У меня Ранг Мозга: RankBrain — новый алгоритм ранжирования Google. Алгоритм ранжирования
Алгоритм ранжирования Яндекс | Блог SEO Дилетанта
О том, что такое поисковая система и как она ранжирует сайты я писала в общих чертах ещё в статье Раскрутка в поисковых системах от 8 августа. Там мы рассмотрели, что из себя представляет поисковая система, как она узнает о новых сайтах, и как она определяет порядок показа сайтов в поисковой выдаче по запросу. Повторюсь, это были общие, и более абстрактные понятия. Сегодня же речь пойдет о конкретном алгоритме ранжирования в поисковой системе Яндекс.
Ещё в прошлом, 2009 году, поисковая система Яндекс перешла на новый алгоритм поиска – Снежинск, в котором используется технология Matrix. Net (Матрикснет). Но все это слова и ни о чем нам не говорят. Что такое Матрикснет? И при чем здесь город Снежинск? Постараемся постепенно во всем разобраться.
Итак, в ноябре 2009 года у Яндекса появился новый поиск. Чтобы понять смысл нового поиска стоит немного обратиться к истории и выяснить, а какой был старый? Ведь я сама начала изучать SEO уже в конце 2009 года, т.е. когда Снежинск с Матрикснетом уже был внедрен. Как строился поиск релевантных документов в поисковой системе Яндекс до Снежинска?
Не забываем, что поисковая система, это всего лишь робот, машина, основанная на математической логике. Т.е. в программу можно заложить математические формулы, х=1, у=3, x<z<y, очевидно, что z=2, т.е. обычная математическая логика. Вот за такие переменные x, y, z были взяты основные показатели сайтов.
Например, x=внутренняя оптимизация, y=внешние ссылки и т.п. Каждой такой переменной присваивалось некое число, а таких переменных было сотни. Все показатели потом "суммировались", т.е. каждому сайту присваивалось определенное число, в соответствии с которым и происходило ранжирование, выстраивание сайтов в определенной последовательности в поисковой выдаче. Естественно, что это самый примитивный пример, только для того, чтобы передать суть.
К чему в итоге это привело. Хоть секрет формулы никогда не раскрывался, всем было известно, что за основу берутся какие-то определенные показатели сайта, и естественно, это привело к тому, что каждый оптимизатор, обладающий аналитическими способностями, опытным путем мог выделить какое-то количество значимых параметров, которые влияют на ранжирование, и начать их использовать для продвижения, т.е. искусственным путем влиять на поисковую выдачу. Подстраивать свой сайт под конкретные показатели.
А раз оптимизаторы научились влиять на поисковую выдачу, значит на первых местах стали появляться сайты, которые, хоть и соответствуют поисковому запросу, но, своим нахождением в топе, не дают возможности пробиться в топ другим сайтам, которые также могут быть интересны и полезны людям. И самое печальное в этой ситуации было то, что в топе было много коммерческих сайтов, у которых были возможности тратить деньги на продвижение.
Что принес с собой новый алгоритм поиска Снежинск со своей технологией Матрикcнет? Я постаралась максимально полно изучить информацию об этом алгоритме ранжирования, и постараюсь передать вам его суть.
За основу были взяты не какие-то определенные показатели сайтов, а сами сайты, которые на взгляд работников Яндекс являются полезными ресурсами с человеческой точки зрения. На сколько оценка этих сайтов была объективной? Мы не можем судить об объективности подхода к этому. Но просто примем на веру.
Опустим кучу негативных отзывов оптимизаторов о том, что Яндекс – коммерческая организация, что его не интересует пользователь, а интересует только заработок с контекстных объявлений. Лично мое мнение такое – плохому танцору всегда что-то мешает:).
Яндекс всегда заявляет, что главная его задача – дать ответ пользователю. Примем это за аксиому. И поверим тому, что для нового алгоритма были отобраны сайты по объективным признакам.
Итак, было выбрано какое-то число определенных запросов, и определенное число сайтов, которые наиболее полно отвечают этим запросам. И специально обученные люди, асессоры, сопоставили каждому запросу определенный документ. Т.е. на их объективно-субъективный взгляд запросу 1 соответствует сайт А, запросу 2 – сайт Б и т.д.
Каждая такая пара "запрос=документ" была проанализирована машиной (программой), которая нашла среди этих документов закономерности (естественно, основываясь все на той же математической логике), и на основе выявленных закономерностей вывела формулу. Вот по этой-то формуле все и стало ранжироваться в поисковой системе Яндекс. Но, есть ряд оговорок.
Первая оговорка – таких формул много. Я могу предположить, что, чуть ли не для каждой тематики и направленности была выведена своя формула. Т.к. невозможно оценивать по одним и тем же признакам коммерческие сайты и не коммерческие, сайты развлекательной тематики с сайтами с научными трудами.
Вторая важная оговорка, что для того, чтобы вывести формулу, в машину в любом случае необходимо было заложить определенные переменные, т.е. показатели сайтов. То, на основании чего машина будет сравнивать сайты между собой.
А опять же, за счет чего можно сравнить сайты между собой? Конечно, тут не могут не рассматриваться внутренние и внешние факторы. Но и они уже не являются определяющими. В свете недавних заявлений Яндекс о снижении влияние SEO-ссылок, какие ещё показатели могут быть определяющими при ранжировании сайтов?
Все больше говорят о таком факторе ранжирования, как поведенческий фактор.
И именно он, по мнению многих, и по оговоркам представителей Яндекс, является определяющим при ранжировании. И, в определенной степени это действительно, может быть правдой.
Итак, в чем заключается уникальность нового алгоритма? Первое, именно человеческий фактор определяет на сколько один сайт интересней другого. С одной стороны, человеческий фактор – это субъективное мнение, одному нравится одно, другому – другое. Но тут скорее вопрос не об интересности, а о том, чтобы документ давал исчерпывающий ответ на заданный вопрос. И именно по этому принципу отбирались документы и присваивались определенным запросам.
И получается, что с другой стороны, машину пытаются обучить мыслить, как человек. Второе вытекает из первого, сотрудники Яндекс учат машину находить закономерности в человеческом мышлении. Машина эти закономерности находит (хорошо или плохо – это другой вопрос), и на основании этих закономерностей выстраивает свою формулу и следовательно поисковую выдачу.
И на самом деле, технология Матрикснет - это не что иное, как машинное обучение.
Благодаря этому, в поисковую выдачу с большей вероятностью попадают именно полезные ресурсы, в которых пользователь действительно находит ответ на свой вопрос. И вот тут важным является то, что, чтобы попасть в топ Яндекс, не обязательно быть старым трастовым ресурсом, не обязательно закупать большое количество ссылок.
Важным является интересный полезный контент, и явный интерес пользователей сети к сайту.
Да, а при чем здесь Снежинск? Дело в том, что именно в новом алгоритме улучшена формула ранжирования по региональным запросам. Т.е. где-бы не находился пользователь, и какие-бы запросы не набирал, приоритет будет отдаваться региональным сайтам, сайтам тех организаций, которые находятся в том же регионе, что и пользователь.
В следующих статьях я собираюсь более детально рассмотреть все возможные факторы, которые оказывают влияние на ранжирование сайтов, естественно, на основе заявлений официальных источников. И, естественно, что невозможно дать исчерпывающий ответ по факторам, т.к. все, что может оказывать влияние на ранжирование сайтов является тайной и не раскрывается представителями Яндекс. Также, постараюсь больше уделить внимание именно поведенческому фактору, по каким признакам определяется поведение пользователя, и почему это является "основным" фактором. Следите за обновлениями блога.amateurblogger.ru
Выявление алгоритмов ранжирования поисковых систем / Хабр
Пища для ума
Когда какое-то время работаешь в сфере SEO, рано или поздно невольно посещают мысли о том, какие же формулы используют поисковики, чтобы поставить сайт в поисковой выдаче выше или ниже. Всем известно, что это все хранится в глубочайшей секретности, а мы, оптимизаторы, знаем только то, что написано в рекомендациях для вебмастеров, и на каких-то ресурсах посвященных продвижению сайтов. А теперь задумайтесь на секунду: что если бы у вас был бы инструмент, который достоверно, с точностью в 80-95% показывал бы, что именно нужно сделать на странице вашего сайта, или на сайте в целом, для того, чтобы по определенному запросу ваш сайт был на первой позиции в выдаче, или на пятой, или просто на первой странице. Мало того, если бы этот инструмент мог бы с такой же точностью определить, на какую позицию выдачи попадете, если выполните те или иные действия. А как только поисковик вводил бы изменения в свою формулу, менял бы важность того или иного фактора, то можно было бы сразу видеть, что конкретно в формуле было изменено. И это только малая доля той информации, которую вы могли бы получить из такого инструмента.Теория
Итак, теория состоит в том, чтобы методом тыка пальцем в небо выяснить, какой фактор влияет на позиции больше или меньше другого фактора. На пальцах это все рассказать очень сложно, поэтому мне пришлось сделать таблицу, которая более менее отобразит то, что я хочу донести.Посмотрели на таблицу? Теперь к делу. Берем любую ключевую фразу, не важно какую, вводим в поисковик и из выдачи берем первых 10 сайтов, это и будут наши подопытные. Теперь нам нужно сделать следующее: написать код, который будет методом тыка менять значимость у факторов (ЗФ в таблице) ранжирования до тех пор, пока наша программка не расположит сайты таким образом, что бы они точно совпадали с выдачей поисковой системы. То есть мы должны методом тыка повторить алгоритм ранжирования поисковика. Значимость самих факторов мы можем определить только как положительную нейтральную или отрицательную.
Теперь по порядку о таблице и факторах. Условно каждому фактору присваиваем значение от 1 до 800 (примерно). Так как достоверно известно, что у Яндекса, например, факторов ранжирования где-то близко к этому числу. Грубо говоря, у нас максимальное число будет таким, сколько факторов ранжирования нам точно известно. У двух факторов не может быть одинакового числа, то есть у каждого фактора значение уникальное. В таблице для каждого фактора отдельная колоночка, и их очень много, физически мне не удастся на одной картинке все разместить.
Теперь вопрос, как вычислить ранг страницы? Очень просто: для начала простая математика, если фактор положительно влияет, мы к рангу страницы прибавляем ранг фактора, если отрицательно, то прибавляем 0. Можно усложнить, сделать 3 варианта и добавить, например, вычитание ранга фактора от ранга страницы, если этот фактор критический, например, грубый спам ключевой фразы.
У нас получается примерно такой алгоритм вычисления ранга страницы. Возьмем его за (PR), а фактор возьмем как (F) и тогда:
PR = Берем первый фактор Если F1 положительный, то делать PR + F1, если F1 отрицательный то делать PR — F1, если F1 нейтральный, то не делать ничего, после этого проверяем так же F2, F3, F4 и так далее, пока факторы не кончатся. А подбор производить таким образом, что бы у каждого фактора попробовать каждое значение ранга. То есть чтобы каждый фактор испробовать в каждом значении.
Вся сложность состоит в том, чтобы учесть все влияющие факторы, вплоть до количества текста на странице и ТИЦа сайта, на котором расположена ссылка на нашу подопытную страницу, и сложность даже не в учете этой информации, а в ее сборе. Потому что вручную собирать всю эту информацию нереально, нужно писать всевозможные парсеры, чтобы наша программка собирала все эти данные автоматически.
Работа очень большая и сложная и требует определенного уровня знаний, но только представьте, какие возможности она откроет после реализации. Я не буду вдаваться во все тонкости вычислений и влияния факторов, не люблю много писанины, мне проще объяснить человеку напрямую.
Сейчас некоторые скажут, что совпадений будет очень много в разных вариациях. Да, будет, но если взять не первую страницу, а, к примеру, первые 50 страниц? Во сколько раз тогда сократится вероятность промаха?
Еще есть сложность в том, что некоторые факторы нам просто негде будет взять, например, мы ни как не сможем учесть поведенческие факторы. Даже если все сайты из выдачи будут под нашим контролем, мы не сможем этого сделать, потому как скорей всего учитываются именно то, как пользователь ведет себя на выдаче, отсюда появляется вторая неизвестная в нашем уравнении, помимо самой позиции.
Что нам даст такой софт после реализации? Нет, точную формулу поисковика он не даст, но точно покажет, какой из факторов влияет на ранжирование сильней, а какой вообще не значительный. А при продвижении мы сможем в эту формулу подставить страницу своего сайта, со своими параметрами, и еще до того, как начать ее продвижение, увидим, на какой позиции будет страница по определенному запросу после того, как поисковик учтет все изменения.
В общем, это очень сложная тема, и очень полезная информация для ума, потому как заставляет подумать, хватит, например, мощности одного компьютера на такие вычисления? А если и хватит, то сколько это займет времени к примеру? Если не удовлетворит результат, то формулу как-то можно усложнять, менять, пока не будет 100% точного результата на 100 страницах выдачи. Более того, можно для чистоты эксперимента подключить около 100 различных сайтов и внедрить на них несуществующую ключевую фразу, а потом по этой же ключевой фразе и отследить алгоритм. Вариантов масса. Нужно работать.
habr.com
Алгоритмы работы и ранжирования поисковых систем Яндекс и Google
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Алгоритм поисковой системы
Алгоритм поисковой системы — это сложная формула, благодаря которой определяются позиции сайта в поисковой выдаче.
Алгоритмы позволяют найти наиболее релевантные сайты по тому или иному запросу пользователя и составить ранжирование этих сайтов в выдаче. По сути, поисковый алгоритм — это совокупность определенных признаков, благодаря которым роботы поисковиков определяют место сайта в выдаче.
Принципы работы поискового алгоритма
У каждой ПС есть свои собственные принципы работы, которые разработчики держат в секрете. Можно лишь составить список общих параметров, по которым они ведут свою работу и оценивают релевантность того или иного сайта и, соответственно, контент на нем:
- возраст;
- название;
- доменный уровень;
- объем сайта и количество страниц;
- популярность контента;
- наличие и соответствие ключевых слов, их количество и распределение по тексту;
- авторитетность ресурса в целом и каждой его страницы;
- индекс цитирования;
- периодичность и системность появления новой информации;
- использование картинок, мультимедийных ресурсов;
- размер ключевых слов и их шрифт;
- расстояние от начала текста до ключевых слов;
- одинаковый стиль на всех страницах;
- наличие мета-тегов;
- количество внутренних переходов на сайте;
- территориальная принадлежность и язык сайта;
- качество ссылочной массы, как внешней, так и внутренней;
- дополнительные параметры.
Таким образом, поисковые машины выбирают ресурсы наиболее соответствующие ключевым словам пользователя и убирают сайты, которые не нужны пользователю или ресурсы с ошибками в оптимизации (некачественный контент, нет уникальности и т. д.). При этом алгоритмы анализируют содержание сайта и принимают решение — соответствует ли ресурс запросу пользователя или нет. В зависимости от этого они присваивают позицию в выдаче. Всем известно, что чем ближе ресурс к топу поисковой выдачи, тем больше у него просмотров.
Алгоритмы систем Яндекс и Google
Яндекс — это поисковая система, ориентированная на русскоязычную аудиторию. Она появилась в 1990 г., когда ее основатели А. Волж и А. Борковский начали работать над программным обеспечением. Этот поисковик значительно уступает корпорации Google на мировом уровне и позиционирует себя как поисковая система номер один в странах СНГ. Яндекс раскрывает больше информации о своих алгоритмах, чем его заокеанский конкурент, соответственно, картина выдачи здесь более ясная. Эта система использует названия русских городов в своих алгоритмах: Магадан, Снежинск, Находка, Обнинск, Конаково, Арзамас и др.
Google — поисковая система, используемая во всем мире. Пожалуй, наиболее отработанная и продвинутая. Основатели этой системы Ларри Пейдж и Сергей Брин, поначалу всего лишь изучали математические особенности Интернета, но в итоге создали одну из лучших поисковых систем во всем мире. Google работает на всех общедоступных языках.
Основные различия двух систем
- Для поискового алгоритма Яндекс крайне важна географическая принадлежность ресурса, соответственно, запросы привязываются по территориальному признаку. Google анализирует IP-адрес пользователя и выдает результаты по соответствующему региону.
- Для поискового алгоритма Google играет большую роль внутренняя перелинковка сайта — чем больше ссылок на внутренние страницы, тем лучше. Здесь тоже нужно знать меру, так как содержание страниц оказывает существенное влияние на оценку поисковика. Яндекс определяет сквозные ссылки сайта как одну, а Google учитывает каждую.
- Для системы Google важен контент сайта. Если нет смысловой нагрузки, уникальности контента и его читабельности, то сайт никогда не будет в топе. Для Яндекса контент играет второстепенную роль.
- Многие SEO-специалисты знают, что продвинуть сайт в системе Google несколько проще, чем в Яндекс, так как индексация сайтов в Яндекс проходит реже и, соответственно, само продвижение занимает намного больше времени.
Как видите, точная формула ранжирования и алгоритм работы поисковика известен только разработчикам. Но, опираясь на базовые принципы работы всех поисковых систем и учитывая общедоступную информацию о тонкостях функционирования отдельных ПС, можно вывести приблизительный алгоритм, который поможет вам при SEO-оптимизации своего сайта.
semantica.in
Изучаем алгоритм текстового ранжирования Яндекса на РОМИП-2006
“Алгоритм текстового ранжирования Яндекса на РОМИП-2006” – статья, написанная работниками Яндекса. Среди авторов сам Илья Сегалович. Описанный алгоритм – экспериментальная поисковая система, созданная для улучшения основного поиска.
Прочитать публикацию можно например здесь: http://www.romip.ru/romip2006/03_yandex.pdf
Стоит ли тратить на нее время? Ведь с момента публикации прошло более 10 лет: огромный срок для SEO. Стоит!
Дело не только в том, что нам ценна любая информация из первых рук – от представителей поисковой системы. И не в том, что ей можно доверять, как серьезной научной публикации.
Что можно узнать из этого исследования
Следите за руками:
- Создатели Яндекса конструируют поиск с нуля.
- В работе используется особая коллекция веб-страниц.
- Одна из характеристик этой выборки текстов – отсутствие поисковой оптимизации (см. пункт 4.3).
То есть. В статье описана не просто еще одна формула ранжирования. В ней также изложены характеристики естественных текстов, которые при этом являются релевантными поисковым запросам.
Алгоритмы ранжирования за 10 лет сильно поменялись и усложнились. Зато подходы к написанию текстов куда стабильнее. Качественная статья десятилетней давности мало отличается от современной в плане содержания. Понятно, что сайты стали сложнее и функциональнее, прибавилось мультимедиа, но основа неизменна. Поэтому многие факторы, работавшие в тогда, могут работать и сейчас – в “настоящем” поиске.
Факторы, определяющие текстовую релевантность
Скриншот формулы и пояснения к ней:

Как видим, формула не такая уж большая и сложная. Всего 5 слагаемых дают оценку текстовой релевантности, которая позволяет неплохо ранжировать документы.
Это еще больше подтверждает высказанную выше мысль о том, что в алгоритме описаны базовые, универсальные принципы текстовой релевантности.
А вот насчет последнего слагаемого – PRF сказать то же самое нельзя. Это мера похожести страницы на документы, которые считаются релевантными. “Похожесть” может рассчитываться по самым разным алгоритмам и не завязана на текстовое содержание. Наверняка с внедрением Matrixnet подходы к оценке сходства сильно поменялась. Поэтому раздел “2.4 Pseudo-relevance feedback” стоит смотреть лишь для понимания общей логики работы поисковой системы.
Перейдем непосредственно к факторам.
Встречаемость слов в документе
Всем известный и самый очевидный фактор ранжирования. В экспериментальной формуле применяется модификация алгоритма BM25.
Интересно, что:
При подсчете количества вхождений слова в документ мы проводим предварительную лемматизацию слов запроса и слов документа. Результат поиска без лемматизации существенно уступает варианту с лемматизацией.
Лемматизация – это приведение слов к начальной форме (“пластиковые” -> “пластиковый”, “окна”->”окно”). То есть спамить сверхточными вхождениями было не слишком осмысленным занятием уже в 2006 году. С позиции этого фактора разные словоформы дают одинаковый вклад в релевантность (и выглядят на странице куда естественнее и привлекательнее).
Еще цитата:
Помимо учета количества слов в документе можно учитывать html-форматирование и позицию слова в документе. Мы учитываем это в виде отдельного слагаемого. Учитывается наличие слова в первом предложении, во втором предложении, внутри выделяющих html тегов.
Учет пар слов
Пара учитывается, когда слова запроса встречаются в тексте подряд (+1), через слово (+0.5) или в обратном порядке (+0.5). Плюс еще специальный случай, когда слова, идущие в запросе через одно, в тексте встречаются подряд (+0.1).
Далее интересная фраза:
Учет встречаемости трех и более слов запроса в документе улучшений в наших экспериментах не дал.
Из этого не следует, что для хорошего ранжирования всегда достаточно вхождения лишь пары слов из запроса. Очевидно, речь идет именно о Wpair слагаемом формулы. Вхождение остальных слов оценивается в следующем слагаемом.
Учет всех слов запроса в документе, учет фраз
Важным фактором помимо перечисленных является наличие в документе всех слов запроса. За наличие всех слов запроса мы добавляем дополнительный «бонус» , пропорциональный сумме idf слов запроса.
Проще говоря, наличие всех слов из поисковой фразы дает бонус к ранжированию, причем за вхождение более редких слов этот бонус выше. Вхождение часто употребляемых на разных страницах слов также даст бонус, но небольшой.
На практике бывает сложно добиться вхождения всех слов всего спектра поисковых запросов в документ. Просто потому, что мы и сами не знаем, по каким ключам можем привлечь трафик, как бы тщательно ни составляли семантическое ядро. Длинный хвост ключевиков настолько длинный, что его не охватить невооруженным глазом. А ведь поисковый спрос еще и меняется со временем, появляются новые пользовательские интересы.
Чтобы автоматизировать решение этой проблемы, добавил в свой анализатор сайта инструмент, который подсказывает часто встречающиеся в ключевых фразах, но не используемые в тексте леммы. Разумеется, все не сводится к простому набору слов. Я ставлю более амбициозную задачу – найти темы, интересные аудитории сайта, но недостаточно хорошо освещенные в тексте. Читайте подробнее в анонсе инструмента.
Помимо наличия слов запроса в документе мы можем учесть наличие в документе текста запроса целиком. Плюс к этому еще небольшой «бонус» дается за наличие в тексте предложений, содержащих значительное количество слов запроса.
Насчет точного вхождения все очевидно, комментировать нечего. А вот второе предложение напоминает нам о том, что просто вхождения всех слов мало. Они должны быть логически связаны и располагаться в одном предложении.
Как все это использовать?
Итак, факторами текстовой релевантности можно считать:
- Частота вхождения леммы в документ.
- Вхождение в первое и второе предложения.
- Вхождение в выделяющие html-теги.
- Вхождение пар слов из запроса.
- Наличие всех слов запроса в тексте (более редкие слова дают больший бонус).
- Наличие точного вхождения фразы для многословных запросов.
- Наличие пассажей (предложений), содержащих значительное количество слов запроса.
Как уже отмечал выше, это основы текстового ранжирования, характеристики естественных релевантных документов. Поэтому, размещая текст на сайте, стоит убедиться, что вы “отработали” каждый из пунктов короткого списка (по-минимуму, без фанатизма). Это отправная точка. Только если начальной оптимизации окажется недостаточно, стоит браться за текстовые анализаторы, ручной анализ ТОПа, LSI и прочую магию.
Работаем строго по закону Парето: простые действия, дающие 80% результата – в первую очередь!
Поделиться
Твитнуть
Поделиться
Отправить
Плюсануть
alexeytrudov.com
Алгоритм ранжирования поисковой системы - Статьи
Качество любой поисковой системы определяется в ее умении быстро найти наилучший вариант ответа на запрос пользователя и сделать это можно, используя алгоритм ранжирования, который представляет собой систему математических формул для оценки определенных факторов, на базе которой поисковая система присваивает сайту (странице) определенный рейтинг. В качестве факторов могут выступать различные показатели, характеризующие документ: наличие слов из запроса, наличие ссылок на документ, авторитетность сайта и др., количество которых может достигать больших величин. Так, на данном этапе Яндекс использует около 250 различных факторов.
Этапы развития алгоритмов Яндекса
Как же происходила эволюция поискового алгоритма в Яндексе? Это интересно всем, кто занимается продвижением сайтов и наша компания не является исключением. Рассмотрим это на нескольких примерах.
Так, 14 апреля 2008г прошел тестирование новый поисковый алгоритм «Магадан», в котором было вдвое увеличено количество факторов ранжирования по сравнению с предыдущим алгоритмом и были введены некоторые элементы новизны. К новым факторам ранжирования стоит отнести ранжирование по запросам, в которых слова в документе находятся далеко друг от друга, например, «хармс цирк вертунов». Однако поиск по многословным запросам не всегда получался удачным, поскольку к выдаче стали попадать сайты с плохими текстами и из-за попадания этих сайтов в топ, усилилась конкуренция по низкочастотным запросам. Яндекс стал также в массовом порядке индексировать зарубежные сайты, что привело к усилению конкуренции по запросам, содержащим иностранные слова, так как в выдаче начали появляться зарубежные сайты.
А нововведения коснулись следующих вопросов: аббревиатуры – так запрос МГУ стал пониматься как Московский Государственный Университет; транслита – запрос Мазда и Mazda оказались тождественными; перехода одной части речи в другую (существительное/глагол). Например, существительное «продвижение» и глагол «продвинуть» становятся адекватными, и запрос «продвинуть сайт» стал релевантен запросу «продвижение сайта». И таким образом, продвижение сайта по запросу, содержащему слова-переходы, становятся более дорогими по сравнению с сайтами, которые продвигаются по ключевому слову, поскольку ему приходится конкурировать и по ключевому слову, и по слову-переходу.
11 сентября 2008г вышла в свет новая версия алгоритма - «Находка», в которой оптимизаторов ожидали нововведения: улучшилось ранжирование по запросам, содержащим стоп-слова: союзы, предлоги; расширился тезаурус (словарь связей) – запрос Авто Ваз стал тождественен запросу АвтоВАЗ и по ряду запросов стали одновременно выдаваться также сайты информационного характера, например, Википедия. Следующим шагом стали поисковые программы «Арзамас», «Арзамас 1.1», «Арзамас 1.2», появление которых произошло соответственно 10 апреля, 24 июня, 20 августа 2009г.
Здесь нововведения коснулись внедрения алгоритма снятия омонимии: определение наиболее частотной формы омонимичной фразы и определение по дополнительным словам из запроса наиболее вероятного смысла фразы. Например, при запросе «стойка лука» выдаются сайты, в которых описана техника стрельбы из лука и правильная стойка при стрельбе. В новой поисковой системе стал происходить также учет региона пользователя. Появилось два типа запроса: гео-зависимый и гео-независимый, когда в одном случае учитывается регион пользователя, а в другом не учитывается и информация выдается для всех пользователей России одинаковой. Учет региона дал возможность развиваться «региональному продвижению» сайтов, но в связи с тем, что Яндекс не всегда мог определить региональную принадлежность, молодым сайтам стало сложнее пробиваться в топ.
Совершенно новая версия поискового алгоритма «Снежинск» анонсировалась 10 ноября 2009г., которая появилась на основном поиске 17 ноября. Основным новшеством для seo оптимизации стало внедрение нового машинного обучения-технологии Матрикснет. Что же произошло? Яндекс сделал так, что продвижение сайтов стало менее подконтрольным оптимизаторам из-за того, что стало трудно отследить влияние отдельных факторов и показателей на позиции сайта, т.е. если раньше можно было путем экспериментирования смоделировать влияние отдельно взятого фактора, то при новой версии это потеряло смысл. Анализируемый фактор в идеальных условиях действует одним определенным образом, при продвижении сайта А - совершенно другим, а при продвижении сайта В – вообще абсолютно иным. Стало существенным образом отличаться ранжирование по гео-зависимым и гео-независимым запросам. Гео-независимые запросы стали отождествляться Яндексом с информационными запросами и многие частотные гео-независимые запросы пропали с первых позиций.
Представители Яндекса недавно поделились также своим пониманием поиска: они считают, что на первую позицию должны попадать компании и фирмы, предлагающие действительно высокое качество, т.е. те, кто хорошо представлен как в сети, так и в оффлайне, поэтому молодой сайт, на который никто не ссылается, не может попасть в топ. Они также вводят значительные изменения в методику анализа текстового содержимого сайтов: страницы, насыщенные ключевыми словами попадают под фильтр и исчезают из выдачи, повышают требования к копирайтингу – к качеству текста. А использование нового типа апдейта – апдейт алгоритма Матрикснет, меняет позиции сайта, не отвечающие требованиям Яндекса.
Что дальше?
Таким образом, Яндекс постоянно старается улучшить алгоритм поиска, старается понять чего же хочет пользователь и есть надежда на то, что качество поиска улучшится, во всяком случае, последние разработки в направлении гео-независимого запроса являются свидетельством этого. В связи с высокими требованиями Яндекса понятно, что развитие услуг по продвижению сайта будет зависеть от грамотно построенного производственного процесса, подбора запросов для сайта, четкого анализа и выполнения технических и текстовых доработок, от регулярного контроля и обновления ссылочной массы, и конечно, учета всех нововведений Яндекса. Поэтому мы полагаем, что наилучшего результата по оптимизации и раскрутке сайта можно достичь только при совместной работе клиента с SEO-компанией.
Узнайте, как мы можем помочь в Вашем случае
www.seo-dream.ru
Что такое Google RankBrain — все о новом алгоритме ранжирования Google
Тематический трафик – альтернативный подход в продвижении бизнеса
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
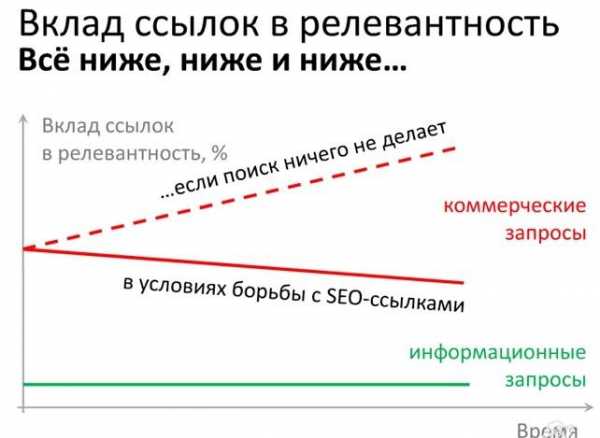
Не так давно, всему интернет-миру был явлен новый сигнал — RankBrain, сразу ставший третьим по значимости фактором при ранжировании страниц в поисковой системе Гугл.
Как известно, поисковый алгоритм Google насчитывает более двух сотен различных сигналов и то, что этот новичок попадает сразу в ТОП-3 вместе с такими тяжеловесами, как ссылки и поведенческие факторы, уже заставляет с ним считаться. Но не будем забегать вперед и сразу начинать его чествовать, а попробуем сначала разобраться чем же он заслужил это почетное место.
«Ранг Мозга» как называет его сам переводчик Гугл:

Что такое Google RankBrain?
Алгоритм представляет собой систему ИИ на базе машинного обучения, призванную помогать при обработке сигналов поиска. На данный момент озвучивается цифра в 3 миллиарда поисковых запросов, которые способен обработать этот новичок за день, причем 15% из них совершенно уникальны (т.е поисковая система видит их впервые).
Этот сигнал призван помочь нам посредством поиска страниц, релевантных запросу, но не содержащих точных вхождений ключевых слов из нашего запроса. Получается, что шанс найти именно нужную информацию — многократно возрастает.
Также RankBrain делает следующее:
- помогает алгоритмам правильно понимать новые запросы;
- выявляет закономерности между, казалось бы, несвязанными вопросами пользователей и помогает понять схожи они или нет;
- распределяет их по тематикам.
За счет самообучения он способен лучше интерпретировать сложные запросы, которые будут поступать от нас с вами в будущем. Связывать их по группам, основываясь на результатах поисковой выдачи, и предоставлять нам наиболее подходящие.
Самостоятелен ли данный алгоритм?
RankBrain — это отнюдь не новый и революционный принцип ранжирования в выдаче. Компания Google не уходит от своего основного поискового алгоритма Humminbird (Колибри), а добавляет к нему различные элементы. Таким элементом и является RankBrain, поскольку он обрабатывает лишь часть запросов, а не все пласты информации.

Позиция веб-страницы, присваиваемая ей в выдаче, определяется посредством сигналов, которые обрабатываются внутри основного алгоритма и на основании которых поисковая система понимает, что нужно показывать пользователю при том или ином запросе.
Пример использования алгоритма ранжирования Rank Brain Google
Возьмем очень длинный и витиеватый запрос «как называется упражнение при котором штанга отрывается от груди».
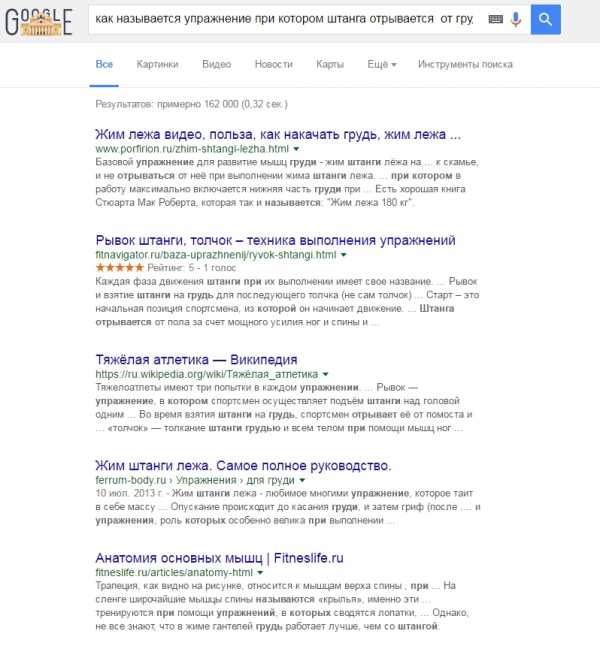
Слово «отрывается» может относиться как листику, висящему на дереве, так и, например, к лапке которую мы отрываем у насекомого.
И, хотя наша формулировка получилась довольно странной и запутанной, Google смог подобрать запрос, максимально удовлетворяющий наши ожидания.
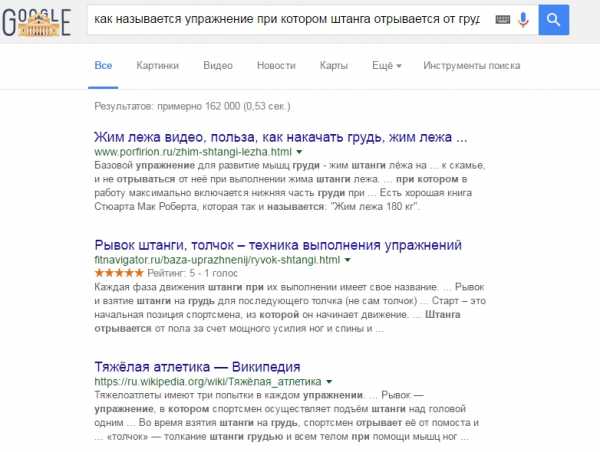
Попробуем еще сильнее испортить жизнь ПС и спросим у нее следующее: «как называется когда штанга отрывается в лежачем положении».
Т.е мы убираем из запроса слово «упражнение» в надежде на то, что поисковик не найдет что нам ответить.
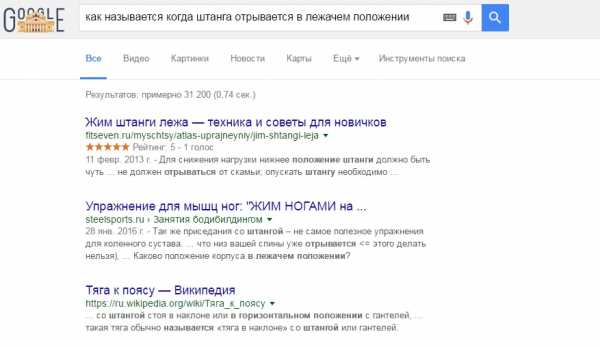
Но поисковая выдача опять выводит страницу релевантную нашему запросу, мы не знаем как алгоритм связывает оба этих вопроса, можно лишь стоить гипотезы на основании этого примера.
Так, почему же новичок пребывает только на третьем месте?
РанкБрейн стартовал в начале 2015 года и работает в во всех странах, на территории которых действует поисковая система Гугл. Он постоянно обучается, но этот процесс происходит оффлайн, т.е на основании групп исторических запросов, сигнал учится строить прогнозы, в случае если все было верно спрогнозировано, запускается новая версия сигнала и цикл повторяется.
По мнению редактора Search Engine Land Дэнни Салливана основную роль при ранжировании по-прежнему играют ссылки, за которые отвечает PageRank и семантика (слова) начиная от слов на странице и заканчивая тем, как Google интерпретирует слова, содержащиеся в запросах.
Сулит ли новый алгоритм ранжирования Google перемены в области SEO?
Хоть о новом сигнале известно и немного, но уже сейчас можно предположить, какие последствия повлечет за собой его внедрение:
- Возрастает надежда на более качественную и соответствующую вашим ожиданиям выдачу, т.к. высокой плотности ключей на странице теперь недостаточно для ее продвижения. Теперь необходимо использовать более обширные словоформы, способные удовлетворить как можно более широкий круг пользователей;
- Необходимо уделить внимание семантике сайта, возможно начать использовать такие форматы, как (pdf и видео), изменить способ подачи контента, размещать и оформлять его именно с точки зрения удобства для пользователя.
semantica.in
Алгоритмы ранжирования поисковых систем
Алгоритм ранжирования – это так называемая сортировка сайтов в выдаче, которая меняется в процессе функционирования той или иной поисковой системы. Существует большое количество факторов, согласно которым происходит ранжирование: рейтинг веб-ресурса, соответствие текста поисковым запросам, объём и качество ссылочной массы.
Сегодня ранжирование интернет-ресурсов основывается на полезности сайта. Для того, чтобы вас заметили поисковики, нельзя обходиться одними seo-приемами (прописывание мета-тегов, внутренней перелинковки, заголовков), уникализированием контента и подписей к изображениям. Очень важно учитывать и поведенческий фактор, т.е. насколько сайт интересен пользователям: глубина просмотра, время, которое пользователи провели на веб-ресурсе, показатели отказов и другие данные из аналитики.
Алгоритмы ранжирования интернет-ресурсов меняются в процессе модернизации поисковых систем и интернета в целом. При улучшении алгоритмов берется во внимание контент, авторитетность, а также внешние и внутренние факторы ранжирования.
Внутренние факторы ранжирования:
- Контент.
- Мета-теги.
- Заголовки и выделение жирным шрифтом.
- Общая структура, навигация и внутренняя перелинковка.
- Внешние ссылки на сторонние интернет-ресурсы.
Полезный и качественный контент – это важнейший фактор ранжирования. Бывает так, что оптимизаторы в погоне за 100% уникальностью текста, забывают о его читабельности и релевантности. Либо не берут во внимание то, как важна актуальность публикуемых материалов.
Важно, чтобы поисковые роботы видели, что мета-теги страницы соответствуют ее наполнению.
Для того, чтобы поисковики вознаградили вас высокой позицией, важно учитывать простые правила: самый важный заголовок с темой статьи выделяем тегами; заголовки более низкого порядка – тегами h3, h4 и т.п., ключевые термины и акценты – жирным шрифтом. Важно помнить, что усердствовать с выделением слов с помощью жирного шрифта не стоит.
Четкая структура сайта – еще один приоритетный момент. А внутренняя перелинковка поможет повысить ранг молодого ресурса. Суть линковки – в связывании внутренних страниц сайта ссылками друг на друга, что поможет нарастить вес каждой из них.
Присутствие на веб-сайте нетематических ссылок на сторонние ресурсы способно понизить позиции в поисковиках. Огромный поток рекламы может себе позволить только сайт с большим весом, а молодым неавторитетным ресурсам такие эксперименты опасны.
Внешние факторы ранжирования:
- Внешние ссылки на сайт.
- Присутствие интернет-ресурса в авторитетных каталогах.
Важно и количество ссылок, и их качество. Благодаря ссылке сайту-акцептору передается от сайта-донора часть веса, т.е. передается тИЦ и PR. Также большое значение играет и релевантность анкоров продвигаемым ключевым запросам.
Например, Яндекс.Каталоге. Это также даст положительный эффект при ранжировании. Ранее вес сайту могла принести регистрация в DMOZ-каталоге, однако в марте 2017 года интернет-каталог был закрыт и больше не принимает сайты на добавление в реестр. Все уже занесенные в каталог сайты находятся по адресу - http://dmoztools.net/.
Дополнительные моменты:
- Домен сайта – его возраст и положительная история.
- Число переходов на веб-ресурс из поисковиков – кликабельность сниппета в поисковой выдаче.
- Возраст сайта и домена – чем дольше и «чище» история сайта и домена, тем больше преимущество перед «новичками» в выдаче.
seo.ru