[jvm-arguments] Настройка производительности JVM для больших приложений. Настройка и оптимизация jvm
[jvm-arguments] Настройка производительности JVM для больших приложений [performance]
Существует огромное количество этой информации.
Сначала профаймируйте код перед настройкой JVM.
Во-вторых, внимательно прочтите документацию по JVM ; вокруг много «городских легенд». Например, флаг -server помогает только в том случае, если JVM остается резидентом и работает некоторое время; -сервер «разворачивает» JIT / HotSpot, и для этого нужно пройти много проходов по тому же пути. -сервер, с другой стороны, замедляет первоначальное выполнение JVM, так как есть еще время настройки.
Есть несколько хороших книг и сайтов вокруг. См., Например, http://www.javaperformancetuning.com/
Посмотрите здесь (или выполните поиск google для настройки hotspot) http://java.sun.com/javase/technologies/hotspot/gc/gc_tuning_6.html
Вы определенно хотите профилировать свое приложение, прежде чем пытаться настроить vm. NetBeans имеет хороший профилировщик, встроенный в него, что позволит вам видеть всевозможные вещи.
Я когда-то рассказывал мне, что GC был взломан для своего приложения - я посмотрел на код и обнаружил, что они никогда не закрывали какие-либо результаты своих запросов к базе данных, поэтому они сохраняли огромное количество байтовых массивов. Как только мы закрыли результаты, время прошло от 20 минут и ГБ памяти до 2 минут и очень небольшой объем памяти. Они смогли удалить параметры настройки JVM, и все было счастливо.
Абсолютно лучший способ ответить на это - выполнить контролируемое тестирование приложения в непосредственной близости от «производственной» среды, которую вы можете создать. Вполне возможно, что использование -сервера, разумного размера начальной кучи и относительно умного поведения последних JVM будет вести себя так же хорошо или лучше, чем подавляющее большинство настроек, которые обычно можно попробовать.
Существует одно конкретное исключение из этого широкого обобщения: в случае, если вы работаете в веб-контейнере, существует очень высокая вероятность того, что вы захотите увеличить настройки постоянного поколения.
Это будет сильно зависеть от вашего приложения и поставщика и версии JVM. Вы должны четко понимать, что вы считаете проблемой с производительностью. Вы обеспокоены некоторыми критическими разделами кода? Вы уже профилировали приложение? Неужели JVM тратит слишком много времени на сбор мусора?
Я, вероятно, начинал бы с опции -verbose: gc JVM, чтобы посмотреть, как работает сбор мусора. Много раз, самое простое исправление, чтобы просто увеличить максимальный размер кучи с -Xmx. Если вы научитесь интерпретировать вывод -verbose: gc, он расскажет вам почти все, что вам нужно знать о настройке JVM в целом. Но делать это самостоятельно не будет волшебным образом, плохо настроенный код просто пойдет быстрее. Большинство параметров настройки JVM предназначены для повышения производительности сборщика мусора и / или объема памяти.
Для профилирования мне нравится yourkit.com
code-examples.net
java - Настройка производительности JVM для больших приложений
Фон
В магазине Java. Проводились целые месяцы, посвященные проверке производительности на распределенных системах, причем основные приложения находятся на Java. Некоторые из них подразумевают продукты, разработанные и проданные самим Sun (затем Oracle).
Я расскажу об уроках, которые я узнал, о какой-то истории о JVM, о некоторых разговорах о внутренних компонентах, о нескольких параметрах и, наконец, о некоторых настройках. Попытка сохранить это до такой степени, чтобы вы могли применить его на практике.
В мире Java быстро меняются вещи, поэтому часть его может быть уже устаревшей с прошлого года, когда я это сделал. (Уже есть Java 10?)
Что вам ДОЛЖНО делать: бенчмарк, контрольный показатель, BENCHMARK!
Когда вам действительно нужно знать о выступлениях, вам нужно выполнить реальные тесты, характерные для вашей рабочей нагрузки. Альтернатив нет.
Кроме того, вы должны контролировать JVM. Включить мониторинг. Хорошие приложения обычно предоставляют веб-страницу мониторинга и/или API. В противном случае существует общая инструментария Java (JVisualVM, JMX, hprof и некоторые флаги JVM).
Помните, что при настройке JVM обычно нет производительности. Это скорее "сбой или не сбой, нахождение точки перехода". Это о том, что, когда вы даете такое количество ресурсов вашему приложению, вы можете последовательно ожидать, что количество выступлений взамен. Знание - это сила.
Спектакли в основном продиктованы вашим приложением. Если вы хотите быстрее, вам нужно написать лучший код.
Что вы будете делать большую часть времени: живите с надежными чувствительными значениями по умолчанию
У нас нет времени для оптимизации и настройки каждого отдельного приложения. Большую часть времени мы просто будем жить с разумными значениями по умолчанию.
Первое, что нужно сделать при настройке нового приложения, - это прочитать документацию. Большинство серьезных приложений поставляется с руководством по настройке производительности, включая рекомендации по настройкам JVM.
Затем вы можете настроить приложение: JAVA_OPTS: -server -Xms???g -Xmx???g
- -server: включить полную оптимизацию (этот флаг на большинстве JVM в настоящее время).
- -Xms -Xmx: установите минимальную и максимальную кучу (всегда одно и то же значение для обоих, что касается единственной оптимизации).
Хорошо, вы знаете обо всех параметрах оптимизации, которые нужно знать о JVM, поздравления! Это было просто: D
Что вы НЕ ДОЛЖНЫ делать, КОГДА-ЛИБО:
Пожалуйста, НЕ копируйте случайную строку, которую вы нашли в Интернете, особенно когда они принимают несколько строк:
-server -Xms1g -Xmx1g -XX:PermSize=1g -XX:MaxPermSize=256m -Xmn256m -Xss64k -XX:SurvivorRatio=30 -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=10 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+PrintGCDateStamps -verbose:gc -XX:+PrintGCDetails -Dsun.net.inetaddr.ttl=5 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=`date`.hprof -Dcom.sun.management.jmxremote.port=5616 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -server -Xms2g -Xmx2g -XX:MaxPermSize=256m -XX:NewRatio=1 -XX:+UseConcMarkSweepGCНапример, эта вещь, найденная на первой странице google, проста. Существуют аргументы, указывающие кратность времени с конфликтующими значениями. Некоторые из них просто форсируют значения JVM по умолчанию (в конечном счете, значения по умолчанию из 2 версий JVM назад). Некоторые из них устарели и просто игнорируются. И, наконец, по крайней мере один параметр настолько недействителен, что он будет последовательно разбивать JVM при запуске им простое существование.
Как выбрать размер памяти:
Прочитайте руководство из своего приложения, оно должно дать некоторые указания. Мониторинг производства и последующая настройка. Выполните некоторые тесты, если вам нужна точность.
Важное примечание. Процесс java займет до максимальная куча PLUS 10%. Накладные расходы X% представляют собой управление кучей, не включенное в кучу.
Вся память, как правило, предварительно распределяется процессом при запуске. Вы можете увидеть процесс, используя максимальную кучу ВСЕ ВРЕМЯ. Это просто неправда. Вам нужно использовать инструменты мониторинга Java, чтобы увидеть, что действительно используется.
Поиск нужного размера:
- Если он сбой с OutOfMemoryException, недостаточно памяти
- Если он не сбой с OutOfMemoryException, это слишком много памяти
- Если это слишком много памяти, но аппаратное обеспечение получило и/или уже оплачено, это идеальный номер, работа выполнена!
JVM6 - бронза, JVM7 - золото, JVM8 - платина...
JVM навсегда улучшается. Сбор мусора - очень сложная вещь, и на нем много умных людей. Это имело колоссальные улучшения в последнее десятилетие, и оно будет продолжать делать это.
Для информационных целей. Это, по крайней мере, 4 доступных сборщика мусора в Oracle Java 7-8 (HotSpot) и OpenJDK 7-8. (Другие JVM могут быть совершенно разными, например, Android, IBM, встроенный):
- SerialGC
- ParallelGC
- ConcurrentMarkSweepGC
- G1GC
- (плюс варианты и настройки)
[Начиная с Java 7 и далее. Код Oracle и OpenJDK частично разделены. GC должен быть (в основном) одинаковым на обеих платформах.]
JVM >= 7 имеют много оптимизаций и выбирают достойные значения по умолчанию. Он немного меняется по платформе. Он уравновешивает несколько вещей. Например, решение включить многоядерную оптимизацию или нет, имеет ли процессор несколько ядер. Вы должны позволить ему это сделать. Не меняйте или не меняйте настройки GC.
Хорошо, если компьютер примет решение для вас (для чего предназначены компьютеры). Лучше иметь настройки JVM на 95% -оптимальные все время, чем заставлять "всегда 8-ядерную агрессивную коллекцию для более низких времен паузы" на всех коробках, половина из которых в конце концов является t2.small.
Исключение. Когда приложение поставляется с руководством по производительности и конкретной настройкой. Это совершенно нормально оставить предоставленные настройки как есть.
Совет. Переход на новую JVM для улучшения последних улучшений может иногда обеспечить хороший прирост без особых усилий.
Специальный случай: -XX: + UseCompressedOops
JVM имеет специальную настройку, которая принудительно использует внутренний индекс 32 бит (чтение: указатели). Это позволяет адресовать 4 294 967 295 объектов * 8 байт адрес = > 32 ГБ памяти. (НЕ следует путать с адресным пространством 4 ГБ для REAL-указателей).
Это снижает общее потребление памяти с потенциальным положительным воздействием на все уровни кеширования.
Пример реальной жизни. В документации ElasticSearch указано, что 32GB 32bits 326 бит node может быть эквивалентно 40-битным 64-битным node с точки зрения фактических данных, хранящихся в памяти.
Заметка об истории. Флаг был известен как неустойчивый в эпоху до java-7 (возможно, даже pre-java-6). Он работал отлично в новой JVM на некоторое время.
Улучшения производительности виртуальных машин Java HotSpot ™
[...] В Java SE 7 использование сжатых oops является стандартным для 64-разрядных процессов JVM, когда -Xmx не указан и для значений -Xmx меньше 32 гигабайт. Для JDK 6 перед выпуском 6u23 используйте флаг -XX: + UseCompressedOops с помощью команды java для включения этой функции.
См.: снова JVM горит впереди по ручной настройке. Тем не менее, интересно узнать об этом =)
Специальный случай: -XX: + UseNUMA
Неравномерный доступ к памяти (NUMA) - это компьютерная память, используемая при многопроцессорной обработке, время доступа к памяти зависит от местоположения памяти относительно процессора. Источник: Wikipedia
Современные системы имеют чрезвычайно сложные архитектуры памяти с несколькими уровнями памяти и кэшами, как частными, так и совместно используемыми, в ядрах и процессорах.
Совершенно очевидно, что доступ к данным в кэше L2 в текущем процессоре намного медленнее, чем для того, чтобы пройти весь путь к карте памяти из другого сокета.
Я считаю, что все продаваемые сегодня системы с несколькими сокетами являются NUMA по дизайну, тогда как все системы потребителей НЕ. Проверьте, поддерживает ли ваш сервер NUMA с помощью команды numactl --show в linux.
Флаг, поддерживающий NUMA, сообщает JVM оптимизировать распределения памяти для базовой аппаратной топологии.
Повышение производительности может быть значительным (например, две цифры: + XX%). Фактически, кто-то переключился с "NOT-NUMA 10CPU 100GB" на "NUMA 40CPU 400GB", возможно, [драматическая] потеря в исполнении, если он не знает о флагове.
Примечание. Обсуждаются обнаружение NUMA и автоматический флаг в JVM http://openjdk.java.net/jeps/163 p >
Бонус. Для этого нужно оптимизировать все приложения, предназначенные для работы на большом аппаратном уровне (т.е. NUMA). Это не относится к Java-приложениям.
К будущему: -XX: + UseG1GC
Последнее улучшение в Garbage Collection - это сборщик G1 (прочитайте: Garbage First).
Он предназначен для высоких ядер, систем с высокой памятью. При абсолютном минимуме 4 ядра + 6 ГБ памяти. Он ориентирован на базы данных и приложения с интенсивной памятью, используя в 10 раз больше и больше.
Короткий вариант, при этих размерах традиционный GC сталкивается с слишком большим количеством данных для обработки сразу, и паузы выходят из-под контроля. G1 разбивает кучу во многих небольших разделах, которые можно управлять независимо и параллельно во время работы приложения.
Первая версия была доступна в 2013 году. Теперь она достаточно зрелая для производства, но в ближайшее время она не станет стандартной. Это стоит попробовать для больших приложений.
Не трогайте: размеры поколений (NewGen, PermGen...)
GC разбивает память на несколько секций. (Не вдаваясь в подробности, вы можете "Google GC Generations" Google.)
Последний раз, когда я проводил неделю, чтобы попробовать 20 различных комбинаций флагов поколений в приложении, принимающем 10000 хитов/с. Я получал великолепный импульс от -1% до +1%.
Генерации Java GC - интересная тема для чтения статей или написания. Они не могут настраиваться, если вы не являетесь частью 1%, которые могут посвятить значительное время ничтожному выигрышу среди 1% людей, которым действительно нужны оптимизации.
Надеюсь, это может вам помочь. Получайте удовольствие от JVM.
Java - лучший язык и лучшая платформа в мире! Иди распространяй любовь: D
qaru.site
| область применения | раздел | название | описание |
| память | общие | -Xms<size>[k|m|G] | исходный размер кучи |
| -Xmx<size>[k|m|G] | максимальный размер кучи | ||
| -Xss<size>[k|m|G] | размер стека вызовов метода | ||
| -XX:NewRatio=<N> | соотношение old generation (tenured) к new generation | ||
| -XX:MinHeapFreeRatio=<N> | минимальное соотношение свободного пространства для уменьшения размера размера поколения | ||
| -XX:MaxHeapFreeRatio=<N> | максимальное соотношение свободного пространства для увеличение размера размера поколения | ||
| молодое поколение | -Xmn<size>[k|m|G] | размер молодого поколения | |
| -XX:NewSize=<size>[k|m|G] | нижняя граница для молодого поколения | ||
| -XX:MaxNewSize=<size>[k|m|G] | верхняя граница для молодого поколения | ||
| -XX:SurvivorRatio=<N> | соотношение eden / ( survivor * 2) | ||
| -XX:YoungGenerationSizeIncrement=<N> | процент увеличения молодого поколения | ||
| старое поколение | -XX:TenuredGenerationSizeIncrement=<N> | процент увеличение старого поколения | |
| область метаданных | -XX:MaxMetaspaceSize=<size>[k|m|G] | размер метаобласти | |
| -XX:+CMSClassUnloadingEnabled | удаление неиспользуемых классов | ||
| сборка мусора | общие | -XX:+ScavengeBeforeFullGC | перед Full GC запуск GC на young generation |
| -XX:+CMSScavengeBeforeRemark | перед фазой remark запуск GC на young generation | ||
| -XX:-DisableExplicitGC | выключаем System.gc() | ||
| -XX:CMSInitiatingOccupancyFraction=<N> | порог заполненности Tenured когда запускается GC | ||
| -XX:InitiatingHeapOccupancyPercent=<N> | порог заполненности heap для запуска фазы mark | ||
| -XX:GCHeapFreeLimit=<N> | отключаем лимит в 2% свободной памяти после выполнения full gc перед возникновением OutOfMemoryError | ||
| -XX:-UseGCOverheadFreeLimit | отключаем лимит в 98% активности GC от времени работы приложение при котором возникает OutOfMemoryError | ||
| -XX:GCTimeLimit=<N> | выставляем порог для сборки мусора от общего времени выполнения приложения, если он превышен и не выставлен предыдущий флаг, то возникает OutOfMemoryError | ||
| Serial GC | -XX:+UseSerialGC | включаем Serial GC | |
| Parallel GC | -XX:+UseParallelGC | включаем Parallel GC | |
| -XX:MaxGCPauseMillis=<N> | максимальное время пауз при сборке | ||
| -XX:GCTimeRatio=<N> | процент времени выполнения GC = 1/(1+N) от общее времени работы приложения | ||
| Concurrent Mark and Swap | -XX:+UseConcMarkSweepGC | включаем Concurrent Mark and Swap GC | |
| -XX:+UseParNewGC | параллельное выполнение молодых сборок | ||
| -XX:+UseParNewGC | параллельное выполнение молодых сборок | ||
| -XX:ParallelGCThreads=<N> | количество потоков, используемые при фазе параллельной сборке мусора | ||
| -XX:ConcGCThreads=<N> | количество потоков, используемых для сборки мусора | ||
| -XX:+CMSScavengeBeforeRemark | запуск фазы remark после сборки на new generation | ||
| -XX:CMSWaitDuration | запуск GC на tenured только после сборки на new generation | ||
| Garbage First | -XX:+UseG1GC | включает сборщик мусора G1 | |
| -XX:MaxGCPauseMillis=<N> | Указывает G1, что в ходе отдельно взятой сборки необходимо избегать пауз дольше N мс | ||
| -XX:GCPauseIntervalMillis=<N> | Указывает G1, что между сборками мусора должно проходить не менее N мс | ||
| -XX:G1HeapRegionSize=<size>[k|m|G] | размер региона | ||
| -XX:ParallelGCThreads=<N> | аналогично тому, что в CMS | ||
| -XX:ConcGCThreads=<N> | |||
| логирование GC | -verbose:gc | включение логирования для GC | |
| -Xloggc:<filename> | запись логов в файл | ||
| -XX:+UseGCLogFileRotation> | разбиение файлов | ||
| -XX:+HeapDumpBeforeFullGC | создание dump'а памяти перед каждым запуском полной сборки мусора | ||
| -XX:NumberOfGCLogFiles=<N> | количество лог файлов | ||
| -XX:+PrintGCDetails | дает расширенные подробности о сборщике мусора | ||
| -XX:+PrintGCDateStamps | сопровождает операции сборщика мусора метками времени | ||
| -XX:+PrintGCApplicationConcurrentTime | время, затраченное на сборщик мусора в условиях, когда потоки приложения продолжают работать | ||
| -XX:+PrintGCApplicationStoppedTime | время затраченное на фазу stop the world | ||
| разное | -XX:+PrintFlagsFinal | отображение опций jvm, с которыми она была запущена | |
| -XX:+HeapDumpOnOutOfMemoryError | дамп при падении на OutOfMemoryError | ||
| -XX:HeapDumpPath=dump.hprof | |||
| -XX:+CompileThreshold=<N> | количество запуска метода после которого происходит JIT оптимизация | ||
| -XX:+UseCompressedOops | уменьшение размера ссылок для экономии памяти | ||
| -XX:+OptimizeStringConcat | преобразование + в StringBuilder | ||
| -XX:+PrintCompilation | показывает какие методы были оптимизированы JIT | ||
| -XX:+AggressiveOpts | агрессивный режим оптимизации | ||
| -XX:+UseStringCache | кэширование string'ов | ||
| Программа jmap | запуск | jmap <pid> | получение состояния памяти |
| ключи | -heap | информация о всей куче | |
| -histo | использование памяти в процентах на каждый класс | ||
| -histo:live | информация о живых объектах | ||
| -dump:live,format=b,file=heap.hprof | сохранение дампа в файл |
www.izebit.ru
Тюнинг JVM на примере одного проекта / Блог компании Luxoft / Хабр
В этой статье я хочу рассказать о полученном опыте оптимизации приложений по памяти с использованием стандартных механизмов оптимизации JVM таких, как различные типы ссылок, стратегиях garbage collection’а, множестве ключей, влияющих на сборку мусора. Уверен, что каждому из вас приходилось жонглировать параметрами для улучшения производительности и вы не найдете в статье какой-то черной магии или рецепта от недостатка памяти, просто хочется поделиться своим опытом.История проекта
Начиналось все прекрасно и безоблачно. Для нужд одного крупного банка было необходимо реализовать калькулятор, вычисляющий значение Value-at-Risk для конкретного инвестиционного портфеля. Как и большинство финансовых приложений методология не подразумевает “тяжелых” вычислений, но поток данных порой по истине огромен.Проблемы обработки большого объема данных обычно решаются за счет двух известных типов масштабирования: вертикального и горизонтального. С вертикальным все обстояло достаточно приемлемо. В нашем распоряжении была машина о 16 ядрах, с 16 GB RAM, Red Hat’ом и Java’ой 1.6. На таком железе можно было достаточно хорошо развернуться что, собственно, мы и успешно делали на протяжении нескольких месяцев.
Все было прекрасно до того момента, как к нам не постучался заказчик и не сказал, что IT-инфраструктура пересмотрена и вместо 16x16 мы имеем 4x1-2: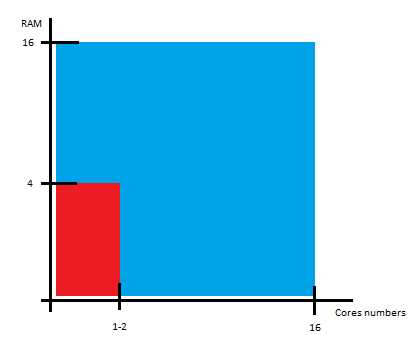 Естественно, было увеличено требование времени работы приложения в несколько раз, но. Передать наши эмоции на тот момент было достаточно трудно, но речь, внезапно, стала сильно приправлена различными аллегориями, аллюзиями и сравнениями.
Естественно, было увеличено требование времени работы приложения в несколько раз, но. Передать наши эмоции на тот момент было достаточно трудно, но речь, внезапно, стала сильно приправлена различными аллегориями, аллюзиями и сравнениями.
Первые попытки
Для начала поясню, что представляет из себя Value-at-Risk калькулятор. Это программа с большим количеством «простых» вычислений, пропускающая сквозь себя большой объем данных.Ключи оптимизации, которые были наиболее полезны:
- -server — крайне полезный ключ, JVM разворачиваем циклы, инлайнит многие функции и т.д.
- Работа со строками: -XX:+UseCompressedStrings, -XX:+UseStringCache, -XX:+OptimizeStringConcat
Итак, у нас доступны следующие типы ссылок:
- Hard/Strong
- Soft
- Weak
- Phantom
Зависимости между ними выглядят примерно так:
Посмотрим, что же гарантирует спецификация по работе с этими типами ссылок. Hard/Strong ссылки — это самые обычные ссылки, которые создаются, когда мы используем ключевое слово «new». Такая ссылка будет удалена, когда количество ссылок на созданный объект достигнет нуля. Мягкие ссылки (Soft) могут быть удалены в случае, если виртуальной машине недостаточно памяти для дальнейшей работы. Слабые ссылки (Weak) могут быть собраны в любой момент, если GC так решит. Фантомная ссылка (Phantom) — это специальный тип ссылок, который необходим для более гибкой файнализации объектов, чем классический finalize.
Hard и Phantom ссылки были сразу же убраны из нашего рассмотрения в силу того, что не дают требуемой функциональности и гибкости. Hard не удаляются в нужный момент, а с файнализацией все было в порядке.
Рассмотрим, к примеру, то, как собираются Weak ссылки:
Видим, что у нас нет никакой гарантии того, что объект будет доступен все время и может быть удален в произвольный момент времени. Из-за этой специфики было решено перестроить внутренние, наиболее «тяжелые» кэши на Soft ссылки. Нами двигало примерно следующее утверждение: «Пусть объект живет в кэше как можно дольше, но в случае недостатка памяти мы сможем вычислить его заново, в силу того, что требования по времени работы были увеличены».
Результаты были существенны, но работы приложения в вожделенных 4ГБ не принесли.
Детальное исследование
Дальнейшие исследования проводились с помощью различных средств профилирования:- Стандартные средства JVM: -XX:+PrintGCDetails, -XX:+PrintGC, -XX:PrintReferenceGC, etc
- MXBean
- VisualVM
Во-первых, необходимо было уменьшить количество генерируемых объектов. Было замечено, что большинство данных имеют схожую структуру: «XXX1:XXX2:XXX3 и тд». Все паттерны типа «XXX» были заменены ссылками на объекты из пула, что дало существенное уменьшение количества создаваемых объектов (примерно в пять раз), а также освободило дополнительный объем драгоценной памяти.
Во-вторых, мы решили более детально поработать со стратегиями сборки мусора. Как мы знаем, у нас доступны следующие стратегии сборки мусора:
- Serial
- Parallel
- Parallel compacting
- Concurrent Mark-Sweep
- G1 collector
G1 был нам недоступен в силу того, что использовалась шестая версия Java. Serial и Parallel мало чем отличаются и не очень хорошо показали себя на нашей задаче. Parallel compacting был и интересен за счет фазы, позволяющий уменьшить дефрагментацию данных. Concurrent Mark-Sweep был интересен за счет того, что позволял уменьшить время на фазу stop-the-world и также не допускал сильную фрагментацию.
После сравнения Parallel compacting и Concurrent Mark-Sweep коллекторов было решено остановиться на втором, что оказалось хорошим решением.
После боевого испытания всех вышеописанных приемов приложение стало полностью совместимо с новыми требованиями и успешно запущено в продакшен! Все с облегчением вздохнули!
Полученный урок
- Помогли ключи работы со строками: -XX:+UseCompressedStrings, -XX:+UseStringCache, -XX:+OptimizeStringConcat и сама специфика строковых данных
- Уменьшение количества используемых объектов
- Тонкая настройка JVM занимаем много времени, но результаты более чем оправдывают себя
- Узнавайте требования как можно раньше! :)
Более развернутую версию проблемы и этапах решения можно будет послушать на приближающейся конференции JPoint, которая пройдет в Санкт-Петербурге.
habr.com
Передовые методики и рекомендации по настройке для обработки больших объектов в WebSphere Enterprise Service Bus
Шаблоны проектирования и настройка
Мартин РоссОпубликовано 31.10.2012
Обеспечение оптимальной производительности систем обработки больших объектов является проблемой, с которой часто сталкиваются пользователи промежуточного программного обеспечения. Как правило, «большими» объектами, требующими особого внимания, могут считаться объекты объемом свыше 1 МБ. Цель настоящей статьи — предоставить необходимую информацию и рекомендации по успешному использованию продукта WebSphere Enterprise Service Bus (ESB) V7 для эффективной обработки больших объектов в 64-разрядной производственной среде.
Важные замечания
Данный раздел содержит важные замечания, которые необходимо учитывать при обработке больших сообщений.
Ограничения JVM
Главные преимущества 64-разрядной архитектуры относятся к управлению памятью и доступности. Увеличенная ширина шины данных позволяет поддерживать объем адресуемой памяти больше 4 ГБ, обычно доступных в 32-разрядной архитектуре. Хотя объем динамической памяти (кучи) Java зависит от типа операционной системы, обычно для 32-разрядной JVM он ограничивается примерно 1,4 ГБ. Поддержка увеличенного объема памяти, которую обеспечивает 64-разрядная архитектура, несколько ослабляет ограничения на размер динамической памяти Java, который при выполнении операций с большими объектами может стать ограничивающим фактором в 32-разрядной системе.
Как правило, для обработки больших объектов следует применять 64-разрядные JVM.
Размер бизнес-объектов, находящихся в оперативной памяти
Следует отметить, что размер бизнес-объектов (BO) может быть значительно больше, чем их представление на шине. Это может быть обусловлено несколькими причинами, в частности, различием в схемах кодировки символов, изменениями, вносимыми при прохождении сообщения по системе, а также копиями BO, создаваемыми во время транзакций для исправления ошибок и восстановления изначальных параметров.
Количество параллельно обрабатываемых объектов
Доступное время отклика, как правило, обратно пропорционально количеству параллельно выполняемых задач обработки объектов, хотя современные аппаратные средства SMP (симметричная мультипроцессорность) позволяют в некоторой степени ослабить эти ограничения. Для достижения наилучшего времени отклика системы можно ограничить количество одновременно обрабатываемых сообщений — это особенно актуально при обработке больших объектов данных из-за возможных нагрузок на динамическую память Java.
Ограничение количества одновременно обрабатываемых сообщений может быть достигнуто за счет:
- ограничения количества пользователей, создающих рабочую нагрузку;
- настройки соответствующего пула потоков для ограничения количества параллельных потоков.
Сеть
Пропускная способность сети может послужить ограничивающим фактором при обработке больших сообщений. Если рассмотреть простую клиент-серверную модель, в которой клиент отправляет сообщения-запросы небольшого размера и получает ответы объемом 50 МБ по локальной сети 1 Гбит/с, то теоретически максимальная пропускная способность может быть рассчитана так:
Пропускная способность сети (1000 Мбит/с) /размер сообщения (400 Мбит) = 2,5 сообщения в секунду
Это равняется достижимому времени отклика 400 мс исходя из одного клиентского потока.
На самом деле номинальная скорость передачи данных сетевого адаптера (NIC) на прикладном уровне не достигается из-за передачи служебных данных нижних уровней (TCP/IP и т. д.) Как правило, максимальная пропускная способность составляет 70% от скорости передачи данных NIC.
При обработке сообщений с помощью многоуровневой конфигурации (рисунок 1) сетевая нагрузка на среднем уровне в два раза больше, чем нагрузка на стороне клиента или поставщика услуги — это приводит к уменьшению достигаемой пропускной способности, описанной в приведенном выше сценарии, наполовину.
Рисунок 1. Многоуровневая конфигурация
Шаблоны проектирования приложения
В данном разделе приведен ряд шаблонов проектирования, позволяющих увеличить производительность обработки больших сообщений.
Разбивка входящих данных
Технология разбивки входящего сообщения подразумевает разбивку большого сообщения на множество мелких для их отдельной передачи на обработку.
Если большое сообщение представляет собой набор более мелких бизнес-объектов, то решение состоит в том, чтобы сгруппировать более мелкие объекты в объединенные объекты размером менее 1 МБ. Если для отдельных объектов существуют временные зависимости или требование «все или ничего», то решение становится более сложным.
Модель Claim Check
Модель Claim Check подразумевает уменьшение размеров находящихся в оперативной памяти бизнес-объектов, если посреднику необходимы лишь некоторые атрибуты большого сообщения.
- Отделить полезную нагрузку от сообщения.
- Извлечь необходимые атрибуты в более мелкий «контрольный» бизнес-объект.
- Сохранить полезную нагрузку большего объема в хранилище данных и сохранить «квитанцию на получение» (Claim Check) в качестве ссылки в «контрольном» бизнес-объекте.
- Обработать более мелкий «контрольный» бизнес-объект, требующий меньшего ресурса памяти.
- В момент, когда снова необходима вся полезная нагрузка, выгрузить больший объем нагрузки из хранилища данных с помощью ключа «квитанция на получение».
- Удалить больший объем полезной нагрузки из хранилища данных.
- Объединить атрибуты в «контрольном» бизнес-объекте с большим наполнением, учитывая измененные атрибуты в «контрольном» бизнес-объекте.
Размещение сервисов
Наиболее важным решением с точки зрения архитектуры является использование отдельной JVM (выделенный сервер) для обработки больших сообщений, особенно при выполнении транзакций по одновременной обработке сообщений небольшого (высокая пропускная способность /низкое время отклика) и большого размера. Данный метод следует применять, если сообщения большого размера приходят нечасто, но характеризуются относительно продолжительным временем отклика.
В системах, обеспечивающих функционирование нескольких сервисов с одновременной обработкой сообщений большого и малого размеров, «сборка мусора» (GC) и непроизводительная загрузка из-за обработки сообщений большего размера могут оказывать отрицательное воздействие на другие сервисы.
Рассмотрим в качестве примера два сервиса:
- Сервис А — преимущественно обрабатывает сообщения большого размера
- Сервис B — преимущественно обрабатывает сообщения малого размера (высокая пропускная способность / низкое время отклика)
Разнесение Сервиса А и Сервиса B по различным JVM дает ряд преимуществ:
- GC и непроизводительная загрузка на обработку сообщений большего размера на стороне Сервиса А не так критично влияют на высокую пропускную способность и низкое время отклика Сервиса B;
- Каждую из JVM можно оптимизировать для своей ожидаемой рабочей нагрузки.
Настройка производительности
В данном разделе приведена информация и рекомендации по ряду параметров настройки, которые следует принимать во внимание, чтобы правильно сконфигурировать настройки для получения оптимальной производительности.
Настройка JVM
В данном разделе приведена информация по настройке JVM.
Что такое «сборка мусора»?
Сборка мусора (GC) — это форма управления памятью JVM. Событием-триггером для GC, как правило, является ошибка выделения ресурсов, которая возникает, когда не удается разместить объект в динамической памяти JVM из-за отсутствия свободного места. GC предназначена для очистки динамической памяти JVM от ненужных объектов, обеспечивая таким образом достаточный объем памяти для объекта, которому до этого было отказано в выделении ресурсов. Если GC была запущена, но для объекта все еще недостаточно свободного объема, то, очевидно, динамическая память JVM заполнена полностью.
«Сборка мусора с учетом поколений» (Generational GC) — это методика, которая наилучшим образом подходит для приложений, создающих множество объектов с непродолжительным временем жизни, что типично для промежуточного программного обеспечения. Динамическая память JVM разделена на три части (область размещенных — Allocate Space, область уцелевших — Survivor Space и хранилище — Tenured Space), и хотя это оптимизирует производительность во многих ситуациях, при обработке больших сообщений необходимо знать, как используется динамическая память JVM. Ограничения, накладываемые на объем динамической памяти JVM, могут послужить ограничивающим фактором на 32-разрядных JVM, поэтому настоятельно рекомендуется не применять методику сборки мусора с учетом поколений для обработки сообщений большого размера. Это не относится к 64-разрядным JVM, так как они обеспечивают поддержку увеличенного объема памяти.
Увеличивать ли размер динамической памяти JVM?
Обработка нескольких больших сообщений, особенно при передаче нескольких параллельных потоков, может привести к переполнению динамической памяти JVM. Увеличение размера динамической памяти JVM в большинстве случаев может решить эту проблему, однако следует придерживаться разумного баланса, чтобы побочные эффекты такого изменения не сказались на производительности.
Увеличение размера динамической памяти JVM для компенсации ее исчерпания позволит разместить больше объектов прежде, чем запустится сборка мусора. При этом побочным эффектом является увеличение интервалов времени между сборками мусора, а также увеличение времени на обработку ошибки выделения ресурсов.
При выполнении сборки мусора все другие потоки JVM временно блокируются. Например, если глобальная сборка мусора в вашей системе обычно длится 3 секунды, в то время как по соглашению об уровне обслуживания (SLA) время отклика составляет 1 секунду, во время этой транзакции длительность отклика в 1 секунду будет превышена.
При использовании 32-разрядной JVM (не рекомендуется для обработки крупных объектов) можно максимизировать пространство, доступное для крупных бизнес-объектов, путем выполнения «сборки мусора с учетом поколений». В результате получим «плоскую память», в которой для размещения временных объектов доступно все пространство динамической памяти, а не только область инкубатора (nursery space).
Существует ли альтернативный подход?
Если сервис одновременно обрабатывает несколько больших сообщений, доступный объем динамической памяти JVM может быть быстро заполнен. Ограничение количества потоков Web-контейнера позволяет администратору дополнительно контролировать количество одновременно обрабатываемых сообщений. Это может помочь в решении проблемы исчерпания динамической памяти JVM без необходимости увеличения ее размеров.
Кроме того, в определенный момент времени можно обеспечить обработку одного большого сообщения путем передачи сообщений в WebSphere ESB только одним клиентом — это позволит снизить объем используемой памяти и обеспечить оптимальное время отклика. Последовательное поступление на WebSphere ESB дросселированных входящих клиентских запросов с большими сообщениями может быть обеспечено за счет применения фронтального сервера обработки клиентских запросов, например устройства DataPower.
В разделе «Настройки администрирования» данной статьи приведены параметры и настройки консоли администрирования WebSphere ESB.
Настройки администрирования
В данном разделе приведены соответствующие параметры, условия настройки, рекомендации и информация о работе в Консоли администрирования.
MDB ActivationSpec
Получить доступ к параметрам настройки MDB ActivationSpec можно следующим образом:
Resources > Resource Adapters > J2C Activation Specifications > ActivationSpec Name(Ресурсы > Адаптеры ресурсов > Спецификации активизации J2C > Имя спецификации активизации) Resources > JMS > Activation Specifications > ActivationSpec Name (Ресурсы > JMS > Спецификации активизации > Имя спецификации активизации)
Рисунок 2. Спецификация активизации
При обработке больших сообщений следует учитывать два свойства:
Рисунок 3. Параметры спецификации активизации
maxConcurrency — это свойство отвечает за количество сообщений, которые могут быть одновременно переданы из очереди JMS в потоки MDB.
maxBatchSize — это свойство определяет количество сообщений, которые передаются с уровня сообщений на прикладной уровень за один шаг.
Пулы потоков
Как правило, необходимо настроить перечисленные ниже пулы потоков:
- Default
- ORB.thread.pool
- WebContainer
Максимальный размер этих пулов можно установить в Servers > Application Servers > Server Name > Thread Pools > Thread Pool Name (Серверы > Серверы приложений > Имя сервера > Пулы потоков > Имя пула потоков)
Рисунок 4. Спецификация активизации
Пул JMS-соединений
Получить доступ к фабрикам соединений JMS (JMS Connection Factories) и фабрикам соединений JMS-очередей (JMS Queue Connection Factories) из Консоли администрирования можно несколькими способами:
Resources > Resource Adapters > J2C Connection Factories > Factory Name (Ресурсы > Адаптеры ресурсов > Фабрики соединений J2C > Имя фабрики)
Resources > JMS > Connection Factories > Factory Name (Ресурсы > JMS > Фабрики соединений > Имя фабрики)
Resources > JMS > Queue Connection Factories > Factory Name (Ресурсы > JMS > Фабрики соединений очередей > Имя фабрики)
Рисунок 5. Фабрики соединений
Для открытия фабрики соединений из панели администрирования необходимо открыть Additional Properties > Connection Pool Properties (Дополнительные параметры > Параметры пула соединений). Здесь можно установить максимальное количество соединений.
Рисунок 6. Параметры фабрики соединения
Заключение
Поддержка увеличенного объема памяти, которую обеспечивает 64-разрядная архитектура, несколько уменьшает ограничения на размер динамической памяти Java, который при выполнении операций с крупными объектами данных может стать ограничивающим фактором в 32-разрядной системе.
Увеличение размера динамической памяти JVM в большинстве случаев может решить эту проблему, однако следует придерживаться разумного баланса, чтобы побочные эффекты такого изменения не сказались на производительности.
- Правильно настройте JVM для обеспечения баланса между интервалами выполнения операций сборки мусора и перерывами между такими операциями.
- Рассмотрите доступные шаблоны проектирования, позволяющие снизить нагрузки на JVM.
- Используйте выделенный сервер для обработки больших сообщений.
- Ограничивайте параллельные или единичные запросы посредством сервера обработки больших сообщений.
Ресурсы для скачивания
Похожие темы
Подпишите меня на уведомления к комментариям
www.ibm.com
Каковы наилучшие настройки JVM для Eclipse? Bilee
Это время года снова: «eclipse.ini принимает 3», настройки ударяются!
alt text http://www.eclipse.org/home/promotions/friends-helios/helios.png
После настроек для Eclipse Ganymede 3.4.x и Eclipse Galileo 3.5.x , здесь подробно рассмотрим «оптимизированный» файл настроек eclipse.ini для Eclipse Helios 3.6.x:
- основанные на параметрах времени выполнения ,
- и используя Sun-Oracle JVM 1.6u21 b7 , выпущенный 27 июля ( некоторые некоторые запатентованные варианты Sun могут быть задействованы ).
( «оптимизировано», я имею в виду возможность запуска полноценного Eclipse на нашей дерьмовой рабочей станции на работе, несколько старых P4 с 2002 года с 2Go RAM и XPSp3. Но я также тестировал те же настройки в Windows7 )
eclipse.ini
ПРЕДУПРЕЖДЕНИЕ : для платформы, отличной от Windows, используйте запатентованную опцию Sun -XX:MaxPermSize вместо запатентованной опции Eclipse --launcher.XXMaxPermSize . То есть: если вы не используете последнюю версию jdk6u21 build 7 . См. Раздел Oracle ниже.
-data ../../workspace -showlocation -showsplash org.eclipse.platform --launcher.defaultAction openFile -vm C:/Prog/Java/jdk1.6.0_21/jre/bin/server/jvm.dll -vmargs -Dosgi.requiredJavaVersion=1.6 -Declipse.p2.unsignedPolicy=allow -Xms128m -Xmx384m -Xss4m -XX:PermSize=128m -XX:MaxPermSize=384m -XX:CompileThreshold=5 -XX:MaxGCPauseMillis=10 -XX:MaxHeapFreeRatio=70 -XX:+CMSIncrementalPacing -XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:+UseFastAccessorMethods -Dcom.sun.management.jmxremote -Dorg.eclipse.equinox.p2.reconciler.dropins.directory=C:/Prog/Java/eclipse_addonsЗаметка: Адаптируйте p2.reconciler.dropins.directory во внешний каталог по вашему выбору. См. Этот ответ SO . Идея состоит в том, чтобы убрать новые плагины в каталог независимо от любой установки Eclipse.
В следующих разделах подробно описано, что находится в этом файле eclipse.ini .
Страшный Oracle JVM 1.6u21 (pre build 7) и Eclipse сбой
Эндрю Нифер предупредил меня об этой ситуации и написал сообщение в блоге о нестандартном аргументе vm ( -XX:MaxPermSize ) и может заставить vms от других поставщиков вообще не запускаться. Но версия eclipse этого параметра ( --launcher.XXMaxPermSize ) не работает с новым JDK (6u21, если вы не используете сборку 6u21 7, см. Ниже).
окончательный решение находится на Eclipse Wiki , а для Helios на Windows только с 6u21 pre build 7 :
- загрузка исправленного файла eclipse_1308.dll (16 июля 2010 г.)
- и поместить его в
Вот и все. Нет настройки для настройки здесь (опять же, только для Helios на Windows с предварительным сборкой 6u21 7 ). Для платформы, отличной от Windows, вам нужно вернуться к запатентованной опции Sun -XX:MaxPermSize .
Проблема основана на регрессии: идентификация JVM не удается из-за ребрендинга Oracle в java.exe и вызвала ошибку 319514 на Eclipse. Андрей позаботился о Bug 320005 – [launcher] --launcher.XXMaxPermSize: isSunVM должен возвращать true для Oracle , но это будет только для Helios 3.6.1. Фрэнсис Аптон , другой коммиттер Eclipse, размышляет над всей ситуацией .
Обновление u21b7, 27 июля : Oracle отменил изменение для следующего выпуска Java 6 и не будет реализовывать его снова до JDK 7 . Если вы используете jdk6u21 build 7 , вы можете вернуться к параметру --launcher.XXMaxPermSize (вариант eclipse) вместо -XX:MaxPermSize (нестандартная опция). Автоматическое обнаружение, происходящее в C launcher shim eclipse.exe , по-прежнему будет искать строку « Sun Microsystems », но с 6u21b7 она будет работать снова.
На данный момент я все еще сохраняю версию -XX:MaxPermSize (потому что я понятия не имею, когда все запустит eclipse в правый JDK).
Неявные `-startup` и` -launcher.library`
В отличие от предыдущих настроек, точный путь для этих модhive больше не задан, что удобно, поскольку он может варьироваться между различными выпусками Eclipse 3.6.x:
- startup: если не указано, исполняемый файл будет выглядеть в каталоге плагинов для пакета org.eclipse.equinox.launcher с самой высокой версией.
- launcher.library: если не указано, исполняемый файл ищет в каталоге plugins соответствующий fragment org.eclipse.equinox.launcher.[platform] с самой высокой версией и использует общую библиотеку с именем eclipse_* внутри.
Использовать JDK6
JDK6 теперь явно требуется для запуска Eclipse:
-Dosgi.requiredJavaVersion = 1.6Этот вопрос SO сообщает о положительной частоте развития в Mac OS.
+ UnlockExperimentalVMOptions
Следующие опции являются частью некоторых экспериментальных вариантов Sun JVM.
-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC -XX:+UseFastAccessorMethodsОб этом сообщается в этом сообщении в блоге, чтобы потенциально ускорить работу Eclipse. См. Все параметры JVM здесь, а также на официальной странице параметров Java Hotspot . Примечание. Подробный список этих опций сообщает, что UseFastAccessorMethods может быть активным по умолчанию.
См. Также «Обновление вашей JVM» :
Напомним, что G1 является новым сборщиком мусора в рамках подготовки к JDK 7, но уже используется в версии версии 6 от u17.
Открытие файлов в Eclipse из командной строки
См. Сообщение в блоге от Andrew Niefer, в котором сообщается об этом новом варианте:
--launcher.defaultAction openFileЭто сообщает программе запуска, что если она вызывается с командной строкой, которая содержит только аргументы, которые не начинаются с « - », то эти аргументы должны обрабатываться так, как если бы они выполнялись « --launcher.openFile ».
eclipse myFile.txtЭто тип командной строки, которую запускающая программа будет получать в windowsх при двойном щелчке файла, связанного с eclipse, или вы выбираете файлы и выбираете « Open With » или « Send To » Eclipse.
Относительные пути будут разрешены сначала против текущего рабочего каталога, а затем – против каталога программ eclipse.
См. Ошибку 301033 для справки. Первоначально ошибка 4922 (октябрь 2001 года, зафиксированная 9 лет спустя).
p2 и диалоговое окно Unsigned Dialog
Если вы устали от этого диалогового windows во время установки ваших многочисленных плагинов:
, добавьте в свой eclipse.ini :
-Declipse.p2.unsignedPolicy=allowСм. Это сообщение в блоге от Криса Анишки и сообщение об ошибке 235526 .
Я хочу сказать, что исследования в области безопасности подтверждают тот факт, что меньше подсказок лучше. Люди игнорируют вещи, которые появляются в streamе того, что они хотят сделать.
Для 3.6 мы не должны выставлять предупреждения в середине streamа – независимо от того, насколько мы упрощаем, люди просто игнорируют их. Вместо этого мы должны собрать все проблемы, не устанавливать эти пакеты с проблемами, а вместо этого возвращать пользователя в точку рабочего процесса, где они могут быть исправлены – добавление доверия, настройка политики безопасности более свободно и т. Д. Это называется безопасным постановка “ .
———- http://www.eclipse.org/home/categories/images/wiki.gif alt text http://www.eclipse.org/home/categories/images/wiki.gif alt text http://www.eclipse.org/home/categories/images/wiki.gif
Дополнительные опции
Эти параметры не находятся непосредственно в eclipse.ini выше, но могут пригодиться при необходимости.
Проблема `user.home` в Windows7
Когда начнется затмение, он будет читать файл хранилища ключей (где хранятся пароли), файл, расположенный в user.home . Если по какой-то причине пользователь user.home не будет корректно разрешать путь полной реализации, Eclipse не запустится. Первоначально, поднятый в этом вопросе SO , если вы это испытываете, вам нужно переопределить файл хранилища ключей на явный путь (не больше user.home для решения в начале)
Добавьте в свой eclipse.ini :
-eclipse.keyring C:\eclipse\keyring.txtЭто отслеживается ошибкой 300577 , она была решена в этом другом вопросе SO .
Режим отладки
Подождите, в Eclipse есть более одного файла настроек. если вы добавите в свой eclipse.ini вариант:
-debug, вы включаете режим отладки, и Eclipse будет искать другой файл настроек: файл .options котором вы можете указать некоторые параметры OSGI. И это здорово, когда вы добавляете новые плагины через папку dropins. Добавьте в свой файл .options следующие настройки, как описано в этом сообщении в блоге « Диагностика отложений » :
org.eclipse.equinox.p2.core/debug=true org.eclipse.equinox.p2.core/reconciler=trueP2 сообщит вам, какие пакеты были найдены в dropins/ папках, какой запрос был сгенерирован и каков план установки. Возможно, это не подробное объяснение того, что на самом деле произошло, и что пошло не так, но оно должно дать вам сильную информацию о том, с чего начать:
- был ли ваш план в плане?
- Была ли проблема с установкой (ошибка P2)
- или, может быть, просто не оптимально включить вашу функцию?
Это происходит от Bug 264924 – [reconciler] Нет диагноза проблем с каплями , что, в конечном итоге, решает следующую проблему:
Unzip eclipse-SDK-3.5M5-win32.zip to ..../eclipse Unzip mdt-ocl-SDK-1.3.0M5.zip to ..../eclipse/dropins/mdt-ocl-SDK-1.3.0M5Это проблемная конфигурация, поскольку OCL зависит от отсутствующей EMF. 3.5M5 не дает диагноза этой проблемы.
Начните затмение. Нет очевидных проблем. Ничего в журнале ошибок.
- Help / About / Plugin указаны org.eclipse.ocl.doc , но не org.eclipse.ocl .
- Help / About / Configuration Сведения Help / About / Configuration не имеет (диагностического) упоминания о org.eclipse.ocl .
- Help / Installation / Information Installed Software не имеет упоминания о org.eclipse.ocl .
Где хорошие маркеры ошибок?
Манифест Класса
Смотрите это сообщение в блоге :
- В Galileo (aka Eclipse 3.5) JDT начал разрешать манифест classа class в библиотеках, добавленных в путь сборки проекта. Это повлияло на то, была ли библиотека добавлена в путь сборки проекта напрямую или через контейнер пути к classам, такой как средство пользовательской библиотеки, предоставленное JDT, или одно, реализованное третьей стороной.
- В Helios это поведение было изменено, чтобы исключить контейнеры classpath из явного разрешения пути classа.
Это означает, что некоторые из ваших проектов больше не могут компилироваться в Helios. Если вы хотите вернуться к поведению Galileo, добавьте:
-DresolveReferencedLibrariesForContainers=trueСм. Ошибку 305037 , ошибка 313965 и ошибку 313890 для справок.
Стек IPV4
В этом вопросе SO упоминается потенциальное исправление, когда вы не получаете доступ к сайтам обновлений плагинов:
-Djava.net.preferIPv4Stack=trueЗдесь упомянут на всякий случай, когда это может помочь в вашей конфигурации.
Оптимизация потенциала JVM1.7×64
В этой статье сообщается:
Для записи самые быстрые варианты, которые я нашел до сих пор для моего стендового теста с 1,7 x64 JVM n Windows:
-Xincgc -XX:-DontCompileHugeMethods -XX:MaxInlineSize=1024 -XX:FreqInlineSize=1024Но я все еще работаю над этим …
www.bilee.com
java - JVM JIT диагностические инструменты и советы по оптимизации
Если вам нужен дамп для мозга, вы можете распечатать полученный код сборки, но это намного ниже уровня, чем у вас уже есть. Я подозреваю, что для HotSpot JVM не существует того, что вы ищете. Я видел презентацию для чего-то подобного на основе JRockit, и, возможно, это сделает его в HotSpot в один прекрасный день.
Я пропустил что-то очевидное здесь? Что делают программисты с поддержкой JVM при оптимизации жестких внутренних контуров, чтобы выяснить, что происходит?
Обычно мне нравится минимизировать производство мусора, и это обычно выполняется достаточно хорошо. например, для задержек в течение нескольких секунд.
Такая микро-оптимизация действительно требует глубокого понимания машинного кода и того, как работают процессоры.
Конечно, низкоуровневые флаги -XX не могут быть единственным вариантом, могут ли они?
Если только там, где это просто, это намного сложнее. Чтобы сбрасывать машинный код, вам нужна дополнительная собственная библиотека, которая не поставляется с JVM.;)
Буду признателен за то, как лучше всего справляться с подобным низкоуровневым материалом на JVM.
Кажется, вы действительно не хотите работать на низком уровне, если можете избежать этого, и я считаю, что это хорошо, сначала вам нужно позаботиться о высоком уровне, потому что микро-оптимизация хороша для микро- но редко подходит для реальных приложений, потому что вам нужно понять все задержки вашей конечной системы, и это можно сделать, даже не глядя на код во многих случаях. то есть основная задержка в вашей базе данных, ОС, диске или сетевом IO.
Мне все еще интересно, есть ли у людей общие советы и инструменты для такого вида деятельности.
Используйте профайлер, и если вы подозреваете, что вам нужно идти ниже, вполне вероятно, что вы упустили что-то гораздо более важное.
qaru.site