Оптимизация TCP/IP стека в Linux, FreeBSD, Mac Os X и других операционных системах. Tcp оптимизация
Оптимизация TCP/IP стека в Linux, FreeBSD, Mac Os X и других операционных системах

Оптимальный размер буфера можно посчитать как пропускная способность*задержку используемого канала.
buffer size = 2 * bandwidth * delayДля определения задержки может быть использована утилита ping или инструментарий типа pathrate для определения емкости канала от точки А до точки В (если пропускная способность между точками переменная). Так как утилита ping дает время прохождения пакета туда и обратно (RTT), то вместо предыдущей может быть использована следущая формула:
buffer size = bandwidth * RTTЕсть 2 параметра настройки TCP, о которых Вы должны знать. Это размер буферов приема/отправки по умолчанию и максимальный размер буферов приема/отправки. Отметьте, что у большинства современных UNIX OS максимальный размер буфера по умолчанию только 256 Кбайт! Ниже мы покажем, как изменить это значение в большинстве современных ОС. Вы врядли захотите увеличить заданный по умолчанию размер буфера, на значение больше чем 128 Кбайт, потому что это может неблагоприятно повлиять на производительность локальной сети. Поэтому вы должны использовать UNIX вызов setsockopt для буферов приема/отправки, чтобы установить оптимальный размер буфера для канала, который вы используете.
Linux
Есть большие отличия между версиями Linux 2.4 и 2.6, но мы сейчас рассмотрим общие вопросы. Чтобы изменить параметры настройки TCP, вам необходимо добавить строки, представленные ниже, к файлу /etc/sysctl.conf и затем выполнить команду sysctl -p.
Как и во всех прочих ОС, размер буферов в Linux очень мал. Применим следущие настройки:
# increase TCP max buffer size setable using setsockopt()net.core.rmem_max = 16777216net.core.wmem_max = 16777216# increase Linux autotuning TCP buffer limits# min, default, and max number of bytes to use# set max to at least 4MB, or higher if you use very high BDP pathsnet.ipv4.tcp_rmem = 4096 87380 16777216net.ipv4.tcp_wmem = 4096 65536 16777216Вы должны также проверить, что следующие параметры установлены в значение по умолчанию, равное 1.
sysctl net.ipv4.tcp_window_scalingsysctl net.ipv4.tcp_timestampssysctl net.ipv4.tcp_sackОтметьте: Вы должны оставить tcp_mem в покое. Значения по умолчанию и так прекрасны.
Другая вещь, которую вы можете захотеть попробовать, что может помочь увеличить пропускную способность TCP, должна увеличить размер очереди интерфейса. Чтобы сделать это, выполните следующее:
ifconfig eth0 txqueuelen 1000Я получал до 8-кратного увеличения быстродействия, делая такую настройку на широких каналах. Делать это имеет смысл для каналов Gigabit Ethernet, но может иметь побочные эффекты, такие как неравное совместное использование между множественными потоками.
Linux 2.4
В Linux 2.4 реализован механизм автоконфигурирования размера буферов отправляющей стороны, но это предполагает, что вы установили большие буфера на получающей стороне, поскольку буфер отправки не будет расти в зависимости от получающего буфера.
Однако, у Linux 2.4 есть другая странность, о которой нужно знать. Например: значение ssthresh для данного пути кэшируется в таблице маршрутизации. Это означает, что, если подключение осуществляет повторную передачу и уменьшает значение окна, то все подключения с тем хостом в течение следующих 10 минут будут использовать уменьшенный размер окна, и даже не будут пытаться его увеличить. Единственный способ отключить это поведение состоит слкдующем (с правами пользователя root):
sysctl -w net.ipv4.route.flush=1Дополнительную информацию можно получить в руководстве sudouser.com
Linux 2.6
Начинаясь с Linux 2.6.7 (с обратным портированием на 2.4.27), linux включает в себя альтернативные алгоритмы управления перегрузкой, помимо традиционного 'reno' алгоритма. Они разработаны таким образом, чтобы быстро оправиться от потери пакета на высокоскоростных глобальных сетях.
Linux 2.6 также включает в себя алгоритмы автоматической оптимизации буферов принимающей и отправляющей стороны. Может применяться тоже решение, чтобы устранить странности ssthresh кэширования, что описанно выше.
Есть пара дополнительных sysctl параметров настройки для 2.6:
# don't cache ssthresh from previous connectionnet.ipv4.tcp_no_metrics_save = 1net.ipv4.tcp_moderate_rcvbuf = 1# recommended to increase this for 1000 BT or highernet.core.netdev_max_backlog = 2500# for 10 GigE, use this# net.core.netdev_max_backlog = 30000Начиная с версии 2.6.13, Linux поддерживает подключаемые алгоритмы управления перегрузкой. Используемый алгоритм управления перегрузки можно задать, используя sysctl переменную net.ipv4.tcp_congestion_control, которая по умолчанию установлена в cubic or reno, в зависимости от версии ядра.
Для получения списка поддерживаемых алгоритмов, выполните:
sysctl net.ipv4.tcp_available_congestion_controlВыбор опций контроля за перегрузкой выбирается при сборке ядра. Ниже представлены некоторые из опций, доступных в 2.6.23 ядрах:
* reno: Традиционно используется на большинстве ОС. (default)* cubic:CUBIC-TCP (Внимание: Есть бага в ядре Linux 2.6.18. Используйте в 2.6.19 или выше!)* bic:BIC-TCP* htcp:Hamilton TCP* vegas:TCP Vegas* westwood:оптимизирован для сетей с потерями
Для очень длинных и быстрых каналов я предлагаю пробовать cubic или htcp, если использование reno желательно. Чтобы установить алгоритм, сделайте следующее:
sysctl -w net.ipv4.tcp_congestion_control=htcpВниманию использующих большие MTU: если вы сконфигурировали свой Linux на использование 9K MTU, а удаленная сторона использует пекеты в 1500 байт, то вам необходимо в 9/1.5 = 6 раз большее значение буферов, чтобы заполнить канал. Фактически, некоторые драйверы устройств распределяют память в зависимости от двойного размера, таким образом Вы можете даже нуждаться в 18/1.5 = в 12 раз больше!
И наконец предупреждение и для 2.4 и для 2.6: для очень больших BDP путей, где окно > 20 MB, вы вероятно столкнетесь с проблемой Linux SACK. Если в "полете" находится слишком много пакетов и наступает событие SACK, то обработка SACKed пакета может превысить таймаут TCP и CWND вернется к 1 пакету. Ограничение размера буфера TCP приблизительно равно 12 Мбайтам, и кажется позволяет избежать этой проблемы, но ограничивает вашу полную пропускную способность. Другое решение состоит в том, чтобы отключить SACK.
FreeBSD
Добавьте это в /etc/sysctl.conf и перезагрузитесь:
kern.ipc.maxsockbuf=16777216net.inet.tcp.rfc1323=1В FreeBSD 7.0 добавлена функция автокогфигурирования буферов. Но значения их можно отредактировать, так как по умолчанию буферы 256 KB, а это очень мало:
net.inet.tcp.sendbuf_max=16777216net.inet.tcp.recvbuf_max=16777216Для общего развития покажу еще несколько параметров, но их дефолтные значения и так хороши:
net.inet.tcp.sendbuf_auto=1 # Send buffer autotuning enabled by defaultnet.inet.tcp.sendbuf_inc=8192 # step sizenet.inet.tcp.recvbuf_auto=1 # enablednet.inet.tcp.recvbuf_inc=16384 # step sizeУ FreeBSD есть кое-какие ограничения, включенным по умолчанию. Это хорошо для модемных подключений, но может быть вредно для пропускной способности на высокоскоростных каналах. Если Вы хотите "нормальное" TCP Reno, сделайте следущее:
net.inet.tcp.inflight.enable=0По умолчанию, FreeBSD кэширует подробности подключения, такие как порог slow start и размер окна перегрузки(congestion windows) с предыдущего подключения на тот же самый хост в течение 1 часа. В то время как это хорошая идея для веб-сервера, но плохая для тестирования пропускной способности, поскольку 1 большой случай перегрузки задушит производительность в течение следующего часа. Чтобы уменьшить этот эффект, установите это:
Solaris
Для Solaris просто сделайте загрузочный скрипт (например, /etc/rc2.d/S99ndd) следующего содержания:
#!/bin/sh# increase max tcp window# Rule-of-thumb: max_buf = 2 x cwnd_max (congestion window)ndd -set /dev/tcp tcp_max_buf 4194304ndd -set /dev/tcp tcp_cwnd_max 2097152# increase DEFAULT tcp window sizendd -set /dev/tcp tcp_xmit_hiwat 65536ndd -set /dev/tcp tcp_recv_hiwat 65536
Windows XP
Самый простой способ настроить TCP под Windows XP состоит в том, чтобы получить DrTCP из "DSL Reports". Установите "Tcp Receive Window" в вычесленное значение BDP (e.g. 4000000), включите "Window Scaling" "Selective Acks" и "Time Stamping".
Для проверки изменений можно воспользоваться редактором реестра. Наша цель - вот эти параметры:
# turn on window scale and timestamp optionHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Tcp1323Opts=3# set default TCP receive window sizeHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpWindowSize=256000# set max TCP send/receive window sizes (max you can set using setsockopt call)HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\GlobalMaxTcpWindowSize=16777216it.icmp.ru
Оптимизация TCP/IP стека в Linux, FreeBSD, Mac Os X и других операционных системах

Данная инструкция предназначена для описания действий по оптимизации параметров протокола TCP.
TCP использует параметр, который называют «congestion window», или CWND, чтобы определить, сколько пакетов можно послать в конечную единицу времени. Чем больший размер congestion window, тем выше пропускная способность. Размер congestion window определяется с помощью алгоритмов TCP «slow start» и «congestion avoidance». Максимальное значение congestion window зависит от объема буфера, назначенного ядром для каждого сокета. Для каждого сокета имеется значение размера буфера, установленное по умолчанию, которое можно изменить программно, используя системный вызов из библиотек прежде, чем будет открыт данный сокет. Так же имеется параметр, задающий максимальный размер буфера ядра. Изменить можно размер как передающего, так и принимающего буфера сокета.
Чтобы получить максимальную пропускную способность, необходимо использовать оптимально установленный размер передающего и принимающего буферов сокета для канала, который вы используете. Если буфера будут слишком маленькими, то congestion window никогда не будет полностью открываться. Если передающий буфер слишком большой, то возможны разрывы управления потоком данных TCP и отправитель может переполнить буфер получателя, что заставит уменьшить окно TCP. Это, вероятно, случится быстрее на хосте-отправителе, чем на хосте-получателе. Чрезмерно большой принимающий буфер — не самая большая проблема, пока у вас есть лишняя память.Оптимальный размер буфера можно посчитать как пропускная способность*задержку используемого канала.
buffer size = 2 * bandwidth * delay
Для определения задержки может быть использована утилита ping или инструментарий типа pathrate для определения емкости канала от точки А до точки В (если пропускная способность между точками переменная). Так как утилита ping дает время прохождения пакета туда и обратно (RTT), то вместо предыдущей может быть использована следущая формула:
buffer size = bandwidth * RTT
Для примера, если ping показывает 50 ms, и от точки А до точки В используются каналы 100 BT Ethernet и OC3 (155 Mbps), значение буферов TCP составит .05 sec * (100 Mbits / 8 bits) = 625 KBytes. (Если вас гложут сомнения, то 10 MB/s будет хорошим первым приближением для сетей ESnet/vBNS/Abilene-like).
Есть 2 параметра настройки TCP, о которых Вы должны знать. Это размер буферов приема/отправки по умолчанию и максимальный размер буферов приема/отправки. Отметьте, что у большинства современных UNIX OS максимальный размер буфера по умолчанию только 256 Кбайт! Ниже мы покажем, как изменить это значение в большинстве современных ОС. Вы врядли захотите увеличить заданный по умолчанию размер буфера, на значение больше чем 128 Кбайт, потому что это может неблагоприятно повлиять на производительность локальной сети. Поэтому вы должны использовать UNIX вызов setsockopt для буферов приема/отправки, чтобы установить оптимальный размер буфера для канала, который вы используете.
Linux
Есть большие отличия между версиями Linux 2.4 и 2.6, но мы сейчас рассмотрим общие вопросы. Чтобы изменить параметры настройки TCP, вам необходимо добавить строки, представленные ниже, к файлу /etc/sysctl.conf и затем выполнить команду sysctl -p.
Как и во всех прочих ОС, размер буферов в Linux очень мал. Применим следущие настройки:
# increase TCP max buffer size setable using setsockopt()net.core.rmem_max = 16777216net.core.wmem_max = 16777216# increase Linux autotuning TCP buffer limits# min, default, and max number of bytes to use# set max to at least 4MB, or higher if you use very high BDP pathsnet.ipv4.tcp_rmem = 4096 87380 16777216net.ipv4.tcp_wmem = 4096 65536 16777216
Вы должны также проверить, что следующие параметры установлены в значение по умолчанию, равное 1.
sysctl net.ipv4.tcp_window_scalingsysctl net.ipv4.tcp_timestampssysctl net.ipv4.tcp_sack
Отметьте: Вы должны оставить tcp_mem в покое. Значения по умолчанию и так прекрасны.
Другая вещь, которую вы можете захотеть попробовать, что может помочь увеличить пропускную способность TCP, должна увеличить размер очереди интерфейса. Чтобы сделать это, выполните следующее:
ifconfig eth0 txqueuelen 1000
Я получал до 8-кратного увеличения быстродействия, делая такую настройку на широких каналах. Делать это имеет смысл для каналов Gigabit Ethernet, но может иметь побочные эффекты, такие как неравное совместное использование между множественными потоками.
Также, по слухам, может помочь в увеличении пропускной способности утилита ‘tc’ (traffic control)
Linux 2.4
В Linux 2.4 реализован механизм автоконфигурирования размера буферов отправляющей стороны, но это предполагает, что вы установили большие буфера на получающей стороне, поскольку буфер отправки не будет расти в зависимости от получающего буфера.
Однако, у Linux 2.4 есть другая странность, о которой нужно знать. Например: значение ssthresh для данного пути кэшируется в таблице маршрутизации. Это означает, что, если подключение осуществляет повторную передачу и уменьшает значение окна, то все подключения с тем хостом в течение следующих 10 минут будут использовать уменьшенный размер окна, и даже не будут пытаться его увеличить. Единственный способ отключить это поведение состоит слкдующем (с правами пользователя root):
sysctl -w net.ipv4.route.flush=1
Дополнительную информацию можно получить в руководстве Ipsysctl.
Linux 2.6
Начинаясь с Linux 2.6.7 (с обратным портированием на 2.4.27), linux включает в себя альтернативные алгоритмы управления перегрузкой, помимо традиционного ‘reno’ алгоритма. Они разработаны таким образом, чтобы быстро оправиться от потери пакета на высокоскоростных глобальных сетях.
Linux 2.6 также включает в себя алгоритмы автоматической оптимизации буферов принимающей и отправляющей стороны. Может применяться тоже решение, чтобы устранить странности ssthresh кэширования, что описанно выше.
Есть пара дополнительных sysctl параметров настройки для 2.6:
# don't cache ssthresh from previous connectionnet.ipv4.tcp_no_metrics_save = 1net.ipv4.tcp_moderate_rcvbuf = 1# recommended to increase this for 1000 BT or highernet.core.netdev_max_backlog = 2500# for 10 GigE, use this# net.core.netdev_max_backlog = 30000
Начиная с версии 2.6.13, Linux поддерживает подключаемые алгоритмы управления перегрузкой. Используемый алгоритм управления перегрузки можно задать, используя sysctl переменную net.ipv4.tcp_congestion_control, которая по умолчанию установлена в cubic or reno, в зависимости от версии ядра.
Для получения списка поддерживаемых алгоритмов, выполните:
sysctl net.ipv4.tcp_available_congestion_control
Выбор опций контроля за перегрузкой выбирается при сборке ядра. Ниже представлены некоторые из опций, доступных в 2.6.23 ядрах:
* reno: Традиционно используется на большинстве ОС. (default)* cubic:CUBIC-TCP (Внимание: Есть бага в ядре Linux 2.6.18. Используйте в 2.6.19 или выше!)* bic:BIC-TCP* htcp:Hamilton TCP* vegas:TCP Vegas* westwood:оптимизирован для сетей с потерями
Для очень длинных и быстрых каналов я предлагаю пробовать cubic или htcp, если использование reno желательно. Чтобы установить алгоритм, сделайте следующее:
sysctl -w net.ipv4.tcp_congestion_control=htcp
Дополнительную информацию по алгоритмам и последствиям их использования можно посмотреть тут.
Вниманию использующих большие MTU: если вы сконфигурировали свой Linux на использование 9K MTU, а удаленная сторона использует пекеты в 1500 байт, то вам необходимо в 9/1.5 = 6 раз большее значение буферов, чтобы заполнить канал. Фактически, некоторые драйверы устройств распределяют память в зависимости от двойного размера, таким образом Вы можете даже нуждаться в 18/1.5 = в 12 раз больше!
И наконец предупреждение и для 2.4 и для 2.6: для очень больших BDP путей, где окно > 20 MB, вы вероятно столкнетесь с проблемой Linux SACK. Если в «полете» находится слишком много пакетов и наступает событие SACK, то обработка SACKed пакета может превысить таймаут TCP и CWND вернется к 1 пакету. Ограничение размера буфера TCP приблизительно равно 12 Мбайтам, и кажется позволяет избежать этой проблемы, но ограничивает вашу полную пропускную способность. Другое решение состоит в том, чтобы отключить SACK.
Linux 2.2
Если вы используете Linux 2.2, обновитесь! Если это не возможно, то добавьте следущее в /etc/rc.d/rc.local:
echo 8388608 > /proc/sys/net/core/wmem_maxecho 8388608 > /proc/sys/net/core/rmem_maxecho 65536 > /proc/sys/net/core/rmem_defaultecho 65536 > /proc/sys/net/core/wmem_default
FreeBSD
Добавьте это в /etc/sysctl.conf и перезагрузитесь:
kern.ipc.maxsockbuf=16777216net.inet.tcp.rfc1323=1
В FreeBSD 7.0 добавлена функция автокогфигурирования буферов. Но значения их можно отредактировать, так как по умолчанию буферы 256 KB, а это очень мало:
net.inet.tcp.sendbuf_max=16777216net.inet.tcp.recvbuf_max=16777216
Для общего развития покажу еще несколько параметров, но их дефолтные значения и так хороши:
net.inet.tcp.sendbuf_auto=1 # Send buffer autotuning enabled by defaultnet.inet.tcp.sendbuf_inc=8192 # step sizenet.inet.tcp.recvbuf_auto=1 # enablednet.inet.tcp.recvbuf_inc=16384 # step size
У FreeBSD есть кое-какие ограничения, включенным по умолчанию. Это хорошо для модемных подключений, но может быть вредно для пропускной способности на высокоскоростных каналах. Если Вы хотите «нормальное» TCP Reno, сделайте следущее:
net.inet.tcp.inflight.enable=0
По умолчанию, FreeBSD кэширует подробности подключения, такие как порог slow start и размер окна перегрузки(congestion windows) с предыдущего подключения на тот же самый хост в течение 1 часа. В то время как это хорошая идея для веб-сервера, но плохая для тестирования пропускной способности, поскольку 1 большой случай перегрузки задушит производительность в течение следующего часа. Чтобы уменьшить этот эффект, установите это:
net.inet.tcp.hostcache.expire=1
В этом случае мы будем все еще кэшировать значения в течение 5 минут, по причинам, описанным в этой статье от Centre for Advanced Internet Architectures (CAIA) at Swinburne University in Autralia. В ней вы также найдете другую интересную информацию о тюнинге FreeBSD. Также можно использовать H-TCP patch for FreeBSD
Для получения информации о тюнинге NetBSD, обратитесь к этой статье.
Внимание: у FreeBSD версий ниже 4.10 нет реализации SACK, что сильно снижает ее производительность по сравнению с другими операционными системами. Вы необходимо обновиться до 4.10 или выше.
Solaris
Для Solaris просто сделайте загрузочный скрипт (например, /etc/rc2.d/S99ndd) следующего содержания:
#!/bin/sh# increase max tcp window# Rule-of-thumb: max_buf = 2 x cwnd_max (congestion window)ndd -set /dev/tcp tcp_max_buf 4194304ndd -set /dev/tcp tcp_cwnd_max 2097152
# increase DEFAULT tcp window sizendd -set /dev/tcp tcp_xmit_hiwat 65536ndd -set /dev/tcp tcp_recv_hiwat 65536
Для получения дополнительной информации, обратитесь к документации Solaris
Windows XP
Самый простой способ настроить TCP под Windows XP состоит в том, чтобы получить DrTCP из «DSL Reports». Установите «Tcp Receive Window» в вычесленное значение BDP (e.g. 4000000), включите «Window Scaling» «Selective Acks» и «Time Stamping».
Провести дополнительную настройку можно с помощью сторонних утилит, таких как SG TCP Optimizer и Cablenut.
Для проверки изменений можно воспользоваться редактором реестра. Наша цель — вот эти параметры:
# turn on window scale and timestamp optionHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Tcp1323Opts=3# set default TCP receive window sizeHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpWindowSize=256000# set max TCP send/receive window sizes (max you can set using setsockopt call)HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\GlobalMaxTcpWindowSize=16777216
Вы можете использовать setsockopt() для программного изменения значения буферов до размера GlobalMaxTcpWindowSize, или можете использовать TcpWindowSize для задания значения буферов по умолчанию всех сокетов. Второй вариант может быть плохой идеей, если у вас мало памяти.
Для получения дополнительной информации, обратитесь к документам Windows network tuning, TCP Configuration Parameters, TCP/IP Implementation Details и Windows 2000/XP Registry Tweaks
Windows Vista
Хорошая новость! У Windows Vista имеется автонастройка TCP. Максимальный размер окна может быть увеличен до 16 MB. Если вы знаете, как сделать его больше. Дайте мне знать.
Vista также включает в себя «Compound TCP (CTCP)», что очень похоже на cubic в Linux. Для задействования этого механизма, необходимо выполнить:
netsh interface tcp set global congestionprovider=ctcp"
Если вы хотите включить/выключить автонастройку, выполните следующие команды:
netsh interface tcp set global autotunninglevel=disablednetsh interface tcp set global autotunninglevel=normal
Внимание, команды выполняются с привилегиями Администратора.
Нет возможности увеличить значение буферов по умолчанию, которое составляет 64 KB. Также, алгоритм автонастройки не используется, если RTT не больше чем 1 ms, таким образом единственный streamTCP переполнит этот маленький заданный по умолчанию буфер TCP.
Для получения дополнительной информации, обратитесь к следующим документам:
* TCP Receive Window Auto-Tuning in Vista* Enterprise Networking with Windows Vista* Why TcpWindowSize does not work in Vista
Mac OSX
Mac OSX настраивается подобно FreeBSD.
sysctl -w net.inet.tcp.win_scale_factor=8sysctl -w kern.ipc.maxsockbuf=16777216sysctl -w net.inet.tcp.sendspace=8388608sysctl -w net.inet.tcp.recvspace=8388608
Для OSX 10.4, Apple также предоставляет патч Broadband Tuner, увеличивающий максимальный размер буферов сокета до 8MB и еще кое-что по мелочи.
Для получения дополнительной информации, обратитесь к OSX Network Tuning Guide.
AIX
Для повышения производительности на SMP системах, выполните:
ifconfig thread
Это позволит обработчику прерываний интерфейов GigE на многопроцессорной машине AIX выполняться в многопоточном режиме.
IRIX
Добавьте в файл /var/sysgen/master.d/bsd такие строки:
tcp_sendspacetcp_recvspace
Максимальный размер буфера в Irix 6.5 составляет 1MB и не может быть увеличен.
Оригинал статьи: http://fasterdata.es.net/TCP-tuning/Перевод: Сгибнев МихаилИсточник: http://dreamcatcher.ru/bsd/017_tcp.html
sudouser.com
Имеет ли TCP Optimizer Работа ускорить мой Интернет?
Оптимизатор TCP
По мере того, как интернет-технология стала более совершенной и интуитивно понятной, легко забыть, что для каждого сайта, видео YouTube или онлайн-игры существует довольно сложный набор протоколов. Эти протоколы контролируют каждый аспект передачи данных и являются причиной того, что мы можем наслаждаться содержимым, доступным в Интернете с такой надежностью.
И, поскольку ПК часто выпускаются с конфигурациями «одного размера для всех», довольно часто бывает, что ваша конфигурация Windows не будет максимально использовать ваше подключение к Интернету. Но, не посещая школу, чтобы стать сетевым специалистом, как узнать, с чего начать, когда нужно оптимизировать сетевое соединение?
К счастью, TCP Optimizer – это свободно доступная утилита , которая автоматически настраивает ваш реестр Windows и сетевые настройки, чтобы наиболее эффективно использовать ваше интернет-соединение.
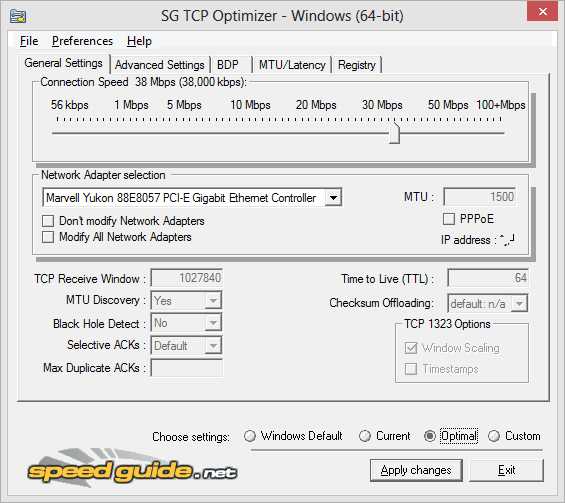 Оптимизатор TCP выглядит сложным, но оптимальных настроек достаточно.
Оптимизатор TCP выглядит сложным, но оптимальных настроек достаточно. Протокол TCP или протокола управления передачей – один из центральных стандартов, на которых основана передача данных в Интернете. Без этого не было бы ни World Wide Web, ни загрузок, ни, по сути, нет Интернета – по крайней мере, не так, как мы знаем.
Главное, что выполняет TCP, – обеспечить, чтобы любой набор пакетов данных, передаваемых на ваш компьютер, был полным и соответствовал тому, что было отправлено. TCP обнаруживает, были ли какие-либо пакеты потеряны или повреждены, запрашивает заменяющие пакеты от создателя данных, если это необходимо, и упорядочивает пакеты в правильном порядке.
Оптимизатор TCP использует специализированные алгоритмы и инновационный продукт задержки полосы пропускания для определения оптимальных настроек для вашего компьютера и подключения к Интернету. Он может использоваться новичками и экспертами, предлагая как автоматизацию, так и тонкую настройку.
Как использовать оптимизатор TCP
Чтобы воспользоваться преимуществами оптимизационной оптимизации TCP Optimizer:
- Загрузите TCP Optimizer.
- Щелкните его правой кнопкой мыши и выберите « Запуск от имени администратора» . Вы должны быть зарегистрированы как администратор или иметь пароль для этого.
- Убедитесь, что выбрана вкладка « Общие настройки ».
- Установите максимальную пропускную способность вашего интернет-соединения в килобитах в секунду. Поскольку провайдеры часто перечисляют скорость соединения в мегабит в секунду, вы можете конвертировать просто умножением на 1000 (то есть 10 мегабит соединение эквивалентно 10 000 килобит). Это не должно быть точным – просто сделайте все возможное, исходя из используемого вами интернет-плана.
- Выберите сетевой адаптер, который подключает ваш компьютер к Интернету. В общем, выберите проводной или беспроводной.
- Выберите « Оптимальные настройки» в нижней части окна.
- Нажмите « Применить изменения» , затем нажмите « ОК» .
- Перезагрузите компьютер после завершения процесса.
Это часто приводит к резкому повышению производительности сети в широком спектре приложений.
Идти дальше
Дальнейшее улучшение может быть достигнуто путем ручной настройки настроек. Тем не менее, слово осторожности в порядке, так как неправильные настройки могут существенно ухудшить производительность. К счастью, разработчики TCP Optimizer предлагают форумы пользователей, где амбициозные могут узнать, как лучше всего настроить и настроить их настройки для повышения производительности.
Стив Хортон
www.reviversoft.com
Оптимизация модемного соединения с Интернетом в Windows 9x. MTU, MSS, NDI, TCP, IP, BLA-BLA-BLA…
Пока цивилизованный мир вовсю осваивает Интернет, используя широкополосный доступ всё ширше посредством выделенных линий, всевозможных кабельных модемов, ISDN, ADSL и прочих непонятных нашему пользователю прибамбасов, мы с вами довольствуемся дешёвой и доступной (пока не ввели повременку) модемной связью, не забывая периодически ругать её за плохое качество и низкую скорость передачи данных.
Однако на сегодня грамотным пользователям достаточно хорошо известно, что иногда удаётся заметно ускорить свою работу с Интернетом, если удачно настроить некоторые слабо документированные параметры операционной системы Windows 9x. То, что при настройке соединения с интернет-провайдером надо первым же делом выставить параметры протокола TCP/IP, стало уже догмой, и многие даже не задумываются, насколько общепринятые настройки подходят именно для их конкретного соединения. Тем более что при этом совершенно не нужно обладать какими-то особыми знаниями — программ, предназначенных для автоматического внесения в реестр Windows всех необходимых изменений настолько много, что создаётся впечатление, будто все начинающие программисты набираются опыта именно на «ускорителях Интернета».
А между тем слепо изменяя установленные в Windows по умолчанию значения на среднестатистические, следуя советам, почерпнутым из разных, порой сомнительных источников, вы можете с равной вероятностью как улучшить скорость прокачки файлов, так и ухудшить её. Точно так же и оставив в покое настройки ОС, вы в ряде случаев будете зря терять время и деньги, не используя по максимуму свой Интернет-доступ. Что же это за таинственные параметры, и каким образом следует выбирать наиболее оптимальные в каждом конкретном случае значения?
MTU
Первым делом, конечно же, надо разобраться с давно навязшим в зубах параметром MTU — Maximum Transmission Unit. В реестре он задаётся таким образом:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Class\NetTrans\000х"MaxMTU"="1500"
Это максимальный размер пакета данных, который может быть передан за один физический кадр по протоколу TCP/IP. Дело в том, что данные от компьютера к компьютеру в Интернете идут не сплошным потоком, а этими самыми кадрами — пакетами строго определённого размера. Если бы все компании и фирмы, имеющие какое-то касательство к Интернету, договорились о едином стандарте на размер этих пакетов, то мы бы использовали каждый такой кадр по максимуму, полностью заполняя каналы передачи данных своими битами. Однако, это не так. Мало того, что при установке нового соединения два удалённых компьютера должны согласовать между собой размер кадра, так ещё и по пути к месту назначения пакет преодолевает целый ряд промежуточных серверов и маршрутизаторов, настройки MTU которых могут быть совершенно различными. При этом слишком большой пакет в пути, скорее всего, будет фрагментироваться и заполняться «воздухом», «балластом», что негативно скажется на эффективности связи. Так, если ваш провайдер имеет установки MTU=576, а у вас в Windows задано MTU=1500, то каждый ваш пакет будет им разбиваться на три по 576 байт: 576+576+576=1728 — то есть, 228 байт балласта будут добавляться к каждому вашему пакету. Но даже если провайдер тоже имеет MTU=1500, то при связи с удалённым сервером вполне может попасться маршрутизатор с меньшим значением MTU, и пакеты опять-таки будут фрагментироваться, замедляя передачу данных. Несколько спасает ситуацию включённая в «Виндах» по умолчанию функция автоматического определения MTU — «PMTU Discovery» или, как её иногда называют — «MTU Auto Discovery», однако процедура вычисления MTU для каждого соединения требует немало времени, что чуть тормозит работу при прокачке небольших файлов и веб-серфинге. Да и в случае несогласования ваших параметров с параметрами провайдера эта функция вряд ли вам поможет. Конечно, существуют некие более-менее общепринятые стандарты для данного параметра, так, например, для Ethernet MTU = 1500 байт, для SLIP — 1006, для PPPoE -1492, для PPP, то есть модемной связи с Интернетом — 576. Но на деле ваш провайдер может выбрать отличное от этих значений число, исходя из того, что ему это по каким-то причинам удобнее. Мы же в результате либо не загружаем свой канал связи полностью, отправляя кадры меньшего размера, чем это позволяет провайдер и часто посещаемые серверы, либо наоборот, наши установки превышают необходимое значение, и большие пакеты идут фрагментированными, что ещё более снижает возможности линии связи.
Каждый такой пакет данных в действительности состоит из нескольких сегментов — заголовка и фактических данных. Та его часть, в которой содержатся только фактические данные, называется MSS (Maximum Segment Size) — это ещё один параметр протокола TCP, определяющий самый большой сегмент данных TCP, которые могут быть переданы за один раз. То есть, MTU = MSS + заголовки TCP/IP. В реестре MSS задаётся так:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"DefaultMSS"="ваше число"
Для заголовка тоже имеется общепринятый размер — это 40 байт (20 байт IP и 20 байт TCP), следовательно, обычно MSS = MTU - 40. По этой причине в определении оптимального размера MTU есть некоторые тонкости.
Давайте изучим передачу данных при разном размере MTU по широкополосной линии T1 (пропускная способность T1=1544000 bits/sec), используя следующую формулу: [( MSS + заголовок ) * 8 битов/байт] / [1544000 бит/sec] = задержка на один хоп (то есть на каждый компьютер в Сети по пути нашего пакета). Используя в этой формуле разные величины MTU, мы можем вычислить задержку одного пакета. Если MTU = 1500, тогда: (1460+40) * 8 / 1544000 = 0.7772 ms. Если же MTU = 576, то: (536+40) * 8 / 1544000 = 0.2924 ms. Предположим, что по пути пакета встречается 10 серверов-хопов, тогда при MTU=1500 получим задержку 7.772 ms, тогда как при 576 — 2.924 ms — разница весьма заметна. Таким образом, очевидно, что меньшие пакеты будут переданы быстрее просто из-за ограничения производительности линии. Однако не всё так просто.
Используя ту же формулу из нашего предшествующего примера, давайте посчитаем, за какой промежуток времени будет передан файл размером 1Mb по той же широкополосной линии T1. Один мегабайт равен 1024 KB и равен 1048576 байтов. Если MTU = 1500, то, как мы выяснили, задержка на один хоп составит 0.7772 ms. Сколько при этом понадобится послать пакетов? 1 Мb/MSS = 1048576/1460 = 718.2, или всего требуется 719 эффективных пакетов, чтобы передать 1 мегабайт. Далее, умножаем 719 пакетов на 0.7772 ms, получаем 558.8068 ms, или 5.588 секунд задержки на один хоп. Если же мы передаём свой файл через 10 хопов, что встречается чаще, чем один, то получаем 55.88 sec — это время, которое мы (вернее, провайдер, имеющий линию T1) потратим на передачу файла в 1Mb при идеальной связи. Если же MTU = 576, тогда: 1 Мb / MSS = 1048576 / 536 = 1956.3, или нужно 1957 пакета, чтобы передать 1 мегабайт. Далее, умножаем количество пакетов на задержку каждого из них: 1957 * 0,2924 = 572,2268 ms, или 5,722 секунды на один хоп. Ну и соответственно на 10 хопов придется 57,22 секунд. Как видим, из-за того, что при использовании больших пакетов передаётся меньше заголовков, реальная скорость передачи файла получается выше. Для того, чтобы передать 1 мегабайт при использовании MTU=1500, приходится пересылать ещё и «довесок» заголовков из 28760 байтов, тогда как при использовании MTU=576 получаем аж 1957 * 40 = 78,280 байтов, то есть дополнительные 49520 байтов заголовков на каждый мегабайт полезной информации. Для нашей 10-хоповой передачи это выливается в лишних 1,34 секунд при передаче каждого мегабайта даже при сверхбыстрой связи. Эта разница, возможно, будет ещё немного выше на практике, так как современные реализации TCP/IP стремятся использовать ещё большие заголовки (например, дополнительные 12 байтов заголовка для отметок времени). Если же провести аналогичные расчёты для связи по модему на скорости 33600, то получим, что на передачу мегабайта информации на расстояние одного хопа, то есть непосредственно вашему провайдеру, будет потрачено в идеале 256 секунд при MTU=1500 и 268 секунд при MTU=576. Разница на одном переходе 12 секунд или около 5%! Но не следует забывать, что эти цифры получатся при условии отсутствия фрагментации пакетов, то есть если у вашего провайдера MTU=1500. Если же это не так, то, разумеется, бОльший, чем нужно, пакет будет фрагментироваться — разбиваться на несколько пакетов и даже разбавляться «воздухом», и связь ухудшится на 10–50 %.
Таким образом, логично считать, что большие пакеты в итоге всё-таки предпочтительнее, и если ваш провайдер настроил свои серверы и маршрутизаторы на большие пакеты, то надо стремиться использовать это на всю катушку, но не забывать и о том, что в Интернете встречаются серверы с MTU=576 (об этом чуть ниже мы ещё поговорим). Тем не менее, если чистая производительность не является окончательной целью, то меньшие пакеты будут более «быстрыми», поскольку они требуют меньше времени для своих путешествий по Сети. Этот эффект может перевешивать все другие достоинства больших пакетов в некоторых интернет-приложениях и онлайновых играх за счёт уменьшения времени отклика удалённого сервера при передаче небольших объёмов информации.
В Интернете по пути следования ваших пакетов, вероятно, встретятся самые разные серверы с самыми разными настройками, но для начала всё-таки желательно определить наилучшее значение MTU при связи только с вашим провайдером, поскольку именно оно может оказать решающее значение при оптимизации вашего доступа в Сеть.
В Windows 95 разработчиками по умолчанию выбрано MTU=1500, что якобы не соответствует оптимальному для модемного соединения значению, которое всеми считается равным 576. В Windows 98 Microsoft уже исправила этот недостаток, и теперь по умолчанию при соединениях ниже 128 килобит в секунду мы имеем MTU=576, что вроде бы должно чаще оказываться наилучшим вариантом. Попробуем разобраться, так ли оно на самом деле.
Итак, есть несколько способов определить значение MTU, оптимальное для связи с вашим интернет-провайдером:
- Послать письмо с вопросом в службу технической поддержки провайдера. Тут, в принципе, всё понятно — если работники провайдера сами в курсе своих собственных настроек, то они дадут вам квалифицированный ответ, который, впрочем, не помешает всё-таки и проверить самолично на практике.
- Подключиться к Интернету в терминальном режиме — иногда при осуществлении регистрации пользователя в одной из строк появляется рекомендуемое значение MTU. Для этого войдите в папку «Удаленный Доступ», найдите там значок своего соединения и, щёлкнув по нему правой кнопкой мыши, выберите пункт «Свойства». На странице «Общие» открывшегося меню жмите кнопку «Настроить» возле строки с названием вашего модема и в диалоге свойств модема переходите на вкладку «Дополнительно», где установите флажок «Выводить окно терминала после соединения». Теперь соединяйтесь с провайдером и при появлении окна терминала вводите вручную имя пользователя и пароль по соответствующим запросам. Если после этого вы увидите что-то типа «Entering PPP mode. Your IP address is ххх.ххх.ххх.ххх. MaxMTU is 1524», то вам повезло — вы получили MTU провайдера. Но и тут нелишним будет проверить это значение лично.
- И, наконец, ручное определение MTU.
Определение MTU вручную
Для адекватных результатов экспериментов обязательно необходимо выставить в операционной системе максимальный размер MTU=1500. Поэтому, если вы уже пытались изменять этот параметр с помощью какой-то программы или вручную в реестре, то обязательно отмените все внесённые изменения, вернув default-настройки. В этом вам помогут утилиты
— выбирайте по вкусу. В реестре же вам придётся проконтролировать это в разделе
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Class\NetTrans\000х
Если найдёте там параметр MaxMTU, то смело удаляйте его. Далее, открываем «Панель Управления» — «Сеть» («Network»), выбираем «Контроллер удаленного доступа» («Dial-Up Adapter») и жмём кнопку «Свойства». На вкладке «Дополнительно» («Advanced») появившегося меню устанавливаем большой размер пакета IP («IP Packet Size» — «Large»). Тем самым мы установили для нашего соединения MTU=1500. Перезагружаем компьютер, чтобы изменения вступили в силу.
Теперь надо установить соединение с Интернетом и посмотреть, будут ли фрагментироваться пакеты различного размера. Для этого можно использовать и стандартную программу Ping из комплекта Windows, задавая ей такие параметры:
PING -f -l 1500 ххх.ххх.ххх.ххх
где «ххх.ххх.ххх.ххх» — IP-адрес тестируемого сервера, а «–I» — это буква L, а не единица. Но гораздо удобнее применять что-нибудь типа утилит CyberKit [6] или IPTools [7] — они дают нам в руки приятный графический интерфейс вместо анахронизма командной строки Ping. Определяем сначала этой же многофункциональной программой IP-адрес одного из серверов вашего провайдера, тем самым мы избежим запросов к DNS–серверу во время тестирования. Примените для этого вкладку «TraceRoute», введя в поле адреса URL провайдера. Теперь полученный IP вводим на странице «Ping», задаём для начала размер пакета 1500 и ставим флажок «Don't fragment» («Не фрагментировать»). В поле, где задаётся количество тестовых пакетов, ставьте штук 5-6 для того, чтобы исключить случайные ошибки. Кстати, тест лучше проводить глубокой ночью, когда на линиях «сидит» мало народа и помех в телефонных сетях минимум. Если никакого ответа не получено (программа Ping.exe выдаёт сообщение «Packet needs to be fragmented but DF set»), и наш пакет потерян, так как фрагментировать мы его запретили, а его размер слишком велик для настроек оборудования провайдера, то начинаем постепенно уменьшать величину пакета до тех пор, пока не станем получать отклики от сервера со значением этого самого «пинга». Так, например, для провайдера CEA мы получим размер неделимого пакета, равный 1472. Означает ли это, что он использует MTU=1472? Нет, у него MTU=1500, просто программа Ping.exe прибавляет к нашим данным заголовок IP (20 Байтов) и ICMP (8 Байтов): 1472+28=1500. Если же вам не повезло, и ваш провайдер выбрал меньшее значение, то ищите его среди таких, чаще всего попадающихся, цифр, также не забывая и о заголовке пакета: 512, 568, 560, 552, 548, 536, 528, 520, 552, 576, 1006, 1024, 1152, 1524.
Таким образом, мы выяснили, что имеем полностью развязанные руки и можем выбирать любой MTU, вплоть до самого большого — 1500. Попробуйте теперь осуществить загрузку одного и того же ZIP-файла размером 1 мегабайт с одного и того же быстрого сервера при разных значениях MTU — максимальном, полученном от провайдера, и рекомендуемом 576. Для чистоты эксперимента, отключите автоопределение MTU — параметр PMTUDiscovery — о том, как его найти в реестре, читайте в конце статьи. Скорее всего, вы обнаружите, что наши расчёты, говорящие о предпочтительности больших пакетов, справедливы. Проведите и такой эксперимент: «пингуйте» наибольшим нефрагментируемым пакетом (в нашем случае это 1472, то бишь MTU=1500) сайты, занесённые в список закладок. Вас ждёт удивительное открытие — оказывается, большинство сайтов прекрасно воспринимают MTU=1500 и все пакеты до них доходят нефрагментированными. Где же тот самый MTU=576, который якобы преобладает в Интернете? Проверьте также и свою любимую сетевую игру при разных MTU. Исходя из полученных данных, а не из того, что вам советуют всевозможные «эксперты», сами никогда не проделывавшие подобных опытов, а повторяющие только то, что принято за истину на загнивающем Западе, вы уже гораздо более объективно определите, какое же значение наилучшим образом согласуется с вашим интернет-доступом — наибольшее или меньшее. Действительно, на качество и скорость работы в Сети сильное влияние оказывает фрагментация пакетов, которая происходит, если большой пакет проходит через сеть, имеющую MTU меньше, чем длина вашего пакета. Можно, конечно, перестраховаться и выбрать самый минимальный размер MTU, при котором пакеты наверняка не будут фрагментироваться, но это может сказаться на быстродействии вашей системы ещё более пагубно, чем использование больших пакетов. На самом же деле, главное — чтобы ваш MTU не превосходил MTU провайдера, при включённой же функции PMTU система сама найдёт для ваших пакетов такой путь в Сети, при котором они не будут фрагментироваться. Кстати, если вы обнаружите, что у провайдера установлено MTU=512 и менее, то есть смысл подумать о его смене — слишком много шлака будет передаваться вместе с вашими данными.
Другие параметры
Не только от одного MTU зависит качество вашей работы в Интернете. Существует немало и других параметров протокола TCP, с которыми стоит поэкспериментировать. Конечно, есть уже некоторые готовые рекомендации и в этом случае, но бездумно им доверяя, вы имеете шанс получить совсем не тот результат, к которому стремитесь. Поэтому и тут крайне желательно для каждого параметра провести свой эксперимент, определяя, какой эффект вызывает его изменение в вашей конкретной системе. Многие из этих параметров легко выставляются с помощью всё тех же незамысловатых утилит, что и MTU.
RWIN — Receive Window — окно приёма, размер буфера, в котором накапливается содержимое области данных (MSS) нескольких полученных пакетов, прежде чем передаётся дальше, например, в браузер. При недостаточном размере этого буфера иногда происходит его переполнение, и поступающие пакеты отвергаются и теряются. Размер RWIN обязательно должен быть кратен MSS и обычно для лучшей эффективности модемного соединения рекомендуется его устанавливать равным 4-8 MSS. Однако чрезмерно большой размер буфера также нежелателен, особенно на плохих линиях — при потере всего одного пакета в случае сбоя на линии будет повторно затребован не один потерянный пакет, а все пакеты из этого буфера, что займёт некоторое время. В реестре находится здесь:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"DefaultRcvWindow"="ваше значение"
TTL — Time To Live — время жизни — количество хопов, то есть промежуточных серверов, через которые может пройти ваш пакет в поисках своего места назначения. Каждый такой сервер добавляет единицу к специальному счётчику в заголовке вашего пакета, и когда счётчик достигает максимально разрешенного значения, пакет считается заблудившимся и прекращает свое существование. По умолчанию TTL равен 32, что сегодня явно недостаточно для разросшегося Интернета — нередки случаи, когда удалённый сервер находится более чем в 32 переходах, поэтому TTL следует увеличить как минимум до 64:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"DefaultTTL"="64"
IPMTU — Internet Protocol MTU — в Windows 98, по сути, это то же самое, что и MTU, но применительно только к контроллеру удалённого доступа. В реестре он упоминается несколько раз:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Class\Net\000х"IPMTU"="1500"HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Class\Net\000х\Ndi\params\IPMTU"default"="1500"@="1500"
PMTU — Path MTU — путевое значение MTU — этот параметр разрешает Windows самой определять оптимальное значение MTU при организации соединения с каждым сервером. При этом серверу посылается ряд нефрагментируемых пакетов разного, постепенно уменьшающегося размера, и, как только очередной пакет достигнет сервера, его размер и считается оптимальным. На эту процедуру, разумеется, требуется некоторое время, и по умолчанию она включена, в связи с чем часто советуют её дезактивировать, что, пожалуй, всё-таки довольно спорно — потерять на этом времени можно больше из-за того, что наилучший размер блока данных определён не будет, и пакеты пойдут фрагментированными. Выключается же этот режим так:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"PMTUDiscovery"="0"
PMTUBlackHoleDetect — обнаружение «чёрных дыр» — установка этого параметра разрешает протоколу TCP пытаться обнаружить никуда не ведущие роутеры и те, что не возвращают ICMP-сообщений о необходимости фрагментации при определении наилучшего MTU. Это, так же, как и любая дополнительная процедура, может замедлять работу в Интернете — попробуйте поэкспериментировать с её отключением:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"PMTUBlackHoleDetect"="0"
SessionKeepAlive — поддержание соединения — определяет, как часто будут посылаться специальные пакеты информации, предотвращающие ваше отключение сервером в случае отсутствия активной работы. Минимум — одна минута, по умолчанию — один час в Windows Me/9X и два часа в Windows 2000. Рекомендуемая установка — 10 минут, параметр задаётся в секундах:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"SessionKeepAlive"="600"
SlowNet — отключение этой функции может сократить задержки в передаче данных, но сей эффект уловить не так-то просто.
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Class\Net\000х"SLOWNET"=hex:00
NDI Cache — Network Device Interface Cache — кэш, в котором хранятся данные о маршрутах движения пакетов, по умолчанию его размер равен нулю. Чтобы его наиболее оптимально задействовать, необходимо установить его размер равным 16 при модемном соединении или 32 при более скоростных подключениях.
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\NWLink\Ndi\params\cachesize@="16"
Примерно там же в реестре обычно рекомендуется выставить ещё некоторые параметры, влияние которых на качество связи проследить вообще чрезвычайно сложно, но попробовать поэкспериментировать с их значениями, тем не менее, можно:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\NWLink\Ndi\params\maxconnect@="64""max"="128""min"="2"HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\NWLink\Ndi\params\maxsockets@="255""max"="1020""min"="32"HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\NETBEUI\Ndi\params\ncbs"default"="32""max"="255""min"="8"HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\NETBEUI\Ndi\params\sessions"default"="32""max"="117""min"="4"
А нижеследующие параметры устраняют, по заверениям Microsoft, какие-то «глюки» Windows и увеличивают скорость работы вашего браузера:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\VxD\MSTCP"BSDUrgent"="1""Tcp1323Opts"=dword:00000003"SackOpts"="1"
А вот так вы увеличите количество одновременных подключений к серверу, что часто бывает весьма полезно:
[HKEY_USERS\.DEFAULT\Software\Microsoft\Windows\CurrentVersion\Internet Settings]"MaxConnectionsPer1_0Server"=dword:0000000a =10"MaxConnectionsPerServer"=dword:00000008 =8
Процедура оптимизации Интернет-соединения — дело весьма хлопотное и неоднозначное. Несмотря на то, что программ, предназначенных якобы для двукратного улучшения связи одним кликом мыши — пруд пруди. И тут, как мы выяснили, совсем не факт, что MTU=576, которое везде рекомендуется западными программистами и экспертами, будет оптимальным и для нас в России. Наши провайдеры сплошь и рядом выбирают для себя MTU=1500 (в том числе и при модном GPRS-соединении), а при «пинговании» удалённых серверов мы обнаруживаем, что пакет такого размера, вопреки всем утверждениям, проходит чаще всего нефрагментированным. При этом, как видно из наших вычислений, чем больше MTU, тем эффективнее используется ваш интернет-доступ. Возможно, наши рассуждения несколько спорны и противоречат общепринятым догмам на этот счёт. Поэтому для того, чтобы настроить вашу систему на максимальную производительность, вам придётся лично: во-первых — выяснить действительное значение MTU своего провайдера; во-вторых — выбрав это значение, убедиться, что пакеты такого размера при связи с чаще всего вами посещаемыми серверами не будут фрагметироваться; в-третьих — провести эксперименты с закачкой одного и того же файла при разных значениях MTU; и в-четвёртых — проверить, как сказывается изменение MTU на сетевых играх, если вас они, конечно, интересуют. Исходя их итогов этих опытов, и стоит решать, какой размер максимального неделимого пакета вам следует в результате выбрать. То, что везде рекомендуется, для вас может оказаться наихудшим вариантом. Аналогично наберитесь терпения и проверьте влияние и других параметров на быстродействие системы — я упомянул далеко не всё, над чем можно поизвращаться. При этом можно даже проверять MTU провайдера регулярно — раз в месяц, в два — не изменилось ли оно, но это уже для маньяков, хоть и не представляет никакой сложности, как мы с вами убедились.
Ссылки- www.magellass.com
- www.download.ru
- www.hms.com
- www.mjs.u-net.com
- www.indeavour.com/html_about_blazenet.htm
- www.cyberkit.net
- www.ks-soft.net/ip-tools.eng/index.htm
sergeytroshin.ru
Внутренние механизмы ТСР, влияющие на скорость загрузки: часть 2
В первой части мы разобрали «трехстороннее рукопожатие» TCP и некоторые технологии — TCP Fast Open, контроль потока и перегрузкой и масштабирование окна. Во второй части узнаем, что такое TCP Slow Start, как оптимизировать скорость передачи данных и увеличить начальное окно, а также соберем все рекомендации по оптимизации TCP/IP стека воедино.
Медленный старт (Slow-Start)
Несмотря на присутствие контроля потока в TCP, сетевой коллапс накопления был реальной проблемой в середине 80-х. Проблема была в том, что хотя контроль потока не позволяет отправителю «утопить» получателя в данных, не существовало механизма, который бы не дал бы это сделать с сетью. Ведь ни отправитель, ни получатель не знают ширину канала в момент начала соединения, и поэтому им нужен какой-то механизм, чтобы адаптировать скорость под изменяющиеся условия в сети.
Например, если вы находитесь дома и скачиваете большое видео с удаленного сервера, который загрузил весь ваш даунлинк, чтобы обеспечить максимум скорости. Потом другой пользователь из вашего дома решил скачать объемное обновление ПО. Доступный канал для видео внезапно становится намного меньше, и сервер, отправляющий видео, должен изменить свою скорость отправки данных. Если он продолжит с прежней скоростью, данные просто «набьются в кучу» на каком-то промежуточном гейтвэе, и пакеты будут «роняться», что означает неэффективное использование сети.
В 1988 году Ван Якобсон и Майкл Дж. Карелс разработали для борьбы с этой проблемой несколько алгоритмов: медленный старт, предотвращение перегрузки, быстрая повторная передача и быстрое восстановление. Они вскоре стали обязательной частью спецификации TCP. Считается, что благодаря этим алгоритмам удалось избежать глобальных проблем с интернетом в конце 80-х/начале 90-х, когда трафик рос экспоненциально.
Чтобы понять, как работает медленный старт, вернемся к примеру с клиентом в Нью-Йорке, пытающемуся скачать файл с сервера в Лондоне. Сначала выполняется трехходовый хэндшейк, во время которого стороны обмениваются своими значениями окон приема в АСК-пакетах. Когда последний АСК-пакет ушел в сеть, можно начинать обмен данными.
Единственный способ оценить ширину канала между клиентом и сервером – измерить ее во время обмена данными, и это именно то, что делает медленный старт. Сначала сервер инициализирует новую переменную окна перегрузки (cwnd) для TCP-соединения и устанавливает ее значение консервативно, согласно системному значению (в Linux это initcwnd).
Значение переменной cwnd не обменивается между клиентом и сервером. Это будет локальная переменная для сервера в Лондоне. Далее вводится новое правило: максимальный объем данных «в пути» (не подтвержденных через АСК) между сервером и клиентом должно быть наименьшим значением из rwnd и cwnd. Но как серверу и клиенту «договориться» об оптимальных значениях своих окон перегрузки. Ведь условия в сети изменяются постоянно, и хотелось бы, чтобы алгоритм работал без необходимости подстройки каждого TCP-соединения.
Решение: начинать передачу с медленной скоростью и увеличивать окно по мере того, как прием пакетов подтверждается. Это и есть медленный старт.
Начальное значение cwnd исходно устанавливалось в 1 сетевой сегмент. В RFC 2581 это изменили на 4 сегмента, и далее в RFC 6928 – до 10 сегментов.
Таким образом, сервер может отправить до 10 сетевых сегментов клиенту, после чего должен прекратить отправку и ждать подтверждения. Затем, для каждого полученного АСК, сервер может увеличить свое значение cwnd на 1 сегмент. То есть на каждый подтвержденный через АСК пакет, два новых пакета могут быть отправлены. Это означает, что сервер и клиент быстро «занимают» доступный канал.
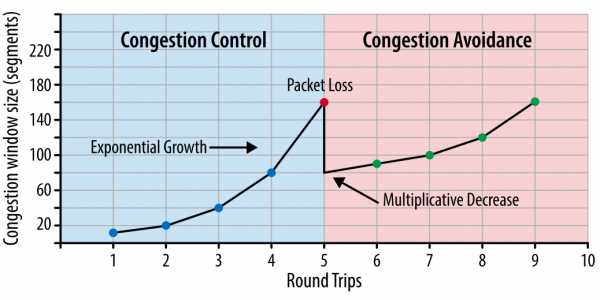
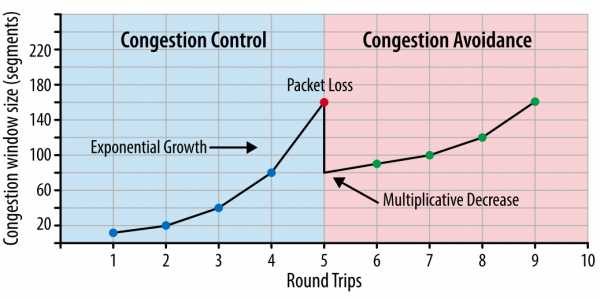 Рис. 1. Контроль за перегрузкой и ее предотвращение.
Рис. 1. Контроль за перегрузкой и ее предотвращение.
Каким же образом медленный старт влияет на разработку браузерных приложений? Поскольку каждое TCP-соединение должно пройти через фазу медленного старта, мы не можем сразу использовать весь доступный канал. Все начинается с маленького окна перегрузки, которое постепенно растет. Таким образом время, которое требуется, чтобы достичь заданной скорости передачи, — это функция от круговой задержки и начального значения окна перегрузки.
Время достижения значения cwnd, равного N.
Чтобы ощутить, как это будет на практике, давайте примем следующие предположения:
- Окна приема клиента и сервера: 65 535 байт (64 КБ)
- Начальное значение окна перегрузки: 10 сегментов
- Круговая задержка между Лондоном и Нью-Йорком: 56 миллисекунд
Несмотря на окно приема в 64 КБ, пропускная способность TCP-соединения изначально ограничена окном перегрузки. Чтобы достичь предела в 64 КБ, окно перегрузки должно вырасти до 45 сегментов, что займет 168 миллисекунд.
Тот факт, что клиент и сервер могут быть способны обмениваться мегабитами в секунду между собой, не имеет никакого значения для медленного старта.
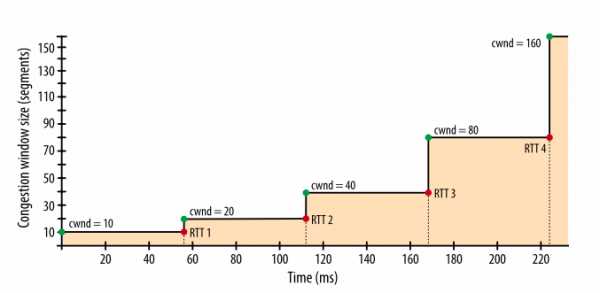
Рис. 2. Рост окна перегрузки.
Чтобы уменьшить время, которое требуется для достижения максимального значения окна перегрузки, можно уменьшить время, требуемое пакетам на путь «туда-обратно» — то есть расположить сервер географически ближе к клиенту.
Медленный старт мало влияет на скачивание крупных файлов или потокового видео, поскольку клиент и сервер достигнут максимальных значений окна перегрузки за несколько десятков или сотен миллисекунд, но это будет одним TCP-соединением.
Однако для многих HTTP-запросов, когда целевой файл относительно небольшой, передача может закончиться до того, как достигнут максимум окна перегрузки. То есть производительность веб-приложений зачастую ограничена временем круговой задержкой между сервером и клиентом.
Перезапуск медленного старта (Slow-Start Restart — SSR)
Дополнительно к регулированию скорости передачи в новых соединениях, TCP также предусматривает механизм перезапуска медленного старта, который сбрасывает значение окна перегрузки, если соединение не использовалось заданный период времени. Логика здесь в том, что условия в сети могли измениться за время бездействия в соединении, и чтобы избежать перегрузки, значение окна сбрасывается до безопасного значения.
Неудивительно, что SSR может оказывать серьезное влияние на производительность долгоживущих TCP-соединений, которые могут временно «простаивать», например, из-за бездействия пользователя. Поэтому лучше отключить SSR на сервере, чтобы улучшить производительность долгоживущих соединений. На Linux проверить статус SSR и отключить его можно следующими командами:
$> sysctl net.ipv4.tcp_slow_start_after_idle $> sysctl -w net.ipv4.tcp_slow_start_after_idle=0Чтобы продемонстрировать влияние медленного старта на передачу небольшого файла, давайте представим, что клиент из Нью-Йорка запросил файл размером 64 КБ с сервера в Лондоне по новому TCP-соединению при следующих параметрах:
- Круговая задержка: 56 миллисекунд
- Пропускная способность клиента и сервера: 5 Мбит/с
- Окно приема клиента и сервера: 65 535 байт
- Начальное значение окна перегрузки: 10 сегментов (10 х 1460 байт = ~14 КБ)
- Время обработки на сервере для генерации ответа: 40 миллисекунд
- Пакеты не теряются, АСК на каждый пакет, запрос GET умещается в 1 сегмент
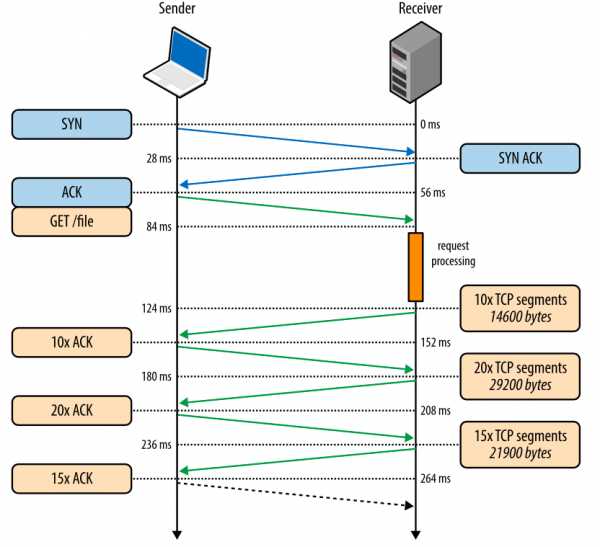 Рис. 3. Скачивание файла через новое TCP-соединение.
Рис. 3. Скачивание файла через новое TCP-соединение.
- 0 мс: клиент начинает TCP-хэндшейк SYN-пакетом
- 28 мс: сервер отправляет SYN-ACK и задает свой размер rwnd
- 56 мс: клиент подтверждает SYN-ACK, задает свой размер rwnd и сразу шлет запрос HTTP GET
- 84 мс: сервер получает HTTP-запрос
- 124 мс: сервер заканчивает создавать ответ размером 64 КБ и отправляет 10 TCP-сегментов, после чего ожидает АСК (начальное значение cwnd равно 10)
- 152 мс: клиент получает 10 TCP-сегментов и отвечает АСК на каждый
- 180 мс: сервер увеличивает cwnd на каждый полученный АСК и отправляет 20 TCP-сегментов
- 208 мс: клиент получает 20 TCP-сегментов и отвечает АСК на каждый
- 236 мс: сервер увеличивает cwnd на каждый полученный АСК и отправляет 15 оставшихся TCP-сегментов
- 264 мс: клиент получает 15 TCP-сегментов и отвечает АСК на каждый
264 миллисекунды занимает передача файла размеров 64 КБ через новое TCP-соединение. Теперь давайте представим, что клиент повторно использует то же соединение и делает такой же запрос еще раз.
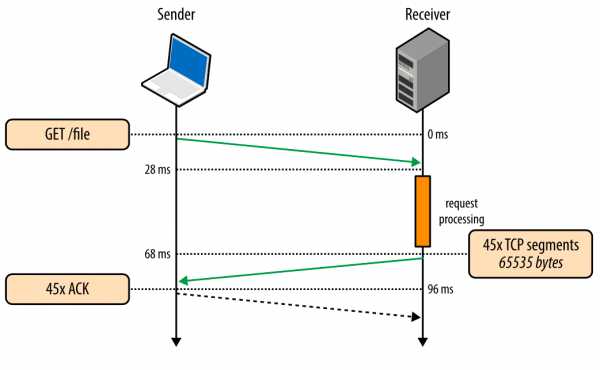 Рис. 4. Скачивание файла через существующее TCP-соединение.
Рис. 4. Скачивание файла через существующее TCP-соединение.
- 0 мс: клиент отправляет НТТР-запрос
- 28 мс: сервер получает НТТР-запрос
- 68 мс: сервер генерирует ответ размером в 64 КБ, но значение cwnd уже больше, чем 45 сегментов, требуемых для отправки этого файла. Поэтому сервер отправляет все сегменты сразу
- 96 мс: клиент получает все 45 сегментов и отвечает АСК на каждый
Тот же самый запрос, сделанный через то же самое соединение, но без затрат времени на хэндшейк и на наращивание пропускной способности через медленный старт, теперь исполняется за 96 миллисекунд, то есть на 275% быстрее!
В обоих случаях тот факт, что клиент и сервер пользуются каналом с пропускной способностью 5 Мбит/с, не оказал никакого влияния на время скачивания файла. Только размеры окон перегрузки и сетевая задержка были ограничивающими факторами. Интересно, что разница в производительности при использовании нового и существующего TCP-соединений будет увеличиваться, если сетевая задержка будет расти.
Как только вы осознаете проблемы с задержками при создании новых соединений, у вас сразу появится желание использовать такие методы оптимизации, как удержание соединения (keepalive), конвейеризация пакетов (pipelining) и мультиплексирование.
Увеличение начального значения окна перегрузки TCP
Это самый простой способ увеличения производительности для всех пользователей или приложений, использующих TCP. Многие операционные системы уже используют новое значение равное 10 в своих обновлениях. Для Linux 10 – значение по умолчанию для окна перегрузки, начиная с версии ядра 2.6.39.
Предотвращение перегрузки
Важно понимать, что TCP использует потерю пакетов как механизм обратной связи, который помогает регулировать производительность. Медленный старт создает соединение с консервативным значением окна перегрузки и пошагово удваивает количество передаваемых за раз данных, пока оно не достигнет окна приема получателя, системного порога sshtresh или пока пакеты не начнут теряться, после чего и включается алгоритм предотвращения перегрузки.
Предотвращение перегрузки построено на предположении, что потеря пакета является индикатором перегрузки в сети. Где-то на пути движения пакетов на линке или на роутере скопились пакеты, и это означает, что нужно уменьшить окно перегрузки, чтобы предотвратить дальнейшее «забитие» сети трафиком.
После того как окно перегрузки уменьшено, применяется отдельный алгоритм для определения того, как должно далее увеличиваться окно. Рано или поздно случится очередная потеря пакета, и процесс повторится. Если вы когда-либо видели похожий на пилу график проходящего через TCP-соединение трафика – это как раз потому, что алгоритмы контроля и предотвращения перегрузки подстраивают окно перегрузки в соответствии с потерями пакетов в сети.
Стоит заметить, что улучшение этих алгоритмов является активной областью как научных изысканий, так и разработки коммерческих продуктов. Существуют варианты, которые лучше работают в сетях определенного типа или для передачи определенного типа файлов и так далее. В зависимости от того, на какой платформе вы работаете, вы используете один из многих вариантов: TCP Tahoe and Reno (исходная реализация), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (по умолчанию на Linux) или Compound TCP (по умолчанию на Windows) и многие другие. Независимо от конкретной реализации, влияния этих алгоритмов на производительность веб-приложений похожи.
Пропорциональное снижение скорости для TCP
Определение оптимального способа восстановления после потери пакета – не самая тривиальная задача. Если вы слишком «агрессивно» реагируете на это, то случайная потеря пакета окажет чрезмерно негативное воздействие на скорость соединения. Если же вы не реагируете достаточно быстро, то, скорее всего, это вызовет дальнейшую потерю пакетов.
Изначально в TCP применялся алгоритм кратного снижения и последовательного увеличения (Multiplicative Decrease and Additive Increase — AIMD): когда теряется пакет, то окно перегрузки уменьшается вдвое, и постепенно увеличивается на заданную величину с каждым проходом пакетов «туда-обратно». Во многих случаях AIMD показал себя как чрезмерно консервативный алгоритм, поэтому были разработаны новые.
Пропорциональное снижение скорости (Proportional Rate Reduction – PRR) – новый алгоритм, описанный в RFC 6937, цель которого является более быстрое восстановление после потери пакета. Согласно замерам Google, где алгоритм и был разработан, он обеспечивает сокращение сетевой задержки в среднем на 3-10% в соединениях с потерями пакетов. PPR включен по умолчанию в Linux 3.2 и выше.
Произведение ширины канала на задержку (Bandwidth-Delay Product – BDP)
Встроенные механизмы борьбы с перегрузкой в TCP имеют важное следствие: оптимальные значения окон для получателя и отправителя должны изменяться согласно круговой задержке и целевой скорости передачи данных. Вспомним, что максимально количество неподтвержденных пакетов «в пути» определено как наименьшее значение из окон приема и перегрузки (rwnd и cwnd). Если у отправителя превышено максимальное количество неподтвержденных пакетов, то он должен прекратить передачу и ожидать, пока получатель не подтвердит какое-то количество пакетов, чтобы отправитель мог снова начать передачу. Сколько он должен ждать? Это определяется круговой задержкой.
BDP определяет, какой максимальный объем данных может быть «в пути»
Если отправитель часто должен останавливаться и ждать АСК-подтверждения ранее отправленных пакетов, это создаст разрыв в потоке данных, который будет ограничивать максимальную скорость соединения. Чтобы избежать этой проблемы, размеры окон должны быть установлены достаточно большими, чтобы можно было отсылать данные, ожидая поступления АСК-подтверждений по ранее отправленным пакетам. Тогда будет возможна максимальная скорость передачи, никаких разрывов. Соответственно, оптимальный размер окна зависит от скорости круговой задержки.
Рис. 5. Разрыв в передаче из-за маленьких значений окон.
Насколько же большими должны быть значения окон приема и перегрузки? Разберем на примере: пусть cwnd и rwnd равны 16 КБ, а круговая задержка равна 100 мс. Тогда:
Получается, что какая бы ни была ширина канала между отправителем и получателем, такое соединение никогда не даст скорость больше, чем 1,31 Мбит/с. Чтобы добиться большей скорости, надо или увеличить значение окон, или уменьшить круговую задержку.
Похожим образом мы можем вычислить оптимальное значение окон, зная круговую задержку и требуемую ширину канала. Примем, что время останется тем же (100 мс), а ширина канала отправителя 10 Мбит/с, а получатель находится на высокоскоростном канале в 100 Мбит/с. Предполагая, что у сети между ними нет проблем на промежуточных участках, мы получаем для отправителя:
Размер окна должен быть как минимум 122,1 КБ, чтобы полностью занять канал на 10 Мбит/с. Вспомните, что максимальный размер окна приема в TCP равен 64 КБ, если только не включено масштабирование окна (RFC 1323). Еще один повод перепроверить настройки!
Хорошая новость в том, что согласование размеров окон автоматически делается в сетевом стэке. Плохая новость в том, что иногда это может быть ограничивающим фактором. Если вы когда-либо задумывались, почему ваше соединение передает со скоростью, которая составляет лишь небольшую долю от имеющейся ширины канала, это происходит, скорее всего, из-за малого размера окон.
BDP в высокоскоростных локальных сетях
Круговая задержка может являться узким местом и в локальных сетях. Чтобы достичь 1 Гбит/с при круговой задержке в 1 мс, необходимо иметь окно перегрузки не менее чем 122 КБ. Вычисления аналогичны показанным выше.
Блокировка начала очереди (Head-of-line blocking – HOL blocking)
Хотя TCP – популярный протокол, он не является единственным, и не всегда – самым подходящим для каждого конкретного случая. Такие его особенности, как доставка по порядку, не всегда необходимы, и иногда могут увеличить задержку.
Каждый TCP-пакет содержит уникальный номер последовательности, и данные должны поступать по порядку. Если один из пакетов был потерян, то все последующие пакеты хранятся в TCP-буфере получателя, пока потерянный пакет не будет повторно отправлен и не достигнет получателя. Поскольку это происходит в TCP-слое, приложение «не видит» эти повторные отправки или очередь пакетов в буфере, и просто ждет, пока данные не будут доступны. Все, что «видит» приложение – это задержка, возникающая при чтении данных из сокета. Этот эффект известен как блокировка начала очереди.
Блокировка начала очереди освобождает приложения от необходимости заниматься упорядочиванием пакетов, что упрощает код. Но с другой стороны, появляется непредсказуемая задержка поступления пакетов, что негативно влияет на производительность приложений.
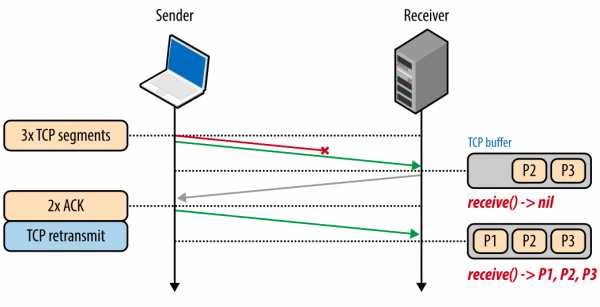 Рис. 6. Блокировка начала очереди.
Рис. 6. Блокировка начала очереди.
Некоторым приложениям может не требоваться гарантированная доставка или доставка по порядку. Если каждый пакет – это отдельное сообщение, то доставка по порядку не нужна. А если каждое новое сообщение перезаписывает предыдущие, то и гарантированная доставка также не нужна. Но в TCP нет конфигурации для таких случаев. Все пакеты доставляются по очереди, а если какой-то не доставлен, он отправляется повторно. Приложения, для которых задержка критична, могут использовать альтернативный транспорт, например, UDP.
Потеря пакетов – это нормально
Потеря пакетов даже нужна для того, чтобы обеспечить лучшую производительность TCP. Потерянный пакет работает как механизм обратной связи, который позволяет получателю и отправителю изменить скорость отправки, чтобы избежать перегрузки сети и минимизировать задержку.
Некоторые приложения могут «справиться» с потерей пакета: например, для проигрывания аудио, видео или для передачи состояния в игре, гарантированная доставка или доставка по порядку не обязательны. Поэтому WebRTC использует UDP в качестве основного транспорта.
Если при проигрывании аудио произошла потеря пакета, аудио кодек может просто вставить небольшой разрыв в воспроизведение и продолжать обрабатывать поступающие пакеты. Если разрыв небольшой, пользователь может его и не заметить, а ожидание доставки потерянного пакета может привести к заметной задержке воспроизведения, что будет гораздо хуже для пользователя.
Аналогично, если игра передает свои состояния, то нет смысла ждать пакет, описывающий состояние в момент времени T-1, если у нас уже есть информация о состоянии в момент времени T.
Оптимизация для TCP
TCP – это адаптивный протокол, разработанный для того, чтобы максимально эффективно использовать сеть. Оптимизация для TCP требует понимания того, как TCP реагирует на условия в сети. Приложениям может понадобиться собственный метод обеспечения заданного качества (QoS), чтобы обеспечить стабильную работу для пользователей.
Требования приложений и многочисленные особенности алгоритмов TCP делает их взаимную увязку и оптимизацию в этой области огромным полем для изучения. В этой статье мы лишь коснулись некоторых факторов, которые влияют на производительность TCP. Дополнительные механизмы, такие как выборочные подтверждения (SACK), отложенные подтверждения, быстрая повторная передача и многие другие осложняют понимание и оптимизацию TCP-сессий.
Хотя конкретные детали каждого алгоритма и механизма обратной связи будут продолжать изменяться, ключевые принципы и их последствия останутся:
Трехходовый хэндшейк TCP несет серьезную задержку;Медленный старт TCP применяется к каждому новому соединению;Механизмы контроля потока и перегрузки TCP регулируют пропускную способность всех соединений;Пропускная способность TCP регулируется через размер окна перегрузки.
В результате скорость, с которой в TCP-соединении могут передаваться данные в современных высокоскоростных сетях зачастую ограничена круговой задержкой. В то время как ширина каналов продолжает расти, задержка ограничена скоростью света, и во многих случаях именно задержка, а не ширина канала является «узким местом» для TCP.
Настройка конфигурации сервера
Вместо того, чтобы заниматься настройкой каждого отдельного параметра TCP, лучше начать с обновления до последней версии операционной системы. Лучшие практики в работе с TCP продолжают развиваться, и большинство этих изменений уже доступно в последних версиях ОС.
«Обновить ОС на сервере» кажется тривиальным советом. Но на практике многие серверы настроены под определенную версию ядра, и системные администраторы могут быть против обновлений. Да, обновление несет свои риски, но в плане производительности TCP, это, скорее всего, будет самым эффективным действием.
После обновления ОС вам нужно сконфигурировать сервер в соответствии с лучшими практиками:
- Увеличить начальное значение окна перегрузки: это позволит передать больше данных в первом обмене и существенно ускоряет рост окна перегрузки
- Отключить медленный старт: отключение медленного старта после периода простоя соединения улучшит производительность долгоживущих TCP-соединений
- Включить масштабирование окна: это увеличит максимальное значение окна приема и позволит ускорить соединения, где задержка велика
- Включить TCP Fast Open: это даст возможность отправлять данные в начальном SYN-пакете. Это новый алгоритм, его должны поддерживать и клиент и сервер. Изучите, может ли ваше приложение извлечь из него пользу.
Возможно вам понадобится также настроить и другие TCP-параметры. Обратитесь к материалу «TCP Tuning for HTTP», который регулярно обновляется Рабочей группой по HTTP.
Для пользователей Linux ss поможет проверить различную статистику открытых сокетов. В командной строке наберите
ss --options --extended --memory --processes --infoи вы увидите текущие одноранговые соединения (peers) и их настройки.
Настройка приложения
То, как приложение использует соединения может иметь огромное влияние на производительность:
- Любая передача данных занимает время >0. Ищите способы уменьшить объем отправляемых данных.
- Приблизьте ваши данные к клиентам географически
- Повторное использование TCP-соединений может быть важнейшим моментом в улучшении производительности.
Исключение ненужной передачи данных, это, конечно, самый важный вид оптимизации. Если же определенные данные все же нужно передавать, важно убедиться, что для них используется подходящий алгоритм сжатия.
Перенос данных поближе к клиентам посредством размещения серверов по всему миру либо с использованием CDN, поможет уменьшить круговую задержку и значительно повысит производительность TCP.
И наконец, во всех случаях, где это возможно, существующие соединения TCP должны использоваться повторно, чтобы избежать задержек, вызванных алгоритмом медленного старта и контроля перегрузки.
В заключение, вот контрольный список того, что нужно сделать для оптимизации TCP:
- Обновите ОС сервера
- Убедитесь, что параметр cwnd установлен равным 10
- Убедитесь, что масштабирование окон включено
- Отключите медленный старт после простоя соединения
- Включите TCP Fast Open, если это возможно
- Исключите передачу ненужных данных
- Сжимайте передаваемые данные
- Расположите серверы ближе к клиентам географически, чтобы снизить круговую задержку
- Используйте повторно TCP-соединения, где это возможно
- Изучите рекомендации Рабочей группы по HTTP
Автор: WEBO Group
Источник
www.pvsm.ru
Как получить и измерить высокоскоростное соединение по TCP / Хабр
Надежная передача данных в Интернете осуществляется на базе протокола TCP (Transmission Control Protocol), спецификация к которому была опубликована почти 30 лет назад. Алгоритм TCP (RFC793), позволяет подключенному устройству адаптироваться для работы в сети на скоростях в пределах десятков мегабит в секунду и задержки до 100 секунд. С бурным развитием новых технологий передачи данных, уже через 10 лет после внедрения стало ясно что производительность протокола не будет хватать для более широких каналов.1) Ограничения TCP
Скорость передачи данных зависит от сетевых и системных характеристик.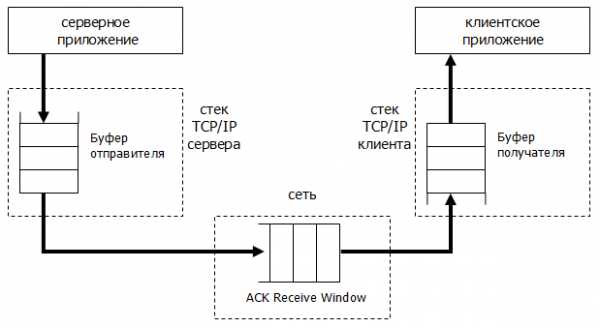 img1 Процесс передачи данных по сети
img1 Процесс передачи данных по сетиa) Буферы Оригинальная конфигурация TCP ограничивает скорость передачи буфером (опция Window Size — «размер окна») и является полем размером в 2^16 байт (до 64 КБайт). Максимальная пропускная способность в данном случае:
Пример: У вас 100 мегабитное соединение к Интернету и до сервера задержка 100 мс. Стандартным стеком TCP, максимальная скорость передачи данных не превысит 10 Мбит/сек ( 524288 бит / 0.1 сек = 5.24 Мбит/сек не смотря на то что у вас 100 мегабитный линк).b) Bandwidth-delay product (BDP)
Производительность TCP в принципе не столько зависит от скорости канала, сколько от так называемом «bandwidth*delay product» или BDP (результат пропускная способность*задержка), который представляет собой число байт необходимых отправителю и получателю для максимального заполнения TCP соединения.
Проблемы производительности возникают в случаях так называемых «длинных и широких труб» (LFN «long fat network»), так как BDP в таком случае превышает размер окна TCP, тем самым ограничивая скорость передачи.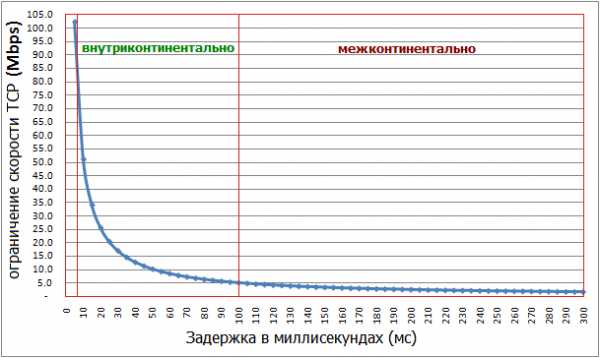 img2 Влияние задержки на максимальную пропускную способность TCP
img2 Влияние задержки на максимальную пропускную способность TCP
Примером могут служить мобильный интернет или быстрый оптический линк. Пример расчетов BDP: a) широкополосный мобильный интернет: 10 Mb/s, 100 ms RTTB×D = 10^7 b/s × 10^-1 s = 10^6 b, or 1 Mb / 125 kB b) высокоскоростная наземной сеть: 1 Gb/s, 10 ms RTTB×D = 10^9 b/s × 10^-2 s = 10^7 b, or 10 Mb / 1.25 MB
Рассчитать BDP можно тут. ”Размер окна” TCP должен превышать BDP для достижение максимальной нагрузки канала.
c) Protocol Overhead По некоторым оценкам около 95% компьютеров мира подключены через технологию Ethernet. Ethernet MTU (полезная нагрузка кадра Ethernet) = макс. 1500 bytes. Если принять во внимание все заголовки Ethernet, IP, TCP, картина будет выглядеть так:img3 Передача одного Ethernet кадра
Цифры указывают размер (в байтах) заголовка для определенного протокола. IFG (Interframe gap) — обязательное межкадровое пространство. Заголовки: preamble, frame delimiter, Ethernet header/FCS – 26 bytes, IFG – 12 bytes, IP header – 20 bytes, TCP header – 20 bytes.
Если исключить VLAN tagging, TCP timestamp и другие опциональные возможности, максимальная полезная нагрузка (Payload) TCP в сетях Ethernet будет:Max TCP Payload= (MTU–TCP–IP) / (MTU+Ethernet+IFG) = (1500–40) / (1500+26+12) = 94.9 %
d) Задержка и потеря пакетов Так как речь идет о надежной передачи информации, потеря пакетов в сети вынуждает TCP передавать повторно сегменты и влияет непосредственно на понижение скорости. Зависимость скорости TCP в соотношении к потери пакетов, определяется формулой Mathis-а:
где: MSS (Maximum segment size) – максимальный размер сегмента TCP (MSS = MTU – packet headers=1460 bytes), MTU — максимальный размер передаваемого блока нижнего уровня OSI (Ethernet MTU = 1500 bytes), RTT — время двусторонней задержки (от одного конца к другому и назад, от англ. Round Trip Time) Ploss — Loss probability (вероятность потерь). Можно обратить внимание что формула не действительна с Ploss = 0. Это нормально, так как в реальном мире всегда есть потери пакетов.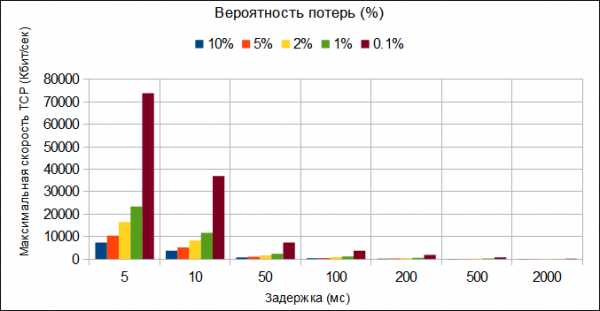 img4 Влияние задержки и потеря пакетов на максимальную пропускную способность TCP
img4 Влияние задержки и потеря пакетов на максимальную пропускную способность TCP
Большинство провайдеров не будет гарантировать потери менее 0.01% (1 пакет из 10`000). Проверить статистику по протоколам можно командой “netstat –s”.
2) Оптимизация TCP
a) усовершенствования протокола В связи с этим были разработаны расширения протокола, описанные в стандарте TCP Extensions for High Performance (RFC1323), которые призваны решить ограничения. Среди них: — TCP Window Scale Option: возможность увеличение Размера Окна до 2^30 (1 ГБайт), — TCP selective acknowledgment (SACK) options: принимающая сторона указывает какие именно пакеты в потоке подтверждены (положительно или отрицательно) (RFC2018), — TCP timestamps: улучшение замеров RTT (Round Trip Time Measurement — RTTM), предотвращение накладки порядковых чисел ACK (Prevention Against Wrapped Sequence numbers — PAWS), — Path MTU discovery: определение максимального MTU на всем пути, — Explicit Congestion Notification (ECN): указывает на перегрузку пути без сбрасывание пакетов (RFC3168).Проверить текущие настройки TCP/IP компьютера можно здесь.
b) aдаптация oперационных систем Несмотря на то что документ RFC1323 был опубликован в далеком 1992 году, в ОС-ы внедряли изменения не сразу.
OS Windows Поддержка RFC1323 появилась начиная с Windows 2000 (XP, Server 2003) и для активации опции необходимо покрутить в реестре. Системы Windows Server 2008, Vista, 7 включают новую реализацию стека протоколов TCP/IP, известную как стек протоколов TCP/IP нового поколения («Next Generation TCP/IP Stack»). Он спроектирован для того, чтобы обеспечивать сетевые технологии Windows на несколько лет вперед. Среди нововведений: — aвтонастройка окна получения (Receive Window Auto-Tuning), — compound TCP: решает проблему низкой производительности в сетях с высокой пропускной способностью с помощью нового алгоритма, вместо алгоритмов, использовавшихся на других платформах, — усовершенствования для сред с высоким уровнем потерь и еще много чего. Многие опции включены по умолчанию. Конфигурация через командную строку.
С подробными процедурами настройки для различных ОС (Windows XP, FreeBSD, Linux, Solaris, Mac OS X), можно ознакомится на сайте суперкомпьютерного центра Питтсбурга.
Примечание: Хотя через маршрутизаторы в основном проходит весь трафик (между разными сетями), отношение к оптимизации TCP имеют только косвенное (в некоторых случаях), так как работают на более нижнем уровне сетевой модели OSI и выполняют функцию определение оптимальных маршрутов и лишь доставку пакетов до назначения.
3) Измерения производительности стека TCP/IP
В сети существуют множество методов измерения скорости подключения к Интернету. Здесь будет рассмотрен случай с использованием утилиты nuttcp («New TTCP»), так как она имеет несколько приятных преимуществ: — простой и эффективный метод измерения пропускной способности канала через TCP или UDP, — кроссплатформенная одно-файловая программа (CLI), — возможность проверки эффективности локального стека TCP/IP (loopback), — стабильная работа сервера (корректное завершения TCP сессий), без подвисаний и падений (как в случае с iperf), — работа клиента из NAT-а.Немного истории: В 1980 году, Mike Muuss (автор ping-а) создал ttcp («Test TCP») — один из первых инструментов тестирования пропускной способности TCP. Многие изменения с тех пор были созданы в различных реализациях и с новыми возможностями. Nuttcp является одной из них. Последняя бета — апрель 2010.
Тестирования работает по схеме клиент-сервер. Измеряется payload — полезная нагрузка (без заголовков). Подключение по порту 5000. Передача данных — 5001 (и выше если указать многопоточный тест).
Сервер — достаточно указать #nuttcp -S Клиент — можно указывать множество опций.
Пример: Сервер FreeBSD, клиент Windows XP SP3, FastEthernet (100Mbps).server-ip# nuttcp –S
опции клиента: -w128 — TCP receive window size = 128 KB -r — receiving (прием, для клиента) -F — устраняет возможные проблемы с соединением если вы в NAT-е -i5 — показывать результат каждые 5 секунд -T15 — длительность тестирования (15 секунд).
TX% и RX% являются загрузкой процессора на передатчике и приемнике.
Проверка производительности железа и стека TCP/IP ОС:C:\> nuttcp.exe -w1m 127.0.0.1 205.0625 MB / 10.00 sec = 172.0189 Mbps 19 %TX 12 %RX
Примеры результатов: — Intel Core 2 Duo (2 core) @ 1.6 GHz/ 1 GB RAM / Windows XP = 1300/1400 Mbps — AMD Athlon X2 Dual-Core 4600 @ 2.4 GHz/ 2 GB RAM / Windows 7 = 2000/2100 Mbps — Intel XEON X5650 (24 cores) @ 2.67GHz/ 8 GB RAM / FreeBSD = 16600/18000 Mbps
Проверяем Download (от сервера к клиенту):C:\> nuttcp.exe -w128 -r -F –i5 -T15 server-ip 56.0166 MB / 5.00 sec = 93.9803 Mbps 56.0575 MB / 5.00 sec = 94.0489 Mbps 56.0338 MB / 5.00 sec = 94.0090 Mbps
168.2676 MB / 15.00 sec = 94.1020 Mbps 3 %TX 10 %RX
some-unix-client# nuttcp -r -F -i5 -T15 server-ip 429.0000 MB / 5.02 sec = 717.3541 Mbps 526.0000 MB / 5.00 sec = 882.0518 Mbps
1371.1741 MB / 15.00 sec = 766.6703 Mbps 26 %TX 39 %RX 3153 host-retrans 0.29 msRTT
Проверяем Upload (от клиента к серверу):C:\> nuttcp.exe -w128 –i5 -T15 server-ip 55.6250 MB / 5.00 sec = 93.3169 Mbps 55.8125 MB / 5.00 sec = 93.6562 Mbps 55.6875 MB / 5.00 sec = 93.4277 Mbps
167.2500 MB / 15.12 sec = 92.7664 Mbps 17 %TX 6 %RX
some-unix-client# nuttcp -i5 -T15 server-ip 422.9375 MB / 5.00 sec = 709.5294 Mbps 420.6875 MB / 5.00 sec = 705.9357 Mbps 456.3750 MB / 5.00 sec = 765.6674 Mbps
1305.3853 MB / 15.06 sec = 727.0077 Mbps 20 %TX 48 %RX 24478 host-retrans 0.29 msRTT
4) Вместо заключения
В процессе тестирования, нужно помнить что максимальная скорость отдельного TCP соединения определяется различными факторами: — максимальная пропускная способность самого медленного участка пути, — время между отправкой запроса и получением ответа (RTT), — большинство задержек на больших расстояниях вызваны скоростью света в волокне (~ 200 км/мс), — дополнительные задержки могут возникнуть в момент перегрузки сети или устройства (сервер, рутер, пк), — автоматическое понижение скорости при обнаружении потерь пакетов (стандартный механизм TCP предотвращения перегрузок), — отсутствие других негативных эффектов (минимальное количество ошибок битов на физическом уровне (Bit Error Rate — исправность сетевой карты и корректная работа драйвера), — один физический линк может нести множество одновременных TCP соединений, — один хост может иметь несколько одновременных соединений, даже с тем же удаленным хостом (быстро проверить можно с TCPView или TCPEye).Популярные speedtest-ы обычно работают в связке browser, flash + geo-локация до ближайшего доступного сервера, что создает: — дополнительную нагрузку на локальную машину (ЦП, память) и сеть (заголовки WWW и т.п.), — выбор сервера может быть не оптимальным, — возможность ошибочных результатов.
И на последок, хотелось бы отметить часто встречаемые проблемы с низкой производительностью сети: — узкое окно TCP (Window Size), — несоответствие Ethernet Duplex, — плохой сетевой кабель.
Ссылки по теме:technet.microsoft.com/en-us/magazine/2007.01.cableguy.aspxfasterdata.es.net/fasterdata/host-tuning
habr.com
Программа для увеличения скорости интернета TCP Optimizer
Как увеличить скорость интернета с помощью программы TCP Optimizer?
Несомненно вопрос о восстановлении удаленных файлов затрагивает многих пользователей, но в этот раз давайте поговорим о «наболевшем», — о скорости интернета…
Хотите увеличить скорость интернета? Желаете ли Вы быстро скачивать большие файлы, торренты, фильмы..? Большинство ответит конечно же да, тогда на сайте undelete-file.ru представляем Вашему вниманию — бесплатная программа для увеличения скорости интернета — TCP Optimizer, которая оптимизирует настройки связанных tcp и ip параметров ОС Windows, тем самым поднимая скорость сети интернет.
TCP Optimizer — это своеобразный «регулятор» скорости соединения, после выбора которой программа ищет лучшие окна параметров tcp и произведёт оптимизацию на этом режиме.
Перед использованием данной программы советуем изменить значение пропускной способности, тем самым скорость можно поднять ещё на 20%.
Открываем Диспетчер задач, жмем Файл — Новая задача (Выполнить) или Пуск — Выполнить
Далее вводим команду gpedit.msc и жмем ОК
Далее как показано на скриншоте в Редакторе локальной групповой политике ищем в папке Планировщика пакетов Qos или Диспетчере пакетов Qos значение Ограничить резервную пропускную способность, как на картинке
В новом окне изменяем настройки Включить — Устанавливаем на «0» (ноль процентов) — Применить — ОК.
Готово, теперь система Windows не будет отбирать «кусочек» инета ( + 20$).
Настройка скорости интернета в TCP Optimizer
Скачать программу для увеличения скорости интернета TCP Optimizer можно ниже, после чего разархивируем скачанный архив и запускаем утилиту. Причем, установка не нужна, скачанная программа сразу же готова к работе.
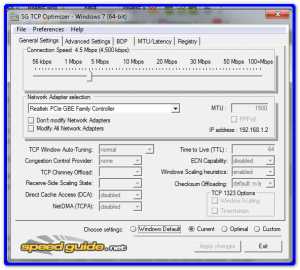
Далее, перемещая ползунок в строчке Connection Speed, указываем максимальную скорость интернет соединения. В данном случае выбрана скорость 8000 кбит в сек или 8 Мегабит в сек, не путать с Мегабайт в секунду — это разные вещи.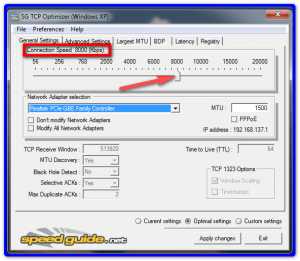 Теперь выбираем в выезжающей колонке Network Adapter selection «раздатчик» интернета (сетевой адаптер), в данном случае это Realtek Pcle GBE Family Controller.
Теперь выбираем в выезжающей колонке Network Adapter selection «раздатчик» интернета (сетевой адаптер), в данном случае это Realtek Pcle GBE Family Controller.
Далее, если используем оптимальные настройки, нажав Optimal settings
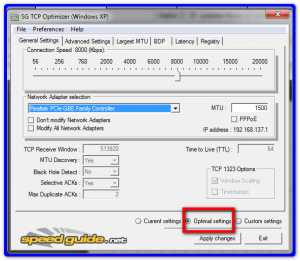 Теперь, кликнув Apply changes, применяем параметры нажимая ОК
Теперь, кликнув Apply changes, применяем параметры нажимая ОК
и перезагружаем компьютер, чтобы сохраненные параметры интернет соединения вступили в силу
Готово, с помощью программы TCP Optimizer для увеличения скорости интернет соединения мы бесплатно оптимизировали tcp параметры и подняли скорость в интернете.
Помимо представленной программы можно использовать ещё одну, прочитав статью как увеличить скорость интернета программой Сheat engine?
Видео как настроить TCP Optimizer для ускорения скорости интернет соединения
Характеристики
| Версия | 3.08 |
| Поддерживаемые ОС | Windows 95/ME/XP/Vista и Windows 7 |
| Авторы | Speedguide |
| Язык | Английский |
| Размер | 644кб |
Утилита TCP Optimizer скачать
Оцените статью:
Источник: undelete-file.ruСрочно рассказать друзьям:
Статья обновлена: 17.02.2018
Интересное на сайте:Категория: Увеличение интернет скорости на ПК
undelete-file.ru