Оптимизация проблемных моментов MySQL. Mysql оптимизация
Оптимизация проблемных моментов MySQL | MySQL
Данная статья является 3 из 3 частей цикла «Оптимизация MySQL»:
- Оптимизация индексов MySQL;
- Оптимизация конфигурации MySQL;
- Оптимизация проблемных моментов MySQL.
Вступление
MySQL в сочетании с РНР является одним из наиболее часто используемых движков баз данных. Направить усилия на то, чтобы ваши базы данных MySQL работали наилучшим образом, это то, что вы должны сделать в первую очередь, когда веб-приложение начинает расти.
В этой серии статей мы рассматриваем, как мы можем оптимизировать установки MySQL. Мы расскажем, как можно оптимизировать нашу базу, конфигурацию MySQL, и как мы можем найти потенциальные проблемы, когда MySQL не работает идеально.
Для работы с нашей базой данных мы будем использовать в основном инструменты из Percona Toolkit. Эта статья посвящена обнаружению причин возникновения проблем.
Активация журнала медленных логов для нахождения проблемных мест MySQL
Прежде всего, нам нужно активировать журнал медленных логов. В журнале медленных логов MySQL будет сообщаться о любых запросах, которые занимают времени больше, чем установлено.
Кроме того, он может дать информацию о любом запросе, не использующем индексы.
Активировать журнал медленных логов просто. Все, что вам нужно сделать, это изменить конфигурационный файл MySQL (который в большинстве случаев находится по адресу /etc/mysql/my.cnf) и добавить в него следующие строки:
log_slow_queries = /var/log/mysql/mysql-slow.log long_query_time = 1 log-queries-not-using-indexesЛюбой запрос, который занимает больше одной секунды или не использует индексы, добавляется в этот журнал.
Анализ журнала медленных логов
Вы можете проанализировать ваш журнал медленных логов вручную, перебирая каждый запрос. Однако можно использовать и автоматизированный инструмент, например pt-query-digest.
С его помощью вы можете проанализировать ваш журнал медленных логов, и он автоматически отсортирует все запросы по времени исполнения.
Давайте запустим его pt-query-digest /var/log/mysql/mysql-slow.log:
Обратите внимание, что у меня было 8 медленных запросов, 6 из них — уникальные. Далее мы видим таблицу с указанием времени, которое заняли определенные действия.
Просмотрите столбец с заголовком 95%, так как в нем приводятся оптимальные средние показатели:
# Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ============= ===== ====== ===== =============== # 1 0x728E539F7617C14D 0.0011 41.0% 3 0.0004 0.00 SELECT blog_article # 2 0x1290EEE0B201F3FF 0.0003 12.8% 1 0.0003 0.00 SELECT portfolio_item # 3 0x31DE4535BDBFA465 0.0003 12.6% 1 0.0003 0.00 SELECT portfolio_item # 4 0xF14E15D0F47A5742 0.0003 12.1% 1 0.0003 0.00 SELECT portfolio_category # 5 0x8F848005A09C9588 0.0003 11.8% 1 0.0003 0.00 SELECT blog_category # 6 0x55F49C753CA2ED64 0.0003 9.7% 1 0.0003 0.00 SELECT blog_articleДавайте рассмотрим первый вид запросов более подробно:
# Query 1: 0 QPS, 0x concurrency, ID 0x728E539F7617C14D at byte 736 ______ # Scores: V/M = 0.00 # Time range: all events occurred at 2014-02-13 22:23:52 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 37 3 # Exec time 40 1ms 352us 406us 375us 403us 22us 366us # Lock time 42 351us 103us 125us 117us 119us 9us 119us # Rows sent 25 9 1 4 3 3.89 1.37 3.89 # Rows examine 24 21 5 8 7 7.70 1.29 7.70 # Query size 47 1.02k 261 262 261.25 258.32 0 258.32 # String: # Hosts localhost # Users * # Query_time distribution # 1us # 10us # 100us ################################################################ # 1ms # 10ms # 100ms # 1s # 10s+ # Tables # SHOW TABLE STATUS LIKE 'blog_article'G # SHOW CREATE TABLE `blog_article`G # EXPLAIN /*!50100 PARTITIONS*/ SELECT b0_.id AS id0, b0_.slug AS slug1, b0_.title AS title2, b0_.excerpt AS excerpt3, b0_.external_link AS external_link4, b0_.description AS description5, b0_.created AS created6, b0_.updated AS updated7 FROM blog_article b0_ ORDER BY b0_.created DESC LIMIT 10GВы также можете увидеть, в какую категорию, в зависимости от времени обработки, попал этот запрос. В данном случае он принадлежит диапазону от 100 микросекунд до 1 миллисекунды.
И, наконец, мы видим фактически сам запрос, который был выполнен.
Для каждого запроса, вы получите такую детальную информацию. Вы можете использовать ее, чтобы проанализировать, какие запросы не использовали индексы, а какие были медленными.
Анализ MySQL при возникновении проблем
Еще один интересный инструмент Percona это pt-stalk. С помощью этого инструмента вы можете получить обзор того, что происходит в MySQL в определенные моменты времени.
Давайте предположим, что сегодня, мы хотим проверить состояние MySQL 4 раза. Мы можем сделать это, запустив следующую команду:
pt-stalk --sleep=21600 --threshold=0 --iterations=4После каждой итерации, pt-stalk записывает все виды данных в папку `/var/lib/pt-stalk/’.
В ней Вы найдете такой список файлов:
-rw-r--r-- 1 root root 11220 Feb 22 14:52 2014_02_22_14_51_35-df -rw-r--r-- 1 root root 121 Feb 22 14:52 2014_02_22_14_51_35-disk-space -rw-r--r-- 1 root root 42870 Feb 22 14:52 2014_02_22_14_51_35-diskstats -rw-r--r-- 1 root root 9 Feb 22 14:52 2014_02_22_14_51_35-hostname -rw-r--r-- 1 root root 3968 Feb 22 14:51 2014_02_22_14_51_35-innodbstatus1 -rw-r--r-- 1 root root 3969 Feb 22 14:52 2014_02_22_14_51_35-innodbstatus2 -rw-r--r-- 1 root root 49980 Feb 22 14:52 2014_02_22_14_51_35-interrupts -rw-r--r-- 1 root root 4146 Feb 22 14:51 2014_02_22_14_51_35-log_error -rw-r--r-- 1 root root 69763 Feb 22 14:51 2014_02_22_14_51_35-lsof -rw-r--r-- 1 root root 36420 Feb 22 14:52 2014_02_22_14_51_35-meminfo -rw-r--r-- 1 root root 82 Feb 22 14:51 2014_02_22_14_51_35-mutex-status1 -rw-r--r-- 1 root root 82 Feb 22 14:52 2014_02_22_14_51_35-mutex-status2 -rw-r--r-- 1 root root 559349 Feb 22 14:52 2014_02_22_14_51_35-mysqladmin -rw-r--r-- 1 root root 139723 Feb 22 14:52 2014_02_22_14_51_35-netstat -rw-r--r-- 1 root root 104400 Feb 22 14:52 2014_02_22_14_51_35-netstat_s -rw-r--r-- 1 root root 12542 Feb 22 14:51 2014_02_22_14_51_35-opentables1 -rw-r--r-- 1 root root 12542 Feb 22 14:52 2014_02_22_14_51_35-opentables2 -rw-r--r-- 1 root root 810 Feb 22 14:52 2014_02_22_14_51_35-output -rw-r--r-- 1 root root 9380 Feb 22 14:51 2014_02_22_14_51_35-pmap -rw-r--r-- 1 root root 34134 Feb 22 14:52 2014_02_22_14_51_35-processlist -rw-r--r-- 1 root root 43504 Feb 22 14:52 2014_02_22_14_51_35-procstat -rw-r--r-- 1 root root 61620 Feb 22 14:52 2014_02_22_14_51_35-procvmstat -rw-r--r-- 1 root root 11379 Feb 22 14:51 2014_02_22_14_51_35-ps -rw-r--r-- 1 root root 335970 Feb 22 14:52 2014_02_22_14_51_35-slabinfo -rw-r--r-- 1 root root 26524 Feb 22 14:51 2014_02_22_14_51_35-sysctl -rw-r--r-- 1 root root 11468 Feb 22 14:51 2014_02_22_14_51_35-top -rw-r--r-- 1 root root 379 Feb 22 14:51 2014_02_22_14_51_35-trigger -rw-r--r-- 1 root root 8181 Feb 22 14:51 2014_02_22_14_51_35-variables -rw-r--r-- 1 root root 2652 Feb 22 14:52 2014_02_22_14_51_35-vmstat -rw-r--r-- 1 root root 312 Feb 22 14:52 2014_02_22_14_51_35-vmstat-overallНу, все это, конечно, интересно, но было бы еще более интересно, получить такие данные на моменты времени, когда что-то идет не так. К счастью, мы можем настроить pt-stalk так, чтобы проверка запускалась при достижении определенных пороговых значений.
Скажем, мы хотим посмотреть, что происходит в тот момент, когда у нас есть 100 подключений:
Добавив —dameonize, мы указываем инструменту работать в фоновом режиме, пока он не будет остановлен. Остальные параметры будут настроены так, чтобы начинать заносить логи в журнал, как только на сайте зарегистрировано 100 соединений одновременно.
Журнал логов, который вы получите, будет точно таким же, как мы описали выше.
Конечно, вы можете использовать и другие условия. Если вы знаете, в чем заключается проблема, вы можете настроить pt-stalk так, чтобы запись начиналась, как только эта проблема возникает.
При том, вы также можете проанализировать лог-файлы и посмотреть, происходит ли что-нибудь странное.
Заключение
Это заключение нашего обзора Percona Toolkit. Мы показали вам много инструментов от Toolkit Percona, которые вы можете использовать, чтобы оптимизировать или проинспектировать конфигурацию MySQL и базы данных.
Если вам интересно узнать о других инструментах Percona, которые еще не были рассмотрены, зайдите, пожалуйста, на эту страницу, и вы найдете там информацию о том, что еще можно сделать с помощью этого инструмента.
Оставьте свой отзыв ниже!
Перевод статьи «Optimizing MySQL Bottlenecks» был подготовлен дружной командой проекта Сайтостроение от А до Я.
www.internet-technologies.ru
Настройка MySQL + оптимизация InnoDB
Настройка MySQL + оптимизация InnoDB
Первоначальная настройка mysql-server
Мой любимый вопрос, задаваемый DBA, которые хотят увеличить производительность MySQL: “какие параметры надо настраивать в первую очередь, сразу после установки сервера?”Я удивлен количеством людей, которые не могут дать ответа на этот вопрос. И еще более удивлен количеством серверов, которые работают с настройками по умолчанию
Для настройки доступно довольно большое количество параметров, но лишь некоторые из них действительно влияют на производительность сервера. После установки этих параметров в правильные для вашего проекта значения, остальные настройки будут лишь незначительно влиять на поведение сервера.
key_buffer_size - очень важный параметр, если вы используете MyISAM-таблицы. Установите его равным 30-40% от имеющейся оперативной памяти, если вы используете только MyISAM. Актуальное для вашей системы значение зависит от индексов, размера данных и рабочего процесса. Помните, MyISAM использует кэш операционной системы для хранения данных и вам необходимо позаботиться о достаточных размерах выделяемой памяти. Во многих случаях, объем данных может быть значительно больше. Проверьте, не используется ли завышенное значение key_buffer. Нередко параметр установлен в значение 4GB при суммарном объеме .MYI-файлов в один гигабайт. Это напрасная трата ресурсов. Если вы используете несколько таблиц MyISAM - понизьте значение этого параметра. Но не опускайте его ниже 16-23 MB - этого будет достаточно для размещения индексов временных таблиц, которые создаются на диске.
innodb_log_buffer_size - значение по умолчанию вполне подойдет для большинства проектов со средней интенсивностью записи и короткими транзакциями. Однако если у вас бывают пики активности или работа с большим объемом данных, вы, вероятно, захотите увеличить значение этого параметра. Не делайте его слишком большим, это повлечет лишний расход памяти. Буфер сбрасывается каждую секунду и вам не нужен бОльший объем памяти. Обычно вполне хватает 8 - 16МB. Чем меньше система - тем меньше должно быть значение.
innodb_flush_logs_at_trx_commit - Вам кажется, что InnoDB в сто раз медленнее MyISAM? Вероятно, вы забыли изменить значение этого параметра. Значение по умолчанию 1 означает, что после каждой завершенной транзакции (или после изменения состояния транзакции) лог должен быть сброшен на диск. Это достаточно дорогая операция, особенно если у вас нет Battery backed up cache. Многие приложения, особенно те, в которых раньше использовался MyISAM будут хорошо работать при значении 2, который означает, что не надо сбрасывать буфер на диск, а следует отправить его в кэш операционной системы. Лог по-прежнему будет сбрасываться на диск каждую секунду и максимум, что вы можете потерять - это 1-2 секунды записей. Значение 0 обеспечивает более высокую скорость, но и более низкую надежность. Есть вероятность потерять транзакции даже при падении mysql-сервера. При значении равном 2 единственная возможность потерять данные - это фатальный сбой операционной системы.
table_cache - открытые таблицы могут разрастаться. Например, таблицы MyISAM помечают MYI-заголовок, как используемый. Вы, конечно же, не хотите, чтобы это происходило слишком часто и это, как правило, хорошее решение. Лучше увеличить размер кэша, чтобы он мог вместить большинство открытых таблиц. Кэш использует некоторое количество памяти и ресурсов ОС, но для современной техники это, как правило, не проблема. Значение 1024 будет оптимальным решением для нескольких сотен открытых таблиц (помните, каждое соединение нуждается в собственной копии). Если у вас много соединений или большое количество открытых таблиц - увеличьте это значение. Я видел системы со значением этого параметра > 100.000
thread_cache - Создание/уничтожение нитей (threads) может ухудшать производительность, особенно если они создаются/уничтожаются при каждом соединении/разъединении. Обычно я устанавилваю значение этого параметра равным 16. Если приложение делает большие прыжки в параллельных соединениях, то можно увидеть, как быстро растет переменная Threads_Created. Параметр предназначен для того, чтобы не создавать новых нитей в нормальных операциях.
query_cache_size - если ваше приложение читает много данных и у вас нет кэша на уровне приложения, этот параметр может неплохо помочь. Но не устанавливайте слишком большого значения - это может замедлить работу и содержание такого кэша может обойтись довольно дорого. Оптимальные значения - от 32MB до 512MB. Тем не менее, проверьте эффективность работы кэша через некоторое время. Вполне возможно, что текущее значение слишком велико.
Примечание: как вы заметили, все эти переменные являются глобальными и зависят от аппаратного обеспечения и устройств хранения данных. Сессионные переменные зависят от специфики конкретного проекта. Если у вас простые запросы, вам совершенно не нужно увеличивать параметр sort_buffer_size, даже если в вашем распоряжении 64GB оперативной памяти. Кроме того, это может снизить производительность. Обычно я оставляю настройку сессионных переменных на второй шаг, уже после оценки фронта работ.
P.S.: в дистрибутиве MySQL есть отличные примеры файла my.cnf для систем различных размеров. Они могут использоваться в качестве базы для ваших собственных файлов конфигурации, главное правильно выбрать шаблон.
Основы оптимизации производительности InnoDB
Проводя опрос среди посетителей раздела Job Opening я задавал им один простой вопрос: если бы у вас был сервер с 16GB RAM, который был бы предназначен для MySQL-сервера с очень большим объемом innodb-таблиц, работающий с стандартным веб-проектом, какие бы настройки вы скорректировали? И самое интересное, что большинство не смогло четко ответить. Поэтому и было принято решение опубликовать эту заметку, которая, возможно, расширит ваши знания об оптимизации программной и аппаратной частей сервера.
Я назвал эту статью Основы оптимизации производительности InnoDB, желая подчеркнуть, что это именно основы. Это универсальные советы, работающие на большинстве систем. Но более точную настройку необходимо производить, исходя из конкретных поставленных задач.
Hardware
Если у вас есть база данных innodb большого объема, и это действительно важные данные, то 16 - 32 GB оперативной памяти будут оптимальным решением. Процессоры - 2*DualCore подойдут для большой нагрузки, а два Quad Core помогут решить проблемы с дальнейшим масштабированием системы. Хотя имеется множество нюансов. Третий момент - это подсистема ввода/вывода. Напрямую подключенный DataStorage с большим количеством дисков и RAID с возможностью сохранения кэша будут отличным выбором. Обычно необходимо 6 - 8 жестких дисков в стандартный блок, но порой может понадобиться и больше. Также обратите внимание на новые 2.5" SAS диски. Они меньше, но часто работают гораздо быстрее, чем обычные HDD. RAID10 хорошо подходит как для хранения, так и для чтения данных, но в случае, если вы можете позволить некоторую избытычность. В противном случае можно сделать RAID5, но опасайтесь случайных записей.
Операционная система
Дя начала: установите 64-битную операционную систему. Часто можно увидеть 32-битный linux, или запущенный в режиме совместимости с 64-bit. Не делайте так. Если вы используете LVM для хранения базы данных, вы сможете более эффективно работать с резервными копиями. Файловая система Ext3 будет оптимальным выбором в большинстве случаев, но если вы запускаете particular roadblocks, то попробуйте XFS. Вы можете использовать опции noatime и nodiratime, если вы используете innodb_file_per_table и большое количество таблиц, но это, в принципе, не столь важно. Также убедитесь, что OS резервирует достаточно большое количество памяти для MySQL.
Опции MySQL InnoDB
Важнейшими опциями являются:innodb_buffer_pool_size - 70 - 80% оперативной памяти. Я ставлю это значение в 12G на системе с 16G RAMinnodb_log_file_size - зависит от необходимого вам объема данных для восстановления, но 256МБ будут разумным компромиссом между производительностью и рамером лог-файлаinnodb_log_buffer_size=4M - 4 мегабайта - нормальное значение, если вы не используете подачу больших блоков данных в InnoDB через каналы (pipes). Если используете, это значение лучше увеличить.innodb_flush_logs_at_trx_commit=2 - если вас не особо заботит ACID, и вы можете себе позволить потерять транзакции за последние секунду или две, в случае полного краха ОС, то установите это значение. Но это может повлечь печальные эффекты при коротких записях транзакций.innodb_thread_concurrency=8 - даже при имеющихся InnoDB Scalability Fixes будет совсем не лишним иметь ограниченное количество потоков. Значение может быть больше или меньше в зависомости от ваших потребностей, но 8 будет оптимальным значением для начала.innodb_flush_method=O_DIRECT - избегайте двойной буферизации и уменьшите активность swap, в большинстве случаев это увеличивает производительность. Но будьте осторожны, если у вас нет RAID с возможностью сохранения данных, операции ввода-вывода могут проходить некорректно и данные могут быть повреждены.innodb_file_per_table - если у вас немного таблиц, используйте эту опцию и рост занимаемого таблицами места не будет бесконтрольным. Эта опция добавлена в MySQL 4.1 и сейчас достаточно стабильна для использования.
Проверьте также, могут ли ваши приложения запускаться в режиме изоляции READ-COMMITED. Если это так, то установите опцию transaction-isolation=READ-COMITTED. Этот вариант увеличит производительность.
Есть еще немало опций, значения которых можно поменять для достижения лучшей производительности. Об этом можно прочитать в заметке Настройка опций mysql-server (перевод) или в одной из наших презентаций.
Настройка приложений для работы с InnoDB
При переходе с типа MyISAM, вам конечно будет интересно, что изменилось и какие новые возможности вам теперь доступны. Во-первых: убедитесь, что вы используете транзакции при обновлениях. Это необходимо для повышения производительности. Во-вторых: готово ли ваше приложение обрабатывать проблемы, которые могут произойти? И в-третьих: возможно вы захотите пересмотреть структуру своих таблиц и посмотреть как вы можете использовать свойства InooDB: распределение по первичному ключу, использование первичного ключа на всех индексах (это позволяет сократить первичеый ключ), быстрый просмотр по первичным ключам (попробуйте использовать это при запросах с JOIN) или большие несжаты индексы (облегчают индексирование).
При помощи этого краткого описания вы сможете провести первичную настройку InnoDB, которая повысит производительность на системах без battery backup, без изменения настроек ОС и не внося изменения в настройки приложений, до сих пор использующих MyISAM
l.wzm.me
Оптимизация работы сервера баз данных, MySQL my.cnf
MySQL является самой распространенной в настоящее время системой управления базами данных. MySQL - свободно распространяемое программное обеспечение, использование программного пакета бесплатно, что при наличии большого количества документации делает пакет популярным как при разработке небольших проектов, так и при создании нагруженных систем. Оптимизация работы сервера баз данных становится необходимой когда замечена нагрузка на систему, создаваемая MySQL
В рамках статьи будут рассмотрены основы оптимизации работы MySQL при повышенной нагрузке
Основной конфигурационный файл
mcedit /etc/mysql/my.cnf
Анализ логов сервера баз данных и использование инструментов диагностики производительности
Цели оптимизации:
- Достижение стабильной работы сервера
- Экономия на модернизации аппаратной части под растущие потребности проекта.
Когда веб проекты разрастаются и текущая конфигурация сервера перестает выдерживать нагрузки - нужно увеличивать объем RAM и выделать проекту больше ресурсов процессора CPU.
Это всегда означает дополнительные расход, особенно если используются не облачные технологии, а физические сервера. Расходы можно сократить или полностью их избежать скорректировав настройки ПО. Оптимизация работы сервера баз данных может занять от нескольких часов до нескольких дней, однако результаты часто оправдывают затраченные усилия.
По умолчанию конфигурация mysql подразумевает следующие значения параметров
[mysqld]set-variable = max_connections=500safe-show-databases
Переменных немного потому, что каждая среда индивидуальна, каждый сервер необходимо настраивать соответствующим образом в зависимости от условий в которых он работает.
Значение max_connections, как правило, ниже 500 устанавливать не стоит. Это объясняется тем, что стандартное количество child процессов (child process) для Apache - 512. Если все они будут использоваться, а в /etc/mysql/my.cnf будет задано значение менее 500 - часть пользователей будут видеть при обращении к ресурсу ошибки.
Параметры, ограничивающие максимальное возможное количество соединений для веб сервера и для сервера баз данных должны иметь примерно одинаковые значения.
Дефолтные настройки во всех случаях нужно менять, без задаваемых непосредственно настроек сервер баз данных не сможет узнать как много оперативной памяти и ресурсов процессора используется. Работа серовера с 256Мб и 16Гб RAM сильно отличаются, для того чтобы обеспечить максимальную производительность MySQL нужна тонкая настройка параметров.
Переменные
MySQL CLI:
SHOW VARIABLES;
SSH (root)
mysqladmin variables или mysqladmin var
mysqladmin variables | grep name-of-variable
Параметры кэширования запросов, которые могут задаваться в my.cnf
thread_cache_size (default 0)
количество потоков, которое сервер должен кэшировать для повторного использования, хорошее значение для начала - 4
table_cache/tables_open_cache(default 64)
количество открытых таблиц для всех потоков
query_cache_limit (default 1M)
максимальный размер запроса который может быть помещен к кеш
query_cache_size (default 0)
поскольку здесь 0, следующий параметр работать не будет4-8М хорошие значения, количество памяти для кэширования запросов
query_cache_type (default 1=on)
0=off, 2=on if needed
Буферы MySQL
key_buffer_size (default 8M)
буфер для индексов таблиц MYISAM, 24-48М нормальные значения
read_buffer_size (default 128K)
последовательный буфер потоков
join_buffer_size (default 128K)
используется под JOIN без индексов, лучшим решением (вместо использования параметра) является ораганизация базы с джойнами которые могут быть проиндексированы - если такой возможности нет джойны ускоряются параметром join_buffer_size
Другие переменные
connect_timeout (MySQL pre-5.1.23: default 5, MySQL 5.1.23+: default 10)количество секунд по просшествии которых сервер баз данных будет выдавать ошибку, при активном веб-сервере значение можно уменьшать чтобы увеличить скорость работы, на медленной машине - можно увеличиватьmax_connect_errors (default 10)максимальное количество единовременных соединений с сервером баз данных с хоста запрос блокируется если он прерывается запросами с того же хоста до момента окончания обработки запроса)блокируются навсегда, очистить можно только из командной оболочки MySQL:
FLUSH HOSTS;
В случае атаки на сервер нужно уменьшать (5) чтобы отсекать попытки соединения, при большой активности веб-сервера можно увеличиватьmax_allowed_packet (default 1M)максимальный размер пакета, при подключенииtmp_table_size (system-specific default)16М - довольно многомаксимальный размер памяти выделяемой под хранение временных данных
Переменные, использование которых не требуется
thread_concurrencyиспользуется только на Solaris, на linux mysql 5.5+ при использовании переменной MySQL не сможет запуститьсяinnodb_thread_concurrencyпохожая на предыдущую переменная, является, тем не менее, совсем другой и относится к innodb
skip-lockingсейчас параметр называется skip-external-locking (по умолчанию используется начиная с MySQL 4.0 - непосредственное указание в конфиге не требуется)
Логирование MySQL
Ведение логов - единственная возможность отслеживать состояние баз данных и действия их пользователей. Никакая оптимизация работы сервера баз данных невозможна без информации о том, какие запросы выполняются и какие ошибки возникают. Логи позволяют отслеживать поведение сервера относительно времени поскольку записи ротируются и хранятся в памяти сервера некоторое количество времени.
Без логирования единственным способом отслеживать состояние MySQL был бы мониторинг.
Есть три вида логов: логи ошибок, общие логи и логи медленных запросов.Error-логиПо умолчанию включены
В общие логи пишется информация о любой активности процессов, обращающихся к таблицам баз данных - по умолчанию выключены.Slow MySQL queriesЛоги медленных запросов по умолчаню выключены, при раскомментировании соответствующей строки в конфигурационном файле в лог будут писаться запросы, выполняющиеся дольше 10 секунд (параметр можно варьировать в ту или иную сторону)
При снижении производительности сервера (или росте нагрузки, что также является типичным проявлением наличия медленных запросов) включается ведение логов медленных запросов, затем эти логи анализируются.
Логирование включается путем раскомментирования соответствующих директив к my.cnf
Включение ведения логов в MySQL 5.0:
Общие логи:
log=/var/lib/mysql/general.log
Логи медленных запросов:
log-slow-queries=/var/lib/mysql
В большинстве случаев на файлы логов устанавливаются права 600 и владелец mysql:mysql
Включение ведения логов в MySQL 5.1.29+:
Общие логи:
general_log
Логи медленных запросов:
slow_query_log
Файлы логов при этом будут созданы автоматически
Мониторинг
top
отображает только один процесс, индивидуально каждый процесс отслеживать возможности нет
atop -r
просмотр логов atop позволит определить причины неполадок на сервере в принципе, если нагрзку создает MySQL - вывод утилиты укажет на это
mtop
innotop
mysqladmin processlist
или
mysqladmin proc
предоставляет полную информацию о процессах MySQL
Образцы конфигурационных файлов MySQL
Найти их можно в каталоге /usr/share/mysql
my-huge.cnfmy-large.cnfmy.small.cnfmy-innodb-heavy-4G.cnfmy-medium.cnf
Использование этих шаблонов не всегда оправдано поскольку в них применяется очень большое количество переменных использование которых в конфиге никак не объясняется, при недостаточном понимании структуры файла шаблоны лучше не использовать.
Также в шаблонах по умолчанию применяются thread_concurrency, что означает невозможность запуска MySQL с шаблонных конфигом в принципе
Инструменты диагностики MySQL
Общая оптимизацияmysqltuner.pl
wget mysqltuner.pl
chmod 755 mysqltuner.pl
Использование
./mysqltuner.pl
или
perl mysqltuner.pl
Сервер баз данных должен работать минимум 24 часа до запуска данной утилиты
mysqlidxchk
Анализирует общие логи или логи медленных запросов и ищет неиспользуемые индексы, их потребуется удалить - это позволит увеличить скорость работы базы данных
wget http://hackmysql.com/scripts/mysqlidxchk-1.1
chmod 755 mysqlidxchk* mysqlidxchk
Использование
./mysqlidxchk --general /var/lib/mysql/ general.log
Парсинг лог-файлов
mysqlsla
Определяет на основании анализа логов медленных запросов и общих логов пользователей которые используют базу больше всего (в процентном отношении)
wget http://hackmysql.com/scripts/mysqlsla
chmod 755 mysqlsla*
mv mysqlsla* mysqlsla
Использование (логирование должно быть включено)
./mysqlsla -lt general /var/lib/mysql/general.log
./mysqlsla -lt slow /var/lib/mysql/slow.log
Формирование отчетов о статусе
mysqlreport
Утилита интерпретирует вывод SHOW STATUS и составляет на основании собранной статистики отчет о работе MySQL
wget http://hackmysql.com/scripts/mysqlreport
chmod 755 mysqlreport
Исопльзование./mysqlreport
Инструмент довольно сложен в использовании и предполагает хорошие знания MySQL
Для MySQL серверов предпочтительно использовать 64-битные системы, нагрузочные тесты показывают, что системы именно с такой разрядностью дают лучшие результаты. Оптимизация работы сервера баз данных по сути заключается в подборе оптимальных параметров в конфигурационном файле. Все остальное зависит от запросов, направляемых на обработку скриптами. Запросы при этом можно проанализировать используя EXPLAIN и сделать более оптимальными добавив индексы.
server-gu.ru
измерять, чтобы ускорять / Блог компании Конференции Олега Бунина (Онтико) / Хабр

Петр Зайцев (Percona)
Сегодня мы поговорим о производительности.Мы посмотрим на то, как подойти правильно к оптимизации MySQL, а также посмотрим на некоторые практические подходы к этому делу. Почему я считаю, что это важно? Дело в том, что когда у вас есть специфическая проблема, вы хотите, например, спросить: «А какой же мне установить размер кэша в MySQL?». Такой вопрос всегда можно ввести в Google или Yandex, и получить на него разумный ответ. Но как получить ответ об общем, о схеме анализа и оптимизации MySQL? Это куда более сложно.

Первая вещь, о которой нужно знать, что производительность MySQL сама по себе на самом деле не важна. И вот я смотрю, молодой человек сзади улыбается: «Как же так? Важна, вроде. О чем же мы говорим, если она не важна?».

На самом деле вашим пользователям, вашему боссу важна, прежде всего, производительность вашего приложения, которое использует MySQL, а может использовать какие-то другие системы. И это то, на чем имеет смысл фокусироваться, потому что если вы смотрите на проблему с точки зрения приложения, то вам открываются некоторые другие, более широкие подходы. Может, MySQL не использовать в некоторых случаях, или использовать его не так.

Также важно, что производительность приложений важна всегда. В каких-то случаях я говорю с людьми, и они мне говорят: «Вот, вы знаете, это у нас отчет. Нам его производительность не важна, занимает он у нас минуту, две или три – нас все устроит». Но если их спросить: «Ребята, а если этот отчет у вас займет месяц, устроит вас это?». Они говорят: «Нет, конечно, не устроит». Значит, производительность важна, просто в головах некоторых людей важная производительность – это значит, что мы можем выполнить какой-нибудь запрос за миллисекунды или за секунды. Люди часто не думают, что даже те процессы, которые занимают минуты и часы, тоже могут быть критичны по производительности. А почему это важно? Потому что часто, когда мы делаем какие-то алгоритмы баз данных, пишем какие-нибудь запросы, их сложность может возвращать нелинейно относительно объема данных. Т.е. может быть, что у нас объем данных вырос всего лишь в 10 раз, а скорость выполнения запроса увеличилась в 100 раз. Создавая сюрприз и неожиданность, что такие тормоза мы совершенно не ожидали.
Что еще важно? То, что производительность и приложения могут быть не обязательно связаны с MySQL. С этим у меня тоже есть интересный случай. Я помню, прихожу к клиенту, смотрю на их MySQL-сервер. И, вроде бы, у них как бы все нормально, длинных запросов нет, загрузка сервера меньше чем 10%, и я их спрашиваю: «Ребята, а почему вы думаете, что это вообще MySQL?» – «Ну, вот сколько мы лет занимаемся, всегда все проблемы производительности – это всегда с MySQL, поэтому мы туда и копаем». Иногда да, но в каких-то случаях и нет.
Еще важно, что даже если проблемы с MySQL, часто решения могут быть не связаны с MySQL. Например, многие из вас знают Андрея Аксенова из Sphinx. Большая часть его бизнеса, особенно в первые годы – это спасать MySQL-пользователей, которые пытались долго и упорно использовать MySQL full text search. Но этот слоник не летает, как с ним не стараться, не пытаться его заставить работать, не скейлится он. В этом случае для таких задач как полнотекстовый поиск использовать Sphinx – это более разумное решение.

И таких инструментов на самом деле много сейчас, которые позволяют решать разные задачи, которые MySQL решает не очень хорошо. Т.е. full text search, есть Sphinx elastic Search – другой вариант. Для каких-то задач Redis или Tarantool подходит куда лучше. Если мы говорим об аналитике данных, то здесь часто подходит решение Hadoop или же Vertica, или каких-то систем, которые нормально обрабатывают данные параллельно. Потому что MySQL любой запрос выполняет только в один поток на одном сервере, что, понятно, на большие объемы совсем не скейлится.

Когда мы говорим о производительности, о чем мы думаем? Прежде всего мы думаем о времени отклика. Почему? Потому что если вы посмотрите на вашего эгоистичного пользователя, то это то, о чем он думает прежде всего. Т.е. если я захожу на веб-сайт или работаю с приложением, и это приложение мне отвечает быстро, то это все, что меня волнует. Ваши всякие queries per second, число запросов в секунду и прочая фигня пользователя интересует мало.
Т.е. прежде всего мы смотрим на приложение и хотим, чтобы оно пользователю отвечало со временем отклика, которое может быть разным для разных приложений, для разных задач. Нет какой-то определенной цифры, что время отклика за полсекунды – это хорошо, а все, что больше – плохо.
Но если мы говорим о реальных приложениях, то часто мы рассматриваем не только время отклика, но и другие вещи. Первый вопрос, что мы хотим, чтобы это время отклика было стабильное. Т.е. с очень многими случаями я сталкиваюсь, что проблема не в том, что время отклика плохое всегда, а в том, что у нас иногда что-то происходит с системой или внешне, которое его ухудшает. Например, часто люди жалуются, что у меня все хорошо работает, но когда я запустил backup, у меня все начинает быть плохо. Надо за такими вещами следить. Или же бывает часто связано с какими-то вещами вроде всплеска загрузки, т.е., может, веб-сайт показали в какой-нибудь известной телевизионной передаче или кто-нибудь еще его упомянул, трафик хлынул, система не справляется.
Следующий вопрос, который мы часто задаем по производительности – это масштабируемость. Многие-многие приложения начинают с достаточно маленьких систем. Маленький объем данных, маленький объем пользователей, у них в планах расти. Нам важно, чтобы те алгоритмы, те запросы, те дизайны, схемы, которые мы используем, не только работали сейчас, но и работали на приложение будущего. И некоторые подходы, которые наиболее оптимальны сегодня, на текущем объеме данных, могут быть хороши, но не скейлятся.
И третий момент – это эффективность, которая тоже важна. Эффективность как с точки зрения использования ресурсов, так и с точки зрения людей, которые требуются для создания этой архитектуры. Например, интересный вариант с Hadoop. Сейчас Hadoop уже лучше, но традиционно, когда Hadoop только начинался, он скейлился на тысячи и тысячи узлов. Но если сравнить эффективность, например, MySQL с Hadoop, то MySQL на одном узле мог сделать то же самое, что Hadoop на десяти. И понятно, что если объем данных достаточно маленький, то использовать MySQL было бы куда более эффективно. Но если нам нужно то, что на один сервер не влазит, то с точки зрения Hadoop, мы можем запустить 1000 или 10 000 узлов. С MySQL мы так поступить не сможем.

С точки зрения нашей масштабируемости мы уже поговорили про нагрузку, про размер данных, и еще важна масштабируемость с точки зрения инфраструктуры. О чем здесь стоит сказать? Что в зависимости от того, в каком вы работаете режиме, вам может быть доступна та или иная инфраструктура. Например, во многих облачных сетях мы не можем так легко масштабироваться вверх. Там сложно сказать: «Я хочу поставить сервер, в котором у нас будет 64 ядра, 1 Тб памяти, 4 очень-очень быстрые флэш-карточки, чтобы я мог 10 Тб локального быстрого флэша получить». Если вы работаете в своем дата-центре, и у вас есть выбор инфраструктуры, вы можете получить это, вы можете подключить такой сервер с 40 Гб Ethernet, или даже не один. Если вы работаете в cloud, то у вас могут быть совершенно другие ограничения, с которыми приходится работать.

Следующий момент, с которым мы часто сталкиваемся. Когда мы разрабатываем реальные приложения, часто у нас производительность – это важная вещь, но это не единственная вещь, о которой приходится заботиться. Например, безопасность. Безопасность, криптование трафика обычно производительность не улучшает, но, наоборот, это те вещи, которые могут снижать производительность, с которыми придется мириться.
Управляемость – другой момент. Т.е. часто наиболее оптимизированный код и структуры – его фиг поймешь потом. Во многих случаях мы сталкиваемся, что люди не хотят супер оптимизировать производительность, если это делает код слишком сложным. И есть другие разные вещи, с которыми приходится считаться. Например, часто могут быть какие-нибудь потребности аудита, в связи с которыми любые изменения данных должны протоколироваться, что добавляет еще дополнительных функций, которые стоят нам чего-то с точки зрения производительности.

Следующий момент, который стоит упомянуть. Это то, что производительность – это та вещь, которую можно улучшать бесконечно. Нет такой системы, которая максимально оптимизирована, и в которой, затратив много денег и времени, нельзя еще улучшить производительность хотя бы на несколько процентов. Это означает, что нам нужно всегда знать, когда остановится, иначе мы просто будем тратить ресурсы совершенно бесполезно. Это значит, что нужно каким-то образом нам определить, какая нам требуется эффективность, производительность системы и т.д. И когда она достигнута, мы можем остановиться.
Следующий момент. Переходя уже к MySQL. Мы говорили, что важно время отклика системы. Теперь давайте посмотрим, что же MySQL, вообще, делает для своих пользователей. А делает он очень простое – мы выполняем запросы на MySQL, селекты, апдейты, инсерты, и он нам через какое-то время откликается. И все, что связано с производительностью MySQL, может быть характеризовано этим откликом на запросы.
Понятно, при разных нагрузках, при разных объемах данных и т.д. Но если мы смотрим на эти запросы и смотрим на их время отклика и фокусируемся на этом в плане оптимизации, мы получим те результаты, которые возможно получить.
Когда мы говорим об оптимизации MySQL? Наверное, стоит сказать одну вещь, которой нет на этом слайде. Это о том, что лучший вопрос что-то оптимизировать – это этого не делать. Очевидно, вы это много от кого слышали, но, что интересно с точки зрения MySQL, что если я приду к большинству людей, мы возьмем приложение включим MySQL-лог и загрузим страничку. В большинстве случаев я найду несколько запросов, которые будут повторяться. Вы знаете, что их можно легко удалить, потому что второй запрос делать бесполезно. Часто я увижу, что данные запрашиваются из базы данных и приложением не используются. Но почему? – «Ну, вот, у меня там этот класс инициализируется, он все поднимает из базы данных, на всякий случай, а на самом деле это мы не используем». Очень часто в приложениях делается куча-куча мусора, которая никому не нужна. Но что, когда мы фокусируемся на оптимизации, над чем мы часто работаем? Первый, очень простой момент, что мы хотим, чтобы наши вопросы выполнялись быстрее, другой момент – мы хотим, чтобы они использовали меньше ресурсов, например, меньше памяти, или с помощью компрессии мы можем оптимизировать систему, чтобы она использовала меньше места на диске. Или же лучше масштабируемость с точки зрения железа, с точки зрения размера данных и т.д.

Если мы говорим об оптимизации и общем подходе, часто мы смотрим на две вещи. Первое – это оптимизация-транзакция. Например, у вас есть приложение, и кто-то говорит: «Вы знаете, у нас есть такая функция поиска или архив, которая тормозит, работает медленнее, чем нам хотелось». Мы можем посмотреть конкретно эту функцию, какие она запросы делает на MySQL, и их оптимизировать. Другой вариант – сказать, а давайте, мы приложение соптимизируем в общем. Тогда мы можем взять посмотреть на все запросы, которые приходят на MySQL, посмотреть, какие из них наиболее медленные, которые используют больше всего ресурсов, и когда мы их оптимизируем, то очевидно, что у нас система будет работать быстрее в общем. Но при этом, если мы используем второй подход, у нас нет гарантий, насколько наш этот тормозной процесс будет оптимизирован, потому что, может быть, что именно он и не создает много нагрузки, может, это какая-то аналитика, которую большой босс смотрит раз в день, и она составляет 0,01% нагрузки, но, тем не менее, она весьма важна.

И понятно, что с точки зрения общей оптимизации мы смотрим на запросы, мы их приоритезируем и дальше их оптимизируем.

С точки зрения запросов. Как я уже говорил, первый вопрос с точки зрения запросов: можем ли мы этих запросов избежать? Потому что часто какие-то запросы бесполезны. Второй вопрос: можем ли мы эти запросы изменить, чтобы они делали меньше работы? Что значит меньше работы? Это значит, чтобы они сканировали меньше строчек, читали меньше данных с диска и т.д. – все это мы называем простым словом «работа».
Какой у нас может быть пример? У нас есть запрос, который выполняется без индекса, он делает очень много работы. Индекс мы добавили – запрос делает меньше работы. Когда это действительно настолько просто, что добавить индекс или изменить настройки MySQL. В других случаях это может быть что-то более сложное, например, у нас может быть плохая схема данных, которая не позволяет нам добавить индекс, чтобы запрос выполнялся быстро. Тогда нам приходится изменять схему данных, а не только индексы запросов. Иногда нам придется применить какие-то другие подходы, например, кэширование. Мы можем кэшировать данные, мы можем сделать какую-то summary table, таблицу, в которую мы прогенерировали все наши результаты, вместо того, чтобы лопатить данные много-много раз каждую секунду.

Следующий вопрос по оптимизации: что важно? Первое – не стоит смотреть только на среднее время выполнения запросов. Потому что среднее время выполнения любого запроса редко проблема, прежде всего, проблема начинается с какими-то, не хочу сказать с экстремальными, но близкими к тому условиями. Например, я помню ребята из Flickr (относительно старый, но крупный хостинг для картинок) рассказывали, что у них проблемы возникли, когда какой-то товарищ залил им 1 млн. картинок через API. Понятно, то, что работало для нормальных пользователей – нормально, в категории 1 тыс., 100 картинок, с 1 млн. картинок уже не работает. С точки зрения среднего запроса, среднего пользователя, это бы не показалось.
Следующий момент – то, что мы хотим тоже смотреть на тренды со временем, потому что некоторые проблемы возникают циклично, может, это связано с месячным биллингом, может, это связанно с тем, что вы раз в неделю удаляете старые данные, и это может показывать проблемы.
Опять-таки, когда мы смотрим запросы, следует думать о будущем. Особенно в development-системах. Я очень часто сталкиваюсь с тем, что разработчики тестируют запросы на каких-то маленьких базах данных в своей конфигурации для тестов и не очень хорошо читают explain в MySQL. В этом случае, когда их запросы выкладываются на продакшн или чуть позже, когда данные начинают резко расти, все это ломается. Нужно учиться читать explain и думать, а как же эти запросы будут работать в будущем.
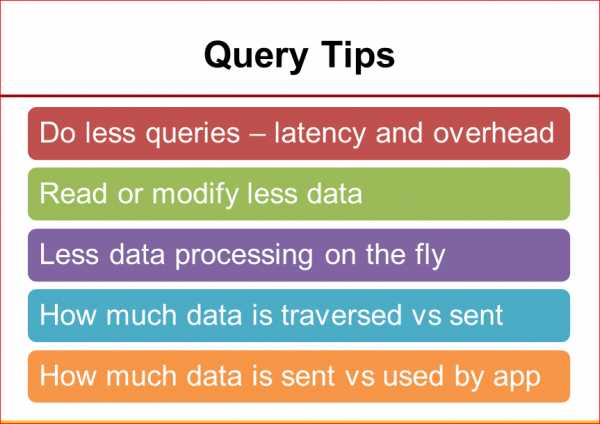
Следующий момент. Понятно, что мы хотим использовать меньше запросов. Даже если мы анализируем то же самое число строк, то чем меньше запросов мы можем использовать, тем лучше. Потому что с каждым запросом у нас добавляется время отклика сети, у нас добавляется дополнительный оверхед на парсинг запросов, на проверку привилегий и прочее. Мы тоже хотим читать и модифицировать как можно меньше данных. Т.е. если мы можем выполнить запрос лимит 10, например, то это куда лучше, чем считать все данные, просто прочитать несколько первых строчек в приложении, а все остальное выкинуть.
То же самое касается, что лучше считывать только те столбцы в базе данных, те колонки, которые приложение реально использует. Потому что MySQL в этих случаях может использовать другие дополнительные оптимизации и выполнять запросы более эффективно.
Дальше. Чем меньше можем обрабатывать данных во время выполнения запросов, тем лучше. Опять-таки, тяжелые запросы, которые делают какие-то сложные агрегации каждый раз для каждого пользователя – это не очень хорошо для большой агрегации, лучше посмотреть, как мы можем это создать как таблицы с кэшем и т.д.
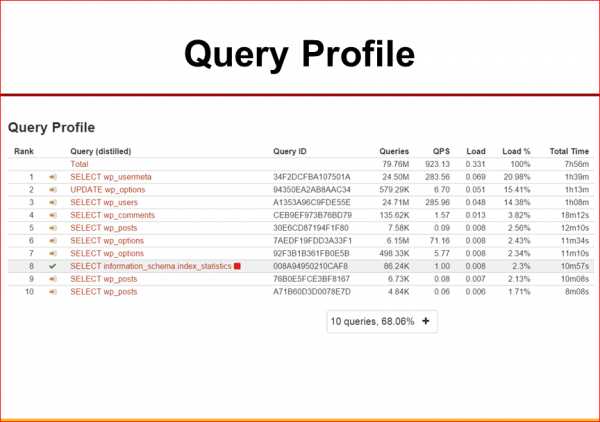
На что можно смотреть? Какие у нас есть интересные метрики? Первая – это мы можем посмотреть, сколько данных MySQL проанализировал относительно того, сколько он их послал клиенту. Эту метрику легко получить из MySQL. Есть для каждого запроса, например, в slow query log данные Rows_sent и Rows_examined. Отношение между ними – это то, на что мы хотим смотреть. Если у нас отношение где-нибудь там от 1 до 10, приложение в целом обычно оптимизировано хорошо. Если мы на каждую строчку, которую мы посылаем из MySQL, обрабатываем 100, а то и 1 тыс., то, скорее всего, у нас есть много возможностей для оптимизации.
Следующий момент – это посмотреть, сколько у нас данных реально было послано с MySQL относительно того, сколько было использовано приложением. Здесь, к сожалению, метрики, которые дает MySQL нет, потому что MySQL данные отдал, и он уже не знает, как вы их используете. Но часто на это вы можете посмотреть сами, по крайней мере, для наиболее тяжелых запросов, которые возвращают очень много данных. Т.е. если вы считали 1 млн. строк на приложение, следует хорошо подумать, а все ли вы их там используете? Вряд ли на одной странице показывается 1 млн. элементов. Может, они как-то агрегируются и в этом случае часто эту работу лучше делать на базе данных.

Следующий момент. Как мы уже говорили, не всегда удается запросы оптимизировать, просто добавив индекс, часто нам приходится менять схему более кардинально, поэтому часто имеет смысл смотреть на оптимизацию схемы и оптимизацию запросов вместе. И здесь есть две вещи:
- это небольшие оптимизации схемы – добавить индекс, может, изменить тип колонки или еще что-нибудь, изменить storage enigne в MySQL;
- сильное изменение схемы и всей архитектуры, которое тоже иногда бывает нужно, но оно обычно требует значительно более серьезного планирования. Т.е. если вы делаете полный реинжиниринг вашей схемы, то это занимает существенное время.
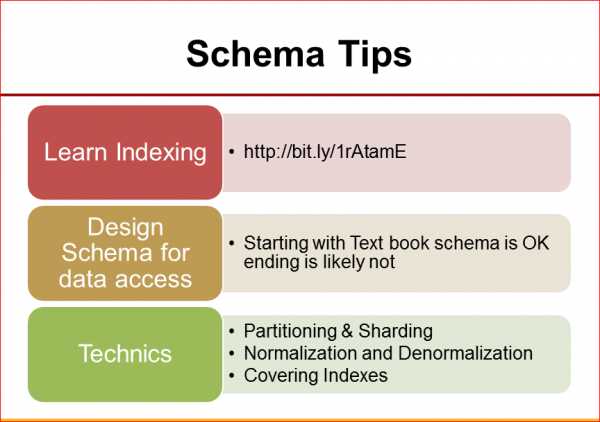
С точки зрения схемы баз данных. Нужно знать, как работают индексы. Я даю ссылку на мою презентацию по этому поводу.
Следующий момент. Когда вы разрабатываете схему, думайте о том, какие запросы у вас будут выполняться. Очень часто я смотрю, что люди делают, в коде используют IR тулзу, которая им делает совершенно абстрактную и «академически» правильную структуру базы данных, которая, к сожалению, не работает. С этого можно начинать, но этим редко удается закончить. Надо смотреть, как на этом работают ваши запросы, и уже дальше думать. И разные техники можете посмотреть, Partitioning & Sharding, нормализация, денормализация данных и т.д. Эти вещи нужно ввести в Google и про них прочитать.

Другие вещи, которые у нас тоже имеют важное значение – конечно, инфраструктура, ОС, MySQL-версия, MySQL-конфигурация. И мы поговорим об этом чуть более подробно.
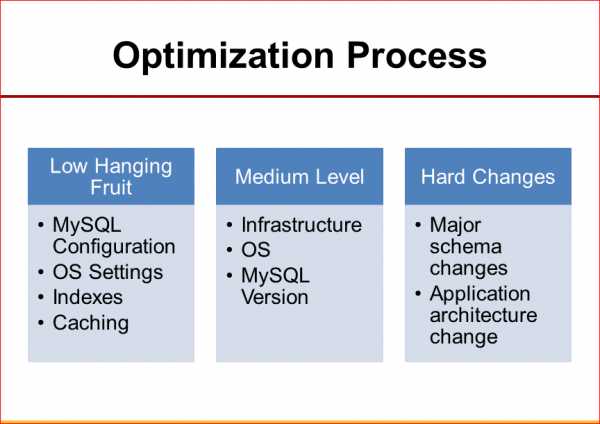
Если у нас есть система, которую нужно оптимизировать, как к этому подходим мы, когда нас часто зовут с точки зрения консалтинга? Во-первых, есть вещи простые, которые можно изменить очень быстро, и этого часто достаточно. Изменить настройки MySQL, может, ОС, добавить какие-то индексы, может быть, включить какое-нибудь кэширование – и это те вещи, которые часто можно сделать буквально за часы.
Следующий вопрос, который более сложный, если нам нужно купить новое железо или сделать какие-нибудь переконфигурации сети, изменить ОС на более новую или проапгрейдить MySQL. Это более сложные вещи, которые занимают дни.
И, наконец, бывают случаи, когда так все плохо, когда даже этого не хватает. Тогда нам нужно перейти уже к тяжелой артиллерии, нам, может, приходится совершенно переделывать схемы базы данных, или же нам приходится изменить архитектуру приложения, сказать, что «знаете, мы теперь делаем шардинг, для этого мы вообще решаем MySQL не использовать» и т.д.
Если вы посмотрите на многие приложения, которые росли, они часто проходят через такие шаги.
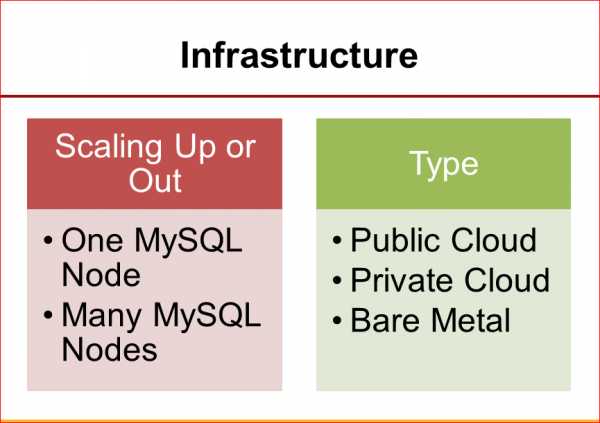
Про инфраструктуру. Здесь нужно понимать, какие у вас опции, можете ли вы скейлится с одним узлом какое-то время, или же вам нужно переходить на архитектуру, которая может работать на многих маленьких машинах, как, например, часто в облачных структурах.

Что у нас важно с точки зрения железа? Нам важны вот эти компоненты:

С точки зрения процессора. Понятно, что сейчас серверные процессоры – это Intel. C MySQL мы видим, что чаще всего используется система с двумя сокетами для процессоров. Что еще важно? Поскольку MySQL может использовать для одного запроса только одно ядро процессора, то часто для нас быстрые процессоры более важны, чем процессоры, в которых много, но медленных кор. Часто это забывается. И также смотрите на такую штуку как turboboost, потому что современные процессоры, если из них используются не все коры, а только одна-две, то они часто могут работать на значительно более высокой тактовой частоте. И часто для нас важна не номинальная частота процессора, а до скольки они будут делать turboboost, потому что если мы будем выполнять тяжелые запросы, но которые использую только одну кору – это то, что будет ограничивать производительность.

Память. Когда мы используем память базы данных, мы ее используем для кэша. Поэтому если данных у вас много, то нам хочется, чтобы памяти тоже было много. Здесь о чем имеет смысл думать – о том, какое соотношение между размером базы данных и памяти. Вся ли она у нас влазит или же какая-то ее часть. Имеет смысл также смотреть на то, какая часть активно используемых данных у вас влазит в память. Понятно, что часто у нас есть большая база данных, но ее серьезная часть используется очень редко, ее держать в памяти дорого, поэтому когда я смотрю на то, насколько хорошо база данных влазит в память, я не смотрю реально на отношение размера базы данных в памяти, но, скорее, на то, сколько у нас операций ввода-вывода происходит. Особенно на чтение, потому что если у нас вся активно используемая база данных в памяти, то операций чтения, которые в дисковой подсистеме, у нас практически не будет.
Следующий для вас интересный достаточно график:
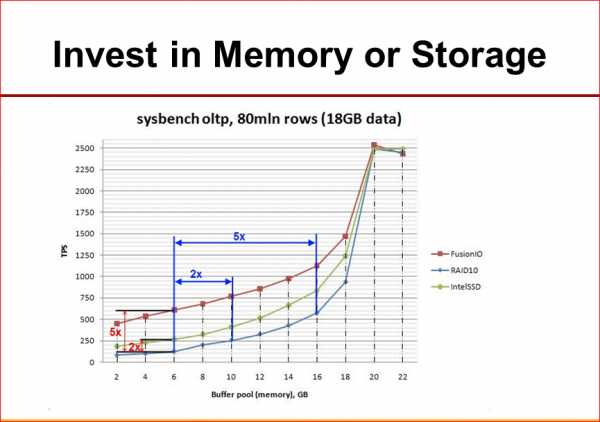
Здесь мы смотрели поведение определенного синтетического бенчмарка с разными объемами памяти и разной конфигурацией системы накопителей. Т.е. у нас синяя – это RAID, самый медленный, красная – это самый быстрый FusionIO. Что мы видим интересного? Если база данных плохо влазит в память, то быстрый сторадж у нас дает очень большое преимущество, т.е. мы видим, что разница в 5 раз внизу. Но когда у нас данные влазят в память все лучше и лучше, то у нас разница между быстрым и медленным стораджами сокращается. Из этого вывод: если у нас есть шанс загнать наш working set в память, то лучше инвестировать в память. Иметь какой-нибудь флаш, но, может быть, не самый быстрый. Но если у вас объем данных уже такой, что в память загонять все равно не удается, то в этом случае часто имеет смысл иметь несколько меньше памяти, но иметь более быстрый сторадж.
Что стоит сказать про сторадж? Понятно, что сейчас есть много разных решений. Наверное, скажу только одну важную вещь, что сейчас, если вы используете MySQL или другие OLT базы данных, то имеет смысл использовать флаш ??, т.е. про диски, которые крутятся, забыли.

С точки зрения сети чаще всего производительность MySQL-сервера упирается во время отклика, а не в пропускную способность, особенно учитывая то, что люди часто делают достаточно много запросов в MySQL на каждую страницу. Часто это бывают сотни запросов, а в некоторых случаях я даже видел и десятки тысяч. Из этого вывод, что мы хотим, чтоб у нас было как можно лучше минимальное время отклика, значит, мы хотим, чтобы у нас MySQL-сервера и application-сервера говорили как можно больше напрямую. Чем меньше шагов сети (network hops), тем лучше. Размещать, например, application-сервер в одном месте, а базу данных в другом, в разных городах, на разных континентах – очень плохая идея, даже если вам говорят, что «а вот у нас лежит между ними свое «оптоволокно» на какие-то Гбиты». Потому скорость света – она конечная, и когда мы говорим о мк или долях мс, она уже начинает влиять правильно.

Выбор операционной системы. MySQL наиболее успешно используется на Linux. Кто-нибудь MySQL на чем-нибудь другом использует? FreeBSD, Windows server. Но большинство крупных проектов использует MySQL все-таки на Linux. В данном случае имеет смысл использовать серверный вариант этой ОС, который и оптимизирован для этого, и который не будет меняться каждые три месяца, и который нужно постоянно апгрейдить. И достаточно новый, особенно, если вы используете новое железо, потому что все, что касается флаш, то, что касается поддержки функциональности новых процессоров – это все поддерживается в более новых ядрах, новых дистрибутивах куда лучше, чем в старых.

Что интересно с точки зрения Linux. На самом деле, его дефолтные настройки для многих MySQL-нагрузок достаточно адекватны. Понятно, что если мы пойдем в какие-то там Google, Facebook – им важны последние 3-5% производительности, они инвестируют много в тюнинг ядра тоже или часто даже компилируют его специально, или патчат, но для большинства людей это не настолько важно. Файловая система – наиболее часто, мы видим, используется либо EXT4 либо XFS. На разных нагрузках либо одна, либо другая может показывать лучшую производительность, но эти две файловые системы. И по ссылке я об этом поговорил более подробно.

Следующий момент – версия MySQL. Что нужно знать? Что новые версии MySQL обычно улучшают производительность. Есть исключения, т.е. если мы используем один поток клиентский и используем очень простые запросы, то на самом деле, поскольку MySQL становится более толстым, пытается делать больше оптимизации запросов, производительность на таких запросах может не существенно, но быть медленнее в новых версиях MySQL. На прошлой неделе вышел MySQL 5.7, что очень классно. Там очень много улучшений, как связанных с оптимайзером, так и с общей масштабируемостью, т.е. если вы хотите максимальной производительности MySQL, на него имеет смысл смотреть, но когда вы будете апгрейдиться, вы можете подождать Percona Server 5.7, который тоже выйдет через некоторое число месяцев.

MySQL-конфигурация. Здесь важно, что дефолты в MySQL-конфигурации плохие. Т.е. с дефолтами для MySQL работать нельзя. Но при этом тоже, не смотрите на него: «Елки-палки! Здесь есть 400 разных настроек». Вам, скорее всего, нужно будет исправить 5-10-20, для того, чтобы получить адекватную производительность. Опять-таки, можете посмотреть мои слайды или вебинар с большими деталями по этому поводу.

Если вам лень туда смотреть, то можно взять эти настройки, ввести их в Google, и вы легко найдете ответы на то, во что их нужно поставить для вашей конфигурации.

Следующий момент – с точки зрения процесса.
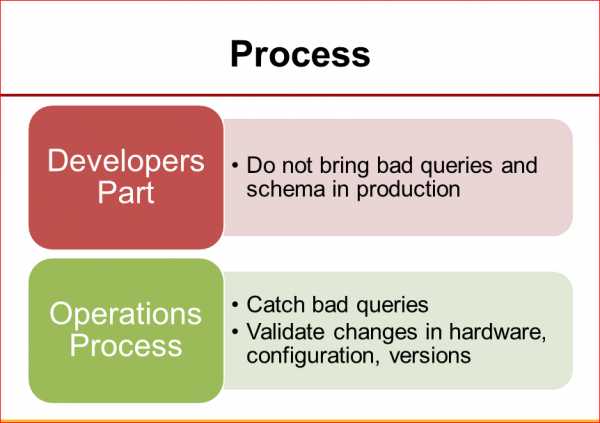
Есть две важные вещи:
- Во-первых, нужно пасти разработчиков, потому что разработчики часто делают плохие запросы, которые, когда мы потом выкладываем код на продакшн, создают проблемы. Т.е. хорошо, если у нас есть процесс, когда мы кем-то, кто понимает базы данных, отслеживаем новые запросы, новые изменения схемы, которые предлагают разработчики. Это очень важная часть процесса.
- Второй вопрос в том, что я никогда не видел, чтобы такой процесс предотвратил все проблемы, но и потому что разработчики, хотя и часто причина проблем с базами данных, но не всегда, иногда это бывает что-нибудь другое. Например, база данных сама в чем-нибудь виновата. Поэтому важно, чтобы уже на операционном уровне был какой-то процесс, чтоб ловить плохие запросы, отслеживать изменения версии MySQL в ОС, в конфигурации, также проверять всякие изменения железа, насколько оно хорошо работает. Очень-очень часто случается, что, например, мы пошли, купили железо, которое лучше, дороже, поставили его, а на самом деле оно работает медленнее, потому что мы там что-то не настроили, драйвер плохой, или Linux что-то еще не поддерживает. Доверяй, но проверяй, как говорится.

Следующий момент. Интересно, что со всеми этими настройками у нас, что бы мы ни изменили – железо, ОС, настройки MySQL – это всегда каким-то образом влияет на производительность запросов. Поэтому, если у вас есть какой-то мониторинг, что вы смотрите на производительность ваших запросов относительно времени, то вы всегда легко поймаете, если что-то вдруг стало плохо.

Значит, это вот тулзы, которые можно для этого использовать.

Я покажу один вариант, что мы сделали недавно. Это интеграция из MySQL performance Schema с Graphite.
Ссылка – http://bit.ly/1KQSNWC
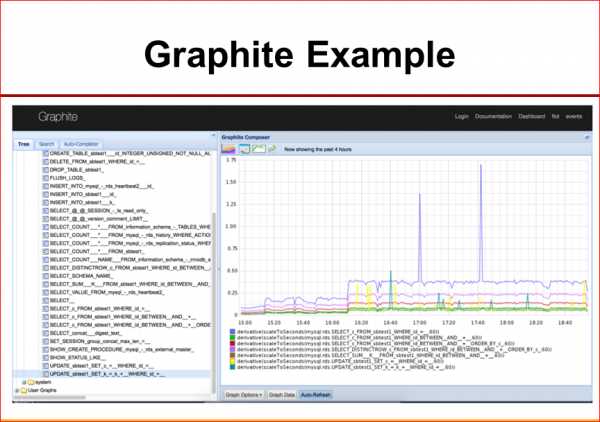
Здесь, вы видите, можно посмотреть суммарное время отклика для любого запроса MySQL, что очень полезно, потому что если начинает у нас что-то быть плохо, мы увидим, что у этого запроса съехал, например, план, теперь у нас занимает резко, в 10 раз больше суммарное время выполнения.
Это о том, что у нас важно. Смотрите за скоростью производительности приложения. И вот несколько хинтов, как их можно оптимизировать.


Ссылка – http://www.meetup.com/moscowmysql/

Ссылка – http://bit.ly/PL16Call
Контакты
» [email protected] Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++.В рамках профессионального фестиваля "Российские интернет-технологии" мы проводим целую секцию по базам данных. Сейчас в ней 16 докладов, из которых нам надо выбрать 9. Вот, что мы уже точно выбрали:
Присоединяйтесь к нам!
habr.com
Оптимизация запросов в MySQL | MySQL
Оптимизация – это изменение системы с целью повышения ее быстродействия.Оптимизацию работы с БД можно разделить на 3 типа:
* оптимизация запросов* оптимизация структуры* оптимизация сервера.
Рассмотрим подробнее оптимизацию запросов.
Оптимизация запросов — наиболее простой и приводящий к наиболее высоким результатам тип оптимизации.
SELECT
Запросами, которые чаще всего поддаются оптимизации, являются запросы на выборку.
Для того чтобы посмотреть как будет выполняться запрос на выборку используется оператор EXPLAIN:http://www.mysql.com/doc/ru/EXPLAIN.htmlС его помощью мы можем посмотреть, в каком порядке будут связываться таблицы и какие индексы при этом будут использоваться.
Основная ошибка начинающих — это отсутствие индексов на нужных полях или создание оных на ненужных полях. Если вы делаете простую выборку наподобие:SELECT * FROM table WHERE field1 = 123То вам нужно проставить индекс на поле field1, если вы используете в выборке условие по двум полям:SELECT * FROM table WHERE field1 = 123 AND field2 = 234То вам нужно создать составной индекс на поля field1, field2.
Если вы используете соединение 2 или более таблиц:
SELECT * FROM a, b WHERE a.b_id = b.idИли в более общем виде:
SELECT * FROM a [LEFT] JOIN b ON b.id = a.b_id [LEFT] JOIN с ON с.id = b.c_idТо вам следует создать индексы по полям, по которым будут присоединятся таблицы. В данном случае это поля b.id и c.id. Однако это утверждение верно только в том случае, если выборка будет происходить в том порядке, в котором они перечислены в запросе. Если, к примеру, оптимизатор MySQL будет выбирать записи из таблиц в следующем порядке: c,b,a, то нужно будет проставить индексы по полям: b.c_id и a.b_id. При связывании с помощью LEFT JOIN таблица, которая идет в запросе слева, всегда будет просматриваться первой.
Про синтаксис создания индексов можно прочитать в документации:http://www.mysql.com/doc/ru/CREATE_INDEX.html
Более подробно про использовании индексов можно прочитать здесь:http://www.mysql.com/doc/ru/MySQL_indexes.html
Иногда бывает такая ситуация, что нам постоянно приходится делать выборки из одной и той же части некоторой очень большой таблицы, например, во многих запросах происходит соединение с частью таблицы:[LEFT] JOIN b ON b.id = a.b_id AND b.field1 = 123 AND b.field2 = 234
В таких случаях может быть разумным вынести эту часть в отдельную временную таблицу:CREATE TEMPORARY TABLE tmp_b TYPE=HEAP SELECT * FROM b WHERE b.field1 = 123 AND b.field2 = 234И работать уже с ней ( про временные таблицы читайте в документации http://www.mysql.com/doc/ru/CREATE_TABLE.html).
Также если мы несколько раз рассчитываем агрегатную функцию для одних и тех же данных, то для ускорения следует сделать такой расчет отдельно и положить его результат во временную таблицу.
Также бывают тормоза, когда люди пытаются в одном запросе «поймать сразу 2-х зайцев», например, на форуме phpclub’а автор следующего запроса спрашивал, почему он тормозит:
SELECT f_m. *, MAX( f_m_v_w.date ) AS last_visited, COUNT( DISTINCT f_b.id ) AS books_num, IF ( f_m.region != 999, f_r.name, f_m.region_other ) AS region_name FROM fair_members f_m LEFT JOIN fair_members_visits_week f_m_v_w ON f_m_v_w.member_id = f_m.id LEFT JOIN fair_regions AS f_r ON f_m.region = f_r.id LEFT JOIN fair_books AS f_b ON f_b.pub_id = f_m.id GROUP BY f_m.idАвтор запроса пытается в одном запросе посчитать максимальное значение атрибута из одной таблицы и кол-во записей в другой таблице. В результате к запросу приходится присоединять 2 разные таблицы, которые сильно замедляют выборку. Для увеличения быстродействия такой выборки необходимо вынести подсчет MAX’а или COUNT’а в отдельный запрос.
Для подсчета кол-ва строк используйте функцию COUNT(*), c указанием "звездочки" в качестве аргумента.
Почему COUNT(*) обычно быстрее COUNT(id), поясню на примере:
Есть таблица message: id | user_id | textс индексом PRIMARY(id), INDEX(user_id)
Нам надо подсчитать сообщения пользователя с заданым $user_id
Сравним 2 запроса:
SELECT COUNT(*) FROM message WHERE user_id = $user_idи
SELECT COUNT(id) FROM message WHERE user_id = $user_idДля выполнения первого запроса нам достаточно просто пробежаться по индексу user_id и подсчитать кол-во записей, удовлетворяющих условию — такая операция достаточно быстрая, т.к., во-первых, индексы у нас упорядочены и ,во-вторых, часто находятся в буфере.
Для выполнения второго запроса мы сначала проходим по индексу, для отбора записей удовлетворяющих условию, после чего если запись попадает под условие, то вытаскиваем ее (запись скорее всего будет на диске) чтобы получить значение id и только потом инкриментим счетчик.
В итоге получаем, что при большом кол-ве записей скорость первого запроса будет выше в разы.
UPDATE, INSERT
Скорость вставок и обновлений в базе зависит от размера вставляемой (обновляемой) записи и от времени вставки индексов. Время вставки индексов в свою очередь зависит от количества вставляемых индексов и размера таблицы. Эту зависимость можно выразить формулой:[Время вставки индексов] = [кол-во индексов] * LOG2( [Размер таблицы] )При операциях обновления под [кол-во индексов] понимаются только те индексы, в которых присутствуют обновляемые поля.Условия в запросах на обновления оптимизируются так же, как и в случае с выборками.
При частом изменении некоторой большой таблицы с большим количеством индексов имеет смысл производить вставки в другую небольшую вспомогательную таблицу с тем же набором полей (но с отсутствием индексов) и периодически перекидывать данные из нее в основную таблицу, очищая вспомогательную. При этом следует учесть, что данные будут выводиться с запозданием, что не всегда может быть возможным.
«Чтобы удалить все строки в таблице, нужно использовать команду TRUNCATE TABLE table_name.» © документация MySQL.
www.internet-technologies.ru
С чего начинать оптимизацию MySQL?
Кролик надел очки.— С чего начинать, Ваше Величество? — спросил он. — Начни с начала, — важно ответил Король, — продолжай, пока не дойдешь до конца.
Льюис Кэрролл. Приключения Алисы в стране чудес.
Эта статья для тех, кто впервые столкнулся с необходимостью оптимизировать производительность MySQL. Статья описывает основные подходы, применяемые сегодня для решения данной задачи в масштабах одного сервера.
Нужна ли оптимизация MySQL?
Итак, вы столкнулись с падением производительности веб-приложения, использующего MySQL. Приложение периодически недоступно, загрузка страниц вашего сайта происходит слишком долго или периодически выдается ошибка "Too many connections". Перед тем, как приступать к оптимизации MySQL, следует проверить следующее:
- Наличие свободного места на диске в рамках дисковой квоты.
- Отсутствие зацикливания в веб-приложении.
- Время отклика вашего web-сервера (ping).
- В случае виртуального хостинга, отсутсвие внешних замедляющих факторов (один из способов это проверить — остановить приложение и выполнить простейший запрос SELECT 2+2; в консоли mysql на сервере. Такой запрос должен выполниться за несколько сотых секунды).
- Отсутствие задержки при подключении к mysql-серверу с сервера веб-приложения. Если такая задержка присутствует, это может быть связано с неправильной работой системы доменных имен (DNS).
Выполнение описанных выше проверок не гарантирует, что проблемы производительности связаны именно с MySQL, но позволит во многих случаях найти стороннюю причину падения производительности.
Путь оптимизации
Предостережение, высказанное Дональдом Кнутом: «Преждевременная оптимизация - корень всех зол» справедливо и для MySQL. Нельзя начинать оптимизацию не выявив узкие места. Если вы создаете приложение, которое должно выдерживать в будущем большую нагрузку, то для нахождения узких мест потребуется создать искусственную нагрузку, аналогичную ожидаемой.
Перечислим различные методы оптимизации в одном из возможных порядков их применения:
- Анализ медленных запросов к базе данных. На этой стадии анализируется журнал медленных запросов (slow query log) и текущий поток запросов к базе (увидеть выполняемые в настоящий момент запросы к базе можно, выполнив команду SHOW FULL PROCESSLIST в консоли MySQL).
- Добавление ключевых полей, оптимизация запросов, оптимизация типов колонок, выбор оптимального механизма хранения (storage engine). На этой ступени устраняются наиболее распространенные причины медленности запросов - отсутствие ключей, неоптимальный выбор типа колонки и неоптимальная форма запроса.
- Переход на виртуальный выделенный сервер (VDS) или на выделенный физический сервер (если это еще не сделано). Время разработчика дорого, поэтому переход на более производительный сервер часто оптимальное решение (бывает, без этого и не обойтись). Кроме того, без прав суперпользователя невозможна оптимизация конфигурации MySQL, а на VDS невозможно гарантировать стабильную производительность, так как приложения других пользователей VDS могут блокировать доступ к диску.
- Оптимизация конфигурации MySQL и параметров операционной системы. На этой стадии настраиваются кэши и буферы MySQL, исходя из потребности приложений. Настраиваются другие параметры MySQL и некоторые параметры операционной системы. См. также статьи «Использование кэшей индексов» и «Кэширование запросов в MySQL».
- Оптимизация структуры базы данных. На этой стадии производится необходимая нормализация или денормализация базы данных. Стадия наиболее трудоемкая в силу того, что изменение структуры данных может потребовать внесения значительных изменений в код приложений, использующих базу данных. К этому методу обычно прибегают на стадии проектирования приложения или если все, описанные выше методы, не дали результата.
Серебряной пули нет
Не существует одного метода, который быстро решил бы все проблемы производительности. Приведенный перечень методов не претендует на полноту, оптимизация производительности СУБД в каждом случае требует индивидуального анализа. Содержание каждого из названных методов постараемся осветить в будущих статьях. С чего начинать оптимизацию? Начните с узких мест и продолжайте, пока будет оставаться хотя бы одно узкое место.
Статья написана по материалам онлайн-курса «Оптимизация производительности MySQL».
© Все права на данную статью принадлежат порталу webew.ru. Перепечатка в интернет-изданиях разрешается только с указанием автора и прямой ссылки на оригинальную статью. Перепечатка в печатных изданиях допускается только с разрешения редакции.
webew.ru
10 лучших приемов оптимизации MySQL

1. LIMIT 1 при выборке одной строки
Есть люди из калифорнии (хотя бы один человек)?
Плохой вариант:
SELECT * FROM USER WHERE state = 'California';Хороший вариант:
SELECT 1 FROM USER WHERE state = 'California' LIMIT 1;2. Оптимизируйте запросы для кеша запросов
Кеширование запросов - один из наиболее эффективных способов повышения производительности.
Плохой вариант:
// кеш НЕ работает $r = mysqli_query("SELECT username FROM user WHERE signup_date >= CURDATE()");Хороший вариант:
// кеш работает! $today_date = date("Y-m-d"); $r = mysqli_query("SELECT username FROM user WHERE signup_date >= '$today_date'");3. Индексируйте поисковые столбцы
Индексы служат не только для первичных ключей и уникальных значений. Также они ускоряют поиск 1).
last_name LIKE 'a%'- используется индекс, быстро.
WHERE post_content LIKE '%tomato%'- индекс не используется, медленно.
Не создавайте индексы на таблицах, число записей в которых меньше нескольких тысяч. Для таких размеров выигрыш от использования индекса будет почти незаметен.http://ruhighload.com/
4. Индексируйте и используйте одинаковые типы столбцов для объединения
Если в приложении много запросов с JOIN, необходимо проиндексировать столбцы, по которым идет объединение, в обоих таблицах.
Также для этих столбцов следует использовать одинаковые типы. Например, при объединении столбцов DECIMAL и INT, по крайней мере один из индексов не будет использоваться. Для строковых столбцов также важна кодировка.
$r = mysqli_query("SELECT company_name FROM users LEFT JOIN companies ON (users.state = companies.state) WHERE users.id = $user_id");Оба столбца state должны быть проиндексированы и быть в одинаковой кодировке, в противном случае MySQL будет использовать полный просмотр таблиц.
5. Избегайте использования SELECT *
Чем больше данных читается, тем медленнее запрос, что связано с операцией чтения с диска. Если сервер базы данных и веб-сервер физически находятся на разных машинах, у вас будет дополнительная задержка на передачу данных.
Не рекомендуется:
$r = mysqli_query("SELECT * FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d['username']}";Лучше:
$r = mysqli_query("SELECT username FROM user WHERE user_id = 1"); $d = mysql_fetch_assoc($r); echo "Welcome {$d['username']}";«*» ускоряет разработку, а также используется «один и тот кеш», если WHERE один и тот же, но выбираются разные поля. Сравните:
-- CASE 1 SELECT username FROM user WHERE user_id = 1; -- получаем имя, результаты запроса кешируется SELECT reg_date FROM user WHERE user_id = 1; -- получаем дату, результаты запроса кешируется -- CASE 2 SELECT * FROM user WHERE user_id = 1; -- получаем все, результаты запроса кешируется SELECT * FROM user WHERE user_id = 1; -- используется кеш первого запроса!6. Пожалуйста, не сортируйте по RAND()
ORDER BY RAND() - «бутылочное горлышко», делающее запросы медленными. Проблема решается с помощью дополнительного кода.
Даже если выбирается всего одна запись, MySQL вначале отсортирует всю таблицу.
Плохо:
$r = mysqli_query("SELECT username FROM user ORDER BY RAND() LIMIT 1");Значительно лучше:
$r = mysqli_query("SELECT count(*) FROM user"); $d = mysql_fetch_row($r); $rand = mt_rand(0,$d[0] - 1); $r = mysqli_query("SELECT username FROM user LIMIT $rand, 1");Таким образом, выбирается случайный номер, меньше чем число результатов, и используется как смещение LIMIT.
Этот же принцип в нескольких вариантах.
7. Используйте ENUM вместо VARCHAR
Тип ENUM очень быстрый и компактный. Внутри он хранится как TINYINT, а внешне выглядит как строка (очень наглядно). Если у вас всего несколько вариантов значений, лучше использовать ENUM.
Например, столбец status, принимающий варианты «active», «inactive», «pending», «expired».
Этот вариант хранения может предложить и сам MySQL, если при вызове PROCEDURE ANALYSE() тип столбца - VARCHAR.
Следует учесть, что теряется совместимость по SQL-92, так как ENUM есть только в MySQL. Также при добавлении нового типа есть проблема ALTER TABLE на больших таблицах.И храните IP адреса как UNSIGNED INT
Вместо VARCHAR(15) следует использовать UNSIGNED INT - он короче на 4 байта. Для перекодирования служат MySQL функции INET_ATON() IP => целое и INET_NTOA() - обратное преобразование. На PHP аналогичные функции long2ip() и ip2long().
$r = "UPDATE usrs SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $u_id";8. Вертикальное партиционирование
Вертикальное партиционирование - прием разделения структуры таблицы по-вертикали для оптимизации.
Пример 1: допустим, из таблицы users домашний адрес пользователя address читается редко. Тогда возможно разделить эту таблицу на две, и хранить адрес отдельно, читая его при необходимости. Такой прием уменьшит размер таблицы users, а маленькие таблицы работают быстрее.
Пример 2: в той же таблице есть поле last_login, обновляемое каждый раз при заходе пользователя. Но при каждом обновлении таблицы перестает работать кеш запросов! Поместив это поле в отдельную таблицу, мы сведем обновление users к минимуму.
Но вначале убедитесь, что эти разделенные таблицы не приходится объединять постоянно, потому как это наоборот, может уменьшить производительность.
9. Небольшие столбцы быстрее
Диск - самая медленная часть системы БД. Уменьшение хранимого объема положительно сказывается на производительности. В документации указан требуемый для хранения различных типов данных размер. Например, для целых.
Если ожидается, что количество записей будет мало, в качестве первичного ключа возможно использовать не INT, а MEDIUMINT, SMALLINT, и даже TINYINT.
Если существенна только дата, то следует ее хранить не как DATETIME, а как DATE.
Но также стоит задуматься о дальнейшем росте, предусмотрев для него такие возможности.
10. Выберите правильную подсистему хранения
Две главные системы MyISAM и InnoDB имеют свои преимущества и недостатки.
MyISAM хороша для чтения, и хуже - для записи. Даже если обновляется только одна строка, блокируется вся таблица, в том числе на чтение. MyISAM очень быстро считает SELECT COUNT(*).
InnoDB содержит более сложный механизм хранения, и может оказаться медленнее для небольших приложений. Однако механизм блокировки реализован на уровне строки, что не блокирует всю таблицу. Также эта система имеет дополнительные возможности, такие как транзакции.
Оригинал статьи
pushorigin.ru