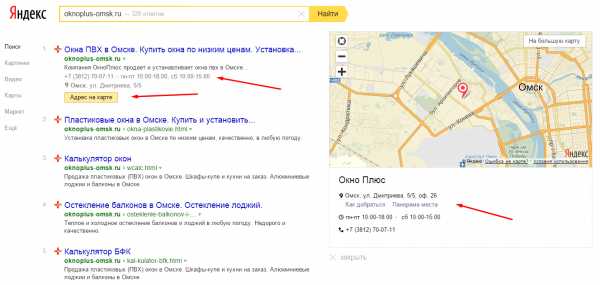
Поисковые системы и их алгоритмы ранжирования. Алгоритмы ранжирования поисковых систем
Поисковые алгоритмы Google и Yandex 🚀 хронология
Все мы не понаслышке знаем о существующих алгоритмах поисковых систем Яндекс и Google. Именно для соблюдения их «постоянно обновляемых» правил все оптимизаторы ломают свой мозг все новыми и новыми способами попасть в ТОП выдачи поиска. Из последних новшеств, которые ощутили на себе владельцы сайтов со стороны ПС — это требования к мобильности интернет-ресурсов и понижение в поиске тех площадок, которые не умеют покупать ссылки. Какие алгоритмы до этого времени, внедренные в поиск, существенно повлияли на ранжирование сайтов? На самом деле, не все оптимизаторы знают, какие технологии, когда и зачем были созданы, чтобы максимально справедливо дать позицию каждому сайту в поиске и очистить выдачу от «хлама». Историю создания и развития поисковых алгоритмов мы и рассмотрим в этой статье.
Яндекс: виды алгоритмов с зачатия до сегодня

Алгоритмы не создавались все в один день, и каждый из них проходил много этапов доработки и преобразования. Основная масса названий алгоритмов Яндекса состоит из названий городов. Каждый из них имеет свои принципы работы, точки взаимодействия и уникальные функциональные особенности, гармонично дополняющие друг друга. Какие алгоритмы есть у Яндекса и как они влияют на сайты, рассмотрим далее.
Помимо информации о поисковых алгоритмах полезной будет и статья про новые фишки в Яндекс Директ. Советы по созданию качественного SEO-контента подходящего для поисковиков Гугл и Яндекс я предлагаю вам прочесть по этой ссылке.
Магадан
Алгоритм «Магадан» распознает аббревиатуры и отожествляет существительные с глаголами. Был впервые запущен в тестовом режиме в апреле 2008, а вторая постоянная версия вышла в свет в мае того же года.
Особенности
«Магадан» выдает пользователю, который написал аббревиатуру, сайты и с расшифровками. Например, если в поисковой строке вбили запрос МВД, то кроме площадок с таким ключевым словом в списке будут присутствовать и те, у кого аббревиатуры нет, но есть расшифровка «Министерство внутренних дел». Распознавание транслитерации дало пользователям возможность не думать на каком языке правильно писать названия, к примеру, Mercedes или Мерседес. Ко всему этому Яндекс включил в список индексирования почти миллиард зарубежных сайтов. Распознавание частей речи и признание их равноценными поисковыми запросами выпустили в один поиск сайты с разными ключевыми фразами. То есть теперь по ключевику «оптимизация сайтов» в выдаче выводятся и площадки с вхождением словосочетания «оптимизировать сайт».
Результаты
После запуска алгоритма «Магадан» стало труднее, в основном, малоавторитетным сайтам. В ранжировании понизились позиции по релевантным запросам малопосещаемые и молодые ресурсы, а на первые места выдвинулись авторитетные, даже с некачественным контентом, учитывая при этом морфологию и разбавленность ключевиков. Из-за учета транслитерации в ТОП Рунета вышли и зарубежные ресурсы. То есть оптимизированный текст по теме мог оказать на второй странице, только потому, что, якобы, по этой же тематике есть более посещаемый сайт или аналогичный зарубежный. Из-за этого резко возросла конкуренция по низкочастотным ключевикам и иностранным фразам. Подорожала и реклама — ставки возросли, потому что ранее сайты конкурировали только по одному конкретному запросу, а теперь и с «коллегами» с морфологическими фразами, транслитерацией, переходящими в другую часть речи словами.
Находка
Алгоритм «Находка » — расширенный тезаурус и внимательное отношение к стоп-словам. Выпущен «на ринг» сразу после «Магадана». Ранжирует основную выдачу с сентября 2008.
Особенности
Это инновационный подход к машинному обучению — ранжирование стало четче и корректней. Расширенный словарь связей и внимательность к стоп-словам в алгоритме «Находка» очень сильно повлияли на поисковую выдачу. К примеру, запрос «СЕО оптимизация» теперь ассоциировался и с ключем «сеооптимизация», а коммерческие сайты разбавлялись информационными порталами, в том числе в списке появились развернутые сниппеты с ответами, по особенному отображалась Википедия.
Результаты
Коммерческие сайты сделали больший акцент на продажные запросы, так как конкуренция увеличилась по информационным не конкретным фразам в несколько раз. В свою очередь, информационные площадки смогли расширить свою монетизацию с помощью страниц рекомендаций, участвуя в партнерских программах. Топовые инфосайты, продвинутые по коммерческим запросам стали продавать ссылки на заказ. Конкуренция ужесточилась.
Арзамас
Алгоритм «Арзамас» — внедрена лексическая статистика поисковых запросов и создана географическая привязка сайта. Первая версия «Арзамаса» (апрель 2009) без геозависимости выпущена сразу в основную выдачу, а «Арзамас 2» с классификатором по привязке сайта к региону анонсирован в августе 2009.
Особенности
Снятие привязки к омонимам облегчила пользователю жизнь, ведь теперь по фразе «американский пирог» выдавались только сайты на тему фильмов, без всяких там рецептов десертов, как могло быть раньше. Привязка к региону совершила прорыв, сместив ключевые фразы с добавкой города на несколько пунктов вниз. Теперь пользователь мог просто ввести слово «рестораны» и увидеть в лидерах только сайты из города его местонахождения. Если помните, раньше нужно было бы ввести более конкретную фразу, например «Рестораны в Санкт-Петербурге», иначе Яндекс мог выдать ответ «уточните запрос — найдено слишком много вариантов». Геонезависимые ключевые слова выдавали только релевантные запросу сайты из любых регионов, без привязки.
Результаты
Ура! Наконец-то сайты из небольших регионов перестали конкурировать с крупными мегаполисами. Выйти в ТОП по своему региону теперь намного проще. Именно в этот период времени была предложена услуга «региональное продвижение». Алгоритм «Армазас» дал возможность мелким компаниям быстрее развиваться в своей местности, но подвох все равно остался. Яндекс не мог определить геолокацию у всех площадок. И как вы сами понимаете — без привязки ресурсы оставались, мягко говоря, в одном не очень приятном месте. Рассмотрение заявки на геозависимость могло длиться несколько месяцев, а молодые сайты без трафика и ссылочной массы (было ограничение по ТИЦ), вообще, не могли подать запрос на присвоение им региональности. Палка о двух концах.
Снежинск
Алгоритм «Снежинск» — усиление геозависимости и уточнение релевантности запросов к выдаче с помощью технологии машинного обучения «Матрикснет». Анонс состоялся в ноябре 2009, а улучшенная модель под именем «Конаково» заработала в декабре того же года.
Особенности
Поисковая выдача стала более точной к вводимым вопросам. Особую роль теперь играет привязка по геолокации — коммерческие сайты не ассоциировались у алгоритма «Снежинск» с регионами, поэтому выпадали из выдачи. Ключевые слова, не привязанные к местности, отожествляются с информационными ресурсами. Сложная архитектура подсчета релевантности сильно усложнила жизнь оптимизаторов, которые заметили, что при малейшем изменении одного из показателей, позиция сайта в выдаче моментально изменялась.
Результаты
На тот момент было отмечено, что закупка внешних ссылок на молодые сайты влияла на показатели новых ресурсов слишком вяло, если сравнить аналогичную закупку на площадку, давненько находящуюся на интернет-рынке. Новые методы определения релевантности контента к поисковым запросам выбрасывали из выдачи сайты, тексты которых были перенасыщены ключевыми фразами. Началась новая эра качественного текста, где во всем должна была быть мера, без нее площадка могла просто попасть под санкции за спам. Коммерческие ресурсы забили панику, потому что выйти по геонезависимым ключевым словам в ТОП (а они были самые высокочастотные) было практически нереально. В связи с этим на блоге Яндекса была опубликована запись, что в идеале хотелось бы видеть на первых страницах коммерческие организации, которые не пишут красиво, а выполняют свою работу хорошо, но для этого придется научить алгоритмы оценивать качество предлагаемых услуг. Так как на данный момент это оказалось непосильной задачей, репутация коммерческих интернет-ресурсов играла ключевую роль в выдаче, как в онлайне так и в оффлайне.
Обнинск
Алгоритм «Обнинск» — улучшение ранжирования и расширения базы географической принадлежности интернет-площадок и снижение влияния на показатели сайта искусственных СЕО-ссылок. Запущен в сентябре 2010.
Особенности
Падает популярность закупки ссылочных масс, появляется понятие «ссылочного взрыва», которого теперь боялись все. Конкуренты могли навредить друг другу возможностью введения алгоритма в заблуждение, закупив на «коллегу» огромное количество ссылок с «плохих источников». После этого конкурент выпадал из поисковой выдачи и долго не мог туда попасть. Геозависимые слова чаще добавляются на разные страницы коммерческих сайтов, чтобы обратить внимание робота на работу с этим регионом.
Результаты
Коммерческие сайты теперь тщательней относятся к своей репутации, что не может не радовать, но многие все равно прибегали к грязным методам (искусственно завышали посещаемость и покупали отзывы). После выпуска алгоритма «Обнинск» более популярной стала закупка вечных ссылок и статей, обычная покупка ссылок уже так не влияла на ранжирование, как раньше, а в случае попадания источника бэклинка под санкции могла потянуть за собой цепную реакцию. Качественные СЕО-тексты — обязательный атрибут любого ресурса. Молодой сайт с уникальным и правильно оптимизированным контентом мог попасть в ТОП.

Краснодар
Алгоритм «Краснодар» — внедрение технологии «Спектр» для разбавления поисковой выдачи, расширения сниппетов и индексация социальных сетей. Запуск состоялся в декабре 2010 года.
Особенности
Технология «Спектр» была создана для классификации запросов по категориям и использовалась в случаях ввода не конкретизированных ключевых фраз. «Краснодар» разбавлял поисковую выдачу, предлагая такому пользователю больше разнообразных вариантов. Например, при фразе «фото Москвы» в поиске можно было увидеть не только общие пейзажи, но и фотографии по категориям типа «достопримечательности», «карты», «рестораны». Был сделан акцент на уникальные названия чего-либо (сайтов, моделей, товаров) — конкретика стала выделяться. Расширенные сниппеты дали возможность сразу в поисковой выдаче показывать пользователям контакты и другие данные организаций.
Результаты
Сильно изменилось ранжирование коммерческих сайтов, особое внимание уделяется деталям (карточкам товаров, разделением короткого описания от общего). Социальная сеть в ВК начала индексироваться и профили участников равноценно теперь видны прямо в поисковой выдаче. Сообщения в форумах могли занимать первые позиции, если имели более расширенный ответ на вопрос пользователя, чем другие сайты.
Рейкьявик
Алгоритм «Рейкьявик» — создана персонализация поисковой выдачи и добавлена технологи «Колдунщики» для отображения предварительных итогов запроса. Улучшена формула подсказок при вводе. Алгоритм запущен в августе 2011 года.
Особенности
Девизом персонализированного поискового результата — «Каждому пользователю — своя выдача». Система запоминания интересов ищущих работала через куки, поэтому если запросы пользователя чаще были связаны, например, с зарубежными ресурсами, в следующий раз в лидерах поисковой выдачи отображались именно они. Подсказки в поисковой строке обновляются каждый час, тем самым расширяя возможности конкретизированного поиска. Конкуренция по высокочастотным запросам возрастает с неимоверной силой.
Результаты
Авторитетные новостные сайты чаще попадают в ТОП из-за расширенного семантического ядра (наличие огромного количества разных низкочастотных ключевых запросов). Увеличение количества страниц под конкретные поисковые запросы на информационных сайтах стала играть одну из главных ролей после выпуска алгоритма «Рейкьвик». Каждая площадка пыталась попасть в закладки пользователя, чтобы стать частью системы персонализации, для этого использовались методы подписки на RSS ленту, всплывающие баннеры-подсказки для занесения сайта в закладки. Интернет-ресурсы начали больше уделять внимания индивидуальному подходу, а не давить на массы.
Калининград
Алгоритм «Калининград» — глобальная персонализация поиска и поисковой строки, упор на поведенческие факторы. Запуск «Калининграда» в декабре 2012 существенно повысил стоимость seo услуг.
Особенности
Интересы пользователя перевернули с ног на голову всю поисковую выдачу — владельцы сайтов, ранее не заботившиеся о комфорте пребывания посетителя на сайте, стали терять трафик с молниеносной скоростью. Теперь Яндекс делил интересы на краткосрочные и долговременные, обновляя свои шпионские базы раз в сутки. Это означало, что сегодня и завтра по одному и тому же запросу одному и тому же пользователю могла показываться совершенно иная выдача. Интересы теперь играют особую роль и пользователю, который ранее интересовался поездками, вбивая фразу такси — показываются услуги такси, а тому, кто постоянно смотрит фильмы — получит в результатах поиска все о кинокомедии «Такси». В поисковой строке каждого «страждущего найти информацию» теперь на первых позициях отображаются подсказки по предыдущим интересам.
Результаты
Оптимизаторы стали охватывать все больше способов задержать пользователя: улучшалось юзабилити, дизайн, контент создается более разнообразный и качественный. При выходе могли всплывать окна типа «вы уверены, что хотите покинуть страницу» и в пользователя впивалась грустная рожица какого-то существа. Хорошо продуманная перелинковка страниц и всегда доступное меню улучшали показатели активности пользователей, чем повышали позиции сайтов в поисковой выдаче. Малопонятные широкому кругу интернет-пользователей сайты сначала просто понижались в позициях, а после и вообще болтались в конце списка предложенных результатов.
Дублин
Алгоритм «Дублин» — улучшена персонализация с помощью определения текущих целей. Это модернизированная версия «Калининграда» вышла в мир в мае 2013.
Особенности
В технологию внедрена функция слежения за изменчивыми интересами пользователей. То есть при наличии двух совершенно разных поисковых взглядов за определенный период времени, алгоритм предпочтет последний и включит его в поисковую выдачу.
Результаты
Для сайтов практически ничего не изменилось. Продолжается борьба не просто за трафик, а за улучшение поведенческих показателей. Старые макеты сайтов начинают забрасываться, потому что проще делать новый, чем пытаться исправить что-то на старом. Предложение услуг шаблонов сайтов увеличивается, начинается конкуренция за удобные и красивые макеты вебресурсов.
Острова
Алгоритм «Острова» — внедрена технология показа интерактивных блоков в поисковой выдаче, позволяя взаимодействовать пользователю с сайтом прямо на странице Яндекс поиска. Алгоритм был запущен в июле 2013 года, с предложением к вебмастерам активно поддержать бета-версию и использовать шаблоны создания интерактивных «островов». Сейчас технология тестируется в закрытом режиме.
Особенности
Теперь пользователю при поиске информации, которую можно узнать сразу из поиска предлагались «острова» — формы и другие элементы, с которыми можно работать, не посещая сайт. Например, вы ищете конкретный фильм или ресторан. По фильму в поиске и справа от него отобразятся блоки с обложкой фильма, его названием, составом актеров, часами прохождения сеансов в кинотеатрах в вашем городе и формой покупки билетов. По ресторану будет показано его фото, адрес, телефоны, форма бронирования столика.
Результаты
Ничего существенного в ранжировании сайтов сначала не изменилось. Единственное, что стало заметным — это появление вебресурсов с интерактивными блоками на первом месте и справа от поисковой выдачи. Если бы количество площадок, принимавших участие в бета-тестировании было значительным, они могли бы вытеснить обычные сайты за счет своей привлекательности и броскости для пользователей. Оптимизаторы задумались об улучшении видимости своего контента в поисковых результатах, добавляя больше фото, видео, рейтинги и отзывы. Лучше живется интернет-магазинам — корректно настроенные карточки товара могут быть отличным интерактивным «островком».
Минусинск
Алгоритм «Минусинск» — при определении SEO-ссылок как таковых, которые были куплены для искажения результатов ранжирования поиска, на сайт ложился фильтр, который существенно портил позиции сайта. Анонсирован «Минусинск» в апреле 2015, полностью вступил в свои права в мае этого же года. Именно с этим алгоритмом и связана знаменитая Санта Барбара Яндекс.

Особенности
Перед выходом «Минусинска» Яндекс в 2014 для тестирования отключил влияние SEO-ссылок по множеству коммерческих ключей в Москве и проанализировал результаты. Итог оказался предсказуемым — покупная ссылочная масса все еще используется, а для поисковой системы — это спам. Выпуск «Минусинска» знаменовался днем, когда владельцы сайтов должны были почистить свои ссылочные профили, а бюджет, который тратится на ссылочное продвижение, использовать для улучшения качества своего интернет-ресурса.
Результаты
«Авторитетные» сайты, которые добились ТОПа благодаря массовой закупке ссылок, вылетели из первых страниц, а некоторые получили санкции за нарушения правил. Качественные и молодые площадки, не наглеющие по бэклинкам, внезапно оказались в ТОП 10. «Попавшие под раздачу» вебсайты, нежелающие долго ждать, создавали новые площадки, перенося контент и ставя заглушку на старые, либо хитро шаманили с редиректом. Примерно через 3 месяца нашли дыру в алгоритме, позволяющую почти моментально снимать данный фильтр.
Массово начинает дорабатываться юзабилити и улучшаться контент. Ссылки закупаются с еще большей осторожностью, а контроль за бэклинками становится одной из функциональных обязанностей оптимизатора.
По данным на сегодня — при неумелой закупке ссылок — даже за 100 ссылок можно получить фильтр. Но если ссылочную массу правильно разбавлять, то смело можно покупать тысячи ссылок как и в старые добрые. То-есть, по сути — сильно выросли ссылочные бюджеты на это самое разбавление, в роли которого выступил крауд и упоминания.
Владивосток
Алгоритм «Владивосток» — внедрение в поиск технологии проверки сайта на полную совместимость с мобильными устройствами. Полный старт проекта произошел в феврале 2016 года.
Особенности
Яндекс сделал очередной шаг навстречу к мобильным пользователям. Специально для них был разработан алгоритм «Владивосток». Теперь для лучшего ранжирования в мобильном поиске сайт обязан соответствовать требованиям мобилопригодности. Чтобы опередить своих конкурентов в поисковой выдаче интернет-ресурс должен корректно отображаться на любом web-устройстве, включая планшеты и смартфоны. «Владивосток» проверяет отсутствие java и flash плагинов, адаптивность контента к расширению экрана (вместимость текста по ширине дисплея), удобство чтения текста и возможность комфортно нажимать на ссылки и кнопки.
Результаты
К запуску алгоритма «Владивосток» мобилопригодными оказались всего 18% сайтов — остальным пришлось быстренько избавляться от «тяжести» на страницах, которая не отображается или мешает корректно отображаться контенту на смартфонах и планшетах. Основным фактором, который влияет на понижение вебсайта в мобильной выдаче — это поведение мобильного пользователя. Во всяком случае, пока. Ведь идеально мобилопригодных сайтов не так уж много, поэтому свободные места в поиске занимают те, кто способен предоставить пользователю максимально комфортные условия, пусть даже не полностью. Из мобильного поиска неадаптированные к мобильным устройствам сайты не выбрасываются, а просто ранжируются ниже тех, кто достиг в улучшении качества предоставления услуг для смартпользователей лучших результатов. На данный момент самый популярный вид заказов макетов сайтов — адаптивные, а не мобильные, как можно было подумать. Прошедшие все требования алгоритма сайты получают максимальное количество мобильного трафика в своей нише.
Google: история создания и развития алгоритмов
Алгоритмы и фильтры Гугла и до сей поры не совсем поняты русскоязычным оптимизаторам. Для компании Google всегда важным моментом являлось скрытие подробностей по методам ранжирования, объясняя это тем, что «порядочным» сайтам боятся нечего, а «непорядочным» лучше не знать, что их ожидает. Поэтому про алгоритмы Гугла до сих слагают легенды и множество информации было получено только после того, как задавались вопросы поддержке, когда сайт проседал в поисковой выдаче. Мелких доработок у Google было столько, что и не перечесть, а на вопросы, что именно изменилось, зарубежная ПС просто отмалчивалась. Рассмотрим основные алгоритмы, которые влияли на позиции сайтов существенно.

Кофеин
Алгоритм «Кофеин» — на первой странице поиска может находиться сразу несколько страниц одного и того же сайта по бренду, появляется возможность пред просмотра. Запуск произошел в июне 2010 года.
Особенности
Выделение сайтов компаний, в случае поиска по бренду. Возле строки с выдачей появляется «лупа» для предосмотра. Ключевые слова по бренду дают положительную тенденцию роста на позициях интернет-ресурса в целом. Обновился индекс Page Rank, при этом PR повысился на известных и посещаемых площадках.
Результаты
Оптимизаторы стали больше уделять внимания брендированию вебсайтов, включая цветовые схемы, логотипы, названия. Ключевые слова на бренд по-особенному выделяли страницы сайта в поиске, а при переходе с такой фразы посетителя на главный page, его позиции в выдаче росли (если до этого ресурс был не лидером). СЕО-оптимизаторы стали закупать больше ссылок для повышения «цитированности». молодым и малоузнаваемым брендам практически невозможно было пробиться в ТОП выдачи.
Panda (Панда)
Алгоритм «Панда» — технология проверки сайта на качество и полезность контента, включая множество СЕО факторов. Сайты с «черным» SEO исключаются из поиска. Анонсирована «Panda» в январе 2012 года.
Особенности
«Панда» вышла в поиск и почистила его от мусора. Именно так можно сказать после того, как множество не релевантных ключевым запросам web-сайты исчезли из выдачи Google. Алгоритм обращает внимание на: переспам ключевыми словами и неравномерное их использование, уникальность контента, постоянство публикаций и обновления, активность пользователя и взаимодействие его с сайтом. Пролистывание посетителя страницы до конца со скоростью чтения считалось положительным фактором.
Результаты
После включения «Панды» огромное количество сайтов поддались санкциям с боку поисковой системы Google и поначалу все думали, что это связано с участием в ссылочных пирамидах и закупкой ссылочных масс. В итоге, СЕОоптимизаторы провели процесс тестирования алгоритма и проанализировали влияние. Вывод экспериментов заключался в том, что «Панда» все-таки проверяет качество сайта на ценность для посетителей. Интернет-ресурсы перестали копипастить и активно принялись за копирайтинг. Поведенческие факторы улучшались за счет преобразования структуры сайта в более удобные варианты, а перелинковка внутри статей с помощью особых выделений стала важной частью оптимизации. Популярность SEO как услуги стремительно возросла. Замечено, что сайты, не соответствующие правилам «Панды», исчезали из поиска очень быстро.
Page Layout (Пейдж Лайот)
Алгоритм «Пейдж Лайот» — технология по борьбе с поисковым спамом, подсчитывающая на страницах web-сайтов соотношение полезного контента к спамному. Запущен в январе 2012 и обновлялся до 2014 включительно.

Особенности
«Page Layout» был создан после многочисленных жалоб пользователей на недобросовестных владельцев сайтов, у которых на страницах подходящего контента было совсем мало или искомые данные оказывались труднодоступными, а иногда вообще отсутствовали. Алгоритм рассчитывал в процентном соотношении нахождение на странице по входящему запросу релевантного контента и спама. На несоответствующие требованиям площадки накладывались санкции и сайт выбрасывался из поиска. К несоблюдению правил размещения документов также относилось забитая рекламой шапка сайта, когда для просмотра текста требовалось перейти на второй экран.
Результаты
Слишком заспамленные рекламой сайты слетели со своих позиций, даже при том, что контент на страницах был оптимизирован под ключевые слова в меру. Нерелевантные запросам страницы были понижены в поисковой выдаче. Но площадок нагло не соблюдая правила и не беспокоясь о комфортности посетителей оказалось не так уже и много. За три обновления алгоритма приблизительное количество ресурсов, попавших под фильтр, оказалось не более 3%.

(Венеция)
Алгоритм «Венеция» — геопривязка сайта к определенному региону, учитывая при этом наличие названий городов на страницах сайта. Запущен в феврале 2012 года.
Особенности
«Венеция» требовала от вебмастеров наличие на их сайтах страницы «О нас», с указанием адреса местоположения, не обращая при этом внимания, что фактического расположения у компании могло и не быть. В контексте алгоритм искал названия городов, чтобы вывести отдельную страницу по указанному в нем региону. Начала использоваться разметка schema-creator.org, чтобы пояснить поисковому роботу свою географическую привязанность.
Результаты
Сайты выпали в поисковой выдаче по тем регионам, о которых они не упоминают на своих страницах, не учитывая геонезависимые запросы. Оптимизаторы активно включают геозависимые ключевые слова и пытаются создавать микроразметку. Контент на каждой странице персонализируется под каждый конкретный город или регион в целом. Активно стал использоваться локализированный линкбилдинг, чтобы повышать позиции по выбранному региону.

(Пингвин)
Алгоритм «Пингвин» — умная технология определения веса сайтов и качества обратных ссылок. Система редактирования накрученных показателей авторитетности интернет-ресурсов. Запущена в поиск в апреле 2012.
Особенности
«Пингвин» нацелен на войну с закупкой обратных ссылок, неестественным, то есть искусственным, набором авторитетности сайта. Алгоритм формирует свою базу значимых ресурсов, исходя от качества бэклинков. Побуждением на запуск «Пингвина» являлось появление ссылочных оптимизаторов, когда любая ссылка на вебресурс имела одинаковый вес и подымала такой сайт в поисковой выдаче. Кроме этого, в поиске начали ранжироваться наравне со стандартными интернет-ресурсами обычные профили пользователей социальных сетей, что еще больше популяризовало раскрутку обычных сайтов с помощью социальных сигналов. Одновременно с этими возможностями алгоритма система стала бороться с нерелевантными вставками поисковых запросов в keywords и в названия доменов.
Результаты
Пингвин «попустил» множество сайтов в поисковой выдаче за неестественный рост обратных ссылок и нерелевантность контента к запросам пользователей. Значимость каталогов и площадок по продаже ссылок быстро снижалось к минимуму, а авторитетных ресурсов (новостных сайтов, тематических и околотематических площадок) росло на глазах. Из-за введения алгоритма «Пингвин» у, практически, всех публичных сайтов был пересчитан PR. Популярность массовой закупки бэклинков резко упала. Сайты максимально начали подгонять ключевые фразы к контенту на страницах площадок. Началась «мания релевантности». Установка социальных кнопок на страницах в виде модулей имела массовый характер за счет быстрой индексации аккаунтов социальных сетей в поиске.
Pirate (Пират)
Алгоритм «Пират» — технология реагирования на жалобы пользователей и выявления фактов нарушения авторских прав. Старт системы произошел в августе 2012 года.
Особенности
«Пират» принимал жалобы авторов на нарушение их авторских прав владельцами сайтов. Кроме текстов и картинок, основной удар на себя приняли площадки с видео-контентом, которые размещали пиратские съемки фильмов из кинотеатров. Описания и рецензии к видео тоже подверглись фильттрованию — теперь не разрешалось копипастить под страхом наложения санкций. За большое количество жалоб на сайт за нарушения, такая площадка выкидывалась из поисковой выдачи.
Результаты
По результатам первого месяца работы «Пирата» от Google на практически всех сайтах, включая видехостинги и онлайн-кинотеатры, были заблокированы к просмотру миллионы видео-файлов, нарушающих права правообладателей. Вебсайты, имеющие только пиратский контент, оказались под санкцией и выпали из поиска. Массовая зачистка от «ворованного» контента продолжается до сих пор.
HummingBird (Колибри)
Алгоритм «Колибри» — внедрение технологии понимания пользователя, когда запросы не соответствуют точным вхождениям. Запущена система «определения точных желаний» в сентябре 2013 года.

Особенности
Теперь пользователь не изменял фразу, чтобы конкретней найти нужную информацию. Алгоритм «Колибри» давал возможность не искать по прямым точным вхождениям, а выдавал результаты из базы «расшифровки пожеланий». Например, пользователь вбивал в поисковую строку фразу «места для отдыха», а «Колибри» ранжировала в поиске сайты с данными о санаториях, отелях, СПА-центрах, бассейнах, клубах. То есть в алгоритме были сгруппирована стандартная база с человеческими фразами об их описании. Понимающая система изменила поисковую выдачу существенно.
Результаты
С помощью технологии «Колибри» сеооптимизаторы смогли расширить свое семантическое ядро и получить больше пользователей на сайт за счет морфологических ключей. Ранжирование площадок уточнилось, потому что теперь учитывались не только вхождения прямых ключевых фраз и релевантных тексту запросов, но и околотематические пожелания пользователей. Появилось понятие LSI-копирайтинг — написание текста, учитывающего латентное семантическое индексирование. То есть теперь статьи писались не только со вставкой ключевых слов, но и максимально включая синонимы и околотематические фразы.

(Голубь)
Алгоритм «Голубь» — система локализации пользователей и привязки поисковой выдачи к месту нахождения. Технология запущена в июле 2014 года.
Особенности
Месторасположение пользователя теперь играло ключевую роль для выдачи результатов. Органический поиск превратился в сплошную геолокацию. Привязка сайтов к Гугл-картам сыграла особую роль. Теперь при запросе пользователя, алгоритм сначала искал ближайшие по местоположению сайты или таргетированный контент, далее шел на удаление от посетителя. Органическая выдача видоизменилась существенно.
Результаты
Локальные сайты быстро возвысились в поиске и получили местный трафик. Интернет-площадки без геозависимости упали в позициях. Снова началась борьба за каждый город и количественно возросли ситуации, когда начали плодить одинаковые сайты с отрерайченным контентом и привязкой к разной местности. До получения точной информации о внедрении алгоритма «Голубь» в русскоязычном интернет-поиске, многие вебмастера думали, что попали под санкции «Пингвина».

(Дружелюбный к мобильным устройствам)
Алгоритм Mobile-Friendly — внедрение технологии проверки сайтов на адаптивность к мобильным устройствам. Система запущена в апреле 2015 года и успела «обозваться» в интернете как: «Мобильный Армагеддон» (mobilegeddon), «Мобильный Апокалипсис» (mobilepocalyse, mobocalypse, mopocalypse).
Особенности
Mobile-Friendly запустил новую эру для мобильных пользователей, рекомендуя оптимизаторам в срочном порядке обеспечить комфортное пребывание мобильных посетителей на их сайтах. Адаптивность площадок к мобильным устройствам стала одним из важнейших показателей заботы владельцев сайтов о своих посетителях. Неадаптивным веб-площадкам пришлось в кратчайшие сроки исправлять недоработки: избавляться от плагинов, не поддерживающихся на планшетах и смартфонах, корректировать размер текста под расширение разных экранов, убирать модули, мешающие пребыванию посетителей с маленьким экранчиком перемещаться по сайту. Кто-то просто верстал отдельную мобильную версию своего интернет-ресурса.
Результаты
Заранее готовые к такому повороту ресурсы получили особое выделение среди других интернет-площадок в поисковой выдаче, а трафик из разнообразных не декстопных устройств на такие вебсайты повысился более чем на 25%. Совсем неадаптивные сайты были понижены в мобильном поиске. Направленность на мобильность сыграла свою роль — на ресурсах свели к минимуму наличие тяжелых скриптов, рекламы и страницы, естественно, начали грузиться быстрее, учитывая, что большинство пользователей с планшетами/смартфонами используют мобильный интернет, который в разы медленнее, чем стандартный.
Резюме
Вот и все
Теперь вам известно, как по годам развивался поиск как для обычных пользователей, так и для «попавших по раздачу» сайтов. Каждый из вышеперечисленных алгоритмов поиска периодически модернизируется. Но это не значит, что оптимизаторам и вебмастерам стоит чего-то бояться (если конечно вы не используете черное СЕО), но держать ухо востро все же стоит, чтобы неожиданно не просесть в поиске из-за очередного нового фильтра.
www.markintalk.ru
Алгоритм - это, поисковые алгоритмы (ПС)
Алгоритмы ПС (поисковые системы) — математические формулы, которые определяют позиции сайтов в результатах выдачи.
На основании ключевых слов поисковые машины определяют сайты наиболее релевантные введенному поисковому запросу. Согласно алгоритму, поисковик анализирует содержимое сайта, находит ключевую фразу из запроса пользователя и делает вывод о том, какую позицию сайту присудить. У каждой поисковой машины есть свои собственные алгоритмы, которые базируются на общих принципах работы алгоритмов.
Алгоритмы Google
Впервые об алгоритмах заговорили, когда Google обзавелся своим собственным поисковым механизмом (Индекс Цитирования). ИЦ был разработан для присвоения позиций страницам сайтов в зависимости от количества и качества внешних ссылок. Таким образом, появился некий стандарт определения релевантности интернет-ресурсов в результатах поиска. Такая технология принесла успех, что обеспечило Google высокую популярность.
Первоначально главным фактором, который Google учитывал при ранжировании сайтов, считался PR, однако не обделял он вниманием и внутреннее наполнение страниц интернет-ресурсов; вскоре в этот список факторов добавились региональность и актуальность данных.
В 2000г. для наилучшего вычисления PR Кришна Бхарат предложил алгоритм Hilltop. Со следующего года Google начал определять коммерческие и некоммерческие страницы, поэтому алгоритм изменили. В 2001г. был добавлен фактор, наделяющий ссылки с трастовых сайтов большим весом.
В 2003г. был разработан алгоритм «Флорида», который вызвал шквал негодования со стороны оптимизаторов. Он игнорировал популярные в то время методы продвижения и сайты с огромным количеством ключевых слов на страницах и с повторяющимися анкорами.
С 2006г. на вооружение был взят алгоритм израильского студента Ори Алона, «Орион», который учитывал качество индексируемых страниц.
В 2007г. был разработан алгоритм «Austin», сильно видоизменивший поисковую выдачу.
В 2009г. появился алгоритм «Caffeine», благодаря которому улучшился поиск Google, а проиндексированных страниц стало больше.
В 2011г. был выпущен новый алгоритм, «Panda», который дает более высокие позиции интернет-ресурсам с качественными текстовыми материалами на страницах.
Алгоритмы Яндекса
Летом в июле 2007г. Яндекс официально заявил о том, что механизмы ранжирования подвержены изменениям. Первым алгоритмом, о котором в 2008г. Яндекс упомянул в одном из своих интервью, был 8SP1, до этого алгоритмам не присваивали никаких имен, а внесенные в алгоритмы изменения оптимизаторы могли определить только методом проб и ошибок.
16 мая 2008г. появился новый алгоритм «Магадан», который располагал таким возможностями, как переработка транслитераций и аббревиатур.
В этом же году был разработан алгоритм «Находка», с его релизом в выдаче стали появляться информационные сайты, как например, Википедия.
Алгоритм «Арзамас», или «Анадырь»(10 апреля 2009г.), положительно повлиял только на региональное продвижение, также были разработаны фильтры для сайтов со всплывающими баннерами (попандеры и кликандеры).
В этом же году в ноябре Яндекс представил алгоритм «Снежинск», в котором ввел в обращение метод машинного обучения, «Матрикснет». Поскольку были введены новые параметры ранжирования, технология продвижения усложнилась: пришлось оптимизировать сайты комплексно.
Официальный релиз «Конаково» состоялся в декабре 2009г., по сути, это была обновленная версия «Снежинска». Благодаря «Конаково» сайты стали ранжироваться по 19 регионам и по 1250 городам России.
В сентябре 2010г. вышел «Обнинск», который комплексно оценивал текстовое содержание сайтов и лучше определял авторство текстовых материалов. Большое количество ключевых слов расценивалось как спам и наказывалось фильтрами. Искусственные ссылки перестали оказывать сильное воздействие на ранжирование сайтов. Продукты копирайтинга стали пользоваться большим спросом.
Декабрь 2010 г. был ознаменован появлением алгоритма «Краснодар», для которого была внедрена специальная технология «Спектр». Яндекс повысил качество поисковой выдачи, научившись разделять запросы на объекты (например, имена, модели) и систематизировать их (техника, лекарства и т.д.). Оптимизаторы стали принимать к сведению поведенческие факторы.
Релиз алгоритма «Рейкьявик» состоятся 17 августа 2011г., он был направлен на улучшение поиска при работе с англоязычными запросами.
Характеристика
Раньше поисковые системы находили всю необходимую информацию, обработав некоторые показатели сайтов, например, заголовки, количество контента, ключевики. Но стремительно развивающаяся оптимизация и появление огромного количества спамных сайтов препятствовали такой работе и вынуждали поисковые системы совершенствовать свои алгоритмы, чтобы игнорировать «плохие», по их мнению, сайты. Таким образом, обновление алгоритмов - это реакция на появление новых методов продвижения.
wiki.rookee.ru
Основы алгоритма поисковых систем | SEOinSoul
Просмотров: 3278Вы прекрасно помните, что совсем недавно я участвовал в конкурсе «Буржуйское SEO». В качестве конкурсного поста была статья об алгоритмах поисковых систем, в частности Google. В ней все разжевано и про текстовое ранжирование, и про частотность ключевых слов, и про зоны на сайте с большим весом, и про поведенческие факторы. В общем полезной информации КУЧА! Поэтому я решил опубликовать статью и на своем блоге. Кто еще не читал, милости прошу.
Алгоритм поисковых систем изнутри
Хороший поисковик не пытается показать страницы, которые лучше всего соответствуют поисковому запросу. Он пытается ответить на этот поисковый запрос. Если это понять, то сразу становится ясным, почему Google и остальные поисковики используют сложный алгоритм, чтобы определить, какие результаты должны быть в выдаче.Алгоритм состоит из множества факторов:внешних – это количество обратных ссылок, социальные рекомендации, например, через различные лайки и кнопку +1внутренних – это текст, структура, скорость загрузки и многое другое
Многие владельцы сайтов и начинающие оптимизаторы задаются вопросом — как раскрутить сайт? На первый взгляд, это совсем несложная работа. Но к сожалению, почти ни один новичок так и не добивается желаемого результата. Все-таки раскрутка сайта — это интеллектуальный и кропотливый труд
Как раз по анализу всех этих факторов Google и определяет, какие сайты отвечают на запросы пользователей.В этой статье мы подробно остановимся на проблемах поисковой системы и их дополнительных решениях. В конце статьи, к сожалению, мы не выявим полный алгоритм Google, но станем на один шаг ближе, чтобы понять некоторые факторы ранжирования.
В статье будут различные формулы, но вы не паникуйте, информация будет не только о формулах. В конечно итоге будет все разжевано уже на конкретные факторы. Для большей наглядности и лучшего восприятия информации я буду использовать иллюстрации немецких «вкусностей» 🙂
 Croquets – длинные, Bitterballen – круглые
Croquets – длинные, Bitterballen – круглые Правда или ложь
Поисковые системы очень сильно эволюционируют в последние годы, однако в первое время они могли иметь дело только с логическими данными. Проще говоря, включен этот запрос в документ или нет. В результате получается либо истина, либо ложь – 1 или 0. При поиске нужно было использовать операторы AND, OR и NOT, для запросов, состоящих из нескольких слов, например. На первый взгляд, это звучит достаточно просто , но и здесь могут возникнуть проблемы.
Пусть у нас есть два документа, состоящих из следующих текстов:1. И в нашем ресторане в Нью-Йорке подают Croquets и Bitterballen2. В Голландии вы получаете Croquets и Frikandellen из стены
Упс, чуть не забыл показать вам Frikandellen
 Если мы создаем поисковую систему, первым шагом будет разметка текста на последовательность символов (лексемы). Мы должны быстро определить из каких выражений состоит документ. Это сделать проще, если мы разложим их на последовательность символов в нашей базе. Лексемы это, по сути, слова в тексте. Как много слов содержит первый документ?
Если мы создаем поисковую систему, первым шагом будет разметка текста на последовательность символов (лексемы). Мы должны быстро определить из каких выражений состоит документ. Это сделать проще, если мы разложим их на последовательность символов в нашей базе. Лексемы это, по сути, слова в тексте. Как много слов содержит первый документ? Когда вы начали отвечать на этот вопрос, вы, вероятно, подумали об определении выражения. Действительно, в примере с Нью-Йорком это должно быть одно выражение. Таким образом в первом примере 10 слов, в втором – 11 слов. Чтобы избежать дублирования в нашей базе, мы будем хранить их тип, а не сами лексемы.
Тип – это уникальная лексема в тексте. В примере номер 1 дважды встречается союз «и». В одном случае он идет с заглавной буквы, в другом – с маленькой. Естественно, они одинаковые, и в таком мы случае мы считаем их одним типом.
За счет хранения всех типов в базе с документами, где мы можем найти эти типы, мы осуществляем поиск по базе данных. При поиске «Croquets» результатом поиска будет 1-ый и 2-ой документы, при поиске «Croquets и Bitterballen» — только 1-ый документ. Проблема этого метода в том, что вы можете получить как много, так и очень мало результатов. К том же, не хватает умения организовать эти самые результаты, т.е. как-то ранжировать. Если хотим улучшить наши методы, тогда мы должны использовать и другие слова в документе. Какие факторы страницы вы бы учитывали при ранжировании, находясь на месте Google?
Зона индексации
Относительно простой способ заключается в использовании зон индексации. Страница может быть разделена на несколько зон. Это могут быть – заголовок, описание, основной контент. Присваивая веса каждому элементу, мы можем определить вес всей страницы. Это один из первых методов поисковых систем. Распределение весов по зонам выглядит следующим образом:
| Зона | Вес |
| Заголовок | 0.4 |
| Описание | 0.1 |
| Контент | 0.5 |
Итак, осуществляем поиск по запросу: “Croquets и Bitterballen”
У нас есть документ со следующими зонами
| Зона | Контент | Логика | Вес |
| Заголовок | Нью-Йорк кафе | 0 | 0 |
| Описание | Кафе с очень вкусными Croquets и Bitterballen | 1 | 0.1 |
| Контент | В нашем ресторане в Нью-Йорке подают Croquets и Bitterballen | 1 | 0.5 |
Итоговый вес: 0.6
В определенный момент все начали злоупотреблять весами, присваиваемые, например описанию. Поэтому Google разделил страницу на зоны и стал присваивать различные веса каждому элементу на странице.
В любом случае, это не так уж и просто как кажется. Все потому, что в интернете каждая документ имеет свою структуру. Если бы все было по стандарту XML, тогда это намного проще. Но при HTML это тяжело даже для машины, т.к. и структуры и теги ограничены. Да, в ближайшем будущем будет HTML 5 и Google поддерживает все микроформаты, но все равно останутся ограничения. Например, если Google присваивает бОльший вес содержимому тега «content», нежели чем содержимому тега «footer», вы вряд ли будете активно использовать «footer».
Для определения основного контента Google делит страницы на блоки. Таким образом, он может судить, какие блоки являются важными, какие нет. Один из методов такого определения – это отношения кода к тексту. Если блок содержит гораздо больше обычного текста, нежели кода – вероятно, это основной контент страницы. Если блок содержит множество ссылок и кода, и мало обычного текста – вероятно, это меню.
Именно поэтому при публикации статей используйте правильный WYSIWYG-редактор (редактор аля MC Word), т.к. некоторые из них используют много ненужного html-кода.
Соотношение кода к тексту, это лишь один из методов, который используют поисковые системы для разделения страниц на блоки. Bill Slawski говорил о выявлении блоков в начале этого года.
Преимущество этого метода в том, что легко можете вычислить вес документа. Но в тоже время является недостатком то, что много документов могут получить один и тот же вес.
Частота запроса
Когда я спрашивал вас о том, какие бы вы использовали факторы для определения релевантности документа, вы наверняка подумали о частоте ключевых слов. Чем чаще используется ключевой запрос в тексте, тем больше увеличивается веса документа, и это логично. Некоторые SEO-конторы придерживаются определенного процента использования ключевого слова в тексте.
Мы же с вами знаем, что это на самом деле не так, но позвольте мне вам показать почему. Я постараюсь это объяснить на основе следующих примеров.
Числа из таблицы ниже, количество вхождений слова в документ (также этот термин называется плотностью). Так какой же документ имеет большую релевантность при запросе: «croquets and bitterballen» ?
| croquets | and | caf? | bitterballen | Amsterdam | … | |
| Doc1 | 8 | 10 | 3 | 2 | 0 | |
| Doc2 | 1 | 20 | 3 | 9 | 2 | |
| DocN | … | … | … | … | … | |
| Query | 1 | 1 | 0 | 1 | 0 |
Результаты для обоих документов будут следующими:Результат (“croquets and bitterballen”, Doc1) = 8 + 10 +2 = 20Результат (“croquets and bitterballen”, Doc2) = 1 + 20 +9 = 30
Документ 2 в этом случае более релевантен запросу. Но здесь союз «и» получает больший вес, а ведь это не справедливо. Это стоп-слово, которому необходимо давать намного меньший вес. Этого можно добиться с помощью обратной частоты документа (TF-IDF). По мере увеличения количества документов, в которых частота ключевого слова растет, IDF наоборот будет уменьшатся.
Вы можете самостоятельно рассчитать IDF путем деления общего количества документов на количество документов, содержащих ключевое слово, и затем взять логарифм от частного.
Предположим, что IDF наших запросов следующий:IDF(croquets) = 5IDF(and) = 0.01IDF(bitterballen) = 2
Тогда мы получим следующие результаты:результат(“croquets and bitterballen”, Doc1) = 8*5 + 10*0.01 + 2*2 = 44.1результат(“croquets and bitterballen”, Doc2) = 1*5 + 20*0.01 + 9*2 = 23.2
Теперь документ 1 имеет больше очков, но сейчас мы не берем во внимание объем. Один документ может содержать гораздо больше контента, чем другой. В таком случае, «длинный» документ очень легко получает больший вес.
Векторная модель
Мы можем разрешить эту ситуацию, вычисляя косинус схожих документов. Точное объяснение теории данного метода выходит за рамки данной статьи, но вы можете считать, что это то самое среднее между ключевыми запросами в документе. Я сделал Excel файл, в котором вы можете самостоятельно с ним по играться. В самом файле есть пояснения по его использованию. Для него понадобятся следующие показатели:1. ключевой запрос – каждое отдельное слово в запросе2. частота документа – сколько документов знает Google, содержащих это ключевое слово3. частота запроса – частота для каждого отдельного слова в документе
Вот конкретный пример, где я использовал актуальную модель. На сайте была страница, которая заточена под запрос «fiets kopen» (покупка велосипеда). Проблема была в том, что по данному запросу в выдаче присутствовала не эта страница, а главная.
Используем формулу IDF (обратная частота документа). Для этого нам понадобится общее количество документов в индексе Google. Примем это значение N = 10.4 миллиарда.
Объяснение столбцов таблицы:tf = частота запросаdf = частота документаidf = обратная частота документаWt,q = вес слова в запросеWt,d = вес слова в документеProduct = Wt,q * Wt,dScore = сумма product
Для главной страницы http://www.fietsentoko.nl/, которая появляется в выдаче:
Итоговый результат: 4.6356
Для страницы http://www.fietsentoko.nl/fietsen/, которая заточена под это ключевое слово
Итоговый результат: 4.54647
Хоть и на второй странице ключевой запрос встречается чаще, в итоге вес ее ниже главной. Это потому что, отсутствует баланс между словами в запросе. После этих расчетов, я увеличил частоту слова «Fiets» и уменьшил «Kopen», который является более общим словом и имеет меньший вес в поисковых системах. Это изменило результат следующим образом:
Итоговый результат: 4.6586
Через несколько дней, в выдаче Google поменялась главная страница на нужную. Из этого можно сделать вывод – не важно сколько раз вы используете слово на странице. Очень важно найти правильный баланс слов для условий ранжирования.
Ускорение процесса
При выполнении таких вычислений для каждого документа, нужно много вычислительных мощностей. Это можно исправить, добавив несколько статических значений. Например, Page Rank хорошо подойдет для статического значения. Поэтому то, чем выше PR, тем больше шансов найти документ на высоких позициях.
Другой возможностью является список «чемпионов». Для каждого запроса брать за пример сайты из ТОПа. И если ваш сайт по многим критериям схож с ним, тогда он, вполне вероятно, также релевантен запросу.
Поведенческие факторы
Используя Поведенческие факторы, поисковая система может изменить запрос пользователя, не сообщая ему. Для начала, здесь нужно определить релевантен документ запросу или нет. Однако в некоторых ПС можно указать это самостоятельно, в Google же такой функции не было в течение длительного времени. Первая попытка это добавление «звездочек», теперь же это осуществляется с помощью кнопки Google +1. Если достаточное количество людей начинают нажимать на кнопку +1, Google начинает пересматривать релевантность документа этому запросу.
Еще один способ для Google заключается в использовании интеллектуального анализа данных. А именно, всегда можно посмотреть CTR различных страниц. Страницы, где CTR высокий и при этом низкий показатель отказов (относительно среднего значения), можно считать актуальными и релевантными. Страницы со слишком высокими показателями отказов будут просто неуместны в выдаче.
Пример того, как мы можем использовать эти данные для корректировки веса ключевого запроса. Все сводится к настройке значения каждого слова в запросе. Формула заключается в следующем:
Допустим, мы применяем следующие значения:Ключевой запрос: +1 (alpha)Релевантный запрос: +1 (beta)Нерелевантный запрос: -0,5 (gamma)
У нас есть следующий запрос:«croquets and bitterballen»
Релевантность следующих документов выглядит следующим образом:Doc1: релевантенDoc2: релевантенDoc3: не релевантен
Новый запрос выглядит следующим образом:
croquets(2) and(1) bitterballen(1) cafe(0.5)
Значение для каждого слова – это вес, который он получает в запросе. Мы можем использовать эти веса в наших векторных расчетах. Слово «Amsterdam» получило отрицательный вес, мы его приравниваем к 0. Таким образом, мы не исключаем слова из результатов поиска. И хотя слова «cafe» не было в исходном запросе, он был добавлен и получил вес в новом запросе.Предположим, что Google использует этот способ определения поведенческих факторов, тогда вы можете взглянуть на документы, которые ранжируются по этому запросу. Используя этот метод, вы можете быть уверены, что получите максимальную отдачу от ПФ.
Сейчас проводится конкурс среди сеошников под названием SEOCAFEинфошность. Уже почти 100 участников, следим за развитием событий.
Выводы:
Вес документу присваивается на основе его содержания. Хотя векторный метод и является достаточно точным, это, безусловно, не единственный метод для вычисления релевантности. Существует много корректировок данной модели, которые остаются только частью полного алгоритма поисковых систем, в частности Google. Мы заглянули в поведенческие факторы, а также *кххх *в панду *кххх (кашель). Надеюсь я дал вам некоторое представление об алгоритмах поисковых систем. Ну а теперь пришло время по играться с Excel-файлом 😉
SEOinSoulВсе формулы и методы актуальны и для Яндекса. Их почти в аналогичном формате можно перенести на российскую поисковую систему. Зная все тонкости и нюансы вам может покориться любой ТОП.
Моя же статья скомуниздена с форума BizzteamsОригинал статьи: Search Engine Algorithm Basics
Постовой: Все вы помните, мой кейс о раскрутке группы Вконтакте. Как быть, тем кто только хочет начать бизнес в соц. сетях, но не знает как и с чего начать? Публичные страницы Вконаткте расскажут о типах сообществах, группах, мероприятиях. Основы вы уже будете знать на зубок..
seoinsoul.ru
Эволюция алгоритмов поисковых систем / Блог компании ALTWeb Group / Хабр

Для поисковых систем важнейшим был всегда вопрос приоритезации сайтов в выдаче. Данный вопрос поднимает две проблемы:
1. Как определить сайт, отвечающий запросу наиболее точно (релевантность). 2. Если пользователи не найдут искомого через поисковик, пользователи предпочтут пользоваться другим поисковиком.
Алгоритм ранжирования также имеет большое значение для правильной оценки онлайн-активов, отсутствие которой в своё время было в числе факторов, породивших образование доткомовского пузыря, в то время как на деле интернет-ресурсы действительно могут являться заурядным ресурсом, подлежащим купле и продаже. Наконец, без понимания «веса сайта» не смогла бы развиваться отрасль онлайновой рекламы. В этих случаях оказывается задействован механизм оценки и мы сталкиваемся с потребностью определить достоверные критерии подобной оценки параметров успешности, релевантности и качества сайта в сравнении с другими ресурсами.
Таким образом, вопрос о присвоении сайту тех или иных параметров на основе собранных данных — первостепенная задача как для поисковиков, так и для работников цифровой индустрии.
Существующие способы учета
Задача ранжирования и оценки интернет-ресурсов может решаться и решается математически и относится к области собора и обработки крупных объёмов статистических данных. Это могут быть:
- PR (Stanford University и Google)
- Browserank (Microsoft)
- DA (Moz)
- TrustRank (Stanford University и Yahoo!)
- ТиЦ (Яндекс)
- DwellRank (Blippex)
Ранжирование по ссылочной массе
Алгоритм ранжирования Google названный в честь Ларри Пейджа, одного из основателей компании — один из первых и, по сути, приведший к созданию гигантской компании в силу своей исчерпывающей актуальности на момент создания в 1996 году.
Этот механизм, равно как и похожие на него, будет оперировать такими понятиями как «ссылочная масса» или «ссылочный граф». В максимально упрощённом виде это будет звучать так: чем больше других ресурсов ссылается на ресурс, тем более значим этот ресурс. Соответственно, он и ранжируется выше. Дальнейшее усложнение алгоритма, нацеленное на более тонкую его настройку, призвано отсеять ссылки со спам-ресурсов путём присвоения того или иного веса ресурсу и соответственно «цены», как в прямом, так и в переносном смысле, тем ссылкам, которые будут на нём располагаться.
Ранжирование по пользовательскому поведению
Поисковики совершенно очевидно не откажутся от ранжирования по ссылочной массе, несмотря на все заверения, однако алгоритмы ранжирования постепенно усложняются и вот уже факторы, основанные на количестве и «цене» ссылок используются для ранжирования наряду с примерно двумя стами других, в которых в особую группу выделяются факторы, основанные на данных о пользовательском поведении по отношению к сайтам и находящимся между ними ссылкам.
Источники данных
Данные собираются через: 1. Надстройки для браузеров (Alexa) 2. Метрику (Яндекс.Метрика, Google Analytics) 3. Специализированные браузеры (Chrome, Яндекс.Браузер)Эти данные используются при ранжировании, формировании цены на сайт, на размещаемые на нём рекламные материалы и на соответствующие публикации.
Желание каждой поисковой системы создать свой собственный браузер и подать его как более быстрый, удобный, содержащий в себе множество дополнительных плюшек — это лишь попытка привлечь пользователей на свою сторону с целью сбора данных. Именно поэтому многие пользователи переходят на альтернативные поисковики: как например ничего не собирающий о пользователе — если верить создателям — DuckDuckGo и другие.Одной из первых попыток создать алгоритм ранжирования, основанный на данных о поведении пользователей, а конкретно — переходам по ссылкам, был BrowseRank, обнародованный в 2008 году на SIGIR, о котором мы уже подробно рассказывали в нашем блоге.
Различия в ранжировании по тем или иным алгоритмам очевидны:
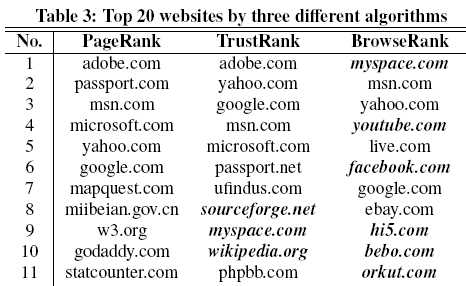
Источник
Выводы
Когда речь заходит о поисковых алгоритмах, мы сталкиваемся с такой проблемой, как неразглашение: как это работает достоверно никто не знает, кроме сотрудников поисковых систем. Таким образом учли «опыт сын ошибок трудных», когда каждый новый удачный и полезный метод ранжирования оказался очень быстро заспамленным методами так называемого «черного» продвижения. Теперь свой алгоритм стараются сделать непрозрачным для SEO специалистов, чтобы на него нельзя было повлиять «взломом», «накрутками» и любым другим путём иначе как через «белые факторы», такие как создание правильной инфраструктуры сайта, разумного контента и удовлетворения нужд потребителя. Несколько «просевший» фактор ранжирования по наличию ссылок дополняется факторами, основанными на поведении пользователей и переходах по ссылкам, как гораздо менее подверженные влиянию извне и, как следствие, предположительно более достоверные.
Больше по теме:Анализ поведения пользователей и персонализация поисковой выдачи. Исследование Яндекс.BrowseRank — Обзор. История появления BrowseRankПрезентация BrowseRank (оригинальный текст на английском)
habr.com
Полезности для вебмастеров и не только — xBB.uz
31.01.2015: Пессимизация. Что это такое и как избежать?
28.01.2015: 5 инструментов продвижения, которые больше не работают
26.01.2015: Простой способ прогнозировать посещаемость сайта
23.01.2015: Что такое верстка сайта и ее виды
21.01.2015: Объем контента сайта и его влияние на позиции в поисковой выдаче
Для вебмастеров
Пессимизация. Что это такое и как избежать? 31.01.2015 Одним из популярных способов продвижения является оптимизация текстового контента под поисковые системы. Это объясняется достаточно высокой эффективностью и относительной простотой. Но часто случается, что веб-мастера чрезмерно увлекаются оптимизацией текстов. Как результат, можно наблюдать переспам ключевых слов или другие злоупотребления. За такие проступки поисковые системы предусматривают наказание, именно оно имеет название пессимизация. 5 инструментов продвижения, которые больше не работают 28.01.2015 Поисковая оптимизация динамично развивается и при ее проведении нужно быть очень аккуратным. Те инструменты, которые недавно работали и давали результаты, могут оказаться бесполезными и вредными. Бывает и наоборот, когда методы, за которые можно было получить наказание от поисковых систем, начинают эффективно работать. Соответственно, оптимизатор должен всегда находиться в курсе тенденций и понимать, какие способы продвижения можно использовать. Простой способ прогнозировать посещаемость сайта 26.01.2015 Узнать будущую посещаемость сайта легко. Но зачем это делать? Если вы собираетесь использовать сайт как рекламную площадку, то еще до того, как приступать к его созданию, вам необходимо понять, сколько людей будут заходить на сайт в будущем. Вы оцениваете видимость сайта и потенциальный трафик по каждому из интересующих вас запросов, и на основании полученной информации создаете семантическое ядро. Это научный подход, который приносит результаты.Для программистов
Программируем на R: как перестать бояться и начать считать 28.11.2014 Возможно, вас заинтересовала проблема глобального потепления, и нужно сравнить погодные показатели с архивными данными времен вашего детства. Калькулятором тут не обойтись. Да и такие программы для обработки электронных таблиц, как Microsoft Excel или Open Calc, пригодны только для простых вычислений. Придется изучать специализированный статистический софт. В этой статье мы расскажем об одном из популярнейших решений — языке программирования R. Smart Install Maker. Создаем установщик 23.11.2014 Появляется все больше инди-разработчиков, которые создают собственное программное обеспечение для компьютеров. Однако, чтобы продукт выглядел качественным, необходимо продумать все до мелочей, в том числе и систему установки программы. Тратить время на написание собственных инсталляторов никто не хочет, поэтому на рынке появляется все больше специализированных утилит, которые все сделают за вас. Они дают целевому пользователю то, что ему необходимо. Функции в языке программирования C++ 18.11.2014 Функцией называют обособленный модуль программы, внутри которого производятся некоторые вычисления и преобразования. Помимо непосредственных вычислений внутри данного модуля могут создаваться и удаляться переменные. Теперь расскажем о том, из каких основных частей состоит функция в C++. Самая первая часть — это тип возвращаемого значения. Он показывает, что будет передавать функция в основную программу после своих внутренних преобразований...Для других IT-специалистов
Роль дизайна в разработке пользовательских интерфейсов 23.11.2014 Разработка программного обеспечения — сложный, трудоемкий процесс, требующий привлечения экспертов разного профиля. Команда опытных программистов способна создать систему, удовлетворяющую любым техническим заданиям заказчика. Однако зачастую вне зоны внимания остается существенный вопрос: а насколько привлекательна разработанная система для пользователя? К сожалению, на сегодняшний день разработчики не всегда готовы дать внятный ответ на этот вопрос. Аренда программного обеспечения 13.11.2014 В последнее время на рынке IT-услуг все большую популярность набирает услуга аренды серверных мощностей с размещенным на них программным обеспечением. Суть услуги состоит в том, что заказчику предоставляется доступ к необходимому программному обеспечению по модели «бизнес-приложения» в аренду. Базы пользователей располагаются на серверах в специально оборудованном дата-центре. Пользователи работают в программе через удаленный рабочий стол. Машина трехмерного поиска 09.11.2014 Поисковые машины, без которых немыслим современный интернет, еще довольно ограничены. Можно искать слова, изображения, а в последние годы и мелодии (по фрагменту, проигранному перед микрофоном). Но как найти, например, аромат яблока? Технологии цифровой обработки запахов пока не очень развиты. Однако есть прогресс в другом направлении — стал возможен поиск 3D-объектов. И судя по растущему количеству 3D-принтеров, это будет востребованный сервис.Для других пользователей ПК и Интернет
YouTube и раритетные видеозаписи. Часть 2 19.01.2015 У скачанного файла *.MP4 напрочь отсутствует звук. Это просто кусок видеопотока, совершенно не проиндексированный, с некорректным заголовком. В Ubuntu воспроизвести его может лишь Gnome MPlayer, да и то без перемотки, без задействования пауз, строго подряд и непрерывно. Из всех бесплатных редакторов, доступных для Ubuntu Linux, переварить такое видео согласился лишь OpenShot. Импортировал и разместил на TimeLine (в области монтажа) без проблем. YouTube и раритетные видеозаписи 17.01.2015 В давние времена много чего записывалось на древние видеокассеты (VHS), большие плоские коробки с рулоном плёнки внутри. Затем контент оцифровывался и попадал на сервис YouTube, ставший для меломанов одним из основных источников добычи старых видеоклипов и концертов. Но пришла беда. Теперь почти все средства скачивания предлагают для загрузки лишь «360p». Этого разрешения хватит для просмотра разве что на маленьком экране телефона в четыре дюйма. Биржи контента. Ситуация к началу 2015 г. Обзор и тенденции. Часть 2 14.01.2015 Требования к качеству статей неуклонно растут. Хозяева бирж приспосабливаются к этому по-разному. Кто-то хитрит и придирается к чему может. Кто-то снижает уникальность из-за одного единственного технического термина в статье. А кто-то, не в силах придумать благовидные способы, просто блокирует и грабит пользователей. Во-вторых, биржи контента всё больше ориентируются на выполнение заданий, а продажа готовых статей становится второстепенной.Для мобильных пользователей
Обзор смартфона Lenovo S580 26.11.2014 В этой статье подробно рассмотрен очередной смартфон Lenovo. Одним из направлений компании является выпуск смартфонов в доступном ценовом сегменте и с достойными характеристиками. Такой моделью и является S580. Качественный дисплей, хорошая камера, нестандартные 8 Гб памяти и производительный процессор обрекают этот смартфон на успех. В ближайшие месяцы он станет хитом продаж. Рассмотрим его внешний вид, функционал, характеристики, время работы. Firefox OS глазами пользователя. Часть 2 22.11.2014 К данному моменту Firefox OS вполне стабильна (по-настоящему) и вполне пригодна для использования теми, кому от смартфона нужны лишь базовые умения. Звонить умеет, Wi-Fi работает, смотреть видео и фотографии можно. Однако о покупке телефона с Firefox OS лучше не думать до тех пор, пока в местных магазинах не начнёт рябить в глазах от таких аппаратов. Ведь тогда и хороший выбор приложений появится, и дизайнеров Mozilla отыщет и на работу примет. Firefox OS глазами пользователя 22.11.2014 Мировосприятие многих сторонников Open Source основано на перманентном ожидания новинок. Когда-нибудь что-то разработают, выпустят, допилят, обвешают плюшками — реальность состоит лишь из надежд на счастливое будущее в заоблачных далях. Мы же в эти самые дали слегка заглянем и посмотрим на Firefox OS глазами ординарного пользователя. После чего, возможно, какие-то надежды развеются и растают, однако истина дороже. Рассматривать будем релиз 2.0.Все публикации >>>
Последние комментарииВсе комментарии >>>
xbb.uz
векторная модель. Понятие частотности термина
 Соскучились по формулам и статьям, которые заставляют мозги пошевелиться и вспомнить школьный курс математики? Один из авторов на Seomoz, видимо, почувствовал эту потребность и написал интересную техническую статью, которую мы с удовольствием перевели.
Соскучились по формулам и статьям, которые заставляют мозги пошевелиться и вспомнить школьный курс математики? Один из авторов на Seomoz, видимо, почувствовал эту потребность и написал интересную техническую статью, которую мы с удовольствием перевели.
Хорошая поисковая система не пытается выдать страницы, которые лучше всего соответствуют входному запросу. Хорошая поисковая система пытается ответить на основной вопрос.
Если Вы понимаете это, то поймете, почему Google (и другие поисковые системы) используют сложный алгоритм для определения того, какие результаты они должны отдавать по тем или иным запросам.
Факторы алгоритма влияющие на ранжирование состоят из точных факторов – количество обратных ссылок и, возможно, некоторых социальных сигналов, такие как кнопки like и +1. Это, как правило, внешние воздействия. Еще есть внутренние факторы непосредственно на самой странице.
Способы построения страницы и различные элементы страницы играют важную роль в алгоритме. Но только путем анализа внутренних и внешних факторов Google может определить, какие страницы могут ответить на вопрос пользователей. Для этого ему нужно анализировать текст на странице.
В этой статье я подробно расскажу про проблемы поисковика и кое-что объясню дополнительно. К сожалению, я не раскрываю алгоритм Google в конце этой статьи, но мы на один шаг приблизимся к тому, чтобы лучше понять изнанку некоторых советов, которые мы часто даем в роли seo-специалистов.
Будут некоторые формулы, но не паникуйте. Эта статья не только о формулах (кроме того, в тексте есть ссылка на файл-калькулятор в формате.xls). И еще кое-что: я буду иллюстрировать некоторые описания фотографиями голландских котлет :)

Правда или ложь
Поисковые системы чрезвычайно эволюционировали за последние годы, но поначалу они могли иметь дело только с логическими операторами. Проще говоря, термин был включен в документ или нет. Что-то было истинным или ложным, 1 или 0.
Кроме того, вы могли использовать операторы И, ИЛИ и НЕТ для поиска документов, которые содержали несколько терминов или исключали термины.
Звучит достаточно просто, но с этим есть некоторые проблемы. Предположим, у нас есть два документа с такими текстами:
Док1: «И наш ресторан в Нью-Йорке подает крокеты и тефтели.»
Док2: «В Голландии Вы получаете крокеты и тефтели с прилавка.»
Если мы должны построить поисковую систему, первый шаг – это разметка текста. Мы хотим иметь возможность быстро определить, какие документы содержат термин. Будет легче, если мы сложим маркеры в базу данных. Один маркер – какой-либо единственный термин в тексте. Итак, сколько маркеров содержит Док1?
В тот момент, когда вы начали отвечать на этот вопрос, вы, наверное, подумали об определении «термина». В действительности, в этом примере «Нью-Йорк» может быть признан одним термином. Способ, которым мы можем определить, что два слова являются одним, выходит за рамки этой статьи, так что на данный момент мы отслеживаем одно слово как отдельную лексему.
Таким образом, мы имеем 10 маркеров в первом документе и 11 во втором. Чтобы избежать дублирования информации в нашей базе данных, мы сохраним типы, а не маркеры.
Типы – это уникальные маркеры в тексте. В примере Док1 дважды содержится маркер «И» (И наш ресторан в Нью-Йорке подает крокеты и тефтели.)
В этом примере я игнорирую то, что «И» появляется один раз с, и еще один раз – без сохранения ценности термина. Как и с определением термина, есть методы, которые указывают, должно ли что-то быть использовано, как имеющее отдельную ценность. В этом случае мы предполагаем, что нет, и что «И» и «и» относятся к одинаковому типу.
Храня все типы в базе данных с документами, где мы можем их найти, мы в состоянии искать в пределах базы данных с помощью логических операторов. Запрос «крокеты» приведет нас и к Дoк1 и Док2, а запрос «крокет и тефтели» вернет результатом только Док1.
Проблема этого метода в том, что вы, вероятно, получите слишком много или слишком мало результатов. Кроме того, он лишен способности организовать результаты. Если нам необходимо усовершенствовать наш метод, мы должны определить, как мы можем использовать остальные маркеры или их отсутствие в документе.
Если бы вы были Google, то какие факторы на странице использовали бы для организации результатов?
Зональные Индексы
Относительно простой метод должен использовать зональные индексы. Веб-страница может быть разделена на различные зоны (title, description, author и body). Добавляя вес к каждой зоне, мы можем компетентно вычислить простую оценку для каждого документа. Это один из первых страничных методов поисковых системах, используемый для определения тематики на странице.
Действие по оценке зональной индексации:
Выполняем следующий поисковой запрос: «крокеты И тефтели». И у нас есть документ со следующими зонами:

Поскольку в какой-момент все начали злоупотреблять весом, который присваивался, например, description, то для Google стало более важно расколоть тело страницы в различных зонах и назначить различный вес на каждую отдельную зону «тела».
Это довольно трудно, потому что сеть содержит разнообразные документов с различными структурами. Интерпретация документа XML для машины довольно проста, но с HTML уже сложнее.
Структура и теги довольно ограничены, что делает анализ более сложным. Конечно, скоро HTML5 станет более общеупотребимым, а кроме того, Google поддерживает микроформаты, но разметка все еще имеет ограничения. Например, если вы знаете, что Google присваивает больше веса на содержание внутри тега content и меньше на содержание тега footer – вы никогда не будете использовать footer.
Чтобы определить контекст страницы, Google делит веб-страницу на блоки. Таким образом поисковик может оценить, какие блоки на странице важны, а какие – нет. Один из методов, которые могут быть при этом использованы – текстовое / кодовое соотношение. Блок на странице, в котором больше текста, чем HTML кода, вероятно, содержит главный контент страницы. Блок, который содержит много ссылок / HTML кода и мало контента – вероятно, меню. Именно поэтому выбор правильного редактора WYSIWYG очень важен, некоторые из этих редакторов используют много мусорного HTML-кода.
Использование сооотношения текст / код является лишь одним из методов, которые поисковая система может использовать для разделения страницы на блоки. Преимущество метода зональной индексации – вы можете довольно просто подсчитать оценку каждого документа. Недостаток – многие документы могут получить одинаковое значение веса.
Частота термина
Когда я просил Вас подумать о факторах страницы, которые вы использовали бы для определения релевантности документа, вы, вероятно, думали о частоте термина. Частота использования поисковых терминов – логичный шаг для оценки веса каждого документа.
Некоторые seo-агентства продолжают писать тексты с использованием определенного процента ключевых слов в тексте. Мы знаем, что этот прием уже не так хорошо работает, но разрешите мне показать – почему именно. Постараюсь объяснить это на основе следующих примеров.
Числа в таблице ниже – количество вхождений слова в документе (также называется частотой термина или tf). Так какой документ будет иметь лучшую оценку по запросу «крокеты и тефтели»?
Оценка для обоих документов будет выглядеть следующим образом:
оценка («крокеты и тефтели», Док1) = 8 + 10 + 2 = 20 оценка («крокеты и тефтели», Док2) = 1+20+9=30
В этом примере Док2 более соответствует запросу. Термин «и» получает больший вес, но разве это справедливо? Это стоп-слово, и мы хотели бы дать ему только небольшую ценность. Мы можем добиться этого с помощью обратной частоты документа (TF-IDF), который является противоположностью частоте документа (DF).
Частота документов – это количество документов, где упоминается термин. Обратная частота документов – ну, в общем, противоположность. По мере увеличения количества документов с упоминанием термина IDF будет сокращаться.
Вы можете рассчитать IDF путем деления общего количества документов у вас в «теле» на количество документов, содержащих слово, а затем взять логарифм этого коэффициента.
Предположим, что IDF нашего запроса является следующим:
IDF (крокеты) = 5 IDF (и) = 0,01 IDF (тефтели) = 2
Тогда Вы получаете следующие оценки:
вес («крокеты и тефтели», Док1) = 8*5 + 10*0.01 + 2*2 = 44.1 вес («крокеты и тефтели», Док2) = 1*5 + 20*0.01 + 2*9 = 23.2
Теперь Док1 имеет большую оценку. Но сейчас мы учитываем длину. Один документ может содержать гораздо больше контента, чем другой, не будучи при этом более релевантным. С помощью этого метода большой документ довольно легко получает высокий бал.
Векторная модель
Мы можем найти выход их этой ситуации, посмотрев на сходство косинуса документа.
Точное объяснение теории, стоящей за этим методом, выходит за рамки этой статьи. Но вы можете думать об этом, как о своего рода золотой середине между запросами терминов в документе. Я сделал файл Excel, так что вы можете поиграть с ним самостоятельно. Объяснение есть в самом файле. Вам необходимы следующие показатели:
Запросы терминов – каждый отдельный термин в запросе Частота документов – сколько документов, содержащих этот запрос, знает Google Частота термина – частота для каждого отдельного запроса термина в документе
Вот пример, где я фактически использовал эту модель. У веб-сайта была целевая страница, разработанная, чтобы ранжироваться по запросу “fiets kopen” (по голландски – «купить велосипеды»). Проблема состояла в том, что по запросу ранжировалась домашняя страница.
Для формулы мы включаем ранее упомянутую обратную частоту документа (IDF). Для этого нам понадобится общее количество документов в индексе Google. Будем считать, что это N = 10.4 миллиардов (на время написания статьи).
Объяснение таблицы ниже:
TF = частота термина DF = частота документа IDF = обратная частота документа Wt, q = вес для термина в запросе Wt, d = вес для термина в документе Продукт = Вес, q * Вес, d Оценка = Сумма продуктов
Главная страница, которая ранжировалась – http://www.fietsentoko.nl/
Страница, которую я хотел ранжировать: http://www.fietsentoko.nl/fietsen/
Хотя во втором документе чаще упоминается нужный термин запроса, оценка документа по запросу была ниже (чем выше – тем лучше). Это произошло из-за отсутствия баланса между терминами запроса.
После этого расчета я изменил текст на странице, увеличив использование термина “fietsen” и снизив использование “kopen”, который является более общим термином в поисковых системах и имеет меньший вес. Это изменило оценку следующим образом:
Через несколько дней Google просканировал страницы, и документ, который я изменил, начал ранжироваться по нужному запросу. Из этого мы можем сделать вывод, что количество упоминаний термина не так важно, важно найти правильный баланс для терминов, которые вы хотите ранжировать.
Ускорение процесса
Чтобы делать этот расчет для каждого документа, соответствующего поисковому запросу, потребуются большие вычислительные мощности. Можно сделать проще – добавлять некоторые статические данные, чтобы определить документы, которые вам нужно оценить.
Например, PageRank является хорошим статическим значением. Когда вы впервые рассчитываете оценку для страниц, которые соответствуют запросу и имеют высокий PageRank, у вас есть хорошие переменные, чтобы найти некоторые документы, которые попадут в топ 10 в любом случае. Другая возможность – использование топ-списков. Для каждого отдельного слова брать только верхний документ N с лучшими результатами по этому слову.
Если у вас есть много запросов слова, вы можете соединить списки, чтобы найти документы, содержащие все запросы слова, и, вероятно, имеющие высокую оценку.
Только если документов, содержащих все слова, слишком мало, вы необходимо искать во всех документах. Таким образом вы можете рассчитать оптимизацию текста не только используя векторную формулу, но и упрощая расчеты благодаря статистическим данным.
Релевантная обратная связь
Релевантная обратная связь означает определенную ценность для слова в запросе, основанную на релеватности документа. Используя обратную связь, поисковая система может изменить запрос пользователя (не сообщая об этом самому пользователю).
В первую очередь здесь нужно определить – релевантен документ или нет. У Google не было такой функции в течение долгого времени. Первое, что они сделали – разрешили добавлять результаты поиска в избранное, теперь это кнопка + 1. Если достаточно многие люди начнут нажимать на кнопку по определенному результату, Google начнет считать документ важным для этого запроса.
Другой метод – смотреть на текущие страницы, которые хорошо ранжируются. Они будут считаться релевантными. Недостатком здесь является текучесть. Если вы ищете «тефтели и крокеты» и все страницы, которые хорошо ранжируются, принадлежат закусочным в Амстердаме, существует опасность, что вы назначите ценность Амстердаму и закончите с одними закусочными в результатах.
Еще один способ для Google – сбор данных. Они могут смотреть на CTR различных страниц. Страницы с высоким CTR и низким показателем отказов можно считать актуальными. Страницы с высокими отказами будут просто неуместны.
(Прим.: данные по +1 и CTR сейчас применимы для продвижения на Западе. У нас это пока не применимо).
Примером того, как мы можем использовать эти данные для корректировки веса слова по запросу, является формула обратной связи Рочио. Это обозначение ценности для каждого термина в запросе и, возможно, добавления дополнительных слов запроса. Формула для этого следующая:
Таблица ниже – объяснение этой формулы. Допустим, мы применяем следующие ценности :
Термин запроса +1 (альфа) Релевантный термин +1 (бета) Нерелевантный термин –0.5 (гамма)
У нас есть следующий запрос: «крокеты и тефтели»
Релеватность следующих документов такова:
Док1: релевантный ДОк2: релевантный Док3: не релевантный
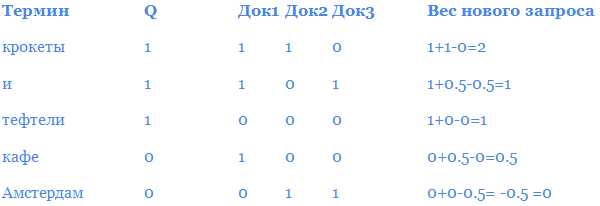
Новые запросы следующие: крокеты (2) и (1) тефтели(1) кафе(0.5)
Ценность для каждого отдельного термина – вес, котоый входит в ваш запрос. Мы можем использовать этот вес в наших векторных вычислениях. Хотя термину «Амстердам» дали счет –0.5, отрицательные величины скорректировались назад к 0. Таким образом мы не исключаем термины из результатов поиска. И хотя «кафе» не появлялось в оригинальном запросе, в новом запросе оно получило вес.
Предположим, что Google использует этот способ релевантной обратной связи когда вы смотрите на страницы, которые уже занимают место по определенному запросу. Используя тот же словарь, вы можете гарантировать, что получите максимальную отдачу от такого способа релевантной обратной связи.
Выводы
Короче говоря, мы рассмотрели одну из возможностей назначения ценности на документ, основанный на содержании страницы. Хотя векторный метод довольно точен, это не единственный метод для вычисления релевантности. Есть много факторов ранжирования, и это также остается только частью полного алгоритма поисковых систем вроде Google.
Мы также рассмотрели релевантную обратную связь. Надеюсь, что показал вам некоторые методы работы поисковика, которые вы можете использовать в работе с внутренними факторами.
Все, хватит. Пока это обмозговать и пойти поиграться с файлом :).
————–
Оригинал: Search Engine Algorithm Basics.Большое спасибо Роману Жаркову за помощь в переводе и вычитке.
blog.aweb.ua
Поисковые системы и их алгоритмы ранжирования
В настоящий момент активные пользователи интернета делятся на тех, у кого уже есть свой сайт и тех, кто только об этом мечтает и готовится к его созданию и продвижению, изучая всё, что может помочь в дальнейших действиях по раскрутке. Никто из пользователей не является противником самому себе и поэтому в будущем попытается достичь такого уровня проекта, который не только удовлетворить амбиции, но и даст возможность заработать в сети на сайте, что вполне разумно, особенно учитывая затраты на его создание и продвижение.
Алгоритмы ранжирования систем поиска
В круг актуальных вопросов начинающего или будущего оптимизатора и веб-мастера в одном лице входит и изучение такого понятия, как поисковые системы и их алгоритмы ранжирования, что поможет более быстро занять во всемирной паутине достойные позиции.
Поисковые системы – это папа и мама в одном лице для владельца сайта, так как именно они с использованием алгоритмов решают насколько тот или иной ресурс представляет ценность для пользователя и достоин быть на верху поисковой выдачи. Естественно, что те проекты, которые находятся на самом верху результатов поиска, особенно по высокочастотным запросам имеют лучшую посещаемость и больше потенциальных клиентов, если сайт коммерческий или читателей, если ресурс пользовательский.
Что такое алгоритмы ПС
Для градации ресурсов поисковые системы используют много различных схем, включая алгоритмы настройки ранжирования, которые играют одну из ключевых ролей. Если посмотреть чисто с научной точки зрения, то алгоритмы ранжирования – это система определённых математических формул, с помощью которой производится оценка различных факторов, по совокупности которых страница и получает рейтинг для поисковой системы, жаль только, что требования поисковых систем меняются чаще, чем погода за окном.
Надо заметить, что точные алгоритмы никому неизвестны и охраняются поисковыми системами, как сверхсекретные документы, чтобы никто не мог подстроиться под них и оказать влияние на ранжирование. Кроме этого просчитать изменение алгоритмов ранжирования ещё сложнее по причине их нестабильности, так как они находятся практически в постоянном изменении в поисках новых более достоверных расчётов ранжирования.
Логичный вывод
Исходя из этого, не стоит забивать голову точными формулами расчёта, так общие направления правильно движения сайта известны и хорошо прописаны в анналах той же поисковой системы Яндекс – делайте сайты для людей! Уникальные и обязательно интересные материалы проекта, его также уникальное, но красивое и понятное оформление, оптимизация текста и ссылочная база, которая со временем станет образовываться сама, так как читатели собственноручно станут делиться ссылками на сайт.
Вот те столпы успеха, которые не поколеблет никакое изменение алгоритмов ни одной из известных на сегодня поисковых систем.
www.zegeberg.ru