Настройка поиска с сортировкой по релевантности для улучшения результатов поиска и производительности. Сортировка по релевантности это
Сортировка по релевантности от Shutterstock
Сегодня я выкладываю перевод еще одной новости от фотобанка Shutterstock, в которой речь пойдет о повышении удобства использования поиска по изображениям для пользователей, приходящих на фотобанк для покупки изображений, с помощью внедрения сортировки по релевантности. Но, в то же время, авторам фотобанка будет полезно знать о запуске такой возможности.
Когда мы проводили опрос среди наших подписчиков, что бы они еще хотели от Shutterstock, многие подписчики фотобанка ответили, что хотели бы получить инструмент, который поможет лучше находить правильное изображение. Предложение принято во внимание!
На этой неделе мы хотим познакомить вас с нововведением в поисковой системе Shutterstock. Представляем вашему вниманию новый вариант сортировки под кодовым названием Relevant.
У нашей поисковой системы, по сути, одна цель – помочь покупателям фотобанка найти наиболее подходящее изображение, согласно заданных вами ключевых слов. С каждым днем наша система поиска становится умнее и умнее!
Теперь, когда покупатели работают с поиском на фотобанке, они видят четыре кнопки, каждая из которых активирует тот или иной фильтр для сортировки результатов поиска: Новые (New), Популярные (Popular), Релевантные (Relevant) и Случайные (Random).
Вроде бы все просто и понятно.
А теперь несколько наиболее частых вопросов и ответы на них по поводу того, как новый способ сортировки принесет авторам фотобанка:
Сортировка по релевантности теперь будет работать как сортировка по умолчанию?
Нет, это просто новая опция в дополнение к уже существующим вариантам сортировки результатов поиска, так что все продолжает работать также и прежде. В будущем мы можем изменить вариант сортировки результатов поиска, который используется по умолчанию, но это будет только при наличии желания покупателей фотобанка.
Как работает сортировка по релевантности?
Мы выстроили систему сортировки по релевантности таким образом, чтобы покупатели могли получить наиболее точные и соответствующие результаты поиска изображений на фотобанке. Система сортировки сконструирована таким образом, что может самосовершенствоваться со временем. Конечно, мы собираемся улучшать ее в зависимости от отзывов, которые будем получать от пользователей. Мы вносим корректировки таким образом, что результаты поиска могут варьироваться как день ото дня, так и от пользователя к пользователю.
Какая разница между сортировкой изображений по популярности и по релевантности?
Сортировка по популярности довольно проста и напрямую зависит от количества скачиваний изображения. А сортировка по релевантности имеет более сложный алгоритм, который учитывает сочетание большого количества различных факторов.
Какой же итог для авторов фотобанка?
Сортировка по релевантности даст больший эффект для изображений с правильно и аккуратно подобранными ключевыми словами. Запуск сортировки по релевантности приведет к увеличению количества скачиваний изображений на фотобанке, принося таким образом пользу авторам, которые очень внимательно и аккуратно подбирают ключевые слова к своим изображениям.
Где еще почитать о том, как правильно подбирать ключевые слова?
Вот несколько ссылок на полезные статьи о ключевых словах:Правильный выбор ключевых слов к редакторским снимкамКлючевые слова и продажи: важность правильного выбораПравильный выбор ключевых слов. Часть 2Новый инструмент от Shutterstock “Тренды ключевых слов”Правильная подборка ключевых слов при атрибутировании
Автор: ShutterbuzzСсылка на оригинал: http://buzz.shutterstock.com/shutterstock-new-search-order
Статья доступна для ознакомления в следующих рубриках: Shutterstock, О микростоках Если Вам понравилась моя статья, то Вы можете получать новые материалы по RSS или подписаться для получения обновлений блога на e-mail:microstock.org.ru
Релевантность поиска - как определить соответствие запросов в выдаче
Релевантность (от англ. «relevant», т. е. «относящийся к теме») – это показатель соответствия документа тематическому запросу, или ожиданиям и потребностям пользователя. Чем выше релевантность запросов, тем больше показанные страницы удовлетворяют информационные потребности.
Пример: что означает релевантность
Содержание статьи
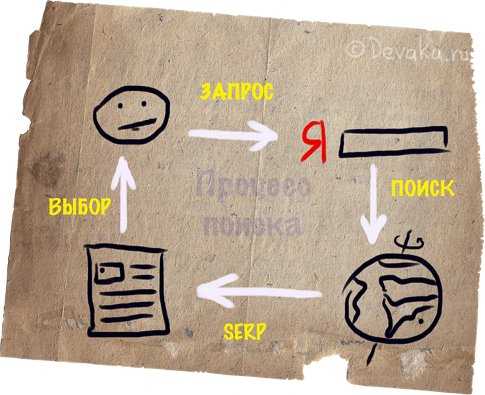
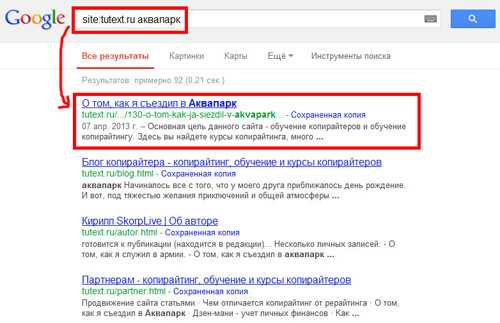
Допустим, мы ввели в поисковую строку «термин релевантность поисковой системы». В выдаче мы видим ссылки на сайты, где рассказывается именно о поисковом продвижении и работе соответствующих алгоритмов поисковиков. Мы получаем ответ на заданный вопрос, т. е. то, ради чего и заходили в поиск. Пользователи довольны – выдача соответствует их потребностям.
Если же в выдаче окажется, например, описание того, что означает слово релевантность с точки зрения неклассической логики, то эта ссылка является нерелевантной. И, скорей всего, в ближайшее время она будет удалена из ТОПа поисковика по выбранному запросу.
Такое иногда случается после первичного анализа соответствия слов в тексте страницы заданным параметрам. Исправляется эта ошибка сравнительно быстро на основе анализа поведенческих факторов. Почему это случается и как поисковики вообще анализируют документы и определяют их содержание, давайте разберемся подробнее.
Как определяется релевантность выдачи
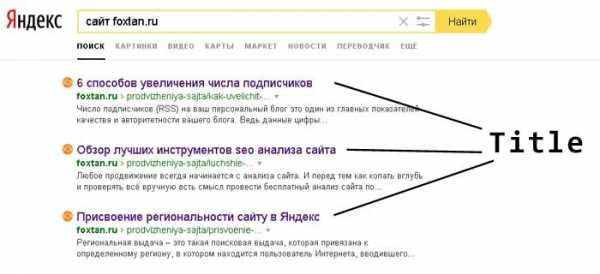
Поисковые системы разрабатывают специальные алгоритмы анализа текстовой информации для определения тематики и подходящих поисковых запросов. При этом учитывается контент на странице, поисковые теги (title, description), содержимое тегов «alt» в картинках.
 В первую очередь поисковые боты сверяют запросы с образцами документов, хранящихся в поисковом индексе. Если число повторов слов соответствует тематике с точки зрения алгоритма релевантности выборки, страница попадает в выдачу.
В первую очередь поисковые боты сверяют запросы с образцами документов, хранящихся в поисковом индексе. Если число повторов слов соответствует тематике с точки зрения алгоритма релевантности выборки, страница попадает в выдачу.
Важно. Количество «ключевых фраз» (тех самых поисковых запросов) не должно превышать определенные показатели, попадающие в понятие «естественности текста» с точки зрения поисковиков. Если превысить число повторов, страница может вообще выпасть из поиска по причине «поискового спама».
Оптимальной считается «плотность» ключевых фраз 2-6% от общего объема документа. Меньшее число повторов приведет к тому, что поисковик «не заметит» тематические «ключи». Большее же, наоборот, с высокой вероятностью будет отнесено к «спаму».
Но понятие релевантности даже для ботов несколько шире, чем плотность вхождения тех или иных фраз. Алгоритмы анализа тематики текстов с каждым годом становятся все сложнее и “умнее”. Они определяют и естественность контента, и общую тематику без учета ключевых фраз. А потому попытки добавить в произвольную статью нужные поисковые запросы давно не работают. Даже наоборот, становятся причиной снижения позиций сайта.
Лучшее решение – писать интересные, полезные и естественные тексты для людей. Тогда у поисковых систем не будет к ним никаких претензий, в том числе, с точки зрения релевантности данных.
Поведенческий фактор
 В случае, когда релевантность результатов поиска изначально определена неправильно (как в примере выше), страница некоторое время будет отображаться в выдаче по «нецелевому запросу», но недолго.
В случае, когда релевантность результатов поиска изначально определена неправильно (как в примере выше), страница некоторое время будет отображаться в выдаче по «нецелевому запросу», но недолго.
После первичного анализа поисковики начинают отслеживать поведение пользователей. А что значит релевантность? Напомним – это точное соответствие поисковому запросу. При ошибке в выдаче, случайной или в результате намеренного «поискового спама», пользователи начнут переходить на сайт с ненужной им информацией и быстро оттуда уходить. Такие кратковременные посещения (менее 30 секунд) поисковые системы называют «отказами».
В случае, когда число отказов при выдаче по определенному запросу высоко, позиции страницы в выдаче снижаются.
Что значит сортировать по релевантности
Мы разобрались, как поисковые системы определяют релевантный поисковый запрос. Дальше все отобранные по тематике документы необходимо отсортировать.
 Позиция сайта в результатах поиска определяется по совокупности следующих факторов:
Позиция сайта в результатах поиска определяется по совокупности следующих факторов:
- Качество контента: текст должен быть уникальным, полезным, естественным. В нем обязательно должны присутствовать ключевые фразы. Причем важно не только их наличие, но и равномерное их расположение, а также присутствие различных словоформ. По сути, таким образом совмещается добавление «ключей» и сохранение естественности и читабельности.
- Метатеги (title и description). В них должны содержаться те же запросы, что и в тексте.
- Свежесть и актуальность контента. Чем чаще вы обновляете информацию и добавляете новый контент, тем выше частота индексации проекта. Как следствие, повышаются его позиции в выдаче.
- Внешние ссылки. На результаты сортировки влияют не только факторы внутренней оптимизации, но и наличие внешней ссылочной массы, а также ключевые слова, из которых состоят анкоры (фразы со «спрятанными» ссылками).
Принцип релевантности для владельца сайта включает в себя качественную оптимизацию сайта под тематические запросы, а также последующее поисковое продвижение, в том числе с применением статейной, скрытой рекламы и других методов увеличения внешней ссылочной массы.
Создание релевантных страниц
Выше мы уже определили критерии, которые важны для создания документа, релевантного поисковым запросам. А также разобрались, каким образом поисковики сортируют страницы, и почему одни сайты оказываются выше, а другие – ниже в результатах поисках, хотя информация и там, и там отвечает на вопрос поиска.
Что делать, чтобы оказаться в числе лидеров? Ответ на этот вопрос – получение комплексного качественного поискового продвижения сайта. Конечно, вы можете и дальше изучать самостоятельно, что значит релевантность, как оптимизировать контент и какие внешние ссылки стоит использовать, чтобы получить положительный результат и не попасть под фильтры Яндекса. Если у вас один или два сайта, и проекты не являются коммерческими, информация нашего блога вам в этом поможет.
Но если вы – владелец интернет-магазина или другого бизнес-сайта, не стоит тратить ваше драгоценное время на эксперименты по продвижению, тем более, что иногда они заканчиваются плачевно. Доверьте свой проект профессионалам, и получайте прибыль от сайта в самые сжатые сроки!
seoklub.ru
Быстрая сортировка по релевантности PDF-документов: нам поможет SWISH++
Задача: имеется куча скачанных статей в формате PDF и нужно их сортировать по каталогам.Решение: можно сидеть и уродоваться месяц, если документов несколько тысяч, а можно воспользоваться свободной поисковой машиной SWISH++
Зачем всё это надоВсё очень просто: я накачал кучу хороших (и не очень) статей по своей специальности с целью расширить кругозор, и теперь надо все эти PDF файлы рассортировать по каталогам. И потом желательно иметь возможность искать внутри них информацию - и не просто по совпадению, а по релевантности: я не помню, в каком pdf-нике находится нужный мне обзор, а имена файлов типа 1234Njhsd.pdf мне мало что говорят. Быть может, это позволяет сделать Beagle, но попробуем обойтись более простыми и лёгкими средствами, которые есть в Дебиан.
Идея!Некоторое время посидев и потыкав по pdf-никам и пытаясь ручонками всё это разобрать, я понял, что надо это спихнуть на машину. Сел и начал думать, методично прочёсывая свой локальный репозиторий Дебиана apt-cache search-ем.Итак, что я хочу? Возможность искать внутри pdf-файлов, но для этого нужно из них выдрать текст. Это несложно, ведь имеется программа pdftotext. В результате своей деятельности она создаёт файл с таким же названием, но расширением txt. Отлично, половина задачи решена. Теперь надо искать по релевантности внутри текстовых файлов.Из пришедших в голову идей:
- поставить небольшой спам-фильтр, типа ifiles, и натренировать его сортировать кидаемые в него текстовые файлы по каталогам.
- поставить какую-нибудь поисковую машину типа mnogosearch, но оно очень здоровое и работает с HTML, а нужен плоский текст.
- поставить поисковую машину SWISH++ в качестве простого, быстрого, гибкого и неприхотливого локального поисковика.
О поисковой машине SWISH++Сведений об этой поисковой машине в Сети не просто мало - их почти нет. Только статья о применении этой системы для серьёзных поисковых запросов. Некоторыми товарищами считается самой быстрой поисковой системой.Из описания дебиановского пакета можно немного узнать об этой программе - Простой Системе Индексации Для Людей. В основном предназначена для использования в качестве простого и быстрого поискового движка, полностью переписана на C++.Основные возможности SWISH++
- Индексирование файлов с тэгами
- Разумное индексирование почтовых и новостных файлов
- Индексирование man-страниц
- Применение фильтров "на лету" вместо индексирования
- Индексирование не-текстовых файлов типа Micorosoft Office (требуется antiword)
- Модульная архитектура индексирования
- Избирательное индексирование новых файлов
- Индексирование удалённых веб-сайтов
- Обработка больших коллекций файлов
- Молниеносная скорость поиска
- Настраиваемое игнорирование слов
- Возможность запуска как поискового сервера (демонизация)
- Лёгкий для разборки формат выдачи результатов
- Тщательно прокомментированный исходный код
Индексация файловПрограмма index++ проводит индексацию текстовых документов: текст, HTML, XML, LaTeX, почта - всё, что представляет собой по сути простые текстовые файлы но, быть может, со вкраплениями служебных тегов. Индексация проводится очень быстро - на Р4 630 (3ГГц) и 2Гб DDRAM каталог из 270 файлов индексируется за 5 секунд, хотя автор программы предупреждает, что индексация - дело, требующее много памяти.Поставив уровень подробности 3, можно попросить систему выводить информацию в процессе индексирования. Уровень подробности на индексацию не влияет, по умолчанию программа действует без шума и пыли.Для индексации (с выводом подробной информации и процессе) текстовых файлов с расширением txt в текущем каталоге и во вложенных рекурсивно даём команду:
index++ -v3 -e "text:*.txt" .Точка в конце важна, читаем мануал и узнаём почему. Вывод будет примерно такой: watters_etal_paleobio_2001.txt (2704 words) WaveMetriconChip64.txt (1351 words) wshedtopoalgoJMIV.txt (4042 words) Ye.IJDAR.1.txt (4470 words) YucelITIP01.txt (1678 words)./edg: morphology.txt (753 words) LuengoEtAl_IbPRIA05.txt (1227 words) Cuisenaire2005_1250.txt (1162 words) icpr2004_nucleus.txt (1234 words) OrtizEtAl_SPIE01.txt (1463 words) Angulo_VIIP04.txt (1658 words) 682.txt (1901 words) comorph.txt (1948 words) index++: ranking index... index++: writing index... index++: done: 00:05 (min:sec) elapsed time 548 files,271 indexed 2465116 words, 1046139 indexed, 56281 unique В результате в текущем каталоге появится файл swish++.index где лежат сведения о проиндексированных файлах. Отлично: такая куча файлов так быстро проиндексирована. Теперь мы готовы искать интересующие нас документы. В конце мануала (краткого, но очень толкового) приводятся ссылки на литературу - чувствуется, автор в этом деле поднаторел очень крупно.Поиск файловПрограмма search++ ищет по запросу в индексированной базе swish++.index, созданной программой index++. Ну, для примера поищу-ка я в этой базе статьи по математической морфологии, в которых нет упоминания про медицину:
$ search++ morphology and erosion and dilation not medicineМгновение спустя вижу результат (вывод сокращён):# results: 125 99 ./Krylov2.txt 3771 Krylov2.txt 49 ./13300407.txt 3103 13300407.txt 46 ./morph2.slides.printing.6.txt 4369 morph2.slides.printing.6.txt 37 ./lecture_morphology_sara.txt 6746 lecture_morphology_sara.txt 30 ./SIGGRAPh3002_Sketch-Mitchell.txt 5308 SIGGRAPh3002_Sketch-Mitchell.txt 26 ./MorphologicalImageProcessing.txt 7642 MorphologicalImageProcessing.txt 25 ./phdsymp2002_ledda.txt 8298 phdsymp2002_ledda.txt 23 ./lab2_manual.txt 9313 lab2_manual.txt 23 ./Project 1.txt 9946 Project 1.txt 22 ./morphology.txt 11212 morphology.txt 22 ./edg/morphology.txt 11212 morphology.txt 22 ./slides-6-geometry.txt 11717 slides-6-geometry.txt 22 ./V1BFOGG8.txt 10797 V1BFOGG8.txt 18 ./71650638.txt 13978 71650638.txt Первая колонка - релевантность, вторая - расположение файла относительно текущей директории, третья - размер файла, четвёртая - имя. Просто и понятно. Можно использовать, как в любом поисковике, AND и NOT для задания более подробной выборки. Анализируя результат поиска, могу сказать, что при релевантности ниже 40-30 можно смело не смотреть тексты - они явно не о том. Результаты этого поиска, кстати, очень даже адекватные: именно это меня и побудило написать скрипты для потоковой сортировки PDF-ников. Но об этом в следующем посте.Ссылки: Всё про эту систему рассказать в одном посте просто нереально. Привожу те крохи, которые наскрёб гугл, яху и яндекс по этой замечательной программе.Домашняя страница проекта на сорсфорж. Здесь много информации по поисковым движкам, и, в частности, про SWISH++, а также статья по поиску в базах данных с использованием перловых скриптов. Документация по SWISH-e, предка SWISH++.
mydebianblog.blogspot.com
Поиск по базе данных с сортировкой по релевантности
Вы здесь: Главная - MySQL - SQL - Поиск по базе данных с сортировкой по релевантности
Недавно мне нужно было для одного из заказчиков сделать поиск, причём не просто вывод всех совпадений, а ещё и с сортировкой по релевантности. Многие программисты (да и я тоже раньше так делал) выведут все совпадения, а потом уже в PHP начинают сортировать по релевантности. Однако, в SQL есть уже отличная возможность поиска по базе данных с сортировкой по релевантности.
Единственное условие - это сделать поля, по которым будет идти поиск, ключами FULLTEXT. А теперь сам запрос:
SELECT *, MATCH `field` AGAINST ('$search') as relev FROM `table` ORDER BY relev DESCВ данном запросе ищутся соответствия в поле "field" ключевому запросу $search (там может быть много слов). А некое количество соответствий попадает в переменную relev (по сути, релевантность), по которой потом происходит сортировка по убыванию. И это будет происходить для каждой записи в таблице.
Всё вроде бы хорошо, однако, если Вы выполните данный запрос, то с удивлением обнаружите, что чтобы Вы не подставляли в $search, а в выборке будут абсолютно все записи. Почему? А потому, что мы не написали WHERE, поэтому даже там, где "relev=0" (то есть вообще ничего не найдено), является одним из результатом выборки. И вот изменённый SQL-запрос будет таким:
SELECT *, MATCH `field` AGAINST ('$search') as relev FROM `table` WHERE MATCH `field` AGAINST ('$search')>0 ORDER BY relev DESCС таким запросом записей без единого совпадения в выборке уже не будет, а все те, где найдено соответствия, будут отсортированы по релевантности.
А что делать, если нам нужно сделать поиск сразу по двумя полям? Тут есть 2 варианта, если Вы создадите 1 общий FULLTEXT для двух полей, то можно написать так:
SELECT *, MATCH `field_1`, `field_2` AGAINST ('$search') as relev FROM `table` WHERE MATCH `field_1`, `field_2` AGAINST ('$search') > 0 ORDER BY relev DESCА если общий ключ создавать не хотите, то тогда надо выполнить такой запрос (каждое из полей должно быть FULLTEXT):
SELECT *, MATCH `field_1` AGAINST ('$search') + MATCH `field_2` AGAINST ('$search') as relev FROM `table` WHERE MATCH `field_1` AGAINST ('$search') + MATCH `field_2` AGAINST ('$search') > 0 ORDER BY relev DESCНо вся прелесть данного поиска по базе данных с сортировкой по релевантности состоит в том, что он выполняется очень быстро. Намного быстрее, чем если Вы будете орудовать строковыми функциями PHP в массивах с записями. Поэтому рекомендую использовать данный SQL-запрос при поиске в большинстве случаев, даже когда не требуется вывод по релевантности.
- Создано 21.11.2012 07:09:47
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href="https://myrusakov.ru" target="_blank"><img src="https://myrusakov.ru//images/button.gif" alt="Как создать свой сайт" /></a>
Она выглядит вот так:
-
Текстовая ссылка:<a href="https://myrusakov.ru" target="_blank">Как создать свой сайт</a>
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи): [URL="https://myrusakov.ru"]Как создать свой сайт[/URL]
myrusakov.ru
Полнотекстовой поиск, сортировка по релевантности
Полнотекстовой поиск, сортировка по релевантности
Сразу приведу пример итогового запроса:
SELECT *, MATCH (title,content) AGAINST ('слово, фраза поиска') as relev FROM `table_name` WHERE MATCH (title,content) AGAINST ('слово, фраза поиска ') ORDER BY relev DESCВ запросе поиск идет по 2м полям title,content и сортирует по релевантности. Чтобы это заработало, нужно создать индекс FULLTEXT, для этих 2х полей, вот таким запросом:
alter table `table_name` add fulltext(title,content)Здесь создается индекс по 2м полям. Возможно, может понадобится поиск по одному или, например, по 3м полям. Смысл такой, перечислить в скобках после fulltext поле/поля(через запятую), по которым будет производится поиск. Соответственно в итоговом поисковом запросе они должны быть перечислены в скобках после MATCH.
FULLTEXT индексы можно, создавать только в таблицах типа MyISAM. Поэтому, возможно, нужно будет преобразовать вашу таблицу к этому типу.
alter table `table_name` type=myisam;Все, теперь приведенный выше запрос будет работать.
Что еще нужно знать:
1. Поиск ведется без учета регистра символов.
2. Нельзя использовать значение поля revel в операторе WHERE. Можно использовать в HAVING (HAVING > 0) и сортировать по нему (ORDER BY relev DESC)
3. За счет индексов FULLTEXT прилично растет объем базы.
4. На небольших объемах, этот способ вполне оправдан из-за простоты реализации. Например, на этом сайте, как раз таким образом организован поиск.
5. На больших объемах данных этот способ поиска использовать грешновато. Если объем данных действительно большой, нужно смотреть в сторону sphinx.
просмотров:5828 | комметариев: 2 просмотров:5828 | комметариев: 2Оставить комментарий:
Возможно вам будет интересно:
web-developments.ru
Настройка поиска с сортировкой по релевантности для организации для Dynamics 365 Customer Engagement
- 07/27/2018
- Время чтения: 15 мин
-
Соавторы
In this article
Применимо к Dynamics 365 (сетевая версия), версия 9.xПрименимо к Dynamics 365 (сетевая версия), версия 8.x
Поиск по релевантности позволяет быстро получить полные результаты единым списком, сортированным по релевантности. Используется выделенная служба поиска независимая от Dynamics 365 (online) на базе Azure, чтобы повысить эффективность поиска Dynamics 365 (online). Как администратор или настройщик вы сможете включать и настраивать поиск по актуальности в пользовательском интерфейсе Dynamics 365 без написания программного кода. Многие из шагов конфигурации будут выглядеть знакомыми вам, так как они используют сходный пользовательский интерфейс в конфигурации быстрого поиска.
Поиск с сортировкой по релевантности доступен в дополнение к другим поискам Dynamics 365, с которыми вы уже знакомы. Можно и дальше использовать быстрый поиск по одной сущности в сетке сущностей. Можно также использовать быстрый поиск по нескольким сущностям (теперь называется поиском с разбивкой по категориям) из поля поиска Поиск данных Dynamics 365 на панели навигации.
Поиск по релевантности обеспечивает следующие преимущества.
Повышение эффективности поиска благодаря внешней индексации и технологии поиска Azure.
Поиск соответствий для каждого слова в поисковом запросе в любом поле сущности. Соответствия могут включать все формы слова, например "поток", "потоковый", "потоком".
Возвращение результатов из всех доступных для поиска сущностей в виде одного списка, сортированного по релевантности, с учетом таких факторов, как число слов-соответствий или близость по отношению друг к другу в тексте.
Совпадения в списке результатов выделены.
Включает возможность поиска документов в примечаниях и вложениях электронной почты и встреч, отслеживаемых в Dynamics 365.
Сравнение поисков Dynamics 365
Существует три типа поиска в Dynamics 365:
Поиск по релевантности
Полнотекстовый быстрый поиск (по одной или нескольким сущностям)
Быстрый поиск (по одной или нескольким сущностям)
В следующей таблице приводятся краткое сравнение 3 доступных поисков.
| Доступность | Доступно для организаций Dynamics 365 (online), которые установили Dynamics 365 (сетевая версия), версия 9.0. Недоступно для организаций Dynamics 365 (on-premises). | Доступны для организаций Dynamics 365 (on-premises), начиная с Dynamics CRM 2015, накопительный пакет обновления 1. | Доступно для организаций Dynamics 365 (online) и организаций Dynamics 365 (on-premises). |
| Включено По умолчанию? | Нет. Администратор должен включить это вручную. | Нет. Администратор должен включить это вручную. | Да |
| Область поиска по одной сущности | Недоступно в сетке сущности. Можно фильтровать результаты поиска по сущности на странице результатов. | Доступно в сетке сущности. | Доступно в сетке сущности. |
| Область поиска по нескольким сущностям | Не существует ограничения на количество сущностей, по которым можно искать. Примечание. Хотя не установлен максимальный лимит на количество сущностей для поиска, фильтр "Типа записей" отображает данные только для 10 сущностей. | Поиски до 10 сущностей, группировка по сущности. | Поиски до 10 сущностей, группировка по сущности. |
| Поведение поиска | Поиск соответствий для каждого слова в поисковом запросе в любом поле сущности. | Поиск соответствий всем словам в условии поиска в одном поле в сущности; однако словам можно сопоставить в любом порядке в поле. | Поиск соответствий как в SQL-запросе с предложениями "Like". Вы должны использовать подстановочные знаки в условии поиска для поиска в строке. Все соответствия должны точно совпадать с условием поиска. |
| Результаты поиска | Возвращает результаты поиска в порядке их релевантности в одном списке. | Для одной сущности возвращает результаты поиска в сетке сущности. Для нескольких сущностей возвращает результаты, сгруппированные по категориям, например по организациям, контактам или интересам. | Для одной сущности возвращает результаты поиска в сетке сущности. Для нескольких сущностей возвращает результаты, сгруппированные по категориям, например по организациям, контактам или интересам. |
Как работает поиск по релевантности
Поиск по релевантности использует те же понятия оценки по умолчанию, как и поиск Azure. Оценка ссылается на вычисление балла поиска для каждого элемента, возвращаемого в результатах поиска. Балл — это показатель актуальности элемента в контексте текущей операции поиска. Чем выше балл, тем релевантнее элемент. В результатах поиска, элементы расположены в порядке от максимума по уменьшению, на основе баллов поиска, высчитанных для каждой из позиций. По умолчанию балл поиска вычисляется на основании статистических свойств данных и запроса. Поиск по релевантности находит документы, содержащие условия поиска в строке запроса, делая упор на документы, содержащие много экземпляров слов в условиях поиска и их близости друг с другом в документе. Балл поиска поднимается еще выше, если термин редок в индексе, но распространен в документе. Затем результаты выстраиваются по баллу поиска, прежде чем они возвращаются. Значения по баллам поиска можно повторить через набор результатов. Например, можно иметь 10 элементов с баллом 1.2, 20 элементов с баллом 1.0 и 20 элемента с баллом 0.5. Если несколько результатов имеют одинаковый балл поиска, порядок элементов с одинаковым баллом не определен и не является стабильным. Повторно выполните запрос и вы можете увидеть смену расположения элементов. Если есть два элемента с одинаковым баллом, нельзя сказать, кто появится первым. Дополнительные сведения: Добавление профилей оценки в индекс поиска (API службы поиска Azure REST)
Поля с функцией поиска анализируются в индексе поиска Azure чтобы предоставить боле естественный удобный для пользователей поиск, на счет разбиения слов на корневые формы, нормализации текста и фильтрации шумовых слов. Все поля с функцией поиска в поиске по релевантности анализируются анализатором естественных языков Корпорация Майкрософт, который использует лемметизацию, чтобы разбивать слова на корневые лингвистические формы. Например, “ran” соответствует “run” и “running”, так как “run” считается базовой формой слова. Стеммеры, такие как полнотекстовые индексы SQL, не имеют никакого лингвистический контекста и только учитывают совпадения, где корень совпадает со словоизменительной формой. Со стеммингом “run” соответствует “running” и “runner”, но не “ran”, потому что он не считает слово “ran” лингвистически связанным с “run”. Все доступные для поиска поля в поиске по релевантности используют анализатор, наиболее точно сопоставляющий базовый язык организации. Для Казахского, это единственный язык, который поддерживается поиском Dynamics 365, но не Azure, все поля проанализированы с помощью анализатора по умолчанию. Для получения дополнительных сведений об анализе языка и списка поддерживаемых языков см.: Поддержка языков (API службы поиска Azure REST).
Результаты поиска
Вы увидите выделенное совпадение, когда искомый термин совпадает с термином в вашем приложении. Они выделяются полужирным шрифтом или курсивом в результатах поиска. Обратите внимание, что эти искомые термины часто возвращаются как только часть полного значения в поле, поскольку выделяются только совпавшие термины. Например, при использовании условия поиска L. Wendell запись для контакта с именем L. Wendell и фамилией Overby возвращается как Wendell Overby в результатах поиска.
Архитектура поиска по релевантности
Поиск по релевантности размещается на основе платформы облачных вычислений и инфраструктуры Azure, использующей поиск Azure, предоставляющий результаты поиска. Изменения, внесенные в Dynamics 365 может начать отображались в поисковую службу через до 15 минут. Чтобы выполнить полую синхронизацию для среднего или большой организации может потребоваться до часа или больше.
На следующей схеме показаны архитектура поиска по релевантности высокого уровня.
Включить поиск по релевантности
Поскольку вы будете предоставлять доступ к вашим данным Dynamics 365 внешней системе, поиск по релевантности отключен по умолчанию. Чтобы включить его, необходимо принять условия согласия. В зависимости от размера организации, может занять до или несколько часов, чтобы данные стали доступными во внешнем индексе поиска после включения поиска. При включении поиска с сортировкой по релевантности этот вариант поиска доступен всем участникам вашей организации.
По умолчанию поиск по релевантности отключен. Чтобы включить поиск по релевантности выполните следующие действия.
Перейдите в Параметры > Администрирование.
Перейдите на вкладку Системные параметры > Общие.
В подобласти Настройка поиска установите флажок Включить поиск по релевантности, как показано ниже.
После включения поиска по релевантности открывается диалоговое окно запроса согласия Включить поиск ". Нажмите кнопку ОК, чтобы выразить свое согласие.
Нажмите кнопку ОК, чтобы закрыть диалоговое окно Системные параметры.
Выберите сущности для поиска по релевантности
Для настройки поиска по релевантности используйте выбор Настроить поиск по релевантности на панели задач, как показано здесь.
Нет предела на количество сущностей, которое можно включить в результатах поиска по релевантности. Однако есть ограничение на общее число полей во внешнем индексе поиска. В настоящее время максимум поддерживающих поиск полей — 1000 для организации. При выборе сущности, которую требуется включить в результатах поиска, вы заметите номер в скобках рядом с именем сущности. Номер показывает количество полей, которое каждая сущность использует во внешнем индексе поиска. Некоторые поля, например Основное имя и ИД, используются совместно несколькими сущностями и не учитываются в итоге. Кроме того, некоторые типы полей используют несколько полей во внешнем индексе поиска, как указано в этой таблице.
| Поиск (клиент, владелец и атрибут типа поиска) | 3 |
| Набор параметров (состояние или атрибут типа состояния) | 2 |
| Все прочие типы полей | 1 |
Панель хода выполнения Всего проиндексировано полей показывает отношение индексированных полей к максимально разрешенному числу доступных для поиска полей.
При достижении предела индексированных полей появится предупреждение. Если требуется добавить несколько полей в индекс, потребуется освободить пространство, удалив часть полей, которые уже в индексе, или удалить целые сущности из поиска по релевантности.
Чтобы выбрать сущности для результатов поиска по релевантности, выполните следующие действия:
Перейдите в раздел Параметры > Настройки.
Щелкните Настроить систему.
В Компоненты, разверните Сущности, а затем щелкните Настроить поиск по релевантности.
Откроется диалоговое окно Выбрать сущности. Щелкните Добавить, чтобы выбрать сущности для результатов поиска. Закончив, нажмите кнопку ОК.
Щелкните Опубликовать все настройки, чтобы изменения вступили в силу.
По умолчанию некоторые готовые системные сущности включаются в поиск по релевантности. Однако пользовательские сущности не включены. Необходимо добавить их к поиску по релевантности.
Настройка поля с функцией поиска для поиска по релевантности
Поля, добавляемые в представлении быстрого поиска становятся частью внешнего индекса поиска. Нет предела количества доступных для поиска полей, которые можно добавить для каждой сущности. Однако есть ограничение на общее число индексированных полей, как было объяснено в предыдущем разделе. Столбцы поиска на Представление быстрого поиска определяют доступные для поиска поля во внешнем индексе поиска. Текстовые поля, такие как "Одна строка текста", "Несколько строк текста", "Результаты поиска " и "Наборы параметров" поддерживают поиск. Поиск столбцов с другими типами данных игнорируется. Столбцы представлений в Представление быстрого поиска определяет поля, выводимые в пользовательском интерфейсе по умолчанию, когда возвращаются сопоставленные результаты. Поля, выделенные, замещают поля, не имеющие выделения. Первые четыре сопоставленных поля отображаются в результатах. Фильтр в представлении быстрого поиска также применяется к результатам поиска с сортировкой по релевантности. Список предложений поиска, не поддерживаемых в поиске с сортировкой по релевантности, см. в приведенной ниже таблице.
Примечание
Некоторые поля, называемые общими полям, являются общими для всех сущностей CRM, определенных в индексе по умолчанию. В их число входят:
- ownerid (Имя подстановки)
- owningbusinessunit (Имя подстановки)
- statecode (Подпись набора параметров)
- statuscode (Подпись набора параметров)
- name (Поле основного имени любой сущности. Оно может совпадать или не совпадать с логическим именем (fullname, subject и т. д.) сущности) Если общее поле добавлено в любую сущность для поиска с сортировкой по релевантности, поиск будет выполнен для этого общего поля по всем сущностям. Однако после выбора определенной сущности через аспект типа записи, поиск с сортировкой по релевантности будет следовать параметрам, которые вы определили для этой конкретной сущности с помощью представления быстрого поиска.
Вы можете использовать представление Быстрый поиск для определения того, какие поля отображаются как фасеты при выполнении поиска пользователями с помощью поиска с сортировкой по релевантности. Все Столбцы представлений с типами данных, отличные от "Строка текста" и "Несколько строк текста", помечены как фасеты и фильтры в индексе. По умолчанию первые четыре поля фасетов в представлении Быстрый поиск для выбранной сущности отображаются как фасеты, когда пользователи используют поиск с сортировкой по релевантности. В любое время можно выбрать только четыре поля как фасеты.
Перейдите в раздел Параметры > Настройки.
Щелкните Настроить систему.
В разделе Компоненты раскройте узел Сущности, затем раскройте требуемую сущность.
В дереве навигации щелкните Просмотр. Дважды щелкните Представление быстрого поиска. На следующем рисунке показано представление Быстрый поиск для сущности Account.
Щелкните Добавить столбцы поиска. В диалоговом окне выберите поля, которые требуется добавить в индекс поиска. При готовности щелкните ОК. На следующем рисунке отображаются поля сущности Account, добавленные во внешний индекс поиска.
Повторите действия для раздела Столбцы представлений.
Щелкните Опубликовать все настройки, чтобы изменения вступили в силу.
Примечание
Изменения в представлении Быстрый поиск также применимы к конфигурациям быстрого поиска для одной сущности и нескольких сущностей (поиск с разбивкой по категориям). Поэтому мы не мешаем вам включать поля, которые не поддерживаются для поиска с сортировкой по релевантности при настройке представления Быстрый поиск. Однако поля неподдерживаемые не синхронизируется с внешним индексом и не появляются в результаты поиска по релевантности.
В случае поиска с сортировкой по релевантности поля в связанной сущности не поддерживаются как поля "Поиск", "Представление" или "Фильтр".
В следующей таблице содержатся операторы Фильтр быстрого поиска, которые не поддерживаются для поиска по релевантности:
| Нравится |
| NotLike |
| BeginsWith |
| DoesNotBeginWith |
| EndWith |
| DoesNotEndWith |
| ChildOf |
| Маска |
| NotMask |
| MaskSelect |
| EqualUserLanguage |
| Под |
| Не под |
| UnderOrEqual |
| Больше |
| AboveOrEqual |
| NotNull |
| Null |
Задать управляемое свойство для поиска по релевантности
Если требуется вставить сущность в поиск по релевантности, управляемое свойство Можно включать с синхронизацию со внешним индексом поиска для этой сущности должно устанавливаться как Истина. По умолчанию, свойство задается на Истина для некоторых готовых системных сущностей и всех настраиваемых сущностей. Некоторые из системных Сущностей невозможно включить для поиска по релевантности.
Для задания управляемого свойства выполните следующие действия:
Перейдите в раздел Параметры > Настройки.
Щелкните Настроить систему.
В разделе Компоненты раскройте узел Сущности, затем щелкните требуемую сущность.
На панели меню щелкните Управляемые свойства. Для Можно включать с синхронизацию со внешним индексом поиска щелкните Истина или Ложь, чтобы задать нужное состояние свойства. Щелкните Установить для выхода, как показано ниже.
Щелкните Опубликовать, чтобы изменения вступили в силу.
Если требуется изменить свойства Можно включать с синхронизацию со внешним индексом поиска на Ложь, необходимо сначала снять выбор сущности из поиска по релевантности. Если сущность включена в поиск по релевантности, появится следующее сообщение: Эта сущность в настоящее время синхронизируется с внешним индексом поиска. Необходимо удалить сущность из внешнего индекса поиска, чтобы свойство Можно включать синхронизацию с внешним индексом поиска можно было установить в значение Ложь. Если для параметра Можно включать синхронизацию с внешним индексом поиска установлено значение Ложь, появится следующее сообщение при попытке включить сущность в поиске по релевантности: "Невозможно включить поиск с сортировкой по релевантности для сущности из-за конфигурации ее управляемых свойств". Для настраиваемых сущностей с особенно чувствительными данными можно рассматривать, не задать ли свойство Можно включать с синхронизацию со внешним индексом поиска на Ложь. Имейте в виде, после установки управляемого решения в целевой системе, вы не сможете изменить значение свойства, так как это управляемое свойство.
Уведомление о конфиденциальности
После включения функции поиска с сортировкой по релевантности данные в участвующих сущностях и атрибутах в экземпляре Dynamics 365 (online) будут синхронизироваться и сохраняться в индексе поиска Azure.
По умолчанию поиск с сортировкой по релевантности выключен. Системный администратор должен включить эту функцию в экземпляре Dynamics 365 (online). После включения поиска с сортировкой по релевантности администраторы и настройщики системы получают полный контроль над данными, которые будут синхронизироваться с индексом поиска Azure.
Настройщики системы могут использовать диалоговое окно Настроить поиск по релевантности в средствах настройки, чтобы включить определенные сущности для поиска, а затем настроить представления быстрого поиска для включенных сущностей, чтобы выбрать доступные для поиска атрибуты. Изменения данных постоянно синхронизируются между Dynamics 365 (online) и поиском Azure по безопасному соединению. Данные конфигурации шифруются, и необходимые секретные ключи сохранятся в Хранилище ключей Azure.
Компоненты и службы Azure, задействованные в функциональности поиска с сортировкой по релевантности, подробно рассматриваются в следующих разделах.
Центр управления безопасностью Microsoft Azure
Службы поиска Azure
Поисковый индекс Azure используется для отображения высококачественных результатов поиска при малом времени отклика. Поиск Azure предоставляет мощные и усовершенствованные возможности поиска следующего поколения для Dynamics 365 (online). Это выделенная служба поиска, не связанная с Dynamics 365 (online), предоставляемая Azure. Все новые индексы поиска Azure шифруются в неактивном состоянии. Если вы присоединились до 24 января 2018 г., вам потребуется повторно индексировать данные, отказавшись от использования поиска с сортировкой по релевантности, подождав час и снова присоединившись к сервису.
База данных SQL Azure
Поиск с сортировкой по релевантности использует База данных SQL Azure для хранения указанных ниже данных.
Данные конфигурации, связанные с организацией, и соответствующий индекс.
Метаданные, связанные со службой поиска и индексами.
Указатели на метаданные системы и данные при синхронизации изменений.
Данные авторизации для обеспечения усиленной защиты на уровне строк.
Концентраторы событий Azure
Компонент Концентраторы событий Azure используется для обмена сообщениями между Dynamics 365 (online) и Azure, а также для ведения рабочих элементов, обрабатываемых в процессе синхронизации. В каждом сообщении хранятся сведения, например код организации и имя сущности, используемые для синхронизации данных.
Azure Service Fabric Cluster
Обработка и индексация данных производятся с помощью микрослужб, развернутых на виртуальных машинах под управлением среды выполнения Service Fabric. API-интерфейсы поиска и процесс синхронизации данных также размещены в кластере Service Fabric.
При создании службы Service Fabric использовался многолетний опыт корпорации Майкрософт в области критически важных облачных служб, и эта служба проверялась в производственных условиях более пяти лет. Это главная технология, которая лежит в основе базовой инфраструктуры Azure и обеспечивает работу различных служб, включая Skype для бизнеса, Intune, Концентраторы событий Azure, фабрику данных Azure, Azure DocumentDB, База данных SQL Azure и Cortana, которые можно масштабировать для обработки более 500 миллионов оценок в секунду.
Масштабируемые наборы виртуальных машин Azure
Гибкие масштабируемые наборы виртуальных машин Azure рассчитаны на поддержку гипермасштабируемых рабочих нагрузок. Кластер Azure Service Fabric работает на масштабируемых наборах виртуальных машин. Микрослужбы для обработки и индексации данных размещены на масштабируемых наборах и работают под управлением среды выполнения Service Fabric.
Хранилище ключей Azure
Для безопасного управления сертификатами, ключами и другими секретными данными, которые используются в процессе поиска, служит Хранилище ключей Azure.
Хранилище Azure (хранилище больших двоичных объектов)
Изменения данных клиентов хранятся в Хранилище больших двоичных объектов Azure до двух дней. Эти большие двоичные объекты шифруются с помощью новейшей функции в пакете SDK службы хранилища Azure, обеспечивая поддержку симметричного и асимметричного шифрования и интеграцию с Хранилище ключей Azure. С помощью Обновление для Dynamics 365 (сетевая версия), декабрь 2016 г. документы в примечаниях и вложениях сообщений электронной почты и встреч также синхронизируются с хранилищем BLOB-объектов.
Служба Azure Active Directory
Azure Active Directory используется для проверки подлинности данных, которыми обмениваются Dynamics 365 (online) и службы Azure.
Azure Load Balancer
Azure Load Balancer служит для распределения входящего трафика между работоспособными экземплярами службы в облачных службах или на виртуальных машинах, заданных в наборе с балансировкой нагрузки. В поиске с сортировкой по релевантности это средство используется для равномерного распределения нагрузки по конечным точкам в развертывании.
Виртуальные сети Azure
Виртуальные машины в кластере Service Fabric, работающие в одной или нескольких подсетях, соединяются между собой с помощью виртуальной сети Azure. Политики безопасности, параметры DNS, таблицы маршрутизации и IP-адреса полностью контролируются в рамках этой виртуальной сети. Для применения ролей безопасности в этой виртуальной сети используются группы безопасности сети. Эти правила разрешают или запрещают передачу сетевого трафика на виртуальные машины в виртуальной сети.
См. также
Использование функции поиска с сортировкой по релевантности для ускоренного получения полных результатов поиска
docs.microsoft.com
Использование функции поиска с сортировкой по релевантности для ускоренного получения более полных результатов поиска
- 07/27/2018
- Время чтения: 12 мин
-
Соавторы
In this article
Применимо к Dynamics 365 (сетевая версия), версия 9.x
В Dynamics 365 можно искать записи в разных сущностях, используя поиск по релевантности или поиск по категориям. Поиск по релевантности возвращает единый список результатов, сортированных по релевантности. Поиск по категориям возвращает результаты поиска, группированные по типам сущностей, таким как организации, контакты или интересы. Чтобы найти записи только одного типа, можно воспользоваться разделом Представление быстрого поиска в сетке сущности.
Что такое поиск с сортировкой по релевантности?
Поиск по релевантности позволяет быстро получить полные результаты по нескольким сущностям единым списком, сортированным по релевантности. Используется выделенная служба поиска, независимая от Dynamics 365 (на базе Azure), чтобы повысить эффективность поиска Dynamics 365.
Поиск по релевантности доступен в дополнение к другим поискам Dynamics 365, с которыми вы уже знакомы. Можно продолжить пользоваться быстрым поиском по одной сущности, используя сетку сущности, или быстрым поиском по нескольким сущностям (поиск с разбивкой по категориям, если поиск с сортировкой по релевантности включен), используя Поиск в данных Dynamics 365 на панели навигации. Чтобы получить более полные результаты быстрее, рекомендуется воспользоваться поиском по релевантности.
Поиск по релевантности обеспечивает следующие преимущества.
Повышение эффективности поиска благодаря внешней индексации и технологии поиска Azure.
Поиск соответствий для каждого слова в поисковом запросе в любом поле сущности. Соответствия могут включать все формы слова, например поток, потоковый или потоком.
Возвращение результатов из всех доступных для поиска сущностей в виде одного списка, сортированного по релевантности, с учетом таких факторов, как число слов-соответствий или близость по отношению друг к другу в тексте.
Выделяет совпадения в списке результатов.
Примечание
- Поиск с сортировкой по релевантности не доступен для организаций Dynamics 365 (on-premises).
- Поиск по релевантности по умолчанию отключен. Администратор должен включить эту функцию для организации. После включения поиска по релевантности необходимо подождать час или около того (в зависимости от размеров организации), прежде чем результаты поиска по релевантности отобразятся в веб-приложении Dynamics 365. Небольшие изменения в индексированных данных могут отображаться в системе примерно через 15 минут.
- При включении поиска с сортировкой по релевантности все пользователи в организации могут использовать его.
- Поиск с сортировкой по релевантности производится на основе текста, и поиск возможен только по полям следующих типов: одна строка текста, несколько строк текста, наборы параметров и подстановки. Он не поддерживает поиск в полях численного типа или типа даты.
Хотя поиск с сортировкой по релевантности находит соответствия по любому слову в условии поиска в любом поле сущности, при быстром поиске — даже при включенном полнотекстовом поиске — все слова из условия поиска должны находиться в одном поле.
В поиске по релевантности чем точнее соответствие, тем выше оно отображается в результатах. Соответствие имеет более высокую релевантность, если больше слов из запроса найдены в непосредственной близости друг от друга. Чем меньше количество текста, в котором найдены слова, тем выше релевантность. Например, если соответствие найдено в названии и адресе компании, это, возможно, является лучшим соответствием, чем обнаружение тех же слов в большой статье, далеко друг от друга. Поскольку результаты возвращаются единым списком, несколько записей могут отображаться друг за другом (организации, возможности, интересы и т. д.). Совпадения в списке выделены.
Использование поиска с сортировкой по релевантности
Если поиск с сортировкой по релевантности включен в организации, он становится механизмом поиска по умолчанию. Если ввести условия поиска в Поиск в данных Dynamics 365 на панели навигации и затем нажать клавишу Ввод или выбрать кнопку поиска, отображается страница с результатами поиска Поиск с сортировкой по релевантности. Результаты поиска отображаются в одном списке в порядке релевантности. Дополнительные сведения о том, как изменить систему поиска по умолчанию, см. в разделе Выбор режима поиска по умолчанию.
Начните новый поиск, введя условие поиска в поле поиска Поиск с сортировкой по релевантности или Поиск в данных Dynamics 365 на панели навигации, как показано здесь.
Используйте синтаксис в условии поиска для получения требуемых результатов. Например, введите серебристый 2-дверный автомобиль, чтобы включить соответствия для любого слова в условии поиска в результаты поиска. Введите автомобиль+серебристый+2-дверный, чтобы найти только соответствия, содержащие все три слова. Введите автомобиль|серебристый|2-дверный для получения результатов, содержащих слово автомобиль, серебристый, "2-дверный или все три эти слова. Дополнительная информация по синтаксису, который можно использовать в поисковых запросах: Простой синтаксис запросов в поиске Azure.
Примечание
Вы увидите выделенное совпадение, когда искомый термин совпадает с терминов в вашем приложении. Совпадения в результатах поиска выделяются полужирным шрифтом или курсивом. Они часто возвращаются как часть полного значения в поле, поскольку выделяются только совпавшие термины.
В Обновление для Dynamics 365 (сетевая версия), декабрь 2016 г. были сделаны следующие усовершенствования в механизме поиска с сортировкой по релевантности:
Можно просмотреть результаты поиска текста в документе, который хранится в Dynamics 365, включая текст в примечаниях, вложениях электронной почты или встречах. Поддерживаются следующие форматы файлов для поиска: PDF, документы Microsoft Office, HTML, XML, ZIP, EML, обычный текст и JSON.
Можно выполнить поиск записей, к которым вам предоставлен общий доступ, и записей, которыми вы владеете.
Примечание
Модели иерархической безопасности не поддерживаются. Даже если вы видите строку в Dynamics 365, поскольку у вас есть к ней доступ благодаря иерархической безопасности, вы не увидите результат при поиске с сортировкой по релевантности.
Можно также выполнить поиск в наборе параметров и просмотрах. Например, допустим, вы хотите найти организации розничной торговли, в названиях которых имеется слово фармацевтические. При поиске по запросу розничные фармацевтические вы получите результат, поскольку имеется соответствие в промышленной отрасли, что является набором параметров, доступным для поиска.
Поскольку результаты могут включать сочетание сущностей, вы можете сузить результаты поиска до определенной сущности, выбрав сущность в раскрывающемся списке Фильтровать по. При фильтрации по определенному типу записи можно включать действия и заметки, связанные с выбранной записью, в результаты поиска. Для этого установите флажок Поиск действий и примечаний для выбранных записей справа от раскрывающегося списка Фильтровать по. Флажок устанавливается после выбора записи в раскрывающемся списке Фильтровать по и снимается, если не выбрать сущность в списке Фильтровать по. Действия и заметки возвращаются как результаты верхнего уровня.
Фильтрация записей с фасетами
В Обновление для Dynamics 365 (сетевая версия), декабрь 2016 г. теперь можно уточнить результаты поиска с помощью фасетов и фильтров. Фасеты доступны на левой панели. Сразу после выполнения поиска доступны следующие глобальные фасеты для четырех самых распространенных полей:
Фасеты типа записей
Чтобы сузить результаты поиска до определенной сущности, выберите сущность в разделе Тип записей.
При фильтрации по определенному типу записей можно включать действия и заметки, связанные с выбранной записью, в результаты поиска. Для этого установите флажок Связанные примечания и действия. Действия и заметки отобразятся в результатах верхнего уровня.
Результаты поиска, найденные во вложениях электронной почты или сущностях встреч, отобразятся в результатах поиска под родительской записью: "Электронная почта" или "Встреча".
При уточнении типа записей область фасета переключается на выбранную сущность, и отображается до четырех фасетов, характерных для сущности. Например, если выбрать сущность "Организация", отобразится фасет Основной контакт в дополнение к глобальным фасетам.
В диалоговом окне Настройка личных параметров можно также выбрать другие фасеты из фасетов, к которым вам предоставил доступ системный администратор или клиент. Параметр пользователя переопределяет параметр по умолчанию. Дополнительные сведения: Настройка фасетов и фильтров для поиска
Фасеты на основе текста
Все просмотры, наборы параметров и типы записей являются фасетами на основе текста. Например, по фасет на основе текста "Владелец" состоит из списка значений полей и соответствующих количеств.
Фильтры в этих фасетах сортируются в убывающем порядке по количеству. Четыре верхних значения фасетов отображаются по умолчанию. Если имеется более четырех значений фасетов, отобразится ссылка ПОКАЗАТЬ БОЛЬШЕ, которую можно выбрать, чтобы развернуть список и просмотреть до 15 верхних значений фасетов. Выберите каждое значение, чтобы отфильтровать результаты поиска для отображения только записей, в которых в поле имеется выбранное значение. Например, если выбрать Елизавета Артемьева, в результатах поиска отобразятся все записи, владельцем которых является Елизавета Артемьева. При выборе значения фасета "Поиск" или "Набор параметров" результаты поиска будут отфильтрованы таким образом, чтобы включать только записи с указанным значением.
Фасеты даты и времени
Как и другие фасеты, фасеты даты и времени можно использовать для фильтрации и просмотра результатов поиска по определенному времени. Чтобы выбрать диапазон значений, перетащите указатель или выберите один из вертикальных столбцов.
Настройка фасетов и фильтров для поиска
Фасеты и фильтры позволяют детализировать и исследовать результаты текущего поиска без необходимости многократно уточнять условие поиска. Настройте требуемые фасеты и фильтры в диалоговом окне Настройка личных параметров.
Примечание
Специалист по настройке системы может настроить взаимодействие по умолчанию для всех сущностей, но вы можете настроить собственные фасеты и фильтры.
Настройка собственных фасетов
Выберите кнопку личных настроек в правом верхнем углу страницы и выберите Параметры.
На вкладке Общие сведения в разделе Выберите режим поиска по умолчанию для поля Фасеты и фильтры выберите Настроить.
В диалоговом окне Настройка фасетов и фильтров укажите фасеты, которые должны отображаться для сущности. Системный администратор или специалист по настройке системы может настроить взаимодействие по умолчанию для всех сущностей, но вы можете настроить собственные параметры здесь.
В раскрывающемся списке Выберите сущность выберите сущность, для которой требуется настроить фасеты. Этот раскрывающийся список содержит только сущности, которые включены для поиска с сортировкой по релевантности.
Для выбранной сущности выберите до четырех полей фасетов. По умолчанию в списке выбираются первые четыре поля фасетов в представлении Быстрый поиск для выбранной сущности. В любое время можно выбрать только четыре поля как фасеты.
Вы можете обновить несколько сущностей одновременно. При выборе кнопки OK сохраняются изменения для всех настроенных сущностей. Для возврата поведения по умолчанию для сущности, настроенной ранее, выберите По умолчанию.
Примечание
- Если специалист по настройке системы удаляет поле или блокирует его для поиска и вы сохранили фасет для этого поля, он больше не будет отображаться как фасет.
- Будут отображаться только поля, которые существуют в решении по умолчанию и которые активированы для поиска специалистом по настройке системы.
Переключиться на поиск по категориям
Поиск по категориям возвращает результаты, сгруппированные по сущностям, например по организациям, контактам или интересам.
Можно сузить результаты поиска, воспользовавшись раскрывающимся списком Фильтровать по, чтобы отобразить результаты для конкретной сущности. Чтобы переключиться с поиска с сортировкой по релевантности на поиск с разбивкой по категориям, выберите Поиск с сортировкой по релевантности, затем выберите Поиск с разбивкой по категориям в раскрывающемся списке. Чтобы вернуться к поиску с сортировкой по релевантности, выберите Поиск с разбивкой по категориям и выберите Поиск с сортировкой по релевантности.
Дополнительные сведения: Поиск записей
Выберите режим поиска по умолчанию
Режим поиска по умолчанию для браузера выбирается из следующих вариантов.
Поиск по релевантности
Поиск с разбивкой по категориям
Использовать последний вариант поиска
Вариант Использовать последний вариант поиска позволяет использовать вариант, который в текущем клиенте браузера был использован последним. Например, если для последнего поиска использовался поиск по релевантности, система продолжит использовать этот поиск до тех пор, пока вы вручную не переключитесь на поиск по категориям.
Чтобы выбрать режим поиска по умолчанию, выполните следующие действия.
Выберите кнопку личных настроек в правом верхнем углу страницы и выберите Параметры.
На вкладке Общие сведения воспользуйтесь раскрывающимся списком Выберите режим поиска по умолчанию, чтобы выбрать Поиск с сортировкой по релевантности, Поиск с разбивкой по категориям или Использовать последний поиск.
Уведомление о конфиденциальности
После включения функции поиска с сортировкой по релевантности данные в участвующих сущностях и атрибутах в экземпляре Dynamics 365 (online) будут синхронизироваться и сохраняться в индексе поиска Azure.
По умолчанию поиск с сортировкой по релевантности выключен. Системный администратор должен включить эту функцию в экземпляре Dynamics 365 (online). После включения поиска с сортировкой по релевантности администраторы и настройщики системы получают полный контроль над данными, которые будут синхронизироваться с индексом поиска Azure.
Настройщики системы могут использовать диалоговое окно Настроить поиск по релевантности в средствах настройки, чтобы включить определенные сущности для поиска, а затем настроить представления быстрого поиска для включенных сущностей, чтобы выбрать доступные для поиска атрибуты. Изменения данных постоянно синхронизируются между Dynamics 365 (online) и поиском Azure по безопасному соединению. Данные конфигурации шифруются, и необходимые секретные ключи сохранятся в Хранилище ключей Azure.
Компоненты и службы Azure, задействованные в функциональности поиска с сортировкой по релевантности, подробно рассматриваются в следующих разделах.
Центр управления безопасностью Microsoft Azure
Службы поиска Azure
Поисковый индекс Azure используется для отображения высококачественных результатов поиска при малом времени отклика. Поиск Azure предоставляет мощные и усовершенствованные возможности поиска следующего поколения для Dynamics 365 (online). Это выделенная служба поиска, не связанная с Dynamics 365 (online), предоставляемая Azure. Все новые индексы поиска Azure шифруются в неактивном состоянии. Если вы присоединились до 24 января 2018 г., вам потребуется повторно индексировать данные, отказавшись от использования поиска с сортировкой по релевантности, подождав час и снова присоединившись к сервису.
База данных SQL Azure
Поиск с сортировкой по релевантности использует База данных SQL Azure для хранения указанных ниже данных.
Данные конфигурации, связанные с организацией, и соответствующий индекс.
Метаданные, связанные со службой поиска и индексами.
Указатели на метаданные системы и данные при синхронизации изменений.
Данные авторизации для обеспечения усиленной защиты на уровне строк.
Концентраторы событий Azure
Компонент Концентраторы событий Azure используется для обмена сообщениями между Dynamics 365 (online) и Azure, а также для ведения рабочих элементов, обрабатываемых в процессе синхронизации. В каждом сообщении хранятся сведения, например код организации и имя сущности, используемые для синхронизации данных.
Azure Service Fabric Cluster
Обработка и индексация данных производятся с помощью микрослужб, развернутых на виртуальных машинах под управлением среды выполнения Service Fabric. API-интерфейсы поиска и процесс синхронизации данных также размещены в кластере Service Fabric.
При создании службы Service Fabric использовался многолетний опыт корпорации Майкрософт в области критически важных облачных служб, и эта служба проверялась в производственных условиях более пяти лет. Это главная технология, которая лежит в основе базовой инфраструктуры Azure и обеспечивает работу различных служб, включая Skype для бизнеса, Intune, Концентраторы событий Azure, фабрику данных Azure, Azure DocumentDB, База данных SQL Azure и Cortana, которые можно масштабировать для обработки более 500 миллионов оценок в секунду.
Масштабируемые наборы виртуальных машин Azure
Гибкие масштабируемые наборы виртуальных машин Azure рассчитаны на поддержку гипермасштабируемых рабочих нагрузок. Кластер Azure Service Fabric работает на масштабируемых наборах виртуальных машин. Микрослужбы для обработки и индексации данных размещены на масштабируемых наборах и работают под управлением среды выполнения Service Fabric.
Хранилище ключей Azure
Для безопасного управления сертификатами, ключами и другими секретными данными, которые используются в процессе поиска, служит Хранилище ключей Azure.
Хранилище Azure (хранилище больших двоичных объектов)
Изменения данных клиентов хранятся в Хранилище больших двоичных объектов Azure до двух дней. Эти большие двоичные объекты шифруются с помощью новейшей функции в пакете SDK службы хранилища Azure, обеспечивая поддержку симметричного и асимметричного шифрования и интеграцию с Хранилище ключей Azure. С помощью Обновление для Dynamics 365 (сетевая версия), декабрь 2016 г. документы в примечаниях и вложениях сообщений электронной почты и встреч также синхронизируются с хранилищем BLOB-объектов.
Служба Azure Active Directory
Azure Active Directory используется для проверки подлинности данных, которыми обмениваются Dynamics 365 (online) и службы Azure.
Azure Load Balancer
Azure Load Balancer служит для распределения входящего трафика между работоспособными экземплярами службы в облачных службах или на виртуальных машинах, заданных в наборе с балансировкой нагрузки. В поиске с сортировкой по релевантности это средство используется для равномерного распределения нагрузки по конечным точкам в развертывании.
Виртуальные сети Azure
Виртуальные машины в кластере Service Fabric, работающие в одной или нескольких подсетях, соединяются между собой с помощью виртуальной сети Azure. Политики безопасности, параметры DNS, таблицы маршрутизации и IP-адреса полностью контролируются в рамках этой виртуальной сети. Для применения ролей безопасности в этой виртуальной сети используются группы безопасности сети. Эти правила разрешают или запрещают передачу сетевого трафика на виртуальные машины в виртуальной сети.
См. также
Настройка поиска с сортировкой по релевантности для улучшения результатов поиска и производительности (руководство администратора)Поиск в Dynamics 365 Поиск записей Создание, изменение и сохранение расширенного поиска
docs.microsoft.com