Инструменты для разработчиков Инструменты для разработчиков. Оптимизация c
профильная оптимизация C++ / Блог компании Microsoft / Хабр
Как сделать нативное приложение более быстрым
Традиционные компиляторы работают с оптимизацией на основе статических исходных файлов. Они анализируют текст исходного файла, но не принимают в расчет данные, вводимые пользователями, о которых просто невозможно знать из кода. Рассмотрим этот псевдокод: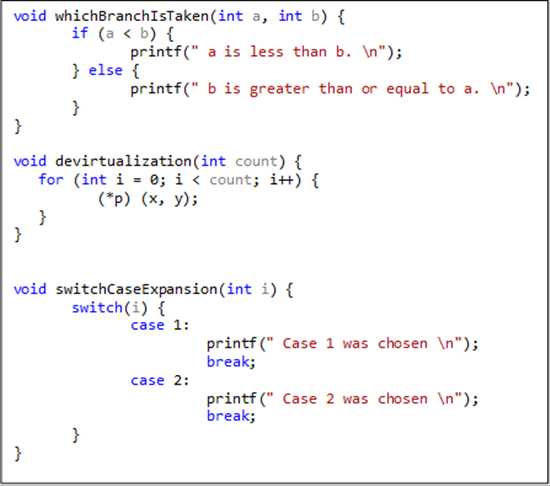
При работе с функцией whichBranchIsTaken компилятор не знает, как часто параметр «a» будет меньше параметра «b», и сколько раз будет применено условие «if» (т. е. компилятор не может предсказывать ветвления). При работе с функциями девиртуализации и switchCaseExpansion компилятор знает недостаточно о значениях *p и i, что делает невозможным оптимизацию девиртуализации и расширений параметров. Эти проблемы проявятся еще ярче, если мы подставим данный фрагмент кода в разные модули (например, разные объектные файлы), поскольку функции традиционной компиляции не могут быть оптимизированы для работы в пределах исходных модулей. Базовая модель компилятора и компоновщика не так уж и плоха, но в ней недостает двух основных возможностей для оптимизации. Во-первых, в ней не используется информация, которую можно было бы получить на основе анализа всех исходных файлов (традиционные компиляторы оптимизируют только отдельные объектные файлы). Во-вторых, в ней не проводится оптимизация на базе ожидаемой или профильной реакции приложения. Первый недостаток может быть исправлен с помощью переключателя компилятора (/GL) или переключателя компоновщика (/LTCG), выполняющего полную оптимизацию программы и необходимого для профильной оптимизации приложения. После того, как оптимизация полной программы включена, вы можете применять профильную оптимизацию. Остановимся на ней подробнее. PGO – это процесс оптимизации компилятора в среде выполнения, применяющий данные профиля, собранные в ходе выполнения важных или требующих высокой производительности пользовательских сценариев, с целью оптимизации приложения. Профильная оптимизация обладает рядом преимуществ по сравнению с традиционной статической оптимизацией, поскольку она принимает в расчет, как будет себя вести приложение в рабочей среде. Благодаря этому оптимизатор может осуществлять оптимизацию по скорости (для частых пользовательских сценариев) или оптимизацию по размеру (для редких сценариев). В результате код становится более лаконичным, что, в конечном счете, повышает производительность приложения.
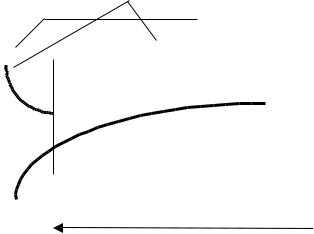
В настоящее время PGO может применяться только на классических приложениях для настольных компьютеров и поддерживается на платформах x86 и х64. PGO представляет собой процесс, состоящий из трех этапов, как это показано на рисунке выше.
- Первый этап обычно называют фазой инструментирования. В ходе этой фазы идет сборка приложения с заданным набором флагов компиляции. В процессе сборки внутренний компилятор добавляет в созданный код пробные инструкции (зонды), которые используются для записи данных обучения, необходимых на следующем этапе. Всего добавляется три типа зондов (входа в функцию, перехода и значений). Зонд входа в функцию измеряет, как часто запрашивалась та или иная функция. Зонд перехода позволяет узнать, сколько раз была достигнута та или иная ветвь кода. Таким образом в ходе фазы обучения компилятор получает информацию о том, как часто «a > b» в фрагменте кода whichBranchisTaken в заданном сценарии обучения. Зонд значений позволяет получить данные для построения гистограммы значений. Например, зонд значений, добавленный в фрагмент кода switchCaseExpansion, позволит получить данные для построения гистограммы значений для переменной индекса switch case i. Получив в ходе обучения информацию о том, какие значения будет принимать переменная «i», компилятор сможет провести оптимизацию для наиболее частых значений, а также таких функций как switchCaseExpansion. Таким образом, по окончании фазы у нас будет инструментированная версия приложения (с зондами) и пустой файл базы данных (.pgd), в которую будет заноситься информация, полученная в ходе следующей фазы.
- Фаза обучения . В ходе этой фазы пользователь запускает инструментированную версию приложения и проигрывает стандартные пользовательские сценарии, требующие высокой производительности. На выходе мы имеем файлы .pgc, содержащие информацию, связанную с различными пользовательскими сценариями. В процессе обучения информация проходит через зонды, добавленные в ходе первой фазы. На выходе мы получаем pgc-файлы appname!# (где appname соответствует названию приложения, а # — единице плюс числу pgc-файлов appname!# в выходном каталоге построения).
- Последняя фаза PGO — оптимизация. В ходе этой фазы создается оптимизированная версия приложения. Помимо этого, информация из pgc-файлов, полученная в ходе фазы обучения, вносится в фоновом режиме в базу данных (файл .pgd), созданную в ходе инструментирования. Внутренний компилятор затем использует эту базу данных для последующей оптимизации кода и построения еще более совершенной версии приложения.
Пользователи PGO зачастую ошибочно считают, что все три фазы (инструментирование, обучение и оптимизация) должны проводиться каждый раз при построении проекта. На самом деле, первые две фазы могут быть исключены при построении последующих версий, а код при этом может претерпевать значительные изменения по сравнению с версией, полученной после фазы обучения приложения. В больших коллективах один разработчик может отвечать за проведение PGO и поддержку базы данных обучения (.pgd) в репозитории исходного кода. Другие разработчики могут синхронизировать свои репозитарии кода с этой базой и использовать файлы обучения для построения PGO-оптимизированных версий приложений. После определенного количества перекомпиляций приложение будет окончательно оптимизировано.
Применение профильной оптимизации
Теперь, когда мы знаем немного больше о профильной оптимизации, рассмотрим ее применение на конкретном примере. Профильную оптимизацию приложения можно осуществлять с помощью Visual Studio или командной строки разработчика. Ниже рассмотрен пример работы в Visual Studio с приложением под условным названием «Nbody Simulation». Если вы хотите узнать больше о PGO в командной строке, обратитесь к этим статьям. Для начала работы загрузите решение в Visual Studio и выберите конфигурацию построения для работы (т.е. «Release»).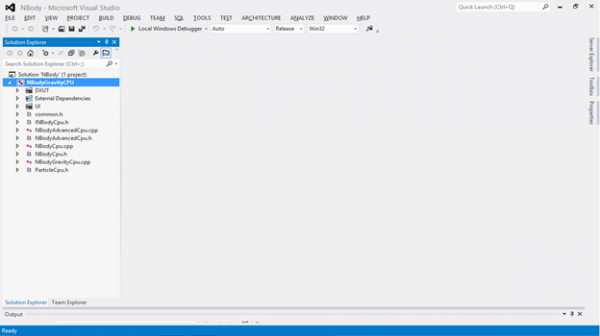
Как было упомянуто выше, PGO состоит из трех этапов: инструментирования, обучения и оптимизации. Для создания инструментированной версии приложения, нажмите правой кнопкой мыши по названию проекта («NBodyGravityCPU») и выберите раздел «Instrument» в меню «Profile Guided Optimization».
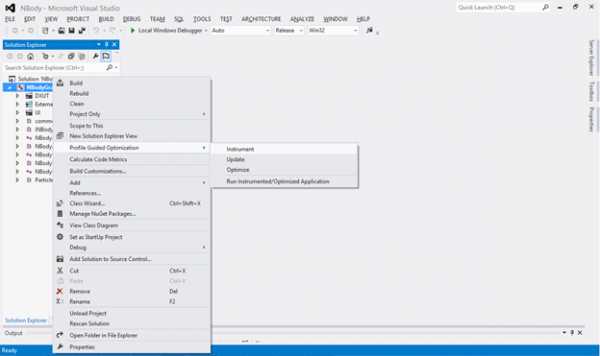
В Visual Studio будет построена инструментированная версия приложения. После этого можно переходить к фазе обучения. Запустите инструментированную версию приложения. Для этого зайдите в меню «Profile Guided Optimization» и выберите «Run Instrumented/Optimized Application». В нашем случае приложение выполняется с максимально большим телом кода (15360), т. к. будет реализован стабильный пользовательский сценарий, требующий высокой производительности. После того как два основных показателя производительности приложения — FPS (кадров в секунду) и GFlop – примут устойчивые значения, вы можете закрыть приложение. На этом фаза обучения будет завершена, а полученные данные будут сохранены в файле .pgc. По умолчанию файл .pgc будет включен в вашу конфигурацию построения, т.е. каталог «Release». Например, в результате этого обучения создается файл NBodyGravityCPU!1.pgc.
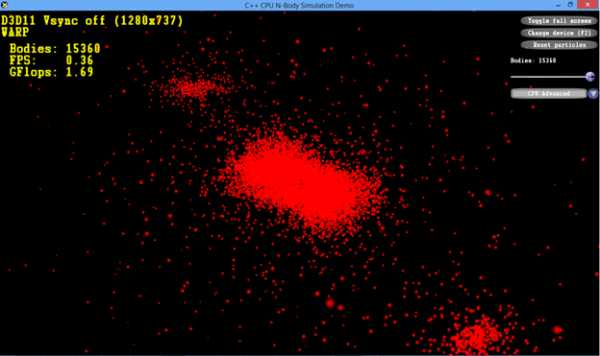
NBody Simulation представляет собой очень простое приложение, созданное исключительно для иллюстрации процесса PGO. В действительности может существовать множество вариантов сценариев обучения приложений. В частности, можно производить обучение в несколько этапов, разделенных по времени. Для записи таких сценариев обучения лучше всего использовать команду pgosweep в командной строке разработчика после того, как инструментированная версия уже создана (напр., в Visual Studio).
В ходе последней фазы PGO создается оптимизированная версия приложения. В меню «Profile Guided Optimization» выберите «Optimize». Будет создана оптимизированная версия приложения. В выходном журнале PGO-построения вы увидите обобщенную информацию о проведенной операции. Как было сказано выше, информация из файлов .pgc, полученная в ходе фазы обучения, включается в базу данных .pgd, которая затем используется матрицей оптимизации внутреннего компилятора. В большинстве случаев (за исключением небольших быстрых приложений) критерий оптимизации скорость/размер определяется соотношением динамических инструкций для определенной функции. Функции с большим числом инструкций (т. н. «горячие») оптимизируются на скорость, а с малым количеством инструкций (т. н. «холодные») – на размер. Это практически все, что вам необходимо для того чтобы начать профильную оптимизацию в ваших приложениях. Попробуйте применить PGO для своих приложений и оцените результаты! И обязательно загляните в блог Инструменты для разработчика, возможно вы найдете там еще какие либо интересные решения! Автор поста — Анкит Астхана (Ankit Asthana) — руководитель программы по внутреннему компилятору Microsoft Visual С++.
habr.com
c++ - Оптимизация g++ за пределами -O3/-Ofast
Большинство ответов предлагают альтернативные решения, такие как разные компиляторы или внешние библиотеки, которые, скорее всего, приведут к большой переработке или интеграции. Я постараюсь придерживаться того, что задает вопрос, и сосредоточиться на том, что можно сделать только с помощью GCC, путем активации флагов компилятора или внесения минимальных изменений в код, по просьбе OP. Это не ответ "вы должны сделать", а больше набор настроек GCC, которые хорошо сработали для меня, и что вы можете попробовать, если они релевантны в вашем конкретном контексте.
Предупреждения относительно исходного вопроса
Прежде чем вдаваться в подробности, несколько предупреждений относительно вопроса, как правило, для людей, которые придут, прочитают вопрос и скажут: "ОП оптимизируется за пределами O3, я должен использовать те же флаги, что и он!".
- -march=native позволяет использовать инструкции, специфичные для данной архитектуры процессора, и которые необязательно доступны в другой архитектуре. Программа может вообще не работать, если работать в системе с другим процессором или быть значительно медленнее (так как это также позволяет mtune=native), поэтому имейте это в виду, если вы решите ее использовать. Подробнее здесь.
- -Ofast, как вы заявили, позволяет оптимизировать нестандартную совместимость, поэтому его следует использовать с осторожностью. Подробнее здесь.
Другие флаги GCC для тестирования
Детали для разных флагов перечислены здесь.
- -Ofast позволяет -ffast-math, что, в свою очередь, позволяет -fno-math-errno, -funsafe-math-optimizations, -ffinite-math-only, -fno-rounding-math, -fno-signaling-nans и -fcx-limited-range. Вы можете пойти еще дальше на оптимизацию расчета с плавающей запятой, выборочно добавив некоторые дополнительные флаги, такие как -fassociative-math, -freciprocal-math, -fno-signed-zeros и -fno-trapping-math. Они не включены в -Ofast и могут дать некоторые дополнительные увеличения производительности при расчетах, но вы должны проверить, действительно ли они приносят вам пользу, и не нарушают никаких вычислений.
- GCC также содержит кучу других флагов оптимизации, которые не включены никакими опциями "-O". Они перечислены как "экспериментальные варианты, которые могут привести к нарушению кода", поэтому их следует использовать с осторожностью, а их эффекты проверяются как путем проверки правильности, так и для бенчмаркинга. Тем не менее, я часто использую -frename-registers, этот вариант никогда не вызывал нежелательных результатов для меня и, как правило, дает заметное увеличение производительности (т.е. Можно измерить при бенчмаркинге). Это тип флага, который сильно зависит от вашего процессора. -funroll-loops также иногда дает хорошие результаты, но зависит от вашего фактического кода.
PGO
GCC имеет функции оптимизации профиля. Существует не так много точной документации по GCC, но, тем не менее, ее запуск достаточно прост.
- сначала скомпилируйте свою программу с помощью -fprofile-generate.
- пусть запускается программа (время выполнения будет значительно медленнее, так как код также генерирует информацию профиля в файлы .gcda).
- перекомпилируйте программу с помощью -fprofile-use. Если ваше приложение многопоточно, добавьте флаг -fprofile-correction.
PGO с GCC может дать потрясающие результаты и действительно значительно повысить производительность (я видел увеличение скорости на 15-20% в одном из проектов, над которыми я недавно работал). Очевидно, что проблема заключается в том, чтобы иметь некоторые данные, которые достаточно репрезентативны для выполнения вашего приложения, что не всегда доступно или легко получить.
Параллельный режим GCC
GCC имеет Параллельный режим, который был впервые выпущен примерно в то время, когда компилятор GCC 4.2 отсутствовал.
В принципе, он предоставляет вам параллельные реализации многих алгоритмов в стандартной библиотеке С++. Чтобы включить их во всем мире, вам просто нужно добавить флаги -fopenmp и -D_GLIBCXX_PARALLEL в компилятор. Вы также можете выборочно включать каждый алгоритм, когда это необходимо, но для этого потребуются незначительные изменения кода.
Вся информация об этом параллельном режиме находится здесь здесь.
Если вы часто используете эти алгоритмы в больших структурах данных и имеете много контекстов аппаратного потока, эти параллельные реализации могут дать огромный прирост производительности. Я использовал только параллельную реализацию sort, но для того, чтобы дать приблизительную идею, мне удалось сократить время сортировки с 14 до 4 секунд в одном из моих приложений (тестовая среда: вектор из 100 миллионов объектов с пользовательская функция компаратора и 8-ядерная машина).
Дополнительные трюки
В отличие от предыдущих разделов точек, эта часть требует небольших изменений в коде. Они также специфичны для GCC (некоторые из них также работают над Clang), поэтому макросы макросов компиляции должны использоваться для сохранения кода в других компиляторах. Этот раздел содержит несколько более сложных методов и не должен использоваться, если у вас нет понимания на уровне сборки того, что происходит. Также обратите внимание, что в настоящее время процессоры и компиляторы довольно умны, поэтому может быть сложно получить какую-либо заметную выгоду от описанных здесь функций.
- GCC встроены, которые перечислены здесь. Конструкции, такие как __builtin_expect, могут помочь компилятору улучшить оптимизацию, предоставив ему информацию прогнозирования ветвей. Другие конструкции, такие как __builtin_prefetch, вносят данные в кеш, прежде чем они будут доступны, и могут помочь уменьшить пропуски кэша.
- которые перечислены здесь. В частности, вы должны изучить атрибуты hot и cold; первый будет указывать компилятору, что функция является hotspot программы и более агрессивно оптимизирует функцию и помещает ее в специальный подраздел текстового раздела для лучшей локальности; более поздняя версия будет оптимизировать функцию для размера и поместить ее в другой специальный подраздел текстового раздела.
Я надеюсь, что этот ответ окажется полезным для некоторых разработчиков, и я буду рад рассмотреть любые изменения или предложения.
qaru.site
профильная оптимизация C++ – Инструменты для разработчиков
Профильная оптимизация это очень интересный способ оптимизации кода приложения всреде выполнения (в команде разработчиков Visual C этот метод называют POGO или PGO, от английского Profile Guided Optimization). Впервые профильная оптимизация была применена в конце 90-х исследовательскими группами в Visual C и Microsoft. Тогда она была рассчитана для архитектуры Itanium. Затем PGO была включена в состав Visual Studio C/C++ 2005. На сегодня это основной процесс оптимизации, значительно повышающий производительность приложений Microsoft и других разработчиков.В этом посте будет рассказано, как создавать более быстрые и высокопроизводительные нативные приложения. Для начала, познакомимся ближе с PGO, а затем рассмотрим на примере (симуляция NBody), как с помощью нескольких простых шагов можно применить этот процесс оптимизации в ваших приложениях. Для работы используйте исходный код изпримера. Для сборки проекта вам понадобится DirectX SDK.
Как сделать нативное приложение более быстрым
Традиционные компиляторы работают с оптимизацией на основе статических исходных файлов. Они анализируют текст исходного файла, но не принимают в расчет данные, вводимые пользователями, о которых просто невозможно знать из кода. Рассмотрим этот псевдокод: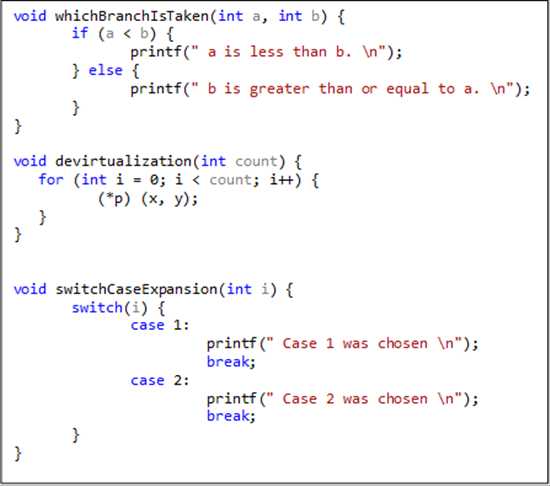
При работе с функцией whichBranchIsTaken компилятор не знает, как часто параметр «a» будет меньше параметра «b», и сколько раз будет применено условие «if» (т. е. компилятор не может предсказывать ветвления). При работе с функциями девиртуализации и switchCaseExpansion компилятор знает недостаточно о значениях *p и i, что делает невозможным оптимизацию девиртуализации и расширений параметров. Эти проблемы проявятся еще ярче, если мы подставим данный фрагмент кода в разные модули (например, разные объектные файлы), поскольку функции традиционной компиляции не могут быть оптимизированы для работы в пределах исходных модулей.Базовая модель компилятора и компоновщика не так уж и плоха, но в ней недостает двух основных возможностей для оптимизации. Во-первых, в ней не используется информация, которую можно было бы получить на основе анализа всех исходных файлов (традиционные компиляторы оптимизируют только отдельные объектные файлы). Во-вторых, в ней не проводится оптимизация на базе ожидаемой или профильной реакции приложения. Первый недостаток может быть исправлен с помощью переключателя компилятора (/GL) или переключателя компоновщика (/LTCG), выполняющего полную оптимизацию программы и необходимого для профильной оптимизации приложения. После того, как оптимизация полной программы включена, вы можете применять профильную оптимизацию. Остановимся на ней подробнее.PGO – это процесс оптимизации компилятора в среде выполнения, применяющий данные профиля, собранные в ходе выполнения важных или требующих высокой производительности пользовательских сценариев, с целью оптимизации приложения. Профильная оптимизация обладает рядом преимуществ по сравнению с традиционной статической оптимизацией, поскольку она принимает в расчет, как будет себя вести приложение в рабочей среде. Благодаря этому оптимизатор может осуществлять оптимизацию по скорости (для частых пользовательских сценариев) или оптимизацию по размеру (для редких сценариев). В результате код становится более лаконичным, что, в конечном счете, повышает производительность приложения.
В настоящее время PGO может применяться только на классических приложениях для настольных компьютеров и поддерживается на платформах x86 и х64. PGO представляет собой процесс, состоящий из трех этапов, как это показано на рисунке выше.
- Первый этап обычно называют фазой инструментирования. В ходе этой фазы идет сборка приложения с заданным набором флагов компиляции. В процессе сборки внутренний компилятор добавляет в созданный код пробные инструкции (зонды), которые используются для записи данных обучения, необходимых на следующем этапе. Всего добавляется три типа зондов (входа в функцию, перехода и значений). Зонд входа в функцию измеряет, как часто запрашивалась та или иная функция. Зонд перехода позволяет узнать, сколько раз была достигнута та или иная ветвь кода. Таким образом в ходе фазы обучения компилятор получает информацию о том, как часто «a > b» в фрагменте кода whichBranchisTaken в заданном сценарии обучения. Зонд значений позволяет получить данные для построения гистограммы значений. Например, зонд значений, добавленный в фрагмент кода switchCaseExpansion, позволит получить данные для построения гистограммы значений для переменной индекса switch case i. Получив в ходе обучения информацию о том, какие значения будет принимать переменная «i», компилятор сможет провести оптимизацию для наиболее частых значений, а также таких функций как switchCaseExpansion. Таким образом, по окончании фазы у нас будет инструментированная версия приложения (с зондами) и пустой файл базы данных (.pgd), в которую будет заноситься информация, полученная в ходе следующей фазы.
- Фаза обучения . В ходе этой фазы пользователь запускает инструментированную версию приложения и проигрывает стандартные пользовательские сценарии, требующие высокой производительности. На выходе мы имеем файлы .pgc, содержащие информацию, связанную с различными пользовательскими сценариями. В процессе обучения информация проходит через зонды, добавленные в ходе первой фазы. На выходе мы получаем pgc-файлы appname!# (где appname соответствует названию приложения, а # — единице плюс числу pgc-файлов appname!# в выходном каталоге построения).
- Последняя фаза PGO — оптимизация. В ходе этой фазы создается оптимизированная версия приложения. Помимо этого, информация из pgc-файлов, полученная в ходе фазы обучения, вносится в фоновом режиме в базу данных (файл .pgd), созданную в ходе инструментирования. Внутренний компилятор затем использует эту базу данных для последующей оптимизации кода и построения еще более совершенной версии приложения.
Пользователи PGO зачастую ошибочно считают, что все три фазы (инструментирование, обучение и оптимизация) должны проводиться каждый раз при построении проекта. На самом деле, первые две фазы могут быть исключены при построении последующих версий, а код при этом может претерпевать значительные изменения по сравнению с версией, полученной после фазы обучения приложения. В больших коллективах один разработчик может отвечать за проведение PGO и поддержку базы данных обучения (.pgd) в репозитории исходного кода. Другие разработчики могут синхронизировать свои репозитарии кода с этой базой и использовать файлы обучения для построения PGO-оптимизированных версий приложений. После определенного количества перекомпиляций приложение будет окончательно оптимизировано.
Применение профильной оптимизации
Теперь, когда мы знаем немного больше о профильной оптимизации, рассмотрим ее применение на конкретном примере. Профильную оптимизацию приложения можно осуществлять с помощью Visual Studio или командной строки разработчика. Ниже рассмотрен пример работы в Visual Studio с приложением под условным названием «Nbody Simulation». Если вы хотите узнать больше о PGO в командной строке, обратитесь к этим статьям. Для начала работы загрузите решение в Visual Studio и выберите конфигурацию построения для работы (т.е. «Release»).
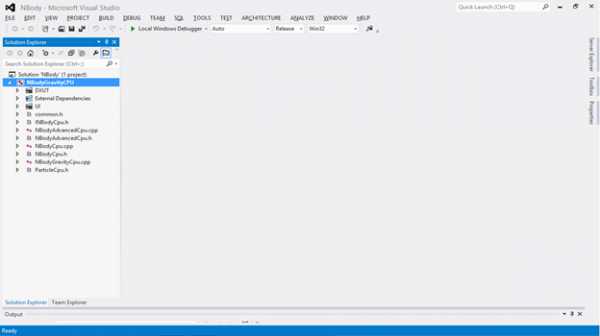
Как было упомянуто выше, PGO состоит из трех этапов: инструментирования, обучения и оптимизации. Для создания инструментированной версии приложения, нажмите правой кнопкой мыши по названию проекта («NBodyGravityCPU») и выберите раздел «Instrument» в меню «Profile Guided Optimization».
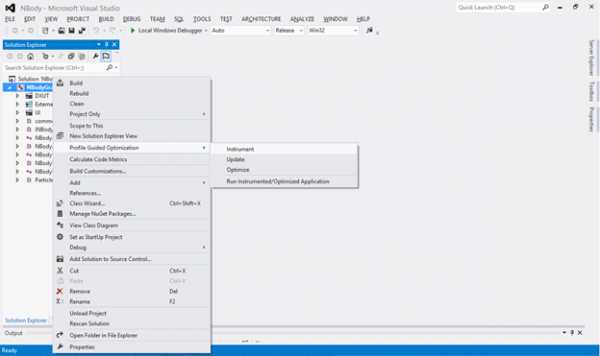
В Visual Studio будет построена инструментированная версия приложения. После этого можно переходить к фазе обучения. Запустите инструментированную версию приложения. Для этого зайдите в меню «Profile Guided Optimization» и выберите «Run Instrumented/Optimized Application». В нашем случае приложение выполняется с максимально большим телом кода (15360), т. к. будет реализован стабильный пользовательский сценарий, требующий высокой производительности. После того как два основных показателя производительности приложения — FPS (кадров в секунду) и GFlop – примут устойчивые значения, вы можете закрыть приложение. На этом фаза обучения будет завершена, а полученные данные будут сохранены в файле .pgc. По умолчанию файл .pgc будет включен в вашу конфигурацию построения, т.е. каталог «Release». Например, в результате этого обучения создается файл NBodyGravityCPU!1.pgc.
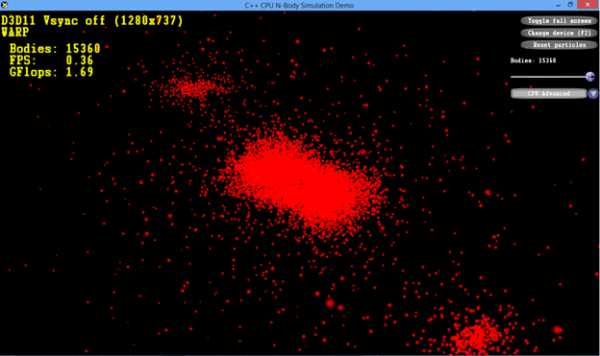
NBody Simulation представляет собой очень простое приложение, созданное исключительно для иллюстрации процесса PGO. В действительности может существовать множество вариантов сценариев обучения приложений. В частности, можно производить обучение в несколько этапов, разделенных по времени. Для записи таких сценариев обучения лучше всего использовать команду pgosweep в командной строке разработчика после того, как инструментированная версия уже создана (напр., в Visual Studio).
В ходе последней фазы PGO создается оптимизированная версия приложения. В меню «Profile Guided Optimization» выберите «Optimize». Будет создана оптимизированная версия приложения. В выходном журнале PGO-построения вы увидите обобщенную информацию о проведенной операции.Как было сказано выше, информация из файлов .pgc, полученная в ходе фазы обучения, включается в базу данных .pgd, которая затем используется матрицей оптимизации внутреннего компилятора. В большинстве случаев (за исключением небольших быстрых приложений) критерий оптимизации скорость/размер определяется соотношением динамических инструкций для определенной функции. Функции с большим числом инструкций (т. н. «горячие») оптимизируются на скорость, а с малым количеством инструкций (т. н. «холодные») – на размер.Это практически все, что вам необходимо для того чтобы начать профильную оптимизацию в ваших приложениях. Попробуйте применить PGO для своих приложений и оцените результаты! И обязательно загляните в блог Инструменты для разработчика, возможно вы найдете там еще какие либо интересные решения! Автор поста — Анкит Астхана (Ankit Asthana) — руководитель программы по внутреннему компилятору Microsoft Visual С++.
blogs.msdn.microsoft.com
Как сделать ваше приложение быстрым: профильная оптимизация C++
Профильная оптимизация это очень интересный способ оптимизации кода приложения в среде выполнения (в команде разработчиков Visual C этот метод называют POGO или PGO, от английского Profile Guided Optimization). Впервые профильная оптимизация была применена в конце 90-х исследовательскими группами в Visual C и Microsoft. Тогда она была рассчитана для архитектуры Itanium. Затем PGO была включена в состав Visual Studio C/C++ 2005. На сегодня это основной процесс оптимизации, значительно повышающий производительность приложений Microsoft и других разработчиков.В этом посте будет рассказано, как создавать более быстрые и высокопроизводительные нативные приложения. Для начала, познакомимся ближе с PGO, а затем рассмотрим на примере (симуляция NBody), как с помощью нескольких простых шагов можно применить этот процесс оптимизации в ваших приложениях. Для работы используйте исходный код из примера. Для сборки проекта вам понадобится DirectX SDK.
Как сделать нативное приложение более быстрым
Традиционные компиляторы работают с оптимизацией на основе статических исходных файлов. Они анализируют текст исходного файла, но не принимают в расчет данные, вводимые пользователями, о которых просто невозможно знать из кода. Рассмотрим этот псевдокод: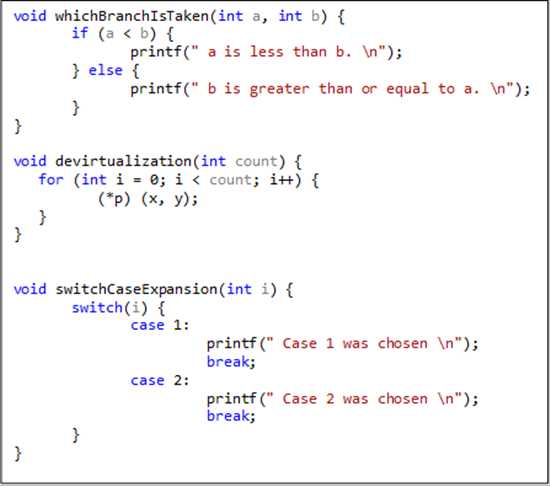
При работе с функцией whichBranchIsTaken компилятор не знает, как часто параметр «a» будет меньше параметра «b», и сколько раз будет применено условие «if» (т. е. компилятор не может предсказывать ветвления). При работе с функциями девиртуализации и switchCaseExpansion компилятор знает недостаточно о значениях *p и i, что делает невозможным оптимизацию девиртуализации и расширений параметров. Эти проблемы проявятся еще ярче, если мы подставим данный фрагмент кода в разные модули (например, разные объектные файлы), поскольку функции традиционной компиляции не могут быть оптимизированы для работы в пределах исходных модулей.Базовая модель компилятора и компоновщика не так уж и плоха, но в ней недостает двух основных возможностей для оптимизации. Во-первых, в ней не используется информация, которую можно было бы получить на основе анализа всех исходных файлов (традиционные компиляторы оптимизируют только отдельные объектные файлы). Во-вторых, в ней не проводится оптимизация на базе ожидаемой или профильной реакции приложения. Первый недостаток может быть исправлен с помощью переключателя компилятора (/GL) или переключателя компоновщика (/LTCG), выполняющего полную оптимизацию программы и необходимого для профильной оптимизации приложения. После того, как оптимизация полной программы включена, вы можете применять профильную оптимизацию. Остановимся на ней подробнее.PGO – это процесс оптимизации компилятора в среде выполнения, применяющий данные профиля, собранные в ходе выполнения важных или требующих высокой производительности пользовательских сценариев, с целью оптимизации приложения. Профильная оптимизация обладает рядом преимуществ по сравнению с традиционной статической оптимизацией, поскольку она принимает в расчет, как будет себя вести приложение в рабочей среде. Благодаря этому оптимизатор может осуществлять оптимизацию по скорости (для частых пользовательских сценариев) или оптимизацию по размеру (для редких сценариев). В результате код становится более лаконичным, что, в конечном счете, повышает производительность приложения.
В настоящее время PGO может применяться только на классических приложениях для настольных компьютеров и поддерживается на платформах x86 и х64. PGO представляет собой процесс, состоящий из трех этапов, как это показано на рисунке выше.
- Первый этап обычно называют фазой инструментирования. В ходе этой фазы идет сборка приложения с заданным набором флагов компиляции. В процессе сборки внутренний компилятор добавляет в созданный код пробные инструкции (зонды), которые используются для записи данных обучения, необходимых на следующем этапе. Всего добавляется три типа зондов (входа в функцию, перехода и значений). Зонд входа в функцию измеряет, как часто запрашивалась та или иная функция. Зонд перехода позволяет узнать, сколько раз была достигнута та или иная ветвь кода. Таким образом в ходе фазы обучения компилятор получает информацию о том, как часто «a > b» в фрагменте кода whichBranchisTaken в заданном сценарии обучения. Зонд значений позволяет получить данные для построения гистограммы значений. Например, зонд значений, добавленный в фрагмент кода switchCaseExpansion, позволит получить данные для построения гистограммы значений для переменной индекса switch case i. Получив в ходе обучения информацию о том, какие значения будет принимать переменная «i», компилятор сможет провести оптимизацию для наиболее частых значений, а также таких функций как switchCaseExpansion. Таким образом, по окончании фазы у нас будет инструментированная версия приложения (с зондами) и пустой файл базы данных (.pgd), в которую будет заноситься информация, полученная в ходе следующей фазы.
- Фаза обучения . В ходе этой фазы пользователь запускает инструментированную версию приложения и проигрывает стандартные пользовательские сценарии, требующие высокой производительности. На выходе мы имеем файлы .pgc, содержащие информацию, связанную с различными пользовательскими сценариями. В процессе обучения информация проходит через зонды, добавленные в ходе первой фазы. На выходе мы получаем pgc-файлы appname!# (где appname соответствует названию приложения, а # — единице плюс числу pgc-файлов appname!# в выходном каталоге построения).
- Последняя фаза PGO — оптимизация. В ходе этой фазы создается оптимизированная версия приложения. Помимо этого, информация из pgc-файлов, полученная в ходе фазы обучения, вносится в фоновом режиме в базу данных (файл .pgd), созданную в ходе инструментирования. Внутренний компилятор затем использует эту базу данных для последующей оптимизации кода и построения еще более совершенной версии приложения.
Пользователи PGO зачастую ошибочно считают, что все три фазы (инструментирование, обучение и оптимизация) должны проводиться каждый раз при построении проекта. На самом деле, первые две фазы могут быть исключены при построении последующих версий, а код при этом может претерпевать значительные изменения по сравнению с версией, полученной после фазы обучения приложения. В больших коллективах один разработчик может отвечать за проведение PGO и поддержку базы данных обучения (.pgd) в репозитории исходного кода. Другие разработчики могут синхронизировать свои репозитарии кода с этой базой и использовать файлы обучения для построения PGO-оптимизированных версий приложений. После определенного количества перекомпиляций приложение будет окончательно оптимизировано.
Применение профильной оптимизации
Теперь, когда мы знаем немного больше о профильной оптимизации, рассмотрим ее применение на конкретном примере. Профильную оптимизацию приложения можно осуществлять с помощью Visual Studio или командной строки разработчика. Ниже рассмотрен пример работы в Visual Studio с приложением под условным названием «Nbody Simulation». Если вы хотите узнать больше о PGO в командной строке, обратитесь к этим статьям. Для начала работы загрузите решение в Visual Studio и выберите конфигурацию построения для работы (т.е. «Release»).
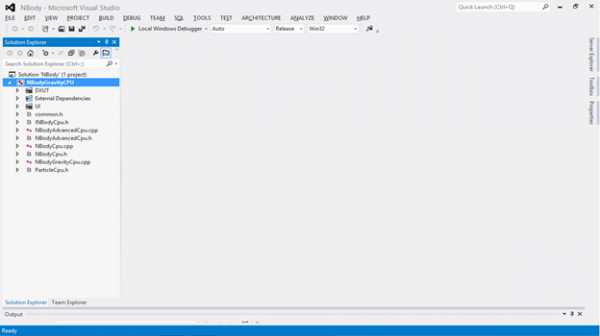
Как было упомянуто выше, PGO состоит из трех этапов: инструментирования, обучения и оптимизации. Для создания инструментированной версии приложения, нажмите правой кнопкой мыши по названию проекта («NBodyGravityCPU») и выберите раздел «Instrument» в меню «Profile Guided Optimization».
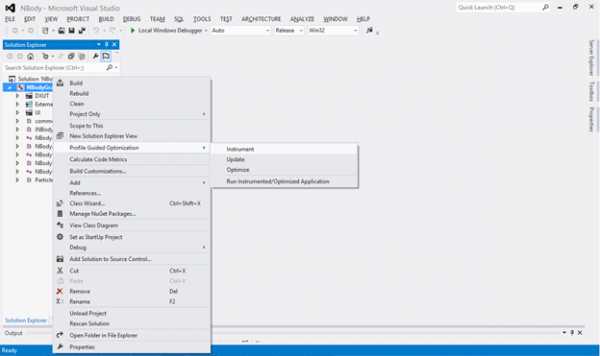
В Visual Studio будет построена инструментированная версия приложения. После этого можно переходить к фазе обучения. Запустите инструментированную версию приложения. Для этого зайдите в меню «Profile Guided Optimization» и выберите «Run Instrumented/Optimized Application». В нашем случае приложение выполняется с максимально большим телом кода (15360), т. к. будет реализован стабильный пользовательский сценарий, требующий высокой производительности. После того как два основных показателя производительности приложения — FPS (кадров в секунду) и GFlop – примут устойчивые значения, вы можете закрыть приложение. На этом фаза обучения будет завершена, а полученные данные будут сохранены в файле .pgc. По умолчанию файл .pgc будет включен в вашу конфигурацию построения, т.е. каталог «Release». Например, в результате этого обучения создается файл NBodyGravityCPU!1.pgc.
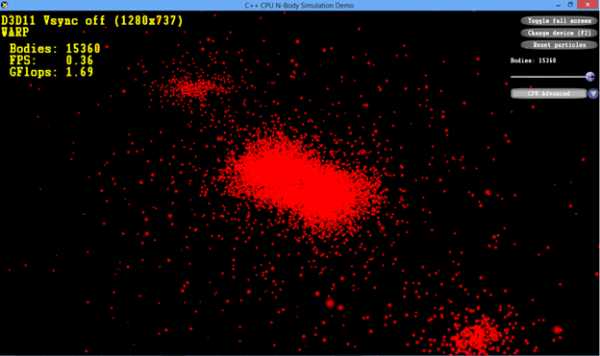
NBody Simulation представляет собой очень простое приложение, созданное исключительно для иллюстрации процесса PGO. В действительности может существовать множество вариантов сценариев обучения приложений. В частности, можно производить обучение в несколько этапов, разделенных по времени. Для записи таких сценариев обучения лучше всего использовать команду pgosweep в командной строке разработчика после того, как инструментированная версия уже создана (напр., в Visual Studio).
В ходе последней фазы PGO создается оптимизированная версия приложения. В меню «Profile Guided Optimization» выберите «Optimize». Будет создана оптимизированная версия приложения. В выходном журнале PGO-построения вы увидите обобщенную информацию о проведенной операции.Как было сказано выше, информация из файлов .pgc, полученная в ходе фазы обучения, включается в базу данных .pgd, которая затем используется матрицей оптимизации внутреннего компилятора. В большинстве случаев (за исключением небольших быстрых приложений) критерий оптимизации скорость/размер определяется соотношением динамических инструкций для определенной функции. Функции с большим числом инструкций (т. н. «горячие») оптимизируются на скорость, а с малым количеством инструкций (т. н. «холодные») – на размер.Это практически все, что вам необходимо для того чтобы начать профильную оптимизацию в ваших приложениях. Попробуйте применить PGO для своих приложений и оцените результаты! И обязательно загляните в блог Инструменты для разработчика, возможно вы найдете там еще какие либо интересные решения! Автор поста — Анкит Астхана (Ankit Asthana) — руководитель программы по внутреннему компилятору Microsoft Visual С++.
Автор: dmandreev
Источник
www.pvsm.ru
optimization - Оптимизация циклов C
Инициализация массива до нуля. Когда J объявляется двойным array - значения массива инициализируется до нуля? Если нет, есть ли быстрый способ установить все элементы в ноль?
Это зависит от того, где выделен массив. Если он объявлен в области файлов или как статический, то стандарт C гарантирует, что все элементы установлены на ноль. То же самое можно гарантировать, если вы установите первый элемент в значение при инициализации, то есть:
double J[151][151] = {0}; /* set first element to zero */Установив первый элемент на что-то, стандарт C гарантирует, что все остальные элементы в массиве будут установлены равными нулю, как если бы массив был статически распределен.
Практически для этого конкретного случая я очень сомневаюсь, что было бы разумно выделить 151 * 151 * sizeof (double) байтов в стеке независимо от того, какую систему вы используете. Вам, вероятно, придется распределять его динамически, и тогда ни одно из вышеизложенных вопросов не имеет значения. Затем вы должны использовать memset(), чтобы установить все байты в ноль.
В относительно медленный цикл ниже, доступ к содержащейся матрице в структурных "данных" медленный компонент или это что-то еще о цикле?
Вы должны убедиться, что вызываемая из него функция встроена. В противном случае вам нечего делать, чтобы оптимизировать цикл: что оптимально, зависит от системы (то есть, как создаются физические кеш-памяти). Лучше оставить такую оптимизацию компилятору.
Вы могли бы, конечно, запутать код с помощью ручных функций оптимизации, таких как отсчет до нуля, а не вверх, или использовать ++ i, а не я ++ и т.д. Но компилятор действительно должен уметь обрабатывать такие вещи для вас.
Что касается сложения матриц, я не знаю о математически наиболее эффективном способе, но я подозреваю, что он незначительно влияет на эффективность кода. Большой вор здесь - двойной тип. Если вам действительно не нужна высокая точность, я бы подумал об использовании float или int для ускорения алгоритма.
qaru.site
профильная оптимизация C++ – Блог Дмитрия Андреева [MSFT]
Профильная оптимизация это очень интересный способ оптимизации кода приложения всреде выполнения (в команде разработчиков Visual C этот метод называют POGO или PGO, от английского Profile Guided Optimization). Впервые профильная оптимизация была применена в конце 90-х исследовательскими группами в Visual C и Microsoft. Тогда она была рассчитана для архитектуры Itanium. Затем PGO была включена в состав Visual Studio C/C++ 2005. На сегодня это основной процесс оптимизации, значительно повышающий производительность приложений Microsoft и других разработчиков.В этом посте будет рассказано, как создавать более быстрые и высокопроизводительные нативные приложения. Для начала, познакомимся ближе с PGO, а затем рассмотрим на примере (симуляция NBody), как с помощью нескольких простых шагов можно применить этот процесс оптимизации в ваших приложениях. Для работы используйте исходный код изпримера. Для сборки проекта вам понадобится DirectX SDK.
Как сделать нативное приложение более быстрым
Традиционные компиляторы работают с оптимизацией на основе статических исходных файлов. Они анализируют текст исходного файла, но не принимают в расчет данные, вводимые пользователями, о которых просто невозможно знать из кода. Рассмотрим этот псевдокод:
При работе с функцией whichBranchIsTaken компилятор не знает, как часто параметр «a» будет меньше параметра «b», и сколько раз будет применено условие «if» (т. е. компилятор не может предсказывать ветвления). При работе с функциями девиртуализации и switchCaseExpansion компилятор знает недостаточно о значениях *p и i, что делает невозможным оптимизацию девиртуализации и расширений параметров. Эти проблемы проявятся еще ярче, если мы подставим данный фрагмент кода в разные модули (например, разные объектные файлы), поскольку функции традиционной компиляции не могут быть оптимизированы для работы в пределах исходных модулей.Базовая модель компилятора и компоновщика не так уж и плоха, но в ней недостает двух основных возможностей для оптимизации. Во-первых, в ней не используется информация, которую можно было бы получить на основе анализа всех исходных файлов (традиционные компиляторы оптимизируют только отдельные объектные файлы). Во-вторых, в ней не проводится оптимизация на базе ожидаемой или профильной реакции приложения. Первый недостаток может быть исправлен с помощью переключателя компилятора (/GL) или переключателя компоновщика (/LTCG), выполняющего полную оптимизацию программы и необходимого для профильной оптимизации приложения. После того, как оптимизация полной программы включена, вы можете применять профильную оптимизацию. Остановимся на ней подробнее.PGO – это процесс оптимизации компилятора в среде выполнения, применяющий данные профиля, собранные в ходе выполнения важных или требующих высокой производительности пользовательских сценариев, с целью оптимизации приложения. Профильная оптимизация обладает рядом преимуществ по сравнению с традиционной статической оптимизацией, поскольку она принимает в расчет, как будет себя вести приложение в рабочей среде. Благодаря этому оптимизатор может осуществлять оптимизацию по скорости (для частых пользовательских сценариев) или оптимизацию по размеру (для редких сценариев). В результате код становится более лаконичным, что, в конечном счете, повышает производительность приложения.
В настоящее время PGO может применяться только на классических приложениях для настольных компьютеров и поддерживается на платформах x86 и х64. PGO представляет собой процесс, состоящий из трех этапов, как это показано на рисунке выше.
- Первый этап обычно называют фазой инструментирования. В ходе этой фазы идет сборка приложения с заданным набором флагов компиляции. В процессе сборки внутренний компилятор добавляет в созданный код пробные инструкции (зонды), которые используются для записи данных обучения, необходимых на следующем этапе. Всего добавляется три типа зондов (входа в функцию, перехода и значений). Зонд входа в функцию измеряет, как часто запрашивалась та или иная функция. Зонд перехода позволяет узнать, сколько раз была достигнута та или иная ветвь кода. Таким образом в ходе фазы обучения компилятор получает информацию о том, как часто «a > b» в фрагменте кода whichBranchisTaken в заданном сценарии обучения. Зонд значений позволяет получить данные для построения гистограммы значений. Например, зонд значений, добавленный в фрагмент кода switchCaseExpansion, позволит получить данные для построения гистограммы значений для переменной индекса switch case i. Получив в ходе обучения информацию о том, какие значения будет принимать переменная «i», компилятор сможет провести оптимизацию для наиболее частых значений, а также таких функций как switchCaseExpansion. Таким образом, по окончании фазы у нас будет инструментированная версия приложения (с зондами) и пустой файл базы данных (.pgd), в которую будет заноситься информация, полученная в ходе следующей фазы.
- Фаза обучения . В ходе этой фазы пользователь запускает инструментированную версию приложения и проигрывает стандартные пользовательские сценарии, требующие высокой производительности. На выходе мы имеем файлы .pgc, содержащие информацию, связанную с различными пользовательскими сценариями. В процессе обучения информация проходит через зонды, добавленные в ходе первой фазы. На выходе мы получаем pgc-файлы appname!# (где appname соответствует названию приложения, а # — единице плюс числу pgc-файлов appname!# в выходном каталоге построения).
- Последняя фаза PGO — оптимизация. В ходе этой фазы создается оптимизированная версия приложения. Помимо этого, информация из pgc-файлов, полученная в ходе фазы обучения, вносится в фоновом режиме в базу данных (файл .pgd), созданную в ходе инструментирования. Внутренний компилятор затем использует эту базу данных для последующей оптимизации кода и построения еще более совершенной версии приложения.
Пользователи PGO зачастую ошибочно считают, что все три фазы (инструментирование, обучение и оптимизация) должны проводиться каждый раз при построении проекта. На самом деле, первые две фазы могут быть исключены при построении последующих версий, а код при этом может претерпевать значительные изменения по сравнению с версией, полученной после фазы обучения приложения. В больших коллективах один разработчик может отвечать за проведение PGO и поддержку базы данных обучения (.pgd) в репозитории исходного кода. Другие разработчики могут синхронизировать свои репозитарии кода с этой базой и использовать файлы обучения для построения PGO-оптимизированных версий приложений. После определенного количества перекомпиляций приложение будет окончательно оптимизировано.
Применение профильной оптимизации
Теперь, когда мы знаем немного больше о профильной оптимизации, рассмотрим ее применение на конкретном примере. Профильную оптимизацию приложения можно осуществлять с помощью Visual Studio или командной строки разработчика. Ниже рассмотрен пример работы в Visual Studio с приложением под условным названием «Nbody Simulation». Если вы хотите узнать больше о PGO в командной строке, обратитесь к этим статьям. Для начала работы загрузите решение в Visual Studio и выберите конфигурацию построения для работы (т.е. «Release»).
Как было упомянуто выше, PGO состоит из трех этапов: инструментирования, обучения и оптимизации. Для создания инструментированной версии приложения, нажмите правой кнопкой мыши по названию проекта («NBodyGravityCPU») и выберите раздел «Instrument» в меню «Profile Guided Optimization».
В Visual Studio будет построена инструментированная версия приложения. После этого можно переходить к фазе обучения. Запустите инструментированную версию приложения. Для этого зайдите в меню «Profile Guided Optimization» и выберите «Run Instrumented/Optimized Application». В нашем случае приложение выполняется с максимально большим телом кода (15360), т. к. будет реализован стабильный пользовательский сценарий, требующий высокой производительности. После того как два основных показателя производительности приложения — FPS (кадров в секунду) и GFlop – примут устойчивые значения, вы можете закрыть приложение. На этом фаза обучения будет завершена, а полученные данные будут сохранены в файле .pgc. По умолчанию файл .pgc будет включен в вашу конфигурацию построения, т.е. каталог «Release». Например, в результате этого обучения создается файл NBodyGravityCPU!1.pgc.
NBody Simulation представляет собой очень простое приложение, созданное исключительно для иллюстрации процесса PGO. В действительности может существовать множество вариантов сценариев обучения приложений. В частности, можно производить обучение в несколько этапов, разделенных по времени. Для записи таких сценариев обучения лучше всего использовать команду pgosweep в командной строке разработчика после того, как инструментированная версия уже создана (напр., в Visual Studio).
В ходе последней фазы PGO создается оптимизированная версия приложения. В меню «Profile Guided Optimization» выберите «Optimize». Будет создана оптимизированная версия приложения. В выходном журнале PGO-построения вы увидите обобщенную информацию о проведенной операции.Как было сказано выше, информация из файлов .pgc, полученная в ходе фазы обучения, включается в базу данных .pgd, которая затем используется матрицей оптимизации внутреннего компилятора. В большинстве случаев (за исключением небольших быстрых приложений) критерий оптимизации скорость/размер определяется соотношением динамических инструкций для определенной функции. Функции с большим числом инструкций (т. н. «горячие») оптимизируются на скорость, а с малым количеством инструкций (т. н. «холодные») – на размер.Это практически все, что вам необходимо для того чтобы начать профильную оптимизацию в ваших приложениях. Попробуйте применить PGO для своих приложений и оцените результаты! И обязательно загляните в блог Инструменты для разработчика, возможно вы найдете там еще какие либо интересные решения! Автор поста — Анкит Астхана (Ankit Asthana) — руководитель программы по внутреннему компилятору Microsoft Visual С++.
blogs.msdn.microsoft.com