Обзор управления емкостью и изменения размера в SharePoint Server 2013. Оптимизация базы данных sharepoint уменьшение кластера
Обзор управления емкостью и изменения размера в SharePoint Server 2013
Применимо к:SharePoint Server 2013 Enterprise, SharePoint Server 2013 Standard
Последнее изменение раздела:2016-12-16
Сводка.Знакомство с использованием данных производительности для планирования емкости среды SharePoint Server 2013 и управления ей.
В этой статье представлен обзор способов эффективного планирования и управления емкостью сред SharePoint Server 2013. В этой статье также рассказано о том, как анализ производительности помогает лучше понять потребность в емкости и оценить возможности планируемого развертывания. Кроме того, рассматривается влияние основных приложений на емкость среды, включая характеристики контента и потребление ресурсов.
| Некоторые значения в этой статье представлены по результатам тестов и других сведений о Продукты SharePoint 2010, и могут не являться конечными значениями для SharePoint Server 2013. Эту статью планируется дополнить необходимыми значениями, ссылками на связанный контент и другими данными. Публикация обновленной версии статьи состоится после выпуска SharePoint Server 2013. |
Управление емкостью представляет собой непрерывный процесс, поскольку такие аспекты реализованного решения, как контент и потребление ресурсов, не могут оставаться неизменными. Необходимо планировать емкость с учетом развития и изменения, чтобы среда на основе SharePoint Server 2013 предоставляла достаточно возможностей для эффективной работы.
Планирование емкости представляет собой лишь один из этапов цикла управления емкостью. Это исходный набор действий, который позволяет архитектору достичь того уровня исходной архитектуры, который, по его мнению, оптимально обеспечивает работоспособность среды SharePoint Server 2013. Модель управления емкостью также предусматривает дополнительные этапы, позволяющие выполнить проверку и настройку исходной архитектуры; а также предоставляет цепь обратной связи для повторного планирования и оптимизации производственной среды, обеспечивающей выполнение задач разработки для оптимального выбора оборудования, топологии и конфигурации.
В этой статье
В документации по управлению емкостью SharePoint Server 2013 используются следующие специальные термины.
-
RPS Запросов в секунду. Количество запросов, получаемое фермой или сервером за одну секунду. Эта величина является стандартным показателем измерения нагрузки сервера или фермы. Количество запросов, обрабатываемых фермой, превышает количество загрузок страницы и действий конечных пользователей. Это обусловлено тем, что каждая страница содержит несколько компонентов, каждый из которых при загрузке страницы создает один или несколько запросов. Затраты на транзакцию для одних запросов могут быть меньше, чем для других. В лабораторных тестах и документации по конкретным примерам в расчет RPS не включены 401 запрос и ответ (связанные с проверкой подлинности), так как они не оказывают значительного влияния на ресурсы фермы.
-
Часы пиковой загрузки Время суток (один или несколько раз в сутки), когда загрузка фермы максимальна.
-
Пиковая загрузка Средняя максимальная загрузка в день, измеряемая в RPS (запросов в секунду).
-
Скачок загрузки Временные скачки загрузки вне обычных часов пиковой загрузки. Такие скачки могут быть вызваны незапланированным увеличением пользовательского трафика, снижением пропускной способности фермы из-за административных операций или сочетанием этих факторов.
-
Вертикальное масштабирование Вертикальным масштабированием называется добавление для сервера таких ресурсов, как процессоры или память.
-
Горизонтальное масштабирование Горизонтальным масштабированием называется добавление дополнительных серверов в ферму.
Чтобы решить, стоит ли вам читать эту статью, рассмотрите следующие вопросы.
| Некоторые ссылки в этом разделе могут относиться к SharePoint Server 2010 и другим более ранним версиям, и будут обновлены при выпуске новых версий SharePoint Server 2013 данного контента. |
Я отвечаю за принятие решений в ИТ-отделе или организации и занимаюсь поиском решения для конкретных задач. Я рассматриваю SharePoint Server 2013 как возможный вариант решения в рамках существующей среды. Сможет ли этот продукт обеспечить функции и возможности масштабирования, соответствующие моим требованиям?
Сведения о способах масштабирования SharePoint Server 2013 в соответствии с требованиями отдельных решений, а также об определении оборудования для обеспечения текущих потребностей см. в следующих разделах настоящей статьи:
Сведения о способах оценки соответствия SharePoint Server 2013 конкретным бизнес-требованиям см. в следующих статьях:
В текущий момент я использую SharePoint Server 2010. Что изменилось в SharePoint Server 2013 и что необходимо учитывать при обновлении? Как обновление повлияет на производительность и масштабируемость моей топологии?
Сведения о других вопросах обновления и рекомендации по планированию и выполнению обновления Office SharePoint Server 2007 см. в следующей статье:
Мы развернули SharePoint Server 2013 и хотим убедиться, что используем необходимое оборудование и топологию. Как проверить архитектуру и правильно ее обслуживать?
Сведения о счетчиках производительности и мониторинга для ферм SharePoint Server 2013 см. в такой статье:
Сведения об использовании средств мониторинга работоспособности, встроенных в интерфейс центра администрирования, см. в следующей статье:
Мы развернули SharePoint Server 2013 и у нас возникли проблемы с производительностью. Как их устранить и оптимизировать среду?
Сведения о счетчиках производительности и мониторинга для ферм SharePoint Server 2013 см. в таких статьях:
Сведения о средствах и методах оптимизации ферм SharePoint Server 2013 см. в следующей статье:
Сведения об устранении неполадок с помощью средств мониторинга работоспособности, встроенных в интерфейс центра администрирования, см. в следующей статье:
Список статей, посвященных управлению емкостью, для определенных служб и компонентов SharePoint Server 2010 (новые статьи добавляются по мере появления) см. в следующей статье:
Сведения о размерах и производительности баз данных см. в следующей статье:
Сведения об удаленном хранилище BLOB-объектов (RBS) см. в следующей статье:
Я хочу знать все про управление емкостью SharePoint Server 2013. С чего начать?
Сведения об общих понятиях управления емкостью и ссылки на дополнительные документы и ресурсы см. в следующей статье:
Дополнительные сведения об управлении емкостью см. в следующих статьях, сопутствующих этой обзорной статье:
После изучения этих статей вы получите необходимые сведения об основных понятиях. Сведения об ограничениях SharePoint Server 2013 см. в следующей статье:
Когда вы будете готовы к определению начальной топологии для среды на основе SharePoint Server 2013, вы сможете изучить библиотеку доступных технических примеров использования и найти наиболее среди них тот, что наиболее совпадает с вашими требованиями. Список примеров использования SharePoint Server 2010 (новые примеры использования SharePoint Server 2013 публикуются по мере доступности) см. в следующей статье:
Сведения о мониторинге работоспособности и устранении неполадок с помощью средств мониторинга работоспособности, встроенных в интерфейс центра администрирования, см. в следующих статьях:
Дополнительные сведения о виртуализации серверов на основе SharePoint Server 2013 см. в следующей статье:
Дополнительные сведения о высокой доступности и аварийном восстановлении см. в следующей статье:
Управление емкостью связано с четырьмя основными аспектами изменения размера решения:
-
Задержка В рамках управления емкостью задержка определяется как период между временем запуска действия пользователем (например, переход по гиперссылке) и временем передачи последнего байта в клиентское приложение или веб-браузер.
-
Пропускная способность Пропускная способность определяется как количество параллельных запросов, которые могут быть обработаны сервером или фермой серверов.
-
Масштаб данных Масштаб данных определяется как размер контента и состав данных, которые могут быть размещены в системе. Структура и распространение баз данных контента существенно влияют на время обработки запросов системой (задержка) и на количество обрабатываемых запросов (пропускная способность).
-
Надежность Надежность представляет собой показатель способности системы достигать заданных целевых значений задержки и пропускной способности.
Основной целью управления емкостью среды является настройка и обслуживание системы, обеспечивающей достижение целевых показателей задержки, пропускной способности, масштаба данных и надежности, установленных для организации.
Задержка или задержка, распознаваемая конечным пользователем, включает три основных компонента:
-
Время, затраченное сервером на получение и обработку запроса.
-
Время, затраченное на передачу запроса и отклика сервера по сети.
-
Время, затраченное на отображение отклика в клиентском приложении.
Для различных организаций определены различные целевые значения задержки в зависимости от бизнес-требований и ожиданий пользователей. Некоторые организации могут позволить себе задержку в несколько секунд, в то время как другим требуется максимальная скорость транзакции. Оптимизация скорости транзакций требует наличия более мощных серверов и клиентов, новейших версий браузера и клиентского приложения, сетевых решений для каналов с высокой пропускной способностью, а также, возможно, дополнительных инвестиций в разработку и настройку страниц.
Некоторые ключевые факторы, увеличивающие задержку, распознаваемую конечным пользователем, а также примеры некоторых распространенных проблем описаны в следующем списке. Эти факторы имеют особое значение в сценариях, где клиенты географически удалены от фермы серверов или осуществляют доступ к ферме посредством сетевого подключения с использованием канала с низкой пропускной способностью.
-
Компоненты, службы или параметры конфигурации, для которых не выполнялась оптимизация, могут вызвать задержку в обработке запросов и повлиять на значение задержки для удаленных и локальных клиентов. Дополнительные сведения см. в разделах Пропускная способность и Надежность далее в этой статье.
-
Веб-страницы, создающие необязательные запросы к серверу при загрузке требуемых данных и ресурсов. Оптимизация подразумевает загрузку минимального количества ресурсов для отрисовки страницы, то есть сокращение размера изображений, статическое хранение ресурсов в папках в целях анонимного доступа, кластеризацию запросов и возможность интерактивной работы со страницей во время асинхронной загрузки ресурсов с сервера. Такие функции оптимизации имеют существенное значение для создания хорошего впечатления при первом посещении сайта.
-
Избыточный объем данных, передаваемых по сети, способствует увеличению задержки и снижению пропускной способности. Например, для изображений и других двоичных объектов следует по возможности использовать сжатый формат (PNG или JPG) вместо растрового (BMP).
Веб-страницы, не оптимизированные для ускорения повторной загрузки страниц. Время загрузки страницы (PLT) сокращается при ее повторной загрузке, поскольку некоторые ресурсы страницы кэшируются в клиенте и браузеру приходится загружать лишь динамический некэшируемый контент. Недопустимые задержки при повторной загрузке страницы зачастую возникают из-за неправильной конфигурации кэша больших двоичных объектов (BLOB) или вследствие отключения кэширования локального браузера на клиентских компьютерах. Оптимизация подразумевает правильное кэширование ресурсов на клиенте.
-
Веб-страницы, содержащие неоптимизированный код JavaScript. Это может замедлить отображение страницы в клиенте. При оптимизации обработка кода JavaScript в клиенте будет отложена до тех пор, пока не загрузится остальная часть страницы; также предпочтительно выполнить вызов скриптов вместо добавления встроенного кода JavaScript.
Пропускная способность выражается в количестве запросов, которые могут быть обработаны фермой серверов за единицу времени, а также зачастую используется для оценки масштаба операций, предположительно поддерживаемых системой, в зависимости от масштабов организации и ее характеристик потребления. Каждая операция характеризуется определенными затратами ресурсов фермы серверов. Для понимания потребностей и развертывания архитектуры фермы, способной последовательно удовлетворять потребности, требуется оценка предполагаемой загрузки и проверка архитектуры под нагрузкой для подтверждения соответствия значения задержки установленному целевому уровню при высоком уровне параллелизма в условиях значительной рабочей нагрузки на систему.
Далее приведены несколько распространенных причин снижения пропускной способности.
-
Недостаточные аппаратные ресурсы Если ферма получает больше запросов, чем она способна обрабатывать параллельно, некоторые запросы помещаются в очередь, в которой обработка каждого последующего запроса задерживается в накопительном порядке до тех пор, пока объем спроса не сократится настолько, чтобы можно было очистить очередь. Далее приведены несколько примеров оптимизации фермы в целях обеспечения более высокой пропускной способности:
-
Убедитесь, что уровень использования процессоров серверов в ферме не превышен. Например, если использование ресурсов ЦП в часы пиковой загрузки или уровень скачков загрузки постоянно превышает 80 %, необходимо добавить дополнительные серверы или перераспределить службы на другие серверы фермы.
-
Убедитесь, что для серверов приложений и веб-серверов доступно достаточно памяти, чтобы в ней полностью содержался кэш. Это позволяет избежать вызовов базы данных для обслуживания запросов некэшированного контента.
-
Если общего доступного объема операций ввода-вывода в секунду для данного диска недостаточно для обеспечения потребности в пиковые часы загрузки, необходимо добавить дополнительные диски или перераспределить базы данных на диски с неполной загрузкой. Дополнительные сведения см. в разделе "Удаление узких мест" статьи Мониторинг и обслуживание SharePoint Server 2013.
-
Если добавления ресурсов для существующих компьютеров недостаточно, чтобы разрешить проблему пропускной способности, следует добавить серверы и перераспределить затронутые функции и службы на новые серверы.
-
-
Неоптимизированные пользовательские веб-страницы Добавление пользовательского кода на часто используемые страницы в производственной среде — распространенная причина возникновения проблем с пропускной способностью. Добавление пользовательского кода может создавать дополнительные полные обходы серверов базы данных или веб-служб для запросов служебных данных. Настройка редко используемых страниц может не оказывать существенного влияния на пропускную способность, однако даже оптимизированный код способен снизить пропускную способность фермы, если запросы к нему отправляются несколько тысяч раз в день. Администраторы SharePoint Server 2013 могут включить панель разработчика для обнаружения пользовательского кода, который требует оптимизации. Далее приведены несколько примеров оптимизации пользовательского кода:
-
Минимизация количества запросов к веб-службам и SQL-запросов.
-
Выбор минимального объема требуемых данных в каждом обращении к серверу базы данных при ограничении количества обязательных полных обходов.
-
Запрет на добавление пользовательского кода на часто используемые страницы.
-
Использование индексов при извлечении фильтрованных данных.
-
-
Ненадежное решение Развертывание пользовательского кода в папках "Bin" может вызвать снижение быстродействия сервера. При каждом запросе страницы, содержащей ненадежный код, SharePoint Server 2013 будет выполнять проверку безопасности, прежде чем разрешить загрузку страницы. За исключением случаев, когда развертывание ненадежного кода обусловлено определенными причинами, необходимо установить пользовательские сборки в глобальный кэш сборок во избежание ненужной проверки безопасности.
technet.microsoft.com
Режем лог-файлы базы SharePoint 2013
Все началось с того, что перестал работать backup фермы SharePoint 2013. На этом моменте я завис на какое-то время, не мог понять в чем же причина. Скрипты в планировщике не менялись, задания планировщика запускаются, но резервное копирование не выполняется. В логах была ошибка, что на диске не хватает свободного места. Места на дисках было достаточно, поэтому я списал на привередливость SharePoint, которому нужно всегда свободного места с запасом.
Причина стала явной только после ручного запуска резервного копирования фермы SharePoint 2013. Где в сообщении был указан примерный размер резервной копии – 103 гигабайта! Хотя, все предыдущие бэкапы занимали не более 30 гигов.
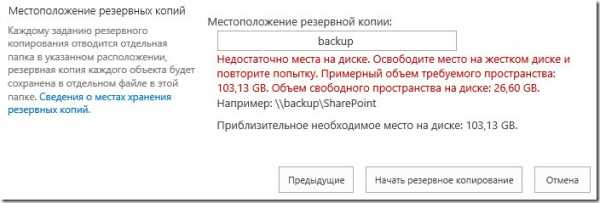
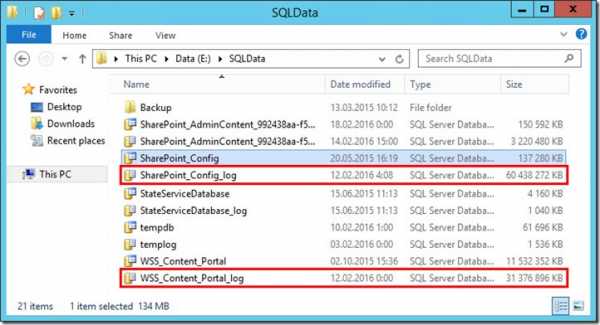
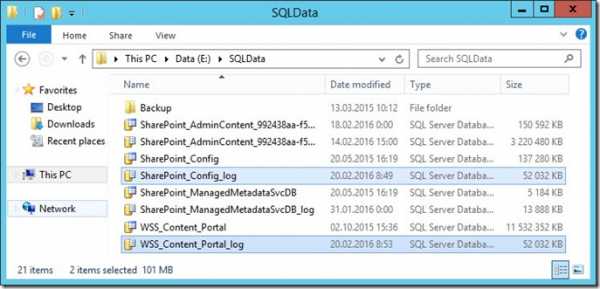
Первая мысль была, что злы пользователи залили на портал 70 гигов данных, которые придется как-то выявлять и удалять. Пошел на SQL сервер смотреть размер баз данных.
Оказалось, что я зря грешил на пользователей – они не виноваты. Такой большой объем заняли лог-файлы двух баз данных — SharePoint_Config и WSS_Content_Portal. В сумме эти два лог-файла заняли почти 90 гигабайт!
Так дело не пойдет, место надо освободить. Для этого запускаем SQL Server Management Studio на SQL сервере.
Раскрываем список баз данных, выбираем первую базу с большим логом, щелкаем по названию этой базы правой кнопкой мыши, и в контекстном меню выбираем Tasks –> Shrink –> Files.
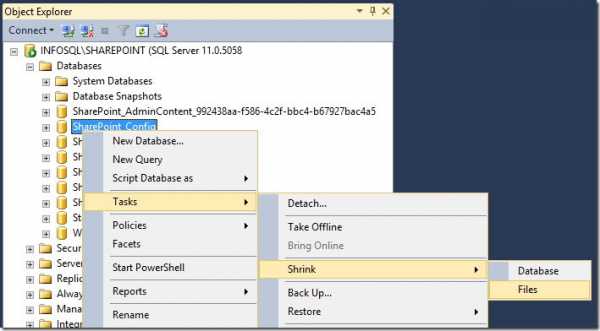
В открывшемся окне проверяем, чтобы был выставлен параметр Release unused space, жмем ОК.
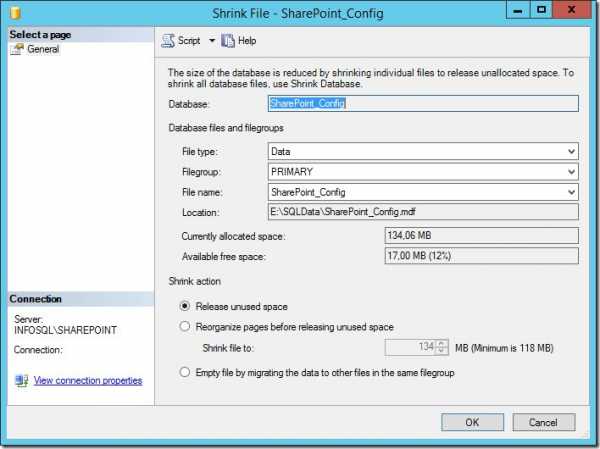
Проверяем размер лог-файла базы данных. Если он не изменился, а у меня он не изменился, то переходим к следующим пунктам.
Сделаем резервную копию лог-файла базы данных. Для этого жмем кнопку New Query и вводим следубщую команду:
BACKUP LOG [SharePoint_Config] TO DISK='E:\Backup.bak' GOгде SharePoint_Config — это имя базы данных, у которой уж слишком большой лог-файл. Указываем путь, куда будет сохранена резервная копия. На диске должно быть достаточно свободного места. И жмем кнопку Execute.
Резервное копирование у меня закончилось ошибкой:
Msg 3201, Level 16, State 1, Line 1 Cannot open backup device 'E:\Backup.bak'. Operating system error 5(Access is denied.). Msg 3013, Level 16, State 1, Line 1 BACKUP LOG is terminating abnormally.Причиной было отсутсвие прав на запись на диск E:\ у учетной записи, под которой работает SQL Server. В моей случае это domain\shpsql. Узнать это можно в списке служб Windows.
Дал права доступа на изменение (Modify) учетке domain\shpsql на диск E:\ и снова нажал кнопку Execute. Во второй раз резервное копирование выполнилось без ошибок (скриншот уже от второй базы данных).
Получил два файла бэкапа на 82 гигабайта в сумме.
Далее меняем Recovery model в свойствах базы данных с Full на Simple.
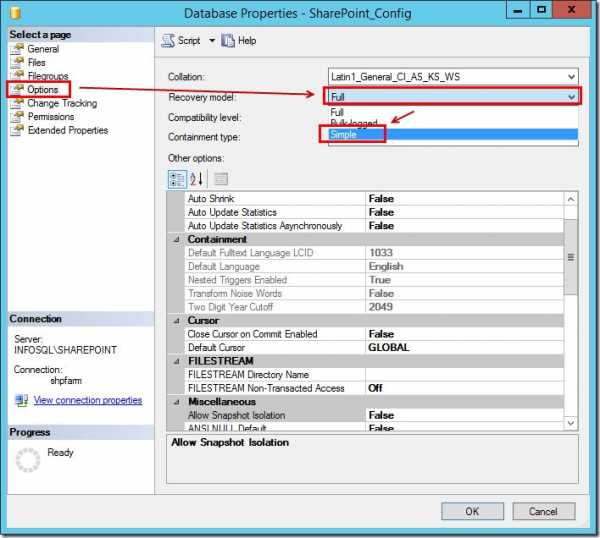
Создаем новый запрос (кнопка New Query) и вводим следующую команду:
DBCC SHRINKFILE('WSS_Content_Portal_log',50)где WSS_Content_Portal_log – название лог-файла соответсвующей базы SharePoint_Config_log.ldf. Цифра 50 означает размер лог-файла в мегабайтах. Для успешного выполнения команды у учетной записи, под которой зашли на сервер, должна быть роль sysadmin. Жмем Execute.На скриншоте снизу показан результат успешного выполнения команды.
Возвращаем Recovery model базы данных в Full (можно сделать и через UI – разницы нет).
В результате лог-файлы стали по 50 мегабайт.
А резервная копия стала нормального размера.
did5.ru
SharePoint Server 2013 – Уменьшаем размер базы данных WSS_UsageApplication
Через некоторое время эксплуатации SharePoint Server 2013 можно заметить значительное увеличение размера файла данных БД WSS_UsageApplication. В эту БД собираются данные об использовании разных компонент SharePoint, и в зависимости от увеличения интенсивности их использования, рост базы будет неизбежен, что само по себе в некоторых ситуациях может оказаться неприятным сюрпризом.
Посмотрим на то, как можно повлиять на данную ситуацию.
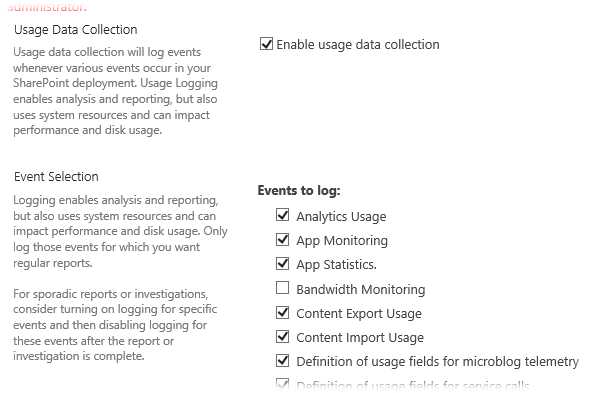
Изменением состава логируемых компонент можно управлять на веб-узле Центра администрирования (Central Administration > Monitoring > Configure usage and health data collection)

Здесь можно включить или выключить как полностью весь сбор данных, так и отдельно взятых компонент…
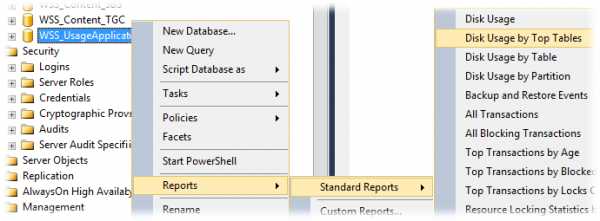
Если по каким-то причинам нет желания полностью отключать сбор данных, то можно подумать о том, как уменьшить объём собираемых данных. Например можно проанализировать то, какого рода данных больше всего попадает в БД WSS_UsageApplication. Для этого можно воспользоваться встроенным функционалом отчётности SQL Management Studio.
Откроем контекстное меню на базе данных и выберем пункты Reports > Standard Reports > Disk Usage by Top Tables
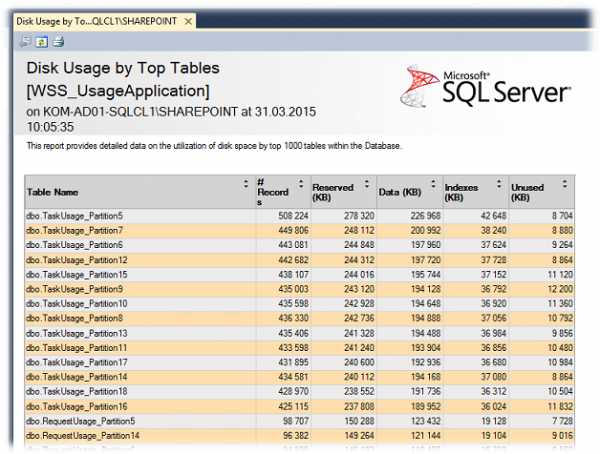
Как видим, в нашем примере больший объём данных составляют записи TaskUsage
Откроем на веб-сервере SharePoint 2013 Management Shell и посмотрим настройку периода хранения собранных событий разного типа..
Get-SPUsageDefinition | Format-Table –AutoSize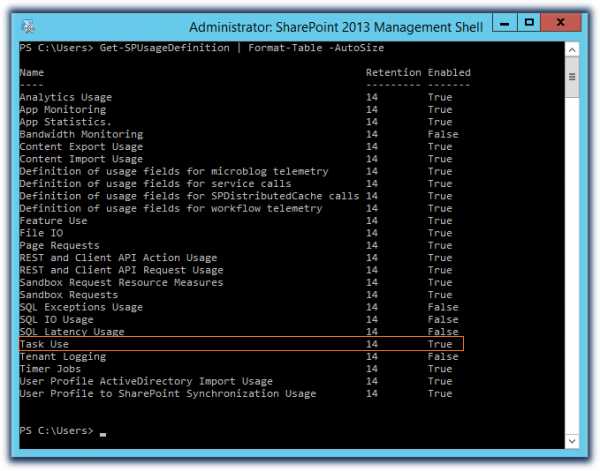
Как видим, для интересующего нас типа событий, впрочем как и для всех остальных, период хранения собранных данных по-умолчанию составляет 14 дней. Соответственно, чтобы снизить объём хранимых данных, мы можем уменьшить количество дней хранения для отдельного типа событий:
Set-SPUsageDefinition -Identity "Task Use" -DaysRetained 3При желании сократить количество дней хранения для всех типов событий используем команду:
Get-SPUsageDefinition | ForEach-Object { Set-SPUsageDefinition $_ –DaysRetained 3}Теперь, чтобы задействовать изменения конфигурации, запустим стандартную задачу обработки данных сбора, которая усечёт все события старше заданного нами количества дней. Сделать это можно на веб-узле Центра администрирования (Central Administration > Monitoring > Configure usage and health data collection > Log Collection Schedule)
В списке заданий обработки событий использования откроем задание Microsoft SharePoint Foundation Usage Data Import и выполним его запуск…
Успешность выполнения задания можно проверить по ссылке Job History
Аналогичную процедуру можно проделать и с помощью SharePoint 2013 Management Shell :
Get-SPTimerJob | Where-Object { $_.title -eq "Microsoft SharePoint Foundation Usage Data Import" } | Start-SPTimerJob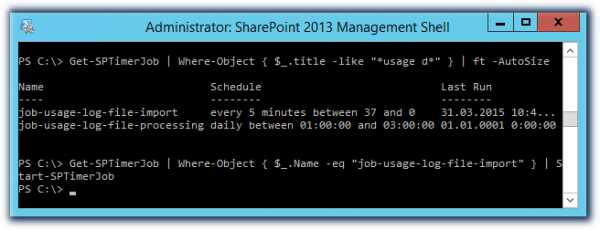
Хотя, учитывая установленный по-умолчанию интервал выполнения задания в 5 минут, позволяет и не выполнять данный шаг, а просто немного подождать, когда задание выполниться автоматически по расписанию.
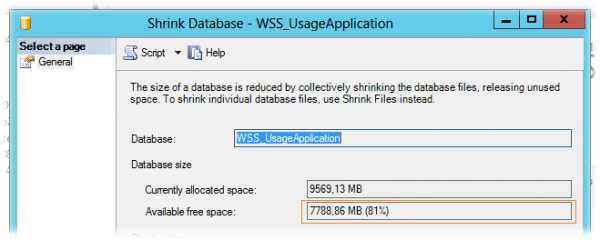
В результате при последующей попытке сокращения неиспользуемого места базы данных с помощью Shrink Database, мы должны увидеть значительный объём, доступный к сжатию.
Источники информации:
Поделиться ссылкой на эту запись:
Похожее
blog.it-kb.ru
Практические рекомендации для повышения быстродействия поиска (Office SharePoint Server 2007)
Обновлено: 2009-07-30
В этой статье приведены некоторые рекомендации по обеспечению исправности и эффективности системы поиска в Microsoft Office SharePoint Server 2007.
Содержание:
Обход и индексация большого количества информации, документов и веб-страниц сильно загружает процессор компьютера. Кроме того, для обхода нужны сетевые и прочие ресурсы. Ферму Office SharePoint Server 2007 необходимо тщательно настроить, чтобы процесс обхода и индексации не ухудшил работу доступной для пользователей службы. Например, обход и индексация контента обычно выполняется в свободное время, когда серверы используются мало — это дает пользователям возможность пользоваться службой в рабочие часы.
Один из способов уменьшить воздействие обхода — запланировать добавочный обход контента вместо полного. При этом индексируются только измененные элементы и используется намного меньше ресурсов компьютера. Полные и добавочные обходы можно запланировать для каждого источника контента. Например, можно запускать добавочные обходы в полночь в выходные, а полные — в полночь по субботам.
Чтобы индекс был полным, необходимо вручную запускать полный обход контента при следующих обстоятельствах:
-
Если администраторы установили обновление или пакет обновлений на серверах фермы.
-
Если администраторы добавили в конфигурацию поиска новое управляемое свойство.
-
Если администраторы добавили или изменили правило обхода контента.
-
При повторной индексации страниц ASP.NET сайтов Windows SharePoint Services 3.0, Microsoft Office SharePoint Server 2007 или Search Server 2008. Программа-обходчик не в состоянии обнаружить время изменения таких веб-страниц. Соответственно, они повторно индексируются только после полного обхода.
-
Для устранения повторяющихся ошибок добавочного обхода контента. В редких случаях, когда добавочный обход на любом уровне хранилища завершается с ошибкой сто раз подряд, сервер индекса удаляет затронутый контент из индекса.
-
Если администраторы восстановили поврежденный индекс.
-
При создании администратором нового сопоставления имени сервера.
-
Если разрешения для контента изменилось, а сам контент — нет, и на серверах не устанавливался пакет исправлений, выпущенный после пакета обновления 1 (KB941442), или более новый пакет обновлений. Без этого пакета исправлений при добавочном обходе не проверяются списки управления доступом (ACL). Если ACL не проверяются, пользователь видит элемент в результатах поиска, даже если администратор удалил разрешение этого пользователя после последнего полного обхода.
В следующих ситуациях Office SharePoint Server 2007 выполняет полный обход контента, хотя запланирован или вручную запущен добавочный обход:
-
Администратор вручную остановил предыдущий обход контента.
-
Администратор восстановил базу данных контента из резервной копии.
Примечание: Если установлено приложение Обновление инфраструктуры для серверов Microsoft Office Servers, можно задать выполнение полного обхода контента в рамках операции восстановления с помощью параметров средства командной строки Stsadm.
-
Администратор отсоединил и повторно присоединил базу данных контента.
-
Если в Office SharePoint Server никогда не выполнялся полный обход контента.
-
Если в журнале изменений нет информации об адресах обхода. Этот журнал позволяет определить, менялся ли контент после последнего обхода. Без таких сведений невозможно выполнить добавочный обход.
-
При изменении учетной записи, используемой для доступа к контенту. Это может быть учетная запись, по умолчанию настроенная для доступа к контента, или запись, заданная в правиле обхода.
-
В случае повреждения индекса.
В таких случаях необходимо тщательно проанализировать последовательность действий, поскольку при запуске обхода вручную или по расписанию выполнение полного обхода контента может потребовать значительного большего количества времени и ресурсов, чем добавочных обход. Это может повлиять на качество обслуживания пользователей.
Чтобы обеспечить максимальную производительность службы поиска Office SharePoint Server 2007, тщательно проанализируйте архитектуру системы. Необходимо определить систему базовых показателей путем тщательного исследования серверов. Рекомендуется периодически повторять тесты производительности, чтобы определять любые изменения и обнаруживать проблемы на ранней стадии их возникновения. В процессе оптимизации с помощью базовых показателей можно определить достигнутый уровень улучшения. В следующих разделах описываются счетчики системного монитора и данные других средств, относящиеся к производительности Office SharePoint Server 2007.
В Office SharePoint Server 2007 все сайты и семейства сайтов размещаются на веб-серверах. Они получают контент, хранящийся на серверах баз данных, и отвечают на запросы пользователей. Поскольку веб-серверы отправляют ответы на все поисковые запросы пользователей, их производительность напрямую влияет на производительность службы поиска. Кроме того, веб-серверы оказывают влияние на процесс индексации, поскольку программа-обходчик при индексации контента Office SharePoint Server отправляет запросы на веб-серверы.
Для отслеживания исправности веб-серверов используются следующие счетчики системного монитора:
-
Процессор/% загруженности процессора/_Total
Этот счетчик является основным показателем активности процессора. Он определяет относительную продолжительность времени, затрачиваемого процессорами на выполнение рабочих потоков. Если среднее значение этого счетчика в течение длительного времени превышает 80 %, это может быть связано с недостаточным быстродействием процессоров и необходимостью обновления системы.
-
Память/Доступно МБ
Этот счетчик определяет объем физической памяти, доступный в настоящий момент для процессов или системы. Если число становится слишком низким, работа системы замедляется, поскольку больше используется подкачка страниц. Следует задуматься об увеличении объема памяти сервера.
-
Веб-служба/Текущих подключений
Этот счетчик определяет число подключений к веб-службе. На веб-серверах Office SharePoint Server 2007 этот счетчик учитывает всех параллельных пользователе, а также программу-обходчик в процессе индексации. С помощью этого счетчика можно определить модель использования подключений и часы максимальной нагрузки. Для этого счетчика не существует предельного значения. Очень высокие значения могут свидетельствовать о хорошей производительности.
Примечание: В ферме Office SharePoint Server с несколькими веб-серверами этот счетчик определяет показатели для подключений только на одном сервере. Дополнительные сведения о мониторинге активности пользователей в рамках всей фермы см. в разделе Мониторинг сервера Office SharePoint Server со службой диагностики SharePoint.
Office SharePoint Server 2007 использует Microsoft SQL Server 2005 или Microsoft SQL Server 2008 для хранения баз данных контента. Хотя сервер индексирования хранит индекс контента в файловой системе, а не в базе данных, метаданные документов и разрешения хранятся в базе данных поиска. Поскольку во многих вариантах поиска проверяются метаданные, и при любом поиске выполняется фильтрация по ролям безопасности, производительность серверов базы данных непосредственно влияет на эффективность поиска.
Для отслеживания исправности серверов баз данных используются следующие счетчики системного монитора:
Процессор/% загруженности процессора/_Total
Этот счетчик является основным индикатором активности процессора и, соответственно, одинаково важен для серверов баз данных и веб-серверов.
LogicalDisk/процент активности диска/имя_диска
Этот счетчик определяет относительную длительность времени, потраченного на обслуживание запросов чтения или записи диском. При поиске рекомендуется отслеживать показатели этого счетчика для диска, на котором располагается база данных поиска. Если среднее значение этого счетчика часто превышает 90%, это может быть связано с недостаточным быстродействием для осуществления поиска.
Система: длина очереди процессора
В среднем значение этого счетчика должно быть меньше количества ядер процессора сервера, умноженного на два.
Память: доступно МБ
Убедитесь, что среднее значение этого счетчика составляет не менее 20 процентов от общего физического объема ОЗУ.
Память: обмен страниц в сек
Среднее значение этого счетчика должно быть меньше 100.
Логический диск: обращений к диску/сек
Этот счетчик определяет общую пропускную способность раздела.
Логический диск: скорость чтения с диска (байт/сек) и скорость записи на диск (байт/сек)
Этот счетчик измеряет общую полосу пропускания конкретного диска.
Логический диск: средняя скорость чтения с диска в сек
Этот счетчик, известный также как счетчик задержки чтения, показывает время извлечения данных. Низкое значение задержки серьезно улучшает скорость ответа на запросы пользователей.
Логический диск: средняя скорость записи на диск в сек
Этот счетчик, известный также как счетчик задержки записи, показывает время записи данных. Низкое значение задержки повышает качество индексации.
LogicalDisk/% активности диска при чтении/имя_диска
Этот счетчик определяет относительную длительность времени, потраченного на обслуживание запросов чтения диском. Если на обработку запросов на чтение диска базы данных поиска затрачивается много времени, это может свидетельствовать о том, что пользователи выполняют много запросов.
LogicalDisk/% активности диска при записи/имя_диска
Этот счетчик определяет относительную длительность времени, потраченного на обслуживание запросов записи. Высокие затраты времени на обработку запросов записи в базу данных поиска являются нормой при индексации.
Примечание: По возможности оптимизируйте эффективность поиска, разместив базу данных поиска на отдельном диске, а не вместе с другими базами. Если отделить ее таким образом, с помощью этих счетчиков логического диска легко будет проверить эффективность поиска, поскольку диск выделен для этой цели.
SQLServer: диспетчер буферов/Ожидаемый срок жизни страницы
Этот счетчик определяет время в секундах, в течение которого страница базы данных находится в пуле буфера без выполнения ссылок на нее. Среднее значение этого счетчика должно превышать 300. Значения ниже 300 секунд с большой долей вероятности свидетельствуют о нехватке памяти на сервере и необходимости ее увеличения.
В Office SharePoint Server 2007 серверы индексирования обходят контент и создают файл индекса. После завершения обхода индекс передается на серверы запросов, которые отвечают на поисковые запросы пользователей.
Если производительность сервера индексирования плохая, пользователи, возможно, ничего не заметят. При этом процесс обхода будет занимать больше времени, иногда настолько, что его не удастся выполнить в нерабочее время и отделить от других процессов, например, от процессов резервного копирования.
Сервер индексирования не всегда удается разместить на отдельном сервере. Это зависит от количества доступных серверов. |
Для мониторинга исправности сервера индексирования в процессе обхода используются следующие счетчики системного монитора:
Подключаемый модуль архивирования данных службы поиска Office Server/Всего документов в первой очереди/Portal_Content
Этот счетчик определяет количество документов в первой очереди подключаемого модуля архивирования. В процессе обхода значение должно быть ниже 500, в остальное время — намного меньше. Если оно выше 500, узким местом может быть диск базы данных поиска на сервере баз данных.
Подключаемый модуль архивирования данных службы поиска Office Server/Всего документов во второй очереди/Portal_Content
Этот счетчик определяет количество документов во второй очереди подключаемого модуля архивирования. Как и в случае с предыдущим счетчиком, в процессе обхода значение должно быть ниже 500.
Средство сбора данных Office Server Search/Бездействующих потоков
Этот счетчик определяет количество потоков в процессе средства сбора данных, ожидающих документов. Если значение счетчика равно 0, средству не хватает ресурсов. Подумайте о сокращении количества одновременных обходов.
Средство сбора данных Office Server Search/Потоков, обращающихся к сети
Этот счетчик определяет количество потоков в процессе средства сбора данных, отправивших запросы в удаленное хранилище данных и ждущих или обрабатывающих ответ. Если значение устойчиво высокое, возможно, проблема в полосе пропускания сети, или сервер индексирования подключен к одному или нескольким медленным узлам при индексации контента.
Средство сбора данных Office Server Search/Потоков фильтрации
Этот счетчик определяет количество потоков, которые получили и фильтруют контент. Высокое значение может свидетельствовать о том, что задержка связана с ресурсами на сервере индексирования.
Средство сбора данных Office Server Search/Потоков в подключаемых модулях
Этот счетчик определяет количество потоков, которые извлекли контент и обрабатывают его с помощью подключаемых модулей, например, IFilters. На этом этапе обхода данные отправляются в базу данных индекса и поиска.
Проекты средства сбора данных Office Server Search/Выполняющихся операций обхода содержимого
Этот счетчик определяет количество обходов в процессе. Значение должно соответствовать количеству источников контента с запланированными обходами, если только администратор не запустил обход вручную.
Средство диагностики SharePoint версии 1.0 (которое иначе называется SPDiag) — это усовершенствованное средство диагностики и анализа, дающее очень широкий диапазон информации о любом сервере или ферме, где используются продукты и технологии SharePoint. С помощью SPDiag можно просматривать очень детализированные снимки конфигураций сервера и фермы. Кроме того, можно объединить и просмотреть информацию из служб IIS, журналов единой службы ведения журналов (ULS) и журналов событий, и исследовать причины проблем с производительностью, например проблемы замедленного прохождения запросов.
SPDiag может выводить графики по данным счетчиков производительности любого сервера в ферме. Кроме того, в средстве есть несколько счетчиков, работающих с данными фермы из журналов IIS. Провести такой анализ на уровне фермы, используя только системный монитор, невозможно.
Для исследования отклика фермы Office SharePoint Server 2007 используются следующие счетчики уровня фермы:
SharePointRequests/Число уникальных IP-адресов клиентов
Этот счетчик определяет количество уникальных клиентов, отправивших запросы за указанный период времени. Обратите внимание, что, если клиенты подключаются к ферме через прокси-сервер, у них будет один и тот же IP-адрес.
SharePointRequests/Число уникальных клиентских агентов
Этот счетчик определяет количество уникальных клиентских агентов (браузеров), отправивших запросы за указанный период времени. Он различает клиенты, которые подключаются к ферме через прокси-сервер, поскольку основывается на данных об агентах, указанных в запросах HTTP браузера.
Примечание: Следующие счетчики определяют количество запросов. Учитываются поисковые запросы и запросы контента.
SharePointRequests/Всего запросов
Этот счетчик определяет общее количество запросов со всеми изменениями за указанный период времени. Показания счетчика нужно обязательно отслеживать одновременно с показаниями других счетчиков, чтобы определить соотношение быстрых и медленных запросов.
SharePointRequests/Количество запросов с ответом за < 1 секунду
Этот счетчик определяет количество запросов, ответ на которые пришел менее чем за 1 секунду. В ферме с высоким уровнем производительности значение этого счетчика приближается к значению счетчика Всего запросов.
SharePointRequests/Количество запросов с ответом за 1 — 5 секунд
Этот счетчик определяет количество запросов, ответ на которые пришел за 1 — 5 секунд. Обычно такая скорость приемлема для пользователей, но рост числа таких запросов с течением времени может свидетельствовать о том, что формируется задержка.
SharePointRequests/Количество запросов с ответом за 5 — 10 секунд
Этот счетчик определяет количество запросов, ответ на которые пришел за 5 — 10 секунд. Пользователи могут закрыть страницу прежде, чем придет ответ.
SharePointRequests/Количество запросов с ответом за > 10 секунд
Этот счетчик определяет количество запросов, ответ на которые пришел более чем за 10 секунд. Если это количество составляет значительную часть от показателя Всего запросов, ферма реагирует плохо, и нужно найти причины задержки и подумать об обновлении аппаратного обеспечения.
Единая служба ведения журнала (ULS) используется для мониторинга и оптимизации производительности системы Office SharePoint Server 2007. ULS применяется как один из методов оптимизации системы. Другие методы предусматривают использование монитора производительности, журналов событий и веб-журналов.
В этом разделе описывается диагностика задержек и снижения производительности службы поиска с использованием журналов службы ULS. С помощью журналов службы ULS можно определять стадии процесса поиска, выполнение которых занимает большую часть времени, что ведет к задержке результатов, возвращаемых пользователям. Также с помощью журналов службы ULS можно оценить улучшения производительности, связанные с изменениями конфигурации системы.
technet.microsoft.com
Рекомендации по использованию SQL Server в ферме SharePoint Server
- 01/08/2018
- Время чтения: 9 мин
In this article
**Применимо к:**SharePoint Foundation 2013, SharePoint Server 2013, SharePoint Server 2016
**Последнее изменение раздела:**2017-09-14
**Сводка.**Узнайте, как реализовать рекомендации для SQL Server в ферме SharePoint Server 2016 и SharePoint Server 2013.
При настройке и обслуживании реляционных баз данных SharePoint Server 2016 в SQL Server 2014 с пакетом обновления 1 (SP1) или SQL Server 2016 необходимо выбрать оптимальные параметры, обеспечивающие максимальную производительность и безопасность. Эти параметры также необходимо выбрать при настройке и обслуживании реляционных баз данных SharePoint Server 2013 в SQL Server 2008 R2 с пакетом обновления 1 (SP1), SQL Server 2012 и SQL Server 2014.
Рекомендации в этой статье расположены в той последовательности, в которой они применяются, от установки и настройки SQL Server до развертывания SharePoint Server и последующего обслуживания фермы. Большинство рекомендаций применимы ко всем версиям SQL Server. Рекомендации, которые относятся только к одной из версий SQL Server, приводятся в отдельных разделах.
Примечание
Если вы планируете использовать компоненты бизнес-аналитики SQL Server в ферме SharePoint Server 2016, необходимо использовать SQL Server 2016 CTP 3.1 или более поздней версии. Теперь можно скачать SQL Server 2016 CTP 3.1 или более поздней версии для надстройки SQL Server PowerPivot для SharePoint. Кроме того, вы можете использовать Power View, установив Службы SQL Server Reporting Services (SSRS) в режиме интеграции с SharePoint и внешнюю надстройку SSRS с помощью установочного носителя SQL Server.Чтобы узнать больше, скачайте новый технический документ Развертывание SQL Server 2016 PowerPivot и Power View в SharePoint 2016. Подробные сведения о настройке и развертывании бизнес-аналитики в ферме SharePoint Server 2016 с несколькими серверами, скачайте документ Развертывание SQL Server 2016 PowerPivot и Power View во многоуровневой ферме SharePoint 2016.
Важно!
Рекомендации, приведенные в этой статье, относятся к системе управления реляционными базами данных SQL Server с SharePoint Server.
Использование выделенного сервера для SQL Server
Чтобы обеспечить оптимальную производительность операций фермы, рекомендуем установить SQL Server на выделенном сервере, на котором не выполняются никакие другие роли фермы и не размещаются базы данных ни для каких других приложений. Единственным исключением является развертывание SharePoint Server 2016 в роли фермы обособленного сервера или SharePoint 2013 на изолированном сервере, который предназначен для разработки и тестирования, но не рекомендуется для использования в рабочей среде. Дополнительные сведения см. в статьях Описание роли MinRole и связанных служб на сервере SharePoint Server 2016 и Установка SharePoint Server 2016 на одном сервере с SQL Server.
Примечание
Рекомендация по использованию выделенного сервера для реляционных баз данных также распространяется на развертывание SQL Server в виртуальной среде.
Настройка определенных параметров SQL Server перед развертыванием SharePoint Server
Чтобы обеспечить согласованность работы и производительности, перед развертыванием SharePoint Server задайте приведенные ниже параметры и настройки.
Не включайте автоматическое создание статистики в базах данных контента SharePoint. Включение автоматического создания статистики не поддерживается в SharePoint Server. SharePoint Server настраивает необходимые параметры во время подготовки и обновления. Ручное включение автоматического создания статистики для базы данных SharePoint может существенно изменить план выполнения запроса. Для обработки статистики в базах данных SharePoint используется либо хранимая процедура (proc_UpdateStatistics), либо средства SQL Server.
Установите максимальную степень параллелизма (MAXDOP) равной 1 для экземпляров SQL Server, в которых размещаются базы данных SharePoint, чтобы обеспечить обслуживание каждого запроса отдельным процессом SQL Server.
Важно!
Любая другая настройка максимальной степени параллелизма приведет к реализации неоптимального плана запроса, что вызовет снижение производительности SharePoint Server.
Чтобы облегчить обслуживание, например упростить перемещение баз данных на другой сервер, создайте псевдонимы DNS, указывающие на IP-адрес, для каждого экземпляра SQL Server. Дополнительные сведения о псевдонимах DNS или имен узлов см. в статье Добавление псевдонима имени узла для экземпляра SQL Server.
Дополнительные сведения об этих настройках и параметрах SQL Server см. в разделе Задание параметров SQL Server.
Защита сервера базы данных перед развертыванием SharePoint Server
Рекомендуем перед развертыванием SharePoint Server запланировать и реализовать защиту сервера базы данных. Дополнительные сведения см. в приведенных ниже разделах.
Настройка производительности и доступности серверов баз данных
Как и в случае с внешними серверами и серверами приложений, конфигурация серверов баз данных оказывает влияние на работу SharePoint Server Отдельные базы данных предъявляют определенные требования к совместному или раздельному расположению с другими базами данных. Дополнительные сведения см. в статьях Описание роли MinRole и связанных служб на сервере SharePoint Server 2016 и Настройка и планирование загрузки SQL Server и хранилища (SharePoint Server).
Рекомендации для баз данных с высокой доступностью, использующих зеркальное отображение, см. в статье Зеркальное отображение базы данных (SQL Server).
SQL Server Отказоустойчивая кластеризация и группы доступности AlwaysOn
В SQL Server 2012 появилась функция групп доступности AlwaysOn, представляющая собой решение для обеспечения высокой доступности и аварийного восстановления, которое является альтернативой решениям для зеркального отображения баз данных и доставки журналов. В настоящее время группы доступности AlwaysOn поддерживают до девяти реплик доступности.
Примечание
Не рекомендуется использовать зеркальное отображение баз данных в следующей версии SQL Server, вместо этого используйте группы доступности AlwaysOn.
Для групп доступности AlwaysOn требуется кластер на основе отказоустойчивой кластеризации Windows Server (WSFC). Для каждой создаваемой группы доступности создается группа ресурсов WSFC. Дополнительные сведения см. в приведенных ниже ресурсах.
Разработка хранилища с учетом оптимальной пропускной способности и управляемости
Мы рекомендуем разделить данные на сервере базы данных по жестким дискам и назначить этим данным приоритеты. В идеальном варианте базу данных tempdb, базы данных контента, базу данных использования, базы данных поиска и журналы транзакций следует размещать на разных жестких дисках. В списке ниже приводятся некоторые рекомендации. Дополнительные сведения см. в разделе Настройка баз данных.
Для сайтов, предназначенных для совместной работы или выполнения большого объема операций обновления, используйте следующее ранжирование для распределения хранения.
Компоненты с наивысшим рангом следует размещать на самых быстрых дисках.
Файлы данных и журналы транзакций tempdb
Файлы журналов транзакций базы данных контента
Базы данных поиска, исключая базу данных администрирования поиска
Файлы данных базы данных контента
На сайте портала, используемом преимущественно в режиме чтения, назначьте данным и поиску более высокий приоритет, чем журналам транзакций, как показано далее.
Компоненты с наивысшим рангом следует размещать на самых быстрых дисках.
Файлы данных и журналы транзакций tempdb
Файлы данных базы данных контента
Базы данных поиска, исключая базу данных администрирования поиска
Файлы журналов транзакций базы данных контента
Результаты тестирования и анализ пользовательских данных показывают, что общая производительность фермы может значительно упасть из-за недостаточно быстрого выполнения дисковых операций ввода-вывода для tempdb. Во избежание данной проблемы выделите для файлов данных tempdb отдельные диски.
Для обеспечения наибольшей производительности поместите файлы данных tempdb в массив RAID 10. Число файлов данных tempdb должно быть равно числу ядер процессоров, а сами файлы данных tempdb должны быть одинакового размера.
Размещайте файлы данных и файлы журналов транзакций базы данных на разных дисках. Если их приходится размещать на одних и тех же дисках из-за дефицита дискового пространства, помещайте на один диск файлы с разными схемами использования, чтобы свести к минимуму вероятность одновременных запросов доступа.
Используйте несколько файлов данных для интенсивно используемых баз данных контента, размещая их на отдельных дисках.
Чтобы повысить управляемость, вместо того чтобы ограничивать размер баз данных, осуществляйте мониторинг и вносите необходимые корректировки, чтобы размер баз данных контента не превышал 200 ГБ.
Примечание
Если ограничить размер баз данных вручную в SQL Server, то в случае превышения емкости могут происходить непредвиденные простои системы.
Правильная настройка подсистем ввода-вывода очень важна для оптимальной производительности и работы систем SQL Server. Дополнительные сведения см. в статье, посвященной наблюдению за использованием диска.
Совет
Учтите, что измерение скорости диска отличается для файлов данных и файлов журналов. Самые быстрые диски для файлов баз данных могут оказаться не самыми быстрыми для файлов журналов. Примите во внимание схемы использования, интенсивность ввода-вывода и размер файлов.
Упреждающий контроль роста размеров файлов данных и журналов
Ниже приведены рекомендации по упреждающему контролю роста размеров файлов данных и журналов.
По мере возможности заранее увеличьте размеры всех файлов данных и журналов до предполагаемых окончательных величин или увеличивайте эти размеры через определенные интервалы, например, каждый месяц, каждые шесть месяцев или перед выгрузкой нового сайта, рассчитанного на большое число операций сохранения, например, как при переносе файлов.
В качестве защитной меры рекомендуем включить авторасширение базы данных, чтобы предотвратить нехватку места для файлов данных и журналов. Примите во внимание приведенные ниже моменты.
По умолчанию для новой базы данных задан шаг увеличения, равный 1 МБ. Так как эта настройка авторасширения по умолчанию приводит к увеличению размера базы данных, не полагайтесь на нее. Вместо этого следуйте рекомендациям, приведенным в разделе Задание параметров SQL Server.
Установите значения авторасширения не в виде процентов, а в виде фиксированного количества мегабайт. Чем больше база данных, тем больше должен быть шаг роста.
Примечание
Настраивать функцию авторасширения для баз данных SharePoint следует с осторожностью. Если задать для авторасширения процентное значение, например 10 %, база данных размером 5 ГБ будет увеличиваться на 500 МБ каждый раз, когда необходимо расширить файл данных. В этом случае может закончиться место на диске.
Рассмотрим сценарий, когда объем контента постепенно растет, например, с шагом в 100 МБ, а для функции авторасширения установлено значение 10 МБ. Затем внезапно возникает потребность в очень большом объеме места для нового сайта управления документацией, начальный размер которого составляет 50 ГБ. В этом случае желательно, чтобы расширение осуществлялось с шагом в 500 МБ, а не 10 МБ.
Для управляемой производственной системы следует использовать авторасширение только как защитную меру на случай неожиданного роста. Не используйте функцию авторасширения для повседневного управления ростом данных и журналов. Вместо этого настройте авторасширение в соответствии с ожидаемым через год увеличением размера файлов и добавьте 20 % для учета возможных ошибок. Кроме того, настройте оповещения о том, что на диске недостаточно места для базы данных или ее размер приближается к максимальному.
Поддерживайте процент доступного пространства по всем дискам на уровне не ниже 25 %, чтобы обеспечить возможность роста размеров и работу в условиях пиковых нагрузок. Если для этого вы добавляете диски в массив RAID или выделяете дополнительное место в хранилище, внимательно следите за размерами дискового пространства, чтобы не допустить нехватки места.
Постоянный мониторинг хранилища и производительности SQL Server
Рекомендуем постоянно осуществлять мониторинг хранилища и производительности SQL Server, чтобы обеспечить адекватную обработку каждым рабочим сервером базы данных назначенной ему нагрузки. Кроме того, такой постоянный мониторинг позволяет создать тесты производительности, которые можно использовать для планирования ресурсов.
Используйте комплексное представление отслеживания ресурсов. При отслеживании не ограничивайтесь ресурсами, характерными для SQL Server. Одинаково важно отслеживать следующие ресурсы на компьютерах, на которых выполняется SQL Server: ЦП, память, коэффициент попадания в кэш и подсистема ввода-вывода.
Если какой-либо из этих ресурсов сервера демонстрирует признаки замедления или перегрузки, воспользуйтесь следующими рекомендациями, опираясь на данные о текущей и прогнозируемой рабочей нагрузке.
Использование сжатия резервных копий для ускорения резервного копирования и уменьшения размера файлов
Сжатие резервных копий позволяет ускорить резервное копирование в SharePoint. Оно доступно в выпусках SQL Server Standard и Enterprise. Если задать сжатие в скрипте резервного копирования или настроить SQL Server для сжатия по умолчанию, можно значительно сократить размер резервных копий базы данных и доставляемых журналов. Дополнительные сведения см. в статьях Сжатие резервных копий (SQL Server) и Сжатие данных или в статье Включение сжатия таблицы или индекса
Благодарности
Группа публикации контента SharePoint Server выражает благодарность указанным ниже авторам, участвовавшим в написании этой статьи.
Кей Ункрот (Kay Unkroth), ведущий руководитель программы, SQL Server
Чак Хайнцельман (Chuck Heinzelman), ведущий руководитель программы, SQL Server
See also
Обзор SQL Server в среде SharePoint Server 2016Настройка и планирование загрузки SQL Server и хранилища (SharePoint Server)
Обеспечение безопасности SharePoint: защита SQL Server в средах SharePoint
technet.microsoft.com
pro4gl.ru » Blog Archive » Оптимизируем области БД
Продолжение перевода Adam Backman «OpenEdge Revealed:Mastering the OpenEdge Database with OpenEdge Management».
Перевод публикуется в виде статей и постоянно редактируется
Области хранения базы данных: оптимизация
В этом разделе речь идет об оптимизации областей базы данных. В этом разделе принято решение обобщить и собрать воедино всю необходимую информацию из разделов данной книги и другой документации. Возможно, что здесь встретятся повторы, но это сделано ради удобства — всё необходимое можно найти в этом разделе.
Цель оптимизации — получить максимальную производительность используя все возможные решения архитектуры операционной системы и OpenEdge RDBMS.
Оптимизация областей хранения данных
Несколько простых правил помогут сделать области хранения данных легко обслуживаемыми и обеспечат оптимальную производительность при работе.
Области хранения
Основные причины для распределния данных по различным областям хранения:
- Управление размером отдельных областей хранения
- Уменьшение фрагментации
- Распределение данных по разным физическим устройствам (размещение областей хранения на разных устройствах)
В прошлых версиях Progress записи таблиц, находящихся в одной области, перемешивались между собой. С течением времени данные размазывались по области, поскольку содержимое таблиц постоянно изменяется. В OpenEdge появились средства для минимизации такой фрагментации, кроме того у базы данных появилась возможность быстрого удаления данных. Если нам необходимо удалить таблицу из области хранения Типа I, то OpenEdge должен обработать отдельно каждую запись в том порядке, в каком задано условие для удаления. В области хранения Типа II возможно выполнение команды «drop table». Таблица удаляется при этом в одну операцию: первый кластер объекта маркируется как свободный. Поскольку кластеры соединены в цепочку, то все остальные кластеры в цепочке также станут свободными. Это довольно редкая операция, но она демонстрирует возможности областей Типа II.
Отделение метасхемы базы от данных пользователей
Отделяя схему и последовательности (sequences) от других объектов вашей базы данных можно упростить обновление вашего приложения. Одна из наиболее частых операций при обновлении — это изменение метасхемы. Метасхема — внутренняя служебная структура базы данных, которая содержит в себе в том числе и описание структуры базы данных. Если мы выделим метасхему в отдельную область, то значительно ускорим её обновление.
Устранение фрагментации данных
Фрагментацию данных можно разделить на два типа — физическую и логическую. Физическая фрагментация данных (Physical scatter) происходит тогда, когда записи одной таблицы распостраняются по всей области хранения и перемешиваются с записями других таблиц. Единственным способом избежать такого развития событий в версии 9 был вынос таблицы в отдельную область хранения. Такое решение делает сопровождение базы данных администратором очень сложным — ведь условие одной таблицы на область резко увеличивала бы количество областей базы данных. Такую структуру базы данных сложно сопровождать.
В OpenEdge 10 была представлена концепция кластеризованных областей хранения (области хранения Типа II — Type II storage area). Области Типа II группируют внутри себя объекты данных. Размер кластера настраивается для каждой области. Размеры кластера могут быть 8, 64 или 512 блоков. Для примера, область Типа II размером 512 блоков для базы данных с блоком 8Kb группирует в кластере почти 4Mb данных или индексов. Такая группировка данных уменьшает физическую фрагментацию записей и увеличивает эффективность работы с данными. Особенно ярко это проявляется при построении отчетов, однако тесты подтверждают ускорение и для остальных типов операций. Следовательно, необходимо использовать области Типа II везде, где это необходимо. Использование областей такого типа уменьшает физическую фрагментацию данных, но от риска логической фрагментации данных не спасает.
Логическая фрагментация возникает тогда, когда записи сохранены в другом порядке, чем они обычно запрашиваются приложением. Записи сохраняются в базе в том порядке, в каком они были введены или же сохраняются в тех местах, где записи были ранее удалены. Обычно с течением времени ваши данные становятся все более логически фрагментированными. Единственное лекарство — это выгрузка и загрузка (dump and load) данных. Для тех приложений, где возможен простой базы данных — это нормальный вариант, но для систем, которые работают в режиме 24×7 это либо невозможно, либо сопряжено с определенной дополнительной работой. Операции выгрузки и загрузки данных рассматриваются ниже. Самое главное — необходимо выгрузить и загрузить данные ровно в том порядке, в котором они чаще всего используются. В большинстве случаев — в порядке, определяемом первичным ключом. Для того, чтобы узнать наиболее используемый индекс при чтении записей в таблице необходимо просмотреть VST-таблицу _IndexStat.
Хотя использование областей Типа II и является почти обязательным, есть случаи когда имеет смысл использование областей Типа I. Эти области можно использовать размещения таблиц с очень малым количеством данных. Итого, общая рекомендация — иметь отдельную область для метасхемы базы данных, одну область Типа I для маленьких таблиц и остальные данные размещать в областях Типа II.
Критерии распределения данных по областям хранения
Существует ряд способов для определения наилучшего распределения данных между областями хранения. Самое первое, что необходимо сделать — это попытаться выделить большие таблицы. Если есть таблицы, которые имеют размер в несколько гигабайт, то они должны быть помещены в отдельные области. Затем надо сгруппировать таблицы с похожими средними размерами записей. Другой, не менее важный фактор — это понимание того, как и когда используются данные таблиц. Если можно четко выделить таблицы, к которым осуществляется круглосуточный доступ и таблицы, которые используются, к примеру, для закрытия дня вечером, то самый лучший выход — это разделение таких таблиц между разными областями для достижения лучшей масштабируемости вашего приложения. Размер таблиц — относителен. Например, таблицу размером 1Gb нельзя считать большой кроме тех случаев, когда база данных имеет сравнимый размер. Необходимо выработать свой критерий для определения того, является ли таблица большой или нет. Пример такого критерия — считать таблицу большой, если её объем превышает 10% от объема вашей базы данных. Для маленьких или средних баз данных количество областей хранения должно быть около десяти. Необходимо отталкиваться от числа 10, увеличивая количество областей после анализа данных для больших баз и уменьшая для маленьких. Это число является хорошей отправной точкой.
Как поступить с индексами?
На этот счет существует множество мнений, но основная рекомендация состоит в том, чтобы не размещать индексы вместе с большими таблицами и иметь отдельную область хранения для размещения индексов больших таблиц. Маленькие таблицы можно размещать вместе с индексами. Еще один подход — распределять данные и индексы по разным областям хранения. К примеру, если в области есть не очень большая таблица, которая интенсивно используется в течении суток, то переместив из области хранения такой таблицы индексы в какую-либо другую область, мы бы уменьшили конкуренцию за доступ к этой области. Такая ситуация довольно редка, но при сомнениях всегда лучше быть более предусмотрительным, чем перемещать данные после загрузки в область.
pro4gl.ru
Изменение хранилища данных для SharePoint 2010 – Блог команды Microsoft SharePoint
RBS (удаленное хранилище больших двоичных объектов) — это набор стандартизированных API, которые позволяют сохранять/извлекать данные больших двоичных объектов без использования основной базы данных SQL, когда для них требуется выделенное хранилище. RBS использует модель поставщика для подключения к любому выделенному хранилищу больших двоичных объектов, которое реализует API-интерфейсы RBS. Концепция удаленного хранилища больших двоичных объектов была введена в SharePoint 2010, и теперь в SharePoint можно устанавливать поставщиков RBS и использовать их для хранения больших двоичных объектов. Документы в библиотеках документов SharePoint являются большими двоичными объектами, и с помощью RBS их можно хранить вне базы данных SQL Server. Это означает, что большие двоичные объекты сохраняются на одном компьютере с SQL Server, хотя они могут находиться на компьютере SQL Server, подключенном к сети.
Выше приведены две диаграммы, на которых показаны стандартные архитектуры SharePoint, использующие удаленное хранилище больших двоичных объектов. В обоих вариантах показан поставщик клиента RBS, установленный на веб-интерфейсе SharePoint. На левой диаграмме показана универсальная реализация RBS, в которой третья сторона реализует RBS для доступа к своему хранилищу. На правой диаграмме показан поставщик RBS SQL Server FILESTREAM, который сохраняет большие двоичные объекты в файловой системе Windows.
Хранение больших двоичных объектов вне базы данных SQL Server позволяет получить следующие преимущества:
· Удаленное хранилище больших двоичных объектов позволяет SharePoint Foundation 2010, работающему на SQL Express, хранить объем данных, превышающий ограничение SQL Express в 4 ГБ. В SQL Express 2008 R2 это ограничение было увеличено до 10 ГБ.
· Производительность некоторых операций может быть улучшена, если средний размер больших двоичных объектов превышает 1 МБ. Это результат тестирования с поставщиком RBS SQL. Ссылка: http://msdn.microsoft.com/en-us/library/cc949109(SQL.100).aspx· Возможна оптимизация хранилища с экономией дискового пространства и расходов на диски при использовании разностного резервного копирования или многоуровневого хранилища.
· Мы провели тестирование на поставщике SQL RBS FILESTREAM, который позволяет использовать удаленное хранилище больших двоичных объектов с подключением iSCSI. Использование iSCSI позволяет применять более дешевое хранилище NAS.
· Независимые поставщики программного обеспечения могут разработать другие возможности оптимизации данных с помощью поддерживаемых открытых API-интерфейсов RBS и SharePoint.
При реализации удаленного хранилища больших двоичных объектов необходимо учитывать следующие факторы:
· Вопрос. Почему вы не реализовали эти увеличенные ограничения данных при запуске SharePoint 2010?
· Ответ. За последние 12 месяцев мы получили дополнительные сведения о том, как клиенты реализуют решения архивации документов в SharePoint. Теперь, предоставляя специальное руководство по масштабированию размера данных и обращая внимание на возможности поддержки, мы можем увеличить ограничение размера данных для SharePoint и отменить ограничение размера данных для сценариев архивации документов.
· Вопрос. Каково новое ограничение размера данных для архивов документов в SharePoint?
· Ответ. Ограничения размера данных не существует, но при построении поддерживаемых масштабных систем необходимо следовать новым инструкциям. Если дополнительные факторы не учитываются должным образом, возможности поддержки ограничиваются.
· Вопрос. Что делать, если мне нужно больше 4 ТБ на ферме SharePoint и это не архив документов?
· Ответ. Вы должны использовать масштабируемую топологию, т. е. иметь несколько баз данных контента на одной ферме и распределять сайты между ними. Каждая база данных контента может расти до 4 ТБ при соблюдении инструкций.
· Вопрос. Что делать, если я неправильно предположил, что ограничение в 200 ГБ можно обойти, если перенести большие двоичные объекты в поставщик удаленного хранилища, таким образом уменьшив объем хранимых данных SQL Server для SharePoint?
· Ответ. Мы рекомендуем выполнить обновление до SharePoint 2010 с пакетом обновления 1 (SP1) и применить новые инструкции ко всем имеющимся данным. Проконсультируйтесь с компанией, у которой вы приобрели поставщик RBS, чтобы убедиться, что он прошел тестирование с SharePoint 2010 с пакетом обновления 1 (SP1). Если у вас есть развертывание, которое выходит за пределы новых и старых ограничений, рекомендуем обратиться в службу технической поддержки Майкрософт и запросить анализ возможностей поддержки. Это платная услуга; инженер службы поддержки определит, может ли поддерживаться ваша текущая реализация или необходимо уменьшить объем данных на каждую базу данных контента.
· Вопрос. Поскольку поддерживается NAS, позволяет ли поставщик SQL Server RBS FILESTREAM использовать для хранения больших двоичных объектов сетевую папку?
· Ответ. Нет, накопитель NAS должен быть подключен с помощью iSCSI и должен отображаться на компьютере SQL Server как локальный диск.
· Вопрос. Будет ли ограничение на размер баз данных контента или на время возврата первого байта поставщиком (20 мс) принудительно применяться в программном обеспечении?
· Ответ. Нет, это ограничения поддержки, которые мы рекомендуем клиентам не превышать для оптимизации производительности и получения наилучшей поддержки от Майкрософт. Они не являются жесткими ограничениями, которые регулируются программным обеспечением SharePoint.
· Вопрос. В какой статье TechNet можно найти сведения о старом ограничении в 200 ГБ?
· Ответ. Эти сведения приведены на странице TechNet "Ограничения планирования емкости SharePoint". Пока удаленные хранилища и большие двоичные объекты конкретно не назывались, ограничение в 200 ГБ было ясно указано для баз данных контента SharePoint, содержащих метаданные и большие двоичные объекты. Эта статья была обновлена информацией о новых ограничениях и удаленных хранилищах больших двоичных объектов, чтобы сделать ее более ясной и избежать неправильного понимания в будущем.
· Вопрос. Может ли большой архив документов иметь несколько семейств сайтов SharePoint?
· Ответ. Да, однако мы рекомендуем, чтобы семейство сайтов размером свыше 100 ГБ было единственным в базе данных контента.
· Вопрос. Может ли большой архив документов иметь несколько библиотек документов?
· Ответ. Да, у вас может быть несколько библиотек документов с разными разрешениями.
· Вопрос. Обязательно ли выполнять обновление до SharePoint 2010 с пакетом обновления 1 (SP1), чтобы воспользоваться преимуществами новых ограничений размеров баз данных контента?
· Ответ. Нет, ограничения применяются к SharePoint 2010 независимо от обновления до версии SP1. Однако мы настоятельно рекомендуем установить SharePoint 2010 с пакетом обновления 1 (SP1) из-за улучшений, которые в нем появились.
blogs.msdn.microsoft.com