Средства анализа и оптимизации локальных сетей. Оптимизация сети
Оптимизация сетевого трафика | Журнал сетевых решений/LAN
Для современных корпоративных сетей передачи данных характерны такие тенденции, как централизация ИТ-ресурсов в ЦОД, активный доступ к ним мобильных пользователей, использование Интернета или выделенных каналов WAN для организации коммуникаций между офисами. Консолидация, виртуализация, облачные вычисления, Web-сервисы, рост числа и разнообразия мобильных устройств, удаленная работа, увеличение объемов хранимых и передаваемых данных, централизация приложений — все это заставляет обратить более пристальное внимание на оптимизацию WAN.
При увеличении загрузки канала WAN потери пакетов происходят чаще, что, в свою очередь, ведет к ухудшению качества работы и увеличению времени отклика приложений. Наращивание пропускной способности каналов (собственных или арендуемых) нередко обходится дорого и не всегда помогает — задержка в сети все равно остается слишком большой. Иногда проблему удается решить (частично или полностью) за счет применения правил приоритетного обслуживания (CoS/QoS), изменения настроек приложений или пересмотра архитектуры решения.
Большинство сетей используются для передачи данных, различающихся как по типу, так и по степени значимости для бизнеса, поэтому многие организации стараются регулировать трафик, чтобы сократить время отклика важных приложений и уменьшить затраты. Критичные приложения получают гарантированную пропускную способность и могут работать с максимальной производительностью. Обычно выбор таких приложений и сервисов (а это могут быть не только голос/видео, но и Office 365) осуществляется при помощи средств мониторинга сети. Однако этих методов не всегда достаточно.
ЧТО ТАКОЕ ОПТИМИЗАЦИЯ WAN?
Нередко самым действенным и экономичным решением оказывается применение средств оптимизации WAN, что позволяет повысить производительность бизнес-приложений без затрат на расширение пропускной способности глобальных сетей. Технологии оптимизации WAN внедряются просто и быстро, при этом изменений в архитектуре сети не требуется.
Чтобы ускорить сетевой трафик, в ЦОД и филиалах компании устанавливают специальные устройства. Их называют контроллерами оптимизации WAN (WAN Optimization Controller, WOC). Эти аппаратные и/или программные решения устраняют или ослабляют основные причины низкой эффективности работы приложений в глобальной сети: ограниченную пропускную способность канала, большую задержку, неэффективность транспортных протоколов и сетевого взаимодействия приложений. Некоторые системы представляют собой интегрированные решения, дополняющие функции оптимизации WAN средствами безопасности (межсетевой экран, функции IPS, VPN и защиты от DoS/DDoS), балансировки нагрузки и маршрутизации приложений.
Применение оборудования оптимизации трафика WAN позволяет снизить требования к пропускной способности, ускорить синхронизацию данных между основным и резервным ЦОД, а иногда использовать Интернет в качестве альтернативы выделенным каналам. Принципы работы WOC заключаются в сокращении объема передаваемых приложениями данных, повышении эффективности использования пропускной способности каналов и ее распределения между приложениями, благодаря чему скорость работы сетевых приложений через каналы WAN подчас приближается к скорости их работы в локальной сети.
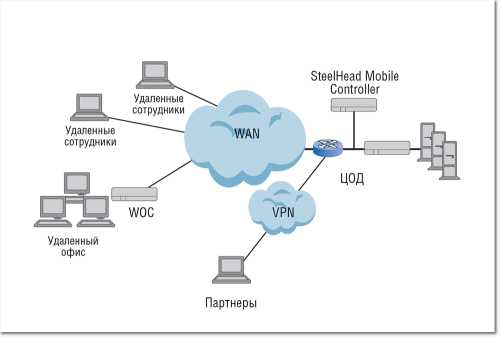
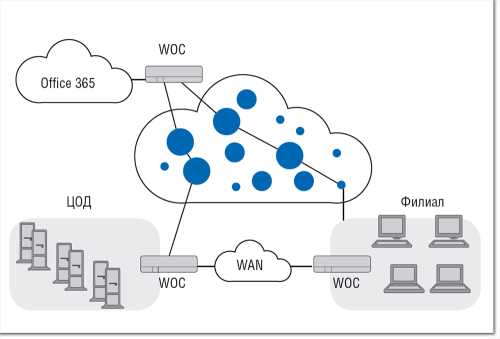
Оборудование WOC обычно подключается к маршрутизаторам глобальной сети со стороны локальной сети (см. Рисунок 1), функции оптимизации WAN со стороны может также выполнять ПО на клиентском устройстве. Кроме того, оптимизация WAN может предлагаться как облачный сервис. По мнению аналитиков Gartner («Магический квадрант» за март 2014 года), лидерами мирового рынка контроллеров оптимизации WAN являются Riverbеd Technology и Silver Peak Systems. Компании Ipanema Technologies, Aryaka и Vintela причислены к «провидцам», Cisco Systems — к «претендентам», а Blue Coat System, Citrix, Exinda, Circadence, Array Network, Sangler и FatPipe Networks — к нишевым игрокам. На мировом рынке оптимизации WAN, оборот которого составляет примерно 3 млрд долларов, доля компании Riverbed оценивается в 50%. На российском рынке, пожалуй, наиболее известны продукты Riverbed, Cisco, Juniper и BlueCoat.
| Рисунок 1. Контроллеры оптимизации обычно устанавливаются за маршрутизаторами на обоих концах канала WAN. |
ДЛЯ ЧЕГО ОНА НУЖНА?
В числе важных факторов, способствующих развитию рынка оптимизаторов WAN, — централизация данных в ЦОД, изменения в схемах резервного копирования (включая репликацию изменений между площадками и резервное копирование в облако), мультимедийные приложения и частные облака. С распространением публичных облачных сервисов технологии оптимизации WAN находят новые области применения.
Основное назначение оптимизаторов глобальной сети, интегрирующих разные технологии оптимизации трафика в одном программно-аппаратном комплексе, — обеспечение быстрого отклика корпоративных приложений в территориально распределенной сети. Их применение не только положительно сказывается на работе приложений, но и позволяет существенно сократить затраты на аренду каналов связи (см. статью автора «Оптимизация глобальной сети» в сентябрьском номере «Журнала сетевых решений/LAN» за 2011 год).
По оценкам экспертов, оптимизаторы WAN могут повысить производительность приложений в 50 раз, причем даже без учета повышения продуктивности труда при малом времени отклика приложений они окупаются всего за полгода благодаря экономии на коммуникациях. Требования к пропускной способности сети уменьшаются на 65–95%, затраты на передачу данных — примерно на 10%, а время отклика приложений (в зависимости от типа данных) — на 60–90%.
Предлагаемые поставщиками решения применяются для ускорения доступа филиалов к удаленным данным, электронной почте, файловым хранилищам и корпоративным приложениям, которые расположены в ЦОД, принадлежащих компаниям или арендуемых ими. Консолидация, виртуализация, облачные вычисления и Web-сервисы создают дополнительную нагрузку на инфраструктуру глобальной сети. Ввиду стремительного распространения облачных технологий и мобильных устройств решения для оптимизации WAN становятся особенно необходимыми.
Успешное внедрение оптимизаторов WAN позволяет уменьшить число локальных приложений и сервисов, активнее использовать облака. Их считают одним из самых мощных инструментов, меняющих «экономику облаков» и интернет-приложений. Кроме того, устройства WOC обеспечивают ускорение процессов резервного копирования/восстановления, репликации и синхронизации баз данных. В некоторых организациях процедура резервного копирования, занимавшая более суток, теперь выполняется за 2–3 ч. Благодаря ускоренной (до 45 раз) репликации можно чаще делать снимки данных и значительно сократить время восстановления.
КАК ЭТО РАБОТАЕТ?
В современных оптимизаторах WAN уже проверенные и давно известные методы сочетаются с новыми технологиями обеспечения QoS и выбора маршрутов, что способствует повышению производительности сетей. За счет дедупликации данных (из передачи исключаются повторяющиеся блоки данных) и устранения избыточных запросов к данным снижаются требования к пропускной способности сети. Оптимизация сетевых протоколов дает возможность сократить задержку, а еще больше уменьшить ее помогает оптимизация на уровне приложений и протоколов верхнего уровня.
В контроллерах оптимизации глобальных сетей традиционно применяется целый ряд технологий: сжатие данных, кэширование, оптимизация протоколов и логики работы приложений. Наиболее распространенные методы — оптимизация соединений TCP с целью ускорения работы приложений и устранения проблем из-за задержек в каналах WAN, уменьшение объема избыточных данных, в том числе за счет дедупликации, сжатия и кэширования данных, объединение пакетов (в большой пакет с одним заголовком), управление QoS с помощью анализа пакетов и их приоритизации по приложениям, протоколам, IP-адресу отправителя или получателя.
Обычно WOC используют алгоритмы потокового сжатия LZ, эффективность которого зависит от типа трафика. Данные страниц HTML сжимаются достаточно хорошо, в то время как с зашифрованными данными это сделать невозможно. Дедупликация позволяет сократить объем передаваемой по сети информации на 65–95%.
С методами аппаратного сжатия комбинируется кэширование данных при доступе к файловым и другим ресурсам. Кэширование означает, что, когда сотрудник филиала загружает файл с центрального сервера, WOC сохраняет локальную копию файла и применяет к ней изменения, синхронизируя их с файлом на сервере. Устройства могут кэшировать уже переданные данные и в дальнейшем передавать только ссылки на них.
На уровне приложений оборудование WOC может оптимизировать протоколы CIFS, NFS, MAPI, HTTP, SSL, SRDF/A, FCIP, SMB v2 и v3, сокращая объем служебных сообщений. Эффективно оптимизируется трафик Lotus Notes, SharePoint, Citrix, SQL, Oracle, СУБД Microsoft и Outlook. Оптимизации подвергается также протокол TCP: для передачи подбирается наилучший размер пакетов, а объем повторно пересылаемых данных уменьшается до 98%.
Методы выбора маршрутов (путей) позволяют задать конкретные маршруты для трафика того или иного типа. При этом учитываются такие параметры, как производительность, безопасность, стоимость или доступность. В отличие от обычных маршрутизаторов, в этих способах оптимизации WAN используется информация о приложениях, которой традиционное сетевое оборудование обычно не располагает. Технология выбора путей предполагает идентификацию трафика приложений с помощью углубленной проверки пакетов (DPI). Эту функцию используют для направления трафика приложений по наилучшим маршрутам и его перенаправления при возникновении проблем с производительностью.
Сочетание разных методов обеспечивает снижение объема передаваемых данных для отдельных видов трафика в 100 и более раз (обычно при пересылке одинаковых или только отредактированных файлов, загрузке обновлений и т. п.), а на рабочих каналах происходит 5–6-кратное сокращение общего объема трафика. Внедрение оптимизаторов WAN позволяет повысить эффективность использования пропускной способности сети, что приводит к заметному улучшению бизнес-процессов.
Оборудование оптимизации следует располагать как можно ближе к источникам и потребителям трафика. WOC обычно устанавливается в начальной и конечной точках канала (с возможностью байпаса при отказе), либо оптимизируемый трафик перенаправляется на него с помощью политик маршрутизации (Policy Based Routing, PBR), а остальной пропускается без изменений. Обычно такое оборудование устанавливают внутри корпоративной сети до выхода трафика за межсетевые экраны / VPN. Если устройство расположить за средством VPN, то все данные, проходящие через оптимизатор, окажутся зашифрованными, поэтому его основные возможности (приоритизация, кэширование, оптимизация протоколов) использоваться не будут. Шифрованный трафик (как и видео) практически не поддается оптимизации традиционными методами.
Классические оптимизаторы поддерживают все больше разнообразных прикладных протоколов и имеют все более широкую функциональность: запуск на платформе WOC виртуальных машин, взаимодействие работающих в них приложений с оптимизатором, использование оптимизаторов для мониторинга, фильтрации трафика и т. п. Да и сами оптимизаторы WAN все чаще обретают виртуальный форм-фактор — такие оптимизаторы можно быстро создавать по запросу и запускать на виртуальных машинах. Этот форм-фактор дает два основных преимущества: гибкость и низкую стоимость оптимизации трафика. Нередко он используется в многоарендной облачной среде.
КАК ВЫБРАТЬ?
Выбор решения оптимизации зависит от типа сетевого трафика. Для разнородного трафика применимы разные средства оптимизации, поэтому общая оценка эффективности WOC для конкретного случая может оказаться некорректной. Чтобы принять обоснованное решение о внедрении таких систем, оборудование оптимизации необходимо протестировать. Например, даже WOC от ведущих вендоров плохо работают с некоторыми сетевыми протоколами. Разработчики WOC применяют разные методы оптимизации, и потребуется определить, какие из них лучше подходят для данного приложения. Кроме того, стоит проанализировать, что именно лучше использовать — виртуальные или физические контроллеры оптимизации.
Наибольший эффект это оборудование дает в сети, где данные передаются с высокой степенью повторяемости. Нередко оптимизаторы WAN устанавливаются на дорогостоящих спутниковых каналах, которые характеризуются большими задержками. В этом случае ускорение работы приложений обеспечивается не только средствами кэширования, но и более эффективным использованием пропускной способности канала.
В настоящее время производители предлагают комплексный подход к оптимизации глобальной сети: они стремятся учесть максимум требований и реализовать как можно больше возможностей для повышения эффективности работы сотрудников в филиалах, ускорения бизнес-процессов и улучшения совместной работы. Кроме того, средства оптимизации WAN включаются в маршрутизаторы, хотя, как правило, это «облегченные версии» WOC — без расширенной дедупликации и ускорения протоколов высокого уровня. Таким путем идут, в частности, Cisco и Juniper.
Расширяются и коммуникационные возможности процессоров. Например, новые процессоры Intel Xeon E5-2600 v3 совместно с набором микросхем Intel Communications Chipset серии 89xx и технологией Intel Quick Assist обеспечивают более высокую скорость сжатия данных, что позволяет разработчикам консолидировать различные коммуникационные нагрузки на базе стандартизированной архитектуры.
Растет интерес к средствам отчетности и контроля, предлагаемым контроллерами оптимизации. Они позволяют продемонстрировать эффективность оптимизатора WAN и планировать увеличение пропускной способности сети. Функции измерения производительности приложений и пользовательских сеансов операторы могут задействовать в качестве инструментов для контроля SLA. Для повышения надежности оптимизаторов WAN используются кластерные конфигурации, резервирование каналов или автоматическое переключение устройства в режим «байпас» (с прозрачным пропуском трафика) при обнаружении неисправности.
ЧТО ВЫБРАТЬ?
Многим специалистам уже знакомы такие контроллеры оптимизации WAN, как Riverbed SteelHead CXA-5050 и CXA-555, Blue Coat Mach5 SG300-25 и SG900-10, Cisco Wide Area Virtualization Engine WAVE-7541, Cisco 4451-AX ISR и 2900-AX ISR, Citrix CloudBridge 2000, Silver Peak Systems VX-1000 и VX-5000, Exinda Networks 6862 и 10862, Ipanema Technologies ip|engine 1000ax и ip|engine 20ax. Рассмотрим некоторые из них подробнее.
Riverbed SteelHead — один из наиболее популярных оптимизаторов WAN. Он обеспечивает ускорение работы с приложениями в облаке и нередко применяется в компаниях с филиальной структурой. Наряду с классическим оптимизатором WAN компания Riverbed разработала версии SteelHead Mobile для мобильных и удаленных пользователей (см. Рисунок 2) и SteelHead SaaS и SteelHead CX для облачных сред.
 |
| Рисунок 2. Riverbed SteelHead Mobile улучшает продуктивность работы мобильных и удаленных пользователей с помощью оптимизации WAN, сконфигурированной для ноутбуков на базе Windows и Mac. |
По данным Riverbed, благодаря SteelHead Mobile доступ удаленных сотрудников к файлам и приложениям выполняется более чем в 19 раз быстрее. Оптимизатор регулирует производительность сети для обеспечения нужд сотен и тысяч удаленных пользователей и управляет политиками, которые содержат правила оптимизации, применяемые к конкретным пользователям или группам. SteelHead SaaS ускоряет работу с приложениями SaaS на 33%, при этом требования к пропускной способности сети сокращаются на 97%. Например, SteelHead используется для оптимизации работы почти миллиона пользователей Microsoft Office 365 (см. Рисунок 3). Решение Riverbed широко применяется в облаках IaaS и в корпоративных виртуальных средах.
 |
| Рисунок 3. Благодаря эффективным алгоритмам оптимизации трафика, SteelHead SaaS оптимизирует работу с облачными сервисами и приложениями SaaS, в частности, значительно повышает производительность при работе пользователей с Office 365. |
Riverbed SteelHead отличается простотой установки за счет автоматического обнаружения оборудования и возможностью строить масштабируемые решения благодаря эффективному использованию кэш-памяти алгоритмами кэширования данных. Установка и настройка Riverbed SteelHead обычно занимает не более 15 мин, и дальнейшего вмешательства администраторов практически не требуется.
Оборудование SteelHead анализирует каждый сетевой пакет, а операционная система Riverbed Optimization System (RiOS) использует комбинацию методов для оптимизации трафика. Дедупликация позволяет устранить избыточные данные, а кэширование — не пересылать повторно данные, к которым часто обращаются пользователи: вместо них передаются 16-байтовые последовательности, по которым SteelHead может определить, что данные уже доставлялись и доступны локально. Например, если сотрудник филиала загружает документ с центрального сервера, редактирует его и отправляет обратно для рассылки коллегам, то SteelHead передает только изменения в документе, по которым затем может собрать новый документ для рассылки.
Устройства SteelHead компании Riverbed оптимизируют трафик на разных уровнях — от транспортного протокола до конкретных приложений, а также используют новые методы выбора путей. По данным вендора, для отдельных приложений производительность WAN увеличивается в 100 раз и более. Для выделения трафика приложений применяется технология углубленной проверки пакетов. Отсюда — широкий спектр приложений, для которых поддерживается оптимизация трафика. Кроме того, установка продуктов SteelHead помогает оптимизировать некоторые сервисы сред VMware vSphere или Microsoft Hyper-V, а также ускорить архивирование и репликацию по каналам WAN. Те же решения можно применять для оптимизации трафика мобильных пользователей.
| Рисунок 4. Система Silver Peak NX9000 для оптимизации трафика WAN. В серию «NX» входит семь моделей с пропускной способностью до 1 Гбит/с, способных обслуживать до 256 одновременных сеансов. |
Согласно результатам независимого тестирования, продукты Riverbed превосходят целый ряд конкурентных решений по производительности сжатия и дедупликации данных, считающихся ключевыми функциями оптимизации WAN. На высоком уровне в Riverbed SteelHead реализованы и средства управления трафиком. Системы Silver Peak серии VX (виртуальные оптимизаторы) и NX (см. Рисунки 4 и 5) тоже показывают высокие результаты по скорости выполнения сжатия и дедупликации данных, однако свои лучшие качества эти решения демонстрируют при обмене данными между ЦОД. Продукты данных двух вендоров лидируют в тестах на производительность.
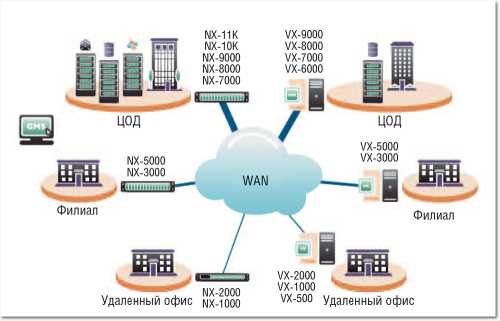 |
| Рисунок 5. Применение продуктов Silver Peak серии VX и NX для оптимизации трафика WAN. |
Среди новых инновационных решений можно выделить Ipanema Technologies ip|engine и Exinda Networks x800 — «контроллеры оптимизации следующего поколения», отличающиеся комплексностью подхода, выходящего за рамки базовых функций. Однако у Exinda, отмечают тестировщики, система управления нуждается в усовершенствовании, а у Ipanema негибкие средства управления трафиком.
| Рисунок 6. Оборудование Cisco Wide Area Application Engine. |
Cisco предлагает линейку продуктов WAAS (см. Рисунок 6) и программное обеспечение оптимизации для маршрутизаторов ISR. Если в качестве граничных маршрутизаторов в корпоративной сети применяется оборудование ISR, то добавление оптимизаторов WAAS будет экономичным решением и даст целый ряд преимуществ. Если же сеть построена на оборудовании другого вендора, стоит рассмотреть иные варианты оптимизации трафика.
| Рисунок 7. Оптимизатор Blue Coat Mach5 построен на базе сервера x86 и может применяться для ускорения работы с приложениями разного типа — от передачи файлов, электронной почты и резервного копирования до видео и Web. |
Базовые функции Blue Coat Mach5 (см. Рисунок 7) и Citrix Systems CloudBridge 2000 соответствуют заявленным, однако эксперты указывают на недостаточную интеграцию средств управления трафиком и сжатия данных у Blue Coat и ограниченную функциональность CloudBridge 2000. Между тем в тестах на оптимизацию трафика HTTP система Blue Coat Mach5 показывает самые высокие результаты среди решений десятка вендоров: в сетях с высокими задержками транзакции выполняются на 260% быстрее. Для сравнения: оборудование серии Silver Peak VX дает улучшение на 234% при средних показателях 170%. Незначительно уступают лидерам Riverbed SteelHead, Ipanema ip|engine, Exinda x800 и Cisco WAAS.
Citrix CloudBridge до средних результатов не дотягивает. Зато, поскольку протокол HDX разработан компанией Citrix, ее платформа CloudBridge является наиболее эффективным средством оптимизации HDX, опережающим по своим показателям решение SteelHead (см. Рисунок 8). В Citrix XenDesktop уже используется сжатие трафика, поэтому Silver Peak VX повышает производительность сети с трафиком HDX лишь на 11%, а Cisco WAAS, Exinda x800-series и Riverbed SteelHead — на 2–3%. Между тем Blue Coat Mach5 и Ipanema ip|engine в некоторых случаях даже снижают ее на 2–4%. В такой ситуации лучше исключить трафик Citrix XenDesktop из оптимизации.
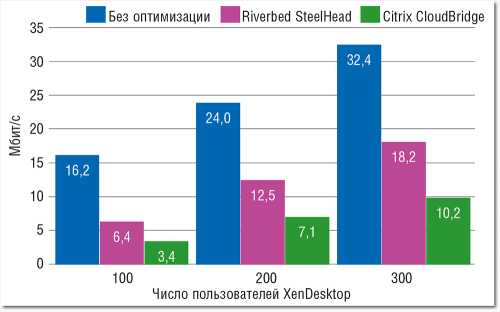 |
| Рисунок 8. В CloudBridge применяются патентованные технологии сжатия трафика XenDesktop и XenApp, а также другие методы оптимизации. Для поддержки эквивалентного числа пользователей XenDesktop устройству SteelHead требуется на 75–85% большая пропускная способность. |
На трафике HTTPS в сетях с большими задержками Blue Coat Mach5 себя проявить не удается. С этой задачей лучше всего справляется оборудование Riverbed: по сравнению с неоптимизированным трафиком скорость транзакций повышается в тестах на 185%. Несколько худшие результаты у Cisco WAAS и Silver Peak VX, а Citrix CloudBridge — среди аутсайдеров. Устройство Ipanema и вовсе не поддерживает оптимизацию HTTPS.
Таким образом, для оптимизации трафика HTTP и HTTPS эксперты рекомендуют Riverbed SteelHead, а в качестве альтернативы можно рассмотреть Silver Peak VX. Если же нужно оптимизировать трафик электронной почты, то стоит присмотреться к оборудованию компании SilverPeak — ее оптимизаторы серии VX дают лучшие результаты в сетях с большими и малыми задержками, но в таких случаях продукты разных вендоров (Blue Coat, Citrix, Exinda, Ipanema и Riverbed) различаются незначительно. Обычно производительность повышается на 140–166%.
Что касается трафика VoIP, он уже и так оптимизирован кодеком, однако некоторый выигрыш контроллеры WOC все же позволяют получить. Например, по данным тестирования, у Silver Peak VX он составляет 9%, у Riverbed SteelHead — 7% при средних показателях не более 3%. Вместе с тем установка оптимизаторов WAN может увеличить вариацию задержки, что ведет к снижению качества связи. Так, в случае применения Silver Peak VX и Riverbed SteelHead вариация в тестовых конфигурациях увеличивалась почти на 10%, тогда как Citrix CloudBridge снижал ее на 16%.
В целом при тестировании оптимизации протоколов лучшие результаты показывают Silver Peak VX и Riverbed SteelHead, опережая Cisco WAAS, Exinda x800 и Ipanema ip|engine. Blue Coat Mach5 и Citrix CloudBridge уступали лидерам в тестах на производительность. По средствам управления трафиком эксперты отдают предпочтение Ipanema ip|engine, выделяя также Exinda x800 и Riverbed SteelHead. Пользователи Cisco ISR могут применять функции управления трафиком, встроенные в IOS. В Blue Coat Mach5, Citrix CloudBridge 2000 и Silver Peak VX они более ограниченны. Например, Citrix CloudBridge 2000 имеет развитые функции приоритизации и применения политик к трафику приложений, но конкретному приложению нельзя выделить гарантированную пропускную способность.
Согласно заявлениям Citrix, ее унифицированная платформа CloudBridge оптимизирует работу с приложениями, развернутыми в филиалах компаний, ЦОД, публичных облаках, в том числе для мобильных пользователей. В последнем случае на мобильных устройствах устанавливается плагин CloudBridge. Для повышения производительности приложений (в частности, Citrix XenDesktop и XenApp, включая шифрованный трафик) Citrix CloudBridge использует оптимизацию протоколов и управление качеством обслуживания (QoS), а детальные отчеты по использованию пропускной способности сети приложениями помогают сетевым администраторам настроить оборудование для более эффективной работы. CloudBridge предлагается как виртуальное или физическое устройство. Его можно развертывать и в многоарендной среде.
По данным Citrix, CloudBridge позволяет поддерживать вчетверо больше виртуальных рабочих станций (до 5 тыс. на одну платформу) и ускоряет любые приложения TCP, включая передачу файлов, системы электронной почты, SSL, ERP, CRM, САПР, репликацию и резервное копирование данных, Microsoft Exchange и SharePoint. CloudBridge предлагается также для организаций с филиальной структурой в качестве опции к Windows Server — для ускорения DHCP, DNS, WINS, работы с файлами и печатью. За счет кэширования ускоряется доступ к видеоконтенту.
CloudBridge способен классифицировать сетевой трафик по приложениям и службам, управлять пропускной способностью, контролировать задержки в сети и перегрузку каналов. Управление и конфигурирование устройствами CloudBridge осуществляется централизованно через Citrix Command Center. Если производительность опускается ниже установленного допустимого уровня, CloudBridge сообщает об этом администратору.
Маршрутизаторы Cisco ISR 4451-X с ОС IOS-XE поддерживают и виртуальные машины. Такой ВМ может быть оптимизатор трафика Cisco Wide Area Application Services (WAAS). Кроме того, Cisco ISR предусматривает лицензию Application Experience (AX), включающую функции WAAS, управления трафиком приложений и сетевой безопасности. В сочетании с утилитой автоматической настройки конфигурации эта лицензия позволяет без особых сложностей дополнить маршрутизатор 4451-X ISR средствами оптимизации сетевого трафика. Наряду с интегрированными в IOS функциями WAAS компания Cisco предлагает автономные оптимизаторы WAVE. В них применяется то же самое ПО, но отсутствуют средства управления трафиком, которые имеются в IOS и IOS-XE.
По возможностям анализа и выявления проблем в сети эксперты отдают пальму первенства Riverbed SteelHead и Exinda x800. Продукты Cisco, Ipanema и Riverbed имеют наиболее развитые инструменты управления, а Riverbed лидирует еще и по простоте использования.
Устройства оптимизации WAN значительно улучшают качество работы пользователей и снижают требования к каналам глобальной сети. Поэтому в условиях ограниченных бюджетов ИТ важно выбирать правильное решение, подходящее для конкретных конфигураций, задач и типов трафика (см. Рисунок 9).
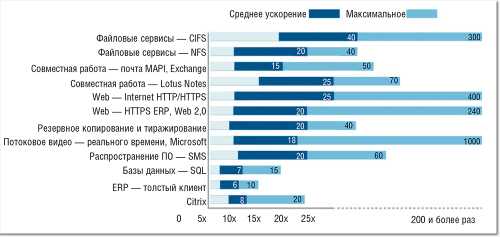 |
| Рисунок 9. Среднее ускорение доставки приложений при использовании Blue Coat Mach5 для оптимизации WAN. |
ЗАКЛЮЧЕНИЕ
Для организации взаимодействия между удаленными офисами и корпоративными ЦОД производители оптимизаторов WAN уже много лет предлагают решения, обеспечивающие ускорение корпоративных приложений, а также удаленный доступ к файлам, электронной почте и системам хранения (см. Рисунок 10). Практический опыт внедрения этих оптимизаторов показывает их высокую эффективность. Применение данного оборудования целесообразно в распределенных корпоративных сетях для передачи данных по каналам WAN, проложенным между удаленными филиалами, офисами и ЦОД (см. Рисунок 11). В таких случаях объем передаваемого трафика снижается в 3–5 раз, а пиковая скорость передачи данных возрастает в 100 и более раз.
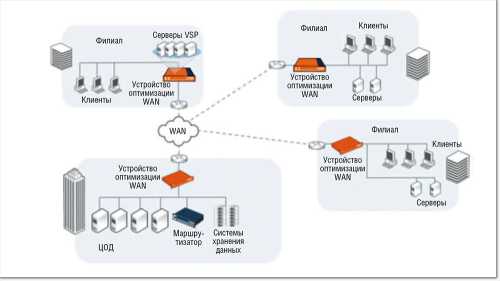 |
| Рисунок 10. Применение контроллеров оптимизации WAN в компании с распределенной структурой. |
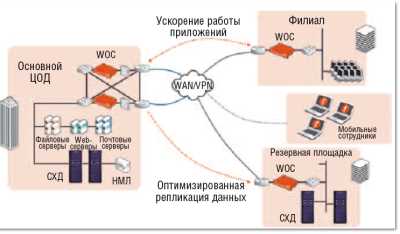 |
| Рисунок 11. Оборудование WOC ускоряет работу с приложениями и оптимизирует репликацию данных на резервную площадку. |
Новые разработки нацелены на оптимизацию облачных сервисов и создание более удобных условий работы для удаленных и мобильных сотрудников. Они отвечают возросшим требованиям к масштабируемости и надежности и могут применяться в качестве виртуальных устройств в виртуализированных ЦОД. С перемещением приложений в облака спрос на оптимизацию WAN будет расти, ведь производительность сети становится ключевым фактором для достижения большей продуктивности. А виртуальные версии оптимизаторов WAN становятся экономичным решением, не уступающим по производительности и надежности физическому оборудованию.
Сергей Орлов — ведущий редактор «Журнала сетевых решений/LAN». С ним можно связаться по адресу: [email protected].
www.osp.ru
Основные задачи оптимизации локальных сетей — Мегаобучалка
Если вы хотите, чтобы ваша сеть работала самым эффективным образом, то вам придется решить для себя следующие задачи:
1. Сформулировать критерии эффективности работы сети. Чаще всего такими критериями служат производительность и надежность, для которых, в свою очередь, требуется выбрать конкретные показатели оценки, например, время реакции и коэффициент готовности, соответственно.
2. Определить множество варьируемых параметров сети, прямо или косвенно влияющих на критерии эффективности. Эти параметры действительно должны быть варьируемыми, то есть нужно убедиться в том, что их можно изменять в некоторых пределах по вашему желанию. Так, если размер пакета какого-либо протокола в конкретной операционной системе устанавливается автоматически и не может быть изменен путем настройки, то этот параметр в данном случае не является варьируемым, хотя в другой операционной системе он может относиться к изменяемым по желанию администратора, а значит и варьируемым. Другим примером может служить пропускная способность внутренней шины маршрутизатора – она может рассматриваться как параметр оптимизации только в том случае, если вы допускаете возможность замены маршрутизаторов в сети.
Все варьируемые параметры могут быть сгруппированы различным образом. Например, параметры отдельных конкретных протоколов (максимальный размер кадра протокола Ethernet или размер окна неподтвержденных пакетов протокола TCP) или параметры устройств (размер адресной таблицы или скорость фильтрации моста, пропускная способность внутренней шины маршрутизатора). Параметрами настройки могут быть и устройства, и протоколы в целом. Так, например, улучшить работу сети с медленными и зашумленными глобальными каналами связи можно, перейдя со стека протоколов IPX/SPX на протоколы TCP/IP. Также можно добиться значительных улучшений с помощью замены сетевых адаптеров неизвестного производителя на адаптеры BrandName.
3. Определить порог чувствительности для значений критерия эффективности. Так, производительность сети можно оценивать логическими значениями «Работает» / «Не работает», и тогда оптимизация сводится к диагностике неисправностей и приведению сети в любое работоспособное состояние. Другим крайним случаем является тонкая настройка сети, при которой параметры работающей сети (например, размер кадра или величина окна неподтвержденных пакетов) могут варьироваться с целью повышения производительности (например, среднего значения времени реакции) хотя бы на несколько процентов. Как правило, под оптимизацией сети понимают некоторый промежуточный вариант, при котором требуется выбрать такие значения параметров сети, чтобы показатели ее эффективности существенно улучшились, например, пользователи получали ответы на свои запросы к серверу баз данных не за 10 секунд, а за 3 секунды, а передача файла на удаленный компьютер выполнялась не за 2 минуты, а за 30 секунд.
Таким образом, можно предложить три различных трактовки задачи оптимизации:
1. Приведение сети в любое работоспособное состояние. Обычно эта задача решается первой, и включает:
- поиск неисправных элементов сети – кабелей, разъемов, адаптеров, компьютеров;
- проверку совместимости оборудования и программного обеспечения;
- выбор корректных значений ключевых параметров программ и устройств, обеспечивающих прохождение сообщений между всеми узлами сети – адресов сетей и узлов, используемых протоколов, типов кадров Ethernet и т.п.
2. Грубая настройка – выбор параметров, резко влияющих на характеристики (надежность, производительность) сети. Если сеть работоспособна, но обмен данными происходит очень медленно (время ожидания составляет десятки секунд или минуты) или же сеанс связи часто разрывается без видимых причин, то работоспособной такую сеть можно назвать только условно, и она безусловно нуждается в грубой настройке. На этом этапе необходимо найти ключевые причины существенных задержек прохождения пакетов в сети. Обычно причина серьезного замедления или неустойчивой работы сети кроется в одном неверно работающем элементе или некорректно установленном параметре, но из-за большого количества возможных виновников поиск может потребовать длительного наблюдения за работой сети и громоздкого перебора вариантов. Грубая настройка во многом похожа на приведение сети в работоспособное состояние. Здесь также обычно задается некоторое пороговое значение показателя эффективности и требуется найти такой вариант сети, у которого это значение было бы не хуже порогового. Например, нужно настроить сеть так, чтобы время реакции сервера на запрос пользователя не превышало 5 секунд.
3. Тонкая настройка параметров сети (собственно оптимизация). Если сеть работает удовлетворительно, то дальнейшее повышение ее производительности или надежности вряд ли можно достичь изменением только какого-либо одного параметра, как это было в случае полностью неработоспособной сети или же в случае ее грубой настройки. В случае нормально работающей сети дальнейшее повышение ее качества обычно требует нахождения некоторого удачного сочетания значений большого количества параметров, поэтому этот процесс и получил название «тонкой настройки».
Даже при тонкой настройке сети оптимальное сочетание ее параметров (в строгом математическом понимании термина «оптимальность») получить невозможно, да и не нужно. Нет смысла затрачивать колоссальные усилия по нахождению строгого оптимума, отличающегося от близких к нему режимов работы на величины такого же порядка, что и точность измерений трафика в сети. Достаточно найти любое из близких к оптимальному решений, чтобы считать задачу оптимизации сети решенной. Такие близкие к оптимальному решения обычно называют рациональными вариантами, и именно их поиск интересует на практике администратора сети или сетевого интегратора.
Поиск неисправностей в сети – это сочетание анализа (измерения, диагностика и локализация ошибок) и синтеза (принятие решения о том, какие изменения надо внести в работу сети, чтобы исправить ее работу).
Анализ– определение значения критерия эффективности (или, что одно и то же, критерия оптимизации) системы для данного сочетания параметров сети. Иногда из этого этапа выделяют подэтап мониторинга, на котором выполняется более простая процедура – процедура сбора первичных данных о работе сети: статистики о количестве циркулирующих в сети кадров и пакетов различных протоколов, состоянии портов концентраторов, коммутаторов и маршрутизаторов и т.п. Далее выполняется этап собственно анализа, под которым в этом случае понимается более сложный и интеллектуальный процесс осмысления собранной на этапе мониторинга информации, сопоставления ее с данными, полученными ранее, и выработки предположений о возможных причинах замедленной или ненадежной работы сети. Задача мониторинга решается программными и аппаратными измерителями, тесторами, сетевыми анализаторами и встроенными средствами мониторинга систем управления сетями и системами. Задача анализа требует более активного участия человека, а также использования таких сложных средств как экспертные системы, аккумулирующие практический опыт многих сетевых специалистов.
Синтез – выбор значений варьируемых параметров, при которых показатель эффективности имеет наилучшее значение. Если задано пороговое значение показателя эффективности, то результатом синтеза должен быть один из вариантов сети, превосходящий заданный порог. Приведение сети в работоспособное состояние – это также синтез, при котором находится любой вариант сети, для которого значение показателя эффективности отличается от состояния «не работает». Синтез рационального варианта сети – процедура чаще всего неформальная, так как она связана с выбором слишком большого и очень разнородного множества параметров сети – типов применяемого коммуникационного оборудования, моделей этого оборудования, числа серверов, типов компьютеров, используемых в качестве серверов, типов операционных систем, параметров этих операционных систем, стеков коммуникационных протоколов, их параметров и т.д. и т.п. Очень часто мотивы, влияющие на выбор «в целом», то есть выбор типа или модели оборудования, стека протоколов или операционной системы, не носят технического характера, а принимаются из других соображений –коммерческих, «политических» и т.п. Поэтому формализовать постановку задачи оптимизации в таких случаях просто невозможно.
Заключение
В результате выполнения курсового проекта была спроектирована структурированная кабельная сеть офисного здания. Были учтены все требования, предъявляемые к проекту. Топология сети, выбор кабельных систем, сетевых протоколов, аппаратного и программного обеспечения рабочих станций, а также сетевое оборудование были выбраны исходя из их целесообразности. В сети предусмотрено согласование разных сред передачи и обеспечение среднего уровня защиты как техническими, так и программными средствами.
Выбранная конфигурация локальной сети допускает возможность дальнейшего ее расширения, добавления новых рабочих станций.
В качестве рабочих станций были выбраны современные компьютеры с характеристиками, которые должны обеспечить стабильную, быструю и надёжную работу сотрудников. Количество мест подобрано с учётом требований санитарных норм и пожарной безопасности.
Список литературы
1. В.П.Косарев и др. Компьютерные системы и сети: Учебное пособие. - М.: Финансы и статистика, 1999 - 356с.
2. В.Г. Олифер, Н.А. Олифер. Компьютерные сети. Принципы, технологии, протоколы.– СПб: Издательство “Питер”, 2000. – 672 с.;
3. Куин Л., Рассел Р. Fast Ethernet. –К.: Издательская группа BNV, 1998. – 448 с.
4. Михаил Гук. Аппаратные средства локальных сетей. Энциклопедия. - СПб: Издательство “Питер”, 2000 – 576с.;
5. Новиков Ю.В., Карпенко Д.Г. Аппаратура локальных сетей: функции, выбор, разработка. – М., Издательство ЭКОМ, 1998. – 288с.
Приложение А – план здания
megaobuchalka.ru
Средства анализа и оптимизации локальных сетей
Основные задачи оптимизации локальных сетей
Если вы хотите, чтобы ваша сеть работала самым эффективным образом, то вам придется решить для себя следующие задачи:
1. Cформулировать критерии эффективности работы сети. Чаще всего такими критериями служат производительность и надежность, для которых в свою очередь требуется выбрать конкретные показатели оценки, например, время реакции и коэффициент готовности, соответственно.
2. Определить множество варьируемых параметров сети, прямо или косвенно влияющих на критерии эффективности. Эти параметры действительно должны быть варьируемыми, то есть нужно убедиться в том, что их можно изменять в некоторых пределах по вашему желанию. Так, если размер пакета какого-либо протокола в конкретной операционной системе устанавливается автоматически и не может быть изменен путем настройки, то этот параметр в данном случае не является варьируемым, хотя в другой операционной системе он может относится к изменяемым по желанию администратора, а значит и варьируемым. Другим примером может служить пропускная способность внутренней шины маршрутизатора - она может рассматриваться как параметр оптимизации только в том случае, если вы допускаете возможность замены маршрутизаторов в сети.
Все варьируемые параметры могут быть сгруппированы различным образом. Например, параметры отдельных конкретных протоколов (максимальный размер кадра протокола Ethernet или размер окна неподтвержденных пакетов протокола TCP) или параметры устройств (размер адресной таблицы или скорость фильтрации моста, пропускная способность внутренней шины маршрутизатора). Параметрами настройки могут быть и устройства, и протоколы в целом. Так, например, улучшить работу сети с медленными и зашумленными глобальными каналами связи можно, перейдя со стека протоколов IPX/SPX на протоколы TCP/IP. Также можно добиться значительных улучшений с помощью замены сетевых адаптеров неизвестного производителя на адаптеры BrandName.
3. Определить порог чувствительности для значений критерия эффективности. Так, производительность сети можно оценивать логическими значениями "Работает"/ "Не работает", и тогда оптимизация сводится к диагностике неисправностей и приведению сети в любое работоспособное состояние. Другим крайним случаем является тонкая настройка сети, при которой параметры работающей сети (например, размер кадра или величина окна неподтвержденных пакетов) могут варьироваться с целью повышения производительности (например, среднего значения времени реакции) хотя бы на несколько процентов. Как правило, под оптимизацией сети понимают некоторый промежуточный вариант, при котором требуется выбрать такие значения параметров сети, чтобы показатели ее эффективности существенно улучшились, например, пользователи получали ответы на свои запросы к серверу баз данных не за 10 секунд, а за 3 секунды, а передача файла на удаленный компьютер выполнялась не за 2 минуты, а за 30 секунд.
Таким образом, можно предложить три различных трактовки задачи оптимизации:
1. Приведение сети в любое работоспособное состояние. Обычно эта задача решается первой, и включает:
поиск неисправных элементов сети - кабелей, разъемов, адаптеров, компьютеров;
проверку совместимости оборудования и программного обеспечения;
выбор корректных значений ключевых параметров программ и устройств, обеспечивающих прохождение сообщений между всеми узлами сети - адресов сетей и узлов, используемых протоколов, типов кадров Ethernet и т.п.
2. Грубая настройка - выбор параметров, резко влияющих на характеристики (надежность, производительность) сети. Если сеть работоспособна, но обмен данными происходит очень медленно (время ожидания составляет десятки секунд или минуты) или же сеанс связи часто разрывается без видимых причин, то работоспособной такую сеть можно назвать только условно, и она безусловно нуждается в грубой настройке. На этом этапе необходимо найти ключевые причины существенных задержек прохождения пакетов в сети. Обычно причина серьезного замедления или неустойчивой работы сети кроется в одном неверно работающем элементе или некорректно установленом параметре, но из-за большого количества возможных виновников поиск может потребовать длительного наблюдения за работой сети и громоздкого перебора вариантов. Грубая настройка во многом похожа на приведение сети в работоспособное состояние. Здесь также обычно задается некоторое пороговое значение показателя эффективности и требуется найти такой вариант сети, у которого это значение было бы не хуже порогового. Например, нужно настроить сеть так, чтобы время реакции сервера на запрос пользователя не превышало 5 секунд.
3. Тонкая настройка параметров сети (собственно оптимизация). Если сеть работает удовлетворительно, то дальнейшее повышение ее производительности или надежности вряд ли можно достичь изменением только какого-либо одного параметра, как это было в случае полностью неработоспособной сети или же в случае ее грубой настройки. В случае нормально работающей сети дальнейшее повышение ее качества обычно требует нахождения некоторого удачного сочетания значений большого количества параметров, поэтому этот процесс и получил название "тонкой настройки".
Даже при тонкой настройке сети оптимальное сочетание ее параметров (в строгом математическом понимании термина "оптимальность") получить невозможно, да и не нужно. Нет смысла затрачивать колоссальные усилия по нахождению строгого оптимума, отличающегося от близких к нему режимов работы на величины такого же порядка, что и точность измерений трафика в сети. Достаточно найти любое из близких к оптимальному решений, чтобы считать задачу оптимизации сети решенной. Такие близкие к оптимальному решения обычно называют рациональными вариантами, и именно их поиск интересует на практике администратора сети или сетевого интегратора.
Поиск неисправностей в сети - это сочетание анализа (измерения, диагностика и локализация ошибок) и синтеза (принятие решения о том, какие изменения надо внести в работу сети, чтобы исправить ее работу).
Анализ - определение значения критерия эффективности (или, что одно и то же, критерия оптимизации) системы для данного сочетания параметров сети. Иногда из этого этапа выделяют подэтап мониторинга, на котором выполняется более простая процедура - процедура сбора первичных данных о работе сети: статистики о количестве циркулирующих в сети кадров и пакетов различных протоколов, состоянии портов концентраторов, коммутаторов и маршрутизаторов и т.п. Далее выполняется этап собственно анализа, под которым в этом случае понимается более сложный и интеллектуальный процесс осмысления собранной на этапе мониторинга информации, сопоставления ее с данными, полученными ранее, и выработки предположений о возможных причинах замедленнной или ненадежной работы сети. Задача мониторинга решается программными и аппаратными измерителями, тесторами, сетевыми анализаторами и встроенными средствами мониторинга систем управления сетями и системами. Задача анализа требует более активного участия человека, а также использования таких сложных средств как экспертные системы, аккумулирующие практический опыт многих сетевых специалистов.
Синтез - выбор значений варьируемых параметров, при которых показатель эффективности имеет наилучшее значение. Если задано пороговое значение показателя эффективности, то результатом синтеза должен быть один из вариантов сети, превосходящий заданный порог. Приведение сети в работоспособное состояние - это также синтез, при котором находится любой вариант сети, для которого значение показателя эффективности отличается от состояния "не работает". Синтез рационального варианта сети - процедура чаще всего неформальная, так как она связана с выбором слишком большого и очень разнородного множества параметров сети - типов применяемого коммуникационного оборудования, моделей этого оборудования, числа серверов, типов компьютеров, используемых в качестве серверов, типов операционных систем, параметров этих опрационных систем, стеков коммуникационных протоколов, их параметров и т.д. и т.п. Очень часто мотивы, влияющие на выбор "в целом", то есть выбор типа или модели обрудования, стека протоколов или операционной системы, не носят технического характера, а принимаются из других соображений - коммерческих, "политических" и т.п. Поэтому формализовать постановку задачи оптимизации в таких случаях просто невозможно. В данной книге основное внимание уделяется этапам мониторинга и анализа сети, как более формальным и автоматизируемым процедурам. В тех случаях, когда это возможно, в книге даются рекомендации по выполнению некоторых последовательностей действий по нахождению рационального варианта сети или приводятся соображения, облегчающие его поиск.
Критерии эффективности работы сети
Все множество наиболее часто используемых критериев эффективности работы сети может быть разделено на две группы. Одна группа характеризует производительность работы сети, вторая - надежность.
Производительность сети измеряется с помощью показателей двух типов - временных, оценивающих задержку, вносимую сетью при выполнении обмена данными, и показателей пропускной способности, отражающих количество информации, переданной сетью в единицу времени. Эти два типа показателей являются взаимно обратными, и, зная один из них, можно вычислить другой.
Время реакции
Обычно в качестве временной характеристики производительности сети используется такой показатель как время реакции. Термин "время реакции" может использоваться в очень широком смыле, поэтому в каждом конкретном случае необходимо уточнить, что понимается под этим термином.
В общем случае, время реакции определяется как интервал времени между возникновением запроса пользователя к каму-либо сетевому сервису и получением ответа на этот запрос (рис. 1.1). Очевидно, что смысл и значение этого показателя зависят от типа сервиса, к которому обращается пользователь, от того, какой пользователь и к какому серверу обращается, а также от текущего состояния других элементов сети - загруженности сегментов, через которые проходит запрос, загруженности сервера и т.п.
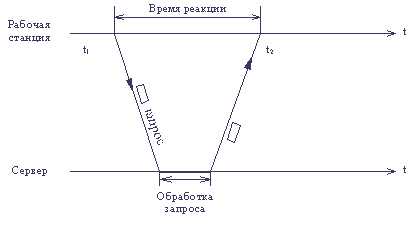
Рис. 1.1. Время реакции - интервал между запросом и ответом
Рассмотрим несколько примеров определения показателя "время реакции", иллюстрируемых рисунком 1.2.
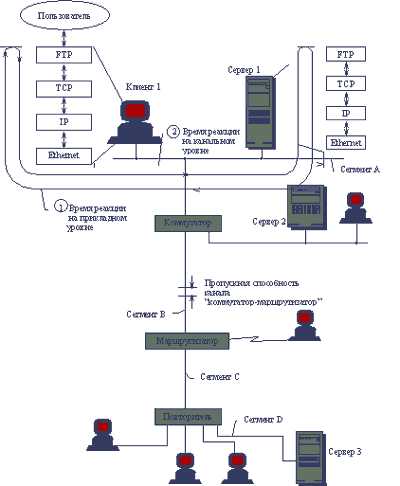
Рис. 1.2. Показатели производительности сети
В примере 1 под временем реакции понимается время, которое проходит с момента обращения пользователя к сервису FTP для передачи файла с сервера 1 на клиентский компьютер 1 до момента завершения этой передачи. Очевидно, что это время имеет несколько составляющих. Наиболее существенный вклад вносят такие составляющие времени реакции как: время обработки запросов на передачу файла на сервере, время обработки получаемых в пакетах IP частей файла на клиентском компьютере, время передачи пакетов между сервером и клиентским компьютером по протоколу Ethernet в пределах одного коаксиального сегмента. Можно было бы выделить еще более мелкие этапы выполнения запроса, например, время обработки запроса каждым из протоколов стека TCP/IP на сервере и клиенте.
Для конечного пользователя таким образом определенное время реакции является понятным и наиболее естественным показателем производительности сети (размер файла, который вносит некоторую неопределенность в этот показатель, можно зафиксировать, оценивая время реакции при передаче, например, одного мегабайта данных). Однако, сетевого специалиста интересует в первую очередь производительность собственно сети, поэтому для более точной ее оценки целесообразно вычленить из времени реакции составляющие, соответствующие этапам несетевой обработки данных - поиску нужной информации на диске, записи ее на диск и т.п. Полученное в результате таких сокращений время можно считать другим определением времени реакции сети на прикладном уровне.
Вариантами этого критерия могут служить времена реакции, измеренные при различных, но фиксированных состояниях сети:
A) Полностью ненагруженная сеть. Время рекции измеряется в условиях, когда к серверу 1 обращается только клиент 1, то есть на сегменте сети, объединяющем сервер 1 с клиентом 1, нет никакой другой активности - на нем присутствуют только кадры сессии FTP, производительность которой измеряется. В других сегментах сети трафик может циркулировать, главное - чтобы его кадры не попадали в сегмент, в котором проводятся измерения. Так как ненагруженный сегмент в реальной сети - явление экзотическое, то данный вариант показателя производительности имеет ограниченную применимость - его хорошие значения говорят только о том, что программное обеспечение и аппаратура данных двух узлов и сегмента обладают необходимой производительностью для работы в облегченных условиях. Для работы в реальных условиях, когда будет иметь место борьба за разделяемые ресурсы сегмента с другими узлами сети, производительность тестируемых элементов сети может оказаться недостаточной.
B) Нагруженная сеть. Это более интересный случай проверки производительности сервиса FTP для конкрентных сервера и клиента. Однако при измерении критерия производительности в условиях, когда в сети работают и другие узлы и сервисы, возникают свои сложности - в сети может существовать слишком большое количество вариантов нагрузки, поэтому главное при определении критериев такого сорта - проведение измерений при некоторых типовых условиях работы сети. Так как трафик в сети носит пульсирующий характер и харакетристики трафика существенно изменяются в засисимости от времени дня и дня недели, то определение типовой нагрузки - процедура сложная, требующая длительных измерений на сети. Если же сеть только проектируется, то определение типовой нагрузки еще больше усложняется.
В примере 2 критерием производительности сети является время задержки между передачей кадра Ethernet в сеть сетевым адаптером клиентского компьютера 1 и поступлением его на сетевой адаптер сервера 3. Этот критерий также относится к критериям типа "время реакции", но соответствует сервису нижнего - канального уровня. Так как протокол Ethernet - протокол дейтаграммного типа, то есть без установления соединений, для которого понятие "ответ" не определено, то под временем реакции в данном случае понимается время прохождения кадра от узла-источника до узла-получателя. Задержка передачи кадра включает в данном случае время распространения кадра по исходному сегменту, время передачи кадра коммутатором из сегмента А в сегмент В, время передачи кадра маршрутизатром из сегмента В в сегмент С и время передачи кадра из сегмента С в сегмент D повторителем. Критерии, относящиеся к нижнему уровню сети, хорошо хактеризуют качества транспортного сервиса сети и являются более информативными для сетевых интеграторов, так как не содержат избыточную для них информацию о работе протоколов верхних уровней.
При оценке производительности сети не по отношению к отдельным парам узлов, а ко всем узлам в целом используются критерии двух типов: средно-взвешенные и пороговые.
Средно-взвешенный критерий представляет собой сумму времен реакции всех или некоторых узлов при взаимодействии со всеми или некоторыми серверами сети по определенному сервису, то есть сумму вида
где Tij - время реакции i-го клиента при обращении к j-му серверу, n - число клиентов, m - число серверов. Если усреднение производится и по сервисам, то в приведеном выражении добавится еще одно суммирование - по количеству учитываемых сервисов. Оптимизация сети по данному критерию заключается в нахождении значений параметров, при которых критерий имеет минимальное значение или по крайней мере не превышает некоторое заданное число.
Пороговый критерий отражает наихудшее время реакции по всем возможным сочетаниям клиентов, серверов и сервисов:
где i и j имеют тот же смысл, что и в предыдущем случае, а k обозначает тип сервиса. Оптимизация также может выполняться с целью минимизации критерия, или же с целью достижения им некоторой заданной величины, признаваемой разумной с практической точки зрения.
Чаще применяются пороговые критерии оптимизации, так как они гарантируют всем пользователям некоторый удовлетворительный уровень реакции сети на их запросы. Средне-взвешенные критерии могут дискриминировать некоторых пользователей, для которых время реакции слишком велико при том, что при усреднении получен вполне приемлемый результат.
Можно применять и болеее дифференцированные по категориям пользователей и ситуациям критерии. Например, можно поставить перед собой цель гарантированть любому пользователю доступ к серверу, находящемуся в его сегменте, за время, не превышающее 5 секунд, к серверам, находящимся в его сети, но в сегментах, отделенных от его сегмента коммутаторами, за время, не превышающее 10 секунд, а к серверам других сетей - за время до 1 минуты.
Пропускная способность
Основная задача, для решения которой строится любая сеть - быстрая передача информации между компьютерами. Поэтому критерии, связанные с пропускной способностью сети или части сети, хорошо отражают качество выполнения сетью ее основной функции.
Существует большое количество вариантов определения критериев этого вида, точно также, как и в случае критериев класса "время реакции". Эти варианты могут отличаться друг от друга: выбранной единицей измерения количества передаваемой информации, характером учитываемых данных - только пользовательские или же пользовательские вместе со служебными, количеством точек измерения передаваемого трафика, способом усреднения результатов на сеть в целом. Рассмотрим различные способы построения критерия пропускной способности более подробно.
Критерии, отличающиеся единицей измерения передаваемой информации. В качестве единицы измерения передаваемой информации обычно используются пакеты (или кадры, далее эти термины будут использоваться как синонимы) или биты. Соответственно, пропускная способность измеряется в пакетах в секунду или же в битах в секунду.
Так как вычислительные сети работают по принципу коммутации пакетов (или кадров), то измерение количества переданной информации в пакетах имеет смысл, тем более что пропускная способность коммуникационного оборудования, работающего на канальном уровне и выше, также чаще всего измеряется в пакетах в секунду. Однако, из-за переменного размера пакета (это характерно для всех протоколов за исключением АТМ, имеющего фиксированный размер пакета в 53 байта), измерение пропускной способности в пакетах в секунду связано с некоторой неопределенностью - пакеты какого протокола и какого размера имеются в виду? Чаще всего подразумевают пакеты протокола Ethernet, как самого распространенного, имеющие минимальный для протокола размер в 64 байта (без преамбулы). Пакеты минимальной длины выбраны в качестве эталонных из-за того, что они создают для коммуникационного оборудования наиболее тяжелый режим работы - вычислительные операции, производимые с каждым пришедшим пакетом, в очень слабой степени зависят от его размера, поэтому на единицу переносимой информации обработка пакета минимальной длины требует выполнения гораздо больше операций, чем для пакета максимальной длины.
Измерение пропускной способности в битах в секунду (для локальных сетей более характерны скорости, измеряемые в миллионах бит в секунду - Мб/c) дает более точную оценку скорости передаваемой информации, чем при использовании пакетов.
Критерии, отличающиеся учетом служебной информации. В любом протоколе имеется заголовок, переносящий служебную информацию, и поле данных, в котором переносится информация, считающаяся для данного протокола пользовательской. Например, в кадре протокола Ethernet минимального размера 46 байт (из 64) представляют собой поле данных, а оставшиеся 18 являются служебной информацией. При измерении пропускной способности в пакетах в секунду отделить пользовательскую информацию от служебной невозможно, а при побитовом измерении - можно.
Если пропускная способность измеряется без деления информации на пользовательскую и служебную, то в этом случае нельзя ставить задачу выбора протокола или стека протоколов для данной сети. Это объясняется тем, что даже если при замене одного протокола на другой мы получим более высокую пропускную способность сети, то это не означает, что для конечных пользователей сеть будет работать быстрее - если доля служебной информации, приходящаяся на единицу пользовательских данных, у этих протоколов различная (а в общем случае это так), то можно в качестве оптимального выбрать более медленный вариант сети. Если же тип протокола не меняется при настройке сети, то можно использовать и критерии, не выделяющие пользовательские данные из общего потока.
При тестировании пропускной способности сети на прикладном уровне легче всего измерять как раз пропускную способность по пользовательским данным. Для этого достаточно измерить время передачи файла определенного размера между сервером и клиентом и разделить размер файла на полученное время. Для измерения общей пропускной способности необходимы специальные инструменты измерения - анализаторы протоколов или SNMP или RMON агенты, встроенные в операционные системы, сетевые адаптеры или коммуникационное оборудование.
Критерии, отличающиеся количеством и расположением точек измерения. Пропускную способность можно измерять между любыми двумя узлами или точками сети, например, между клиентским компьютером 1 и сервером 3 из примера, приведенного на рисунке 1.2. При этом получаемые значения пропускной способности будут изменяться при одних и тех же условиях работы сети в зависимости от того, между какими двумя точками производятся измерения. Так как в сети одновременно работает большое число пользовательских компьютеров и серверов, то полную характеристику пропускной способности сети дает набор пропускных способностей, измеренных для различных сочетаний взаимодействующих компьютеров - так называемая матрица трафика узлов сети. Существуют специальные средства измерения, которые фиксируют матрицу трафика для каждого узла сети.
Так как в сетях данные на пути до узла назначения обычно проходят через несколько транзитных промежуточных этапов обработки, то в качестве критерия эффективности может рассматриваться пропускная способность отдельного промежуточного элемента сети - отдельного канала, сегмента или коммуникационного устройства.
Знание общей пропускной способности между двумя узлами не может дать полной информации о возможных путях ее повышения, так как из общей цифры нельзя понять, какой из промежуточных этапов обработки пакетов в наибольшей степени тормозит работу сети. Поэтому данные о пропускной способности отдельных элементов сети могут быть полезны для принятия решения о способах ее оптимизации.
В рассматриваемом примере пакеты на пути от клиентского компьютера 1 до сервера 3 проходят через следующие промежуточные элементы сети:
Сегмент АR КоммутаторR Сегмент ВR МаршрутизаторR Сегмент СR ПовторительR Сегмент D.
Каждый из этих элементов обладает определенной пропускной способностью, поэтому общая пропускная способность сети между компьютером 1 и сервером 3 будет равна минимальной из пропускных способностей составляющих маршрута, а задержка передачи одного пакета (один из вариантов определения времени реакции) будет равна сумме задержек, вносимых каждым элементом. Для повышения пропускной способности составного пути необхдимо в первую очередь обратить внимание на самые медленные элементы - в данном случае таким элементом скорее всего будет маршрутизатор.
Имеет смысл определить общую пропускную способность сети как среднее количество информации, переданной между всеми узлами сети в единицу времени. Общая пропускная способность сети может измеряться как в пакетах в секунду, так и в битах в секунду. При делении сети на сегменты или подсети общая пропускная способность сети равна сумме пропускных способностей подсетей плюс пропускная способность межсегментных или межсетевых связей.
Показатели надежности и отказоустойчивости
Важнейшей характеристикой вычислительной сети является надежность - способность правильно функционировать в течение продолжительного периода времени. Это свойство имеет три составляющих: собственно надежность, готовность и удобство обслуживания.
Повышение надежности заключается в предотвращении неисправностей, отказов и сбоев за счет применения электронных схем и компонентов с высокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечения тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Надежность измеряется интенсивностью отказов и средним временем наработки на отказ. Надежность сетей как распределенных систем во многом определяется надежностью кабельных систем и коммутационной аппаратуры - разъемов, кроссовых панелей, коммутационных шкафов и т.п., обеспечивающих собственно электрическую или оптическую связность отдельных узлов между собой.
Повышение готовностипредполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления циркуляции информации в сети после обнаружения неисправности. Повышение готовности представляет собой борьбу за снижение времени простоя системы.
Критерием оценки готовности является коэффициент готовности, который равен доле времени пребывания системы в работоспособном состоянии и может интерпретироваться как вероятность нахождения системы в работоспособном состоянии. Коэффициент готовности вычисляется как отношение среднего времени наработки на отказ к сумме этой же величины и среднего времени восстановления. Системы с высокой готовностью называют также отказоустойчивыми.
Основным способом повышения готовности является избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Вычислительные сети включают большое количество элементов различных типов, и для обеспечения отказоустойчивости необходима избыточность по каждому из ключевых элементов сети. Если рассматривать сеть только как транспортную систему, то избыточность должна существовать для всех магистральных маршрутов сети, то есть маршрутов, являющихся общими для большого количества клиентов сети. Такими маршрутами обычно являются маршруты к корпоративным серверам - серверам баз данных, Web-серверам, почтовым серверам и т.п. Поэтому для организации отказоустойчивой работы все элементы сети, через которые проходят такие маршруты, должны быть зарезервированы: должны иметься резервные кабельные связи, которыми можно воспользоваться при отказе одного из основных кабелей, все коммуникационные устройства на магистральных путях должны либо сами быть реализованы по отказоустойчивой схеме с резевированием всех основных своих компонентов, либо для каждого коммуникационного устройства должно иметься резервное аналогичное устройство.
Переход с основной связи на резервную или с основного устройства на резервное может происходить как в автоматическом режиме, так и вручную, при участии администратора. Очевидно, что автоматический переход повышает коэффициент готовности системы, так как время простоя сети в этом случае будет существенно меньше, чем при вмешательстве человека. Для выполнения автоматических процедур реконфигурации необходимо иметь в сети интеллектуальные коммуникационные устройства, а также централизованную систему управления, помогающую устройствам распознавать отказы в сети и адекватно на них реагировать.
Высокую степень готовности сети можно обеспечить в том случае, когда процедуры тестирования работоспособности элементов сети и перехода на резервные элементы встроены в коммуникационные протоколы. Примером такого типа протоколов может служить протокол FDDI, в котором постоянно тестируются физические связи между узлами и концентраторами сети, а в случае их отказа выполняется автоматическая реконфигурация связей за счет вторичного резервного кольца. Существуют и специальные протоколы, поддерживающие отказоустойчивость сети, например, протокол SpanningTree, выполняющий автоматический переход на резервные связи в сети, построенной на основе мостов и коммутаторов.
Существуют различные градации отказоустойчивых компьютерных систем, к которым относятся и вычислительные сети. Приведем несколько общепринятых определений:
высокая готовность (highavailability) - характеризует системы, выполненные по обычной компьютерной технологии, использующие избыточные аппаратные и программные средства и допускающие время восстановления в интервале от 2 до 20 минут;
устойчивость к отказам (faulttolerance) - характеристика таких систем, которые имеют в горячем резерве избыточную аппаратуру для всех функциональных блоков, включая процессоры, источники питания, подсистемы ввода/вывода, подсистемы дисковой памяти, причем время восстановления при отказе не превышает одной секунды;
непрерывная готовность (continuousavailability) - это свойство систем, которые также обеспечивают время восстановления в пределах одной секунды, но в отличие от систем устойчивых к отказам, системы непрерывной готовности устраняют не только простои, возникшие в результате отказов, но и плановые простои, связанные с модернизацией или обслуживанием системы. Все эти работы проводятся в режиме online. Дополнительным требованием к системам непрерывной готовности является отсутствие деградации, то есть система должна поддерживать постоянный уровень функциональных возможностей и производительности независимо от возникновения отказов.
Так как сети обслуживают одновременно большое количество пользователей, то при расчете коэффициента готовности необходимо учитывать это обстоятельство. Коэффициент готовности сети должен соответствовать доле времени, в течение которого сеть выполняла с должным качеством свои функции для всех пользователей. Очевидно, что в больших сетях очень трудно обеспечить значения коэффициента готовности, близкие к единице.
Между показателями производительности и надежности сети существует тесная связь. Ненадежная работа сети очень часто приводит к существенному снижению ее производительности. Это объясняется тем, что сбои и отказы каналов связи и коммуникационного оборудования приводят к потере или искажению некоторой части пакетов, в результате чего коммуникационные протоколы вынуждены организовывать повторную передачу утерянных данных. Так как в локальных сетях восстановлением утерянных данных занимаются как правило протоколы транспортного или прикладного уровня, работающие с тайм-аутами в несколько десятков секунд, то потери производительности из-за низкой надежности сети могут составлять сотни процентов.
Параметры оптимизации транспортной подсистемы
На выбранный критерий оптимизации сети влияет большое количество параметров различных типов. В наибольшей степени на производительность сети влияют:
используемые коммуникационные протоколы и их параметры;
доля и характер широковещательного трафика, создаваемого различными протоколами;
топология сети и используемое коммуникационное оборудование;
интенсивность возникновения и харакетр ошибочных ситуаций;
конфигурация программного и аппаратного обеспечения конечных узлов.
Влияние на производительность сети типа коммуникационного протокола и его параметров
Задача выбора коммуникационных протоколов может решаться относительно независимо для канального уровня с одной стороны (Ethernet, TokenRing, FDDI, FastEthernet, ATM) и пары "сетевой - транспортный протокол" с другой стороны (IPX/SPX, TCP/IP, NetBIOS).
Каждый протокол имеет свои особенности, предпочтительные области применения и настраиваемые параметры, что и дает возможность за счет выбора и настройки протокола влиять на производительность и надежность сети. Настройка протокола может включать в себя изменение таких параметров как:
максимально допустимый размер кадра,
величины тайм-аутов (в том числе время жизни пакета),
для протоколов, работающих с установлением соединений - размер окна неподтвержденных пакетов, а также некоторых других.
studfiles.net
Средства анализа и оптимизации локальных сетей
Основные задачи оптимизации локальных сетей
Если вы хотите, чтобы ваша сеть работала самым эффективным образом, то вам придется решить для себя следующие задачи:
1. Cформулировать критерии эффективности работы сети. Чаще всего такими критериями служат производительность и надежность, для которых в свою очередь требуется выбрать конкретные показатели оценки, например, время реакции и коэффициент готовности, соответственно.
2. Определить множество варьируемых параметров сети, прямо или косвенно влияющих на критерии эффективности. Эти параметры действительно должны быть варьируемыми, то есть нужно убедиться в том, что их можно изменять в некоторых пределах по вашему желанию. Так, если размер пакета какого-либо протокола в конкретной операционной системе устанавливается автоматически и не может быть изменен путем настройки, то этот параметр в данном случае не является варьируемым, хотя в другой операционной системе он может относится к изменяемым по желанию администратора, а значит и варьируемым. Другим примером может служить пропускная способность внутренней шины маршрутизатора - она может рассматриваться как параметр оптимизации только в том случае, если вы допускаете возможность замены маршрутизаторов в сети.
Все варьируемые параметры могут быть сгруппированы различным образом. Например, параметры отдельных конкретных протоколов (максимальный размер кадра протокола Ethernet или размер окна неподтвержденных пакетов протокола TCP) или параметры устройств (размер адресной таблицы или скорость фильтрации моста, пропускная способность внутренней шины маршрутизатора). Параметрами настройки могут быть и устройства, и протоколы в целом. Так, например, улучшить работу сети с медленными и зашумленными глобальными каналами связи можно, перейдя со стека протоколов IPX/SPX на протоколы TCP/IP. Также можно добиться значительных улучшений с помощью замены сетевых адаптеров неизвестного производителя на адаптеры BrandName.
3. Определить порог чувствительности для значений критерия эффективности. Так, производительность сети можно оценивать логическими значениями "Работает"/ "Не работает", и тогда оптимизация сводится к диагностике неисправностей и приведению сети в любое работоспособное состояние. Другим крайним случаем является тонкая настройка сети, при которой параметры работающей сети (например, размер кадра или величина окна неподтвержденных пакетов) могут варьироваться с целью повышения производительности (например, среднего значения времени реакции) хотя бы на несколько процентов. Как правило, под оптимизацией сети понимают некоторый промежуточный вариант, при котором требуется выбрать такие значения параметров сети, чтобы показатели ее эффективности существенно улучшились, например, пользователи получали ответы на свои запросы к серверу баз данных не за 10 секунд, а за 3 секунды, а передача файла на удаленный компьютер выполнялась не за 2 минуты, а за 30 секунд.
Таким образом, можно предложить три различных трактовки задачи оптимизации:
1. Приведение сети в любое работоспособное состояние. Обычно эта задача решается первой, и включает:
поиск неисправных элементов сети - кабелей, разъемов, адаптеров, компьютеров;
проверку совместимости оборудования и программного обеспечения;
выбор корректных значений ключевых параметров программ и устройств, обеспечивающих прохождение сообщений между всеми узлами сети - адресов сетей и узлов, используемых протоколов, типов кадров Ethernet и т.п.
2. Грубая настройка - выбор параметров, резко влияющих на характеристики (надежность, производительность) сети. Если сеть работоспособна, но обмен данными происходит очень медленно (время ожидания составляет десятки секунд или минуты) или же сеанс связи часто разрывается без видимых причин, то работоспособной такую сеть можно назвать только условно, и она безусловно нуждается в грубой настройке. На этом этапе необходимо найти ключевые причины существенных задержек прохождения пакетов в сети. Обычно причина серьезного замедления или неустойчивой работы сети кроется в одном неверно работающем элементе или некорректно установленом параметре, но из-за большого количества возможных виновников поиск может потребовать длительного наблюдения за работой сети и громоздкого перебора вариантов. Грубая настройка во многом похожа на приведение сети в работоспособное состояние. Здесь также обычно задается некоторое пороговое значение показателя эффективности и требуется найти такой вариант сети, у которого это значение было бы не хуже порогового. Например, нужно настроить сеть так, чтобы время реакции сервера на запрос пользователя не превышало 5 секунд.
3. Тонкая настройка параметров сети (собственно оптимизация). Если сеть работает удовлетворительно, то дальнейшее повышение ее производительности или надежности вряд ли можно достичь изменением только какого-либо одного параметра, как это было в случае полностью неработоспособной сети или же в случае ее грубой настройки. В случае нормально работающей сети дальнейшее повышение ее качества обычно требует нахождения некоторого удачного сочетания значений большого количества параметров, поэтому этот процесс и получил название "тонкой настройки".
Даже при тонкой настройке сети оптимальное сочетание ее параметров (в строгом математическом понимании термина "оптимальность") получить невозможно, да и не нужно. Нет смысла затрачивать колоссальные усилия по нахождению строгого оптимума, отличающегося от близких к нему режимов работы на величины такого же порядка, что и точность измерений трафика в сети. Достаточно найти любое из близких к оптимальному решений, чтобы считать задачу оптимизации сети решенной. Такие близкие к оптимальному решения обычно называют рациональными вариантами, и именно их поиск интересует на практике администратора сети или сетевого интегратора.
Поиск неисправностей в сети - это сочетание анализа (измерения, диагностика и локализация ошибок) и синтеза (принятие решения о том, какие изменения надо внести в работу сети, чтобы исправить ее работу).
Анализ - определение значения критерия эффективности (или, что одно и то же, критерия оптимизации) системы для данного сочетания параметров сети. Иногда из этого этапа выделяют подэтап мониторинга, на котором выполняется более простая процедура - процедура сбора первичных данных о работе сети: статистики о количестве циркулирующих в сети кадров и пакетов различных протоколов, состоянии портов концентраторов, коммутаторов и маршрутизаторов и т.п. Далее выполняется этап собственно анализа, под которым в этом случае понимается более сложный и интеллектуальный процесс осмысления собранной на этапе мониторинга информации, сопоставления ее с данными, полученными ранее, и выработки предположений о возможных причинах замедленнной или ненадежной работы сети. Задача мониторинга решается программными и аппаратными измерителями, тесторами, сетевыми анализаторами и встроенными средствами мониторинга систем управления сетями и системами. Задача анализа требует более активного участия человека, а также использования таких сложных средств как экспертные системы, аккумулирующие практический опыт многих сетевых специалистов.
Синтез - выбор значений варьируемых параметров, при которых показатель эффективности имеет наилучшее значение. Если задано пороговое значение показателя эффективности, то результатом синтеза должен быть один из вариантов сети, превосходящий заданный порог. Приведение сети в работоспособное состояние - это также синтез, при котором находится любой вариант сети, для которого значение показателя эффективности отличается от состояния "не работает". Синтез рационального варианта сети - процедура чаще всего неформальная, так как она связана с выбором слишком большого и очень разнородного множества параметров сети - типов применяемого коммуникационного оборудования, моделей этого оборудования, числа серверов, типов компьютеров, используемых в качестве серверов, типов операционных систем, параметров этих опрационных систем, стеков коммуникационных протоколов, их параметров и т.д. и т.п. Очень часто мотивы, влияющие на выбор "в целом", то есть выбор типа или модели обрудования, стека протоколов или операционной системы, не носят технического характера, а принимаются из других соображений - коммерческих, "политических" и т.п. Поэтому формализовать постановку задачи оптимизации в таких случаях просто невозможно. В данной книге основное внимание уделяется этапам мониторинга и анализа сети, как более формальным и автоматизируемым процедурам. В тех случаях, когда это возможно, в книге даются рекомендации по выполнению некоторых последовательностей действий по нахождению рационального варианта сети или приводятся соображения, облегчающие его поиск.
Критерии эффективности работы сети
Все множество наиболее часто используемых критериев эффективности работы сети может быть разделено на две группы. Одна группа характеризует производительность работы сети, вторая - надежность.
Производительность сети измеряется с помощью показателей двух типов - временных, оценивающих задержку, вносимую сетью при выполнении обмена данными, и показателей пропускной способности, отражающих количество информации, переданной сетью в единицу времени. Эти два типа показателей являются взаимно обратными, и, зная один из них, можно вычислить другой.
Время реакции
Обычно в качестве временной характеристики производительности сети используется такой показатель как время реакции. Термин "время реакции" может использоваться в очень широком смыле, поэтому в каждом конкретном случае необходимо уточнить, что понимается под этим термином.
В общем случае, время реакции определяется как интервал времени между возникновением запроса пользователя к каму-либо сетевому сервису и получением ответа на этот запрос (рис. 1.1). Очевидно, что смысл и значение этого показателя зависят от типа сервиса, к которому обращается пользователь, от того, какой пользователь и к какому серверу обращается, а также от текущего состояния других элементов сети - загруженности сегментов, через которые проходит запрос, загруженности сервера и т.п.
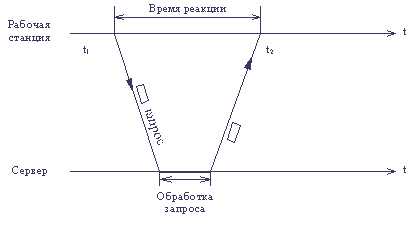
Рис. 1.1. Время реакции - интервал между запросом и ответом
Рассмотрим несколько примеров определения показателя "время реакции", иллюстрируемых рисунком 1.2.
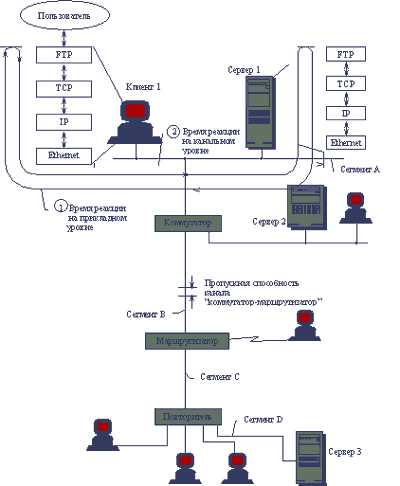
Рис. 1.2. Показатели производительности сети
В примере 1 под временем реакции понимается время, которое проходит с момента обращения пользователя к сервису FTP для передачи файла с сервера 1 на клиентский компьютер 1 до момента завершения этой передачи. Очевидно, что это время имеет несколько составляющих. Наиболее существенный вклад вносят такие составляющие времени реакции как: время обработки запросов на передачу файла на сервере, время обработки получаемых в пакетах IP частей файла на клиентском компьютере, время передачи пакетов между сервером и клиентским компьютером по протоколу Ethernet в пределах одного коаксиального сегмента. Можно было бы выделить еще более мелкие этапы выполнения запроса, например, время обработки запроса каждым из протоколов стека TCP/IP на сервере и клиенте.
Для конечного пользователя таким образом определенное время реакции является понятным и наиболее естественным показателем производительности сети (размер файла, который вносит некоторую неопределенность в этот показатель, можно зафиксировать, оценивая время реакции при передаче, например, одного мегабайта данных). Однако, сетевого специалиста интересует в первую очередь производительность собственно сети, поэтому для более точной ее оценки целесообразно вычленить из времени реакции составляющие, соответствующие этапам несетевой обработки данных - поиску нужной информации на диске, записи ее на диск и т.п. Полученное в результате таких сокращений время можно считать другим определением времени реакции сети на прикладном уровне.
Вариантами этого критерия могут служить времена реакции, измеренные при различных, но фиксированных состояниях сети:
A) Полностью ненагруженная сеть. Время рекции измеряется в условиях, когда к серверу 1 обращается только клиент 1, то есть на сегменте сети, объединяющем сервер 1 с клиентом 1, нет никакой другой активности - на нем присутствуют только кадры сессии FTP, производительность которой измеряется. В других сегментах сети трафик может циркулировать, главное - чтобы его кадры не попадали в сегмент, в котором проводятся измерения. Так как ненагруженный сегмент в реальной сети - явление экзотическое, то данный вариант показателя производительности имеет ограниченную применимость - его хорошие значения говорят только о том, что программное обеспечение и аппаратура данных двух узлов и сегмента обладают необходимой производительностью для работы в облегченных условиях. Для работы в реальных условиях, когда будет иметь место борьба за разделяемые ресурсы сегмента с другими узлами сети, производительность тестируемых элементов сети может оказаться недостаточной.
B) Нагруженная сеть. Это более интересный случай проверки производительности сервиса FTP для конкрентных сервера и клиента. Однако при измерении критерия производительности в условиях, когда в сети работают и другие узлы и сервисы, возникают свои сложности - в сети может существовать слишком большое количество вариантов нагрузки, поэтому главное при определении критериев такого сорта - проведение измерений при некоторых типовых условиях работы сети. Так как трафик в сети носит пульсирующий характер и харакетристики трафика существенно изменяются в засисимости от времени дня и дня недели, то определение типовой нагрузки - процедура сложная, требующая длительных измерений на сети. Если же сеть только проектируется, то определение типовой нагрузки еще больше усложняется.
В примере 2 критерием производительности сети является время задержки между передачей кадра Ethernet в сеть сетевым адаптером клиентского компьютера 1 и поступлением его на сетевой адаптер сервера 3. Этот критерий также относится к критериям типа "время реакции", но соответствует сервису нижнего - канального уровня. Так как протокол Ethernet - протокол дейтаграммного типа, то есть без установления соединений, для которого понятие "ответ" не определено, то под временем реакции в данном случае понимается время прохождения кадра от узла-источника до узла-получателя. Задержка передачи кадра включает в данном случае время распространения кадра по исходному сегменту, время передачи кадра коммутатором из сегмента А в сегмент В, время передачи кадра маршрутизатром из сегмента В в сегмент С и время передачи кадра из сегмента С в сегмент D повторителем. Критерии, относящиеся к нижнему уровню сети, хорошо хактеризуют качества транспортного сервиса сети и являются более информативными для сетевых интеграторов, так как не содержат избыточную для них информацию о работе протоколов верхних уровней.
При оценке производительности сети не по отношению к отдельным парам узлов, а ко всем узлам в целом используются критерии двух типов: средно-взвешенные и пороговые.
Средно-взвешенный критерий представляет собой сумму времен реакции всех или некоторых узлов при взаимодействии со всеми или некоторыми серверами сети по определенному сервису, то есть сумму вида
где Tij - время реакции i-го клиента при обращении к j-му серверу, n - число клиентов, m - число серверов. Если усреднение производится и по сервисам, то в приведеном выражении добавится еще одно суммирование - по количеству учитываемых сервисов. Оптимизация сети по данному критерию заключается в нахождении значений параметров, при которых критерий имеет минимальное значение или по крайней мере не превышает некоторое заданное число.
Пороговый критерий отражает наихудшее время реакции по всем возможным сочетаниям клиентов, серверов и сервисов:
где i и j имеют тот же смысл, что и в предыдущем случае, а k обозначает тип сервиса. Оптимизация также может выполняться с целью минимизации критерия, или же с целью достижения им некоторой заданной величины, признаваемой разумной с практической точки зрения.
Чаще применяются пороговые критерии оптимизации, так как они гарантируют всем пользователям некоторый удовлетворительный уровень реакции сети на их запросы. Средне-взвешенные критерии могут дискриминировать некоторых пользователей, для которых время реакции слишком велико при том, что при усреднении получен вполне приемлемый результат.
Можно применять и болеее дифференцированные по категориям пользователей и ситуациям критерии. Например, можно поставить перед собой цель гарантированть любому пользователю доступ к серверу, находящемуся в его сегменте, за время, не превышающее 5 секунд, к серверам, находящимся в его сети, но в сегментах, отделенных от его сегмента коммутаторами, за время, не превышающее 10 секунд, а к серверам других сетей - за время до 1 минуты.
Пропускная способность
Основная задача, для решения которой строится любая сеть - быстрая передача информации между компьютерами. Поэтому критерии, связанные с пропускной способностью сети или части сети, хорошо отражают качество выполнения сетью ее основной функции.
Существует большое количество вариантов определения критериев этого вида, точно также, как и в случае критериев класса "время реакции". Эти варианты могут отличаться друг от друга: выбранной единицей измерения количества передаваемой информации, характером учитываемых данных - только пользовательские или же пользовательские вместе со служебными, количеством точек измерения передаваемого трафика, способом усреднения результатов на сеть в целом. Рассмотрим различные способы построения критерия пропускной способности более подробно.
Критерии, отличающиеся единицей измерения передаваемой информации. В качестве единицы измерения передаваемой информации обычно используются пакеты (или кадры, далее эти термины будут использоваться как синонимы) или биты. Соответственно, пропускная способность измеряется в пакетах в секунду или же в битах в секунду.
Так как вычислительные сети работают по принципу коммутации пакетов (или кадров), то измерение количества переданной информации в пакетах имеет смысл, тем более что пропускная способность коммуникационного оборудования, работающего на канальном уровне и выше, также чаще всего измеряется в пакетах в секунду. Однако, из-за переменного размера пакета (это характерно для всех протоколов за исключением АТМ, имеющего фиксированный размер пакета в 53 байта), измерение пропускной способности в пакетах в секунду связано с некоторой неопределенностью - пакеты какого протокола и какого размера имеются в виду? Чаще всего подразумевают пакеты протокола Ethernet, как самого распространенного, имеющие минимальный для протокола размер в 64 байта (без преамбулы). Пакеты минимальной длины выбраны в качестве эталонных из-за того, что они создают для коммуникационного оборудования наиболее тяжелый режим работы - вычислительные операции, производимые с каждым пришедшим пакетом, в очень слабой степени зависят от его размера, поэтому на единицу переносимой информации обработка пакета минимальной длины требует выполнения гораздо больше операций, чем для пакета максимальной длины.
Измерение пропускной способности в битах в секунду (для локальных сетей более характерны скорости, измеряемые в миллионах бит в секунду - Мб/c) дает более точную оценку скорости передаваемой информации, чем при использовании пакетов.
Критерии, отличающиеся учетом служебной информации. В любом протоколе имеется заголовок, переносящий служебную информацию, и поле данных, в котором переносится информация, считающаяся для данного протокола пользовательской. Например, в кадре протокола Ethernet минимального размера 46 байт (из 64) представляют собой поле данных, а оставшиеся 18 являются служебной информацией. При измерении пропускной способности в пакетах в секунду отделить пользовательскую информацию от служебной невозможно, а при побитовом измерении - можно.
Если пропускная способность измеряется без деления информации на пользовательскую и служебную, то в этом случае нельзя ставить задачу выбора протокола или стека протоколов для данной сети. Это объясняется тем, что даже если при замене одного протокола на другой мы получим более высокую пропускную способность сети, то это не означает, что для конечных пользователей сеть будет работать быстрее - если доля служебной информации, приходящаяся на единицу пользовательских данных, у этих протоколов различная (а в общем случае это так), то можно в качестве оптимального выбрать более медленный вариант сети. Если же тип протокола не меняется при настройке сети, то можно использовать и критерии, не выделяющие пользовательские данные из общего потока.
При тестировании пропускной способности сети на прикладном уровне легче всего измерять как раз пропускную способность по пользовательским данным. Для этого достаточно измерить время передачи файла определенного размера между сервером и клиентом и разделить размер файла на полученное время. Для измерения общей пропускной способности необходимы специальные инструменты измерения - анализаторы протоколов или SNMP или RMON агенты, встроенные в операционные системы, сетевые адаптеры или коммуникационное оборудование.
Критерии, отличающиеся количеством и расположением точек измерения. Пропускную способность можно измерять между любыми двумя узлами или точками сети, например, между клиентским компьютером 1 и сервером 3 из примера, приведенного на рисунке 1.2. При этом получаемые значения пропускной способности будут изменяться при одних и тех же условиях работы сети в зависимости от того, между какими двумя точками производятся измерения. Так как в сети одновременно работает большое число пользовательских компьютеров и серверов, то полную характеристику пропускной способности сети дает набор пропускных способностей, измеренных для различных сочетаний взаимодействующих компьютеров - так называемая матрица трафика узлов сети. Существуют специальные средства измерения, которые фиксируют матрицу трафика для каждого узла сети.
Так как в сетях данные на пути до узла назначения обычно проходят через несколько транзитных промежуточных этапов обработки, то в качестве критерия эффективности может рассматриваться пропускная способность отдельного промежуточного элемента сети - отдельного канала, сегмента или коммуникационного устройства.
Знание общей пропускной способности между двумя узлами не может дать полной информации о возможных путях ее повышения, так как из общей цифры нельзя понять, какой из промежуточных этапов обработки пакетов в наибольшей степени тормозит работу сети. Поэтому данные о пропускной способности отдельных элементов сети могут быть полезны для принятия решения о способах ее оптимизации.
В рассматриваемом примере пакеты на пути от клиентского компьютера 1 до сервера 3 проходят через следующие промежуточные элементы сети:
Сегмент АR КоммутаторR Сегмент ВR МаршрутизаторR Сегмент СR ПовторительR Сегмент D.
Каждый из этих элементов обладает определенной пропускной способностью, поэтому общая пропускная способность сети между компьютером 1 и сервером 3 будет равна минимальной из пропускных способностей составляющих маршрута, а задержка передачи одного пакета (один из вариантов определения времени реакции) будет равна сумме задержек, вносимых каждым элементом. Для повышения пропускной способности составного пути необхдимо в первую очередь обратить внимание на самые медленные элементы - в данном случае таким элементом скорее всего будет маршрутизатор.
Имеет смысл определить общую пропускную способность сети как среднее количество информации, переданной между всеми узлами сети в единицу времени. Общая пропускная способность сети может измеряться как в пакетах в секунду, так и в битах в секунду. При делении сети на сегменты или подсети общая пропускная способность сети равна сумме пропускных способностей подсетей плюс пропускная способность межсегментных или межсетевых связей.
Показатели надежности и отказоустойчивости
Важнейшей характеристикой вычислительной сети является надежность - способность правильно функционировать в течение продолжительного периода времени. Это свойство имеет три составляющих: собственно надежность, готовность и удобство обслуживания.
Повышение надежности заключается в предотвращении неисправностей, отказов и сбоев за счет применения электронных схем и компонентов с высокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечения тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Надежность измеряется интенсивностью отказов и средним временем наработки на отказ. Надежность сетей как распределенных систем во многом определяется надежностью кабельных систем и коммутационной аппаратуры - разъемов, кроссовых панелей, коммутационных шкафов и т.п., обеспечивающих собственно электрическую или оптическую связность отдельных узлов между собой.
Повышение готовностипредполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления циркуляции информации в сети после обнаружения неисправности. Повышение готовности представляет собой борьбу за снижение времени простоя системы.
Критерием оценки готовности является коэффициент готовности, который равен доле времени пребывания системы в работоспособном состоянии и может интерпретироваться как вероятность нахождения системы в работоспособном состоянии. Коэффициент готовности вычисляется как отношение среднего времени наработки на отказ к сумме этой же величины и среднего времени восстановления. Системы с высокой готовностью называют также отказоустойчивыми.
Основным способом повышения готовности является избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Вычислительные сети включают большое количество элементов различных типов, и для обеспечения отказоустойчивости необходима избыточность по каждому из ключевых элементов сети. Если рассматривать сеть только как транспортную систему, то избыточность должна существовать для всех магистральных маршрутов сети, то есть маршрутов, являющихся общими для большого количества клиентов сети. Такими маршрутами обычно являются маршруты к корпоративным серверам - серверам баз данных, Web-серверам, почтовым серверам и т.п. Поэтому для организации отказоустойчивой работы все элементы сети, через которые проходят такие маршруты, должны быть зарезервированы: должны иметься резервные кабельные связи, которыми можно воспользоваться при отказе одного из основных кабелей, все коммуникационные устройства на магистральных путях должны либо сами быть реализованы по отказоустойчивой схеме с резевированием всех основных своих компонентов, либо для каждого коммуникационного устройства должно иметься резервное аналогичное устройство.
Переход с основной связи на резервную или с основного устройства на резервное может происходить как в автоматическом режиме, так и вручную, при участии администратора. Очевидно, что автоматический переход повышает коэффициент готовности системы, так как время простоя сети в этом случае будет существенно меньше, чем при вмешательстве человека. Для выполнения автоматических процедур реконфигурации необходимо иметь в сети интеллектуальные коммуникационные устройства, а также централизованную систему управления, помогающую устройствам распознавать отказы в сети и адекватно на них реагировать.
Высокую степень готовности сети можно обеспечить в том случае, когда процедуры тестирования работоспособности элементов сети и перехода на резервные элементы встроены в коммуникационные протоколы. Примером такого типа протоколов может служить протокол FDDI, в котором постоянно тестируются физические связи между узлами и концентраторами сети, а в случае их отказа выполняется автоматическая реконфигурация связей за счет вторичного резервного кольца. Существуют и специальные протоколы, поддерживающие отказоустойчивость сети, например, протокол SpanningTree, выполняющий автоматический переход на резервные связи в сети, построенной на основе мостов и коммутаторов.
Существуют различные градации отказоустойчивых компьютерных систем, к которым относятся и вычислительные сети. Приведем несколько общепринятых определений:
высокая готовность (highavailability) - характеризует системы, выполненные по обычной компьютерной технологии, использующие избыточные аппаратные и программные средства и допускающие время восстановления в интервале от 2 до 20 минут;
устойчивость к отказам (faulttolerance) - характеристика таких систем, которые имеют в горячем резерве избыточную аппаратуру для всех функциональных блоков, включая процессоры, источники питания, подсистемы ввода/вывода, подсистемы дисковой памяти, причем время восстановления при отказе не превышает одной секунды;
непрерывная готовность (continuousavailability) - это свойство систем, которые также обеспечивают время восстановления в пределах одной секунды, но в отличие от систем устойчивых к отказам, системы непрерывной готовности устраняют не только простои, возникшие в результате отказов, но и плановые простои, связанные с модернизацией или обслуживанием системы. Все эти работы проводятся в режиме online. Дополнительным требованием к системам непрерывной готовности является отсутствие деградации, то есть система должна поддерживать постоянный уровень функциональных возможностей и производительности независимо от возникновения отказов.
Так как сети обслуживают одновременно большое количество пользователей, то при расчете коэффициента готовности необходимо учитывать это обстоятельство. Коэффициент готовности сети должен соответствовать доле времени, в течение которого сеть выполняла с должным качеством свои функции для всех пользователей. Очевидно, что в больших сетях очень трудно обеспечить значения коэффициента готовности, близкие к единице.
Между показателями производительности и надежности сети существует тесная связь. Ненадежная работа сети очень часто приводит к существенному снижению ее производительности. Это объясняется тем, что сбои и отказы каналов связи и коммуникационного оборудования приводят к потере или искажению некоторой части пакетов, в результате чего коммуникационные протоколы вынуждены организовывать повторную передачу утерянных данных. Так как в локальных сетях восстановлением утерянных данных занимаются как правило протоколы транспортного или прикладного уровня, работающие с тайм-аутами в несколько десятков секунд, то потери производительности из-за низкой надежности сети могут составлять сотни процентов.
Параметры оптимизации транспортной подсистемы
На выбранный критерий оптимизации сети влияет большое количество параметров различных типов. В наибольшей степени на производительность сети влияют:
используемые коммуникационные протоколы и их параметры;
доля и характер широковещательного трафика, создаваемого различными протоколами;
топология сети и используемое коммуникационное оборудование;
интенсивность возникновения и харакетр ошибочных ситуаций;
конфигурация программного и аппаратного обеспечения конечных узлов.
Влияние на производительность сети типа коммуникационного протокола и его параметров
Задача выбора коммуникационных протоколов может решаться относительно независимо для канального уровня с одной стороны (Ethernet, TokenRing, FDDI, FastEthernet, ATM) и пары "сетевой - транспортный протокол" с другой стороны (IPX/SPX, TCP/IP, NetBIOS).
Каждый протокол имеет свои особенности, предпочтительные области применения и настраиваемые параметры, что и дает возможность за счет выбора и настройки протокола влиять на производительность и надежность сети. Настройка протокола может включать в себя изменение таких параметров как:
максимально допустимый размер кадра,
величины тайм-аутов (в том числе время жизни пакета),
для протоколов, работающих с установлением соединений - размер окна неподтвержденных пакетов, а также некоторых других.
studfiles.net
Оптимизация локальных сетей
Автор: фирмы "Cisco Systems"
Оптимизация локальных сетей
1.1. Основные задачи оптимизации локальных сетей
Если вы хотите, чтобы ваша сеть работала самым эффективным образом, то вам придется решить для себя следующие задачи:
1. Cформулировать критерии эффективности работы сети. Чаще всего такими критериями служат производительность и надежность, для которых в свою очередь требуется выбрать конкретные показатели оценки, например, время реакции и коэффициент готовности, соответственно.
2. Определить множество варьируемых параметров сети, прямо или косвенно влияющих на критерии эффективности. Эти параметры действительно должны быть варьируемыми, то есть нужно убедиться в том, что их можно изменять в некоторых пределах по вашему желанию. Так, если размер пакета какого-либо протокола в конкретной операционной системе устанавливается автоматически и не может быть изменен путем настройки, то этот параметр в данном случае не является варьируемым, хотя в другой операционной системе он может относится к изменяемым по желанию администратора, а значит и варьируемым. Другим примером может служить пропускная способность внутренней шины маршрутизатора - она может рассматриваться как параметр оптимизации только в том случае, если вы допускаете возможность замены маршрутизаторов в сети.
Все варьируемые параметры могут быть сгруппированы различным образом. Например, параметры отдельных конкретных протоколов (максимальный размер кадра протокола Ethernet или размер окна неподтвержденных пакетов протокола TCP) или параметры устройств (размер адресной таблицы или скорость фильтрации моста, пропускная способность внутренней шины маршрутизатора). Параметрами настройки могут быть и устройства, и протоколы в целом. Так, например, улучшить работу сети с медленными и зашумленными глобальными каналами связи можно, перейдя со стека протоколов IPX/SPX на протоколы TCP/IP. Также можно добиться значительных улучшений с помощью замены сетевых адаптеров неизвестного производителя на адаптеры BrandName.
3. Определить порог чувствительности для значений критерия эффективности. Так, производительность сети можно оценивать логическими значениями "Работает"/ "Не работает", и тогда оптимизация сводится к диагностике неисправностей и приведению сети в любое работоспособное состояние. Другим крайним случаем является тонкая настройка сети, при которой параметры работающей сети (например, размер кадра или величина окна неподтвержденных пакетов) могут варьироваться с целью повышения производительности (например, среднего значения времени реакции) хотя бы на несколько процентов. Как правило, под оптимизацией сети понимают некоторый промежуточный вариант, при котором требуется выбрать такие значения параметров сети, чтобы показатели ее эффективности существенно улучшились, например, пользователи получали ответы на свои запросы к серверу баз данных не за 10 секунд, а за 3 секунды, а передача файла на удаленный компьютер выполнялась не за 2 минуты, а за 30 секунд.
Таким образом, можно предложить три различных трактовки задачи оптимизации:
1. Приведение сети в любое работоспособное состояние. Обычно эта задача решается первой, и включает:
поиск неисправных элементов сети - кабелей, разъемов, адаптеров, компьютеров;
проверку совместимости оборудования и программного обеспечения;
выбор корректных значений ключевых параметров программ и устройств, обеспечивающих прохождение сообщений между всеми узлами сети - адресов сетей и узлов, используемых протоколов, типов кадров Ethernet и т.п.
2. Грубая настройка - выбор параметров, резко влияющих на характеристики (надежность, производительность) сети. Если сеть работоспособна, но обмен данными происходит очень медленно (время ожидания составляет десятки секунд или минуты) или же сеанс связи часто разрывается без видимых причин, то работоспособной такую сеть можно назвать только условно, и она безусловно нуждается в грубой настройке. На этом этапе необходимо найти ключевые причины существенных задержек прохождения пакетов в сети. Обычно причина серьезного замедления или неустойчивой работы сети кроется в одном неверно работающем элементе или некорректно установленом параметре, но из-за большого количества возможных виновников поиск может потребовать длительного наблюдения за работой сети и громоздкого перебора вариантов. Грубая настройка во многом похожа на приведение сети в работоспособное состояние. Здесь также обычно задается некоторое пороговое значение показателя эффективности и требуется найти такой вариант сети, у которого это значение было бы не хуже порогового. Например, нужно настроить сеть так, чтобы время реакции сервера на запрос пользователя не превышало 5 секунд.
3. Тонкая настройка параметров сети (собственно оптимизация). Если сеть работает удовлетворительно, то дальнейшее повышение ее производительности или надежности вряд ли можно достичь изменением только какого-либо одного параметра, как это было в случае полностью неработоспособной сети или же в случае ее грубой настройки. В случае нормально работающей сети дальнейшее повышение ее качества обычно требует нахождения некоторого удачного сочетания значений большого количества параметров, поэтому этот процесс и получил название "тонкой настройки".
Даже при тонкой настройке сети оптимальное сочетание ее параметров (в строгом математическом понимании термина "оптимальность") получить невозможно, да и не нужно. Нет смысла затрачивать колоссальные усилия по нахождению строгого оптимума, отличающегося от близких к нему режимов работы на величины такого же порядка, что и точность измерений трафика в сети. Достаточно найти любое из близких к оптимальному решений, чтобы считать задачу оптимизации сети решенной. Такие близкие к оптимальному решения обычно называют рациональными вариантами, и именно их поиск интересует на практике администратора сети или сетевого интегратора.
Поиск неисправностей в сети - это сочетание анализа (измерения, диагностика и локализация ошибок) и синтеза (принятие решения о том, какие изменения надо внести в работу сети, чтобы исправить ее работу).
- Анализ - определение значения критерия эффективности (или, что одно и то же, критерия оптимизации) системы для данного сочетания параметров сети. Иногда из этого этапа выделяют подэтап мониторинга, на котором выполняется более простая процедура - процедура сбора первичных данных о работе сети: статистики о количестве циркулирующих в сети кадров и пакетов различных протоколов, состоянии портов концентраторов, коммутаторов и маршрутизаторов и т.п. Далее выполняется этап собственно анализа, под которым в этом случае понимается более сложный и интеллектуальный процесс осмысления собранной на этапе мониторинга информации, сопоставления ее с данными, полученными ранее, и выработки предположений о возможных причинах замедленнной или ненадежной работы сети. Задача мониторинга решается программными и аппаратными измерителями, тесторами, сетевыми анализаторами и встроенными средствами мониторинга систем управления сетями и системами. Задача анализа требует более активного участия человека, а также использования таких сложных средств как экспертные системы, аккумулирующие практический опыт многих сетевых специалистов.
- Синтез - выбор значений варьируемых параметров, при которых показатель эффективности имеет наилучшее значение. Если задано пороговое значение показателя эффективности, то результатом синтеза должен быть один из вариантов сети, превосходящий заданный порог. Приведение сети в работоспособное состояние - это также синтез, при котором находится любой вариант сети, для которого значение показателя эффективности отличается от состояния "не работает". Синтез рационального варианта сети - процедура чаще всего неформальная, так как она связана с выбором слишком большого и очень разнородного множества параметров сети - типов применяемого коммуникационного оборудования, моделей этого оборудования, числа серверов, типов компьютеров, используемых в качестве серверов, типов операционных систем, параметров этих опрационных систем, стеков коммуникационных протоколов, их параметров и т.д. и т.п. Очень часто мотивы, влияющие на выбор "в целом", то есть выбор типа или модели обрудования, стека протоколов или операционной системы, не носят технического характера, а принимаются из других соображений - коммерческих, "политических" и т.п. Поэтому формализовать постановку задачи оптимизации в таких случаях просто невозможно. В данной книге основное внимание уделяется этапам мониторинга и анализа сети, как более формальным и автоматизируемым процедурам. В тех случаях, когда это возможно, в книге даются рекомендации по выполнению некоторых последовательностей действий по нахождению рационального варианта сети или приводятся соображения, облегчающие его поиск.
1.2. Критерии эффективности работы сети
Все множество наиболее часто используемых критериев эффективности работы сети может быть разделено на две группы. Одна группа характеризует производительность работы сети, вторая - надежность.
Производительность сети измеряется с помощью показателей двух типов - временных, оценивающих задержку, вносимую сетью при выполнении обмена данными, и показателей пропускной способности, отражающих количество информации, переданной сетью в единицу времени. Эти два типа показателей являются взаимно обратными, и, зная один из них, можно вычислить другой.
1.2.1. Время реакции
Обычно в качестве временной характеристики производительности сети используется такой показатель как время реакции. Термин "время реакции" может использоваться в очень широком смыле, поэтому в каждом конкретном случае необходимо уточнить, что понимается под этим термином.
В общем случае, время реакции определяется как интервал времени между возникновением запроса пользователя к каму-либо сетевому сервису и получением ответа на этот запрос (рис. 1.1). Очевидно, что смысл и значение этого показателя зависят от типа сервиса, к которому обращается пользователь, от того, какой пользователь и к какому серверу обращается, а также от текущего состояния других элементов сети - загруженности сегментов, через которые проходит запрос, загруженности сервера и т.п.
Рис. 1.1. Время реакции - интервал между запросом и ответом
Рассмотрим несколько примеров определения показателя "время реакции", иллюстрируемых рисунком 1.2.
Рис. 1.2. Показатели производительности сети
В примере 1 под временем реакции понимается время, которое проходит с момента обращения пользователя к сервису FTP для передачи файла с сервера 1 на клиентский компьютер 1 до момента завершения этой передачи. Очевидно, что это время имеет несколько составляющих. Наиболее существенный вклад вносят такие составляющие времени реакции как: время обработки запросов на передачу файла на сервере, время обработки получаемых в пакетах IP частей файла на клиентском компьютере, время передачи пакетов между сервером и клиентским компьютером по протоколу Ethernet в пределах одного коаксиального сегмента. Можно было бы выделить еще более мелкие этапы выполнения запроса, например, время обработки запроса каждым из протоколов стека TCP/IP на сервере и клиенте.
Для конечного пользователя таким образом определенное время реакции является понятным и наиболее естественным показателем производительности сети (размер файла, который вносит некоторую неопределенность в этот показатель, можно зафиксировать, оценивая время реакции при передаче, например, одного мегабайта данных). Однако, сетевого специалиста интересует в первую очередь производительность собственно сети, поэтому для более точной ее оценки целесообразно вычленить из времени реакции составляющие, соответствующие этапам несетевой обработки данных - поиску нужной информации на диске, записи ее на диск и т.п. Полученное в результате таких сокращений время можно считать другим определением времени реакции сети на прикладном уровне.
Вариантами этого критерия могут служить времена реакции, измеренные при различных, но фиксированных состояниях сети:
A) Полностью ненагруженная сеть. Время рекции измеряется в условиях, когда к серверу 1 обращается только клиент 1, то есть на сегменте сети, объединяющем сервер 1 с клиентом 1, нет никакой другой активности - на нем присутствуют только кадры сессии FTP, производительность которой измеряется. В других сегментах сети трафик может циркулировать, главное - чтобы его кадры не попадали в сегмент, в котором проводятся измерения. Так как ненагруженный сегмент в реальной сети - явление экзотическое, то данный вариант показателя производительности имеет ограниченную применимость - его хорошие значения говорят только о том, что программное обеспечение и аппаратура данных двух узлов и сегмента обладают необходимой производительностью для работы в облегченных условиях. Для работы в реальных условиях, когда будет иметь место борьба за разделяемые ресурсы сегмента с другими узлами сети, производительность тестируемых элементов сети может оказаться недостаточной.
B) Нагруженная сеть. Это более интересный случай проверки производительности сервиса FTP для конкрентных сервера и клиента. Однако при измерении критерия производительности в условиях, когда в сети работают и другие узлы и сервисы, возникают свои сложности - в сети может существовать слишком большое количество вариантов нагрузки, поэтому главное при определении критериев такого сорта - проведение измерений при некоторых типовых условиях работы сети. Так как трафик в сети носит пульсирующий характер и харакетристики трафика существенно изменяются в засисимости от времени дня и дня недели, то определение типовой нагрузки - процедура сложная, требующая длительных измерений на сети. Если же сеть только проектируется, то определение типовой нагрузки еще больше усложняется.
В примере 2 критерием производительности сети является время задержки между передачей кадра Ethernet в сеть сетевым адаптером клиентского компьютера 1 и поступлением его на сетевой адаптер сервера 3. Этот критерий также относится к критериям типа "время реакции", но соответствует сервису нижнего - канального уровня. Так как протокол Ethernet - протокол дейтаграммного типа, то есть без установления соединений, для которого понятие "ответ" не определено, то под временем реакции в данном случае понимается время прохождения кадра от узла-источника до узла-получателя. Задержка передачи кадра включает в данном случае время распространения кадра по исходному сегменту, время передачи кадра коммутатором из сегмента А в сегмент В, время передачи кадра маршрутизатром из сегмента В в сегмент С и время передачи кадра из сегмента С в сегмент D повторителем. Критерии, относящиеся к нижнему уровню сети, хорошо хактеризуют качества транспортного сервиса сети и являются более информативными для сетевых интеграторов, так как не содержат избыточную для них информацию о работе протоколов верхних уровней.
При оценке производительности сети не по отношению к отдельным парам узлов, а ко всем узлам в целом используются критерии двух типов: средно-взвешенные и пороговые.
Средно-взвешенный критерий представляет собой сумму времен реакции всех или некоторых узлов при взаимодействии со всеми или некоторыми серверами сети по определенному сервису, то есть сумму вида
где Tij - время реакции i-го клиента при обращении к j-му серверу, n - число клиентов, m - число серверов. Если усреднение производится и по сервисам, то в приведеном выражении добавится еще одно суммирование - по количеству учитываемых сервисов. Оптимизация сети по данному критерию заключается в нахождении значений параметров, при которых критерий имеет минимальное значение или по крайней мере не превышает некоторое заданное число.
Пороговый критерий отражает наихудшее время реакции по всем возможным сочетаниям клиентов, серверов и сервисов:
где i и j имеют тот же смысл, что и в предыдущем случае, а k обозначает тип сервиса. Оптимизация также может выполняться с целью минимизации критерия, или же с целью достижения им некоторой заданной величины, признаваемой разумной с практической точки зрения.
Чаще применяются пороговые критерии оптимизации, так как они гарантируют всем пользователям некоторый удовлетворительный уровень реакции сети на их запросы. Средне-взвешенные критерии могут дискриминировать некоторых пользователей, для которых время реакции слишком велико при том, что при усреднении получен вполне приемлемый результат.
Можно применять и болеее дифференцированные по категориям пользователей и ситуациям критерии. Например, можно поставить перед собой цель гарантированть любому пользователю доступ к серверу, находящемуся в его сегменте, за время, не превышающее 5 секунд, к серверам, находящимся в его сети, но в сегментах, отделенных от его сегмента коммутаторами, за время, не превышающее 10 секунд, а к серверам других сетей - за время до 1 минуты.
1.2.2. Пропускная способность
Основная задача, для решения которой строится любая сеть - быстрая передача информации между компьютерами. Поэтому критерии, связанные с пропускной способностью сети или части сети, хорошо отражают качество выполнения сетью ее основной функции.
Существует большое количество вариантов определения критериев этого вида, точно также, как и в случае критериев класса "время реакции". Эти варианты могут отличаться друг от друга: выбранной единицей измерения количества передаваемой информации, характером учитываемых данных - только пользовательские или же пользовательские вместе со служебными, количеством точек измерения передаваемого трафика, способом усреднения результатов на сеть в целом. Рассмотрим различные способы построения критерия пропускной способности более подробно.
Критерии, отличающиеся единицей измерения передаваемой информации. В качестве единицы измерения передаваемой информации обычно используются пакеты (или кадры, далее эти термины будут использоваться как синонимы) или биты. Соответственно, пропускная способность измеряется в пакетах в секунду или же в битах в секунду.
Так как вычислительные сети работают по принципу коммутации пакетов (или кадров), то измерение количества переданной информации в пакетах имеет смысл, тем более что пропускная способность коммуникационного оборудования, работающего на канальном уровне и выше, также чаще всего измеряется в пакетах в секунду. Однако, из-за переменного размера пакета (это характерно для всех протоколов за исключением АТМ, имеющего фиксированный размер пакета в 53 байта), измерение пропускной способности в пакетах в секунду связано с некоторой неопределенностью - пакеты какого протокола и какого размера имеются в виду? Чаще всего подразумевают пакеты протокола Ethernet, как самого распространенного, имеющие минимальный для протокола размер в 64 байта (без преамбулы). Пакеты минимальной длины выбраны в качестве эталонных из-за того, что они создают для коммуникационного оборудования наиболее тяжелый режим работы - вычислительные операции, производимые с каждым пришедшим пакетом, в очень слабой степени зависят от его размера, поэтому на единицу переносимой информации обработка пакета минимальной длины требует выполнения гораздо больше операций, чем для пакета максимальной длины.
Измерение пропускной способности в битах в секунду (для локальных сетей более характерны скорости, измеряемые в миллионах бит в секунду - Мб/c) дает более точную оценку скорости передаваемой информации, чем при использовании пакетов.
Критерии, отличающиеся учетом служебной информации. В любом протоколе имеется заголовок, переносящий служебную информацию, и поле данных, в котором переносится информация, считающаяся для данного протокола пользовательской. Например, в кадре протокола Ethernet минимального размера 46 байт (из 64) представляют собой поле данных, а оставшиеся 18 являются служебной информацией. При измерении пропускной способности в пакетах в секунду отделить пользовательскую информацию от служебной невозможно, а при побитовом измерении - можно.
Если пропускная способность измеряется без деления информации на пользовательскую и служебную, то в этом случае нельзя ставить задачу выбора протокола или стека протоколов для данной сети. Это объясняется тем, что даже если при замене одного протокола на другой мы получим более высокую пропускную способность сети, то это не означает, что для конечных пользователей сеть будет работать быстрее - если доля служебной информации, приходящаяся на единицу пользовательских данных, у этих протоколов различная (а в общем случае это так), то можно в качестве оптимального выбрать более медленный вариант сети. Если же тип протокола не меняется при настройке сети, то можно использовать и критерии, не выделяющие пользовательские данные из общего потока.
При тестировании пропускной способности сети на прикладном уровне легче всего измерять как раз пропускную способность по пользовательским данным. Для этого достаточно измерить время передачи файла определенного размера между сервером и клиентом и разделить размер файла на полученное время. Для измерения общей пропускной способности необходимы специальные инструменты измерения - анализаторы протоколов или SNMP или RMON агенты, встроенные в операционные системы, сетевые адаптеры или коммуникационное оборудование.
Критерии, отличающиеся количеством и расположением точек измерения. Пропускную способность можно измерять между любыми двумя узлами или точками сети, например, между клиентским компьютером 1 и сервером 3 из примера, приведенного на рисунке 1.2. При этом получаемые значения пропускной способности будут изменяться при одних и тех же условиях работы сети в зависимости от того, между какими двумя точками производятся измерения. Так как в сети одновременно работает большое число пользовательских компьютеров и серверов, то полную характеристику пропускной способности сети дает набор пропускных способностей, измеренных для различных сочетаний взаимодействующих компьютеров - так называемая матрица трафика узлов сети. Существуют специальные средства измерения, которые фиксируют матрицу трафика для каждого узла сети.
Так как в сетях данные на пути до узла назначения обычно проходят через несколько транзитных промежуточных этапов обработки, то в качестве критерия эффективности может рассматриваться пропускная способность отдельного промежуточного элемента сети - отдельного канала, сегмента или коммуникационного устройства.
Знание общей пропускной способности между двумя узлами не может дать полной информации о возможных путях ее повышения, так как из общей цифры нельзя понять, какой из промежуточных этапов обработки пакетов в наибольшей степени тормозит работу сети. Поэтому данные о пропускной способности отдельных элементов сети могут быть полезны для принятия решения о способах ее оптимизации.
В рассматриваемом примере пакеты на пути от клиентского компьютера 1 до сервера 3 проходят через следующие промежуточные элементы сети:
Сегмент АR КоммутаторR Сегмент ВR МаршрутизаторR Сегмент СR ПовторительR Сегмент D.
Каждый из этих элементов обладает определенной пропускной способностью, поэтому общая пропускная способность сети между компьютером 1 и сервером 3 будет равна минимальной из пропускных способностей составляющих маршрута, а задержка передачи одного пакета (один из вариантов определения времени реакции) будет равна сумме задержек, вносимых каждым элементом. Для повышения пропускной способности составного пути необхдимо в первую очередь обратить внимание на самые медленные элементы - в данном случае таким элементом скорее всего будет маршрутизатор.
Имеет смысл определить общую пропускную способность сети как среднее количество информации, переданной между всеми узлами сети в единицу времени. Общая пропускная способность сети может измеряться как в пакетах в секунду, так и в битах в секунду. При делении сети на сегменты или подсети общая пропускная способность сети равна сумме пропускных способностей подсетей плюс пропускная способность межсегментных или межсетевых связей.
1.2.3. Показатели надежности и отказоустойчивости
Важнейшей характеристикой вычислительной сети является надежность - способность правильно функционировать в течение продолжительного периода времени. Это свойство имеет три составляющих: собственно надежность, готовность и удобство обслуживания.
Повышение надежности заключается в предотвращении неисправностей, отказов и сбоев за счет применения электронных схем и компонентов с высокой степенью интеграции, снижения уровня помех, облегченных режимов работы схем, обеспечения тепловых режимов их работы, а также за счет совершенствования методов сборки аппаратуры. Надежность измеряется интенсивностью отказов и средним временем наработки на отказ. Надежность сетей как распределенных систем во многом определяется надежностью кабельных систем и коммутационной аппаратуры - разъемов, кроссовых панелей, коммутационных шкафов и т.п., обеспечивающих собственно электрическую или оптическую связность отдельных узлов между собой.
Повышение готовностипредполагает подавление в определенных пределах влияния отказов и сбоев на работу системы с помощью средств контроля и коррекции ошибок, а также средств автоматического восстановления циркуляции информации в сети после обнаружения неисправности. Повышение готовности представляет собой борьбу за снижение времени простоя системы.
Критерием оценки готовности является коэффициент готовности, который равен доле времени пребывания системы в работоспособном состоянии и может интерпретироваться как вероятность нахождения системы в работоспособном состоянии. Коэффициент готовности вычисляется как отношение среднего времени наработки на отказ к сумме этой же величины и среднего времени восстановления. Системы с высокой готовностью называют также отказоустойчивыми.
Основным способом повышения готовности является избыточность, на основе которой реализуются различные варианты отказоустойчивых архитектур. Вычислительные сети включают большое количество элементов различных типов, и для обеспечения отказоустойчивости необходима избыточность по каждому из ключевых элементов сети. Если рассматривать сеть только как транспортную систему, то избыточность должна существовать для всех магистральных маршрутов сети, то есть маршрутов, являющихся общими для большого количества клиентов сети. Такими маршрутами обычно являются маршруты к корпоративным серверам - серверам баз данных, Web-серверам, почтовым серверам и т.п. Поэтому для организации отказоустойчивой работы все элементы сети, через которые проходят такие маршруты, должны быть зарезервированы: должны иметься резервные кабельные связи, которыми можно воспользоваться при отказе одного из основных кабелей, все коммуникационные устройства на магистральных путях должны либо сами быть реализованы по отказоустойчивой схеме с резевированием всех основных своих компонентов, либо для каждого коммуникационного устройства должно иметься резервное аналогичное устройство.
Переход с основной связи на резервную или с основного устройства на резервное может происходить как в автоматическом режиме, так и вручную, при участии администратора. Очевидно, что автоматический переход повышает коэффициент готовности системы, так как время простоя сети в этом случае будет существенно меньше, чем при вмешательстве человека. Для выполнения автоматических процедур реконфигурации необходимо иметь в сети интеллектуальные коммуникационные устройства, а также централизованную систему управления, помогающую устройствам распознавать отказы в сети и адекватно на них реагировать.
Высокую степень готовности сети можно обеспечить в том случае, когда процедуры тестирования работоспособности элементов сети и перехода на резервные элементы встроены в коммуникационные протоколы. Примером такого типа протоколов может служить протокол FDDI, в котором постоянно тестируются физические связи между узлами и концентраторами сети, а в случае их отказа выполняется автоматическая реконфигурация связей за счет вторичного резервного кольца. Существуют и специальные протоколы, поддерживающие отказоустойчивость сети, например, протокол SpanningTree, выполняющий автоматический переход на резервные связи в сети, построенной на основе мостов и коммутаторов.
Существуют различные градации отказоустойчивых компьютерных систем, к которым относятся и вычислительные сети. Приведем несколько общепринятых определений:
- высокая готовность (highavailability) - характеризует системы, выполненные по обычной компьютерной технологии, использующие избыточные аппаратные и программные средства и допускающие время восстановления в интервале от 2 до 20 минут;
- устойчивость к отказам (faulttolerance) - характеристика таких систем, которые имеют в горячем резерве избыточную аппаратуру для всех функциональных блоков, включая процессоры, источники питания, подсистемы ввода/вывода, подсистемы дисковой памяти, причем время восстановления при отказе не превышает одной секунды;
- непрерывная готовность (continuousavailability) - это свойство систем, которые также обеспечивают время восстановления в пределах одной секунды, но в отличие от систем устойчивых к отказам, системы непрерывной готовности устраняют не только простои, возникшие в результате отказов, но и плановые простои, связанные с модернизацией или обслуживанием системы. Все эти работы проводятся в режиме online. Дополнительным требованием к системам непрерывной готовности является отсутствие деградации, то есть система должна поддерживать постоянный уровень функциональных возможностей и производительности независимо от возникновения отказов.
Так как сети обслуживают одновременно большое количество пользователей, то при расчете коэффициента готовности необходимо учитывать это обстоятельство. Коэффициент готовности сети должен соответствовать доле времени, в течение которого сеть выполняла с должным качеством свои функции для всех пользователей. Очевидно, что в больших сетях очень трудно обеспечить значения коэффициента готовности, близкие к единице.
Между показателями производительности и надежности сети существует тесная связь. Ненадежная работа сети очень часто приводит к существенному снижению ее производительности. Это объясняется тем, что сбои и отказы каналов связи и коммуникационного оборудования приводят к потере или искажению некоторой части пакетов, в результате чего коммуникационные протоколы вынуждены организовывать повторную передачу утерянных данных. Так как в локальных сетях восстановлением утерянных данных занимаются как правило протоколы транспортного или прикладного уровня, работающие с тайм-аутами в несколько десятков секунд, то потери производительности из-за низкой надежности сети могут составлять сотни процентов.
masters.donntu.org
Истории из практики оптимизации сети / Блог компании КРОК / Хабр
Привет! Я с коллегами оптимизирую имеющиеся каналы. Нас постоянно путают то с оптическими уплотнителями, то с инженерами-кабельщиками, то, вообще, с грузчиками.
А наша работа – это разбор стека протоколов и его полная перекомпоновка под особенности канала, настройка оптимальных размеров фрейма, сбор нескольких пакетов на канал с большим latency в один, дедупликация, обычное сжатие, разбор SSL и пересборка с тем же сертификатом. Решается это в самом простом случае установкой специального железа на принимающей и передающей стороне. Поскольку до каждой точки надо добраться, мы ещё и работаем выездными инженерами. И, как у любых выездных инженеров, историй у нас море. Ниже я расскажу несколько, только поменяю ряд второстепенных обстоятельств, чтобы нельзя было узнать заказчика.
Например, идут ночные работы в очень крупном магазине. Админ заказчика и наш инженер зашли в час ночи в серверную, работают. Инженер вышел в туалет, вернулся. Через пару минут – стук в дверь. Открывают — и сразу влетает ГБР с автоматами, сразу ногами по корпусу, мордой в пол и в наручники.
Потом подъезжают полиция и главный по магазину. Главный оценивает ситуацию и веско заявляет: — Вот этого знаю, это наш админ. А вот этого не знаю. Забирайте. Кончилось, к счастью, хорошо. Админ с пола шипит: — Мы ж тебе писали! Главный достаёт телефон, читает: — Будут ночные работы… я и такой-то… Аааа, вон что, — поворачивается к полиции и с явной жалостью продолжает: — Придётся отпустить.
Не заметили, как стало хорошо
Воткнули мобильные оптимизаторы на банковские машины в одном филиале. Надо сказать, что интернет там был такой «хороший», что образ виртуальной машины мы в итоге доставляли туда на диске. Так вот, в этом образе был софтверный агент, который работает с железками в данном случае, в ЦОДе. Подключили, раздали триальные лицензии – и понеслось тестовое внедрение.Обратной связи нет: ну, думаем, ладно, значит, им там не надо оптимизатора. Может, канал поправили. Но! Через три месяца звонят, хотят полное. Оказалось, что триал закончился, и они внезапно заметили, как стало плохо. Что интересно – как стало хорошо, даже не пикнули, ни слова. А как обратно стало плохо – пользователи завалили жалобами руководство.
Телефонный хулиган
Делали тестовое внедрение систем диагностики сети. Развернули комплекс в дата-центре, он потихоньку обучается. А надо сказать, что местная инфраструктура росла в результате постепенного слияния компаний, поэтому не очень гомогенна. В смысле, используется много систем, и каждая показывает ситуацию на своем уровне, а целой картины по трафику приложений нет ни у кого.В этот момент они как раз запускали новое приложение, которое хорошо показало себя в тестовом сегменте, но в промышленной сети под нагрузкой его ещё не видели. Внедрили, но из-за сложной структуры об этом знали не все ИТ-специалисты. Через 3-4 дня после включения сервиса начались проблемы с ip-телефонией. А колл-центр был на ней. Причём звонки теряли во всех направлениях. Клиентские. Полдня пытались решить проблему своими средствами, но никак не могли отловить причину – баг плавающий, и то воспроизводится, то нет.
Админы постучали к нам спросить, можно ли систему диагностики нашу использовать для детектива. Там стоит «Каскад», он как раз трафик разбирать на лету умеет. Вошли в режим отладки и начали смотреть за сетевыми аномалиями.
Выяснилось, что новый сервис использовал те же порты, что и у телефонии. Новый трафик с теми же портами начал попадать в приоритет и вытеснять голос. После этого изменили настройки классификации трафика телефонии.
Похожая ситуация была в одном крупном колл-центре оператора. Абонент звонит, он оператора слышит, а оператор его – нет. Больше месяца местные сетевики искали решение своими средствами и силами — надо сказать, что так долго, потому что баг был плавающий, и детектировать его было достаточно нетривиально. В итоге дело дошло до московской команды, точнее, до их топа. Тот постучал чем-то по столу и поставил дедлайн. Обратились к нам. Мы привезли ту же самую систему диагностики Ривербеда. Собрали трафик с разных сегментов — сравнили и в реалтайме начали смотреть качество голоса на разных сегментах. В течение 5-6 часов нашли сбойный коммутатор, у которого слетели очереди. Там была странная проблема с железом, время от времени летели настройки. С телом хулигана разбиралась уже команда – мы просто поменяли коммутатор, и это полностью закрыло вопрос.
Никогда не обновляйтесь в пятницу после обеда
С обновлением ещё история была отличная. Тоже банк, но уже другой. Админ обновил прошивки балансировщиков около 12 ночи. Примерно в два один из них начал молча дропать трафик, который ему чем-то не нравился. Далеко не весь. Случайные пакеты. Обнаружили это ещё через несколько минут, когда безопасник из Хабаровска заподозрил что-то странное с транзакцией. Ещё через 6 минут классическая тревога, «икс-команда, на выезд». Причём предварительный диагноз – аппаратный сбой в коммутаторе ядра. Как обычно, лифт, внизу ждут кладовщики с новым коммутатором, по машинам – и туда. К счастью, пока ехали, мой коллега, который подцепился удалённо, разобрался и откатил прошивки балансировщиков.Сила прогресса
Поставили оптимизатор в режиме обучения на объект в банке. Местный админ должен был перекинуть его в боевой режим, как он «освоится» с местными потоками. Обычно от дня до недели на профилирование, потому что есть ещё особенности с безопасниками. Там была нужна небольшая перекоммутация с ночным бдением, поэтому, наверное, за два месяца ничего не происходило в плане переключения. Железка получала свою копию трафика и терпеливо училась. Банк был в процессе закупки в несколько этапов, поэтому главный админ использовал эту лицензию для другого объекта. Мол, здесь и так хорошо пока, ближе к пику поставим.А потом у них упал (и очень серьёзно) наземный канал (а, может, он и не упал, и админ знал про то, что его придётся менять – и потому не врубил оптимизатор в период, когда придётся жить без резерва). Они прыгнули на спутник. Телепорт был прямо на крыше, им уже неоднократно пользовались, поэтому, по логике, проблем быть не должно. Предполагалось переждать на нём две недели, пока подведут новую наземную линию. Но за время, прошедшее с последнего долгого сидения на спутнике, приклад немного обновился и стал требовательнее к полосе.
Проще говоря, работать софт стал плохо.
А через сутки пришли клиенты. Обслуживание шло медленно, народ путался, кто за кем стоит, закольцовывали очереди и неплохо так виртуализировались, занимая сразу несколько из них. Виртуальных посетителей в банке стояло под три сотни, физических – раза в четыре меньше. Примерно раз в три часа у всей этой системы очередей случался kernel panic, и дело грозило дойти до драки.
У нас срочно запросили ещё одну лицензию на продажу. Так мы и узнали всю эту историю. Далее технический прогресс помог людям решить свои проблемы.
Спасибо, парни
Репликация базы между Москвой и очень далёким городом России. Полоса – спутник. Трафик гоняется сжатой базой, рывками, неоптимальными пакетами, часто теряется. Мы предложили оптимизаторы. С ними репликации пошли быстрее, очереди запросов не копились, полоса (как обычно) утилизировалась много больше. Но было ещё куда расти. Основная точка – нам очень не нравилось, что реплицировалась сжатая база. Сжатое разбирать и ускорять – толка считанные проценты. Гораздо лучше было гонять сырую базу, чтобы её разбирали сами железки.Сырую базу не могли гонять по какой-то причине, она не проходила дальше файрволла. Мы поковырялись в настройках, и через пару дней сырая боевая база стала летать нормально. Тут подключились стандартные возможности их железа, освободилось процессорное время (уходившее на сжатие) – из 27 часов на репликацию они стали попадать в 23. При том, что мы с оптимизаторами делали 12-14. И тут нам сообщают, что всё, спасибо, мужики, задача была в SLA уложиться. Уже укладываемся. Оптимизаторы ваши крутые, но сейчас пока хватит.
Так мы сами себе во время выполнения заказа отменили этот заказ.
Сервер за бутылку
Делаем пилотное внедрение ривербедовского оптимизатора трафика на одном особо крупном промышленном объекте. Устройство большое, полноценная стойка. Серверная на объекте на втором этаже, а на первом – непосредственно цех, торчит арматура, ходят суровые чумазые мужики. Под серверной какой-то административный блок, там учёт и контроль.Так вот, идём мы через этот цех, и тут из-за одного из станков выруливают двое прямо ярко выраженных представителей рабочего класса. Как положено – на лице следы то ли краски, то ли мазута по форме очков, на головах оцарапанные каски. Говорят: — Слушайте, а можно вы железку пока снимать не будете? Мы: — В смысле? Мы как раз за ней. Один замялся: — А это, сколько она стоит? Вопрос, конечно, очень насторожил. Пробуем выиграть время: — Мы не имеем права с вами обсуждать условия контракта. Второй рабочий сразу переходит к делу: — Ну примерно? Мы её себе купить хотим. Тут мы слегка окосели. Мужики не совсем верно истолковали наше молчание, и решили, что всё, можно начинать торговаться: — Ну… за ЯЩИК водки отдадите?
Мы кое-как от них отбились, объяснили, что оптимизатор стоит не один десяток тысяч долларов и быстро-быстро дошли до серверной. Там и начали выяснять, что это было.
Оказалось, что это не просто работяги, а операторы АРМ, которые отвечают, в частности, за отчётность. И у них бывают такие жизненные периоды, когда они приходят в этот административный блок работать. Там стоит их ERP, куда надо вбивать данные. Канал DSL, причём из тех, что не очень далеко ушли от ISDN. Тонкий, шумный как пустой товарняк, отдаёт наследием 90-х, в общем – заводская классика. А приложение современное, «болтливое», гоняет кучу шифрованного трафика. Поэтому лаги между щелчком по выпадающему списку и его показом – секунд 10-20. В лучшем случае. А вбивать там ого-го сколько всего. Ситуация несколько отягчается тем, что стучат они одним пальцем и часто ошибаются, поэтому приходится возвращаться назад. Что не добавляет особой радости из-за всё тех же лагов.
Так вот, они узнали, что та чудо-железяка, которую с помпой тащили через весь завод на второй этаж – это оптимизатор трафика. В целом, они бы ничего не поняли, если бы не постояли за спиной у тех, кто тестировал этот девайс в соседнем кабинете, где всё тот же ривербед был подключен на пилот. В этот момент они сразу всё осознали и попросились на пару дней туда для детального теста. Их пустили.
В итоге они за 2 последних дня апреля сделали весь нужный отчёт. Это их очень впечатлило, потому что пару прошлых лет они тусили на заводе на майские праздники как минимум до 6-го. По итогам они решили, что надо бы такую железку, может, даже за свои купить, скинувшись из зарплаты. Не хотелось оставаться сверхурочно хоть ты тресни.
Естественно, таких цен они просто не ждали.
Через пару часов мы выходим сказать грузчикам, что всё готово, можно забирать. На выходе уже ждут два наших героя: — Мужики, а давайте вы её оставите для тестов ещё на месяц, а? ЯЩИК дадим.
Чем кончилось – не знаю. Руководство холдинга после тестового внедрения купило несколько десятков железных оптимизаторов. Попала ли к нашим парням железка в итоге или нет, не могу сказать, но очень хочу верить, что попала. Ну или хотя бы им установили программный агент, который умеет отвечать «большому» серверу.
Ссылки:
habr.com
Оптимизация сетевого оборудования — МегаЛекции
Хотя имеется очень мало возможностей для непосредственной оптимизации сетевого адаптера, но сам выбор хорошего адаптера может удвоить производительность WindowsNTServer. Для выбора сетевого адаптера имеются некоторые соображения. Во-первых, нужно выбирать такой адаптер, который использует всю разрядность шины ввода-вывода компьютера. Если компьютер имеет шину EISA, то нужен адаптер для этой шины, а не 8- или 16-разрядный адаптер.
Во-вторых, выбор сетевого адаптера включает выбор драйвера адаптера. Для WindowsNT нужно выбирать адаптер, сертифицированный для работы по спецификации NDIS 3.x. Такую информацию можно найти в списке WindowsNTHardwareCompatibility.
С сетевой активностью связано большое количество счетчиков. Все сетевые компоненты WindowsNT - Server, Redirector, протоколы NetBIOS, NWLink, TCP/IP - генерируют набор статистических параметров. Ненормальное значение сетевого счетчика часто говорит о проблемах с памятью, процессором или диском сервера. Следовательно, наилучший способ наблюдения за сервером состоит в наблюдении за сетевыми счетчиками в сочетании с наблюдением за такими счетчиками, как %ProcessorTime, %DiskTime и Pages/sec.
Например, если сервер показывает резкое увеличение счетчика Pages/sec одновременно с падением счетчика Totalbytes/sec, то это может говорить о том, что компьютеру не хватает физической памяти для сетевых операций.
Оптимизация сервиса рабочей станции
Хотя редиректор WindowsNT (сервис Workstation) является самонастраивающимся, администратор должен следить за показаниями нескольких счетчиков:
· Current Commands;
· Network Errors/sec;
· Remote Server Bottlenecks.
CurrentCommands - это количество команд, которые находятся в очереди к редиректору. Если это число больше, чем одна команда на один сетевой адаптер, то редиректор может быть узким местом в системе. Это может происходить по трем причинам:
· Сервер, с которым взаимодействует редиректор, работает медленней, чем редиректор;
· Сеть испытывает перегрузки;
· Редиректор более загружен, чем адаптер;
Если выявлена перегруженность сети, можно ее несколько разгрузить за счет сегментации сети.
NetworkErrors/sec - это интенсивность возникновения серьезных сетевых ошибок, обнаруженных редиректором. Наличие таких ошибок говорит о том, что нужны дополнительные исследования. Целесообразно использовать для этой цели регистратор событий EventLog.
Производительность редиректора может ограничиваться за счет низкой производительности удаленных серверов, с которыми взаимодействует редиректор. В PerformanceMonitor есть два счетчика - ReadsDenied/sec и WritesDenied/sec, ненулевые значения которых свидетельствуют о том, что удаленные серверы испытывают трудности с выделением оперативной памяти. Необходимо проверить серверы, с которыми данный редиректор обменивается большими файлами. Если на них нет возможности увеличить объем памяти, используемой для режима RAW протокола SMB (этот режим рассматривается ниже), то на рабочей станции нужно запретить использование этого режима. Это делается с помощью установки переменных UseRawReads и UseRawWrites в состояние False.
Оптимизация сервера
Оптимизация WindowsNTServer подобна оптимизации WindowsNTWorkstation за несколькими исключениями:
· Компоненты, поддерживающие пользовательский интерфейс, такие как мышь, клавиатура и видеоподсистема, меньше нуждаются в оптимизации, так как в большинстве случаев компьютер с WindowsNTServer не будет поддерживать интерактивный доступ пользователей.
· Серверные компоненты в данном случае более важны, чем редиректор. Если память является узким местом, то можно уменьшить память, выделенную для редиректора и увеличить для сервера.
· Если сервер выполняет приложения, написанные в модели клиент-сервер, такие как SQLServer, SNAServer или приложения, поддерживающие механизм RPC, то к диску будет обращаться меньше приложений, так что распределение файлов между несколькими дисками может оказаться весьма полезным.
Серверные компоненты WindowsNT можно сконфигурировать из панели Network утилиты ControlPanel. Имеется четыре общих установки:
· MinimizeMemoryUsed - минимизация используемой памяти, изначально уменьшает до 10 максимальное число соединений с клиентами.
· Balance - баланс между потребляемой памятью и производительностью, поддерживается до 64 соединений.
· MaximizeThroughputForFileSharing - выделяется память для максимально поддерживаемого числа соединений (до 71 000 соединений).
· MaximizeThroughputForNetworkApplications - выделяется память для максимально поддерживаемого числа соединений, но для кэша выделяется меньше памяти, чем в предыдущем случае.
Процесс обработки сетевых запросов сервером можно наблюдать с помощью счетчика WorkItemShortage объекта Server, а влиять на этот процесс можно путем задания значений для двух переменных базы Registry - InitialWorkItems и MaximumWorkItems. WorkItem - это рабочая структура, которая используется сервером для постановки в очередь сетевых запросов от клиентов. Если сервер перегружен, то запрос от клиента может быть отклонен, так как в наличии нет свободной рабочей структуры для его фиксации. При возникновении такого события PerformanceMonitor наращивает значение счетчика WorkItemShortage. Администратор должен отслеживать этот счетчик и изменять значения переменных Registry, если это необходимо.
Два счетчика информируют администратора о том, что сервер достиг границы максимально доступной для него памяти:
· PoolNonpagedFailures - количество попыток получения памяти из пула не охваченной страничным механизмом памяти, которые были неудачными из-за недостатка ресурсов. Эти события ясно указывают на то, что в компьютере не хватает физической памяти для работы сервера в данной конфигурации.
· PoolPagedFailures - количество попыток получения памяти из пула свободных страниц, которые были неудачными из-за недостатка ресурсов. Это говорит либо о недостатке физической памяти, либо о недостаточном размере страничного файла.
Рекомендуемые страницы:
Воспользуйтесь поиском по сайту:
megalektsii.ru