200 факторов ранжирования в Google (Часть 2). 200 факторов ранжирования google
200 факторов ранжирования Google
Идея о необходимости подобного исследования буквально витала в воздухе. Сегодняшняя реальность такова, что интернет-пространство меняется быстро — стало больше контента, больше данных, больше устройств, плюс пользователи стали очень нетерпеливыми, у них гораздо больше требований к используемым сайтам. Что уж говорить о поисковых системах. Ранжирование Google меняется постоянно, почти в режиме реального времени — средний показатель изменчивости — 4,9 из 10 (данные SEMrush Sensor для US). Если раньше все было более-менее статично, то теперь мы видим в SERP большое количество элементов – новости, врезки с видео, расширенные сниппеты и т.д. Если вы следите за новостями, то знаете, что Google вводит изменения буквально одно за другим.
Чем же являются эти изменения для seo-специалистов и их клиентов? Для большинства изменения — это опасность, опасность потери достигнутых позиций, трафика, денежного и временного ресурсов. И это вполне справедливо и понятно. Хотелось бы только уточнить, что изменения = опасность, только в том случае, если к ним не приспособиться. А если к изменениям быть готовым, то они превращаются в новые возможности. Именно эту задачу призвано решить проведенное исследование, а именно — выявить устойчивые паттерны в механизме ранжирования Google, которые могут быть полезны как клиентам компании, так и мировому SEO-сообществу.
Полученные специалистами SEMrush данные помогают приоритизировать задачи на основании того, что важно, а что нет. Важность задач без трендов, данных по рынку и опыта конкурентов определить невозможно.
Для исследования был взят ТОП 100 органических позиций по 600.000 ключевым словам по всему миру (основная доля – 200.000 – Google US, затем Европа, Австралия и проч). Полученные данные были проанализированы от и до – были отсмотрены факторы внутренней оптимизации сайтов, ссылающиеся домены и данные по трафику (clickstream-данные).
Специалисты SEMrush считают, что в разных по конкурентному климату нишах действуют разные законы, поэтому ключевые слова были сгруппированы по частоте поисковых запросов.

Далее внутри первых трех групп ключевых слов была проведена сегментация на короткие (до 3 слов включительно) и длинные (4+ слова) ключи.
По полученным данным была проведена оценка важности факторов, а не корреляционный анализ одного фактора и позиций в Google. Анализ проводился при помощи алгоритма Random Forest и вспомогательных инструментов, таких как R Project, MySQL, Excel.
Основные выводы исследования:
Количество ссылающихся доменов и их важность для ранжирования в Google
Исследование показало, что количество рефдоменов на 1-й позиции в группе высокочастотных ключевых слов в 2 раза выше, чем 10-ой, и почти в 20 раз выше, чем на 20-й позиции.
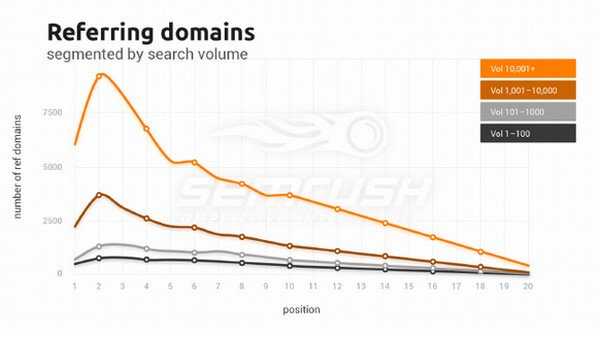
Мы видим, что для высокочастотных ключевых слов медиана на первых позициях – почти 10k рефдоменов, что в 10 раз больше, чем для низкочастотных.
Что касается ссылающихся доменов, то исследование показало, что:
• на более высоких позициях количество ссылающихся доменов выше• чем выше частота запросов ключевого слова, тем больше рефдоменов• кривая для НЧ ключевых слов почти плоская, а для ВЧ очень крутая
Все это позволяет сделать вывод о том, что бэклинки до сих пор важны для SEO. В высококонкурентной нише царят киты с огромными ссылочными профилями (медиана 10k доменов!). Для низкочастотных кейвордов конкуренция не столь высока (медиана в 10 раз меньше) и хороший линкбилдинг может привести к прекрасным результатам.
Длина контента и ее важность для ранжирования в Google
Анализ показал, что на более высоких позициях длина контента больше. Так, в ТОП 3 длина контента на 45% больше, чем на 20-ой позиции по всем группам ключевых слов:
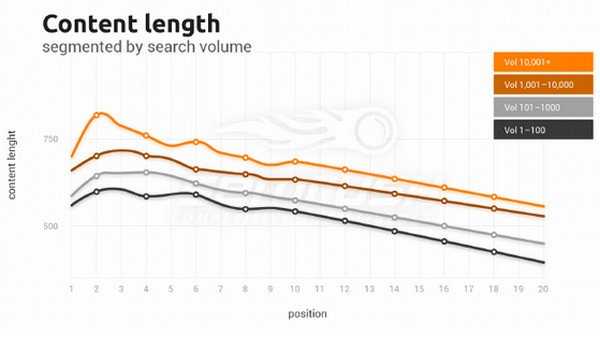
Длина контента для длинных ключевых слов на 20% больше, чем для коротких:

Это говорит о том, что чем выше частота запросов кейворда, тем больше длина контента, а страницы, выдающиеся по коротким ключевым словам и длинным ключевым словам – РАЗНЫЕ.
Вхождение ключевого слова в заголовок и его важность для ранжирования в Google
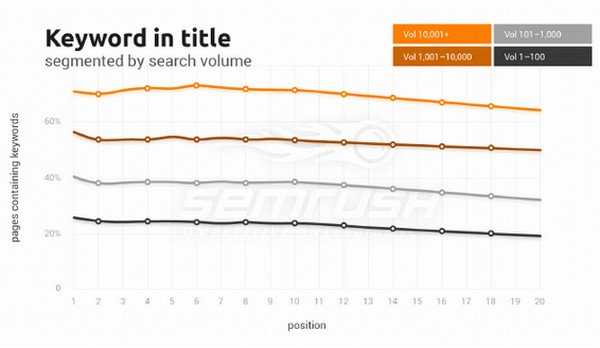
Исследование показало, что 18% доменов на первых позициях по ВЧ-кейвордам и 45% доменов на первых позициях по НЧ-кейвордам не имеют вхождения ключевого слова в title:
Безопасность сайта (HTTPS) и ее важность для ранжирования Google
По результатам исследования оказалось, что 65% доменов в ТОП 3 по ВЧ-кейвордам уже перешли на защищенный протокол HTTPS:

Как видим, уровень внедрения HTTPS очень внушительный. Свыше 50% доменов в ТОП 3 во всех группах ключевых слов уже работают на защищенном протоколе. Интересно, что страницы, ранжирующиеся по длинным словам в высокочастотной группе, на 10% имеют HTTPS домены в ТОПе.
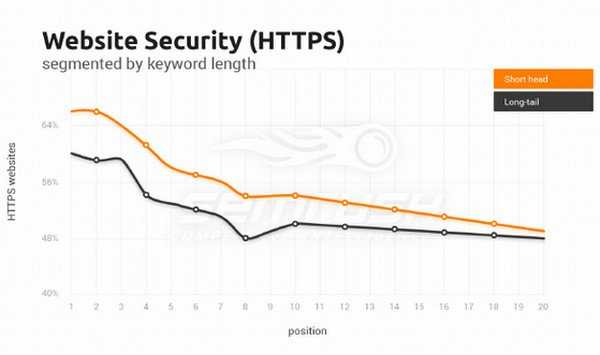
Однако внедрение HTTPS все-таки идет семимильными шагами. Уже невозможно конкурировать без HTTPS в высокочастотной группе.
Bounce rate (показатель отказов) и его важность для ранжирования Google
Мы увидели, что показатель отказов сильно увеличивается после ТОП 3:
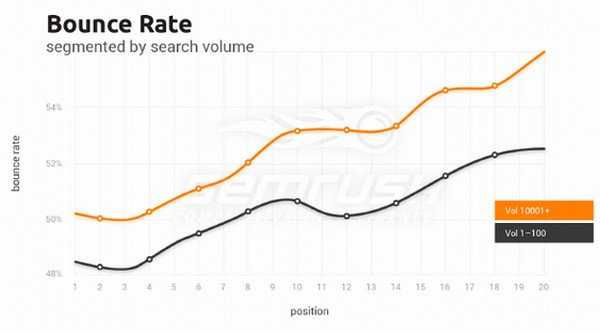
И сильно снижается по мере приближения к верху выдачи. Возможные причины: большее доверие пользователей к доменам в ТОПе, релевантный контент и быстрая загрузка сайта.
User signals (сигналы того, как юзеры взаимодействую с сайтом) пока слишком «шумные» для Гугла, но высокий показатель отказов сигнализирует о том, что пользователи не взаимодействуют с вашим сайтом, как вы этого хотите.
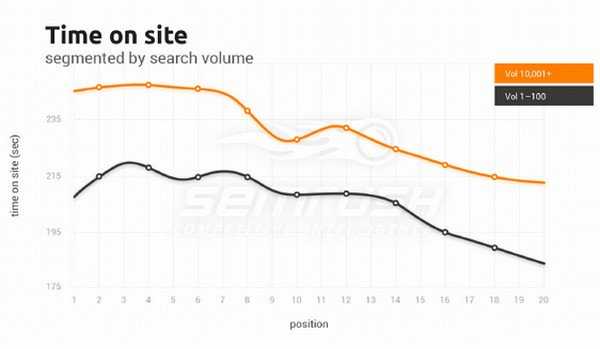
Время на сайте и его важность для ранжирования Google
Анализ показал, что время на сайте достаточно сильно повышается по мере приближения к верху SERPа, но для ТОП 4 оно примерно одинаковое:
Количество страниц за одну сессию и его важность для ранжирования Google
Количество посещенных страниц сайта достаточно сильно повышается по мере приближения к верху выдачи, но для ТОП 4 оно примерно одинаковое.
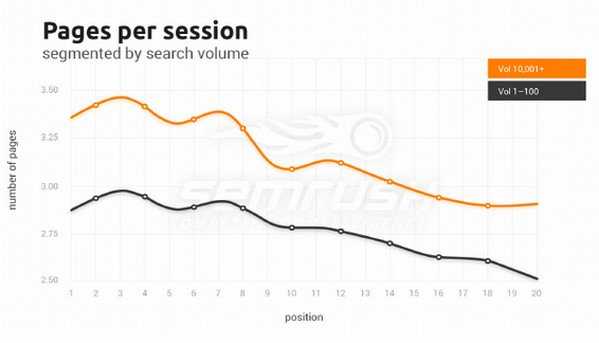
В среднем, пользователь посещает 3-3,5 страницы сайта после перехода на него из выдачи Google. Специалисты SEMrush пришли к выводу, что большое количество страниц за один визит может быть результатом большего доверия к доменам на верхних позициях, релевантности контента и хорошей скорости загрузки сайта.
Трафик (все визиты и уникальные визиты) и его важность для ранжирования Google
Количество визитов сильно повышается (для ВЧ) по мере приближения к верху выдачи:
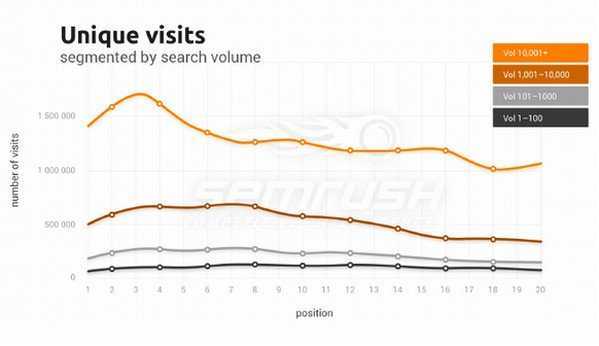
Домены, занимающие первые позиции по ВЧ ключевым словам имеют в 3 раза больше визитов, чем домены по НЧ:

Если убрать из приведенного графика поисковый трафик, то картина не сильно изменится, что в принципе говорит о том, что трафик из поисковиков не имеет значительного влияния на позиции в выдаче.

Показатели поведения пользователей для сайтов ТОП 3


Все проанализированные факторы позволили нам распределить их по важности для ранжирования Google следующим образом:

Что делать с полученной информацией? Безусловно, ее нужно использовать для повышения позиций своего сайта в Google!
Несколько советов от специалистов SEMrush:
#1Убедитесь, что длина контента достаточна для цели, которую вы преследовали. Контент должен быть релевантным и отвечающим на запрос пользователя.
#2Сравните свой контент с контентом своих конкурентов и убедитесь, что ваш контент по длине и релевантности обходит конкурентов.
#3Получайте обратные ссылки. Правильная работа со ссылочным поможет продвинуться в выдаче, если вы оптимизируете страницу по словам с частотой запросов менее 10 000.
#4Переходите на HTTPS. Это уже фактор ранжирования, даже если не такой мощный. Переход в любом случае увеличит конверсию и доверие пользователей к вашему сайту.
#5Проверьте страницы с высоким показателем отказов, которые уже ранжируются в Google. Определите слова, по которым ранжируются страницы и сделайте контент более релевантным.
#6Проверьте скорость загрузки сайта. Оптимизируйте ее до 3 секунд и менее. Это снизит показатель отказов и повысит кликабельность вашего сниппета в выдаче.
kreklama.ru
200 факторов ранжирования в Google (Часть 2)
Замечание перед статьёй. Её автором является Браен Дин, соответственно, во всех местах статьи, где встречаются местоимения “я” или “мне” подразумевается сам автор.
P.S. Огромное спасибо Сергею Кокшарову за статью.
Специальные правила алгоритмов
- Алгоритм Google QDF*: Google дает преимущество новым web-страницам для определенных поисковых запросов.
(QDF – Query Deserves Freshness – (дословно) запрос заслуживает свежего)
- Алгоритм Google QDD*: Google может добавить немного разнообразности на странице поисковых результатов для таких ключевых слов, как “Apple” или “рубин”.
(QDD – Query Deserves Diversity – (дословно) запрос заслуживает разнообразия)
- Пользовательская история посещенных сайтов: Сайты, которые вы часто посещаете, будучи подключенным к Google будут иметь преимущество на странице результатов поиска в соответствии с вашими запросами.
-
Пользовательская история поисковых запросов: Цепочка поисковых результатовзависит от того, что вы искали ранее. Например, сначала вы искали “обзоры”, а потом «фильмы», вероятнее всего, что Google в первую очередь покажет сайты с обзорами фильмов.
-
Таргетинг по местоположению: Google отдает предпочтение сайтам с локальным IP и сайтам с национальными доменами (о них мы уже говорили).
-
Безопасный поиск: Поисковые результаты, содержащие материалы для взрослых не будут выведены пользователям в включенным параметром безопасный поиск.
-
Google+ Круги: В поисковых результатах Google отдает предпочтение сайтам, добавленным в Google+ Круги.
144. DMCA* Жалобы: Google понижает релевантность web-страниц с DMCA жалобами.
(DMCA – Digital Millennium Copyright Act – Закон об авторских правах в цифровую эпоху)
- Разнообразность доменов: После, так называемого “Bigfoot апдейта” на каждой странице результатов поиска стало большее разнообразие доменов.
-
Запросы, связанные с сделками: Иногда Google показывает разные результаты для ключевых слов связанных с сделками (покупки, шоппинг), например запросы о рейсах.
-
Поиск по местным результатам: Google часто ставит местные Google+ результаты выше других, «нормальных».
- Google Новости: Определенные ключевые слова могут вывести результаты в блоке Google Новости:
- Предпочтение бренду: После Vince апдейта, Google в определенных, узких поисковых запросах может отдавать предпочтение более брендовым результатам.
-
Результаты связанные с шопингом: Иногда Google показывает Google шопинг результаты в «естественном» поисковом результате:
- Результаты связанные с картинками: Google отдает преимущество «естественным» спискам для поисковых результатов связанных с картинками на запросы, которые как правило приходятся на поиск в Google Картинки.
-
Факторы социальных сетей
- Количество твитов: Как и ссылки, твиты ссылающиеся на страницу могут увеличить ее релевантность в Google.
-
Авторитетность твиттер аккаунтов: Вполне вероятно, что ссылки в твитах от аккаунтов с тоннами подписчиков (таких как например аккаунт Леонардо ДиКаприо) будут иметь большую ценность, чем ссылки от каких-нибудь новых или маловлиятельных аккаунтов.
-
Количество лайков на Facebook: Хотя Google и не может следить за большинством Facebook аккаунтов, Вполне возможно, он рассматривает количество лайков на аккаунте Facebook с вашей ссылкой как слабый, но все же положительный фактор релевантности.
-
Количество поделившихся вашей ссылкой на Facebook: Этот показатель чем-то похож с обратными ссылками поэтому может иметь большую ценность, чем лайки.
-
Авторитетность Facebook аккаунтов пользователей: Также как и в случае с твиттером, ссылки от более авторитетных Facebook аккаунтов могут иметь большую ценность.
-
Количество «пинов» на Pinterest: Pinterest – это сумасшедше популярная социальная медиа сеть со большим количеством публичных данных. Наверное поэтому Google рассматривает число «пинов» на Pinterest как один из факторов социальных сетей.
-
Количество голосов на социальных «обменниках»: Вполне возможно, что Google использует число поделившихся ссылкой на таких сайтах как Reddit, Stumbleupon и Digg как еще один тип факторов социальных сетей.
-
Количество Google+1: Хотя Matt Cutts заявил, что Google+ не имеет “прямого влияния” на релевантность, сложно поверить, что Google не стали принимать во внимание данные со своей социальной сети.
-
Авторитетность Google+ аккаунтов пользователей: Логично, что Google отдавать предпочтения «+1» от авторитетных аккаунтов, чем с тех у которых даже мало подписчиков.
-
Проверенное авторство на информацию в Google+: В Феврале 2013 года, GoogleCEO Eric Schmidt авторитетно заявил:
Внутри поисковых запросов, информация от проверенного аккаунта будет иметь большую релевантность, чем информация без подобной проверки, в результате, большинство пользователей будет просто кликать на топовые, проверенные результаты.
Проверенное авторство на информацию может также служить залогом доверия у поисковой машины.
- Факторы релевантности социальных сетей: Возможно, Google использует информацию о релевантности аккаунтов, которые делятся ссылками, а также о тексте, окружающим ссылку.
-
Влияние факторов релевантности социальных сетей на уровне сайта: Данные факторы могут увеличить в целом авторитетность сайта, что следствие повышает и релевантность каждой отдельной страницы.
Факторы брендов
- «Якорный» текст названия бренда: Фирменный «якорный» текст — это просто, но действенно. Является одним из факторов бренда.
-
Поисковые запросы и бренды: Проше простого: люди ищут бренды. Если люди ищут ваш сайт в Google (например: “Backlinko twitter”, Backlinko + “факторы релевантности”), Google примет это во внимание, когда будет определять бренд.
-
У сайта есть страница на Facebook и лайки: Коротко. Бренды имеют тенденцию заводить страницы на Facebook с большим количеством лайков.
-
У сайта есть Twitter аккаунт и подписчики: Большое количество подписчиков в Twitter аккунте является знаком популярности данного бренда.
-
Официальная страница компании на «Linkedin»: Большинство бизнес компаний имеют страницы на «Linkedin».
-
Сотрудники на «Linkedin»: Rand Fishkin считает, что наличие у ваших сотрудников аккаунтов на «Linkedin» говорит о том, что они, собственно, работают в вашей компании, а это является знаком популярности бренда.
-
Принципы социальных сетей: Аккаунт в социальной сети с 10000 подписчиками и 2 сообщениями на странице, будет иметь куда меньше ценности, чем тот же аккаунт, но множеством сообщений (фактор пользовательского взаимодействия).
-
Упоминание о бренде на новостных сайтах: По-настоящему крупные бренды упоминаются в разделе новостей Google каждый день. Более того, некоторые бренды даже имеют их собственный раздел на первой страницы новостей:
- Цитирование: О брендах хорошо упоминается без ссылок. Вероятно, Google больше обращает внимание на упоминание о брендах не закрепленных в ссылки.
-
Количество RSS подписчиков: Учитывая, что Google является владельцем популярного сервиса RSS, имеет смысл то, что количество ваших подписчиков на RSSтакже является фактором популярности бренда.
-
Наличие офиса компании в списке Google+: У настоящих компаний есть собственный офис. Возможно поэтому Google использует данный фактор, чтобы определить, является ли ваша компания крупным брендом или нет.
-
Сайт, платящего налоги предприятия: SEOMoz опубликовал статью о том, что Google может обращать внимание на тот фактор, связан ли ваш сайт с платящим налоги предприятием или нет.
Факторы находящегося на сайте спама
- Санкции от алгоритма Panda: Сайты с низкокачественным контентом (как правило«фермы» контента) имеют, куда меньшую релевантность благодаря санкциям от алгоритма Panda.
-
Наличие ссылок на «Плохих соседей»: Наличие на сайте ссылок на «плохих соседей» — это сайты, которые могут нанести вред пользователю или которые используют грязные способы для повышения своей релевантности, является отрицательным фактором для релевантности вашего сайта.
-
Редиректы: Наличие хитрых редиректов (перенаправлений) на вашем сайте это очень и очень плохо. Если такой факт обнаружится, у сайта не просто упадет релевантность – он перестанет индексироваться Google.
-
Всплывающая или отвлекающая реклама: В нашей знакомой директиве Googleговорится, что наличие подобной рекламы на сайте, показатель его низкого качества.
-
Сверх оптимизация сайта: Включает в себя все факторы на уровне страниц, таких как: начинка ключевыми словами, начинка ключевыми словами в тегах «title», «h2» и.т.д, чрезмерное употребление ключевых слов.
-
Сверх оптимизация страницы: Многие говорят, что, в отличие от алгоритма Panda, Penguin больше нацеливается на отдельные страницы (да и только по определенным ключевым словам.
-
Большое количество объявлений: «Алгоритм макета страницы» накладывает санкции на сайты с чрезмерно большим количеством рекламы и небольшим количеством контента.
-
Скрытые партнерские ссылки: Если зайти слишком далеко в попытках скрывать партнерские ссылки (особенно с клоакингом), можно также получить определенные санкции от Google.
-
Партнерские сайты: Не секрет, что Google не в восторге от партнерских сайтов, поэтому многие думают, что такие сайты могут быть под дополнительным контролем.
-
Компьютерно сгенерированный контент: Google также не фанат компьютерно сгенерированного контента. Если он обнаружит, что ваш сайт содержит такой контент, это повлечет за собой жесткие санкции, вплоть до прекращения индексации данного сайта.
-
Чрезмерное повышение PageRank: Если зайти слишком далеко в попытках поднять PageRank, посредством установления атрибута «nofollow» на все исходящие ссылки или на большинство внутренних, может служить сигналом попытки обмануть систему.
-
Помеченный за спам IP адрес: Если IP вашего сервера было помечено Google за спам, это может навредить всем сайтам находящимся на данном сервере.
-
Спамминг в meta тэгах: Переборщить с количеством ключевых слов можно и в meta тэгах. Если Google посчитает, что вы добавляете ключевые слова в meta теги, чтобы обмануть систему, он может наложить жесткие санкции.
Факторы спама во внешних ссылках
- Неестественно большой приток ссылок: Внезапный, и неестественный наплыв ссылок на ваш сайт, безусловно является признаком фальшивости такой ссылки.
-
Санкции алгоритма Penguin: Сайты с санкциями от Google Penguin значительно уменьшают свою релевантность.
-
Низкокачественные ссылки: Большое количество ссылок с ресурсов, которые используются для черного SEO продвижения (такие как комментарии в блогах и на форумах), может служить сигналом попытки обмануть систему.
-
Тематика ссылающихся на вас сайтов: Известный сайт MicroSiteMasters.comобнаружил, что сайты с неестественно большим количеством ссылок от несвязанных по тематике сайтов могут быть подозрительны для алгоритма Penguin.

- Предупреждение о низкокачественных ссылках: Google отправляет тысячи сообщений с советами как обнаружить фальшивые ссылки. После этого, как правило, идет падение релевантности, хотя не в 100% случаев.
-
Ссылки с сайтов с одинаковым IP class C: Наличие неестественно большого количество ссылок от сайтов с одним и тем же IP сервера, может служить знаком блогов сети построения ссылок.
-
“Яд” в якорном тексте: Наличие слова “яд” в якорном тексте (особенно ключевых слов на медицинскую тематику) указывающих на ваш сайт, может быть знаком взломанного сайта или спама. Соответственно, понижение релевантности.
-
Санкции, выдаваемые в ручную: Как известно, Google уже приложил руку к вручную выдаваемым санкциям, как например, с историей о крахе известного цветочного интернет магазина Interflora.
-
«Продажные» ссылки: Такие ссылки, определенно могут повлиять на PageRank и соответственно на релевантность сайта.
-
Google Песочница: Новые сайты, которые получают внезапное прибавление ссылок иногда помещаются в Google песочница, где временно ограничены в релевантности.
-
Google «Dance»: Google «Dance» может временно «встряхнуть» релевантность сайта. Согласно патенту Google, это может быть способ определить, пытается ли сайт обмануть систему или нет.
-
Отклонение ссылок: Используя данный инструмент можно снять последствия ручных или алгоритмических санкций сайтам, которые стали жертвами черного SEO.
-
Пересмотр требования: Успешный пересмотр требований может увеличить санкции.
Огромное спасибо Сергею Кокшарову за ценную статью!!!
Я что-нибудь забыл?
Я вам рассказал о 200 факторах релевантности…плюс парочка сверху.
Я потратил более 20 часов, чтобы написать эту статью, рыская по интернету в поисках каждого фактора.
Спасибо ещё раз Михаилу за перевод и предоставление материала.Подписываемся на его твиттер @tuknov.
Официальный источник: 200 факторов ранжирования в Google
Понравилось? Расскажи всем!
blog.teampoint.su
200 факторов ранжирования Google ‒ это миф… | Фарма Блог №1
Никто кроме инженеров поискового отдела Google не знает всех факторов ранжирования. Однако, если вы введёте запрос «200 факторов ранжирования», то получите несколько сотен результатов в выдаче. Первый раз Google объявил об использовании 200 факторов ранжирования 10 мая 2006 года, во Всемирный день свободы печати.
Более подробно об этом вы можете прочитать в блоге самого Мэтта Каттса. Скорее всего, это число было выбрано, чтобы показать журналистам, насколько сложен алгоритм ранжирования Google. Если бы аудитория состояла из специалистов по информационным технологиям, то цифра была бы другая. Кроме того, в 2010 году Мэтт Каттс ещё раз упомянул, что Google учитывает более, чем 200 факторов ранжирования, каждый из которых, в свою очередь, имеет более 50 вариаций.
А теперь подумайте: вы уверены, что действительно знаете значение слов «ранжирование» и «индексация»? Многие начинающие или недостаточно опытные вебмастеры используют их как синонимы, хотя в действительности это два совершенно разных понятия и совершенно разные этапы работы поисковой системы.
Индексация ‒ это один из четырёх взаимосвязанных и взаимозависимых этапов в работе поисковой системы. Вот эти этапы:1. Сбор данных.2. Обработка.3. Индексация.4. Поиск.
Индексация ‒ это процесс обнаружения и отображения ресурсов во всей сети, которые связаны с искомой фразой или словом. Эту работу поисковая система выполняет самостоятельно, хотя вебмастера и могут ей помочь путём оптимизации своих сайтов. Таким образом, с помощью индексации поисковик решает, на каких ресурсах находится ответ на запрос пользователя, но не в каком порядке их размещать в выдаче. Это происходит на следующем этапе. На втором этапе учитываются все нюансы, включая историю поиска и тип устройства, с которого пришёл поисковый запрос. Но самую главную роль здесь играет контекст.

Третий этап включает в себя 4 шага:1. Понимание поискового запроса. Поисковый алгоритм «Колибри» как раз и разработан, чтобы лучше понимать контекст поисковых запросов пользователей, уделяя больше внимания вкладываемому в поисковый запрос смыслу, а не ориентируясь исключительно на ключевые слова.2. Выборку документов из индекса с учётом тэга.3. Фильтрацию и группировку. После того, как Google проанализирует запрос и отберёт подходящие источники, в дело вступает фильтр «Панда» и другие спам-фильтры.4. Ранжирование. Именно на этом этапе Google использует энное число факторов ранжирования, но не раньше.
Не стоит забывать, что содержание и вид поисковой выдачи во многом ещё зависит и от устройства, с которого был сделан поисковой запрос.
Почему в среде вебмастеров так устойчивы мифы вроде «200 факторов ранжирования»? Потому что они воспринимаются не столько как источник информации, сколько в качестве панацеи, выполнив все предписания которой, можно уверенно подняться в выдаче и занять её верхние строчки. Возьмём для примера вот этот список и начнём с самого простого.
1. Плотность ключевых слов (фактор ранжирования №7).
Сердце кровью обливается, когда я читаю: «…хотя этот фактор уже не так важен как прежде, Google все ещё использует плотность ключевых слов для определения релевантности страницы…» Плотность ключевых никогда не была фактором ранжирования. Ноги этого мифа растут из трудов Стивена Робертсона и Карена Джонсона 70-80 годов, в которых, в частности, они разработали формулу ранжирования, известную как «Okapi BM25». Может, оно и было актуально тогда, но сейчас на дворе 2014 год. Ключевые слова используются, чтобы сайт попал в поле зрения поисковика. Но и только. Нередки случаи, когда страница ранжируется по запросу, ключевых слов на который страница даже и не содержала, но Google посчитал остальной контекст достаточно подходящим.
2. Скрытое семантическое индексирование (факторы ранжирования №18/19).
Скрытое семантическое индексирование было разработано и запатентовано в 1990 году, ещё до появления Интернета. Целью его создания была индексация небольших (содержащих менее 10 000 документов) баз данных. На основе скрытого индексирования был разработан инструмент для генерации ключевых слов, который как обещалось, умел бы находить синонимы и близкие по смыслу слова. Совершенно ясно, что для Интернета подобный метод не подходит, поскольку база данных того же Google гораздо более объёмна, да к тому же слишком часто меняется.
3. YouTube (фактор ранжирования №76).
Нет сомнений, что в своей выдаче Google отдаёт предпочтения видео с YouTube. Каким боком это повернуть к факторам ранжирования? Здесь налицо манипуляция выдачей с целью вывести в топ свои сервисы, но это никак не фактор ранжирования.Классический пример того, как наукообразные факты оказываются недостоверными и даже опасными.
4. Доступность сайта (фактор ранжирования №69).
Если ваш сайт часто бывает недоступен и постоянно выдаёт Error 500, он будет понижен в выдаче. Абсолютно верно. Однако, здесь речь об индексации, а не о ранжировании. Помните, что было сказано выше о важности правильного понимания терминов?
5. Ключевое слово в домене (фактор ранжирования №3).
Этот «фактор» попал в список, поскольку в 2011 году ряд вебмастеров (и я в том числе) заметили, что EMD и PMD имели явное преимущество в ранжировании. Но уже в 2013 году при проведении такого же исследования, результаты оказались не столь убедительными. Следует иметь ввиду, что это всего лишь субъективное мнение, основанное на личном опыте, но никак на фактор ранжирования.
6. TLD определённой страны (фактор ранжирования №10).
Действительно, домены верхнего уровня имеют более сильный геотаргетинг, чем сайты в поддоменах или папках. Однако ни один SEO-специалист в мире не будет утверждать, что домен верхнего уровня всегда ранжируется лучше, чем сайт с именем домена более низкого уровня. Неправда и то, что сайты, расположенные на домах .es или .it не могут хорошо ранжироваться за пределами Google.es или Google.it. В одной из своих прошлых статей я приводил пример, когда сайты с латиноамериканскими TLD ранжировались выше, чем сайты с доменным именем .es в Google.es. Такое часто бывает в региональных версиях Google. Этот пункт наглядно демонстрирует то, как банальное незнание может привести к опасному заблуждению.
7. Использование Google Analytics и Google Webmaster Tools (фактор ранжирования №78).
Цитирую: «Некоторые уверены, что использование этих двух инструментов способствует ускорению индексации и непосредственно влияет на позиции в выдаче». «Некоторые уверены»?! Кто такие эти «некоторые»? Студенты, тусующиеся на форуме? Специалисты по информационным технологиям? Ну кто, кто же? Всё это не более чем домыслы.
8. Гостевые посты (фактор ранжирования №91).
Ссылку (или несколько ссылок) из гостевого поста могут посчитать попыткой манипулировать выдачей и будут рассматривать как спам с последующим понижением в выдаче. Опять же, речь идёт о применении спам-фильтра и соответственно третьей стадии поиска, а не о ранжировании.
9. Лайки и число репостов на Фейсбуке (фактор ранжирования №157/158).
Google не видит лайки и не знает, сколько людей нажало на кнопку «Поделиться». Поэтому они не могут быть фактором ранжирования. И точка. Это подтверждается словами Мэтта Каттса: «Мы за единые стандарты в открытом Интернет-пространстве. Мы не хотим зависеть от компаний, вроде Фейсбук или Твиттер, чьи данные нам недоступны для сканирования». Между социальными сигналами и позицией в выдаче действительно есть связь, но эта связь не является причинно-следственной. Здесь скорее всего ступают в силу поведенческие факторы, которые опосредованным образом влияют на ранжирование.
10. Сотрудники в LinkedIn (фактор ранжирования №171).
Это заблуждение основано на статье Рэнда Фишкина, написанной в 2011 году. Но только в этой статье речь шла совсем о другом. Рэнд там высказал предположение (абсолютно верное), что в будущем Google начнёт учитывать «брендовые» сигналы. Но там ни слова не было о том, что Google собирается учитывать регистрацию сотрудников на LinkedIn.
Все ли списки факторов ранжирования плохие? Нет, но вместо изучения голой теории лучше создать сайт и проверить на практике, какие из советов работают, а какие нет, а также на собственном опыте понять принципы работы поисковой системы.
www.rxpblog.com
200 факторов ранжирования GOOGLE. Как попасть на первое место в поиске. — WEB-STUDIO.PRO — Создание сайтов Владивосток

SeoProfy создали инфографику, посвященную факторам ранжирования в поисковой системе Google, которые так или иначе влияют на позиции в поиске.
Для облегчения понимания я расшифрую имена, названия и термины, встречающиеся в тексте.
Мэтт Каттс — ведущий специалист Google в области интернет-спама и оптимизации.
SEOMoz — сообщество профессионалов в области seo и интернет-маркетинга с более чем десятилетней историей.
WHOIS (Who Is) — автоматизированная система, предоставляющая публичный доступ к информации о доменном имени и его администраторе.
TLD — сокращение от Top Level Domain, означает домен высшего уровня.
LSI — сокращенно от latent semantic indexing, переводится как латентно-семантическое индексирование. Индекс LSI отвечает за скрытую семантику, которая меняет значение в зависимости от контекста. Благодаря чему поисковые машины «понимают», что именно запрашивают люди и какие статьи им хотелось бы прочитать. А роботы, индексирующие сайты глобальной сети, показывают наиболее релевантные по смыслу в ТОПе.
PageRank — статический вес страницы, который отражает ее популярность на фоне остальных. Чем больше страниц с высоким PageRank (PR) ссылается на другую страницу, тем выше PR этой страницы.
Аарон Уолл — автор SEO-блога и книги SEO-Book.
Disavow Tool — сервис, позволяющий попросить Google не принимать во внимание определенные ссылки при оценке сайта.
Google Dance — разница выдачи результатов поиска в разных частях света. В течении каждого месяца проводится плановая переиндексация страниц, т.е. добавление новых ресурсов (посредством проверки доступного сетевого пространства google-ботами) и перерасчет PageRank уже проиндексированных страниц. Обновление индекса базы происходит постепенно, так как количество страниц определяется миллиардными показателями, а работа с ними занимает определенное время. В течении этого периода часть устаревшей информации еще имеется в наличии, а новая только появляется. Эта несостыковка объясняет довольно ощутимую разницу выдачи результатов.
Фильтр Sandbox — фильтр «Песочница» от Google для молодых сайтов. Создан для борьбы с сайтами-однодневками и черными методами раскрутки. «Симптомы песочницы»: молодой сайт не может пробиться в ТОП выдачи ПС, при этом, несмотря на низкие позиции, хорошо индексируется. Срок действия данного фильтра от нескольких месяцев до года. Под действие данного фильтра попадают не все сайты. Наиболее велики шансы попасть в «песочницу» у коммерческих сайтов и у сайтов, использующих различные методы для быстрого наращивания ссылочной массы.
Алгоритм Penguin нацелен на борьбу с неестественными обратными ссылками.
Google Panda — алгоритм ранжирования поисковой системы Google, направленный на выдачу качественного, полнотекстового контента. На пару с Penguin образуют особый поисковых алгоритмов, когда на первый план выходит не нахождение в интернете релевантного контента, а «вычищение» всей более-менее релевантной поисковой выдачи от «переоптимизированных» сайтов.
Рэнд Фишкин (Rand Fishkin) — основатель компании SEOMoz.
Google Caffeine — алгоритм, позволяющий анализировать информацию в Интернете по частям и непрерывно обновлять поисковый индекс. То есть, результаты поиска будут отображать максимально свежую информацию, вне зависимости от времени и места публикации.
Google’s Quality Rater Guidelines — рекомендации для веб-мастеров, соблюдая которые вы поможете Google найти и проиндексировать ваш сайт, а также определить его рейтинг.
IP класс C — диапазон частных ip-адресов 192.168.0.0 — 192.168.255.255.
200 факторов ранжирования GOOGLE

web-studio.pro
200 факторов ранжирования Google – миф? - публикация
В блоге Moz известный итальянский SEO-специалист Жанлука Фиорелли (Gianluca Fiorelli) подверг сомнению существование 200 факторов ранжирования Google.
По мнению оптимизатора, полный и окончательный список 200 факторов ранжирования не существует. Тем не менее, до сих пор статистика его распространения, например в Buzzsumo, впечатляет:
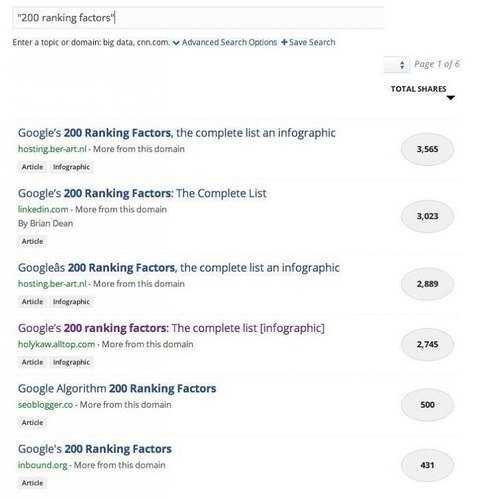
Согласно Фиорелли, целью написания его поста на эту тему была не критика взглядов авторов таких списков, в числе которых Брайан Дин (Brian Dean), который в августе опубликовал апдейт «полного списка» факторов, впервые представленного Backlinko в 2013 году. Он написал его потому, что эти списки, по его мнению, бесполезны и опасны. А также, он надеется помочь людям, особенно новому поколению оптимизаторов, понять, что окончательный и полный список факторов ранжирования Google не существует.
Более того, некоторые факторы, появляющиеся в таких списках:
- Являются мифами.
- Являются факторами корреляции, а не причинно-следственными факторами.
- Представлены с целью достичь цифру в 200 факторов.
Происхождение мифа
По словам Фиорелли, историю создания мифа о «200 факторах ранжирования Google» он узнал от своего друга, SEO-специалиста Джорджио Тавернити (Giorgio Taverniti).
Впервые Google, в лице Алана Юстаса (Alan Eustace), заявил, что он использует 200 факторов ранжирования, на пресс-дне 10 мая 2006 года:
С учетом того, что точная фраза была «более 200 факторов ранжирования», можно сделать вывод, что «200» было приближенным числом.
Возможно, как предполагает Фиорелли, оно было предложено журналистам, чтобы объяснить сложность алгоритма Google. Если бы аудитория состояла из специалистов в области информационных технологий, вероятно, Юстас выразился бы по-другому.
Другим доказательством является тот факт, что в 2010 году Мэтт Каттс (Matt Cutts) собственнолично заявил, что, да, Google насчитывает более 200 факторов ранжирования, но каждый фактор имеет до 50 вариаций.
Важность понимания значения используемых терминов и слов
Многие SEO-специлисты, по словам Фиорелли, используют слова «ранжирование» («ranking») и индексирование («indexing») как синонимы, в то время как они являются совершенно разными концептами и стадиями работы поисковой системы.
«Индексирование» – одна из четырех взаимосвязанных и взаимозависимых фаз работы поисковой системы:
- Сканирование – сбор данных поисковым роботом (Crawling).
- Парсинг – синтаксический анализ сайтов (Parsing).
- Индексирование (Indexing).
- Поиск (Search).
Индексирование – это процесс обнаружения и картирования ресурсов всей сети, которые связаны со словом или фразой. Это то, что делают поисковые системы, но не поисковые оптимизаторы. Даже, если SEO-специалисты могут помочь работе поисковых систем, оптимизируя сайт.
Индекс, как объяснил Фиорелли Энрико Альтавилла (Enrico Altavilla), используется для определения, какие ресурсы следует предложить в качестве ответа на запрос и слова/фразы, из которых он состоит, а не в каком порядке их предложить - это уже функция фазы ранжирования.
Ранжирование – заключительный момент четвертой фазы – поиска.
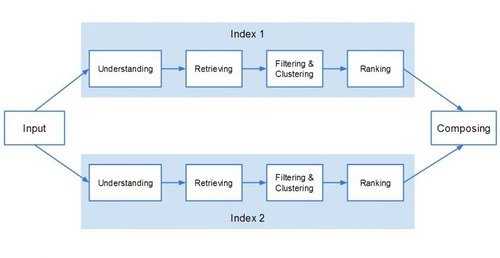
Контекст играет главную роль на стадии поиска и почти на каждом шаге этой стадии учитываются характеристики пользователей и устройств.
Как видно на изображении выше, поисковая фаза состоит из четырех различных стадий:
- Понимание входа, предоставляемого пользователем в виде запроса. Очень вероятно, что в этот момент работает алгоритм «Колибри» (Hummingbird), потому что Google для лучшего понимания входа модифицирует и расширяет запрос и только после этого переходит на вторую стадию.
- Извлечение документов из индекса, принимая во внимание команды типа «noindex».
- Фильтрация и кластеризация. Как только Google понял вход и извлек соответствующие документы из индекса, он применяет фильтры типа алгоритма «Панда» (Panda) и другие спам-фильтры, а также реже рассматриваемый фильтр Safe-Search и часто забываемый Private Search layer (персонализация).
- Ранжирование. На этой стадии Google применяет Х факторов ранжирования, но не ранее. И они должны быть рассмотрены и подсчитаны для каждого вида индекса Google
- универсального поиска;
- поиска изображений;
- локального поиска;
- и т.д.
Не следует также забывать и тот факт, что контент и его расположение, формирующие SERP, зависят от многих вещей. Например, от используемого устройства.
Разбор конкретных пунктов списка факторов ранжирования
По словам Фиорелли, оптимизаторы любят списки факторов ранжирования. Они выступают не только потенциальным источником информации, но и обнадеживают. При том, что подобные списки являются всего лишь последовательностью мифов.
Для примера итальянский SEO-специалист предлагает взять «Список 200 факторов ранжирования Google», представленный Backlinko, как наиболее распространенный из опубликованных списков.
Фиорелли рассмотрел только 10 из указанных в списке факторов:
1. Плотность ключевых слов [Фактор ранжирования № 17]
По мнению Фиорелли, этот показатель никогда не был фактором ранжирования Google. Если он когда-либо и имел релевантность как фактор ранжирования, это было в Плейстоциновую эру поисковых машин.
Сейчас 2014 год, и Google только что отпраздновал свой 16-й день рождения.
По-прежнему очевидно, что имея ключевые слова, оптимизаторы хотят причислить их как фактор ранжирования к тексту интернет-документа. Однако также известно, что возможно сделать сайт ранжируемым по конкретным ключевым словам вообще без указания их на странице, если Google посчитает достаточно последовательными и релевантными внешние сигналы, связанные с ключевыми словами сайта.
2. Латентно-семантический индекс (LSI) [факторы № 18/19]
В этом примере Фиорелли процитировал Билла Славски (Bill Slawski), который в блоге Inbound.org написал следующее:
«Скрытое семантическое индексирование было изобретено в 1990 году, перед появлением всемирной паутины. Оно было разработано, чтобы помочь индексировать небольшие базы данных документов (менее 10 тыс. единиц).
Некоторые компании начали продажу инструментов генерирования ключевых слов для LSI (LSI Keyword generation tools), которые обещали, что могут помочь идентифицировать синонимы и слова с одинаковым или похожим значением.
Эта идея провалилась в том, что процесс LSI требует доступа к базе данных для вычисления, какие слова являются синонимами, – и единственные люди, имеющие доступ к базе данных Google для проведения такого анализа (что невозможно с того времени, как индекс Google стал слишком большим и изменяется слишком часто) – это сотрудники Google».
3. YouTube [фактор ранжирования № 76]
«Нет сомнения, что видео YouTube отдается предпочтение в поисковой выдаче».
Как это может быть фактором ранжирования? В конечном счете, это монополистическое использование Google своей собственной поисковой системы, но фактор ранжирования?
По мнению итальянского SEO-специалиста, это – классический пример того, как подобные списки претендуют на научность, но при этом они ненадежны и даже опасны.
4. Uptime сайта [фактор № 69]
«Долгое «отключение» вашего сайта из-за технических работ или проблем на сервере может навредить вашей релевантности».
Здесь, по мнению Фиорелли, автор списка прав: если Google после нескольких попыток увидит, что сайт возвращает ответ сервера 500, он начнет понижать его в выдаче.
Прав, но в случае, если говорить о проблеме индексирования, вызванной проблемой сканирования, а не ранжирования. Здесь Фиорелли еще раз упомянул о важности понимания точного значения употребляемых слов.
5. Ключевое слово в качестве первого слова в имени домена [фактор № 3]
Список факторов ранжирования включает этот фактор по той причине, что в 2011 году коллегия оптимизаторов посчитала, что EMD и PMD имели явное преимущество в ранжировании, и объявили об этом в исследовании факторов ранжирования Moz (Search Ranking Factors Survey).
В 2013 году Moz опубликовал новую редакцию данного исследования, и мнения тех же оптимизаторов разделились.
Самое главное – понимание того, что это были всего лишь мнения SEO-специалистов. Они могут рассматриваться (со всеми оговорками) как возможные, но с учетом того, что они основаны на личном опыте.
Любые мнения, даже авторитетные, – это всего лишь мнения, а не наука, не говоря о факторах ранжирования.
6. TLD (домен верхнего уровня) определенной страны [фактор № 10]
Это правда, что сTLD предлагает более сильную индикацию геотаргетинга Google, чем геотаргетированные вложенные папки и поддомены.
Однако, как может подтвердить любой SEO-специалист в мире, сайт с сTLD-доменом не обязательно ранжируется выше, чем сайт с родовым именем домена.
Неверно и то, что сайты с именами домена .es и .it не могут хорошо ранжироваться за пределами Google.es или Google.it.
Прошлой весной Фиорелли в посте в State of Digital приводил много примеров, когда сайты с латиноамериканскими сTLD ранжировались выше, чем сайты с доменным именем .es в Google.es. В комментариях к посту видно, что это распространенная ситуация в каждой региональной версии Google.
Этот «фактор ранжирования» – наглядный пример того, как подобные списки могут смешивать правильную информацию и опасное неведение (в значении «отсутствие знаний или информации по данной теме»).
7. Использование Google Analytics и Инструментов для вебмастеров Google (Google Webmaster Tools) [фактор № 78]
«Некоторые считают, что имея эти две программы, установленные на сайте, можно улучшить индексирование его страниц. Они также могут непосредственно влиять на позицию сайта в выдаче, предоставляя Google больше данных…»
«Некоторые считают»? Кто? Студент, разглагольствующий на форуме? Специалист по информационным технологиям? По мнению Фиорелли, это – чистой воды спекуляция.
8. Посты от гостей сайта [фактор № 91]
Если говорить о том, насколько опасны могут быть посты гостей сайта, то речь идет о спаме.
Таким образом, если ссылка (или серия ссылок) из постов гостей рассматривается как имеющая манипулятивную природу, следует говорить о спам-фильтрах (третьей стадии поиска), а не о ранжировании. Опять же, важно понимание значений употребляемых слов, подчеркнул Фиорелли.
9. Количество лайков страницы и количество пользователей, поделившихся ссылкой на страницу, в Facebook [фактор № 157/158]
Google не может видеть лайки и репосты в Facebook. Поэтому они не могут быть фактором ранжирования.
Об этом же сказал и Мэтт Каттс:
«Нам нравятся стандарты, которые доступны в открытом интернет-пространстве. Если мы не способны просканировать что-либо – типа Facebook – мы не хотим зависеть от таких данных».
Наибольшая ошибка здесь – неразбериха между причинно-следственной связью и корреляцией. Сила социальных сигналов – это сила корреляции.
Фиорелли комментировал ранее в посте Маркуса Тобера (Marcus Tober) в Moz, что репосты в социальных сетях не являются прямой причиной хороших позиций ресурса в выдаче, но могут помочь их получить:
Репосты в социальных сетях > лучшая видимость > создание второго эшелона обратных ссылок > улучшенные возможности для получения органических обратных ссылок от пользователей, обнаруживших контент, которым поделились другие.
10. Сотрудники в LinkedIn [фактор № 171]
Здесь, по мнению Фиорелли, – предел абсурда.
Backlinko определяет сотрудников, указанных в социальной сети LinkedIn, в качестве сигнала популярности бренда. Проблема в том, что сигнал брендинга не является сигналом ранжирования.
Автор списка ссылается на старый пост Рэнда Фишкина (Rand Fhiskin), написанный в 2011 году. Но в том посте речь шла совершенно о другом. Рэнд представил свою (верную) гипотезу, что в будущем Google начнет обращать внимание на сигналы «брендинга» в порядке создания именованных объектов, способных отражать оффлайн-релевантность в онлайн-присутствии.
В том посте Рэнд никогда не указывал сотрудников в LinkedIn в качестве фактора ранжирования.
На этих 10 пунктах списка 200 факторов ранжирования Фиорелли остановился, отметив, что мог бы указать на большее количество заблуждений и ошибок.
Тем не менее, по его словам, его намерение – не разобрать полностью список, а показать SEO-специалистам и, особенно, их молодому поколению, что использование подобных списков не приносит пользы. Его цель – призвать людей не создавать их.
«Все ли списки факторов ранжирования плохие? - Нет», - отвечает на свой же вопрос Фиорелли.
Он считает, что можно найти серьезные исследования, нацеленные на понимание, почему конкретные сайты ранжируются выше, чем другие.
Исследование факторов ранжирования Moz, упомянутое ранее, и Searchmetrics Ranking Factors study – наиболее цитируемые примеры таких исследований.
Тем не менее, существует огромная разница между исследованиями и простой инфографикой/ постами, куда входят и предполагаемые «200 факторов ранжирования»: они являются корреляционными исследованиями, проведенными вслед за научными.
Следовательно, они всего лишь сообщают об общих характеристиках сайтов, которые высоко ранжируются в SERP. Их можно использовать в качестве примера лучших практик для использования, если они применимы к сайту, но не более того, считает Фиорелли.
www.prostoweb.com.ua
Топики по тегу «200 факторов ранжирования Google»
Факторы домена
Возраст доменаМетт Катс: "Разница между возрастом домена пол года или год не столь важна. Другими словами, они учитывают возраст домена но он не так важен.
Появление ключевых слов в домене высшего уровня
Этот фактор уже не является настолько мощным, но иметь ключевое слово в домене всё ещё считается сигналом релевантности сайта. Ведь зачем-то они до сих пор выделяют жирным ключевик в имени домена.
Ключевик как первое слово домена
Домен начинающийся релевантным ключевиком, имеет преимущество над доменами, в которых ключевик в середине или его нет вообще.
Длительность регистрации домена
Google: «Ценные (легитимные) домены часто бывают оплачены на несколько лет вперёд, в то время, как доры (нелегитимные) нечасто используются дольше года. Таким образом, дата истечения срока регистрации домена может быть фактором определения легитимности сайта».
Ключевик в имени поддомена
Также, SEOMoz подтвердили, что ключевое слово в поддомене позитивно влияет на ранжирование.
История домена
Сайт с постоянно меняющимся владельцем или несколькими «дропами» может сообщить Google о необходимости «сбросить» историю сайта, отменяя все ссылки на этот домен.
Домены прямого вхождения(EMD)
Такие домены всё ещё могут «выстрелить», если сайт действительно качественный. В случае, когда на домене прямого вхождения находится сайт низкого качества его «зарежет» новое обновление EMD.
Публичный vs приватный WHOIS
Приватная информация WHOIS может означать, что сайту «есть что скрывать».
Оштрафованный владелец в WHOIS
Если Google определяет некоего человека, как спаммера, логично предположить, что его вебсайты будут «зарезаны».
Домен высшего уровня мс привязкой к стране (TLD)
TLD страны (.ua .ru .pl) позитивно влияют на рейтинг сайта внутри стран, но негативно — на глобальный.
Факторы оптимизации сайта
Факторы оптимизации сайта
Ключевик в заголовке
Мета тайтл — это второй по важности контент страницы (первым считается само наполнение) и поэтому является мощным сигналом релевантности.
Заголовок начинается ключевиком
Если в начале тайтла стоит ключевое слово, его эффективность выше, чем у тайтлов с ключевиком в конце.
Ключевик в мета-дескрипшене
Это ещё один знак релевантности.
Ключевое слово присутствует в h2
h2 как «второй тайтл», посылает очередной сигнал релевантности в Google, согласно результатам исследования.
Ключевик — самая часто повторяемая фраза в документе
Появление ключевика чаще, чем остальных слов вероятно так же считается сигналом релевантности.
Скорость загрузки страницы в HTML
Google и Bing используют скорость загрузки как фактор ранжирования. Боты могут весьма точно просчитать её, основываясь на коде страницы и размере файлов.
Величина наполнения
Большой контент имеет высшую вероятность сработать и предпочитается коротким поверхностным статьям.
Плотность ключевиков
Хотя она и не так важна, как раньше, но плотность ключевых слов всё ещё используется Google для определения темы страницы.
Латентное семантическое индексирование (LSI) ключей в контенте
LSI помогает поисковикам выделить нужное значение многозначных слов например (розетка и Розетка — интернет-магазин) Наличие и отсутствие LSI так же может служить сигналом качества контента.
LSI ключевики в заголовке и дескрипшене
Так же как и с контентом страницы, LSI ключевики в мета тегах вероятно помогают Google разобраться в синонимах, что может служить сигналом релевантности.
REL=CANONICAL
Этот тег, при условии правильного использования, не позволит Google посчитать контент на страницах дублированным.
Дублированный контент
Идентичны контент на страницах сайта (даже слегка видоизменённый) может плохо повлиять на видимость в поисковиках.
Оптимизация изображений
Изображения на странице также шлют сигналы релевантности из: имён файлов, текста в описании, тайтла, дескрипшена и подписи.
Скорость загрузки страницы в CHROME
Google может использовать данные юзеров Chrome, чтобы более точно просчитать скорость загрузки.
Масштабы обновления контента
Значимость обновлений и правок также является фактором свежести. Добавление и удаление целых секций — более значимое обновление, чем смена порядка нескольких слов.
Время обновления контента
Обновление Google Caffeine предпочитает свежий контент, особенно для поисковых запросов, привязанных во времени. Google сам подсвечивает этот фактор, показывая последнее обновление для некоторых страниц.
История обновлений
Как часто обновлялась страница? Частота обновлений тоже играет немаловажную роль в факторе свежести.
Ключевик в h3, h4, тегах
Ключевики в качестве подзаголовков h3 и h4 могут быть слабым сигналом релевантности.
Положение ключевиков
Если ключевое слово находиться среди первых ста слов контента страницы — это также мощный сигнал релевантности.
Качество исходящих ссылок
Много CEOшников считают, что ссылка на авторитетные сайты помогают слать сигналы релевантности в Google
Порядок слов в ключевике
Точное совпадение запроса поисковика в контенте страницы сработает лучше, чем такая же ключевая фраза, но с другим порядком слов.
Тема исходящих ссылок
Поисковики могут использовать контент сайта, на которые ссылаются ваши страницы, как сигнал релевантности. Например, если у вас есть страница о пилах, ссылающаяся на страницу о кино, Google может решить, что ваш сайт посвящен фильму «Пила».
Оригинальный контент
Уникален ли контент? Если он скопирован с других индексированных страниц, он не будет так хорошо ранжироваться, как оригинал, или попадёт в индекс Поддержки.
Полезный вспомогательный контент
Грамотность — это качественный сигнал, хотя Каттс в 2011 сделал несколько противоречивых заявлений о её важности.
Количество внутренних ссылок, ведущих на страницу
Слишком много исходящих ссылок могут негативно повлиять на видимость в поисковиках.
Количество исходящих ссылок
Это количество указывает на важность данной страницы сайта, по сравнению со всеми остальными.
Мультимедиа
Изображения, видеоуроки и другие элементы служат сигналом качества контента.
Битые ссылки
Слишком много битых ссылок на странице может означать брошенный или запущенный сайт согласно засветившимуся документу для Службы Рейтинга Google, они являются сигналом к проверке качества главной страницы.
Качество внутренних ссылок ведущих на страницу
Внутренние ссылки с важных страниц домена имеют преимущество над такими же ссылками с второстепенных страниц.
Партнёрские ссылки
Сами по себе они не повлияют на рейтинг, но если их слишком много алгоритм Google может уделить больше внимания остальным сигналам качества, чтобы удостовериться, что это не один из «штампованных» партнёрских сайтов.
Сложность текста
Google без сомнения оценивает сложность контента на страницах.
Ошибки HTML и утверждение WC3
Множество HTML ошибок или кривой код могут означать плохое качество сайта. Также, множество SEOшников считают утверждение WC3 слабым сигналом качества сайта.
PAGERANG страницы
В целом, страницы с более высоким PR, также будут иметь более высокую релевантность и наоборот.
Авторитет домена хоста страницы
При равных остальных условиях, страницы с авторитетными доменами хоста будут выше в рейтинге.
Путь URL
Ближе к главной странице — выше авторитет.
Длина URL
Search Engine Journal сообщает, что слишком длинные URL могут негативно повлиять на видимость в поисковиках.
Категория страниц
Категория страниц также сигнал релевантности. Страница являющаяся частью тесно связанной с ней категории будет посчитана более релевантной, чем страница, значащаяся в менее или вообще не связанной с ней категории.
Редакторы
Никаких подтверждений пока нет, но Google подавали заявление на патент по системе, позволяющей редакторам (людям) влиять на результаты выдачи.
Теги в WORDPRESS
Теги — это сигналы релевантности в Wordpress специфике.
Ключевик в URL
Ещё один сигнал релевантности.
Источники ссылки
Цитирование источников и ссылок, как это делается в научных работах, может быть знаком качества. The Google QualityGuidelines говорят, что проверяющие должны смотреть на источники, когда смотрят на определённые страницы.
Цепочка URL
Категории в цепочке URL читаются Google и подают сигнал о тематике страницы.
Приоритет страницы в карте сайта
Он известен из sitemap.xml и может влиять на ранжирование страницы.
Списки
Нумерованные и просто выделенные списки позволяют разбить контент на части, делая его более удобным для читателя. Google с эти согласен и предпочитает именно такой контент.
Количество других ключевиков по которым ранжируется страница
Если страница ранжируется на нескольким ключевикам, она может давать Google дополнительный сигнал о качестве.
Слишком много исходящих ссылок
Google: «Часть страниц имеет слишком много ссылок, затмевая страницу и отвлекая от основного документа».
Удобство страницы
Google: «Разметка на высококачественных страницах делает основной контент предельно видимым и удобным к рассмотрению».
Возраст страницы
Не смотря на то, что Google предпочитает свежий контент, старая, регулярно обновляемая страница может ранжироваться лучше чем новая.
Припаркованные домены
Обновление Google в декабре 2011 снизило поисковую видимость припаркованных доменов.
Факторы уровня сайта
Контент освящает ценные и уникальные взгляды
Google объявили войну на сайты, которые не привносят ничего нового или полезного, особенно — «штампированные! партнёрские сайты.
Страница обратной связи
Тот самый Google Quality Guidelines сообщает, что предпочтительны сайты с »соответствующим количеством контактной информации". Особенно хорошо если она совпадает с WHOIS.
"Траст" домена
Доверие к сайту измеряющееся количеством исходящих ссылок на сайты с высоким доверием, являются мощным фактором ранжирования.
Архитектура сайта
Хорошая архитектура сайта (особенно silo структура) помогает Google организовать ваш контент согласно тематике.
Обновления сайта
Как часто происходит обновление сайта и главное — когда был добавлен новый контент — этот фактор свежести в масштабах всего сайта.
Количество страниц
Количество страниц на вебсайте — слабый сигнал авторитета. Как минимум, большие сайты большие сайты легко отличить от "штампованных" и заглушек.
Наличие карты сайта
Карта сайта позволяет поисковикам индексировать ваши страницы легче и тщательней, повышая поисковую видимость.
Аптайм сайта
Постоянные "технические работы" и "упавший" сервер может очень плохо повлиять на рейтинг и даже вызвать "вылетание" сайта из индекса.
Местонахождение сервера
Местонахождение сервера вполне может повлиять на ранжирование сайта по географическим регионам. Особенно это важно при поиске с гео-привязкой.
Сертификат SSL (на сайтах eCommerce)
Google подтвердили, что индексируют SSL сертификаты. Таким образом, сайты Ecommerce с этими сертификатами имеют преимущество.
Условия и конфиденциальность
Страницы с условиями предоставления и политикой конфиденциальности говорят Google, что сайт заслуживает доверия.
Дублированный контент на сайте
Наполняя сайт контентом, скопированным с других сайтов, вы получаете мизерные шансы нормального ранжирования.
Навигация BREADCRUMB
Это стиль интуитивно понятной архитектуры сайта, помогающий пользователям и поисковикам постоянно знать, где именно он находиться.
Youtube
Без сомнений, видео на Youtube имеет преимущество в поисковой выдаче (вероятно по тому, что это сервис Google)
Ревью пользователей/репутация сайта
Ревью на специализированных сайтах типа Yelp.com RipOffReport.com скорее всего сыграют свою роль для алгоритм. Google даже опубликовал свой подход к пользовательским ревью, когда известный сайт по продаже очков пойман на мошенничестве, совершённом ради обратных ссылок.
Юзабилити сайта
www.megaindex.org
200 факторов ранжирования Google – миф?
В блоге Moz известный итальянский SEO-специалист Жанлука Фиорелли (Gianluca Fiorelli) подверг сомнению существование 200 факторов ранжирования Google.
По мнению оптимизатора, полный и окончательный список 200 факторов ранжирования не существует. Тем не менее, до сих пор статистика его распространения, например в Buzzsumo, впечатляет:
Согласно Фиорелли, целью написания его поста на эту тему была не критика взглядов авторов таких списков, в числе которых Брайан Дин (Brian Dean), который в августе опубликовал апдейт «полного списка» факторов, впервые представленного Backlinko в 2013 году. Он написал его потому, что эти списки, по его мнению, бесполезны и опасны. А также, он надеется помочь людям, особенно новому поколению оптимизаторов, понять, что окончательный и полный список факторов ранжирования Google не существует.
Более того, некоторые факторы, появляющиеся в таких списках:
- Являются мифами.
- Являются факторами корреляции, а не причинно-следственными факторами.
- Представлены с целью достичь цифру в 200 факторов.
Происхождение мифа
По словам Фиорелли, историю создания мифа о «200 факторах ранжирования Google» он узнал от своего друга, SEO-специалиста Джорджио Тавернити (Giorgio Taverniti).
Впервые Google, в лице Алана Юстаса (Alan Eustace), заявил, что он использует 200 факторов ранжирования, на пресс-дне 10 мая 2006 года:
С учетом того, что точная фраза была «более 200 факторов ранжирования», можно сделать вывод, что «200» было приближенным числом.
Возможно, как предполагает Фиорелли, оно было предложено журналистам, чтобы объяснить сложность алгоритма Google. Если бы аудитория состояла из специалистов в области информационных технологий, вероятно, Юстас выразился бы по-другому.
Другим доказательством является тот факт, что в 2010 году Мэтт Каттс (Matt Cutts) собственнолично заявил, что, да, Google насчитывает более 200 факторов ранжирования, но каждый фактор имеет до 50 вариаций.
Важность понимания значения используемых терминов и слов
Многие SEO-специлисты, по словам Фиорелли, используют слова «ранжирование» («ranking») и индексирование («indexing») как синонимы, в то время как они являются совершенно разными концептами и стадиями работы поисковой системы.
«Индексирование» – одна из четырех взаимосвязанных и взаимозависимых фаз работы поисковой системы:
- Сканирование – сбор данных поисковым роботом (Crawling).
- Парсинг – синтаксический анализ сайтов (Parsing).
- Индексирование (Indexing).
- Поиск (Search).
Индексирование – это процесс обнаружения и картирования ресурсов всей сети, которые связаны со словом или фразой. Это то, что делают поисковые системы, но не поисковые оптимизаторы. Даже, если SEO-специалисты могут помочь работе поисковых систем, оптимизируя сайт.
Индекс, как объяснил Фиорелли Энрико Альтавилла (Enrico Altavilla), используется для определения, какие ресурсы следует предложить в качестве ответа на запрос и слова/фразы, из которых он состоит, а не в каком порядке их предложить — это уже функция фазы ранжирования.
Ранжирование – заключительный момент четвертой фазы – поиска.
Контекст играет главную роль на стадии поиска и почти на каждом шаге этой стадии учитываются характеристики пользователей и устройств.
Как видно на изображении выше, поисковая фаза состоит из четырех различных стадий:
- Понимание входа, предоставляемого пользователем в виде запроса. Очень вероятно, что в этот момент работает алгоритм «Колибри» (Hummingbird), потому что Google для лучшего понимания входа модифицирует и расширяет запрос и только после этого переходит на вторую стадию.
- Извлечение документов из индекса, принимая во внимание команды типа «noindex».
- Фильтрация и кластеризация. Как только Google понял вход и извлек соответствующие документы из индекса, он применяет фильтры типа алгоритма «Панда» (Panda) и другие спам-фильтры, а также реже рассматриваемый фильтр Safe-Search и часто забываемый Private Search layer (персонализация).
- Ранжирование. На этой стадии Google применяет Х факторов ранжирования, но не ранее. И они должны быть рассмотрены и подсчитаны для каждого вида индекса Google:
- универсального поиска;
- поиска изображений;
- локального поиска;
- и т.д.
Не следует также забывать и тот факт, что контент и его расположение, формирующие SERP, зависят от многих вещей. Например, от используемого устройства.
Разбор конкретных пунктов списка факторов ранжирования
По словам Фиорелли, оптимизаторы любят списки факторов ранжирования. Они выступают не только потенциальным источником информации, но и обнадеживают. При том, что подобные списки являются всего лишь последовательностью мифов.
Для примера итальянский SEO-специалист предлагает взять «Список 200 факторов ранжирования Google», представленный Backlinko, как наиболее распространенный из опубликованных списков.
Фиорелли рассмотрел только 10 из указанных в списке факторов:
1. Плотность ключевых слов [Фактор ранжирования № 17]
По мнению Фиорелли, этот показатель никогда не был фактором ранжирования Google. Если он когда-либо и имел релевантность как фактор ранжирования, это было в Плейстоциновую эру поисковых машин.
Сейчас 2014 год, и Google только что отпраздновал свой 16-й день рождения.
По-прежнему очевидно, что имея ключевые слова, оптимизаторы хотят причислить их как фактор ранжирования к тексту интернет-документа. Однако также известно, что возможно сделать сайт ранжируемым по конкретным ключевым словам вообще без указания их на странице, если Google посчитает достаточно последовательными и релевантными внешние сигналы, связанные с ключевыми словами сайта.
2. Латентно-семантический индекс (LSI) [факторы № 18/19]
В этом примере Фиорелли процитировал Билла Славски (Bill Slawski), который в блоге Inbound.org написал следующее:
«Скрытое семантическое индексирование было изобретено в 1990 году, перед появлением всемирной паутины. Оно было разработано, чтобы помочь индексировать небольшие базы данных документов (менее 10 тыс. единиц).
Некоторые компании начали продажу инструментов генерирования ключевых слов для LSI (LSI Keyword generation tools), которые обещали, что могут помочь идентифицировать синонимы и слова с одинаковым или похожим значением.
Эта идея провалилась в том, что процесс LSI требует доступа к базе данных для вычисления, какие слова являются синонимами, – и единственные люди, имеющие доступ к базе данных Google для проведения такого анализа (что невозможно с того времени, как индекс Google стал слишком большим и изменяется слишком часто) – это сотрудники Google».
3. YouTube [фактор ранжирования № 76]
«Нет сомнения, что видео YouTube отдается предпочтение в поисковой выдаче».
Как это может быть фактором ранжирования? В конечном счете, это монополистическое использование Google своей собственной поисковой системы, но фактор ранжирования?
По мнению итальянского SEO-специалиста, это – классический пример того, как подобные списки претендуют на научность, но при этом они ненадежны и даже опасны.
4. Uptime сайта [фактор № 69]
«Долгое «отключение» вашего сайта из-за технических работ или проблем на сервере может навредить вашей релевантности».
Здесь, по мнению Фиорелли, автор списка прав: если Google после нескольких попыток увидит, что сайт возвращает ответ сервера 500, он начнет понижать его в выдаче.
Прав, но в случае, если говорить о проблеме индексирования, вызванной проблемой сканирования, а не ранжирования. Здесь Фиорелли еще раз упомянул о важности понимания точного значения употребляемых слов.
5. Ключевое слово в качестве первого слова в имени домена [фактор № 3]
Список факторов ранжирования включает этот фактор по той причине, что в 2011 году коллегия оптимизаторов посчитала, что EMD и PMD имели явное преимущество в ранжировании, и объявили об этом в исследовании факторов ранжирования Moz (Search Ranking Factors Survey).
В 2013 году Moz опубликовал новую редакцию данного исследования, и мнения тех же оптимизаторов разделились.
Самое главное – понимание того, что это были всего лишь мнения SEO-специалистов. Они могут рассматриваться (со всеми оговорками) как возможные, но с учетом того, что они основаны на личном опыте.
Любые мнения, даже авторитетные, – это всего лишь мнения, а не наука, не говоря о факторах ранжирования.
6. TLD (домен верхнего уровня) определенной страны [фактор № 10]
Это правда, что сTLD предлагает более сильную индикацию геотаргетинга Google, чем геотаргетированные вложенные папки и поддомены.
Однако, как может подтвердить любой SEO-специалист в мире, сайт с сTLD-доменом не обязательно ранжируется выше, чем сайт с родовым именем домена.
Неверно и то, что сайты с именами домена .es и .it не могут хорошо ранжироваться за пределами Google.es или Google.it.
Прошлой весной Фиорелли в посте в State of Digital приводил много примеров, когда сайты с латиноамериканскими сTLD ранжировались выше, чем сайты с доменным именем .es в Google.es. В комментариях к посту видно, что это распространенная ситуация в каждой региональной версии Google.
Этот «фактор ранжирования» – наглядный пример того, как подобные списки могут смешивать правильную информацию и опасное неведение (в значении «отсутствие знаний или информации по данной теме»).
7. Использование Google Analytics и Инструментов для вебмастеров Google (Google Webmaster Tools) [фактор № 78]
«Некоторые считают, что имея эти две программы, установленные на сайте, можно улучшить индексирование его страниц. Они также могут непосредственно влиять на позицию сайта в выдаче, предоставляя Google больше данных…»
«Некоторые считают»? Кто? Студент, разглагольствующий на форуме? Специалист по информационным технологиям? По мнению Фиорелли, это – чистой воды спекуляция.
8. Посты от гостей сайта [фактор № 91]
Если говорить о том, насколько опасны могут быть посты гостей сайта, то речь идет о спаме.
Таким образом, если ссылка (или серия ссылок) из постов гостей рассматривается как имеющая манипулятивную природу, следует говорить о спам-фильтрах (третьей стадии поиска), а не о ранжировании. Опять же, важно понимание значений употребляемых слов, подчеркнул Фиорелли.
9. Количество лайков страницы и количество пользователей, поделившихся ссылкой на страницу, в Facebook [фактор № 157/158]
Google не может видеть лайки и репосты в Facebook. Поэтому они не могут быть фактором ранжирования.
Об этом же сказал и Мэтт Каттс:
«Нам нравятся стандарты, которые доступны в открытом интернет-пространстве. Если мы не способны просканировать что-либо – типа Facebook – мы не хотим зависеть от таких данных».
Наибольшая ошибка здесь – неразбериха между причинно-следственной связью и корреляцией. Сила социальных сигналов – это сила корреляции.
Фиорелли комментировал ранее в посте Маркуса Тобера (Marcus Tober) в Moz, что репосты в социальных сетях не являются прямой причиной хороших позиций ресурса в выдаче, но могут помочь их получить:
Репосты в социальных сетях > лучшая видимость > создание второго эшелона обратных ссылок > улучшенные возможности для получения органических обратных ссылок от пользователей, обнаруживших контент, которым поделились другие.
10. Сотрудники в LinkedIn [фактор № 171]
Здесь, по мнению Фиорелли, – предел абсурда.
Backlinko определяет сотрудников, указанных в социальной сети LinkedIn, в качестве сигнала популярности бренда. Проблема в том, что сигнал брендинга не является сигналом ранжирования.
Автор списка ссылается на старый пост Рэнда Фишкина (Rand Fhiskin), написанный в 2011 году. Но в том посте речь шла совершенно о другом. Рэнд представил свою (верную) гипотезу, что в будущем Google начнет обращать внимание на сигналы «брендинга» в порядке создания именованных объектов, способных отражать оффлайн-релевантность в онлайн-присутствии.
В том посте Рэнд никогда не указывал сотрудников в LinkedIn в качестве фактора ранжирования.
На этих 10 пунктах списка 200 факторов ранжирования Фиорелли остановился, отметив, что мог бы указать на большее количество заблуждений и ошибок.
Тем не менее, по его словам, его намерение – не разобрать полностью список, а показать SEO-специалистам и, особенно, их молодому поколению, что использование подобных списков не приносит пользы. Его цель – призвать людей не создавать их.
«Все ли списки факторов ранжирования плохие? — Нет», — отвечает на свой же вопрос Фиорелли.
Он считает, что можно найти серьезные исследования, нацеленные на понимание, почему конкретные сайты ранжируются выше, чем другие.
Исследование факторов ранжирования Moz, упомянутое ранее, и Searchmetrics Ranking Factors study – наиболее цитируемые примеры таких исследований.
Тем не менее, существует огромная разница между исследованиями и простой инфографикой/ постами, куда входят и предполагаемые «200 факторов ранжирования»: они являются корреляционными исследованиями, проведенными вслед за научными.
Следовательно, они всего лишь сообщают об общих характеристиках сайтов, которые высоко ранжируются в SERP. Их можно использовать в качестве примера лучших практик для использования, если они применимы к сайту, но не более того, считает Фиорелли.
csslike.me