Оптимизация запросов сервера Sql. Оптимизация запросов sql server
Оптимизация запросов SQL MS SQL Server
Чтобы проанализировать один запрос за один раз, щелкните его правой кнопкой мыши в окне сценария SSMS и выберите опцию «Анализ запроса в DTA». Для этой рабочей нагрузки выберите опцию «сохранить все существующие PDS», чтобы избежать загрузки рекомендаций по drop для индексов, не используемых в запросе на рассмотрении.
Чтобы выполнить более одного первого захвата файла трассировки с образцом типичной рабочей нагрузки, вы можете проанализировать это с помощью DTA.
Существуют простые шаги, которые должны выполняться при записи SQL Query: –
1-Возьмите имя столбцов в запросе select вместо *
2 – Избегайте подзапросов
3 – Избегайте использования оператора оператора IN
4-Использование в качестве фильтра в группе By
5-Don не сохраняет изображение в базе данных, а не сохраняет изображение. Путь в базе данных. Ex: сохранение изображения в БД занимает большое пространство, и каждый раз при необходимости будет выполнять сериализацию при сохранении или извлечении изображений в базе данных.
6 – Каждая таблица должна иметь первичный ключ
7-Каждая таблица должна иметь как минимум один кластерный индекс
8-Каждая таблица должна иметь соответствующее количество некластеризованного индекса. Некластеризованный индекс должен быть создан в столбцах таблицы на основе выполняемого запроса
9-Следующие приоритетные заказы должны соблюдаться при создании любого индекса a) Предложение WHERE, b) Предложение JOIN, c) Предложение ORDER BY, d) Предложение SELECT
10 – Не использовать Views или заменять виды исходной исходной таблицей
11-Триггеры не должны использоваться, если это возможно, включить логику триггера в хранимой процедуре
12 – Удалите любые adhoc-запросы и вместо этого используйте Хранимую процедуру
13-Проверьте, есть ли по крайней мере 30% HHD пуст, он будет немного улучшать производительность
14. Если возможно, переместите логику UDF в SP
15 – Удалите ненужные соединения из таблицы
16 – Если в запросе используется курсор, посмотрите, есть ли другой способ избежать использования этого (либо с помощью SELECT … INTO, либо INSERT … INTO и т. Д.).
sqlserver.bilee.com
Оптимизация производительности запросов SQL Server
В процессе оптимизации серверабазы данных требуется настройка производительности отдельныхзапросов. Это так же (а может быть, и поболее) принципиально, чем настройкадругих частей, влияющих на производительность сервера, к примеруконфигурации аппаратного и программного обеспечения.
Даже если сервер базы данныхупотребляет самое массивное аппаратное обеспечение на свете, горсточкаплохо себя ведущих запросов может плохо отразиться на егопроизводительности. Практически, даже один плохой запрос (время от времениих именуют «вышедшими из-под контроля») может вызвать суровоепонижение производительности базы данных.
Напротив, узкая настройка набора болеедорогих либо нередко выполняемых запросов может очень повыситьпроизводительность базы данных. В этой статье я планирую разглядетьнекие технологии, которые можно использовать для идентификациилибо узкой опции самых дорогих и плохо работающих запросов ксерверу.
Анализ плановвыполнения
Обычно при настройке отдельных запросов стоитначать с рассмотрения плана выполнения запроса. В нем описанапоследовательность физических и логических операций, которые SQLServerTM употребляет для выполнения запросаи вывода хотимого набора результатов. План выполнения делает вфазе оптимизации обработки запроса компонент ядра базы данных,который именуется оптимизатором запросов, принимая во вниманиемного разных причин, к примеру использованные в запросепредикаты поиска, задействованные таблицы и условия объединения,перечень возвращенных столбцов и наличие нужных индексов, которыеможно использовать в качестве действенных путей доступа кданным.
В сложных запросах количество всех вероятныхперестановок может быть не малым, потому оптимизатор запросов неоценивает все способности, а пробует отыскать «подходящий» для данногозапроса путь. Дело в том, что отыскать безупречный план может быть невсегда. Даже если б это было может быть, цена оценки всехспособностей при разработке безупречного плана просто перевесила бывесь выигрыш в производительности. Исходя из убеждений админабазы данных принципиально осознать процесс и его ограничения.
Существует несколько методов извлечения планавыполнения запроса:
В Management Studio есть функции отображения реального иориентировочного плана выполнения, представляющие план вграфической форме. Это более комфортная возможностьконкретной проверки и, по сути, более нередкоприменяемый метод отображения и анализа планов выполнения(примеры из этой статьи я буду иллюстрировать графическимипланами, сделанными конкретно таким методом).Разные характеристики SET, к примеру, SHOWPLAN_XML иSHOWPLAN_ALL, возвращают план выполнения в виде документа XML,описывающего план в виде специальной схемы, либо набора строк стекстовым описанием каждой операции.Классы событий профайлера SQL Server, к примеру, Showplan XML,позволяют собирать планы выполнения выражений способомтрассировки.
Хотя XML-представление плана выполнения не самыйудачный для юзера формат, эта команда позволяет использоватьбез помощи других написанные процедуры и служебные программки дляанализа, поиска заморочек с производительностью и фактическихороших планов. Представление на базе XML можно сохранить в файлс расширением sqlplan, открывать в Management Studio и создаватьграфическое представление. Не считая того, эти файлы можно сохранять дляследующего анализа без необходимости воспроизводить их всякий раз,как этот анализ пригодится. Это в особенности полезно для сопоставленияпланов и выявления возникающих с течением времени конфигураций.
Оценка ценывыполнения
1-ое, что необходимо осознать — это как генерируютсяпланы выполнения. SQL Server употребляет оптимизатор запроса набазе цены, другими словами пробует сделать план выполнения смалой оценочной ценой. Оценка делается на базестатистики рассредотачивания доступных оптимизатору на момент проверкикаждой использованной в запросе таблицы данных. Если таковойстатистики нет либо она уже устарела, оптимизатору запроса не хватитнужной инфы и оценка, вероятнее всего, окажется неточной. Втаких случаях оптимизатор переоценит либо недооценит ценавыполнения разных планов и изберет не самый лучший.
Существует несколько всераспространенных, нонеправильных представлений о ориентировочной цены выполнения.В особенности нередко считается, что ориентировочная цена выполненияявляется неплохим показателем того, сколько времени займет выполнениезапроса и что эта оценка позволяет отличить отличные планы от нехороших.Это ошибочно. Во-1-х, есть много документов касающихся того, вкаких единицах выражается ориентировочная цена и имеют ли онипрямое отношение ко времени выполнения. Во-2-х,так как значение это примерно и возможно окажется неверным,планы с большенными оценочными затратами время от времени оказываются существенноэффективнее исходя из убеждений ЦП, ввода/вывода и времени выполнения,невзирая на предположительно высшую цена. Это нередко случаетсяс запросами, где задействованы табличные переменные. Так какстатистики по ним не существует, оптимизатор запросов нередкоподразумевает, что в таблице есть всего одна строчка, хотя их во многораз больше. Соответственно, оптимизатор изберет план на базенеточной оценки. Это означает, что при сопоставлении планов выполнениязапросов не следует полагаться лишь на ориентировочную цена.Включите в анализ характеристики STATISTICS I/O и STATISTICS TIME, чтобнайти настоящую цена выполнения в терминал ввода/вывода ивремени работы ЦП.
Тут стоит упомянуть об особенном типе планавыполнения, который именуется параллельным планом. Таковой план можноизбрать при отправке на сервер с несколькими ЦП запроса,поддающегося параллелизации (В принципе, оптимизатор запросарассматривает внедрение параллельного плана исключительно в том случае,если цена запроса превосходит определенное настраиваемоезначение.) Из-за дополнительных расходов на управление несколькимипараллельными процессами выполнения, связанными с рассредотачиваниемзаданий, выполнением синхронизации и сведением результатов,параллельные планы обходятся дороже, что отражает их ориентировочнаяцена. Тогда чем все-таки они лучше более дешевеньких, непараллельных планов? Благодаря использованию вычислительной мощностинескольких ЦП параллельные планы обычно выдают итог резвеестандартных. Зависимо от определенного сценария (включая такиепеременные, как доступность ресурсов с параллельной нагрузкой другихзапросов) эта ситуации для кого-либо возможно окажется желательной. Еслиэто ваш случай, необходимо будет указать, какие из запросов можноделать по параллельному плану и сколько ЦП может использоватькаждый. Для этого необходимо настроить наивысшую степень параллелизмана уровне сервера и по мере надобности настроить обход этого правилана уровне отдельных запросов при помощи параметра OPTION (MAXDOPn).
Анализ планавыполнения
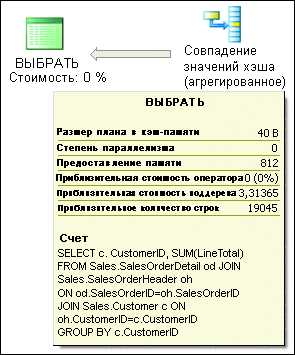
Сейчас разглядим обычный запрос, его планвыполнения и некие методы увеличения производительности.Представим, что я выполняю этот запрос в Management Studio свключенным параметром включения реального плана выполнения в примеребазы данных Adventure Works SQL Server 2005:
SELECT c.CustomerID, SUM(LineTotal)FROM Sales.SalesOrderDetail odJOIN Sales.SalesOrderHeader ohON od.SalesOrderID=oh.SalesOrderIDJOIN Sales.Customer c ON oh.CustomerID=c.CustomerIDGROUP BY c.CustomerID
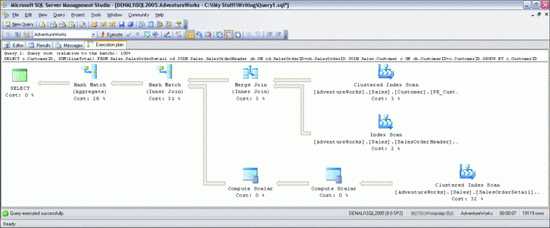
В конечном итоге я вижу план выполнения, изображенный нарис. 1. Этот обычной запрос вычисляетполное количество заказов, размещенных каждым клиентом в базе данныхAdventure Works. Смотря на этот план, вы видите, как ядро базы данныхобрабатывает запросы и выдает итог. Графические планывыполнения читаются сверху вниз, справа влево. Каждый значоксоответствует выполненной логической либо физической операции, астрелки — потокам данных меж операциями. Толщина стрелоксоответствует количеству переданных строк (чем толще, тем больше).Если поместить курсор на один из значков оператора, появится желтоватаяподсказка (такая, как на рис. 2) сосведениями о данной операции.
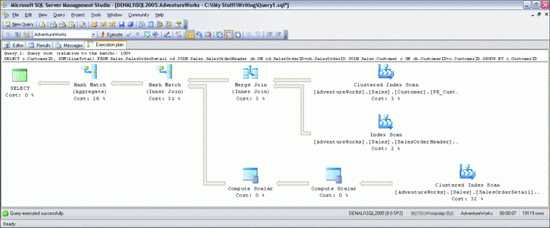 Рис.1 Пример плана выполнения
Рис.1 Пример плана выполнения
 Рис.2 Сведения об операции
Рис.2 Сведения об операции
Смотря на операторы, можно рассматриватьпоследовательность выполненных шагов:
Ядро базы данных делает операцию сканированиякластеризированных индексов с таблицей Sales.Customer и возвращаетстолбец CustomerID со всеми строчками из этой таблицы.Потом оно делает сканирование индексов (некластеризированных) над одним из индексов из таблицыSales.SalesOrderHeader. Это индекс столбца CustomerID, нопредполагается, что в него заходит столбец SalesOrderID (ключкластеризации таблицы). Сканирование возвращает значения обоихстолбцов.Результаты обоих сеансов сканирования соединяются воединыжды в столбцеCustomerID при помощи физического оператора слияния (это один из3-х вероятных физических методов выполнения операции логическогообъединения. Операция производится стремительно, но входные данныеприходится сортировать в объединенном столбце. В этом случае обеоперации сканирования уже вернули строчки, рассортированные встолбце CustomerID, так что дополнительную сортировку делать ненеобходимо).Потом ядро базы данных делает сканированиекластеризированного индекса в таблице Sales.SalesOrderDetail,извлекая значения 4 столбцов (SalesOrderID, OrderQty,UnitPrice и UnitPriceDiscount) из всех строк таблицы(предполагалось, что возвращено будет 123,317 строк. Как видно изпараметров Estimated Number of и and Actual Number of Rows на рис. 2, вышло конкретно это число, так чтооценка оказалась очень четкой).Строчки, приобретенные при сканировании кластеризованного индекса,передаются оператору вычисления цены, умноженной накоэффициент, чтоб вычислить значение столбца LineTotal для каждойстрочки на базе столбцов OrderQty, UnitPrice и UnitPriceDiscount,упомянутых в формуле.2-ой оператор вычисления цены, умноженной накоэффициент, применяет к результату предшествующего вычисления функциюISNULL, как и подразумевает формула вычисленного столбца. Онзавершает вычисление в столбце LineTotal и возвращает егопоследующему оператору вкупе со столбцом SalesOrderID.Вывод оператора слияния с шага 3 соединяется воединыжды с выводомоператора цены, умноженной на коэффициент с шага 6 ивнедрением физического оператора совпадения значений хэша.Потом к группе строк, возвращенных оператором слияния позначению столбца CustomerID и вычисленному сводному значению SUMстолбца LineTotal применяется другой оператор совпадения значенийхэша.Последний узел, SELECT — это не физический либо логическийоператор, а местозаполнитель, соответственный сводным результатамзапроса и цены.
В сделанном на моем ноутбуке плане выполненияориентировочная цена равнялась 3,31365 (как видно на рис. 3). При выполнении с включенной функциейSTATISTICS I/O ON отчет по запросу содержал упоминание о 1,388логических операциях чтения из 3-х задействованных таблиц.Процентное значение под каждым оператором — это его цена впроцентах от общей ориентировочной цены всего плана. На планена рис. 1 видно, что большая часть общейцены связана со последующими 3-мя операторами: сканированиекластеризованного индекса таблицы Sales.SalesOrderDetail и дваоператора совпадения значений хэша. Перед тем как приступить коптимизации, хотелось отметить одно очень обычное изменение в моемзапросе, которое позволило на сто процентов убрать два оператора.
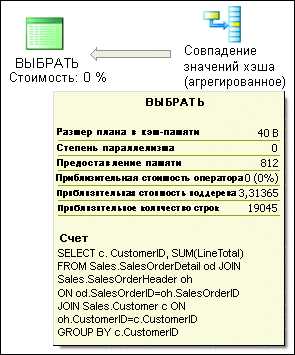 Рис. 3 Общая ориентировочная цена выполнениязапроса
Рис. 3 Общая ориентировочная цена выполнениязапроса
Так как я возвращал из таблицы Sales.Customerтолько столбец CustomerID, и тот же столбец включен в таблицуSales.SalesOrderHeaderTable в качестве наружного ключа, я могувполне исключить из запроса таблицу Customer без конфигурациилогического значения либо результата нашего запроса. Для этогоупотребляется последующий код:
SELECT oh.CustomerID, SUM(LineTotal)FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader ohON od.SalesOrderID=oh.SalesOrderIDGROUP BY oh.CustomerID
Вышел другой планвыполнения, который изображен на рис.4.
Рис.4 План выполнения после устраненияиз запроса таблицы Customer
Вполне устранены две операции — сканированиекластеризированного индекса таблицы Customer и слияние Customer иSalesOrderHeader, а совпадение значений хэша заменено на куда болееэффективную операцию слияния. При всем этом для слияния таблицSalesOrderHeader и SalesOrderDetail необходимо возвратить строчки обеихтаблиц, рассортированные по общему столбцу SalesOrderID. Для этогооптимизатор кластера выполнил сканирование кластеризованного индексатаблицы SalesOrderHeader заместо того, чтоб использоватьсканирование некластеризованного индекса, который был бы дешевле сточки зрения ввода/вывода. Это неплохой пример практическоговнедрения оптимизатора запроса, так как экономия, получающаясяпри изменении физического метода слияния, оказалась большедополнительной цены ввода/вывода при сканированиикластеризованного индекса. Оптимизатор запроса избрал получившуюсякомбинацию операторов, так как она дает мало вероятнуюпримерную цена выполнения. На моем компьютере, невзирая на то,что количество логических считываний возросло (до 1,941), временныеиздержки ЦП стали меньше, и ориентировочная цена выполненияданного запроса свалилась на 13 процентов (2,89548).
Представим, что я желаю еще сделать лучшепроизводительность запроса. Я направил внимание на сканированиекластеризованного индекса таблицы SalesOrderHeader, которое сейчасявляется самым дорогим оператором плана выполнения. Так как длявыполнения запроса необходимо всего два столбца, можно сделатьнекластеризованный индекс, где содержатся только эти два столбца.Таким макаром, заместо сканирования всей таблицы можно будетпросканировать индекс еще наименьшего размера. Определение индексаможет смотреться приблизительно так:
CREATE INDEX IDX_OrderDetail_OrderID_TotalLineON Sales.SalesOrderDetail (SalesOrderID) INCLUDE (LineTotal)
Направьте внимание, что всделанном индексе есть вычисленный столбец. Это может быть не всегда —все находится в зависимости от определения такового столбца.
Создав этот индекс и выполнив тот же запрос, яполучил новый план, который изображен на рис.5.
Рис.5 Оптимизированный план выполнения
Сканирование кластеризованного индекса таблицыSalesOrderDetail заменено некластеризованным сканированием с приметнонаименьшими затратами на ввод/вывод. Не считая того, я исключил один изоператоров вычисления цены, умноженной на коэффициент,так как в моем индексе уже есть вычисленное значение столбцаLineTotal. Сейчас ориентировочная цена плана выполнениясоставляет 2,28112 и при выполнении запроса делается 1,125логических считываний.
Упражнение. Запрос заказа покупателя
Вопрос. Вот вам наглядный пример запроса заказа покупателя.Попытайтесь получить определение индекса: выясните, наличие какихстолбцов превратит его в индекс покрытия данного запроса и воздействуетли порядок столбцов на производительность.
Ответ. Я предложил высчитать лучший индекспокрытия для сотворения таблицы Sales.SalesOrderHeader на примерезапроса из моей статьи. При всем этом необходимо сначала отметить,что запрос употребляет только два столбца из таблицы: CustomerID иSalesOrderID. Если вы пристально прочитали эту статью, то увидели,что в случае с таблицей SalesOrderHeader индекс покрытия запроса ужесуществует, это индекс CustomerID, который косвенно содержит столбецSalesOrderID, являющийся ключом кластеризации таблицы.
Естественно, я разъяснял и то, почему оптимизатор запроса не сталиспользовать этот индекс. Да, можно вынудить оптимизатор запросаиспользовать этот индекс, но это решение было бы наименее действенным,чем имеющийся план с операторами сканирования кластеризованногоиндекса и слияния. Дело в том, что оптимизатор запроса пришлось быприневолить или выполнить дополнительную операцию сортировки,нужную для использования слияния, или откатиться вспять, киспользованию наименее действенного оператора совпадения значений хэша.В обоих вариантах ориентировочная цена выполнения выше, чем всуществующем плане (версия с оператором сортировки работала быв особенности плохо), потому оптимизатор запроса не будет ихиспользовать без принуждения. Итак, в данной ситуации лучшесканирования кластеризованного индекса будет работать тольконекластеризованный индекс в столбцах SalesOrderID, CustomerID. Приэтом необходимо отметить, что столбцы должны идти конкретно в такомпорядке:
CREATE INDEX IDX_OrderHeader_SalesOrderID_CustomerIDON Sales.SalesOrderHeader (SalesOrderID, CustomerID)
Если вы создадите этот индекс, в плане выполнения будетприменено не сканирование кластеризованного индекса, асканирование индекса. Разница значимая. В этом случаенекластеризованный индекс, который содержит только два столбца,приметно меньше всей таблицы в виде кластеризованного индекса.Соответственно, при считывании подходящих данных будет меньшезадействован ввод/вывод.
Также этот пример указывает, что порядок столбцов в вашеминдексе может значительно воздействовать на его эффективность дляоптимизатора запросов. Создавая индексы с несколькими столбцами,непременно имейте это в виду.
Индекс покрытия
Индекс, сделанный из таблицы SalesOrderDetail,представляет собой так именуемый «индекс покрытия». Этонекластеризованный индекс, где содержатся все столбцы, нужныедля выполнения запроса. Он избавляет необходимость сканирования всейтаблицы при помощи операторов сканирования таблицы либокластеризованного индекса. На самом деле индекс представляет собойуменьшенную копию таблицы, где содержится подмножество ее столбцов.В индекс врубаются только столбцы, которые нужны для ответа назапрос либо запросы, другими словами только то, что «покрывает» запрос.
Создание индексов покрытия более нередкихзапросов — один из самых обычных и всераспространенных методов узкойопции запроса. В особенности отлично он работает в ситуациях, когда втаблице несколько столбцов, но запросы нередко ссылаются лишь нанекие из их. Создав один либо несколько индексов покрытия, можносущественно повысить производительность соответственных запросов,потому что они будут обращаться к приметно наименьшему количеству данных и,соответственно, количество вводов/выводов сократится. Все же,поддержка дополнительных индексов в процессе модификации данных(операторы INSERT, UPDATE и DELETE) предполагает некие расходы.Следует верно найти, оправдывает ли повышениепроизводительности эти дополнительные расходы. При всем этом учтитесвойства собственной среды и соотношение количества запросов SELECTи конфигураций данных.
Не страшитесь создавать индексы с несколькимистолбцами. Они бывают существенно полезнее индексов с однимстолбцом, и оптимизатор запросов почаще их употребляет для покрытиязапроса. Большая часть индексов покрытия содержит несколькостолбцов.
С моим примером запроса можно сделать ещекое-что. Создав индекс покрытия таблицы SalesOrderHeader, можнодополнительно улучшить запрос. При всем этом будет примененосканирование некластеризованного индекса заместо кластеризованного.Предлагаю вам выполнить это упражнение без помощи других. Попытайтесьполучить определение индекса: выясните, наличие каких столбцовпревратит его в индекс покрытия данного запроса и воздействует липорядок столбцов на производительность. Решение см. в боковой панели«Упражнение. Запрос заказа покупателя».
Индексированные представления
Если выполнение моего примера запроса оченьпринципиально, я могут пойти незначительно далее и сделать индексированноепредставление, в каком на физическом уровне хранятся материализованныерезультаты запроса. При разработке индексированных представленийесть некие подготовительные условия и ограничения, но еслиих получится использовать, производительность очень повысится.Направьте внимание, что расходы на сервис индексированныхпредставлений выше, чем у обыденных индексов. Их необходимо использовать состорожностью. В этом случае определение индекса смотрится приблизительнотак:
CREATE VIEW vTotalCustomerOrdersWITH SCHEMABINDINGASSELECT oh.CustomerID, SUM(LineTotal) AS OrdersTotalAmt, COUNT_BIG(*) AS TotalOrderLinesFROM Sales.SalesOrderDetail odJOIN Sales.SalesOrderHeader ohON od.SalesOrderID=oh.SalesOrderIDGROUP BY oh.CustomerID
Направьте внимание на параметр WITH SCHEMABINDING,без которого нереально сделать индекс такового представления, ифункцию COUNT_BIG(*), которая будет нужно в этом случае, если в нашемопределении индекса содержится обобщенная функция (в этом случаеSUM). Создав это представление, я могу сделать и индекс:
CREATE UNIQUE CLUSTERED INDEX CIX_vTotalCustomerOrders_CustomerIDON vTotalCustomerOrders(CustomerID)
При разработке этого индекса итог запроса,включенного в определение представления, материализуется и на физическом уровнесохраняется на обозначенном диске. Направьте внимание, что все операциимодификации данных начальной таблицы автоматом обновляют значенияпредставления на базе определения.
Если перезапустить запрос, то итог будетзависеть от применяемой версии SQL Server. В версиях Enterprise либоDeveloper оптимизатор автоматом сравнит запрос с определениеминдексированного представления и употребляет это представление,заместо того чтоб обращаться к начальной таблице. На рис. 6 приведен пример получившегося планавыполнения. Он состоит из одной-единственной операции — сканированиякластеризованного индекса, который я сделал на базе представления.Ориентировочная цена выполнения составляет всего 0,09023 и привыполнении запроса делается 92 логических считывания.
Рис.6 План выполнения прииспользовании индексированного представления
Это индексированное представление можно создаватьи использовать и в других версиях SQL Server, но для полученияаналогичного эффекта нужно поменять запрос и добавить прямуюссылку на представление при помощи подсказки NOEXPAND, приблизительнотак:
SELECT CustomerID, OrdersTotalAmtFROM vTotalCustomerOrders WITH (NOEXPAND)
Видите ли, верно использованныеиндексированные представления возможно окажутся очень массивнымиорудиями. Идеальнее всего их использовать в оптимизированных запросах,выполняющих агрегирование огромных объемов данных. В версииEnterprise можно усовершенствовать много запросов, не изменяякода.
Поиск запросов,нуждающихся в настройке
Как я определяют, что запрос стоит настроить? Яищу нередко выполняемые запросы, может быть, с низкой ценойвыполнения в отдельном случае, но в целом более дорогие, чембольшие, но редкие запросы. Это не означает, чтопоследние настраивать не надо. Я просто считаю, что для началанеобходимо сосредоточиться на более нередких запросах. Потому что же ихотыскать?
К огорчению, самый надежный способ достаточно сложени предугадывает отслеживание всех выполненных запросов к серверу сследующий группировкой по подписям. При всем этом текст запроса среальными значениями характеристик заменяется на замещающий текст,который позволяет избрать однотипные запросы с различными значениями.Подписи запроса сделать тяжело, так что это непростой процесс. ИцикБен-Ган (Itzik Ben-Gan) обрисовывает решение с внедрениемпользовательских функций в среде CLR и постоянных выражений в собственнойкнижке «Microsoft SQL Server 2005 изнутри: запросы T-SQL».
Существует очередной способ, куда более обычной, ноне настолько надежный. Можно положиться на статистику всех запросов,которая хранится в кэше плана выполнения, и опросить их свнедрением динамических административных представлений. На рисунке 7 есть пример запроса текста и планавыполнения 20 запросов из кэша, у каких полное количествологических считываний оказалось наибольшим. При помощи этогозапроса очень комфортно стремительно отыскивать запросы с наибольшимколичеством логических считываний, но есть и некие ограничения.Он показывает только запросы с планами, кэшированными на моментпуска. Не кэшированные объекты не показываются.
Рис. 7 Поиск 20 самых дорогих исходя из убеждений ввода/вывода при считывании запросов.
SELECT TOP 20 SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,((CASE qs.statement_end_offsetWHEN -1 THEN DATALENGTH(qt.text)ELSE qs.statement_end_offsetEND – qs.statement_start_offset)/2)+1),qs.execution_count,qs.total_logical_reads, qs.last_logical_reads,qs.min_logical_reads, qs.max_logical_reads,qs.total_elapsed_time, qs.last_elapsed_time,qs.min_elapsed_time, qs.max_elapsed_time,qs.last_execution_time,qp.query_planFROM sys.dm_exec_query_stats qsCROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qtCROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qpWHERE qt.encrypted=0ORDER BY qs.total_logical_reads DESC
Найдя запросы с нехороший производительностью,разглядите их планы и найдите методы оптимизации при помощитехнологий индексирования, которые я обрисовал в этой статье. Вы не напраснопотратите время, если добьетесь фуррора.
Успешной опции!
Комментирование на данный момент запрещено, но Вы можете оставить
на Ваш сайт.
hodovik72.ru
Основы оптимизации запросов SQL Server
Mastering the Basics of SQL Server Query Optimization
Duration 01:09:01
Открыть все курсы от udemyMastering the Basics of SQL Server Query Optimization - Полный список уроков
Развернуть / Свернуть- Урок 1. An Introduction to This Course 00:01:26
- Урок 2. The SQL Engine 00:01:16
- Урок 3. The Query Processing Process 00:01:30
- Урок 4. The Search Space 00:01:44
- Урок 5. Whats In the Cost 00:01:32
- Урок 6. Plan Cache Reuse 00:01:20
- Урок 7. What Causes Recompilation 00:00:51
- Урок 8. Terminology 00:04:02
- Урок 9. Anatomy of Execution Plan 00:02:34
- Урок 10. Execution Plan Output Options 00:01:37
- Урок 11. Scan VS Seek 00:01:56
- Урок 12. Scanning Demos 00:02:09
- Урок 13. Seeking Demos 00:03:06
- Урок 14. The Bookmark Lookup 00:04:08
- Урок 15. Aggregations 00:02:02
- Урок 16. Hash Match Operator 00:03:05
- Урок 17. Joins - The Nested Loop 00:01:54
- Урок 18. Joins - The Merge Join 00:01:25
- Урок 19. Joins - The Hash Join 00:01:17
- Урок 20. Parallelism Introduction 00:01:13
- Урок 21. Statistics Contain 3 Key Pieces of Information in DBCC SHOW_STATISTICS 00:01:35
- Урок 22. Anatomy of a Statistic Header,Vector and Histogram 00:04:24
- Урок 23. Out of Date Statistics 00:01:17
- Урок 24. Stale Statistics Demo 00:01:16
- Урок 25. Maintaining Statistics 00:01:25
- Урок 26. Setting Up Statistics Maintenance Job 00:04:35
- Урок 27. The Scan On Large Tables 00:03:23
- Урок 28. Using SET STATISTICS IO ON 00:02:46
- Урок 29. Non-Clustered Indexes on Heaps 00:02:44
- Урок 30. The No Good Sort Operator 00:03:29
- Урок 31. Unwinding The Spool 00:02:00
В основе СУБД SQL Server лежат два основных компонента: механизм хранения и процессор запросов, также называемый реляционным механизмом.
В этом курсе мы сосредоточимся только на процессоре запросов. Эта часть движка принимает все запросы к SQL Server и создает план для оптимального выполнения.
Твоя оценка
Следи за последними обновлениями и новостями в нашем coursehunters.club, или вступай в наш канал telegram.Комментарии
Похожие курсы
13-05-2017en 56 уроков pluralsight What Every Developer Should Know About SQL Server PerformanceЭтот курс предназначен рассказать разработчикам о основах SQL Server, показывая инструменты, которые вам нужны для устранения неполадок и проблем производительности.
Duration 03:21:21
13-05-2017en 61 урок lyndacom Developing Microsoft SQL Server 2016 DatabasesВ этом курсе Адам Уилберт показывает опытным администраторам SQL Server как разрабатывать базу данных SQL Server 2016. Узнайте как создавать таблицы данных, включая временные таблицы и таблицы с переменными а также схемы. А также вы узнаете как обеспечить целостность данных с помощью ограничений и защитить свою базу данных на уровне пользователя.Мы также мы создадем индексы для оптимизации производительности и убедимься что ваша база данных SQL...
Duration 04:05:32
coursehunters.net
| В процессе оптимизации сервера базы данных требуется настройка производительности отдельных запросов. Это так же (а может быть, и более) важно, чем настройка других элементов, влияющих на производительность сервера, например конфигурации аппаратного и программного обеспечения. Даже если сервер базы данных использует самое мощное аппаратное обеспечение на свете, горсточка плохо себя ведущих запросов может плохо отразиться на его производительности. Фактически, даже один неудачный запрос (иногда их называют «вышедшими из-под контроля») может вызвать серьезное снижение производительности базы данных. Напротив, тонкая настройка набора наиболее дорогих или часто выполняемых запросов может сильно повысить производительность базы данных. В этой статье я планирую рассмотреть некоторые технологии, которые можно использовать для идентификации или тонкой настройки самых дорогих и плохо работающих запросов к серверу. Анализ планов выполнения Обычно при настройке отдельных запросов стоит начать с рассмотрения плана выполнения запроса. В нем описана последовательность физических и логических операций, которые SQL ServerTM использует для выполнения запроса и вывода желаемого набора результатов. План выполнения создает в фазе оптимизации обработки запроса компонент ядра базы данных, который называется оптимизатором запросов, принимая во внимание много различных факторов, например использованные в запросе предикаты поиска, задействованные таблицы и условия объединения, список возвращенных столбцов и наличие полезных индексов, которые можно использовать в качестве эффективных путей доступа к данным. В сложных запросах количество всех возможных перестановок может быть огромным, поэтому оптимизатор запросов не оценивает все возможности, а пытается найти «подходящий» для данного запроса путь. Дело в том, что найти идеальный план возможно не всегда. Даже если бы это было возможно, стоимость оценки всех возможностей при разработке идеального плана легко перевесила бы весь выигрыш в производительности. С точки зрения администратора базы данных важно понять процесс и его ограничения. Существует несколько способов извлечения плана выполнения запроса: В Management Studio есть функции отображения реального и приблизительного плана выполнения, представляющие план в графической форме. Это наиболее удобная возможность непосредственной проверки и, по большому счету, наиболее часто используемый способ отображения и анализа планов выполнения (примеры из этой статьи я буду иллюстрировать графическими планами, созданными именно таким способом). Различные параметры SET, например, SHOWPLAN_XML и SHOWPLAN_ALL, возвращают план выполнения в виде документа XML, описывающего план в виде специальной схемы, или набора строк с текстовым описанием каждой операции. Классы событий профайлера SQL Server, например, Showplan XML, позволяют собирать планы выполнения выражений методом трассировки. Хотя XML-представление плана выполнения не самый удобный для пользователя формат, эта команда позволяет использовать самостоятельно написанные процедуры и служебные программы для анализа, поиска проблем с производительностью и практически оптимальных планов. Представление на базе XML можно сохранить в файл с расширением sqlplan, открывать в Management Studio и создавать графическое представление. Кроме того, эти файлы можно сохранять для последующего анализа без необходимости воспроизводить их каждый раз, как этот анализ понадобится. Это особенно полезно для сравнения планов и выявления возникающих со временем изменений. Оценка стоимости выполнения Первое, что нужно понять — это как генерируются планы выполнения. SQL Server использует оптимизатор запроса на основе стоимости, то есть пытается создать план выполнения с минимальной оценочной стоимостью. Оценка производится на основе статистики распределения доступных оптимизатору на момент проверки каждой использованной в запросе таблицы данных. Если такой статистики нет или она уже устарела, оптимизатору запроса не хватит необходимой информации и оценка, скорее всего, окажется неточной. В таких случаях оптимизатор переоценит или недооценит стоимость выполнения различных планов и выберет не самый оптимальный. Существует несколько распространенных, но неверных представлений о приблизительной стоимости выполнения. Особенно часто считается, что приблизительная стоимость выполнения является хорошим показателем того, сколько времени займет выполнение запроса и что эта оценка позволяет отличить хорошие планы от плохих. Это неверно. Во-первых, есть много документов касающихся того, в каких единицах выражается приблизительная стоимость и имеют ли они непосредственное отношение ко времени выполнения. Во-вторых, поскольку значение это приблизительно и может оказаться ошибочным, планы с большими оценочными затратами иногда оказываются значительно эффективнее с точки зрения ЦП, ввода/вывода и времени выполнения, несмотря на предположительно высокую стоимость. Это часто случается с запросами, где задействованы табличные переменные. Поскольку статистики по ним не существует, оптимизатор запросов часто предполагает, что в таблице есть всего одна строка, хотя их во много раз больше. Соответственно, оптимизатор выберет план на основе неточной оценки. Это значит, что при сравнении планов выполнения запросов не следует полагаться только на приблизительную стоимость. Включите в анализ параметры STATISTICS I/O и STATISTICS TIME, чтобы определить истинную стоимость выполнения в терминал ввода/вывода и времени работы ЦП. Здесь стоит упомянуть об особом типе плана выполнения, который называется параллельным планом. Такой план можно выбрать при отправке на сервер с несколькими ЦП запроса, поддающегося параллелизации (В принципе, оптимизатор запроса рассматривает использование параллельного плана только в том случае, если стоимость запроса превышает определенное настраиваемое значение.) Из-за дополнительных расходов на управление несколькими параллельными процессами выполнения, связанными с распределением заданий, выполнением синхронизации и сведением результатов, параллельные планы обходятся дороже, что отражает их приблизительная стоимость. Тогда чем же они предпочтительнее более дешевых, не параллельных планов? Благодаря использованию вычислительной мощности нескольких ЦП параллельные планы обычно выдают результат быстрее стандартных. В зависимости от конкретного сценария (включая такие переменные, как доступность ресурсов с параллельной нагрузкой других запросов) эта ситуации для кого-то может оказаться желательной. Если это ваш случай, нужно будет указать, какие из запросов можно выполнять по параллельному плану и сколько ЦП может задействовать каждый. Для этого нужно настроить максимальную степень параллелизма на уровне сервера и при необходимости настроить обход этого правила на уровне отдельных запросов с помощью параметра OPTION (MAXDOP n). Анализ плана выполнения Теперь рассмотрим простой запрос, его план выполнения и некоторые способы повышения производительности. Предположим, что я выполняю этот запрос в Management Studio с включенным параметром включения реального плана выполнения в примере базы данных Adventure Works SQL Server 2005: SELECT c.CustomerID, SUM(LineTotal)FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader ohON od.SalesOrderID=oh.SalesOrderIDJOIN Sales.Customer c ON oh.CustomerID=c.CustomerIDGROUP BY c.CustomerID В итоге я вижу план выполнения, изображенный на рис. 1. Этот простой запрос вычисляет общее количество заказов, размещенных каждым клиентом в базе данных Adventure Works. Глядя на этот план, вы видите, как ядро базы данных обрабатывает запросы и выдает результат. Графические планы выполнения читаются сверху вниз, справа налево. Каждый значок соответствует выполненной логической или физической операции, а стрелки — потокам данных между операциями. Толщина стрелок соответствует количеству переданных строк (чем толще, тем больше). Если поместить курсор на один из значков оператора, появится желтая подсказка (такая, как на рис. 2) со сведениями о данной операции.
Рис. 1 Пример плана выполнения
Рис. 2 Сведения об операции Глядя на операторы, можно анализировать последовательность выполненных этапов: Ядро базы данных выполняет операцию сканирования кластеризированных индексов с таблицей Sales.Customer и возвращает столбец CustomerID со всеми строками из этой таблицы. Затем оно выполняет сканирование индексов (не кластеризированных) над одним из индексов из таблицы Sales.SalesOrderHeader. Это индекс столбца CustomerID, но подразумевается, что в него входит столбец SalesOrderID (ключ кластеризации таблицы). Сканирование возвращает значения обоих столбцов. Результаты обоих сеансов сканирования объединяются в столбце CustomerID с помощью физического оператора слияния (это один из трех возможных физических способов выполнения операции логического объединения. Операция выполняется быстро, но входные данные приходится сортировать в объединенном столбце. В данном случае обе операции сканирования уже возвратили строки, рассортированные в столбце CustomerID, так что дополнительную сортировку выполнять не нужно). Затем ядро базы данных выполняет сканирование кластеризированного индекса в таблице Sales.SalesOrderDetail, извлекая значения четырех столбцов (SalesOrderID, OrderQty, UnitPrice и UnitPriceDiscount) из всех строк таблицы (предполагалось, что возвращено будет 123,317 строк. Как видно из свойств Estimated Number of и and Actual Number of Rows на рис. 2, получилось именно это число, так что оценка оказалась очень точной). Строки, полученные при сканировании кластеризованного индекса, передаются оператору вычисления стоимости, умноженной на коэффициент, чтобы вычислить значение столбца LineTotal для каждой строки на основе столбцов OrderQty, UnitPrice и UnitPriceDiscount, упомянутых в формуле. Второй оператор вычисления стоимости, умноженной на коэффициент, применяет к результату предыдущего вычисления функцию ISNULL, как и предполагает формула вычисленного столбца. Он завершает вычисление в столбце LineTotal и возвращает его следующему оператору вместе со столбцом SalesOrderID. Вывод оператора слияния с этапа 3 объединяется с выводом оператора стоимости, умноженной на коэффициент с этапа 6 и использованием физического оператора совпадения значений хэша. Затем к группе строк, возвращенных оператором слияния по значению столбца CustomerID и вычисленному сводному значению SUM столбца LineTotal применяется другой оператор совпадения значений хэша. Последний узел, SELECT — это не физический или логический оператор, а местозаполнитель, соответствующий сводным результатам запроса и стоимости. В созданном на моем ноутбуке плане выполнения приблизительная стоимость равнялась 3,31365 (как видно на рис. 3). При выполнении с включенной функцией STATISTICS I/O ON отчет по запросу содержал упоминание о 1,388 логических операциях чтения из трех задействованных таблиц. Процентное значение под каждым оператором — это его стоимость в процентах от общей приблизительной стоимости всего плана. На плане на рис. 1 видно, что большая часть общей стоимости связана со следующими тремя операторами: сканирование кластеризованного индекса таблицы Sales.SalesOrderDetail и два оператора совпадения значений хэша. Перед тем как приступить к оптимизации, хотелось отметить одно очень простое изменение в моем запросе, которое позволило полностью устранить два оператора.
Рис. 3 Общая приблизительная стоимость выполнения запроса Поскольку я возвращал из таблицы Sales.Customer только столбец CustomerID, и тот же столбец включен в таблицу Sales.SalesOrderHeaderTable в качестве внешнего ключа, я могу полностью исключить из запроса таблицу Customer без изменения логического значения или результата нашего запроса. Для этого используется следующий код: SELECT oh.CustomerID, SUM(LineTotal)FROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader ohON od.SalesOrderID=oh.SalesOrderIDGROUP BY oh.CustomerID Получился другой план выполнения, который изображен на рис. 4. Рис. 4 План выполнения после устранения из запроса таблицы Customer Полностью устранены две операции — сканирование кластеризированного индекса таблицы Customer и слияние Customer и SalesOrderHeader, а совпадение значений хэша заменено на куда более эффективную операцию слияния. При этом для слияния таблиц SalesOrderHeader и SalesOrderDetail нужно вернуть строки обеих таблиц, рассортированные по общему столбцу SalesOrderID. Для этого оптимизатор кластера выполнил сканирование кластеризованного индекса таблицы SalesOrderHeader вместо того, чтобы использовать сканирование некластеризованного индекса, который был бы дешевле с точки зрения ввода/вывода. Это хороший пример практического применения оптимизатора запроса, поскольку экономия, получающаяся при изменении физического способа слияния, оказалась больше дополнительной стоимости ввода/вывода при сканировании кластеризованного индекса. Оптимизатор запроса выбрал получившуюся комбинацию операторов, поскольку она дает минимально возможную примерную стоимость выполнения. На моем компьютере, несмотря на то, что количество логических считываний возросло (до 1,941), временные затраты ЦП стали меньше, и приблизительная стоимость выполнения данного запроса упала на 13 процентов (2,89548). Предположим, что я хочу еще улучшить производительность запроса. Я обратил внимание на сканирование кластеризованного индекса таблицы SalesOrderHeader, которое теперь является самым дорогим оператором плана выполнения. Поскольку для выполнения запроса нужно всего два столбца, можно создать некластеризованный индекс, где содержатся только эти два столбца. Таким образом, вместо сканирования всей таблицы можно будет просканировать индекс гораздо меньшего размера. Определение индекса может выглядеть примерно так: CREATE INDEX IDX_OrderDetail_OrderID_TotalLineON Sales.SalesOrderDetail (SalesOrderID) INCLUDE (LineTotal) Обратите внимание, что в созданном индексе есть вычисленный столбец. Это возможно не всегда — все зависит от определения такого столбца. Создав этот индекс и выполнив тот же запрос, я получил новый план, который изображен на рис. 5. Рис. 5 Оптимизированный план выполнения Сканирование кластеризованного индекса таблицы SalesOrderDetail заменено некластеризованным сканированием с заметно меньшими затратами на ввод/вывод. Кроме того, я исключил один из операторов вычисления стоимости, умноженной на коэффициент, поскольку в моем индексе уже есть вычисленное значение столбца LineTotal. Теперь приблизительная стоимость плана выполнения составляет 2,28112 и при выполнении запроса производится 1,125 логических считываний. Упражнение. Запрос заказа покупателя Вопрос. Вот пример запроса заказа покупателя. Попробуйте получить определение индекса: выясните, наличие каких столбцов превратит его в индекс покрытия данного запроса и повлияет ли порядок столбцов на производительность. Ответ. Я предложил рассчитать оптимальный индекс покрытия для создания таблицы Sales.SalesOrderHeader на примере запроса из моей статьи. При этом нужно в первую очередь отметить, что запрос использует только два столбца из таблицы: CustomerID и SalesOrderID. Если вы внимательно прочли эту статью, то заметили, что в случае с таблицей SalesOrderHeader индекс покрытия запроса уже существует, это индекс CustomerID, который косвенно содержит столбец SalesOrderID, являющийся ключом кластеризации таблицы. Конечно, я объяснял и то, почему оптимизатор запроса не стал использовать этот индекс. Да, можно заставить оптимизатор запроса использовать этот индекс, но это решение было бы менее эффективным, чем существующий план с операторами сканирования кластеризованного индекса и слияния. Дело в том, что оптимизатор запроса пришлось бы принудить либо выполнить дополнительную операцию сортировки, необходимую для использования слияния, либо откатиться назад, к использованию менее эффективного оператора совпадения значений хэша. В обоих вариантах приблизительная стоимость выполнения выше, чем в существующем плане (версия с оператором сортировки работала бы особенно плохо), поэтому оптимизатор запроса не будет их использовать без принуждения. Итак, в данной ситуации лучше сканирования кластеризованного индекса будет работать только некластеризованный индекс в столбцах SalesOrderID, CustomerID. При этом нужно отметить, что столбцы должны идти именно в таком порядке:CREATE INDEX IDX_OrderHeader_SalesOrderID_CustomerIDON Sales.SalesOrderHeader (SalesOrderID, CustomerID) Если вы создадите этот индекс, в плане выполнения будет использовано не сканирование кластеризованного индекса, а сканирование индекса. Разница существенная. В данном случае некластеризованный индекс, который содержит только два столбца, заметно меньше всей таблицы в виде кластеризованного индекса. Соответственно, при считывании нужных данных будет меньше задействован ввод/вывод. Также этот пример показывает, что порядок столбцов в вашем индексе может существенно повлиять на его эффективность для оптимизатора запросов. Создавая индексы с несколькими столбцами, обязательно имейте это в виду. Индекс покрытия Индекс, созданный из таблицы SalesOrderDetail, представляет собой так называемый «индекс покрытия». Это некластеризованный индекс, где содержатся все столбцы, необходимые для выполнения запроса. Он устраняет необходимость сканирования всей таблицы с помощью операторов сканирования таблицы или кластеризованного индекса. По сути индекс представляет собой уменьшенную копию таблицы, где содержится подмножество ее столбцов. В индекс включаются только столбцы, которые необходимы для ответа на запрос или запросы, то есть только то, что «покрывает» запрос. Создание индексов покрытия наиболее частых запросов — один из самых простых и распространенных способов тонкой настройки запроса. Особенно хорошо он работает в ситуациях, когда в таблице несколько столбцов, но запросы часто ссылаются только на некоторые из них. Создав один или несколько индексов покрытия, можно значительно повысить производительность соответствующих запросов, так как они будут обращаться к заметно меньшему количеству данных и, соответственно, количество вводов/выводов сократится. Тем не менее, поддержка дополнительных индексов в процессе модификации данных (операторы INSERT, UPDATE и DELETE) подразумевает некоторые расходы. Следует четко определить, оправдывает ли увеличение производительности эти дополнительные расходы. При этом учтите характеристики своей среды и соотношение количества запросов SELECT и изменений данных. Не бойтесь создавать индексы с несколькими столбцами. Они бывают значительно полезнее индексов с одним столбцом, и оптимизатор запросов чаще их использует для покрытия запроса. Большинство индексов покрытия содержит несколько столбцов. С моим примером запроса можно сделать еще кое-что. Создав индекс покрытия таблицы SalesOrderHeader, можно дополнительно оптимизировать запрос. При этом будет использовано сканирование некластеризованного индекса вместо кластеризованного. Предлагаю вам выполнить это упражнение самостоятельно. Попробуйте получить определение индекса: выясните, наличие каких столбцов превратит его в индекс покрытия данного запроса и повлияет ли порядок столбцов на производительность. Решение см. в боковой панели "Упражнение. Запрос заказа покупателя". Индексированные представления Если выполнение моего примера запроса очень важно, я могут пойти немного дальше и создать индексированное представление, в котором физически хранятся материализованные результаты запроса. При создании индексированных представлений существуют некоторые предварительные условия и ограничения, но если их удастся использовать, производительность сильно повысится. Обратите внимание, что расходы на обслуживание индексированных представлений выше, чем у обычных индексов. Их нужно использовать с осторожностью. В данном случае определение индекса выглядит примерно так: CREATE VIEW vTotalCustomerOrdersWITH SCHEMABINDINGASSELECT oh.CustomerID, SUM(LineTotal) AS OrdersTotalAmt, COUNT_BIG(*) AS TotalOrderLinesFROM Sales.SalesOrderDetail od JOIN Sales.SalesOrderHeader ohON od.SalesOrderID=oh.SalesOrderIDGROUP BY oh.CustomerID Обратите внимание на параметр WITH SCHEMABINDING, без которого невозможно создать индекс такого представления, и функцию COUNT_BIG(*), которая потребуется в том случае, если в нашем определении индекса содержится обобщенная функция (в данном случае SUM). Создав это представление, я могу создать и индекс: CREATE UNIQUE CLUSTERED INDEX CIX_vTotalCustomerOrders_CustomerID ON vTotalCustomerOrders(CustomerID) При создании этого индекса результат запроса, включенного в определение представления, материализуется и физически сохраняется на указанном диске. Обратите внимание, что все операции модификации данных исходной таблицы автоматически обновляют значения представления на основе определения. Если перезапустить запрос, то результат будет зависеть от используемой версии SQL Server. В версиях Enterprise или Developer оптимизатор автоматически сравнит запрос с определением индексированного представления и использует это представление, вместо того чтобы обращаться к исходной таблице. На рис. 6 приведен пример получившегося плана выполнения. Он состоит из одной-единственной операции — сканирования кластеризованного индекса, который я создал на основе представления. Приблизительная стоимость выполнения составляет всего 0,09023 и при выполнении запроса производится 92 логических считывания. Рис. 6 План выполнения при использовании индексированного представления Это индексированное представление можно создавать и использовать и в других версиях SQL Server, но для получения аналогичного эффекта необходимо изменить запрос и добавить прямую ссылку на представление с помощью подсказки NOEXPAND, примерно так: SELECT CustomerID, OrdersTotalAmtFROM vTotalCustomerOrders WITH (NOEXPAND) Как видите, правильно использованные индексированные представления могут оказаться очень мощными орудиями. Лучше всего их использовать в оптимизированных запросах, выполняющих агрегирование больших объемов данных. В версии Enterprise можно усовершенствовать много запросов, не изменяя кода. Поиск запросов, нуждающихся в настройке Как я определяют, что запрос стоит настроить? Я ищу часто выполняемые запросы, возможно, с невысокой стоимостью выполнения в отдельном случае, но в целом более дорогие, чем крупные, но редко встречающиеся запросы. Это не значит, что последние настраивать не нужно. Я просто считаю, что для начала нужно сосредоточиться на более частых запросах. Так как же их найти? К сожалению, самый надежный метод довольно сложен и предусматривает отслеживание всех выполненных запросов к серверу с последующий группировкой по подписям. При этом текст запроса с реальными значениями параметров заменяется на замещающий текст, который позволяет выбрать однотипные запросы с разными значениями. Подписи запроса создать тяжело, так что это сложный процесс. Ицик Бен-Ган (Itzik Ben-Gan) описывает решение с использованием пользовательских функций в среде CLR и регулярных выражений в своей книге «Microsoft SQL Server 2005 изнутри: запросы T-SQL». Существует еще один метод, куда более простой, но не столь надежный. Можно положиться на статистику всех запросов, которая хранится в кэше плана выполнения, и опросить их с использованием динамических административных представлений. На рисунке 7 есть пример запроса текста и плана выполнения 20 запросов из кэша, у которых общее количество логических считываний оказалось максимальным. С помощью этого запроса очень удобно быстро находить запросы с максимальным количеством логических считываний, но есть и некоторые ограничения. Он отображает только запросы с планами, кэшированными на момент запуска. Не кэшированные объекты не отображаются. Рис. 7 Поиск 20 самых дорогих с точки зрения ввода/вывода при считывании запросов.SELECT TOP 20 SUBSTRING(qt.text, (qs.statement_start_offset/2)+1, ((CASE qs.statement_end_offsetWHEN -1 THEN DATALENGTH(qt.text)ELSE qs.statement_end_offsetEND - qs.statement_start_offset)/2)+1), qs.execution_count, qs.total_logical_reads, qs.last_logical_reads,qs.min_logical_reads, qs.max_logical_reads,qs.total_elapsed_time, qs.last_elapsed_time,qs.min_elapsed_time, qs.max_elapsed_time,qs.last_execution_time,qp.query_planFROM sys.dm_exec_query_stats qsCROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qtCROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qpWHERE qt.encrypted=0ORDER BY qs.total_logical_reads DESC Обнаружив запросы с плохой производительностью, рассмотрите их планы и найдите способы оптимизации с помощью технологий индексирования, которые я описал в этой статье. Вы не зря потратите время, если добьетесь успеха. Удачной настройки! |

jober.do.am
Оптимизация запросов SQL Server? MS SQL Server
… и, к моему удивлению, он не возвращает результаты в приемлемое время. Впервые я запустил его в производственной среде, как 3 секунды исполнения. Теперь он работает до таймаута (внутри приложения C #, 30 секунд). Основная цель: «Дайте мне самые последние места от любого трекера и информацию об устройствах пользователей, глядя на 2 минуты назад». Любые подсказки по оптимизации этого запроса?
Индексы: где угодно, но где столбцы предложения (ReceivedTime, OSType, Notify).
О плане исполнения, это огромная вещь, и это не слишком знакомо мне. Должен ли я вставить его здесь? 🙂
SELECT tl.*,d.* FROM TrackerLocations AS tl inner join Trackers t on tl.TrackerId = t.TrackerId inner join Devices d on t.UserId = d.UserId WHERE tl.ReceivedTime = (SELECT MAX(tl2.ReceivedTime) FROM TrackerLocations tl2 WHERE tl2.TrackerId = tl.TrackerId and tl2.ReceivedTime >= @searchTerm) and d.RegistrationId <> '' and d.OSType <> 3 and d.Notify = 1Я бы предложил попробовать индекс ( TrackerId , ReceivedTime ) и, возможно, просто ReceivedTime . Но, без профилирования и фактического плана выполнения, это просто выстрел в темноте.
Создавайте индексы на TrackerLocations.TrackerId и Trackers.TrackerId . Также Devices.UserId и Trackers.UserId для второго JOIN . Наконец, посмотрите на создание индекса в TrackerLocations.ReceivedTime а также для WHERE .
В общем, первое, на что нужно обратить внимание, чтобы оптимизировать такие запросы, – это проверить, есть ли у вас индексы в ваших критериях присоединения. Кроме того, если у вас есть какой-то фильтр ( WHERE ), это может быть еще одно место для добавления индекса.
Трудно сказать, где именно вам нужно оптимизировать, не глядя на план выполнения запроса. В него может питаться множество факторов, включая количество записей в каждой таблице. Не переусердствуйте, создавая индексы, – они оказывают влияние на производительность, например, при вставке новых данных. Лучший совет – просто протестировать с разными индексами и посмотреть, дает ли план выполнения некоторые подсказки.
потому что я не знаю, как выглядит план выполнения для этого запроса. Я могу только продолжать то, что, по моему мнению, поможет ускорить результаты.
- У вас есть первичные ключи и ограничения внешнего ключа
- Эти индексы затем индексируются
кроме того, я попытался бы использовать CTE, чтобы ограничить объединившиеся результаты чем-то влияющим (Not Tested) :
;WITH cte_loc AS ( SELECT tl.* FROM TrackerLocations tl WHERE tl.ReceivedTime >= DATEADD (MINUTE,-2,GETUTCDATE()) ),cte_loc2 AS ( SELECT TrackerId ,MAX(ReceivedTime) AS MaxReceivedTime FROM cte_loc GROUP BY TrackerId ),cte_dev AS ( SELECT tl.TrackerId, d.* FROM cte_loc2 tl INNER JOIN Trackers t ON tl.TrackerId = t.TrackerId INNER JOIN Devices d ON t.UserId = d.UserId WHERE d.OSType <> 3 AND d.Notify = 1 ) SELECT tl.*, d.* FROM cte_loc AS tl INNER JOIN cte_loc2 tl2 ON tl.TrackerId = tl2.TrackerId AND tl.ReceivedTime = tl2.MaxReceivedTime LEFT JOIN cte_dev d ON tl.TrackerId = d.TrackerIdПоскольку вы ищете последнюю версию ReceivedTime за последние 2 минуты, вам захочется создать индекс в формате ReceivedTime в порядке DESC. Важна часть заказа DESC. Это также поможет с функцией MAX. Вы также можете попробовать индексировать (ReceivedTime DESC, TrackerID) .
sqlserver.bilee.com
sql - Оптимизация запросов SQL Server
Я унаследовал этот адский запрос, предназначенный для разбивки на страницы в SQL Server.
Он получает только 25 записей, но, согласно SQL Profiler, он читает 8091, 208 пишет и занимает 74 миллисекунды. Предпочитаю, чтобы это было немного быстрее. В столбце deployDate ORDER BY deployDate.
У кого-нибудь есть идеи о том, как его оптимизировать?
SELECT TOP 25 textObjectPK, textObjectID, title, articleCredit, mediaCredit, commentingAllowed,deployDate, container, mediaID, mediaAlign, fileName AS fileName, fileName_wide AS fileName_wide, width AS width, height AS height,title AS mediaTitle, extension AS extension, embedCode AS embedCode, jsArgs as jsArgs, description as description, commentThreadID, totalRows = Count(*) OVER() FROM (SELECT ROW_NUMBER() OVER (ORDER BY textObjects.deployDate DESC) AS RowNumber, textObjects.textObjectPK, textObjects.textObjectID, textObjects.title, textObjects.commentingAllowed, textObjects.credit AS articleCredit, textObjects.deployDate, containers.container, containers.mediaID, containers.mediaAlign, media.fileName AS fileName, media.fileName_wide AS fileName_wide, media.width AS width, media.height AS height, media.credit AS mediaCredit, media.title AS mediaTitle, media.extension AS extension, mediaTypes.embedCode AS embedCode, media.jsArgs as jsArgs, media.description as description, commentThreadID, TotalRows = COUNT(*) OVER () FROM textObjects WITH (NOLOCK) INNER JOIN containers WITH (NOLOCK) ON containers.textObjectPK = textObjects.textObjectPK AND (containers.containerOrder = 0 or containers.containerOrder = 1) INNER JOIN LUTextObjectTextObjectGroup tog WITH (NOLOCK) ON textObjects.textObjectPK = tog.textObjectPK AND tog.textObjectGroupID in (3) LEFT OUTER JOIN media WITH (NOLOCK) ON containers.mediaID = media.mediaID LEFT OUTER JOIN mediaTypes WITH (NOLOCK) ON media.mediaTypeID = mediaTypes.mediaTypeID WHERE (((version = 1) AND (textObjects.textObjectTypeID in (6)) AND (DATEDIFF(minute, deployDate, GETDATE()) >= 0) AND (DATEDIFF(minute, expireDate, GETDATE()) <= 0)) OR ( (version = 1) AND (textObjects.textObjectTypeID in (6)) AND (DATEDIFF(minute, deployDate, GETDATE()) >= 0) AND (expireDate IS NULL))) AND deployEnglish = 1 ) tmpInlineView WHERE RowNumber >= 51 ORDER BY deployDate DESCqaru.site
sql-server-2008 - Оптимизация запросов сервера Sql
Я оптимизирую большой SP в Sql Server 2008, который использует много динамических Sql. Это запрос, который ищет базу данных с рядом необязательных параметров и не соответствует кодированию для каждой возможной комбинации параметров. Динамический sql оказался наиболее эффективным методом его выполнения. Sql striung построен, включая параметры, а затем передается в sp_executesql с помощью списка параметров. При запуске в SSMS с любой комбинацией параметров он выполняется очень быстро (< 1s) и возвращает результаты. Однако при запуске из приложения Windows Forms это занимает значительно больше времени.
Я читал, что разница в опции ARITHABORT может привести к этому (как по умолчанию в SSMS и OFF в ADO), однако я не уверен, что если это исправление устраняет проблему или ее маскирует? Разница в настройках имеет значение для самого запроса или это означает, что Sql Server будет использовать разные планы выполнения кэширования? Если это так, нужно очистить кеш и статистику reset игровое поле?
Я также читал разные точки зрения в настройке OPTION RECOMPILE. Я понимаю, что когда sp_executesql используется с списком параметров, тогда каждая комбинация параметров создает плоскость выполнения, но поскольку возможные комбинации параметров конечны, это приведет к оптимизированным запросам. Другие источники утверждают, что в начале любого SP, который использует динамический sql, должно быть установлено значение ON.
Я понимаю, что разные ситуации требуют разных настроек, но я хочу понять их дальше, прежде чем пытаться сорвать на моем очень загруженном сервере производства 24x7. Извиняюсь за блуждания, я думаю, мой вопрос сводится к:
Что заставляет sql работать по-разному в SSMS и Window Forms? Если это ARITHABORT, то это проблема, связанная с планами выполнения, или я должен включить ее как сервер по умолчанию? Каков оптимальный способ запуска запросов с динамическим sql?
qaru.site