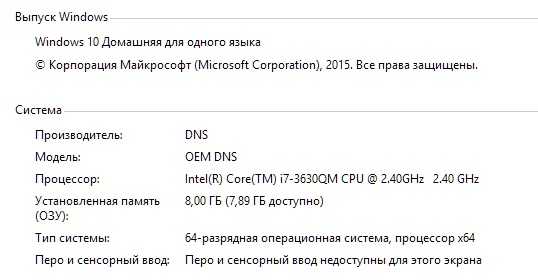
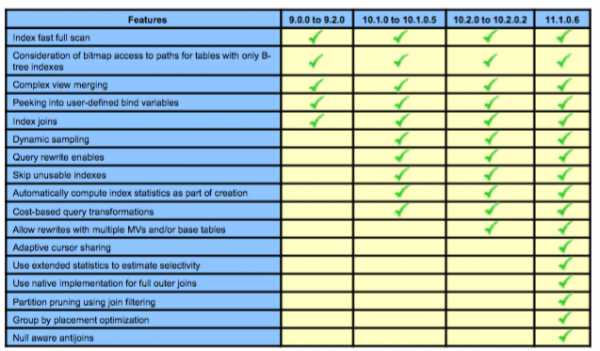
Файловые системы Linux. Btrfs. Btrfs оптимизация
Файловая система Btrfs | Losst
Переход на новую файловую систему, это всегда сложная задача. Мы уже доверяем старой, проверенной файловой системе. Она может даже имеет некоторые ограничения функциональности и производительности, но зато никогда нас не подводила. Новые файловые системы предлагают очень большое количество функций, но возникает вопрос, можно ли им доверять?
Одной из таких файловых систем является Btrfs. Это относительно новая файловая система, которая появилась в 2007 году и была разработана компанией Oracle. Она предлагает очень широкий набор новых возможностей и поэтому сильно интересует пользователей, но до сих пор в сети ходят слухи, что эта файловая система еще не пригодна для постоянного использования. В этой статье мы попытаемся разобраться какие возможности нам дает Btrfs, а также действительно ли ее уже можно использовать.
Содержание статьи:
Что такое Btrfs?
Как я уже сказал, Btrfs была разработана компанией Oracle в 2007 году. Одной расшифровки названия нет, одни говорят, что это значит B-tree FS, другие Better Fs. Также как и в других файловых системах, все данные хранятся на диске по определенным адресам. Эти адреса сохранены в метаданных. И тут уже начинаются различия. Все метаданные организованны в виде b-деревьев. Это дает большую производительность при работе с файловой системой, а также позволяет добавлять неограниченное количество файлов.
Но даже это еще не все. Когда вы перезаписываете файл, данные не перезаписываются, а лишь модифицированная часть копируется в новое место, Затем просто обновляются метаданные. Это позволяет создавать мгновенные снимки файловой системы, которые не занимают места на диске, пока не было внесено много изменений. Если же старый блок больше не нужен, потому что он не является частью какого-либо снимка, то он автоматически удаляется.
Из-за своей структуры Btrfs имеет огромные возможности, например, она может работать с современными очень большими носителями данных. Максимальный размер файловой системы составляет 16 Экзабайт. Это все возможно благодаря правильному использованию пространства на диске. Другие файловые системы используют жесткий диск целиком, от начала до конца для записи своей структуры.
Btrfs поступает по-другому. Каждый диск, независимо от его размера делится на блоки по 1 Гб для данных и 256 Мб для метаданных. Затем эти блоки собираются в группы, каждая из которых может храниться на разных устройствах, количество таких блоков в группе может зависеть от уровня RAID для группы. Менеджер томов уже интегрирован в файловую систему, поэтому больше никакое дополнительное ПО использовать не нужно.
Защита и сжатие данных тоже поддерживается на уровне файловой системы так что здесь вам тоже не нужны дополнительные программы. Также файловая система btrfs поддерживает зеркалирование данных на нескольких носителях. Вот другие особенности btrfs, которые можно упомянуть:
- Поддержка снимков файловой системы, только для чтения или для записи;
- Контрольные суммы для данных и метаданных с помощью алгоритма crc32. Таким образом, можно очень быстро определить любые повреждения блока;
- Сжатие с помощью Zlib и Lzo;
- Оптимизация для работы с SSD, файловая система автоматически определяет ssd и начинает вести себя по-другому;
- Фоновый процесс для обнаружения и исправления ошибок, а также дефрагментации и дедупликации в реальном времени;
- Поддерживается преобразование из ext4 и ext3 и обратно.
Все это очень хорошо, но можно ли уже использовать эту файловую систему? Попробуем разобраться и с этим.
Готова ли Btrfs к использованию?
Вокруг Btrfs до сих пор сохранилось много неправильных представлений. Многие из них происходят от реальных проблем, которые были в начале разработки файловой системы. Но люди, просматривая эту информацию не смотрят на ее дату. Да Btrfs действительно была нестабильной и неустойчивой. Было очень много проблем с потерей данных и много пользователей писали об этом, но это было еще в 2010 году.
Самая важная часть файловой системы - это ее формат хранения на диске. Но формат файловой системы Btrfs уже зафиксирован, это случилось еще в 2012 году и он больше не изменяется без крайней необходимости. Это само по себе достаточно, чтобы признать стабильность btrfs.
Но почему же Btrfs считается многими нестабильной? Этому есть несколько причин. Во-первых, это боязнь пользователей к новым технологиям. Это было не только в Linux, но и в Microsoft, при их переходе на NTFS, и в Apple. Но здесь есть некоторый парадокс, файловая система XFS прошла 20 лет стабильного развития, но самой стабильной файловой системой считается ext4, которая была разработана из форка ext3 в 2006 году. Фактически она на год старше Btrfs.
Вторая причина в активной разработке, хотя формат хранения данных заморожен, основная кодовая база еще активно разрабатывается и там есть еще много места для улучшения производительности и внедрения новых функций.
Но уже есть много подтверждений, что файловая система готова. Эта файловая система используется на серверах Facebook, где компания хранит свои важные данные. А это уже само по себе важный фактор. Над улучшением файловой системы работают такие компании как Facebook, SuSE, RedHat, Oracle, Intel и другие. Эта файловая система используется в SUSE Linux Enterprise по умолчанию, начиная с выпуска 12. Все эти факторы вместе доказывают, что файловая система вполне готова к использованию. А учитывая функциональность и особенности btrfs ее уже можно использовать.
Использования Btrfs
Почему стоит использовать Btrfs и стоит ли вообще, разобрались. Теперь хотелось бы показать немного практики, чтобы вы могли оценить эту файловую систему в действии. Я буду приводить примеры на основе Ubuntu. Сначала установим инструменты для управления файловой системой:
sudo apt install btrfs-tools
Создание файловой системы btrfs
Сначала нужно создать файловую систему. Допустим, у нас есть два жестких диска /dev/sdb и /dev/sdc, мы хотим создать на них единую файловую систему с зеркалированием данных. Для этого достаточно выполнить:
sudo mkfs.btrfs /dev/sdb /dev/sdc
По умолчанию будет использоваться RAID0 для данных (без дублирования, и RAID1 для метаданных (дублирование на один диск). При использовании одного диска метаданные тоже дублируются, если вы хотите отключить это поведение можно использовать опцию -m single:
sudo mkfs.btrfs -m single /dev/sdb
Но делая это, вы повышаете опасность потери данных, поскольку если метаданные будут утеряны, то данные тоже.
Посмотреть информацию о только что созданной файловой системе вы можете командой:
sudo btrfs filesystem show /dev/sdb
Или обо всех подключенных файловых систем:
sudo btrfs filesystem show
Монтирование btrfs
Для монтирования используйте обычную команду:
sudo mount /dev/sdb /mnt
Вы можете монтировать любой из дисков, это приведет к одинаковому эффекту. Строчка в /etc/fstab будет выглядеть так:
/dev/sdb /mnt btrfs defaults 0 1
Теперь смотрим информацию о занимаемом месте на дисках:
sudo btrfs filesystem df /mnt
Сжатие в btrfs
Для включения сжатия достаточно добавить опцию compress при монтировании. Ей можно передать алгоритм lzo или zlib:
sudo mount -o compress=lzo /dev/sdb /mnt$ sudo mount -o compress=zlib /dev/sdb /mnt
Восстановление Btrfs
Для восстановления поврежденной Btrfs используйте опцию монтирования recovery:
sudo mount -o recovery /dev/sdb /mnt
Изменение размера
Вы можете изменить размер тома в реальном времени, для этого используйте команду resize:
sudo btrfs filesystem resize -2g /mnt
Уменьшит размер на 2 гигабайта. Затем увеличим на 1 Гигабайт:
sudo btrfs filesystem resize +1g /mnt
Создание подтомов
Вы можете создавать логические разделы, подтома внутри основного раздела с помощью Btrfs. Они могут быть примонтированы внутри основного раздела:
sudo btrfs subvolume create /mnt/sv1$ sudo btrfs subvolume create /mnt/sv2$ sudo btrfs subvolume list /mnt
Монтирование подтомов
Вы можете примонтировать подтом по id, полученному с помощью последней команды:
sudo umount /dev/sdb
sudo mount -o subvolid=258 /dev/sdb /mnt
Или вы можете использовать имя:
sudo mount -o subvol=sv1 /dev/sdb /mnt
Удаление подтомов
Сначала подключите корень btrfs вместо подтома:
sudo umount /mnt
sudo mount /dev/sdb /mnt/
Чтобы удалить подтом можно использовать путь монтирования, например:
sudo btrfs subvolume delete /mnt/sv1/
Создание мгновенных снимков
Файловая система Btrfs позволяет создавать мгновенные снимки изменений. Для этого используется команда snapshot. Например, создадим файл, затем сделаем снимок:
touch /mnt/sv1/test1 /mnt/sv1/test2
Создаем снимок:
sudo btrfs subvolume snapshot /mnt/sv1 /mnt/sv1_snapshot
Дефрагментация btrfs
Из-за использования копирования при записи может возникать фрагментация. Чтобы запустить дефрагментацию файловой системы используйте команду:
Выводы
Как видите, файловая система btrfs очень интересная и перспективная. К тому же она уже полностью готова к использованию и достаточно стабильна. А вы уже пользуетесь Btrfs? Собираетесь пользоваться после прочтения статьи? Напишите в комментариях внизу!
Оцените статью:
Загрузка...losst.ru
Improving performance (Русский) - ArchWiki
Эта страница нуждается в сопроводителе
Статья не гарантирует актуальность информации. Помогите русскоязычному сообществу поддержкой подобных страниц. См. Команда переводчиков ArchWikiЭта статья является ретроспективным анализом и кратким изложением того, как увеличить производительность в Arch Linux.
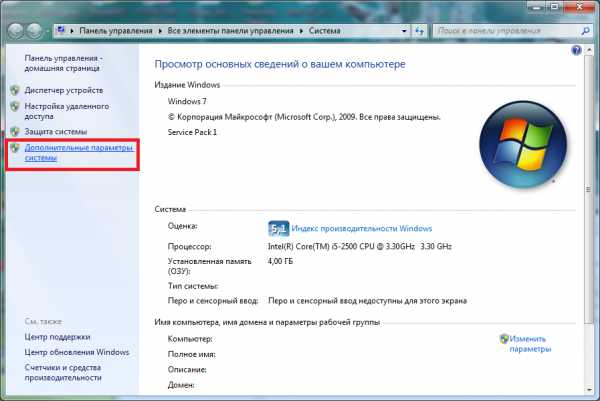
Основы
Узнай свою систему
Лучший способ настроить систему — определить «узкие места», т.е. подсистемы, которые снижают общую скорость работы. Как правило, они могут определены, зная характеристики системы, однако есть несколько основных признаков:
- Если компьютер начинает медленнее работать при запуске «больших» приложений, таких как OpenOffice и Firefox, запущенных одновременно, то существует большая вероятность того, что объём оперативной памяти недостаточен. Чтобы проверить объём оперативной памяти, используйте эту команду:
- Если время загрузки очень большое и если приложения запускаются медленно при первом запуске, но потом работают нормально, то, вероятнее всего, жёсткий диск работает медленно. Скорость жёсткого диска может быть измерена с помощью команды hdparm:
Это только скорость чтения с диска и не является абсолютным критерием, но значение скорости выше 40 МБ/с можно считать приемлимым для средней системы.
- Если загрузка процессора постоянно высокая, даже когда есть достаточно оперативной памяти, то снижение загрузки процессора является приоритетной задачей. Загрузку процессора можно контролировать множеством способов, например, используя команду top (а лучше htop):
- Если медленно работают только те приложения, которые используют ускорение (direct rendering), т.е. где используется видеокарта (видеоплееры, игры и т.п.), то увеличение производительности видеокарты возможно будет достичь. Чтобы убедиться в этом, поставьте mesa-demos:
Затем попробуйте запустить эту команду на 20 секунд (vblank_mode=0 отключает вертикальную синхронизацию у свободных драйверов):
$ vblank_mode=0 glxgearsЕсли у вас ниже 300 FPS, то, возможно, у вас отключён direct rendering. Чтобы проверить это, введите команду:
$ glxinfo | grep directПервое, что необходимо сделать
Самый простой и эффективный способ повысить общую производительность — это использовать легковесные окружения (Desktop Environment) и легковесные приложения:
- Использовать оконный менеджер вместо среды рабочего стола. Вы можете выбрать dwm, Openbox или JWM.
- Выберите минималистичные оркужения рабочего стола (не GNOME и KDE), а, например, LXDE или Xfce.
- Используйте легковесные приложения. См. список приложений и темы на форуме, посвящённые легким и быстрым приложениям: 2007, 2008, 2009, and 2010.
- Удалите из запуска все ненужные демоны. Для этого надо сначала посмотреть какие демоны запущены:
Затем, если вам, например, не нужен avahi-daemon.service, ввести:
# systemctl disable avahi-daemonЖёсткие диски
Выбор и настройка файловых систем
Выбор лучшей файловой системы под особенности системы является очень важным, так как каждая файловая система имеет свои сильные стороны. В File systems кратко рассматриваются наиболее популярные файловые системы. Вы можете также найти полезные статьи здесь.
Резюме
- XFS: Высокая производительность при работе с большими файлами. Низкая скорость при работе с маленькими файлами. Хороший выбор для /home.
- Reiserfs: Хорошая производительность при работе с маленькими файлами. Хороший выбор для /var.
- Ext3: Средняя производительность, надёжность.
- Ext4: Превосходная общая производительность, надёжность, имеет проблемы с производительностью SQLite и другими базами данных.
- JFS: Хорошая общая производительность, низкое потребление ресурсов процессора.
- Btrfs: Превосходная общая производительность (лучше чем у ext4), надёжна (как только станет стабильной). Множество функций. Тем не менее эта файловая система находится на стадии разработки, и рассматривается как нестабильная. Не используйте эту файловую систему, если вы не знаете, что вы делаете, и не готовы к возможной потери данных.
Параметры монтирования
Опции монтирования позволяют легко увеличить скорость без переформатирования. Они могут быть установлены при использовании команды mount:
$ mount -o option1,option2 /dev/partition /mnt/partitionЧтобы сделать эти опции постоянными, измените свой /etc/fstab
/dev/partition /mnt/partition partitiontype option1,option2 0 0Два параметра, которые увеличивают проивзодительность почти всех файлов систем — это noatime, nodiratime. Первый является расширением второго, который применяется только к каталогам (noatime применяется и к каталогам и к файлам). В редких случаях, например если вы используете mutt, это может стать причиной незначительных проблем. Их вы можете использовать вместо параметра relatime.
Ext3
Смотри Ext3 Filesystem Tips.
JFS
Смотри JFS Filesystem.
XFS
Для оптимизации скорости создайте XFS командой:
# mkfs.xfs -l internal,lazy-count=1 size=128m -d agcount=2 /dev/thetargetpartitionТакой специфичный для XFS параметр монтирования как logbufs=8 может увеличить производительность.
#/etc/fstab LABEL=XFSHOME /home xfs noatime,logbufs=8 0 1Reiserfs
Параметр data=writeback увеличивает скорость, но это может привести к повреждению данных при отключении питания. Опция монтирования ((Codeline | notail)) увеличивает пространство, используемое файловой системы примерно на 5 %, но и повышает общую скорость. Вы также можете уменьшить нагрузку на диск, располагая файловую систему и журнал на разных дисках. Сделать это можно следующим образом:
# mkreiserfs –j /dev/hda1 /dev/hdb1Тут /dev/hda1 будет зарезервирован для журнала, а /dev/hdb1 для данных. Вы можете узнать больше о ReiserFS в этой статье.
Btrfs
Btrfs — новая файловая система, позволяющая делать онлайн дефрагментацию, имеющая оптимизированный режим для твердотельных накопителей, запись снапшотов, изменение размера раздела без потери данных и другие возможности. Btrfs находится в активной разработке и поддерживается ядром (в экспериментальном режиме). Больше можно узнать на Btrfs домашней странице проекта.
mkinitcpio.conf для btrfs
Для Btrfs в качестве некорневой файловой системы модули и зависимости загружаются, когда это необходимо. При использовании btrfs в качестве корневой файловой системы в загрузочном ramdisk должен быть соответствующий модуль. Модуль btrfs зависит от libcrc32c. Вам нужно добавить crc32c модули в /etc/mkinitcpio.conf, как показано ниже:
MODULES="crc32c libcrc32c zlib_deflate btrfs"Это позволяет избежать ошибок, таких как «неизвестный символ» при загрузке Btrfs модулей. См. также mkinitcpio-btrfs.
Сжатие /usr
Одним из способов увеличить скорость чтения данных с диска — это сжатие, т.к. уменьшается объём данных для чтения. Однако данные должны быть распакованы, что увеличит нагрузку на ЦП. Некоторые файловые системы поддерживают прозрачное сжатие, такие как Btrfs и Reiserfs4, но их сжатия ограничивается 4K (btrfs 128К) размер блока. Поэтому в этом руководстве рассматривается сжатие /usr в SquashFS и последующее монтирование через Aufs. Это экономит довольно много места, как правило две трети, и приложения запускаются быстрее. Однако установка, обновление или перестановка приложений будут перезаписывать несжатый /usr, поэтому вам придётся периодически сжимать /usr. SquashFS уже включён в ядро, Aufs можно найти в extra репозитории, так что перекомпиляция ядра не требуется. Чтобы всё это заработало, нужно установить всего два пакета:
# pacman -S aufs2 squashfs-toolsЭта команда установит Aufs модули и некоторые утилиты для файловой системы SquashFS. Теперь нам понадобятся две директории. Одна для сохранения сжатого /usr в режиме «только для чтения» и вторая — для записи изменений с момента последнего сжатия, т.е. «для записи».
$ mkdir -p /squashed/usr/{ro,rw}Кэширование файлов
Есть такой параметр vm.vfs_cache_pressure. Он влияет на тенденцию ядра освобождать оперативную память, использованную для кэширования объектов ФС. Значение по умолчанию 100. При значении 0, объекты он кэширует (в оперативную память) навсегда. Чем больше значение, тем чаще ядро занимается чисткой их (так будет больше свободной оперативной памяти). Если у вас оперативной памяти не хватает (например, всего 2 ГБ), то лучше поставить 1000:
# sysctl -w vm.vfs_cache_pressure=1000Эта команда будет действует только на текущий сеанс ОС. А чтобы при каждом старте ОС действовало, надо:
# echo "vm.vfs_cache_pressure=1000" >> /etc/sysctl.d/99-sysctl.confПроцессор
Единственный способ увеличить производительность ЦП — его разгон (оверклокинг). Так как это сложный рискованный процесс, производить его рекомендуется только экспертам. Не забывайте, что у многих материнских плат под процессоры Intel отключена возможность разгона.
Также многие Intel Core i5 и i7, даже после правильного оверклокинга через BIOS или UEFI, не могут сообщить правильную частоту acpi_cpufreq и многим другим утилитам.
VeryNice
VeryNice — демон, который доступен в AUR под названием veryniceAUR. Он занимается динамической регулировкой приоритетов (nice level) приложений. Чем больше приоритет, тем относительно больше ресурсов будет выделено именно этому приложению. Это особенно может пригодиться для мультимедиа приложений (например, чтобы проигрывание и запись видео была без особых задержек). Просто определите важные процессы в /etc/verynice.conf как goodexe, а ненужные CPU-hungry (например, make, gcc, g++ при компиляции) как badexe. При большой нагрузкe всё это сильно поднимет отзывчивость системы.
Однако для PulseAudio приоритет надо править в файле /etc/pulse/daemon.conf, после чего произвести перезагрузку.
wiki.archlinux.org
Файловые системы Linux. Btrfs. | LinuxRussia.com
В начале XXI века современной файловой системе уже недостаточно всего лишь быстро работать с файлами и защищать их от повреждений. ZFS показала нам всю мощь технологии Copy-on-Write (CoW, копирование-при-записи) в задачах сохранения данных. Для Linux была создана Btrfs — новая стандартная ФС, построенная на технологии CoW. Судя по тому, что Apple активно доделывает свою APFS, которая также использует CoW, набор возможностей ZFS/Btrfs действительно даёт новый уровень комфорта для пользователя. Чтобы ощутить его, достаточно попробовать Btrfs самим.
Немного теории для понимания.
Вы создаёте файл, внутри которого — строчка «Девочка Таня у клетки ходила». Сохраняете его на обычную ФС, например, на Ext4 или NTFS. Теперь, если вы откроете файл и добавите в него вторую строчку «Снова не надо кормить крокодила», файловая система при сохранении полностью перезапишет прежнюю версию файла. То есть, той версии файла, где в нём только одна строка, больше не существует.
Теперь проделаем то же самое на Btrfs. Создание файла с одной строкой проходит так же, но когда вы добавляете в файл вторую строку и сохраняете, проявляется то самое копирование-при-записи. Прежняя версия файла не перезаписывается, он остаётся нетронутой, а строка «Снова не надо кормить крокодила» дописывается в свободное место ФС.
Когда вы хотите прочитать этот файл, вы видите только последнюю версию, но с помощью утилиты btrfs можно вернуть его к прежним состояниям. Таким образом Btrfs может сохранять историю изменений каждого файла — надобность в журналировании отпадает, Btrfs просто периодически запоминает состояние ФС, и при малейшей ошибке откатывается к прежней версии.
Использование Btrfs в Ubuntu.
Установщик Ubuntu давно поддерживает Btrfs, так что никаких проблем с этим нет:
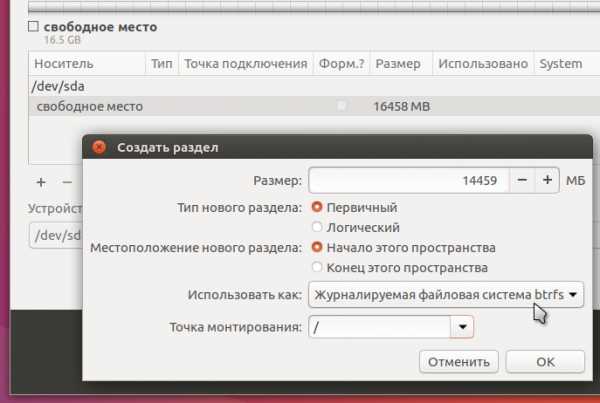
Btrfs оперирует томами или subvolumes — это как бы разделы внутри файловой системы. «Как бы» — потому что тома больше похожи на каталоги, чем на разделы. Но такой особый каталог можно монтировать как раздел. Установщик Ubuntu создаёт отдельные тома для системы и для домашнего каталога:
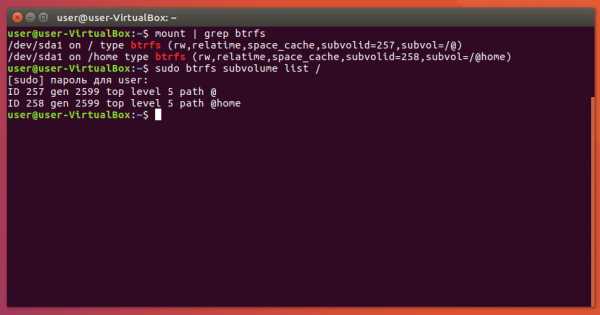
Так делается потому, что намного быстрее и легче сохранить состояние целого тома, чем состояние каждого из тысяч файлов в этом томе. Вторая команда показывает, что на Btrfs созданы тома @ и @home, но увидеть их в файловом менеджере не получится. Нужно сначала примонтировать корень Btrfs (не путать с корнем системы):
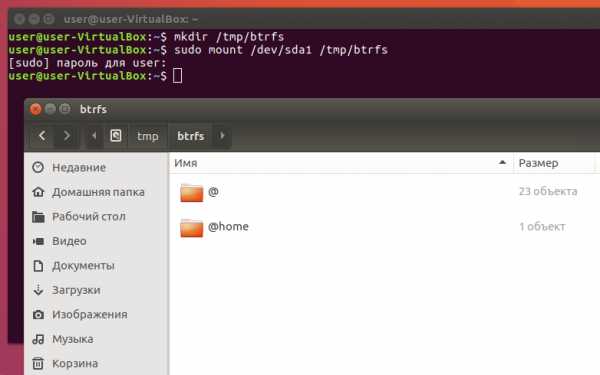
Что можно делать с томами Btrfs.
Экономия места на накопителе.
Для любого тома можно включить прозрачное сжатие по одному из двух алгоритмов: zlib и lzo. Первый лучше сжимает, зато второй на порядок быстрее работает. Для системы обычно используют lzo, а zlib имеет смысл на больших объёмах, которые редко читаются. Включается сжатие опцией монтирования compress=lzo в файле /etc/fstab:
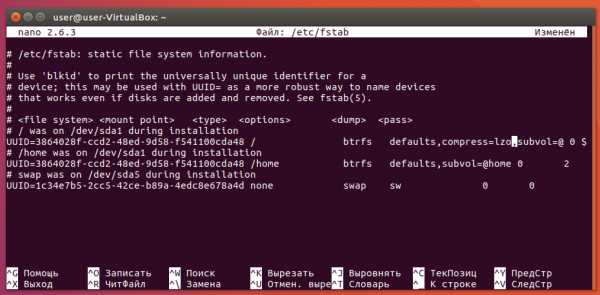
После перезагрузки сжатие будет активировано. Обратите внимание, как монтируется том в указанный каталог — через опцию subvol=нужный_том.
Страховка от неудачных обновлений.
Перед каждым апдейтом системы я делаю снапшот системного тома. Вот так это может выглядеть в Ubuntu:
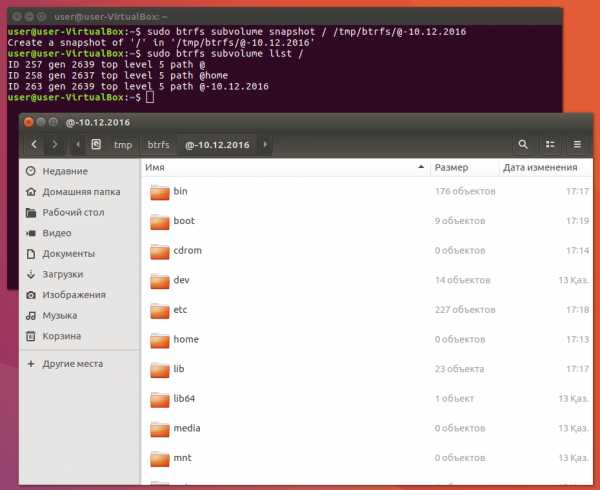
Так же можно сохранять и том с домашним каталогом, и вообще любой том. Снапшот Btrfs по умолчанию открыт для записи, но можно создать снапшот только для чтения:
sudo btrfs subvolume snapshot -r исходный_том снапшот
Представьте, что после обновления ваша система работает с ошибками или вообще не загружается. Тогда вам нужно будет просто указать в /etc/fstab последний снапшот в качестве системного тома через опцию subvol=нужный_том. Это можно сделать с помощью LiveCD.
Одна ФС на сколько угодно накопителей.
Для виртуальной машины с Ubuntu я создал 1 виртуальный накопитель. Представим, что на нём закончилось место. В таком случае я могу добавить ещё один виртуальный накопитель в настройках Virtualbox, а потом добавить его и к Btrfs:
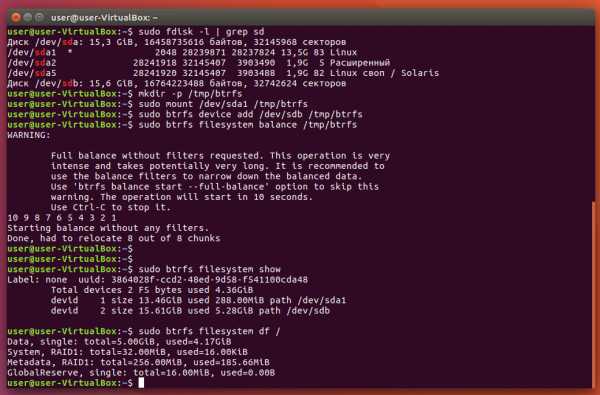
Как видите, Btrfs автоматически применила модель RAID1 — отзеркалировала данные на добавленный накопитель, но уровни RAID можно менять. То же самое можно делать и на реальной машине — добавлять и удалять накопители без необходимости переразбивать их и форматировать заново.
Использование Btrfs на SSD.
Как было сказано в прошлой статье, технология CoW приводит к высокой фрагментации файлов — все изменения в них записываются кусочками в разные места ФС. Именно поэтому Btrfs (а также ZFS) рекомендуется использовать на SSD, на которых фрагментация совершенно не ощущается.
Btrfs — достаточно современная и продвинутая файловая система, она поддерживает SSD, что называется, «из коробки». В журнале ядра можно увидеть такие строки:
По последней строчке видно, что Btrfs сама определила, что находится на SSD, и автоматически включила режим поддержки твердотельных накопителей. Этот режим также можно включить одноимённой опцией монтирования. Благодаря этому режиму Btrfs показывает высокую скорость на многопоточных операциях.
Но следует иметь в виду, что SSD-режим не включает в себя поддержку TRIM! Поэтому его нужно либо включать опцией монтирования discard, либо же регулярно запускать программу fstrim. В Ubuntu есть отдельный юнит systemd для периодической отработки этой программы, активировать его можно такой командой:
sudo systemctl enable fstrim.timer
Предотвращение деградации скорости.
У Btrfs есть одна неприятная архитектурная особенность: она упаковывает мелкие файлы прямо в дерево метаданных. Дерево метаданных это что-то вроде содержания в книге или поисковой системы в Интернете — в общем, очень важная вещь.
По умолчанию в дерево сохраняются файлы размером до 4 Кб, и вот здесь таится опасность. Из-за того, что размер файла заранее неизвестен, а диапазон размеров широк, дерево метаданных Btrfs сильно разрастается, что негативно отражается на скорости работы ФС.
Чтобы избежать этого, можно сильно ограничить максимальный размер файла, который будет упакован в дерево. Делается это опцией монтирования max_inline с указанием размера файла в байтах — конечно, в файле /etc/fstab:
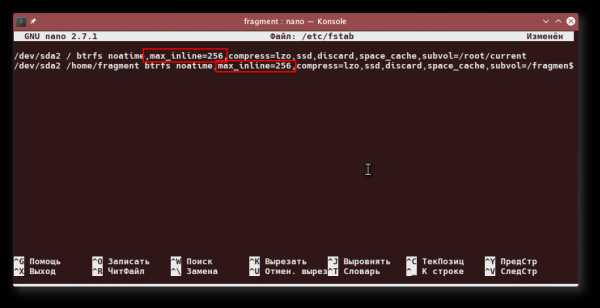
Теперь в дерево будут сохраняться только файлы размером до 256 байтов. Можно вообще отключить упаковку, указав 0 после знака «равно».
Кстати, нелишним будет отключить обновление временных меток при каждом обращении к файлу. Это делается опцией noatime. Это немного прибавляет скорости работы ФС, а на SSD ещё имеет смысл и потому, что сокращает количество записей на него.
Отключение CoW для томов и файлов.
Одно из выгодных отличий Btrfs от ZFS — возможность полностью отключить Copy-on-Write. Это может быть нелишним на HDD, чтобы снизить фрагментацию и повысить скорость. Но даже на SSD большие файлы, которые часто перезаписываются, могут из-за CoW замедлять работу всей файловой системы. К таким файлам можно отнести образы виртуальных машин и базы данных.
Отключить CoW можно на уровне тома, с помощью опции монтирования nodatacow:
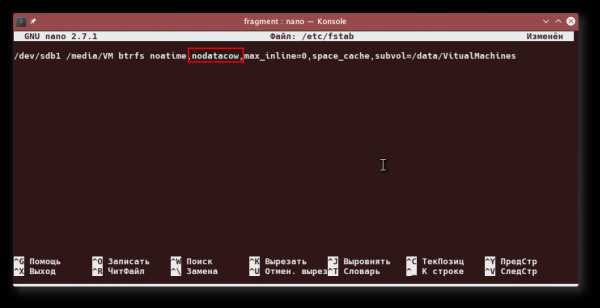
Но этот вариант может не сработать из-за запутанной системы зависимостей опций монтирования между томами. В этом случае можно отключить CoW на уровне атрибутов файла, с помощью команды:
chattr -R +C нужный_каталог
Казалось бы, ключ «+C» должен, по логике, включать CoW, но нет, всё наоборот. Чтобы включить CoW, нужно применить ту же команду, но уже с ключом «-C».
Анализ состояния Btrfs.
Часто люди не понимают, как правильно узнавать количество свободного и занятого места на Btrfs. Дело в том, что из-за снапшотов и сжатия обычные утилиты «сходят с ума» и показывают неправильные данные. Поэтому нужно использовать утилиту btrfs:
Её вывод тоже не очень понятен, так что разберём по строкам.
В первой строке пишутся совокупные объёмы выделенного и занятого места. Слово «single» означает, что Btrfs используется на одиночном накопителе. «Total» показывает, сколько места доступно, причём оно может быть намного меньше общего количества места на накопителе. Паниковать не стоит, просто Btrfs выделяет место порциями. Закончится одна порция — будет выделена ещё одна. Ну, а «used» показывает, сколько места на файловой системе реально занято.
Вторая строка отображает, сколько места занято под системный резерв. Нечто подобное есть и в Ext4.
Третья строка интереснее — в ней можно увидеть, сколько занимает то самое дерево метаданных. На скриншоте видно, что под дерево выделено 2 Гб, из которых заняты около 600 Мб. Эти показатели учитываются в первой строке.
Наконец, в четвёртой строчке показана информация о резервной области, но уже относящейся к самой Btrfs. Она нужна для того, чтобы даже на полностью забитой ФС можно было удалять и создавать тома и снапшоты.
Таким образом, чтобы узнать, сколько места реально занято на Btrfs, нужно смотреть на показатель «used» в первой строчке вывода команды:
sudo btrfs filesystem df нужный_путь
www.linuxrussia.com
Solid state drive (Русский) - ArchWiki
Ссылки по теме
Эта страница нуждается в сопроводителе
Статья не гарантирует актуальность информации. Помогите русскоязычному сообществу поддержкой подобных страниц. См. Команда переводчиков ArchWikiТвердотельные накопители (SSD) не достаточно просто подключить чтобы они заработали должным образом. Необходимо учитывать некоторые специфичные вещи для достижения оптимальной производительности, такие как выравнивание разделов, выбор файловой системы, поддержка TRIM и т.д. Статья пытается охватить общую информацию и ключевые понятия, чтобы позволить пользователям получить максимальную отдачу от твердотельных дисков под Linux. Рекомендуется прочесть статью полностью перед тем, как следовать рекомендациям.
Примечание: Хотя статья и предназначена для пользователей Linux, большая часть информации может относиться также и к другим операционным системам, таким как BSD, Mac OS X или Windows.
Обзор
Преимущества перед HDD
- Высокая скорость чтения. В 2-3 раза быстрее современных HDD (7200 об/мин на интерфейсе SATA2).
- Устойчивая скорость чтения. Скорость чтения не уменьшается на протяжении всего объёма диска, тогда как производительность HDD падает при перемещении головок от края пластин к центру.
- Минимальное время доступа. Приблизительно в 100 раз быстрее HDD. Например, 0,1 мс для SSD против 12-20 мс для HDD.
- Высокая степень надежности.
- Отсутствие движущихся частей.
- Минимальный нагрев.
- Минимальное потребление энергии. 1-2 Вт для SSD против 10-30 Вт для HDD (в зависимости от об/мин).
- Легкие. Идеальное решение для ноутбуков.
Недостатки
- Цена за единицу объёма (сотни рублей за ГБ на SSD, тогда как стоимость ГБ на HDD измеряется копейками).
- Ёмкость представленных моделей SSD намного ниже оной для HDD.
- Большие ячейки памяти требуют различных оптимизаций файловых систем. Низкий уровень доступа скрыт за контроллером, в то время как современные ОС могли бы использовать низкий уровень для собственных оптимизаций.
- Разделы и файловые системы требуют специальных оптимизаций. Размер страницы и размер стираемой страницы автоматически не определяется.
- Ячейки изнашиваются. MLC-ячейки, произведённые по 50нм техпроцессу, могут выдерживать до 10 тысяч циклов записи; 35нм обычно выдерживают всего 5000 циклов, а 25нм — 3000 (чем меньше техпроцесс, тем больше плотность и ниже цена). Если участки записи распределены соответствующим образом, не слишком малы и верно выровнены, это увеличивает срок жизни ячеек пропорционально общему объёму. Ежедневные объёмы записи должны быть сбалансированными в течение всего срока службы. Однако, тесты [1][2][3] проведённые на современных SSD показали, что износ накопителя является незначительным, а срок службы SSD сравним с оным для HDD, даже при больших объёмах записи.
- Сложные прошивки и контроллеры. В них часто встречаются баги. Современные потребляют мощность, сравнимую с HDD. Они реализуют подобие журнально-структурированной файловой системы со сборкой мусора, переводят команды SATA, изначально предназначенные для HDD; некоторые реализуют сжатие на лету. Также контроллер распределяет циклы записи по всей области диска для предотвращения быстрого износа ячеек, объединяет несколько команд записи мелких данных в одну, опять же, для увеличения продолжительности жизни диска. Наконец, они перемещают ячейки с данными по диску, чтобы те со временем не потеряли содержимое.
- Может падать производительность в зависимости от заполненности диска. Не все производители реализовывают сборку мусора достаточно хорошо, поэтому фрагментированное свободное пространство не всегда объединяется в целые ячейки.
На что обращать внимание перед покупкой
Есть несколько ключевых особенностей, на которые стоит обратить внимание до покупки SSD.
- Родная поддержка TRIM. Это жизненно необходимая функция для продления срока службы SSD и предотвращения уменьшения производительности операций записи от времени.
- Ключевым моментом является покупка SSD верного объема. Для эффективной работы разделы во всех файловых системах должны быть заполнены не более, чем на 75%.
Советы по увеличению производительности SSD
Выравнивание разделов
Смотрите Partitioning#Partition alignment.
TRIM
Примечание: TRIM дословно переводится как "подрезка", "подравнивать". - прим. пер.
Большинство SSD накопителей поддерживают команду ATA_TRIM, с помощью которой осуществляется одинаковая производительность и распределение износа. За подробностями, описывающими производительность до и после использования TRIM обратитесь к этому учебнику.
Начиная с ядра linux версии 3.7, следующие файловые системы поддерживают TRIM: Ext4, Btrfs, JFS, VFAT, XFS.
VFAT поддерживает TRIM только с помощью флага монтирования 'discard', а не с помощью fstrim.
Раздел #Выбор файловой системы в этой статье содержит более подробную информацию.
Проверьте, поддерживается ли TRIM
# hdparm -I /dev/sda | grep TRIM * Data Set Management TRIM supported (limit 1 block)Чтобы понять, в чём отличие между "limit 1 block" и "limit 8 blocks", обратитесь к статье wikipedia:TRIM#ATA
Включите TRIM с помощью флагов монтирования
Используйте следующий флаг монтирования в вашем /etc/fstab, чтобы получить преимущества команды TRIM, описанные выше:
/dev/sda1 / ext4 defaults,noatime,discard 0 1 /dev/sda2 /home ext4 defaults,noatime,discard 0 2 Примечание:- TRIM не включается по умолчанию при использовании шифрования блочных устройств на SSD; для дополнительной информации смотрите Dm-crypt/TRIM support for SSD.
- Нет необходимости использовать флаг discard, если вы периодически запускаете fstrim.
- Использование флага discard для корневого раздела с файловой системой ext3 приведёт к тому, что он будет смонтирован в режиме только-чтение.
Важно: Вы должны убедиться, что ваш SSD поддерживает TRIM перед тем, как пытаться монтировать раздел с флагом discard. Иначе вы можете потерять данные!
Применение TRIM по раписанию cron
Примечание: Этот метод не работает для файловых систем VFAT.
Безусловно рекомендуется включать TRIM на поддерживаемых SSD накопителях. Однако, иногда на некоторых SSD это может приводить к замедлению работы при удалении файлов. Если это ваш случай, вы можете использовать fstrim как альтернативу.
# fstrim -v /Раздел, который вы хотите "подтримить" должен быть примонтирован и должен быть указан точкой монтирования.
Если вам больше подходит данный способ, хорошей идеей будет запуск этой команды время от времени с помощью планировщика cron. Чтобы запускать эту команду ежедневно, установите cron пакет (cronie), реализация которого по умолчанию установлена на запуск ежечасных, ежедневных, еженедельных и ежемесячных заданий. Обратите внимание, что cronie systemd сервис не включен по умолчанию в новых установках Arch. Чтобы добавить эту команду в список ежедневных заданий cron, просто создайте скрипт script, содержащий эту команду и положите его в /etc/cron.daily, /etc/cron.weekly, и т.д. Если выбран этот способ, то рекомендуется подобрать соответствующие значения nice и ionice. После того как проделаете всё это, уберите опцию discard из /etc/fstab.
Примечание: Сначала вы должны попробовать использовать способ с опцией монтирования discard. Данный же способ нужно выбирать только если первый вам не подошёл для нормальной реализации TRIM.
Применение TRIM по systemd таймеру
Пакет util-linux предоставляет systemd юнит файлы fstrim.service и fstrim.timer . Если включить таймер, то сервис будет активироваться еженедельно, подравнивая все примонтированные файловые системы на устройствах, поддерживающих операцию discard.
Включение TRIM с помощью tune2fs (Discouraged)
Вы можете статически установить флаг trim с помощью tune2fs:
# tune2fs -o discard /dev/sdXYВключение TRIM для LVM
Измените значение опции issue_discards с 0 на 1 в файле /etc/lvm/lvm.conf.
Примечание: Enabling this option will "issue discards to a logical volumes's underlying physical volume(s) when the logical volume is no longer using the physical volumes' space (e.g. lvremove, lvreduce, etc)" (смотрите lvm.conf(5) и/или вписанные комментарии в /etc/lvm/lvm.conf). As such it does not seem to be required for "regular" TRIM requests (file deletions inside a filesystem) to be functional.Включение TRIM для dm-crypt
Важно: The discard option allows discard requests to be passed through the encrypted block device. This improves performance on SSD storage but has security implications. See Dm-crypt/TRIM support for SSD for more information.For non-root filesystems, configure /etc/crypttab to include discard in the list of options for encrypted block devices located on a SSD (see Dm-crypt/System configuration#crypttab).
For the root filesystem, follow the instructions from Dm-crypt/TRIM support for SSD to add the right kernel parameter to the bootloader configuration.
Планировщик ввода/вывода
Рассмотрим переход со стандартного CFQ планировщика (Completely Fair Queuing) к планировщикам NOOP или Deadline. Последние два обеспечивают повышение производительности SSD. Планировщик NOOP, например, реализует простую очередь входящих запросов чтения/записи без их переупорядочивания или группировки тех, что физически расположены ближе на накопителе. На SSD, в отличие от HDD, время доступа одинаково для всех секторов, поэтому изменение порядка запросов не имеет смысла.
Arch по умолчанию использует планировщик CFQ. Убедиться в этом можно, выведя содержимое файла /sys/block/sdX/queue/scheduler:
$ cat /sys/block/sdX/queue/scheduler noop deadline [cfq]Планировщик, используемый в данный момент, в списке доступных планировщиков выделен квадратными скобками.
Вы можете поменять планировщик прямо на лету, без необходимости перезагрузки:
# echo noop > /sys/block/sdX/queue/schedulerили:
$ sudo tee /sys/block/sdX/queue/scheduler <<< noopЭто непостоянный способ (то есть ваше изменение отменится после перезагрузки). Чтобы убедиться в том, что изменения вступили в силу, снова посмотрите содержимое файла и убедитесь, что теперь "noop" в квадратных скобках.
Параметр ядра (для единственного накопителя)
Если в системе единственным устройством накопления является SSD, то рекомендуется настроить планировщик ввода/вывода для всей системы с помощью параметра ядра elevator=noop.
Использование udev как для одного накопителя, так и для нескольких разных
This article or section is out of date.
Хотя вышеописанные методы будут работать без проблем, ниже представлено также довольно надёжное решение. Следует отметить, что с переходом на systemd, файл rc.local больше не существует. Следовательно, было бы предпочтительнее использовать систему, которая отвечает за устройства, в первую очередь для реализации планировщика. В нашем случае это udev, и чтобы осуществить задуманное, всё что нам нужно — простое udev-правило.
Создайте файл в директории /etc/udev/rules.d с именем, например, '60-schedulers.rules'. Запишите в него следующие строки:
# установка планировщика deadline для SSD ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="0", ATTR{queue/scheduler}="deadline" # установка планировщика cfq для HDD ACTION=="add|change", KERNEL=="sd[a-z]", ATTR{queue/rotational}=="1", ATTR{queue/scheduler}="cfq"Конечно же вы можете заменить deadline/cfq любыми другими планировщиками. Изменения вступают в силу после перезагрузки. Чтобы проверить сработало ли правило, выполните команду
$ cat /sys/block/sdX/queue/scheduler #где X — буква физического накопителяПримечание: Имейте в виду, CFQ является планировщиком по умолчанию, так что второе правило на самом деле не нужно, если вы пользуетесь стандартным ядром. Также в примере имя правила начинается с числа 60, т. к. это число udev использует для своих строгих правил именования. Блочные устройства в этом диапазоне чисел могут модифицироваться, и это безопасная позиция для данного правила. Однако, правило может называться как угодно, при этом оканчиваться на '.rules'. (Источник: falconindy и w0ng на своём блоге)
Разделы подкачки на SSD
Можно размещать раздел подкачки на SSD. Но с другой стороны, современные компьютеры, имеющие более 2 ГБ оперативной памяти, используют раздел подкачки очень редко. Заметным исключением являются системы, которые используют спящий режим. Следующая оптимизация для SSD уменьшает "swappiness" системы, чтобы избежать записей подкачки:
# echo 1 > /proc/sys/vm/swappinessИли можно просто изменить файл /etc/sysctl.d/40-swappiness.conf как рекомендуется в вики-статье Maximizing Performance[broken link: invalid section]:
vm.swappiness=1 vm.vfs_cache_pressure=50Hdparm shows "frozen" state
Some motherboard BIOS' issue a "security freeze" command to attached storage devices on initialization. Likewise some SSD (and HDD) BIOS' are set to "security freeze" in the factory already. Both result in the device's password security settings to be set to frozen, as shown in below output:
:~# hdparm -I /dev/sda Security: Master password revision code = 65534 supported not enabled not locked frozen not expired: security count supported: enhanced erase 4min for SECURITY ERASE UNIT. 2min for ENHANCED SECURITY ERASE UNIT.Operations like formatting the device or installing operating systems are not affected by the "security freeze".
The above output shows the device is not locked by a HDD-password on boot and the frozen state safeguards the device against malwares which may try to lock it by setting a password to it at runtime.
If you intend to set a password to a "frozen" device yourself, a motherboard BIOS with support for it is required. A lot of notebooks have support, because it is required for hardware encryption, but support may not be trivial for a desktop/server board. For the Intel DH67CL/BL motherboard, for example, the motherboard has to be set to "maintenance mode" by a physical jumper to access the settings (see [4], [5]).
Warning: Do not try to change the above lock security settings with hdparm unless you know exactly what you are doing.
If you intend to erase the SSD, see Securely wipe disk#hdparm and below[broken link: invalid section].
Очистка ячеек памяти SSD
В некоторых случаях, пользователь может полностью сбросить ячейки SSD в состояние, подобное моменту покупки нового накопителя, таким образом добиться заводской производительности. Скорость записи уменьшается со временем даже с поддержкой TRIM. TRIM работает только с удалением файлов, но не с перемещением и инкрементальными сохранениями.
Сброс ячеек легко выполнить за 3 шага, описанных в вики-статье SSD memory cell clearing.
Resolving NCQ Errors
Some SSDs and SATA chipsets do not work properly with Linux Native Command Queueing (NCQ). The tell-tale dmesg errors look like this:
[ 9.115544] ata9: exception Emask 0x0 SAct 0xf SErr 0x0 action 0x10 frozen [ 9.115550] ata9.00: failed command: READ FPDMA QUEUED [ 9.115556] ata9.00: cmd 60/04:00:d4:82:85/00:00:1f:00:00/40 tag 0 ncq 2048 in [ 9.115557] res 40/00:18:d3:82:85/00:00:1f:00:00/40 Emask 0x4 (timeout)These may be resolved by one of the following methods:
- Update the firmware on the SSD. See SSD#Firmware updates[broken link: invalid section].
- Update the BIOS/UEFI on the motherboard. See Flashing BIOS from Linux.
- Disable NCQ on boot. Add libata.force=noncq to the kernel command line in the Bootloader configuration.
If these do not resolve the problem or cause other issues, file a bug report.
Советы для уменьшения операций чтения/записи
Основной идеей долговечного использования SSD является перенос интенсивных операция ввода/вывода в оперативную память или HDD, в основном из-за большого размера блока очистки (512 КиБ в некоторых случаях).
Примечание: 32ГБ SSD с посредственным 10-кратным показателем write amplification, стандартными 10000 циклами чтения/записи и 10ГБ записей в день дают 8 лет жизни. Также, дольше живут диски с наибольшими объемами и современными контроллерами, которые имеют меньший показатель write amplification.
Используйте команду iotop -oPa и отсортируйте по количеству записей, чтобы увидеть сколько пишется на диск.
Продуманная схема разделов
Если в системе установлены одновременно оба типа дисков (HDD и SSD), то рекомендуется монтировать раздел /var на HDD, чтобы продлить жизнь SSD, избежав на нём множества операций чтения/записи.
Если же SSD является единственным диском в системе, и нет возможности использовать его совместно с HDD, разумно так же выделить отдельный раздел для /var, чтобы в дальнейшем при возникновении ошибки было легче восстановить систему. Например, если программа использовала всё доступное пространство в /, какой-либо лог превысил все разумные размеры, и т. п.
Опция монтирования noatime
Монтируйте разделы SSD с опцией noatime. См. раздел Параметры монтирования.
Существует несколько ключевых параметров монтирования, используемых в /etc/fstab для разделов на SSD.
- noatime - Во время чтения файлов не будет обновляться поле atime файловой системы, указывающее время последнего доступа к файлу. Важность данного параметра в том, что он убирает необходимость системы производить "ненужные" операции записи когда файл всего-навсего необходимо прочитать. Т. к. эти операции записи могут быть достаточно интенсивными при чтении большого количества файлов, отключение может дать неплохой прирост производительности и срока жизни. Заметьте, что информация о времени последней записи файла будет по-прежнему обновляться каждый раз, когда файл будет изменён.
- Однако, эта опция может вызвать проблемы с некоторыми программами, такими как Mutt, т. к. время доступа к файлу станет меньше, чем время изменения, что вызовет проблемы в работе. Использование опции relatime вместо noatime позволит быть уверенным, что поле atime никогда не станет меньше, чем время изменения.
- discard - Параметр discard включает команду TRIM для ядер версии 2.6.33 и выше. Не работает с файловой системой ext3; если всё же он включен на ext3, корневой раздел будет смонтирован только для чтения.
Важно: Пользователь должен убедиться ещё ДО попытки монтирования раздела с опцией discard, что он работает на ядре версии 2.6.33 или выше, а также, что его SDD поддерживает TRIM. Иначе можно потерять данные!
Расположите часто используемые файлы в оперативной памяти
Профили браузеров
Довольно просто можно перенести профили браузеров, таких как chromium, firefox, opera, и т.д. в оперативную память через tmpfs и использовать rsync для синхронизации с копиями на диске. Таким образом можно так же заметно сократить количество операций чтения/записи.
В AUR есть несколько пакетов для автоматизации этой операции, например profile-sync-daemonAUR.
Другие файлы
По этой же вышеописанной причине можно расположить в оперативной памяти раздел /srv/http (если запущен web-сервер). Аналогом profile-sync-daemonAUR здесь будет anything-sync-daemonAUR, который позволяет определить любую директорию для синхронизации с оперативной памятью.
Важно: Не пытайтесь добавлять /var/log в anything-sync-daemon. Systemd очень разозлится на это.
Компиляция в tmpfs
Перенос интенсивной компиляции в /tmp — отличная идея продления срока жизни диска. Если у вас имеется более 4ГБ оперативной памяти, строку tmp из /etc/fstab нужно изменить, чтобы раздел использовал больше половины доступной памяти, через параметр size=, т. к. /tmp при компиляции растёт очень быстро.
Пример для машины с 8ГБ оперативки:
tmpfs /tmp tmpfs nodev,nosuid,size=7G 0 0Отключение журналирования ФС
Использование журналируемых ФС типа ext3 или ext4 с отключенным журналом тоже сократит количество записей на SSD. Очевидным недостатком этого будет являться потеря данных при неудачном размонтировании (резкое отключение питания, блокировка ядра и т. д.). Однако, Ted Tso выступает в защиту журналирования на современных SSD, т. к. по его тестам оно незначительно влияет на количество записей в большинстве случаев:
Количество записанных данных (в мегабайтах) на ФС ext4 с параметром noatime.
| 367.0 | 353.0 | 3.81 % |
| 207.6 | 199.4 | 3.95 % |
| 6.45 | 3.73 | 42.17 % |
"Результаты показали, что записанный объём при работе с большим количеством мета-данных почти в 2 раза выше, чем реальный размер файлов. Это ожидаемо, т. к. все изменения в блоках мета-данных сначала пишутся в журнал, и транзакция журнала сбрасывается перед тем, как мета-данные будут записаны в конечное положение на диск. Однако же, для обычных задач, где данные пишутся сразу за мета-данными, разница в лишних операциях записи минимальна."
Примечание: Пример make clean из таблицы выше показывает важность переноса компиляции в tmpfs как рекомендовано в предыдущем разделе!
Выбор файловой системы
Существуют различные варианты файловых систем на выбор, включая Ext2/3/4, Btrfs, и т. д.
Btrfs
Поддержка Btrfs включена в ядро с версии 2.6.29. Некоторые считают, что она является не достаточно стабильной для повседневного использования, в то время как есть и явные сторонники этого потенциального преемника ext4. Рекомендуется прочитать статью Btrfs для дополнительного ознакомления.
Ext4
Ext4 — ещё одна файловая система, поддерживающая SSD. Считается стабильной и пригодной для повседневного использования с версии ядра 2.6.28. В отличие от Btrfs, ext4 не умеет автоматически определять тип диска; пользователь сам должен явно включить поддержку команды TRIM, используя параметр монтирования discard в fstab (или командой tune2fs -o discard /dev/sdaX). См. официальную документацию ядра для подробного ознакомления c ext4.
XFS
Many users do not realize that in addition to ext4 and btrfs, XFS has TRIM support as well. This can be enabled in the usual ways. That is, the choice may be made of either using the discard option mentioned above, or by using the fstrim command. More information can be found on the XFS wiki.
JFS
As of Linux kernel version 3.7, proper TRIM support has been added. So far, there is not a great wealth of information of the topic but it has certainly been picked up by Linux news sites. It is apparent that it can be enabled via the discard mount option, or by using the method of batch TRIMs with fstrim.
Другие файловые системы
Существуют также другие файловые системы, специально предназначенные для SSD, например F2FS.
Обновление прошивок
OCZ
Для дисков компании OCZ имеется утилита командной строки для Linux (i686 и x86_64) на официальном форуме или в AUR ocztoolboxAUR
См. также
wiki.archlinux.org
Btrfs (Русский) - ArchWiki
Состояние перевода: На этой странице представлен перевод статьи Btrfs. Дата последней синхронизации: 7 Декабря 2016. Вы можете помочь синхронизировать перевод, если в английской версии произошли изменения.Из Wikipedia:Btrfs:
Btrfs (файловая система основанная на структурах B-деревьев, произносится как "butter F S", "better F S", "b-tree F S", или просто как аббревиатура) эта файловая система работает по принципу «копирование при записи» (COW), первоначально разработанная Oracle Corporation для использования в Linux. Разработка Btrfs началась в 2007, а в августе 2014 файловая система была помечена как стабильная.Из Btrfs Wiki:
Btrfs это новая файловая система для Linux с принципом копирования при записи (CoW), направленная на реализацию дополнительных функций с особым упором на отказоустойчивость, восстановление и простоту администрирования. Совместная разработка Oracle, Red Hat, Fujitsu, Intel, SUSE, STRATO и многих других, Btrfs распространяется под лицензией GPL, что позволяет внести свой вклад любому желающему.Подготовка
Официальные ядра linux и linux-lts содержат поддержку Btrfs. Если вы хотите разместить загрузчик на разделе с файловой системой Btrfs, проверьте, поддерживает ли ваш boot loader Btrfs.
Установите пакет пользовательских утилит btrfs-progs.
Создание раздела диска Btrfs
Btrfs может обладать всем устройством хранения данных, заменяя схемы разбиения MBR или GPT, используя подтома для имитации разделов. Не нужно разбивать разделы, чтобы просто создать файловую систему Btrfs[broken link: invalid section] на существующем разделе который был создан с использованием другого метода. There are some limitations to partitionless single disk setups:
To overwrite the existing partition table with Btrfs, run the following command:
# mkfs.btrfs /dev/sdXFor example, use /dev/sda rather than /dev/sda1. The latter would format an existing partition instead of replacing the entire partitioning scheme.
Install the boot loader like you would for a data storage device with a Master Boot Record. See Syslinux#Manual install or GRUB#Install to partition or partitionless disk[broken link: invalid section].
Важно: GRUB strongly discourages installation to a partitionless disk.
Создание файловой системы
Файловая система Btrfs может быть создана с нуля или конвертирована из имеющейся ext3/ext4.
Создание новой файловой системы
Файловая система на одном устройстве
Для форматирования раздела:
# mkfs.btrfs -L mylabel /dev/partitionВ Btrfs размер блока по умолчанию 16KB. Для того чтобы использовать больший размер блока для данных/метаданных, укажите значение nodesize с помощью -n как показано в примере с 16KB блоками:
# mkfs.btrfs -L МояМетка -n 16k /dev/partitionФайловая система на нескольких устройствах
Важно:- As of August 2016, the RAID 5, RAID 6 mode of Btrfs is considered fatally flawed, and shouldn't be used for "anything but testing with throw-away data." [1]
- Some boot loaders such as Syslinux do not support multi-device file systems.
Multiple devices can be entered to create a RAID. Supported RAID levels include RAID 0, RAID 1, RAID 10, RAID 5 and RAID 6. The RAID levels can be configured separately for data and metadata using the -d and -m options respectively. By default the data is striped (raid0) and the metadata is mirrored (raid1). See Using Btrfs with Multiple Devices for more information about how to create a Btrfs RAID volume as well as the manpage for mkfs.btrfs.
# mkfs.btrfs -d raid0 -m raid1 /dev/part1 /dev/part2 ...You must include either the udev hook or the btrfs hook in /etc/mkinitcpio.conf in order to use multiple btrfs devices in a pool. See the Mkinitcpio#Common hooks article for more information.
Примечание: If the disks in your multi-disk array have different sizes, this may not use the full capacity of all drives. In order to utilize the full capacity of all disks, use -d single instead of -d raid0 -m raid1 (metadata mirrored, data not mirrored and not striped)
Примечание: Mounting such a filesystem may result in all but one of the according .device-jobs getting stuck and systemd never finishing startup due to a bug in handling this type of filesystem.See #RAID for advice on maintenance specific to multi-device Btrfs file systems.
Конвертация Ext3/4 в Btrfs
Важно: As of mid-to-late 2015, there are many reports on the btrfs mailing list about incomplete/corrupt/broken conversions. The situation is improving as patches are being submitted, but proceed very carefully. Make sure you have working backups of any data you cannot afford to lose. See Conversion from Ext3 on the btrfs wiki.Boot from an install CD, then convert by doing:
# btrfs-convert /dev/partitionMount the partion and test the conversion by checking the files. Be sure to change the /etc/fstab to reflect the change (type to btrfs and fs_passno [the last field] to 0 as Btrfs does not do a file system check on boot). Also note that the UUID of the partition will have changed, so update fstab accordingly when using UUIDs. chroot into the system and rebuild the GRUB menu list (see Install from existing Linux and GRUB articles). If converting a root filesystem, while still chrooted run mkinitcpio -p linux to regenerate the initramfs or the system will not successfully boot. If you get stuck in grub with 'unknown filesystem' try reinstalling grub with grub-install /dev/partition and regenerate the config as well grub-mkconfig -o /boot/grub/grub.cfg.
After confirming that there are no problems, complete the conversion by deleting the backup ext2_saved sub-volume. Note that you cannot revert back to ext3/4 without it.
# btrfs subvolume delete /ext2_savedFinally balance the file system to reclaim the space.
Настройка файловой системы
Копирование при записи (CoW)
По умолчанию, Btrfs использует Копирование при записи для всех файлов постоянно. Чтобы узнать как это реализовано и какие есть преимущества и недостатки, смотрите the Btrfs Sysadmin Guide section.
Отключение CoW
To disable copy-on-write for newly created files in a mounted subvolume, use the nodatacow mount option. This will only affect newly created files. Copy-on-write will still happen for existing files.
To disable copy-on-write for single files/directories do:
$ chattr +C /dir/fileThis will disable copy-on-write for those operation in which there is only one reference to the file. If there is more than one reference (e.g. through cp --reflink=always or because of a filesystem snapshot), copy-on-write still occurs.
Примечание: From chattr man page: "For btrfs, the 'C' flag should be set on new or empty files. If it is set on a file which already has data blocks, it is undefined when the blocks assigned to the file will be fully stable. If the 'C' flag is set on a directory, it will have no effect on the directory, but new files created in that directory will have the No_COW attribute."
Совет: In accordance with the note above, you can use the following trick to disable copy-on-write on existing files in a directory: $ mv /path/to/dir /path/to/dir_old $ mkdir /path/to/dir $ chattr +C /path/to/dir $ cp -a /path/to/dir_old/* /path/to/dir $ rm -rf /path/to/dir_oldMake sure that the data are not used during this process. Also note that mv or cp --reflink as described below will not work.
Принудительное CoW
To force copy-on-write when copying files use:
$ cp --reflink source destThis would only be required if CoW was disabled for the file to be copied (as implemented above). See the man page on cp for more details on the --reflink flag.
Сжатие
Btrfs supports transparent compression, meaning every file on the partition is automatically compressed. This not only reduces the size of files, but also improves performance, in particular if using the lzo algorithm, in some specific use cases (e.g. single thread with heavy file IO), while obviously harming performance on other cases (e.g. multithreaded and/or cpu intensive tasks with large file IO).
Compression is enabled using the compress=zlib or compress=lzo mount options. Only files created or modified after the mount option is added will be compressed. However, it can be applied quite easily to existing files (e.g. after a conversion from ext3/4) using the btrfs filesystem defragment -calg command, where alg is either zlib or lzo. In order to re-compress the whole file system with lzo, run the following command:
# btrfs filesystem defragment -r -v -clzo /Совет: Compression can also be enabled per-file without using the compress mount option; simply apply chattr +c to the file. When applied to directories, it will cause new files to be automatically compressed as they come.
When installing Arch to an empty Btrfs partition, use the compress option when mounting the file system: mount -o compress=lzo /dev/sdxY /mnt/. During configuration, add compress=lzo to the mount options of the root file system in fstab.
Подтома
"A btrfs подтома (subvolume) is not a block device (and cannot be treated as one) instead, a btrfs subvolume can be thought of as a POSIX file namespace. This namespace can be accessed via the top-level subvolume of the filesystem, or it can be mounted in its own right." [2]
Each Btrfs file system has a top-level subvolume with ID 5. It can be mounted as / (by default), or another subvolume can be mounted[broken link: invalid section] instead.
See the following links for more details:
Создание подтома
Чтобы создать подтом:
# btrfs subvolume create /path/to/subvolumeПросмотр подтомов
Чтобы просмотреть список текущих подтомов по пути:
# btrfs subvolume list -p путьУдаление подтома
Для удаления подтома:
# btrfs subvolume delete /path/to/subvolumeПопытка удалить каталог /путь/к/подтому без использования указанной выше команды не удалит подтом.
Монтирование подтомов
Subvolumes can be mounted like file system partitions using the subvol=/path/to/subvolume or subvolid=objectid mount flags. For example, you could have a subvolume named subvol_root and mount it as /. One can mimic traditional file system partitions by creating various subvolumes under the top level of the file system and then mounting them at the appropriate mount points. Thus one can restore a file system (or part of it) to a previous state easily using #Snapshots[broken link: invalid section].
Совет: Changing subvolume layouts is made simpler by not using the toplevel subvolume (ID=5) as / (which is done by default). Instead, consider creating a subvolume to house your actual data and mounting it as /.
Примечание: "Most mount options apply to the whole filesystem, and only the options for the first subvolume to be mounted will take effect. This is due to lack of implementation and may change in the future." [3] See the Btrfs Wiki FAQ for which mount options can be used per subvolume.See Snapper#Suggested filesystem layout, Btrfs SysadminGuide#Managing Snapshots, and Btrfs SysadminGuide#Layout for example file system layouts using subvolumes.
Изменение подтома по умолчанию
The default sub-volume is mounted if no subvol= mount option is provided. To change the default subvolume, do:
# btrfs subvolume set-default subvolume-id /where subvolume-id can be found by listing[broken link: invalid section].
Примечание: After changing the default subvolume on a system with GRUB, you should run grub-install again to notify the bootloader of the changes. See this forum thread. Важно: Changing the default subvolume with btrfs subvolume set-default will make the top level of the filesystem inaccessible when the default subvolume is mounted . Reference: Btrfs Wiki Sysadmin Guide.Commit Interval
The resolution at which data are written to the filesystem is dictated by Btrfs itself and by system-wide settings. Btrfs defaults to a 30 seconds checkpoint interval in which new data are committed to the filesystem. This can be changed by appending the commit mount option in /etc/fstab for the btrfs partition.
LABEL=arch64 / btrfs defaults,noatime,ssd,compress=lzo,commit=120 0 0System-wide settings also affect commit intervals. They include the files under /proc/sys/vm/* and are out-of-scope of this wiki article. The kernel documentation for them resides in Documentation/sysctl/vm.txt.
SSD TRIM
Файловая система Btrfs способна освобождать неиспользуемые блоки из SSD-диска, поддерживающего команду TRIM. Больше информации о задействовании и использовании TRIM можно найти в разделе Solid State Drives#TRIM.
Использование
Показать использованное/свободное место
General linux userspace tools such as /usr/bin/df will inaccurately report free space on a Btrfs partition. It is recommended to use /usr/bin/btrfs to query a Btrfs partition. Below is an illustration of this effect, first querying using df -h, and then using btrfs filesystem df:
$ df -h / Filesystem Size Used Avail Use% Mounted on /dev/sda3 119G 3.0G 116G 3% / $ btrfs filesystem df / Data: total=3.01GB, used=2.73GB System: total=4.00MB, used=16.00KB Metadata: total=1.01GB, used=181.83MBNotice that df -h reports 3.0GB used but btrfs filesystem df reports 2.73GB for the data. This is due to the way Btrfs allocates space into the pool. The true disk usage is the sum of all three 'used' values which is inferior to 3.0GB as reported by df -h.
Примечание: If you see an entry of type unknown in the output of btrfs filesystem df at kernel >= 3.15, this is a display bug. As of this patch, the entry means GlobalReserve, which is kind of a buffer for changes not yet flushed. This entry is displayed as unknown, single in RAID setups and is not possible to re-balance.Another useful command to show a less verbose readout of used space is btrfs filesystem show:
# btrfs filesystem show /dev/sda3The newest command to get information on free/used space of a is btrfs filesystem usage:
# btrfs filesystem usageПримечание: The btrfs filesystem usage command does not currently work correctly with RAID5/RAID6 RAID levels.
Дефрагментация
This article or section needs expansion.
Btrfs supports online defragmentation. To defragment the metadata of the root folder:
# btrfs filesystem defragment /This will not defragment the entire file system. For more information read this page on the Btrfs wiki.
To defragment the entire file system verbosely:
# btrfs filesystem defragment -r -v /RAID
Btrfs offers native "RAID" for #Multi-device file system[broken link: invalid section]s. Notable features which set btrfs RAID apart from mdadm are self-healing redundant arrays and online balancing. See the Btrfs wiki page for more information. The Btrfs sysadmin page also has a section with some more technical background.
Важно: Parity RAID (RAID 5/6) code has multiple serious data-loss bugs in it. See the Btrfs Wiki's RAID5/6 page and a bug report on linux-btrfs mailing list for more detailed information.Scrub
The Btrfs Wiki Glossary says that Btrfs scrub is "[a]n online filesystem checking tool. Reads all the data and metadata on the filesystem, and uses checksums and the duplicate copies from RAID storage to identify and repair any corrupt data."
Важно: A running scrub process will prevent the system from suspending, see this thread for details.Start manually
To start a (background) scrub on the filesystem which contains /:
# btrfs scrub start /To check the status of a running scrub:
# btrfs scrub status /Запуск службы или таймера
The btrfs-progs package brings the [email protected] unit for monthly scrubbing the specified mountpoint. Enable the timer with an escaped path, e.g. [email protected] for / and [email protected] for /home. You can use the systemd-escape tool to escape a given string, see systemd-escape(1) for examples.
You can also run the scrub by starting [email protected] (with the same encoded path). The advantage of this over # btrfs scrub is that the results of the scrub will be logged in the systemd journal.
Balance
"A balance passes all data in the filesystem through the allocator again. It is primarily intended to rebalance the data in the filesystem across the devices when a device is added or removed. A balance will regenerate missing copies for the redundant RAID levels, if a device has failed." [5] See Upstream FAQ page.
On a single-device filesystem a balance may be also useful for (temporarily) reducing the amount of allocated but unused (meta)data chunks. Sometimes this is needed for fixing "filesystem full" issues.
# btrfs balance start / # btrfs balance status /Снимки
"A snapshot is simply a subvolume that shares its data (and metadata) with some other subvolume, using btrfs's COW capabilities." See Btrfs Wiki SysadminGuide#Snapshots for details.
To create a snapshot:
# btrfs subvolume snapshot source [dest/]nameTo create a readonly snapshot add the -r flag. To create writable version of a readonly snapshot, simply create a snapshot of it.
Примечание: Snapshots are not recursive. Every nested subvolume will be an empty directory inside the snapshot.
Отправить / получить
A subvolume can be sent to stdout or a file using the send command. This is usually most useful when piped to a Btrfs receive command. For example, to send a snapshot named /root_backup (perhaps of a snapshot you made of / earlier) to /backup you would do the following:
# btrfs send /root_backup | btrfs receive /backupThe snapshot that is sent must be readonly. The above command is useful for copying a subvolume to an external device (e.g., a USB disk mounted at /backup above).
You can also send only the difference between two snapshots. For example, if you have already sent a copy of root_backup above and have made a new readonly snapshot on your system named root_backup_new, then to send only the incremental difference to /backup do:
# btrfs send -p /root_backup /root_backup_new | btrfs receive /backupNow a new subvolume named root_backup_new will be present in /backup.
See Btrfs Wiki's Incremental Backup page on how to use this for an incremental backups and for tools that automate the process.
Известные проблемы
Несколько ограничений должны быть известны перед использованием.
Шифрование
Btrfs has no built-in encryption support, but this may come in future. Users can encrypt the partition before running mkfs.btrfs. See dm-crypt/Encrypting an entire system#Btrfs subvolumes with swap.
Existing Btrfs file systems can use something like EncFS or TrueCrypt, though perhaps without some of Btrfs' features.
Файл подкачки (Swap)
Btrfs does not yet support swap files. This is due to swap files requiring a function that Btrfs does not have for possibility of file system corruption [6]. Patches for swapfile support are already available [7] and may be included in an upcoming kernel release. As an alternative a swap file can be mounted on a loop device with poorer performance but will not be able to hibernate. Install the package systemd-swap to automate this.
Ядро Linux-rt
This article or section is out of date.
As of version 3.14.12_rt9, the linux-rt[broken link: invalid section] kernel does not boot with the Btrfs file system. This is due to the slow development of the rt patchset.
Tips and tricks
Checksum hardware acceleration
Verify if Btrfs checksum is hardware accelerated:
$ dmesg | grep crc32c Btrfs loaded, crc32c=crc32c-intelIf you see crc32c=crc32c-generic, it is probably because your root partition is Btrfs, and you will have to compile crc32c-intel into kernel to make it work. Note: put crc32c-intel into mkinitcpio.conf does NOT work.
Corruption recovery
btrfs-check cannot be used on a mounted file system. To be able to use btrfs-check without booting from a live USB, add it to the initial ramdisk:
/etc/mkinitcpio.conf BINARIES="/usr/bin/btrfs"Regenerate the initial ramdisk using mkinitcpio.
Then if there is a problem booting, the utility is available for repair.
Примечание: If the fsck process has to invalidate the space cache (and/or other caches?) then it is normal for a subsequent boot to hang up for a while (it may give console messages about btrfs-transaction being hung). The system should recover from this after a while.
See the Btrfs Wiki page for more information.
Загрузка в снимки с помощью GRUB
You can manually create a GRUB#GNU/Linux menu entry with the rootflags=subvol= argument. The subvol= mount options in /etc/fstab of the snapshot to boot into also have to be specified correctly.
Alternatively, you can automatically populate your GRUB menu with btrfs snapshots when regenerating the GRUB configuration file by using grub-btrfsAUR or grub-btrfs-gitAUR.
Использование подтомов Btrfs с systemd-nspawn
See the Systemd-nspawn#Use Btrfs subvolume as container root and Systemd-nspawn#Use temporary Btrfs snapshot of container articles.
Решение проблем
See the Btrfs Problem FAQ for general troubleshooting.
GRUB
Смещение разделов
Примечание: The offset problem may happen when you try to embed core.img into a partitioned disk. It means that it is OK to embed grub's core.img into a Btrfs pool on a partitionless disk (e.g. /dev/sdX) directly.GRUB can boot Btrfs partitions, however the module may be larger than other file systems. And the core.img file made by grub-install may not fit in the first 63 sectors (31.5KiB) of the drive between the MBR and the first partition. Up-to-date partitioning tools such as fdisk and gdisk avoid this issue by offsetting the first partition by roughly 1MiB or 2MiB.
Отсутствует root
Users experiencing the following: error no such device: root when booting from a RAID style setup then edit /usr/share/grub/grub-mkconfig_lib and remove both quotes from the line echo " search --no-floppy --fs-uuid --set=root ${hints} ${fs_uuid}". Regenerate the config for grub and the system should boot without an error.
Ошибка BTRFS: open_ctree failed
As of November 2014 there seems to be a bug in systemd or mkinitcpio causing the following error on systems with multi-device Btrfs filesystem using the btrfs hook in mkinitcpio.conf:
BTRFS: open_ctree failed mount: wrong fs type, bad option, bad superblock on /dev/sdb2, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg|tail or so. You are now being dropped into an emergency shell.A workaround is to remove btrfs from the HOOKS array in /etc/mkinitcpio.conf and instead add btrfs to the MODULES array. Then regenerate the initramfs with mkinitcpio -p linux (adjust the preset if needed) and reboot.
See the original forums thread and FS#42884 for further information and discussion.
You will get the same error if you try to mount a raid array without one of the devices. In that case you must add the degraded mount option to /etc/fstab. If your root resides on the array, you must also add rootflags=degraded to your kernel parameters.
Примечание: As of August 2016, a potential workaround for this bug is to mount the array by a single drive only in /etc/fstab, and allow btrfs to discover and append the other drives automatically. Group-based identifiers such as UUID and LABEL appear to contribute to the failure. For example, a two-device RAID1 array consisting of 'disk1' and disk2' will have a UUID allocated to it, but instead of using the UUID, use only /dev/mapper/disk1 in /etc/fstab.For a more detailed explanation, see the following blog post.
Проверка btrfs
Важно: Since Btrfs is under heavy development, especially the btrfs check command, it is highly recommended to create a backup and consult the following Btfrs documentation before executing btrfs check with the --repair switch.
The btrfs check command can be used to check or repair an unmounted Btrfs filesystem. However, this repair tool is still immature and not able to repair certain filesystem errors even those that do not render the filesystem unmountable.
See Btrfsck for more information.
Смотрите также
- Официальный сайт
- Performance related
- Miscellaneous
wiki.archlinux.org
Случайные заметки: Файловая система Btrfs
Это конспект моего доклада на семинаре, организованном нашей LUG совместно с университетом. Опять же, времени было пшик, так что доклад весьма обзорный.
Речь пойдёт о файловой системе нового поколения. Традиционно ФС играла значительную роль в организации Unix-систем. И во многом именно свойствами ФС определялись свойства той или иной реализации Unix.
Файловая система должна хранить файлы и обеспечивать доступ к ним. При этом к ней предъявляется большое количество требований, зачастую взаимоисключающих: поддержка файлов любого размера, высокая производительность операций ввода/вывода, масштабируемость и т.д. Давно стало ясно, что ни одна файловая система не может быть одинаково эффективна во всех случаях. Поэтому все современные реализации Unix поддерживают работу с несколькими типами ФС одновременно. Есть такое выражение: "Linux - это Unix сегодня", и ядро Linux поддерживает свыше 50 (!) типов ФС.
В 2005-м году компания Sun Microsystems представила файловую систему ZFS, которая стала прорывом в области файловых систем. Из-за лицензионной политики Sun ZFS не может быть включена в ядро Linux. Однако в 2007-м году началась разработка файловой системы нового поколения для Linux - Btrfs. Разработку оплачивает компания Oracle, однако код выпускается под лицензией GNU GPL и входит в ядро Linux начиная с релиза 2.6.29, вышедшего на этой неделе.
Приведу фрагмент интервью Chris Mason - основного разработчика Btrfs:
-
Опишите Btrfs своими словами.
-
Btrfs - это новая файловая система, выпускаемая под GPL, которая разрабатывается с учётом масштабируемости на очень большие объёмы носителей. Масштабируемость означает не только возможность адресовать блоки носителя, но также возможность работать с повреждениями данных и метаданных. Это означает наличие инструментов для проверки и восстановления файловой системы без отмонтирования, и интегрированную проверку контрольных сумм, чтобы определять ошибки.
-
Является ли Btrfs наследницей какой-нибудь другой ФС?
-
Да, всех их :) Здесь много идей из ReiserFS, отложенное размещение и другие идеи из XFS. ZFS популяризовала идею, что подсчёт контрольных сумм данных может быть быстрым, и что управление логическими томами может быть лучше. Идеи по реализации управления томами пришли из AdvFS.
Итак, основные возможности, которые будут в Btrfs:
-
Поддержка доступных на запись снапшотов (аналог клонов ZFS). Кроме того, здесь можно создавать снапшоты снапшотов.
-
Поддержка сложных многодисковых конфигураций --- RAID уровней 0, 1, 5, 6 и 10, а также реализация различных политик избыточности на уровне объектов ФС --- то есть возможно назначить, к примеру, зеркалирование для какого-либо каталога или файла.
-
Флаги совместимости, необходимые для изменения дискового формата в новых версиях btrfs с сохранением совместимости со старыми.
-
Гибридные пулы. btrfs старается перемещать наиболее используемые данные на самое быстрое устройство, вытесняя с него "залежавшиеся" блоки. Эта политика хорошо согласуется с появившейся недавно моделью использования SSD (Solid State Drive).
-
Балансировка данных между устройствами в btrfs возможна сразу после добавления диска к пулу, отдельной командой --- а не только постепенно, в процессе использования (как это реализовано в ZFS).
-
Он-лайн конфигурирование RAID будет реализовано на уровне объектов файловой системы --- субтомов, снапшотов, файлов. Возможно будет также устанавливать некоторые параметры ввода-вывода для каталогов --- с наследованием этих свойств всеми дочерними объектами.
Большинство из этих возможностей уже реализованы и работают.
С точки зрения устройства ФС, можно выделить следующие основные моменты, которые делают возможными все перечисленные особенности в сочетании с очень хорошей производительностью:
-
B-деревья везде, где они имеют смысл
-
Copy-on-write везде, где это имеет смысл
-
Политика блокировок - высокая гранулярность блокировок.
B-деревья и дали название файловой системе (B-tree FS). B-деревья - это сильноветвящиеся деревья (B-деревья почему-то часто путают с двоичными деревьями, видимо, из-за буквы B, но она означает Block; у каждого узла в B-дереве обычно несколько тысяч потомков), каждый узел которых, в свою очередь, содержит большое количество записей (они обычно организуются в двоичное сбалансированное дерево; в частности, в Btrfs используются красно-чёрные деревья). Читаются и пишутся узлы B-дерева целиком, что даёт значительный выигрыш в производительности.
Copy-on-write (CoW) - это алгоритм, предназначенный для ситуаций, когда нужно создавать много похожих объектов. Рассмотрим, например, создание снапшота ФС. Снапшот - это мгновенная копия всех данных части ФС в данный момент времени. Реализация "в лоб" предусматривает создание копий всех файлов, что займёт много времени и много дискового пространства. При использовании CoW создаётся только один новый объект - копия корневого каталога, а на всех файлах, на которые ссылается корневой, ставится специальная метка. Когда приложение пытается писать в "помеченный" каталог, ФС прозрачно для приложения делает его копию (помечая при этом все файлы в этом каталоге), и приложение пишет уже в созданную копию. Таким образом, создаются копии только изменившихся данных, и только тогда, когда данные действительно изменяются. Это позволяет сделать операцию создания снапшотов почти мгновенной даже для очень больших разделов. Это немаловажно, т.к. одно из основных требований к операции создания снапшота - атомарность, т.е. эта операция не должна прерываться (и конфликтовать) никакими другими операциями. В Btrfs CoW используется не только при создании снапшотов, но и при ведении журнала и многих внутренних операциях.
Блокировки - это сущность, позволяющая избежать конфликтов при одновременном доступе к данным из разных потоков. Поток, который хочет внести изменение в некоторую структуру данных, сначала проверяет, не заблокирована ли она другим потоком; если заблокирована - ждёт, пока блокировка не будет освобождена, иначе сам захватывает блокировку, и освобождает её по окончании записи. Когда речь идёт о доступе к сложным структурам данных, возникает вопрос о политике блокировок. Нужно ли блокировать всю структуру целиком, или каждый элемент в отдельности, или элементы какими-то группами? Чем крупнее единица блокировки, тем меньше блокировок, и меньше накладных расходов. Чем мельче - тем более эффективно расходуется процессорное время, т.к. потокам приходится ждать гораздо меньше. Btrfs стремится блокировать как можно меньшие элементы структур (но не слишком мелкие).
Ещё один пункт, связанный с блокировками, специфичен для ядра. В ядре есть два вида блокировок: spin-lock и мьютексы. При использовании spin-lock ожидающий поток "крутится" в бесконечном цикле. При использовании мьютексов - поток переходит в заблокированное состояние TASK_INTERRUPTIBLE, и "пробуждается" планировщиком автоматически при освобождении блокировки. Понятно, что мьютексы более эффективны, т.к. не тратят процессорное время на пустые циклы. Но мьютексы не могут быть использованы в контексте обработчика прерывания, т.к. в этом состоянии планировщик не работает. Значительная часть функций любой ФС может быть вызвана как из обработчика прерывания, так и в контексте задачи. Поэтому во многих функциях приходится использовать менее эффективные спин-блокировки.
Btrfs использует новый тип блокировок, которые могут работать в обоих режимах (и их можно переключать между режимами). Таким образом, один и тот же код будет использовать мьютексы в контексте задачи и спин-блокировки в режиме прерывания.
Ещё одна особенность Btrfs: все структуры ФС могут находиться в произвольных местах раздела, они связаны между собой указателями. Этой особенностью обладают и некоторые другие ФС, но разработчики Btrfs нашли ей новое применение: конвертация разделов из других ФС (сейчас реализована конвертация из ext2/3, конвертер из ext4 в разработке, теоретически можно создать конвертеры из других ФС). При конвертации структуры Btrfs создаются в местах раздела, помеченных в исходной ФС как свободные. В Btrfs создаётся специальный файл, в который входят блоки, занятые структурами исходной ФС. Таким образом, эти блоки оказываются помеченными как занятые. Кроме того, этот файл представляет собой образ исходной ФС, который можно примонтировать (mount -o loop). Это позволяет выполнить откат к предыдущей ФС. Чтобы освободить место на диске, достаточно просто удалить файл с образом исходной ФС (возможность отката, соответственно, пропадёт).
Одна из особенностей современных ФС не так давно вызвала небольшой скандал. Дело в том, что в ядрах unix (и linux) код ФС не занимается непосредственно записью данных на диск. Данные записываются в страницы памяти, и эти страницы помечаются как "грязные", и затем их сбрасывает на диск отдельный поток ядра (pdflush). Так вот, при использовании современных ФС (в той новости речь шла про ext4, но теми же свойствами обладают и XFS, и Btrfs, и многие другие) интервал между записью данных в страничный кэш и их записью на диск может достигать 150 секунд (больше двух минут). Unix традиционно пишется для хорошего оборудования. В частности, предполагается, что в любой системе, от которой нужна надёжность, применяются UPS. Поэтому большая задержка записи является не недостатком, а преимуществом: это даёт возможность разместить данные более удачно, и избежать фрагментации. А при использовании на менее надёжном оборудовании нужно просто перенастроить ядро средствами sysctl, чтобы заставить pdflush срабатывать чаще.
Другая недавно вышедшая ФС для Linux - это Ext4. Она учитывает многие наработки современных ФС (экстенты, delayed allocation итп), но при этом основана на коде Ext3. Это более продвинутая ФС, чем та же ext3, по тестам она во многих случаях даёт бОльшую производительность и может быть рекомендована для использования на многих машинах уже сейчас. Но при этом её не назовёшь ФС нового поколения: архитектура осталась от ext3.
Btrfs сейчас в стадии experimental, разработчики предупреждают, что сейчас её имеет смысл использовать только для тестирования и экспериментов. Даже дисковый формат до сих пор окончательно не устаканился. Но при этом это безусловно ФС нового поколения, по архитектуре она напоминает разве что ZFS, но не старые ФС linux-ядра.
Больше всего Btrfs похожа на ZFS от компании Sun. Btrfs не поддерживает диски такого астрономического объёма, как zfs, но вряд ли это в ближайшее время будет иметь практическое значение. Зато Btrfs имеет некоторые возможности, отсутствующие в zfs: снапшоты снапшотов и скоростные приоритеты дисков, оптимизацию для ssd-накопителей. Но ZFS уже вовсю используется на production-серверах, а использование btrfs станет массовым, видимо, года через два (если предполагать, что распространение btrfs будет развиваться также, как zfs).
Измерения производительности Btrfs сейчас мало информативны, т.к. оптимизация в разгаре. Однако уже сейчас Btrfs обходит zfs по производительности некоторых операций.
Основные возможности Btrfs уже реализованы. Дисковый формат близок к стабилизации, если он и будет меняться, то не сильно. Только что завершена реализация обработки ситуации нехватки места на диске (проблема в том, что фактическая запись на диск может происходить уже после закрытия файла программой, и было не совсем очевидно, как передать ошибку записи программе). Вовсю идёт поиск и исправление других ошибок. В разработке специальный ioctl-API для поддержки транзакционного I/O (несколько операций, объединённых в транзакцию, могут быть выполнены все или не выполнены совсем; кроме всего прочего, это позволяет минимизировать количество проверок между операциями в одной транзакции). Ближайшая задача - реализация удаления снапшотов, первый вариант кода уже появился в рассылке.
iportnov.blogspot.com
Настройка Ubuntu для работы с SSD
Начиная с Ubuntu 14.04 разработчики позаботились о поддержке SSD. Система сама периодически запускает функцию TRIM на SSD, никаких discard в fstab больше не требуется. И многие другие советы, которые можно найти в интернете уже не актуальны, не создавайте себе проблем, просто пользуйтесь. Данная статья уже сильно урезана, оставлены только актуальные советы, да и те совсем не обязательны.
Как всем известно SSD очень быстры, но имеют один маленький (или не маленький) недостаток - ограниченное число циклов записи. Т.е. их надо стараться больше использовать на чтение, а запись свести к минимуму, дабы свести риск выхода из строя диска раньше времени к минимуму. Статья написана для Ubuntu 14.04 и более новых версий.
/etc/fstab – один из важных файлов ОС, который исполняется во время загрузки системы. В нем описаны какие разделы накопителей и как именно монтируется в файловую систему ОС. Открываем:
gksu gedit /etc/fstabОтключаем swap
Если уж SSD приобретен, то вполне можно добавить памяти в машину и отключить swap. Для этого будет достаточно уже 4GiB (используйте утилиты free и top, чтобы узнать сколько памяти потребляет ОС) Если памяти достаточно, ставим систему без свопа или отключаем его, если система уже установлена.Комментируем (#) строку со словом swap
#UUID=xxxx-xxxx-xxxx-xxxx none swap sw 0 0Для систем, у которых systemd надо еще отключить службу
systemctl --type swap sudo systemctl mask <имя юнита> # или sudo ln -s /dev/null /etc/systemd/system/<имя юнита>Если же памяти для задач ОС маловато, то пробуем настроить приоритет использования swap
Опции монтирования
Для BTRFS:
UUID=aeade6fd-2b24-4e59-bc8c-6f1791338b0c / btrfs compress=lzo,defaults,subvol=@ 0 1compress - сжатие файлов (lzo - рекомендумое значение, быстрое сжатие; zlib - выше уровень сжатия, но значительно медленнее, больше нагрузка ЦПУ, больше потребление батареи на ноутбуках.
После применения этой опции новые файлы будут сжиматься при записи, а также старые при изменении. Если хотите сжать уже установленную систему нужно применить команду дефрагментации со сжатием.
Часто рекомендуют опцию discard - активирует TRIM для SSD. Опция discard не использована в силу того, что в Ubuntu начиная с версии 14.04 разработчики позаботились о пользователях. Система сама периодически делает fstrim-all, эта команда тримит SSD в момент запуска (команды), а не на лету как discard. Но результат один, деградации скорости не будет.
Как видим BTRFS хорошо приспособлена для SSD. Ранее BTRFS имела проблемы с производительностью, особенно при установке пакетов. Сейчас, на свежих ядрах 4.* я не вижу этой проблемы, работает быстро.
Кэш apt в ОЗУ
tmpfs /var/cache/apt/archives tmpfs defaults 0 0Кэш apt не будет сохраняться на диске и при переустановке пакетов, потребуется их выкачивать заново. Кроме того это не сильно поможет нашему SSD, т.к. пакеты сжатые, а при установке занимают в 5-10 раз больше места, чем в архиве. Также это увеличит использование ОЗУ. После включения убедитесь, что в системе хватает памяти для выполнения ваших задач
Для SSD не требуется дефрагментация. В данном случае она применена для того, чтобы сжать файлы уже установленной системы
Для выполнения нужно загрузиться в живую сессию, примонтировать раздел с BTRFS и применить команду дефрагментации со сжатием:
sudo btrfs fi def -clzo -r /media/<путь до раздела btrfs>/{@,@home}У себя я получил коэффициент сжатия 0.63, было 5.21 ГБ, стало 3.7 ГБ, т.е. в 1.5 раза меньше запись на SSD в процессе дальнейшей работы. Замечу, что я не храню на SSD плохо сжимаемые файлы - аудио, видео, фото и т.п., они размещены на другом разделе.
1) Mozilla Firefox
Правка → Настройки → Дополнительные → Сеть → Поставить галочку «Отключить автоматическое управление кэшем» → Установить значение в 0.
2) Opera
Ctrl+F12 → Расширенные → История → Дисковый кэш → Отключено
3) Chromium/Google Chrome
К сожалению этот браузер не умеет отключать дисковый кэш полностью из GUI.Настройки → Дополнительные инструменты → Инструменты разработчика (Ctrl+Shift+I) → Настройки (значек шестеренки) → поставить галочку Disable cache (while DevTools is open)
Не уверен в актуальности этих настроек. Сам не использую в силу снижения надежности ФС, если их применить. Кто обладает достоверной информацией скорректируйте или поделитесь на форуме в теме обсуждения данной статьи.
Открываем /etc/sysctl.conf:
sudo gedit /etc/sysctl.confПриоритет использования swap
Если памяти маловато, то можно просто уменьшить агрессивность свопинга. В /etc/sysctl.conf добавляем строчку
vm.swappiness=10Параметр управляет процентным соотношением свободной памяти при котором начнётся свопинг.
Хотя, если у вас мало ОЗУ и вы купили себе SSD… то вы поступили не верно.
Все параметры описаны здесь
sudo hdparm -I /dev/sdX | grep -i trimsdX - ваш SSD.
help.ubuntu.ru