Тонкая настройка сетевого стека на Windows-хостах. Оптимизация подавления ack что это
Тонкая настройка сетевого стека на Windows-хостах
Привет.
Сетевая подсистема в Windows NT прошла достаточно длительный путь – изначально являясь сетевой операционной системой, NT сразу ставила задачу предоставлять надежные, сбалансированные и эффективные сетевые решения.
Беда в том, что с точки зрения большинства админов под “настройкой сетевых параметров” понимаются видные глазом базовые минимальные пункты – как задание IP-адреса, маски и шлюза, а даже тот факт, что IP-адресов на интерфейсе может быть несколько, уже вызывает удивление.
Фактически же количество сетевых настроек в Windows NT достаточно велико, и, хорошо зная работу сетевой подсистемы, можно ощутимо улучшить работу ОС. И наоборот тоже. Поэтому данная статья обязательна к ознакомлению тем, кто хочет “покрутить параметры”.
Диспозиция
Я предполагаю, что Вы, товарищ читатель, знаете на приемлемом уровне протокол TCP, да и вообще протоколы сетевого и транспортного уровней. Чем лучше знаете – тем больше КПД будет от прочтения данной статьи.
Речь будет идти про настройку для ядра NT 6.1 (Windows 7 и Windows Server 2008 R2). Всякие исторические ссылки будут, но сами настройки и команды будут применимы к указанным ОС, если явно не указано иное.
В тексте будут упоминаться ключи реестра. Некоторые из упоминаемых ключей будут отсутствовать в официальной документации. Это не страшно, но перед любой серьёзной модификацией рабочей системы лучше фиксировать то, что Вы с ней делаете, и всегда иметь возможность удалённого доступа, не зависящую от состояния сетевого интерфейса (например KVM).
Это – первая часть статьи. Потому что настроек достаточно много. В следующей части я расскажу про другие.
Содержание
- Работаем с RSS
- Работаем с CTCP
- Работаем с NetDMA
- Работаем с DCA
- Работаем с ECN
- Работаем с TCP Timestamps
- Работаем с WSH
- Работаем с MPP
Поехали.
Настраиваем RSS в Windows
Аббревиатура RSS обычно ассоциируется совсем с другим, нежели с настройкой TCP. Хотя, в общем, это у всех по-разному – кто-то PHP с ходу расшифровывает как Penultimate Hop Popping, а кто-то думает, что КВД – это НКВД без первой буквы. Все люди разные. Мы будем говорить про тот RSS, который Receive Side Scaling.
Суть технологии RSS достаточно проста – входящий поток данных сетевого уровня разбивается на несколько очередей, обработка каждой из которых (вызов прерываний, копирование информации) производится выделенным виртуальным процессором (т.е. или отдельным физическим, или ядром). То есть в случае наличия нескольких процессоров Вы можете распределить интенсивный сетевой трафик по ним, снизив количество вызовов прерываний, переключений контекста, очистки кэша и прочих неприятностей, которые, если происходят много тысяч раз в секунду, могут ощутимо навредить производительности системы в целом.
Суть-то простая, да вот в реализации столько тонкостей, что можно написать отдельную статью. Пока это не является целью, поэтому постараюсь описать оные тонкости сжато и компактно :)
Для начала необходимо, чтобы сетевая карта умела формировать вышеупомянутые очереди, и умела делать это хорошо. По сути, эта задача требует от сетевой карты функционала, отдалённо напоминающего CEF (который Cisco Express Forwarding) – коммутации 3го уровня с определением и разделением отдельных потоков пакетов. Давайте попробуем разобраться на примере, как и зачем это может работать.
Допустим, у Вас есть быстрый сетевой адаптер (например, 10Гбит), и по нему к Вам приходит много данных. И эти данные хорошо разделяются на много потоков (например, когда мы ведём вебинары, на каждого слушателя идёт почти по десятку TCP-сессий, а слушателей бывает и 40). По сути, все эти потоки данных выглядят потоками только на транспортном уровне, а на сетевом сливаются в общий поток. Это, в общем, и есть работа протоколов транспортного уровня – мультиплексировать потоки данных от различных приложений на различных хостах. Но от этого нашей принимающей стороне не легче – ведь ей надо из входящего потока сформировать:
- Отдельные сессии TCP – т.е. для каждой поддерживать session state, буферы данных, состояние cwnd/rwnd, состояние sack’ов и ack’ов вообще
- Отдельные буферы для каждого фрагментированного IP-пакета
- Отдельные очереди (ведь трафик может обладать приоритетами)
И практически каждое событие во всей этой пачке сессий – это вызов прерывания и его обработка. Крайне затратно, особенно учитывая, допустим, негативный сценарий (10 гигабит поток, ip-пакеты по 1КБ). Можно даже сказать проще – ощутимое количество процентов мощности процессора (весьма дорогого, заметим) уйдёт на решение этих задач тех.обслуживания. Как с этим бороться? Да просто – пусть адаптер формирует отдельные очереди пакетов – тогда на каждую из них можно “привязать” свой процессор/ядро, и нагрузка в плане прерываний и прочего распределится. Но тут нас поджидает неочевидная проблема.
Дело в том, что просто так распределить не получится. Т.е. если мы придумаем очень простой критерий распределения (например, две очереди, четные пакеты – налево, нечетные – направо), то у нас может получиться следующая ситуация – у потоков данных часть пакетов попадёт в “четную” очередь, а часть – в “нечетную”. А в этом случае мы потеряем все возможные бонусы, возникающие при обработке непрерывного потока пакетов (обычно эти бонусы выглядят как “первый пакет обрабатываем по-полной, кэшируем все возможные результаты обработки, и все последующие пакеты обрабатываем по аналогии”). Т.е. нам надо всячески избегать ситуации, когда одному процессору придётся, обрабатывая, например, поток очень однотипных мультимедийных пакетов (какой-нибудь RTP например), пытаться “сбегать почитать” в соседнюю очередь. Скажем проще – никуда он вообще бегать тогда не будет, а придётся тогда нам выключать всяческие ускорения обработки TCP/UDP/IP-потоков, потому что работать они будут только в случае ситуации, когда весь поток однотипных пакетов обрабатывается одним ядром/процессором. А это приведёт к тому, что на процессоры придётся переводить вообще всю нагрузку по обработке сетевых данных, что с гарантией “убьёт” даже достаточно мощный CPU.
То есть, наша задача-максимум – это распределить входящие данные по нескольким отдельным очередям приёма, да так, чтобы потоки пакетов легли в очереди “целиком”, да и ещё желательно, чтобы заполнились эти очереди равномерно. Тогда мы и распределим нагрузку по процессорным ядрам, и не потеряем другие возможности по ускорению обработки потоков пакетов. Для решения этой задачи нам надо будет действовать сообща – и ОС, и оборудованию.
Хороший RSS начинается с сетевой карты. В сетевых картах, которые умеют RSS (а уже понятно, что это не карты минимального уровня), такой функционал есть – например в очень даже недорогой Intel 82576 (в моём случае – встроена в сервер) есть функционал и включения RSS сразу, и выбора количества очередей – 1, 2, 4 или 8.
Почему же количество очередей RSS будет выбираться из целочисленных степеней двойки? Тут начинается интересное, что будет роднить логику работы RSS и, допустим, логику балансировки у etherchannel.
Дело в том, что для того, чтобы определить “принадлежность” пакета к потоку, RSS использует следующую логику – берутся несколько ключевых полей пакета – SRC IP, DST IP, код протокола L4, SRC PORT, DST PORT – и от них вычисляется хэш, по последним битам которого (соответственно, для 2х очередей достаточно и одного бита, для 4х – двух, для 8 – трёх) и определяется принадлежность пакета к буферу. Соответственно, пакеты одного протокола, идущие с одного фиксированного порта и IP-адреса на другой адрес и порт, будут формировать поток и попадать в одну очередь. Такой подход достаточно быстр и прост с точки зрения балансировщика, но, как понятно, никак не решает ситуацию “Есть два стула две TCP-сессии – одна 1% канала занимает, другая 99%”. И даже не гарантирует, что обе эти сессии не попадут (с вероятностью 1/2) в одну и ту же очередь, что вообще превратит всю задачу в бессмыслицу.
Поэтому, в общем-то, остановимся на следующем факте – если у сетевой карты есть поддержка RSS, то её надо как минимум включить, чтобы первичное разделение входящего трафика на несколько очередей, притом с сохранением потоков, происходило без участия CPU.
Ну а вот дальше – уже задача операционной системы – что есть не один, а несколько потоков, и на каждый надо выделить свой процессор или ядро. Это как раз и будет тот самый RSS, который мы будем включать. Он уже будет создавать в драйвере NDIS отдельные очереди и выделять на каждую из них по процессору/ядру.
Нововведением в Windows Server 2008 R2 является то, что этим можно управлять – правда, только через реестр. В частности, управлению будут поддаваться 2 параметра – стартовое количество процессорных ядер, выделяемое для всех RSS-очередей на адаптере, и максимальное количество ядер для данной задачи. Параметры эти будут находиться по адресу HKLM\SYSTEM\CurrentControlSet\Control\Class\гуид сетевого адаптера\номер сетевого адаптера\ и называться, соответственно, *RssBaseProcNumber и *MaxRSSProcessors.
Пример использования данных параметров – допустим, у Вас есть сервер с 16 ядрами (2 процессора по 8 ядер или 4 по 4 – не суть). Есть три сетевых адаптера – один используется для управления системой, два других – для привязки к ним виртуальных машин. Вы можете выставить указанные параметры только у двух интерфейсов, на которых будет подразумеваться высокая нагрузка, притом следующим образом – поставить RssBaseProcNumber равным 2, а MaxRSSProcessors – например, 12. Тогда тот интерфейс, который будет активнее принимать трафик, сможет “отъесть” до 12 ядер системы на обработку очередей, при этом не надо будет жестко задавать этот параметр вручную (это удобно, если нагрузка переместится на другой интерфейс). Безусловно, в этом примере надо, чтобы сетевые адаптеры тоже поддерживали RSS, и, желательно, хотя бы очередей 8.
Подводя итоги – RSS – это достаточно практичная и нужная технология, требующая поддержку и со стороны оборудования, и со стороны операционной системы. И становящаяся всё более актуальной, так как на данный момент скорости сетевых интерфейсов растут, равно как и количество процессорных ядер, а, следовательно, старый подход, когда одно ядро “разгребает” единую входящую очередь, становится всё менее эффективным.
Как включить RSS в Windows
netsh interface tcp set global rss=enabled
Настраиваем логику алгоритма контроля перегрузки (CTCP) в Windows
Compound TCP – это Microsoft’овский протокол управления “окном перегрузки” (congestion window). Адресно предназначен для форсированного изменения окна при работе в сетевых средах с относительно большой задержкой (например, по WiMax или спутниковым каналам). Соответственно, не сильно полезен в сценарии широкополосного доступа в Интернет или работе по локальной сети.
По сути, всё, что он делает, это форсирует быстрое увеличение окна со стороны отправителя в случае, если обнаруживается, что сеть имеет малое время отклика, и быстро уменьшает окно в случае задержек на канале.
Как включить CTCP в Windows
netsh interface tcp set global congestionprovider=ctcp
Настраиваем использование NetDMA в Windows
NetDMA – достаточно интересная функция. Смысл её применения есть тогда, когда у Вас не поддерживается Chimney Offload и Вы хотите ускорить обработку сетевых подключений. NetDMA позволяет копировать без участия CPU данные (в общем, как и любой DMA-доступ) из приемных буферов сетевого стека сразу в буферы приложений, чем снимает с CPU данную задачу по тупому выполнению чего-то типа rep movsd.
Говоря проще, если Ваша сетевая плата не может “вытащить” на себя полную обработку TCP-соединений, то NetDMA хотя бы разгрузит процессор от самой унылой части задачи по обслуживанию сетевых соединений – копированию данных между сетевой подсистемой и использующими её приложениями.
Что нужно для включения NetDMA в Windows
Нужно оборудование, которое поддерживает NetDMA – в случае Windows это процессор с поддержкой технологий семейства Intel® I/O Acceleration Technology (I/OAT), которые, в свою очередь, входят в Intel Virtual Technology for Connectivity (VT-c). Включение NetDMA на оборудовании AMD эффекта, увы, не принесёт – не поверив, проверил на домашнем феноме 1055T – действительно, NetDMA не включается.
Как включить NetDMA в Windows
Локально:
netsh interface tcp set global netdma=enabled
Через Group Policy:
Откройте ключ HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\, создайте в нём параметр EnableTCPA вида 32bit DWORD и поставьте его в единицу
Секретный уровень
Если Вы дочитали до этого места, то дальше не читайте – опасно. Но вообще, в том же ключе – HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\ – есть параметр MinPacketSizeToDma, тоже типа 32bit DWORD, который, что и логично, исходя из его названия, указывает минимальный размер пакета, для которого имеет смысл инициировать DMA-передачу. Параметр данный выставляется автоматически и его тюнинг имеет слабый практический смысл – т.е. в принципе можно представить ситуацию, когда система поставит слишком малый параметр, и будет слишком часто переключаться на DMA, а Вы это поправите вручную, но очень слабо могу представить себе КПД этой операции – выяснять сие путём достаточно кропотливых синтетических тестов, чтобы выиграть призрачные доли процента на единственной операции в единственной подсистеме, притом доли эти будут укладываться в погрешность измерений, весьма уныло.
Настраиваем использование DCA (прямого доступа к кэшу NetDMA) в Windows
По сути, Direct Cache Access – это дополнение к NetDMA, которое появляется только в NetDMA 2.0 и является опциональным (т.е. факт наличия NetDMA не говорит о том, что DCA будет работать). Задачи, которые решает DCA, просты – он “привязывает” конкретную сетевую сессию к определённому ядру процессора, и позволяет копировать данные не по трассе “сетевой интерфейс”->”оперативная память”->”кэш процессора”, а напрямую с сетевого интерфейса в кэш процессора. В ряде сценариев (быстрая сеть и много сессий и ядер CPU) выигрыш может быть ощутимым – судя по исследованиям IEEE за 2009й год, в случае загруженной на ~80% 10Gbit сети плюс 12ти ядер нагрузка CPU падает примерно на треть.
Технология работоспособна для гигабитных и более быстрых сетевых адаптеров. И, как понятно, имеет смысл только в случае, когда сетевой адаптер не умеет Chimney Offload (что, в общем-то, уже достаточно сложно – в случае наличия нагрузки, при которой DCA эффективен, обычно используются сетевые адаптеры, которые на аппаратном уровне умеют обрабатывать TCP).
Кстати, интересный момент – DCA есть в Windows Server 2008, но не работает в Vista. В NT 6.1 работает везде, включая Windows 7.
Как включить DCA в Windows
Предварительно – обязательно включить NetDMA.
Локально:
netsh interface tcp set global dca=enabled
Через Group Policy:
Откройте ключ HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\, создайте в нём параметр EnableDCA вида 32bit DWORD и поставьте его в единицу
Настраиваем уведомления о перегрузке (ECN’ы) в Windows
Технология ECN в явном виде относится и к IP, а не только к TCP, но все равно про неё стоит тут написать.
Протокол IP изначально не особо любил технологии класса Quality of Service – QOS, поэтому в заголовке IPv4 выделен байт с целью “использовать для целей управления качеством”. Притом этот байт может содержать данные в разных форматах, и то, как его интерпретировать, решает конкретный хост. Используется два возможных формата данного байта – DSCP (он же DiffServ) и IP Precedence. По умолчанию этот байт (называющийся ToS – Type of Service) обрабатывается как IP Precedence и представляет собой копию данных канального уровня (в него копируются три бита от CoS – Class of Service, которые передаются в 802.3 кадре в составе 802.1p компонента заголовка 802.1Q).
Но нас будет интересовать ситуация, когда в заголовке IP-пакета – в поле ToS, разумеется – данные интерпретируются в формате DSCP. В этом случае на номер класса трафика отдаётся 6 бит (что даёт возможность сделать в организации 2^6 = 64 класса трафика и удобно управлять приоритетами), а оставшиеся 2 бита отдаются как раз на сигнализацию о “заторах”.
Говоря проще, если у промежуточного устройства буфер пакетов близок к перегрузке, то оно сигнализирует Вам, отправляя служебный пакет на IP отправителя, что “пакеты скоро будет некуда девать и придётся их выбрасывать, притормози”. Отправляет их, выставляя как раз специфические биты в поле ToS. Соответственно, включая поддержку данной технологии, Вы будете включать и возможность генерации подобных пакетов, и возможность анализа оных.
Простейший пример ситуации, в которой это поможет – на пути Вашего трафика стоит маршрутизатор, который в Вашу сторону смотрит интерфейсом со скоростью 1 Gbit, а дальше – интерфейсом со скоростью 100 Mbit. Если Вы будете отдавать ему трафик с максимально возможной скоростью, то его очередь пакетов, пытающихся “выйти” через интерфейс со скорость 100 Mbit, очень быстро переполнится, и если он не сможет Вам об этом сказать (ну или если Вы не включите со своей стороны возможность услышать эти сообщения от него), то ему придётся просто в определённый момент перестать принимать пакеты, сбрасывая их. А это приведёт к тому, что начнётся потеря данных, которые надо будет восстанавливать – а служебный трафик при восстановлении данных достаточно значителен. Т.е. гораздо проще передать чуть медленнее, чем потерять много пакетов и выяснить это на уровне TCP-подключения, после чего запрашивать их повторно, теряя время и тратя трафик.
Кстати, проверить поддержку ECN ближайшим маршрутизатором можно бесплатной утилитой Internet Connectivity Evaluation Tool.
Как включить ECN в Windows
netsh interface tcp set global ecn=enabled
Настраиваем TCP Timestamps (по RFC 1323) в Windows
TCP Timestamps – базовая низкоуровневая технология, которая позволяет стеку TCP измерять два важных параметра для соединения: RTTM (задержку канала) и PAWS (защита от дублирующихся TCP-сегментов). В случае, если TCP Timestamps не включены хотя бы с одной стороны подключения, оба механизма вычисления этих параметров отключены и система не может высчитать данные значения. Это приводит к тому, что становится невозможным быстро и эффективно менять размер окна TCP (без знания времени задержки на канале-то). Поэтому включать TCP Timestamps в случае работы с большими объёмами данных (например, обращение к быстрому серверу в локальной сети – типовой сценарий корпоративной LAN) необходимо – ведь иначе протокол TCP не сможет быстро “раскачать” окно передачи.
Как включить TCP Timestamps в Windows
netsh interface tcp set global timestamps=enabled
Побочные эффекты включения TCP Timestamps в Windows
Практически не наблюдаются. Рост локальной загрузки CPU отсутствует, т.к. алгоритм достаточно прост, рост объёмов служебного трафика – так же (RTTM высчитывается, исходя из “времени оборота” обычных сегментов TCP, а не каких-то специальных дополнительных).
Настраиваем автоматический подбор размера окна TCP (WSH) в Windows
Данный параметр достаточно прост. Эта настройка – Window Scale Heuristic – говорит о том, будете ли Вы сами выбирать логику поведения протокола TCP для выбора размеров окна, либо отдадите это на усмотрение операционной системе.
То есть при включенном алгоритме WSH вышеупомянутый тюнинг окна TCP – выбор между disabled/highlyrestricted/restricted/normal/experiemental – будет делаться автоматически и Ваша настройка параметра autotuninglevel будет просто игнорироваться. При просмотре будет появляться служебное окно с текстом "The above autotuninglevel setting is the result of Windows Scaling heuristics overriding any local/policy configuration on at least one profile".
Как включить Window Scaling Heuristic в Windows
netsh interface tcp set heuristics wsh=enabled
Настраиваем базовую безопасность TCP (параметр Memory Pressure Protection) в Windows
Данная функция предназначена для защиты от достаточно известной атаки – локального отказа в обслуживании, вызванного тем, что удалённый атакующий инициирует множество TCP-сессий к нашей системе, система выделяет под каждую сессию буферы и оперативная память, возможно, заканчивается (ну или просто забивается до степени, когда начинается свопинг и производительность ощутимо падает.
Параметр включен по умолчанию в Windows Server 2008 R2, поэтому обычно нет смысла его настраивать, но если что – Вы можете его включить вручную. Более того, Вы можете выбрать, на каких портах эту защиту включать, а на каких – нет. Это имеет смысл, если доступны снаружи лишь некоторые порты, а не все.
Как включить Memory Pressure Protection в Windows
netsh interface tcp set security mpp=enabled
Включение MPP для отдельного порта (например, у нас наружу опубликован веб-сервер)
netsh int tcp set security startport=80 numberofports=1 mpp=enabled
Выключение MPP для всех портов, кроме указанного (например, кроме LDAP)
netsh int tcp set security startport=1 numberofports=65535 mpp=disablednetsh int tcp set security startport=389 numberofports=1 mpp=enablednetsh int tcp set security startport=636 numberofports=1 mpp=enabled
Дополнительно
На самом деле, можно включать или выключать MPP для протоколов IP разных версий отдельно, а не глобально для всех. Для этого будут два ключа реестра с предсказуемыми названиями:
- HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\EnableMPP
- HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip6\Parameters\EnableMPP
Параметр EnableMPP в каждом из случаев имеет тип 32bit DWORD и ставится либо в единицу, либо в нуль.
Вместо заключения
Данный краткий обзор части возможностей настроек сетевой подсистемы Windows имеет собой цель не побудить к немедленной правке всего вышеупомянутого, а показать то, что в данной ОС присутствует достаточно много инструментов тюнинга, хорошее знание которых может очень позитивно повлиять на работу системы. Только надо учитывать, что хорошее знание – это не “какая утилитка какие ключики правит”, а в первую очередь – отличное знание базовых сетевых технологий, которое, увы, сейчас в сообществе специалистов по Windows встречается крайне редко. Но я верю, что у Вас, при надлежащем системном подходе, всё будет хорошо.
UPDATE
Написал вторую часть статьи.
Дата последнего редактирования текста: 2013-10-05T07:18:01+00:00
Возможно, вам будет также интересно почитать эти статьи с нашей Knowledge Base
www.atraining.ru
часть 1 / Блог компании WEBO Group / Хабр
 Ускорение каких-либо процессов невозможно без детального представления их внутреннего устройства. Ускорение интернета невозможно без понимания (и соответствующей настройки) основополагающих протоколов — IP и TCP. Давайте разбираться с особенностями протоколов, влияющих на скорость интернета.
Ускорение каких-либо процессов невозможно без детального представления их внутреннего устройства. Ускорение интернета невозможно без понимания (и соответствующей настройки) основополагающих протоколов — IP и TCP. Давайте разбираться с особенностями протоколов, влияющих на скорость интернета.IP (Internet Protocol) обеспечивает маршрутизацию между хостами и адресацию. TCP (Transmission Control Protocol) обеспечивает абстракцию, в которой сеть надежно работает по ненадежному по своей сути каналу.
Протоколы TCP/IP были предложены Винтом Серфом и Бобом Каном в статье «Протокол связи для сети на основе пакетов», опубликованной в 1974 году. Исходное предложение, зарегистрированное как RFC 675, было несколько раз отредактировано и в 1981 году 4-я версия спецификации TCP/IP была опубликована как два разных RFC:
- RFC 791 – Internet Protocol
- RFC 793 – Transmission Control Protocol
TCP обеспечивает нужную абстракцию сетевых соединений, чтобы приложениям не пришлось решать различные связанные с этим задачи, такие как: повторная передача потерянных данных, доставка данных в определенном порядке, целостность данных и тому подобное. Когда вы работаете с потоком TCP, вы знаете, что отправленные байты будут идентичны полученным, и что они придут в одинаковом порядке. Можно сказать, что TCP больше «заточен» на корректность доставки данных, а не на скорость. Этот факт создает ряд проблем, когда дело доходит до оптимизации производительности сайтов.
Стандарт НТТР не требует использования именно TCP как транспортного протокола. Если мы захотим, мы можем передавать НТТР через датаграммный сокет (UDP – User Datagram Protocol) или через любой другой. Но на практике весь НТТР трафик передается через TCP, благодаря удобству последнего.
Поэтому необходимо понимать некоторые внутренние механизмы TCP, чтобы оптимизировать сайты. Скорее всего, вы не будете работать с сокетами TCP напрямую в своем приложении, но некоторые ваши решения в части проектирования приложения будут диктовать производительность TCP, через который будет работать ваше приложение.
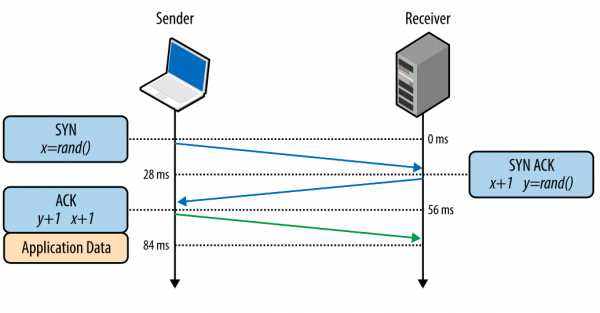
Тройное рукопожатие
Все TCP-соединения начинаются с тройного рукопожатия (рис. 1). До того как клиент и сервер могут обменяться любыми данными приложения, они должны «договориться» о начальном числе последовательности пакетов, а также о ряде других переменных, связанных с этим соединением. Числа последовательностей выбираются случайно на обоих сторонах ради безопасности.SYN
Клиент выбирает случайное число Х и отправляет SYN-пакет, который может также содержать дополнительные флаги TCP и значения опций.SYN ACK
Сервер выбирает свое собственное случайное число Y, прибавляет 1 к значению Х, добавляет свои флаги и опции и отправляет ответ.АСК
Клиент прибавляет 1 к значениям Х и Y и завершает хэндшейк, отправляя АСК-пакет.Рис. 1. Тройное рукопожатие.
После того как хэндшейк совершен, может быть начат обмен данными. Клиент может отправить пакет данных сразу после АСК-пакета, сервер должен дождаться АСК-пакета, чтобы начать отправлять данные. Этот процесс происходит при каждом TCP-соединении и представляет серьезную сложность плане производительности сайтов. Ведь каждое новое соединение означает некоторую сетевую задержку.
Например, если клиент в Нью-Йорке, сервер – в Лондоне, и мы создаем новое TCP-соединение, это займет 56 миллисекунд. 28 миллисекунд, чтобы пакет прошел в одном направлении и столько же, чтобы вернуться в Нью-Йорк. Ширина канала не играет здесь никакой роли. Создание TCP-соединений оказывается «дорогим удовольствием», поэтому повторное использование соединений является важной возможностью оптимизации любых приложений, работающих по TCP.
TCP Fast Open (TFO)
Загрузка страницы может означать скачивание сотен ее составляющих с разных хостов. Это может потребовать создания браузером десятков новых TCP-соединений, каждое из которых будет давать задержку из-за хэндшейка. Стоит ли говорить, что это может ухудшить скорость загрузки такой страницы, особенно для мобильных пользователей.TCP Fast Open (TFO) – это механизм, который позволяет снизить задержку за счет того, что позволяет отправку данных внутри SYN-пакета. Однако и у него есть свои ограничения: в частности, на максимальный размер данных внутри SYN-пакета. Кроме того, только некоторые типы HTTP-запросов могут использовать TFO, и это работает только для повторных соединений, поскольку использует cookie-файл.
Использование TFO требует явной поддержки этого механизма на клиенте, сервере и в приложении. Это работает на сервере с ядром Linux версии 3.7 и выше и с совместимым клиентом (Linux, iOS9 и выше, OSX 10.11 и выше), а также потребуется включить соответствующие флаги сокетов внутри приложения.
Специалисты компании Google определили, что TFO может снизить сетевую задержку при HTTP-запросах на 15%, ускорить загрузку страниц на 10% в среднем и в отдельных случаях – до 40%.
Контроль за перегрузкой
В начале 1984 года Джон Нейгл описал состояние сети, названное им как «коллапс перегрузки», которое может сформироваться в любой сети, где ширина каналов между узлами неодинакова.Когда круговая задержка (время прохождения пакетов «туда-обратно») превосходит максимальный интервал повторной передачи, хосты начинают отправлять копии одних и тех же датаграмм в сеть. Это приведет к тому, что буферы будут забиты и пакеты будут теряться. В итоге хосты будут слать пакеты по нескольку раз, и спустя несколько попыток пакеты будут достигать цели. Это называется «коллапсом перегрузки».
Нейгл показал, что коллапс перегрузки не представлял в то время проблемы для ARPANETN, поскольку у узлов была одинаковая ширина каналов, а у бэкбона (высокоскоростной магистрали) была избыточная пропускная способность. Однако это уже давно не так в современном интернете. Еще в 1986 году, когда число узлов в сети превысило 5000, произошла серия коллапсов перегрузки. В некоторых случаях это привело к тому, что скорость работы сети падала в 1000 раз, что означало фактическую неработоспособность.
Чтобы справиться с этой проблемой, в TCP были применены несколько механизмов: контроль потока, контроль перегрузки, предотвращение перегрузки. Они определяли скорость, с которой данные могут передаваться в обоих направлениях.
Контроль потока
Контроль потока предотвращает отправку слишком большого количества данных получателю, которые он не сможет обработать. Чтобы этого не происходило, каждая сторона TCP-соединения сообщает размер доступного места в буфере для поступающих данных. Этот параметр — «окно приема» (receive window – rwnd).Когда устанавливается соединение, обе стороны задают свои значения rwn на основании своих системных значений по умолчанию. Открытие типичной страницы в интернете будет означать отправку большого количества данных от сервера клиенту, таким образом, окно приема клиента будет главным ограничителем. Однако, если клиент отправляет много данных на сервер, например, загружая туда видео, тогда ограничивающим фактором будет окно приема сервера.
Если по каким-то причинам одна сторона не может справиться с поступающим потоком данных, она должна сообщить уменьшенное значение своего окна приема. Если окно приема достигает значения 0, это служит сигналом отправителю, что не нужно более отправлять данные, пока буфер получателя не будет очищен на уровне приложения. Эта последовательность повторяется постоянно в каждом TCP-соединении: каждый АСК-пакет несет в себе свежее значение rwnd для обеих сторон, позволяя им динамически корректировать скорость потока данных в соответствии с возможностями получателя и отправителя.
 Рис. 2. Передача значения окна приема.
Рис. 2. Передача значения окна приема.
Масштабирование окна (RFC 1323)
Исходная спецификация TCP ограничивала 16-ю битами размер передаваемого значения окна приема. Это серьезно ограничило его сверху, поскольку окно приема не могло быть более 2^16 или 65 535 байт. Оказалось, что это зачастую недостаточно для оптимальной производительности, особенно в сетях с большим «произведением ширины канала на задержку» (BDP – bandwidth-delay product).Чтобы справиться с этой проблемой в RFC 1323 была введена опция масштабирования TCP-окна, которая позволяла увеличить размер окна приема с 65 535 байт до 1 гигабайта. Параметр масштабирования окна передается при тройном рукопожатии и представляет количество бит для сдвига влево 16-битного размера окна приема в следующих АСК-пакетах.
Сегодня масштабирование окна приема включено по умолчанию на всех основных платформах. Однако промежуточные узлы, роутеры и сетевые экраны могут переписать или даже удалить этот параметр. Если ваше соединение не может полностью использовать весь канал, нужно начать с проверки значений окон приема. На платформе Linux опцию масштабирования окна можно проверить и установить так:
$> sysctl net.ipv4.tcp_window_scaling $> sysctl -w net.ipv4.tcp_window_scaling=1 В следующей части мы разберемся, что такое TCP Slow Start, как оптимизировать скорость передачи данных и увеличить начальное окно, а также соберем все рекомендации по оптимизации TCP/IP стека воедино.habr.com
Тонкая настройка сетевого стека на Windows-хостах (часть вторая)
Привет.
Это – вторая часть статьи. Поэтому всё, что относится к первой, относится и к этой. В этой, правда, будет больше настроек сетевых адаптеров, но не суть. Не буду повторяться, разве что в плане диспозиции.
Диспозиция
Я предполагаю, что Вы, товарищ читатель, знаете на приемлемом уровне протокол TCP, да и вообще протоколы сетевого и транспортного уровней. Ну и канального тоже. Чем лучше знаете – тем больше КПД будет от прочтения данной статьи.
Речь будет идти про настройку для ядра NT 6.1 (Windows 7 и Windows Server 2008 R2). Всякие исторические ссылки будут, но сами настройки и команды будут применимы к указанным ОС, если явно не указано иное.
В тексте будут упоминаться ключи реестра. Некоторые из упоминаемых ключей будут отсутствовать в официальной документации. Это не страшно, но перед любой серьёзной модификацией рабочей системы лучше фиксировать то, что Вы с ней делаете, и всегда иметь возможность удалённого доступа, не зависящую от состояния сетевого интерфейса (например KVM).
Содержание (то, что зачёркнуто, было в первой части статьи)
Работаем с RSSРаботаем с CTCPРаботаем с NetDMAРаботаем с DCAРаботаем с ECNРаботаем с TCP TimestampsРаботаем с WSHРаботаем с MPP
- Работаем с управлением RWND (autotuninglevel)
- Работаем с Checksum offload IPv4/IPv6/UDP/TCP
- Работаем с Flow Control
- Работаем с Jumbo Frame
- Работаем с AIFS (Adaptive Inter-frame Spacing)
- Работаем с Header Data Split
- Работаем с Dead Gateway Detection
Работаем с управлением RWND (autotuninglevel)
Данный параметр тесно связан с описаным ранее параметром WSH – Window Scale Heuristic. Говоря проще, включение WSH – это автоматическая установка данного параметра, а если хотите поставить его вручную – выключайте WSH.
Параметр определяет логику управление размером окна приёма – rwnd – для TCP-соединений. Если Вы вспомните, то размер этого окна указывается в поле заголовка TCP, которое называется window size и имеет размер 16 бит, что ограничивает окно 2^16 байтами (65536). Этого может быть мало для текущих высокоскоростных соединений (в сценариях вида “с одного сервера по IPv6 TCPv6-сессии и десятигигабитной сети копируем виртуалку” – совсем тоскливо), поэтому придуман RFC 1323, где описывается обходной способ. Почему мало? Потому что настройка этого окна по умолчанию такова:
- Для сетей со скоростью менее 1 мегабита – 8 КБ (если точнее, 6 раз по стандартному MSS – 1460 байт)
- Для сетей со скоростью 100 Мбит и менее, но более 1 Мбит – 17 КБ (12 раз по стандартному MSS – 1460 байт)
- Для сетей со скоростью выше 100 Мбит – 64 КБ (максимальное значение без поддержки RFC 1323)
Способ обхода, предлагаемый в RFC 1323, прост и красив. Два хоста, ставящих TCP-сессию, согласовывают друг с другом параметр, который является количеством бит, на которые будет сдвинуто значение поля windows size. То есть, если они согласуют этот параметр равный 2, то оба из них будут читать это поле сдвинутым “влево” на 2 бита, что даст увеличение параметра в 2^2=4 раза. И, допустим, значение этого поля в 64К превратится в 256К. Если согласуют 5 – то поле будет сдвинуто “влево” на 5 бит, и 64К превратится в 2МБ. Максимальный поддерживаемый Windows порог этого значения (scaling) – 14, что даёт максимальный размер окна в 1ГБ.
Как настраивается RWND в Windows
Существующие варианты настройки этого параметра таковы:
- netsh int tcp set global autotuninglevel=disabled – фиксируем значение по умолчанию (для гигабитного линка это будет 64K), множитель – нуль. Это поможет, если промежуточные узлы (например, старое сетевое оборудование) не понимает, что значение окна TCP – это не поле window size, а оно, модифицированное с учётом множителя scaling.
- netsh int tcp set global autotuninglevel=normal – оставляем автонастройку, значение множителя – не более 8.
- netsh int tcp set global autotuninglevel=highlyrestricted – оставляем автонастройку, значение множителя – не более 2.
- netsh int tcp set global autotuninglevel=restricted – оставляем автонастройку, значение множителя – не более 4.
- netsh int tcp set global autotuninglevel=experimental – оставляем автонастройку, значение множителя – до 14.
Ещё раз – если Вы включите WSH, он сам будет подбирать “максимальный” множитель, на котором достигается оптимальное качество соединения. Подумайте перед тем, как править этот параметр вручную.
Работаем с Checksum offload IPv4/IPv6/UDP/TCP
Данная пачка технологий крайне проста. Эти настройки снимают с CPU задачи проверки целостности полученых данных, которые (задачи, а не данные) являются крайне затратными. То есть, если Вы получили UDP-датаграмму, Вам, по сути, надо проверить CRC у ethernet-кадра, у IP-пакета, и у UDP-датаграммы. Всё это будет сопровождаться последовательным чтением данных из оперативной памяти. Если скорость интерфейса большая и трафика много – ну, Вы понимаете, что эти, казалось бы, простейшие операции, просто будут занимать ощутимое время у достаточно ценного CPU, плюс гонять данные по шине. Поэтому разгрузки чексумм – самые простые и эффективно влияющие на производительность технологии. Чуть подробнее про каждую из них:
IPv4 checksum offload
Сетевой адаптер самостоятельно считает контрольную сумму у принятого IPv4 пакета, и, в случае, если она не сходится, дропит пакет.
Бывает продвинутая версия этой технологии, когда адаптер умеет сам проставлять чексумму отправляемого пакета. Тогда ОС должна знать про поддержку этой технологии, и ставить в поле контрольной суммы нуль, показывая этим, чтобы адаптер выставлял параметр сам. В случае chimney, это делается автоматически. В других – зависит от сетевого адаптера и драйвера.
IPv6 checksum offload
Учитывая, что в заголовке IPv6 нет поля checksum, под данной технологией обычно имеется в виду “считать чексумму у субпротоколов IPv6, например, у ICMPv6”. У IPv4 это тоже подразумевается, если что, только у IPv4 субпротоколов, подпадающих под это, два – ICMP и IGMP.
UDPv4/v6 checksum offload
Реализуется раздельно для приёма и передачи (Tx и Rx), соответственно, считает чексуммы для UDP-датаграмм.
TCPv4/v6 checksum offload
Реализуется раздельно для приёма и передачи (Tx и Rx), соответственно, считает чексуммы для TCP-сегментов. Есть тонкость – в TCPv6 чексумма считается по иной логике, нежели в UDP.
Общие сведения для всех технологий этого семейства
Помните, что все они, по сути, делятся на 2 части – обработка на адаптере принимаемых данных (легко и не требует взаимодействия с ОС) и обработка адаптером отправляемых данных (труднее и требует уведомления ОС – чтобы ОС сама не считала то, что будет посчитано после). Внимательно изучайте документацию к сетевым адаптерам, возможности их драйверов и возможности ОС.
Ещё есть заблуждение, гласящее примерно следующее “в виртуалках всё это не нужно, ведь это все равно работает на виртуальных сетевухах, значит, считается на CPU!”. Это не так – у хороших сетевых адаптеров с поддержкой VMq этот функционал реализуется раздельно для каждого виртуального комплекта буферов отправки и приёма, и в случае, если виртуальная система “заказывает” этот функционал через драйвер, то он включается на уровне сетевого адаптера.
Как включить IP,UDP,TCP checksum offload в Windows
Включается в свойствах сетевого адаптера. Операционная система с данными технологиями взаимодействует через минипорт, читая настройки и учитывая их в случае формирования пакетов/датаграмм/сегментов для отправки. Так как по уму это всё реализовано в NDIS 6.1, то надо хотя бы Windows Server 2008.
Работаем с Flow Control
Вы наверняка видели в настройках сетевых адаптеров данный параметр. Он есть практически на всех, поскольку технология данная (официально называемая 802.3x) достаточно простая и древняя. Но это никак не отменяет её эффективность.
Суть технологии проста – существует множество ситуаций, когда приём кадра L2 нежелателен (заполнен буфер приёма, перегружена шина данных, загружен порт получателя). В этом случае без управления потоком кадр придётся просто отбросить (обычный tail-drop). Это повлечёт за собой последующее обнаружение потери пакета, который был в кадре, и долгие выяснения на уровне протоколов более высоких уровней (того же TCP), что и как произошло. Иными словами, потеря 1.5КБ кадра превратится в каскад проблем, согласований и выяснений, на которые будет затрачено много времени и куда как больше трафика, чем если бы потери удалось избежать.
А избежать её просто – надо отправить сигнальный кадр с названием PAUSE – попросить партнёра “притормозить на чуток”. Соответственно, надо, чтобы устройство умело и обрабатывать такие кадры, и отправлять их. Кадр устроен просто – это 802.3 с вложением с кодом 0x0001, отправляемое на мультикастовый адрес 01-80-C2-00-00-01, внутри которого – предлагаемое время паузы.
Включайте поддержку этой технологии всегда, когда это возможно – в таком случае в моменты пиковой нагрузки сетевая подсистема будет вести себя более грамотно, сокращая время перегрузки за счёт интеллектуального управления загрузкой канала.
Как включить Flow control в Windows
Включается в свойствах сетевого адаптера. Операционная система с данной технологией не взаимодействует. Не забудьте про full duplex.
Работаем с Jumbo Frame
Исторически размер данных кадра протокола Ethernet – это 1.5КБ, что в сумме со стандартным заголовком составляет 1518 байт, а в случае транкинга 802.1Q – 1522 байт. Соответственно, этот размер оставался, а скорости росли – 10 Мбит, 100 Мбит, 1 Гбит. Скорость в 100 раз выросла – а размер кадра остался. Непорядок. Ведь это обозначает, что процессор в 100 раз чаще “дёргают” по поводу получения нового кадра, что объём служебных данных также остался прежним. Совсем непорядок.
Идея jumbo frame достаточно проста – увеличить максимальный размер кадра. Это повлечёт огромное количество плюсов:
- Улучшится соотношение служебных и “боевых” данных – ведь вместо, допустим, 4х IP-пакетов можно отправить один.
- Уменьшится число переключений контекста – можно будет реже инициировать функцию “пришёл новый кадр”.
- Можно соответствующим образом увеличить размеры PDU верхних уровней – пакета IP, датаграммы UDP, сегмента TCP – и получить соответствующие преимущества.
Данная технология реализуема только на интерфейсах со скоростями 1 гбит и выше. Если Вы включите jumbo frames на уровне сетевого адаптера, а после согласуете скорость в 100 мбит, то данная настройка не будет иметь смысла.
Для увеличения максимального размера кадра есть достаточно технологических возможностей – например, длина кадра хранится в поле размером в 2 байта, поэтому менять формат кадра 802.3 не нужно – место есть. Ограничением является логика подсчёта CRC, которая становится не очень эффективна при размерах >12К, но это тоже решаемо.
Самый простой способ – выставить у адаптера данный параметр в 9014 байт. Это является тем, что сейчас “по умолчанию” называется jumbo frame и шире всего поддерживается.
Есть ли у данной технологии минусы? Есть. Первый – в случае потери кадра из-за обнаружения сбоя в CRC Вы потеряете в 6 раз больше данных. Второй – появляется больше сценариев, когда будет фрагментация сегментов TCP-сессий. Вообще, в реальности эта технология очень эффективна в сценарии “большие потоки не-realtime данных в локальной сети”, учитывайте это. Копирование файла с файл-сервера – это целевой сценарий, разговор по скайпу – нет. Замечу также, что протокол IPv6 более предпочтителен в комбинации с Jumbo frame.
Как включить Jumbo frame в Windows
Включается в свойствах сетевого адаптера (естественно, только гигабитного). Операционная система с данной технологией не взаимодействует, автоматически запрашивая у сетевой подсистемы MTU канального уровня.
Работаем с AIFS (Adaptive Inter-frame Spacing)
Данная технология предназначена для оптимизации работы на half-duplex сетях со скоростями 10/100 мегабит, и, в общем-то, сейчас не особо нужна. Суть её проста – в реальной жизни, при последовательной передаче нескольких ethernet-кадров одним хостом, между ними есть паузы – чтобы и другие хосты могли “влезть” и передать свои данные, и чтобы работал механизм обнаружения коллизий (который CSMA/CD). Иначе, если бы кадры передавались “вплотную”, хост, копирующий по медленной сети большой поток данных, монополизировал бы всю сеть для себя. В случае же full-duplex данная мера уже не сильно интересна, потому что ситуации “из N хостов одновременно может передавать только один” нет. Помните, что включая данную технологию, Вы позволяете адаптеру уменьшать межкадровое расстояние ниже минимума, что приведёт к чуть более эффективному использованию канала, но в случае коллизии Вы получите проблему – “погибнет” не только один кадр, но и соседний (а то и несколько).
Данные паузы называются или interframe gap, или interframe spacing. Минимальное штатное значение этого параметра – 96 бит. AIFS уменьшает это значение до:
- 47 бит в случае канала 10/100 МБит.
- 64 бит в случае канала 1 ГБит.
- 40 бит в случае канала 10 ГБит.
Как понятно, чисто технически уменьшать это значение до чисел менее 32 бит (размер jam) совсем неправильно, поэтому можно считать 32 бита технологическим минимумом IFS.
Процесс, который состоит в приёме потока кадров с одним IFS и отправкой с другим IFS, иногда называется IFG Shrinking.
В общем, говоря проще – негативные эффекты этой технологии есть, но они будут только на 10/100 Мбит сетях в режиме half-duplex, т.к. связаны с более сложным сценарием обработки коллизий. В остальном у технологии есть плюс, Вы получите небольшой выигрыш в части эффективности загрузки канала в сценарии “плотный поток от одного хоста”.
Да, не забудьте, что коммутатор должен “понимать” ситуацию, когда кадры идут плотным (и более плотным, чем обычно) потоком.
Как включить Adaptive Inter-frame Spacing в Windows
Включается в свойствах сетевого адаптера. Операционная система с данной технологией не взаимодействует.
Работаем с Header Data Split
Фича достаточно интересна и анонсирована только в NDIS 6.1. Суть такова – допустим, что у Вас нет Chimney Offload и Вы обрабатываете заголовки программно. К Вам приходят кадры протокола Ethernet, а в них, как обычно – различные вложения протоколов верхних уровней – IP,UDP,TCP,ICMP и так далее. Вы проверяете CRC у кадра, добавляете кадр в буфер, а после – идёт специфичная для протокола обработка (выясняется протокол сетевого уровня, выясняется содержимое заголовка и предпринимаются соответствующие действия). Всё логично.
Но вот есть одна проблема. Смотрите. Если Вы приняли, допустим, сегмент TCP-сессии, обладающий 10К данных, то, по сути, последовательность действий будет такая (вкратце):
- Сетевая карта: Обработать заголовок 802.3; раз там 0x0800 (код протокола IPv4), то скопировать весь пакет и отдать наверх на обработку. Ведь в данные нам лезть незачем – не наша задача, отдадим выше.
- Минипорт: Прочитать заголовок IP, понять, что он нормальный, найти код вложения (раз TCP – то 6) и скопировать дальше. Данные-то не нам не нужны – это не наша задача, отдадим выше.
- NDIS: Ага, это кусок TCP-сессии номер X – сейчас изучим его и посмотрим, как и что там сделано
Заметили проблему? Она проста. Каждый слой читает свой заголовок, который исчисляется в байтах, а тащит ради этого путём копирования весь пакет.
Технология Header-Data Split адресно решает этот вопрос – заголовки пакетов и данные хранятся отдельно. Т.е. когда при приёме кадра в нём обнаруживается “расщепимое в принципе” содержимое, то оно разделяется на части – в нашем примере заголовки IP+TCP будут в одном буфере, а данные – в другом. Это сэкономит трафик копирования, притом очень ощутимо – как минимум на порядки (сравните размеры заголовков IP, который максимум 60 байт, и размер среднего пакета). Технология крайне полезна.
Как включить Header-Data Split в Windows
Включится оно само, как только сетевой драйвер отдаст минипорту флаг о поддержке данной технологии. Можно выключить вручную, отдав NDIS_HD_SPLIT_COMBINE_ALL_HEADERS через WMI на данный сетевой адаптер – тогда минипорт будет “соединять” головы и жо не-головы пакетов перед отправкой их на NDIS. Это может помочь в ситуациях, когда адаптер некорректно “расщепляет” сетевой трафик, что будет хорошо заметно (например, ничего не будет работать, потому что TCP-заголовки не будут обрабатываться корректно). В общем и целом – включайте на уровне сетевого адаптера, и начиная с Windows Server 2008 SP2 всё дальнейшее будет уже не Вашей заботой.
Работаем с Dead Gateway Detection
Данный механизм – один из самых смутных. Я лично слышал вариантов 5 его работы, все из которых были неправильными. Давайте разберёмся.
Первое – для функционирования этого механизма надо иметь хотя бы 2 шлюза по умолчанию. Не маршрутов, вручную добавленых в таблицу маршрутизации через route add например, а два и более шлюза.
Второе – этот механизм работает не на уровне IP, а на уровне TCP. Т.е. по сути, это обнаружение повторяющихся ошибок при попытке передать TCP-данные, и после этого – команда всему IP-стеку сменить шлюз на другой.
Как же будет работать этот механизм? Логика достаточно проста. Стартовые условия – механизм включен и параметр TcpMaxDataRetransmissions настроен по-умолчанию, то есть равен 5. Допустим, что у нас на данный момент есть 10 tcp-подключений.
- На каждое подключение создаётся т.н. RCE – route cache entry – строчка в кэше маршрутов, которая говорит что-то вида такого “все соединения с IP-адреса X на IP-адрес Y ходят через шлюз Z, пересчитывать постоянно это не нужно, потому что полностью обрабатывать таблицу маршрутизации ради 1го пакета – уныло и долго. Ну, этакий Microsoft’овский свичинг L3 типа CEF. :)
- Соединение N1 отправляет очередной сегмент TCP-сессии. В ответ – тишина. Помер.
- Соединение N1 отправляет тот же сегмент TCP-сессии, уже имея запись, что 1 раз это не получилось. В ответ – опять тишина. Нет ACK’а. И этот сегмент стал героем.
- Соединение N1 нервничает и отправляет тот же сегмент TCP-сессии. ACK’а нет. Соединение понимает, что так жить нельзя и делает простой вывод – произошло уже 3 сбоя отправки, что больше, чем половина значения TcpMaxDataRetransmissions, которое у нас 5. Соединение объявляет шлюз нерабочим и заказывает смену шлюза.
- ОС выбирает следующий по приоритету шлюз, обрабатывает маршрут и генерит новую RCE-запись.
- Счётчик ошибок сбрасывается на нуль, и всё заново – злополучный сегмент соединения N1 опять пробуют отправить.
Когда такое происходит для более чем 25% соединений (у нас их 10, значит, когда такое случится с 3 из них), то IP-стек меняет шлюз по-умолчанию. Уже не для конкретного TCP-соединения, а просто – для всей системы. Счётчик количества “сбойных” соединений сбрасывается на нуль и всё готово к продолжению.
Как настроить Dead Gateway Detection в Windows
Для настройки данного параметра нужно управлять тремя значениями в реестре, находящимися в ключе:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\
Все они имеют тип 32bit DWORD и следующую логику настройки:
- TcpMaxDataRetransmissions – Количество повторных передач TCP-сегментов. От этого числа берётся критерий “Более половины”.
- TcpMaxConnectRetransmissions – То же самое, но для повторных попыток подключения, а не передачи сегментов данных.
- EnableDeadGWDetect – Включён ли вообще алгоритм обнаружения “мёртвого” шлюза. Единица – включён, нуль – отключен.
Вместо заключения
Сетевых настроек – много. Знать их необходимо, чтобы не делать лишнюю работу, не ставить лишний софт, который кричит об “уникальных возможностях”, которые, на самом деле, встроены в операционную систему, не разрабатывать дурацкие архитектурные решения, базирующиеся на незнании матчасти архитектором, и в силу множества других причин. В конце концов, это интересно.
Если как-нибудь дойдут руки – будет новая часть статьи.
Дата последнего редактирования текста: 2013-10-05T07:17:01+00:00
Возможно, вам будет также интересно почитать эти статьи с нашей Knowledge Base
www.atraining.ru