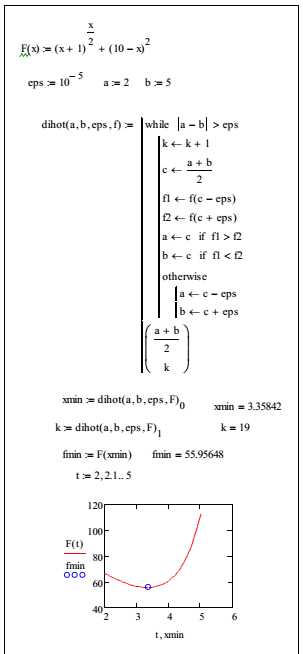
Оптимизация сложных запросов MySQL. Оптимизация mysql запросов
Оптимизация запросов MySQL | aNNiMON.com
Прощай, MyISAMПервым делом я решил посмотреть на саму структуру базы данных. Оказалось, половина таблиц была на движке MyISAM, а половина на InnoDB.
MyISAM хорош для тех таблиц, в которых данные в основном читаются, а не пишутся. Например, наш раздел Категории или правила сайта. Если в таблицу часто делается запись, это снижает производительность, потому что MyISAM на время добавления блокирует всю таблицу полностью.
После перехода на PDO все операции с базой данной проходят в специальном классе. Добавив туда простой логгер запросов с выводом [время - запрос], я мог видеть, какие таблицы обновлялись при открытии той или иной страницы.
Такой таблицей оказалась таблица пользователей. При каждом открытии страницы обновляется счётчик переходов и местоположение (главная, форум, статьи и т.д.). MyISAM здесь не место.
Сразу отмечу, что напрямую менять движок и вообще какие-то критические данные, тем более такой таблицы как users, никак нельзя. На локалке можно. А в продакшене лучше сделать копию:
CREATE TABLE `users_innodb` LIKE `users`;
INSERT `users_innodb` SELECT * FROM `users`;
ALTER TABLE `users_innodb` ENGINE=INNODB;
RENAME TABLE `users` TO `users_myisam`, `users_innodb` TO `users`;
ALTER TABLE `users` ENGINE=INNODB;
ALTER TABLE `ablogs_rdm` ENGINE=INNODB;
ALTER TABLE `ablogs_com_rdm` ENGINE=INNODB;
-- ...
ALTER TABLE `writers_rdm` ENGINE=INNODB;
ALTER TABLE `writers_com_rdm` ENGINE=INNODB;
MyISAM и FULLTEXT INDEXВ MySQL 5.5 полнотекстовый индекс был доступен только для MyISAM. По этой причине мы и держали форум на этом движке. Изредка случались ситуации, когда после написания сообщения в теме просто не показывались какие-то свежие посты. Это вина MyISAM.
В MySQL 5.6 FULLTEXT появился и для InnoDB, так что:
ALTER TABLE `forum` ENGINE=INNODB;
Типы столбцовСледующее, на что я обратил внимание — типы столбцов. В статьях, альбомах, уголке писателя и кодах раздел, запись и комментарий классифицируются по значению столбца type. al - раздел, cm - комментарий, ph - запись (фотография). Больше никаких значений нет, только эти три.
Столбец type имел тип VARCHAR(2). Конечно, лучшим решением было бы перепроектировать БД, чтобы у разделов, комментариев и записей были свои таблицы, но у нас legacy проект, поэтому можно просто сменить VARCHAR на ENUM:
ALTER TABLE `albums` CHANGE `type` `type` ENUM('al','cm','ph') NOT NULL;
ИндексыУ некоторых таблиц индексы либо отсутствовали, либо не включали в себя нужные столбцы.
Например, не было индексов для столбцов type, которые я на прошлом этапе переделывал. А ведь очень много запросов именно на тип и смотрят.
ПримерВозьмём запрос на получение комментариев некоторого пользователя в уголке писателя.
EXPLAIN SELECT * FROM `writers`
WHERE `type` = 'cm' AND `userid` = 1720
ORDER BY `time` DESC;
Добавляем индекс для типа:
ALTER TABLE `writers` ADD INDEX `type` (`type`);
Теперь вместо всей таблицы из 864 строк, было просмотрено 686 строк по индексу type.
Добавляем индекс для пользователя:
ALTER TABLE `writers` ADD INDEX `userid` (`userid`);
Теперь было просмотрено 38 записей по индексу userid.
Индекс для двух столбцовОднако самым эффективным будет индекс для двух столбцов: type + userid. Удаляем предыдущие индексы и добавляем новый.
ALTER TABLE `writers`
DROP INDEX `type`,
DROP INDEX `userid`,
ADD INDEX `type_user` (`type`, `userid`);
Уникальный индексСтолбец с логином в JohnCMS уникален. Не может быть двух пользователей с одинаковыми логинами, поэтому для этого столбца лучше подойдёт индекс UNIQUE. Это поможет и быстрее найти пользователя, и не даст записать в таблицу повторяющееся значение. Что было до:
А вот, что стало после смены индекса на уникальный:
ALTER TABLE `users`
DROP INDEX `name_lat`,
ADD UNIQUE INDEX `name_lat` (`name_lat`);
Теперь запись нашлась без дополнительных проверок.
В итоге, добавив к остальным таблицам пару нужных индексов, удалось заметно ускорить открытие страниц. Однако на главной дневников страница по-прежнему открывалась более полутора-двух секунд, а на локалке вообще за 3.Переписываем запросыДневникиСчётчик запросов показал, что на главной дневников было около 30 запросов. И это всего лишь для вывода 5 дневников на страницу с количеством комментариев и самой последней записью.
Сперва выбирались пять дневников, то есть записей с type = 'dir'. Затем для каждого такого дневника, то есть в цикле, выполнялись ещё запросы: 1. Получение информации о пользователе. 2. Количество записей в дневнике. 3. Последняя запись. 4. Количество комментариев у последней записи. 5. Количество непрочитанных комментариев.
Итого, один запрос на получение списка дневников, 25 запросов в цикле для каждого дневника и несколько для проверок и очистки старых непрочитанных.
Список дневников:
SELECT * FROM `diaries`
WHERE `type` = 'dir'
ORDER BY `time` DESC
LIMIT :start, 5
SELECT * FROM `diaries`
WHERE `type` = 'txt'
AND `userid` = :userid
ORDER BY `time` DESC
LIMIT 1
SELECT COUNT(*) FROM `diaries`
WHERE `type` = 'txt'
AND `userid` = :userid
Было:
SELECT COUNT(*) FROM `diaries`
WHERE `type` = 'dir'
SELECT COUNT(DISTINCT `userid`) FROM `diaries`
WHERE `type` = 'txt'
Благодаря группировке мы можем в одном запросе получить список последних записей пользователя и их количество.
SELECT * FROM `diaries` d
INNER JOIN (
SELECT
MAX(`time`) as `record_date`,
COUNT(*) as `records_count`
FROM `diaries`
WHERE `type` = 'txt'
GROUP BY `userid`
) r
- WHERE d.type = 'txt' AND d.`time` = r.record_date
ORDER BY d.`time` DESC
LIMIT :start, 5
Сюда же можно добавить и информацию о пользователе.
SELECT * FROM `diaries` d
INNER JOIN (
SELECT
MAX(`time`) as `record_date`,
COUNT(*) as `records_count`
FROM `diaries`
WHERE `type` = 'txt'
GROUP BY `userid`
) r
LEFT JOIN `users` u ON u.id = d.userid
WHERE d.type = 'txt' AND d.`time` = r.record_date
ORDER BY d.`time` DESC
LIMIT :start, 5
ФорумСледующим на очереди оптимизации был форум. Вывод темы занимал от одной секунды на обычных темах, до трёх-четырёх секунд на большой теме в 80000 постов.
SELECT
`forum`.*,
`users`.*,
`cms_ban_users`.*
FROM `forum`
LEFT JOIN `users`
ON `forum`.`user_id` = `users`.`id`'
LEFT JOIN `cms_ban_users`
ON `module` = "forum"
AND `cms_ban_users`.`mid` = `forum`.`id`'
WHERE
`forum`.`type` = "m"
AND `forum`.`refid` = :refid
LIMIT
:start, :total
Здесь уже было уменьшено количество запросов, но это лишь снизило скорость. Дело в том, что сообщений в теме может быть очень много и ко всем им придётся делать LEFT JOIN. В теме с 80000 сообщений это большая нагрузка, нужен другой способ оптимизации.
Я решил максимально упростить первый запрос, чтобы даже проход по большому количеству сообщений выполнялся быстро. Для этого нужно убрать все объединения.
SELECT * FROM `forum`
WHERE `type` = "m" AND `refid` = :refid
LIMIT :start, :total
Баны:
SELECT * FROM `cms_ban_users`
WHERE `module` = "forum" AND `mid` IN :ids
SELECT * FROM `users`
WHERE `id` IN :user_ids
SELECT * FROM `forum_files`
WHERE `post` IN :ids
Удаление записей в связанных таблицахВ движке во многих местах удаление происходит таким образом: выбираются сначала данные, зачастую id, а потом в цикле они берутся и выполняется запрос на удаление.
Например, удаление дневника.
// Очистка комментариев
$stmt = DB::query(
"SELECT * FROM `diaries`
WHERE `type` = 'txt' AND `userid` = ?",
[$id]);
while ($diary = $stmt->fetch()) {
DB::query("DELETE FROM `diaries`
WHERE `type` = 'com' AND `com_id` = ?",
[$diary['id']);
}
// Удаление записей
DB::exec("DELETE FROM `diaries`
WHERE `type` = 'txt' AND `userid` = ?");
// Очистка комментариев
$diaryIds = DB::prepareAndExec(
"SELECT `id` FROM `diaries`
WHERE `type` = 'txt' AND `userid` = ?",
[$id])->fetchAll(PDO::FETCH_COLUMN);
$sql = implode(',', $diaryIds);
DB::exec("DELETE FROM `diaries`
WHERE `type` = 'com' AND `com_id` IN ($sql)");
// Удаление записей
DB::exec("DELETE FROM `diaries`
WHERE `type` = 'txt' AND `userid` = ?",
[$id]);
DB::exec("DELETE d, com FROM `diaries` d
LEFT JOIN `diaries` com
ON com.`com_id` = d.id
AND com.`type` = 'com'
WHERE d.`type` = 'txt'
AND d.userid = ?",
[$id]);
ИтогиВ итоге сайт стал открываться очень быстро. Прирост скорости на всех страницах приблизительно в 6 раз. На форуме и дневниках заметно больше. Да и PHP 7.1 стал намного шустрее, по сравнению с версией 5.4, которая была раньше.
annimon.com
Оптимизация mysql запросов. - Support
Работа с базой данных зачастую самое слабое место в производительности многих web приложений. И об этом должны заботиться не только администраторы баз данных. Программисты должны выбирать правильную структуру таблиц, писать оптимизированные запросы и хороший код. Далее перечислены методы оптимизации работы с MySQL для программистов.
1. Оптимизируйте запросы для кэша запросов
У большинства MySQL серверов включено кэширование запросов. Один из наилучших способов улучшения производительности — просто предоставить кэширование самой базе данных. Когда какой-либо запрос повторяется много раз, его результат берется из кэша, что гораздо быстрее прямого обращения к базе данных.Основная проблема в том, что многие просто используют запросы, которые не могут быть закэшированны:
// запрос не будет кэширован
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// а так будет!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
Причина в том, что в первом запросе используется функция CURDATE(). Это относиться ко всем функциям, подобным NOW(), RAND() и другим, результат которых недетерминирован. Если результат функции может измениться, то MySQL не кэширует такой запрос. В данном примере это можно предотвратить вычислением даты до выполнения запроса.
2. Используйте EXPLAIN для ваших запросов SELECT
Используя EXPLAIN, вы можете посмотреть, как именно MySQL выполняет ваш запрос. Это может помочь вам избавиться от слабых мест производительности и других проблем в вашем запросе или в структуре таблиц.Результат EXPLAIN покажет вам, какие используются индексы, как выбираются и сортируются таблицы и т.д.Возьмите ваш SELECT запрос (он может быть сложным, с объединениями) и добавьте в начало ключевое слово EXPLAIN. Для этого вы можете использовать phpmyadmin. В результате вы получите очень интересную таблицу. Для примера, пусть я забыл добавить индекс в таблицу, которая участвует в объединении:
После добавления индекса для поля group_id:
Теперь вместо 7883 строк, выбираются только 9 и 16 строк из двух таблиц. Перемножение всех чисел в столбце rows даст число прямо пропорциональное производительности запроса.
3. LIMIT 1, когда нужна единственная строка
Иногда, обращаясь к таблице, вы точно знаете, что вам нужна только одна конкретная строка. Например, нужно получить одну уникальную строку или просто проверить существование записей, удовлетворяющих запросу WHERE.В этом случае, добавление LIMIT 1 в ваш запрос будет оптимальнее. Таким образом, база данных остановит выборку записей, после нахождения первой же, вместо того, чтобы выбрать всю таблицу или индекс.
// есть пользователи в Alabama?
// можно так:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama'");
if (mysql_num_rows($r) > 0) {
// ...
}
// но так лучше:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama' LIMIT 1");
if (mysql_num_rows($r) > 0) {
// ...
}
4. Индексируйте поля, по которым ищите
Индекс это не только основной или уникальный ключ. Это так же любые столбцы в таблице, которые вы используете для поиска и их можно проиндексировать.
Как вы можете заметить, это правило также применимо для части строк, например — «last_name LIKE 'a%'». При поиске с начала строки, MySQL использует индекс этого столбца.Вы так же должны понимать, что это не сработает для регулярных выражений. Например, когда вы ищите слово (т.е. «WHERE post_content LIKE '%apple%'»), то от обычного индекса не будет никакого толку. Лучше будет использовать полнотекстовый поиск или создать вашу собственную систему индексации.
5. Индексируйте поля для объединения и используйте для них одинаковые типы столбцов
Если ваше приложение содержит много объединений таблиц, вам необходимо проиндексировать в обеих таблицах поля, используемые для объединения. Это повлияет на то, как MySQL делает внутреннюю оптимизацию объединений.Так же эти столбцы должны быть одного типа. Например, если вы объединяете столбец DECIMAL со столбцом INT из другой таблицы, MySQL не сможет использовать хотя бы один из индексов. Даже кодировки символов должны быть одного типа для строковых столбцов.
// выборки компаний в штате пользователя
$r = mysql_query("SELECT company_name FROM users
JOIN companies ON (users.state = companies.state)
users.id = $user_id");
// обе колонки state должны быть проиндексированны
// они обе должны иметь один тип данных и кодировку символов
// а иначе MySQL сделает полную выборку из этих таблиц
6. Не используйте ORDER BY RAND()
(Имеется в виду выборка единственной строки. Примечание переводчика)
Это одна из тех вещей, который выглядят очень хорошо на первый взгляд, но многие начинающие программисты попались на эту удочку. Вы даже не представляете, какое слабое место в производительности возникнет, если будете использовать это в запросах.Если вам действительно нужен случайный порядок строк в запросе, то есть лучшие способы сделать это. Конечно, это приведет к дополнительному коду, но позволит избавиться от слабого места в производительности, которое будет сужаться экспоненциально при увеличении данных. Проблема в том, что MySQL будет выполнять RAND() (а это нагрузка на процессор) для каждой строки при сортировке, выдавая только одну строку.
Таким образом вы выберите случайный номер, который меньше количества строк и используете его для смещения в LIMIT.
7. Избегайте SELECT *
Чем больше данных считывается из таблицы, тем медленнее запрос. Это увеличивает время работы с хранилищем данных. Также, когда сервер базы данных установлен отдельно от web-сервера, будет большая задержка при передаче данных по сети.Прописывать, какие именно столбцы из запроса вам нужны — хорошая привычка.
// не очень хорошо:
$r = mysql_query(«SELECT * FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d['username']}»;
// лучше:
$r = mysql_query(«SELECT username FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d['username']}»;
// разница более значительна при большем наборе данных.
8. Старайтесь всегда создать поле ID
В каждой таблице нужно поле id, которое будет PRIMARY KEY, AUTO_INCREMENT, а так же иметь тип INT. Так же неплохо, чтобы оно было UNSIGNED, т.к. вряд ли у идентификатора будут отрицательные значения.Даже если в вашей таблице пользователей есть уникальное поле username, не делаете его основным ключом. Использование поля VARCHAR, как основного ключа, очень медлительно. Да и структура вашего кода, относящаяся к пользователям, будет гораздо лучше, если у каждого пользователя будет свой внутренний идентификатор.Есть так же и внутренние операции MySQL, использующие первичный ключ. И это становиться очень важно для более сложных конфигураций базы данных (кластеры, распараллеливание и т.д.)Исключение из этого правила составляют «таблицы ассоциаций», используемые для связи «многие-ко-многим» между 2 таблицами. Например, таблица «posts_tags», содержит 2 поля: post_id, tag_id, который используется для объединения между двумя таблицами «Posts» и «Tags». Эта таблица будет иметь первичный ключ составленный из 2 полей.
9. Используйте ENUM вместо VARCHAR
ENUM — очень быстрый и компактный тип поля. Значения в нем храниться так же, как TINYINT, но отображаются как в строковом поле. Это делает его незаменимым в некоторых случаях.Если у вас есть поле, в котором будет вполне определенный набор значений, используйте ENUM вместо VARCHAR. Например, если есть поле «status», его значения могут быть «active», «inactive», «pending», «expired» и т.д.Можно даже получить от MySQL «совет» о том, как перестроить таблицу. Если у вас есть поле VARCHAR, MySQL может предложить заменить его на ENUM. Для этого используется PROCEDURE ANALYSE(), описанная ниже.
10. Используйте подсказки от PROCEDURE ANALYSE()
PROCEDURE ANALYSE() анализирует структуру вашей таблицы и данные в ней, и выдает возможные советы по оптимизации. Это возможно только при наличии реальных данных в таблице, т.к. анализ делается в основном на их основе.Например, если вы создали первичный ключ типа INT, а записей не очень много, MySQL может предложить заменить его на MEDIUMINT. Или, если используется VARCHAR в котором есть несколько уникальных значений, будет предложен ENUM.В phpmyadmin в структуре таблице есть ссылка «Анализ структуры таблицы», результат которой может быть, например, следующим:
11. Используйте NOT NULL, если это возможно
Если есть особые причины использовать NULL — используйте его. Но перед этим спросите себя — есть ли разница между пустой строкой и NULL (для INT — 0 или NULL). Если таких причин нет, используйте NOT NULL.NULL занимает больше места и, к тому же, усложняет сравнения с таким полем. Избегайте его, если это возможно. Тем не менее, бывают веские причины использовать NULL, это не всегда плохо.Из документации MySQL:«Столбцы NULL занимают больше места в записи, из-за необходимости отмечать, что это NULL значение. Для таблиц MyISAM, каждое поле с NULL занимает 1 дополнительный бит, который округляется до ближайшего байта».
12. Prepared Statements
Есть множество преимуществ в использовании prepared statements, как для безопасности, так и для улучшения производительности. Prepared statements фильтруют значения данных, добавляемых в запрос, что защищает запросы от SQL инъекций. Конечно, вы можете фильтровать переменные вручную, но тут может сказаться человеческая забывчивость и невнимательность. Конечно, это не столь важно при использовании какого-либо фреймворка или ORM.Поскольку статья посвящена оптимизации, отмечу также выгоды для нее. Они проявляются, когда запрос выполняется много раз в приложении. Вы можете использовать для prepared statement разные значения, но MySQL будет разбирать запрос только один раз.Кроме того, последние версии MySQL компилируют prepared statements в бинарную форму, что позволяет повысить эффективность.Раньше многие программисты избегали prepared statements по одной единственной причине — они не кэшировались MySQL, но с версии 5.1 это не так.Посмотрите mysqli extension для использования prepared statements или воспользуйтесь абстракцией базы данных, например, PDO.
// создаем a prepared statement
if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
// привязываем значения
$stmt->bind_param("s", $state);
// выполняем
$stmt->execute();
// привязываем результат
$stmt->bind_result($username);
// получаем данные
$stmt->fetch();
printf("%s is from %s\n", $username, $state);
$stmt->close();
}
13. Небуферизованные запросы
Обычно, делая запрос, скрипт останавливается и ждет результата его выполнения. Вы можете изменить это, используя небуферизованные запросы.Хорошее описание есть в документации функции mysql_unbuffered_query():
«mysql_unbuffered_query() отправляет SQL-запрос в MySQL, не извлекая и не автоматически буферизуя результирующие ряды, как это делает mysql_query(). С одной стороны, это сохраняет значительное количество памяти для SQL-запросов, дающих большие результирующие наборы. С другой стороны, вы можете начать работу с результирующим набором срезу после получения первого ряда: вам не нужно ожидать выполнения полного SQL-запроса»
Однако есть определенные ограничения. Вам придется считывать все записи или вызывать mysql_free_result()прежде, чем вы сможете выполнить другой запрос. Так же вы не можете использовать mysql_num_rows() илиmysql_data_seek() для результата функции.
14. Храните IP в UNSIGNED INT
Многие программисты хранят IP адреса в поле типа VARCHAR(15), не зная что можно хранить его в целочисленном виде. INT занимает 4 байта и имеет фиксированный размер поля.Убедитесь, что используете UNSIGNED INT, т.к. IP можно записать как 32 битное беззнаковое число.Используйте в запросе INET_ATON() для конвертирования IP адреса в число, и INET_NTOA() для обратного преобразования. Такие же, такие функции есть и в PHP — ip2long() и long2ip() (в php эти функции могут вернуть и отрицательные значения. замечание от хабраюзера The_Lion).
$r = "UPDATE users SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $user_id";
15. Таблицы фиксированного размера (статичные) — быстрее
Если каждая колонка в таблице имеет фиксированный размер, то такая таблица называется «статичной» или «фиксированного размера». Пример колонок не фиксированной длины: VARCHAR, TEXT, BLOB. Если включить в таблицу такое поле, она перестанет быть фиксированной и будет обрабатываться MySQL по-другому.Использование таких таблицы увеличит эффективность, т.к. MySQL может просматривать записи в них быстрее. Когда надо выбрать нужную строку таблицы, MySQL может очень быстро вычислить ее позицию. Если размер записи не фиксирован, ее поиск происходит по индексу.Так же эти таблицы проще кэшировать и восстанавливать после падения базы. Например, если перевести VARCHAR(20) в CHAR(20), запись будет занимать 20 байтов, вне зависимости от ее реального содержания.Используя метод «вертикального разделения», вы можете вынести столбцы с переменной длиной строки в отдельную таблицу.
16. Вертикальное разделение
Вертикальное разделение — означает разделение таблицы по столбцам для увеличения производительности.Пример 1. Если в таблице пользователей хранятся адреса, то не факт что они будут нужны вам очень часто. Вы можете разбить таблицу и хранить адреса в отдельной таблице. Таким образом, таблица пользователей сократиться в размере. Производительность возрастет.Пример 2. У вас есть поле «last_login» в таблице. Оно обновляется при каждом входе пользователя на сайт. Но все изменения в таблице очищают ее кэш. Храня это поле в другой таблице, вы сведете изменения в таблице пользователей к минимуму.Но если вы будете постоянно использовать объединение этих таблиц, это приведет к ухудшению производительности.
17. Разделяйте большие запросы DELETE и INSERT
Если вам необходимо сделать большой запрос на удаление или вставку данных, надо быть осторожным, чтобы не нарушить работу приложения. Выполнение большого запроса может заблокировать таблицу и привести к неправильной работе всего приложения.Apache может выполнять несколько параллельных процессов одновременно. Поэтому он работает более эффективно, если скрипты выполняются как можно быстрее.Если вы блокируете таблицы на долгий срок (например, на 30 секунд или дольше), то при большой посещаемости сайта, может возникнуть большая очередь процессов и запросов, что может привести к медленной работе сайта или даже к падению сервера.Если у вас есть такие запросы, используйте LIMIT, чтобы выполнять их небольшими сериями.
while (1) {
mysql_query("DELETE FROM logs WHERE log_date <= '2009-10-01' LIMIT 10000");
if (mysql_affected_rows() == 0) {
// удалили
break;
}
// небольшая пауза
usleep(50000);
}
18. Маленькие столбцы быстрее
Для базы данных работа с жестким диском, возможно, является самым слабым местом. Маленькие и компактные записи обычно лучше с точки зрения производительности, т.к. уменьшают работу с диском.В документации к MySQL есть список требований к хранилищам данных для всех типов данных.Если ваша таблица будет хранить мало строк, то не имеет смысла делать основной ключ типом INT, возможно лучше будет сделать его MEDIUMINT, SMALLINT или даже TINYINT. Если вам не нужно хранить время, используйте DATE вместо DATETIME.Однако будьте осторожны, что бы не вышло как с Slashdot.
19. Выбирайте правильный тип таблицы
Два основных типа таблиц — MyISAM и InnoDB, у каждого есть свои плюсы и минусы.MyISAM хорошо считывает из таблиц большое количество данных, но он плох для записи. Даже если вы изменяете всего одну строку, блокируется вся таблица, и ни один процесс не может ничего из нее прочитать. MyISAM очень быстро выполняет запросы типа SELECT COUNT(*).У InnoDB более сложный механизм хранения данных, и он может быть медленнее, чем MyISAM, для маленьких приложений. Но он поддерживает блокировку строк, что более эффективно при масштабировании. Так же поддерживаются некоторые дополнительные функции, такие операции как транзакции.Подробнее:MyISAM Storage EngineInnoDB Storage Engine
20. Используте ORM
Используя ORM, можно получить определенную оптимизацию работы. Все, что можно сделать с помощью ORM, можно сделать и вручную. Но это требует дополнительной работы и более высокого уровня знаний.ORM замечателен для «ленивой» загрузки данных. Это означает выборку данных по мере необходимости. Но необходимо быть осторожным, т.к это может привести к появлению множества маленьких запросов, что приведет к снижению производительности.ORM также может объединять несколько запросов в пакеты, вместо отправки каждого отдельно.Моя любимая ORM для PHP — Doctrine.
21. Будьте осторожны с постоянными соединениями
Постоянные соединения предназначены для уменьшения расходов на установление связи с MySQL. Когда соединение создается, оно остается открытым после завершения работы скрипта. В следующий раз, этот скрипт воспользуется этим же соединением.mysql_pconnect() в PHPНо это звучит хорошо только в теории. Из моего личного опыта (и опыта других), использование этой возможности не оправдывается. У вас будут серьезные проблемы с ограничением по числу подключений, памятью и так далее.Apache создает много параллельных потоков. Это основная причина, почему постоянные соединения не работаю так хорошо, как бы хотелось. Перед использованием mysql_pconnect() посоветуйтесь с вашим сисадмином.
Источник: http://blog.kron0s.com/top-20-mysql-best-practices2
support.nic.ua
Оптимизация запросов в MySQL
Оптимизация – это изменение системы с целью повышения ее быстродействия. Оптимизацию работы с БД можно разделить на 3 типа:оптимизация запросовоптимизация структурыоптимизация сервера.
Рассмотрим подробнее оптимизацию запросов.
Оптимизация запросов - наиболее простой и приводящий к наиболее высоким результатам тип оптимизации.
SELECT Запросами, которые чаще всего поддаются оптимизации, являются запросы на выборку.Для того чтобы посмотреть как будет выполняться запрос на выборку используется оператор EXPLAIN:http://www.mysql.com/doc/ru/EXPLAIN.htmlС его помощью мы можем посмотреть, в каком порядке будут связываться таблицы и какие индексы при этом будут использоваться.
Основная ошибка начинающих - это отсутствие индексов на нужных полях или создание оных на ненужных полях. Если вы делаете простую выборку наподобие:
SELECT * FROM table WHERE field1 = 123 То вам нужно проставить индекс на поле field1, если вы используете в выборке условие по двум полям:SELECT * FROM table WHERE field1 = 123 AND field2 = 234 То вам нужно создать составной индекс на поля field1, field2.Если вы используете соединение 2 или более таблиц:
SELECT * FROM a, b WHERE a.b_id = b.id Или в более общем виде:SELECT * FROM a [LEFT] JOIN b ON b.id = a.b_id [LEFT] JOIN с ON с.id = b.c_id То вам следует создать индексы по полям, по которым будут присоединятся таблицы. В данном случае это поля b.id и c.id. Однако это утверждение верно только в том случае, если выборка будет происходить в том порядке, в котором они перечислены в запросе. Если, к примеру, оптимизатор MySQL будет выбирать записи из таблиц в следующем порядке: c,b,a, то нужно будет проставить индексы по полям: b.c_id и a.b_id. При связывании с помощью LEFT JOIN таблица, которая идет в запросе слева, всегда будет просматриваться первой.Про синтаксис создания индексов можно прочитать в документации:http://www.mysql.com/doc/ru/CREATE_INDEX.html
Более подробно про использовании индексов можно прочитать здесь:http://www.mysql.com/doc/ru/MySQL_indexes.html
Иногда бывает такая ситуация, что нам постоянно приходится делать выборки из одной и той же части некоторой очень большой таблицы, например, во многих запросах происходит соединение с частью таблицы:
[LEFT] JOIN b ON b.id = a.b_id AND b.field1 = 123 AND b.field2 = 234 В таких случаях может быть разумным вынести эту часть в отдельную временную таблицу: CREATE TEMPORARY TABLE tmp_b TYPE=HEAP SELECT * FROM b WHERE b.field1 = 123 AND b.field2 = 234 И работать уже с ней ( про временные таблицы читайте в документации http://www.mysql.com/doc/ru/CREATE_TABLE.html).Также если мы несколько раз рассчитываем агрегатную функцию для одних и тех же данных, то для ускорения следует сделать такой расчет отдельно и положить его результат во временную таблицу.
Также бывают тормоза, когда люди пытаются в одном запросе «поймать сразу 2-х зайцев», например, на форуме phpclub’а автор следующего запроса спрашивал, почему он тормозит:
SELECT f_m. *, MAX( f_m_v_w.date ) AS last_visited, COUNT( DISTINCT f_b.id ) AS books_num, IF ( f_m.region != 999, f_r.name, f_m.region_other ) AS region_name FROM fair_members f_m LEFT JOIN fair_members_visits_week f_m_v_w ON f_m_v_w.member_id = f_m.id LEFT JOIN fair_regions AS f_r ON f_m.region = f_r.id LEFT JOIN fair_books AS f_b ON f_b.pub_id = f_m.id GROUP BY f_m.id Автор запроса пытается в одном запросе посчитать максимальное значение атрибута из одной таблицы и кол-во записей в другой таблице. В результате к запросу приходится присоединять 2 разные таблицы, которые сильно замедляют выборку. Для увеличения быстродействия такой выборки необходимо вынести подсчет MAX’а или COUNT’а в отдельный запрос.Для подсчета кол-ва строк используйте функцию COUNT(*), c указанием "звездочки" в качестве аргумента.
Почему COUNT(*) обычно быстрее COUNT(id), поясню на примере:
Есть таблица message: id | user_id | textс индексом PRIMARY(id), INDEX(user_id)
Нам надо подсчитать сообщения пользователя с заданым $user_id
Сравним 2 запроса:
SELECT COUNT(*) FROM message WHERE user_id = $user_id иSELECT COUNT(id) FROM message WHERE user_id = $user_id Для выполнения первого запроса нам достаточно просто пробежаться по индексу user_id и подсчитать кол-во записей, удовлетворяющих условию - такая операция достаточно быстрая, т.к., во-первых, индексы у нас упорядочены и ,во-вторых, часто находятся в буфере.Для выполнения второго запроса мы сначала проходим по индексу, для отбора записей удовлетворяющих условию, после чего если запись попадает под условие, то вытаскиваем ее (запись скорее всего будет на диске) чтобы получить значение id и только потом инкриментим счетчик.
В итоге получаем, что при большом кол-ве записей скорость первого запроса будет выше в разы.
UPDATE, INSERT Скорость вставок и обновлений в базе зависит от размера вставляемой (обновляемой) записи и от времени вставки индексов. Время вставки индексов в свою очередь зависит от количества вставляемых индексов и размера таблицы. Эту зависимость можно выразить формулой: [Время вставки индексов] = [кол-во индексов] * LOG2( [Размер таблицы] ) При операциях обновления под [кол-во индексов] понимаются только те индексы, в которых присутствуют обновляемые поля. Условия в запросах на обновления оптимизируются так же, как и в случае с выборками.При частом изменении некоторой большой таблицы с большим количеством индексов имеет смысл производить вставки в другую небольшую вспомогательную таблицу с тем же набором полей (но с отсутствием индексов) и периодически перекидывать данные из нее в основную таблицу, очищая вспомогательную. При этом следует учесть, что данные будут выводиться с запозданием, что не всегда может быть возможным.
«Чтобы удалить все строки в таблице, нужно использовать команду TRUNCATE TABLE table_name.» © документация MySQL.
Ответы на многие вопросы по оптимизации запросов можно найти в мануале: http://www.mysql.com/doc/ru/Query_Speed.html
progerson.ru
Оптимизация сложных запросов MySQL
Введение
MySQL — весьма противоречивый продукт. С одной стороны, он имеет несравненное преимущество в скорости перед другими базами данных на простейших операциях/запросах. С другой стороны, он имеет настолько неразвитый (если не сказать недоразвитый) оптимизатор, что на сложных запросах проигрывает вчистую.
Прежде всего хотелось бы ограничить круг рассматриваемых проблем оптимизации «широкими» и большими таблицами. Скажем до 10m записей и размером до 20Gb, с большим количеством изменяемых запросов к ним. Если в вашей в таблице много миллионов записей, каждая размером по 100 байт, и пять несложных возможных запросов к ней — это статья не для Вас. Рассматривается движок MySQL innodb/percona — в дальнейшем просто MySQL.
Большинство запросов не являются очень сложными. Поэтому очень важно знать как построить индекс для использования нужным запросом и/или модифицировать запрос таким образом, чтобы он использовал уже имеющиеся индексы. Мы рассмотрим работу оптимизатора для выбора индекса обычных запросов (select_type=simple), без джойнов, подзапросов и объединений.
Отбросим простейшие случаи для очень небольших таблиц, для которых оптимизатор зачастую использует type=all (полный просмотр) вне зависимости от наличия индексов — к примеру, классификатор с 40-ка записями. MySQL имеет алгоритм использования нескольких индексов (index merge), но работает этот алгоритм не очень часто, и только без order by. Единственный разумный способ пытаться использовать index merge — случаи выборки по разным столбцам с OR.
Еще одно отступление: подразумевается что читатель уже знаком с explain. Часто сам запрос немного модифицируется оптимизатором, поэтому для того, чтобы понять, почему использовался или нет тот или иной индекс, следует вызвать
explain extended select xxx;а затем
show warnings;который и покажет измененный оптимизатором запрос.
Покрывающий индекс — от толстых таблиц к индексам
Итак задача: пусть у нас есть довольно простой запрос, который выполняется довольно часто, но для такого частого вызова относительно медленно. Рассмотрим стратегию приведения нашего запроса к using index, как к наиболее быстрому выбору.
Почему using index? Да, MySQL используют только B-tree индексы, но тем не менее MySQL старается по возможности держать индексы целиком в памяти — собственно и это дает сказочный прирост производительности MySQL по отношению к другим базам данных. К тому же оптимизатор зачастую предпочтет использовать хоть и не лучший, но уже загруженный в память индекс, нежели более лучший, но на диске (для type=index/range). Отсюда несколько выводов:
- слишком тяжелые индексы — зло. Либо они не будут использоваться потому что они еще не в памяти, либо их не будут грузить в память потому что при этом вытеснятся другие индексы.
- если размер индекса сопоставим с размером таблицы, либо совокупность используемых индексов для разных частых запросов существенно превышает размер памяти сервера — существенной оптимизации не добиться.
- Нюанс — индексировать/сортировать по TEXT — обрекать себя на постоянный using filesort.
Один тонкий момент, про который иногда забываешь — MySQL создает только кластерные индексы. Кластерный — по сути указывающий не на абсолютное положение записи в таблице, а (условно) на запись первичного ключа, который в свою очередь позволяет извлечь саму искомую запись. Но MySQL, не мудрствуя лукаво, для того чтобы обойтись без второго лукапа, поступает просто — расширяя любой ключ на ширину первичного ключа. Таким образом если у вас в таблице primary key (ID), key (A,B,C), то в реальности у вас второй ключ не (A,B,C), а (A,B,C,ID). Отсюда мораль — толстый первичный ключ суть зло.
Следует указать на разницу в кешировании запросов в разных базах. Если PostgreSQL/Oracle кешируют планы запросов (как бы prepare for some timeout), то MySQL просто кеширует СТРОКУ запроса (включая значение параметров) и сохраняет результат запроса. То есть если последовательно селектировать
select AAA from BBB where CCC=DDDнесколько раз — то, если DDD не содержит изменяющихся функций, и таблица AAA не изменилась (в смысле используемой изоляции), результат будет взят прямо из кеша. Довольно спорное улучшение.
Таким образом, считаем, что мы не просто вызываем один и тот же запрос несколько раз. Параметры запроса меняются, данные таблицы меняются. Наилучший вариант — использование покрывающего индекса. Какой же индекс будет покрывающим?
- Во-первых, смотрим на клоз order by. Используемый индекс должен начинаться с тех же столбцов что упомянуты в order by, в той же или в полностью обратной сортировке. Если сортировка не прямая и не обратная — индекс не может быть использован. Здесь есть одно но… MySQL до сих пор не поддерживает индексов со смешанными сортировками. Индекс всегда asc. Так что если у вас есть order by A asc, B desc — распрощайтесь с using index.
- Столбцы, которые извлекаются, должны присутствовать в покрывающем индексе. Очень часто это невыполнимое условие в связи с бесконечным ростом индекса, что, как известно, зло. Поэтому существует способ обойти этот момент — использование self join'а. То есть разделение запроса на выбор строк и извлечение данных. Во-первых, выбираем по заданному условию только столбцы первичного ключа (который всегда присутствует в кластером индексе), и во-вторых, полученный результат джойним к селекту всех требуемых столбцов, используя этот самый первичный ключ. Таким образом у нас будет чистый using index в первом селекте, и eq_ref (суть множественный const) для второго селекта. Итак, мы получаем что-то похожее на: select AAA,BBB,CCC,DDD from tableName as a join tableName as b using (PK) «where over table b»
- Далее клоз where. Здесь в худшем случае мы можем перебрать весь индекс (type=index), но по возможности стоит стремиться использовать функции, не выводящие за рамки type=range (>, >=, <, <=, like «xxx%» и так далее). Используемый индекс должен включать все поля из where, для того чтобы сохранить using index. Как уже было отмечено выше — можно пытаться использовать index_merge — но зачастую это просто не возможно со сложными условиями.
Собственно, это все, что можно сделать для случая, когда мы имеем только один вид запроса. К сожалению, оптимизатор MySQL не всегда при наличии покрывающего индекса может выбрать именно его для выполнения запроса. Что ж, в таком случае приходится помогать оптимизатору с помощью стандартных хинтов use/force index.
Вычленение толстых полей из покрывающего индекса — от толстых индексов к тонким
Но что делать, если у нас запросы бывают нескольких видов, или требуются разные сортировки и при этом используются толстые поля (varchar)? Просто посчитайте размер индекса поля varchar(100) в миллионе записей. А если это поле используется в разных видах запросов — для которых у нас разные покрывающие индексы? Возможно ли иметь в памяти только ОДИН индекс по этому толстому полю, сохранив при этом ту же (или почти ту же) производительность в разных запросах? Итак — последний пункт.
- Толстые и тонкие поля. Очевидно, что иметь несколько РАЗНЫХ вариантов ключей с использованием толстых полей — непозволительная роскошь. Поэтому по возможности мы должны пытаться иметь только один ключ начинающийся на толстое поле. И здесь уместно использовать некоторый искусственный алгоритм замены условий. То есть заменить условие по толстому полю на джойн по результатам этого условия. К примеру: select A from tableName where A=1 or fatB='test'
вместо создания ключа key(fatB, A) мы создадим тонкий ключ key(A) и толстый key(fatB). И перепишем условие след образом.
create temporary table tmp as select PK from tableName where fatB='test'; select A from tableName left join tmp using (PK) where A=1 or tmp.PK is not null;
Следовательно, мы можем иметь много тонких ключей, для разных запросов и только один толстый по полю fatB. Реальная экономия памяти, при почти полном сохранении производительности.
Задание для самостоятельного разбора
Требуется создать минимальное количество ключей (с точки зрения памяти) и оптимизировать запросы вида:
select A,B,C,D from tableName where A=1 and B=2 or C=3 and D like 'test%'; select A,C,D from tableName where B=3 or C=3 and D ='test' order by B;Список используемой литературы
- High Performance MySQL, 2nd EditionOptimization, Backups, Replication, and MoreBy Baron Schwartz, Peter Zaitsev, Vadim Tkachenko, Jeremy D. Zawodny, Arjen Lentz, Derek J. BallingPublisher: O'Reilly MediaReleased: June 2008Pages: 712
- www.mysqlperformanceblog.com
Автор: Milovantsev
www.pvsm.ru
sql - Оптимизация запросов MySQL - присоединиться?
Во-первых, я бы использовал другой стиль синтаксиса. ANSI-92 имеет 20 лет, чтобы лечь, и многие РСУБД фактически рекомендуют не использовать обозначение, которое вы использовали. Это не будет иметь никакого значения в этом случае, но это действительно очень хорошая практика по целому ряду причин (что я позволю вам исследовать и принять решение о себе).
Окончательный ответ и синтаксис примера:
SELECT o.*, p.name, p.amount, p.quantity FROM orders INNER JOIN products ON orders.id = products.order_id WHERE orders.timestamp >= '2012-01-01' AND orders.timestamp < '2012-02-01' AND orders.total != '0.00' ORDER BY orders.timestamp ASCПоскольку таблица orders является той, на которую вы делаете начальную фильтрацию, это очень хорошее место, чтобы начать оптимизацию.
С DATE(o.timestamp) BETWEEN x AND y вам удастся получить все даты и время в январе. Но для этого требуется вызвать функцию DATE() в каждой строке таблицы orders (аналогично тому, что означает RBAR). СУРБД не может видеть через функцию, чтобы просто знать, как избежать траты времени. Вместо этого мы должны сделать эту оптимизацию, переустановив математику, чтобы она не нуждалась в функции в поле, которое мы фильтруем.
orders.timestamp >= '2012-01-01' AND orders.timestamp < '2012-02-01'Эта версия позволяет оптимизатору знать, что вы хотите, чтобы блок дат был последовательным друг с другом. Он назвал диапазон поиска. Он может использовать индекс, чтобы очень быстро найти первую запись и последнюю запись, которые соответствуют этому диапазону, а затем выберите каждую запись между ними. Это позволяет избежать проверки всех записей, которые не подходят, и даже избегает проверки всех записей в середине диапазона; нужно искать только границы.
Это предполагает, что все записи упорядочены по дате и что оптимизатор может это увидеть. Для этого вам нужен индекс. Имея это в виду, кажется, есть два основных индекса покрытия, которые вы могли бы использовать: - (id, timestamp) - (timestamp, id)
Первое - это то, что я вижу, люди используют больше всего. Но это заставляет оптимизатора выполнять поиск по timestamp шкале для каждого id отдельно. И поскольку каждый id вероятно, имеет другое значение timestamp, вы ничего не получили.
Второй индекс - это то, что я рекомендую.
Теперь оптимизатор может полностью заполнить эту часть вашего запроса, исключительно быстро...
SELECT o.* FROM orders WHERE orders.timestamp >= '2012-01-01' AND orders.timestamp < '2012-02-01' ORDER BY orders.timestamp ASCКак это бывает, даже ORDER BY был оптимизирован с предлагаемым индексом. Это уже в том порядке, в котором вы хотите, чтобы данные выводились. После объединения нет необходимости повторно сортировать все.
Затем, чтобы выполнить total != '0.00', все строки в вашем диапазоне все еще проверяются. Но вы уже сузили диапазон так сильно, что это, вероятно, будет хорошо. (Я не буду вдаваться в это, но вы, скорее всего, не сможете использовать индексы в MySQL для оптимизации этого и поиска диапазона timestamp.)
Тогда у вас есть ваше соединение. Это оптимизировано индексом, который у вас уже есть (products.order_id). Для каждой записи, выбранной вышеприведенным фрагментом, оптимизатор может выполнять поиск по индексу и очень быстро идентифицировать соответствующие записи.
Все это предполагает, что в подавляющем большинстве случаев каждая строка порядка имеет одну или несколько строк продукта. Если, к примеру, только в очень немногих заказах были какие-то ряды продуктов, возможно, быстрее сначала выбрать интересующие строки товаров; в основном глядя на соединения, происходящие в обратном порядке.
Оптимизатор действительно принимает это решение для вас, но полезно знать, что он это делает, а затем предоставить индексы, которые вы оцениваете, будут для него наиболее полезными.
Вы можете проверить план объяснения, чтобы увидеть, используются ли индексы. Если нет, ваша попытка помочь была проигнорирована. Вероятно, из-за статистики данных, предполагающих другой порядок соединения, было лучше. Если это так, вы можете затем предоставить индексы, чтобы помочь в этом порядке соединений.
qaru.site
Оптимизация mysql запросов. - Support
Работа с базой данных зачастую самое слабое место в производительности многих web приложений. И об этом должны заботиться не только администраторы баз данных. Программисты должны выбирать правильную структуру таблиц, писать оптимизированные запросы и хороший код. Далее перечислены методы оптимизации работы с MySQL для программистов.
1. Оптимизируйте запросы для кэша запросов
У большинства MySQL серверов включено кэширование запросов. Один из наилучших способов улучшения производительности — просто предоставить кэширование самой базе данных. Когда какой-либо запрос повторяется много раз, его результат берется из кэша, что гораздо быстрее прямого обращения к базе данных.Основная проблема в том, что многие просто используют запросы, которые не могут быть закэшированны:
// запрос не будет кэширован
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// а так будет!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
Причина в том, что в первом запросе используется функция CURDATE(). Это относиться ко всем функциям, подобным NOW(), RAND() и другим, результат которых недетерминирован. Если результат функции может измениться, то MySQL не кэширует такой запрос. В данном примере это можно предотвратить вычислением даты до выполнения запроса.
2. Используйте EXPLAIN для ваших запросов SELECT
Используя EXPLAIN, вы можете посмотреть, как именно MySQL выполняет ваш запрос. Это может помочь вам избавиться от слабых мест производительности и других проблем в вашем запросе или в структуре таблиц.Результат EXPLAIN покажет вам, какие используются индексы, как выбираются и сортируются таблицы и т.д.Возьмите ваш SELECT запрос (он может быть сложным, с объединениями) и добавьте в начало ключевое слово EXPLAIN. Для этого вы можете использовать phpmyadmin. В результате вы получите очень интересную таблицу. Для примера, пусть я забыл добавить индекс в таблицу, которая участвует в объединении:
После добавления индекса для поля group_id:
Теперь вместо 7883 строк, выбираются только 9 и 16 строк из двух таблиц. Перемножение всех чисел в столбце rows даст число прямо пропорциональное производительности запроса.
3. LIMIT 1, когда нужна единственная строка
Иногда, обращаясь к таблице, вы точно знаете, что вам нужна только одна конкретная строка. Например, нужно получить одну уникальную строку или просто проверить существование записей, удовлетворяющих запросу WHERE.В этом случае, добавление LIMIT 1 в ваш запрос будет оптимальнее. Таким образом, база данных остановит выборку записей, после нахождения первой же, вместо того, чтобы выбрать всю таблицу или индекс.
// есть пользователи в Alabama?
// можно так:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama'");
if (mysql_num_rows($r) > 0) {
// ...
}
// но так лучше:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama' LIMIT 1");
if (mysql_num_rows($r) > 0) {
// ...
}
4. Индексируйте поля, по которым ищите
Индекс это не только основной или уникальный ключ. Это так же любые столбцы в таблице, которые вы используете для поиска и их можно проиндексировать.
Как вы можете заметить, это правило также применимо для части строк, например — «last_name LIKE 'a%'». При поиске с начала строки, MySQL использует индекс этого столбца.Вы так же должны понимать, что это не сработает для регулярных выражений. Например, когда вы ищите слово (т.е. «WHERE post_content LIKE '%apple%'»), то от обычного индекса не будет никакого толку. Лучше будет использовать полнотекстовый поиск или создать вашу собственную систему индексации.
5. Индексируйте поля для объединения и используйте для них одинаковые типы столбцов
Если ваше приложение содержит много объединений таблиц, вам необходимо проиндексировать в обеих таблицах поля, используемые для объединения. Это повлияет на то, как MySQL делает внутреннюю оптимизацию объединений.Так же эти столбцы должны быть одного типа. Например, если вы объединяете столбец DECIMAL со столбцом INT из другой таблицы, MySQL не сможет использовать хотя бы один из индексов. Даже кодировки символов должны быть одного типа для строковых столбцов.
// выборки компаний в штате пользователя
$r = mysql_query("SELECT company_name FROM users
JOIN companies ON (users.state = companies.state)
users.id = $user_id");
// обе колонки state должны быть проиндексированны
// они обе должны иметь один тип данных и кодировку символов
// а иначе MySQL сделает полную выборку из этих таблиц
6. Не используйте ORDER BY RAND()
(Имеется в виду выборка единственной строки. Примечание переводчика)
Это одна из тех вещей, который выглядят очень хорошо на первый взгляд, но многие начинающие программисты попались на эту удочку. Вы даже не представляете, какое слабое место в производительности возникнет, если будете использовать это в запросах.Если вам действительно нужен случайный порядок строк в запросе, то есть лучшие способы сделать это. Конечно, это приведет к дополнительному коду, но позволит избавиться от слабого места в производительности, которое будет сужаться экспоненциально при увеличении данных. Проблема в том, что MySQL будет выполнять RAND() (а это нагрузка на процессор) для каждой строки при сортировке, выдавая только одну строку.
Таким образом вы выберите случайный номер, который меньше количества строк и используете его для смещения в LIMIT.
7. Избегайте SELECT *
Чем больше данных считывается из таблицы, тем медленнее запрос. Это увеличивает время работы с хранилищем данных. Также, когда сервер базы данных установлен отдельно от web-сервера, будет большая задержка при передаче данных по сети.Прописывать, какие именно столбцы из запроса вам нужны — хорошая привычка.
// не очень хорошо:
$r = mysql_query(«SELECT * FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d['username']}»;
// лучше:
$r = mysql_query(«SELECT username FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d['username']}»;
// разница более значительна при большем наборе данных.
8. Старайтесь всегда создать поле ID
В каждой таблице нужно поле id, которое будет PRIMARY KEY, AUTO_INCREMENT, а так же иметь тип INT. Так же неплохо, чтобы оно было UNSIGNED, т.к. вряд ли у идентификатора будут отрицательные значения.Даже если в вашей таблице пользователей есть уникальное поле username, не делаете его основным ключом. Использование поля VARCHAR, как основного ключа, очень медлительно. Да и структура вашего кода, относящаяся к пользователям, будет гораздо лучше, если у каждого пользователя будет свой внутренний идентификатор.Есть так же и внутренние операции MySQL, использующие первичный ключ. И это становиться очень важно для более сложных конфигураций базы данных (кластеры, распараллеливание и т.д.)Исключение из этого правила составляют «таблицы ассоциаций», используемые для связи «многие-ко-многим» между 2 таблицами. Например, таблица «posts_tags», содержит 2 поля: post_id, tag_id, который используется для объединения между двумя таблицами «Posts» и «Tags». Эта таблица будет иметь первичный ключ составленный из 2 полей.
9. Используйте ENUM вместо VARCHAR
ENUM — очень быстрый и компактный тип поля. Значения в нем храниться так же, как TINYINT, но отображаются как в строковом поле. Это делает его незаменимым в некоторых случаях.Если у вас есть поле, в котором будет вполне определенный набор значений, используйте ENUM вместо VARCHAR. Например, если есть поле «status», его значения могут быть «active», «inactive», «pending», «expired» и т.д.Можно даже получить от MySQL «совет» о том, как перестроить таблицу. Если у вас есть поле VARCHAR, MySQL может предложить заменить его на ENUM. Для этого используется PROCEDURE ANALYSE(), описанная ниже.
10. Используйте подсказки от PROCEDURE ANALYSE()
PROCEDURE ANALYSE() анализирует структуру вашей таблицы и данные в ней, и выдает возможные советы по оптимизации. Это возможно только при наличии реальных данных в таблице, т.к. анализ делается в основном на их основе.Например, если вы создали первичный ключ типа INT, а записей не очень много, MySQL может предложить заменить его на MEDIUMINT. Или, если используется VARCHAR в котором есть несколько уникальных значений, будет предложен ENUM.В phpmyadmin в структуре таблице есть ссылка «Анализ структуры таблицы», результат которой может быть, например, следующим:
11. Используйте NOT NULL, если это возможно
Если есть особые причины использовать NULL — используйте его. Но перед этим спросите себя — есть ли разница между пустой строкой и NULL (для INT — 0 или NULL). Если таких причин нет, используйте NOT NULL.NULL занимает больше места и, к тому же, усложняет сравнения с таким полем. Избегайте его, если это возможно. Тем не менее, бывают веские причины использовать NULL, это не всегда плохо.Из документации MySQL:«Столбцы NULL занимают больше места в записи, из-за необходимости отмечать, что это NULL значение. Для таблиц MyISAM, каждое поле с NULL занимает 1 дополнительный бит, который округляется до ближайшего байта».
12. Prepared Statements
Есть множество преимуществ в использовании prepared statements, как для безопасности, так и для улучшения производительности. Prepared statements фильтруют значения данных, добавляемых в запрос, что защищает запросы от SQL инъекций. Конечно, вы можете фильтровать переменные вручную, но тут может сказаться человеческая забывчивость и невнимательность. Конечно, это не столь важно при использовании какого-либо фреймворка или ORM.Поскольку статья посвящена оптимизации, отмечу также выгоды для нее. Они проявляются, когда запрос выполняется много раз в приложении. Вы можете использовать для prepared statement разные значения, но MySQL будет разбирать запрос только один раз.Кроме того, последние версии MySQL компилируют prepared statements в бинарную форму, что позволяет повысить эффективность.Раньше многие программисты избегали prepared statements по одной единственной причине — они не кэшировались MySQL, но с версии 5.1 это не так.Посмотрите mysqli extension для использования prepared statements или воспользуйтесь абстракцией базы данных, например, PDO.
// создаем a prepared statement
if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
// привязываем значения
$stmt->bind_param("s", $state);
// выполняем
$stmt->execute();
// привязываем результат
$stmt->bind_result($username);
// получаем данные
$stmt->fetch();
printf("%s is from %s\n", $username, $state);
$stmt->close();
}
13. Небуферизованные запросы
Обычно, делая запрос, скрипт останавливается и ждет результата его выполнения. Вы можете изменить это, используя небуферизованные запросы.Хорошее описание есть в документации функции mysql_unbuffered_query():
«mysql_unbuffered_query() отправляет SQL-запрос в MySQL, не извлекая и не автоматически буферизуя результирующие ряды, как это делает mysql_query(). С одной стороны, это сохраняет значительное количество памяти для SQL-запросов, дающих большие результирующие наборы. С другой стороны, вы можете начать работу с результирующим набором срезу после получения первого ряда: вам не нужно ожидать выполнения полного SQL-запроса»
Однако есть определенные ограничения. Вам придется считывать все записи или вызывать mysql_free_result()прежде, чем вы сможете выполнить другой запрос. Так же вы не можете использовать mysql_num_rows() илиmysql_data_seek() для результата функции.
14. Храните IP в UNSIGNED INT
Многие программисты хранят IP адреса в поле типа VARCHAR(15), не зная что можно хранить его в целочисленном виде. INT занимает 4 байта и имеет фиксированный размер поля.Убедитесь, что используете UNSIGNED INT, т.к. IP можно записать как 32 битное беззнаковое число.Используйте в запросе INET_ATON() для конвертирования IP адреса в число, и INET_NTOA() для обратного преобразования. Такие же, такие функции есть и в PHP — ip2long() и long2ip() (в php эти функции могут вернуть и отрицательные значения. замечание от хабраюзера The_Lion).
$r = "UPDATE users SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $user_id";
15. Таблицы фиксированного размера (статичные) — быстрее
Если каждая колонка в таблице имеет фиксированный размер, то такая таблица называется «статичной» или «фиксированного размера». Пример колонок не фиксированной длины: VARCHAR, TEXT, BLOB. Если включить в таблицу такое поле, она перестанет быть фиксированной и будет обрабатываться MySQL по-другому.Использование таких таблицы увеличит эффективность, т.к. MySQL может просматривать записи в них быстрее. Когда надо выбрать нужную строку таблицы, MySQL может очень быстро вычислить ее позицию. Если размер записи не фиксирован, ее поиск происходит по индексу.Так же эти таблицы проще кэшировать и восстанавливать после падения базы. Например, если перевести VARCHAR(20) в CHAR(20), запись будет занимать 20 байтов, вне зависимости от ее реального содержания.Используя метод «вертикального разделения», вы можете вынести столбцы с переменной длиной строки в отдельную таблицу.
16. Вертикальное разделение
Вертикальное разделение — означает разделение таблицы по столбцам для увеличения производительности.Пример 1. Если в таблице пользователей хранятся адреса, то не факт что они будут нужны вам очень часто. Вы можете разбить таблицу и хранить адреса в отдельной таблице. Таким образом, таблица пользователей сократиться в размере. Производительность возрастет.Пример 2. У вас есть поле «last_login» в таблице. Оно обновляется при каждом входе пользователя на сайт. Но все изменения в таблице очищают ее кэш. Храня это поле в другой таблице, вы сведете изменения в таблице пользователей к минимуму.Но если вы будете постоянно использовать объединение этих таблиц, это приведет к ухудшению производительности.
17. Разделяйте большие запросы DELETE и INSERT
Если вам необходимо сделать большой запрос на удаление или вставку данных, надо быть осторожным, чтобы не нарушить работу приложения. Выполнение большого запроса может заблокировать таблицу и привести к неправильной работе всего приложения.Apache может выполнять несколько параллельных процессов одновременно. Поэтому он работает более эффективно, если скрипты выполняются как можно быстрее.Если вы блокируете таблицы на долгий срок (например, на 30 секунд или дольше), то при большой посещаемости сайта, может возникнуть большая очередь процессов и запросов, что может привести к медленной работе сайта или даже к падению сервера.Если у вас есть такие запросы, используйте LIMIT, чтобы выполнять их небольшими сериями.
while (1) {
mysql_query("DELETE FROM logs WHERE log_date <= '2009-10-01' LIMIT 10000");
if (mysql_affected_rows() == 0) {
// удалили
break;
}
// небольшая пауза
usleep(50000);
}
18. Маленькие столбцы быстрее
Для базы данных работа с жестким диском, возможно, является самым слабым местом. Маленькие и компактные записи обычно лучше с точки зрения производительности, т.к. уменьшают работу с диском.В документации к MySQL есть список требований к хранилищам данных для всех типов данных.Если ваша таблица будет хранить мало строк, то не имеет смысла делать основной ключ типом INT, возможно лучше будет сделать его MEDIUMINT, SMALLINT или даже TINYINT. Если вам не нужно хранить время, используйте DATE вместо DATETIME.Однако будьте осторожны, что бы не вышло как с Slashdot.
19. Выбирайте правильный тип таблицы
Два основных типа таблиц — MyISAM и InnoDB, у каждого есть свои плюсы и минусы.MyISAM хорошо считывает из таблиц большое количество данных, но он плох для записи. Даже если вы изменяете всего одну строку, блокируется вся таблица, и ни один процесс не может ничего из нее прочитать. MyISAM очень быстро выполняет запросы типа SELECT COUNT(*).У InnoDB более сложный механизм хранения данных, и он может быть медленнее, чем MyISAM, для маленьких приложений. Но он поддерживает блокировку строк, что более эффективно при масштабировании. Так же поддерживаются некоторые дополнительные функции, такие операции как транзакции.Подробнее:MyISAM Storage EngineInnoDB Storage Engine
20. Используте ORM
Используя ORM, можно получить определенную оптимизацию работы. Все, что можно сделать с помощью ORM, можно сделать и вручную. Но это требует дополнительной работы и более высокого уровня знаний.ORM замечателен для «ленивой» загрузки данных. Это означает выборку данных по мере необходимости. Но необходимо быть осторожным, т.к это может привести к появлению множества маленьких запросов, что приведет к снижению производительности.ORM также может объединять несколько запросов в пакеты, вместо отправки каждого отдельно.Моя любимая ORM для PHP — Doctrine.
21. Будьте осторожны с постоянными соединениями
Постоянные соединения предназначены для уменьшения расходов на установление связи с MySQL. Когда соединение создается, оно остается открытым после завершения работы скрипта. В следующий раз, этот скрипт воспользуется этим же соединением.mysql_pconnect() в PHPНо это звучит хорошо только в теории. Из моего личного опыта (и опыта других), использование этой возможности не оправдывается. У вас будут серьезные проблемы с ограничением по числу подключений, памятью и так далее.Apache создает много параллельных потоков. Это основная причина, почему постоянные соединения не работаю так хорошо, как бы хотелось. Перед использованием mysql_pconnect() посоветуйтесь с вашим сисадмином.
Источник: http://blog.kron0s.com/top-20-mysql-best-practices2
support.nic.ua
Оптимизация mysql запросов. - Support
Работа с базой данных зачастую самое слабое место в производительности многих web приложений. И об этом должны заботиться не только администраторы баз данных. Программисты должны выбирать правильную структуру таблиц, писать оптимизированные запросы и хороший код. Далее перечислены методы оптимизации работы с MySQL для программистов.
1. Оптимизируйте запросы для кэша запросов
У большинства MySQL серверов включено кэширование запросов. Один из наилучших способов улучшения производительности — просто предоставить кэширование самой базе данных. Когда какой-либо запрос повторяется много раз, его результат берется из кэша, что гораздо быстрее прямого обращения к базе данных.Основная проблема в том, что многие просто используют запросы, которые не могут быть закэшированны:
// запрос не будет кэширован
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// а так будет!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
Причина в том, что в первом запросе используется функция CURDATE(). Это относиться ко всем функциям, подобным NOW(), RAND() и другим, результат которых недетерминирован. Если результат функции может измениться, то MySQL не кэширует такой запрос. В данном примере это можно предотвратить вычислением даты до выполнения запроса.
2. Используйте EXPLAIN для ваших запросов SELECT
Используя EXPLAIN, вы можете посмотреть, как именно MySQL выполняет ваш запрос. Это может помочь вам избавиться от слабых мест производительности и других проблем в вашем запросе или в структуре таблиц.Результат EXPLAIN покажет вам, какие используются индексы, как выбираются и сортируются таблицы и т.д.Возьмите ваш SELECT запрос (он может быть сложным, с объединениями) и добавьте в начало ключевое слово EXPLAIN. Для этого вы можете использовать phpmyadmin. В результате вы получите очень интересную таблицу. Для примера, пусть я забыл добавить индекс в таблицу, которая участвует в объединении:
После добавления индекса для поля group_id:
Теперь вместо 7883 строк, выбираются только 9 и 16 строк из двух таблиц. Перемножение всех чисел в столбце rows даст число прямо пропорциональное производительности запроса.
3. LIMIT 1, когда нужна единственная строка
Иногда, обращаясь к таблице, вы точно знаете, что вам нужна только одна конкретная строка. Например, нужно получить одну уникальную строку или просто проверить существование записей, удовлетворяющих запросу WHERE.В этом случае, добавление LIMIT 1 в ваш запрос будет оптимальнее. Таким образом, база данных остановит выборку записей, после нахождения первой же, вместо того, чтобы выбрать всю таблицу или индекс.
// есть пользователи в Alabama?
// можно так:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama'");
if (mysql_num_rows($r) > 0) {
// ...
}
// но так лучше:
$r = mysql_query("SELECT * FROM user WHERE state = 'Alabama' LIMIT 1");
if (mysql_num_rows($r) > 0) {
// ...
}
4. Индексируйте поля, по которым ищите
Индекс это не только основной или уникальный ключ. Это так же любые столбцы в таблице, которые вы используете для поиска и их можно проиндексировать.
Как вы можете заметить, это правило также применимо для части строк, например — «last_name LIKE 'a%'». При поиске с начала строки, MySQL использует индекс этого столбца.Вы так же должны понимать, что это не сработает для регулярных выражений. Например, когда вы ищите слово (т.е. «WHERE post_content LIKE '%apple%'»), то от обычного индекса не будет никакого толку. Лучше будет использовать полнотекстовый поиск или создать вашу собственную систему индексации.
5. Индексируйте поля для объединения и используйте для них одинаковые типы столбцов
Если ваше приложение содержит много объединений таблиц, вам необходимо проиндексировать в обеих таблицах поля, используемые для объединения. Это повлияет на то, как MySQL делает внутреннюю оптимизацию объединений.Так же эти столбцы должны быть одного типа. Например, если вы объединяете столбец DECIMAL со столбцом INT из другой таблицы, MySQL не сможет использовать хотя бы один из индексов. Даже кодировки символов должны быть одного типа для строковых столбцов.
// выборки компаний в штате пользователя
$r = mysql_query("SELECT company_name FROM users
JOIN companies ON (users.state = companies.state)
users.id = $user_id");
// обе колонки state должны быть проиндексированны
// они обе должны иметь один тип данных и кодировку символов
// а иначе MySQL сделает полную выборку из этих таблиц
6. Не используйте ORDER BY RAND()
(Имеется в виду выборка единственной строки. Примечание переводчика)
Это одна из тех вещей, который выглядят очень хорошо на первый взгляд, но многие начинающие программисты попались на эту удочку. Вы даже не представляете, какое слабое место в производительности возникнет, если будете использовать это в запросах.Если вам действительно нужен случайный порядок строк в запросе, то есть лучшие способы сделать это. Конечно, это приведет к дополнительному коду, но позволит избавиться от слабого места в производительности, которое будет сужаться экспоненциально при увеличении данных. Проблема в том, что MySQL будет выполнять RAND() (а это нагрузка на процессор) для каждой строки при сортировке, выдавая только одну строку.
Таким образом вы выберите случайный номер, который меньше количества строк и используете его для смещения в LIMIT.
7. Избегайте SELECT *
Чем больше данных считывается из таблицы, тем медленнее запрос. Это увеличивает время работы с хранилищем данных. Также, когда сервер базы данных установлен отдельно от web-сервера, будет большая задержка при передаче данных по сети.Прописывать, какие именно столбцы из запроса вам нужны — хорошая привычка.
// не очень хорошо:
$r = mysql_query(«SELECT * FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d['username']}»;
// лучше:
$r = mysql_query(«SELECT username FROM user WHERE user_id = 1»);
$d = mysql_fetch_assoc($r);
echo «Welcome {$d['username']}»;
// разница более значительна при большем наборе данных.
8. Старайтесь всегда создать поле ID
В каждой таблице нужно поле id, которое будет PRIMARY KEY, AUTO_INCREMENT, а так же иметь тип INT. Так же неплохо, чтобы оно было UNSIGNED, т.к. вряд ли у идентификатора будут отрицательные значения.Даже если в вашей таблице пользователей есть уникальное поле username, не делаете его основным ключом. Использование поля VARCHAR, как основного ключа, очень медлительно. Да и структура вашего кода, относящаяся к пользователям, будет гораздо лучше, если у каждого пользователя будет свой внутренний идентификатор.Есть так же и внутренние операции MySQL, использующие первичный ключ. И это становиться очень важно для более сложных конфигураций базы данных (кластеры, распараллеливание и т.д.)Исключение из этого правила составляют «таблицы ассоциаций», используемые для связи «многие-ко-многим» между 2 таблицами. Например, таблица «posts_tags», содержит 2 поля: post_id, tag_id, который используется для объединения между двумя таблицами «Posts» и «Tags». Эта таблица будет иметь первичный ключ составленный из 2 полей.
9. Используйте ENUM вместо VARCHAR
ENUM — очень быстрый и компактный тип поля. Значения в нем храниться так же, как TINYINT, но отображаются как в строковом поле. Это делает его незаменимым в некоторых случаях.Если у вас есть поле, в котором будет вполне определенный набор значений, используйте ENUM вместо VARCHAR. Например, если есть поле «status», его значения могут быть «active», «inactive», «pending», «expired» и т.д.Можно даже получить от MySQL «совет» о том, как перестроить таблицу. Если у вас есть поле VARCHAR, MySQL может предложить заменить его на ENUM. Для этого используется PROCEDURE ANALYSE(), описанная ниже.
10. Используйте подсказки от PROCEDURE ANALYSE()
PROCEDURE ANALYSE() анализирует структуру вашей таблицы и данные в ней, и выдает возможные советы по оптимизации. Это возможно только при наличии реальных данных в таблице, т.к. анализ делается в основном на их основе.Например, если вы создали первичный ключ типа INT, а записей не очень много, MySQL может предложить заменить его на MEDIUMINT. Или, если используется VARCHAR в котором есть несколько уникальных значений, будет предложен ENUM.В phpmyadmin в структуре таблице есть ссылка «Анализ структуры таблицы», результат которой может быть, например, следующим:
11. Используйте NOT NULL, если это возможно
Если есть особые причины использовать NULL — используйте его. Но перед этим спросите себя — есть ли разница между пустой строкой и NULL (для INT — 0 или NULL). Если таких причин нет, используйте NOT NULL.NULL занимает больше места и, к тому же, усложняет сравнения с таким полем. Избегайте его, если это возможно. Тем не менее, бывают веские причины использовать NULL, это не всегда плохо.Из документации MySQL:«Столбцы NULL занимают больше места в записи, из-за необходимости отмечать, что это NULL значение. Для таблиц MyISAM, каждое поле с NULL занимает 1 дополнительный бит, который округляется до ближайшего байта».
12. Prepared Statements
Есть множество преимуществ в использовании prepared statements, как для безопасности, так и для улучшения производительности. Prepared statements фильтруют значения данных, добавляемых в запрос, что защищает запросы от SQL инъекций. Конечно, вы можете фильтровать переменные вручную, но тут может сказаться человеческая забывчивость и невнимательность. Конечно, это не столь важно при использовании какого-либо фреймворка или ORM.Поскольку статья посвящена оптимизации, отмечу также выгоды для нее. Они проявляются, когда запрос выполняется много раз в приложении. Вы можете использовать для prepared statement разные значения, но MySQL будет разбирать запрос только один раз.Кроме того, последние версии MySQL компилируют prepared statements в бинарную форму, что позволяет повысить эффективность.Раньше многие программисты избегали prepared statements по одной единственной причине — они не кэшировались MySQL, но с версии 5.1 это не так.Посмотрите mysqli extension для использования prepared statements или воспользуйтесь абстракцией базы данных, например, PDO.
// создаем a prepared statement
if ($stmt = $mysqli->prepare("SELECT username FROM user WHERE state=?")) {
// привязываем значения
$stmt->bind_param("s", $state);
// выполняем
$stmt->execute();
// привязываем результат
$stmt->bind_result($username);
// получаем данные
$stmt->fetch();
printf("%s is from %s\n", $username, $state);
$stmt->close();
}
13. Небуферизованные запросы
Обычно, делая запрос, скрипт останавливается и ждет результата его выполнения. Вы можете изменить это, используя небуферизованные запросы.Хорошее описание есть в документации функции mysql_unbuffered_query():
«mysql_unbuffered_query() отправляет SQL-запрос в MySQL, не извлекая и не автоматически буферизуя результирующие ряды, как это делает mysql_query(). С одной стороны, это сохраняет значительное количество памяти для SQL-запросов, дающих большие результирующие наборы. С другой стороны, вы можете начать работу с результирующим набором срезу после получения первого ряда: вам не нужно ожидать выполнения полного SQL-запроса»
Однако есть определенные ограничения. Вам придется считывать все записи или вызывать mysql_free_result()прежде, чем вы сможете выполнить другой запрос. Так же вы не можете использовать mysql_num_rows() илиmysql_data_seek() для результата функции.
14. Храните IP в UNSIGNED INT
Многие программисты хранят IP адреса в поле типа VARCHAR(15), не зная что можно хранить его в целочисленном виде. INT занимает 4 байта и имеет фиксированный размер поля.Убедитесь, что используете UNSIGNED INT, т.к. IP можно записать как 32 битное беззнаковое число.Используйте в запросе INET_ATON() для конвертирования IP адреса в число, и INET_NTOA() для обратного преобразования. Такие же, такие функции есть и в PHP — ip2long() и long2ip() (в php эти функции могут вернуть и отрицательные значения. замечание от хабраюзера The_Lion).
$r = "UPDATE users SET ip = INET_ATON('{$_SERVER['REMOTE_ADDR']}') WHERE user_id = $user_id";
15. Таблицы фиксированного размера (статичные) — быстрее
Если каждая колонка в таблице имеет фиксированный размер, то такая таблица называется «статичной» или «фиксированного размера». Пример колонок не фиксированной длины: VARCHAR, TEXT, BLOB. Если включить в таблицу такое поле, она перестанет быть фиксированной и будет обрабатываться MySQL по-другому.Использование таких таблицы увеличит эффективность, т.к. MySQL может просматривать записи в них быстрее. Когда надо выбрать нужную строку таблицы, MySQL может очень быстро вычислить ее позицию. Если размер записи не фиксирован, ее поиск происходит по индексу.Так же эти таблицы проще кэшировать и восстанавливать после падения базы. Например, если перевести VARCHAR(20) в CHAR(20), запись будет занимать 20 байтов, вне зависимости от ее реального содержания.Используя метод «вертикального разделения», вы можете вынести столбцы с переменной длиной строки в отдельную таблицу.
16. Вертикальное разделение
Вертикальное разделение — означает разделение таблицы по столбцам для увеличения производительности.Пример 1. Если в таблице пользователей хранятся адреса, то не факт что они будут нужны вам очень часто. Вы можете разбить таблицу и хранить адреса в отдельной таблице. Таким образом, таблица пользователей сократиться в размере. Производительность возрастет.Пример 2. У вас есть поле «last_login» в таблице. Оно обновляется при каждом входе пользователя на сайт. Но все изменения в таблице очищают ее кэш. Храня это поле в другой таблице, вы сведете изменения в таблице пользователей к минимуму.Но если вы будете постоянно использовать объединение этих таблиц, это приведет к ухудшению производительности.
17. Разделяйте большие запросы DELETE и INSERT
Если вам необходимо сделать большой запрос на удаление или вставку данных, надо быть осторожным, чтобы не нарушить работу приложения. Выполнение большого запроса может заблокировать таблицу и привести к неправильной работе всего приложения.Apache может выполнять несколько параллельных процессов одновременно. Поэтому он работает более эффективно, если скрипты выполняются как можно быстрее.Если вы блокируете таблицы на долгий срок (например, на 30 секунд или дольше), то при большой посещаемости сайта, может возникнуть большая очередь процессов и запросов, что может привести к медленной работе сайта или даже к падению сервера.Если у вас есть такие запросы, используйте LIMIT, чтобы выполнять их небольшими сериями.
while (1) {
mysql_query("DELETE FROM logs WHERE log_date <= '2009-10-01' LIMIT 10000");
if (mysql_affected_rows() == 0) {
// удалили
break;
}
// небольшая пауза
usleep(50000);
}
18. Маленькие столбцы быстрее
Для базы данных работа с жестким диском, возможно, является самым слабым местом. Маленькие и компактные записи обычно лучше с точки зрения производительности, т.к. уменьшают работу с диском.В документации к MySQL есть список требований к хранилищам данных для всех типов данных.Если ваша таблица будет хранить мало строк, то не имеет смысла делать основной ключ типом INT, возможно лучше будет сделать его MEDIUMINT, SMALLINT или даже TINYINT. Если вам не нужно хранить время, используйте DATE вместо DATETIME.Однако будьте осторожны, что бы не вышло как с Slashdot.
19. Выбирайте правильный тип таблицы
Два основных типа таблиц — MyISAM и InnoDB, у каждого есть свои плюсы и минусы.MyISAM хорошо считывает из таблиц большое количество данных, но он плох для записи. Даже если вы изменяете всего одну строку, блокируется вся таблица, и ни один процесс не может ничего из нее прочитать. MyISAM очень быстро выполняет запросы типа SELECT COUNT(*).У InnoDB более сложный механизм хранения данных, и он может быть медленнее, чем MyISAM, для маленьких приложений. Но он поддерживает блокировку строк, что более эффективно при масштабировании. Так же поддерживаются некоторые дополнительные функции, такие операции как транзакции.Подробнее:MyISAM Storage EngineInnoDB Storage Engine
20. Используте ORM
Используя ORM, можно получить определенную оптимизацию работы. Все, что можно сделать с помощью ORM, можно сделать и вручную. Но это требует дополнительной работы и более высокого уровня знаний.ORM замечателен для «ленивой» загрузки данных. Это означает выборку данных по мере необходимости. Но необходимо быть осторожным, т.к это может привести к появлению множества маленьких запросов, что приведет к снижению производительности.ORM также может объединять несколько запросов в пакеты, вместо отправки каждого отдельно.Моя любимая ORM для PHP — Doctrine.
21. Будьте осторожны с постоянными соединениями
Постоянные соединения предназначены для уменьшения расходов на установление связи с MySQL. Когда соединение создается, оно остается открытым после завершения работы скрипта. В следующий раз, этот скрипт воспользуется этим же соединением.mysql_pconnect() в PHPНо это звучит хорошо только в теории. Из моего личного опыта (и опыта других), использование этой возможности не оправдывается. У вас будут серьезные проблемы с ограничением по числу подключений, памятью и так далее.Apache создает много параллельных потоков. Это основная причина, почему постоянные соединения не работаю так хорошо, как бы хотелось. Перед использованием mysql_pconnect() посоветуйтесь с вашим сисадмином.
Источник: http://blog.kron0s.com/top-20-mysql-best-practices2
support.nic.ua