Низкоуровневые оптимизации. Уровень оптимизации это
[compiler-flags] Является ли уровень оптимизации -О3 опасным в g ++? [g++] [optimization]
В первые дни gcc (2,8 и т. Д.) И во времена egcs, а redhat 2,96-O3 иногда был довольно багги. Но это уже более десяти лет назад, и -O3 не сильно отличается от других уровней оптимизации (в баггичности).
Тем не менее, он имеет тенденцию выявлять случаи, когда люди полагаются на неопределенное поведение, из-за более строгого соблюдения правил и, особенно, угловых случаев, языка (ов).
Как личное замечание, я запускаю программное обеспечение для производства в финансовом секторе уже много лет с -O3 и еще не сталкивался с ошибкой, которой бы не было, если бы я использовал -O2.
По многочисленным просьбам, здесь добавление:
-O3 и особенно дополнительные флаги, такие как -funroll-loops (не поддерживаемые -O3), иногда могут приводить к генерации большего количества машинного кода. При определенных обстоятельствах (например, на процессоре с исключительно небольшим кэшем команд L1) это может привести к замедлению из-за того, что весь код, например, некоторая внутренняя петля теперь больше не подходит для L1I. Как правило, gcc пытается не создавать столько кода, но поскольку он обычно оптимизирует общий случай, это может произойти. Параметры, особенно подверженные этому (например, разворачивание цикла), обычно не включаются в -O3 и соответственно помечены на man-странице. Как правило, рекомендуется использовать -O3 для генерации быстрого кода и возвращаться обратно к -O2 или -O (который пытается оптимизировать размер кода), когда это необходимо (например, когда профилировщик указывает на пропуски L1I).
Если вы хотите максимально оптимизировать оптимизацию, вы можете настроить gcc через --param расходы, связанные с определенными оптимизациями. Кроме того, обратите внимание, что gcc теперь имеет возможность добавлять атрибуты в функции, которые управляют настройками оптимизации только для этих функций, поэтому, когда вы обнаружите, что у вас есть проблема с -O3 в одной функции (или вы хотите попробовать специальные флаги только для этой функции) вам не нужно компилировать весь файл или даже весь проект с помощью O2.
otoh кажется, что нужно соблюдать осторожность при использовании -Ofast, который гласит:
-Ofast позволяет оптимизировать все -O3. Он также позволяет оптимизировать, которые недействительны для всех стандартных совместимых программ.
что заставляет меня сделать вывод, что -O3 предназначен для полного соответствия стандартам.
Да, O3 более груб. Я разработчик компилятора, и я обнаружил явные и очевидные ошибки gcc, вызванные генерацией O3 при сбое инструкций по сборке SIMD при создании моего собственного программного обеспечения. Из того, что я видел, большинство программных продуктов поставляется с O2, что означает, что O3 получит меньше внимания на тестирование и исправления ошибок.
Подумайте об этом так: O3 добавляет больше преобразований поверх O2, что добавляет больше преобразований поверх O1. Статистически говоря, больше преобразований означает больше ошибок. Это верно для любого компилятора.
code-examples.net
уровень оптимизации - это... Что такое уровень оптимизации?
уровень оптимизации nIT. Optimierungsgrad
- уровень оплаты труда
- уровень освещённости
Смотреть что такое "уровень оптимизации" в других словарях:
Уровень фактора — 6. Уровень фактора Фиксированное значение фактора относительно начала отсчета Источник: ГОСТ 24026 80: Исследовательские испытания. Планирование эксперимента. Термины и определения … Словарь-справочник терминов нормативно-технической документации
РДМУ 109-77: Методические указания. Методика выбора и оптимизации контролируемых параметров технологических процессов — Терминология РДМУ 109 77: Методические указания. Методика выбора и оптимизации контролируемых параметров технологических процессов: 73. Адекватность модели Соответствие модели с экспериментальными данными по выбранному параметру оптимизации с… … Словарь-справочник терминов нормативно-технической документации
МР 2.6.1.0066-12: Применение референтных диагностических уровней для оптимизации радиационной защиты пациента в рентгенологических исследованиях общего назначения — Терминология МР 2.6.1.0066 12: Применение референтных диагностических уровней для оптимизации радиационной защиты пациента в рентгенологических исследованиях общего назначения: 75 % й квантиль (75 % й процентиль или верхний квартиль) значение… … Словарь-справочник терминов нормативно-технической документации
Референтный диагностический уровень (РДУ) — установленное значение стандартной дозы или стандартного произведения дозы на площадь пучка рентгеновского излучения при типовых рентгенодиагностических процедурах в регионе или стране. Значение РДУ обычно устанавливают равным 75 % му квантилю… … Словарь-справочник терминов нормативно-технической документации
Основной уровень фактора — 7. Основной уровень фактора Натуральное значение фактора, соответствующее нулю в безразмерной шкале Источник: ГОСТ 24026 80: Исследовательские испытания. Планирование эксперимента. Термины и определения … Словарь-справочник терминов нормативно-технической документации
Верхний уровень фактора — 15. Верхний уровень фактора Допустимое максимальное отклонение фактора от основного уровня, соответствующее плюс единице в безразмерной шкале Источник: РДМУ 109 77: Методические указания. Методика выбо … Словарь-справочник терминов нормативно-технической документации
Нижний уровень фактора — 16. Нижний уровень фактора Допустимое минимальное отклонение фактора от основного уровня, соответствующее минус единице в безразмерной шкале Источник: РДМУ 109 77: Методические указания. Методика выбор … Словарь-справочник терминов нормативно-технической документации
Unix File System — UFS Разработчик CSRG Файловая система UNIX file system Дата представления (4.2BSD) Структура Содержимое папок таблица Ограничения Макси … Википедия
ВЫСШЕЕ ОБРАЗОВАНИЕ — уровень образования, получаемый на базе среднего в высших уч. заведениях и подтверждаемый официально признанными документами (дипломами, сертификатами и т. п.). В. о. результат усвоения такой совокупности систематизиров. знаний и навыков… … Российская педагогическая энциклопедия
система — 4.48 система (system): Комбинация взаимодействующих элементов, организованных для достижения одной или нескольких поставленных целей. Примечание 1 Система может рассматриваться как продукт или предоставляемые им услуги. Примечание 2 На практике… … Словарь-справочник терминов нормативно-технической документации
Система автоматического регулирования — Совокупность функциональных групп, обеспечивающих автоматическое изменение одной или нескольких координат технологического объекта управления с целью достижения заданных значений регулируемых величин или оптимизации определенного критерия… … Словарь-справочник терминов нормативно-технической документации
universal_ru_de.academic.ru
Низкоуровневые оптимизации
Андрей Аксенов Всю жизнь пишет низкоуровневый код, в 2018 все еще делает поисковый движок Sphinx.Андрей Аксенов: Здравствуйте, меня зовут Андрей Аксенов. Сегодня мы будем говорить о непростой работе, которая называется "низкоуровневой оптимизацией" и которую время от времени приходится делать.

Низкоуровневая оптимизация
Оптимизация, как известно, это зло. Поэтому ею никто не занимается. Хотя, на самом деле, заниматься ей надо на двух разных уровнях. На высоком уровне – логарифмическая оптимизация: должны быть правильные структуры данных, правильные алгоритмы, которые по ним бегают. Низкоуровневая оптимизация тоже нужна: допустим, вы уже сделали свой хеш из строк, и его можно реализовать как обычно, а можно правильно – и он будет работать хорошо.
Про высокий уровень я пока предметно говорить затрудняюсь. Для того чтобы говорить предметно, нужен конкретный пример – какой-нибудь алгоритм, который никому не интересен, кроме лично меня. У меня он ровно в одном месте в проекте появился для решения какой-то сильно своеобразной задачи, и больше никому не нужен.
Лучше поговорить о низком уровне. Он нужен везде.
Низкий уровень в природе один – это ассемблер, потому что иначе быть не может. Все, что выше ассемблера, недостаточно низко. Однако... Поскольку сейчас 2011-й год, ассемблеров стало много.

Существует ассемблер марки C99. C++ в стандарте, ремикс 2003-го года, 2011-го и т.д. В принципе, GVM и виртуальная машина на базе dotNet (Erlang - в том числе) в некотором роде тоже являются высокоуровневым ассемблером. Но я про них знаю мало, поэтому буду говорить про C++.
Почему про него? Достаточно близко к оборудованию. Можно создать код, который будет транслироваться в машинный код. Компиляторы достаточно хорошо работают, хотя некоторые демоны и компилятор на HotSpot, Java, dotNet вызывают затруднения. Кроме того, "Cи"-компилятор используется многими, в отличие от Erlang , Husky или Deploy, не говоря уже о функционировании на мобильном телефоне…
Существует все еще немало стороннего софта, который создан "Cи". Иногда приходится им пользоваться для устранения неисправностей.
Немаловажная деталь – я не знаком глубоко с работой других ассемблеров. Java-код написать смогу, но рассказать, как устроены GVM или провести оптимизацию не смогу.

Что самое главное? Лозунг. Потому что 90% слушателей уйдет с одной мыслью в голове и надо, чтобы эта мысль была правильная.
Например, в компьютерной графике RealTime 3D лозунг, который принадлежит компании Nvidia и ATI, – “Batch, batch, batch”. Чтобы за одну секунду можно было отправить, грубо говоря, 500, 1000, 2000 запросов на отрисовку треугольничков. Когда у вас большая база, которая слишком велика для размещения на сервере, тогда актуален лозунг “Шард, шард, шард”. И так далее.
Самая важная задача – найти правильный слоган для оптимизации.
В нашем случае это “Bench, bench, bench”. Это нематерное слово, насколько я знаю. В смысле, «бенчмарк, бенчмарк и еще раз бенчмарк».

Ближе к делу. Узкие места бывают 3 видов. Можно "упереться" в диск, память или процессор. Сегодня нас интересует только память и процессор. Пробежимся по верхам.

Что надо знать про память на базовом уровне?
Ценник доступа может быть разным – в зависимости от того, как вы эту память используете. Память – это не нечто волшебное с неизменной ценой доступа к каждому биту, она несколько сложнее.
Память работает не байтами, а линейками байт того или иного размера. У памяти есть L1, L2 кеш (хотя он бывает не в памяти, а на процессоре). Этот кэш необходимо очищать.
С памятью лучше работать по выровненным адресам, чем по невыровненным. Повторюсь – это неравномерно. Доступ к байту по смещению, не являющемуся степенью «двойки» (условно говоря), оказывается медленнее.

Что нужно знать про ЦП?
Краткий опорный план по оптимизации на низком уровне таков. Есть регистры, инструкции, кэш кода и так далее – надо понимать, как устроен процессор. Надо знать, какая стоит инструкция, какие есть классы инструкций. Необходимо представлять, как можно посчитать одно, другое, третье.

Более подробно о том, чего стоит память, чего стоит работа с ней.
Два стандартных показателя – полоса пропускания (англ. Bandwidth) и задержка (англ. Latency). Выполняем линейное чтение из памяти. Получается более 4 ГБ в секунду на ноутбуке, более 12 ГБ на сервере. Примитивный тест производительности (англ. benchmark), который честно читает память, честно суммирует регион памяти и потом печатает результат на stdout.
Казалось бы, все прекрасно. Скорость хорошая, чего еще нужно?
На самом деле, все не так просто. Как был устроен тест производительности, который получил 4 ГБ в секунду? Брал 100 миллионов 32-битных чисел и просто линейно их суммировал. Нулевое, первое, второе, третье. Линейно "бежал" по памяти.
Попробуем усложнить задачу. Берем и суммируем число № 0, число № 1024, число № 2048 и так далее. Потом точно так же с шагом в 1000 int’ов, начиная с первого. Потом начиная со второго. Так 1024 раза.
Для чего мы это делаем? Для того чтобы симулировать доступ к памяти, который плохо кэшируется.
В основном, тесты производительности выполняются на ноутбуке, поэтому цифры даны для него, если не указано иное. Внезапно вместо 4 ГБ в секунду получается 195. 2 секунды на 100 миллионов случайных доступов к памяти, 50 в секунду. В пересчете на такты процессора, которых тоже ограниченное количество, последовательный доступ выливается в 1-2 такта процессора, что почти идеально – лучше быть не может. В полтакта сложно вообще уложиться. Случайный доступ существенно дороже – в десятки раз. 40-60 тактов.
Немаловажная деталь. Случайным образом "скакать" по памяти "дорого". Вместо четырех с лишним гигов в секунду внезапно и полгига не получается.

Дальше ситуация ухудшается, потому что на практике вам почти никогда не надо будет читать один поток данных из памяти и что-то с ним делать. Скорее всего, вам надо будет делать с вашими данными что-то другое.
Например, второй тривиальный тест производительности. Давайте возьмем два "куска" памяти и просто сложим. Два вектора сложим в памяти. Больших вектора, по 100 миллионов чисел. 100 миллионов раз проделаем операцию *c++ = (*a++) + (*b++), где c, a и b считаются, соответственно, либо линейно, либо из случайных мест памяти. Линейно падение скорости составляет 4 раза. Мы видим, что помимо собственно чтения и "упора" в память, цикл увеличения указателей и прочее, потому что он настолько быстр. Тем не менее, скорость падает более ожидаемых трех раз.
Если все это делать псевдослучайным образом (случайно "скакать" по памяти с большим шагом, чтобы симулировать постоянное "выбивание" кэша), то получается совсем тоскливо. Выходит 36 мегабайт в секунду и на одну операцию сложения двух чисел, которая, формально говоря, выполняется за один такт процессора, мы тратим не 1 такт, а около 240.

Почему так все плохо?
Потому что память – повторюсь – это не магический черный ящик, который просто работает быстро, как пулемет. Это несколько более сложная структура и медленная вдобавок ко всему. Чтение из памяти проходит через каскад тампонов (через 2-3 тампона).
Напрямую с памятью процессор никогда не работает, по большому счету. Вместо этого он сначала идет в кэш первого уровня, который на самом кристалле маленький (8-16 килобайт), пытается в нем что-то найти. Если неудача – идет в более крупный кэш второго уровня, который тоже на кристалле. Если опять неудача – идет в основную память и, поскольку это сравнительно медленно, подтягивает из этой самой основной памяти не 1 байт, который вы запросили, а "полоску" – 32, 64, 128 байт.
Именно по этой причине все и работает так медленно, если мы, чтобы вынуть очередное число из буфера, "скачем" с шагом 4 килобайта. На каждые 4 байта внезапно случается потеря кэша, идет подтягивание 64-х байт из памяти – и все плохо.
Незатейливый тест производительности, который меняет шаг, крайне наглядно показывает проблему. Читали линейно – у нас практически не было потерь кэша. Увеличили шаг в 2 раза – каждые 64 байта как читались за 1 удар, так и читаются. Но теперь этих линеек по 64 байта мы считаем ровно в 2 раза больше, потому что на первом проходе читаем каждый четный int, на втором – каждый нечетный. Скорость ровно в 2 раза и падает. Соответственно, вплоть до шага 64 байта скорость линейного чтения из памяти падает, как и предсказано наукой, по 2 раза на каждое увеличение шага в 2 раза. После этого стабилизируется и начинает падать медленнее. Значит, размер L1 кэш-линии на том процессоре, на котором я тестировался, 64 байта.
Изменяем эксперимент. Меряем другую штуку. Только что обмерили L1 кеш и увидели, какой эффект он дает. Если никуда не скакать, если читать по 4 байта с шагом 4 байта, то 4400 мегов секунду. Если 4 байта читать каждые 8 байт – 2200, 4 байта каждые 16 – 1100 и так далее.
Изменяем условия эксперимента.

Вместо того чтобы менять шаг, меняем данные. Обрабатываем не "полгектара" данных, а поменьше. "Поведение" вот такое. Смотрим, как буфер уменьшается вплоть до определенного предела – до 4-х, 3-х, 2,3 мегабайт (не спрашивайте, почему именно 0,3 – я не знаю). На 2,1 уже начались краевые эффекты.
Скорость одинаковая – 195 мегабайт в секунду (чтение). Начиная с 2 МБ размера буфера, который многократно суммируется, начинает ускоряться. При размере буфера 1 МБ и сотни итераций – еще ускоряться и так далее.
Опять все сходится. Почему так произошло? Почему в тот момент, когда мы суммируем буфер 2 МБ, "прыгая" по нему шагом, у нас скорость 600 МБ в секунду, а как только буфер 2,3 МБ (заметьте) – скорость 195 МБ в секунду (внезапно в 3 с чем-то раза меньше). Потому что все сходится. На лаптопе 2 МБ кэша, а не 2,3. Эти лишние 0,3 и дают "смертельный" эффект.

Последняя мелкая деталь - выравнивание. Проводим третий эксперимент. Вместо того чтобы читать по тому адресу, который ОС отдала и который выровнен, потому что любой вменяемый аллокатор данные выравнивает, прибавляем к нему «единичку». Совершенно внезапно скорость падает на 7-8 % просто из-за того, что ты читаешь данные не по выровненному на границу 32-х битов адресу. Это, на самом деле хорошая ситуация, которая на архитектуре Intel. Оно, во-первых, работает, во-вторых, тормозит всего на 8 %. На SPARC оно просто "падает", на ARM оно работает, но читает не тот результат.
Каковы выводы?

Выводы из всех затейливых тестов можно сделать достаточно простые.
Если вам надо обработать очень много данных, будет лучше делать это линейно. Максимально линейно, насколько возможно.
Если линейно никак не получается (а зачастую это не получается, естественно), то нужно всеми усилиями добиваться того, чтобы рабочий комплект (англ. working set) влезал хотя бы в L2 кэш (2 МБ, 4, 12 – сколько у вас на целевом сервере).
Если можно "поиграть в Тетрис" и переложить данные в памяти так, чтобы они лежали более локально, чтобы работа могла производиться как раз без произвольных скачков по памяти, а хотя бы с помощью произвольных скачков в пределах L2 кеша (2 МБ), то обязательно нужно "поиграть в Тетрис" и это сделать. Это имеет смысл. 2,3 МБ – 200 МБ в секунду обработка, 2 МБ – 700 МБ в секунду. Уменьшив размер данных и переложив их так, чтобы обрабатывать по 1 и 1 за раз, увеличили скорость теоретически в 3 раза.
Если можно это сделать, то чтение записи нужно выровнять на границу скольких-то байт (естественно, если это не мешает всему остальному). Профит от этого дела – 7-8 %. От непопадания в кеш можно потерять значительно больше.
Начинаем с чистого листа. Глава № 2, почти не связанная с тем, что было сказано сейчас.
Она будет про процессор и всю ту дрянь, про которую хочется знать.

«Минута истории». Когда-то давным-давно, 30 лет назад был процессор 88, у которого были 8-битные регистры al, bl и другие. Потом придумали 286-й. У него 16-битные регистры. Потом появился 386-й – у него 32-битные регистры. Примерно так и происходит. Каждый вид регистров с чем-то совместим.
В любом современном процессоре у вас найдется набор регистров, который уходит по причинам совместимости где-то на 30-40 лет назад и восходит к родным i88 или что-то типа того.
Важно то, что процессор имеет какой-то набор регистров. Тут, скорее всего, может быть какая-то фактическая ошибка, потому что я хотел проверить, сколько конкретно новых клевых 64-битных регистров на amd64 архитектуре.
Есть набор регистров, с которыми, собственно, процессор работает. До тех пор, пока вы в эти регистры укладываетесь, все хорошо. Если вы в них не уложитесь, все будет плохо. Отсюда – внимание – мгновенный и очевидный вывод. Почему архитектура amd64 (64-битные сервера) «намного круче» (в кавычках), чем, например, архитектура 686-я или 386-я, с которой она, в принципе, совместима?
Просто потому, что у вас для проведения сложной счетной операции доступно намного больше регистров в любой конкретный момент времени. На самом деле, кажется, что их много – 8 штук. Но как только тебе надо сложить 3 числа и как только надо держать 3 указателя на 3 разных буфера, собственно 3 этих числа и какой-то счетчик, регистры кончатся мгновенно. Тебе постоянно надо входить в память, а память – это медленно. В тот момент, когда используется L1 кэш, это еще не очень медленно, но можно "увязнуть".
Поэтому 64-битная архитектура (amd64) намного лучше. Регистров больше, соответственно, "влезает" в них больше. Получается быстрее. Она лучше, но ровно до тех пор, пока не хуже, потому что переход может повлечь за собой неприятности.

Поговорим про те самые инструкции процессора. Доклад у меня начинался про C++, а первый кусок кода, который в нем появился – это ассемблер. Как на самом деле работает инструкция что-нибудь типа «давайте возьмем и прибавим к члену класса что-нибудь»? Она не работает в одну волшебную инструкцию «давайте возьмем и прибавим к члену класса что-нибудь». Она разбивается на микродействия, если угодно, инструкции. Примерно такие 3.
Сначала "подтягиваем" значение, с которым собираемся работать, из памяти в регистр. Увеличиваем это значение, вдобавок в предположение, что наша переменная b уже лежит в регистре. Кладем ее обратно. Сравните с кодом, который теоретически может сгенерировать компилятор на выражение a+b. Он ровно втрое меньше. Невероятно, но факт.

Не компиляторы и не всегда справляются с простыми задачами. Вот такой примитивный цикл в 2 строки, который активно использует какой-то счетчик в классе, крайне плохо оптимизируется с компилятором VS 2005 (и, по-моему, с VS 2008 тоже). Под рукой не было, проверить не удалось.
Тест № 1. Вот этот код как он есть. Сколько-то много итераций – 1 миллион, 100 миллионов, 1 миллиард, что-то вроде того. 700 миллисекунд.
Тест № 2. Берем переменную Counter и вместо нее везде пишем вот этот самый iRes. В самом конце записываем iRes обратно в поле класса Counter. Совершенно внезапно код, сгенерированный Visual Studio, начинает работать за 400 миллисекунд, а не за 700. Разница почти в 2 раза.
Что за плюсы у gcc? Gcc "видит", что можно в течение цикла работать с регистром. Он эту запись "догадывается" вынести за регистр сам. Visual Studio, соответственно, не догадывается.
Соответственно, там можно поймать такую смешную оптимизацию. Если вы достаточно активно используете член класса, то иногда компилятор с этим не справляется. В данном случае «косяк» компилятора, который есть в Visual Studio. Но они все не без греха. Это не значит, что gcc идеален. Это значит, что gcc сломается в каком-то другом месте, про которое мы еще не знаем.
Как обнаружить такую ошибку? Не знаю, как. Надо знать, что процессор работает с инструкциями и примерно прикидывать, что какая делает. Глянуть в disas, найти там "фарш" из трех инструкций, кучу совершенно ненужных загрузок из памяти и записи в память, ужаснуться и попытаться что-то сделать. Только так.
В данном случае решение такое: временно вынести член в локальную переменную. Внезапно код разгоняется в 2 раза синтетически.

Еще один замечательный момент, который надо понимать про ЦП. Опять же, все требует затрат. Код – это тоже данные, которые тоже лежат в памяти. С ним тоже надо как-то работать, поэтому нельзя сделать длинную "простыню" кода, которая чудесным образом будет быстро читаться. Внезапно возникает целый ряд проблем. Во-первых, вместо того чтобы весь код подставлять вместо вызова, надо зачем-то вводить функции, чтобы размер бинарника был 1 мегабайт, а не 200.
В некоторых местах вместо того, чтобы плодить вызов функции, надо функцию встраивать. Внезапно возникает понятие конвенции вызова. Дескать, если мы уж делаем вызов функции, то как именно мы это делаем? Как именно мы передаем аргументы, как именно мы собираемся возвращать значение?
В общем, из-за того, что код – это тоже данные в памяти, доступ к ним тоже не "бесплатен", внезапно возникает целый ряд вопросов. Что встраивать, что не встраивать, как с этим быть? Все это непонятно.

Еще один момент, который стоит знать про процессор. Современный процессор может выполнять инструкции в параллель. Начиная, по-моему, с Pentium-1, появились Pipes. Там их было 2, поэтому было очень прикольно писать код на ассемблере в 2 строчки. Если ты правильно эти строчки написал (а именно развел зависимости, чтобы 2 инструкции были независимы друг от друга), то 2 инструкции спарились и выполнились за 1 такт.
Дальше ситуация ухудшилась, поскольку процессоры стали более сложными. Вместо двух явных конвейеров внутри их стало много. Операции, более сложные, чем сложение, на самом деле, разбиваются на микрооперации. Регистры, которых вечно не хватает, процессор может внутри себя как-то ловко переименовать, инструкции он тоже может перестроить (в смысле, выполнить не в том порядке, в котором они не то что в программе на "Си" написаны, а не в том порядке, в котором они в машинном коде написаны).
Я просто знаю, что оно есть, и знаю это для одной простой вещи, если угодно. Не всегда то, что ты видишь даже в машинном коде, коррелирует с тем, как устроена реальная жизнь.

Ветвления
Последний момент про важные с точки зрения оптимизации "внутренности" ЦП. Есть понятие ветвления, несмотря на то, что оператор GoTo много лет назад заклеймили, и его почти нигде нет на высоком уровне. Внутри, в процессоре он по-прежнему есть. Вот такой код на "Си" в одну строчку транслируется в несколько инструкций. Сравниваем регистр с чем-нибудь, делаем условный переход.
В тот момент, когда происходит переход, это опять не "бесплатно", потому что переход условный. Процессор-то не знает, куда "бежать". Раньше заранее сделать предвыборку вообще не мог. Сейчас процессоры «умные»: пытаются следить, где какой переход куда перешел и заранее "подтягивать" из памяти именно тот код, с которым следующей инструкции, вероятно, придется работать. Зачем это знать с точки зрения оптимизации на языке хоть чуть-чуть повыше ассемблера?
Первое. Ветвления, опять же, не "бесплатны". Второе. В компиляторах какое-то время назад появились макросы, типа analysis likely, unlikely и так далее, которые позволяют вам "намекнуть" компилятору, что этот переход в 99 % случаев пойдет не туда. Теоретически это позволяет вам сделать более быстрый код.

Последний момент про ветвления. Мы, наконец-то, начинаем всплывать на уровень C++.
Это существует только на "Си". Давайте напишем 2 совершенно аналогичных кода. Первый – с кучей if(). If()_a=1 else if()_a=2 else и так далее. Или давайте напишем switch(). Что будет работать быстрее?
Правильный ответ – switch(). Удивительный правильный ответ. Он будет работать быстрее, даже когда в этом switch() всего 2-3 значения. Почему? Когда вы делаете тот самый switch() с набором константных значений, компилятор считает, например, оптимальную хеш-функцию от входного аргумента, строит табличку переходов. Опять же – много чем занимается, но в итоге делает намного меньше работы.
Грубо говоря, один линейный расчет функций, который сравнительно быстрый, и один jump. В отличие от простыни if(), в случае которой компилятор обязан сгенерировать кучу инструкций «cmp – перешли – cmp – перешли – cmp – перешли»… Переход ветвлений не "бесплатный". Процессор загружен.

Тест произодительности
Наконец-то, еще 3 строчки C++. Насколько это дело не бесплатное? Первый вариант кода – вот оригинал, в котором я для краткости вместо if написал тернарный оператор. 274 миллисекунды. A, b, c, d константны, на протяжении цикла, как видно, не изменяются. Тем не менее, компилятор до этого "додуматься" не может.
Если мы вынесем if a=b за пределы цикла и напишем, соответственно, if a=b один цикл, иначе другой цикл – в полтора раза. Понятное дело, что это полтора раза на крохотной синтетике. Понятное дело, что на общем фоне вы из подобных оптимизаций добьетесь максимум 1 – 10%. Это к вопросу о сильной "небесплатности" ветвлений и к вопросу о том, как с ней бороться.

Еще есть ряд проблем с вычислениями про плавающую точку.
FPU-часть в Visual Studio очень "тормозная" по умолчанию. Удивительный факт № 1 – ее можно резко разогнать ключом командной строки. Внезапно все начинает работать втрое быстрее.
Удивительный факт № 2. Написав достаточно простой код… На слайде – код суммирования того самого массива из 100 миллионов с плавающей запятой, написанный на SSE. 2 строчки, которые страшны, но не смертельны. Он работает еще в 2 раза быстрее, как видите. Или в 6 раз быстрее, чем то оригинал, сгенирированный Visual Studio.
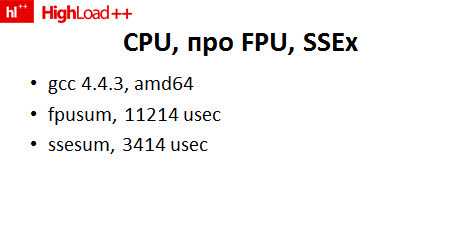
В случае с gcc тоже не все так хорошо. Несмотря на то, что gcc в последнее время умный, и на правильной платформе генерирует вместо тормозного FPU-кода сравнительно быстрый SSE-код, он все равно его генерирует по одному элементу за раз. Вручную "выпиленный" цикл суммирования чисел (синтетический пример, конечно), тем не менее, работает быстрее под gcc тоже.
Теперь про FPU, про который за 3 секунды можно сказать только то, что иногда он очень хорошо перекладывается и на SSE, векторизуется, потому что SSE – это минимум 4 флота за раз, в зависимости от версии, а в более "толстых" версиях – и побольше. Соответственно, работая с "толстыми" 128-битными регистрами по 4 флота за раз, удается выиграть до 3-4 (иногда и больше) раз по скорости. Отдельный плюс от SSE еще в том, что некоторые странные инструкции выполняются существенно быстрее, чем на FPU. Например, корень квадратный считается на SSE с дикой скоростью, по сравнению с ним.

В том же самом тесте мне, наконец, удалось получить эффект от ручного разворачивания цикла. Годы идут, а приемы не меняются. Как вручную развернуть цикл 100 лет назад давало эффект – так оно до сих пор дает. Другое дело, что эффект не сильно огромен, тем не менее, свои 5 % выиграть удается.
Что делают 2 магические строчки по сравнению с примитивным суммированием по одному флоту за раз? Во-первых, мы переписали все на SSE и суммируем по 4 флота за раз. Во-вторых, вместо того чтобы при суммировании векторов постоянно дописывать что-то к аргументу, мы немного разнесли зависимости, что позволило процессору спарить инструкции лучше, и дало честные 5 %.
Последняя часть теоретическая часть про компилятор

Что нужно знать про компилятор? Что используем в качестве компилятора, вроде понятно. Надо знать про всякие флаги сборки, которые иногда могут сильно удивить, про конвенции вызова, про define (хотя это больше про MSVC).

Флаги сборки
Если выставить не ту платформу, то компилятор сгенерирует код из предыдущего столетия, который рассчитан на процессор 20-летней давности i386, который будет далеко не оптимально исполняться. Надо быть бдительными, потому что умолчания даже на Linux могут удивить. Я регулярно вижу такие системы: 64-битный сервер генерирует 32-битный код, который на 64-битной платформе исполняется достаточно плохо.
У Visual Studio традиционно с этим нехорошо. По умолчанию он традиционно "скатывается" в i386, по большому счету. Ему вручную придется ставить архитектуру более "умную", чем 386. Ему надо "подсказывать", что все-таки SSE уже наступил везде. Вдобавок надо что-то сделать, чтобы он более внятно обрабатывал операции с плавающей точкой (потому что по умолчанию он какой-то совершенно безумный код генерирует).
Еще одна специфическая вещь для Visual Studio - это знаменитый edit and continue. Совершенно замечательная опция, я ей ни разу не пользовался. Тем не менее, как-то раз случайно выяснилось, что когда у вас включен "edit and continue" в дебажной сборке, то она станет медленнее в 3 раза.
Я никогда не пользуюсь этим, а трата неплохая. Это к вопросу о том, что надо знать о компиляторе. У него есть настройки, и их надо менять, иначе результаты удивляют.

Конвенции вызова по умолчанию тоже могут удивить. Этим страдает, в основном, Visual Studio. У gcc ситуация получше, но тоже иногда сталкивался. По умолчанию он компилирует в сравнительно тормозной __cdecl. Это конвенция вызова. Все данные, которые будут переданы в вызываемую функцию, "гоняются" через память, через стек. Соответственно, ставишь __fastcall – и внезапно все начинает работать чуть быстрее. Intrinsics тоже по умолчанию в Visual Studio отключены. В gcc, слава Богу, включены.
Intrinsics, несмотря на страшное название, это просто функция типа взятия модуля, копирования строк и так далее. Суть в том, что когда тот же strcpy() можно встроить, gcc это по умолчанию честно делает. Visual Studio – нет. Тоже вручную надо "подпихивать". Еще Visual Studio очень "любит" включать отладочные итераторы (для тех, кто пользуется SCL), что тоже снижает производительность в разы.
Наверное, для безопасности такие настройки выставлены, но код они дают "тормозной".

Совершенно не связанный с конкретным компилятором момент – это и беда 99 % программ (если не 100 %). Это борьба с аллокациями. Старая добрая аллокация памяти как 20 и 100 лет назад была медленная, так и до сих пор есть.
malloc()/free() – "дорогое" явление. Крайне желательно его хотя бы ликвидировать. Крайне желательно его заменять на какой-нибудь более внятный аллокатор. Делать большие аллокации памяти – на любом компиляторе в любой среде будет более или менее приемлемо. Много мелких аллокаций "из коробки" до сих пор никто не делает. Это до сих пор нереально.
Несмотря на то что теоретически в библиотеках, в операционной системе и так далее поддержка для мелких аллокаций должна бы совершенствоваться, очередной раз (раз в три года) выпилив ручной пул на миллион объектов, в котором ты вручную распределяешь элементы, с удивлением выясняешь, что все равно это до сих пор быстрее, чем пользоваться malloc()/free(). Прогресс местами куда-то идет, но местами стоит на месте. Аллокации – это как раз такое место.

"Боевой" пример вот какой. Секретный проект по вкручиванию морфологического словаря в Sphinx был выбран за то, что это, во-первых, показательная оптимизация, во-вторых, это сторонний код (не я его писал). Тем не менее, его удалось "взгреть" в 3 раза. Подчеркиваю – его удалось ускорить без каких-то алгоритмических фокусов. Алгоритм какой был, такой и остался. Структура данных какая была, такая и осталась.
Более того. Основной бинарный "кусок" памяти (который как в памяти сидит, так и сидит) вообще ни на бит не изменился. Просто на уровне реализации удалось выиграть 3 раза.
Каким образом? Чтобы чуть лучше понимать, каким образом, надо понимать, что делает критичный код.
Ты ему даешь на вход словоформу – он возвращает так называемый набор лемм (корневых форм). Внутри у него то, что авторы aot называют «конечный автомат», в принципе, похоже на обычное дерево. На каждом уровне есть ряд значений и указатель на следующий уровень.
Все это достаточно внятно запаковано. Многие сотни мегабайт данных пакуются в 10-20 мегабайт аккуратно упакованного суффиксного дерева.

История любви была вот такая. Начинал я с 12-ти секунд в aot лог, закончил четырьмя секундами в aot лог. Чисто для понимания – вот эти 12 секунд и 4 секунды, ради чего все делалось, на фоне всей остальной индексации, которая занимала 5 секунд. 5 секунд на индексацию и 12 секунд на морфологический словарь меня как-то морально беспокоили. Поэтому я предположил, что можно быстрее, и, действительно, можно быстрее суммарно в 3 раза. Недлинным рядом из восьми шажков.

Шажок № 1. Предельно прост и всегда работает. Ищем в коде fastpath – тот путь кода, который проходит, грубо говоря, в 90 % случаев (на самом деле, меньше в том конкретном контексте, но неважно) – и "закорачиваем" его. В случае aot и индексации в полнотекстовый оператор таким fastpath – это, очевидно, индексация суперкоротких слов – предлогов из 1-2 букв, всяческих коротеньких слов из 2-3 букв.
Строим список стоп-слов, вбиваем проверку на однобуквенное, но нерусское слово и на 12 наиболее частых двухбуквенных, 6 наиболее частых трехбуквенных предлогов прямо в код. Причем вбиваем их, как положено, не сравнением строк, а двумя чтениями двух байт и сравнением целочисленной константы с word. Тот самый switch против if, между прочим.
Внезапно получаем +18 % производительности – за счет того, что "выкинули" однобуквенные слова, за счет того, что "закоротили" один из наиболее быстрых путей. Внезапно еще 8,6 % за то, что "закоротили" один из часто используемых путей, когда часто используемый предлог «на» вообще не надо обрабатывать. Он долго и нудно обрабатывается, а на выходе он тебе отдает словоформу «на» для предлога «на». "Закоротив" этот код, получили 9 %. Мелочь, а приятно.

Шаг № 3. Где-то в дебрях есть такой пример кода, где в какую-то рекурсивную функцию передается по ссылке (не копированием) обычный, стандартный std::string. Замена, которая вместо std::string начала туда-сюда "гонять" ссылку на байтовый буфер и длину этого байтового буфера, каким-то чудесным образом дала +16 %. Честно говоря, я даже не понял, каким именно. Просто выкинул и забыл.
Очевидно, в случае передачи string, который оказался недостаточно тонким. Байтовые указатели и длина оказались еще тоньше, чем string.

Совершенно тот же трюк в другом месте. Был вот такой паттерн в коде. Набиваем вектор каких-то результатов чем-то, сортируем его – возвращаем самый лучший результат. Честно говоря, это уже был интеграционный код. Переписал в форму.

Вместо того чтобы возвращать "толстые" значения, строки, возвращаем индексы. Потом внутри этого самого CheckAndUpdate генерируем те же самые строки, которые раньше возвращали через vector, и каждую сравниваем с текущим лучшим значением, каждую возвращаем и так далее.
Казалось бы, ничего не изменилось. Но +16 %. За счет того, что туда-сюда между функциями в программе "гоняется" меньше данных. Вместо вектора строк гоняется вектор int’ов. Каждая конкретная строка генерируется в маленьком буфере. Вместо того чтобы добавить в память сотню строчек по 16 байт, мы каждую новую строчку просто генерируем на месте локально.
Там существенно менее чудовищные цифры. Тем не менее, очередные 16 %. Таким же образом передаем туда-сюда меньше данных.

Шаг № 5. Совсем простой, но неожиданно хороший. Там была очень странная функция привода в русский регистр, которая была настраиваемой в зависимости от разных опций. Дескать, если такая опция стоит, то вот так приводим, а если такая – то вот так. Она достаточно неплохо была написана для функции, которая настраиваема. Но трансляция по один раз посчитанной байтовой таблице дала свои 10 %. Я тупо упростил код. Убрал код, который был очень общим, заменил его примитивным, зато максимально быстрым фильтром по таблице.

Шаг № 6. Опять тот же самый паттерн. Где-то внутри программы, туда-сюда "гонялся" вектор между функциями из (казалось бы) мелких структур. 3 слова, 6 байт. Заменил его тупо на vector<DWORD> – внезапно получил +10 %. Хотя, казалось бы, он крохотный. 6-байтные структуры. Более того, их там не 10 миллионов, их там максимум 10-20 штук. Тем не менее, оказалось, что гонять по 4 байта на 10 % выгоднее, чем по 6.

Предпоследний шаг. Результат всех действий внутри рекурсивной процедуры обхода дерева, конечного автомата, trie – как угодно его назови – записывался в обычный советский STL-вектор. Заменить его на статический DWORD на стыку, с маркером конца (там, где список кончается, то ли 0, то ли -1 – не помню) дало внезапно +40 %.
На самом деле, ничего внезапного, потому что вектор динамический и постоянно туда-сюда – «распредели память, отдай память, распредели память, отдай память».
Если остаться в рамках любимого STL, не заменяя его на статический буфер, просто вынести его в глобальную переменную и сделать reserve, мгновенно испортив всю многопоточность, которая иногда бывает нужна, толк, в принципе, есть. Но существенно меньше. 40 % не удавалось добиться. 20-30 %, по-моему, было, но не более того.

Последний шаг. Честно говоря, самый большой, потому что все предыдущие изменения были, грубо говоря, однострочными. Каждый dif на каждом шаге менял по 20 строк. Этот, по-моему, поменял 50. Самый-самый внутренний цикл, когда совсем ничего уже придумать не мог, вместо того чтобы оставить рекурсивные функции, я развернул в цикл.
Там для каждого узла (англ. node) на определенном уровне мы получали число "детей" и обходили всех "детей". Этот самый обход – я делал стек вручную, по большому счету. Вот этот iChild, iChildMax – это состояние функции в точке вызова. Вручную все сделал, развернул рекурсию, свои 5 % получил из кода.

При всем при этом постоянно присутствовал неявный шаг номер 0. Нужно постоянно делать тесты производительности и профилирование.
Цикл «набросали черновик, сделали замер, если замер показал, что да, эффект от оптимизации есть» был проделан от 30 до 100 раз. В итоге десяток чистовиков тут описанных было за коммитом. Десяток – потому что некоторые из шагов делались в 2-3 подшажка. Десяток черновиков, которые пробовали всякое, другое, разное был просто сразу выкинут. Цикл «быстрый черновик, быстрый замер» показывает, что толку нет.

Какие фокусы стоит выбрать?
В данном конкретном примере видов фокусов всего-навсего 3.
Сделали fastpath. Убрали сложные расчеты на очень частых путях исполнения кода. Это те самые шаги 1 и 2.
Существенно сократили давление на память и на stack, которое, в основном, возникало из-за "гоняния" туда-сюда всяких аргументов. Это подавляющая часть шагов, как выяснилось, в данном случае.
В одном месте просто убрали очень сложный код, заменили его на простой табличный поиск. В итоге, напомню, выигрыш в 3 раза и общее время индексации, соответственно, сократилось в 2 раза.

Есть еще миллион разных фокусов, которые можно делать, когда ты занимаешься оптимизацией. Убирать лишнюю индирекцию при обращении к тем или иным структурам данных, пулить аллокации, писать аллокации вручную, перекладывать данные так, чтобы они локально лежали. Убирать «плохие» общие структуры, типа хеша строки и вектора, заменяя их на совсем простые варианты, хорошо заточенные под конкретную задачу.
В конце концов, можно заниматься всякими фокусами, которые специфичны для архитектуры. Те самые замены switch на if, вынос if за цикл и так далее, и тому подобное. В конце концов, была одна оптимизация, где замена байта на int дала эффект вполне измеримый. Почему? Потому что когда ты работаешь с байтом, компилятор генерирует инструкцию movzx постоянно, а это медленнее, чем работать с int’ами. Замена байта на int дала вполне ощутимые 2 %.
Мораль одна. Вот куча приемов. Вот куча знаний про RAM, про ЦП, которыми надо обладать. Общее правило, мантра всего одна – если можно не работать, значит, нужно не работать. Если можно код не исполнять, лучше не исполнять. Работу не делать, данные туда-сюда не перекладывать, в память ничего не писать, функции не вызывать.
Ничего не делать. Идеальный код, исполняется максимально быстро.

Если работать приходится, то избежать этого, к несчастью, нельзя. Работать надо по минимуму. Я только про код сейчас говорю. Мы его оптимизируем.

Процесс достаточно простой. Очень нудный и очень незатейливый: профилирование, тест производительности, повтор. Я беру каждый лишний 1 %. 20 раз взяв по 1 % здесь, по 10 % там – получается в итоге ускорить код от 3 до 7-10 раз. Собственно, все.
profyclub.ru
|
|
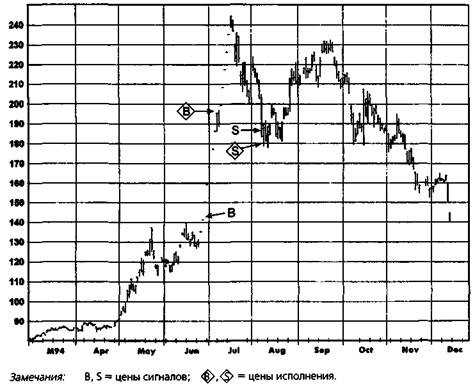
ОПТИМИЗАЦИЯ СИСТЕМ Оптимизация означает процесс отыскания набора параметров, который приводит к максимальной эффективности данной системы на определенном рынке. Основное предположение оптимизации состоит в том, что набор параметров, который проявил себя наилучшим образом в прошлом, имеет большую вероятность хорошей результативности и в будущем. (Вопрос о том, является ли это предположение верным, адресован следующему разделу.) Рисунок 20.2.ШИРОКИЙ РАЗРЫВ МЕЖДУ ЦЕНОЙ СИГНАЛАИ РЕАЛЬНЫМ УРОВНЕМ ОТКРЫТИЯ ПОЗИЦИИ, ВЫЗВАННЫЙМНОГОЧИСЛЕННЫМИ ОСТАНОВКАМИ ТОРГОВ:ДЕКАБРЬ 1994, КОФЕ
Например, если при тестировании простой системы пробоя кто-то обнаружит, что набор параметров N = 7 демонстрирует наилучшее соотношение прибыли и риска, но эта результативность резко падает для наборов параметра М<5иМ>9, в то время как все наборы в диапазоне от N = 25 до N = 54 дают относительно хороший результат, то было бы намного разумнее выбрать набор параметров из последнего диапазона. Почему? Потому что исключительная результативность набора N = 7 склоняет к мысли о своеобразии исторических цен, которые вряд ли повторятся. Тот факт, что близкие наборы параметров дают слабую результативность, предполагает, что нет оснований для доверия к торговле при наборе параметров N = 7. Напротив, широкий диапазон стабильной результативности для наборов из области 25 < N < 54 предполагает, что набор, взятый из середины этого диапазона, скорее всего, приведет к успешной торговле. Определение прибыльных областей для системы с единственным параметром требует не больше труда, чем просмотр колонки цифр. В системе с двумя параметрами придется строить таблицу измерений результативности, в которой колонки соответствуют возрастающим значениям одного параметра, а строки — возрастающим значениям второго. При таком способе придется визуально отыскивать зоны прибыльности. В случае системы с тремя параметрами может использоваться та же процедура, если один из параметров предполагает лишь небольшое количество дискретных значений. Например, в случае системы пересечения скользящих средних с временной задержкой в качестве подтверждающего правила, в которой тестируются три значения временной задержки, можно было бы построить три двухмерные таблицы результативности — по одной для каждого из значений временной задержки. Обнаружение прибыльных областей для более сложных систем, однако, потребовало бы применения компьютеризированных процедур поиска.4. Временная стабильность. Как уже было разобрано в предыдущем разделе, важно убедиться в том, что хорошая результативность для всего периода в целом действительно представляет весь период, а не отражает несколько изолированных интервалов экстраординарной результативности. Хотя введение различных измерений результативности в процедуру оптимизации даст более полную картину, оно при этом сильно затрудняет задачу. Скорее всего, многие трейдеры сочтут такую сложную процедуру оценки результативности непрактичной. В этом смысле трейдер может найти утешение в том факте, что наборы параметров с наибольшим доходом, как правило, также демонстрируют и наименьшее текущее падение стоимости активов (речь идет о различных наборах параметров для одной системы). Следовательно, при оптимизации единственной системы измерение соотношения прибыль/риск или даже простое измерение прибыли будут приводить к результатам, похожим на те, что возникают и при более сложной оценке результативности. Таким образом, несмотря на то, что многофакторная оценка результативности теоретически предпочтительна, она часто оказывается необязательной. Однако при сравнении наборов параметров из совершенно различных систем, точные оценки риска, устойчивости к изменению параметров и временной устойчивости оказываются чрезвычайно важными. Сказанное выше представляет собой теоретическую дискуссию по поводу концепций и процедур оптимизации и изначально подразумевает, что оптимизация улучшает будущую результативность системы. Тем не менее, как обсуждается на этом сайте, жизнеспособность оптимизации — это большой вопрос. Торговля в зонах Вход в рынок Выход из рынка Система пробоя дней ускорения Выбор временного периода
|
 Основной вопрос, который должен рассматриваться при оптимизации, заключается в том, какие критерии следовало бы использовать при определении наилучшей результативности. Часто наилучшую результативность интерпретируют как максимальную прибыль. Однако подобное определение не полно. В идеале при сравнении результативности следовало бы рассматривать четыре фактора.1. Прибыль, выраженная в процентах. Прибыль, измеренная по отношению к активам, необходимым при торговле с помощью системы..
Основной вопрос, который должен рассматриваться при оптимизации, заключается в том, какие критерии следовало бы использовать при определении наилучшей результативности. Часто наилучшую результативность интерпретируют как максимальную прибыль. Однако подобное определение не полно. В идеале при сравнении результативности следовало бы рассматривать четыре фактора.1. Прибыль, выраженная в процентах. Прибыль, измеренная по отношению к активам, необходимым при торговле с помощью системы..progi-forex.ru