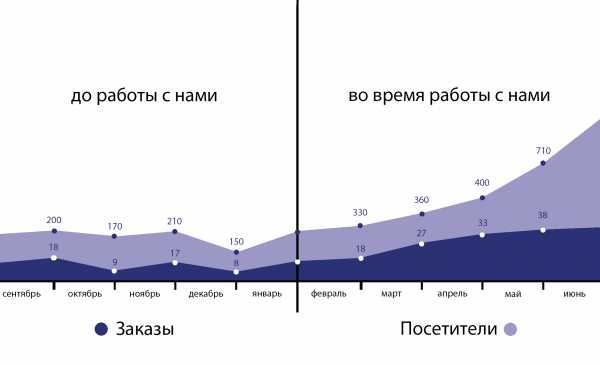
Appropriate use of mysql Optimize Table. Оптимизация mysql таблиц
Как оптимизировать таблицы InnoDB в MySQL
I'll assume you are using innodb_file_per_table for this answer.
There is more than one meaning to "InnoDB fragmentation":
- .ibd file is fragmented, and is very large whereas the dataset is small
- Index pages are fragmented in that there are too many pages to contain little data, in which case they could be merged.
Please consider this post I wrote a while back: it shows how after purging many rows from a large table, the data file is fragmented (i.e. it is very large in the filesystem -- it's a known issue these files never reduce in size). And yet the indexes were not fragmented by the end of deletion: this is because InnoDB properly merges pages as they become empty(er).
The OPTIMIZE command indeed does not apply on InnoDB. What it does is rebuild the table (exactly like an ALTER). See this:
mysql [localhost] {msandbox} (test) > create table t(id int) engine=innodb; mysql [localhost] {msandbox} (test) > optimize table t; +--------+----------+----------+-------------------------------------------------------------------+ | Table | Op | Msg_type | Msg_text | +--------+----------+----------+-------------------------------------------------------------------+ | test.t | optimize | note | Table does not support optimize, doing recreate + analyze instead | | test.t | optimize | status | OK | +--------+----------+----------+-------------------------------------------------------------------+And now it's time for the real discussion: what exactly are you trying to achieve? Unless your database is completely stale, there will always be some fragmentation. It is natural to the process of adding, removing and updating rows in your table.
Fragmentation is not that evil: free space can get reclaimed by new data. If you tables are not very large, then just forget about the whole thing. For very large tables, you might gain some disk space by optimizing the table. But ask yourself: how soon would the table reach same fragmentation? An hour? A day? A week? IMHO in all these cases it is pointless to optimize the table.
Nevertheless, if a large table is massively purged of data, which is not expected to return, I'm all for optimizing it. Say you realize you have some redundant data which consists some 30% of your table size. Sure, it would be great to have that disk space back.
Bottom line: only consider these issues with very large tables; only if you have issues with disk space.
dba.stackovernet.com
Соответствующее использование таблицы оптимизации mysql
Baron Schwartz, the author of that post, is one of the coauthors of High Performance MySQL, 3rd Edition, one of the best books out there regarding MySQL performance. While the argument of authority is not always a good one, I would like to remark that probably he knows what he is saying.
While everything he says is correct -in my humble opinion-, you must understand the actual underlying argument: defragmenting an InnoDB table is in many cases useless (for performance), and many people recommending to do it frequently are wrong.
Fragmentation and page-splitting is a delicate topic, which people like Jeremy Cole http://blog.jcole.us/2013/04/09/innodb-bugs-found-during-research-on-innodb-data-storage/ and Facebook engineers have mentioned a lot (specially, regarding to compression): https://www.facebook.com/note.php?note_id=10150348315455933 and its implications on performance.
Many times, your performance is load-dependent- Do you insert using an auto-increment? Do you insert and delete many times in the middle of your table? Can you afford the extra disk space if your table is very dynamic?
There are some good practices that I can recommend you (which is probably what you want):
- Defragment only if you have done a batch DELETE of lots of records (and you do not intend to insert them back). In other cases, it may not be necessary. If you want to know if there is a huge difference between logical data and file size, compare the .idb file with the data + index size from show table status.
- Speedup insertion by inserting always in PRIMARY KEY order, so you do not force unnecessary page splits.
- Use partitioning to isolate changes that may alter the internal structure of the table.
- There is no way to "optimize the secondary indexes", but I would never find such a thing necessary. The change buffer makes sure that changes/rebalances to indexes are done asyncronously without huge performance problems. A BTREE should always be balanced, so assuming your change buffer is not full and the purge thread deletes old row records promptly, your performance should be ok. One way I can think of "optimizing secondary indexes", as you called it, is DROPing the index and recreating it (asuming you are using the InnoDB Plugin or MySQL 5.5+), but I see absolutely no reason to do that.
Of course, if you really want to dig into this topic, create some tables, defragment them and check if you actually have some gain afterwards. In general, tablespace handling and statistics gathering is something relatively automatic on InnoDB.
dba.stackovernet.com
sql - оптимизация для объединения многих таблиц в mysql
Если столбец speed не уникален в этих таблицах (и, вероятно, это не так, поскольку вы сказали, что добавили индекс со speed в качестве ведущего столбца...
Если в этих таблицах имеется несколько строк с одинаковым значением speed, тогда ваш запрос может создать огромный промежуточный набор.
Давайте сделаем простую математику. Если в каждой таблице есть две строки с одинаковым значением скорости, операции JOIN между a и b будут создавать 4 строки для этой скорости. Когда мы добавляем соединение к c, с двумя другими строками, это всего 8 строк. Когда мы объединяем все 22 таблицы, каждая с двумя строками, мы находимся на уровне 2 ^ 22 или более 4 миллионов строк. И тогда весь набор строк со всем тем же значением для speed должен быть обработан в операции GROUP BY для устранения дубликатов.
(Конечно, если какая-либо из таблиц не имеет строки для того же значения speed, тогда запрос будет генерировать нулевые строки для этой speed.)
Лично я выбрал синтаксис синтаксиса старой школы для операции JOIN и вместо этого использовал ключевое слово JOIN. И я переместил бы предикаты соединения из предложения WHERE в соответствующее предложение ON.
Я также сделал бы одну из таблиц "драйвером" для всех соединений, я бы использовал ссылку на одну и ту же таблицу в каждом из объединений. (Мы знаем, что если a=b и b=c, то a=c. Но я не уверен в оптимизаторе MySQL, независимо от того, будем ли мы указывать a=b and a=c вместо a=b and b=c.
Если в каждой из таблиц имеется относительно небольшое количество различных значений speed, но много строк с одинаковым значением, я бы рассмотрел возможность использования встроенных представлений, чтобы получить одну строку для каждой скорости из каждой таблицы. MySQL может использовать подходящий индекс для оптимизации операции GROUP BY для каждой отдельной таблицы... Я бы выбрал индексы покрытия... например
ON wspeed20 (speed, pid, 'or') ON wspeed24 (speed, pid, 'or')К сожалению, производная таблица (результат запроса встроенного представления) не индексируется, поэтому операции JOIN могут быть дорогими (для большого количества строк из каждого запроса встроенного представления).
SELECT a.month,a.roadTypeID,a.speed,a.pid,a.or, b.pid, b.or, c.pid, c.or, d.pid, d.or, e.pid, e.or, f.pid, f.or, g.pid, g.or, h.pid, h.or, i.pid, i.or, j.pid, j.or, k.pid, k.or, l.pid, l.or, m.pid, m.or, n.pid, n.or, o.pid, o.or, p.pid, p.or, q.pid, q.or, r.pid, r.or, s.pid, s.or, t.pid, t.or, u.pid, u.or, v.pid, v.or FROM (SELECT speed, pid, 'or' FROM wspeed2 GROUP BY speed) a JOIN (SELECT speed, pid, 'or' FROM wspeed3 GROUP BY speed) b ON b.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed20 GROUP BY speed) c ON c.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed24 GROUP BY speed) d ON d.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed25 GROUP BY speed) e ON e.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed26 GROUP BY speed) f ON f.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed27 GROUP BY speed) g ON g.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed63 GROUP BY speed) h ON h.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed65 GROUP BY speed) i ON i.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed68 GROUP BY speed) j ON j.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed69 GROUP BY speed) k ON k.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed70 GROUP BY speed) l ON l.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed71 GROUP BY speed) m ON m.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed72 GROUP BY speed) n ON n.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed73 GROUP BY speed) o ON o.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed74 GROUP BY speed) p ON p.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed75 GROUP BY speed) q ON q.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed76 GROUP BY speed) r ON r.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed77 GROUP BY speed) s ON s.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed78 GROUP BY speed) t ON t.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed81 GROUP BY speed) u ON u.speed = a.speed JOIN (SELECT speed, pid, 'or' FROM wspeed82 GROUP BY speed) v ON v.speed = a.speedЭто может сократить количество строк, которые необходимо объединить (опять же, если имеется большое количество повторяющихся значений для speed и небольшое количество различных значений для speed). Но опять же операции JOIN между производные таблицы не будут иметь доступных индексов. (По крайней мере, не в версиях MySQL до 5.6.)
qaru.site