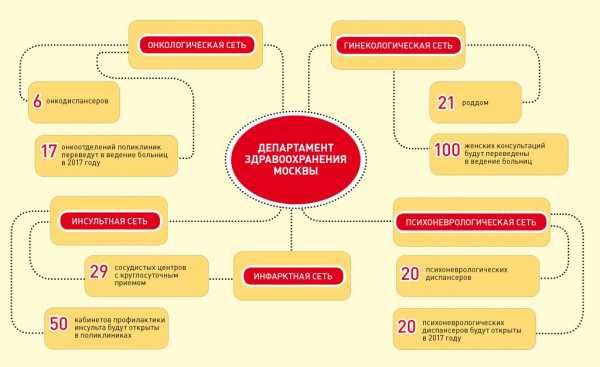
Методы информационного поиска. Методы и приемы оптимизации информационного поиска
Методы информационного поиска
Типология методов поиска
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен по нескольким методам, значительно различающимся как по эффективности и качеству поиска, так и по типу извлекаемой информации. В ряде случаев приходится использовать весьма трудоемкие методы - результат того стоит.
Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
Непосредственный поиск с использованием гипертекстовых ссылок
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью броузера.
Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн узлов, "ручной" просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое "копание" уступает место более глубокому анализу. Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
Использование поисковых машин
Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов Cети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать. Если делать все правильно, то формирование списка ключевых слов требует предварительной работы по составлению тезауруса.
Поиск с применением специальных средств
Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска.
Одна из технологий этого метода основана на применении специализированных программ - спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию. Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы). Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин). В ряде случаев этот метод может быть очень эффективен.
Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
Анализ новых ресурсов
Поиск по новообразованным ресурсам может оказаться необходимым при проведении повторных циклов поиска, поиска наиболее свежей информации или для анализа тенденций развития объекта исследования в динамике.
Другой возможной причиной может явиться то, что большинство поисковых машин обновляет свои индексы со значительной задержкой, вызванной гигантскими объемами обрабатываемых данных, и эта задержка обычно тем больше, чем менее популярна интересующая вас тема. Это соображение может оказаться весьма существенным при проведении поиска в узкоспециальной предметной области.
Технология поиска с использованием поисковых машин
Определение географических регионов поиска
Поскольку проведение информационного поиска преследует практические цели - маркетинговые, производственные, сугубо утилитарные и тому подобные, - практическая ценность информационного ресурса может зависеть и от географического расположения соответствующего источника.
Составление тезауруса
Для эффективного использования поисковых серверов необходим список ключевых слов, организованный с учетом семантических отношений между ними, т.е. тезаурус. При составлении тезауруса необходимо предусмотреть обработку синонимов, омонимов и морфологических вариаций ключевых слов.
Использование законов Зипфа
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется ранг частоты. Вероятность обнаружения слова в тексте = частота вхождения слова / число слов в тексте. Зипф нашел, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:
С = (частота вхождения слов X ранг частоты) / число слов
Это значит, что график зависимости ранга от частоты - равносторонняя гипербола.
Зипф также установил, что зависимость количества слов с данной частотой от частоты - также гипербола и постоянная для всех текстов в пределах одного языка.
Что можно извлечь из этих законов? Исследования вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой как правило являются предлогами, частицами, местоимениями, в английском языке - артиклями (так называемые "стоп-слова"), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Основываясь на этой закономерности, можно предложить следующую методику.
Составление списка ключевых слов
Правильный набор ключевых слов имеет определяющее значение для оптимального поиска информации. К примеру, задав поисковой машине в качестве ключевого слова "МАРП", мы получим список документов, в которых встречается эта аббревиатура (Московское Агентство по Развитию Предпринимательства). Но если нас интересуют документы по более широкой теме, например: развитие предпринимательства, и мы сформируем простой запрос из этих двух слов, то поисковая машина выдаст нам список из сотен тысяч наименований, ориентироваться в котором будет весьма непросто.
Поэтому для составления оптимального набора ключевых слов используют процедуру, основанную на применении законов Зипфа, которая заключается в следующем: берут любой текст-источник, близкий к искомой теме, т.е. "образец", и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, Web-страница, любой другой документ. Анализ текста производится таким образом:
- Удаление из текста стоп-слов.
- Вычисление частоты вхождения каждого слова и составление списка, в котором слова расположены в порядке убывания их частоты.
- Выбор диапазона частот, лежащего в середине списка, и отбор из этого диапазона слов, наиболее полно соответствующих смыслу текста.
- Составление запроса к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором ИЛИ (OR). Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов (расположению их в порядке убывания частоты вхождения слов запроса в документ), применяемому в большинстве поисковых машин, на первых страницах списка практически все документы окажутся релевантными, причем документ-источник может находиться далеко от начала.
Более адекватной представляется структура тезауруса в виде так называемых семантических срезов, где для каждого основного термина отдельно строится таблица сопутствующих слов и слов шумовых (которые не должны встречаться в источнике), - некоторые поисковые машины (AltaVista) позволяют это использовать. Таким образом, вместо единой иерархической структуры терминов мы получаем пакет таблиц, которые могут расширяться и модифицироваться отдельно.
Отбор поисковых машин
Устанавливается последовательность использования поисковых машин в соответствии с убыванием ожидаемой эффективности поиска с применением каждой машины.
Всего известно около 180 поисковых серверов, различающихся по регионам охвата, принципам проведения поиска (а следовательно, по входному языку и характеру воспринимаемых запросов), объему индексной базы, скорости обновления информации, способности искать "нестандартную" информацию и тому подобное. Основными критериями выбора поисковых серверов являются объем индексной базы сервера и степень развитости самой поисковой машины, то есть уровень сложности воспринимаемых ею запросов.
Более подробно поисковые машины описаны в разделе курса "Сетевые средства поиска информации" .
Составление и выполнение запросов к поисковым машинам
Это наиболее сложный и трудоемкий этап, связанный с обработкой большого количества информации (в основном шумовой). На основе тезауруса формируются запросы к выбранным поисковым серверам, после чего возможно уточнение запроса с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска. Данные с ресурсов, признанных релевантными, собираются для последующего анализа.
Формирование запросов
Как формат, так и семантика запросов варьируются в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы составляются так, чтобы область поиска была максимально конкретизирована и сужена.
Предпочтение отдается использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится пробная реализация запросов - как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Языки запроса различных машин поиска в основном являются сочетанием следующих функций:
Операторы булевой алгебры AND, OR, NOT:
- AND (И) - осуществляется поиск документов, содержащих все термины, соединенные данным оператором;
- OR (ИЛИ) - искомый текст должен содержать хотя бы один из терминов, соединенных данным оператором;
- NOT (НЕ) - поиск документов, в тексте которых отсутствуют термины, следующие за данным оператором.
- Операторы расстояния - ограничивают порядок следования и расстояния между словами, например:
- NEAR - второй термин должен находиться на расстоянии от первого, не превышающем определенного числа слов;
- FOLLOWED BY - термины следуют в заданном порядке;
- ADJ - термины, соединенные оператором, являются смежными.
- Возможность усечения терминов - использование символа " * " вместо окончания термина позволяет включить в искомый список все слова, производные от его начальной части (шаблона).
- Учет морфологии языка - машина автоматически учитывает все формы данного термина, возможные в языке, на котором ведется поиск.
- Возможность поиска по словосочетанию, фразе.
- Ограничение поиска элементом документа (слова запроса должны находиться именно в заголовке, первом абзаце, ссылках и т.д.).
- Ограничения по дате опубликования документа.
- Ограничения на количество совпадений терминов.
- Возможность поиска графических изображений.
- Чувствительность к строчным и прописным буквам.
Результат запроса (список ссылок) обрабатывается в два этапа. На первом этапе производится отсечение очевидно нерелевантных источников, попавших в выборку в силу несовершенства поисковой машины или недостаточной "интеллектуальности" запроса. Параллельно проводится семантический анализ, имеющий целью уточнение тезауруса для модификации последующих запросов. Дальнейшая обработка производится путем последовательного обращения на каждый из найденных ресурсов и анализа находящейся там информации.
Анализ ресурсов и сбор информации
Первичный анализ ресурсов основывается на аннотациях - в случае их наличия, и в необходимых случаях - на ознакомлении с информационным наполнением ресурса. Информация с отобранных источников извлекается с использованием соответствующих конкретному источнику методов, что может потребовать значительных коммуникационных, вычислительных и дисковых ресурсов.
Кратко можно выделить следующие типы информационных Web-ресурсов:
- коммерческие сайты компаний;
- вторичные информационные сайты;
- источники аналитической информации;
- региональные информационные ресурсы.
В русскоязычной части Интернета в настоящее время доступен ряд ресурсов, предоставляющих вторичную информацию, как правило, в табулированной форме. Предоставление информации для публикации в подобных источниках является более дешевым вариантом для компаний, не имеющих собственного представительства в Интернете.
Проблемы, возникающие в процессе поиска
Одна из проблем является чисто методологической. Для проведения эффективного поиска мы заинтересованы в одновременном решении двух противоположных задач:
- увеличение охвата с целью извлечения максимального количества значимой информации;
- уменьшение охвата с целью минимизации шумовой информации.
Нетрудно видеть, что одновременно осуществить это довольно сложно, хотя зачастую все-таки возможно. Один из методов, если поисковая машина позволяет, - это введение явных ограничений (запрещенных слов). Другой состоит в правильном формировании запросов, в частности, в предпочтении нескольких конкретизированных запросов одному общему. К сожалению, весьма ограниченный входной язык большинства машин не оставляет особенного простора для творчества в этом направлении.
Другая проблема - многовариантность человеческого языка. Если в английском языке некоторые слова имеют множество различных значений, то русский отличается богатством морфологических вариаций слов, а для полноты поиска необходимо учитывать еще и синонимы.
Часто в области российского Интернета возникают чисто технические трудности из-за различных кодировок информации. Российские поисковые машины распознают кодировки пользователя и искомого сайта, но совместить их удается не всегда.
Еще одна особенность русскоязычной части сети - ее нестабильность. Постоянно изменяются адреса и структура сайтов, они появляются и исчезают, и поисковые машины не успевают обновлять свои базы индексированных данных, поэтому значительная часть списка документов, выданного вам машиной, может оказаться недоступной. Появление в сентябре 1997 г. системы Яndex-Web, обновляющей свои данные раз в неделю, обозначило качественный скачок вперед в решении этой проблемы.
coolreferat.com
Методы информационного поиска
Типология методов поиска
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен по нескольким методам, значительно различающимся как по эффективности и качеству поиска, так и по типу извлекаемой информации. В ряде случаев приходится использовать весьма трудоемкие методы - результат того стоит.
Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
Непосредственный поиск с использованием гипертекстовых ссылок
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью броузера.
Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн узлов, "ручной" просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое "копание" уступает место более глубокому анализу. Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
Использование поисковых машин
Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов Cети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать. Если делать все правильно, то формирование списка ключевых слов требует предварительной работы по составлению тезауруса.
Поиск с применением специальных средств
Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска.
Одна из технологий этого метода основана на применении специализированных программ - спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию. Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы). Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин). В ряде случаев этот метод может быть очень эффективен.
Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
Анализ новых ресурсов
Поиск по новообразованным ресурсам может оказаться необходимым при проведении повторных циклов поиска, поиска наиболее свежей информации или для анализа тенденций развития объекта исследования в динамике.
Другой возможной причиной может явиться то, что большинство поисковых машин обновляет свои индексы со значительной задержкой, вызванной гигантскими объемами обрабатываемых данных, и эта задержка обычно тем больше, чем менее популярна интересующая вас тема. Это соображение может оказаться весьма существенным при проведении поиска в узкоспециальной предметной области.
Технология поиска с использованием поисковых машин
Определение географических регионов поиска
Поскольку проведение информационного поиска преследует практические цели - маркетинговые, производственные, сугубо утилитарные и тому подобные, - практическая ценность информационного ресурса может зависеть и от географического расположения соответствующего источника.
Составление тезауруса
Для эффективного использования поисковых серверов необходим список ключевых слов, организованный с учетом семантических отношений между ними, т.е. тезаурус. При составлении тезауруса необходимо предусмотреть обработку синонимов, омонимов и морфологических вариаций ключевых слов.
Использование законов Зипфа
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется ранг частоты. Вероятность обнаружения слова в тексте = частота вхождения слова / число слов в тексте. Зипф нашел, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:
С = (частота вхождения слов X ранг частоты) / число слов
Это значит, что график зависимости ранга от частоты - равносторонняя гипербола.
Зипф также установил, что зависимость количества слов с данной частотой от частоты - также гипербола и постоянная для всех текстов в пределах одного языка.
Что можно извлечь из этих законов? Исследования вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой как правило являются предлогами, частицами, местоимениями, в английском языке - артиклями (так называемые "стоп-слова"), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Основываясь на этой закономерности, можно предложить следующую методику.
Составление списка ключевых слов
Правильный набор ключевых слов имеет определяющее значение для оптимального поиска информации. К примеру, задав поисковой машине в качестве ключевого слова "МАРП", мы получим список документов, в которых встречается эта аббревиатура (Московское Агентство по Развитию Предпринимательства). Но если нас интересуют документы по более широкой теме, например: развитие предпринимательства, и мы сформируем простой запрос из этих двух слов, то поисковая машина выдаст нам список из сотен тысяч наименований, ориентироваться в котором будет весьма непросто.
Поэтому для составления оптимального набора ключевых слов используют процедуру, основанную на применении законов Зипфа, которая заключается в следующем: берут любой текст-источник, близкий к искомой теме, т.е. "образец", и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, Web-страница, любой другой документ. Анализ текста производится таким образом:
- Удаление из текста стоп-слов.
- Вычисление частоты вхождения каждого слова и составление списка, в котором слова расположены в порядке убывания их частоты.
- Выбор диапазона частот, лежащего в середине списка, и отбор из этого диапазона слов, наиболее полно соответствующих смыслу текста.
- Составление запроса к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором ИЛИ (OR). Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов (расположению их в порядке убывания частоты вхождения слов запроса в документ), применяемому в большинстве поисковых машин, на первых страницах списка практически все документы окажутся релевантными, причем документ-источник может находиться далеко от начала.
Более адекватной представляется структура тезауруса в виде так называемых семантических срезов, где для каждого основного термина отдельно строится таблица сопутствующих слов и слов шумовых (которые не должны встречаться в источнике), - некоторые поисковые машины (AltaVista) позволяют это использовать. Таким образом, вместо единой иерархической структуры терминов мы получаем пакет таблиц, которые могут расширяться и модифицироваться отдельно.
Отбор поисковых машин
Устанавливается последовательность использования поисковых машин в соответствии с убыванием ожидаемой эффективности поиска с применением каждой машины.
Всего известно около 180 поисковых серверов, различающихся по регионам охвата, принципам проведения поиска (а следовательно, по входному языку и характеру воспринимаемых запросов), объему индексной базы, скорости обновления информации, способности искать "нестандартную" информацию и тому подобное. Основными критериями выбора поисковых серверов являются объем индексной базы сервера и степень развитости самой поисковой машины, то есть уровень сложности воспринимаемых ею запросов.
Более подробно поисковые машины описаны в разделе курса "Сетевые средства поиска информации".
Составление и выполнение запросов к поисковым машинам
Это наиболее сложный и трудоемкий этап, связанный с обработкой большого количества информации (в основном шумовой). На основе тезауруса формируются запросы к выбранным поисковым серверам, после чего возможно уточнение запроса с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска. Данные с ресурсов, признанных релевантными, собираются для последующего анализа.
Формирование запросов
Как формат, так и семантика запросов варьируются в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы составляются так, чтобы область поиска была максимально конкретизирована и сужена.
Предпочтение отдается использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится пробная реализация запросов - как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
mirznanii.com
Методы информационного поиска - Информация
Методы информационного поиска
Типология методов поиска
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен по нескольким методам, значительно различающимся как по эффективности и качеству поиска, так и по типу извлекаемой информации. В ряде случаев приходится использовать весьма трудоемкие методы - результат того стоит.
Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
Непосредственный поиск с использованием гипертекстовых ссылок
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью броузера.
Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн узлов, "ручной" просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое "копание" уступает место более глубокому анализу. Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
Использование поисковых машин
Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов Cети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать. Если делать все правильно, то формирование списка ключевых слов требует предварительной работы по составлению тезауруса.
Поиск с применением специальных средств
Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска.
Одна из технологий этого метода основана на применении специализированных программ - спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию. Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы). Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин). В ряде случаев этот метод может быть очень эффективен.
Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
Анализ новых ресурсов
Поиск по новообразованным ресурсам может оказаться необходимым при проведении повторных циклов поиска, поиска наиболее свежей информации или для анализа тенденций развития объекта исследования в динамике.
Другой возможной причиной может явиться то, что большинство поисковых машин обновляет свои индексы со значительной задержкой, вызванной гигантскими объемами обрабатываемых данных, и эта задержка обычно тем больше, чем менее популярна интересующая вас тема. Это соображение может оказаться весьма существенным при проведении поиска в узкоспециальной предметной области.
Технология поиска с использованием поисковых машин
Определение географических регионов поиска
Поскольку проведение информационного поиска преследует практические цели - маркетинговые, производственные, сугубо утилитарные и тому подобные, - практическая ценность информационного ресурса может зависеть и от географического расположения соответствующего источника.
Составление тезауруса
Для эффективного использования поисковых серверов необходим список ключевых слов, организованный с учетом семантических отношений между ними, т.е. тезаурус. При составлении тезауруса необходимо предусмотреть обработку синонимов, омонимов и морфологических вариаций ключевых слов.
Использование законов Зипфа
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется ранг частоты. Вероятность обнаружения слова в тексте = частота вхождения слова / число слов в тексте. Зипф нашел, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:
С = (частота вхождения слов X ранг частоты) / число слов
Это значит, что график зависимости ранга от частоты - равносторонняя гипербола.
Зипф также установил, что зависимость количества слов с данной частотой от частоты - также гипербола и постоянная для всех текстов в пределах одного языка.
Что можно извлечь из этих законов? Исследования вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой как правило являются предлогами, частицами, местоим
www.studsell.com
Методы информационного поиска
Типология методов поиска
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен по нескольким методам, значительно различающимся как по эффективности и качеству поиска, так и по типу извлекаемой информации. В ряде случаев приходится использовать весьма трудоемкие методы - результат того стоит.
Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
Непосредственный поиск с использованием гипертекстовых ссылок
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью броузера.
Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн узлов, "ручной" просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое "копание" уступает место более глубокому анализу. Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
Использование поисковых машин
Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов Cети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать. Если делать все правильно, то формирование списка ключевых слов требует предварительной работы по составлению тезауруса.
Поиск с применением специальных средств
Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска.
Одна из технологий этого метода основана на применении специализированных программ - спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию. Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы). Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин). В ряде случаев этот метод может быть очень эффективен.
Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
Анализ новых ресурсов
Поиск по новообразованным ресурсам может оказаться необходимым при проведении повторных циклов поиска, поиска наиболее свежей информации или для анализа тенденций развития объекта исследования в динамике.
Другой возможной причиной может явиться то, что большинство поисковых машин обновляет свои индексы со значительной задержкой, вызванной гигантскими объемами обрабатываемых данных, и эта задержка обычно тем больше, чем менее популярна интересующая вас тема. Это соображение может оказаться весьма существенным при проведении поиска в узкоспециальной предметной области.
Технология поиска с использованием поисковых машин
Определение географических регионов поиска
Поскольку проведение информационного поиска преследует практические цели - маркетинговые, производственные, сугубо утилитарные и тому подобные, - практическая ценность информационного ресурса может зависеть и от географического расположения соответствующего источника.
Составление тезауруса
Для эффективного использования поисковых серверов необходим список ключевых слов, организованный с учетом семантических отношений между ними, т.е. тезаурус. При составлении тезауруса необходимо предусмотреть обработку синонимов, омонимов и морфологических вариаций ключевых слов.
Использование законов Зипфа
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется ранг частоты. Вероятность обнаружения слова в тексте = частота вхождения слова / число слов в тексте. Зипф нашел, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:
С = (частота вхождения слов X ранг частоты) / число слов
Это значит, что график зависимости ранга от частоты - равносторонняя гипербола.
Зипф также установил, что зависимость количества слов с данной частотой от частоты - также гипербола и постоянная для всех текстов в пределах одного языка.
Что можно извлечь из этих законов? Исследования вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой как правило являются предлогами, частицами, местоимениями, в английском языке - артиклями (так называемые "стоп-слова"), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Основываясь на этой закономерности, можно предложить следующую методику.
Составление списка ключевых слов
Правильный набор ключевых слов имеет определяющее значение для оптимального поиска информации. К примеру, задав поисковой машине в качестве ключевого слова "МАРП", мы получим список документов, в которых встречается эта аббревиатура (Московское Агентство по Развитию Предпринимательства). Но если нас интересуют документы по более широкой теме, например: развитие предпринимательства, и мы сформируем простой запрос из этих двух слов, то поисковая машина выдаст нам список из сотен тысяч наименований, ориентироваться в котором будет весьма непросто.
Поэтому для составления оптимального набора ключевых слов используют процедуру, основанную на применении законов Зипфа, которая заключается в следующем: берут любой текст-источник, близкий к искомой теме, т.е. "образец", и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, Web-страница, любой другой документ. Анализ текста производится таким образом:
- Удаление из текста стоп-слов.
- Вычисление частоты вхождения каждого слова и составление списка, в котором слова расположены в порядке убывания их частоты.
- Выбор диапазона частот, лежащего в середине списка, и отбор из этого диапазона слов, наиболее полно соответствующих смыслу текста.
- Составление запроса к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором ИЛИ (OR). Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов (расположению их в порядке убывания частоты вхождения слов запроса в документ), применяемому в большинстве поисковых машин, на первых страницах списка практически все документы окажутся релевантными, причем документ-источник может находиться далеко от начала.
Более адекватной представляется структура тезауруса в виде так называемых семантических срезов, где для каждого основного термина отдельно строится таблица сопутствующих слов и слов шумовых (которые не должны встречаться в источнике), - некоторые поисковые машины (AltaVista) позволяют это использовать. Таким образом, вместо единой иерархической структуры терминов мы получаем пакет таблиц, которые могут расширяться и модифицироваться отдельно.
Отбор поисковых машин
Устанавливается последовательность использования поисковых машин в соответствии с убыванием ожидаемой эффективности поиска с применением каждой машины.
Всего известно около 180 поисковых серверов, различающихся по регионам охвата, принципам проведения поиска (а следовательно, по входному языку и характеру воспринимаемых запросов), объему индексной базы, скорости обновления информации, способности искать "нестандартную" информацию и тому подобное. Основными критериями выбора поисковых серверов являются объем индексной базы сервера и степень развитости самой поисковой машины, то есть уровень сложности воспринимаемых ею запросов.
Более подробно поисковые машины описаны в разделе курса "Сетевые средства поиска информации" .
Составление и выполнение запросов к поисковым машинам
Это наиболее сложный и трудоемкий этап, связанный с обработкой большого количества информации (в основном шумовой). На основе тезауруса формируются запросы к выбранным поисковым серверам, после чего возможно уточнение запроса с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска. Данные с ресурсов, признанных релевантными, собираются для последующего анализа.
Формирование запросов
Как формат, так и семантика запросов варьируются в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы составляются так, чтобы область поиска была максимально конкретизирована и сужена.
Предпочтение отдается использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится пробная реализация запросов - как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Языки запроса различных машин поиска в основном являются сочетанием следующих функций:
Операторы булевой алгебры AND, OR, NOT:
- AND (И) - осуществляется поиск документов, содержащих все термины, соединенные данным оператором;
- OR (ИЛИ) - искомый текст должен содержать хотя бы один из терминов, соединенных данным оператором;
- NOT (НЕ) - поиск документов, в тексте которых отсутствуют термины, следующие за данным оператором.
- Операторы расстояния - ограничивают порядок следования и расстояния между словами, например:
- NEAR - второй термин должен находиться на расстоянии от первого, не превышающем определенного числа слов;
- FOLLOWED BY - термины следуют в заданном порядке;
- ADJ - термины, соединенные оператором, являются смежными.
- Возможность усечения терминов - использование символа " * " вместо окончания термина позволяет включить в искомый список все слова, производные от его начальной части (шаблона).
- Учет морфологии языка - машина автоматически учитывает все формы данного термина, возможные в языке, на котором ведется поиск.
- Возможность поиска по словосочетанию, фразе.
- Ограничение поиска элементом документа (слова запроса должны находиться именно в заголовке, первом абзаце, ссылках и т.д.).
- Ограничения по дате опубликования документа.
- Ограничения на количество совпадений терминов.
- Возможность поиска графических изображений.
- Чувствительность к строчным и прописным буквам.
Результат запроса (список ссылок) обрабатывается в два этапа. На первом этапе производится отсечение очевидно нерелевантных источников, попавших в выборку в силу несовершенства поисковой машины или недостаточной "интеллектуальности" запроса. Параллельно проводится семантический анализ, имеющий целью уточнение тезауруса для модификации последующих запросов. Дальнейшая обработка производится путем последовательного обращения на каждый из найденных ресурсов и анализа находящейся там информации.
Анализ ресурсов и сбор информации
Первичный анализ ресурсов основывается на аннотациях - в случае их наличия, и в необходимых случаях - на ознакомлении с информационным наполнением ресурса. Информация с отобранных источников извлекается с использованием соответствующих конкретному источнику методов, что может потребовать значительных коммуникационных, вычислительных и дисковых ресурсов.
Кратко можно выделить следующие типы информационных Web-ресурсов:
- коммерческие сайты компаний;
- вторичные информационные сайты;
- источники аналитической информации;
- региональные информационные ресурсы.
В русскоязычной части Интернета в настоящее время доступен ряд ресурсов, предоставляющих вторичную информацию, как правило, в табулированной форме. Предоставление информации для публикации в подобных источниках является более дешевым вариантом для компаний, не имеющих собственного представительства в Интернете.
Проблемы, возникающие в процессе поиска
Одна из проблем является чисто методологической. Для проведения эффективного поиска мы заинтересованы в одновременном решении двух противоположных задач:
- увеличение охвата с целью извлечения максимального количества значимой информации;
- уменьшение охвата с целью минимизации шумовой информации.
Нетрудно видеть, что одновременно осуществить это довольно сложно, хотя зачастую все-таки возможно. Один из методов, если поисковая машина позволяет, - это введение явных ограничений (запрещенных слов). Другой состоит в правильном формировании запросов, в частности, в предпочтении нескольких конкретизированных запросов одному общему. К сожалению, весьма ограниченный входной язык большинства машин не оставляет особенного простора для творчества в этом направлении.
Другая проблема - многовариантность человеческого языка. Если в английском языке некоторые слова имеют множество различных значений, то русский отличается богатством морфологических вариаций слов, а для полноты поиска необходимо учитывать еще и синонимы.
Часто в области российского Интернета возникают чисто технические трудности из-за различных кодировок информации. Российские поисковые машины распознают кодировки пользователя и искомого сайта, но совместить их удается не всегда.
Еще одна особенность русскоязычной части сети - ее нестабильность. Постоянно изменяются адреса и структура сайтов, они появляются и исчезают, и поисковые машины не успевают обновлять свои базы индексированных данных, поэтому значительная часть списка документов, выданного вам машиной, может оказаться недоступной. Появление в сентябре 1997 г. системы Яndex-Web, обновляющей свои данные раз в неделю, обозначило качественный скачок вперед в решении этой проблемы.
baza-referat.ru
Методы поисковой оптимизации - реферат, курсовая работа, диплом, 2017
13
1. Назначение и классификация методов поисковой оптимизации
В связи со сложностью объектов проектирования критерии качества и ограничения задачи параметрической оптимизации (1.5), как правило, слишком сложны для применения классических методов поиска экстремума. Поэтому на практике предпочтение отдается методам поисковой оптимизации. Рассмотрим основные этапы любого метода поиска.
Исходными данными в методах поиска являются требуемая точность метода ?и начальная точка поиска Х 0.
Затем выбирается величина шага поиска h, и по некоторому правилу происходит получение новых точек Х k+1 по предыдущей точке Х k , при k = 0,1,2,… Получение новых точек продолжают до тех пор, пока не будет выполнено условие прекращения поиска. Последняя точка поиска считается решением задачи оптимизации. Все точки поиска составляют траекторию поиска.
Методы поиска могут отличаться друг от друга процедурой выбора величины шага h (шаг может быть одинаковым на всех итерациях метода или рассчитываться на каждой итерации), алгоритмом получения новой точки и условием прекращения поиска.
Для методов, использующих постоянную величину шага, h следует выбирать значительно меньше точности ??h ). Если при выбранной величине шага h не удается получить решение с требуемой точностью, то нужно уменьшить величину шага и продолжить поиск из последней точки имеющейся траектории.
В качестве условий прекращения поиска принято использовать следующие:
все соседние точки поиска хуже, чем предыдущая;
Ф(Xk+1 ) - Ф(X k) , то есть значения целевой функции Ф(Х) в соседних точках (новой и предыдущей) отличаются друг от друга на величину не больше, чем требуемая точность ;
то есть все частные производные в новой точке поиска практически равны 0 или отличаются от 0 на величину, не превышающую заданной точности .
Алгоритм получения новой точки поиска Хk+1 по предыдущей точке Хk свой для каждого из методов поиска, но всякая новая точка поиска должна быть не хуже предыдущей: если задача оптимизации является задачей поиска минимума, то Ф(Хk+1) Ф(Хk).
Методы поисковой оптимизации принято классифицировать по порядку производной целевой функции, используемой для получения новых точек. Так, в методах поиска нулевого порядка не требуется вычисления производных, а достаточно самой функции Ф(Х). Методы поиска первого порядка используют первые частные производные, а методы второго порядка используют матрицу вторых производных (матрицу Гессе).
Чем выше порядок производных, тем более обоснованным является выбор новой точки поиска и тем меньше число итераций метода. Но при всём этом возрастает трудоемкость каждой итерации из-за необходимости численного расчета производных.
Эффективность поискового метода определяют по числу итераций и по количеству вычислений целевой функции Ф(Х) на каждой итерации метода (N). Рассмотрим наиболее распространенные методы поиска, расположив их в порядке уменьшения числа итераций.
Для методов поиска нулевого порядка справедливо следующее: в методе случайного поиска нельзя заранее предсказать количество вычислений Ф(Х) на одной итерации N, а в методе покоординатного спуска N 2n, где n- количество управляемых параметров X = ( x1, x2.,…,xn).
Для методов поиска первого порядка справедливы следующие оценки: в градиентном методе с постоянным шагом N=2n; в градиентном методе с дроблением шага N = 2n + n1, где n1 - число вычислений Ф(Х), необходимых для проверки условия дробления шага; в методе наискорейшего спуска N=2n+n2, где n2 - число вычислений Ф(Х), необходимых для расчета оптимальной величины шага; а в методе Давидона - Флетчера - Пауэлла (ДФП) N = 2 n + n3, где n3 - число вычислений Ф(Х), необходимых для расчета матрицы, приближающей матрицу Гессе ( для величин n1, n2, n3 справедливо соотношение n1< n2<< n3 ).
И, наконец, в методе второго порядка - методе Ньютона N = 3n2. При получении данных оценок предполагается приближенное вычисление производных по формулам конечных разностей / 6 /:
13
13
то есть для вычисления производной первого порядка нужно знать два значения целевой функции Ф(Х) в соседних точках, а для второй производной - значения функции в трех точках.
На практике широкое применение нашли метод наискорейшего спуска и метод ДФП, как методы с оптимальным соотношением числа итераций и их трудоемкости.
2. Методы поиска нулевого порядка
2.1. Метод случайного поиска
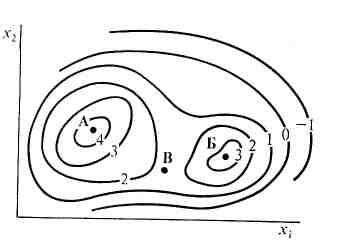
В методе случайного поиска исходными данными являются требуемая точность метода , начальная точка поиска Х0= ( x10, x2. 0,…,xn0) и величина шага поиска h. Поиск новых точек производится в случайном направлении, на котором и откладывается заданный шаг h (рис. 2.1), таким образом получают пробную точку Х^ и проверяют, является ли пробная точка лучшей, чем предыдущая точка поиска. Для задачи поиска минимума это означает, что
Ф(Х^) Ф(Хk), k = 0,1,2…(2.4)
Если условие (2.4) выполнено, то пробную точку включают в траекторию поискаХ k+1 = Х^. В противном случае, пробную точку исключают из рассмотрения и производят выбор нового случайного направления из точки Х k, k = 0,1,2,.
Несмотря на простоту данного метода, его главным недостатком является тот факт, что заранее неизвестно, сколько случайных направлений потребуется для получения новой точки траектории поиска Хk+1, что делает затраты на проведение одной итерации слишком большими. Кроме того, поскольку при выборе направления поиска не используется информация о целевой функции Ф(Х), число итераций в методе случайного поиска очень велико.
В связи с этим метод случайного поиска используется для исследования малоизученных объектов проектирования и для выхода из зоны притяжения локального минимума при поиске глобального экстремума целевой функции /6/.
13
2.2. Метод покоординатного спуска
В отличие от метода случайного поиска, в методе покоординатного спуска в качестве возможных направлений поиска выбирают направления, параллельные осям координат, причем движение возможно как в сторону увеличения, так и уменьшения значения координаты.
Исходными данными в методе покоординатного спуска являются величина шага h и начальная точка поиска Х0= ( x10, x2. 0,…,xn0). Движение начинаем из точки Х0 вдоль оси x1 в сторону увеличения координаты. Получим пробную точку Х^ с координатами ( x10+h, x20,…,xn0), при k = 0.
Сравним значение функции Ф(Х^) с значением функции в предыдущей точке поиска Хk. Если Ф(Х^) Ф(Хk) (мы предполагаем, что требуется решить задачу минимизации целевой функции Ф(Х)), то пробную точку включают в траекторию поиска(Х k+1 = Х^).
В противном случае, пробную точку исключаем из рассмотрения и получаем новую пробную точку, двигаясь вдоль оси x1 в сторону уменьшения координаты. Получим пробную точку Х^ = ( x1k-h, x2.k,…,xnk). Проверяем, если Ф(Х^) > Ф(Хk), то продолжаем движение вдоль оси x2 в сторону увеличения координаты. Получим пробную точку Х^= ( x1k, x2.k+h,…,xnk) и т.д. При построении траектории поиска повторное движение по точкам, вошедшим в траекторию поиска, запрещено. Получение новых точек в методе покоординатного спуска продолжается до тех пор, пока не будет получена точка Хk, для которой все соседние 2n пробных точек (по всем направлениям x1, x2.,…,xn в сторону увеличения и уменьшения значения каждой координаты) будут хуже, то есть Ф(Х^) > Ф(Хk). Тогда поиск прекращается и в качестве точки минимума выбирается последняя точка траектории поиска Х* = Хk.
13
3. Методы поиска первого порядка
3.1. Структура градиентного метода поиска
В методах поиска первого порядка в качестве направления поиска максимума целевой функции Ф(Х) выбирается вектор градиент целевой функции grad (Ф(Хk)), для поиска минимума - вектор антиградиент -grad (Ф(Хk)). При этом используется свойство вектора градиента указывать направление наискорейшего изменения функции:
13
Для изучения методов поиска первого порядка важно также следующее свойство: вектор градиент grad (Ф(Хk)) направлен по нормали к линии уровня функции Ф(Х) в точке Хk(см. рис. 2.4). Линии уровня - это кривые, на которых функция принимает постоянное значение (Ф(Х) = соnst).
В данной главе мы рассмотрим 5 модификаций градиентного метода:
градиентный метод с постоянным шагом,
градиентный метод с дроблением шага,
метод наискорейшего спуска,
метод Давидона-Флетчера-Пауэлла,
двухуровневый адаптивный метод.
3.2. Градиентный метод с постоянным шагом
В градиентном методе с постоянным шагом исходными данными являются требуемая точность , начальная точка поиска Х0 и шаг поиска h.
Получение новых точек производится по формуле:
13
Формула (2.7) применяется, если для функции Ф(Х) необходимо найти минимум. Если же задача параметрической оптимизации ставится как задача поиска максимума, то для получения новых точек в градиентном методе с постоянным шагом используется формула:
13
Каждая из формул (2.6), (2.7) является векторным соотношением, включающим n уравнений. Например, с учетом Хk+1= ( x1k+1, x2.k+1,…,xnk+1), Хk= ( x1k, x2.k,…,xnk) формула (2.6) примет вид:
13
или в скалярном виде
13
В общем виде (2.9) можно записать:
13
В качестве условия прекращения поиска во всех градиентных методах используется, как правило, комбинация двух условий: Ф(Xk+1 ) - Ф(X k) или
13
13
В градиентном методе можно несколько сократить число итераций, если научиться избегать ситуаций, когда несколько шагов поиска выполняются в одном и том же направлении.
3.3. Градиентный метод с дроблением шага
В градиентном методе с дроблением шага процедура подбора величины шага на каждой итерации реализуется следующим образом.
Исходными данными являются требуемая точность , начальная точка поиска Х0 и начальная величина шага поиска h (обычно h = 1). Получение новых точек производится по формуле:
13
где hk- величина шага на k-ой итерации поиска, при hkдолжно выполняться условие:
13
Если величина hk такова, что неравенство (2.13) не выполнено, то производится дробление шага до тех пор, пока данное условие не будет выполнено. Дробление шага выполняется по формуле hk = hk , где 0 1.Такой подход позволяет сократить число итераций, но затраты на проведение одной итерации при всём этом несколько возрастают.
3.4. Метод наискорейшего спуска
В методе наискорейшего спуска на каждой итерации градиентного метода выбирается оптимальный шаг в направлении градиента.
Исходными данными являются требуемая точность , начальная точка поиска Х0.
Получение новых точек производится по формуле:
13
то есть выбор шага производится по результатам одномерной оптимизации по параметру h.
Основная идея метода наискорейшего спуска заключается в том, что на каждой итерации метода выбирается максимально возможная величина шага в направлении наискорейшего убывания целевой функции, то есть в направлении вектора-антиградиента функции Ф(Х) в точке Хk( рис. 2. 4).
13
При выборе оптимальной величины шага необходимо из множества ХМ = { Х Х = Хk- hgrad Ф(Хk), h[0,) } точек, лежащих на векторе градиенте функции Ф(Х), построенном в точке Хk, выбрать ту, где функция Ф(h) = Ф(Хk - h grad Ф(Хk)) принимает минимальное значение.
На практике целевые функции являются гораздо более сложными, линии уровня также имеют сложную конфигурацию, но в любом случае справедливо следующее: из всех градиентных методов в методе наискорейшего спуска наименьшее число итераций, но некоторую проблему представляет поиск оптимального шага численными методами, так как в реальных задачах, возникающих при проектировании РЭС, применение классических методов нахождения экстремума практически невозможно.
13
4. Методы поиска второго порядка
Несмотря на простоту реализации, метод наискорейшего спуска не рекомендуется в качестве “серьезной” оптимизационной процедуры для решения задачи безусловной оптимизации функции многих переменных, так как для практического применения он работает слишком медленно. Причиной этого является тот факт, что свойство наискорейшего спуска является локальным свойством, поэтому необходимо частое изменение направления поиска, что может привести к неэффективной вычислительной процедуре. Более точный и эффективный метод решения задачи параметрической оптимизации (1.5) можно получить, используя вторые производные целевой функции (методы второго порядка). Они базируются на аппроксимации (то есть приближенной замене) функции Ф(Х) функцией (Х),
13
где G(X0)- матрица Гессе (гессиан, матрица вторых производных), вычисленная в точке Х0:
Формула (2.17) представляет собой первые три члена разложения функции Ф(Х) в ряд Тейлора в окрестности точки Х0, поэтому при аппроксимации функции Ф(Х) функцией (Х) возникает ошибка не более чем (Х-Х0)3. С учетом (2.17) в методе Ньютона исходными данными являются требуемая точность и начальная точка поиска Х0 , а получение новых точек производится по формуле:
13
где G-1(Хk) - матрица, обратная к матрице Гессе, вычисленная в точке поиска Хk( G(Хk) G-1(Хk) = I, где I - единичная матрица).
Библиографический список
1. Кофанов Ю.Н. Теоретические основы конструирования, технологии и надежности радиоэлектронных средств. - М.: Радио и связь, 1991. - 360 с.
2. Норенков И.П., Маничев В.Б. Основы теории и проектирования САПР.- М.: Высш. шк., 1990.- 335 с.
3. Самойленко Н.Э. Основы проектирования РЭС. - Воронеж: ВГТУ, 1998. - 60 с.
4. Фролов В.Н., Львович Я.Е. Теоретические основы конструирования, технологии и надежности РЭА. - М.: Радио и связь, 1988. - 265 с.
5. Батищев Д.И. Поисковые методы оптимального проектирования. - М.: Сов. Радио, 1975. - 216 с.
6. Банди Б. Методы оптимизации. Вводный курс. - М.: Радио и связь, 1988.- 128 с.
7. Батищев Д.И., Львович Я.Е., Фролов В.Н. Оптимизация в САПР. Воронеж: Изд-во Воронеж. гос. ун-та, 1997. 416 с.
8. Автоматизация проектирования РЭС: Учеб. пособие для вузов О.В. Алексеев, А.А. Головков, И.Ю. Пивоваров и др.; Под. ред О.В. Алексеева. М: Высш. шк., 2000. 479 с.
referatwork.ru