Решено Оптимизация TCP, Win и возможная борьба с лагами. Оптимизация tcp
Оптимизация TCP — Dreamcatcher.ru
Автор: TCP Tuning GuideПеревод: Сгибнев Михаил
Вступление
Данная инструкция предназначена для описания действий по оптимизации параметров протокола TCP. TCP использует параметр, который называют «congestion window», или CWND, чтобы определить, сколько пакетов можно послать в конечную единицу времени. Чем больший размер congestion window, тем выше пропускная способность. Размер congestion window определяется с помощью алгоритмов TCP «slow start» и «congestion avoidance». Максимальное значение congestion window зависит от объема буфера, назначенного ядром для каждого сокета. Для каждого сокета имеется значение размера буфера, установленное по умолчанию, которое можно изменить программно, используя системный вызов из библиотек прежде, чем будет открыт данный сокет. Так же имеется параметр, задающий максимальный размер буфера ядра. Изменить можно размер как передающего, так и принимающего буфера сокета.
Чтобы получить максимальную пропускную способность, необходимо использовать оптимально установленный размер передающего и принимающего буферов сокета для канала, который вы используете. Если буфера будут слишком маленькими, то congestion window никогда не будет полностью открываться. Если передающий буфер слишком большой, то возможны разрывы управления потоком данных TCP и отправитель может переполнить буфер получателя, что заставит уменьшить окно TCP. Это, вероятно, случится быстрее на хосте-отправителе, чем на хосте-получателе. Чрезмерно большой принимающий буфер — не самая большая проблема, пока у вас есть лишняя память.
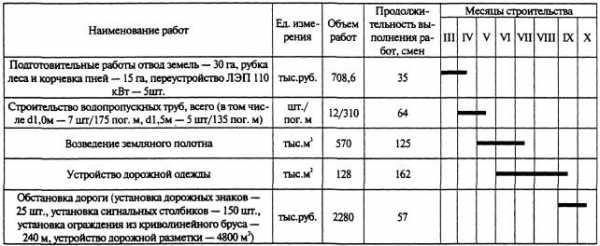
Оптимальный размер буфера можно посчитать как пропускная способность*задержку используемого канала.buffer size = 2 * bandwidth * delay Для определения задержки может быть использована утилита ping или инструментарий типа pathrate для определения емкости канала от точки А до точки В (если пропускная способность между точками переменная). Так как утилита ping дает время прохождения пакета туда и обратно (RTT), то вместо предыдущей может быть использована следущая формула:buffer size = bandwidth * RTT Для примера, если ping показывает 50 ms, и от точки А до точки В используются каналы 100 BT Ethernet и OC3 (155 Mbps), значение буферов TCP составит .05 sec * (100 Mbits / 8 bits) = 625 KBytes. (Если вас гложут сомнения, то 10 MB/s будет хорошим первым приближением для сетей ESnet/vBNS/Abilene-like).
Есть 2 параметра настройки TCP, о которых Вы должны знать. Это размер буферов приема/отправки по умолчанию и максимальный размер буферов приема/отправки. Отметьте, что у большинства современных UNIX OS максимальный размер буфера по умолчанию только 256 Кбайт! Ниже мы покажем, как изменить это значение в большинстве современных ОС. Вы врядли захотите увеличить заданный по умолчанию размер буфера, на значение больше чем 128 Кбайт, потому что это может неблагоприятно повлиять на производительность локальной сети. Поэтому вы должны использовать UNIX вызов setsockopt для буферов приема/отправки, чтобы установить оптимальный размер буфера для канала, который вы используете.
Linux
Есть большие отличия между версиями Linux 2.4 и 2.6, но мы сейчас рассмотрим общие вопросы. Чтобы изменить параметры настройки TCP, вам необходимо добавить строки, представленные ниже, к файлу /etc/sysctl.conf и затем выполнить команду sysctl -p.
Как и во всех прочих ОС, размер буферов в Linux очень мал. Применим следущие настройки:# increase TCP max buffer size setable using setsockopt()net.core.rmem_max = 16777216net.core.wmem_max = 16777216# increase Linux autotuning TCP buffer limits# min, default, and max number of bytes to use# set max to at least 4MB, or higher if you use very high BDP pathsnet.ipv4.tcp_rmem = 4096 87380 16777216net.ipv4.tcp_wmem = 4096 65536 16777216 Вы должны также проверить, что следующие параметры установлены в значение по умолчанию, равное 1.sysctl net.ipv4.tcp_window_scalingsysctl net.ipv4.tcp_timestampssysctl net.ipv4.tcp_sack Отметьте: Вы должны оставить tcp_mem в покое. Значения по умолчанию и так прекрасны.
Другая вещь, которую вы можете захотеть попробовать, что может помочь увеличить пропускную способность TCP, должна увеличить размер очереди интерфейса. Чтобы сделать это, выполните следующее:ifconfig eth0 txqueuelen 1000 Я получал до 8-кратного увеличения быстродействия, делая такую настройку на широких каналах. Делать это имеет смысл для каналов Gigabit Ethernet, но может иметь побочные эффекты, такие как неравное совместное использование между множественными потоками.
Также, по слухам, может помочь в увеличении пропускной способности утилита ‘tc’ (traffic control)
Linux 2.4
В Linux 2.4 реализован механизм автоконфигурирования размера буферов отправляющей стороны, но это предполагает, что вы установили большие буфера на получающей стороне, поскольку буфер отправки не будет расти в зависимости от получающего буфера.
Однако, у Linux 2.4 есть другая странность, о которой нужно знать. Например: значение ssthresh для данного пути кэшируется в таблице маршрутизации. Это означает, что, если подключение осуществляет повторную передачу и уменьшает значение окна, то все подключения с тем хостом в течение следующих 10 минут будут использовать уменьшенный размер окна, и даже не будут пытаться его увеличить. Единственный способ отключить это поведение состоит слкдующем (с правами пользователя root):sysctl -w net.ipv4.route.flush=1 Дополнительную информацию можно получить в руководстве Ipsysctl.
Linux 2.6
Начинаясь с Linux 2.6.7 (с обратным портированием на 2.4.27), linux включает в себя альтернативные алгоритмы управления перегрузкой, помимо традиционного ‘reno’ алгоритма. Они разработаны таким образом, чтобы быстро оправиться от потери пакета на высокоскоростных глобальных сетях.
Linux 2.6 также включает в себя алгоритмы автоматической оптимизации буферов принимающей и отправляющей стороны. Может применяться тоже решение, чтобы устранить странности ssthresh кэширования, что описанно выше.
Есть пара дополнительных sysctl параметров настройки для 2.6:# don't cache ssthresh from previous connectionnet.ipv4.tcp_no_metrics_save = 1net.ipv4.tcp_moderate_rcvbuf = 1# recommended to increase this for 1000 BT or highernet.core.netdev_max_backlog = 2500# for 10 GigE, use this# net.core.netdev_max_backlog = 30000 Начиная с версии 2.6.13, Linux поддерживает подключаемые алгоритмы управления перегрузкой. Используемый алгоритм управления перегрузки можно задать, используя sysctl переменную net.ipv4.tcp_congestion_control, которая по умолчанию установлена в cubic or reno, в зависимости от версии ядра.
[ad name=»Google Adsense»] Для получения списка поддерживаемых алгоритмов, выполните:sysctl net.ipv4.tcp_available_congestion_control Выбор опций контроля за перегрузкой выбирается при сборке ядра. Ниже представлены некоторые из опций, доступных в 2.6.23 ядрах:- reno: Традиционно используется на большинстве ОС. (default)
- cubic:CUBIC-TCP (Внимание: Есть бага в ядре Linux 2.6.18. Используйте в 2.6.19 или выше!)
- bic:BIC-TCP
- htcp:Hamilton TCP
- vegas:TCP Vegas
- westwood:оптимизирован для сетей с потерями
Для очень длинных и быстрых каналов я предлагаю пробовать cubic или htcp, если использование reno желательно. Чтобы установить алгоритм, сделайте следующее:sysctl -w net.ipv4.tcp_congestion_control=htcp Дополнительную информацию по алгоритмам и последствиям их использования можно посмотреть тут.
Вниманию использующих большие MTU: если вы сконфигурировали свой Linux на использование 9K MTU, а удаленная сторона использует пекеты в 1500 байт, то вам необходимо в 9/1.5 = 6 раз большее значение буферов, чтобы заполнить канал. Фактически, некоторые драйверы устройств распределяют память в зависимости от двойного размера, таким образом Вы можете даже нуждаться в 18/1.5 = в 12 раз больше!
[ad name=»Google Adsense»] И наконец предупреждение и для 2.4 и для 2.6: для очень больших BDP путей, где окно > 20 MB, вы вероятно столкнетесь с проблемой Linux SACK. Если в «полете» находится слишком много пакетов и наступает событие SACK, то обработка SACKed пакета может превысить таймаут TCP и CWND вернется к 1 пакету. Ограничение размера буфера TCP приблизительно равно 12 Мбайтам, и кажется позволяет избежать этой проблемы, но ограничивает вашу полную пропускную способность. Другое решение состоит в том, чтобы отключить SACK.Если вы используете Linux 2.2, обновитесь! Если это не возможно, то добавьте следущее в /etc/rc.d/rc.local:echo 8388608 > /proc/sys/net/core/wmem_maxecho 8388608 > /proc/sys/net/core/rmem_maxecho 65536 > /proc/sys/net/core/rmem_defaultecho 65536 > /proc/sys/net/core/wmem_defaultFreeBSD
Добавьте это в /etc/sysctl.conf и перезагрузитесь:kern.ipc.maxsockbuf=16777216net.inet.tcp.rfc1323=1 В FreeBSD 7.0 добавлена функция автокогфигурирования буферов. Но значения их можно отредактировать, так как по умолчанию буферы 256 KB, а это очень мало:net.inet.tcp.sendbuf_max=16777216net.inet.tcp.recvbuf_max=16777216 Для общего развития покажу еще несколько параметров, но их дефолтные значения и так хороши:net.inet.tcp.sendbuf_auto=1 # Send buffer autotuning enabled by defaultnet.inet.tcp.sendbuf_inc=8192 # step sizenet.inet.tcp.recvbuf_auto=1 # enablednet.inet.tcp.recvbuf_inc=16384 # step size У FreeBSD есть кое-какие ограничения, включенным по умолчанию. Это хорошо для модемных подключений, но может быть вредно для пропускной способности на высокоскоростных каналах. Если Вы хотите «нормальное» TCP Reno, сделайте следущее:net.inet.tcp.inflight.enable=0 По умолчанию, FreeBSD кэширует подробности подключения, такие как порог slow start и размер окна перегрузки(congestion windows) с предыдущего подключения на тот же самый хост в течение 1 часа. В то время как это хорошая идея для веб-сервера, но плохая для тестирования пропускной способности, поскольку 1 большой случай перегрузки задушит производительность в течение следующего часа. Чтобы уменьшить этот эффект, установите это:net.inet.tcp.hostcache.expire=1 В этом случае мы будем все еще кэшировать значения в течение 5 минут, по причинам, описанным в этой статье от Centre for Advanced Internet Architectures (CAIA) at Swinburne University in Autralia. В ней вы также найдете другую интересную информацию о тюнинге FreeBSD. Также можно использовать H-TCP patch for FreeBSD
Для получения информации о тюнинге NetBSD, обратитесь к этой статье.
Внимание: у FreeBSD версий ниже 4.10 нет реализации SACK, что сильно снижает ее производительность по сравнению с другими операционными системами. Вы необходимо обновиться до 4.10 или выше.
Solaris
Для Solaris просто сделайте загрузочный скрипт (например, /etc/rc2.d/S99ndd) следующего содержания:#!/bin/sh# increase max tcp window# Rule-of-thumb: max_buf = 2 x cwnd_max (congestion window)ndd -set /dev/tcp tcp_max_buf 4194304ndd -set /dev/tcp tcp_cwnd_max 2097152
# increase DEFAULT tcp window sizendd -set /dev/tcp tcp_xmit_hiwat 65536ndd -set /dev/tcp tcp_recv_hiwat 65536 Для получения дополнительной информации, обратитесь к документации Solaris
Windows XP
Самый простой способ настроить TCP под Windows XP состоит в том, чтобы получить DrTCP из «DSL Reports». Установите «Tcp Receive Window» в вычесленное значение BDP (e.g. 4000000), включите «Window Scaling» «Selective Acks» и «Time Stamping».
Провести дополнительную настройку можно с помощью сторонних утилит, таких как SG TCP Optimizer и Cablenut.
Для проверки изменений можно воспользоваться редактором реестра. Наша цель — вот эти параметры:# turn on window scale and timestamp optionHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Tcp1323Opts=3# set default TCP receive window sizeHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpWindowSize=256000# set max TCP send/receive window sizes (max you can set using setsockopt call)HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\GlobalMaxTcpWindowSize=16777216 Вы можете использовать setsockopt() для программного изменения значения буферов до размера GlobalMaxTcpWindowSize, или можете использовать TcpWindowSize для задания значения буферов по умолчанию всех сокетов. Второй вариант может быть плохой идеей, если у вас мало памяти.
Для получения дополнительной информации, обратитесь к документам Windows network tuning,TCP Configuration Parameters,TCP/IP Implementation Details иWindows 2000/XP Registry Tweaks
Windows Vista
Хорошая новость! У Windows Vista имеется автонастройка TCP. Максимальный размер окна может быть увеличен до 16 MB. Если вы знаете, как сделать его больше, дайте мне знать.
Vista также включает в себя «Compound TCP (CTCP)», что очень похоже на cubic в Linux. Для задействования этого механизма, необходимо выполнить:netsh interface tcp set global congestionprovider=ctcp" Если вы хотите включить/выключить автонастройку, выполните следующие команды:netsh interface tcp set global autotunninglevel=disablednetsh interface tcp set global autotunninglevel=normal Внимание, команды выполняются с привилегиями Администратора.
Нет возможности увеличить значение буферов по умолчанию, которое составляет 64 KB. Также, алгоритм автонастройки не используется, если RTT не больше чем 1 ms, таким образом единственный streamTCP переполнит этот маленький заданный по умолчанию буфер TCP.
Для получения дополнительной информации, обратитесь к следующим документам:
Mac OSX
Mac OSX настраивается подобно FreeBSD.sysctl -w net.inet.tcp.win_scale_factor=8sysctl -w kern.ipc.maxsockbuf=16777216sysctl -w net.inet.tcp.sendspace=8388608sysctl -w net.inet.tcp.recvspace=8388608 Для OSX 10.4, Apple также предоставляет патч Broadband Tuner, увеличивающий максимальный размер буферов сокета до 8MB и еще кое-что по мелочи.
Для получения дополнительной информации, обратитесь к OSX Network Tuning Guide.
AIX
Для повышения производительности на SMP системах, выполните:ifconfig thread Это позволит обработчику прерываний интерфейов GigE на многопроцессорной машине AIX выполняться в многопоточном режиме.
IRIX:
Добавьте в файл /var/sysgen/master.d/bsd такие строки:
tcp_sendspacetcp_recvspace Максимальный размер буфера в Irix 6.5 составляет 1MB и не может быть увеличен.
Уважайте труд автора и переводчика, не ищите дешевой славы — оставляйте ссылки и копирайты при размещении статьи на своем ресурсе!
Реклама на сайте висит не просто так! Спасибо!
[ad name=»Google Adsense»]dreamcatcher.ru
Оптимизация TCP - Записная книжка сисадмина
Различные параметры оптимизации TCP
Для Win7
Просмотр глобальных параметров TCP
netsh int tcp show global
Обратите внимание на строку “Поставщик надстройки контроля перегрузки”. Если там не ctcp, то можно поменять её так:
netsh interface tcp set global congestionprovider=ctcp
Будет разрешено использование дополнительного алгоритма контроля перегрузки CTCP.
Для WinXP
Небольшие изменения в реестре:
| 1 2 3 4 5 6 | # turn on window scale and timestamp option HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Tcp1323Opts=3 # set default [[Протоколы|TCP]] receive window size HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpWindowSize=256000 # set max [[Протоколы|TCP]] send/receive window sizes (max you can set using setsockopt call) HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\GlobalMaxTcpWindowSize=16777216 |
Linux
| 1 2 3 4 | echo 7 > /proc/sys/net/ipv4/tcp_fin_timeout echo 1 > /proc/sys/net/ipv4/tcp_orphan_retries Уменьшаем количество SYN-ACK проб (по умолчанию 5) echo 2 > /proc/sys/net/ipv4/tcp_synack_retries |
После наступления тишины, сколько держать соединение открытым (по умолчанию 7200 - два часа!)
| 1 | echo 60 > /proc/sys/net/ipv4/tcp_keepalive_time |
Увеличиваем размер возможной SYN очереди (по умолчанию 1024)
| 1 | echo 4096 > /proc/sys/net/ipv4/tcp_max_syn_backlog |
Если ответа на проверку нет, то с интервалом в 10 секунд повторить (по умолчанию 75)
| 1 | echo 10 > /proc/sys/net/ipv4/tcp_keepalive_intvl |
Сколько делать проб до закрытия соединения (по умолчанию 9).
| 1 | echo 5 > /proc/sys/net/ipv4/tcp_keepalive_probes |
Увеличиваем максимальный размер памяти отводимой для TCP буферов:
| 1 2 | echo "4096 65536 16777216" > /proc/sys/net/ipv4/tcp_wmem echo "4096 65536 16777216" > /proc/sys/net/ipv4/tcp_rmem |
Увеличиваем размер очереди пакетов на сетевом интерфейсе, особенно полезно для Gigabit Ethernet
| 1 | ifconfig eth0 txqueuelen 1000 |
Слишком много TIME_WAIT
Если
показывает много (у меня до 54 000+ доходило), то можно
| 1 2 3 4 | echo 2 > /proc/sys/net/ipv4/tcp_tw_recycle #таймаут в 2 сек echo 2 > /proc/sys/net/ipv4/tcp_tw_reuse #таймаут в 2 сек sysctl net.ipv4.tcp_tw_recycle=1 #разрешаем использовать повторно sysctl net.ipv4.tcp_tw_reuse=1 #разрешаем использовать повторно |
у меня сразу упало до 16 000+
wikiadmin.net
Оптимизация TCP, Win и возможная борьба с лагами
Полезно
Не знаю, как поведут себя данные фиксы на этом сервере,но на руофе они мне очень помогали...
Приемы, увеличивающие, отзывчивость игры и в некоторых случаях, устраняющие лаги:
Данные действия применимы и тестировались на Windows 7.- пуск – выполнить – regedit
- ищем там HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet \Services\Tcpip\Parameters\Interfaces
- ищем там интерфейс, по которому у вас работает интернет, если не в курсе, то делаем следующий шаг во всех строках папки Interfaces
- правой кнопкой в поле справа, создать параметр DWORD (битность значения не имеет), называем его TcpAckFrequency, потом правой кнопкой на нем, изменить, ставим шестнадцатеричную галочку и пишем значение 1
- идем в HKEY_LOCAL_MACHINE\SOFTWARE \Microsoft\MSMQ\Parameters
- в месте указанном в пункте 5 ищем TCPNoDelay, если нету создаем DWORD параметр с таким названием и присваиваем значение 1
Если ветка, указанная в пункте 5, отсутствует, то делается следующее:Открываем – Пуск – Панель управления – Программы и Компоненты – (слева) Включение и отключение компонентов Windows.Там находим пункт – Сервер очереди сообщений Майкрософт (MSMQ), и ставим галочку напротив него и все галочки внутри в выпадающем списке компонентов. Перегружаемся, идем в реестр и видим там нужную нам запись
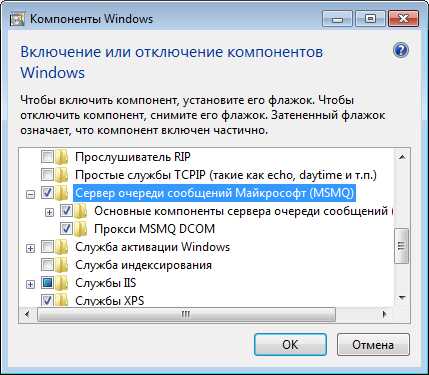
Есть вариант изменения ключа рееста
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsNT \CurrentVersion\Multimedia\SystemProfileИмя: NetworkThrottlingIndex (если нет - создаем)Параметр: DWORD
Значение означает количество пакетов не мультимедиа трафика в 1 миллисекунду, по умолчанию 10. Можно попробовать увеличить число или просто поставить шестнадцатеричное FFFFFFFF, в последнем случае полностью отключится регулирование трафика.
Дополнительные параметры:
Эти параметры так же способны оптимизировать сетевой обмен для нашего случая. При выборе их значений я руководствовался личным опытом, а не просто верил на слово различным советам. Я временно сижу на 3G интернете, где пинг сам по себе не очень, особенно в вечернее время, и мне ниже перечисленные настройки помогли. Однако, есть риск, что какой-нибудь параметр из них может и ухудшить ситуацию с пингом (хоть и не на много), поэтом я назвал их дополнительными и необязательными к выставлению.Раздел HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet \Services\Tcpip\Parameters
- SackOptsВыборочная передача поврежденных данных. Отлично помогает в борьбе с лагами, если клиент не кривой. Рекомендуемое значение: 1 (единица).Чтобы отключить: 0
- EnablePMTUDiscoveryАвтоматически определять максимальный размер передаваемого блока данных.Рекомендуемое значение: 1 (единица).Чтобы отключить: 0
- EnablePMTUBHDetectВключает алгоритм обнаружения маршрутизаторов типа "черная дыра". Видел советы по выставлению этого параметра в 0, однако, для себя я не заметил влияние этого параметра на пинг, а надежная связь нужна всем =)Рекомендуемое значение:1 (единица).Чтобы отключить: 0
- DisableTaskOffloadПозволяет разгрузить центральный процессор, освободив его от вычислений контрольных сумм для протокола TCP, переложив эту задачу на сетевой адаптер.Рекомендуемое значение: 0 (нуль).Чтобы отключить: 1Недостаток: Если возникли сбои в соединениях - отключите параметр.
- DefaultTTLОпределяет максимальное время нахождения пакета IP в сети, если он не может попасть на узел назначения. Это позволяет значительно ограничить количество маршрутизаторов, через которые может пройти пакет IP, прежде чем будет отброшен (вдруг пакет заблудился, зачем мы будем его ждать?).Рекомендуемое десятичное значение: 64Чтобы отключить: удалить параметр
- NonBestEffortLimitОтключает резервирование пропускной способности канала для QoS.Рекомендуемое значение: 0 (нуль).
Сетевые твики:
Начиная с этой версии ОС появились дополнительные сетевые параметры, которые могут нам пригодится. Данные твики представляют собой команды, в данном случае, сразу содержащие рекомендуoldro.me
Оптимизация TCP/IP стека в Linux, FreeBSD, Mac Os X и других операционных системах

Данная инструкция предназначена для описания действий по оптимизации параметров протокола TCP.
TCP использует параметр, который называют «congestion window», или CWND, чтобы определить, сколько пакетов можно послать в конечную единицу времени. Чем больший размер congestion window, тем выше пропускная способность. Размер congestion window определяется с помощью алгоритмов TCP «slow start» и «congestion avoidance». Максимальное значение congestion window зависит от объема буфера, назначенного ядром для каждого сокета. Для каждого сокета имеется значение размера буфера, установленное по умолчанию, которое можно изменить программно, используя системный вызов из библиотек прежде, чем будет открыт данный сокет. Так же имеется параметр, задающий максимальный размер буфера ядра. Изменить можно размер как передающего, так и принимающего буфера сокета.
Чтобы получить максимальную пропускную способность, необходимо использовать оптимально установленный размер передающего и принимающего буферов сокета для канала, который вы используете. Если буфера будут слишком маленькими, то congestion window никогда не будет полностью открываться. Если передающий буфер слишком большой, то возможны разрывы управления потоком данных TCP и отправитель может переполнить буфер получателя, что заставит уменьшить окно TCP. Это, вероятно, случится быстрее на хосте-отправителе, чем на хосте-получателе. Чрезмерно большой принимающий буфер — не самая большая проблема, пока у вас есть лишняя память.Оптимальный размер буфера можно посчитать как пропускная способность*задержку используемого канала.
buffer size = 2 * bandwidth * delay
Для определения задержки может быть использована утилита ping или инструментарий типа pathrate для определения емкости канала от точки А до точки В (если пропускная способность между точками переменная). Так как утилита ping дает время прохождения пакета туда и обратно (RTT), то вместо предыдущей может быть использована следущая формула:
buffer size = bandwidth * RTT
Для примера, если ping показывает 50 ms, и от точки А до точки В используются каналы 100 BT Ethernet и OC3 (155 Mbps), значение буферов TCP составит .05 sec * (100 Mbits / 8 bits) = 625 KBytes. (Если вас гложут сомнения, то 10 MB/s будет хорошим первым приближением для сетей ESnet/vBNS/Abilene-like).
Есть 2 параметра настройки TCP, о которых Вы должны знать. Это размер буферов приема/отправки по умолчанию и максимальный размер буферов приема/отправки. Отметьте, что у большинства современных UNIX OS максимальный размер буфера по умолчанию только 256 Кбайт! Ниже мы покажем, как изменить это значение в большинстве современных ОС. Вы врядли захотите увеличить заданный по умолчанию размер буфера, на значение больше чем 128 Кбайт, потому что это может неблагоприятно повлиять на производительность локальной сети. Поэтому вы должны использовать UNIX вызов setsockopt для буферов приема/отправки, чтобы установить оптимальный размер буфера для канала, который вы используете.
Linux
Есть большие отличия между версиями Linux 2.4 и 2.6, но мы сейчас рассмотрим общие вопросы. Чтобы изменить параметры настройки TCP, вам необходимо добавить строки, представленные ниже, к файлу /etc/sysctl.conf и затем выполнить команду sysctl -p.
Как и во всех прочих ОС, размер буферов в Linux очень мал. Применим следущие настройки:
# increase TCP max buffer size setable using setsockopt()net.core.rmem_max = 16777216net.core.wmem_max = 16777216# increase Linux autotuning TCP buffer limits# min, default, and max number of bytes to use# set max to at least 4MB, or higher if you use very high BDP pathsnet.ipv4.tcp_rmem = 4096 87380 16777216net.ipv4.tcp_wmem = 4096 65536 16777216
Вы должны также проверить, что следующие параметры установлены в значение по умолчанию, равное 1.
sysctl net.ipv4.tcp_window_scalingsysctl net.ipv4.tcp_timestampssysctl net.ipv4.tcp_sack
Отметьте: Вы должны оставить tcp_mem в покое. Значения по умолчанию и так прекрасны.
Другая вещь, которую вы можете захотеть попробовать, что может помочь увеличить пропускную способность TCP, должна увеличить размер очереди интерфейса. Чтобы сделать это, выполните следующее:
ifconfig eth0 txqueuelen 1000
Я получал до 8-кратного увеличения быстродействия, делая такую настройку на широких каналах. Делать это имеет смысл для каналов Gigabit Ethernet, но может иметь побочные эффекты, такие как неравное совместное использование между множественными потоками.
Также, по слухам, может помочь в увеличении пропускной способности утилита ‘tc’ (traffic control)
Linux 2.4
В Linux 2.4 реализован механизм автоконфигурирования размера буферов отправляющей стороны, но это предполагает, что вы установили большие буфера на получающей стороне, поскольку буфер отправки не будет расти в зависимости от получающего буфера.
Однако, у Linux 2.4 есть другая странность, о которой нужно знать. Например: значение ssthresh для данного пути кэшируется в таблице маршрутизации. Это означает, что, если подключение осуществляет повторную передачу и уменьшает значение окна, то все подключения с тем хостом в течение следующих 10 минут будут использовать уменьшенный размер окна, и даже не будут пытаться его увеличить. Единственный способ отключить это поведение состоит слкдующем (с правами пользователя root):
sysctl -w net.ipv4.route.flush=1
Дополнительную информацию можно получить в руководстве Ipsysctl.
Linux 2.6
Начинаясь с Linux 2.6.7 (с обратным портированием на 2.4.27), linux включает в себя альтернативные алгоритмы управления перегрузкой, помимо традиционного ‘reno’ алгоритма. Они разработаны таким образом, чтобы быстро оправиться от потери пакета на высокоскоростных глобальных сетях.
Linux 2.6 также включает в себя алгоритмы автоматической оптимизации буферов принимающей и отправляющей стороны. Может применяться тоже решение, чтобы устранить странности ssthresh кэширования, что описанно выше.
Есть пара дополнительных sysctl параметров настройки для 2.6:
# don't cache ssthresh from previous connectionnet.ipv4.tcp_no_metrics_save = 1net.ipv4.tcp_moderate_rcvbuf = 1# recommended to increase this for 1000 BT or highernet.core.netdev_max_backlog = 2500# for 10 GigE, use this# net.core.netdev_max_backlog = 30000
Начиная с версии 2.6.13, Linux поддерживает подключаемые алгоритмы управления перегрузкой. Используемый алгоритм управления перегрузки можно задать, используя sysctl переменную net.ipv4.tcp_congestion_control, которая по умолчанию установлена в cubic or reno, в зависимости от версии ядра.
Для получения списка поддерживаемых алгоритмов, выполните:
sysctl net.ipv4.tcp_available_congestion_control
Выбор опций контроля за перегрузкой выбирается при сборке ядра. Ниже представлены некоторые из опций, доступных в 2.6.23 ядрах:
* reno: Традиционно используется на большинстве ОС. (default)* cubic:CUBIC-TCP (Внимание: Есть бага в ядре Linux 2.6.18. Используйте в 2.6.19 или выше!)* bic:BIC-TCP* htcp:Hamilton TCP* vegas:TCP Vegas* westwood:оптимизирован для сетей с потерями
Для очень длинных и быстрых каналов я предлагаю пробовать cubic или htcp, если использование reno желательно. Чтобы установить алгоритм, сделайте следующее:
sysctl -w net.ipv4.tcp_congestion_control=htcp
Дополнительную информацию по алгоритмам и последствиям их использования можно посмотреть тут.
Вниманию использующих большие MTU: если вы сконфигурировали свой Linux на использование 9K MTU, а удаленная сторона использует пекеты в 1500 байт, то вам необходимо в 9/1.5 = 6 раз большее значение буферов, чтобы заполнить канал. Фактически, некоторые драйверы устройств распределяют память в зависимости от двойного размера, таким образом Вы можете даже нуждаться в 18/1.5 = в 12 раз больше!
И наконец предупреждение и для 2.4 и для 2.6: для очень больших BDP путей, где окно > 20 MB, вы вероятно столкнетесь с проблемой Linux SACK. Если в «полете» находится слишком много пакетов и наступает событие SACK, то обработка SACKed пакета может превысить таймаут TCP и CWND вернется к 1 пакету. Ограничение размера буфера TCP приблизительно равно 12 Мбайтам, и кажется позволяет избежать этой проблемы, но ограничивает вашу полную пропускную способность. Другое решение состоит в том, чтобы отключить SACK.
Linux 2.2
Если вы используете Linux 2.2, обновитесь! Если это не возможно, то добавьте следущее в /etc/rc.d/rc.local:
echo 8388608 > /proc/sys/net/core/wmem_maxecho 8388608 > /proc/sys/net/core/rmem_maxecho 65536 > /proc/sys/net/core/rmem_defaultecho 65536 > /proc/sys/net/core/wmem_default
FreeBSD
Добавьте это в /etc/sysctl.conf и перезагрузитесь:
kern.ipc.maxsockbuf=16777216net.inet.tcp.rfc1323=1
В FreeBSD 7.0 добавлена функция автокогфигурирования буферов. Но значения их можно отредактировать, так как по умолчанию буферы 256 KB, а это очень мало:
net.inet.tcp.sendbuf_max=16777216net.inet.tcp.recvbuf_max=16777216
Для общего развития покажу еще несколько параметров, но их дефолтные значения и так хороши:
net.inet.tcp.sendbuf_auto=1 # Send buffer autotuning enabled by defaultnet.inet.tcp.sendbuf_inc=8192 # step sizenet.inet.tcp.recvbuf_auto=1 # enablednet.inet.tcp.recvbuf_inc=16384 # step size
У FreeBSD есть кое-какие ограничения, включенным по умолчанию. Это хорошо для модемных подключений, но может быть вредно для пропускной способности на высокоскоростных каналах. Если Вы хотите «нормальное» TCP Reno, сделайте следущее:
net.inet.tcp.inflight.enable=0
По умолчанию, FreeBSD кэширует подробности подключения, такие как порог slow start и размер окна перегрузки(congestion windows) с предыдущего подключения на тот же самый хост в течение 1 часа. В то время как это хорошая идея для веб-сервера, но плохая для тестирования пропускной способности, поскольку 1 большой случай перегрузки задушит производительность в течение следующего часа. Чтобы уменьшить этот эффект, установите это:
net.inet.tcp.hostcache.expire=1
В этом случае мы будем все еще кэшировать значения в течение 5 минут, по причинам, описанным в этой статье от Centre for Advanced Internet Architectures (CAIA) at Swinburne University in Autralia. В ней вы также найдете другую интересную информацию о тюнинге FreeBSD. Также можно использовать H-TCP patch for FreeBSD
Для получения информации о тюнинге NetBSD, обратитесь к этой статье.
Внимание: у FreeBSD версий ниже 4.10 нет реализации SACK, что сильно снижает ее производительность по сравнению с другими операционными системами. Вы необходимо обновиться до 4.10 или выше.
Solaris
Для Solaris просто сделайте загрузочный скрипт (например, /etc/rc2.d/S99ndd) следующего содержания:
#!/bin/sh# increase max tcp window# Rule-of-thumb: max_buf = 2 x cwnd_max (congestion window)ndd -set /dev/tcp tcp_max_buf 4194304ndd -set /dev/tcp tcp_cwnd_max 2097152
# increase DEFAULT tcp window sizendd -set /dev/tcp tcp_xmit_hiwat 65536ndd -set /dev/tcp tcp_recv_hiwat 65536
Для получения дополнительной информации, обратитесь к документации Solaris
Windows XP
Самый простой способ настроить TCP под Windows XP состоит в том, чтобы получить DrTCP из «DSL Reports». Установите «Tcp Receive Window» в вычесленное значение BDP (e.g. 4000000), включите «Window Scaling» «Selective Acks» и «Time Stamping».
Провести дополнительную настройку можно с помощью сторонних утилит, таких как SG TCP Optimizer и Cablenut.
Для проверки изменений можно воспользоваться редактором реестра. Наша цель — вот эти параметры:
# turn on window scale and timestamp optionHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Tcp1323Opts=3# set default TCP receive window sizeHKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpWindowSize=256000# set max TCP send/receive window sizes (max you can set using setsockopt call)HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\GlobalMaxTcpWindowSize=16777216
Вы можете использовать setsockopt() для программного изменения значения буферов до размера GlobalMaxTcpWindowSize, или можете использовать TcpWindowSize для задания значения буферов по умолчанию всех сокетов. Второй вариант может быть плохой идеей, если у вас мало памяти.
Для получения дополнительной информации, обратитесь к документам Windows network tuning, TCP Configuration Parameters, TCP/IP Implementation Details и Windows 2000/XP Registry Tweaks
Windows Vista
Хорошая новость! У Windows Vista имеется автонастройка TCP. Максимальный размер окна может быть увеличен до 16 MB. Если вы знаете, как сделать его больше. Дайте мне знать.
Vista также включает в себя «Compound TCP (CTCP)», что очень похоже на cubic в Linux. Для задействования этого механизма, необходимо выполнить:
netsh interface tcp set global congestionprovider=ctcp"
Если вы хотите включить/выключить автонастройку, выполните следующие команды:
netsh interface tcp set global autotunninglevel=disablednetsh interface tcp set global autotunninglevel=normal
Внимание, команды выполняются с привилегиями Администратора.
Нет возможности увеличить значение буферов по умолчанию, которое составляет 64 KB. Также, алгоритм автонастройки не используется, если RTT не больше чем 1 ms, таким образом единственный streamTCP переполнит этот маленький заданный по умолчанию буфер TCP.
Для получения дополнительной информации, обратитесь к следующим документам:
* TCP Receive Window Auto-Tuning in Vista* Enterprise Networking with Windows Vista* Why TcpWindowSize does not work in Vista
Mac OSX
Mac OSX настраивается подобно FreeBSD.
sysctl -w net.inet.tcp.win_scale_factor=8sysctl -w kern.ipc.maxsockbuf=16777216sysctl -w net.inet.tcp.sendspace=8388608sysctl -w net.inet.tcp.recvspace=8388608
Для OSX 10.4, Apple также предоставляет патч Broadband Tuner, увеличивающий максимальный размер буферов сокета до 8MB и еще кое-что по мелочи.
Для получения дополнительной информации, обратитесь к OSX Network Tuning Guide.
AIX
Для повышения производительности на SMP системах, выполните:
ifconfig thread
Это позволит обработчику прерываний интерфейов GigE на многопроцессорной машине AIX выполняться в многопоточном режиме.
IRIX
Добавьте в файл /var/sysgen/master.d/bsd такие строки:
tcp_sendspacetcp_recvspace
Максимальный размер буфера в Irix 6.5 составляет 1MB и не может быть увеличен.
Оригинал статьи: http://fasterdata.es.net/TCP-tuning/Перевод: Сгибнев МихаилИсточник: http://dreamcatcher.ru/bsd/017_tcp.html
sudouser.com
TCPOptimizer - повышение скорости интернет, оптимизация, уменшение пинга.
Предлагаю вашему вниманию программу, с помощью которой вы можете оптимизировать ваше интернет соединение, повысить скорость, стабилизировать и уменьшить пинг в он-лайн играх.1. Скачиваем установку самой программы из данной темы во вложении.2. Устанавливаем на ваш компьютер.3. Запускаем от имени администратора.4. Выставляем настройки для он-лайн игр, как показано на скринах:
Вкладка "General Settings"Выбираем свою сетевую карту для настройки. "Network Adapter selection"В шкале скорости, выставляем скорость своего интернет соединения.
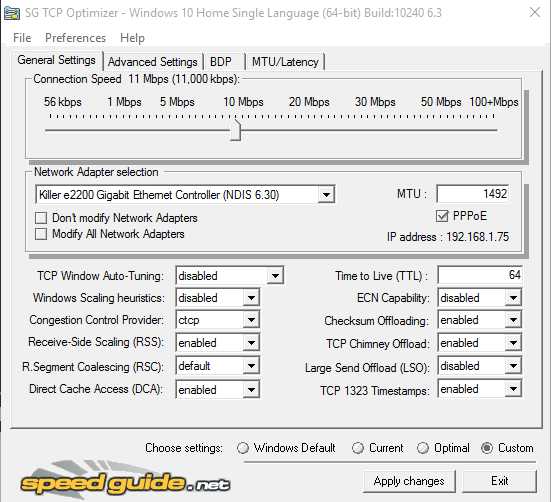
Вкладка "Advanced Settings"
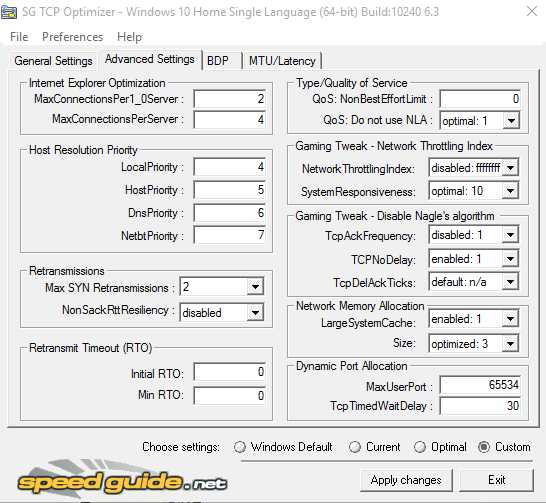
5. Нажимаем применить - "Apply changes"6. Программа в новом окне, покажет какие изменение будут приняты, в данном окошке обязательно выставляем галочку возле "backup", это нужно для восстановления прежних настроек интернет соединения в windows.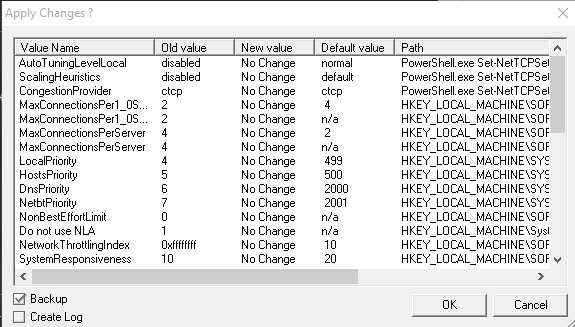
7. Нажимаем "ОК" - после программа применит новые настройки интернет соединения и попросить перезагрузить систему, перезагружаем.
Все готово!
Если есть какие то вопросы или же предложения, задавайте в этой теме.
Как и обещал, перевод на русский инструкции - "TCP Optimizer"
1. Введение
TCP Optimizer – это программа с легким, интуитивным интерфейсом для настройки TCP/IP параметров широкополосных соединений на текущих (и некоторых устаревших) версиях Windows. TCP Optimizer Version 4 работает на всех версиях Windows, начиная от XP/NT/2000/2003, Windows Vista/7/2008 Server и заканчивая более свежими Windows 8, 2012 Server, а также Windows 10. Настройки всех вышеперечисленных ОС разные, поэтому программа предложит только поддерживаемый набор опций для выбранной операционной системы. При создании TCP Optimizer были учтены все нюансы Microsoft относительно TCP/IP, а также документы RFC, имеющие отношение к программе. Утилита может править все важные реестры с параметрами конфигурации TCP/IP; в новых версиях Windows оперирует командлетами PowerShell; содержит в себе все твики, перечисленные нами ранее в статьях об улучшении скорости передачи, и в целом делает опыт работы с твиками легким, как бриз.
Ниже мы опишем все опции, доступные в TCP Optimizer. Некоторые из опций могут быть доступны только для Windows 8 и выше.
2. Пользование программой. Краткий обзор.
Если вам не хочется знакомиться со всей документацией, приведенной ниже, или же вам нужны твики прямо сейчас, просто выполните все пункты этой короткой инструкции:
Запустите программу от имени администратора: чтобы сделать это, нажмите по ярлычку программы правой кнопкой мыши, выберите «Свойства», перейдите в раздел «Совместимость» -> «Запуск от имени администратора» -> OK.Установите бегунок на максимальную скорость Интернет-соединения (согласно данным Интернет-провайдера).Выберите тип сетевого устройства, через которое осуществляется выход в Интернет (или поставьте галочку напротив «Изменять все сетевые устройства»).Внизу в меню настроек выберите «Оптимальные».Кликните «Применить». Решите, будете ли вы создавать резервную копию и лог, и перезагрузите компьютер.
Всю оставшуюся работу за вас сделает TCP Optimizer, он же оптимизирует ваше Интернет-соединение. Со списком всех значимых изменений вы сможете ознакомиться предварительно, до того как они будут применены на компьютере. Программу можно использовать для быстрого восстановления пользовательских настроек, а при желании – для экспериментов с другими настройками. Возможно для последнего, вам придется сначала ознакомиться со всей документацией и нашими статьями о твиках, чтобы понять значение тех или иных настроек и их действие.
Чтобы узнать больше обо всех особенных параметрах программы, пожалуйста, прочитайте следующие главы.
Заметка: Вам нужно будет заходить в программу под своей учетной записью (некоторые опции работают только с учетными записями), а также под именем администратора, чтобы у программы появились права на изменение некоторых настроек.
3. Общие настройки
Ниже дано краткое описание всех опций вкладки «Общие настройки» в программе TCP Optimizer в текущей версии Windows.
Скорость соединения
Этот бегунок позволяет выбрать максимально возможную скорость Интернет-соединения, которая заявлена вашим Интернет-провайдером. Не нужно указывать здесь текущую скорость соединения или заносить сюда результат теста на замер скорости. Здесь требуется максимальная теоретическая скорость вашего соединения. Заметьте, что скорость указывается в Мбайт/с, что означает мегабайт в секунду (не путайте с простыми мегабайтами).
Перемещение бегунка скорости соединения будет влиять на оптимальный размер окна TCP. В старых версиях Windows изменение положения бегунка сразу ведет к подсчету оптимального для данной скорости размера окна приема TCP. В новых операционных системах Windows данное действие может изменить алгоритм автоматической настройки окна приема TCP («restricted» для скоростей ниже 1 Мбайт/с; «normal» для большинства широкополосных соединений; «experimental» для скоростей свыше 90 Мбайт/с). Заметьте, что значение «experimental» в разделе автонастройки окна TCP должно использоваться с осторожностью.
Выбор сетевых устройств
В списке будут указываться все подключенные/активные сетевые устройства, распознанные системой. Если при помощи разворачивающегося вниз меню будет выбран определенный сетевой адаптер, его IP адрес будет отражаться в правом нижнем углу текущей секции. Также вы можете одновременно изменять или не изменять все сетевые устройства.
В этом разделе программы можно установить пользовательское значение MTU (максимальный размер блока данных). Для стандартных подключений значение MTU равно 1500 байтам, исключение составляют PPPoE соединения и некоторые подключения через DSL-модемы. Индекс MTU следует исправлять только для них. Например, максимальное значение MTU для инкапсуляции Windows PPPoE будет равно 1480 байтам (а иногда и 1492).
Заметка: В редких случаях программа может неправильно распознать предпочитаемое сетевое устройство. Это не будет сильно влиять на производительность нашего продукта. В этом случае нужно просто поставить галочку напротив «Изменять все сетевые устройства». Мы были бы очень вам благодарны, если бы вы сообщали нам о таких случаях, чтобы мы могли улучшить программу.
Автоматическая настройка окна приема TCP
Эта настройка регулирует алгоритм для определения размера окна приема TCP в Windows. Маленькое окно приема TCP может ограничивать высокоскоростные соединения с большой задержкой, коими являются все широкополосные Интернет-соединения. Для большинства соединений мы рекомендуем выбирать значение «normal» при настройке этого параметра. Вам нужно будет также убедиться, что вы отключили «Windows Scaling heuristics» (эвристика масштабирования окна TCP) ниже, чтобы ОС Windows не изменяла этот параметр автоматически.
Вот пара исключений, для которых не обязательно выставлять значение автонастройки TCP «normal»:1. Если скорость Вашего соединения менее 1 Мбит/с, вы можете выбрать значение «highlyrestricted» (строго ограничено).2. Если у вас соединение типа dial-up, вы можете выбрать «disabled» (отключено; так как для вашей скорости не потребуется буфер больше, чем на 64KB).3. Если скорость Вашего соединения около/свыше 100 Мбит/с, вы можете выбрать «experimental» (экспериментальный). Однако, чтобы обеспечить хорошую стабильность передачи данных, этот параметр нуждается в более пристальном изучении. Если у вас возникли какие-либо трудности со значением «experimental», пожалуйста, верните значение на «normal» и поделитесь своим опытом на форумах или напишите нам на электронную почту.
Эвристика масштабирования окна TCP
Если эта опция оставлена включенной, Windows может ограничить размер окна относительно значения по умолчанию в любой точке в любое время, в которое посчитает, что условия сети оправдывают действия. Когда Windows ограничивает размер окна TCP, оно не всегда возвращается к стандартным значениям. Настоятельно рекомендуется установить этот параметр на «disabled», чтобы сохранить пользовательские параметры автонастройки TCP.
Поставщик надстройки контроля перегрузки
Обычно TCP удается избежать перегрузки сети за счет плавного увеличения размера окна отправки на старте соединения. При работе с широкополосными соединениями чтобы полностью использовать доступную пропускную способность алгоритмы протокола также не увеличивают размер окна довольно быстро. Compound TCP – это новый метод контроля перегрузки, который увеличивает размер окна отправки TCP для широкополосных соединений (с большим RWIN и BDP) более агрессивно. Протокол CTCP максимизирует пропускную способность благодаря отслеживанию задержек и потерь данных.
В большинстве стандартных сценариев следует выбирать «CTCP».
CTCP (Compound TCP) увеличивает размер окна приема TCP и количество отправляемых данных. Этот протокол улучшает пропускную способность широкополосных Интернет-соединений с большим уровнем задержки.DCTCP (Data Center TCP) регулирует размер окна TCP основываясь на уведомлениях о перегрузке сети ECN. Протокол повышает пропускную способность локальных соединений и соединений с маленькой задержкой. Заметьте, что этот протокол может работать только на операционных системах модификации Server.
Масштабирование на стороне приема (RSS)
RSS позволяет параллельно обрабатывать принимаемые пакеты на нескольких процессорах, избегая при этом переотправки пакетов. Эта опция разделяет пакеты в потоки и использует разные процессоры для обработки каждого потока.
Если у вас два и более процессора, рекомендуется эту опцию включить. Однако эффект будет только если сетевое устройство поддерживает RSS.
Объединение полученных сегментов (RSC)
Функция объединения полученных сегментов (RSC) позволяет сетевому адаптеру объединять множественные пакеты TCP/IP, получаемые в единой передаче, в большие по размеру пакеты (до 64 км). Таким образом, сетевому стеку приходиться обрабатывать меньше заголовков пакетов. Это уменьшает нагрузку на сервер с интенсивным вводом-выводом и процессор.
Рекомендуется включить эту опцию для улучшения пропускной способности и выключить для увеличения задержки и производительности компьютера в играх.
Прямой доступ к кэшу (DCA)
Прямой доступ к кэшу (DCA) позволяет поддерживаемому устройству ввода-вывода, например, сетевому контроллеру, размещать данные прямо в кэш-памяти процессора. Задача DCA – уменьшить задержку памяти и улучшить пропускную способность каналов в высокоскоростных (гигабитных) средах. Необходимо, чтобы устройства ввода-вывода, системные чипсеты и процессоры поддерживали DCA.
Рекомендуется включить опцию при наличии гигабитного сетевого адаптера и поддерживаемого оборудования.
Заметка: эффект DCA более заметен на старых процессорах.
Время жизни пакета (TTL)
Эта настройка определяет по умолчанию время жизни пакета (TTL) согласно коду в заголовке исходящего IP-пакета. TTL определяет максимальный временной интервал в секундах (или хопах), в течение которого IP-пакет может существовать в сети до достижения своего назначения. По сути, это определенное количество маршрутизаторов, через которые IP-пакету позволено пройти, прежде чем он исчезнет. Эта настройка не влияет на скорость напрямую, однако заниженное значение этого параметра может помешать пакетам достигать дальние серверы. А завышенное значение будет забирать лишнее время на распознавание потерянных пакетов.
Рекомендованное значение – 64.
Мощность ECN
ECN (Explicit Congestion Notification, RFC 3168) – это механизм, который предоставляет маршрутизаторам альтернативный метод работы с перегрузкой сети. Его задача – снизить число ретрансмиссий. По сути, ECN свидетельствует о том, что причиной любой потери пакета является перегрузка маршрутизатора. Эта опция позволяет столкнувшимся с перегрузкой роутерам помечать отброшенные пакеты и разрешает клиентам автоматически снижать скорость передачи для предотвращения дальнейшей потери пакетов. Обычно протокол TCP/IP реагирует на перегрузку сетей отбрасыванием пакетов. Когда же к делу подключается ECN, то поддерживающий ECN роутер вместо отбрасывания пакета вставляет в IP-заголовок бит с целью оповещения о перегрузке. Получатель передает уведомление о перегрузке отправителю. Последний в свою очередь должен среагировать на отброску пакетов. В современных реализациях протокола TCP/IP опция ECN по умолчанию отключена, так как это может спровоцировать проблемы при наличии устаревших маршрутизаторов, которые отбрасывают пакеты с битом ECN или же просто игнорируют бит.
Обычно рекомендуется отключать опцию. Включать ее следует с осторожностью, так как некоторые маршрутизаторы отбрасывают пакеты с ECN-битом, что ведет к потере пакетов или к иным проблемам. Однако для ECN-поддерживающих маршрутизаторов включенная опция может сократить время задержки в некоторых играх и улучшить скорость соединения, несмотря на потерю пакетов.
Заметка: в некоторых играх издателя EA Games при входе в профиль возникают проблемы с вводом логина (возможно проблема в ECN-поддержке роутера).
Разгрузка контрольной суммы
Эта опция позволяет сетевому адаптеру подсчитать контрольное число при передаче пакетов и определить контрольную сумму при получении пакетов на свободный процессор, сокращая трафик по шине PCI. Разгрузка контрольной суммы также требуется для работы некоторых других stateless-объектов, таких как RSS (масштабирование на стороне приема), RSC (объединение полученных сегментов) и LSO (разгрузки большой отправки).
Рекомендуется включить функцию.
Разгрузка канала TCP Chimney
TCP Chimney позволяет освободить процессор главного компьютера от обработки TCP-трафика и переложить эту функцию на сетевой адаптер. Это помогает улучшить процесс обработки сетевых данных на вашем компьютере, не прибегая к помощи дополнительных программ и не теряя в производительности или безопасности системы. Программы, которые в настоящее время заняты обработкой сетевых заголовков, работают лучше в связке с опцией TCP Chimney. В прошлом активирование этой опции имело ряд негативных последствий из-за драйверов сетевых адаптеров, содержащих ошибки. Однако работа этой опции со временем стала более отлаженной. Она очень полезна для процессоров клиентских компьютеров и для высокоскоростных широкополосных соединений. Не рекомендуется в некоторых серверных средах.
Рекомендуется включить функцию.
Заметка: Не работает с NetDMA (NetTDMA не поддерживается Windows 8 и выше).
Разгрузка сегментации LSO
При включенной опции сетевой адаптер используется для завершения сегментации данных, так как теоретически он это делает быстрее, чем программное обеспечение операционной системы. Это улучшает скорость передачи данных и уменьшает нагрузку на центральный процессор. Проблемы с применением этой опции встречаются на многих уровнях, включая проблемы с драйверами сетевых адаптеров. Известно, что с драйверами Intel и Broadcom эта опция включается по умолчанию. В связи с этим может возникнуть множество трудностей.
Рекомендуется отключить функцию.
Отметки времени TCP 1323
Согласно RFC 1323, отметки времени предназначены для повышения надежности передачи посредством ретрансмиссии неподтвержденных сегментов по истечению интервала времени RTO (интервала до повторной передачи). Проблема отметок времени заключается в том, что они добавляют дополнительных 12 байт к 20-байтному TCP-заголовку каждого пакета, таким образом, ведя к расходу полосы в связи с увеличением заголовка.
Рекомендуется отключить функцию.
Заметка: В Windows Vista/7 из опций TCP 1323 мы рекомендуем оставить включенной только «Window Scaling».
Сеть прямого доступа к памяти NetDMA (Windows Vista/7)
NetDMA (TCPA) дает расширенные возможности использования прямого доступа к памяти. По сути, эта опция позволяет более эффективно размещать сетевые данные, минимизируя при этом нагрузку на процессор. Опция NetDMA освобождает процессор от хранения пакетов данных, передаваемых с буферов сетевой карты в буферы приложений при помощи движка DMA. Опция должна поддерживаться вашим BIOS, а ваш процессор должен поддерживать технологию Intel I/O Acceleration (I/OAT).
Рекомендуется использовать или опцию разгрузки TCP Chimney или NetDMA, но никогда вместе.
NetDMA не поддерживается Windows 8 и выше.
4. Продвинутые настройки
Этот раздел рассказывает о секции программы под названием «Продвинутые настройки», актуальной для текущих версий Windows.
Оптимизация Internet Explorer
Согласно спецификации HTTP 1.1 в RFC 2616 между клиентом и веб-сервером рекомендуется использовать не более 2 параллельных соединений по умолчанию. Равнозначно спецификация HTTP 1.0 рекомендует использовать не более 4 параллельных соединений (HTTP 1.0 не может обеспечить долговременное соединение, поэтому выигрывает за счет большего количества параллельных соединений). Традиционно Internet Explorer учитывал рекомендации RFC, однако после выпуска IE8, Firefox 3 и Chrome 4 большинство лидирующих браузеров отошли от этих рекомендаций в поисках более высокой скорости загрузки веб-страниц и увеличили число параллельных соединений с серверами до 6 как для HTTP 1.0, так и для 1.1.
Мы же рекомендуем довести количество параллельных соединений до 8-10 на сервер ввиду усложнившейся архитектуры веб-страниц и появления большого количества их элементов. Таким образом, установление множественных соединений оправдывается, особенно для широкополосных Интернет-соединений. Заметьте, что устанавливать более 10 соединений не рекомендуется, так как некоторые веб-серверы ограничивают количество параллельных соединений на одно IP и могут прервать или отбросить такие соединения. Помимо прочих проблем это приведет к незагруженным страницам и к негативному пользовательскому опыту.
Приоритеты разрешений хоста
Эта опция предназначена для повышения приоритета DNS/имени хоста посредством повышения приоритета четырех связанных по умолчанию процессов. Важно отметить, что опция повышает приоритет всех четырех связанных процессов в сравнении с сотнями других активных процессов и держит их в строгом соответствии очереди. Также важно отметить, что в таких случаях мы рекомендуем выбирать здесь значение «optimal» не для того, чтобы создать конфликт между приоритетами других процессов. Будьте осторожны, выбирая другое значение.
Чтобы узнать об этом подробнее, ознакомьтесь с нашей статьей о твике для установления приоритетов разрешений хоста.
Ретрансмиссии
Два значения в этой секции программы контролируют процесс восстановления соединения системой.
Max SYN Retransmissions: позволяет задать число попыток восстановления соединения при помощи SYN пакетов.Non Sack RTT Resiliency: контролирует расчет времени возврата повторных передач для клиентов без SACK. Это помогает замедлить клиентские соединения за счет того, что TCP/IP становится менее агрессивным в ретрансмиссии пакетов.
Интервал до повторной передачи (RTO) для Windows 8 и выше
Интервал до повторной передачи (RTO) определяет, сколько миллисекунд будет затрачено на обработку неподтвержденных данных прежде, чем соединение будет разорвано. Эта опция помогает сократить задержки в ретрансмиссии данных. Значение интервала Initial RTO по умолчанию, равное 3000мс (3 секундам), может быть сокращено до ~2с (за исключением удаленных локаций) для современных широкополосных соединений с низким уровнем задержки. Для соединений с большой задержкой (спутники, удаленные локации) слишком агрессивное снижение этого значения может привести к досрочным ретрансмиссиям. Не стоит постоянно пренебрегать лимитом RTO. Рекомендуемое минимальное значение Min RTO по умолчанию равно 300мс.
Смотри документ RFC 6298
Кэширование ошибок DNS - Windows 7/Vista/2k/XP
Эта опция предназначена для предотвращения занесения в кэш-память отрицательных ответов DNS.
MaxNegativeCacheTtl: определяет, как долго в кэше DNS будет храниться запись об отрицательном ответе (работает только для Windows XP/2003).
NegativeCacheTime: определяет, как долго в кэше DNS будет храниться запись об отрицательном ответе (работает только для Windows 2000/2008/Vista/Windows 7, аналогично MaxNegativeCacheTtl).
NetFailureCacheTime: определяет, как долго DNS-клиент будет отправлять запросы после обнаружения разрыва сети. В течение этого интервала времени DNS-клиент разошлет всем запросам уведомление об истечении срока ожидания ответа. Если значение этой опции будет равно «0», то она будет отключена и DNS продолжит отправлять запросы, несмотря на обрыв сети.
NegativeSOACacheTime: определяет, как долго в кэше DNS будет храниться запись об отрицательном ответе, в то время как начальная запись зоны SOA (Start of Authority) будет оставаться в кэше DNS.
Тип/качество обслуживания
Этот раздел связан с политикой QoS и с планировщиком пакетов QoS в Windows.
NonBestEffortLimit: планировщик пакетов QoS в Windows 7/8/8.1 по умолчанию резервирует 20% сетевого трафика для QoS-приложений, требующих приоритета. Заметьте, резервирование трафика происходит только при активных QoS-приложениях, требующих приоритета в трафике, таких как, например, Windows Update. Выставляя этот параметр на «0» вы убережете Windows от резервирования 20% трафика для такого рода приложений.
Do not use NLA (не используйте NLA): эта не описанная в документации опция является частью tcpip.sys, отвечающей за изменение QoS DSCP-значения. Microsoft требует, чтобы системы Windows 7/8 присоединялись к домену, а также чтобы этот домен был видим специальному сетевому адаптеру для применения политики локальной группы и для настройки DSCP-значения. Если выставить сюда «1», то это уберет все ограничения и позволить вам задать DSCP-значение для всех сетевых устройств, не являясь частью домена. В рамках политики локальных групп DSCP-значение может быть отрегулировано при помощи gpedit.msc.
Игровой твик – опция Network Throttling Index и System Responsiveness (скорость отклика системы)
Network Throttling Index: Windows использует механизм троттлинга, чтобы ограничить обработку немультимедийного сетевого трафика. Так как обработка сетевых пакетов является слишком ресурсо-затратной задачей, цель троттлинга заключается в том, чтобы помочь процессору пропустить некоторые такты для предоставления приоритетного доступа мультимедийным программам. В некоторых случаях, например для гигабитных сетей и некоторых онлайн игр, будет лучше отключить троттлинг для достижения максимальной пропускной способности.
SystemResponsiveness: мультимедийные приложения используют Планировщика классов мультимедиа (MMCSS) для получения приоритетного доступа к ресурсам процессора, при этом они не ущемляют фоновые приложения с более низким приоритетом. А вот на работу с фоновыми приложениями по умолчанию уходит 20% ресурсов процессора. Таким образом, на обработку мультимедиа и некоторых игр остается только 80% отдачи процессора. Optimizer может освободить закрепленные за фоновыми приложениями 20% ресурсов процессора для того, чтобы предоставить их играм.
Заметка: На некоторых серверных операционных системах (Windows 2008 Server) значение SystemResponsiveness может быть выставлено на 100 вместо 20 по умолчанию. При таких значениях больший приоритет все равно будет отдаваться фоновым сервисам, нежели мультимедиа.
Игровой твик – отключаем алгоритм Нейгла
Алгоритм Нейгла был разработан для объединения маленьких пакетов в единый, больший по размеру пакет для более производительной передачи. Несмотря на то, что алгоритм повышает пропускную способность сети и сокращает количество TCP/IP-заголовков, он все же ненадолго задерживает отправку маленьких пакетов. Отключение алгоритма сокращает задержку/пинг в некоторых играх, однако может негативно сказаться на передаче файлов. В Windows алгоритм Нейгла включен по умолчанию.
TcpAckFrequency: «1» для игр и Wi-FI (отключает нейглинг), небольшие значения больше «2» для лучшей пропускной способности.TcpNoDelay: «1» для игр (отключает нейглинг), «0» чтобы включить нейглингTcpDelAckTicks: «0» для игр (отключает), «1-6» означает 100-600мс. Установка значения «1» сокращает эффект алгоритма (по умолчанию 2=200мс).
Смотри также: статьи об игровых твиках.
Распределение сетевой памяти
При перекидке большого количества/объемных файлов по локальной сети в Windows иногда можно столкнуться с ошибками в распределении памяти, особенно когда у других клиентов установлена отличная от Windows операционная система. Если такое случается, вы можете наблюдать следующую ошибку в логе Event Viewer:
Event ID: 2017 «The server was unable to allocate from the system nonpaged pool because the server reached the configured limit for nonpaged pool allocations». (Сервер не смог выделить память из невыгружаемого пула памяти, так как достигнут указанный в конфигурации верхний предел). Или такую: «Not enough server storage is available to process this command» (На сервере недостаточно памяти для обработки команды).
Чтобы избежать этих ошибок, вам нужно заставить Windows перераспределить память между сетевыми сервисами и обменом файлами. Настройки в этой секции программы оптимизируют машину под файловый сервер, чтобы соответственно распределять ресурсы.
LargeSystemCache: мы рекомендуем выставить здесь значение «1», чтобы позволить кэшу выходить за рамки 8 МБ.
Size: значение «1» уменьшает используемую память, «2» разделяет используемую память поровну, «3» является оптимальным значением для обмена файлами и работы сетевых приложений.
Динамическое назначение портов
Временные (эфемерные) порты TCP/IP с номерами выше 1024 являются необходимыми для операционной системы. При нормальной сетевой загрузке в Windows 8/2012 вполне справляются настройки по умолчанию. Однако с увеличением сетевой загрузки может понадобиться отрегулировать две настройки реестра для увеличения доступности порта и уменьшения времени ожидания отклика неиспользуемого порта.
MaxUserPort: обозначает максимальное число используемых портов. По необходимости здесь рекомендуется выставить значение от 16384 до 65534 десятичной.
TcpTimedWaitDelay: время ожидания перед подключением портов в секундах. По умолчанию мы рекомендуем выставлять время подключения порта в 30 секунд. Но, в зависимости от вашей версии Windows время по умолчанию может варьироваться от 120 до 240 секунд.
5. Результат задержки пропускной способности (BDP)
Эта секция содержит калькулятор произведения полосы пропускания канала на задержку. BDP является очень важной концепцией в работе TCP/IP, которая напрямую относится к размеру окна TCP (RWIN). Здесь отражается лимит максимально возможной пропускной способности. BDP играет особенно важную роль в высокоскоростных сетях/ в сетях с большой задержкой, коими являются большинство широкополосных Интернет-соединений. Это один из самых важных факторов, влияющих на производительность TCP/IP.
Bandwidth*Delay Product или коротко BDP задает количество информации, которая может быть передана по сети. Эта опция показывает доступность полосы пропускания канала и уровень задержки туда-обратно, или RTT.
Проще говоря, BDP утверждает следующее:
BDP (биты) = общая доступная скорость передачи (бит/сек) * время задержки (сек)
или, если RWIN/BDP считается в байтах, а время задержки в миллисекундах:
BDP (байты) = общая доступная скорость передачи (Кбайт/сек) * время задержки (мс)
Что это значит? Окно TCP является буфером, определяющим размер данных, которые могут быть переданы за время ожидания сервером подтверждения отправки. По сути, размер буфера регулируется при помощи BDP. Если BDP (или окно приема) ниже, чем задержка и доступная скорость передачи, мы не сможем заполнить канал ввиду того, что клиент не сможет отправить подтверждение достаточно быстро. Трансмиссия не может превышать значение окна приема/задержки. Поэтому окно приема должно быть достаточно большим для соответствия произведению максимально доступной скорости передачи на максимально ожидаемую задержку.
Хотя в современных вариантах Windows нельзя напрямую изменять размер окна приема TCP, вы все равно можете отрегулировать, насколько агрессивно алгоритм автонастройки TCP будет повышать значение RWIN.
6. Задержка
Этот раздел программы позволяет протестировать значение задержки вашего Интернет-соединения. Здесь можно выбрать число хостов, количество пингов на один хост и размер пакета ICMP. После запуска этот инструмент программы последовательно пропингует все хосты, затем вычислит максимальную и среднюю задержку в миллисекундах, а также установит коэффициент потери пакетов (если потеря присутствует).
Этот инструмент может быть использован также для эффективного подсчета максимально ожидаемой задержки и для дальнейшего выведения BDP/RWIN. Чтобы выполнить эту задачу, мы рекомендуем использовать большее количество хостов (чем по умолчанию, равное 5) и больший размер пакета (так как большие по размеру пакеты имеют больший уровень задержки), а также использовать среднее значение RTT умноженное надвое, нежели максимальное RTT для определения максимально ожидаемой задержки.
Заметки:При пинговке хостов больше используется ICMP, чем TCP. Некоторые роутеры предоставляют очень низкий приоритет трафику ICMP, и как результат вы можете столкнуться с большим процентом потери пакетов.Большие пакеты имеют больший уровень задержки.RTT изменяется в зависимости от времени суток, загруженности сети и т.д.При перегрузке сети некоторые узлы могут отбрасывать или игнорировать все повторные запросы ICMP.
7. Меню
Разворачивающееся меню «Файл» содержит в себе ряд опций для восстановления настроек из файла, для экспорта или импорта настроек TCP Optimizer. Здесь пользователи могут обмениваться файлами, которые содержат в себе информацию о ключах, удаленных, добавленных и исправленных значениях и обо всех важных параметрах. Все это можно экспортировать на другую машину или же сохранить для своего дальнейшего пользования. Здесь же можно сбросить настройки TCP/IP и Winsock, чтобы восстановить сетевое соединение, потерпевшее крушение.
Меню «Настройки», расположенное правее, имеет два раздела. В первом – «Максимальная задержка» – выставляется число в миллисекундах. Оно используется для подсчета оптимального размера окна приема. Это влияет на оптимальные настройки, рекомендуемые программой. Поэтому если вы точно не знаете, за что отвечает данное число, оставьте его по умолчанию – 300 мс. В основном, чем больше это число, тем больше программа рекомендует выставлять размер окна приема в разделе «Оптимальные настройки» при одинаковой скорости соединения, и наоборот. Эта опция имеет большее значение для тех версий Windows, которые поддерживают прямую установку размера окна приема.
Вторая секция меню «Настройки» – «Вкладка задержек: адреса для пинга» – содержит список URL-адресов, используемых в секции задержек для измерения текущего времени RTT (задержки туда и обратно, задержки подтверждения, пинга, задержки), действительного для множественных хостов.
Меню «Помощь» программы Optimizer содержит ссылки на документацию и лицензионное соглашение, а также располагает некоторой общей информацией о продукте.
8. Подменю «Применить»
Это подменю предлагает предварительный просмотр списка всех изменений прежде, чем они будут применены. В левом углу располагаются переключатели, позволяющие пользователю создать резервную копию перед подтверждением любых изменений. Если вы столкнулись с какими-либо проблемами в TCP Optimizer, то вы можете выставить флажок напротив «Создать лог» в левом углу подменю. Это поможет отследить, как операционная система отреагировала на выполнение команд. Лог всех обработанных команд может сильно помочь при решении проблем, связанных с программой и проследить за реакцией операционной системы. Создание этого лога поможет устранить любые проблемы, с которыми вы можете столкнуться в программе. Для новичков также рекомендуется создавать резервные копии всех настроек для легкого восстановления системы.
Некоторые изменения могут быть применены без перезагрузки ПК. Однако большинству изменений все же требуется перезагрузка компьютера.
macro-game.com
часть 2 / Блог компании WEBO Group / Хабр
В первой части мы разобрали «тройное рукопожатие» TCP и некоторые технологии — TCP Fast Open, контроль потока и перегрузкой и масштабирование окна. Во второй части узнаем, что такое TCP Slow Start, как оптимизировать скорость передачи данных и увеличить начальное окно, а также соберем все рекомендации по оптимизации TCP/IP стека воедино.
Медленный старт (Slow-Start)
Несмотря на присутствие контроля потока в TCP, сетевой коллапс накопления был реальной проблемой в середине 80-х. Проблема была в том, что хотя контроль потока не позволяет отправителю «утопить» получателя в данных, не существовало механизма, который бы не дал бы это сделать с сетью. Ведь ни отправитель, ни получатель не знают ширину канала в момент начала соединения, и поэтому им нужен какой-то механизм, чтобы адаптировать скорость под изменяющиеся условия в сети.Например, если вы находитесь дома и скачиваете большое видео с удаленного сервера, который загрузил весь ваш даунлинк, чтобы обеспечить максимум скорости. Потом другой пользователь из вашего дома решил скачать объемное обновление ПО. Доступный канал для видео внезапно становится намного меньше, и сервер, отправляющий видео, должен изменить свою скорость отправки данных. Если он продолжит с прежней скоростью, данные просто «набьются в кучу» на каком-то промежуточном гейтвэе, и пакеты будут «роняться», что означает неэффективное использование сети.
В 1988 году Ван Якобсон и Майкл Дж. Карелс разработали для борьбы с этой проблемой несколько алгоритмов: медленный старт, предотвращение перегрузки, быстрая повторная передача и быстрое восстановление. Они вскоре стали обязательной частью спецификации TCP. Считается, что благодаря этим алгоритмам удалось избежать глобальных проблем с интернетом в конце 80-х/начале 90-х, когда трафик рос экспоненциально.
Чтобы понять, как работает медленный старт, вернемся к примеру с клиентом в Нью-Йорке, пытающемуся скачать файл с сервера в Лондоне. Сначала выполняется тройное рукопожатие, во время которого стороны обмениваются своими значениями окон приема в АСК-пакетах. Когда последний АСК-пакет ушел в сеть, можно начинать обмен данными.
Единственный способ оценить ширину канала между клиентом и сервером – измерить ее во время обмена данными, и это именно то, что делает медленный старт. Сначала сервер инициализирует новую переменную окна перегрузки (cwnd) для TCP-соединения и устанавливает ее значение консервативно, согласно системному значению (в Linux это initcwnd).
Значение переменной cwnd не обменивается между клиентом и сервером. Это будет локальная переменная для сервера в Лондоне. Далее вводится новое правило: максимальный объем данных «в пути» (не подтвержденных через АСК) между сервером и клиентом должно быть наименьшим значением из rwnd и cwnd. Но как серверу и клиенту «договориться» об оптимальных значениях своих окон перегрузки. Ведь условия в сети изменяются постоянно, и хотелось бы, чтобы алгоритм работал без необходимости подстройки каждого TCP-соединения.
Решение: начинать передачу с медленной скоростью и увеличивать окно по мере того, как прием пакетов подтверждается. Это и есть медленный старт.
Начальное значение cwnd исходно устанавливалось в 1 сетевой сегмент. В RFC 2581 это изменили на 4 сегмента, и далее в RFC 6928 – до 10 сегментов.
Таким образом, сервер может отправить до 10 сетевых сегментов клиенту, после чего должен прекратить отправку и ждать подтверждения. Затем, для каждого полученного АСК, сервер может увеличить свое значение cwnd на 1 сегмент. То есть на каждый подтвержденный через АСК пакет, два новых пакета могут быть отправлены. Это означает, что сервер и клиент быстро «занимают» доступный канал.
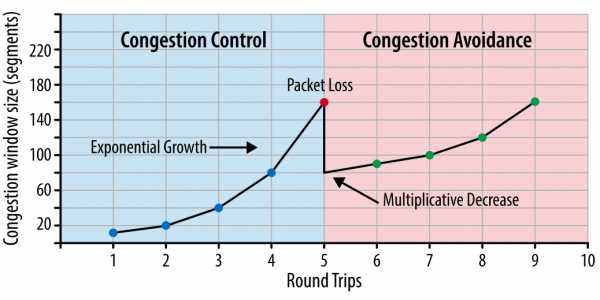
Рис. 1. Контроль за перегрузкой и ее предотвращение.
Каким же образом медленный старт влияет на разработку браузерных приложений? Поскольку каждое TCP-соединение должно пройти через фазу медленного старта, мы не можем сразу использовать весь доступный канал. Все начинается с маленького окна перегрузки, которое постепенно растет. Таким образом время, которое требуется, чтобы достичь заданной скорости передачи, — это функция от круговой задержки и начального значения окна перегрузки.
Время достижения значения cwnd, равного N.
Чтобы ощутить, как это будет на практике, давайте примем следующие предположения:- Окна приема клиента и сервера: 65 535 байт (64 КБ)
- Начальное значение окна перегрузки: 10 сегментов
- Круговая задержка между Лондоном и Нью-Йорком: 56 миллисекунд
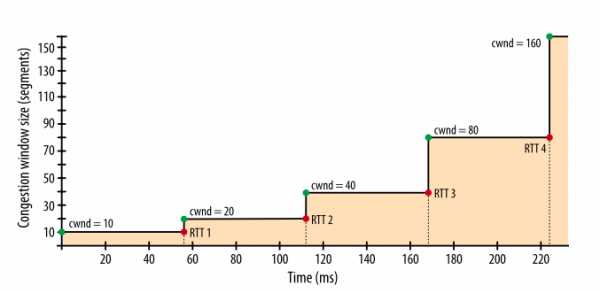 Рис. 2. Рост окна перегрузки.
Рис. 2. Рост окна перегрузки.Чтобы уменьшить время, которое требуется для достижения максимального значения окна перегрузки, можно уменьшить время, требуемое пакетам на путь «туда-обратно» — то есть расположить сервер географически ближе к клиенту.
Медленный старт мало влияет на скачивание крупных файлов или потокового видео, поскольку клиент и сервер достигнут максимальных значений окна перегрузки за несколько десятков или сотен миллисекунд, но это будет одним TCP-соединением.
Однако для многих HTTP-запросов, когда целевой файл относительно небольшой, передача может закончиться до того, как достигнут максимум окна перегрузки. То есть производительность веб-приложений зачастую ограничена временем круговой задержкой между сервером и клиентом.
Перезапуск медленного старта (Slow-Start Restart — SSR)
Дополнительно к регулированию скорости передачи в новых соединениях, TCP также предусматривает механизм перезапуска медленного старта, который сбрасывает значение окна перегрузки, если соединение не использовалось заданный период времени. Логика здесь в том, что условия в сети могли измениться за время бездействия в соединении, и чтобы избежать перегрузки, значение окна сбрасывается до безопасного значения.Неудивительно, что SSR может оказывать серьезное влияние на производительность долгоживущих TCP-соединений, которые могут временно «простаивать», например, из-за бездействия пользователя. Поэтому лучше отключить SSR на сервере, чтобы улучшить производительность долгоживущих соединений. На Linux проверить статус SSR и отключить его можно следующими командами:
$> sysctl net.ipv4.tcp_slow_start_after_idle $> sysctl -w net.ipv4.tcp_slow_start_after_idle=0 Чтобы продемонстрировать влияние медленного старта на передачу небольшого файла, давайте представим, что клиент из Нью-Йорка запросил файл размером 64 КБ с сервера в Лондоне по новому TCP-соединению при следующих параметрах:- Круговая задержка: 56 миллисекунд
- Пропускная способность клиента и сервера: 5 Мбит/с
- Окно приема клиента и сервера: 65 535 байт
- Начальное значение окна перегрузки: 10 сегментов (10 х 1460 байт = ~14 КБ)
- Время обработки на сервере для генерации ответа: 40 миллисекунд
- Пакеты не теряются, АСК на каждый пакет, запрос GET умещается в 1 сегмент
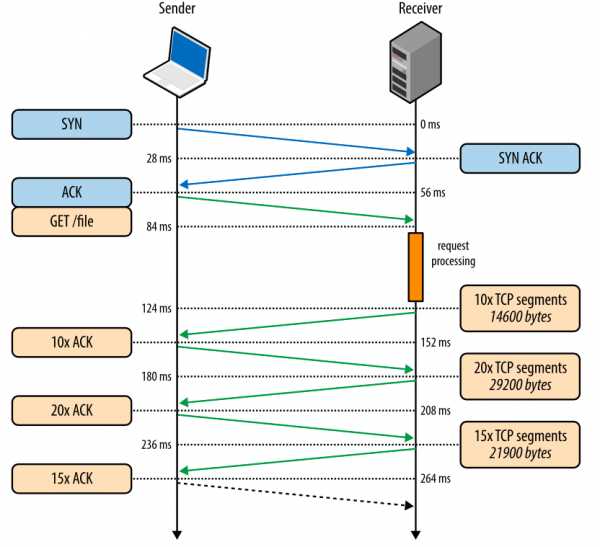 Рис. 3. Скачивание файла через новое TCP-соединение.
Рис. 3. Скачивание файла через новое TCP-соединение.- 0 мс: клиент начинает TCP-хэндшейк SYN-пакетом
- 28 мс: сервер отправляет SYN-ACK и задает свой размер rwnd
- 56 мс: клиент подтверждает SYN-ACK, задает свой размер rwnd и сразу шлет запрос HTTP GET
- 84 мс: сервер получает HTTP-запрос
- 124 мс: сервер заканчивает создавать ответ размером 64 КБ и отправляет 10 TCP-сегментов, после чего ожидает АСК (начальное значение cwnd равно 10)
- 152 мс: клиент получает 10 TCP-сегментов и отвечает АСК на каждый
- 180 мс: сервер увеличивает cwnd на каждый полученный АСК и отправляет 20 TCP-сегментов
- 208 мс: клиент получает 20 TCP-сегментов и отвечает АСК на каждый
- 236 мс: сервер увеличивает cwnd на каждый полученный АСК и отправляет 15 оставшихся TCP-сегментов
- 264 мс: клиент получает 15 TCP-сегментов и отвечает АСК на каждый
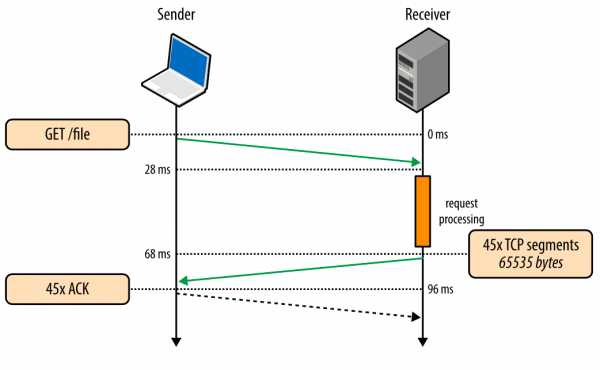 Рис. 4. Скачивание файла через существующее TCP-соединение.
Рис. 4. Скачивание файла через существующее TCP-соединение.
- 0 мс: клиент отправляет НТТР-запрос
- 28 мс: сервер получает НТТР-запрос
- 68 мс: сервер генерирует ответ размером в 64 КБ, но значение cwnd уже больше, чем 45 сегментов, требуемых для отправки этого файла. Поэтому сервер отправляет все сегменты сразу
- 96 мс: клиент получает все 45 сегментов и отвечает АСК на каждый
В обоих случаях тот факт, что клиент и сервер пользуются каналом с пропускной способностью 5 Мбит/с, не оказал никакого влияния на время скачивания файла. Только размеры окон перегрузки и сетевая задержка были ограничивающими факторами. Интересно, что разница в производительности при использовании нового и существующего TCP-соединений будет увеличиваться, если сетевая задержка будет расти.
Как только вы осознаете проблемы с задержками при создании новых соединений, у вас сразу появится желание использовать такие методы оптимизации, как удержание соединения (keepalive), конвейеризация пакетов (pipelining) и мультиплексирование.
Увеличение начального значения окна перегрузки TCP
Это самый простой способ увеличения производительности для всех пользователей или приложений, использующих TCP. Многие операционные системы уже используют новое значение равное 10 в своих обновлениях. Для Linux 10 – значение по умолчанию для окна перегрузки, начиная с версии ядра 2.6.39.Предотвращение перегрузки
Важно понимать, что TCP использует потерю пакетов как механизм обратной связи, который помогает регулировать производительность. Медленный старт создает соединение с консервативным значением окна перегрузки и пошагово удваивает количество передаваемых за раз данных, пока оно не достигнет окна приема получателя, системного порога sshtresh или пока пакеты не начнут теряться, после чего и включается алгоритм предотвращения перегрузки.Предотвращение перегрузки построено на предположении, что потеря пакета является индикатором перегрузки в сети. Где-то на пути движения пакетов на линке или на роутере скопились пакеты, и это означает, что нужно уменьшить окно перегрузки, чтобы предотвратить дальнейшее «забитие» сети трафиком.
После того как окно перегрузки уменьшено, применяется отдельный алгоритм для определения того, как должно далее увеличиваться окно. Рано или поздно случится очередная потеря пакета, и процесс повторится. Если вы когда-либо видели похожий на пилу график проходящего через TCP-соединение трафика – это как раз потому, что алгоритмы контроля и предотвращения перегрузки подстраивают окно перегрузки в соответствии с потерями пакетов в сети.
Стоит заметить, что улучшение этих алгоритмов является активной областью как научных изысканий, так и разработки коммерческих продуктов. Существуют варианты, которые лучше работают в сетях определенного типа или для передачи определенного типа файлов и так далее. В зависимости от того, на какой платформе вы работаете, вы используете один из многих вариантов: TCP Tahoe and Reno (исходная реализация), TCP Vegas, TCP New Reno, TCP BIC, TCP CUBIC (по умолчанию на Linux) или Compound TCP (по умолчанию на Windows) и многие другие. Независимо от конкретной реализации, влияния этих алгоритмов на производительность веб-приложений похожи.
Пропорциональное снижение скорости для TCP
Определение оптимального способа восстановления после потери пакета – не самая тривиальная задача. Если вы слишком «агрессивно» реагируете на это, то случайная потеря пакета окажет чрезмерно негативное воздействие на скорость соединения. Если же вы не реагируете достаточно быстро, то, скорее всего, это вызовет дальнейшую потерю пакетов.Изначально в TCP применялся алгоритм кратного снижения и последовательного увеличения (Multiplicative Decrease and Additive Increase — AIMD): когда теряется пакет, то окно перегрузки уменьшается вдвое, и постепенно увеличивается на заданную величину с каждым проходом пакетов «туда-обратно». Во многих случаях AIMD показал себя как чрезмерно консервативный алгоритм, поэтому были разработаны новые.
Пропорциональное снижение скорости (Proportional Rate Reduction – PRR) – новый алгоритм, описанный в RFC 6937, цель которого является более быстрое восстановление после потери пакета. Согласно замерам Google, где алгоритм и был разработан, он обеспечивает сокращение сетевой задержки в среднем на 3-10% в соединениях с потерями пакетов. PPR включен по умолчанию в Linux 3.2 и выше.
Произведение ширины канала на задержку (Bandwidth-Delay Product – BDP)
Встроенные механизмы борьбы с перегрузкой в TCP имеют важное следствие: оптимальные значения окон для получателя и отправителя должны изменяться согласно круговой задержке и целевой скорости передачи данных. Вспомним, что максимально количество неподтвержденных пакетов «в пути» определено как наименьшее значение из окон приема и перегрузки (rwnd и cwnd). Если у отправителя превышено максимальное количество неподтвержденных пакетов, то он должен прекратить передачу и ожидать, пока получатель не подтвердит какое-то количество пакетов, чтобы отправитель мог снова начать передачу. Сколько он должен ждать? Это определяется круговой задержкой.BDP определяет, какой максимальный объем данных может быть «в пути»
Если отправитель часто должен останавливаться и ждать АСК-подтверждения ранее отправленных пакетов, это создаст разрыв в потоке данных, который будет ограничивать максимальную скорость соединения. Чтобы избежать этой проблемы, размеры окон должны быть установлены достаточно большими, чтобы можно было отсылать данные, ожидая поступления АСК-подтверждений по ранее отправленным пакетам. Тогда будет возможна максимальная скорость передачи, никаких разрывов. Соответственно, оптимальный размер окна зависит от скорости круговой задержки.Рис. 5. Разрыв в передаче из-за маленьких значений окон.
Насколько же большими должны быть значения окон приема и перегрузки? Разберем на примере: пусть cwnd и rwnd равны 16 КБ, а круговая задержка равна 100 мс. Тогда:
Получается, что какая бы ни была ширина канала между отправителем и получателем, такое соединение никогда не даст скорость больше, чем 1,31 Мбит/с. Чтобы добиться большей скорости, надо или увеличить значение окон, или уменьшить круговую задержку.
Похожим образом мы можем вычислить оптимальное значение окон, зная круговую задержку и требуемую ширину канала. Примем, что время останется тем же (100 мс), а ширина канала отправителя 10 Мбит/с, а получатель находится на высокоскоростном канале в 100 Мбит/с. Предполагая, что у сети между ними нет проблем на промежуточных участках, мы получаем для отправителя:
Размер окна должен быть как минимум 122,1 КБ, чтобы полностью занять канал на 10 Мбит/с. Вспомните, что максимальный размер окна приема в TCP равен 64 КБ, если только не включено масштабирование окна (RFC 1323). Еще один повод перепроверить настройки!
Хорошая новость в том, что согласование размеров окон автоматически делается в сетевом стэке. Плохая новость в том, что иногда это может быть ограничивающим фактором. Если вы когда-либо задумывались, почему ваше соединение передает со скоростью, которая составляет лишь небольшую долю от имеющейся ширины канала, это происходит, скорее всего, из-за малого размера окон.
BDP в высокоскоростных локальных сетях
Круговая задержка может являться узким местом и в локальных сетях. Чтобы достичь 1 Гбит/с при круговой задержке в 1 мс, необходимо иметь окно перегрузки не менее чем 122 КБ. Вычисления аналогичны показанным выше.Блокировка начала очереди (Head-of-line blocking – HOL blocking)
Хотя TCP – популярный протокол, он не является единственным, и не всегда – самым подходящим для каждого конкретного случая. Такие его особенности, как доставка по порядку, не всегда необходимы, и иногда могут увеличить задержку.Каждый TCP-пакет содержит уникальный номер последовательности, и данные должны поступать по порядку. Если один из пакетов был потерян, то все последующие пакеты хранятся в TCP-буфере получателя, пока потерянный пакет не будет повторно отправлен и не достигнет получателя. Поскольку это происходит в TCP-слое, приложение «не видит» эти повторные отправки или очередь пакетов в буфере, и просто ждет, пока данные не будут доступны. Все, что «видит» приложение – это задержка, возникающая при чтении данных из сокета. Этот эффект известен как блокировка начала очереди.
Блокировка начала очереди освобождает приложения от необходимости заниматься упорядочиванием пакетов, что упрощает код. Но с другой стороны, появляется непредсказуемая задержка поступления пакетов, что негативно влияет на производительность приложений.
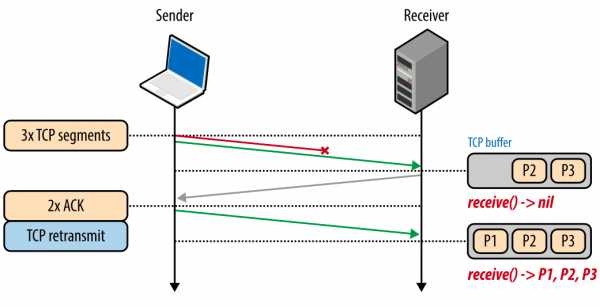 Рис. 6. Блокировка начала очереди.
Рис. 6. Блокировка начала очереди.
Некоторым приложениям может не требоваться гарантированная доставка или доставка по порядку. Если каждый пакет – это отдельное сообщение, то доставка по порядку не нужна. А если каждое новое сообщение перезаписывает предыдущие, то и гарантированная доставка также не нужна. Но в TCP нет конфигурации для таких случаев. Все пакеты доставляются по очереди, а если какой-то не доставлен, он отправляется повторно. Приложения, для которых задержка критична, могут использовать альтернативный транспорт, например, UDP.
Потеря пакетов – это нормально
Потеря пакетов даже нужна для того, чтобы обеспечить лучшую производительность TCP. Потерянный пакет работает как механизм обратной связи, который позволяет получателю и отправителю изменить скорость отправки, чтобы избежать перегрузки сети и минимизировать задержку.Некоторые приложения могут «справиться» с потерей пакета: например, для проигрывания аудио, видео или для передачи состояния в игре, гарантированная доставка или доставка по порядку не обязательны. Поэтому WebRTC использует UDP в качестве основного транспорта.
Если при проигрывании аудио произошла потеря пакета, аудио кодек может просто вставить небольшой разрыв в воспроизведение и продолжать обрабатывать поступающие пакеты. Если разрыв небольшой, пользователь может его и не заметить, а ожидание доставки потерянного пакета может привести к заметной задержке воспроизведения, что будет гораздо хуже для пользователя.
Аналогично, если игра передает свои состояния, то нет смысла ждать пакет, описывающий состояние в момент времени T-1, если у нас уже есть информация о состоянии в момент времени T.
Оптимизация для TCP
TCP – это адаптивный протокол, разработанный для того, чтобы максимально эффективно использовать сеть. Оптимизация для TCP требует понимания того, как TCP реагирует на условия в сети. Приложениям может понадобиться собственный метод обеспечения заданного качества (QoS), чтобы обеспечить стабильную работу для пользователей.Требования приложений и многочисленные особенности алгоритмов TCP делает их взаимную увязку и оптимизацию в этой области огромным полем для изучения. В этой статье мы лишь коснулись некоторых факторов, которые влияют на производительность TCP. Дополнительные механизмы, такие как выборочные подтверждения (SACK), отложенные подтверждения, быстрая повторная передача и многие другие осложняют понимание и оптимизацию TCP-сессий.
Хотя конкретные детали каждого алгоритма и механизма обратной связи будут продолжать изменяться, ключевые принципы и их последствия останутся:
- Тройное рукопожатие TCP несет серьезную задержку;
- Медленный старт TCP применяется к каждому новому соединению;
- Механизмы контроля потока и перегрузки TCP регулируют пропускную способность всех соединений;
- Пропускная способность TCP регулируется через размер окна перегрузки.
Настройка конфигурации сервера
Вместо того, чтобы заниматься настройкой каждого отдельного параметра TCP, лучше начать с обновления до последней версии операционной системы. Лучшие практики в работе с TCP продолжают развиваться, и большинство этих изменений уже доступно в последних версиях ОС.«Обновить ОС на сервере» кажется тривиальным советом. Но на практике многие серверы настроены под определенную версию ядра, и системные администраторы могут быть против обновлений. Да, обновление несет свои риски, но в плане производительности TCP, это, скорее всего, будет самым эффективным действием.
После обновления ОС вам нужно сконфигурировать сервер в соответствии с лучшими практиками:
- Увеличить начальное значение окна перегрузки: это позволит передать больше данных в первом обмене и существенно ускоряет рост окна перегрузки
- Отключить медленный старт: отключение медленного старта после периода простоя соединения улучшит производительность долгоживущих TCP-соединений
- Включить масштабирование окна: это увеличит максимальное значение окна приема и позволит ускорить соединения, где задержка велика
- Включить TCP Fast Open: это даст возможность отправлять данные в начальном SYN-пакете. Это новый алгоритм, его должны поддерживать и клиент и сервер. Изучите, может ли ваше приложение извлечь из него пользу.
Для пользователей Linux ss поможет проверить различную статистику открытых сокетов. В командной строке наберите
ss --options --extended --memory --processes --info и вы увидите текущие одноранговые соединения (peers) и их настройки.Настройка приложения
То, как приложение использует соединения может иметь огромное влияние на производительность:- Любая передача данных занимает время >0. Ищите способы уменьшить объем отправляемых данных.
- Приблизьте ваши данные к клиентам географически
- Повторное использование TCP-соединений может быть важнейшим моментом в улучшении производительности.
Перенос данных поближе к клиентам посредством размещения серверов по всему миру либо с использованием CDN, поможет уменьшить круговую задержку и значительно повысит производительность TCP.
И наконец, во всех случаях, где это возможно, существующие соединения TCP должны использоваться повторно, чтобы избежать задержек, вызванных алгоритмом медленного старта и контроля перегрузки.
В заключение, вот контрольный список того, что нужно сделать для оптимизации TCP:
- Обновите ОС сервера
- Убедитесь, что параметр cwnd установлен равным 10
- Убедитесь, что масштабирование окон включено
- Отключите медленный старт после простоя соединения
- Включите TCP Fast Open, если это возможно
- Исключите передачу ненужных данных
- Сжимайте передаваемые данные
- Расположите серверы ближе к клиентам географически, чтобы снизить круговую задержку
- Используйте повторно TCP-соединения, где это возможно
- Изучите рекомендации Рабочей группы по HTTP
habr.com
Оптимизация TCP/IP настроек для Windows Server
Нужно понимать, что Microsoft делает ставку на бизнес сектор, а это значит, что системы по-умолчанию могут работать медленно, но стабильно.
Проблема: сервер на базе Windows Server 2012 под высокой нагрузкой устаналивает быстрые TCP соединения с бэкэндом. Профилирование сетевого трафика показало 3 проблемы:
- Тысячи закрытых соединений, но ресурсы ещё не освобождены (соединения в статусе TIME_WAIT)
- Тысячи полузакрытых соединений (в статусе FIN_WAIT_2)
- Нехватка портов для открытия новых соединений
Прежде чем что-либо оптизировать нужны факты, что проблема действительно есть. Здесь на помощь придут инструменты наподобие:
- TCPView
- netstat
- WireShark
Wireshark показал, что проблема на уровне сети есть – потери пакетов. Ниже пару скриншотов двух других инструментов:
Оптимизация TCP/IP протокола
Только трусы делают бекапы на проде, поэтому не стоит его делать перед тем как менять что-нибудь в реестре или в недрах системе.
Начиная с Windows Server 2008 настройки производительности достаточно сильно улучшены. Настроек много (Microsoft. Network Optimization или вот здесь TCP/IP Registry Values for Microsoft ), но есть пару тех, что нам нужно.
MaxUserPort
Когда сервер устанавливает соединение с чем-то внешним по TCP/IP, он открывает сокет и выбирает динамический порт. По-умолчанию, диапазон динамических портов от 1024 по 5000 порт, т.е. 3976 возможных одновременно открытых портов. Увеличим по максимум эту цифру.
Добавляем ключ в реестр:Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\ParametersValue: MaxUserPortData Type: REG_DWORDRange: 5000 to 65534Default value: 5000Recommended value: 65534
Смотри Microsoft. Network Optimization
TcpTimedWaitDelay
Когда соединение TCP закрывается, то сокет сразу не освобождается, а переходит в статус TIME_WAIT и ресурсы освободятся только через определённое время. По умолчанию, только через 4 минуты. Снизим это время до минимума – 30 секунд.
Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\ParametersValue: TcpTimedWaitDelayData Type: REG_DWORDRange: 30 to 300Default value: 240Recommended value: 30
Смотри Microsoft. Network Optimization
TcpFinWait2Delay
Система будет держать полузакрытые соединения по-умолчанию 2 минуты. Снизим тоже до 30 секунд.
Key: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\ParametersValue Type: REG_DWORDValid Range: 30–294,967,295Default: 120Recommended value: 30
Смотри TCP/IP Registry Values for MicrosoftНапоследок отключим autotuning tcp протоколаnetsh int tcp set global autotuninglevel=disabledи перегрузим машину.
Заключение:
Настройки выше не устранили главную причину (нестабильность сети), но это позволило стабилизировать работу систему самого сервера, и как минимум в логах теперь меньше ошибок.
it-band.by