Накрутка поведенческих факторов в 2018 году, мифы и реальность. Программа по накрутке поведенческих факторов
Накрутка поведенческих факторов в 2018 году, мифы и реальность
Котики расшифровали один из докладов (Октавиан Низамов: «Работает ли накрутка поведенческих факторов?»), прозвучавших на конференции Baltic Digital Days 2018. Мы постарались подвергнуть его минимальной редактуре (но сократили немало) и использовать в оформлении статьи слайды презентации к докладу, чтобы не упустить суть.
Напоминаем также, что можно припасть, так сказать, к первоисточникам, изучив все доклады самостоятельно. Просто купив видео.
Известно, что где-то с декабря 2014 года стало немодным накручивать поведенческие факторы. До этого это была весьма крутая тема, но потом были проблемы. За этот период много всяких накопилось: слухов, сплетен, версий, как это всё сейчас обстоит на самом деле.
Мы решили немного ситуацию разъяснить, понять, что является вымыслом, что мифом и как там на самом деле все обстоит.
Некоторые доклады и кейсы на эту тему уже публиковались. В прошлом году Денис Нарижный эту тему освещал. Чего нам не хватило в этой информации: во-первых, кейсы достаточно закрытые, потому что чаще всего это на каких-то реальных проектах делалось, палить их никто не будет, всё непроверяемое, надо только верить докладчику. Информации очень мало, посмотреть как-то сложно.
Вторая проблема — это то, что достаточно маленькая выборка применялась, всегда вставали вопросы по поводу того, это реально поведенческое или, может, фартануло. Сайты с историей, которые использовались в таких экспериментах, мы понимаем, они дополнительно нарушают картину. Мы не знаем, может, они под фильтрами сидят, может вышли из-под фильтров, непонятно.
Базовые гипотезы
В декабре прошлого года мы планировали этот эксперимент. Выработали базовые гипотезы, которые хотели проверить. Самое фундаментальное касательно Яндекса, у нас 4 гипотеза. Самое главное — как реагируют, хорошо ли реагируют, работает ли.
Второе — это на уровне слухов у нас есть такая гипотеза, что Яндекс отличает, кто занимается накруткой, владелец сайта или конкурент, чтобы случайно не получилось, что забанят сайт, который крутили конкуренты. Попробуем тоже проверить.
Третья гипотеза про то, что Яндекс по-разному подходит к пользователям с историей и без истории. Если пользователь без истории, то он его игнорирует. Еще хотелось бы понять, действительно ли разная степень рисковости инструментов, публичные сервисы, непубличные сервисы, насколько это влияет на опасность этого мероприятия.
Про Гугл гипотез, как и слухов, поменьше. Главное состоит в том, что в гугле поведенческие не тащат, не работают. И сама поисковая система об этом заявляет, и много на эту тему размышлений.
Вытекающее из этого — это то, что, если не работают поведенческие, то и забанить за них не могут тоже.
План рассказа такой: сначала расскажу про технологию, как именно крутили, какие методы использовали, инструменты, потом про сайты, которые были у нас подопытными и общую хронологию, потом резюмирую.
Технология экспериментов
Мы, честно говоря, хотели использовать несколько разных сервисов, но ничего живого сейчас не нашли. В реальности, только у Морозова какой-то развивающий живой сервис оказался нам доступен. Причем, там мы взяли два интересных варианта. Один — это старый, классический Юзератор, который не изменился за эти годы, и новый инструмент — это, так называемый SEO-бонус.
Основные силы мы потратили на работу вручную. Мы пытались крутить поведенческие вручную, тоже интересная часть эксперимента.
Юзератор
Про Юзератор, может, кто-то не знает или забыл. В принципе, система работы такая, что заказчик платит за каждую сессию, там система, что исполнитель на свой компьютер ставит специальную программу, она дает пошаговые инструкции, какие-то контрольные скриншоты снимаются. Исполнители — это реальные люди, с разных айпи-адресов работающие. В основном декстопы, потому что программа для декстопов. Оплата для исполнителей фиксированная. Отмечу, что шаблон поведения пользователя-исполнителя, достаточно фиксированный в юзераторе. Это достаточно типизированная схема.
SEO-бонус
Отличие в том, что нет программы, которая устанавливается на комп. Есть телеграм-бот, который раздает задания. Отличие в том, что сами задания максимально упрощены, и дается на одного исполнителя одно задание в день.
Во-первых, это больше мобильных.
Во-вторых, это более реалистичный пользователь. Первая система его провоцирует сидеть, долбить в течение часов много запросов, это может выглядеть не очень реалистично.
Ручная накрутка
По ручной накрутке мы арендовали сервер, на котором поднимали некоторое количество виртуальных машин. Каждая машина свою конфигурацию имеет. Соответственно, там операционная система, разрешение свое.
«Владелец» и «Конкурент»
Еще нам нужно было проверить гипотезу с владельцем и конкурентов.
Соответственно, каждую группу мы делили на подгруппы. Одна подгруппа у нас максимально компрометировала себя, бегала в аккаунт юзератора, сразу вебмастер, всякие расширения ставила.
«Конкурент» вел себя осторожно, никак себя не выдавал.
По ручной накрутке использовали виртуалочки с разными конфигурациями. Три браузера, в каждом браузере стоят профили пользовательские. Что важно, каждому пользователю мы выделила резидентный прокси. Это прокси не хостинг провайдеров, а именно реальные айпишники.
Чтобы реалистичная картина была нашей пользовательской базы взяли выгрузку с метрики сайта, у которого много посещений, примерную картинку составили. Примерно наша толпа выглядела так: было 56 виртуальных машин, умножить на 3 браузера, получается 168 вариантов конфигураций, плюс в каждой конфигурации получается по несколько десятков профилей, такая организованная команда.
Пользователи с историей и без
Для ручной накрутки нам нужно было проверить гипотезу «пользователь с историей, без истории».
Соответственно, часть пользователей работала по сценарию максимально приближенному к реальному, то есть это аккаунт в Яндексе, залогиненный, привязанный к телефону, к Яндекс Диску, даже к соцсетям. Мы постарались, чтобы это было красиво.
А чистая сессия в режиме инкогнито.
Плюс еще усложнили, что наши «живые» пользователи вели себя немного по-разному, не единым паттерном, как в юзераторе. Кто-то поочередно прокликивал все сайты, доходя до нашего целевого, кто-то пролистывал, заходил на наш целевой, кто-то как по системе юзератора, переформулировал запрос, то есть некий сценарий для этого дела использовался.
Формула была принята примерно такая: брали частотность запроса и от нее 20-30% докручивали, если только этот запрос находит в топ-50, либо в топ-20, потому что СЕО-бонус только от топ-20 начиная и выше работает. Если это совсем низкочастотка (5 и меньше), то просто 1-2 визита в месяц. По брендовым запросам формула другая была. Они, по сути своей, нулевые, потому что бренды у нас вымышленные были. Значит, мы просто крутили сколько надо, пока не доходили до топ-5.
Тематика
С одной стороны, мы не хотели брать тематику супер-конкурентную, пластиковые окна, например, потому что это затянуло бы эксперимент, и мы могли не уложиться.
С другой стороны, нужно было достаточно большую и обширную, где много сайтов, много предложений и достаточно много ключей. У нас в тематике получилось около 250 не нулевых ключей, продвигались по Москве, питомники котят мейнкун.
Что продвигали? Для этих задач создали 21 сайт. Почему 21? Это 7 групп. По основным группам. Юзератор: 6 сайтов делится на 2 подгруппы (владелец, конкурент), СЕО-бонус аналогично 6 сайтов, владелец, конкурент, ручная накрутка — с историей, без истории, и три сайта — контрольная группа, которые мы принципиально не крутили, чтобы понять, не сами ли по себе они растут.
Домены были все новые. Домены без истории. Все примерно в одно время зарегистрированы. Айпишники разнесли, хостинги публичные. Постарались, чтобы айпишник не пересекались. Сайты все на вордпрессе, шаблоны разные. Количество страниц у нас одинаковое было, и метрику, аналитику, серч-консоль и веб-мастер поставили.
Базовая оптимизация в виде текстов, в виде каталога сделали. По региональности добавили в веб-мастер по Яндексу, в Гугле просто организации создали на гугл-мапсе, как положено, чтобы региональность была в порядке.
Старт эксперимента
С начала января мы приступили к работе. В течение января мы эти сайты готовили, писали тексты, вся работа была в течение января сделана. Сайты выглядят примерно так.
Незатейливый дизайн, все изображения из интернета, каталог без хитростей, сео-текст внизу страницы. Для каждого сайта придумали уникальное имя бренда, это для нас было важно, дальше поймем почему. Из контактных данных всё очень скромно: адрес, е-мейл.
Первого февраля мы были готовы к индексации.
В феврале пошла индексация. Мы рассчитывали, что за февраль у нас всё успешно произойдет. Какие-то позиции получат топ-50, топ-70, и мы сможем начать их красиво крутить. Поначалу так и было.
Но они все зашли и вышли. Все. С нуля начали, нулем закончили. Это немного для оказалось неожиданностью, поэтому мы на конец февраля оказались с нулевыми позициями.
Это был Яндекс, Гугл тоже неохотно заходил в индекс. Здесь такой инсайд получается, что, если мы захотим крутить молодой, нулевой сайт в Яндексе, хорошо бы, наверно, первую волну не пропустить, тогда вы много времени сэкономите.
Тогда мы в марте решили, что надо начинать крутить по брендам. Бреды мы составляли очень просто. Допустим, питомник мейнкунов и название наше фирменное «Wild beauty» — это наш брендовый запрос. На это дело мы выделили два месяца.
Крутим брендовые, откликаются остальные. Вяленько откликаются. В юзераторе крутим как конкурент, как владелец. В сео-бонусе откликаются получше. Все сайты как-то среагировали.
На владельца и на конкурента одинаково среагировали, в принципе. Ручная, в принципе, как сео-бонус.
Получается, то же самое. При этом сами брендовые — это нулевые запросы, их никто не ищет, они втаскиваются моментально на первую, вторую позицию. Это легко происходит.
Для нас здесь важный инсайд: тащим брендовые, тащится основная семантика. Даже достаточно высокочастотные запросы.
Брендовые в Гугле тоже среагировали на нашу деятельность, затаскиваются, но менее охотно. Усилий потратить пришлось больше на это дело, крутить больше пришлось.
Самая главная неприятность, что они не затаскивают другие запросы.
Ты крутишь этот запрос, он крутится, другой запрос рядом не крутится. Так среагировала наша семантика, то есть никак. Все методы одинаково плохо. Контрольная группа такая же.
Мы подошли к тому, что пора крутить основное семантическое ядро с целевыми запросами, которые нас интересуют. Мы на этом этапе срезали часть участников. В каждой группе оставили по одному сайту. В первую очередь, потому что это реально трудозатратно. Мы недооценили сначала — насколько, потому что семантика достаточно большая. Во-вторых, нам было интересно, есть сайты, которые мы покрутили и бросили, что с ними будет.
Доказательство гипотез по Яндексу
Про то, что в Яндексе накрутка работает, мы научно доказали. Работает и неплохо. То, что пользователи без истории не принимаются в учет поисковой системы — это фейк. На самом деле, очень замечательно принимаются, если отличие между пользователями только в том, что: есть история или нет истории, наши замечательные реалистичные аккаунты никак не повлияли, в инкогнито тот же самый результат.
То, что Яндекс умеет отличить накрутку владельца от накрутки конкурента. К сожалению, у нас ничего не забанили.
Мы очень хотели. Мы крутились как могли. Пять месяцев мы крутили. Еще месяц подождать? Хорошо. Будем ждать. Мы не смогли ничего доказать.
Единственное, вытекает, что эффективность накрутки — владелец ты, не владелец — не отличает никто. Можно на этот счет не парится, но, наверно, есть риск бана.
Мы не смогли сказать ничего, научно обоснованного, по поводу безопасности. Наверно, опасность существует.
Доказательство гипотез по Google
Мы определенно опровергли тех скептиков, которые говорили, что гугл игнорирует поведенческий фактор вовсе. Он их не игнорирует, он их принимает во внимание, но немного по-своему. Санкции мы не получили, поэтому ничего сказать более определённого не можем.
Общие выводы
Понятно, в Яндексе и Гугле накрутка работает. Ручная накрутка по нашей технологии работает лучше всего в Яндексе, хотя и другие методы тоже работают. Интересно, что в Гугл среднестатистически как-то всё телепалось, но для пользователей наших ручных без истории был абсолютный ноль. Гугл действительно игнорирует пользователей без истории. Это мы можем определенно заключить из этого эксперимента.
Еще такой инсайдик, что, если мы бросаем сайт, он не обрушивается моментально, он может продолжать расти, может продолжать стабильно сохраняться, но, может быть, какое-то снижение. В принципе, такой импульс стартовый ему дается, и он сохраняется за ним, по крайней мере, на дистанции трех месяцев с лишним.
Сколько это стоило
Немного расскажу про стоимость эксперимента, во сколько нам это обошлось. Основные затраты у нас получились — это трудозатраты, потому что это такая морока и такая рутина.
Причем, это нельзя перепоручить начинающему специалисту. Мы в ценах клиентов обычно считаем такие затраты.
Больше 600 тысяч мы потратили при таком раскладе, больше 400 часов ушло.
Если говорить про внешние затраты, которые мы платили деньгами непосредственно, 250 тысяч у нас вышло на домены, прокси, хостинги и так далее. Сам юзератор, мы думали, что сможем больше денег слить, не смогли больше. Старались как могли, 33 тысячи удалось нам потратить за 5 месяцев на все сайты. Если бы было желание, мы бы еще полгода работали, то мы бы, наверно, размахнулись.
Немного размышлений
Крутить или не крутить сервисами?
С одной стороны, соблазнительно, потому что затраты достаточно маленькие, эффект вполне ощутим, но рискованность на наш взгляд в данном случае перевешивает, потому что, что касается публичного сервиса, спалиться как не фиг делать.
Мы даже попробовали, как исполнители в сеобонусе зашли, мы на третий день себе свое же задание получили. Слить базу всех исполнителей никаких проблем, а из юзератора еще проще. Там не нужно нано-технологий, просто сливаешь базу и по списку банишь.
Либо понимать риски, либо не рисковать.
Насчет ручного. Тут такое получается, что с одной стороны, круто, с другой стороны, дорого. Все равно не исключены риски. Мы какую-то технологию применили здесь, но надо очень много экспериментов поставить, чтобы определить на 100%, что не забанится, что ты никаких ошибок не допустишь, не спалишься. Теоретически риски существуют, но, наверно, их меньше. Проект должен быть стоящий, чтобы в него такие ресурсы вкладывать.
Вопросы после доклада
— Спасибо за доклад. У меня вопрос: а вы использовали что-то а-ля Зеннопостера или пробовали эмуляцию браузера, чтобы автоматизировать ручную накрутку?— Мы не строили цех по ручной накрутке. Мы эксперимент просто делали. На этой дистанции смысла не было автоматизировать сильно.— Спасибо. Вы говорили, что бренд подключали, и смежные запросы в Гугле не доходили…— Почти. Нет, кое-что выходило.— Использовали с топонимом, и доходило ли с топонимом?— Нет. Не использовали.— Только бренд?— Да.— Вы на каждый запрос или на каждый сайт использовали отдельный айпи?— На каждый пользовательский профиль отдельный айпи. Пересекались ли они с одного айпишникка на разных сайтах? Может быть, какой-то процесс пересечений был. Такой задачи строго не стояло, в принципе.— Спасибо, информативный доклад. Слышали, наверно, что баны по пфам идут апдейтно. Один апдейт, скашивается сразу большое количество сайтов.— Наслышаны.— Слышали за время эксперимента, был ли апдейт по поведенческим банам?— Не могу ответить на этот вопрос. Мы не говорим, что доказали, что не забанят. Возможно, забанили бы.— Спасибо за доклад. Вопрос по экономической целесообразности. Если взять лучшую методику. Экономическая целесообразность. Сколько они могли бы заработать на этой теме? И второе: стоимость юзератора, вроде сеопикап стоит порядка 80 рублей за клик, а ты, по-моему, меньше указал.— Есть юзератор, там порядке 11 рублей. Это первая схема. Второй инструмент был сеобонус, там люди в телеграмчике, вконтактике, им задания присылают и всё, это не сеопикап.— А пикап вы не использовали?— Нет. У нас не так много денег.— Понятно. А по экономике?— Мы такой задачи не ставили, вычислить, насколько это целесообразно. Мы не ставили задачу определить, насколько это выгодно. Просто проверили основные гипотезы, и вопрос о цене не стоял. Конечно, если ты будешь ставить это на поток, наверно, ты автоматизируешь, оптимизируешь, и потом экономика будет другая, нежели у нас. Я просто рассказал экономику нашего эксперимента, а не того, как это будет у других ребят.
madcats.ru
Подробно о BrowseRank, алгоритме учета поведенческих факторов. Программа о накрутке поведенческого фактора
Независимый эксперт аналитик, руководитель отдела поисковой аналитики «Викимарт»
Несколько дней назад я вел программу на Мегаиндекс.ТВ, в которой мы со Станиславом Ставским обсуждали возможности учета поведения пользователей для ранжирования документов. Главный фокус программы: попытки накруток поведенческих факторов, реакция поиска на эти действия, перспективы. Наша точка зрения состоит в том, что у поиска много возможностей эффективно обнаруживать накрутки, что мы проиллюстрировали на примерах. Поэтому целесообразнее тратить время и ресурсы на улучшение сайта, что обеспечит естественное улучшение ранжирования.
При этом, конечно, хорошо бы понимать, что именно учитывают поисковые системы при анализе поведения пользователей в выдаче и на сайтах. Как ни странно, весьма немногие оптимизаторы и вебмастера знают о BrowseRank, технологии учета поведения пользователей от Microsoft (pdf, англ.). Хотя этой разработке уже 3 года, полагаю, она вполне актуальна.
Граф кликов вместо ссылочного графа
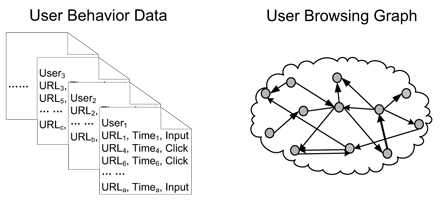
Основное отличие BrowseRank от PageRank — структура графа. В технологии PageRank узлами графа являются документы, а ребрами — ссылки. В технологии BrowseRank ребра образуют не ссылки, но клики (переходы). Помимо этого, сохраняется мета-информация о продолжительности сессии в рамках документа.
Очевидны два существенных преимущества BrowseRank:
- существенно лучшая устойчивость к ссылочному спаму,
- учет продолжительности сессии позволяет оценить полезность документа для посетителя.
Поведенческий граф более достоверно отражает процесс веб-серфинга, а, следовательно, он более полезен для расчета важности документов. Большее число посещений страницы и большее проведенное время означают большую важность страницы.
Основной источник данных о поведении пользователей — браузерные бары. Все ведущие поисковые системы имеют плагины, обеспечивающие мониторинг активности большой доли аудитории.
Для обработки данных о поведении пользователей предложено использовать цепи Маркова с непрерывным временем. Экспериментальные данные демонстрируют преимущество алгоритма BrowseRank по сравнению с алгоритмами PageRank и TrustRank в определении важности документов, борьбе со спамом и ранжировании.
По сути, собираемые данные можно представить записью вида URL; TIME; TYPE [input | click]. Предполагается два пути перехода на документ: по ссылке с другого документа (click), либо набором url в адресной строке браузера (input). Механизм извлечения данных о переходах:
- Сегментация сессии. Новая сессия инициируется в случае 30-минутной и более паузы с момента предыдущей активности, либо в случае ввода названия сайта в адресную строку.
- Формирование пар url. В рамках каждой сессии создаются пары url из соседних записей. Пара url означает, что переход был осуществлен при помощи ссылки.
- Формирование начального распределения. В каждой сессии, сегментированной по типу перехода, первый url введен непосредственно пользователем. Такие url мы считаем «доверительными» и называем этот трафик «зеленым». Обрабатывая данные о поведении пользователей, мы считаем переходы на эти url следствием случайного распределения. Нормализация на частоту посещения этих документов дает начальные вероятности посещения соответствующих страниц.
- Извлечение продолжительности сессии. Для каждой пары url продолжительность сессии первого url вычисляется простой разностью дат. Если url был последним в сессии, возможны два варианта. Для сессий, сегментированных по времени, продолжительность просмотра последнего url рассчитывается на основании данных о просмотрах других страниц. Для сессий, сегментированных по типу, время просмотра последнего url рассчитывается исходя из времени начала следующей сессии.
Результаты применения BrowseRank
Microsoft провела два исследования. Первый был проведен на уровне сайта для выявления важных сайтов и подавления спама. Второй эксперимент был проведен на уровне документа для тестирования BrowseRank с целью улучшения ранжирования.
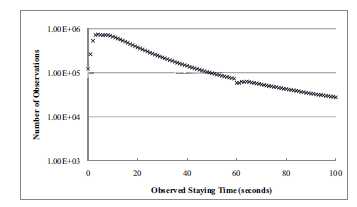
Для первого эксперимента использовался набор данных из примерно 3 миллиардов записей, содержащий примерно 950 миллионов уникальных url. Любопытно, что распределение количества просмотров по времени просмотра отлично описывается классической экспонентой. В рамках этого эксперимента постраничные не использовались, они были агрегированы на уровне сайтов. Полученный поведенческий граф состоял из 5.6 миллионов узлов и 53 миллионов ребер.
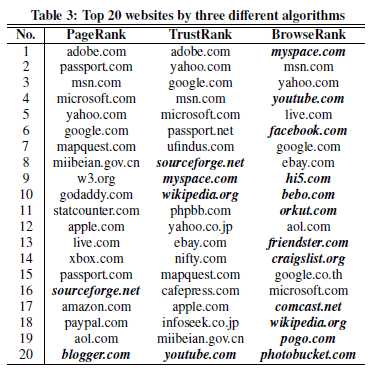
Любопытна выборка ТОП20 сайтов, полученных ранжированием по трем разным алгоритмам. Видно, что BrowseRank отлично отранжировал MySpace, Youtube, Facebook и прочие сайты, для которых характерно большое время сессии. Обратите внимание, это данные 2008 года. Очевидно, в нашу эпоху социальных сетей и коммуникационных сервисов различие между PageRank и BrowseRank было бы еще более значительным.
На случайной выборке в 10 тысяч сайтов, вручную размеченной асессорами, показано, что BrowserRank эффективнее, чем TrustRank и PageRank решает задачу фильтрации спам-сайтов.
Второй эксперимент не менее интересен.
Факторы ранжирования документов можно грубо разделить на две группы: факторы релевантности и факторы важности. Предполагаем итоговую функцию релевантности линейной комбинацией этих двух групп факторов:
Θ * rankrelevance + (1-Θ) * rankimportance,
где Θ лежит в интервале [0;1].
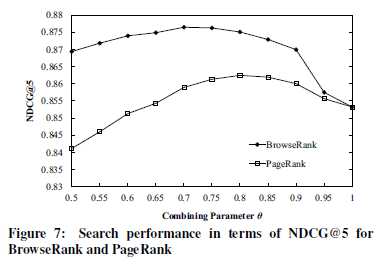
Данные получены на выборке из сайтов, полученных для 8000 запросов. Каждая пара запрос-документ оценивалась тремя асессорами по бинарной шкале [релевантно; не релевантно]. Релевантными сочтены документы, получившие по запросу не менее 2 оценок «релевантно».
Результат: алгоритм BrowseRank обеспечивает существенно лучшее качество вплоть до полного подавления факторов важности факторами релевантности (Θ ~ 0.9).
Несколько слов о попытках накруток и манипуляциях
Может ли поиск эффективно отфильтровать накрутки? Безусловно. Чтобы понять это, достаточно трех фактов:
- поиск оперирует колоссальным объемом незаспамленных данных,
- у поиска достаточно ресурсов для построения срезов и анализа активностей пользователей в этих срезах,
- поиск может использовать эталонные выборки пользователей, сайтов и активностей для обнаружения накруток.
Ну и, наконец, простые логические доводы для тех, кто не верит в технологии.
Совершенно очевидно, что поисковые системы начали собирать и использовать для ранжирования поведенческие факторы задолго до публичного освещения этой деятельности. Наивно думать, что разработчики не сделали выводов из судьбы предыдущей красивой идеи — учета ссылок как меры рекомендации. Уверен, проблема защиты от спама поведенческих факторов была детально проработана, благо недостатка в непредвзятой информации не было.
Резюме: существенно продуктивнее потратить время на легальные способы удлинения сессии и повышения «пользовательского счастья». Благо, таких способов предостаточно.
www.seonews.ru
Накрутка поведенческих факторов | Wiki-Web.ru
Некоторое время назад поисковая система Yandex сделала вывод, что поведенческие факторы являются основой поискового продвижения. И это стало причиной применения не совсем прозрачных методов для их улучшения.
Под поведенческими (социальными) факторами подразумевается действие интернет пользователя на каком-то конкретном ресурсе. Основными из них являются:
- просмотренные страницы, их количество, глубина;
- время, проведенное на сайте;
- повторные посещения площадки, их количество;
- возвраты на предыдущие страницы;
- отказы от просмотра и многое другое.
Но все чаще вместо реальных данных о поведенческих факторах, на различных сайтах наблюдается искусственная их накрутка в виде автонакрутки или через подкупленных посетителей.
Автонакрутка
Этот способ очень действенный и позволяет быстро набирать высокую посещаемость ресурса. Но вместе с тем, он очень рискованный и опасный. Улучшение социальных факторов в таком случае осуществляется с помощью ботов, специальных программ, которые вычисляются довольно легко, так как действуют однотипно, в автоматическом режиме. Поисковые системы сразу «видят» разницу между ботами и действиями реальных посетителей.
Купленные пользователи
Такой метод повысить кликабельность сайта менее распространен, но тоже встречается. Хотя и он легко вычисляется поисковыми системами. Главным отличием реальных пользователей от «живой накрутки» является алгоритм действий. В первую очередь юзеры, которые посещают страницы ресурса за деньги, просто кликают по страницам, не выбирая, не заказывая и не покупая ничего. А довольно часто они вообще находятся далеко от того региона, где действует продвигаемый коммерческий веб-сайт. Соответственно, их интерес имеет совсем другой характер, нежели предлагаемый на портале продукт.
Поисковые системы также оперативно обращают внимание на резкие скачки активности посещения. Они свидетельствуют об использовании искусственной технологии продвижения.
Кроме того, поисковые системы и применяемые в них алгоритмы детально изучают социальные факторы всех интернет ресурсов. Поэтому в ТОП попадают исключительно те площадки, которые отвечают интересам пользователей и соответствуют требуемым критериям качества.
Легальной работой сайта и реальными поведенческими факторами являются те, у которых наблюдается не только временный рост трафика и конверсии, но и стабильное увеличение объема продаж.
wiki-web.ru
Накрутка поведенческих факторов | Бизнес реально и виртуально
Как вы знаете, поисковики учитывают три основных фактора, ранжирования сайтов в поисковой выдаче.
1.Внутренние факторы.
Включают в себя контент, внутреннюю перелинковку, дизайн, юзабилити. А так же техническое состояние сайта.
2.Внешние факторы.
Это внешние ссылки, их количество и качество. То есть факторы, не относящиеся к внутреннему содержанию сайта.
3.Поведенческие факторы.
Включают в себя, поведение пользователя на сайте. Точка входа, время нахождения на странице, количество переходов на внутренние страницы, и другие действия которые пользователь совершает на сайте.
После того как поисковые системы, научились отслеживать поведение пользователя на сайте. Они выделили поведенческие факторы как приоритетные при продвижении. Правда надежного алгоритма распознавания накрутки этих факторов, выработать не успели.
SEO компании почувствовав слабину, в течении прошлого года снимали деньги с клиентов продвигая их сайты, используя не совсем белые методы.
В интернете появились ботнеты и другие программы типа, Userator имитирующие поведение большого количества людей на сайте. В результате, новенькие коммерческие сайты попадали в топ по всем видам запросов, за самое короткое время.
Вебмастера, проанализировав ситуацию, и поняв в чем дело так же стали применять накрутку поведенческих факторов, изобретая все новые методы.
Конечно, так долго продолжаться не могло. В Яндексе вконце концов исправили допущенную ошибку. И начали раздачу слонов, то есть фильтров. Под раздачу попали как сеокомпании так и их клиенты. Не обошел Яндекс своим “вниманием” и тех, кто только экспериментировал, с поведенческими факторами.
После массовых репрессий, сеошники вовсе не отказались от накрутки П.Ф. Просто стали использовать программную накрутку, против своих конкурентов. А для продвижения своих сайтов, начали более масштабно использовать людские ресурсы.Согласитесь, всегда найдутся люди, которые за определенную плату, побродят, сколько нужно на каком нужно сайте и нажмут какие нужно кнопки.
Кроме того, в социальных сетях стали создаваться группы, которые своими действиями помогают сайтам добраться до первой страницы выдачи.
Последний способ накрутки поведенческих факторов – самый большой головняк для поисковиков. Если действия системы Userator и ей подобных, поисковики научились вычислять, то определить с какой целью человек зашел на страницу довольно трудно.Как происходит накрутка поведенческих факторов.
Вы написали отличную статью, и она попала в выдачу. Так как ваш блог молодой, и заслуг перед поисковиками не имеет, статья окажется, в зависимости от конкурентности запроса ,на десятой или на двадцатой странице.
Как попасть в топ – 10? Нужно что бы у вас появились читатели. На десятой, а тем более на двадцатой странице таковых нет по определению. Так далеко заходят лишь вебмастера, и то только в поисках своего блога.
Вот тут то и поможет группа из соц. сети. Люди заходят на сайт через поисковую строку, набрав запрос, по которому вы продвигаете статью. Проделав определенные действия, группа из 30ти- 50ти человек через две три недели, способна вплотную подвести сайт, к первой странице, по низкочастотному запросу.
А дальше, если статья действительно стоящая, появятся целевые посетители. Согласитесь, что при таком подходе трудно предъявить кому- либо обвинения.
Но Яндекс уже сделал заявление, что все вышеперечисленные действия, считает спамом, и будет принимать соответствующие меры в отношении сайтов, которые их используют.
Наверняка, точного алгоритма по выявлению накрутки поведенческих факторов, с помощью лузеров, у Яндекса пока нет. Но то, что они работают в этом направлении, и работа закончится положительным результатом, это сомнений не вызывает.
Поэтому, применять или не применять эти методы продвижения, решайте сами. Фишка заключается вот в чем: Яндекс, после того как научится распознавать ручную накрутку, вполне может, используя новые алгоритмы, проверить все сохраненные логи, тогда наказание неизбежно.
Противостояние вебмастеров , и поисковых машин, которое началось с появлением первой версии поисковой машины к сожалению, продолжается до сих пор. И скорее всего, будет продолжаться, пока поисковики не научатся отсекать поисковый спам.Если накрутка поведенческих факторов не будет учитываться в ранжировании сайтов, то необходимость применении этого способа продвижения, отпадет сама собой.
В конце хочу сообщить вам уважаемые друзья что я решил подать заявку на участие в марафоне под названием – Поведенческий фактор на блоге . Который организовывают Игорь Таушев и Олег Кмета автор блога - http://blog.rabotaposisteme.ru/А теперь хочу поделиться с некоторыми из вас плагином , который направляет комментатора на страницу указанную в настройках. Почему некоторых, потому что у многих, этот плагин уже стоит. Напишите комментарий и узнаете, как он работает. Название плагина и его короткое описание в статье – Плагины для WordPress.
Получайте самые интересные новые публикации на свой email:Похожие записи :
www.kokh.ru