Преждевременная оптимизация архитектуры. Преждевременная оптимизация
Дональд Кнут — Викицитатник
Дональд Эрвин Кнут (Donald Ervin Knuth, 10 января 1938) — американский учёный, почётный профессор нескольких университетов в разных странах, преподаватель и идеолог программирования.
- Лучший способ в чём-то разобраться до конца — это попробовать научить этому компьютер.
- Опасайтесь багов в приведенном коде; я доказал его корректность, но не запускал.
- Математические формулы не могут «принадлежать» кому-либо! Математика принадлежит Богу.
- Я не могу заказать блюдо в ресторане потому, что постоянно смотрю на шрифты в меню.
- Самая важная вещь в языке программирования — его имя. Язык не будет иметь успеха без хорошего имени. Я недавно придумал очень хорошее имя, теперь осталось изобрести подходящий язык.
Преждевременная оптимизация[править]
| Преждевременная оптимизация — корень всех зол. — статья «Structured Programming with go to Statements» в сборнике «Computing Surveys» (Vol. 6, № 4, декабрь 1974, стр. 268). | |
| Premature optimization is the root of all evil. |
| Преждевременная оптимизация — корень всех (или большинства) проблем в программировании. — лекция «Computer Programming as an Art», напечатанная в сборнике «Communications of the ACM» (Vol. 17, Issue 12, декабрь 1974, стр. 671). | |
| Premature optimization is the root of all evil (or at least most of it) in programming. |
Через 15 лет Кнут в своей статье «The Errors of TeX»[1] высказывание об оптимизации упоминает как изречение Энтони Хоара: «But I also knew, and forgot, Hoare’s dictum that premature optimization is the root of all evil in programming». Поэтому эти цитаты могут быть ошибочно приписаны Хоару, а не самому Кнуту. При этом сам Хоар в 2004 году в своём письме Ганцу Генвитцу (англ. Hans Genwitz) с сайта phobia.com предполагает, что это высказывание принадлежит
Преждевременная оптимизация
Оригинал статьи: Premature OptimizationАвтор: Brad BollenbachПеревод: Сергей Бирюков
Недавно в The Onion мне попалась прекрасная статья:
Исследования показывают: работа на рабочем месте способствует продуктивности (En)
Согласно статье, секрет продуктивности на работе — собственно, в работе:
«Мы открыли удивительную вещь: просто выполняя свою работу, сотрудники могут существенно повысить качество товаров и услуг», — говорит заместитель помощника по труду Шарлотта Понтичелли, автор доклада. — Для многих людей это может стать настоящей революцией в рабочем процессе».
Не то чтобы я тут же поверил прочитанному, но должен признаться, исследование сразило меня наповал:
По результатам можно с уверенностью сказать, что заниматься делом — на 100% продуктивнее, чем слушать музыку и проверять почту, на 100% продуктивнее, чем слоняться по офису и общаться с коллегами, на 100% продуктивнее, чем играть в онлайн-тетрис, на 100% продуктивнее, чем смотреть на YouTube ролики с передачами из далёкого детства, на 100% продуктивнее, чем читать блоги со сплетнями о знаменитостях и вести в ICQ диалоги с друзьями, на 100% продуктивнее, чем дремать, и на 98.2% продуктивнее, чем не явиться на работу.
Всё это было бы смешно… Если бы оставалось выдумкой.
Дональд Кнут, знаменитый учёный-программист, однажды сказал: «Преждевременная оптимизация — корень всех зол». Он предостерегал программистов от чрезмерного упорства в стремлении сделать свой код Совершенно Идеальным. То же самое относится к знакомству с женщинами, поиску работы, созданию бизнеса, повышению продуктивности, к управлению временем, приведению в порядок финансов и целому ряду других забот.
Личное развитие — гонка за знанием. Самый быстрый способ достичь своих целей — не тратить время на поиск информации о достижении целей; а писать код, общаться с женщинами, получить ИНН, написать первую главу своей книги — сделать то, что считаешь необходимым для достижения своей цели. Нет смысла изучать управление временем до того, как ты решишь, что делать со своей жизнью. Проводить часы на форумах по соблазнению, не встречаясь активно с людьми вживую — даром потраченное время.
Прекрасный способ изучить язык программирования — что-нибудь на нём написать. Так же и в личном развитии: начни с конкретной проблемы. Знание лучше всего опереть на каркас из проб и ошибок. Не можешь найти свою страсть? (En) Что именно ты успел попробовать? Не знаешь, как попросить у девушки номер телефона? «Почему бы нам не обменяться номерами?» дало какой-нибудь результат? Польза от литературы по личному развитию начинается лишь там, где заканчиваются твои собственные попытки, продиктованные здравым смыслом.
Конечно, изъяны, которые мы видим в других — отражение наших собственных недостатков. Скорее всего, я не обратил бы на эту вредную привычку никакого внимания , если бы она не успела отхватить пару сотен часов и моей жизни. В последнее время я чрезвычайно требователен к своим привычкам потребления.
Пару месяцев назад, например, я почти перестал появляться на форумах по соблазнению. Я не только понял, что чисто аналитический подход вреден и сильно уступает реальному опыту, но также задал себе простой вопрос: Мне действительно нужно это читать? Как изменится моя жизнь, если я не буду? Лучше или хуже станут результаты?
Действие и принесло ответ. Мои результаты улучшились. Я встречал лучших женщин, почти не тратя энергию на манипулирование, и сократил своё участие в форумах с двух часов в день до двух часов в месяц. Я почувствовал гораздо больше удовольствия от естественного поведения, чем от механического применения заранее подготовленных приёмов.
Простой вопрос, помогающий мне избегать преждевренной оптимизации: Как с наилучшей пользой я могу потратить время прямо сейчас? Прочитать книгу о постановке целей или взять и поставить несколько целей? Разузнать о подходящих для знакомства местах или просто начать общаться с любой из десятков женщин, окружающих меня каждый день? Любое дело, которое не является оптимальным в данный момент — пустая трата времени.
© 2007 Brad Bollenbach. Опубликовано с разрешения автора.
Подписаться на новые статьи
10.02.02008 | Продуктивность, Успех, Юмор
Другие статьи:
sergeybiryukov.ru
Запоздалая оптимизация / Хабр
Вашему вниманию предлагается перевод статьи Дениса Форбса (Dennis Forbes) "The Sad Reality of Post-Mature Optimization". Превосходные иллюстрации также взяты из оригинальной статьи.На каком этапе разработки пора обратить внимание на производительность? В какой момент оптимизация перестает быть преждевременной и становится своевременной?
Распространенное мнение таково: заботьтесь о производительности только тогда, когда вы уже написали большую часть кода. Казалось бы, всё очень просто: запускаем профилировщик, находим все проблемные места в коде и оптимизируем их. При таком подходе результат (вроде бы!) должен быть таким же, как если бы вы думали о производительности с самого начала. Знакомые слова, правда?
Проработав в индустрии не один год и завершив не один десяток проектов, могу с уверенностью заявить: это полная чепуха. На самом деле всё происходит совсем по-другому.
Вот что должен показать профилировщик, если запустить его на идеальной, гипотетической программе, которая с самого начала писалась с учетом высоких требований к производительности. Все методы в ней выполняются одинаково быстро, и мест, где бы просаживалась производительность, просто нет.
Когда вы натравливаете профилировщик на проект, написанный под лозунгом «скажем "нет" преждевременной оптимизации!», вы ожидаете увидеть что-то в этом духе.
На практике такого не случится никогда. Ни-ког-да. Если вы не ставили производительность во главу угла с самого начала, то неэффективные решения будут появляться повсюду, заражая каждый квадратный килобайт кода в вашем проекте. Зачем использовать хэш-таблицы, когда можно втупую итерировать по громадному массиву? Зачем писать SQL-запросы, когда можно использовать LINQ на каждый чих, постоянно отфильтровывая огромный объем избыточных данных?
В большинстве случаев профилировщик нарисует вам вот что:
Эта ситуация абсолютно типична. Если вы не задумались о производительности с первых дней проекта — поверьте, вы не вспомните о ней до самого конца. Не надо тешить себя надеждами типа «мы найдем самую неэффективную функцию, быстренько ее оптимизируем, и всё сразу заработает быстрее!». При таком подходе зараженными окажутся все функции, и точечное лечение вам не поможет. Закон Мура тоже не придет вам на помощь: производительность отдельно взятого процессорного ядра практически не меняется вот уже несколько лет. Девять женщин никогда не смогут родить ребенка за один месяц; так и в вашем случае мечты о том, что рано или поздно хорошее железо позволит вашей программе работать быстро, разобьются о физические ограничения.
Хотите примеров из жизни? Пожалуйста. Минимальное время рендеринга одной страницы бизнес-портала SugarCRM — в районе 100 миллисекунд, даже на самом лучшем железе. В мире веб-приложенй такое положение дел никого особо не смущает (все уже давно привыкли к тому, что каждый клик на веб-странице обрабатывается по несколько секунд), но ситуация дошла до того, что малое время отклика стало для некоторых веб-сервисов серьезным конкурентным преимуществом. Мне очень нравится интернет-радио Rdio, но если я найду его аналог, который не будет доставать меня секундными задержками между переключениями страниц, то я немедленно перейду на него.
У вас редко получается пофиксать все баги перед релизом; точно так же у вас не получится решить все проблемы с производительностью в короткие сроки. Ситуация очень схожа с попыткой распараллелить алгоритм, который изначально не был для этого предназначен: в принципе, это возможно, но скорее всего потребуется переписать всё с нуля.
Подытожу вышесказанное: полезный принцип, высказанный Кнутом, был доведен до полного абсурда. Когда кто-то говорит о преждевременной оптимизации, он почти наверняка имеет в виду совсем не то, что имел в виду Кнут.
habr.com
optimization - Когда оптимизация преждевременна?
Стоит отметить, что оригинальная цитата Кнута взята из статьи, которую он написал, поощряя использование goto в тщательно отобранных и измеренных областях как способ устранения горячих точек. Его цитата была предостережением, который он добавил, чтобы оправдать свое обоснование использования goto, чтобы ускорить эти критические петли.
[...] снова, это заметная экономия в общей скорости движения, если, скажем, среднее значение n составляет около 20, а если обычная процедура выполняется примерно в миллион раз в программе. Такая петля Оптимизация [с помощью gotos] не является трудной для изучения, и, поскольку у меня есть сказал, что они подходят только в небольшой части программы, но они часто дают значительную экономию. [...]
И продолжает:
Традиционная мудрость, которую разделяют многие современные программисты призывает игнорировать эффективность в малом; но я считаю, что это просто чрезмерная реакция на злоупотребления, которые, по их мнению, практикуются pennywise-and-pound-doolish программисты, которые не могут отлаживать или поддерживать их "оптимизированные" программы. В установленных инженерных дисциплинах 12% улучшение, легко полученное, никогда не считается маргинальным; и я полагают, что одна и та же точка зрения должна преобладать в разработке программного обеспечения. из Конечно, я бы не стал делать такую оптимизацию на одной задаче, но когда речь идет о подготовке качественных программ, я не хочу ограничить себя инструментами, которые лишают меня такой эффективности [т.е. gotoв этом контексте].
Имейте в виду, как он использовал "оптимизированный" в кавычках (программное обеспечение, вероятно, фактически не эффективно). Также обратите внимание на то, как он не просто критикует этих программистов "pennywise-and-pound-doolish", но и людей, которые реагируют, предлагая вам всегда игнорировать небольшую неэффективность. Наконец, к часто цитируемой части:
Нет никаких сомнений в том, что грааль эффективности приводит к злоупотреблениям. Программисты тратят огромное количество времени на размышления или беспокоиться о скорости некритических частей их программ, и эти попытки эффективности фактически оказывают сильное негативное воздействие, когда отладки и обслуживания. Мы должны были забыть о небольших эффективность, скажем, в 97% случаев; преждевременная оптимизация - это корень от всего зла.
... а затем еще немного о важности инструментов профилирования:
Часто бывает ошибкой делать априорные суждения о том, какие части программы действительно важны, поскольку универсальный опыт программисты, которые использовали измерительные инструменты, заключались в том, что их интуитивные догадки терпят неудачу. После работы с такими инструментами в течение семи лет, Я убедился, что все составители, написанные с этого момента, должны быть предназначен для предоставления всем программистам обратной связи, указывающей, что части их программ стоят больше всего; действительно, эта обратная связь должны предоставляться автоматически, если только это не было специально выключен.
Люди злоупотребляли его цитатой повсюду, часто предполагая, что микрооптимизация преждевременна, когда вся его статья защищала микро-оптимизацию! Одна из групп людей, которых он критиковал, кто вторит этой "общепринятой мудрости", поскольку он всегда игнорирует эффективность в малом, часто злоупотребляет своей цитатой, которая первоначально была направлена, в частности, против таких типов, которые препятствуют всем формам микро-оптимизации.
Тем не менее, это была цитата в пользу надлежащим образом примененных микрооптимизаций при использовании опытной стороны, имеющей профилировщик. Сегодня аналоговый эквивалент может быть похож: "Люди не должны делать слепые удары при оптимизации своего программного обеспечения, но пользовательские распределители памяти могут иметь огромное значение, когда применяются в ключевых областях для улучшения локальности ссылок" или "Рукописный код SIMD с использованием SoA rep действительно сложно поддерживать, и вы не должны использовать его повсюду, но он может потреблять память намного быстрее, если применять ее надлежащим образом с помощью опытной и управляемой руки".
Каждый раз, когда вы пытаетесь продвигать тщательно применяемые микрооптимизации, такие как Кнут, вышеописанный, полезно отказаться от отказа от ответственности, чтобы препятствовать тому, чтобы новички были слишком возбуждены и слепо взялись за оптимизацию, например, переписывать все свое программное обеспечение для использования goto. Это отчасти то, что он делал. Его цитата была фактически частью большого заявления об отказе от ответственности, так же, как кто-то, совершавший прыжок с мотоцикла через пылающий огонь, мог бы добавить отказ в том, что любители не должны пытаться это делать дома, одновременно критикуя тех, кто пытается без надлежащего знания и снаряжения,.
То, что он считал "преждевременными оптимизациями", было оптимизацией, применяемой людьми, которые фактически не знали, что они делают: не знали, действительно ли оптимизация была необходима, не измеряли с помощью надлежащих инструментов, возможно, не понимали характер их компилятора или компьютерной архитектуры и, прежде всего, были "pennywise-and-pound-doolish", что означало, что они упускали из виду большие возможности для оптимизации (сэкономить миллионы долларов), пытаясь ущипнуть гроши, и все при создании кода они больше не могут эффективно отлаживать и поддерживать.
Если вы не вписываетесь в категорию "pennywise-and-pound-foolish", то вы не досрочно оптимизируете стандарты Knuth, даже если вы используете goto, чтобы ускорить критическую (что вряд ли поможет многим оптимизаторам сегодня, но если это произойдет, и в действительно критической области, то вы не будете преждевременно оптимизироваться). Если вы на самом деле применяете то, что вы делаете, в областях, которые действительно необходимы, и они действительно извлекают выгоду из этого, тогда вы прекрасно делаете это в глазах Кнута.
qaru.site
Преждевременная оптимизация архитектуры / Хабр

Евгений Потапов и Антон Баранов из компании ITSumma рассказывают об оптимизации на опережение. Это — расшифровка доклада Highload++.
Мы занимаемся круглосуточной поддержкой и администрированием веб сайтов. Работаем в Иркутске с 2008 года. Сейчас штат 50 человек. Главный офис в Иркутске, есть офис в Санкт-Петербурге и Москве. На данный момент у нас более 200 активных клиентов, с которыми происходит более 100 активных чатов в день. Мы получаем порядка 150 тысяч активных оповещений в месяц о проблемах наших клиентов. Среди наших клиентов — множество разных компаний, есть известные: Lingualeo, AlterGeo, CarPrice, «Хабрахабр», KupiVip, «Наше Радио». Есть много интернет магазинов. Род наших занятий: мы должны в течение 15 минут среагировать на то, что случилась беда, и попытаться её быстро починить.
Откуда берётся беда, эти проблемы на серверах?
- Главная причина — это новая версия приложений. Выложили новую версию сайта, обновили код — что-то сломалось, всё перестало работать, нужно чинить.
- Второе — это проблемы, связанные с ростом нагрузки и масштабированием. Либо это проект, который очень быстро растет, и нужно что-то с этим делать. Либо это проект, который организовал маркетинговую кампанию — чёрная пятница, пришли много людей, не были готовы, всё сломалось — нужно масштабироваться и готовиться к будущему.
- Третья по статистике причина аварий очень интересная. Это аварии, связанные с ошибками планирования архитектуры проекта. То есть беда, которая происходит не из-за того, что пришел трафик и всё упало, не из-за того, что произошла ошибка в коде, а из-за того, что архитектура проекта была устроена так, что она привела к ошибке.
Ошибки планирования архитектуры
Если посмотреть на другие индустрии, то сегодня не происходит так, что после постройки здания оно рушится. Если такое и случается, то довольно редко. После прокладки водопровода не происходит такого, что он немедленно ломается. В IT подобное происходит довольно часто. Строится какая-то архитектура, а когда она релизится, то выясняется, что она не подходит под условия, которые были, либо она очень долго делается, либо возникают другие проблемы.Сама индустрия IT довольно новая, не наработавшая старые практики, а любые новые решения создают дополнительную сложность, которая уменьшает надежность эксплуатации этих решений. Чем сложнее решение, тем сложнее его эксплуатировать.
Есть, так называемый Закон Луссера. В 40-е годы Германия запускала по Великобритании ракеты «Фау-2». Какие-то долетали точно, какие-то нет. Они решили исследовать в чем причина. Оказалось, что если у вас есть много разных компонентов, и вы усложняете данную систему, то сложность системы (то есть риск того что она может не выдержать) — это не вероятность того, что система попадет в аварию, не самая меньшая вероятность этой системы, не какого-то из компонентов этой системы, а произведение вероятностей риска каждого из компонентов.
Если вероятность аварии с участием одного компонента 5%, а другого — 20%, то общий риск будет не 20%, а 24%. Всё будет очень плохо. Чем больше у вас компонентов, тем больше у вас возникает беды.
Причины создания сложности
Не каждый день мы видим инженера, который строит офлайн-систему и говорит: «Я сейчас придумаю как сделать сложнее». А в разработке, в эксплуатации мы видим очень много ситуаций, когда мы приходим на смену ребятам или в новую команду и видим систему, которая непонятно зачем так сделана, кроме того, что так было интереснее.- Первый вариант — решение данной проблемы уникальное. Нельзя нигде найти, как решить эту проблему, что с этим сделать. Мы начинаем придумывать как её решить, наступаем на грабли, понимаем, что это нужно переделать и так далее.
- Иногда случается, что решение есть, но оно нам не известно, а найти мы возможности не имеем. На инженеров в авиастроении учатся долго, а технологии в IТ так быстро меняются, что вуз не может подготовить к проверенным и готовым практикам. Приходится изучать все заново. Иногда при создании какого-то решения, которое когда-то уже было выполнено, что не известно, ты придумываешь всё заново. Поэтому система усложняется, ты приводишь её к риску и всё становится плохо.
- Интересный случай, который возникает достаточно часто. IT это одна из немногих профессий, где людям очень интересно работать. Есть много очень интересных технологий, которые можно попробовать, есть много всего на что хочется посмотреть. Например, давайте попробуем вставить docker в нашем проекте. Очень многие хотят и пытаются придумать где именно его попробовать. В итоге желание попробовать решение из чистого интереса создает особенную сложность. Например, сантехник прокладывая трубу не думает, может быть я её заверну 4 раза, интересно, вдруг вода всё-таки будет идти в кран. В IT мы такое видим достаточно часто.

Мы хотим на основании тех примеров, которые мы видим из жизни, свои практики. Попытаться помочь на какие штуки не стоит наступать и как с этим жить.
Рассмотрим развитие проекта по трём категориям. То есть, как он от самого старта, когда он совсем небольшой или даже идея проекта развивается до какого-то крупного, высоконагруженного проекта, известного по всей стране, по всему миру.
Когда вы создаете проект, как правило, вы предполагаете, что после старта, первых рекламных компаний, в социальных сетях с 25 подписчиками, ваша посещаемость составит 3000-5000 RPS. Нужно к этому как-то подготовиться, чтобы мощности выдержали эту посещаемость. Тут мы сразу вспоминаем, не даром на каждом углу маркетологи говорят нам про облака. Облака – это очень надежно. Это очень хорошо, замечательно. Буквально везде это слышно.
Чтобы развеять этот миф, мы привели статистику работы uptime'a Amazon'a.

Облако Amazon’a одно из самых быстрорастущих в мире, а также одно из самых крупных. Как вы видите, ничего идеального в этом мире нет. Даже у Amazon’a бывают фейлы, связанные с теми или иными причинами.
Нам всегда говорят, что облако масштабируется. Мы легко можем от одного ядра, от 1 GB до кучи ядер, кучи GB памяти отмасштабировать сервер, на котором находится наш проект. На самом деле все это действительно миф, потому что облака расположены на физических машинах, как и расположено все остальное. Есть лимит, он заключатся в количестве оперативной памяти на этой машине и количестве ядер на этой машине. Вы рано или поздно упретесь в то, что облако не даст вам отмасштабироваться до нужного вам размера. Самый идеальный вариант для вашего проекта, даже на моменте его запуска это отдельный выделенный сервер, ничего надежнее и проще в этом мире пока не придумали. Сейчас железо стоит довольно недорого и за небольшие деньги можно приобрести довольно неплохой выделенный сервер.
Какие же у нас бывают проблемы на выделенных серверах?
В какой-то момент мы понимаем, что проект растет и ждем нагрузку. Сталкиваемся с вопросами, которые возникают. Это горизонтальное масштабирование и резервирование проекта. Нам нужно быть уверенными, что в случае падения основного сервера, проект будет продолжать работать.Что мы предпринимаем в таких случаях?
Мы балансируем трафик на проект между несколькими веб инстансами. Так же мы делаем несколько инстансов серверов баз данных, которые реплицируются и между которыми нагрузка балансируется.Основную ошибку, которую допускают в этом случае это то, что все веб сервисы находятся в одной стойке. То есть у нас есть несколько физических веб серверов, которые от всего застрахованы, за одним исключением. Это всё находится в одном дата центре, чаще всего в пределах одной стойки. Конечно же, в случае падения дата центра, это ни от чего не защитит.
В этом случаем мы приходим к выводу что, резервные инстансы, резервные сервера должны находится в другом дата центре. Вторая непреложная истина, которую мы должны понять. Если у нас есть резервные инстансы на которые мы в случае чего можем пустить трафик, это не говорит нам о том, что у нас есть бэкап. Самое главное, что надо понимать, виртуализация — это скорее боль, нежели облегчение страданий. Потому что как правило с виртуализацией связаны свои ощутимые проблемы, мы не рекомендуем с ними работать.
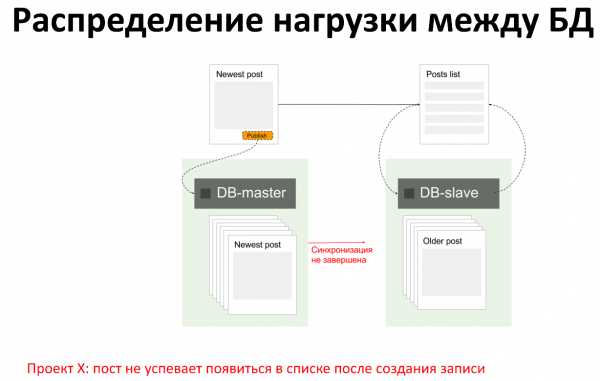
Какие у нас бывают проблемы, когда мы используем несколько инстансов серверов баз данных? Самая частая проблема, например, когда у нас есть запись на master, есть чтение со slave. Когда мы записали что-то на master, в это время приложение прочитало что-то со slave, но изменения ещё не отреплицировались и slave ещё не знает о том, что мы что-то записали на master. В этом случае мы получим неактуальные данные со slave.
В этом случае мы понимаем, что нам нужно:
- Мониторинг статус репликации (работает она или нет)
- Мониторинг отставания репликации, бывают ситуации что репликация есть, но из-за нюансов и факторов она имеет задержку в сутки или больше
- Мониторинг консистентности репликации (данные на slave соответствуют данным на master)
В целом идея записать что-то в master, а затем прочитать это со slave не совсем хорошая, потому что к проблемам с целостностью данных. Но мы довольно часто это видим, хочется этого как-то избегать.
Когда мы используем балансировку нагрузку на веб-проект между несколькими веб-нодами у нас могут возникнуть разные проблемы. Например, в качестве входной точки часто используют единый балансировщик нагрузки, то есть на него указывают А-запись, трафик через него балансируется между веб-нодами. В этом случае балансировщик является точкой отказа. В случае его падения проект схлопнется, потому что некому будет балансировать нагрузку между веб-нодами.
Есть такой тонкий, деликатный момент. Балансировка трафика между вашими веб-нодами она должна быть настроена с учетом failover’a. То есть когда мы балансируем, приложение которое осуществляет балансировку оно должно постоянно опрашивать веб-ноды на случай если какая-то из-них откажет, то она должна быть исключена из процесса балансинга. Иначе, может получится нехорошая ситуация, когда у нас половина проекта загрузилась, а половина нет. Потому к половину ресурсов были отбалансированы на ту веб-ноду, которая упала часа 3 назад.
Что же делать с файлами?
В наше время, когда очень много медиа, картинок, видео на проектах. Очень хочется иметь общее хранилище, которое будет подключено ко всем web-nod’ам и каждая web-nod’а сможет по отдельности работать с файлами, записывать, читать. Что же делают в этом случае?Самым простым и понятным решением кажется использование NFS, этой технологии много лет, много где используется, у каждого на слуху, почему бы и не использовать? Проблем с синхронизаций там не было, настройка проще не куда. Очень часто начинают использовать эту технологию.
С NFS есть проблемы, глобальные. В случае, когда у нас между серверами, между master’ом NFS веб-нодами, на которое это NFS подмонтирована, нарушилась связь. Либо в случае, например, когда нам пришлось перезагрузить NFS master, нам необходимо перезагружать и веб-ноды. Почему? Потому что, монтирование зависает и с этой точкой ничего нельзя сделать, пока сервер не будет перезагружен физически. Эта давняя проблема NFS, она повсеместно встречается, адекватного решения для этого нет, в рамках NFS.
Отдельно интересная тема, это то как организуется деплой проектов. По сути у нас 1-2 сервера, у нас нет сложности выложить код с простого git pull’a и простого скрипта, который сохранит предыдущие версии проекта в одном месте, деплой в новое и сменит всем линк. Но git pull это не очень интересно. CI гораздо интереснее. Очень часто среди наших клиентов, небольшие проекты пытаются внедрять CI раньше, чем им это нужно. На то чтобы создать продвинутую систему деплоя с continuous integration / delivery уходит очень много ресурсов, которые создают дополнительную сложность.
Во-первых, самая частая ошибка, которую мы видим, есть крутая система деплоя. Люди выкладывают новый код и не могут одной кнопкой сделать откат кода, при этом у них обычные реляционные базы, они накатывают миграции, в рамках деплоя не учитывают, что эти миграции могут привести к тому что новая версия БД не сможет работать со старым кодом. После выкладки деплоя выясняется нужно срочно откатиться, потому что всё сломалось. Мы откатываем на старый код, а старый код не может работать с новой базой, но продолжает писать какие-то данные. Мы снова ставим новую версию, чтобы хоть как-то выжить, у нас уже есть данные со старой версии, которые снова записались, данные с новой версии, которые тоже записались, все перемешалось и непонятно как жить. Есть overhead на то чтобы создать, внедрить и поддерживать эту систему.
По сути мы внедряем новую систему, надо проверить что она работает. Проверить, что она сама не выложит код, а не превратит wwwroot в пустое место, как было у некоторых наших клиентов. Дополнительная сложность вовремя деплоя, если мы сделали какую-то систему выкладки и не проверили, что она хорошо работает, тот же самый откат на production’e. Как проверить, что вы откатитесь? Нужно выбрать время, а если этот проект, который начинает приносить деньги, то никто не хочет подвергать проект риску, все думают, что всё будет работать, а когда нужно будет сможем откатиться. В итоге создаются проблемы, обязательно нужно проверить возможность отката и проверить, что у вас всё работает. Лучше на этом этапе придерживаться простых решений, скриптом выкладывать новую версию кода и с этим жить.
На этапе, когда мы подходим к тому, что наш проект, стал среднего размера, уже немаленький, но уже и не крупный. У нас назревает вопрос, что надо что-то делать с NFS, на что её заменить?
Из того, что попадется под руки, это CEPH. Его можно использовать, все хорошо, отзывы положительные. Но CEPH достаточно сложна в настройке, если не знать мелочей, нюансов и тонкостей в настройтре CEPH, то мы на выходе можем столкнуться с тем, что эта файловая система работает не так, как мы от нее ожидаем. Для того чтобы научиться с ней работать нужно затратить много человеко-ресурсов, много времени. Поэтому можно использовать что-то легкое, например, MOOSEFS. Почему нет?
Всё идеально, конфигурируется элементарно, в ней копятся какие-то данные, хранилище размазано по нескольким nod’ам, которые отведены только для хранения файлов, везде всё примонтировано, всё замечательно и работает. Но, внезапный сбой по питанию. В дата центре отрубился основный канал, генератор подхватил, но немного позже, чем надо было для того чтобы сервер не вырубился.
Что же у нас случается?
У нас случается ситуация, когда у нас несколько десятков терабайт статики, которые размазаны по нескольким серверам, они должны друг с другом синхронизироваться после сбоя по питанию, после того как они поднялись и т.д. Прошло 2 дня, мы думаем, много файлов, думаем, что нужно еще немного подождать, прошло 4 дня, на 90% синхронизация MOOSEFS упала и начала синхронизироваться заново. Проект уже 5 дней без статики, это не очень хорошо. Мы начинаем искать решение проблемы. Мы находим решение проблемы на китайском форуме, на котором три поста в треде посвящено тому, как починить эту файловую систему в подобной ситуации. Там всё на китайском, все доходчиво, есть образцы конфигов, всё хорошо расписано.Онлайн переводчик немного переврал смысл, но скорее всего всё хорошо. Мы не можем работать с такой файловой системой, у которой такая поддержка. Поэтому мы по-прежнему работаем с MOOSEFS, в случае сбоев по питанию, мы молимся и плачем. Вопрос с выбором замены до сих пор открытый.
У нас к этому моменту уже есть система деплоя, более-менее отлаженная. Это могут быть скрипты, может быть это CI и это всё работает. Но у нас есть ошибки деплоя, в production проскакивают иногда. Бывает, что prod валяется с 500 ошибкой из-за бага в коде. С чем это может быть связано?
Например, у нас есть база данных на dev и на prod окружениях, за одним тонким нюансом. На prod окружении в базе данных у нас 10 гигабайт данных, а на dev окружении 50 мегабайт. Например, на dev’e тысяча записей в табличках, с которыми мы работаем, а на prod’e миллион. Соответственно, когда у нас запросы выполняется на dev’e он отрабатывает за сотые доли секунды, а на prod’e он может занимать десятки секунд.
Еще один тонкий момент. Когда мы тестируем код на dev окружении, мы тестируем код на окружении, на котором работает только тестирование этого кода. Там нет сторонней нагрузки. На prod’e нагрузка всегда есть. Поэтому всегда стоит учитывать, что те результаты, которые вы получили на dev’e без нагрузки, на prod’e могут быть другими. То есть когда нагрузка от вашего нового кода совпадет с общей нагрузкой системы, результаты могут вас не порадовать.
Так же часто случается. На dev’e все оттестировали, всё работает, базы данных одинаковые, всё замечательно, всё должно работать, нагрузка не должна пошатнуться, все хорошо, за одним тонким исключением, мы деплоимся на prod, а у нас ошибка 500. Почему так? Потому что у нас не установлен какой-то модуль или какое-то расширение, настройка где-то не прописана. У нас разная конфигурация ПО. Это также стоит учитывать.
Это встречается реже, но встречается. Например, у нас скрипт работает на dev сервере на одном ядре, оно, например, 4 ГГц, на нем быстренько отработал и всё хорошо. А prod’e ядер много, но они все по 2 ГГц, время исполнения кода на одном ядре не тоже самое, что было на dev сервере. Такие нюансы в различие конфигураций железа dev и prod серверов тоже стоит учитывать и делать на них скидку.
Камень преткновения — это высокая нагрузка на базы данных
Это одна из самых наиболее встречаемых задач в нашей практике. Как же избавится от нагрузки на базу данных?Первое, что приходит на ум это поставить более мощное железо. Более мощный процессор, больше памяти, быстрые диски и проблема решится сама. На самом деле нет. Потому что рано или поздно мы упремся и в это железо и наступит какой-то потолок.
Тюнинг сервера. Отлично решение проблемы, когда программисты приходят к системным администраторам и говорят, что сервер базы данных настроен не оптимально. Если подправить эти настройки, то всё образуется, запросы станут выполнятся быстрее и всё станет лучше. Все наши проблемы будут исправлены с помощью перехода на другую СУБД. То есть, например, у нас MySQL тормозит, если мы перейдем на PostgeSQL, а лучше на MariaDB мы все эти проблемы исправим как класс, всё будет работать быстро, идеально и т.д. Проблему искать стоит искать не в СУБД, а копнуть глубже логически.
Что мы делаем, чтобы понять в чем у нас камень преткновения?
С чем связно то, что база данных начала генерировать довольно большую нагрузку и железо не справляется. Нам надо собрать статистику, для начала понять какие запросы выполняются дольше всего. Мы накопили некий пул запросов для того, чтобы их проанализировать. Какие-то запросы сформировать, чтобы выявить общие черты и т.д.Также необходимо составить статистику по числу запросов. Например, если у нас база данных тормозить только с 3 до 4 по полуночи, то возможно в этот момент происходит импорт где у нас количество insert’ов в базу данных возрастает на порядок. Так же стоит задуматься о кластеризации данных. Яркий пример, у нас есть табличка со статистикой. Допустим, она хранится за последний год. Мы постоянно делаем из неё выборки, 95% этих выборок касаются только последней недели. Возможно, имеет смысл данные из этой таблицы кластеризовать таким образом, чтобы у нас было 12 разных табличек, каждая из них бы хранила данные за конкретный месяц. В этом случае, когда мы будем делать какую-то выборку у нас будут браться данные из одной таблички, где будет условно в 12 раз меньше записей.
Самое интересное – это то, что происходит на крупных проектах
Поскольку там не технологические ошибки, которые мы видим часто, а там есть несколько течений. Проект вырос, хочется экспериментировать, хочется, чтобы всё работало само по себе, и мы могли с этим жить.Первое, что мы видим это любовь технических специалистов к новым технологиям. Проект большой, всё работает понятно, задачи регулярные, хочется придумать что-то действительно новое. Поскольку люди хотят, чтобы работать им было интересно. Есть несколько цитат, которые, мы берем в свои игры чата техподдержки, где людям хочется использовать какую-то технологию, но не знают для чего её применять. Хотим использовать docker и consul в своём проекте. Раскидаем сервисы по docker’y, будем через consul понимать кто, куда будет ходить. Consul положим в один из docker’ов, если consul упадет мы всё потеряем, но с этим можно жить. Давайте обновлять конфигурацию только через chef, если нам срочно придется раскидать какую-то конфигурацию и где-то chef клиенты у нас упадут, нам придется сначала наладить chef клиент, но мы сможем централизованно обновлять конфигурации. Но обновить отдельно что-то по серверам будет сложно, но это будет хорошо.
Давайте сделаем кластер. Это интересная шутка, когда людям хочется сделать кластер из чего-то. Давайте сделаем кластер из RabbitMQ и будем читать данные оттуда и оттуда и всё будет отказоустойчивое. Если один из RabbitMQ упадет, второй будет жить, на самом деле нет, но ничего страшного.
Любовь к новым технологиям
Нельзя использовать технологии ради технологий. Прекратите это в какой-то мере, но я уверен, что это не прекратится, потому что нам всем хочется пробовать новое, но иногда нужно пытаться удержать себя.В большом проекте простые действия становятся гораздо сложнее. Если мы знаем, что хотим всегда использовать новый софт, если на каком-то старом нашем проекте, где один сервер всё было хорошо, то на новом все обновить это сложные операции и это занимает не 2 часа, а может занимать несколько недель, особенно плохо, если мы решим это сделать в production силами разработчиков, а не слаженной командой, которая продумала как это обновлять.
Вторая болезненная штука, которая становится модной сейчас это вера в то что автоматизация работает и админы не нужны. Наш кластер будет отказоустойчивым, мы будем балансировать между всеми веб серверами, а наши load-балансеры будут работать. Если мы это делаем в amazon web service, у нас падает весь регион, падает все балансеры, все инстансы, всё становится плохо.
«Оно само перебалансируется в случае аварии». Очень частая штука, которую мы видим, когда автоматическая балансировка приводит к тому, что с одного места на другое должны перекинуться, но почему-то перекидываться на тот же код, который уже тормозит, либо начинает перекидываться между инстансами, которые все тормозят вместе, либо просто в никуда. Проект начинает идти в систему, которой не существует.
Наш стэк технологий полностью исключает такую ситуацию. Решение, про которое мы прочитали на stackoverflow, reddit’e и Хабрахабре, не может врать.
Буквально года два назад я здесь делал доклад про наш опыт использования OpenStack, когда очень много компаний хотели использовать OpenStack, потому что классно использовать штуку, которая позволит тебе взять несколько больших машин и спокойно как в amazon’e на них раскидывать виртуалки, очень просто и удобно. К сожалению, в OpenStack’e того времени, когда ты запускаешь инстанс и удаляешь его, то после этого нельзя будет не запускать, не удалять до тех пор, пока ты не перезапустишь несколько daemon’ов OpenStack’a.
Нам было интересно в какой момент это происходит. У некоторых работает, у других нет. Потому что ребята, которые сказали, что у нас OpenStack работает отлично, у нас есть 4 человека на fulltime’e которые его поддерживают. Они регулярно смотрят, что он OpenStack работает, если не работает начинают его быстро чинить. Те люди, которые говорят, что та или иная технология работает, у них либо есть достаточные ресурсы для этого чтобы эту технологию использовать, либо не знают, что эта технология может сломаться и верят в это, либо возможно они зарабатывают на этом деньги, тот же docker получает огромные инвестиции.
Как же с этим жить?
Я предпочитаю не верить в то, что оно может само не падать, что так или иначе оно никогда не сломается и само будет перебалансироваться. Кроме того, как быть параноиком мы советов дать не можем.Очень интересная вещь в работе больших проектах. Выкладки идут постоянно, бизнес хочет постоянных изменений. Мы сделали хороший проект, который живет, там нечему особо тормозить, поэтому мы забываем про регулярные оптимизации. У одного из клиентов на одной из выкладок в итоге произошла выкладка где на одной из страниц генерировала 8 тысяч запросов sql.
Частые деплои. Они настолько частные что не видно изменений.
Что получается на практике?
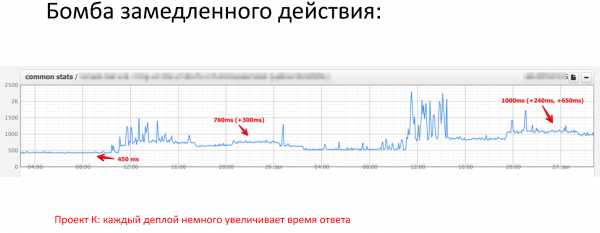
Если мы посмотрим на график за последние несколько часов, у нас было 3 деплоя. Первый деплой сделал лишь немного, добавив 300 миллисекунд к 450 миллисекундному ответу, следующий деплой добавил еще 240 миллисекунд, следующий уже суммарно 650 миллисекунд.
Мы уже получили секундный ответ, всё плохо
Большие проекты не проверяют то, как в итоге это все будет на production’e не только тестирование деплоя, но и повышением нагрузки каким-то тестированием. На самом деле многие хотят это сделать и научиться это делать, но мало кто действительно это делает. Будет классно если многие большие проекты научатся нагрузочно тестировать хотя бы мажорные версии выкладок кода.
Вместо выводов
- Не всё новое – хорошее.
- Не всё что интересно – нужное.
- Не всё что крутое – полезное.
Дополнение по поводу паранойи в деплое в крупных проектах. Когда у вас много трафика вы имеете возможность протестировать свой деплой, каким образом? Вы можете новый код выкатить на сервера, куда направите часть ваших посетителей, условно 10%, посмотрите не возникнет ли резких пиков нагрузки от того, что пользователь начнет тыкать какую-то кнопочку и т.д. подобная схема деплоя, когда мы делаем разделение клиентов и часть отправляем в качестве фокус группы отправляем на новый код, это довольно широко применяется и может помочь избежать довольно многих проблем основной части клиентов. Гораздо лучше протестировать на 10%, чем на 100%.
Евгений Потапов и Антон Баранов — Преждевременная оптимизация архитектурыhabr.com
О цитате “Преждевременная оптимизация – корень всех зол”
Многие специалисты компьютерной области знают (ну, или хотя бы слышали) следующее высказывание:
Преждевременная оптимизация - корень всех зол в программировании
Большая часть этих самых компьютерных специалистов склоняется к мысли, что автором этой цитаты является Дональд Кнут и хотя для многих программистов не важно, кто на самом деле является автором, у меня этот вопрос вызывал интерес и я решил заняться им более подробно.
Существует как минимум три разновидности этой фразы, которая встречается в различных трудах Дональда Кнута.
Первый вариант: Преждевременная оптимизация - корень всех зол в программировании Оригинал: Premature optimization is the root of all evil Источник: 1974 год, лекция, посвященная вручению премии Тьюринга, Computer Programming as an Art, Communications of the ACM, Volume 17, Issue 12, Dec. 1974 (see p.671)). Полная версия оригинала: The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.
Второй вариант: Нам следует забывать о небольшой эффективности, например, в 97% случаев: преждевременная оптимизация - корень всех зол. Хотя мы не должны отказываться от своих возможностей в этих критических 3% Оригинал: We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3. Источник: 1974 год, статья Structured Programming with go to Statements, ACM Computing Surveys, Vol 6, No. 4, Dec. 1974 (see p.268) (эта статья является критикой статьи Эдсгера Дейкстры Go To Statement Considered Harmful).
Третий вариант: Я также знал, но забыл афоризм Хоара о том, что преждевременная оптимизация — корень всех зол в программировании Оригинал: But I also knew, and forgot, Hoare’s dictum that premature optimization is the root of all evil in programming. Источник: 1989 год, статья The Errors of Tex, Software—Practice & Experience, Volume 19, Issue 7 (July 1989), pp. 607–685, а также в книге Literate Programming (p. 276)
Все три варианта появились в трудах Дональда Кнута, но судя по третьей цитате складывается впечатление, что изначальным автором фразы был другой знаменитый ученый в области компьютерной науки Тони Хоар (C.A.R. Hoare), также лауреат премии Тьюринга, автор быстрой сортировки, Логики Хоара и много чего другого.
С момента выхода в свет The Errors of Tex, прошло уже два десятка лет, но до сих пор нигде не удается найти информацию, подтверждающую слова Кнута о том, что автором этой фразы является именно Хоар. Более того, сам Хоар в 2004 году в личной переписке с Hans Genwits написал о том, что он НЕ является автором этой цитаты (оригинал здесь):
Dear Hans, I’m sorry I have no recollection how this quotation came about.? I might have attributed it to Edsger Dijkstra. I think it would be fair for you assume it is common culture or folklore. Tony.
На самом деле не так и важно, кто является автором этого высказывания, Дональд Кнут, Эдсгер Дейкстра, Тони Хоар, или кто-то не столь именитый в области компьютерных наук. Важно то, что эта фраза стала известной именно благодаря Дональду Кнуту.
Ну и последнее, помните, Дональд Кнут говорил о 97%, а не о 100%;)
sergeyteplyakov.blogspot.com
premature-optimization - Правильно ли я понимаю преждевременную оптимизацию?
Ключевым аспектом цитаты Кнута для меня является "пенни-мудрый и фунт-глупый". Это то, как он в конечном счете описал преждевременный оптимизатор - кто-то торгуется за спасение копейки, когда есть фунты, которые нужно сохранить, и изо всех сил пытается поддерживать "оптимизированный" (обратите внимание на то, как он использовал здесь цитаты).
Я нахожу, что многие люди часто цитируют небольшую часть бумаги Кнута. Было бы полезно использовать goto для ускорения критических путей выполнения в программном обеспечении.
Более полная цитата:
[...] это заметная экономия в общей скорости работы, если, скажем, среднее значение n составляет около 20, а если обычная процедура выполняется примерно в миллион раз в программе. Такая оптимизация цикла [с использованием gotos] не является трудной для изучения, и, как я уже сказал, они подходят только в небольшой части программы, но они часто дают значительную экономию. [...]
Традиционная мудрость, которой пользуются многие из сегодняшних инженеров-программистов, требует игнорировать эффективность в малом; но я верю это просто чрезмерная реакция на злоупотребления, которые, по их мнению, практикуются программистами с плюсом-мудрой и фунт-глупыми, которые не могут отлаживать или поддерживать свои "оптимизированные" программы. В установленном инженерном дисциплины 12% улучшение, легко получается, никогда не рассматривается маргинальный; и я считаю, что та же точка зрения должна преобладать в программном обеспечении машиностроение. Конечно, я бы не стал заниматься такими оптимизациями работа, но когда речь идет о подготовке качественных программ, Я не хочу ограничивать себя инструментами, которые меня отрицают эффективность.
Нет никаких сомнений в том, что грааль эффективности приводит к злоупотреблениям. Программисты тратят огромное количество времени на размышления или беспокоиться о скорости некритических частей их программ, и эти попытки эффективности фактически оказывают сильное негативное воздействие, когда отладки и обслуживания. Мы должны были забыть о небольших эффективность, скажем, в 97% случаев; преждевременная оптимизация - это корень от всего зла.
Часто бывает ошибкой делать априорные суждения о том, какие части программы действительно важны, поскольку универсальный опыт программисты, которые использовали измерительные инструменты, заключались в том, что их интуитивные догадки терпят неудачу. После работы с такими инструментами в течение семи лет я убедился, что все составители, написанные с этого момента, должны быть разработаны, чтобы предоставить всем программистам обратную связь, указывающую, какие части их программ стоят больше всего; действительно, эта обратная связь должна предоставляться автоматически, если она не была специально отключена.
После того, как программист знает, какие части его подпрограмм действительно важны, будет полезно преобразование, такое как удвоение циклов. Обратите внимание, что это преобразование вводит операторы go to, а также выполняет несколько других оптимизаций цикла.
Итак, это происходит от человека, который действительно был глубоко заинтересован в производительности на микроуровне, и в то время (оптимизаторы получили гораздо больше сейчас), использовал goto для скорости.
В основе этого принципа Кнута "преждевременного оптимизатора" лежит:
- Оптимизация на основе сущностей/суеверий/человеческих интуиций без опыта и измерений (оптимизация вслепую без фактического знания того, что вы делаете).
- Оптимизация таким образом, что экономит пенни за фунты (неэффективная оптимизация).
- Ищете абсолютный максимальный пик эффективности для всего.
- Поиск эффективности в некритических путях.
- Попытка оптимизировать, когда вы едва можете поддерживать/отлаживать свой код.
Ничто из этого не связано с сроками ваших оптимизаций, но с опытом и пониманием - от понимания критических путей до понимания того, что фактически обеспечивает производительность.
Такие вещи, как тест-ориентированная разработка и преобладающая ориентация на дизайн интерфейса, не были освещены в бумаге Кнута. Это более современные концепции и идеи. В основном он занимался реализацией.
Тем не менее, это хорошее дополнение к совету Кнута - стремиться к установлению правильности сначала посредством тестирования и интерфейсных дизайнов, которые оставляют вам место для оптимизации, не нарушая все.
Если мы попытаемся применить современную интерпретацию Кнута, я бы добавил туда "корабль". Даже если вы оптимизируете истинные критические пути своего программного обеспечения с измеренной природой, самое быстрое программное обеспечение в мире бесполезно, если оно никогда не поставляется. Помня об этом, вы должны сделать разумные компромиссы.
Я склоняюсь к простому переходу в базу данных несколько раз, что я думаю, это правильный ход. Более важно, чтобы я закончил проект, и я чувствую, что меня забивают из-за оптимизации как это. Мой вопрос: правильно ли это стратегия, когда избегая преждевременной оптимизации?
Это будет для вас добра, чтобы выработать лучшее решение, принимая во внимание некоторые из этих пунктов выше, поскольку вы наиболее глубоко понимаете свои собственные требования.
Важным фактором, который я хотел бы предложить, является то, что если это критический для производительности путь, связанный с большой нагрузкой, для разработки ваших публичных интерфейсов таким образом, чтобы оставлять достаточно места для оптимизации.
Например, не создавайте систему частиц с зависимостями клиента с интерфейсом Particle. Это не дает возможности оптимизировать, когда у вас есть только инкапсулированное состояние и реализация одной частицы для работы. В этом случае вам может потребоваться внести каскадные изменения в вашу кодовую базу для оптимизации. Гоночный автомобиль не может использовать свою скорость, если дорога имеет длину всего 10 метров. Вместо этого ориентируйтесь на интерфейс ParticleSystem, который объединяет миллион частиц, например, с операциями более высокого уровня, которые, когда это возможно, имеют дело с частицами навалом. Это оставляет вам много возможностей для оптимизации, не нарушая ваши проекты, если вы обнаружите, что вам нужно оптимизировать.
Перфекционистская сторона меня хочет сделать все оптимальным и Совершенно в первый раз, но я нахожу, что это усложняет дизайн совсем немного.
Теперь эта часть звучит немного преждевременно. Обычно ваш первый проход должен быть направлен на простоту. Простота часто идет рука об руку с разумно быстро, быстрее, чем вы можете подумать, даже если вы делаете какую-то избыточную работу.
Во всяком случае, я надеюсь, что эти моменты помогут хотя бы добавить еще кое-что к рассмотрению.
qaru.site