на WordPress ставят галочку, чтобы система закрывала сайт от индексации (и забывают потом убрать её). Тогда Вордпресс автоматом ставит вам такой роботс, чтобы поисковики не включали ваш сайт в индекс, и это — самая страшная ошибка. Те страницы, на которые вы намерены получать трафик, обязательно должны быть открыты для индексации.
Потом, если вы не закрыли ненужные страницы от индексации, в индекс может попасть, как я уже говорил выше, очень много мусора (ненужных страниц), и они могут занять в индексе место нужных страниц.
Вообще, если вкратце, неправильный роботс грозит вам тем, что часть страниц не попадет в поиск и вы лишитесь части посетителей.
Как создать файл robots.txt
В Блокноте или другом редакторе создаем файл с расширением .txt, чтобы он в итоге назывался robots.txt. Заполняем его правильно (дальше расскажу, как) и загружаем в корень сайта. Готово!
Вот тут разработчик сайта Loftblog создает файл с нуля в режиме реального времени и делает настройку роботс:
Пример правильного robots.txt для WordPress
Составить правильный robots.txt для сайта WordPress проще всего. Я сам видел очень много таких роботсов (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Sitemap: http://znet.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 61 62 63 64 65 66 67 68 69 |
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ Host: znet.ru
User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
Sitemap: http://znet.ru/sitemap.xml |
Этот роботс для WordPress довольно проверенный. Большую часть задач он выполняет — закрывает версию для печати, файлы админки, результаты поиска и так далее.
«Универсальный» роботс
Если вы ищете какое-то решение, которое подойдет для всех сайтов на всех CMS (или для лендинга), «волшебную таблетку» — такой нет. Для всех CMS одинаково хорошо подойдет лишь решение, при котором вы говорите разрешить все для индексации:
В остальном — нужно отталкиваться от системы, на которой написан ваш сайт. Потому что у каждой из них уникальная структура и разные разделы/служебные страницы.
Роботс для Joomla
Joomla — ужасный движок, вы ужасный человек, если до сих пор им пользуетесь. Дублей страниц там просто дофига. В основном нормально работает такой код (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: http://znet.ru/sitemap.xml User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
User-agent: * Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Sitemap: http://znet.ru/sitemap.xml
User-agent: Yandex Disallow: /administrator/ Disallow: /cache/ Disallow: /includes/ Disallow: /installation/ Disallow: /language/ Disallow: /libraries/ Disallow: /media/ Disallow: /modules/ Disallow: /plugins/ Disallow: /templates/ Disallow: /tmp/ Disallow: /xmlrpc/ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml |
Но я вам настоятельно советую отказаться от этого жестокого движка и перейти на WordPress (а если у вас интернет-магазин — на Opencart или Bitrix). Потому что Joomla — это жесть.
Robots для Битрикса
Как составить robots.txt для Битрикс (обязательно замените znet.ru на название вашего сайта, если хотите копировать):
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
User-agent: * Disallow: /bitrix/ Disallow: /upload/ Disallow: /search/ Allow: /search/map.php Disallow: /club/search/ Disallow: /club/group/search/ Disallow: /club/forum/search/ Disallow: /communication/forum/search/ Disallow: /communication/blog/search.php Disallow: /club/gallery/tags/ Disallow: /examples/my-components/ Disallow: /examples/download/download_private/ Disallow: /auth/ Disallow: /auth.php Disallow: /personal/ Disallow: /communication/forum/user/ Disallow: /e-store/paid/detail.php Disallow: /e-store/affiliates/ Disallow: /club/$ Disallow: /club/messages/ Disallow: /club/log/ Disallow: /content/board/my/ Disallow: /content/links/my/ Disallow: /*/search/ Disallow: /*PAGE_NAME=search Disallow: /*PAGE_NAME=user_post Disallow: /*PAGE_NAME=detail_slide_show Disallow: /*/slide_show/ Disallow: /*/gallery/*order=* Disallow: /*?print= Disallow: /*&print= Disallow: /*register=yes Disallow: /*forgot_password=yes Disallow: /*change_password=yes Disallow: /*login=yes Disallow: /*logout=yes Disallow: /*auth=yes Disallow: /*action=ADD_TO_COMPARE_LIST Disallow: /*action=DELETE_FROM_COMPARE_LIST Disallow: /*action=ADD2BASKET Disallow: /*action=BUY Disallow: /*print_course=Y Disallow: /*bitrix_*= Disallow: /*backurl=* Disallow: /*BACKURL=* Disallow: /*back_url=* Disallow: /*BACK_URL=* Disallow: /*back_url_admin=* Disallow: /*index.php$ Host: znet.ru Sitemap: http://znet.ru/sitemap.xml |
Как правильно составить роботс
У каждой поисковой системы есть свой User-Agent. Когда вы прописываете юзер-эйджент, то вы обращаетесь к какой-то определенной поисковой системе. Вот названия ботов поисковых систем:
Google: GooglebotЯндекс: YandexМэйл.ру: Mail.RuYahoo!: SlurpMSN: MSNBotРамблер: StackRambler
Это основные, которые включают ваш сайт в текстовые индексы поисковиков. А вот их вспомогательные роботы:
Googlebot-Mobile — это юзер-агент для мобильныхGooglebot-Image — это для картинокMediapartners-Google — этот робот сканирует содержание обьявлений AdSenseAdsbot-Google — это для качества целевых страниц AdWordsMSNBot-NewsBlogs – это для новостей MSN
Сначала в любом нормальном роботсе идет указание юзер-агента, а потом директивы ему. Юзер-агента мы указываем в первой строке, вот так:
Это будет обращение к роботу Яндекса. А вот обращение ко всем роботам всех систем сразу:
После юзер-агента идут указания, относящиеся именно к нему. Пример:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: *?* Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Allow: /wp-content/uploads/ |
Сначала мы прописываем директивы для всех интересующих нас юзер-агентов. Затем дополняем их тем, что нас интересует, и заканчиваем обычно ссылкой на XML-карту сайта:
Sitemap: http://znet.ru/sitemap.xml
Sitemap: http://znet.ru/sitemap.xml |
А вот что прописывать в директивах — это для каждой CMS, как я уже писал выше, по-разному. Но в принципе можно выделить основные типы страниц, которые нужно закрывать во всех роботсах.
Что нужно закрывать в нем
Всю эту хрень нужно закрыть от индексации:
- Страницы поиска. Обычно поиск генерирует очень много страниц, которые нам не будут нести трафика;
- Корзина и страница оформления заказа. Обычно они не должны попадать в индекс;
- Страницы пагинации. Некоторые мастера знают, как получать с них трафик, но если вы не профессионал, лучше закройте их;
- Фильтры и сравнение товаров могут генерировать мусорные страницы;
- Страницы регистрации и авторизации. На этих страницах вводится только конфиденциальная информация;
- Системные каталоги и файлы. Каждый ресурс включает в себя административную часть, таблицы CSS, скрипты. В индексе нам это все не нужно;
- Языковые версии, если вы не продвигаетесь в других странах и они нужны вам чисто для информации;
- Версии для печати.
Как закрыть страницы от индексации и использовать Disallow
Вот чтобы закрыть от индексации какой-то тип страниц, нам потребуется она. Disallow – директива для запрета индексации. Чтобы закрыть, допустим, страницу znet.ru/page.html на своем блоге, я должен добавить в роботс:
А если мне нужно закрыть все страницы, которые начинаются с http://znet.ru/instrumenty/? То есть страницы http://znet.ru/instrumenty/1.html, http://znet.ru/instrumenty/2.html и другие? Тогда я добавляю такую строку в роботс:
Короче, это самая нужная директива.
Нужно ли использовать директиву Allow?
Крайне редко ей пользуюсь. Вообще, она нужна для того, чтобы разрешать роботу индексировать определенные страницы. Но он индексирует все, что не запрещено. Так что Allow я почти не использую. За исключением редких случаев, например, таких:
Допустим, у меня в роботсе закрыта категория /instrumenty/. Но страницу http://znet.ru/instrumenty/44.html я должен открыть для индексации. Тогда у меня в роботс тхт будет написано так:
Disallow: /instrumenty/ Allow: /instrumenty/44.html
Disallow: /instrumenty/ Allow: /instrumenty/44.html |
В таком случае проблема будет решена. Как пишет Яндекс, «При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow». Короче, Allow я использую тогда, когда нужно перебить требования какой-то из директив Disallow.
Регулярные выражения
Когда прописываем директивы, мы можем использовать спецсимволы * и $ для создания регулярных выражений. Для чего они нужны? Давайте на практике рассмотрим:
User-agent: Yandex Disallow: /cgi-bin/*.aspx
User-agent: Yandex Disallow: /cgi-bin/*.aspx |
Такая директива запретит Яндексу индексировать страницы, которые начинаются на /cgi-bin/ и заканчиваются на .aspx, то есть вот эти страницы:
/cgi-bin/loh.aspx/cgi-bin/pidr.aspx
И подобные им будут закрыты.
А вот спецсимвол $ «фиксирует» запрет какой-то конкретной страницы. То есть такой код:
User-agent: Yandex Disallow: /example$
User-agent: Yandex Disallow: /example$ |
Запретит индексировать страницу /example, но не запрещает индексировать страницы /example-user, /example.html и другие. Только конкретную страницу /example.
Для чего нужна директива Host
Если сайт доступен сразу по нескольким адресам, директива Host указывает главное зеркало одного ресурса. Эту директиву распознают только роботы Яндекса, остальные поисковики забивают на нее болт. Пример:
User-agent: Yandex Disallow: /page Host: znet.ru
User-agent: Yandex Disallow: /page Host: znet.ru |
Host используется в robots только один раз. Если же их будет указано несколько, учитываться будет только первая директива.
Что такое Crawl-delay
Директива Crawl-delay устанавливает минимальное время между завершением загрузки роботом страницы 1 и началом загрузки страницы 2. То есть если у вас в роботсе добавлено такое:
User-agent: Yandex Crawl-delay: 2
User-agent: Yandex Crawl-delay: 2 |
То таймаут между загрузками двух страниц составит две секунды.Это нужно, если ваш сервер плохо выдерживает запросы на загрузку страниц. Но я скажу так: если это так и есть, то ваш сервер — говно, и тут не Crawl-delay нужно устанавливать, а менять сервер.
Нужно ли указывать Sitemap в роботсе
В конце роботса нужно указывать ссылку на сайтмап, да. Я вам скажу, что это очень круто помогает индексации.
Был у меня один сайт, который хреново индексировался месяца полтора, когда я еще только начинал в SEO. Я не мог никак понять, в чем причина. Оказалось, я просто не указал путь к сайтмапу. Когда я это сделал — все нужные страницы через 1 апдейт уже попали в индекс.
Указывается путь к сайтмапу так:
Sitemap: http://znet.ru/sitemap.xml
Sitemap: http://znet.ru/sitemap.xml |
Это если ваша карта сайта открывается по этому адресу. Если она открывается по другому адресу — прописывайте другой.
Прочие рекомендации к составлению
Рекомендую соблюдать:
- В одной строке — одна директива;
- Без пробелов в начале строк;
- Директива будет работать, только если написана целиком и без лишних знаков;
- Как пишет сам Яндекс, «Если для данной страницы сайта подходит несколько директив, то робот выбирает последнюю в порядке появления в сортированном списке»;
- Правильный код роботс должен содержать как минимум одну директиву Dissallow.
А вот еще видео для продвинутых с вебмастерской Яндекса:
Как запретить индексацию всего сайта
Вот этот код поможет закрыть сайт от индексации:
User-agent: * Disallow: /
Пригодиться это может, если вы делаете новый сайт, но он еще не готов, и поэтому его лучше закрыть, чтобы он во время доработки не попал под какой-нибудь фильтр АГС.
Как проверить, правильно ли составлен файл
В Яндекс Вебмастере и Гугл Вебмастере есть инструмент, который поможет вам понять, правильно ли составлен роботс. Рекомендую обязательно проверять файл в этих сервисах перед размещением. В Яндекс Вебмастере вы также сможете добавить список страниц, чтобы проверить, разрешены ли они к индексации роботом.
znet.ru
Файл robots.txt для сайта WordPress
Приветствую вас, дорогие читатели!
Сегодня расскажу вам о правильной настройке robots txt для сайта wordpress. Это очень важная вещь, которая должна быть на каждом сайте и которая способна значительно повлиять на индексацию вашего сайта, причём как в лучшую так и в худшую сторону. Здесь всё зависит от того насколько правильно вы всё сделаете.
Вы ведь не хотите, чтобы из-за каких то двух-трёх неправильно написанных строк в robots.txt ваш сайт опустился в выдаче?Тогда читайте статью до конца.
Навигация по статье:

Зачем вообще нужен robots.txt?
До появления CMS для поисковых роботов процесс индексации выглядел достаточно просто. Он просто приходил на ваш сайт и сканировал все HTML страницы которые там есть, а затем заносил их к себе в базу для последующей обработки.
После появления CMS данный процесс значительно усложнился в первую очередь потому, что в папке вашего сайта на хостинге появилось огромное количество файлов движка, которые не содержат никакого ценного контента для поискового робота. И среди этой кучи файлов с кодом бедному роботу нужно найти те две – три статьи, которые вы опубликовали, и которые, по вашему мнению, должны попасть в выдачу.
Можете представить, сколько лишней работы приходится проделывать роботу и сколько мусора может попасть в выдачу?
С целью хоть как то упростить индексацию был придуман robots.txt, который содержит в себе набор команд, с описанием тех папок, которые не нужно индексировать, а также указывающей поисковому роботу путь к карте сайта, о важности которой мы поговорим в одной из следующих статей.
Что представляет собой файл robots.txt?
Это простой текстовый файл с расширением .txt, который можно создать при помощи программы Блокнот или любой другой. Данный файл размещается в корне вашего сайта wordpress, то есть в той папке, куда вы загружаете все файлы сайта, где у вас находятся папки wp-content, wp-admin и так далее.
Названия должно быть обязательно написано строчными символами вот так: «robots.txt».
Какие команды должен содержать данный файл для WordPress?
- 1.User-agent: — здесь вы указываете для какого поискового робота предназначен данный набор команд.
Возможные значения:
- Yandex
- GoogleBot
- Mail.ru
- Aport и некоторые другие.
Если вы не хотите прописывать команды для каждого поискового робота, то можете поставить значение «*»Это будет означать, что данные команды должны выполняться для всех роботов.
Должно получиться так:User-agent: *
- 2.Disallow: команда запрещающая индексировать определённый файлы или папки.
Например:Disallow: /wp-login.phpDisallow: /wp-register.php
- 3.Sitemap: указывает ссылку на карту сайта.
Например: //impuls-web.ru/sitemap.xml
- 4.Host: здесь указывается домен вашего сайта без http://
Например: Host: impuls-web.ru
Как должен выглядеть robots txt для сайта wordpress?
Каждая CMS имеет свою структуру файлов и папок, поэтому для каждой из них нужно создавать свой robots.txt.
Для сайта WordPress robots.txt обычно выглядит так:

Файл с данным кодом можно скачать по ссылке ниже и загрузить к себе на сайт
Только не забудьте вместо impuls-web.ru подставить домен вашего сайта.
Обратите внимание, что в данном файле прописаны команды только для роботов яндекса и всех остальных. Google в последнее время не обращает особого внимания на этот файл и индексирует всё подряд, поэтому писать команды для него не имеет смысла.
Важно также не запретить ничего лишнего, так как это может привести к проблемам с индексацией и как следствие понижению позиций сайта в выдаче.
Как проверить robots.txt
Это можно сделать через яндекс-вебмастер. Для этого нужно:
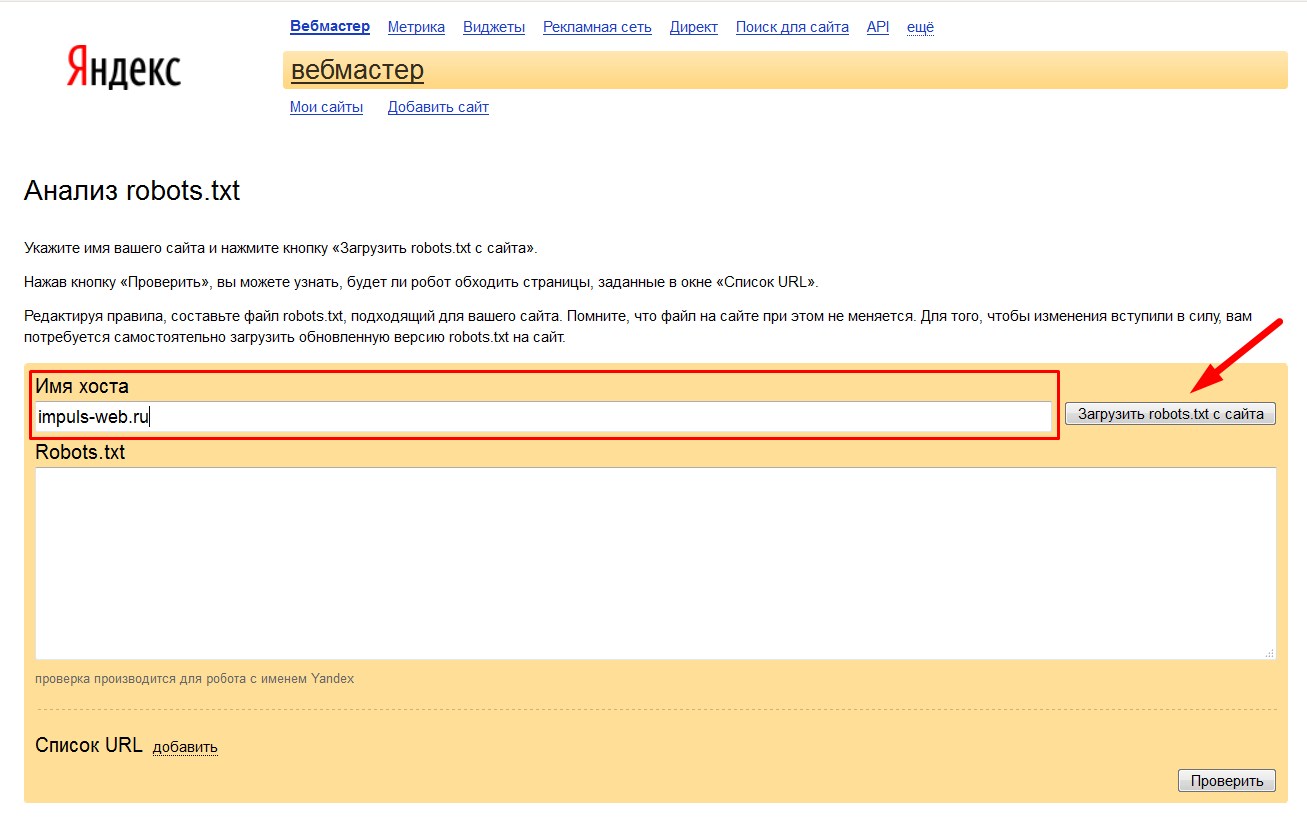
- 1.Перейти по ссылке https://webmaster.yandex.ru/robots.xml (Анализ robots.txt)
- 2.В поле «Имя хоста» введите домен вашего сайта и нажмите на кнопку «Загрузить robots.txt с сайта»
- 3.Нажимаем на кнопку «Проверить» и смотрим на результат. Если не возникло никаких ошибок, то результат будет выглядеть приблизительно так как на скриншоте ниже
- 4.В идеале ещё бы проверить главную страницу, страницу категорий, страницу записей и другие типы страниц wordpress и убедиться что они могут нормально индексироваться. Для этого нужно взять ссылки на эти страницы и добавить их в пункт «Список URL»
- 5.Нажимаем кнопку «Проверить»
- 6.Смотрим результат. Все добавленные вами страницы должны быть разрешены.




Заключение
Использование robots.txt на сайте wordpress позволяет упростить поисковому роботу процесс индексации за счёт того что вы сами указываете ему какие файлы нужно индексировать, а какие нет. Но не стоит этим злоупотреблять и пытаться перехитрить робота запрещая ему индексировать дубли страниц, к примеру, или какие то страницы с контентом, которые вы бы не хотели чтобы он индексировал.
Поисковые роботы стали более обученные и обмануть их не так то просто. Они все равно будут сканировать запрещённые в robots.txt файлы и папки, но будут уделять им меньшее значение и обрабатывать по другим алгоритмам. Поэтому если среди этих файлов он найдёт страницы, которые похожи на страницы с контентом, то он всё равно поместит их выдачу, несмотря на ваши запреты.
Вывод: использовать robots.txt у себя н сайте стоит, но запрещайте в нём только папки и файлы движка. Страницы с контентом в данном файле запрещаться не должны. Это может привести к неправильной обработке роботом полученных данных и возникновению проблем с индексацией.

Надеюсь, что у вас не возникнет никаких проблем ни с созданием и проверкой данного файла, ни с индексированием в целом! Желаю вам успехов в этом деле и если вам есть что сказать или спросить по данной теме – не стесняйтесь и пишите мне через комментарии! Я обязательно отвечу на все ваши вопросы.
Также подписывайтесь на рассылку, чтобы не пропустить ничего интересного.
С уважением Юлия Гусарь
impuls-web.ru
Делаем правильный robots.txt для WordPress
robots.txt – это файл, в котором записаны правила для поисковых роботов, которые гласят о том, как индексировать весь сайт. Очевидно, что от содержания этого файла зависит успешность всей стратегии продвижения. В этой статье я вам покажу, как сделать правильный robots.txt для WordPress.

robots.txt – это файл, который задаёт правила индексации. От того, какие правила заданы в этом файле, зависит то, какие страницы сайта будут присутствовать в том или ином поисковике.

Отсутствие robots.txt или его неверное содержание повлечёт неправильную индексацию и может стать причиной наложения поисковых фильтров, что не позволит сайту развиться.
 Правильный robots.txt для WordPress
Правильный robots.txt для WordPress
Чтобы сделать правильный robots.txt для WordPress, создайте текстовый файл с расширением .txt и назовите его robots. Заполните его правилами, которые вам необходимы. Файл нужно сохранить в корневую папу сайта через FTP.
Если файл robots.txt будет назван как-то иначе или будет иметь другое расширение или будет находиться не в корневой папке, то поисковики его не увидят, и поэтому сочтут, что этого файла вовсе нет.
Готовый правильный robots.txt для WordPress вы можете скачать по ссылке ниже. Только поменяйте «https://example.ru» на свой сайт, а «https://example.ru/sitemap.xml» на свою карту сайта.
robots.txt для WordPress
Перед использованием, извлеките из архива.
Теперь поясню, что означает каждое выражение. robots.txt состоит из директив, каждая директива обозначает какое-либо правило. Директивы могут иметь свои параметры. robots.txt для WordPress, который вы скачали выше, содержит следующие правила:
- User-agent. Здесь указывается имя робота, для которого идут правила ниже. Правила для указанного робота заканчиваются перед следующим User-agent. Если директива имеет значение «*» (звёздочка), то эти правила относятся ко всем роботам. Каждый робот поисковой системы имеет своё имя, у многих поисковых систем есть по несколько роботов с разными именами. Список популярных User-agent можете скачать по ссылке ниже.
Перед использованием, извлеките из архива.
- Disallow. Эта директива запрещает индексирование частей сайта, путь к которым в ней указан. Так, «Disallow: /wp-admin» — означает, что «example.ru/wp-admin» в поиске участвовать не будет. Правило «Disallow: */trackback» означает, что «example.ru/любое_значение/trackback» не будет индексироваться. Установка символа «*» означает любое значение. Аналогично с «Disallow: /*?*» — это правило показывает, что не будут индексироваться все страницы, имеющие в адресе знак «?», независимо от того, что написано до этого знака и после.
- Allow. Правильный robots.txt для WordPress обычно не содержит этой директивы, но она может иногда пригодиться. Это то же самое, что и «Disallow», только наоборот, то есть, это разрешающее правило. Так, например, если вы заблокировали «example.ru/wp-admin», но вам нужно проиндексировать какою-то одну страницу в каталоге «wp-admin», например «page.php», то необходимо создать такое правило «Allow: wp-admin/page.php». Тогда страница будет индексировать, несмотря на запрет.
Правильный robots.txt для WordPress в Яндексе
Правильный robots.txt для WordPress должен иметь отдельную часть для Яндекса, как в примере, который можно скачать выше. Для этого поисковика обязательно необходимо указать следующие директивы:
- Host. Это адрес главного зеркала сайта, либо с WWW, либо без WWW. Главное зеркало также должно быть настроено в файле .htaccess. Подробнее тут.
- Sitemap. Это адрес к карте сайта XML формата (для роботов). Необходимо указать полный путь до карты, например «https://example.ru/sitemap.xml».
Роботы Яндекса также понимают правило «Crawl-delay». Оно указывает, с какой периодичность робот может сканировать сайт. Указывается в секундах, например, «Crawl-delay: 2.5» указывает, что робот может посещать страницу не чаще, чем один раз в 2,5 секунды. Эта директива может быть полезна, если сканирующий робот оказывает слишком большую нагрузку на сайт.
Если хотите, то можно узнать, как выглядит файл robots.txt на любом сайте. Для этого напишите в браузере адрес «https://example.ru/robots.txt» (вместо «example.ru» целевой сайт).
wp-system.ru
Файл Robots.txt для WordPress
Поисковые боты следуют инструкциям, содержащимися в файле robots.txt, который обязательно должен находиться в корневой директории, чтобы боты начинали индексацию страницы, читая находящийся в нем условия. Если в общих чертах, то это значит, что robots для WordPress допускает поисковых роботов к индексации, только тех директорий, которые разрешены им.
Говоря о возможностях и преимуществах файла robots.txt, то их достаточно много. К примеру, одни из важных это:
• оставляет за пределами индексирования некоторые разделы сайта, которые не предназначены для поиска. Это могут быть области, содержащие приватную информацию или определенного содержания контент;
• у файла есть возможность ограничить доступ разнообразным роботам, которые сканируют ресурс на наличие адресов электронной почты, чтобы в дальнейшем рассылать на них спам;
• можно с его помощью полностью запретить индексацию ресурса или сделать это частично. Это часто необходимо при проведении реконструкции или создании сайта.
Очень важно использовать правильно созданный файл robots для WordPress, так как от него будет зависеть то, насколько успешно пройдет индексация сайта. Такой, правильно созданный файл, скроет большое количество данных, которые дублируют основную информацию. Также он закроет от поисковиков все папки из внутренних директорий, которые не несут никакой нагрузки, а только могут создать лишний плагиат, что снизит сайт в итоговой выдаче поиска.
Создание правильного файла robots для WordPress
Чтобы файл robots принимали поисковые роботы Яндекса и Гугла, нужна определенная последовательность командных строк. Код, представленный ниже, будет оптимальным вариантом для этих поисковых систем. Итак, последовательность, с некоторыми допущения, должна быть такой:
• User-agent; • Disallow; • Allow; • Sitemap; • Host.Теперь стоит рассмотреть каждый пункт более подробно:
1. Строка User-agent:, определяет какие поисковые роботы, должны следовать правилам, указанным в нижележащих строках. Если правила должны соблюдаться всеми роботами, то после двоеточия ставится знак «*». А если правила пишутся для соблюдения конкретным роботом, то после двоеточия прописываем его имя, Yandex или Googlebot.
2. Строка Disallow, содержит ссылки, по которым роботам запрещается ходить. Таких строк может быть несколько, и они будут начинаться с /feed (RSS сайта), /cgi-bin (список скриптов), /trackback или со значений страниц поиска.
3. Допущение относится именно к строке Allow, которая необязательно должна стоять после команды Disallow, она может прописываться и до нее. Эта строка содержит исключения, которые разрешают роботам индексировать всю информацию, находящуюся по ссылкам. В основном это относится к /uploads.
4. В строке Sitemap нужно указать путь к файлу с картой сайта, который должен быть в формате XML. Выглядит это, так: http:// */sitemap.xml. Сколько подобных файлов, столько и, должно быть, строк с указанием пути к ним.
5. Строка Host, должна содержать местонахождение главного зеркала сайта, чтобы роботы Яндекса, могли индексировать все сайты одинаково. Прописывать эту команду надо через пустую строку от всех остальных, независимо от того где она будет стоять, вначале или в конце.
Стоит напомнить, что подобная структура robots для WordPress, подходит только роботам Яндекса и Гугла. Для других поисковых систем, подобная последовательность некорректна, и будет иметь немного другой вид.
Недостатки системы
Система WordPress, имеет ряд недостатков, и одним из основных недочетов, является то, что в ней постоянно создается очень большое количество дублей главных страниц. При публикации контента на сайте, сразу же появляется его дубли, которые возникают в различных категориях поиска, в архивах, в метках, в ленте RSS, и еще во многих местах. Именно для исправления всех этих недостатков системы, и существует файл robots.txt.
Процесс скрытия ненужных дубликатов, достаточно прост. Необходимо создать в текстовом редакторе файл robots для WordPress, который работает не только с этой системой, но и с другими. Итак, последовательность создания:
• файл должен содержать определенный код, закрывающий от поисковых систем определенные страницы с помощью устанавливаемых фильтров. Также можно закрыть целые директории и папки;
• исключить возникновение зеркал, путем ввода в файл единственно верного адреса ресурса;
• указать нахождение карты сайта, чтобы процесс индексации, при появлении на сайте новых страниц, проходил быстрее.
На многих сайтах можно заметить различное содержимое файла robots.txt – это говорит о том что каждый настраивает его под себя. Но в общем обзоре начинка файла такая:
User-agent: *Disallow: /cgi-binDisallow: /wp-admin/Disallow: /wp-includes/Disallow: /wp-content/plugins/Disallow: /wp-content/cache/Disallow: /wp-content/themes/Disallow: /wp-trackbackDisallow: /wp-feedDisallow: /wp-commentsDisallow: /category/Disallow: /author/Disallow: /page/Disallow: */trackbackDisallow: */commentsDisallow: /*.php
User-agent: YandexDisallow: /cgi-binDisallow: /wp-admin/Disallow: /wp-includes/Disallow: /wp-content/plugins/Disallow: /wp-content/cache/Disallow: /wp-content/themes/Disallow: /wp-trackbackDisallow: /wp-feedDisallow: /wp-commentsDisallow: /category/Disallow: /author/Disallow: /page/Disallow: */trackbackDisallow: */commentsDisallow: /*.php
Host: site.ru
Sitemap: http://site.ru/sitemap.xmlSitemap: http://site.ru/sitemap.xml.gz
После того как, все эти операции выполнены, файл необходимо загрузить в корневую папку WordPress, и он начнет работать.
wordsmall.ru
Плагин Robots txt для WordPress
Здравствуйте!Хочу предложить всем, кто использует WordPress, плагин RobotsTxT от автора блога BlogGood.ru и StepkinBLOG.RU.Плагин RobotsTxT поможет автоматически создать файл «robots.txt» с готовым стандартным кодом, если, естественно, у вас его на сайте не было.Также у плагина RobotsTxT есть возможность редактировать файл «robots.txt».Плагин бесплатный и на русском языке.
Плагин RobotsTxT для WordPress

Скачать плагин
Как использовать плагин RobotsTxT
1). Скачайте и установите плагин.Для этого перейдите в админ-панели «Плагины» => «Добавить новый»:

2). Далее нажмите «Загрузить плагин» и укажите на архив скаченного плагина:

После активации плагина с левой стороны меню появится раздел «RobotsTxT». Перейдите по нему:

3). Если у вас не был создан файл «robots.txt», тогда вы сразу увидите две кнопки:
«Создать robots.txt с готовым кодом» и «Создать robots.txt без кода».
→ Если вы нажмете на кнопку «Создать robots.txt с готовым кодом», то создастся файл «robots.txt» с готовым стандартным кодом. После этого вы сможете вносить свои изменения и сохранять.
→ Если вы нажмете на кнопку «Создать robots.txt без кода», то создастся чистый файл «robots.txt». После этого вы сможете внести свой код, сохранить и редактировать.

Я думаю, вы останетесь довольны моим изобретением ))). Ведь в нем нет ничего лишнего, все просто, а огромный плюс в том, что плагин на понятном русском языке!
Скачать плагин
Понравился пост? Помоги другим узнать об этой статье, кликни на кнопку социальных сетей ↓↓↓
Последние новости категории:
Похожие статьи
Популярные статьи:
Добавить комментарий
Метки: wordpress
bloggood.ru
Файл robots.txt для WordPress
Опубликовано: 5 ноября 2012
Просмотров: 4803
Файл robots.txt позволяет запретить индексирование определенных разделов сайта, а также указать главное зеркало сайта, указать путь до xml карты сайта и задать дополнительные параметры индексации для роботов поисковых систем. Вот такой функциональностью обладает этот маленький, но полезный файл.
Самый простой файл robots.txt для WordPress, при наличии которого ваш сайт будет более менее нормально индексироваться, выглядит следующим образом:
User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /themes/ Disallow: /trackback/ Disallow: /feed/ Disallow: /comment/ Disallow: /tag/ Disallow: /author/ Disallow: /search/ Disallow: /rss/ Disallow: /*.js Disallow: /*.inc Disallow: /*.css Disallow: /*? Disallow: /*.gz Host: www.site.net Sitemap: http://www.site.net/sitemap.xmlВ дополнение к этому файлу я рекомендую использовать плагин Platinum SEO Pack, который позволяет не только оптимизировать title, description и meta, но и настроить индексирование страниц с архивами авторов, тегов, категорий и т.д.
Перед настройкой индексации рекомендую прочесть о том, что не нужно индексировать на WordPress сайте.
Это полезная статья? - Ставь лайк!
Участвуй в развитии блога и сообщества

Подписывайтесь и получайте полезные статьи на почту!
www.onwordpress.ru
описание, пример, настройка, как создать
 robots.txt — файл с инструкциями для роботов поисковых систем по обходу содержимого вашего сайта или блога. Данный файл находится в корне сайта, и в нем нужно прописать некоторые директивы для различных поисковиков, то есть он нужен, в первую очередь для SEO. В данной статье речь пойдёт о файле robots.txt для wordpress, но описанные принципы применимы для любого движка.
robots.txt — файл с инструкциями для роботов поисковых систем по обходу содержимого вашего сайта или блога. Данный файл находится в корне сайта, и в нем нужно прописать некоторые директивы для различных поисковиков, то есть он нужен, в первую очередь для SEO. В данной статье речь пойдёт о файле robots.txt для wordpress, но описанные принципы применимы для любого движка.
Если указанного файла на вашем сайте не имеется, создайте его в любом текстовом редакторе (или скачайте по ссылке в этой статье) и поместите на сервере в корне вашего ресурса. Поисковый робот при заходе на ваш сайт в первую очередь ищет именно этот файл, поскольку в нем находятся инструкции для дальнейшей работы робота.
В общем сайт может существовать и без этого файла, но, например, яндекс вебмастер расценивает его отсутствие как ошибку, так же как и отсутствие директив host и карты сайта.
Пример файла robots.txt
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/ Host: site.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/ User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ User-agent: Mediapartners-Google Disallow: User-Agent: YaDirectBot Disallow: Sitemap: http://site.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 |
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/ Host: site.ru
User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/
User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /search Disallow: */trackback/ Disallow: */feed Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: */wp-json/* Allow: /wp-content/uploads/
User-agent: Googlebot-Image Allow: /wp-content/uploads/
User-agent: YandexImages Allow: /wp-content/uploads/
User-agent: Mediapartners-Google Disallow:
User-Agent: YaDirectBot Disallow:
Sitemap: http://site.ru/sitemap.xml |
Вы можете скачать этот файл по ссылке в формате zip и взять его за шаблон.
Обратите внимание, что нужно заменить site.ru на адрес вашего ресурса.
Настройка robots.txt
Нельзя говорить о каком-то стандартном или самом правильном robots.txt. Для каждого сайта в нем могут быть свои директивы в зависимости от установленных плагинов и т.д.
Рассмотрим основные применяемые инструкции.
User-Agent означает, что следующие после него инструкции предназначены именно для этого юзерагента. В данном случае под юзерагентом подразумевается название поискового робота. Рекомендуется создать разные разделы для основных поисковых систем, то есть для Яндекс, Гугл, а в нашем случае еще и для mail. Инструкции для прочих агентов находятся в блоке со «*».
Директива disallow означает, что адреса страниц, соответствующие указанной после нее маске, не подлежат обходу и индексации. Например, маска /wp-admin закрывает все файлы из служебного каталога wp-admin.
Сайт WP содержит большое количество служебных папок, индексировать которые поисковикам не нужно. Поэтому рекомендуется сделать так, чтобы поисковик не тратил на них ресурсы, а индексировал лишь необходимое.
Команда allow обладает, соответственно, противоположным смыслом и указывает, что эти адреса можно обходить.
Директива host (ее требует яндекс) указывает основное зеркало сайта (то есть с www или без).
Sitemap указывает на адрес карты сайта, обычно — sitemap.xml. В том случае, если карты сайта у вас нет, ее желательно создать. (Статья о создании карты сайта.)
Кроме того, для гугл нужно открыть некоторые используемые файлы js и css. Робот google хочет видеть все файлы, в том числе стили и скрипты, участвующие в формировании страницы. Эти инструкции могут отличаться в зависимости от конфигурации сайта. Рекомендую прочитать статью Что делать с сообщением — Googlebot не может получить доступ к файлам CSS и JS на сайте.
delaemsait.info