Инструкция по SEO для WordPress сайтов и не только. Руководство по поисковой оптимизации сайтов
Руководство по SEO JavaScript-сайтов. Часть 2. Проблемы, эксперименты и рекомендации / Блог компании RUVDS.com / Хабр

Сегодня, во второй части перевода, Томаш Рудски расскажет о наиболее распространённых SEO-ошибках, которым подвержены сайты, основанные на JavaScript, обсудит последствия грядущего отказа Google от механизма AJAX-сканирования, поговорит о предварительном рендеринге и об изоморфном JavaScript, поделится результатами экспериментов по индексированию. Здесь, кроме того, он затронет тему особенностей ранжирования сайтов различных видов и предложит вспомнить о том, что помимо Google есть и другие поисковики, которым тоже приходится сталкиваться с веб-страницами, основанными на JS.
О ресурсах, необходимых для успешного формирования страницы
Если, по вашему мнению, Googlebot вполне сможет обработать некую страницу, но при этом оказывается, что данная страница не индексируется так, как нужно, проверьте, чтобы внешние и внутренние ресурсы (JS-библиотеки, например), требуемые для формирования страницы, были доступны поисковому роботу. Если он не сможет что-то загрузить и правильно воссоздать страницу, об её индексировании можно и не говорить.О периодическом использовании Google Search Console
Если вы вдруг столкнулись со значительным падением рейтинга сайта, который до этого работал стабильно и надёжно, рекомендую воспользоваться описанными ранее средствами Fetch и Render для того, чтобы проверить, в состоянии ли Google правильно обработать ваш сайт.В общем случае, полезно время от времени использовать Fetch и Render на произвольном наборе страниц сайта для того, чтобы проверить возможность его правильной обработки поисковиком.
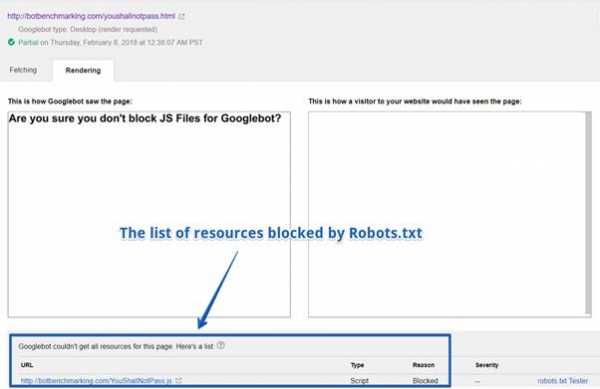 Список ресурсов, заблокированных с помощью Robots.txt
Список ресурсов, заблокированных с помощью Robots.txt
Опасное событие onClick
Помните о том, что Googlebot — это не настоящий пользователь, поэтому примите как должное то, что он не «щёлкает мышью» по ссылкам и кнопкам и не заполняет формы. У этого факта есть немало практических последствий:- Если у вас имеется интернет-магазин и некие тексты скрыты под кнопками вроде «Подробнее…», но при этом они не присутствуют в DOM до щелчка по соответствующей кнопке, Google эти тексты не прочтёт. Это же имеет отношение и к ссылкам, появляющимся по такому же принципу в меню.
- Все ссылки должны содержать параметр href. Если вы полагаетесь только на событие onClick, Google такие ссылки не воспримет.
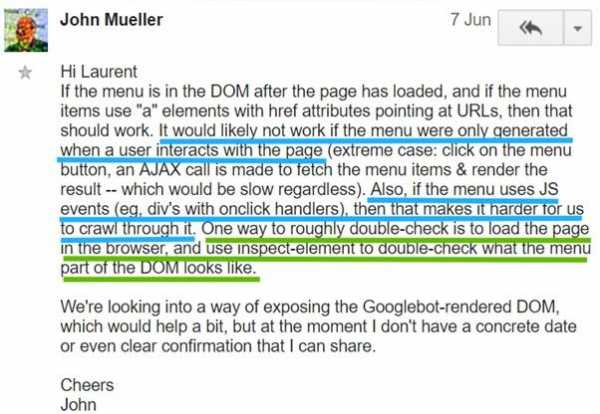 Комментарий Джона Мюллера, подтверждающий вышесказанное
Комментарий Джона Мюллера, подтверждающий вышесказанноеВ одном из моих предыдущих материалов, который посвящён использованию Chrome 41 для исследования сайтов, имеется краткое руководство, демонстрирующее процесс проверки меню на предмет доступности его для системы индексирования Google. Советую с этим материалом ознакомиться.
Использование значков # в ссылках
Всё ещё распространена практика, в соответствии с которой JS-фреймворки создают URL-адреса со знаком #. Существует реальная опасность того, что Googlebot не обработает подобные ссылки.- Плохой URL: example.com/#/crisis-center/
- Плохой URL: example.com#URL
- Хороший URL: example.com/crisis-center/
Возможно вы решите, что всё это не имеет особого значения. Действительно — большое дело — всего один дополнительный символ в адресе. Однако, это очень важно.
Позволю себе в очередной раз процитировать Джона Мюллера:
«(…) С нашей точки зрения, если мы видим тут нечто вроде знака #, это означает, что то, что идёт за ним, возможно, неважно. По большей части, индексируя содержимое, мы подобные вещи игнорируем (…). Когда вам нужно сделать так, чтобы это содержимое действительно появилось в поиске, важно, чтобы вы использовали ссылки, выглядящие более статично».
В итоге можно сказать, что веб-разработчикам стоит постараться, чтобы их ссылки не выглядели как нечто вроде example.com/resource#dsfsd. При использовании фреймворков, формирующих такие ссылки, стоит обратиться к их документации. Например, Angular 1 по умолчанию, использует адреса, в которых применяются знаки #. Исправить это можно, соответствующим образом настроив $locationProvider. А вот, например, Angular 2 и без дополнительных настроек использует ссылки, которые хорошо понимает Googlebot.
О медленных скриптах и медленных API
Многие сайты, основанные на JavaScript испытывают проблемы с индексированием из-за того, что Google приходится слишком долго ждать результатов работы скриптов (имеется в виду ожидание их загрузки, разбора, выполнения). Медленные скрипты могут означать, что Googlebot быстро исчерпает бюджет сканирования вашего сайта. Добейтесь того, чтобы ваши скрипты были быстрыми, и Google не приходилось бы слишком долго ждать их загрузки. Тем, кто хочет узнать подробности об этом, рекомендую ознакомиться с этим материалом, посвящённым оптимизации процесса визуализации страниц.Плохая поисковая оптимизация и SEO с учётом особенностей сайтов, основанных на JavaScript
Хочу поднять здесь проблему, которая может повлиять даже самую лучшую поисковую оптимизацию сайтов.
Важно помнить, что SEO с учётом особенностей JavaScript выполняется на базе традиционной поисковой оптимизации. Невозможно хорошо оптимизировать сайт с учётом особенностей JS, не добившись достойной оптимизации в обычном смысле этого слова. Иногда, когда вы сталкиваетесь с проблемой SEO, вашим первым ощущением может стать то, что это связано с JS, хотя, на самом деле, проблема — в традиционной поисковой оптимизации.
Не буду вдаваться в подробности подобных ситуаций, так как это уже отлично объяснил Джастин Бриггс в своём материале «Core Principles of SEO for JavaScript», в разделе «Confusing Bad SEO with JavaScript Limitations». Рекомендую почитать эту полезную статью.
Со второго квартала 2018 года Googlebot не будет использовать AJAX-сканирование
Компания Google сообщила о том, что со второго квартала 2018 года она больше не будет использовать AJAX-сканирование (AJAX Crawling Scheme). Значит ли это, что Google прекратит индексировать сайты, используя Ajax (асинхронный JavaScript)? Нет, это не так.Стоит сказать о том, что AJAX-сканирование появилось в те времена, когда компания Google поняла, что всё больше и больше сайтов использует JS, но не могла правильно обрабатывать такие сайты. Для того, чтобы решить эту проблему, веб-мастерам предложили создавать особые версии страниц, предназначенные для поискового робота и не содержащие JS-скриптов. К адресам этих страниц надо было добавлять _=escaped_fragment_=.
На практике это выглядит так: пользователи работают с полноценным и приятно выглядящим вариантом example.com, а Googlebot посещает не такой симпатичный эквивалент сайта, к которому ведёт ссылка вида example.com?_=escaped_fragment_= (это, кстати сказать, всё ещё очень популярный подход подготовки материалов для ботов).
Вот как это работает (изображение взято из блога Google).
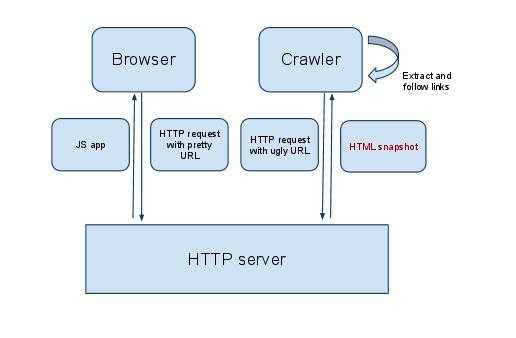 Разные версии сайта для пользователей и для ботов
Разные версии сайта для пользователей и для ботовБлагодаря такому подходу веб-мастера получили возможность убить двух зайцев одним выстрелом: и пользователи довольны, и поисковый робот счастлив. Пользователи видят версию сайта, оснащённую возможностями JavaScript, а поисковые системы могут правильно индексировать страницы этого сайта, так как им достаются лишь обычные HTML и CSS.
О проблемах AJAX-сканирования
 Сообщение об отключении AJAX-сканирования
Сообщение об отключении AJAX-сканированияКак это повлияет на веб-разработчиков?
- Google теперь будет формировать страницы сайтов своими средствами. Это означает, что разработчикам необходимо обеспечить то, чтобы у Google была техническая возможность сделать это.
- Googlebot прекратит посещать ссылки, содержащие _=escaped_fragment_= и начнёт запрашивать те же материалы, которые предназначены для обычных пользователей.
Будет ли Google использовать самый современный браузер для обработки страниц?
Сейчас неясно, планирует ли Google обновлять свою службу обработки сайтов с целью поддержки самых свежих технологий. Нам остаётся лишь надеяться на то, что это будет сделано.Как быть тем, кто не хочет, чтобы Google обрабатывал его страницы, основанные на JS, а довольствовался лишь заранее подготовленными страницами?
Я много об этом думал, и именно поэтому решил спросить Джона Мюллера на форуме, посвящённом JavaScript SEO, о том, могу ли я обнаружить Googlebot по User-Agent и просто отдать ему заранее подготовленную версию сайта. Вопрос Джону Мюллеру о версии сайта, подготовленной специально для Googlebot
Вопрос Джону Мюллеру о версии сайта, подготовленной специально для GooglebotВот что он ответил:
 Ответ Джона Мюллера
Ответ Джона МюллераДжон согласен с тем, что разработчик можете узнать, что его сайт сканирует Googlebot, проверяя заголовок User-Agent и отдать ему заранее подготовленный HTML-снимок страницы. Вдобавок к этому он советует регулярно проверять снимки страниц для того, чтобы быть уверенным в том, что предварительный рендеринг страниц работает правильно.
Не забудьте про Bing!
Представим себе, что Googlebot идеально обрабатывает сайты, основанные на JS-фреймворках и с ним у вас нет никаких сложностей. Значит ли это, что можно забыть обо всех проблемах, связанных с индексированием таких сайтов? К сожалению — не значит. Вспомним о поисковике Bing, который, в США, применяет около трети интернет-пользователей.В настоящее время разумно будет считать, что Bing вообще не занимается обработкой JavaScript (ходят слухи, что Bing обрабатывает JS на страницах с высоким рейтингом, но мне не удалось найти ни одного подтверждения этим слухам).
Позвольте мне рассказать об одном интересном исследовании.
Angular.io — это официальный веб-сайт Angular 2+. Некоторые страницы этого сайта созданы в виде одностраничных приложений. Это означает, что их исходный HTML-код не содержит никакого контента. После загрузки такой страницы подгружается внешний JS-файл, средствами которого и формируется наполнение страниц.
 Сайт Angular.io
Сайт Angular.ioВозникает такое ощущение, что Bing не видит содержимого этого сайта!
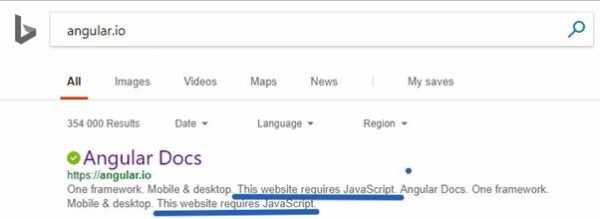 Bing не видит содержимого сайта Angular.io
Bing не видит содержимого сайта Angular.ioЭтот сайт занимает вторую позицию по ключевому слову «Angular» в Bing.
Как насчёт запроса «Angular 4». Снова — вторая позиция, ниже сайта AngularJS.org (это — официальный сайт Angular 1). По запросу «Angular 5» — опять вторая позиция.
Если вам нужны доказательства того, что Bing не может работать с Angular.io — попытайтесь найти какой-нибудь фрагмент текста с этого сайта, воспользовавшись командой site. У вас ничего не получится.
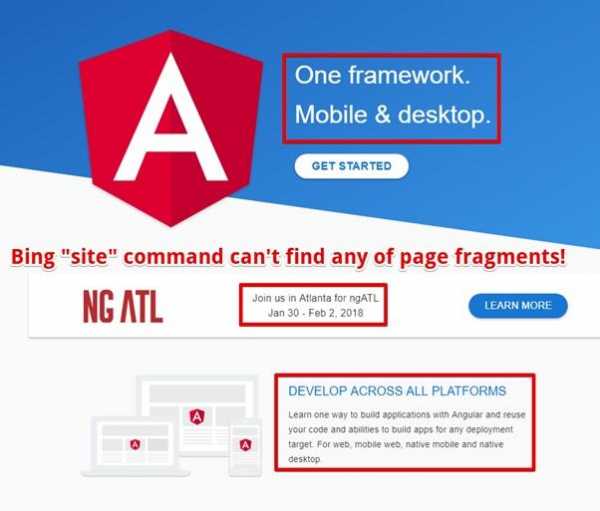 Выбор фрагмента текста для проверки
Выбор фрагмента текста для проверки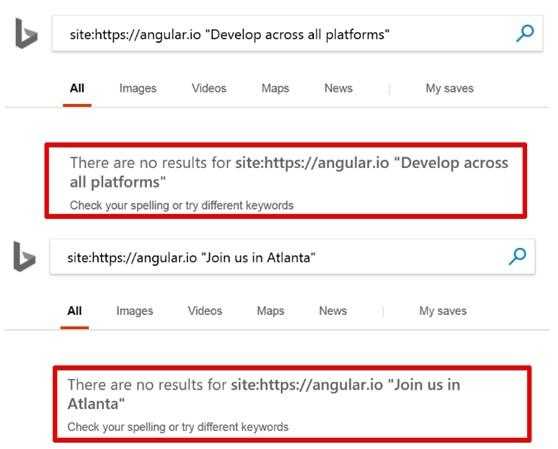 Текст, при поиске по сайту, не найден
Текст, при поиске по сайту, не найденПо мне, так это странно. Получается, что официальный сайт Angular 2 не может быть нормально просканирован и проиндексирован роботом Bingbot.
А как насчёт Яндекса? Angular.io даже не входит в топ-50 результатов при поиске по слову «Angular» в Яндексе!
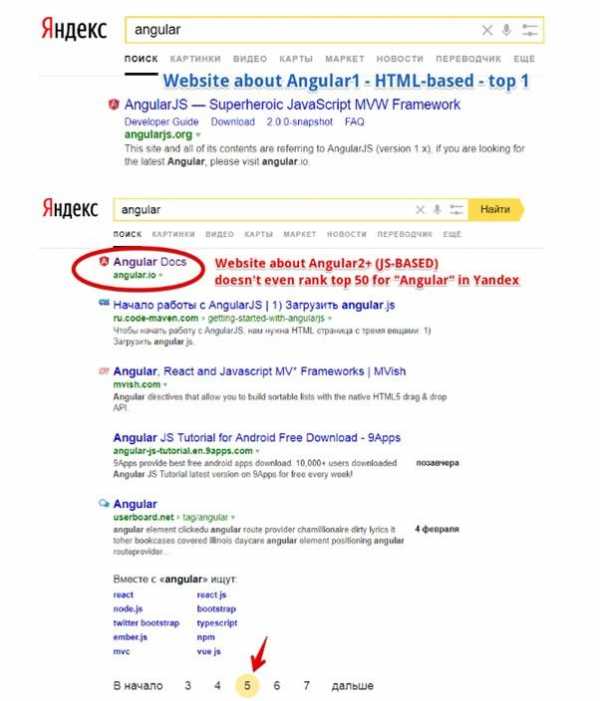 Сайт Angular.io в Яндексе
Сайт Angular.io в ЯндексеВ Твиттере я обратился к команде Angular.io, задал им вопрос о том, планируют ли они что-то делать для того, чтобы их сайт могли индексировать поисковые системы вроде Bing, но они, на момент написания этого материала, пока не ответили мне.
Собственно говоря, из вышесказанного можно сделать вывод о том, что, в стремлении внедрять на свои сайты новые веб-технологии не стоит забывать о Bing и о других поисковиках. Тут можно порекомендовать два подхода: изоморфный JavaScript и предварительный рендеринг.
Предварительный рендеринг и изоморфный JavaScript
Когда вы замечаете, что Google испытывает сложности с индексацией вашего сайта, рендеринг которого выполняется на клиенте, вы можете рассмотреть возможность использования предварительного рендеринга или преобразования сайта в изоморфное JavaScript-приложение.Какой из подходов лучше?
- Предварительный рендеринг применяется в тех случаях, когда вы замечаете, что поисковые роботы не в состоянии правильно сформировать страницы вашего веб-сайта и вы выполняете эту операцию самостоятельно. Когда робот посещает ваш сайт, вы просто отдаёте ему HTML-копии страниц (они не содержат JS-кода). В то же время, пользователи получают версии страниц, оснащённых возможностями JS. Копии страниц используются лишь ботами, но не обычными пользователями. Для предварительного рендеринга страниц вы можете применять внешние сервисы (вроде prerender.io), или использовать инструменты вроде PhantomJS или Chrome без пользовательского интерфейса на своих серверах.
- Изоморфный JavaScript — это ещё один популярный поход. При его применении и поисковая система, и пользователи, при первой загрузке страницы, получают все необходимые данные. Затем загружаются JS-скрипты, которые работают уже с этими, предварительно загруженными, данными. Это хорошо и для обычных пользователей, и для поисковых систем. Данный вариант рекомендуется к использованию, его поддерживает даже Google.
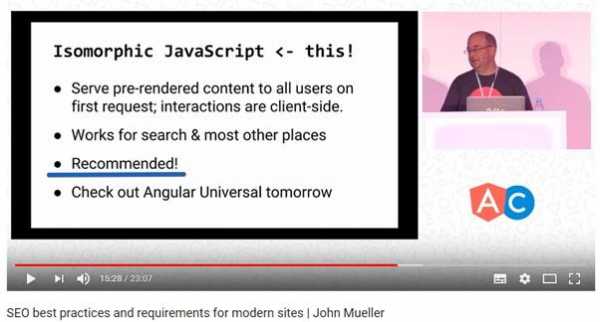 Google рекомендует изоморфный JavaScript
Google рекомендует изоморфный JavaScriptОднако тут есть одна проблема, которая заключается в том, что многие разработчики не могут правильно создавать изоморфные JavaScript-приложения.
Если вас привлекает серверный рендеринг — посмотрите документацию по используемому вами JS-фреймворку. Например, в случае с Angular вы можете применить Angular Universal. Если вы работаете с React — почитайте документацию и посмотрите этот учебный курс на Udemy.
React 16 (он вышел в ноябре) принёс в сферу серверного рендеринга множество улучшений. Одно из таких улучшений — функция RenderToNodeStream, которая упрощает весь процесс серверного рендеринга.
Если говорить об общем подходе к серверному рендерингу, то хотелось бы отметить одну важную рекомендацию. Она заключается в том, что если нужно, чтобы сайт рендерился на сервере, разработчикам следует избегать использования функций, которые напрямую воздействуют на DOM.
Всегда, когда это возможно, дважды подумайте прежде чем работать напрямую с DOM. Если вам нужно взаимодействие с DOM браузера — воспользуйтесь Angular Renderer или абстракцией рендеринга.
Одинаково ли Googlebot обрабатывает HTML и JS-сайты?
Мы, в Elephate, провели некоторые эксперименты для того, чтобы выяснить, насколько глубоко Googlebot может продвинуться в обнаружении ссылок и в переходах по ним в случае сканирования сайтов, использующих лишь HTML, и сайтов, основанных на JavaScript.Исследование дало поразительные результаты. В случае HTML-сайта Googlebot смог проиндексировать все страницы. Однако, при обработке сайта, основанного на JS, вполне обычной была ситуация, когда Googlebot не добрался даже до его второго уровня. Мы повторили эксперимент на пяти различных доменах, но результат всегда был одним и тем же.
 Эксперимент по индексированию HTML-сайтов и сайтов, основанных на JS
Эксперимент по индексированию HTML-сайтов и сайтов, основанных на JSБартош Горалевич обратился к Джону Мюллеру из Google, и задал ему вопрос об источниках проблемы. Джон подтвердил, что Google видит ссылки, сгенерированные средствами JavaScript, но «Googlebot не стремится их сканировать». Он добавил: «Мы не сканируем все URL, или сканируем все их быстро, особенно когда наш алгоритм не уверен в ценности URL. Ценность контента — неоднозначный аспект тестовых сайтов».
Если вы хотите углубиться в эту тему, рекомендую взглянуть на этот материал.
Подробности об эксперименте по индексированию тестовых сайтов
Хочу поделиться некоторыми моими идеями относительно вышеописанного эксперимента. Так, нужно отметить, что хотя исследуемые сайты были созданы лишь в экспериментальных целях, к их наполнению применялся один и тот же подход. А именно, их тексты были созданы средствами Articoolo — интересного генератора контента, основанного на технологиях искусственного интеллекта. Он выдаёт довольно хорошие тексты, которые определённо лучше моей писанины.Googlebot получал два очень похожих веб-сайта и сканировал лишь один из них, предпочитая HTML-сайт сайту, на котором применяется JS. Почему это так? Выдвину несколько предположений:
- Гипотеза №1. Алгоритмы Google классифицировали оба сайта как тестовые, после чего назначили им фиксированное время выполнения. Скажем, это может быть что-то вроде индексирования 6-ти страниц, или 20 секунд рабочего времени (загрузка всех ресурсов и формирование страниц).
- Гипотеза №2. Googlebot классифицировал оба сайта как тестовые. В случае с JS-сайтом он отметил, что загрузка ресурсов занимает слишком много времени, поэтому просто не стал его сканировать.
Есть немалая вероятность того, что если вы создадите новый сайт, который рендерится на клиенте, вы попадёте в точно такую же ситуацию, как и мы. Googlebot, в таком случае, просто не станет его сканировать. Именно тут заканчивается теория и начинаются реальные проблемы. Кроме того, главная проблема здесь заключается в том, что нет практически ни одного примера из реальной жизни, когда веб-сайт, или интернет-магазин, или страница компании, на которых применяется клиентский рендеринг, занимают высокую позицию в поисковой выдаче. Поэтому я не могу гарантировать того, что ваш сайт, наполненный возможностями JavaScript, получит столь же высокую позицию в поиске, как и его HTML-эквивалент.
Вы можете решить, что, наверняка, большинство SEO-специалистов это и так знают, и большие компании могут направить определённые средства на борьбу с этими проблемами. Однако, как насчёт небольших компаний, у которых нет средств и знаний? Это может представлять реальную опасность для чего-то вроде сайтов маленьких семейных ресторанов, которые используют визуализацию на стороне клиента.
Итоги
Подведём краткие итоги, обобщив в следующем списке выводы и рекомендации:- Google использует Chrome 41 для рендеринга веб-сайтов. Эта версия Chrome была выпущена в 2015-м году, поэтому она не поддерживает все современные возможности JavaScript. Вы можете использовать Chrome 41 для того, чтобы проверить, сможет ли Google правильно обрабатывать ваши страницы. Подробности об использовании Chrome 41 можно найти здесь.
- Обычно недостаточно анализировать лишь исходный HTML-код страниц сайта. Вместо этого следует взглянуть на DOM.
- Google — это единственная поисковая система, которая широко применяет рендеринг JavaScript.
- Не следует использовать кэш Google для проверки того, как Google индексирует содержимое страниц. Анализируя кэш? можно лишь увидеть то, как ваш браузер интерпретирует HTML-данные, которые собрал Googlebot. Это не имеет отношения к тому, как Google обрабатывает эти данные перед индексированием.
- Регулярно используйте инструменты Fetch и Render. Однако не полагайтесь на их тайм-ауты. При индексировании могут применяться совершенно другие тайм-ауты.
- Освойте команду site.
- Обеспечьте присутствие пунктов меню в DOM ещё до того, как пользователь вызывает это меню щелчком мыши.
- Алгоритмы Google пытаются определить ценность ресурса с точки зрения целесообразности обработки этого ресурса для формирования страницы. Если, по мнению этих алгоритмов, ресурс ценности не представляет, Googlebot, возможно, не станет его загружать.
- Веб-разработчикам стоит стремиться к тому, чтобы обеспечить скорость выполнения скриптов (множество экспериментов указывают на то, что Google вряд ли станет ждать результатов выполнения скрипта, включая этап загрузки, более 5 секунд). Кроме того, постарайтесь оптимизировать скрипты. Как правило, большинство скриптов можно улучшать и улучшать!
- Если Google не может сформировать страницу, используя JavaScript, он может решить проиндексировать изначально загруженный HTML. Это может очень плохо сказаться на одностраничных приложениях, так как Google, при таком подходе, проиндексирует пустую страницу.
- Нет практически ни одного реального примера сайта, применяющего рендеринг средствами клиента, который занимает высокие позиции в поисковой выдаче. Как вы думаете, почему?
Уважаемые читатели! Сталкивались ли вы, в личной практике, с проблемами индексации сайтов, основанных на JS-фреймворках?
habr.com
Руководство по поисковой оптимизации сайта Google, пошаговые инструкции
В одной из нашей статей мы уже перечисляли основные принципы, как выдержать рекомендации по обеспечению качества и сделать качественный сайт глазами Google. В этой статье пойдет речь о Руководстве по поисковой оптимизации.
Данное руководство было составлено компанией Гугл для внутреннего использования, однако в 2013 году компания приняла решение поделиться им с веб-мастерами по 2-м причинам:
- улучшить качество сайтов в целом;
- дать возможность веб мастерам выделить свои сайты среди конкурентов
В кратком руководстве по поисковой рекомендации Google указаны основные 3 совета. Рассмотрим каждую рекомендацию руководства по отдельности.
1. Выделите сайт в результатах поиска
Вы уже обращали внимание, что в результатах поиска не встречается 2 одинаковых сниппета. Если прислушиваться рекомендаций по уникализации и выделению сайта в результатах поиска, шанс появления двух одинаковых описаний исключен. Для начала давайте разберемся, что такое сниппет и почему он так важен для поисковика.
Сниппет (от англ. snippet — фрагмент) — это отрывок или превью описательной части сайта, он предназначен для краткого ознакомления с его содержимым до перехода на сам сайт).
Пример сниппета по запросу «Руководство по поисковой оптимизации сайта«:
 снипет по запросу «Руководство по поисковой оптимизации сайта»
снипет по запросу «Руководство по поисковой оптимизации сайта»Каждый snippet состоит из 3-х основных частей:
- заголовок (мета тайтл)
- url (адрес, по которому доступна страница)
- описание (мета описание)
Фразой «выделите сайт в результатах поиска» Google рекомендует выделить Ваш сниппет. Здесь имеется в виду создать интересный и кликабельный заголовок страницы (meta title), тематический url, а также содержательное описание страницы (meta description).
Почему это важно?
С одной стороны, большинство современных CMS позволяют свободно управлять всеми 3-мя частями сниппета. С другой стороны, не каждый веб мастер хочет этим заниматься на этапе разработки сайта. Очень часто созданные и сверстанные страницы тестового проекта переносятся на живой сайт. После индексации в результатах поиска появляются шедевральные сниппеты.
Пример, как нельзя делать:
- заголовок: «Главная страница»
- url: ?id=2
- пусто или дублирует заголовок
Очень важно при создании метатэгов понять простую вещь: пользователь должен захотеть перейти на ваш сайт. Если пользователь ищет информацию о продвижении сайтов в Киеве, в сниппете должна идти речь об этом. Мало кому понравится, если показать на сайте иной контент, не связанный с раскруткой.
2. Распознавание изображений
Google внимательно относится к изображениям на сайтах: согласно рекомендациям поисковой системы изображения на странице придают ей положительный user-experience. По этой причине у поисковика есть правила размещения изображений:
- понятные и короткие названия картинок
- наличие содержательного alt атрибута
- подпись под картинкой
Реализация этих правил крайне проста через CMS, не будем на этом останавливаться. Разве что, порекомендуем веб-мастерам не увлекаться избыточным описанием alt либо переспамом (злоупотребление ключевыми словами). Читайте статью о ключевых словах Гугл.
3. Добавляйте новый контент
Гугл рекомендует посмотреть на сайт глазами Вашего клиента и увидеть в нем витрину. Если витрина не обновляется полгода, она становится менее интересна покупателям.
Дело в том, что поисковая система заходит на ваш сайт и сканирует его ежедневно. При этом Google сопоставляет текущие материалы вашего сайта с предыдущим сканированием. Если Ваш сайт не обновляется, ему уделяется намного меньше внимания со стороны поисковой системы.
Согласитесь, чтобы придумать и написать интересную статью, затем разместить ее на сайте, прописать красивые метатэги, alt для картинок — уходит много времени. Не легче ли ничего не делать? Гугл ценит труды веб мастера, поэтому игра стоит свеч.
На этом краткое руководство по поисковой оптимизации сайта заканчивается. Как видите, выдержать 3 рекомендации не составляет труда.
www.seo-design.ua
Руководство по оптимизации сайта под поисковые системы. Часть 2 – Познаём поисковые системы
Задачи поисковых систем
Задачи, стоящие перед поисковыми системами, просты – они должны давать точные и релевантные ответы на любой запрос. Если у вас есть свой сайт, то вы заинтересованы в максимально качественном ранжировании поисковых машин. Исключением являются сайты, которые раскручиваются благодаря большому количеству спама в текстах. Новые методы продвижения ведут к появлению фильтрующих технологий поисковых систем. Поэтому методы раскрутки, актуальные сегодня, уже завтра могут привести к пессимизации и даже бану сайта.Что ищут поисковые машины?
В результате поиска пользователь получает список сайтов, релевантных запросу – SERP – страницы результатов поиска. Что именно ищет поисковая машина на сайте:
• страницы, в которых присутствует точная фраза запроса• страницы, в которых присутствует любое слово из запроса• страницы, которые содержат однокоренные запросу слова, например, машина – машинный
Если на найденную страницу ведут ссылки с других сайтов, в которых прописаны данные ключевые слова, сайт будет выше оценен поисковыми системами. Также большое внимание уделяется заголовкам (h2, h3, h4), содержащим искомые ключевые слова.
Что такое PageRank (PR)?
Google – один из самых популярных поисковиков, около 65% всех поисковых запросов в мире приходятся на этого интернет-гиганта. Определяющим фактором ранжирования сайтов в Google являются ссылки – их количество, качество и содержание входящих ссылок на ваш сайт. Метод оценки сайтов поисковой системе Google является PageRank. Однако отметим, что есть сайты, PR которых 5, а на сайте стоит более 1000 ссылок и сайты PR которых 7, а ссылок не больше 100.
Определить PR можно, установив Google Toolbar или seobook .com/firefox/seo-for-firefox.html»>плагин SEO для Firefox. PR сайта и его позиции в поисковиках не одно и то же. Например, структура SERP’а (Search Engine Result Pages) меняется каждый час. Понять принцип увеличения рейтинга сайтов пытаются лучшие умы интернета. Вся трудность в том, что алгоритм ранжирования сайтов постоянно модифицируется. Это позволяет избегать чрезмерного воздействия на позиции сайтов, в противном случае – все ссылки SERP вели бы на сайты, наполненные спамом, рекламой и прочим нерелевантным контентом.
Поисковые машины определяют позиции сайта после его индексации. Каждая страница сайта ранжируется по отдельности. Поэтому важно, чтобы на внутренних страницах сайта присутствовали ссылки с других страниц. При вложенности страниц рейтинг ссылок уменьшается пропорционально вложенности.
Как представить свой сайт
Чтобы привлечь посетителей на свой ресурс, вы должны представить его..Чтобы сделать это качественней, нужно знать, чего хотят поисковые системы и принцип их работы по индексации новых сайтов. Одним из основополагающих факторов является создание правильной внешней ссылочной структуры. Ответим на следующий вопрос: как пользователи приходят на сайт? Обычно существует два варианта: они приходят на сайт по ссылкам с других сайтов или по ссылкам, выданным поисковыми системами.
Внешняя ссылочная структура
Вы, как владелец сайта, должны быть заинтересованы в увеличении количества входящих ссылок. Их должно быть много и они должны быть качественными. Однако этого не достаточно, вот некоторые факторы, влияющие на вес ссылки:
1. Качество ссылок. Чем выше рейтинг страницы, с которой идет ссылка, тем большим весом обладает сама ссылка. Страница должна быть с хорошим и релевантным контентом. Избегайте некачественных ссылок, они могут привести к понижению рейтинга вашей страницы.2. Текст ссылки. Качество ссылки во многом зависит от ссылочного текста, который должен содержать ключевое(ые) слово(а) или фразы, название компании или URL вашего сайта. При составлении текста ссылки пользуйтесь осмысленными фразами и помните о пользователях, которым надоел спам. Не нагромождайте слова, по такой ссылке никто не перейдёт.3. Количество ссылок на страницу. Большое количество ссылок на одной странице ведет к уменьшению общего веса страницы. Это происходит потому, что каждая ссылка получает часть веса страницы. К тому же, если вы перелинкованы со страницей с большим количеством ссылок, поисковый робот может не дойти до вашей, особенно если ссылка находится внизу HTML-документа и/или рейтинг страницы невысок.
4. Нераспознаваемые ссылки. Также существуют ссылки, которые просто не распознаются поисковыми роботами – это обычно JavaScript и Flash ссылки. Они не индексируются поисковыми роботами и поэтому не влияют на вес страницы. Такие ссылки не позволяют продвинуться дальше первой страницы. Не слушайте тех, кто говорит, что поисковики научились их расшифровывать. Flash постоянно модифицируется и написание нового парсера – очень трудоёмкое занятие, тем более что Flash – закрытый продукт и не предоставляет исходных кодов.5. Ссылки » nofollow «. Существует ещё один тип ссылок, который никак не влияет на вес страницы. Это обычные ссылки с значением «nofollow» в атрибуте «rel». Так, по ссылке <a href=»http://www.mutinydesign.co.uk» rel=»nofollow»>Mutiny Design</a> не пройдет ни один поисковый бот. Такие ссылки часто встречаются на форумах, блогах, комментариях и т.д.
20 способов построить внешнюю ссылочную структуру
Теперь мы знаем, как прописывать ссылки, пришло время научиться их проставлять. Существует много методов их размещения. Многие плохо разбираются в «ссылкостроительстве», они предпочитают покупать ссылки и не тратить время на организацию естественной ссылочной структуры. Однако такой результат, в большинстве случаев, временный. По истечении проплаченного времени, ссылка удаляется, тем самым снижая рейтинг сайта. Существуют черные и белые методы «ссылкостроительства». Ниже мы рассмотрим последние:
1. Обмен ссылками – старейший и очень эффективный метод. Достаточно просто связаться с владельцем ресурса и предложить обменяться ссылками. Многие владельцы положительно ответят, так как тоже заинтересованы в этом. Не поленитесь, изучите сайт партнера. Ссылки должны быть со значимым текстом и вести на страницу с тем контентом, ключевые слова которого прописаны в ссылке.2. Поставьте на меня ссылку – этот метод сложнее двустороннего обмена ссылками, особенно если ваш сайт коммерческий или конкурирующий. Ваш сайт должен выгодно отличаться от многих других, например, уникальным контентом, который заинтересует владельца нужной вам ссылки.3. Закладки – Кнопка «добавить в закладку» и «сделать стартовой/избранной» – хороший путь привлечения и возвращения посетителей на свой сайт. Некоторые посетители, посетив ресурс однажды, возвращаются к нему снова и снова. Но отсутствие возможности поставить закладку приведет к тому, что пользователь может не вспомнить адрес сайта. Однако и это не означает, что кнопки нужно разместить по всему сайту. Определите наиболее полезные для пользователя страницы, например, новости, форум и т.п., и только на них проставьте кнопки.4. Итернет-каталоги – регистрация сайта в интернет-каталогах – хорошая и проверенная SEO-тактика. Она достаточно проста и не требует много времени. Самым известным интернет-каталогом является DMOZ, в России популярностью пользуется каталог Яндекс. Единственной проблемой остаётся инертность таких каталогов, поэтому рекомендуется как можно чаще регистрировать вновь свой ресурс. Есть много SEO-консультантов, которые берут большие деньги за регистрацию в интернет-каталогах. Это пустая трата деньги, потому что регистрация абсолютно бесплатна.5. Друзья – у вас есть друзья, которые ведут свой блог? Попробуйте разместить там свою ссылку или обменяйтесь ими. Ссылки на сайтах друзей могут содержать более гибкий ссылочный текст, а при необходимости их можно отредактировать.6. Блоги – блоги играют очень большую роль в раскрутке сайта. Образовалась целая индустрия ведения онлайн-дневников. Такие крупные организации, как Microsoft и Adobe также используют их для ведения своих агрессивных маркетинговых кампаний. Часто сотрудники компании ведут свои дневники, повышая количество ссылок на сайт своей организации. Однако просто писать интересные статьи – не достаточно, нужно собрать сообщество пользователей. Это обеспечит ресурс постоянным притоком пользователей.7. Пишите статьи – это могут быть статьи для вашего блога, например. Интересные и полезные статьи могут стать дополнительным источником ссылок. Однако это не должны быть тексты, начинающиеся с «как я провёл лето» или «наша компания выполнила работу в срок».8. Пишите скрипты – если вы или кто-либо из вашей компании половину дня проводит за написанием различных скриптов и программ, то вы можете воспользоваться этим для раскрутки своего ресурса. Простые, бесплатные и понятные программы (исходники) и JavaScript’ы пользуются огромной популярностью у непрофессионалов. Также можно доступно объяснить основы HTML и CSS, наиболее известные баги в браузерах, связанные с отображением содержимого.9. Контент, доступный локально – великолепная возможность раскрутиться. Справочники, пособия, учебники. Если в них присутствует ссылка на сайт, объясняющий тот или иной термин или пример, то по ней пройдёт большинство читающих этот документ.10. Pay Per Click – если вы не можете сами раскрутить сайт и не хотите платить SEO- консультантам, воспользуйтесь контекстной рекламой с оплатой Pay Per Click (плата за переход). Она позволит пробиться в топ поисковых запросов на какое-то время. Если у вас действительно хороший и качественный сайт с интересным контентом, многие владельцы других ресурсов поставят на него ссылки.11. Социальные закладки - сегодня появляется все больше сайтов социальных закладок, например, memori.ru, bobrdobr.ru, Digg или del.icio.us. Одна из функций социальных закладок заключается в том, чтобы хранить ссылки не в своем браузере, а на специальном сайте. Такое хранение закладок в интернете позволяет вам просматривать интересующие вас сайты с любого компьютера. Закладки можно хранить как в закрытом (доступными только для вас), так и открытом (доступном для всех пользователей) режимах. Если контент сайта действительно хороший, пользователи могут ставить закладки на ваш сайт.12. Государственные и образовательные домены – домены первого уровня .gov и .edu или .ac имеют больший вес, по сравнению с обычными доменами. Соответственно и ссылки, расположенные на таких сайтах, ценятся очень высоко.13. Торговые организации и крупные предприятия традиционно высоко ценятся поисковыми машинами ввиду правильно подобранного контента и четко определённой тематики.14. Сообщества – вступление в сообщество – тоже помогает повысить рейтинг вашего сайта. Небольшое сообщество всегда радо видеть новых участников. Однако помните, не все ссылки с онлайн-блогов учитываются поисковыми системами.15. Конкурент, который не конкурент – если вы не крупная международная компания и работаете только в пределах своего города/региона, то может оказаться полезным обменяться ссылками с компанией, имеющим то же направление деятельности, что и ваше, только находящийся в другом регионе или даже за границей. Одинаковая тематика сайтов только сыграет вам на руку.16. Wikipedia – онлайн-энциклопедия использует в ссылках атрибут «nofollow», поэтому они не учитываются поисковыми системами. Однако есть предположения, что Google учитывает исходящие ссылки с этого ресурса.17. Сайты сообществ – например, сайты знакомств или сообщества на Rambler.ru. Их посещаемость очень велика и есть смысл поучаствовать в этом.18. Спонсируйте – это один из незамысловатых вариантов, но требующих больших денежных средств. Спонсорство позволяет размещать ссылки на сайтах организаций, которые вы спонсируете.19. Ссылка на ссылку – если ваша ссылка ведёт на страницу сайта с очень хорошей репутацией, постарайтесь получить обратную ссылку с данной страницы.20. Покупка ссылок – Если вы пытались выполнить всё перечисленное выше и у вас ничего не получилось, то остаётся покупать ссылки. Несмотря на то, что это временные меры, они приносят хороший результат.
Источник: seonews.ru
Рекомендуем ещё
seosbornik.kz
Руководство по SEO JavaScript-сайтов. Часть 1. Интернет глазами Google / Блог компании RUVDS.com / Хабр
Представляем вашему вниманию перевод первой части материала, который посвящён поисковой оптимизации сайтов, построенных с использованием JavaScript. Речь пойдёт об особенностях сканирования, анализа и индексирования таких сайтов поисковыми роботами, о проблемах, сопутствующих этим процессам, и о подходах к решению этих проблем.В частности, сегодня автор этого материала, Томаш Рудски из компании Elephate, расскажет о том, как сайты, которые используют современные JS-фреймворки, вроде Angular, React, Vue.js и Polymer, выглядят с точки зрения Google. А именно, речь пойдёт о том, как Google обрабатывает сайты, о технологиях, применяемых для анализа страниц, о том, как разработчик может проанализировать сайт для того, чтобы понять, сможет ли Google нормально этот сайт проиндексировать.
JavaScript-технологии разработки веб-сайтов в наши дни весьма популярны, поэтому может показаться, что они уже достигли достаточно высокого уровня развития во всех мыслимых направлениях. Однако, в реальности всё не так. В частности, разработчики и SEO-специалисты всё ещё находятся в самом начале пути к тому, чтобы сделать сайты, построенные на JS-фреймворках, успешными в плане их взаимодействия с поисковыми системами. До сих пор множество подобных сайтов, несмотря на их популярность, занимают далеко не самые высокие места в поисковой выдаче Google и других поисковых систем.
Может ли Google сканировать и анализировать сайты, основанные на JavaScript?
Ещё в 2014-м компания Google заявляла о том, что их системы неплохо индексируют сайты, использующие JavaScript. Однако, несмотря на эти заявления, всегда давались рекомендации осторожно относиться к этому вопросу. Взгляните на это извлечение из оригинала материала «Совершенствуем понимание веб-страниц» (здесь и далее выделение сделано автором материала):«К сожалению, индексация не всегда проходит гладко, что может привести к проблемам, влияющим на позицию вашего сайта в результатах поиска … Если код JavaScript слишком сложный или запутанный, Google может проанализировать его некорректно… Иногда JavaScript удаляет контент со страницы, а не добавляет его, что также затрудняет индексацию».
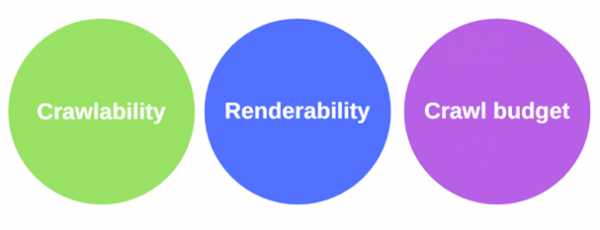 Возможность сканирования, возможность анализа и бюджет сканирования
Возможность сканирования, возможность анализа и бюджет сканированияДля того, чтобы понять, сможет ли поисковая система правильно обработать сайт, то есть, обработать его так, как того ожидает создатель сайта, нужно учесть три фактора:
- Возможность сканирования сайта: системы Google должны быть способны просканировать сайт, учитывая его структуру.
- Возможность анализа сайта: системы Google не должны испытывать проблем в ходе анализа сайта с использованием технологий, используемых для формирования его страниц.
- Бюджет сканирования: времени, выделенного Google на обработку сайта, должно хватить для его полноценной индексации.
О клиентском и серверном рендеринге
Говоря о том, может ли Google сканировать и анализировать сайты, использующие JavaScript, нам нужно затронуть две очень важные концепции: рендеринг, или визуализация страниц, на стороне сервера, и на стороне клиента. Эти идеи необходимо понимать каждому специалисту по SEO, который имеет дело с JavaScript.При традиционном подходе (серверный рендеринг), браузер или робот Googlebot загружают с сервера HTML-код, который полностью описывает страницу. Все необходимые материалы уже готовы, браузеру (или роботу) нужно лишь загрузить HTML и CSS и сформировать готовую к просмотру или анализу страницу. Обычно поисковые системы не испытывают никаких проблем с индексацией сайтов, использующих серверный рендеринг.
Всё большую популярность получает метод визуализации страниц на стороне клиента, который имеет определённые особенности. Эти особенности иногда приводят к проблемам с анализом таких страниц поисковыми системами. Весьма распространена ситуация, когда при первоначальной загрузке данных браузер (или Googlebot) получает пустую HTML-страницу.
Фактически, на такой странице либо вовсе нет данных, подходящих для анализа и индексации, либо их очень мало. Затем в дело вступают JavaScript-механизмы, которые асинхронно загружают данные с сервера и обновляют страницу (изменяя DOM).
Если на вы используете методику визуализации на стороне клиента, вам нужно убедиться в том, что Google в состоянии правильно сканировать и обрабатывать страницы вашего сайта.
JavaScript и ошибки
HTML и JS коренным образом различаются в подходах к обработке ошибок. Единственная ошибка в JavaScript-коде может привести к тому, что Google не сможет проиндексировать страницу. Позвольте мне процитировать Матиаса Шафера, автора работы «Надёжный JavaScript»: «JS-парсер не отличается дружелюбием. Он совершенно нетерпим к ошибкам. Если он встречает символ, появление которого в определённом месте не ожидается, он немедленно прекращает разбор текущего скрипта и выдаёт SyntaxError. Поэтому единственный символ, находящейся не там, где нужно, единственная опечатка, может привести к полной неработоспособности скрипта.»Ошибки разработчиков фреймворков
Возможно вы слышали об эксперименте по SEO в применении к JavaScript-сайтам, который провёл Бартош Горалевич, занимающий должность CEO в компании Elephate, для того, чтобы узнать, может ли Google индексировать веб-сайты, созданные с использованием распространённых JS-фреймворков. Список исследованных технологий
Список исследованных технологийВ самом начале выяснилось, что Googlebot не в состоянии анализировать страницы, созданные с использованием Angular 2. Это было странно, так как Angular создан командой Google, поэтому Бартош решил выяснить причины происходящего. Вот что он пишет по этому поводу:
«Оказалось, что имелась ошибка в QuickStart Angular 2, в чём-то вроде учебного руководства, посвящённого тому, как готовить к работе проекты, основанные на этом фреймворке. Ссылка на это руководство присутствовала в официальной документации. Было выяснено, что команда Google Angular допустила ошибку, которая была исправлена 26-го апреля 2017 года».
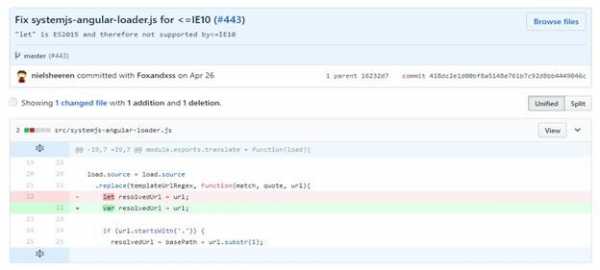 Ошибка в Angular 2
Ошибка в Angular 2Исправление ошибки привело к возможности нормального индексирования тестового сайта на Angular 2.
Этот пример отлично иллюстрирует ситуацию, когда единственная ошибка может привести к тому, что Googlebot оказывается не в состоянии проанализировать страницу.
Масла в огонь подливает и то, что ошибка была совершена не новичком, а опытным человеком, участвующим в разработке Angular, второго по популярности JS-фреймворка.
Вот ещё один отличный пример, который, по иронии судьбы, снова связан с Angular. В декабре 2017-го Google исключила из индекса несколько страниц сайта Angular.io (веб-сайт, основанный на Angular 2+, на котором применяется технология визуализации на стороне клиента). Почему это произошло? Как вы можете догадываться, одна ошибка в их коде сделала невозможной визуализацию страниц средствами Google и привела к масштабному исключению страниц из индекса. Позже ошибка была исправлена.
Вот как Игорь Минар из Angular.io это объяснил:
«Учитывая то, что мы не меняли проблематичный код в течение 8 месяцев, и мы столкнулись со значительным падением трафика с поисковых систем, начиная примерно с 11 декабря 2017, я полагаю, что за это время что-то изменилось в системе сканирования сайтов, что и привело к тому, что большая часть сайта оказалась исключённой из поискового индекса, что, в свою очередь, стало причиной падения посещаемости ресурса.»
Исправление вышеупомянутой ошибки, препятствующей анализу страниц ресурса Angular.io, было возможным благодаря опытной команде JS-разработчиков, и тому факту, что они реализовали ведение журнала ошибок. После того, как ошибка была исправлена, Google снова смог проиндексировать проблемные страницы.
О сложности сканирования сайтов, построенных с использованием JavaScript
Вот как происходит сканирование и индексирование обычных HTML-страниц. Тут всё просто и понятно:- Googlebot загружает HTML-файл.
- Googlebot извлекает ссылки из кода страницы, в результате он может параллельно обрабатывать несколько страниц.
- Googlebot загружает CSS-файлы.
- Googlebot отправляет все загруженные ресурсы системе индексирования (Caffeine).
- Caffeine индексирует страницу.
Однако процесс усложняется, если работа ведётся с веб-сайтом, основанным на JavaScript:
- Googlebot загружает HTML-файл.
- Googlebot загружает CSS и JS-файлы.
- После этого Googlebot должен использовать Google Web Rendering Service (WRS) (эта система является частью Caffeine) для того, чтобы разобрать, скомпилировать и выполнить JS-код.
- Затем WRS получает данные из внешних API, из баз данных, и так далее.
- После того, как страница собрана, её, в итоге, может обработать система индексирования.
- Только теперь робот может обнаружить новые ссылки и добавить их в очередь сканирования.
- Разбор, компиляция и выполнение JS — это операции, которые требуют немалых затрат времени.
- В случае с сайтами, на которых интенсивно используется JavaScript, Google приходится ждать до тех пор, пока будут выполнены все вышеописанные шаги прежде чем можно будет проиндексировать содержимое страниц.
- Процесс сборки страницы — это не единственная медленная операция. Это также относится к процессу обнаружения новых ссылок. На сайтах, интенсивно использующих JS, Google обычно не может обнаружить новые ссылки до того, как страница не будет полностью сформирована.
 Индексирование HTML-страницы и страницы, формируемой средствами JS
Индексирование HTML-страницы и страницы, формируемой средствами JSТеперь мне хотелось бы проиллюстрировать проблему сложности JavaScript-кода. Готов поспорить, что 20-50% посетителей вашего сайта просматривают его с мобильного устройства. Знаете ли вы о том, сколько времени занимает разбор 1 Мб JS-кода на мобильном устройстве? По информации Сэма Сакконе из Google, Samsung Galaxy S7 тратит на это примерно 850 мс, а Nexus 5 — примерно 1700 мс! После разбора JS-кода его ещё нужно скомпилировать и выполнить. А на счету — каждая секунда.
Если вы хотите больше узнать о бюджете сканирования, советую почитать материал Барри Адамса «JavaScript and SEO: The Difference Between Crawling and Indexing». SEO-специалистам, имеющим дело с JavaScript, особенно полезными будут разделы «JavaScript = Inefficiency» и «Good SEO is Efficiency». Заодно можете посмотреть и этот материал.
Google и браузер, выпущенный 3 года назад
Для того чтобы понять, почему при сканировании сайтов, использующих JS, у Google могут возникнуть проблемы, стоит поговорить о технических ограничениях Google.Я уверен, что вы используете самую свежую версию вашего любимого браузера. Однако в Google дело обстоит не так. Тут, для рендеринга веб-сайтов, используется Chrome 41. Этот браузер был выпущен в марте 2015-го года. Ему уже три года! И браузер Google Chrome, и JavaScript за эти годы чрезвычайно сильно развились.
В результате оказывается, что существует множество современных возможностей, которые просто недоступны для робота Googlebot. Вот некоторые из его основных ограничений:
- Chrome 41 лишь частично поддерживает современный синтаксис JavaScript ES6. Например, он не понимает новые языковые конструкции.
- Интерфейсы, вроде IndexedDB и WebSQL, отключены.
- Куки, локальные хранилища и сессионные хранилища очищаются при перезагрузке страницы.
- И, опять же, перед нами браузер, который был выпущен три года назад!
Теперь, когда вы знаете, что для формирования страниц Google использует Chrome 41, найдите время на то, чтобы загрузить этот браузер и проверить собственные веб-сайты для того, чтобы понять, может ли этот браузер нормально с ними работать. Если нет — загляните в консоль Chrome 41 для того, чтобы попытаться узнать, что может быть причиной ошибок.
Кстати, раз уж заговорили об этом, вот мой материал, посвящённый работе с Chrome 41.
Современные возможности JavaScript и индексирование сайтов
Как быть тому, кто стремится использовать современные возможности JS, но при этом, хочет, чтобы Google нормально индексировал его сайты? На этот вопрос отвечает данный кадр из видео: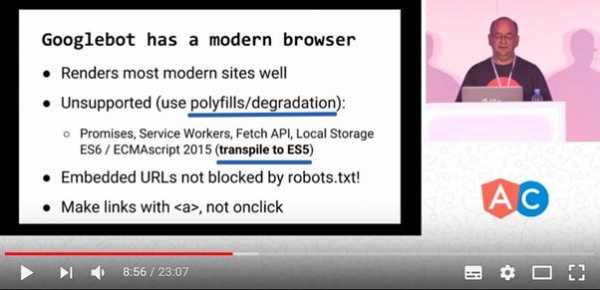 Современные возможности JavaScript и индексирование страниц
Современные возможности JavaScript и индексирование страницБраузер, применяемый в Google для формирования страниц сайтов, основанных на JS, может правильно обрабатывать сайты, использующие современные возможности JS, однако, разработчикам таких сайтов потребуется приложить для этого некоторые усилия. А именно, использовать полифиллы, создавать упрощённую версию сайта (используя технику постепенной деградации) и выполнять транспиляцию кода в ES5.
Постепенная деградация и полифиллы
Популярность JavaScript росла очень быстро, а теперь это происходит быстрее, чем когда бы то ни было. Однако некоторые возможности JavaScript просто не реализованы в устаревших браузерах (так уж совпало, что Chrome 41 — это как раз такой браузер). Как результат, нормальный рендеринг сайтов, использующих современные возможности JS, в таких браузерах невозможен. Однако, веб-мастера могут это обойти, используя технику постепенной деградации.Если вам хочется реализовать некоторые современные возможности JS, которые поддерживают лишь немногие браузеры, в таком случае вам нужно обеспечить использование упрощённой версии вашего веб-сайта в других браузерах. Помните о том, что версию Chrome, которую использует Googlebot, определённо, нельзя считать современной. Этому браузеру уже три года.
Выполняя анализ браузера, вы можете в любое время проверить, поддерживает он некую возможность или нет. Если он эту возможность не поддерживает, вы, вместо неё, должны предложить нечто такое, что подходит для этого браузера. Эта замена и называется полифиллом.
Кроме того, если нужно, чтобы сайт мог быть обработан поисковыми роботами Google, вам совершенно необходимо использовать транспиляцию JS-кода в ES5, то есть, преобразование тех конструкций JS, которые не понимает Googlebot, в конструкции, понятные ему.
Например, когда транспилятор встречает выражение let x=5 (большинство старых браузеров эту конструкцию не поймут), он преобразует его в выражение var x=5 (эта конструкция понятна всем браузерам, в том числе и Chrome 41, который играет для нас особую роль).
Если вы используете современные возможности JavaScript и хотите, чтобы ваши сайты правильно обрабатывались поисковыми роботами Google, вам, определённо, стоит использовать транспиляцию в ES5 и полифиллы.
Тут я стараюсь объяснить всё это так, чтобы было понятно не только JS-разработчикам, но и, например, SEO-специалистам, которые далеки от JavaScript. Однако, в детали мы не вдаёмся, поэтому, если вы чувствуете потребность лучше разобраться в том, что такое полифиллы — взгляните на этот материал.
Googlebot — это не настоящий браузер
Когда вы путешествуете по интернету, ваш браузер (Chrome, Firefox, Opera, или любой другой) загружает ресурсы (изображения, скрипты, стили) и показывает вам страницы, из всего этого собранные.Однако, Googlebot работает не так, как обычный браузер. Его цель — проиндексировать всё, до чего он может дотянуться, загружая при этом только самое важное.
Всемирная паутина — это огромное информационное пространство, поэтому Google оптимизирует систему сканирования с учётом производительности. Именно поэтому Googlebot иногда не посещает все страницы, на посещение которых рассчитывает веб-разработчик.
Ещё важнее то, что алгоритмы Google пытаются выявить ресурсы, которые необходимы с точки зрения формирования страницы. Если какой-то ресурс выглядит, с этих позиций, не особенно важным, он попросту может быть не загружен роботом Googlebot.
Googlebot и WRS избирательно загружают материалы, выбирая только самые важныеВ результате может оказаться так, что сканер не станет загружать некоторые из ваших JS-файлов, так как его алгоритмы решили, что, с точки зрения формирования страницы, они не важны. То же самое может произойти и из-за проблем с производительностью (то есть, в ситуации, когда выполнение скрипта занимает слишком много времени).
Хочу отметить, что Том Энтони заметил одну интересную особенность в поведении робота Googlebot. Когда используется JS-функция setTimeout, настоящий браузер получает указание подождать определённое время. Однако, Googlebot не ждёт, он выполняет всё немедленно. Этому не стоит удивляться, так как цель роботов Google заключается в том, чтобы проиндексировать весь интернет, поэтому их оптимизируют с учётом производительности.
Правило пяти секунд
Многие эксперименты в области SEO указывают на то, что, в целом, Google не может ждать окончания выполнения скрипта, который выполняется более 5 секунд. Мои эксперименты, похоже, это подтверждают.Не принимайте этот как должное: добейтесь того, чтобы ваши JS-файлы загружались и завершали работу менее чем за 5 секунд.
Если ваш веб-сайт загружается по-настоящему медленно, вы можете многое потерять. А именно:
- Посетителям сайта будет некомфортно с ним работать, они могут его покинуть.
- У Google могут возникнуть проблемы с анализом страниц.
- Это может замедлить процесс сканирования сайта. Если страницы медленны, Google может решить, что его роботы замедляют ваш сайт и снизить частоту сканирования. Подробнее об этом можно почитать здесь.
Обычная ошибка в плане производительности, которую совершают разработчики, заключается в том, что они помещают код всех компонентов страницы в единственный файл. Но если пользователь переходит на домашнюю страницу проекта, ему совершенно не нужно загружать то, что относится к разделу, предназначенному для администратора сайта. То же самое справедливо и в применении к поисковым роботам.
Для решения проблем с производительностью рекомендуется найти соответствующее руководство по применяемому JS-фреймворку. Его стоит изучить и выяснить, что можно сделать для ускорения сайта. Кроме того, советую почитать этот материал.
Как взглянуть на интернет глазами Google?
Если вы хотите взглянуть на интернет, и, особенно, на свой веб-сайт, глазами роботов Google, вы можете воспользоваться одним из двух подходов:- Используйте инструменты Fetch (сканирование) и Render (отображение) из Google Search Console (очевидно!). Но не полагайтесь на них на 100%. Настоящий Googlebot может иметь таймауты, отличающиеся от тех, которые предусмотрены в Fetch и Render.
- Используйте Chrome 41. Как уже было сказано, достоверно известно, что Google использует для рендеринга загружаемых роботами страниц Chrome 41. Загрузить этот браузер можно, например, здесь. Использование Chrome 41 имеет множество преимуществ перед применением загрузки страниц с использованием Google Search Console:
- Благодаря использованию Chrome 41 вы можете видеть журнал ошибок, выводимый в консоль браузера. Если вы столкнётесь с ошибками в этом браузере, вы можете быть практически полностью уверены в том, что и Googlebot столкнётся с теми же ошибками.
- Инструменты Fetch и Render не покажут вам результаты отрисовки DOM, а браузер покажет. Используя Chrome 41 вы можете проверить, увидит ли Googlebot ваши ссылки, содержимое панелей, и так далее.
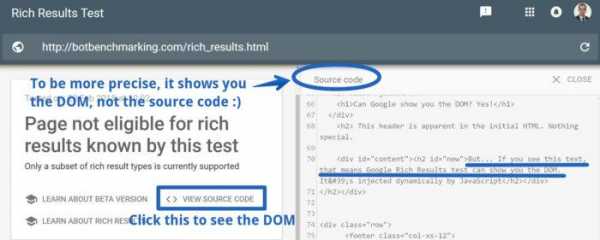 Инструмент Rich Results Test
Инструмент Rich Results TestИнструменты Fetch и Render и проверка тайм-аутов системы индексирования
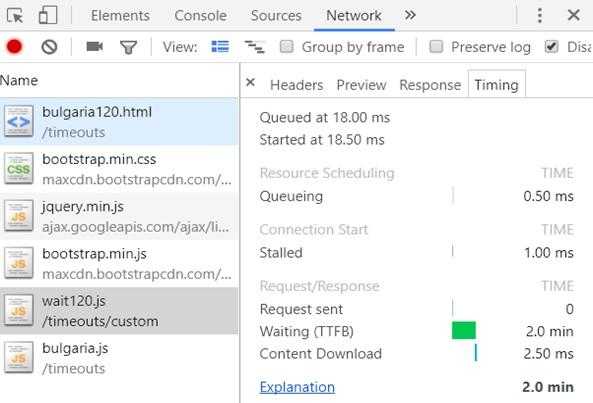
Инструменты Fetch и Render могут лишь сообщить вам о том, имеет ли Google техническую возможность сформировать анализируемую страницу. Однако не полагайтесь на них, когда речь заходит о тайм-аутах. Я часто сталкивался с ситуацией, когда Fetch и Render были способны вывести страницу, но система индексирования Google не могла проиндексировать эту страницу из-за используемых этой системой тайм-аутов. Вот доказательства этого утверждения.Я провёл простой эксперимент. Первый JS-файл, включённый в анализируемую страницу, загружался с задержкой в 120 секунд. При этом технической возможности избежать этой задержки не было. Nginx-сервер был настроен на двухминутное ожидание перед выдачей этого файла.
 Проект, используемый для эксперимента
Проект, используемый для эксперимента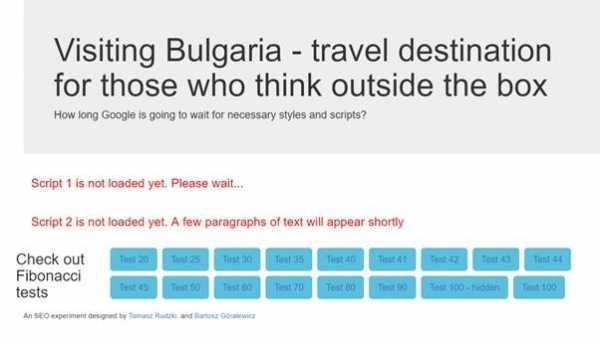 Страница экспериментального проекта
Страница экспериментального проектаОказалось, что инструменты Fetch и Render ждали загрузки скрипта 120 секунд (!), после чего страница выводилась правильно.
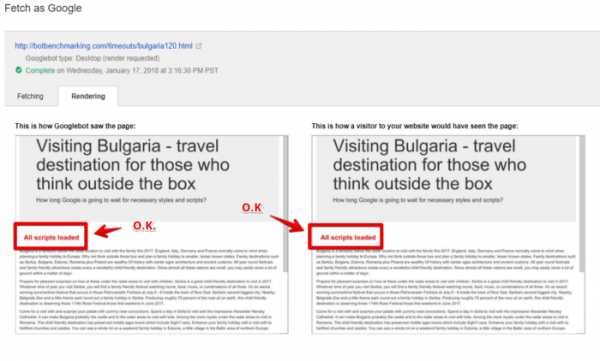 Анализ страницы средствами Fetch и Render
Анализ страницы средствами Fetch и RenderОднако система индексирования оказалась не такой терпеливой.
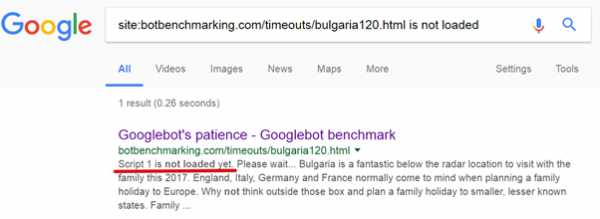 Результаты индексирования экспериментального сайта
Результаты индексирования экспериментального сайтаЗдесь видно, что система индексирования Google просто не стала дожидаться загрузки первого скрипта и проанализировала страницу без учёта результатов работы этого скрипта.
Как видите, Google Search Console — это отличный инструмент. Однако пользоваться им следует только для проверки технической возможности анализа страницы роботами Google. Не используйте это средство для того, чтобы проверить, дождётся ли система индексирования загрузки ваших скриптов.
Анализ кэша Google и сайты, интенсивно использующие JavaScript
Многие специалисты в области SEO применяли кэш Google для поиска проблем с анализом страниц. Однако эта методика не подходит для сайтов, интенсивно использующих JS, так как сам по себе кэш Google представляет собой исходный HTML, который Googlebot загружает с сервера (обратите внимание — это многократно подтверждено Джоном Мюллером из Google).Материал из кэша GoogleПросматривая содержимое кэша, вы видите, как ваш браузер интерпретирует HTML, собранный средствами Googlebot. Это не имеет никакого отношения к формированию страницы для целей индексирования. Если вы хотите узнать подробности о кэше Google — взгляните на этот материал.
Использование команды site вместо анализа кэша Google
В настоящий момент один из лучших способов проверки того, были ли какие-то данные проиндексированы Google, заключается в использовании команды site.Для того чтобы это сделать, просто скопируйте какой-нибудь фрагмент текста с вашей страницы и введите в поисковике Google команду следующего вида:
site:{your website} "{fragment}"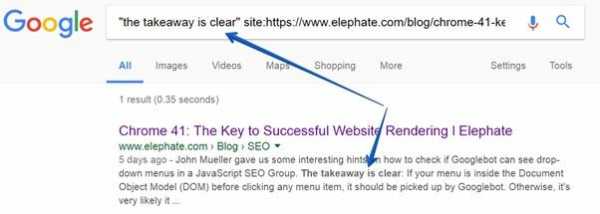 Команда site
Команда siteЕсли вы, в ответ на такую команду, увидите в поисковой выдаче искомый фрагмент, это значит, что данные были проиндексированы.
Тут хотелось бы отметить, что подобные поисковые запросы рекомендуется выполнять в анонимном режиме. Несколько раз у меня были случаи, когда редакторы сайта меняли тексты, и по какой-то причине команда site сообщала о том, что проиндексированы были старые тексты. После переключения в анонимный режим браузера эта команда стала выдавать правильный результат.
Просмотр HTML-кода страницы и аудит сайтов, основанных на JS
HTML-файл представляет собой исходную информацию, которая используется браузером для формирования страницы. Я предполагаю, что вам известно, что такое HTML-документ. Он содержит сведения о разметке страницы — например, о разбиении текста на абзацы, об изображениях, ссылках, он включает в себя команды для загрузки JS и CSS-файлов.Посмотреть HTML-код страницы в браузере Google Chrome можно, вызвав щелчком правой кнопки мыши контекстное меню и выбрав команду View page source (просмотр кода страницы).
Однако, воспользовавшись этим режимом просмотра кода страницы, вы не увидите динамического содержимого (то есть тех изменений, которые внесены в страницу средствами JavaScript).
Вместо этого следует анализировать DOM. Сделать это можно с помощью команды того же меню Inspect Element (просмотреть код).
Различия между исходным HTML-кодом, полученным с сервера, и DOM
Исходный HTML-код, полученный с сервера (то, что выводится по команде View page source) — это нечто вроде кулинарного рецепта. Он предоставляет информацию о том, какие ингредиенты входят в состав некоего блюда, содержит инструкции по приготовлению. Но рецепт — это не готовое блюдо.DOM (команда Inspect Element) — это блюдо, приготовленное по «HTML-рецепту». В самом начале браузер загружает «рецепт», потом занимается приготовлением блюда, и уже в итоге, после того, как страница полностью загружена, перед нами появляется нечто «съедобное».
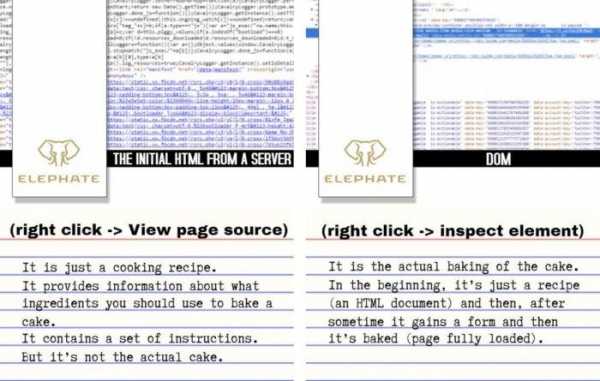 HTML, загруженный с сервера, и DOM
HTML, загруженный с сервера, и DOMОбратите внимание на то, что если Google не удаётся сформировать страницу на основе загруженного HTML-кода, он может просто проиндексировать этот исходный HTML-код (который не содержит динамически обновляемого содержимого). Подробности об этом можно найти в данном материале Барри Адамса. Барри, кроме того, даёт советы, касающиеся того, как быстро сравнить исходный HTML и DOM.
Итоги
В этом материале мы поговорили о том, как Google обрабатывает сайты, которые созданы с применением JavaScript-технологий. В частности, огромное значение имеет то, что для анализа страниц в Google используется Chrome 41. Это накладывает определённые ограничения на применение JavaScript.Во второй части перевода этого материала речь пойдёт о том, на что стоит обратить внимание для того, чтобы JS-сайты нормально индексировались поисковыми системами. Там же будут подняты ещё некоторые темы, касающиеся SEO и JavaScript.
Уважаемые читатели! Как вы анализируете свои сайты, проверяя, индексирует ли их Google так, как вы этого ожидаете?
habr.com
Инструкция по SEO для Wordpress сайтов
 Приветствую всех подписчиков и гостей сайта MoneyMakers-Team.ru.
Приветствую всех подписчиков и гостей сайта MoneyMakers-Team.ru.
После того как мы с вами уже подобрали доменное имя для своего сайта используя качественные инструменты для подбора домена своему сайту и по инструкции с картинками установили на него WordPress или какой-нибудь другой движок для сайтов, которые мы рассматривали в рейтинге платных и бесплатных CMS для вашего сайта, нам уже можно приступать к написанию уникальных статей на своем сайте. Но как быть если нашему сайту уже несколько недель или месяцев, а на счетчике посещений до сих пор мозолит глаза цифра ноль. Вот здесь друзья и начинается самое интересное, это знакомство с поисковыми системами и SEO продвижение вашего сайта или блога в сети.
Краткое содержание :
Что же такое SEO и зачем оно вообще нужно?
Это то без чего вы не сможете монетизировать свой сайт или блог. Никакой прибыли вы не получите с не оптимизированного сайта. Чтобы получать доход, вам просто необходимо заняться SEO оптимизацией вашего детища именно сейчас и не откладывайте на завтра! И далее я лучше использую скриншот с Википедии и не буду пытаться объяснить данное слово по своему.
И так, когда вы уже просмотрели скриншот с Вики я продолжу повествование и скажу, что поисковая оптимизация, это очень важная составляющая при создании блога или сайта, не важно ВордПресс блог это или сайт на совершенно другом движке или вовсе без CMS. Но из-за отличающейся основы этих блогов от других, SEO для них немного отличается от оптимизации для обычных сайтов. В нашем случае нам больше потребуется ориентироваться на структуризацию нашего сайта и нашу творческую фантазию, для написания уникальных статей, которыми будем привлекать внимание не только поисковых систем но и друзей, знакомых в социальных сетях, которые в свою очередь захотят (должны захотеть) поделится ссылкой на вашу статью со своими друзьями и знакомыми. Данное руководство от меня, должно стать для вас отправной точкой, надежным стартом, если можно так выразится, так как в этом материале я дам именно те советы, которые действительно работают и помогут вам в раскрутке сайта или блога без затрат на то собственных средств, на это понадобится лишь ваше время. Статья должна получиться довольно большой, но я вас уверяю, если вы начнете прямо во время чтения данной статьи применять все советы о которых я расскажу, это займет не так много времени как вам может показаться.
У вас может возникнуть логичный вопрос, зачем мне все это делать если вон вагон и маленькая тележка кривых и косых сайтов в ТОП 10 выдачи постоянно и все у них замечательно или я просто могу купить рекламу у поисковых систем Google и Яндекс и не парить себе мозг по поводу какой-то там непонятной SEO оптимизации. Если вы так считаете, то либо у вас слишком много денег и вам больше некуда расти (как вам кажется), тогда вам действительно будет легче заплатить специалистам в этой отрасли или вы просто новичок и вам кажется, что те кривые и косые сайты (как мне казалось раньше) попали случайно в ТОП выдачи поисковых систем по тем или иным поисковым запросам. Поисковая оптимизация вашего детища, может принести ощутимую разницу в посещаемость и окупаемость вашего сайта, это может принести десятки тысяч новых посетителей и сотни, тысячи новых клиентов. Поэтому если вы задумываетесь о получении естественного трафика с поисковых систем Google и Яндекс без каких-либо затрат, тогда вам просто необходимо прочитать и применить на своем сайте те методики о которых я расскажу в этой статье. Таким образом вы сможете переступить ту черту от ГС (говносайта) и перейти на более высокий уровень вашего проекта в целом. И неважно блог это у вас или интернет-магазин. SEO это именно то, что поможет вам в монетизации вашего детища.
SEO на ваших страницах
Это техническая сторона в рамках нашего проекта, которую нам с вами необходимо использовать, а это в свою очередь даст нашему сайту преимущество над другими сайтами, при определении рейтинга в выдаче поисковых систем по определенному запросу. Структура постоянных ссылок, заголовки страниц нашего сайта, веб-семантика и многого другое, очень сильно влияет на ранжирование. До того как вы начали продвижение своего сайта вам обязательно нужно хорошо подумать над всеми этими деталями, чтобы выжать максимум от позиций вашего проекта в поисковых системах Google и Яндекс.
Оптимизация «Заголовков статей»

На самом деле по умолчанию WordPress не настроен на хорошее продвижение вашего сайта с самого начала его существования и поэтому все нужно сделать самому, иначе мы не добьемся успеха в оптимизации. Когда наш сайт создан, заголовок статьи будет выглядеть вот так :
Имя блога ==> "Архив" ==> Ключевое слово ==> Название вашего материала
Вы возможно подумаете, что это вполне нормально, но я вас спешу разочаровать, это как раз тот случай, когда все закончится даже не начавшись и о высоких позициях в поисковиках можно забыть. Вам необходимо запомнить кое-что, поисковики при определении позиций, больше обратят внимание на те сайты у которых общая масса ключевых слов ближе к началу, а не в конце. Теперь, когда вы об этом знаете у вас более высокий шанс вырваться в ТОП выдачи и начать делать деньги.
Если у вас статический сайт, то проблем с этим у вас не должно возникать, так как при создании новой страницы, вы можете просто озаглавить её и на этом проблема закрыта. А вот в случае с WordPress не все так легко как хотелось бы. Здесь нам на помощь приходит ТОП плагин ин зе ворлд и называется он All in One SEO! С помощью данного произведения искусства мы провернем с вами все это дело буквально за пару кликов мышью. Для того, чтобы начать использовать сие чудо, сначала его как и другие плагины нужно найти, затем установить и после этого активировать в панели управления плагинами.
Настройки плагина All in One SEO на моем блоге :
Сразу поясню почему именно такие настройки заголовков я установил. Я хочу создать сайту, проще говоря создать свой бренд. Поэтому я и оставил blog title в заголовке. Некоторые могут сказать, что это неправильно и не стоит это того, чтобы повторять одно и тоже на каждой странице в выдаче, но я хочу и поэтому так и сделал. Если вас не интересует узнаваемость вашего ресурса, вы можете убрать blog title и оставить только %page_title%, это поставит вас еще выше в выдаче поисковиков чем меня.
Пример того как выглядит мой сайт в поисковой выдаче Google :
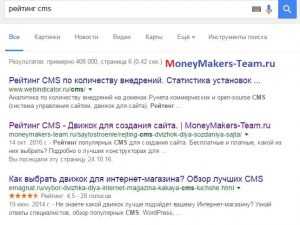
Кстати, статье о рейтинге CMS всего десять дней, а она уже на 4-й странице в поиске по короткому запросу «Рейтинг CMS» (сам себя не похвалишь, никто этого не сделает :))
Оптимизация «Описания статьи» :
Я замечал, что авторы в своем большинстве не обращают внимания на описание статьи и таким образом в поисковой выдаче мы часто не находим интересующую нас информацию. Если бы я не оптимизировал описание статьи, то в выдаче под ссылкой на мой блог вы бы увидели начальный текст статьи :Приветствую всех подписчиков и гостей сайта MoneyMakers-Team.ru. Сегодня я кратко расскажу вам о рейтинге существующих CMS ...Но так как для этой статьи я установил описание, то текст под ссылкой как вы видите отличается и выглядит вот так :Рейтинг популярных CMS для создания сайта. Бесплатные и платные, какой из них выбрать? Подробно о лучших конструкторах для ...Как видите, название статьи «Инструкция по SEO для WordPress сайтов и не только.» отличается от ссылки на сайте где вы сейчас находитесь, а все потому, что я использую плагин оптимизировал заголовок и описание для этой статьи еще перед её написанием и выглядит это вот так :
Эти настройки находятся чуть ниже визуального редактора в котором вы пишете на своем ВордПресс, если вы уже установили это расширение. Я настоятельно рекомендую каждый раз при создании нового материала, тщательно обдумывать заголовок и описание к нему.
Постоянные ссылки на ваши страницы :
Существует два поисковых гиганта Google и Яндекс в которых нам необходимо продвигать наш сайт и чтобы увеличить свои шансы в этой затее, нам нужно предоставить этим ребятам хорошо оптимизированный сайт и дружественную структуру каждого нашего URL. Я с уверенностью могу заявить, что Google очень чувствителен к структуре ссылок, поэтому специально для него, нам нужно сделать наши URL как можно понятнее. После создания вашего блога, все URL вашего сайта выглядят в числовом представлении :http://moneymakers-team.ru/?p=16Непонятно что находится на данной странице, так как названия нет, просто порядковое число, которое генерировалось при создании нового материала или страницы. Наша задача состоит в том, чтобы сделать ссылку более человечной и понятной для всех окружающих. Для этого нам понадобится зайти в «Настройки», далее перейти в раздел «Постоянные ссылки» и установить такие значения как у меня на скриншоте :
При такой настройке постоянных ссылок, мы в результате получаем URL такого вида :http://moneymakers-team.ru/saytostroenie/rejting-cms-dvizhok-dlya-sozdaniya-sajta/
Как видите я использую структуру /%category%/%postname%/, но приемлемо использовать и просто /%postname%/. После этих небольших изменений ваши ссылки станут лучше распознаваться поисковиками и соответственно позиции ваши будут гораздо выше тех, кто еще не позаботился о постоянных ссылках.
XHTML Семантика
Еще одна вещь, которая играет значимую роль в оптимизации сайта, это семантика. ТОП сайты хорошо составлены, приятны на глаз и их легко просматривать, на то они и ТОПы. Для поисковых ботов можно выделить с помощью семантической разметки именно те ключевые слова, которые на нужно и помогает им правильно оценить сайт для получения более релевантных ключей. Нужно не забывать о том, что в 90% бесплатных шаблонов для WordPress неверно настроена эта разметка и вам придется самим заняться этим. Но я не гуру в этом, поэтому можете попробовать поискать полную информацию об этом на просторах интернета. Могу только вкратце рассказать об этом. Зачастую в боковой панели находятся заголовки выделенные с помощью <h3> тега, которые ну никак не заслуживают такого применения. Вы должны понимать, что такие заголовки на вашем сайте как «Реклама» или «Облако меток» просто не заслуживают заключения в этот тег. Такие заголовки должны быть заключены в <h5> или даже <h5>, так как они не несут никакой ценности для вашего сайта, а вот продвижению вашего проекта могут навредить. Зачастую дизайнеры делают одну и ту же ошибку и дают названию сайта тег <h2> на главной странице, что в принципе не плохо, но вот на других страницах, название сайта уже не так актуально, ведь идет просмотр контента и здесь уже есть что заключить в этот тег, чтобы выделить его из общего списка слов. Более разумно заключить в этот тег название статьи в таком случае.
Перелинковка, хлебные крошки и похожие статьи
Отличный способ сделать сайт немного доступнее для поисковых систем. Не забывайте в каждом новом материале указывать ссылку с анкором на любую схожую по тематике статью с вашего блога. При прибывании на какой-либо странице вашего сайта поисковый бот так же должен находить родительские рубрики и соседние страницы вашего блога. Это так называемая иерархия статей.
Еще в перелинковке помогут такие плагины как Breadcrumb NavXT с помощью которого можно создать так называемые хлебные крошки, которые будут отображать где вы захотите полный путь на вашу статью. Существует еще одно хорошее дополнение WordPress Related Posts с помощью которого можно добавить в конце вашей статьи блок со схожими статьями, как установлено у меня, тем самым предлагая читателю, что-то интересное и позволит ему еще немного задержаться на вашем ресурсе. Чем меньше у вас процент отказов тем более привлекательным становится ваша площадка для рекламодателей AdSence и Яндекс Директа.
Оптимизация внешних ссылок
Это наверное одно из самых важных аспектов SEO на мой взгляд. Скрывайте ваши внешние ссылки от поисковых систем, поверьте мне это необходимо сделать всем (кроме наших конкурентов). Необходимо все ненужные внешние ссылки (особенно рекламные) с вашего сайта заключить в тег rel="nofollow". Представьте себе березу — это ваш сайт, а березовый сок, это ваш Google PR страницы, а внешняя ссылка это топор. Таким образом при размещении открытой внешней ссылки вы каждый раз все сильнее и сильнее рубите по вашей березе и из нее вытекает тот самый березовый сок, который в нашем случае Google PR. Ваша позиция в выдаче поисковых систем будет гораздо ниже вашего конкурента, если у него внешних ссылок ноль, а у вас хотя бы одна. Поисковые системы считают продажными сайты с большим количеством внешних ссылок. Это значительно замедлит ваш сайт и соответственно его монетизацию.
Дубли страниц и контента, это большая проблема

Наш вордпресс имеет очень много функций, которые могут даже навредить нашему блогу и дублирование контента одна из таких функций, которая будет мешать нам в продвижении и не давать нам заработать на сайте. Категории, архивы, теги это именно те функции, которые дублируются постоянно на вашем блоге, особенно это касается тех товарищей, которые показывают все записи полными, не сокращая их и таким образом на главной будет дублироваться контент, который уже находится у вас в одной из записей. Тоже самое происходит когда один и тот же материал находится у вас в двух и более категориях. Но всего этого можно не боятся если правильно настроить ваш файл robots.txt. Как я уже убедился на собственном опыте, правильного так сказать файла robots.txt множество видов и мнения некоторых блогеров, оптимизаторов, вебмастеров могут очень сильно отличатся друг от друга, но я покажу вам свой файл, а делать такой же или искать решение дальше, дело ваше естественно. Мой robots.txt :User-agent: *Disallow: /cgi-binDisallow: /wp-adminDisallow: /wp-includesDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /trackbackDisallow: */trackbackDisallow: */*/trackbackDisallow: */*/feed/*/Disallow: */feedDisallow: /*?*Allow: */uploadsAllow: /wp-*.pngAllow: /wp-*.jpgAllow: /wp-*.jpegAllow: /wp-*.gif
User-agent: YandexDisallow: /cgi-binDisallow: /wp-adminDisallow: /wp-includesDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /trackbackDisallow: */trackbackDisallow: */*/trackbackDisallow: */*/feed/*/Disallow: */feedDisallow: /*?*Allow: */uploadsAllow: /wp-*.pngAllow: /wp-*.jpgAllow: /wp-*.jpegAllow: /wp-*.gif
Host: moneymakers-team.ru
Sitemap: http://moneymakers-team.ru/sitemap.xml.gzSitemap: http://moneymakers-team.ru/sitemap.xml
SiteMap — Карта вашего сайта для ускорения индексации

Для того, чтобы собрать автомобиль, инженерам обязательно потребуется план изделия без которого если они и соберут его, то выполнена эта работа будет за несколько лет, а то и десятков лет (видимо так и работают наши инженеры). В нашем случае инженеры это поисковые боты, а автомобиль, это наш проект, который они должны быстро и качественно собрать, а мы с вами уже будем думать продавать потом этот автомобиль или зарабатывать деньги на нем не выходя из дому. В этом им и поможет карта сайта, которую вы можете создать и вручную, но я бы посоветовал вам использовать плагин Google XML Sitemaps для вашего блога, ведь с помощью этого плагина и пары нажатий на кнопку мыши вы создадите собственную карту вашего блога.
Скорость загрузки страниц вашего сайта
Нельзя недооценивать показатель скорости загрузки страниц вашего сайта, так как это напрямую влияет на скорость и периодичность индексации вашего сайта поисковыми роботами. Чтобы повысить скорость загрузки вашего WordPress существует множество различных плагинов и способов, но я скажу только о двух наиболее важных вещах для вас, это плагин WP-Super Cache и хороший хостинг. WP-Super Cache повышает производительность и ускоряет загрузку ваших страниц, таким образом снижается нагрузка на сервер и вы будете застрахованы от падений вашего сайта в случае получения тонны посетителей. По поводу хорошего хостинга я особо много сказать вам не могу, но мой опыт подсказывает, что BestHosting которым я сейчас пользуюсь мне полностью подходит и за время существования моего блога проблем с доступностью не возникало.
Оптимизация картинок на вашем проекте
На некоторых блогах мы можем читать много интересной и полезной информации, но когда на таком блоге нет изображений он выглядит сухо и безжизненно (мое личное мнение). Поэтому я предпочитаю добавлять во всех своих записях хотя бы одну, две картинки, которые либо подчеркивают мысль излагаемую в материале, либо подсказывают и раскрывают суть вопроса, иногда картинки юмористического характера, которые на мой взгляд немного подбадривают читателя. Так вот, каждая картинка как и ссылки, тексты и теги так же индексируются поисковыми роботами. Не упускайте возможности получать дополнительный трафик с ваших изображений. Для того, чтобы ваши картинки начали давать вам трафик, нужно каждой картинке добавлять alt тег. Например картинка, которую вы видите в начале статьи имеет alt тег — seo-dlja-saitov-worpress-i-ne-tolko, таким образом моя картинка будет найдена по запросу — сео для сайтов вордпресс. Но конечно не сразу, все по мере индексации, на все это нужно время. Поэтому при загрузке изображения на свой сайт убедитесь, что картинка имеет человеческое название, а не просто набор букв или цифр. И кстати говоря не указывайте название картинок кириллицей иначе alt тег вашего изображения после загрузки на хостинг будет выглядеть примерно так %D0%A1%D0%BA%D0%B0%D1%87%D0%B0%D1%82%D1%8C-%D0%B0%D1%80%D1%85%D0%B8%D0%B2-%D0%B2%D0%BE%D1%80%D0%B4%D0%BF%D1%80%D0%B5%D1%81%D1%81-250x246.jpg. Страшно выглядит? Именно так и выглядят ссылки на мои картинки из первых записей блога…
Социальные сети и подписка на ваш блог, сайт
Вы должны понимать, что 99% посетителей вашего проекта скорее всего не вернутся, если вы не запомнитесь им с первого взгляда или в будущем не напомните о себе. Для этого вам нужно будет реализовать подписку на ваш блог, чтобы любой из читателей мог за один клик подписаться на новые материалы вашего блога. Все мы живые люди и у нас много дел, забот и хлопот, поэтому не забывайте напоминать вашим читателям о себе, создавайте группы, странички и личные аккаунты во всевозможных соц.сетях. Это нужно для того, чтобы заинтересованный в ваших материалах пользователь мог подписаться на вашу группу в ВК или Facebook и в дальнейшем следить за новостями из своего аккаунта в социальной сети. Советую прочитать статью о том зачем же вашему сайту нужна бизнес страница в Facebook.
Но есть одна проблема. Для того, чтобы ваш сайт или блог вызывал больше доверия у читателя в социальных сетях, вам нужен хороший старт. Я имею ввиду накрутку подписчиков, лайков, репостов в социальных сетях. Как и где это сделать, вы можете прочитать в статье Раскрутка групп и аккаунтов в социальных сетях.
На этом все Друзья. Огромное спасибо всем, кто прочитал данный материал. Рекомендую подписаться на мой блог, чтобы следить за новыми интересными записями о получении прибыли в интернете, зарабатывая на сайте и без него.
Если у Вас до сих пор нет своего блога, то это легко исправить, ведь недавно я как раз написал о том как установить WordPress движок на хостинг.
Удачи и неограниченного заработка вместе с MoneyMakers-Team.ru
Поделитесь этой информативной статьей со своими друзьями в социальных сетях, это сделать очень легко нажав на соответствующие кнопки под этим сообщением. Спасибо!
moneymakers-team.ru
Руководство по оптимизации сайта под поисковые системы
- При индексации поисковые системы учитывают метатеги. Важные метатэги — <TITLE>, <META name=»DESCRIPTION»> и <META name=»keywords»>. Слова из тэга TITLE имеют наибольший вес для поисковых систем, чем остальной текст страницы. Также тэги TITLE и DESCRIPTION страницы используются для ее представления в списке результатов поиска.
- Постарайтесь, чтобы каждая страница вашего сайта имела уникальные тэги TITLE и DESCRIPTION, описывающие информацию на странице. При составлении заголовков и описаний попытайтесь уложиться в 20–25 слов, так как слишком длинные TITLE и DESCRIPTION игнорируются поисковыми системами.
- В метатэге KEYWORDS перечислите наиболее важные ключевые слова и словосочетания для данной страницы. Не используйте слова, которые не встречаются в тексте, так как в этом случае они не будут учитываться поисковыми системами. Также, не повторяйте ключевые слова несколько раз, так как частое повторение может быть расценено поисковой системой как спам.
- При составлении списка ключевых слов необходимо оценить их правильность и популярность при помощи сервисов Яндекс.Директ, Рамблер-Ассоциации и Бегун / Подбор слов. Также статистику по поисковым запросам можно поискать, используя гостевой вход к статистике сайтов в Hotlog. Помните, что оптимизация по большому количеству низкочастотных запросов эффективнее, чем по одному высокочастотному.
- Важно правильно расположить ключевые слова на странице. Ключевые слова и словосочетания обязательно должны использоваться в тэге <TITLE>, в имени файла, в пути к файлу, в заголовках на странице в тегах h2 — H6, в выделенных жирным шрифтом областях. Ключевые слова лучше размещать в первых абзацах текста.
- Используйте ключевые слова для названия графических файлов и в подписях к картинкам в тэге ALT=»описание картинки».
- Потарайтесь чтобы средняя частота употребления ключевых слов в тексте составляла 2-7%. Слишком высокая плотность ключевых слов будет расценена поисковой системой как спам, поэтому не используйте невидимый текст.
- Используйте поисковые слова и словосочетания с часто употребляемыми ошибками.
- Места, где не стоит использовать ключевые слова:
Комментарии
<!— ключевые слова —>
Скрытые поля форм
<INPUT type=”hidden”name=”автомобиль”
value=”toyota corolla”>
- Для повышения PageRank в Google необходимо создать хорошую систему навигации внутри сайта. Структура сайта, когда все страницы ссылаются на главную, придает больше веса главной, а при перекрестных ссылках PageRank страниц примерно одинаков. На каждой странице сайта Внешние ссылки обязательны, т.к. при их отсутствии PageRank будет нулевым.
- Текстовая ссылка с точки зрения поисковой системы более эффективна чем баннер.
- Чем меньше ссылок на другие сайты на вашей странице тем выше ее PageRank (индекс цитирования) в поисковой системе Google. Постарайтесь убрать с главной страницы ссылки на различные рейтинги, топы и т.д. Для сайтов партнеров лучше сделать отдельный раздел либо ограничиться 2-3 ссылками на странице.
- Обменивайтесь ссылками с сайтами, уже зарегистрированными в этих каталогах. Создайте у себя на сайте аннотированный тематический каталог. Если ваш сайт имеет хорошую посещаемость, обязательно участвуйте в рейтинге Rambler Top100. Многие новички начинают свое знакомство с Интернетом с этого каталога. Так вы можете попасть в закладки или в список любимых сайтов на чьей-нибудь странице.
- При обмене ссылками следите чтобы сайт-партнер ставил на вас прямую ссылку. Ссылки с использованием скриптов часто игнорируются поисковыми системами при подсчете индекса цитирования.
- Текст в ссылке на ваш сайт должен содержать ключевые слова. Не пускайте процесс обмена ссылками на самотек. В явном виде укажите, какой вы хотите видеть ссылку на ваш сайт. Напишите владельцам сайтов, установившим на вас ссылку и попросите их ее изменить.
- В гиперссылках используйте тэг TITLE=»описание ссылки» — аналог тэга ALT для картинок.
Пример: ;
- Для увеличения тематического индекса цитирования, т.е. авторитетности сайта по заданной тематике, зарегистрируйте сайт в каталогах ODP, Yandex и Rambler Top100.
- Регистрация в каталоге Яндекса — один из самых эффективных способов увеличения тематического индекса цитирования, а при проведении оптимизации сайта под поисковые системы и поисковой раскрутке — обязательный пункт проводимых мероприятий.
Подробнее о регистрации в каталоге Яндекса
Кроме того, большинство сервисов автоматической регистрации являются инструментом для сбора email адресов. Так что готовьтесь не к росту числа посетителей с поисковых систем, а к увеличению количества спама, приходящего на ваш почтовый ящик.
Что касается FFA ( Free For All ) каталогов, то если кто и получает от этого выгоду, так это только каталоги, но никак не хозяева сайтов, так как, зачастую, обязательным условием регистрации является размещение прямой ссылки на каталог (заметим, ссылки, которая устанавливается вебмастером вручную), а ссылка на ваш сайт из каталога добавляется автоматически.
Яндекс и Google открыто заявляют, что не будут учитывать ссылки, установленные только для повышения индекса цитирования. FFA каталоги и доски объявлений с возможностью автоматического добавления URL сайта заносятся поисковыми системами в «черный список» и ссылки из них игнорируются либо имеют ничтожный вес при подсчете индекса цитирования.
Так, согласно Лицензии, Яндекс «исключает из подсчета ссылки, предназначенные лишь для «накачивания» релевантности в поисковой системе. Удаление таких ссылок делается вручную. Яндекс старается учитывать только «естественные» ссылки, то есть те, которые вебмастер ставит для посетителей своего сайта. Неестественные ссылки — это ссылки, поставленные в целях получения других благ нежели удобства своего пользователя. Работа с ссылками в этом смысле аналогична работе с текстом. Яндекс старается учитывать текст сайта, написанный для чтения людьми (а не для обмана поисковых машин — белым по белому, фонтом -3 и т.д.)».
- Используйте теги h2-h4 для выделения заголовков, основных идей на своих страницах, для поисковых систем слова, в этих тегах, имеют большее значение, чем остальной текст. Для уменьшения размеров букв в тэгах h2 — H6 используйте спецификацию CSS.Также, важную информацию необходимо выделять жирным шрифтом и подчеркиванием. Содержимое тега h2 должно совпадать с содержимым заголовка страницы.
- Обязательно включайте ваш географический адрес во все страницы сайта. Новое поколение поисковых роботов ищет названия стран, городов, zip коды для помощи людям в нахождении магазинов или каких либо услуг рядом с местом жительства.
- Постарайтесь использовать HTML код версий 2.0 или 3.2. Поисковые системы некорректно работают с фрэймами, Javascript, и динамическими меню. Текст и ссылки, установленные во Flash-анимации игнорируются многими поисковиками, поэтому используйте карту сайта или дублируйте меню во flash гипертекстовыми ссылками. Для flash-сайта необходимо создать html версию.
- Не делайте свои страницы слишком большими, разбивайте их на несколько частей, так как на страницах с большим объемом текста ключевые слова имеют меньшую плотность размещения и становятся менее заметными для поисковых систем. Кроме того, ключевые слова и словосочетания должны быть размешены как можно ближе к началу страницы (в первых абзацах).
- Постарайтесь избегать специальных символов ?, =, %, & в динамических адресах страниц. Если вы используете динамические страницы, их адреса можно преобразовать в статические при помощи модуля mod_rewrite.
- Не используйте методы поискового спама, т.к. это может дать кратковременный эффект, но рано или поздно ваш сайт заметит либо администрация поисковой системы либо вебмастера сайтов-конкурентов. Как вы думаете, что они сделают?
12.10.2005 Promo.By
promo.by