Тема: «Пертинентность информационного поиска». Пертинентность и релевантность
Подробно о релевантности и немного о пертинентности |
Чтобы вы прочитали эту статью с должной степень внимания, скажу так:
Содержание статьи
Сделаете статью релевантной – попадете в ТОП!
Но для этого сначала надо узнать, что это такое?
Релевантность – один из таких терминов, которые, казалось бы, очень просты, но на самом деле довольно сложны для понимания и для практической работы.
Если вы сделаете запрос – что такое релевантность – то увидите массу различных сайтов SEO- фирм, где разьсняется это понятие. Суть их объяснений сводится к следующему: это – формальное соответствие запроса содержанию страницы, которое определяется по плотности ключевых слов. Разместите нужное количество ключевых слов на странице (они пишут о 4-5% плотности) и ваша статья будет релевантной по тому или иному запросу.
Но ведь это – прошлый век!
Такое обьяснение было верным на заре развития интернета, когда поисковики пребывали в младенческом состоянии и, действительно, оперировали только плотностью ключевых слов. Но с той поры утекло много воды!
Я хоть и не оптимизатор, но все же давайте попробуем вместе с вами самостоятельно разобраться в этом вопросе.
Под релевантностью в Интернете понимается смысловое соответствие запроса и полученного результата.
Обратите внимание: здесь ключевое слово – «смысловое». Другими словами, ответы, которые поисковики предлагают пользователю, должны соответствовать смыслу его запроса.
Приведу такой пример. Пользователь пишет простой запрос – «кино» (простой, понятно, для него самого). Что поисковик должен показать в ответ? – Перечень кинофильмов в кинотеатрах города? Или пользователь хочет скачать какой-то кинофильм? А, может, он просто решил посмотреть что-нибудь он-лайн? Или его интересует самостоятельное создание фильма? А может, ему нужен реферат про кино? Или перечень поговорок и крылатых фраз на эту тему?
Перечень подобных вопросов можно продолжать и дальше, но поисковой системе надо выбрать те документы, которые ЭТОГО КОНКРЕТНОГО пользователя действительно заинтересуют.
Теперь вам становится понятным, что одними ключевыми словами проблему релевантности поисковик решить не в состоянии – в каждом из найденных документов будет слово «кино» (даже в этой статье), но все они (документы) имеют разную тематическую направленность.
Поэтому поисковые системы прибегают к очень сложным алгоритмам для определения релевантности. Конечно, такие алгоритмы – самая большая тайна поисковиков, ибо чем релевантнее поиск какой-то поисковой машины, тем чаще к ней обращаются пользователи. Тем более авторитетной становится эта поисковая машина и тем выше будут доходы ее владельцев (за счет рекламы).
Итак, на самом первом этапе происходит отбор документов, соответствующих ТЕКСТУ запроса (например, «кино»), на основании ключевых слов. Далее, поисковик должен вычислить, что же имеется в виду в этом запросе, каков его смысл. Здесь используются дополнительные факторы, которые можно разделить на внутренние и внешние.
Внутренние факторы
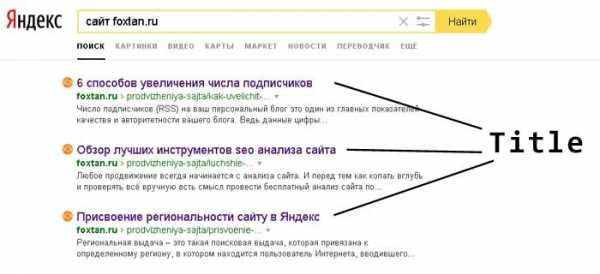
- Размещение ключевых слов на странице, прежде всего, в заголовке (title) и описании (description).
- Наличие словоформ ключевого слова и синонимов (например, кино – кинофильм — картина).
- Общий обьем информации на странице,
- Наличие страниц со смежными темами (описание автомобиля и гарантийные/ремонтные мастерские)
- Перелинковка с другими страницами на сайте,
- Свежесть информации (как часто обновляется контент на странице).
Есть и другие факторы, но эти – самые, пожалуй, главные. Причем, обратите на это внимание, все эти факторы полностью находятся во власти вебмастера и ими надо пользоваться.
Внешние факторы
- Ссылочная популярность статьи и сайта в целом. Чем чаще ссылаются на страницу, тем лучше, причем особую ценность имеют ссылки со сходных по тематике сайтов. Не случайно Яндекс ввел понятие тематического индекса цитирования (тИЦ). Но самое главное – чтобы по этим ссылкам переходили люди, значит, ссылка (и ваш сайт) для них представляет определенный интерес. Ведь вебмастер может разместить ссылки на любые сайты, но уж если он выбрал ваш ресурс, то, значит, он считает его наиболее подходящим и рекомендует для посещения.
- Количество посещений страницы пользователями со страниц поиска, с других сайтов, из социальных сетей и их поведение там (о последнем – чуть ниже).
- Возраст страницы и сайта в целом. Причем, старые страницы должны обновляться (помните про свежесть информации).
Необходимо заметить, что вебмастера стали находить пути для воздействия на внешние факторы, что неудивительно: будет спрос — будет и предложение. Конечно, размещение статей и отдельных ссылок на платной основе на сторонних ресурсах существует довольно давно, но относительно недавно появились новые сервисы, которые (тоже на платной основе) имитируют деятельность реального посетителя на сайте.
Здесь я не имею ввиду примитивные сервисы типа юзератора и его аналогов, появились новые сервисы, где вы можете поручить исполнителям совершить то или иное действие, например, написать комментарий, сделать ссылку в соц.сетях и т.д. А такие действия это уже не просто посещение страницы пользователем, а свидетельство того, что его эта страница чем-то заинтересовала, что она релевантна (не запросу, нет, — его просто не было) его интересам. Я писал уже о такой бирже – liked.ru, рекомендую ею воспользоваться, пока поисковики не нашли противоядие.
Но это серый метод продвижения, рано или поздно поисковики прихлопнут такую возможность для нас. А если вы хотите, чтобы страницы вашего сайта всегда находились в ТОПе (а, значит, были релевантными), то нам усвоить еще один термин – пертинентность.
Что такое пертинентность?
Пертинентность – это как раз то, что не оставляет камня на камне от рассуждений SEO- фирм, о чем и писал в начале статьи. Этот термин звучит устрашающе, но на деле он означает простую вещь:
Пертинентность – это соответствие выдаваемой информации поисковой системой ожиданиям пользователя.
Понятно, что это чисто субьективный фактор. В приведенном мною примере о запросе «кино» могут быть различные ответы, поскольку поисковик пытается определить — что же вам надо. И, скажем, покажет расписание сеансов в кинотеатре. Релевантный ли этот ответ? Да! Соответствует ли он вашему запросу (вы хотели посмотреть фильм онлайн)? Нет!
На мой взгляд, пертинентность – это составная часть релевантности, она показывает поисковику, что он показал что-то не то и надо уточнить поиск. Хотя иногда эти понятия разделяют и чуть ли не противопоставляют. Но они сходятся в одной точке – в поисковой выдаче, которая обязана учитывать и обьективные, и субьективные факторы, иначе в глазах человека она – нерелевантна.
Вот здесь и появляется знаменитый показатель отказов. Если человек пробыл на страничке всего несколько секунд и опять обратился к результатам выдачи, значит, эта страница его совсем не заинтересовала, она – не пертинентна. Конечно, причины для отказов могут быть разные, но сейчас не об этом речь.
Давайте подумаем, как ведет себя человек на пертинентной странице? Он не спеша начинает читать – прокручивает страницу вниз, водит по строчкам курсором, возвращается к особо интересным местам или к началу статьи, чтобы начать чтение сначала и т.д. Все эти действия легко отслеживаются поисковиками.
Как человек ведет себя на особо понравившихся страницах? Кроме того, что я сказал выше, он может написать комментарий или задать вопрос автору через форму связи, скопировать URL страницы, занести ее в закладки браузера, расшарить в соц.сетях (т.е. сообщить о ней друзьям) и т.д. И эти действия легко отслеживаются «старшими братьями».
И все эти действия – прямой сигнал поисковикам – это страница релевантна и пертинентна. Им остается только зафиксировать этот сигнал и учесть его в результатах выдачи для других людей: смотрите, вот эта статья понравилась людям, может, и вам понравится?
Вот поэтому я и говорю, что пертинентность – это составная часть релевантности, это инструмент для ее уточнения. И именно поэтому, представители любой поисковой системы постоянно говорят: делайте контент для людей, чтобы он им был нужен и полезен.
В Интернете этот термин не слишком широко распространен, он появился тогда, когда обострилась конкурентная борьба на поисковом рынке, когда поисковики стали вынуждены изучать поведение пользователей. Именно поэтому и выросло значение так называемых поведенческих факторов, поскольку именно они показывают насколько пертинентна (а значит, и релевантна) та или иная страница.
Теперь, я думаю, вам понятно, что на поведенческие факторы надо обращать самое пристальное внимание.
Как вы думаете: эта моя статья релевантна и пертинентна заголовку (т.е. вашему запросу) или нет?
P.S. Если вы не желаете морочить себе голову всякими релевантностями, пертинентностями и, вообще, продвижением сайта в поисковых системах, обратитесь к профессионалам, таким как компания Web-Promo (адрес сайта — webpromo). Они проведут вам комплексное продвижение сайта и у вас все будет в полном порядке
а судьи кто? #технологии #СЭД #ECMJ
«Отсортировано по релевантности» говорит мне ежедневно Яндекс, давая тем самым понять, что существует некий великий и ужасный критерий, который позволяет поисковику показать мне, что он может находить то, что, по его мнению, наилучшим образом удовлетворит моим потребностям.
1. Релевантность и пертинентность
Вообще говоря, релевантность – это степень соответствия результатов поиска введённому поисковому запросу, которая вычисляется по каким-то хитрым формулам, учитывающим частоту употребления слова в просматриваемом тексте, а если слов в поисковом запросе было несколько, то при подсчёте релевантности учитывается ещё и близость искомых слов по отношению друг к другу. Есть подозрение, что при поиске в глобальной сети при вычислении релевантности также учитывается и число посещения сайтов (например, ссылки на Wikipedia всегда находишь первыми или вторыми в списке), и ещё ряд других таинственных критериев. В целом, релевантность – довольно размытое понятие, которое не даёт вообще никакого понятия о том, найду ли я на сайте (в документе) то, что я действительно хотела найти, т.е. является ли результат запроса пертинентным. Пертинентность определяет степень семантического соответствия результатов поиска запросу. Например, я искала рецепт приготовления какого-нибудь блюда из лука и, будучи неопытным пользователем, набрала в строке поиска только слово «лук». С точки зрения системы документ с классификацией видов стрелкового оружия будет абсолютно релевантным запросу, и это верно, но такой результат для пользователя пертинентным являться не будет.
Вынуждена согласиться с тем, что поисковый движок попросту не может самостоятельно оценить пертинентность запроса, поскольку не умеет, как и большинство людей, читать мысли, а ещё его очень легко обмануть. Что же мы имеем в итоге? Поисковики подменяют пертинентность релевантностью, пытаясь таким вот формализованным образом подменить неформализуемое понятие.
2. Отображение релевантности
Поисковые движки разнообразных систем (будь то специализированные сервисы в интернете, или модули прикладных программ) на подмене понятий не останавливаются. Некоторые из них предлагают пользователю посмотреть ещё и числовое значение релевантности, например, в процентах: от 0 до 100, или шкалу релевантности запроса (навроде: у кого релевантнее, у того и шкала длиннее), а иногда и вовсе и то, и другое.
Скажем, ищу я слово «собака», получаю списки сущностей (документов или сайтов), возле ссылки на каждый из которых указано некое числовое значение, скажем, возле ссылки на книгу о породах собак будет стоять значение, близкое к 90%, потому что искомое слово, по всей видимости, очень часто в указанной книжке встречается. Хорошо, я согласна, скорее всего такой запрос будет пертинентным. Однако, что если я создам документ, в котором 500 раз напишу слово «собака» подряд и больше ничего? Удивительно, но такой документ будет самым наирелевантнейшим по запросу «собака». Если алгоритм позволит, то релевантность запроса будет близка к тысяче процентов. О пертинентности промолчу. А ещё я видела результаты поиска, у которых релевантность была нулевой, но в список результатов поиска их всё же пустили. Наверное, из жалости.
Нужны ли мне были эти цифры, пригодились ли они мне хоть раз в жизни? Нет. Сама по себе цифра не даёт вообще никакого понятия о том, что было найдено по запросу. Ну и что, что у одного документа 90%, а у другого 93, мне вообще вот тот был нужен, у которого почему-то 27% указано. Нужна ли мне шкала? Тоже сомнительно. Шкала нужна, чтобы сравнить, опять же, что? Количественные оценки релевантности! Хм… Снова не то. Цифры релевантности нужны только при отладке алгоритма поиска, пользователю их видеть не нужно. Достаточно, на мой взгляд, отсортировать.
3. «А судьи кто?»
Релевантность – хороший способ формализовать оценку похожести документа, найденного поисковым движком, исходному запросу пользователя. Однако, релевантность результата в данный момент даёт большую степень пертинентности только в том случае, если запрос был грамотно (читай «по-машинному») сформулирован (иногда с использованием спецсимволов поискового движка). Пользователь, имеющий представление о том, что система работает в рамках алгоритма, подменяет обычный человеческий язык машинным, но ведь как сказал американский писатель Спайдер Робинсон: «Я как писатель-фантаст уверен, что этот чёртов робот должен говорить на человеческом языке, а не наоборот».
В общем случае пользователь хочет задать запрос на естественном языке (без использования логических операторов и проч.) и получить пертинентный результат. Как мы уже поняли, высокая степень релевантности не всегда подразумевает высокую степень пертинентности. Что же может помочь системе сформировать наиболее пертинентный результат?
Возможно, это поможет сделать история запросов конкретного пользователя. Так, например, для сервера ECM-системы ничего сложного не составляет вести историю запросов и полученных результатов в работе одного и того же пользователя. Этого пользователя при общем подсчёте статистики можно объединить в группу с другими пользователями (например, выполняющими сходные функции делопроизводителя или руководителя).
Таким образом, сильно упрощённый алгоритм работы поискового движка для получения пертинентных результатов может быть следующим:
- Пользователь вводит запрос и получает список результатов, релевантных этому запросу.
- Пользователь просматривает список релевантных результатов и отмечает те из них, что оказались пертинентны запросу. В этот момент устанавливается связка по пертинентности между запросом и отдельным его результатом.
- При последующем вводе того же самого запроса отмеченные значком пертинентности релевантные результаты обладают приоритетом перед результатами, не отмеченными таким значком.
Возникает вопрос: как отмечать результаты, пертинентные запросу? У современных систем есть все возможности для этого: подавляющее большинство поисковиков в интернете при демонстрации результатов поиска всегда предоставляют пользователю фрагмент текста, в котором фигурируют искомые слова (а Googleдаже организует красивый предпросмотр страничек). Так, при некоторых допущениях, можно сказать, что если пользователь перешёл по ссылке, то он счёл результат пертинентным (отмечать галочкой, а ещё хуже заставлять пользователя проставлять процент пертинентности – это пример дьявольского моветона). В конце концов, ведь как-то же организована контекстная реклама и прочие фишки. Запомнить пользователя можно не только по ip, но ещё и привязав его к своему поисковику посредством почтового ящика на том же сервере.
Для ECM-систем всё ещё проще: пользователи в условиях ограниченности базы данных и более медленного её роста (по сравнению с интернетом) обычно знают, что они ищут (документ с известным названием, известного автора, недавно открытый и проч.), из чего следует, что сам факт открытия документа, найденного среди прочих по запросу, практически подтверждает пертинетность результата запросу.
Набрав, таким образом, некую статистику, система сможет с повышенной вероятностью давать пользователю не только математически верный результат (релевантный), но также и семантически соответствующий его запросу (пертинентный).
А судьи – мы.
ecm-journal.ru
Пертинентность поиска - новый тренд в конкуренции поисковых систем
Руководитель проекта TextStyle
«Я мыслю, значит, я существую!»
Рене Декарт
Это статья для опытных SEO-шников и интернет-маркетологов. Тем, кто не может выговорить слово «пертинентность» (от англ.: «pertinent» — уместность, принадлежность), следует научиться это делать. Идея познакомить аудиторию SEOnews с более высоким понятием, чем релевантность пришла ко мне после того, как я побывал на защите кандидатской у моего коллеги, известного блогера Алексея Терехова. Хотя он не из Москвы, но для защиты приехал на суд диссертационной комиссии моего Института Печати (там, где я делаю работу по исследованиям пользовательского трафика). Тема у Алексея была «Разработка методов и инструментальных средств повышения пертинентности поиска в современных информационных средах». В материалах SEOnews я также не нашел упоминания про П.
Что же такое пертинентность и чем она отличается от релевантности?
Существует множество определений релевантности. Например, ГОСТ 7.73-96 гласит: «релевантный: соответствие полученной информации информационному запросу».
Таким образом, релевантность определяется исключительно алгоритмами поиска конкретной поисковой системы.
В том же ГОСТе говорится: «пертинентность; пертинентный: соответствие полученной информации информационной потребности», то есть пертинентность определяет степень соответствия между ожиданиями пользователя и результатами поиска.
По Яндекса велению по МОЕМУ хотению...
Начнем с того, что сначала пользователю начинает чего-то хотеться: если брать коммерческие потребности, то, как сказал Владимир Долгов (руководитель «Гугл Россия»): «Пользователь эгоистичен: ему подавай все самое лучшее по дешевой цене и, желательно, за углом».
Поскольку потребности человека неограниченны, то, в зависимости от своей лени (двигателя прогресса, кстати), пользователь пытается ДУМАТЬ, что бы такое «СПРОСИТЬ», чтобы удовлетворить свои материальные и нематериальные потребности. Все ли пользователи умеют эффективно общаться с машиной? Очевидно, что когда процент пользователей Интернет достигает 50% от взрослого населения (а в развитых странах еще выше), то среди этой массы очень малая доля программистов или IT-шников, которые умеют говорить с компьютером на его «языке». И распространенный на Западе (и у нас) глагол: «To google» не просто говорит «иди поищи», а именно «воспользуйся новым навыком интернет поиска»!
Human Computer Interaction (HCI)
Избушка-избушка, повернись к лесу передом, а к Ивану задом, и, немного наклонись!
Из одной современной сказки
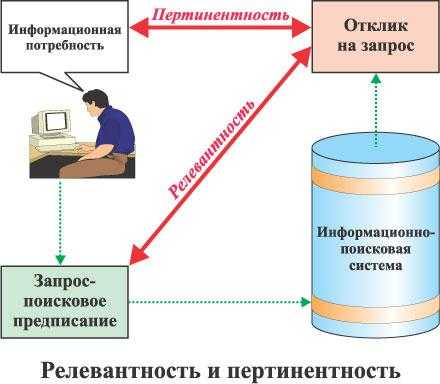
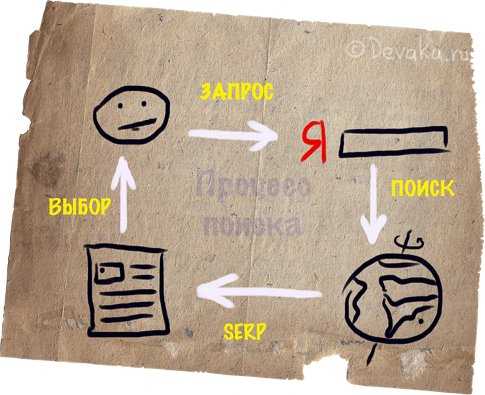
Не все могут представить, насколько общение человека с вычислительной машиной было трудным. Вот как рисовали схему человеко-машинного взаимодействия 30 лет назад:
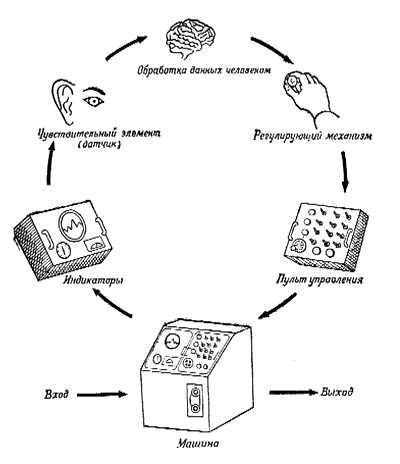
С тех пор схема практически не изменилась, только теперь не пользователь учится «понимать» машину, а машина пользователя. В эпоху конкуренции чья «машинка» лучше это будет делать, ту пользователь и «купит» (сравните разницу в привлекательности устройств с сенсорным управлением и кнопочным). Также и в веб-поиске: простой пользователь, которому поисковая машина не смогла подсказать «где купить слона даром за амбаром», считает эту поисковую систему «тупой».
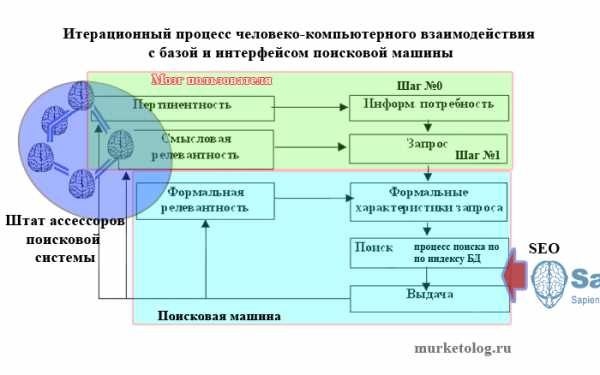
На этой, мною доработанной, замечательной схеме нарисованы все шаги (и внешние влияния) на человеко-машинное взаимодействие процесса интернет поиска.
Оптимизаторы и асессоры поисковых систем
А судьи кто?
Кто-то из великих.
Добившись релевантности (не у всех, к сожалению это получилось) поисковые системы поняли, что пора ступить на ступеньку выше: заняться удовлетворением информационной потребности огромной массы (неопытных) пользователей, которые не то, что не знают что ищут, а не знают, КАК спросить, так, чтобы удовлетворить свою потребность.
Вообще говоря, релевантность может сильно отличаться от пертинентности, однако данные понятия постоянно путают при толковании до того, что понятие П. так и не прижилось (то есть осталось жить только в узкой научной среде, а также среде разработчиков поисковых систем).
Очевидно, что прочесть мысли и понять, что же ищет пользователь, который вбивает общий запрос, например «девочки» поисковая система не может, поэтому она старается сразу пользователя перевести на выдачу по уточняющим запросам. Именно поэтому, по словам Андрея Себранта, сейчас в Яндексе менее 10% запросов составляют однословные запросы.
Создать у пользователя ощущение, что поиск ему «по нраву» и призваны асессоры (тоже для многих, новое слово, с которым нужно свыкаться). Помните у Гоголя «коллежский асессор»: название чина происходило от должности асессора (заседателя) в петровских коллегиях, кроме коллегий асессоры были в Сенате, Синоде, надворных судах и губернских судах, а также губернских правлениях. Кстати, Платон Щукин (собирательный образ работников техподдержки Яндекса: взято, очевидно, из известной поговорки «На то и щука, чтобы плотва не дремала»).
Чем же пертинентность может быть полезна оптимизатору? Для более глубокого понимания задач поисковых систем! Так же, как и осознание того, что юзабилити сайта влияет на выдачу, в случае, если SEO-шник видит нерелевантную выдачу, и решает, что «яндекс совсем сдурел», то на самом деле он сделал выдачу ПЕРТИНЕНТНОЙ! Нужны примеры? Пожалуйста:
Информационная потребность пользователя: «послушать Билана, что-нибудь, что недавно крутили по радио»
Поисковый запрос: «дима билан скачать» (пользователь, исходя из своего пользовательского опыта — User Experience ведь привык ранее скачивать музыку, ведь ему было сложно послушать ее в онлайн, только немногочисленные ролики на YouTube).
Что же выдает ему Яндекс?
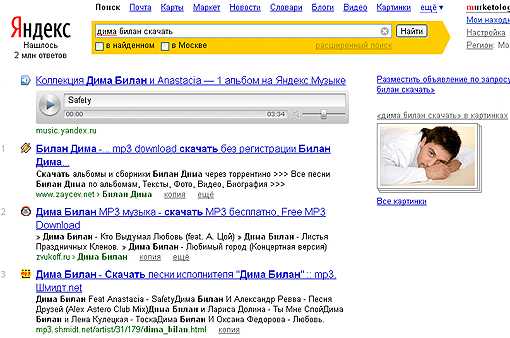
Релевантен ли нулевой результат? Не совсем! Ведь там нельзя скачать музыку. Удовлетворяет ли он информационную потребность пользователя «послушать здесь и сейчас Диму Билана»? Да!
Это и есть пертинентность поиска.
www.seonews.ru
О «релевантности» и «пертинентности» стр. 3
О «релевантности» и «пертинентности»
Существует множество определений релевантности. Например, ГОСТ 7.73-96 гласит: «релевантный: соответствие полученной информации информационному запросу». Таким образом, релевантность определяется исключительно алгоритмами поиска конкретной поисковой системы. В том же ГОСТе говорится, что «пертинентность; пертинентный: соответствие полученной информации информационной потребности», то есть пертинентность определяет степень соответствия между ожиданиями пользователя и результатами поиска. Вообще говоря, релевантность может сильно отличаться от пертинентности, однако данные понятия постоянно путают при толковании.
Например, в русской версии энциклопедии Wikipedia утверждается: «Релевантность (от английского relevant — уместный, относящийся к делу) применительно к результатам работы поисковой системы — степень соответствия искомого и найденного, уместность результата... Основным методом ранжирования является TF*IDF — метод ранжирования, который используется в большинстве поисковых систем... Его смысл сводится к тому, что чем больше локальная частота термина в документе (TF) и больше «редкость» (т.е. обратная встречаемость в документах) термина в коллекции (IDF), тем выше вес данного документа по отношению к термину — то есть документ будет выдаваться раньше в результатах поиска по данному термину». Если следовать определениям ГОСТа, то в первом из приведенных предложений речь идет о пертинентности, а далее обсуждается способ расчета ранга, т.е. один из механизмов определения релевантности.
Во времена Сэлтона* информационно-поисковых систем Internet еще не было, и предложенные им алгоритмы расчета весов терминов, индексирования документов и ранжирования результатов поиска предназначались для информационно-поисковых систем, работающих только с научно-технической информацией. Существенная особенность данной предметной области состояла в уникальности каждого документа. По этой причине было интуитивно понятно, что в идеальном случае при поиске конкретного документа релевантность и пертинентность должны совпадать.
Однако из-за субъективности пертинентности добиться точного совпадения нельзя: любая поисковая система настраивается на информационные нужды усредненного, а не конкретного пользователя. Для удовлетворения нужд конкретного пользователя и были придуманы разные способы коррекции результатов поиска по релевантности. Фактически, учет цитируемости документа в других документах является одним из них. Google PR (Page Rank) и ИЦ «Яндекса» — это методы достижения релевантности, основанные на цитируемости. Задолго до начала использования механизма цитируемости в Internet существовала база данных цитируемости научно-технических материалов, известная как «Индекс цитируемости Гарфилда». К слову, 15 июля исполнилось 50 лет с момента опубликования основополагающего труда Евгения Гарфилда Citation indexes for Science: A New Dimension in Documentation through Association of Ideas. Первый печатный индекс цитирования был выпущен в 1964 году, а два года спустя стал доступен на магнитных лентах.
Индекс Гарфилда использовали для неформальной оценки качества работы научных кадров. Естественно, как только цитируемость стала влиять на финансирование научных работ и зарплату ученых, у оцениваемых возникло желание «поправлять» свои показатели за счет влияния на этот индекс. Появились самоцитирование, перекрестное цитирование и ряд других способов повышения рейтинга. Однако все эти способы неминуемо приводили к ухудшению как релевантности поиска, так и пертинентности. Поначалу ситуация в Internet была идентична той, что наблюдалась в мире научно-технической информации, но с ростом коммерческой привлекательности Сети картина стала меняться.
Скажем, вы хотите купить книгу Дэна Брауна «Код да Винчи». В результате поиска вы получаете список Internet-магазинов, предлагающих эту книгу, причем цена везде примерно одинакова, а доставка является бесплатной. Вы удовлетворены? Безусловно. А вот по поводу релевантности ссылок на Internet магазины возникает масса вопросов. Для пользователя они все равны, а для системы — нет, поскольку для нее каждый магазин имеет свою оценку. Кроме того, для потребителя рекламная ссылка имеет ту же пертинентность, что и все остальные, а для системы, которая может получать вознаграждение за рекламу, она должна иметь гораздо больший вес. Собственно, именно поэтому рекламные ссылки и размещают во многих системах перед списком «нерекламных» или в тех местах, где пользователь обязательно обратит на них внимание.
Другой пример. По утверждению поисковой системы Lycos, запрос «Памела Андерсон» возглавляет список самых популярных запросов за последние десять лет. Очевидно, что знаменитое видео уникально, а вот количество сайтов, на которых оно размещено, даже трудно сосчитать. И хотя пользователь удовлетворится практически любым из них, владельцам сайтов далеко не безразлично, на какой из них придут потребители.
Как указывают исследователи из Корнельского университета, в подавляющем большинстве случаев пользователи выбирают из результатов поиска первые две позиции. А это означает: для того чтобы пользователь увидел ссылку и воспользовался ею, она должна попасть хотя бы на первую страницу поиска. Вот здесь-то и начинается то, что принято называть поисковой оптимизацией.
4 десяток:
/Magazin/cgi-bin/Sb_95/pr_95.exe?!33
Об оценки документальных систем
Теория оценки документальных АИПС в настоящее время несовершенна, и по образному выражению Д. Г. Лахути эти вопросы находятся на инфантильной стадии разработанности. Критерии технической эффективности - точность и полнота результатов информационного поиска - не всегда, как показывает опыт, служат в достаточной степени объективной и достоверной оценкой фактических результатов работы системы. Например, за формально хорошим параметром точности (свыше 73%) в рассматриваемом ниже АИПС по огнеупорным изделиям и материалам обнаружилось, как показало обследование, аномально большое количество шумовой, явно не нужной пользователям информации.
Основные претензии к качеству информации, предоставляемой данной системой, были связаны, как представляется, с недостаточной пертинентностью поисков, обусловленной следующими основными причинами.
Излишняя декомпозиция запросов, когда при обслуживании в режиме ИРИ информационная потребность пользователя раскрывалась в виде серии из 7-10 очень конкретных запросов о частных аспектах исследования. При большой глубине индексирования рефератов (около 15 терминов на один документ) это естественным образом приводило к неоднократной выдаче информации на разные запросы из серии. На релевантность информационного поиска повторная выдача информации никак не влияла.
Обслуживание по чрезмерно широким запросам, когда на один ретроспективный запрос абонент получал 1-2 тыс. документов. Хотя непосредственно "в дело шла" только малая часть информации формальная точность оценивалась как высокая.
Другие причины снижения пертинентности. Несогласованность разных форм информационного обслуживания. В системе, помимо режима ИРИ, какое-то время работала служба ТОР - тематического обеспечения разработок. Отсутствие согласованности между ними приводило к тому, что одни и те же документы поступали к пользователям (тоже в декомпонированном виде) по разным каналам обслуживания.
Вся информация, направляемая в отдел 5-7 индивидуальным абонентам ИРИ, просматривалась заведующим, и он сам распределял её между своими сотрудниками. Естественное тематическое пересечение документов в 5-7 выдачах ИРИ субъективно воспринимается данным пользователем, как неоправданное дублирование информации. Релевантность оставалась высокой.
Абонент умер, уволился, сменил тему исследования. Обслуживание в режиме ИРИ, тем не менее, продолжается безадресно, "в никуда".
Из всего выше сказанного вытекает, что причинами многих претензий относительно "шума" в документальных АИПС могут являться не только, и, может быть, даже не столько недостатки в используемых технических, математических и лингвистических средствах (ППП, индексирование, тезаурус), сколько особенности постановки работы в подсистеме информационного обслуживания. Возможно, что есть основания различать и раздельно оценивать два уровня или плана оценок типа точности/полноты: релевантность и полноту результатов документального поиска (эти два показателя едва ли должны превышать обычные 70%) и такие же характеристики применительно к информационному обслуживанию пользователей.
Есть основания полагать, что понятие "пертинентность" - это точность последнего плана, то есть точность информационного обслуживания. Особенность данного термина в том, что в отличие от "релевантности", соотносимой с "полнотой", нет понятия и термина, оппозитивных (бинарная оппозиция) пертинентности: импертинентность? - неблагозвучно, адекватность/неадекватность? - слишком абстрактные понятия. Тем не менее потребность в них, видимо, ощущается, а содержание "импертинентности-неадеквантности" в общем виде охарактеризовано выше.
http://poiskbook.kiev.ua/nti05.html
Релевантность и пертинентность
Вероятно вычленить центральную проблему современных информационных потоков, то она состоит в качественном различии понятий "релевантность" и "пертинентность". Сам факт наличия этих двух терминов говорит о том, что различие было известно всегда, но в условиях ограниченных объемов данных им можно было пренебречь, так как потребитель, в явном виде просмотрев всю релевантную выборку, мог отобрать то, что ему нужно. Сегодня, же когда зачастую это становится невозможным, несовпадение релевантности с пертинентностью выступает на первый план. Действительно, если из 10 тысяч предъявленных ИПС документов все являются пертинентными, то потребитель будет удовлетворен, по крайней мере в первом приближении, прочитав любое их число. Остальные он может просто проигнорировать без особого ущерба для достижения поставленной цели. В некоторых областях отмеченная закономерность эффективно используется. Так, например, службы синдикации новостей обслуживают своих клиентов, при том, что количество охватываемых источников информации практически у любой из них в настоящее время не превосходит 10 тысяч. При этом следует отметить, что проблему полноты новостной информации такой подход позволил решить, оставив, однако, нерешенной проблему формирования достаточного для пользователя объема информации.
Существующие ИПС изначально проектировались для обеспечения именно релевантности выборки по отношению к формальным запросам, и в этом их главная слабость в современных условиях. Низкий, а точнее говоря, неконтролируемый уровень пертинентности выборки с высоким уровнем ее релевантности порождает различные ситуации, допускающие более или менее общую типизацию.
[Наиболее простой и очевидный случай: по запросу "президент" можно получить кроме необходимых новостей рекламу отеля "Президент", прайс-листы сигарет "Президент" и т. п. Теоретически, с таким информационным мусором можно бороться, составляя изощренные запросы из 200-300 поисковых терминов с активным использованием контекстной близости и операций отрицания, но это сложная работа, требующая времени, определенной подготовки и практического опыта. Во всяком случае, у обычного пользователя есть шанс получить желаемое, прибегнув к помощи профессионалов. Предположим, пользователя интересуют специальные работы по методам кодирования текстовой информации. Он составляет соответствующий запрос и получаете набор документов, которые действительно посвящены этой теме. Но ему предъявляются классические учебники теории связи, тогда как требуется получить последние публикации с оригинальными результатами. Здесь уже расширение запроса, скорее всего, не поможет, поскольку его обработка, какой бы сложной она ни была, предполагает использование того, что содержится в тексте документа в явном виде и может быть реализовано лингвистическими средствами. Далее, пусть пользователь действительно получил ссылку на обзор по теме, содержащий то, что ему нужно. Но неприятность при этом заключается в том, что оказывается, что именно этот обзор уже лежит у него на столе, и, значит, нет нужды искать его в базах данных, а другие обзоры, возможно, находятся где-то в конце списка ссылок, но этого он никогда не узнает. И справиться с такой ситуацией намного сложнее, чем с первыми двумя, потому что факт наличия у пользователя некоторых данных никак не отражен в самих данных.]
uchebana5.ru
Релевантность - это... Что такое Релевантность?
Релева́нтность (лат. relevo — поднимать, облегчать) в информационном поиске — семантическое соответствие поискового запроса и поискового образа документа.[1] В более общем смысле, одно из наиболее близких понятию качества «релевантности» — «адекватность», то есть не только оценка степени соответствия, но и степени практической применимости результата, а также степени социальной применимости варианта решения задачи.[источник не указан 732 дня]
Виды релевантности
Содержательная релевантность
Соответствие документа информационному запросу, определяемое неформальным путем.[1]
Формальная релевантность
Соответствие, определяемое путем сравнения образа поискового запроса с поисковым образом документа по определенному алгоритму.[1]
Одним из методов для оценки релевантности является TF-IDF-метод. Его смысл сводится к тому, что чем больше локальная частота термина (запроса) в документе (TF) и больше «редкость» (то есть чем реже он встречается в других документах) термина в коллекции (IDF), тем выше вес данного документа по отношению к термину — то есть документ будет выдаваться раньше в результатах поиска по данному термину. Автором метода является Gerard Salton (в дальнейшем доработан Karen Sparck Jones).[источник не указан 732 дня]
Пертинентность
Пертине́нтность (лат. pertineo — касаюсь, отношусь) — соответствие найденных информационно-поисковой системой документов информационным потребностям пользователя, независимо от того, как полно и как точно эта информационная потребность выражена в тексте информационного запроса. Иначе говоря, это соотношение объёма полезной информации к общему объёму полученной информации.[1]
Примечания
- ↑ 1 2 3 4 Словарь по кибернетике / Под редакцией академика В. С. Михалевича. — 2-е. — Киев: Главная редакция Украинской Советской Энциклопедии имени М. П. Бажана, 1989. — 751 с. — (С48). — 50 000 экз. — ISBN 5-88500-008-5
См. также
Литература
xn--httpsdic-56g3h1cya1j.academic.ru