Алгоритмы ранжирования Яндекс: история развития. Ранжирования алгоритм
PR PageRank - алгоритм ссылочного ранжирования
Продолжая публикацию статей по теме различных показателей сайта, сегодня речь пойдет про пузомерку от поисковика Google PageRank. Которая, имеет сокращенное называние PR.
Влияние PR при ранжировании.
PR не оказывает существенного влияния на позиции страниц сайта в выдаче. Потому что это не главный критерий при определении позиций. Но если взять две страницы разных сайтов одинаковых по релевантности то выше будет находиться та страница, у которой выше PageRank.
PR играет роль, когда происходит ранжирование по односложному запросу. При таком раскладе очень много страниц являются релевантными запросу. И в таком прецеденте главную роль и будет играть PageRank.
Как устроен PageRank?
Основатели компании Google Ларри Пейдж и Сергей Брин придумали и потом успешно внедрили PageRank в свой самый известный и популярный поисковик во всем мире.
Расчет показателя PR применяется к каждой странице сайта (в отличие от ТИЦ расчет которого ведется для всего сайта). Но, так же как и в случае с ТИЦ рассчитывается PageRank путем учета входящих ссылок. Только учитывается не вес сайта, на котором расставлены ссылки а вес страницы, на которой расположена исходящая ссылка.
Ранжирование выдачи поисковой системы Google выглядит примерно так:
- В первую очередь поисковик выбирает из основного индекса страницы, в которых встречается поисковый запрос.
- Потом он выбирает из этих страниц те, в которых плотность ключевиков выше (из поискового запроса).
- Затем он анализирует анкоры ссылок, которые ведут с сайтов доноров, и проверяет в тексте плотность ключевиков.
- И в итоге позиции страниц с равной релевантностью корректируются путем учета показателей Page Rank.
Для чего нужен PR?
PR представляет из себя критерий ценности определенной веб-страницы. Внешние ссылки, проставленные на качественных трастовых сайтах влияют на его величину. Большое количество ссылок влияют на рост Page Rank.
Желательно что бы Page Rank передающей страницы был высоким ведь по ссылке передается ее статический вес. И так же желательно что бы на этой странице было как можно меньше ссылок на другие внешние страницы. Потому что PR страницы будет поделен между всеми ссылками в равной доле.
Одна страница передает через ссылку меньше 10% статического веса, и именно этот процент PR будет делиться на все ссылки. В идеале заполучить ссылку со страницы Page Rank которой равен 10. И будет вообще отлично, если эта ссылка единственная на странице.

Запрещаем передачу PageRank.
Запретить передачу PR не трудно. Всего то и нужно добавить rel="nofollow" в ссылку и статический вес не будет передаваться по внешним ссылкам. Но зато PageRank будет передаваться по внутренним ссылкам.
Так вы противодействуете оттоку PageRank с вашего сайта и накапливаете его тем самым повышая статвес на страницах ресурса.
Подсчитывая PR Google учтет все ссылки, как внутренние и внешние кроме ссылок, которые расположены на забаненых сайтах. И не факт что главная страница будет иметь наибольший PageRank некоторые внутренние страницы могут быть ей равны или даже вовсе быть выше.
Проверяется PR, так же как и ТИЦ на всевозможных сервисах, во всем цвете представленных в интернете, в SEO расширениях для браузеров и установив специальные счетчики себе на сайт.
mustic.ru
Алгоритмы ранжирования веб-сайтов и их критерии
Сегодня ни один современный пользователь сети интернет не представляет свою жизнь без поисковой системы. Ведь именно она в первую очередь приходит на помощь, когда пользователь ищет информацию. Каждую секунду в поисковую систему люди вбивают миллионы запросов, ищут нужную им информацию. Все что им нужно, получить ответ на свой вопрос, а вебмастера думают над тем, как сделать так, чтобы именно их сайт заинтересовал пользователя. А для этого необходимо быть в топе поисковой выдачи.
Исходя из этого, многие владельцы сайтов занимаются поисковым продвижением. Ведь именно такое продвижение является самым лучшим, так как приносит качественный и нужный трафик на сайт. Поисковые системы используют алгоритмы ранжирования, с помощью которых они определяют, на каком месте выдачи будет сайт. И хотя вся эта информация секретная и вряд ли когда-то будет где-то опубликована, большие специалисты продвижения уже знают основные параметры, которые помогут попасть в топ поисковых машин.

Алгоритмы, которые управляют поисковой выдачей, это целый набор правил и оценки. Поисковые машины, перед тем как отдать сайт в выдачу и определить ему место в поиске, очень тщательно проверяют сайт на всевозможные параметры. И также сравнивают с другими сайтами, по этому же запросу.
Всегда нужно изучать алгоритмы, которые являются первостепенными, приоритетными для поисковиков. А так же регулярно следить за тем, как поисковые машины изменяют алгоритмы, совершенствуют принципы отбора и так далее. Это связано с тем, что современные поисковые системы очень часто добавляют новые алгоритмы, улучшают работу старых, дорабатывают систему поиска. Все это нужно для того, чтобы забрать у недобросовестных оптимизаторов возможность влиять на поисковую выдачу, выдавать только те сайты, ту информацию, которую ищут люди.
Частотность и спам
Ещё с самого начала поисковые системы работали исключительно с ключевыми словами. Некоторое время назад можно было просто написать в тексте десяток ключевых слов и сайт попадал в топ. При этом никаких ограничений со стороны поисковых машин не было и быть не могло. Сегодня же всё поменялось. Да, сегодня при поисковой оптимизации также важно вписывать ключевые слова в содержание.
Но сегодня поисковые системы используют накопленную статистику, и они легко определяют, где контент написан для поисковых роботов, а где для пользователей. И также современные поисковики научились карать черных оптимизаторов, причём безжалостно.

Сегодня поисковым системам мало заполнить текст ключевыми словами. Они проверяют контент на уникальность, размеры текстов и даже тавтологию. Именно поэтому в поисковой выдаче на самых первых местах находятся те сайты, которые создаются специально для людей, раскрывают информацию, отвечают на вопросы. Сложно конечно, сказать, на что конкретно поисковые роботы обращают внимание. Но точно можно сказать, что в первую очередь на популярность сайтов влияет то, чтобы пользователь получил нужную ему информацию.
Профиль ссылок
Сегодня для сайта немаловажно то, что его цитируют, ссылаются, упоминают. Именно поэтому поисковые системы тщательно отслеживают все ссылки, которые ведут на сайт. Таким образом, поисковые системы видят, что ваш сайт обсуждают, ссылаются на него. В глазах поисковых систем это говорит о качественном, уникальном контенте, который очень полезен для людей.
Что люди делают на сайте?
Одним из главных показателей привлекательности и полезности сайта являются поведенческие факторы. Для поисковых систем крайне важно знать и отслеживать, что пользователи делают на вашем сайте, соответствует ли контент запросу. И также проверяются другие параметры. Эту нужно для того, чтобы понимать насколько удобно пользователю на сайте. Существуют, конечно, способы повлиять на поведенческие факторы, используя запрещенные программы, сайты, людей.
Но также важно помнить о том, что если поисковая система определит нарушения в продвижении, она очень жёстко накажет. И, скорее всего, сайт будет вообще удален из поисковой выдачи. Поисковые машины очень жестоко карают тех, кто использует искусственные показатели, даже если сайт был мегапопулярным и посещаемым. Для поисковых машин все сайты одинаковы.

Существует огромное количество алгоритмов, с помощью которых поисковые системы определяют качество и место в поиске для сайта. Но они постоянно меняются или убираются вообще. А те алгоритмы, которые описаны выше, являются приоритетными для поисковых машин. И если сейчас продвигать свои сайты в поисковых системах не ради заработка, а ради людей, то поисковая система рано или поздно заметит эту стратегию и будет выдвигать сайт в топ. А значит, сайт будет высоко посещаемым, популярным, с качественным трафиком и хорошим доходом.
- Создано 28.03.2018 08:00:00
- Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
myrusakov.ru
Алгоритм ссылочного ранжирования PageRank и линейная алгебра
Недавно прочитал любопытную книгу Стивен Строгац. Удовольствие от х. Автор рассказывает около 30 занимательных (и поучительных) историй из области математики. В одной из историй говорится о принципах работы PageRank – алгоритма ссылочного ранжирования, впервые использованного в Google. Тема актуальна и довольна проста для понимания. Так что слово Стивену Строгацу…
В те далекие времена, когда Google еще не существовало, поиск в сети был безнадежным занятием. Сайты, предлагаемые старыми поисковыми машинами, часто не соответствовали запросу, а те, которые содержали нужную информацию, были либо глубоко запрятаны в списке результатов, либо вообще отсутствовали. Алгоритмы на основе анализа ссылок решили проблему, проникнув в суть парадокса, подобного коанам дзен: в результате поиска в интернете должны были отображаться лучшие страницы. А что же, делает страницу лучшей? Когда на нее ссылаются другие не менее хорошие страницы.

Скачать заметку в формате Word или pdf
Звучит подобно рассуждениям про замкнутый круг. Так и есть. Именно поэтому все настолько сложно. Ухватившись за эту идею и превратив ее в преимущество, алгоритм анализа ссылок дает решение поиска в сети в стиле джиу-джитсу. Этот подход построен на идеях, взятых из линейной алгебры, изучения векторов и матриц. Если вы хотите выявить закономерности в огромном скоплении данных или выполнить гигантские вычисления с миллионами переменных, линейная алгебра предоставит для этого все необходимые инструменты. С ее помощью был построен фундамент для алгоритма PageRank [1], положенного в основу Google. Она также помогает ученым классифицировать человеческие лица, провести анализ голосования в Верховном суде, а также выиграть приз Netflix (вручаемый команде, сумевшей улучшить более чем на 10% систему Netflix, на основе которой составляются рекомендации для просмотра лучших фильмов).
Чтобы изучить линейную алгебру в действии, рассмотрим, как работает алгоритм PageRank. А чтобы выявить его сущность без лишней суеты, представим игрушечную паутину, состоящую всего из трех страниц, связанных между собой следующим образом:
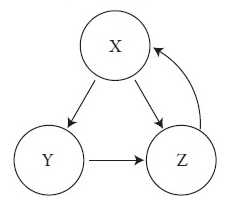
Рис. 1. Небольшая сеть из трех сайтов
Стрелки указывают, что страница X содержит ссылку на страницу Y, однако Y не отвечает ей взаимностью. Наоборот, Y ссылается на Z. Тем временем X и Z ссылаются друг на друга.
Какие страницы самые важные в этой маленькой паутине? Вы можете подумать, что это невозможно определить из-за недостатка информации об их содержимом. Но такой способ мышления устарел. Беспокойство по поводу контента вылилось в неудобный способ ранжирования страниц. Компьютеры мало понимают в смысловом наполнении, а люди не справляются с тысячами новых страниц, которые каждый день появляются в сети.
Подход, придуманный Ларри Пейджем и Сергеем Брином, аспирантами университета и основателями Google, состоял в том, чтобы позволить страницам самим ранжироваться в определенном порядке, голосуя ссылками. В приведенном выше примере страницы X и Y ссылаются на Z, благодаря чему Z становится единственной страницей с двумя входящими ссылками. Следовательно, она и будет самой популярной страницей в данной среде. Однако если ссылки поступают со страниц сомнительного качества, они станут работать против себя. Популярность сама по себе ничего не значит. Главное — иметь ссылки с хороших страниц.
И здесь мы снова оказывается в замкнутом круге. Страница считается хорошей, если на нее ссылаются хорошие страницы, но кто изначально решает, какие из них хорошие? Это решает сеть. Вот как все происходит. [2]
Алгоритм Google назначает для каждой страницы дробное число от 0 до 1. Это численное значение называется PageRank и измеряет «важность» страницы по отношению к другим, высчитывая относительное количество времени, которое гипотетический пользователь потратит на ее посещение. Хотя пользователь может выбирать более чем из одной исходящей ссылки, он выбирает ее случайно с равной вероятностью. При таком подходе страницы считаются более авторитетными, если они чаще посещаются.
А поскольку индексы PageRank определяются как пропорции, их сумма по всей сети должна составлять 1. Этот закон сохранения предполагает другой, возможно, более осязаемый способ визуализации PageRank. Представьте его как жидкое вещество, текущее по сети, количество которого уменьшается на плохих страницах и увеличивается на хороших. С помощью алгоритма мы пытаемся определить, как эта жидкость распределяется по Интернету на протяжении длительного времени.
Ответ получим в результате многократно повторяющегося следующего процесса. Алгоритм начинается с некоего предположения, затем обновляет все значения PageRank, распределяя жидкость в равных частях по исходящим ссылкам, после этого она проходит несколько кругов, пока не установится определенное состояние, при котором страницы получат причитающуюся им долю.
Изначально алгоритм задает равные доли, что позволяет каждой странице получить одинаковое количество PageRank. В нашем примере три страницы, и каждая из них начинает движение по алгоритму со счетом 1/3.

Рис. 2. Начальные значения PageRank
Затем счет обновляется, отображая реальное значение каждой страницы. Правило состоит в том, что каждая страница берет свой PageRank с последнего круга и равномерно распределяет его по всем страницам, на которые ссылается. Следовательно, обновленное значение страницы X после прохождения первого круга по-прежнему равно 1/3, поскольку именно столько PageRank она получает от Z, единственной страницы, которая на нее ссылается. При этом счет страницы Y уменьшается до 1/6, так как она получает только половину PageRank от X после предыдущего круга. Вторая половина переходит к странице Z, что делает ее победителем на данном этапе, поскольку она добавляет себе еще 1/6 от страницы X, а также 1/3 от Y, и всего получается 1/2. Таким образом, после первого круга мы имеем следующие значения PageRank:
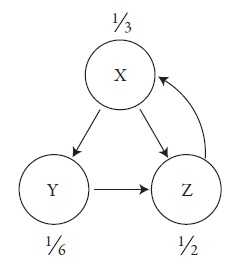
Рис. 3. Значения PageRank после одного обновления
В последующих кругах правило обновления остается прежним. Если обозначить через х, у, z текущий счет страниц X, Y и Z, то в результате обновления получим такой счет:
х’ = z
у’ = ½ x
z’ = ½ х + у,
где штрихи говорят о том, что произошло обновление. Подобные многократно повторяющиеся вычисления удобно выполнять в электронной таблице (или вручную, если сеть маленькая, как в нашем случае).
После десяти повторений обнаружим, что от обновления к обновлению цифры практически не меняются. К этому моменту доля X составит 40,6% от всего PageRank, доля Y — 19,8%, а Z — 39,6%. Эти значения подозрительно близки к числам 40, 20 и 40%, что говорит о том, что алгоритм должен к ним сходиться. Так и есть. Эти предельные значения алгоритм Google и определяет для сети как PageRank.

Рис. 4. Предельные значения PageRank
Вывод для данной маленькой сети такой: страницы X и Z одинаково важны, несмотря на то что у Z в два раза больше входящих ссылок. Это и понятно: страница X равна Z по значимости, поскольку она получает от нее полное одобрение, однако взамен дает ей лишь половину своего одобрения. Вторая половина отправляется Y. Это также объясняет, почему Y достается только половина от долей X и Z.
Интересно, что эти значения можно получить, не прибегая к многократным итерациям. Надо просто подумать над условиями, определяющими стационарное состояние. Если после очередного обновления ничего не меняется, то x’ = x, y’ = y и z’ = z. Поэтому, заменив переменные со штрихом в уравнениях обновлений на их эквиваленты без штрихов, получим систему уравнений
х = z
y = ½ x
z = ½ x + y,
при решении которой x = 2y = z. Поскольку сумма значений x, y и z должна равняться 1, отсюда следует, что x = 2/5, y = 1/5 и z = 2/5, что соответствует ранее найденным значениям.
Сложности начинаются там, где в уравнениях присутствует огромное количество переменных, как это происходит в реальной сети. Поэтому одной из центральных задач линейной алгебры является разработка более быстрых алгоритмов для решения больших систем уравнений. Даже незначительные усовершенствования этих алгоритмов ощущаются практически во всех сферах жизни — от расписания авиарейсов до сжатия изображения.
Однако самой существенной победой линейной алгебры, с точки зрения ее роли в повседневной жизни, безусловно, стало решение парадокса дзен-буддизма для ранжирования страниц. «Страница хороша в той мере, в какой хорошие страницы ссылаются на нее». Переведенный в математические символы, этот критерий становится алгоритмом PageRank.
Поисковик Google стал тем, чем он есть сегодня, после решения уравнения, которое и мы с вами только что решили, но с миллиардами переменных — и, соответственно, с миллиардными прибылями.
[1] Согласно Google термин PageRang происходит от имени одного из основателей Google Ларри Пейджа, а не от английского слова page (страница).
[2] Для простоты я представлю только базовую версию алгоритма PageRank. Для обработки сетей с некоторыми другими структурными свойствами его необходимо изменить. Предположим, в сети есть страницы, которые ссылаются на другие, но те, в свою очередь, на них не ссылаются. В процессе обновления эти страницы потеряют свой PageRank. Они отдают его другим, и он больше не восполняется. Таким образом, в конце концов они получат значения PageRank, равные нулю, и с этой точки зрения становятся неразличимыми.
С другой стороны, существуют сети, где некоторые страницы или группы страниц открыты для накапливания PageRank, но при этом не делают ссылок на другие страницы. Подобные страницы действуют как накопители PageRank.
Чтобы избежать подобных результатов, Брин и Пейдж изменили свой алгоритм следующим образом. После каждого этапа в процессе обновления данных все текущие значения PageRank уменьшаются на постоянный коэффициент, так что их сумма будет меньше 1. Затем остатки PageRank равномерно распределяются между всеми узлами в сети, как будто «сыплются с неба». Таким образом, алгоритм завершается действием уравнивания, распределяющим значения PageRank между самыми «бедными» узлами.
Более тщательно математика PageRank и интерактивные исследования рассматриваются в работе E. Aghapour, T. P. Chartier, A. N. Langville, and K. E. Pedings, Google PageRank: The mathematics of Google (http://www.whydomath.org/node/google/index.html).
baguzin.ru
Яндекс - алгоритмы ранжирования | Разработка сайтов

С момента основания поисковой системы Яндекс было разработано и внесено в действие немалое количество алгоритмов ранжирования, которые разрешают субъективно оценивать рентабельность рабочих файлов согласно с основными поисковыми запросами посетителей. С годами разрабатывались все более современные способы и методы для обхода спама, включались все новые и новые критерии, которые разрешают отсеивать излишнюю информацию. Ниже проанализируем основные нововведения, которые были достаточно популярным на протяжении последнего десятка лет.
Этапы введения поисковых алгоритмов в поисковике Яндекс
(2007-2018 гг.)
2.07.2007. На данном этапе была разработана 7 версия ранжирования Яндекс, которая разрешала отображать один и тот же запрос разным пользователям в разной цветовой гамме. Это разрешит оценивать релевантность запросов даже невооруженным глазом.
20.12.2007-17.01-2008 годов. Вносятся существенные коррективы в возможность ранжирования поисков. Появляется возможность фильтровать «прогоны», которые разрешают накручивать ссылочные факторы. Внедрение получило название «Версия 8».
16.05.2008, 02.07.2008. Вносится программа Магадан, которая обеспечивает полную оценку всевозможных сокращений, аббревиатур. Алгоритм легко воспринимает синонимы и владеет тонкостями по распознаванию расширения вложенного файла. Версия 2.0 разрешила искать изысканность контента и раскручивать новые факторы для поиска, учитывая основные запросы пользователей.
01.09 2008 года. Находка – метод, который разрешает блокировать выдачу в поисковике результаты с учетом стоп-слов. Включается функция тезаурус.
10.04, 24.06, 20.08, 23.09,28.09.2009 года. Арзамас. Название способа созвучно с именованием региона пользователя. Версия 1.1 имеет геозависимость, разработан для МСК, СПБ и ЕКБ. Версия 1.2. – новая современная форма, которая становится полностью геонезависимой. Версия +16 отличается геонезавимимыми критериями для 16 регионов РФ. 1.5 – новая форма, которая движется на пути к полной геонезависимости во всем мире. 1.5 SP1 характеризуется наиболее качественной формулой для полностью свободных геозапросов.
17.11.2009. MatrixNet (Снежинск) – разработано 19 формул, которые обеспечивают право на выполнение ранжирования, имеет большую популярность в РФ и максимально оперативно вносит коррективы в поисковые запросы, вносящие пользователем вручную.
22.12.2009, 11.03.2010. Конаково – негласное название метода. В документально оформлении звучит название «Обнинск». Конаково 1.1 включает разработку более 1250 формул для гео независимых запросов.
14.09.2010. Обнинск. На данном этапе повышается производительность релевантности пользовательских запросов. Независимость с «гео точки зрения» повышается к 70%.
15.12.2010. Краснодар – методика, которая разрешает разделять запросы пользователя на отдельные интенты. Здесь повышается уровень локализации выдаваемых результатов. Под действие новой формулы алгоритма попадает около 1300 городов РФ.
17.08.2011. Рейкьявик. Такой алгоритм обеспечивает обработку региональных особенностей пользователя сети, что является одним из первых источников для идентификации ІР-адреса.
12.12.2012. Калининград – здесь учитываются все региональные предпочтения юзеров, повышается критерий отбора среди избранных сайтов и среди пользователей сети.
30.05.2013. Дублин. На этом этапе учитываются все самые важные факторы, на которые обращается пользователь при поиске нужной ему информации. Происходит автоматическая подстройка алгоритма под пользователя в режиме реального времени.
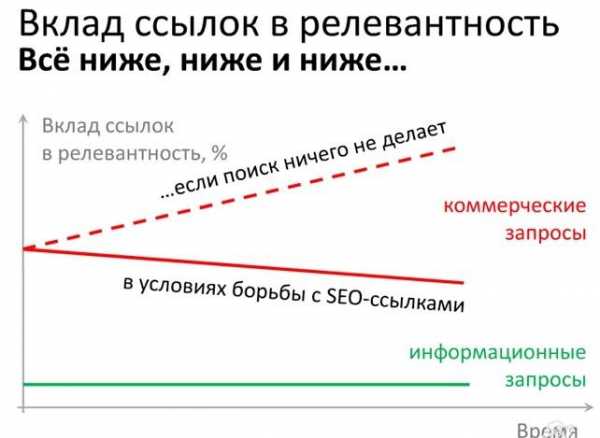
12.03.2014. Началово. Алгоритм предусматривает выполнения поиска без применения ссылок. Формула применяется для коммерческих целей среди пользователей Московского региона.
05.06.2014. Одесса. Используется алгоритм «Острова», который вносит дизайнерские новинки под видом морей и океанов, но как показала практика, такое оформление не принесло желаемые результаты, и вскоре вышло из ряда.
01.04.2015. Амстердам. Являет своеобразную дополнительную карточку, которая разрешает выводить общую информацию о предмете запроса сразу справа от основных результатов. В своей базе Яндекс хранит более 10 миллионов разнообразных форм, доступных для поиска.
15.05.2015. Минусинск. На данном этапе повышается употребление СЕО, которое отображается на странице. Ранжирование по любым запросам пользуется популярностью исключительно в Московском регионе.
14.09.2015. Киров. Этот алгоритм повышает вероятность для улучшения общей релевантности ряда документов, оценка которых устанавливается на показателе «Rel+». Эта оценка позволяет выводить более точную поведенческую информацию, которая соответствует многочисленным запросам пользователей в Московском регионе. Дальше планируется внедрение такого проекта по всей территории РФ.
02.2016. Владивосток. Проект предусматривает выполнение всего необходимого для более скорой адаптации сайта к оформлению со стороны переносного устройства, будь то мобильный телефон или планшетный компьютер. Разрабатываются адаптированные проекты для каждой базы.
02.11.2016. Палех. Обеспечивается возможность искать информацию, которая имеет малейшее сходство с запросом, который был прописан пользователем. Алгоритм легко вычисляет пары пользовательских запросов, которые обоснованы на искусственной сети. Главная цель такого алгоритма заключается в том, чтобы повысить качество выдаваемой информации даже по мало востребованным запросам, на которые, кажется, иногда найти информации практически невозможно.
23.03.2017. Баден-Баден. Алгоритм разрешает находить информацию по ранее переоптимизированным текстам. На данном этапе система сама разрешает находить необходимую информацию после введения нескольких слов из предполагаемого запроса.
22.08.2017. Королев. Алгоритм ранжирования был введен на этапе «Палеха». Главная особенность заключается в получении возможности искать нужную информацию, сопоставляя его с теми интентами, которые будут соответствовать запросу пользователя. Отличие от «Палеха» заключается в том, что здесь анализируется весь документ, а не всего лишь его заголовок.
Название алгоритмов не является официальным, название городом используется с целью соблюдения более оптимальной очередности передачи информации.
С целью блокировки распространения спам-информации, Яндекс разработал ряд специализированных алгоритмов, которые разрешают вести активную борьбу с сайтами-нарушителями. Вместе с развитием алгоритмов для ранжирования вводятся в действие методы, которые разрешают вносить соответствующие санкции в отмену на продвижение обманных методов для раскрутки собственного сайта. На протяжении всего периода времени эти методы борьбы усовершенствовались, что на сегодняшнем этапе развития интернет индустрии позволяет получать максимально эффективные результаты.
Список наиболее распространенных антиспам-алгоритмов от Яндекса
За содержимое текста
«Переспам» — специальный фильтр, который разрешает снизить уровень релевантности выдаваемой информации по определенной фразе, которая была прописана пользователем в поисковике.
«Переоптимизация» — алгоритм, который можно применять в ручном режиме, и он разрешает существенно снизить конечное значение релевантности документа в целом.
«Текстовый антиспам» — относительно новый алгоритм, который снижает уровень релевантности запроса на 50 и более пунктов.
«Баден-Баден» — один из наиболее востребованных алгоритмов от Яндекс. Блокирует выдачу наиболее оптимизированных страниц. На данном этапе обеспечивается полноценный анализ содержимого документа, а не его название.
За используемые ссылки
«Ссылочный взрыв» — штрафует следы, которые приводят к отображению естественно большого количества ссылок со стороны подозрительных сайтов. Доноры, которые применяются во время работы такого алгоритма, в дальнейшем считаются ненадежными и больше не используются для фильтрации в поисковой системе.
«Спам из ссылок» — метод, который применятся для тех сайтов, которые используют различные методы для манипуляции ссылками/ссылочными прогонами.
«Внутренний/Внешний Непот» — исключается вероятность перелинковки нескольких ссылок, расположенных на одной странице. Полностью блокирует вероятность для продвижения спам-информации через внешние ссылки.
«Минусинск» — является одним из самых сильных воздействий, которые применяются с целью понижения уровня поисковых запросов через SEO-ссылки.
За поведенческую информацию
«Накрутка ПФ» — алгоритм, который штрафует сайт, пытающийся провести накрутку кликов со стороны поведенческого фактора человека, используя мотивированный трафик и эмуляцию действий юзера в поисковике. Алгоритм пользуется огромным спросом и разрешает фильтровать сайты по ТОПу.
«Кликджекинг» — снижает вероятность для распределения запросов на сайте пользователя. Для этого на странице размещаются невидимые элементы, с которыми пользователь ведет работу, не зная об этом. При использовании такого метода, владельцы сайтов имеют возможность отыскать всю необходимую информацию о потенциальном клиенте через социальные сети, начиная с его номера мобильного, заканчивая семейным или финансовым положением. При этом, очень важно, что простой пользователь сети об этом может даже не догадываться.
Ассоциированность сайтов в группу
«Аффилированность» — специальная программа, которая направляет на переход по одной лишь ссылке, блокирует выдачу дополнительной информации, что тем самым способствует более скорой раскрутке одного сайта.
Продвижение рекламной продукции
«Назойливая реклама» — существенно снижается вероятность для ранжирования сайтов, на которых происходит выдача назойливой рекламы.
«18+»
Фильтр для взрослых — из видимости просто пропадают запросы, что соответствуют запросу «18+». Домен срабатывает только по итогам точного запроса или убрав ненужную фильтрацию. Такая фильтрация используется для всего документа или для каждого раздела сайта по отдельности.
«На идентичные сниппеты» — разрешает объединять те ссылки, которые выдают информацию, которая пересекается с запрашиваемой и той, которая требуется для сниппета.
Излишняя и неправдоподобная реклама понижает вероятность для ранжирования сайтов, включая все содержимое из уведомлений и всплывающих окон.
Заблуждения для владельцев мобильных девайсов.
Элементы, которые не помечены, как реклама, но все же имеют свойство выводить человека из рационального предрасположения.
Направленность
Обман поисковика
Происходит полное ограничение по ранжированию сайтов.
Блокируется вероятность для воссоздания псевдо-сайтов и сайтов-партнерок.
inetmagazine.ru
Анализ доклада «Алгоритм текстового ранжирования Яндекса» с РОМИП-2006 — Netpeak Blog
Наш аналитический отдел (в лице Дениса Шенцева, Алексея Борща, Кирилла Левенца и меня) подготовил ряд статей про алгоритмы поисковых систем. Постараемся подавать информацию максимально доступным языком, чтобы приблизиться к пониманию того, как работают поисковые системы.
Данная статья — адаптация статьи Яндекса. Все комментарии, которые приведены ниже, касаются только этой конкретной публикации, а не поисковой системы в целом. Многое, что характерно для реальных поисковиков, в комментариях может быть не учтено.
Список показателей которые учитываются формулой описанной в статье:
- частота использования ключевых слов в других документах;
- частота использования ключевых слов внутри текущего документа;
- выделение ключевых слов тегами и их расстояние до начала документа;
- длина документа;
- число пар слов которые подряд идут в запросе в таком же виде встречаются в тексте;
- число ключевых слов из запроса которые вообще встречаются в тексте;
- встречается ли весь запрос в тексте.
Алгоритм ранжирования проводит лемматизацию слов документа и запроса, поэтому не имеет значения в какой форме будет использоваться слово или его синонимы (разные формы будут считаться за одну и туже лемму). Для запроса была использована строка: «купить ноутбук с доставкой одесса» (здесь и далее кавычки для того чтоб отделить слова от текста, при запросе их не было). Рассмотрим как будет работать формула для нашего примера и какие параметры будут у первых 4-х сайтов из выдачи Yandex.
Расчет релевантности документа к запросу производится по формуле:
- Wsingle — вклад отдельных слов из запроса;
- Wpair — вклад пар слов;
- Wallwords — вклад вхождения всех слов из запроса;
- Wphrase — вклад вхождения всего запроса;
- Whalfphrase — вклад вхождения части запроса.
В оригинальной статье использовалось еще дополнительное слагаемое Wprf — за похожесть документа на документы из вершины выдачи, но мы его пока не будем учитывать. В наших расчетах коэффициенты k1, k2, k3 — нам также не известны поэтому предположим, что они равны 1.
1. Учет отдельных слов:
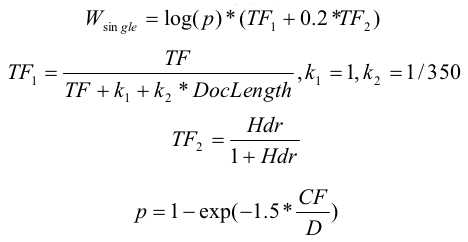
TF — частота вхождения слова в документ ( = число_вхождений_слова / длину_документа). Значения частот для слов из запроса, для каждого из мест в топ выдаче:
- 1 место — "купить" 13, "ноутбук" 93, "с" 28, "доставкой" 7, "одесса" 11 раз
- 2 место — "купить" 22, "ноутбук" 50, "с" 2, "доставкой" 2, "одесса" 2 раза
- 3 место — "купить" 42, "ноутбук" 12, "с" 7, "доставкой" 10, "одесса" 9 раз
- 4 место — "купить" 2, "ноутбук" 92, "с" 83, "доставкой" 7, "одесса" 5 раз
DocLength — длина документа в словах;
- 1 место — 2589 слов
- 2 место — 1385
- 3 место — 1325
- 4 место — 3425
Hdr — сумма весов слова за форматирование. Согласно авторам статьи:
Учитывается наличие слова в первом предложении, во втором предложении, внутри выделяющих html тегов.
Но какие конкретно числа используются авторы не уточнили (в наших расчетах будем считать этот параметр равным 0).
D — число документов в коллекции. Для получения конкретного значения можно воспользоваться поиском фразы "lang:ru" с помощью yandex.ru. Полученное при этом количество документов и будем считать за число документов в коллекции. В нашем случае в выдачу попало 2379 млн. документов.
CF — число вхождений слова в коллекцию документов (число документов, в которых слово встретилось хотя-бы раз). Конкретные числа для слов из нашего запроса получились следующими:
- "купить" 651 млн. документов
- "ноутбук" 35 млн.
- "с" 2344 млн.
- "доставкой" 163 млн.
- "одесса" 68 млн.
Wsingle мы рассчитывали для каждого слова и в Score добавляли их сумму.
2. Учет пар слов:
p1, p2 — рассчитываются так-же как и для Wsingle; TF — количество вхождений пары слов, с учетом весов. Пара учитывается, когда слова запроса встречаются в тексте подряд (+1), через слово (+0.5) или в обратном порядке (+0.5). Плюс еще специальный случай, когда слова, идущие в запросе через одно, в тексте встречаются подряд (+0.1).
- 1 место — "купить ноутбук" 6 раз, "ноутбук c доставкой" 1, "доставкой одесса" 2 раза
- 2 место — "купить ноутбук" 1
- 3 место — "купить ноутбук" 1
- 4 место — ни одна пара не встретилась ни разу.
Остальные пары в документах не встречались.
3. Учет всех слов:
Nmiss — число слов которые не встретились в документе. Для рассматриваемых сайтов это число оказалось одинаковым.
4. Учет запроса целиком:
TF — число вхождений запроса целиком, деленное на длину документа. Для топа значение получилось 0 для всех сайтов.
5. Учет части запроса:
Это слагаемое учитывалось когда сумма idf слов запроса в предложении (в формуле — сумма логарифмов) больше половины суммы idf всех слов запроса. TF здесь – количество учитываемых предложений в тексте деленное на число предложений в документе. Для нашей 4-ки это опять получился 0, т.к. там таких предложений не оказалось. Для сравнения предположим что мы создали документ и хотим рассчитать его релевантность для запроса. Пусть числовые значения для него будут иметь вид:
- слов в документе 400
- "купить" 3, "ноутбук" 10, "с" 1, "доставкой" 3, "одесса" 2
- "купить ноутбук" 1, "ноутбук c доставкой" 1, "доставкой одесса" 1 раз.
Остальные значения пусть будут такими же как и топовой четверки. Окончательные числа соберем в таблицу и посмотрим, что получилось. Таблица полученных значений для нашего примера:
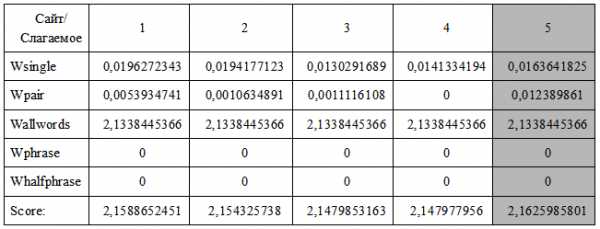
И так можно видеть, что показатель релевантности у созданной странички оказался даже лучше чем у первого места. Это можно объяснить следующими факторами:
- относительно (первой 4-ки документов) небольшим размера документа;
- наличия пар ключевых слов идущих подряд (даже небольшого количества)
Комментарии
I. Часто употребляемые слова слабо влияют на релевантность, или вообще игнорируются. Чем больше раз слово из запроса встречается в документах коллекции, тем менее оно информативно — тем меньше вклад этого слова в релевантность.
Если слово будет только в одном документе из всей коллекции, то вклад этого слова в релевантность будет наибольшим. Если слово встречается в каждом документе 1 или больше раз, то вклад такого слова в релевантность будет равен 0. При этом чем больше документов в коллекции, тем большее количество употреблений допустимо (употребление прямо пропорционально числу документов), при сохранении той же релевантности. Если число документов увеличится в 2 раза, то релевантность сохранится если и частота употребления также увеличится в 2 раза. Поэтому стоит акцентировать внимание лишь на те слова, которые имеют относительно малую частоту, и использовать одно и тоже слово как можно в меньшем числе документов. Ключевые слова стоит выделять с помощью форматирования. Используйте их как можно ближе к началу документа.
II. Одно и тоже ключевое слово не должно употребляться в тексте документа много раз. Важен сам факт его наличия. Зависимость релевантности от частоты слова носит не линейный характер. Общий принцип, что чем чаще встречается слово в документе, тем больше будет его релевантность — верен. Однако начиная с определенного значения увеличение частоты перестаёт влиять на релевантность. На графике приведено схематическое поведение влияния частоты вхождения слова на релевантность.
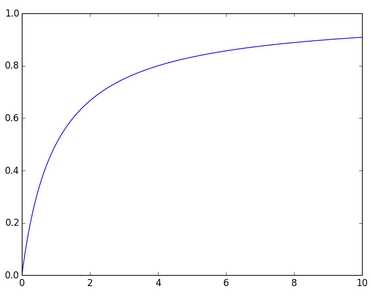
Горизонтальная ось — частота слова. Вертикальная — релевантность
Размер документа не должен быть слишком объемным или слишком коротким (желательно таким же как среднее значение остальных документов или меньше).
Частота отдельного слова не должна быть большой, важен сам факт наличия такого слова. Приоритет в количестве различных ключевых слов из тематики документа, их должно быть как можно больше, но из одной определенной тематики, чтобы увеличить шансы документа быть найденным.
III. Используйте ключевые слова в словосочетаниях. Ключевые слова по возможности должны образовывать все возможные парные словосочетания друг с другом. Повторения одинаковых пар стоит избегать. Т.е. как и в пункте II лучше много разных, чем много повторяющихся. На словосочетания длиной больше 3-х слов не стоит акцентировать внимание.
IV. Желательно чтоб слова из потенциальных запросов присутствовали в документе. Не помешает наличие разных ключевых слов по тематике документа. При этом количество одинаковых слов или форм одного и того же слова должно быть как можно меньше.
V. Половина слов в предложениях — тематические. Желательно чтобы каждое предложение содержало половину слов из потенциального запроса. Порядок следования слов стоит согласовать с пунктом III.
VI. Зная какой должна быть релевантность к конкретному запросу мы можем указать конкретные значения для числа вхождений каждого слова. Взяв в качестве значения релевантности запросу оценку для сайтов из топа выдачи можно оптимально подбирать количество вхождений каждого отдельного слова. Из минусов такого подхода — мы становимся зависимыми от конкретного запроса или набора запросов (но это если не учитывать что поисковики расширяют запросы).
netpeak.net
Алгоритмы ранжирования Яндекс: история развития
На протяжении очень долгого времени алгоритмы ранжирования Яндекс оставались «секретом» для пользователей. Специалисты поисковой системы Яндекс предпочитали не информировать пользователей сети интернет об изменениях алгоритмов ранжирования.
Алгоритмы ранжирования Яндекс
12007 годИ только в 2007 году сотрудники компании Яндекс стали информировать своих пользователей о введении новшеств в поисковой алгоритм. Это немного облегчив продвижение сайтов для многих вебмастеров.
Стоит отметить, что алгоритмы ранжирования Яндекс постоянно изменяются. Благодаря этим изменениям добавляется более новый и совершенный функционал, который очень облегчает работу с данным поисковиком. Также благодаря изменению алгоритмов ранжирования устраняются баги, происходит обновление фильтров и ограничителей, подгоняется более точная выдача информации, которая максимально соответствует первоначальному запросу.
В мае 2008 года, специалистами компании Яндекс был выпущен новый алгоритм, который носит название «Магадан».
Алгоритм Магадан
В данном алгоритме увеличено в два раза количество факторов ранжирования, значительно улучшен классификатор по местонахождению пользователя (геотаргетинг). Также в алгоритме «Магадан» присутствуют такие инновационные решения как добавление классификаторов для контента и ссылок. Значительно увеличена скорость поисковика по поиску информации по вводимым ключевым запросам (благодаря данному алгоритму поисковик способен выдавать информацию даже с текстами, которые имеют дореволюционную орфографию).
В июле того же года вышла новая версия алгоритма «Магадан», в которой присутствовали дополнительные факторы ранжирования, например, такие как определение уникальности текста и информации, определение принадлежности контента к порнографическому и прочее.
3сентябрь 2008 годУже в сентябре 2008 года, компания Яндекс выпускает новый алгоритм, который носит название «Находка».
Благодаря появлению данного алгоритма значительно улучшилась работа со словарями в поисковой системе Яндекс, значительно возросло качество ранжирования по запросам, в которых присутствовали стоп – слова (союзы и предлоги). Также в данном алгоритме был разработан абсолютно новый подход к машинальному обучению (машина стала различать разные запросы, и стала менять для разных запросов факторы ранжирования, в расчетной формуле поисковой выдачи).
4апрель 2009 годНовый алгоритм под названием «Арзамас» или «Анадырь» был выложен в поисковой системе Яндекс в апреле 2009 года.
Алгоритм Арзамас
Благодаря введению этого алгоритма поисковая система Яндекс научилась более точно и значительно лучше понимать русский язык, что дало возможность более точно разрешать неоднозначные слова в запросах. Также данный алгоритм позволил учитывать, поисковой системой, регион, в котором находится пользователь. Благодаря чему пользователи стали получать более точную и более полезную информацию по запрашиваемому вопросу, которая имела максимальное отношения к региону, в котором находился пользователь.
При этом следует отметить, что в разных регионах выдаваемая информация тоже разная, несмотря на один и тот же вводимый пользователем запрос. Также в данном алгоритме поиска значительно улучшена формула, которая позволяет удобнее работать с многословными запросами. Были введены более жесткие фильтры для страниц с попандер-баннерами (Pop-Under баннер появляется на всех страницах сайта и не имеет отношение к тематике сайта), кликандер(Click-ander реклама, появляющаяся на странице при первом клике посетителя) и бодиклик (Bodyclic -сервис тизерной рекламы).
5ноябрь 2009 годВ ноябре 2009 года вышел новый алгоритм, который носит название «Снежинск».
Алгоритм Снежинск
В этом алгоритме введены дополнительные функции и параметры ранжирования, которые позволяют применять несколько тысяч поисковых параметров для одного документа. Также в данном алгоритме присутствовали новые региональные параметры, были внедрены фильтры АГС (фильтры сайтов намерено пытающихся влиять на поисковую выдачу, проще, анти говно сайт), и значительно улучшился поиск оригиналов контента в сети интернет. Также в данном алгоритме присутствовала самообучающаяся система MatrixNet.
6декабрь 2009 годВ декабре 2009 года появился новый алгоритм под названием «Конаково».
Этот алгоритм был всего лишь улучшенной версией алгоритма «Снежинск» и в нем было улучшено только локальное ранжирование. В сентябре 2010 года вышел новый алгоритм «Обнинск». В этом алгоритме было улучшено ранжирование по территориально независимым запросам, было введено ограничение влияния искусственных ссылок на ранжирование. Также благодаря данному алгоритму значительно улучшилась процедура определения авторского текста, и был значительно расширен словарь транслитерации.
72010 годВ декабре 2010 года вышел новый алгоритм под названием «Краснодар».
Для создания этого алгоритма была специально разработана новая технология, которая называется Спектр. Благодаря этому алгоритму поисковая система Яндекс стала классифицировать запросы и выделять из них объекты, присваивая запросам определенную категорию (товары, услуги и прочее).
82014 годОчередной убойный выстрел Яндекс — Алгоритмы ранжирования Яндекс больше не будут учитывать ссылки при ранжировании. Согласно последним заявлениям, в начале 2014 года будет запущено ранжирование без ссылок. Из факторов ранжирования Яндекс уберут все ссылочные факторы. Это нововведение коснется только коммерческих запросов и сначала будет опробовано на Москве и Московской области. Авторы новшеств, создатели АГС Яндекс.
©SeoJus.ru
Другие уроки SEO учебника
(Всего просмотров 148)
Статьи по теме
Поделиться ссылкой:
seojus.ru
Алгоритмы ранжирования Google и Яндекс. Факторы влияющие на выдачу
В этом материале вкратце расскажу о существующих ныне алгоритмах ранжирования популярнейших в СНГ поисковых машин Google и Яндекс.Если вашей целью является продвижение собственного сайта и вы проживаете в московской области, то возможно вам помогут вот эти ребята: http://navirazhe.ru/sozdanie-prodvizhenie-saitov-kolomna
Помимо вполне конкретных факторов ранжирования, например, таких как возраст домена и ключевые слова в доменном имени, существуют и более обширные алгоритмы. Правильнее было бы сказать обновления одного общего алгоритма, но т.к. они являются совокупностью множества нововведений и доработок, принято рассматривать их обособленно. Именно поэтому у них есть свои имена.
Алгоритмы Google
Freshness
Определяет свежесть контента. Для некоторых типов поисковых запросов этот параметр является основным при ранжировании. При анализе Google опирается на следующие характеристики: дата создания контента, масштаб и частота изменений, соотношение старых и новых страниц.Панда
Задача Панды выявить полезный контент и отсечь от топа низкокачественную информацию. Для того чтобы понять, как относиться к вашему сайту Панда, честно ответьте на вопрос: "Помогает ли мой сайт реальным людям?"Пингвин
Данный алгоритм призван бороться с неестественными ссылками. Сюда относятся: покупные ссылки, ссылки по обмену, ссылки с сайтов-сателлитов, ссылки с нерелевантных сайтов. Ссылки так же должны приносить пользу, а не служить средством накрутки рейтинга.Колибри
Более "умный" алгоритм, способный относиться к запросам не только как к набору ключевых слов, но и понимать их смысл. К примеру, если вы спросите "сколько стоит доллар", то поисковик поймёт, что вам нужен курс валюты.Опоссум
Самое последнее обновления Google, внёсшее изменение в ранжирование локальных компаний. Выросли позиции фирм, точно не входящих в конкретную локацию, но находящихся вблизи от неё.Алгоритмы Яндекса
Механизмы Яндекса во многом схожи со схемами Google, но есть и отличия.Минусинск
Яндекс непрерывно ведёт борьбу с seo-ссылками, как и Пингвин, а алгоритм "Минусинск" стал очередным и очень серьезным ударом по рынку неестественных ссылок. Результатом его работы является понижение рейтинга не продающих ссылки сайтов, а их покупателей.Владивосток
Пожалуй самый свежий алгоритм. Учитывает адаптивность сайтов для мобильных устройств. Механизм обращает внимание на горизонтальную прокрутку, а так же элементы не работающие в мобильных браузерах. Благодаря этому алгоритму выдача для мобильных устройств и десктопа могут значительно отличаться.Итог
Алгоритмы поисковых машин постоянно совершенствуются с учетом происходящих изменений, но основной рецепт попадания на верхние строки выдачи остаётся неизменным — ваш контент должен быть полезен пользователю.9net.ru