Оптимизация и профилирование запросов Sql. Оптимизация запросов sql oracle
sql - Оптимизация запроса с подзапросом в Oracle
Здравствуйте. Есть запрос. Отрабатывает в sql-developer 60 секунд. Второй раз запускаю 8 секунд, 3 раз 3.5 секунды. Кэшируется вообщем. Минут через 10 та же история. Наверное за это время кэш падает. Когда этот запрос первый раз выполянется из кода c# на строчке rdr.Read() вообще выполняется минут 5-10 rdr - OracleDataReader. Не понимаю что ещё можно упростить в запросе. Всё и так проиндексировано кроме поелей edit_state и primary_date. Вообщем вот запрос и explain plan к нему.
SELECT r.id FROM INTERSHOP.JOURNAL_RECORDS r WHERE r.edit_state = 0 AND r.journal_id = 515 AND r.journal_table_id = 1 AND ( SELECT STRING_VALUE FROM journal_field_data f WHERE r.id = f.journal_record_id AND field_name = 'SERTIF_NUMB' ) = :SERTIF_NUMB ORDER BY r.PRIMARY_DATE DESC;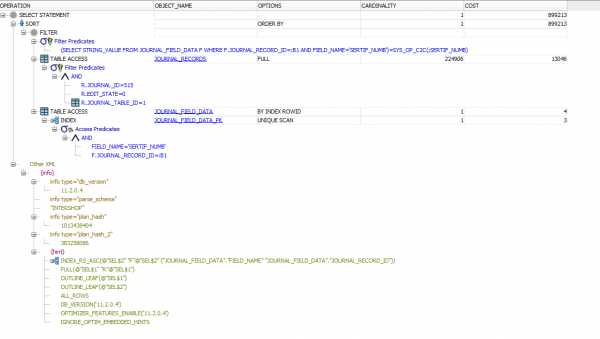
Если я правильно понял то там где написано full очень много занимает памяти, но там всё проиндексировано. И я немного не понимаю но неужели order by весит ещё больше? Подскажите пожалуйста что тут можно сделать. Я уже даже не знаю что попробовать.
UPDИсправленный вариант запроса:
SELECT r.id FROM INTERSHOP.JOURNAL_RECORDS r LEFT JOIN journal_field_data f ON r.id = f.journal_record_id WHERE r.edit_state = 0 AND r.journal_id = 515 AND r.journal_table_id = 1 AND field_name = 'SERTIF_NUMB' AND f.STRING_VALUE = :SERTIF_NUMB ORDER BY r.PRIMARY_DATE DESC;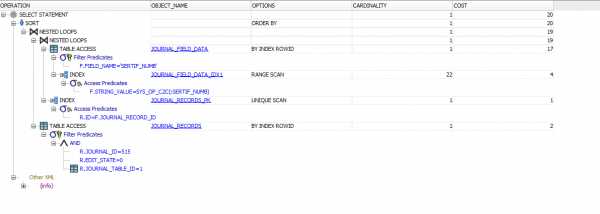
ru.stackoverflow.com
[optimization] Как использовать Explain Plan для оптимизации запросов? [oracle] [sql]
Вы получаете больше, чем это, в зависимости от того, что вы делаете. Проверьте эту страницу плана объяснения . Я немного предполагаю, что вы используете Oracle и знаете, как запустить скрипт для отображения вывода плана. Что может быть более важно для начала, это смотреть на левую сторону для использования определенного индекса или нет и как этот индекс используется. Вы должны видеть такие вещи, как «(Полный)», «(по индексу Rowid)» и т. Д., Если вы делаете объединения. Стоимость будет следующей вещью, на которую следует обратить внимание, при этом более низкие затраты будут лучше, и вы заметите, что если вы делаете соединение, которое не использует индекс, вы можете получить очень большую стоимость. Вы также можете прочитать подробности о столбцах плана объяснения .
У вас есть нечеткий конец леденца.
Нет абсолютно никакого способа, изолированно, без тонны дополнительной информации и опыта, взглянуть на план объяснений и определить, что (если что-либо) вызывает менее оптимальную производительность. Если настройка запроса может быть уменьшена до 10-ступенчатого процесса, это будет сделано автоматическим процессом. Я собирался перечислить все, что вам нужно понять, чтобы быть эффективными в этом, но это был бы очень длинный список.
единственный короткий ответ, который я могу придумать ... - искать шаги в плане, которые проходят через больше байтов, чем вы предполагали. Затем подумайте о том, как вы можете уменьшить это число ... с помощью индекса или разбиения.
Серьезно, возьмите книгу Льюиса Джонатана об основанных на стоимости Oracle Fundementals
Получите книгу Tom Kyte по базе данных Oracle Architecture и арендуйте каюту в лесу в течение нескольких недель.
code-examples.net
optimization - оптимизация запросов sql
Итак, вот план объяснения для запроса, который соединяется только с конкатенированной строкой:
SQL> explain plan for 2 select e.* from emp e 3 join big_table bt on bt.col2 = 'search'||trim(to_char(e.empno)) 4 / Explained. SQL> select * from table(dbms_xplan.display) 2 / PLAN_TABLE_OUTPUT -------------------------------------------------------------------------------- Plan hash value: 179424166 ------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1052 | 65224 | 43 (0)| 00:00:01 | | 1 | NESTED LOOPS | | 1052 | 65224 | 43 (0)| 00:00:01 | | 2 | TABLE ACCESS FULL| EMP | 20 | 780 | 3 (0)| 00:00:01 | |* 3 | INDEX RANGE SCAN | BIG_VC_I | 53 | 1219 | 2 (0)| 00:00:01 | ------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("BT"."COL2"='search'||TRIM(TO_CHAR("E"."EMPNO"))) 15 rows selected. SQL>Конечно, это предполагает, что объединенный столбец проиндексирован, иначе это не будет иметь никакого значения.
Другое, что нужно помнить, состоит в том, что столбцы, которые запрашиваются, могут повлиять на план. Эта версия выбирает из BIG_TABLE, а не EMP.
SQL> explain plan for 2 select bt.* from emp e 3 join big_table bt on (bt.col2 like 'search%' 4 and bt.col2 = 'search'||trim(to_char(e.empno))) 5 / Explained. SQL> select * from table(dbms_xplan.display) 2 / PLAN_TABLE_OUTPUT --------------------------------------------------------------------------------------------------------------- Plan hash value: 4042413806 ------------------------------------------------------------------------------------------ | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ------------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | 46 | 4 (0)| 00:00:01 | | 1 | NESTED LOOPS | | | | | | | 2 | NESTED LOOPS | | 1 | 46 | 4 (0)| 00:00:01 | |* 3 | INDEX FULL SCAN | PK_EMP | 1 | 4 | 1 (0)| 00:00:01 | |* 4 | INDEX RANGE SCAN | BIG_VC_I | 1 | | 2 (0)| 00:00:01 | | 5 | TABLE ACCESS BY INDEX ROWID| BIG_TABLE | 1 | 42 | 3 (0)| 00:00:01 | ------------------------------------------------------------------------------------------ Predicate Information (identified by operation id): --------------------------------------------------- 3 - filter('search'||TRIM(TO_CHAR("E"."EMPNO")) LIKE 'search%') 4 - access("BT"."COL2"='search'||TRIM(TO_CHAR("E"."EMPNO"))) filter("BT"."COL2" LIKE 'search%') 19 rows selected. SQL>optimization - Оптимизация и профилирование запросов Sql
Чтобы использовать план выполнения (который является описанием того, как база данных будет выполнять ваш запрос), нужно понять, какие варианты доступны для нее (база данных), и принять решение о том, сделан ли выбор Оптимизатор был правильным. Это требует больших знаний и опыта.
Для работы, которую я выполняю (обработка ETL), "проблемы" производительности обычно попадают в одну из двух категорий:
- Запрос занимает много времени, потому что чтение большого количества данных занимает много времени:)
- Оптимизатор сделал ошибку и выбрал неправильный план выполнения.
Для (1) я должен решить, могу ли я реструктурировать данные по-разному, поэтому я сканирую меньше данных. Индексы редко используются, так как меня интересуют достаточно большие подмножества, чтобы сделать индексированный доступ медленнее, чем полное сканирование таблицы. Например, я могу сохранить горизонтальное подмножество данных (последние 30 дней) или вертикальное подмножество данных (10 столбцов вместо 80) или совокупность данных. В любом случае это уменьшит размер данных, чтобы увеличить скорость обработки. Конечно, если данные используются только один раз, я только что переместил проблему в другом месте.
Для (2) я обычно начинаю с проверки "Cardinality" (num rows) в верхней строке в xplan. Если я знаю, что мой запрос возвращает 5 000 000 строк, но он говорит 500, я могу быть уверен, что оптимизатор где-то испортился. Если полная мощность находится в правильном шаровом парке, я начинаю с другого конца и проверяю каждый шаг плана, пока не нахожу первую большую ошибку оценки. Если мощность ошибочна, метод соединения, вероятно, ошибочен между этой таблицей и следующей, и эта ошибка будет каскадироваться через остальную часть плана.
Google для "Настройка по обратной связи по мощности", и вы найдете статью, написанную Вольфгангом Брейтлингом, которая описывает (в гораздо большем смысле) неприглядный подход. Это действительно хорошо читать!
Кроме того, обязательно держитесь Блог Джонатана Льюиса. если что-то о оптимизаторе Oracle он не знает, это не стоит знать. Он написал лучшую книгу по этому вопросу. Ознакомьтесь с Основами Oracle на основе затрат. Если бы я мог отправить одну книгу вовремя себе, это было бы так.
Эксперт Oracle Database Architecture от Tom Kyte (человек, стоящий за "Ask tom" ), также является удивительным. Мое первое чтение этой книги было разочарованием, потому что я искал "советы по настройке" и не нашел ни одного. Во время моего второго чтения я понял, что, зная, как работает база данных, вы можете исключить целые классы проблем с производительностью, "конструируя для производительности", начиная с запуска, а не "добавляя" производительность в конце:)
SQL Tuning от Dan Tow, является еще одним удивительным, прочитанным для основы того, как точно можно определить оптимальный план выполнения. Это знание может использоваться как способ устранения неполадок плана выполнения (или принуждения оптимизатора к его выполнению).
Если вы сделали это так далеко, сейчас самое время поиграть с подсказками. Не раньше.
qaru.site