Что учитывается при ранжировании сайтов в поисковой системе Яндекс? Ранжирование результатов поиска в яндекс
Что учитывается при ранжировании сайтов в поисковой системе Яндекс?
Давайте разберемся, что же учитывается в ранжировании, а также разберем некоторые сигналы, о которых нужно думать и вообще всегда совершенствовать их на своем сайте.
Начнем с такой картинки:

Как вы думаете, что означает эта картинка? Гербы городов, да, но что это за города? Есть вариант, что это Минусинск, но слишком много гербов для одного Минусинска, но направление правильное. Все эти гербы – это гербы городов, названия которых носят наши алгоритмы.
Развитие поиска Яндекса
Как же развивался поиск? Понятно, наверное, каждому, что поиск невозможен без самого главного – это без текстов, которые расположены на сайте.
Собственно, с этого поиск и начинался. Было несколько достаточно больших алгоритмов, которые назывались «Магадан», «Находка» и многое другое, которые были именно ориентированы на текст.
На расширение возможностей работы с текстом, на расширение возможности какой-то обработки и переформулировки текстов, которые поступают нам от сайтов и запросы, которые поступают нам от пользователей.
Это самое главное без чего не может находиться ни один сайт, он не может без текстов занимать хорошие позиции. Сайт, полностью сделанный из картинок, никогда, скорее всего, не будет на первой позиции, если он не один вообще по этому запросу.
Развитие поиска. Тексты
Из чего состоят тексты?
Текст важен на самом деле везде, где он есть на вашем сайте. Поисковый робот получает много всяких тегов и весь текст, который содержится на вашем сайте.
Итак, начнем с того, с чего начинается каждый сайт – это <TITLE>.
Понятно, что большинство пользователей даже не понимают, зачем он нужен. Мы никогда не смотрим, что же там написано на вкладке. Нам нужна иконка и какое-то название, чтобы мы могли как-то инициировать, а все остальное, что там пишется, нам зачастую неважно.
Но пользователь идет <TITLE> в результаты поиска. Когда мы осуществляем поиск, этот заголовок каждого сайта во многих случаях выбирается именно из того, что содержится в теге <TITLE>. Это не гарантирует, что всегда это будет выбираться, но если <TITLE> составлен качественно, хорошо, интересно для пользователя и содержит какие-то ключевые слова, и отражает самое главное – суть страницы, для которой он прописан, то он может быть выбран.
Я встречал очень много различных примеров, и сейчас мы рассмотрим пример, где неправильно работали с этим тегом.
Тег <BODY> – основной тег, в котором содержится весь текст, который есть на странице. В тексте довольно часто встречаются ошибки. Весь этот текст, который есть на странице, часто не индексируются нами, и мы не находим тот или иной сайт по запросам пользователей, потому что мы просто не знаем, что там есть этот текст.
Кто-то берет и потом дозагружает, например, текст как-то скриптами или закрывает его случайно каким-то тегом его индекс. В результате текст не попадает к нашему роботу, и мы возвращаемся к той же проблеме, что пользователь спрашивает: «А почему мой сайт не находится по запросу лютики-цветочки?». Да потому, что мы, когда индексировали сайт, этот текст вообще не видели на странице. Нужно всегда следить за тем, что получает робот.
Это легко проверяется с помощью служебных запросов: url:, сайт:. Дописав к этим запросам какой-то запрос, именно состоящий из слов, вы всегда можете узнать есть ли возможность найтись у этой страницы по этому запросу.
Следующее – это заголовки, которые есть на странице.
О них много говорят, но я до сих пор встречаю сайты, где с этими заголовками работают неправильно. Очень часто никто не соблюдает иерархию этих заголовков, пытаясь насытить страницу заголовками <h2>. Практически всегда <h2>, <h2>, <h2>.
Старайтесь, чтобы на вашей странице заголовки или соблюдалась иерархия, или разделять страницы на раздельные таким образом, что на одной странице есть <h2>, а остальной контент вынесен на другую страницу, чтобы они как-то делились по смыслу, чтобы это было легко читать и с этим можно было легко работать.
Следующее, где важен текст – это анкоры.
Анкоры – это текст ссылки, который вы встречаете на том или ином сайте, когда он ссылается на ваш сайт или на какой-то другой. Этот текст тоже нами учитывается, и часто сайты могут быть найдены именно по анкор текстам.
Я думаю, вы встречали случаи, когда в результатах поиска видите, что найден сайт и у него немножко серым написано, что сайт найден по ссылке. Если на вашем сайте нет этих текстов, то не значит, что он не может быть найден. Он может быть найден, если на вас кто-то ссылался теми или иными разными словами, можно хорошими, можно плохими.
И следующее, что часто бывает – это текст рядом с картинкой.
Кто-то этим просто пренебрегает и считает, что для него это не нужно. Но есть такой поиск по картинкам – для тех, кто не слышал и оттуда есть достаточно очень хороший трафик на различные сайты. Сами вспомните, как вы себя иногда ведете, когда что-то ищите.
Мы часто ищем какой-нибудь товар или что-то еще в поиске по картинкам. Нам интересно, как же она выглядит, посмотреть на нее визуально. Найдя эту картинку в поиске по картинкам, мы, не обязательно все, а какая-то часть пользователей переходит на сайт, который там указан. И, возможно, там приобретает что-то.
Сайты, которые прекрасно это понимают, уже озаботились тем, что помимо стандартного тега <ALT> у картинки, у него был еще достаточно хороший сопроводительный текст вокруг картинки, который полностью отражает, о чем она и вообще для чего она здесь расположена.

Давайте рассмотрим пример. Пару дней назад я его встретил в результатах поиска – это сайт кинотеатра «Соловей». Но в его контенте, как в <TITLE>, так и, если мы его откроем там, нигде нет упоминания о слове «соловей», а запросов «кинотеатр «Соловей»» достаточно много. Здесь его нет нигде, соответственно, в результатах поиска это даже не видно.
Подставляются те, что есть на этом сайте и заголовок, и описание «Кинотеатр на Красной Пресне». Конечно, вы скажите, что те, кто знают, они прекрасно найдут, а те, кто не знают, им покажется, что поиск ответил не релевантно. Так этот сайт не заботится об этом, у него встречается название «соловей» только в картинке, в логотипе, которую мы не индексируем.
Картинку мы индексируем, но текст на этой картинке мы не индексируем. Это хорошее задание для тех, кто на самом деле занимается этим сайтом.
Развитие поиска. Ссылки

Часто слышу, что ссылки – это уже не столько фактор, сколько бренд. Я, наверное, слышу о них везде, куда я не приду. Например, на профильную конференцию, там везде ссылки. Яндекс. Ссылки это прям мантра у всех. Но я полностью согласен с тем, что написано здесь.
Очень многие о них думают, но мало кто понимает для чего они нужны сайту и несут ли они вообще какую-то пользу или наоборот какой-то вред вашему сайту. Об этом надо думать. Есть гораздо больше вещей – факторов, сигналов, которые нами используются и которые приносят пользу вашему сайту и вашим пользователям. Ссылки зачастую такой пользы не приносят.
Развитие поиска. Региональность
Поиск, развиваясь, старался учитывать все больше и больше факторов, и мы анализировали запрос и видели, что в разных регионах пользователям интересны разные сайты, и внедряли ряд алгоритмов под разными названиями.
Алгоритмы представлены на слайде, которые учитывали региональность сайтов:
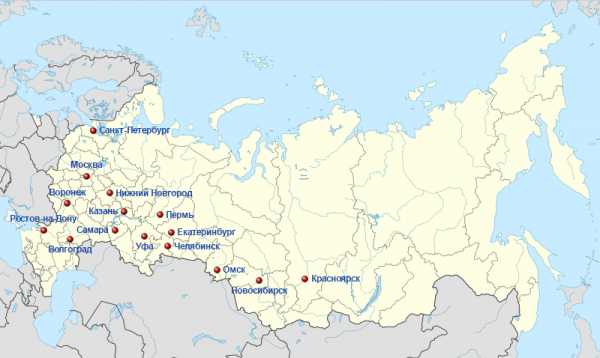
В каждом регионе у нас разные результаты поиска по геозависимым запросам. Прекрасно понимаете для чего это делалось, потому что пользователь, например, из Кемерово, ищущий пиццу, абсолютно не нужны сайты из Москвы, ему нужны сайты именно из Кемерово.
И аналогичная ситуация с Москвой. Нам не нужна пицца из Кемерово в большинстве случаев. Эта региональность, о ней тоже поступает очень много вопросов от вебмастеров, поэтому давайте немножко разберемся, как же с ней правильно работать. Что можно делать?
Во-первых, этой региональностью можно управлять в отношении своего сайта, чтобы поисковая система всегда понимала, к какому региону относится ваш сайт, на какой регион он работает.
Одна из первых рекомендаций – это всегда придерживаться региональности в контенте. В этом случае мы, как поисковая система, можем понять, к какому региону относится ваш сайт, определить его автоматически и присвоить вашему сайту. Это не значит, что достаточно только указать какие-то региональные контакты.
Важно, если вы работаете над определенным регионом, дать пользователю понять, когда он заходит на ваш сайт, что вы работаете с этим регионом. Вы готовы предоставлять ему услугу не хуже, чем в том месте, где находится сама ваша компания. Это очень важно.
Если, помимо этой рекомендации придерживаться региональности в контенте, вы всегда можете присвоить, указать адрес своей компании в Яндекс. Справочнике. Это тоже очень важно.
Если вы не можете указать конкретный адрес, то вы можете указать регион, на который работает ваш сайт в Яндекс. Вебмастере или в Яндекс. Каталоге:
Я рекомендую всегда придерживаться примерно той последовательности, которая изображена именно на этом слайде. Потому что автоматически придерживаться в контенте всегда понятно, для чего вы это делаете. В Справочнике, если вы можете добавить, то это отлично, остальное можно не добавлять, это уже по вашему желанию.
В каждом регионе у пользователей свои интересы и, продолжая анализировать запросы, мы видели, что у разных пользователей еще разные интересы по отношению к разным сайтам.
Кому интересны игры, интересуется играми, сайтами про игры. Те, кто интересуется фильмами, интересны фильмы. Поэтому мы внедрили такой алгоритм, как «Краснодар», который учитывал разнообразие:
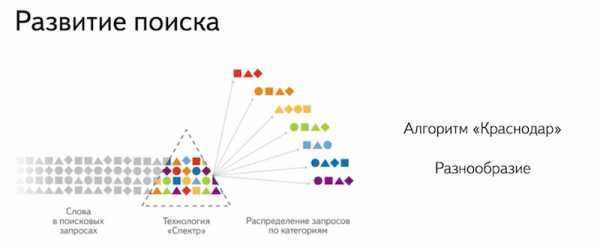
И по одному и тому же запросу два человека, сидящих рядом друг с другом, могли получать абсолютно разные результаты поиска. Например, по запросу «Пушкин» кто-то получает информацию о великом писателе, а другой пользователь по запросу «Пушкин» …
Мы учли разнообразие и увидели, что по разным запросам пользователям появляются разные результаты поиска. Поэтому мы внедряли это разнообразие, которое по запросу «Пушкин» показывало не только все о великом писателе, потому что о нем содержится очень много информации в Интернете, но и другие какие-то объекты.
Например, город Пушкин и т.д., и это касается всего. По запросу «ягуар» вы можете найти информацию не только о животном «ягуар», но и о машине. Стали удовлетворяться интересы очень многих пользователей.
Теперь поговорим о то, что такое персональность.
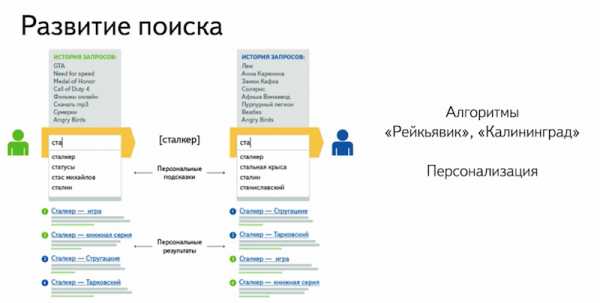
Разные пользователи, интересуясь различными объектами, очень часто направлены на какие-то определенные области запросов. Мы стали внедрять эту персональность, которая отразилась, как в результатах поиска, когда вы по запросу, например, «сталкер» один пользователь видит результаты, которые относятся к играм, а рядом сидящий пользователь видит запросы, которые относятся к фильмам.
Это отразилось не только в результатах поиска, но и в поисковых подсказках. Когда вы вводите запрос, вы всегда можете увидеть какую-то подсказу, которую вы вводили недавно или которая относится к определенной теме.
Развитие поиска. Учитывается юзабилити.
Развивая поиск и видя, что интересы достаточно разные, отношение к сайтам у всех пользователей тоже разное, мы стали обращать внимание на то, как пользователи работают с сайтами, что они с ними делают, какие им сайты нравятся, а какие нет, поэтому стали учитывать юзабилити.
И в юзабилити очень много различных деталей, на которые стоит обращать внимание. Важно, чтобы на вашем сайте была логичная структура, чтобы пользователь, когда попадает на ваш сайт, понимал, что в интернет-магазине, перейдя каталог, он может видеть список товаров. В этом списке товаров он может выбрать каждый товар.
Важно, чтобы была понятная навигация. Очень много пользователей попадает на те или иные страницы сайтов из результатов поиска и потом не знают, что же дальше делать – уйти в результаты поиска или как-то можно дальше с этим сайтом работать.
У меня очень частый кейс, когда я перешел на какой-то товар, я потом не знаю, как же мне попасть на главную страницу этого сайта. Там нигде нет кнопки, ни в навигации, там нет стандартного логотипа, на который мы привыкли кликать и переходить на главную, нет там ничего.
Понятно, что мы можем работать с адресной строкой, мы можем работать с какими-то элементами управления браузера, но всегда можно подсказать пользователю в интерфейсе и сделать понятную навигацию. Это упростит работу с вашим сайтом и, возможно, он на вашем сайте останется дольше, чем на тех, где нет понятной навигации.
Понятный интерфейс. Я думаю, что здесь даже детально не надо ничего раскрывать. Мы должны открывать с вами сайт и представлять, для чего нам кнопки в правом блоке, для чего нам кнопки в левом блоке, и чтобы у нас не было такого, что мы видим кнопки, но не знаем для чего они, а это какое-то ключевое преимущество вашего сайта.
Должен быть внятный дизайн.
Важно, чтобы реклама дополняла основной контент вашего сайта. Она не должна быть такой самоцелью сделать сайт только для рекламы. Большинству пользователей это будет бесполезно, если там не будет основного контента, как-то связанного с этой рекламой.
И самое главное – основной контент должен быть на главном месте. Не должно быть сайтов, которые вы открываете и на первой же странице, на первом экране у вас какой-то огромный баннер или информация только о компании, а пользователь перешел на страницу пылесосов.
Если у вас страница пылесосов, то показывайте ему сразу пылесос, а всю другую информацию, например, о компании или что-то еще старайтесь размазать по странице так, чтобы она была понятна.
Источник (видео): Что учитывается при ранжировании сайтов – Антон Роменский
o-es.ru
Компания Яндекс — Технологии — Результаты поиска
Страница результатов поиска — это ответ Яндекса на вопрос, который пользователь задал в поисковой строке. Она содержит не только ссылки на страницы, на которых нашлась нужная информация, но и дополнительные ответы, которые могут быть полезны пользователю — например, краткую справку об объекте, подходящий колдунщик или контекстные объявления Директа. Яндекс ведёт параллельный поиск по разным массивам информации, и на странице результатов поиска могут появляться картинки, видео и карты, музыкальный плеер, ссылки на товары на Маркете и другие данные. Перейти к ответам другого сервиса можно с помощью вертикального меню в левой части страницы.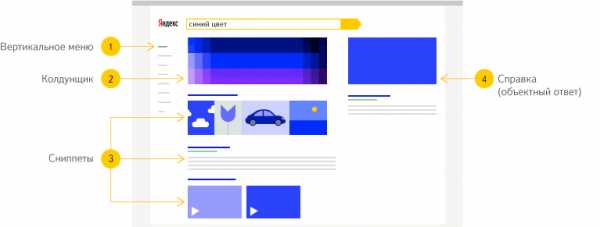
Этот текст рассказывает о том, как выглядят и как устроены результаты поиска по интернету — сниппеты сайтов, найденых по запросу пользователя.
Сниппет — это ссылка на найденную в интернете страницу, с заголовком, небольшим текстом, содержащим основную информацию о документе, и специальными элементами, которые могут меняться в зависимости от типа запроса.
Яндексу важно не просто показать релевантные ответы, но и описать их максимально информативно — так, чтобы пользователь мог понять, какой ответ подходит ему лучше всего сразу, не тратя время на переходы по нескольким ссылкам.
Для заголовка результата поиска Яндекс чаще всего использует заголовок самого документа. Если он слишком длинный, система выбирает фрагмент, который больше всего подходит по смыслу к заданному запросу. Бывает, что у документа нет заголовка или заголовок не соответствует содержанию. Например, названия файлов в формате doc или pdf часто короткие и малоинформативные. В таких случаях Яндекс создаёт заголовок самостоятельно, основываясь на текстах ссылок на документ, заголовках в самом тексте документа и его содержании.
Для формирования описания страницы программа выбирает все фрагменты текста документа со словами из запроса. Каждый из таких фрагментов разбивается ещё на несколько частей — например, со словами из запроса в начале, в конце и в середине. Затем программа сравнивает их между собой и выбирает лучшие — они и попадают в сниппет.
При этом учитываются несколько десятков факторов. Одни из них повышают шансы попадания фрагмента в описание, другие — наоборот. Например, если слово содержится в длинном предложении, высока вероятность, что это часть повествования, а не навигационная ссылка. Значит, это хороший фрагмент для сниппета. Кроме того, Яндекс старается выбирать фрагменты из разных частей текста — так можно полнее описать содержание страницы. А вот фрагмент, схожий с заголовком текста страницы, вряд ли окажется в описании — чтобы не дублировать информацию.
Для каждого фактора компьютерная система рассчитывает коэффициент. С помощью машинного обучения она учится сама понимать значимость факторов, основываясь на данных от специалистов-асессоров. Они просматривают некоторые наборы сниппетов, вручную разделяют их на хорошие и плохие и сообщают эти оценки системе. Затем система уже без помощи людей строит формулу, по которой создает сниппеты.
При ответе на общие, неоднозначные запросы в сниппеты попадают уточняющие слова. Например, описания результатов поиска по запросу [буратино] будут встречаться слова «сказка», «мюзикл» и «огнемётная система». О том, какие слова помогают пользователю сориентироваться, Яндекс узнаёт, анализируя то, как люди переформулируют и уточняют свои запросы, и рассчитывая значимость этих уточнений.
Сниппет оформляется так, чтобы пользователю было легче его воспринимать. Заголовки выделены синим цветом — так традиционно выделяются ссылки в текстах веб-страниц. Узнать знакомый ресурс помогает небольшой фирменный значок сайта, слева от заголовка. Если заголовок или текст описания содержит прописные буквы, Яндекс старается сделать их строчными — так проще читать.
Чтобы было легче «зацепиться глазом», все слова из запроса в результатах поиска выделены жирным шрифтом. При этом Яндекс умеет сопоставлять аббревиатуры и их расшифровки, полные имена, сокращения и инициалы, числа и их текстовое написание. Например, по запросу [петр 1] Яндекс найдет документы, которые содержат и «Петр I», и «Петр первый», и выделит в сниппетах разные варианты написания имени.
Яндекс старается сделать так, чтобы пользователи могли быстро найти ответ — иногда даже сразу на странице результатов поиска. Для разных ответов нужна разная дополнительная информация. Например, если человек задаёт в запросе название организации, возможно, ему нужно узнать, где она находится или как с ней связаться. Чтобы не пришлось тратить время на поиски страницы с контактами на сайте организации, Яндекс добавляет в сниппет её телефон, физический адрес и кнопку, открывающую карту с нужным объектом.
Если Яндексу известна структура сайта, он показывает её пользователю. Под описанием появляются ссылки на его наиболее посещаемые страницы (например, «Контакты», «Галерея» или «Каталог товаров») — чтобы при желании пользователь мог перейти в нужный раздел, тратя меньше кликов и трафика. А адрес документа Яндекс преобразует в навигационную цепочку — названия разделов и подразделов сайта, из которых состоит путь до документа.
Для некоторых предметных областей Яндекс добавляет в ответ специальную информацию. Например, пользователь, который ищет какой-нибудь товар, увидит рейтинг магазина-продавца с Яндекс.Маркета, а ответ на запрос с моделью автомобиля будет содержать объявления о продаже подходящих машин. Благодаря таким сниппетам пользователь экономит время и трафик, а организация получает посетителя сайта, заинтересованного именно в её услугах.
 Владельцы сайтов могут улучшить представление своих ресурсов в результатах поиска Яндекса. Множество инструментов для этого есть на сервисе Яндекс.Вебмастер.
Владельцы сайтов могут улучшить представление своих ресурсов в результатах поиска Яндекса. Множество инструментов для этого есть на сервисе Яндекс.Вебмастер.yandex.ru
Компания Яндекс — Главные новости — Новый алгоритм ранжирования
Интернет, 26 марта 2004. Яндекс изменил алгоритм ранжирования и добавил новые возможности в поиск.
Новый алгоритм учитывает социальную структуру интернета. Он умеет отличать мнение людей от технической, вспомогательной и рекламной информации, то есть лучше распознавать, какой ресурс является авторитетным в своей области.
Также введена дополнительная очистка результатов поиска от дубликатов. Теперь пользователь избавлен от повторения в списке найденного почти одинаковой информации.
«Поиск в интернете — это серьезная наука, поэтому для повышения качества сервиса в Яндексе проводятся регулярные исследования, — говорит Илья Сегалович, технический директор компании. — в прошлом году мы организовали отдел асессоров — пользователей, которые систематически по заданной методике оценивают релевантность результатов. Обратная связь от асессоров дает нам возможность настраивать параметры алгоритма ранжирования и увеличивать точность поиска» .
Стало удобнее работать с региональной информацией. Теперь Яндекс автоматически определяет, в каком городе находится компьютер, с которого поступил запрос, и, если уточнение по региону имеет смысл, предлагает повторить поиск, ограничив его сайтами данного региона.
Поиск поддерживает шесть языков: к русскому и английскому добавились украинский, белорусский, французский и немецкий. Язык документов и сайтов определяется автоматически, а ограничить область поиска нужным языком можно в настройках или расширенном поиске.
Расширенный поиск стал проще и функциональней, заданные с его помощью ограничения теперь видны на странице найденных результатов. Благодаря «умной подсказке» , пользователи расширенного поиска смогут увидеть сформированный запрос, как если бы он был задан на русском языке.
КонтактыКомпания «Яндекс»Елена Колмановская, главный редакторТелефон: +7 (495) 739-7000Факс: +7 (495) 739-7070Электронная почта: [email protected]
yandex.ru
Особенности регионального ранжирования в Яндексе (доклад на конференции "Неделя Байнета 2016")
Регион пользователя стал учитываться Яндексом при ранжировании сайтов в апреле 2009 года. Тогда в анонсе релиза нового алгоритма «Арзамас» в блоге разработчиков Яндекса появилось следующее сообщение (https://yandex.ru/blog/webmaster/3425):«…Теперь поиск Яндекса учитывает регион пользователя. Начиная с "Арзамаса", результаты поиска по одному и тому же запросу могут быть разными в разных регионах… В ранжировании стали учитываться факторы, позволяющие понять, что данная страница важна пользователям именно "своего" региона…»
Регион пользователя по умолчанию определяется автоматически. Однако, в отличие от поисковой системы Google, у Яндекса есть дополнительная возможность задать этот регион вручную на странице http://tune.yandex.ru/region/: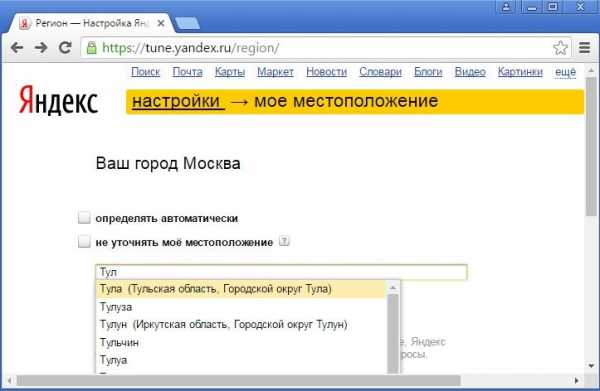
Также в Яндексе можно менять регион результатов поиска с помощью get-параметра lr непосредственно в URL страницы поисковой выдачи (значение lr=15 соответствует городу Тула):
 Список номеров наиболее распространенных регионов можно найти на странице https://yandex.ru/yaca/geo.c2n. Но на самом деле их много больше. Различными методами перебора удавалось найти десятки тысяч уникальных значений номеров для различных населенных пунктов, регионов, территорий и стран.
Список номеров наиболее распространенных регионов можно найти на странице https://yandex.ru/yaca/geo.c2n. Но на самом деле их много больше. Различными методами перебора удавалось найти десятки тысяч уникальных значений номеров для различных населенных пунктов, регионов, территорий и стран. В свою очередь запросы делятся на геонезависимые (ГНЗ) и геозависимые (ГЗ). Для геонезависимых запросов выдача не зависит от значения региона (значения параметра lr) в одной стране, для таких запросов влияние региональности документов на ранжирование равно нулю (lr=15 – Тула, lr=213 – Москва):
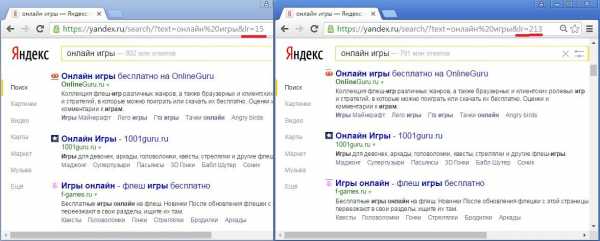
В случае же геозависимых запросов выдача от региона зависит:
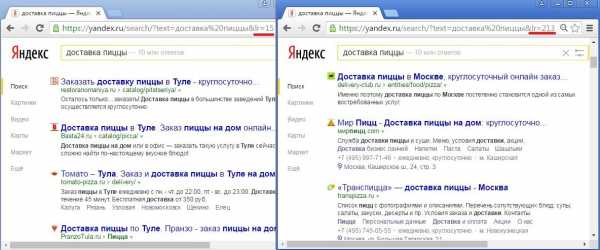
Заметим, что у геозависимых запросов появляется характерный признак – подсветка в сниппетах названия региона.
Кстати, геозависимость запроса – величина не бинарная. Сила влияния региональности документа на ранжирование зависит от степени геозависимости запроса. Выше я привел пример сильно-геозависимого запроса (доставка пиццы), выдача по которому в разных регионах отличается очень заметно. Но есть и запросы со слабой геозависимостью, где различия в региональных выдачах минимальны:
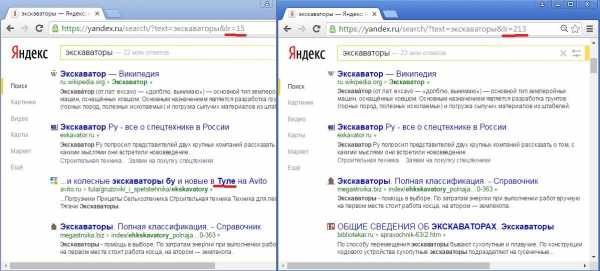
Стоит отметить, что не каждый регион из пронумерованных Яндексом имеет собственную выдачу для геозависимых запросов. Так, например, выдача для регионов из дальнего зарубежья может практически не отличаться даже по сильно-геозависимым запросам:
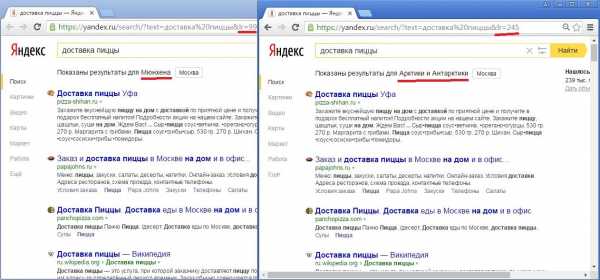
Существует также и особый класс запросов – это запросы, содержащие в себе топонимы, т.е. названия населенных пунктов. Формально эти запросы являются геонезависимыми, т.к. выдача по ним не зависит от региона пользователя. Однако по факту регион, указанный в тексте запроса, влияет на ранжирование, и он же подсвечивается в сниппетах, т.к. является ключевым словом запроса:
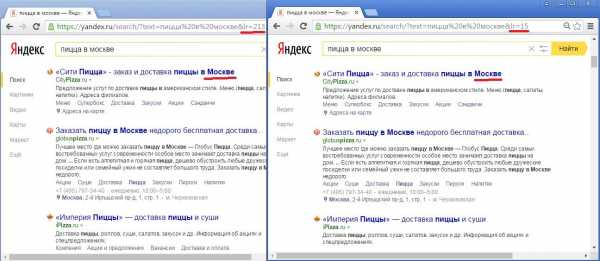
Дело в том, что ГНЗ без топонипов выдача строится по формуле для страны (например, для российских пользователей – по так называемой «общероссийской» формуле), а выдача для запросов с топонимами – по формуле для того региона, который указан в запросе. Это нужно обязательно иметь в виду.
Вообще умение правильно классифицировать геозависимость запросов играет очень большое значение. Так как геозависимые и геонезависимые запросы ранжируются в Яндексе различными формулами, то, к примеру, продвижение одной станицы сайта одновременно по разным типам запросов может вызвать определенные затруднения – у разных формул разные оптимальные значения различных факторов ранжирования.
Казалось бы, что проще – взять и сравнить выдачи по одному запросу для двух разных регионов? В общем-то этот метод определения геозависимости запроса прекрасно работал до недавнего времени, но с запуском «многорукого бандита», перемешивающего топ выдачи, сильно повышается вероятность получения для геонезависимого на самом деле запроса отличающихся выдач в разных регионах, т.е. ложноположительного срабатывания проверки на геозависимость. Да что там говорить о разных регионах, когда даже выдачи по одному запросу для одного региона на одном компьютере в одном браузере, полученные в разные моменты времени, могут отличаться.
Не так давно мне удалось сконструировать достаточно интересный способ проверки запроса на геонезависимость, который не зависит от проделок «многорукого бандита», а также других вещей, искажающих органическую выдачу – различных примесей к органике, пост-штрафов, экспериментов разработчиков Яндекса и т.п. О нем я писал ранее в блоге: http://www.ludkiewicz.ru/2016/05/blog-post.htmlВажную роль в ранжировании геозависимых запросов играет совпадение региона поисковой выдачи и региона сайта.
Иерархию уровней региональности в Яндексе можно представить следующим образом (от более широкого к более узкому):
Весь мир
Континент (напр., Евразия)
Часть света (напр. Европа – кроме России и стран СНГ),
СНГ (только для стран СНГ, кроме России)
Страна (напр., Россия)
Укрупненный регион (напр., Центральный федеральный округ – только для России)
Регион (напр., Тульская область – для отдельных стран)
Район (напр., Городской округ Тула – для отдельных стран)
Населенный пункт (напр., Тула)
Часть населенного пункта (напр., Менделеевский – для отдельных населенных пунктов)
Так вот, самое сильное влияние на выдачу по геозависимым запросам оказывает совпадение региональности выдачи и региональности документа на самом нижнем уровне – как правило, это населенный пункт. Совпадение на более высоких уровнях имеет намного более слабый эффект. Одно из самых распространенных заблуждений, связанных с региональным ранжированием – что присвоение сайту региона более высокого уровня (например, «Россия») даст ему заметное преимущество в ранжировании по всем более нижним уровням (в рамках данного примера – всем населенным пунктам России). Это не так. Сайт с присвоенным регионом «Россия» будет ранжироваться в конкретном населенном пункте России, например, в городе Тула, ровно так же, как сайт, которому привязан к любому населенному пункту из другого российского региона – ведь совпадение региональности в этом случае произойдет также на уровне страны. И будет неизбежно проигрывать при прочих равных сайтам из Тульской области. А сайты из других городов Тульской области, в свою очередь, при прочих равных будут проигрывать сайтам, привязанным к городу Тула. То есть, чем выше в представленной иерархии региональности находится уровень совпадения регионов поисковой выдачи и сайта, тем хуже будет ранжироваться сайт по геозависимым запросам.
В связи с этим нужно запомнить простое правило – если Вы хотите хорошо ранжироваться в выдаче для конкретного населенного пункта, необходимо присвоить сайту/документу в качестве региона непосредственно этот населенный пункт.
Существуют следующие возможности для привязки определенного региона к сайту:
Задание регионов редакторами при регистрации в Яндекс.Каталоге (максимум 7 регионов)
- Задание региона владельцем сайта в Яндекс.Вебмастере (всего 1 регион, при этом необходимо указать страницу сайта, которая содержит информацию о региональной принадлежности). Причем, бета-версия Яндекс.Вебмастера на данный момент имеет более богатый выбор регионов для присвоения сайту, чем основная версия, например, там можно выбрать части населенных пунктов.
Получение регионов из физических адресов организации, к которой привязан сайт, при регистрации организации в Яндекс.Справочнике (неограниченное количество регионов, необходимо пройти процедуру валидации указанного физического адреса организации)
Автоматическое определение региона по найденной в контенте сайта геоинформации (неограниченное количество регионов, региональную привязку могут получать отдельные страницы сайта)
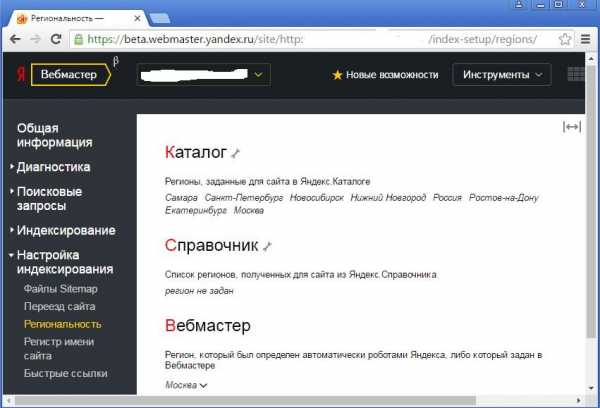
Проверить, какие регионы присвоены сайту, можно разными способами. Официальный способ – с помощью соответствующего режима Яндекс.Вебмастера («География сайта – Регион сайта» в основной версии и «Настройки индексирования – Региональность» в бета-версии). Я рекомендую использовать бета-версию, как дающую более информативный ответ, в частности, там региональная привязка классифицирована по источникам присвоения:
 Альтернативный способ я упоминал в своей статье «Сеанс поисковой магии, или смещения в языке запросов Яндекса». Это проверка региональной привязки для отдельного документа с помощью оператора языка запросов Яндекса cat: с использованием в качестве его значений определенных смещений, которые суммируются с кодом проверяемого региона. Для проверки региональной привязки, заданной через Яндекс.Каталог можно использовать документированное смещение 11000000:
Альтернативный способ я упоминал в своей статье «Сеанс поисковой магии, или смещения в языке запросов Яндекса». Это проверка региональной привязки для отдельного документа с помощью оператора языка запросов Яндекса cat: с использованием в качестве его значений определенных смещений, которые суммируются с кодом проверяемого региона. Для проверки региональной привязки, заданной через Яндекс.Каталог можно использовать документированное смещение 11000000: 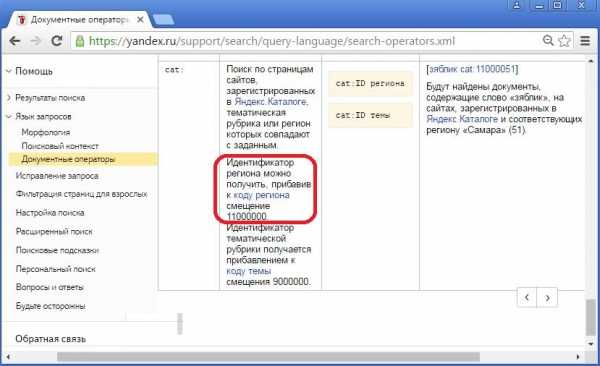
Существуют также недокументированные смещения:
21000000 – региональность, присвоенная через Яндекс.Вебмастер или автоматически
31000000 – региональность, присвоенная автоматически
51000000 – региональность, присвоенная автоматически
61000000 – региональность, присвоенная автоматически
71000000 – региональность, присвоенная автоматически
81000000 – региональность, присвоенная через Яндекс.Справочник
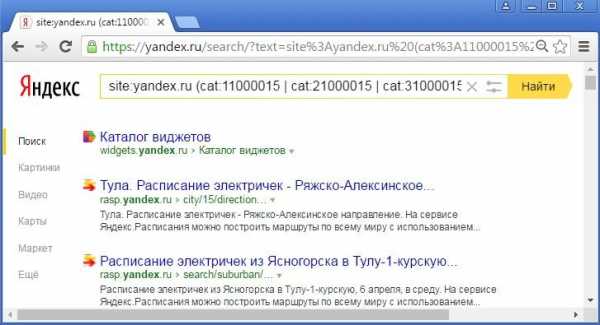
Скомбинировав эти смещения в одном запросе, мы можем получить универсальный запрос для проверки привязки к определенному региону как отдельного документа, так и группы документов, например, всех документов с конкретного сайта. Например, для города Тула с кодом региона 15, комбинация смещений будет выглядеть следующим образом:
(cat:11000015 | cat:21000015 | cat:31000015 | cat:51000015 | cat:61000015 | cat:71000015 | cat:81000015)
Можно убедиться, что, к примеру, для сайта yandex.ru привязку к региону «Тула», имеют, в основном, страницы сервиса Яндекс.Расписания, очевидно, получившие эту привязку автоматически вследствие упоминания топонима «Тула» в своем контенте:
Отдельно стоит упомянуть о наследовании поддоменами региональности от основного (родительского) домена. Поддомены наследуют по умолчанию те регионы родительского домена, которые были присвоены через Яндекс.Каталог (однако, информация о наследуемых регионах не отображается в Яндекс.Вебмастере). Регионы же, присвоенные через Яндекс.Справочник, поддоменом не наследуются. Наследование поддоменом регионов от родительского домена может быть аннулировано в случаях:
регистрации поддомена в Яндекс.Каталоге как самостоятельного ресурса;
отдельной привязки поддомена к зарегистрированной в в Яндекс.Справочнике организации;
присвоения поддомену региона через Яндекс.Вебмастер.
В обратную сторону (от поддомену к родительскому домену) перехода региональности не происходит вне зависимости от способа её привязки к поддомену.
Зачастую перед сайтом стоит задача хорошего ранжирования по геозависимым запросам в нескольких регионах. Для этого необходима привязка к сайту всех интересующих регионов. С учетом особенностей различных способов привязки региона к сайту можно обозначить две основные стратегии присвоения регионов для мультирегиональных сайтов.
В силу того, что Яндекс.Каталог представляется наименее предпочтительным инструментом ввиду отсутствия гибкости и ограничения на количество регионов, будем рассматривать варианты региональной привязки через Яндекс.Справочник и Яндекс.Вебмастер.
Стратегия на основе Яндекс.Справочника подходит для случаев, когда нет проблем с верификацией физических адресов организации в интересующих регионах. В реквизитах каждого такого физического адреса организации, зарегистрированного в Яндекс.Справочнике, нужно прописать адрес сайта. Важный момент – вследствие того, что поддомены не наследуют от родительского домена региональную привязку, полученную через Яндекс.Справочник, всю важную для мультирегионального ранжирования информацию следует располагать на основном домене.
Стратегия на основе присвоения региона через Яндекс.Вебмастер подходит для случаев, когда возникают проблемы с верификацией физических адресов организации в интересующих регионах через Яндекс.Справочник. Дело в том, что эта процедура довольно жесткая, и не все сайты в состоянии ее пройти для всех интересующих их регионов, т.к. надо иметь реально работающий офис по указанному при регистрации адресу. Верификация же региональной привязки через Яндекс.Вебмастер гораздо более мягкая, единственное требование – наличие страницы, содержащей региональную принадлежность (например, «Контакты»). Однако региональная привязка в Яндекс.Вебмастере ограничена только одним регионом. Поэтому возникает необходимость создания под каждый интересующий регион отдельного регионального поддомена. Эти поддомены можно зарегистрировать в Яндекс.Вебмастере, как отдельные сайты, и привязать через него к каждому поддомену соответствующий регион.
www.ludkiewicz.ru