PostgreSQL и btrfs — слон на маслянной диете. Оптимизация btrfs
Файловая система Btrfs
Нашел доклад с семинара о новой файловой системе, пока находится в разработке и стадии тестирования но уже можно посмотреть что представляет из себя эта интересная разработка.
Речь пойдёт о файловой системе нового поколения. Традиционно ФС играла значительную роль в организации Unix-систем. И во многом именно свойствами ФС определялись свойства той или иной реализации Unix.
Файловая система должна хранить файлы и обеспечивать доступ к ним. При этом к ней предъявляется большое количество требований, зачастую взаимоисключающих: поддержка файлов любого размера, высокая производительность операций ввода/вывода, масштабируемость и т.д. Давно стало ясно, что ни одна файловая система не может быть одинаково эффективна во всех случаях. Поэтому все современные реализации Unix поддерживают работу с несколькими типами ФС одновременно. Есть такое выражение: "Linux - это Unix сегодня", и ядро Linux поддерживает свыше 50 (!) типов ФС.
В 2005-м году компания Sun Microsystems представила файловую систему ZFS, которая стала прорывом в области файловых систем. Из-за лицензионной политики Sun ZFS не может быть включена в ядро Linux. Однако в 2007-м году началась разработка файловой системы нового поколения для Linux - Btrfs. Разработку оплачивает компания Oracle, однако код выпускается под лицензией GNU GPL и входит в ядро Linux начиная с релиза 2.6.29, вышедшего на этой неделе.
Приведу фрагмент интервью Chris Mason - основного разработчика Btrfs:
-
Опишите Btrfs своими словами.
-
Btrfs - это новая файловая система, выпускаемая под GPL, которая разрабатывается с учётом масштабируемости на очень большие объёмы носителей. Масштабируемость означает не только возможность адресовать блоки носителя, но также возможность работать с повреждениями данных и метаданных. Это означает наличие инструментов для проверки и восстановления файловой системы без отмонтирования, и интегрированную проверку контрольных сумм, чтобы определять ошибки.
-
Является ли Btrfs наследницей какой-нибудь другой ФС?
-
Да, всех их :) Здесь много идей из ReiserFS, отложенное размещение и другие идеи из XFS. ZFS популяризовала идею, что подсчёт контрольных сумм данных может быть быстрым, и что управление логическими томами может быть лучше. Идеи по реализации управления томами пришли из AdvFS.
Итак, основные возможности, которые будут в Btrfs:
-
Поддержка доступных на запись снапшотов (аналог клонов ZFS). Кроме того, здесь можно создавать снапшоты снапшотов.
-
Поддержка сложных многодисковых конфигураций --- RAID уровней 0, 1, 5, 6 и 10, а также реализация различных политик избыточности на уровне объектов ФС --- то есть возможно назначить, к примеру, зеркалирование для какого-либо каталога или файла.
-
Флаги совместимости, необходимые для изменения дискового формата в новых версиях btrfs с сохранением совместимости со старыми.
-
Гибридные пулы. btrfs старается перемещать наиболее используемые данные на самое быстрое устройство, вытесняя с него "залежавшиеся" блоки. Эта политика хорошо согласуется с появившейся недавно моделью использования SSD (Solid State Drive).
-
Балансировка данных между устройствами в btrfs возможна сразу после добавления диска к пулу, отдельной командой --- а не только постепенно, в процессе использования (как это реализовано в ZFS).
-
Он-лайн конфигурирование RAID будет реализовано на уровне объектов файловой системы --- субтомов, снапшотов, файлов. Возможно будет также устанавливать некоторые параметры ввода-вывода для каталогов --- с наследованием этих свойств всеми дочерними объектами.
Большинство из этих возможностей уже реализованы и работают.
С точки зрения устройства ФС, можно выделить следующие основные моменты, которые делают возможными все перечисленные особенности в сочетании с очень хорошей производительностью:
-
B-деревья везде, где они имеют смысл
-
Copy-on-write везде, где это имеет смысл
-
Политика блокировок - высокая гранулярность блокировок.
B-деревья и дали название файловой системе (B-tree FS). B-деревья - это сильноветвящиеся деревья (B-деревья почему-то часто путают с двоичными деревьями, видимо, из-за буквы B, но она означает Block; у каждого узла в B-дереве обычно несколько тысяч потомков), каждый узел которых, в свою очередь, содержит большое количество записей (они обычно организуются в двоичное сбалансированное дерево; в частности, в Btrfs используются красно-чёрные деревья). Читаются и пишутся узлы B-дерева целиком, что даёт значительный выигрыш в производительности.
Copy-on-write (CoW) - это алгоритм, предназначенный для ситуаций, когда нужно создавать много похожих объектов. Рассмотрим, например, создание снапшота ФС. Снапшот - это мгновенная копия всех данных части ФС в данный момент времени. Реализация "в лоб" предусматривает создание копий всех файлов, что займёт много времени и много дискового пространства. При использовании CoW создаётся только один новый объект - копия корневого каталога, а на всех файлах, на которые ссылается корневой, ставится специальная метка. Когда приложение пытается писать в "помеченный" каталог, ФС прозрачно для приложения делает его копию (помечая при этом все файлы в этом каталоге), и приложение пишет уже в созданную копию. Таким образом, создаются копии только изменившихся данных, и только тогда, когда данные действительно изменяются. Это позволяет сделать операцию создания снапшотов почти мгновенной даже для очень больших разделов. Это немаловажно, т.к. одно из основных требований к операции создания снапшота - атомарность, т.е. эта операция не должна прерываться (и конфликтовать) никакими другими операциями. В Btrfs CoW используется не только при создании снапшотов, но и при ведении журнала и многих внутренних операциях.
Блокировки - это сущность, позволяющая избежать конфликтов при одновременном доступе к данным из разных потоков. Поток, который хочет внести изменение в некоторую структуру данных, сначала проверяет, не заблокирована ли она другим потоком; если заблокирована - ждёт, пока блокировка не будет освобождена, иначе сам захватывает блокировку, и освобождает её по окончании записи. Когда речь идёт о доступе к сложным структурам данных, возникает вопрос о политике блокировок. Нужно ли блокировать всю структуру целиком, или каждый элемент в отдельности, или элементы какими-то группами? Чем крупнее единица блокировки, тем меньше блокировок, и меньше накладных расходов. Чем мельче - тем более эффективно расходуется процессорное время, т.к. потокам приходится ждать гораздо меньше. Btrfs стремится блокировать как можно меньшие элементы структур (но не слишком мелкие).
Ещё один пункт, связанный с блокировками, специфичен для ядра. В ядре есть два вида блокировок: spin-lock и мьютексы. При использовании spin-lock ожидающий поток "крутится" в бесконечном цикле. При использовании мьютексов - поток переходит в заблокированное состояние TASK_INTERRUPTIBLE, и "пробуждается" планировщиком автоматически при освобождении блокировки. Понятно, что мьютексы более эффективны, т.к. не тратят процессорное время на пустые циклы. Но мьютексы не могут быть использованы в контексте обработчика прерывания, т.к. в этом состоянии планировщик не работает. Значительная часть функций любой ФС может быть вызвана как из обработчика прерывания, так и в контексте задачи. Поэтому во многих функциях приходится использовать менее эффективные спин-блокировки.
Btrfs использует новый тип блокировок, которые могут работать в обоих режимах (и их можно переключать между режимами). Таким образом, один и тот же код будет использовать мьютексы в контексте задачи и спин-блокировки в режиме прерывания.
Ещё одна особенность Btrfs: все структуры ФС могут находиться в произвольных местах раздела, они связаны между собой указателями. Этой особенностью обладают и некоторые другие ФС, но разработчики Btrfs нашли ей новое применение: конвертация разделов из других ФС (сейчас реализована конвертация из ext2/3, конвертер из ext4 в разработке, теоретически можно создать конвертеры из других ФС). При конвертации структуры Btrfs создаются в местах раздела, помеченных в исходной ФС как свободные. В Btrfs создаётся специальный файл, в который входят блоки, занятые структурами исходной ФС. Таким образом, эти блоки оказываются помеченными как занятые. Кроме того, этот файл представляет собой образ исходной ФС, который можно примонтировать (mount -o loop). Это позволяет выполнить откат к предыдущей ФС. Чтобы освободить место на диске, достаточно просто удалить файл с образом исходной ФС (возможность отката, соответственно, пропадёт).
Одна из особенностей современных ФС не так давно вызвала небольшой скандал. Дело в том, что в ядрах unix (и linux) код ФС не занимается непосредственно записью данных на диск. Данные записываются в страницы памяти, и эти страницы помечаются как "грязные", и затем их сбрасывает на диск отдельный поток ядра (pdflush). Так вот, при использовании современных ФС (в той новости речь шла про ext4, но теми же свойствами обладают и XFS, и Btrfs, и многие другие) интервал между записью данных в страничный кэш и их записью на диск может достигать 150 секунд (больше двух минут). Unix традиционно пишется для хорошего оборудования. В частности, предполагается, что в любой системе, от которой нужна надёжность, применяются UPS. Поэтому большая задержка записи является не недостатком, а преимуществом: это даёт возможность разместить данные более удачно, и избежать фрагментации. А при использовании на менее надёжном оборудовании нужно просто перенастроить ядро средствами sysctl, чтобы заставить pdflush срабатывать чаще.
Другая недавно вышедшая ФС для Linux - это Ext4. Она учитывает многие наработки современных ФС (экстенты, delayed allocation итп), но при этом основана на коде Ext3. Это более продвинутая ФС, чем та же ext3, по тестам она во многих случаях даёт бОльшую производительность и может быть рекомендована для использования на многих машинах уже сейчас. Но при этом её не назовёшь ФС нового поколения: архитектура осталась от ext3.
Btrfs сейчас в стадии experimental, разработчики предупреждают, что сейчас её имеет смысл использовать только для тестирования и экспериментов. Даже дисковый формат до сих пор окончательно не устаканился. Но при этом это безусловно ФС нового поколения, по архитектуре она напоминает разве что ZFS, но не старые ФС linux-ядра.
Больше всего Btrfs похожа на ZFS от компании Sun. Btrfs не поддерживает диски такого астрономического объёма, как zfs, но вряд ли это в ближайшее время будет иметь практическое значение. Зато Btrfs имеет некоторые возможности, отсутствующие в zfs: снапшоты снапшотов и скоростные приоритеты дисков, оптимизацию для ssd-накопителей. Но ZFS уже вовсю используется на production-серверах, а использование btrfs станет массовым, видимо, года через два (если предполагать, что распространение btrfs будет развиваться также, как zfs).
Измерения производительности Btrfs сейчас мало информативны, т.к. оптимизация в разгаре. Однако уже сейчас Btrfs обходит zfs по производительности некоторых операций.
Основные возможности Btrfs уже реализованы. Дисковый формат близок к стабилизации, если он и будет меняться, то не сильно. Только что завершена реализация обработки ситуации нехватки места на диске (проблема в том, что фактическая запись на диск может происходить уже после закрытия файла программой, и было не совсем очевидно, как передать ошибку записи программе). Вовсю идёт поиск и исправление других ошибок. В разработке специальный ioctl-API для поддержки транзакционного I/O (несколько операций, объединённых в транзакцию, могут быть выполнены все или не выполнены совсем; кроме всего прочего, это позволяет минимизировать количество проверок между операциями в одной транзакции). Ближайшая задача - реализация удаления снапшотов, первый вариант кода уже появился в рассылке.
lna.org.ru
Оптимизация Linux: жесткий диск (HDD)
Недавно ставил на второй свой компьютер Linux, и обратил внимание, что каждый раз при установке приходится править, например, файл /etc/fstab и не на добавление/удаление разделов - уж с этим чуть ли не любой линукс-установщик справляется на все сто, - а на добавление опций монтирования…
Странно, что это не добавлено разработчиками по умолчанию… В общем, захотелось посвятить пост оптимизации жесткого диска в Linux, ведь большинство обычных пользователей совершенно все в этой части оставляют по умолчанию после установки… Объясню, что я имею ввиду поподробнее…
Прежде всего, собственно при установке Линукс необходимо корневой раздел системы устанавливать как можно ближе к началу диска. Это обусловлено тем, что данные начинают располагаться от центра диска, чтобы при чтении обеспечить доступ к данным с минимальной амплитудой вращения.
Так, проверить скорость чтения можно командой:
| hdparm -t /dev/sda1 /dev/sda1: Timing buffered disk reads: 280 MB in 3.02 seconds = 92.85 MB/sec hdparm -t /dev/sda8 /dev/sda7: Timing buffered disk reads: 160 MB in 3.02 seconds = 53.06 MB/sec |
hdparm -t /dev/sda1 /dev/sda1: Timing buffered disk reads: 280 MB in 3.02 seconds = 92.85 MB/sec hdparm -t /dev/sda8 /dev/sda7: Timing buffered disk reads: 160 MB in 3.02 seconds = 53.06 MB/sec
Разница заметна…
Далее… Прежде, чем заниматься настройкой свежеустановленной системы, я всегда открываю файл /etc/fstab для того, чтобы изменить там значения монтирования по умолчанию - сколько дистрибутивов я не пробовал устанавливать, все время в опциях монтирования стояло defaults…
Итак, открываем файл /etc/fstab, в котором содержатся сведения о монтируемых при загрузке разделах. Ну и добавляем опции монтирования на выбор, в зависимости от того, что нужно получить в итоге… Опции зависят от файловой системы:
| ReiserFS: acl,user_xattr,noatime,nodiratime,notail,barrier=flush Ext3/Ext4: acl,user_xattr,noatime,nodiratime,barrier=1 XFS: defaults,noatime,nodiratime,logbufs=8,logbsize=32k,biosize=16,allocsize=512m,barrier |
ReiserFS: acl,user_xattr,noatime,nodiratime,notail,barrier=flush Ext3/Ext4: acl,user_xattr,noatime,nodiratime,barrier=1 XFS: defaults,noatime,nodiratime,logbufs=8,logbsize=32k,biosize=16,allocsize=512m,barrier
Обозначает все это следующие функции:
- user_xattr – расширенные атрибуты файлов (используются для индексирования)
- barrier – команда очистки кэша
- noatime и nodiratime – отключение записи времени последнего доступа (для файлов/директорий)
- allocsize – размер заранее резервируемой области на диске. Высокое значение помогает избежать фрагментации
- biosize – размер I/O-блоков по умолчанию
- logbufs – количество встроенных буферов для ведения журнала
- logbsize – размер буфера
- notail - не упаковывать хвосты больших файлов - улучшает производительность - увеличивает используемое для хранения место(~5%) - для применения этой опции надо перезаписать находящиеся на ней файлы!
Еще одним моментом можно назвать оптимизацию журналирования файловой системы - в большинстве дистрибутивов по умолчанию при создании раздела ext3/ext4 используется тип журналирования Ordered (упорядоченный), потому что он обеспечивает наилучшее соотношение скорости и безопасности. Однако, наибыстрейшим режимом является Writeback (журналирование после записи): он осуществляет наименьшее журналирование. Есть при этом недостаток, что можно потерять некоторые данные, например, при непредвиденном отключении питания компьютера, однако, например, для ноутбука это не самый худший вариант 🙂
Для включения режима Writeback желательно загрузиться в другой дистрибутив или с LiveCD, ибо необходимо, чтобы корневой раздел был размонтирован:
| tune2fs -O has_journal -o journal_data_writeback /dev/sda1 |
tune2fs -O has_journal -o journal_data_writeback /dev/sda1
Также неплохо было бы включить режим индексирования директорий, который увеличивает скорость чтения и записи «в» и «из» каталогов вашего жесткого диска. Это полностью безопасный и рекомендованный режим.
Сначала нужно указать режим журналирования:
| tune2fs -O dir_index /dev/sda1 |
tune2fs -O dir_index /dev/sda1
Затем – включить индексацию существующих директорий:
Выполнение команды e2fsck может занять немного времени – это зависит от размера раздела диска и количества директорий в нем…
В ядра 2.6.х включен параметр swappiness, который определяет количество свободно памяти в процентах, при котором система начинает «свопить», то есть записывать данные не в оперативную память, а на жесткий диск. По умолчанию выставляется значение 60%, что мне лично кажется чрезмерно завышенным и способствует преждевременному включению swap, что не может не отражаться на жестком диске и его живучести… т.е. если память забита и мы запускаем программу (особенно большую) винту приходится одновременно и считывать библиотеки и данные для запускаемой программы и записывать в своп «устаревшие» страницы - отсюда долгие запуски софта и снижение отзывчивости системы.
Для уменьшения значения нужно в файл /etc/sysctl.conf добавить строчку
Только следует помнить, что очень маленькое значение при малом обьеме оперативной памяти может вызвать при сборке большого проекта или запуске тяжелого софта недостаток памяти (не страшно, но тот же тяжелый софт просто не запустится)…
Понятно, что это не все советы по оптимизации жесткого диска в Линукс, однако даже этого хватит, чтобы заметно ускороить работу системы…
pingvinoff.net
Обзор EXT4 vs Btrfs vs XFS
Если честно, многие люди задумываются о поисках лучшей файловой системы для своего компьютера. У пользователей Windows и MacOS X небольшой выбор, им доступна только одна стандартная файловая система, NTFS и HFS+. В операционной системе Linux все по-другому, здесь доступно множество файловых систем на любой вкус. Очень широко в Linux используется ext4, но есть несколько поводов попробовать что-то новое. Например, btrfs vs xfs. Но действительно ли она лучше других? Давайте сначала рассмотрим самые популярные файловые системы и особенности их работы, так сказать, сделаем небольшое сравнение.
Содержание статьи:
Как работает файловая система?
Если вы незнакомы с основами работы файловых систем, скажу об этом несколько слов чтобы вы смогли лучше понять, в чем разница btrfs vs ext4 vs xfs. Файловые системы используются для того, чтобы контролировать способ записи данных на диск, доступ к этим данным, а также хранят информацию, метаданные о файлах. Это не просто запрограммировать, но файловые системы постоянно совершенствуются. Постоянно дорабатывается новая функциональность, и они становятся более эффективными.
Зачем нужны разделы?
У многих пользователей смутные представления, о том, зачем нужны разделы диска. Все операционные системы поддерживают создание и удаление разделов. Linux использует более одного раздела на диске, даже при использовании стандартной процедуры установки. Одной из главных целей разделения дисков на разделы, это повышение безопасности, в случае возникновения ошибок.
При разделении жесткого диска на разделы, данные могут быть сгруппированы и разделены. При возникновении ошибок, будут потеряны только те, которые находились на поврежденном разделе. Данные на всех остальных разделах, скорее всего, останутся в целости и сохранности. Это было особенно важно, когда в Linux еще не существовало журналируемых файловых систем, и любое неожиданное отключение питания могло привести к катастрофе.
Повышение безопасности и надежности при использовании разделов означает, что при повреждении одной части операционной системы останутся доступны данные в других разделах. На данный момент, это самый важный фактор использования разделов. Например, пользователи могут использовать скрипты или программы, которые заполняют дисковое пространство. Если диск содержит только один большой раздел, то когда свободное место закончится, то система полностью перестанет работать. А вот если пользователи хранят данные на различных разделах, то переполнение затронет только один раздел, а системный и остальные разделы продолжат нормально функционировать.
Помните, что журналируемая файловая система защищает только от повреждения при отключении питания, и неожиданном отключении устройств хранения данных. Но оно не защитит вас от битых блоков и логических ошибок в файловой системе. В таких случаях нужно использовать массив нескольких дисков (RAID).
Зачем выбирать другую файловую систему?
Файловая система EXT4 это улучшенная версия EXT3, которая, в свою очередь, не что иное, как переработанная EXT2. EXT4 - очень стабильная файловая система, которая была выбрана по умолчанию в большинстве дистрибутивов Linux, за несколько последних лет. Но ее код уже порядочно устарел. Кроме того, пользователи Linux хотят новых возможностей и функций, которых нет в EXT4, но они есть в других файловых системах, например, btrfs vs xfs. Существует программное обеспечение, реализующее эти функции, но поддержка на уровне файловой системы будет работать намного быстрее. Дальше мы кратко рассмотрим каждую из предложенных файловых систем, чтобы вы смогли выбрать какая файловая система btrfs или ext4 лучше именно для вас.
Файловая система Ext4
У Ext4 есть некоторые ограничения, которые даже сейчас намного впечатляют. Максимальный размер файла составляет 17 терабайт. А это гораздо больше, чем емкость жесткого диска доступного среднестатистическому покупателю. В то же время самый больший размер раздела который можно создать с ext4 - 1 экзабайт, это примерно 11529215 терабайт. Как известно, Ext4 работает быстрее EXT3. Как и все современные файловые системы, она журналируемая, а это значит, что EXT4 будет вести журнал расположения файлов на диске, а также записывать туда любые изменения данных. Несмотря на все эти возможности, она не поддерживает прозрачное сжатие, дедупликацию данных и прозрачное шифрование. Снимки состояния технически поддерживаются, но это только экспериментальная функция.
Файловая система Btrfs
Btrfs - это файловая система, разработанная с нуля. Она существует потому, что ее разработчик захотел расширить функциональность стандартной файловой системы такими возможностями, как снимки состояния, объединение, контрольные суммы, прозрачное сжатие, и многими другими. Btrfs не зависит от Ext4, но реализует ее лучшие идеи и преимущества, а также свои дополнительные возможности, которые будут очень полезны пользователям, и особенно предприятиям. Для предприятий, использующих серьезные программы с очень большими базами данных, одно пространство файловой системы на нескольких дисках будет очень полезным. Дедупликация данных уменьшит фактически занимаемое данными пространство на диске. А зеркалирование данных с Btrfs станет намного проще.
Пользователи по-прежнему могут создавать несколько разделов, так как им не нужно зеркалить данные на разных дисках. Учитывая, что Brtfs может охватить несколько жестких дисков, она поддерживает в 16 раз больше дискового пространства, чем Ext4. Максимальный размер раздела в Btrfs - 16 экзабайт, максимальный размер файла такой же. В сравнении EXT4 vs btrfs, последняя оказывается на первом месте.
Файловая система XFS
XFS считается расширенной файловой системой. Это высоко производительная 64-битная, журналируемая файловая система. Поддержка XFS была добавлена в ядро в 2002 году. А в 2009 она была использована в Red Hat Enterprise Linux 5.4. Максимальный размер файла в этой файловой системе восемь экзабайт. Но у XFS существуют некоторые ограничения. Например, раздел этой ФС не может быть уменьшен, а также наблюдается низкая производительность при работе с большим количеством файлов. Теперь в RHEL 7.0 XFS используется как файловая система по умолчанию.
Заключение и выводы
К сожалению, дата финального релиза Btrfs точно неизвестна. Но официально, эта файловая система следующего поколения по-прежнему классифицируется как нестабильная. Тем не менее, если вы будете устанавливать Ubuntu последней версии, установщик предложит возможность выбрать Btrfs в качестве основной файловой системы. Когда Btrfs станет стабильной неизвестно, но Ubuntu не будет использовать ее как файловую систему по умолчанию, пока она не начнет считаться полностью стабильной.
На данный момент Btrfs используется как файловая система по умолчанию для корня в OpenSUSE. Как видите, у разработчиков огромный фронт работ, так как еще не все особенности реализованы, а также она отстает в производительности, если сравнивать Ext4 vs btrfs.
Так что же лучше использовать? До сих пор Ext4 была победителем, несмотря на идентичную производительность. Но почему? Ответ - удобство и популярность. Ext4 - по-прежнему отличная файловая система для рабочих станций и настольных компьютеров. Она поставляется по умолчанию, а потому пользователь получит ее просто установив ОС. Кроме того, Ext4 поддерживает разделы до 1 экзабайт и файлы до 16 терабайт, а это по-прежнему очень много.
Btrfs предлагает большие объемы до 16 экзабайт как для разделов так и для файлов, а также повышение отказоустойчивости. Но она до сих пор позиционируется как надстройка над файловой системой, а не интегрирована в операционную систему ФС. Например, чтобы отформатировать раздел в Btrfs необходимо, чтобы был установлен набор инструментов Btrfs.
Даже если скорость передачи данных не очень важна, есть такая характеристика, как скорость работы с файлами. В Btrfs есть много полезных функций: копирование при записи, контрольные сумы, снимки, очистка, самовосстановление данных, дедупликация, а также другие интересные улучшения, которые обеспечивают сохранность данных. В ней только недостает функции ZFS - Z-RAID, так что RAID пока находиться на экспериментальной стадии. Для обычного хранения данных Btrfs лучше подходит чем Ext4, но как будет на самом деле покажет время. Что использовать btrfs или ext4 - это только дело вашего вкуса.
На данный момент Ext4 - лучший выбор для обычных пользователей, так как она распространяется как файловая система по умолчанию, а также она быстрее Btrfs при передаче файлов. Btrfs, безусловно, стоит попробовать, но полностью заменять ext4 еще рано, это можно будет сделать лишь через несколько лет. Забавно, то же самое, говорили и несколько лет назад, с тех пор много чего поменялось, но Btrfs все еще не считается стабильной.
Источник
Если у вас есть другое мнение по этому поводу, оставляйте комментарии!
Кстати, если вы используете Windows и Linux на одной машине, вам может быть интересна моя статья: Подключение ext4 в Windows
Оцените статью:
Загрузка...losst.ru
btrfs
Файловая система ZFS от Sun Microsystems, вышедшая в 2005 году, явилась настоящим прорывом в области архитектуры универсальных файловых систем общего назначения. Однако цели и задачи, которые ставят перед собой разработчики новой файловой системы btrfs от компании Oracle, впечатляют даже после знакомства с особенностями ZFS, которую, казалось бы, никто не сможет превзойти еще много лет.
Btrfs, о начале разработки которой было объявлено в июне 2007 года, находится сейчас на стадии альфаверсии. Тем не менее, основные ее возможности ясны, и многие из них можно попробовать уже сейчас. Посмотрим подробнее, что именно предлагает пользователям Chris Mason — основной разработчик btrfs:
-
Поддержка доступных на запись снапшотов (аналог клонов ZFS).
-
Поддержка субтомов — множественных именованных корней в одной файловой системе с общим пулом хранения.
-
Поддержка сложных многодисковых конфигураций — RAID уровней 0, 1, 5, 6 и 10, а также реализация различных политик избыточности на уровне объектов ФС — то есть возможно назначить, к примеру, зеркалирование для какоголибо каталога или файла.
-
Copyonwrite (COW) журналирование.
-
Контроль целостности блоков данных и метаданных с помощью контрольных сумм.
-
Зеркалирование метаданных даже в однодисковой конфигурации.
-
Полностью распределенное блокирование. Давно известно, что все составные объекты множественного доступа, защищаемые глобальной блокировкой, имеют серьезные проблемы с производительностью. В btrfs распределенное блокирование реализовано для верхних уровней всех Bдеревьев. Алгоритмы обработки метаданных продуманы таким образом, что бы не удерживать блокировки на разделяемых данных во время ожидания ввода/вывода. В ZFS этому вопросу также уделено достаточно серьезное внимание.
-
Поддержка ACL.
-
Защита от потери данных.
-
Выбор хэшалгоритма.
-
Поддержка NFS.
-
Флаги совместимости, необходимые для изменения дискового формата в новых версиях btrfs с сохранением совместимости со старыми.
-
Резервные копии суперблока, по крайней мере — по одной на устройство.
-
Скоростные приоритеты для дисков. Дискитемы btrfs (своего родадескрипторы дисков пула; их роль и структура будут показаны ниже) имеют поля для хранения показателей производительности устройства. Эти счетчики учитываются при выборе устройства для размещения данных того или иного типа. Аллокатор также стремиться выбирать наименее занятый диск для равномерного распределения нагрузки по всему пулу.
-
Гибридные пулы. btrfs старается перемещать наиболее используемые данные на самое быстрое устройство, вытесняя с него "залежавшиеся" блоки. Эта политика хорошо согласуется с появившейся недавно моделью использования SSD (Solid State Drive). В частности, компания Sun Microsystems планирует в 2008 году начать выпуск серверов с небольшими SDD, используемыми в качестве быстрой памяти для наиболее "популярных" данных. К слову сказать, в ZFS возможности приоретизации дискового трафика не предусмотрено, поэтому Sun вынуждена будет реализовывать ее на более высоких уровнях, теряя универсальность такого решения. Справедливости ради стоит заметить, что поддержка приоритетов устройств может быть относительно легко добавлена и в ZFS — правда, ценой изменения дискового формата.
-
Directoryоперации с деревом корней. Дерево корней в btrfs хранит глобальную информацию о субтомах и снапшотах пула, а также о других группах метаданных. Со временем дерево корней станет настоящим каталогом и будет поддерживать все характерные системные вызовы.
-
Балансировка данных между устройствами в btrfs возможна сразу после добавления диска к пулу, отдельной командой — а не только постепенно, в процессе использования (как это реализовано в ZFS).
-
Диски для горячей замены, поддержка которых появилась и в ZFS.
-
Онлайн конфигурирование RAID будет реализовано на уровне объектов файловой системы — субтомов, снапшотов, файлов. Возможно будет также устанавливать некоторые параметры вводавывода для каталогов — с наследованием этих свойств всеми дочерними объектами.
-
Выделение и резервирование objectid. В настоящее время вновь выделенный objectid (аналог номера inode) представляет собой число, равное последнему objectid+1. Более оптимально будет резервирование диапазона objectid каждым каталогом, для чего планируется вести специальный итем (итемом здесь называется объект B-дерева , инкапсулирующий какиелибо сторонние, не относящиеся к самому дереву данные). Код выделения inode также должен искать "дыры" в пространстве ключей, а не просто инкрементировать последний.
-
Производительность вызова fsync(), фиксирующего на диск все грязные данные, является для btrfs большей проблемой, нежели для других ФС, т.к. объем побочного дискового трафика (за счет множества метаданных, разбросанных по разным Bдеревьям) достаточно велик. Путем решения проблемы видится создание своеобразного журнала логических операций и частичный сброс только пользовательских данных. При частичной фиксации вызов fsync() будет сбрасывать на диск изменившиеся части только одного дерева, занося информацию об остальных модификациях в особый итем дерева корней. Смонтированная после крэша ФС будет считывать эти данные и вносить оставшиеся изменения уже во время эксплуатации пула, не заметно для пользователя.
-
Конвертер из ext2/3/4.
Дизайн
Btrfs реализована на простых и хорошо известных механизмах. Все они должны давать хороший результат и сразу после mkfs, однако более важным разработчики сочли сохранение хорошей производительности на старой, интенсивно используемой файловой системе.
Btrfs, как и подавляющее большинство современных файловых систем, начинается с суперблока, отстоящего на 16 Kb от начала диска. Его структура описана в ctree.h:
Диски, принадлежащие файловой системе, описываются devитемами, которые, в настоящее время, является частью суперблока, а в будущем будут вынесены в отдельное B-дерево, продублированное на каждом из дисков:
Все остальные метаданные btrfs являются частью какоголибо B-дерева. Причем количество деревьев гораздо меньше количества типов метаданных — то есть во многих из них хранятся объекты различных, но логически связанных классов. Это напоминает архитектуру reiserfs и reiser4 — когда вся файловая система, по сути, является одним большим B-деревом, состоящем из данных и метаданных всех разновидностей. Как будет показано далее, это далеко не последнее сходство btrfs с файловыми система компании NameSys.
Структура B-дерева
Реализация B-дерева btrfs (это классическое B+ дерево с данными в листьях и указателями в узлах) обеспечивает базовую функциональность для эффективного хранения и поиска большого количества типов данных. Btreeкод знает только о трех структурах: ключи, итемы и заголовки блоков (см. ctree.h):
Внутренние узлы дерева содержат только пары ключитем, листья же разбиты на две секции, растущие к середине узла. В начале листового узла хранятся итемы фиксированного размера, в конце — данные этих итемов. Данные итема интерпретируются на более высоких уровнях согласно полю type соответствующего ключа. См. ctree.h:
Заголовок блока дерева содержит контрольную сумму содержимого блока, UUID (Universally Unique Identifier — универсальный уникальный идентификатор стандарта OSF DCE) файловой системы, которой принадлежит блок, уровень блока в дереве и смещение, по которому блок располагается на диске. Эти поля позволяют проверить целостность метаданных при чтении. В будущем планируется также хранить здесь 64битный sequenceномер, которые будет содержаться также и в родительском для данного блока узле. Это позволит файловой системе обнаруживать и исправлять фантомные записи на диск (когда блок пишется по ошибочным координатам). Заметим, что использовать для этих целей контрольную сумму дочернего узла нельзя, т.к. она не хранится в его родителе для упрощения отката транзакции. Sequenceномер будет эквивалентен времени вставки блока в дерево, в то время как контрольная сумма вычисляется еще до размещения блока и, к тому же, меняется при каждой модификации блока.
Поле generation соответствует ID транзакции, в рамках которой был размещен или переразмещен данный блок. Оно позволяет легко поддерживать инкреметальные бэкапы (снапшоты) и подсистему COWтранзакций — совершенно так же, как это сделано в ZFS.
Структуры данных файловой системы
Каждый объект файловой системы имеет objectid, динамически выделяемый при его создании.
Поле offset ключа хранит логическое смещение данных в пределах описываемого объекта. Например, для файловых экстентов это будет смещение экстента от начала файла. Поле type содержит идентификатор типа итема, а также зарезервированное пространство для расширения в будущем.
Inodes
Inodes хранятся в структуре btrfs_inode_item (ctree.h), поле offset ключа inode итема всегда равно нулю, поле type — единице. Таким образом, математически, ключ inodeитема является наименьшим среди всех итемов данного объекта. Inode-итем хранит традиционные statданные:
Поле compat_flags введено для реализации совместимости со старыми версиями файловой системы. Те или иные биты отведены под флаги версии во всех структурах данных btrfs для того, что бы безопасно изменять дисковый формат ФС даже после официального релиза.
Файлы
Содержимое маленьких файлов (размером не более блока) может храниться прямо в B-дереве, в данных экстентитема. В этом случае поле offset ключа экстент итема хранит смещение данных внутри файла, а поле size структуры btrfs_item показывает, сколько места в листе занимает данный итем. Таких своеобразных экстентитемов может быть несколько на файл.
Большие файлы хранятся в экстентах. Структура btrfs_file_extent_item содержит ID транзакции размещения экстента (поле generation) и пару [смещение,длина], описывающую его положение на диске. Эскстент также хранит логическиеы смещение и длину в уже существующем экстенте. Это позволяет btrfs безопасно писать в средину длинного экстента без предварительного перечитывания старых данных файла (относящихся к предыдущему снапшоту, к примеру).
Контрольные суммы данных файла хранятся в B-дереве в csumитеме с соответствующим objectid (структура btrfs_csum_item, ctree.h). Поле offset ключа csumитема указывает на смещение защищаемого участка данных от начала файла. Один такой итем может хранить несколько контрольных сумм. Csum-итем используется только для файловых (больших) экстентов, встроенные в дерево маленькие файлы защищаются контрольной суммой в заголовке блока. Если csum итем для некоторого пакета данных не представлен, пакет считается не инициализированным — при чтении возвращается блок нулей (в будущем поведение в этом случае будет выбирается пользователем при создании ФС — может возвращаться также код ошибки EIO).
Каталоги
Каталоги btrfs индексируются двумя способами. Для поиска по имени файла используется индекс, составленный из objectid каталога, константы BTRFS_DIR_ITEM_KEY и 64битного хэша имени. По умолчанию используется TEA хэш, но могут быть добавлены и другие алгоритмы (определяется по полю flags в inode каталога). Второй способ индексирования используется вызовом readdir(), возвращающем данные в порядке возрастания номеров inodes, приближенном к порядку следования блоков на диске (согласно принятой политике размещения). Этот способ дает большую производительность при чтении данных большими пакетами (бэкапы, копирование, и т.д.), а также позволяет быстро проверить линковку inode с каталогом (подсчет количества ссылок на файл при fsck). Этот индекс состоит из objectid каталога, константы BTRFS_DIR_INDEX_KEY и inode objectid.
Учет ссылок на экстенты
Учет ссылок на объекты — основа любой файловой системы с поддержкой снапшотов. Для каждого экстента, выделенного дереву или файлу, btrfs записывает количество ссылок в структуре btrfs_extent_item. Деревья, хранящие эту информацию, служат также картами выделенных экстентов файловой системы. Некоторые деревья не поддерживают учета ссылок и защищаются только COW журналированием. Однако структура экстентитемов одинаков для всех выделенных блоков.
Группы блоков
Группы блоков позволяют оптимизировать аллокатор путем разбиения диска на участки длиной от 256 Mb. Для каждого участка доступна информация о свободных блоках. Поле block_group каждого inode хранит номер предпочитаемой группы блоков, в которой btrfs будет стараться разместить новые данные объекта. Группа блоков — просто надстройка над сегментом (см. ниже), позволяющая быстро оценить количество свободного пространства и тип (данные/метаданные) без обращения к дереву сегментов, которое происходит, когда найден сегмент, располагающий достаточным пространством и подходящим типом.
Группа блоков имеет флаг, показывающий, данные или метаданные она хранит. При создании ФС 33% групп блоков выделяются под метаданные, 66% — под данные. При заполнении диска это предпочтение может быть пересмотрено, однако, в любом случае, btrfs старается избежать смешивания данных и метаданных в одной группе блоков. Это решение существенно улучшает производительность fsck и уменьшает количество перемещений головок диска при отложенной записи ценой небольшого увеличения количества перемещений при чтении.
Деревья свободных экстентов
Деревья свободных экстентов, в том числе, служат btrfs для разбиения доступного дискового пространства на участки с различными политиками выделения блоков. Каждое дерево экстентов владеет сегментом указанного диска, блоки которого могут быть выделены объектам различных субтомов. Политики будут определять, каким образом распределять данные по доступным деревьям экстентов, позволяя пользователю назначать зеркалирование, распределение данных (strippping) или квотирование различных частей диска.
Btrfs будет интегрирована с менеджером дисков для упрощения управления большими пулами хранения. Основная идея состоит в назначении по крайней мере одного дерева экстентов для каждого диска для предоставления пользователю возможности назначать их субтомам, каталогам или файлам.
Обратные ссылки
Обратные ссылки в btrfs служат для:
-
Учета всех владельцев ссылки на экстент для корректного его освобождения.
-
Обеспечения информации для быстрого поиска ссылающихся на данный экстент объектов, если некоторый блок нуждается в исправлении или переразмещении.
-
Упрощения перемещения блока при урезании ФС и других операциях управления пулом.
Обратные ссылки на файловые экстенты
На файловые экстенты могут ссылать следующие объекты:
-
Снапшоты, субтома и различные их поколения
-
Разные файлы внутри одного субтома
-
Разные логические экстенты внутри одного файла
Структура обратной ссылки такова (ctree.h):
При выделении файлового экстента эти поля заполняются следующей информацией: objectid корня субтома, id транзакции, inode objectid и смещение в файле. При захвате ссылки на лист новая обратная ссылка добавляется для каждого файлового экстента. Это похоже на создание экстента, однако поле generation инициализируется идентификатором текущей транзакции. При удалении файлового экстента или некоторого снапшота, находится и удаляется соответствующая обратная ссылка.
Обратные ссылки на btree-экстенты
Ссылки на btree-экстенты могут захватывать следующие объекты:
Хранение всеобъемлющей информации для полноценного обратного отображения потребовало бы хранения наименьшего ключа данного листового блока в обратной ссылке. Это не удобно, т.к. при каждой модификации (например, изменении поля offset, что происходит достаточно часто) этого ключа пришлось бы модифицировать и ссылку.
Вместо этого btrfs хранит только objectid наименьшего ключа на том же уровне, что и данный блок. Поиск по дереву останавливается на уровень выше, чем записано в обратной ссылке.
В некоторых деревья btrfs учет обратных ссылок не ведется: например, в деревьях экстентов и корней. Обратные ссылки в этих деревьях всегда имеют поле generation=0.
При размещении блока дерева создается такая обратная ссылка:
Уровень хранится в поле objectid структуры btrfs_extent_ref, т.к. максимальный уровень равен 255, а минимальный objectid 256. Таким образом btrfs отличает файловые обратные ссылки от btreeссылок.
Если ссылка на блок захватывается неким объектом, в дерево также вставляется обратная ссылка с соответствующими данными о владельце и транзакции.
Построение ключа обратной ссылки
Обратная ссылка имеет 4 64битных поля, которые хэшируются в единственно 64битное значение, что помещается в поле offset ключа. Поле objectid ключа соответствует ID описываемого объекта, а поле type инициализируется константой BTRFS_EXTENT_REF_KEY.
Снапшоты и субтома
Субтома представляют собой именованные Bдеревья, содержащие иерархию файлов и каталогов, и имеют inodes в дереве корней. Субтом может быть ограничен квотой на количество блоков; на все блоки и файловые экстенты, принадлежащие субтому, ведется учет ссылок для поддержки снапшотов. Предельное количество субтомов в файловой систмеме btrfs — 2^64.
Снапшоты по внутренней структуре идентичны субтомам, однако их корневой блок изначально разделяется с другим (родительским) субтомом. Когда снапшот создан, файловая система увеличивает количество ссылок на корневой блок, и далее подсистема COWтранзакций фиксирует изменения, сделанные в корневых блоках сбутома и снапшота, уже в разных местах. Снапшоты btrfs доступны на запись и бесконечно рекурсивны. При необходимости создания readonly снапшота его блочная квота устанавливается в единицу сразу при инициализации.
Корни B-деревьев
Каждая файловая система формата btrfs состоит из нескольких корней B-деревьев. Только что созданная ФС имеет корни для:
-
Дерева корней
-
Дерева выделенных экстентов
-
Дерева defaultсубтома
Дерево корней содержит корневые блоки для дерева экстентов, а также корневые блоки и имена деревьев для каждого субтома и снапшота в ФС. При фиксации транзакции указатели на корневые блоки обновляются по COW семантике в этом дереве, и его новый корневой блок записывается в уперблок btrfs.
Дерево корней организовано в виде каталога всех других деревьев файловой системы и имеет directiryитемы для хранения имен снапшотов и субтомов. Каждый субтом имеет objectid в этом дереве и не менее одной структуры btrfs_root_item. Directoryитемы отображают имена субтомов на их rootитемы Т.к. ключ rootитема обновляется на каждой транзакции, directoryитем ссылается на номер поколения, что позволяет всегда найти наиболее новую версию какоголибо корня. Структура root-итема (ctree.h):
Деревья свободных экстентов используются для управления выделением дискового пространства. Доступное место может быть разделено между несколькими деревьями экстентов для уменьшения влияния блокировок и реализации различных политик выделения для разных участков диска.
Суперблок btrfs указывает на дерево корней, которое, в свою очередь, содержит указатели на деревья свободных экстентов и субтомов (субтома хранятся в rootитемах). Дерево корней также имеет указатель на каталог, отображающий имена субтомов на rootитемы в дереве корней. Показанная файловая система имеет один субтом с именем "default" и один его снапшот с именем "snap".
Многодисковые конфигурации
Btrfs, как и основной ее аналог — ZFS — поддерживает организацию сложных пулов хранения из нескольких дисков. Основные ее возможности в этой области таковы:
-
Зеркалирование метаданных в конфигурации до N зеркал (N>2)
-
Зеркалирование метаданных на одном устройстве
-
Зеркалирование экстентов данных
-
Обнаружение ошибок записи с помощью контрольных сумм и их коррекиция из зеркальной копии
-
Распределенные (stripped) экстенты данных
-
Различные политики зеркалирования на одном устройстве
-
Эффективное перемещение данных между устройствами
-
Эффективное переконфигурирование хранилища
-
Динамическое выделение пространства для каждого субтома
Если бы btrfs полагалась на device mapper или MD для реализации поддержки многодисковых конфигураций, она потеряла бы большинство из своих сильных сторон: обработку и корректировку ошибок записи с помощью контрольных сумм, перемещение данных между устройствами и, как следствие, возможность изменения размера тома, гибкие политики выделения, зеркалирование метаданных даже на единственном диске. Именно поэтому в btrfs, как и в ZFS, реализован собственный уровень объединения устройств, не полагающийся на уже существующие в Linux программные RAIDсистемы.
В настоящее время btrfs поддерживает конфигурации RAID0, RAID1 и RAID10, реализация RAID5 и RAID6 запланирована.
Сегменты (storage chunks)
Сегментом btrfs называется обособленный участок диска с логической адресацией. Все указатели на экстенты работают с сегментными адресами вместо физических дисковых. Суперблок имеет особую секцию, отображающую сегменты на дисковые адреса через дерево сегментов. Код сегментации — единственная часть btrfs, имеющая дело с физическими адресами. Весь остальной драйвер работает с сегментными.
Каждый сегмент располагает пространством, выделенным с одного или нескольких устройств, для реализации зеркала или распределенного хранилища (stripe).
Минимальный размер сегмента btrfs равен 256 Mb, средний — 1/100 объема устройства.
Каждый сегмент располагает единственным деревом выделенных экстентов и имеет обратную ссылку на это дерево.
Разрешение сегментных адресов
Каждому устройству, добавляемому к файловой системе, назначается 64 битный идентификатор (device ID). Информация обо всех устройствах пула отсортирована по device ID в особом B-дереве. Каждый корень дерева в ФС связан с единственным деревом сегментов для разрешения сегментных адресов. ID сегмента продублирован в каждом блоке дерева, поэтому может использоваться во время fsck.
Размещение сегментов
Каждое устройство, добавленное в пул, имеет дерево размещения, отслеживающее, какая область диска какому сегменту назначена. Обратные ссылки в этом дереве отслеживают, какой сегмент размещен в какой части устройства. Так как экстентов на устройство приходится относительно немного, это дерево разделяется несколькими дисками.
Сегменты назначаются некоторому дереву выделения экстентов и используются для разрешения запросов на размещение экстентов для данных и метаданных. При расширении файловой системы, сегменты добавляются в дерево динамически. Дерево размещения экстентов осуществляет выделения пространства в сегментах, отслеживает свободное место в них и обратные ссылки на связанные экстенты других сегментов.
Управление сегментами
Логическая адресация позволяет достаточно просто перемещать сегменты. Дерево выделенных экстентов, владеющее данным сегментом, располагает информацией о занятых/свободных участках сегмента, и может гибко и эффективно управлять копированием только необходимых данных.
Устройства в файловой системе могут быть удалены или сбалансированы благодаря перемещению сегментов. На вновь добавленное устройство могут быть перенесены существующие сегменты с других дисков (для балансировки нагрузки). Диск может использоваться и только для новых размещений.
Восстановление зеркальных пулов осуществляется путем обхода дерева выделенных экстентов, проверки наличия недоступных дисков и следования по обратным ссылкам размещенных на них сегментов. Каждый сегмент исправляется индивидуально, так что можно ограничить исправление обходом только тех сегментов, которые действительно используются.
Разрешение ID дисков
Идентификатор устройства хранится в суперблоке диска. Устройства сканируются утилитой btrfsctl для построения списка дисков, назначенных файловой системе с данным UUID. Деревья сегментов также хранят информацию о каждом из устройств, так что корректность списка может быть проверена во время монтирования.
Btrfs для администратора
Попробуем btrfs в работе.
Исходные тексты модуля ядра и утилит стабильной версии доступны по ссылке [2].
Модуль ядра собираем и устанавливаем так (не забываем, что он зависит от CONFIG_LIBCRC32C; заголовки ядра также должны быть доступны по пути /lib/modules/`uname r`/build):
make
make install
Набор утилит btrfsprogs использует libuuid, которая входит в состав e2fsprogs — то есть при сборке нужны соответствующие заголовки. В дистрибутивах необходимый пакет обычно называется e2fsprogsdevel или libuuiddevel. Сборка btrfsprogs производится также вполне привычно:
make
make install
Теперь попробуем создать и смонтировать файловую систему на одном диске — здесь все вполне традиционно:
modprobe btrfs
mkfs.btrfs /dev/sda1
mkfs.btrfs можно использовать с опциями:
-
b, bytecount — задает размер файловой системы
-
l, leafsize — задает размер листового узла дерева
-
n, nodesize — задает размер внутреннего узла дерева
-
s, sectorsize — задает размер минимального выделяемого элемента (не менее физического сектора диска)
Монтируем субтом default (создается по умолчанию):
mount -t btrfs /dev/sda1 /mnt/test
Можно смонтировать не какой-либо субтом, а все дерево корней:
mount -t btrfs /dev/sda1 /mnt/test -o subvol=.
Тогда содержимое субтома default окажется в папке /mnt/test/default.
Создать новый субтом можно командой:
btrfsctl -s new_subvol /mnt/test
Видим что, теперь в папке /mnt/test 2 элемента: default и new_subvol.
Посмотрим, как btrfs создает снапшоты:
btrfsctl -s new_subvol_snap /mnt/test/new_subvol
Также с помощью btrfsctl можно поменять размер файловой системы (если она еще не занимает весь диск или в пул было добавлено новое устройство):
btrfsctl -r +4g /mnt/test
btrfs версии 0.14 — первый релиз с поддержкой многодисковых пулов.
К существующей файловой системе можно добавлять устройства, но пока нельзя удалять (пока также не понятно, как удалять снапшоты). Обработка ошибок чтения или аппаратуры также еще толком не оттестирована, так что проверка работы btrfs в экстремальных условиях пока не возможна.
Так можно создать btrfs на двух дисках:
mkfs.btrfs /dev/sda1 /dev/sda2
Распределенный пул (stripe):
mkfs.btrfs -m raid0 /dev/sda1 /dev/sda2
Зеркало:
mkfs.btrfs -m raid1 /dev/sda1 /dev/sda2
Этой командой можно создать ФС, не зеркалируюущую метаданные на одном диске:
mkfs.btrfs -m single /dev/sda1
После создания btrfs команде mount можно передавать любой из дисков. Однако следует учитывать, что после выгрузки модуля btrfs.ko (после перезагрузки в том числе) необходимо пройтись по всем дисковым устройствам вашей системы командой:
btrfsctl -a
Или передать ей только используемые устройства:
btrfsctl -A /dev/sda1
Команда btrfsshow выдаст список всех обнаруженных файловых систем с их UUID и задействованными устройствами.
Добавить новый диск в пул можно так:
mount -t btrfs /dev/sda1 /mnt/test -o subvol=.
btrfs-vol -a /dev/sda3 /mnt/test
Файловую систему можно сбалансировать — то есть распределить часть данных и метаданных между существующими и вновь добавленным диском:
btrfs-vol -b /mnt/test
Также в btrfsprogs включена программаконвертер файловой системы из ext3. В версии 0.16 пакета утилит код конвертера имеется, однако сборка его по умолчанию отключена, так как безопасно использовать его пока рано. Если риск возможной потери данных вас не пугает, собрать и использовать его можно так:
cd btrfs-progs
make convert
./btrfs-convert /dev/sda4
Простота реализации подобного конвертера основана на том, что btrfs почти не имеет метаданных с фиксированным дисковым положением (практически, это только суперблок). Более того, COWсемантика btrfs позволяет сохранить не тронутой оригинальную ext3 с возможностью отката на нее даже после внесения изменений в btrfsкопию.
Конвертер использует libe2fs для чтения метаданных ext3, и размещает метаданные btrfs только в свободных блоках оригинальной файловой системы. Работает он в такой последовательности:
- Копирует первый мегабайт диска в "запас"
- Читает каталоги и inodes, создает их копии в btrfs
- Вставляет ссылки на блоки данных ext3 в метаданные btrfs
Смонтируем снапшот ext3: mount -t btrfs /dev/sda4 /mnt/test -o subvol=ext2_saved
Смонтируем образ оригинальной ФС: mount -t ext3 -o loop /mnt/test/image /mnt/ext3
Выполнить откат можно так: umount /mnt/ext3 umount /mnt/test btrfs-convert -r /dev/sda4
Если необходимости в откате больше нет, и нужно освободить место, занимаемое метаданными ext3, достаточно просто удалить файл image в снапшоте ext2_saved. Если есть желание избавиться от всех данных ext3 — удаляем сам снапшот.
Ссылки
1. Официальный сайт проекта: btrfs.wiki.kernel.org 2. Исходники btrfs: www.kernel.org/pub/linux/kernel/people/mason/btrfs 3. "Архитектура ZFS": www.filesystems.nm.ru/my/zfs_arch.pdf Свежую версию этого документа, а также аналогичные по тематике статьи и переводы можно найти на www.filesystems.nm.ruwww.raaar.ru
PostgreSQL и btrfs — слон на маслянной диете / Хабр
Недавно, просматривая статью на вики про файловые системы, заинтересовался btrfs, а именно его богатыми возможностями, стабильным статусом и главное — механизмом прозрачного сжатия данных. Зная, как легко жмутся базы данных содержащие текстовую информацию, мне стало любопытно уточнить на сколько это применимо в сценарии использования например с postgres.Данное тестирование конечно нельзя назвать полным, ибо задействовано только чтение и то линейное. Но результаты уже заставляют поразмыслить на тему возможного перехода на btrfs в определенных случаях.
Но основная цель — узнать мнение сообщества о том, на сколько это разумно и каких подводных камней может таить в себе подход прозрачного сжатия на уровне файловой системы.
Для тех, кто не хочет тратить время, сразу расскажу про полученные выводы. БД PostgreSQL размещенная на btrfs c опцией compress=lzo, сокращает объем бд в двое (в сравнении с любыми ФС без сжатия) и при использовании многопоточного, последовательного чтения, значительно сокращает нагрузку на дисковую подсистему.
Итак, что в наличии
Физический сервер — 1 шт- CPU: 2 Сокета по 6 ядер
- RAM: 48 ГБ
- Storage:
- 2x — SAS 10K 300GB в конфигурации RAID 1 + 0 — для ОС и основной бд postgres
- 2x — SAS 10K 300GB в конфигурации RAID 1 + 0 — для тестов
- OS: Ubuntu 14.04.2 — 3.16.0-41
- PG: 9.4.4 x86_64
Методика тестирования
Итак, у нас имеется физическая машина с 2-мя дисками: на первой хранится основная бд postgres(которая после initdb), а второй диск полностью, без создания на нем разметки форматируется в тестируемые ФС(ext4, btrfs lzo/zlib).На испытуемый диск кладется табличное пространство из резервной копии, которое участвует в тестировании, сделанное с помощью pg_basebackup. Восстанавливается так же и основная бд postgres.
Суть тестирования заключается в последовательном чтении пяти таблиц — клонов в пять потоков.
Скрипт экстремально простой и являет собой обычный «explain analyze».
Каждая таблица имеет размер 13ГБ, общий объем ~ 65ГБ.
Данные для графиков берем из sar с самыми простыми параметрами: «sar 1» — CPU ALL; «sar -d 1» — I/O.
Перед каждым запуском сбрасываем pagecache с помощью команды:
free && sync && echo 3 > /proc/sys/vm/drop_caches && free Проверяем завершение фоновых процессов:SELECT sa.pid, sa.state, sa.query FROM pg_stat_activity sa;Цифры
Размеры
| btrfs-zlib | 156GB | 35GB | 4.4 |
| btrfs-lzo | 156GB | 67GB | 2.3 |
| ext4 | 156GB | 156GB | 1 |
Последовательное чтение (explain analyze)
| btrfs-zlib | 302000 ms |
| btrfs-lzo | 262000 ms |
| ext4 | 420000 ms |
Графики
Загрузка CPU| btrfs-zlib | 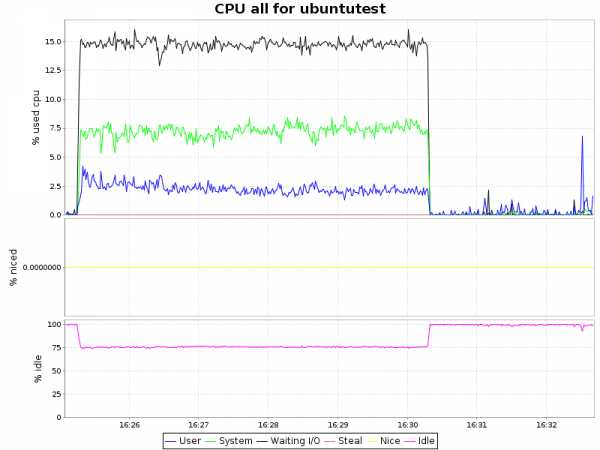 |
| btrfs-lzo | 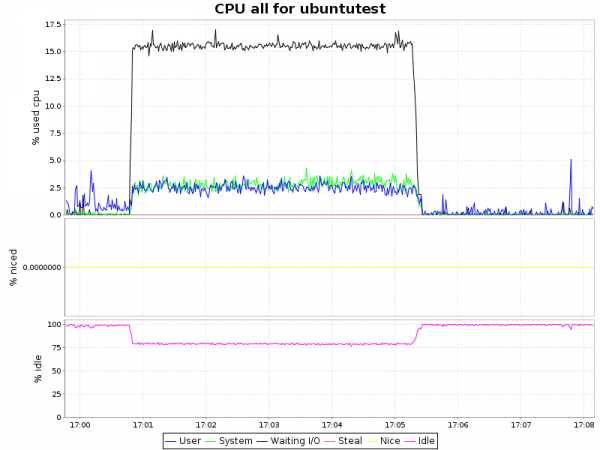 |
| ext4 | 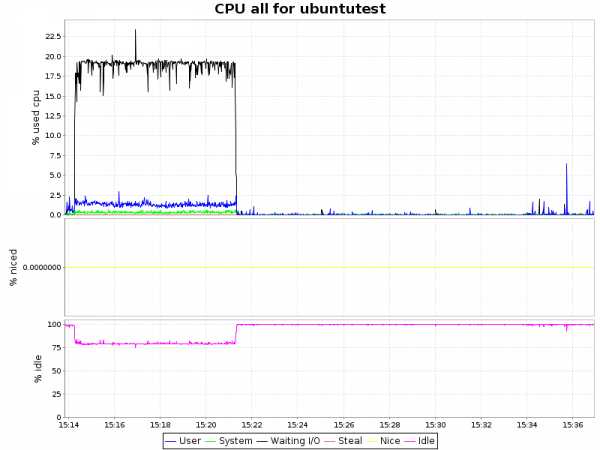 |
| btrfs-zlib | 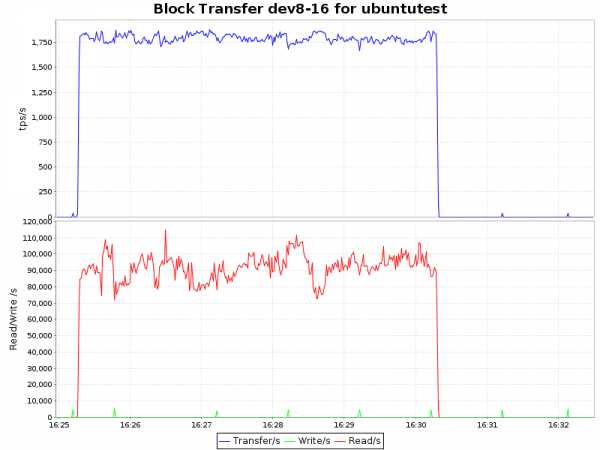 |
| btrfs-lzo | 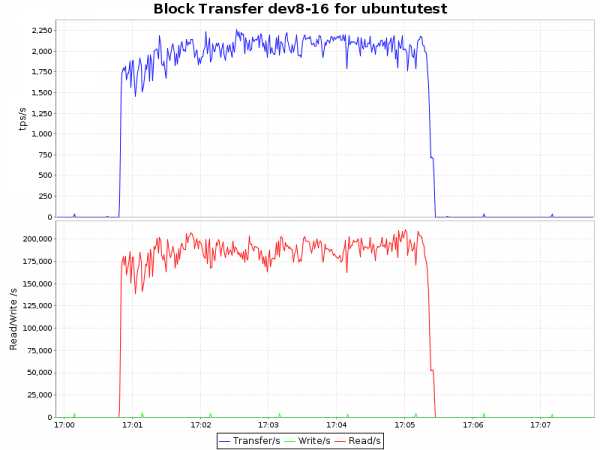 |
| ext4 | 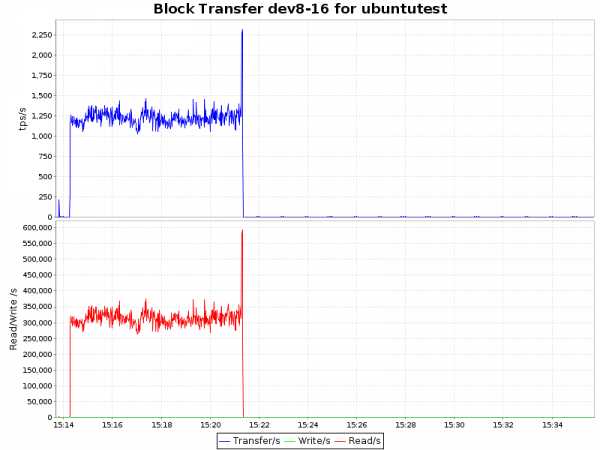 |
| btrfs-zlib | 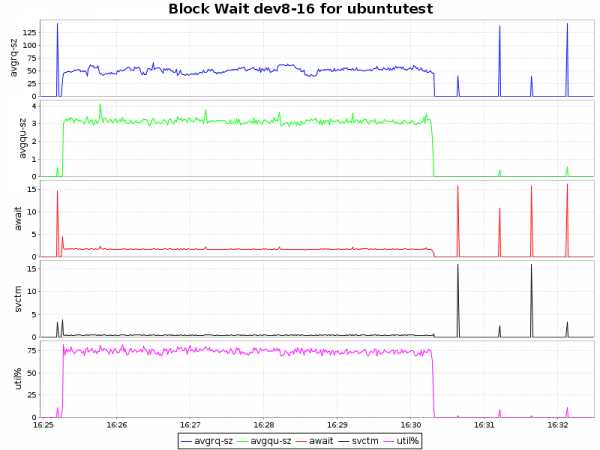 |
| btrfs-lzo | 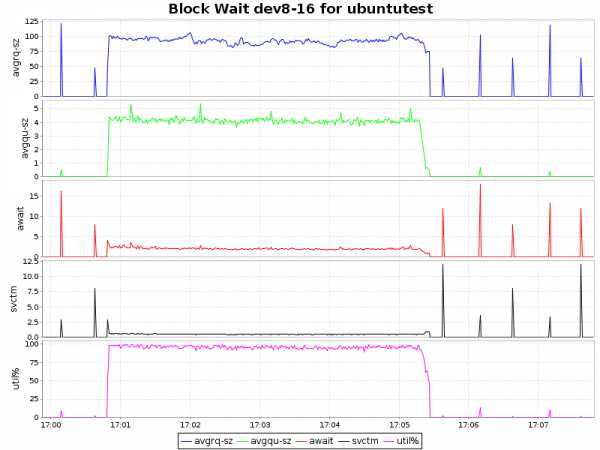 |
| ext4 | 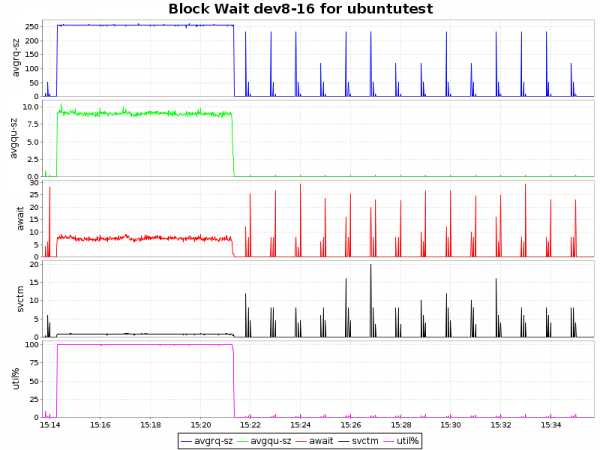 |
Вывод
Как видно из графиков, сжатие с алгоритмом lzo дает лишь незначительную нагрузку на ЦП, что в купе с 2-х кратным уменьшением объемов занимаемого пространства и некоторым ускорением делает такой подход крайней привлекательным. Zlib жмет нашу БД в 4 раза, но при этом нагрузка на процессор возрастает уже ощутимо (~ 7.5% процессорного времени), что для определенных сценариев так же вполне приемлемо. Однако btrfs лишь недавно приобрел статус стабильного (с ядра 3.10) и внедрять в продуктивную среду возможно преждевременно. С другой стороны, наличие синхронной реплики решает и этот вопрос.P.S.
На сколько мне известно, zlib и, вероятно, lzo используют инструкции из SSE 4.2, что уменьшает загрузку процессоров и вполне возможно, что в некоторых средах виртуализации высокая загрузка процессора не даст воспользоваться преимуществами сжатия.Если кто подскажет как влиять на это, то я постараюсь перепроверить разницу с аппаратным ускорением и без.
habr.com
Оптимизация Ubuntu (и прочих Linux-ов) под SSD / Хабр
Доброго времени суток всем читающим. В данной мини-статье мне хотелось бы собрать и рассмотреть основные моменты оптимизации работы (и, конечно, продления жизненного цикла ) твердотельных накопителей. Практически всю информацию можно легко найти в сети, но тут я попытаюсь упомянуть пару подводных камней. Первое, с чего стоит начать — это выбор файловой системы. Если система на десктопе — то особо вопросов не возникает — брать журналируемую ext4 — у которой масса преимуществ перед остальными ФС. Да, будет больше циклов записи на носитель, но будет гарантия того, что в случае сбоя питания вы не потеряете данные. На ноутбуках, нетбуках — имеются батареи, и вероятность отключения из-за потери питания — практически нулевая (но, конечно, всякое бывает), в связи с чем журналирование, обычно рекомендуют отключать. Если это очень хочется сделать, то после установки системы грузимся с liveCD, и пишем в терминалеtune2fs -O ^has_journal /dev/sda1 e2fsck -f /dev/sda1
Другие способы не рекомендуются — потеряете поддержку TRIM. Также не стоит отключать журнал, добавляя параметр "writeback" в конфигурацию fstab — система не запустится из-за ошибки монтирования (если до этого был включен трим).
Следующее, что нужно учесть — файл подкачки. Под моим никсом (сейчас — убунту 11.04) обычно пишется код, смотрятся фильмы в HD и активно серфится интернет. За это время файл подкачки не понадобился ни разу, максимальное потребление ОЗУ было 1Гб, из 2х доступных в нетбуке. Если Ваш сценарий использования системы подобен моему, или у Вас не десктоп — файл подкачки не нужен. Иначе стоит его перенести на HDD. Если журналирование еще можно оставить, ввиду его относительной безобидности, то своп-раздел — однозначно зло, сжирающее как ограниченные циклы перезаписи, так и недешевые гигабайты, количеством которых современные SSD пока не могут похвастаться.
Ну вот, система поставлена — можно заниматься оптимизацией! Самый первый шаг — включение TRIM — главная технология, которая должна продлить жизнь и распределить нагрузку SSD. Делается очень просто — открываем fstab (например так)
gksudo gedit /etc/fstab
ищем строчки«UUID=[NUMS-AND-LETTERS] / ext4 errors=remount-ro 0 1» и заменяем на «UUID=[NUMS-AND-LETTERS] / ext4 disсard,errors=remount-ro 0 1»
Обычно по умолчанию трим отключен, но выкладываю способ проверить — заходим под рут и выполняем команды
1. dd if=/dev/urandom of=tempfile count=10 bs=512k oflag=direct //запись 5Мб рандомных данных
2. hdparm --fibmap tempfile //Ищем любой стартовый LBA адрес у файла
3. hdparm --read-sector [ADDRESS] /dev/sdX //Читаем данные со стартового LBA адреса файла, замените [ADDRESS] на свой Starting LBA address из вывода предыдущей команды
4. rm tempfile //Теперь удалим временный файл и синхронизируем ФС: 5. sync
Повторяем пункт 3 — и смотрим на вывод консоли. Если выведутся нули — то трим работает. Если вы исправили fstab, перезагрузились, но трим не активировался — ищите ошибки в неверном отключении журналирования.
Далее стоит вспомнить о том, что наш никс очень любит вести разнообразные логи. И либо перенести их на HDD, либо держать в ОЗУ до перезагрузки системы. Я считаю, что если у Вас дома не сервер — то оптимален второй вариант, и реализуется он добавлением в fstab следующих строчекtmpfs /tmp tmpfs defaults 0 0 tmpfs /var/tmp tmpfs defaults 0 0 tmpfs /var/lock tmpfs defaults 0 0 tmpfs /var/spool/postfix tmpfs defaults 0 0
По умолчанию, после каждого открытия файла — система оставляет отметку времени последнего открытия — лишние операции записи. Отучить просто — добавить в fstab перед параметрамиdisсard,errors=remount-ro 0 еще парочку опций — relatime,nodiratime Первая разрешает записывать только время изменения (порой необходимо для стабильной работы некоторых программ), вторая — отменяет запись времени доступа к директориям. В принципе, вместо relatime можно поставить и noatime, который вообще ничего не будет обновлять.
После этого стоит настроить отложенную запись — ядро будет копить данные, ожидающие записи на диск, и записывать их либо при острой необходимости, либо по истечении таймаута. Я ставлю таймаут на 60 секунд, кто-то — на 150. Для этого открываем /etc/sysctl.conf и добавляем параметры vm.laptop_mode = 5 // Включение режимаvm.dirty_writeback_centisecs = 6000 время в сСк. Т.е. 100ед = 1секунда
И, напоследок, отключаем I/O планировщик, который был когда-то нужен для лучшего позиционирования головок HDD. Для этого заходит в конфиг граба /etc/default/grub и в строчку GRUB_CMDLINE_LINUX_DEFAULT=«quiet splash» вставляем параметр elevator=noop По пути можно убрать ненужный и малоинформатиынй сплэш-скрин, сократив время старта системы еще на секунду, просто убрав quiet splash.
Вот, в общем основные моменты. Дальше стоит проявить фантазию — например, перенести куда-нибудь, или вовсе отключить кеш браузеров и тд. В награду за проделанные манипуляции Ваш SSD прослужит вам верой и правдой, и с каждым стартом будет радовать хорошей скоростью.
Update Многи замечают о необходимости выравнивания разделов. Товарищу isden большое спасибо за ссылку на тему. wiki.archlinux.org/index.php/SSD#Partition_Alignment Если не хотите рисковать — то журнал лучше не отключать. Тогда гарантированно будет работать трим, и некоторая защита данных от крупных системных сбоев.
Внизу — несколько ссылок, по которым получал информацию.vasilisc.com/ssd_ubuntutokarchuk.ru/2011/01/enable-trim-support-in-ubuntusites.google.com/site/linuxoptimization/home/ssd
habr.com
Btrfs - Gentoo Wiki
This page is a translated version of the page Btrfs and the translation is 86% complete.Btrfs — это copy-on-write (копирование при записи (CoW)) файловая система для Linux, предназначенная для реализации расширенных возможностей, с уделением особого внимания отказоустойчивости, восстановлению и простоте администрирования. Совместно разработана Oracle, Red Hat, Fujitsu, Intel, SUSE, STRATO и многими другими. Btrfs лицензирована под GPL лицензией и открыта для участия всех желающих.
Возможности
Ext4 является безопасной и стабильной и может обрабатывать большие файловые системы с экстентами, но зачем переключаться? Хотя Btrfs все еще считается экспериментальной, стабильность её растет, и время, когда Btrfs станет файловой системой по умолчанию для систем Linux, становится все ближе. Некоторые дистрибутивы Linux уже начали переключаться на нее в своих текущих релизах. Btrfs имеет ряд дополнительных функций, общих с ZFS, которые и сделали файловую систему ZFS популярной для BSD дистрибутивов и устройств NAS.
- "Копирование при записи" и создание снимков - Делает инкрементные резервные копии безболезненными даже из "активной" файловой системы или виртуальной машины (ВМ).
- Контрольные суммы уровня файла - Метаданные для каждого файла включают контрольную сумму, которая используется для обнаружения и исправления ошибок.
- Сжатие - Файлы могут быть сжаты и распакованы "на лету", что ускоряет работу чтения.
- Автоматическая дефрагментация - Файловые системы настраиваются фоновым потоком, в то время как они используются.
- Подтома - Файловые системы могут совместно использовать одно общее пространство (pool) вместо того, чтобы размещаться в собственных разделах.
- RAID - Btrfs осуществляет свои собственные реализации RAID, поэтому LVM или mdadm не требуются для RAID. В настоящее время поддерживаются RAID 0 и 1; на подходе RAID 5 и 6.
- Разделы являются необязательными - Хотя Btrfs может работать с разделами, она может напрямую использовать неформатированные устройства (/dev/<device>).
- Дедупликация данных - Существует ограниченная поддержка дедупликации данных; однако, дедупликация в конечном итоге станет стандартной функцией в Btrfs. Это позволяет Btrfs экономить место, сравнивая файлы через бинарные изменения (binary diff).
В будущем новые кластерные файловые системы легко могут использовать Btrfs с её копированием при записи и другими расширенными функциями для своих хранилищ объектов. Ceph - один из примеров кластерной файловой системы, которая выглядит очень перспективно и может использовать Btrfs.
Установка
Ядро
Активируйте следующий параметр ядра, чтобы включить поддержку файловой системы Btrfs:
Ядро Включение Btrfs в ядре
File systems ---> <*> Btrfs filesystemEmerge
Пакет sys-fs/btrfs-progs содержит утилиты необходимые для работы с файловой системой Btrfs.
root #emerge --ask sys-fs/btrfs-progs
Использование
Ввод длинных команд Btrfs может быстро надоесть. Каждая команда (кроме начальной команды btrfs) может быть сведена к очень короткому набору инструкций. Этот метод полезен при работе в командной строке, чтобы уменьшить количество вводимых символов.
Например, ниже показана длинная команда, чтобы дефрагментировать файловую систему расположенную в /.
root #btrfs filesystem defragment -v /
Сократите каждую из длинных команд после команды btrfs, уменьшив их до их уникального, кратчайшего префикса. В этом контексте уникальный означает, что нет других команд btrfs, которые соответствуют команде в самом коротком её варианте. Укороченная версия указанной команды:
Никакие другие команды btrfs не начинаются с fi; filesystem - единственная. То же самое относится к подкоманде de команды filesystem.
Создание
ПредупреждениеКоманда mkfs.btrfs необратимо уничтожит все содержимое раздела, который будет форматироваться. Пожалуйста убедитесь, что выбран правильный раздел перед запуском какой-либо mkfs команды!
Чтобы создать файловую систему Btrfs на разделе /dev/sdXN:
root #mkfs.btrfs /dev/sdXN
В примере выше замените N на номер раздела, а X на букву диска. Например, чтобы отформатировать в Btrfs третий раздел на первом диске запустите:
root #mkfs.btrfs /dev/sda3
ВажноДля всех разделов Btrfs в файле /etc/fstab в последней колонке нужно выставить 0. Нет нужды запускать fsck.btrfs и btrfsck при каждом запуске системы.
Монтирование
После создания, файловую систему можно смонтировать несколькими способами:
- mount - смонтировать вручную.
- fstab - определить точку монтирования в файле /etc/fstab, что позволит автоматически монтировать файловую систему во время загрузки.
- съемные носители - автоматическое монтирование по запросу (полезно для USB-носителей).
- AutoFS - автоматическая настройка для доступа к файловой системе.
Конвертация ext* файловых систем
Можно сконвертировать файловые системы ext2, ext3 и ext4 в Btrfs с помощью утилиты btrfs-convert.
Следующие инструкции подходят только для преобразования отмонтированных файловых систем. Чтобы сконвертировать root-раздел, загрузитесь с системного аварийного диска (SystemRescueCD работает отлично) и запустите команду конвертации для root-раздела.
Сперва убедитесь, что отмонтировали раздел:
root #umount <mounted_device>
Проверьте целостность файловой системы с помощью соответствующей утилиты fsck. Далее показан пример для файловой системы ext4:
root #fsck.ext4 -f <unmounted_device>
Воспользуйтесь btrfs-convert для того чтобы сконвертировать отформатированное в ext* устройство в Btrfs:
root #btrfs-convert <unmounted_device>
Убедитесь, что после форматирования устройства не забыли отредактировать файл /etc/fstab и изменить значение в колонке файловая система с ext4 на Btrfs:
Файл /etc/fstabЗамена ext4 на btrfs
<device> <mountpoint> btrfs defaults 0 0Дефрагментация
Другая полезная функция Btrfs это онлайн дефрагментация. Чтобы дефрагментировать файловую систему root с Btrfs запустите:
root #btrfs filesystem defragment -r -v /
ПредупреждениеДефрагментация с версиями ядра [1] и, таким образом, может значительно увеличить использование пространства. Убедитесь, что достаточно свободного места и не слишком много снимков на диске, так как заполненные разделы btrfs могут быть очень медленными.Сжатие
Btrfs поддерживает прозрачное сжатие с помощью алгоритмов zlib и lzo.
Можно сжать конкретный файл с помощью атрибутов файла:
Параметр монтирования compress по умолчанию сжимает все вновь созданные файлы. Чтобы повторно сжать всю файловую систему выполните следующую команду:
root #btrfs filesystem defragment -r -v -clzo /
В зависимости от производительности процессора и диска использование сжатия lzo может улучшить общую пропускную способность.
Можно использовать алгоритм сжатия zlib вместо lzo. zlib более медленный, но имеет более высокую степень сжатия:
root #btrfs filesystem defragment -r -v -czlib /
Compression level
Since kernel version 4.15.0[2], zlib compression can now be set by levels 1-9. For example, to set zlib to maximum compression at mount time:
root #mount -o compress=zlib:9 /dev/sdXY /path/to/btrfs/mountpoint
Or to set minimal compression:
root #mount -o compress=zlib:1 /dev/sdXY /path/to/btrfs/mountpoint
Or adjust compression by remounting:
root #mount -o remount,compress=zlib:3 /path/to/btrfs/mountpoint
The compression level should be visible in /proc/mounts or by checking the most recent output of dmesg |grep -i btrfs.
root #dmesg |grep -i btrfs
[ 0.495284] Btrfs loaded, crc32c=crc32c-intel [ 3010.727383] BTRFS: device label My Passport devid 1 transid 31 /dev/sdd1 [ 3111.930960] BTRFS info (device sdd1): disk space caching is enabled [ 3111.930973] BTRFS info (device sdd1): has skinny extents [ 9428.918325] BTRFS info (device sdd1): use zlib compression, level 3Compression ratio and disk usage
The usual userspace tools for determining used and free space like du and df may provide inaccurate results on a Btrfs partition due to inherent design differences in the way files are written compared to ,for example, ext2/3/4[3].
It is therefore advised to use the du/df alternatives provided by the btrfs userspace tool btrfs filesystem. In Addition to that, The compsize tool found from the sys-fs/compsize package can be helpful in providing additional information regarding compression ratios and the disk usage of compressed files. The following are example uses of these tools for a btrfs partition mounted under /media/drive.
user $btrfs filesystem du -s /media/drive
Total Exclusive Set shared Filename 848.12GiB 848.12GiB 0.00B /media/drive/user $btrfs filesystem df /media/drive
Data, single: total=846.00GiB, used=845.61GiB System, DUP: total=8.00MiB, used=112.00KiB Metadata, DUP: total=2.00GiB, used=904.30MiB GlobalReserve, single: total=512.00MiB, used=0.00Buser $compsize /media/drive
Processed 2262 files, 112115 regular extents (112115 refs), 174 inline. Type Perc Disk Usage Uncompressed Referenced TOTAL 99% 845G 848G 848G none 100% 844G 844G 844G zlib 16% 532M 3.2G 3.2GRAID
Создать RAID в Btrfs гораздо проще, чем создать RAID с помощью mdadm.
Самый простой способ создать RAID, это использовать все устройства:
root #mkfs.btrfs -m raid1 <device1> <device2> -d raid1 <device1> <device2>
Converting between RAID modes is possible with the balance sub-command. For example, say a multiple device RAID 1 is mounted at /srv. It is possible to convert this RAID1 to RAID0 with using the following command:
root #btrfs balance start -dconvert=raid0 -mconvert=raid0 --force /srv
RAID mode conversion can be performed while the filesystem is online and in use. Possible RAID modes in btrfs include RAID0, RAID1, RAID5, RAID6, and RAID10. See the upstream BTRFS wiki for more information.
ПредупреждениеВ настоящее время не безопасно использовать уровни RAID 5 или 6[4]. В уровнях RAID 5 и 6 были исправления[5] в Linux 4.12, но общее состояние по-прежнему помечено как нестабильное.[6][7]. Пользователям, которые хотят использовать функции btrfs RAID5 или RAID6, рекомендуется проверять страницу состояния btrfs на предмет стабильности указанных уровней перед их использованием.Подтома
Как уже упоминалось выше в списке функций, Btrfs может создавать подтома. Подтома могут быть использованы, чтобы лучше организовать и управлять данными. Они становятся особенно мощными в сочетании с моментальными снимками. Важное различие должно быть сделано между подтомами Btrfs и подтомами созданными менеджером логических томов (LVM). Подтома Btrfs не являются устройствами уровня блока, они представляют собой пространства имен файлов POSIX.[8] Они могут быть созданы в любом месте файловой системы и будут действовать как любой другой каталог в системе с одной оговоркой: подтома могут быть смонтированы и размонтированы. Подтома вкладываемы (подтома могут быть созданы внутри других подтомов), и легко создаются или удаляются.
ЗаметкаПодтом не может быть создан между разными файловыми системами Btrfs. Если /dev/sda и /dev/sdb содержат отдельные (не RAID-массивы) файловые системы Btrfs, то нет возможности, чтобы подтом можно было бы распределить по двум файловым системам. Снимок можно перенести из одной файловой системы в другую, но он не может охватывать обе. Он должен быть на /dev/sda или /dev/sdb.
Создание
Чтобы создать подтом, выполните следующую команду внутри пространства имен файловой системы Btrfs:
root #btrfs subvolume create <dest-name>
Замените <dest-name> на желаемое место и имя подтома. Например, если существует файловая система btrfs в /mnt/btrfs, подтом может быть создан внутри неё, используя следующую команду:
root #btrfs subvolume create /mnt/btrfs/subvolume1
Список
Чтобы увидеть созданный(е) подтом(а), используйте команду subvolume list в соответствующем месте файловой системы Btrfs. Если текущий каталог находится где-то внутри файловой системы Btrfs, следующая команда отобразит подтом(а), которые существуют в файловой системе:
root #btrfs subvolume list .
Если в точке монтирования файловой системы Btrfs, существуют подтома, созданные командой из примера выше, вывод команды списка будет выглядеть примерно так:
root #btrfs subvolume list /mnt/btrfs
ID 309 gen 102913 top level 5 path mnt/btrfs/subvolume1Удаление
Подтома могут быть корректно удалены с помощью команды subvolume delete, за которой следует путь к подтому. Все доступные пути подтомов в файловой системе Btrfs можно увидеть, используя приведенную выше команду списка.
root #btrfs subvolume delete <subvolume-path>
Как и выше, замените <subvolume-path> на фактический путь к подлежащему удалению подтому. Чтобы удалить подтом, используемый в приведенных выше примерах, будет выполнена следующая команда:
root #btrfs subvolume delete /mnt/btrfs/subvolume1
Delete subvolume (no-commit): '/mnt/btrfs/subvolume1'Снимки
Снимки - это подтома, которые обмениваются данными и метаданными с другими подтомами. Это стало возможным благодаря способности Btrfs копирование при записи (CoW).[8] Снимки можно использовать для нескольких целей, одной из которых является создание резервных копий структур файловой системы в определенные моменты времени.
Если корневая файловая система - это Btrfs, то можно создать снимок с помощью команды subvolume snapshot:
root #mkdir -p /mnt/backup/rootfs
root #btrfs subvolume snapshot / /mnt/backup/rootfs/
Следующий небольшой сценарий оболочки можно добавить в cron задание, срабатывающее в определенное время, для создания снимка/резервной копии корневой файловой системы, отформатированной в Btrfs. Временные метки могут быть скорректированы с учетом предпочтений пользователя.
Файл btrfs_snapshot.shПример задачи cron для снятия снимка с root файловой системы Btrfs
#!/bin/bash NOW=$(date +"%Y-%m-%d_%H:%M:%S") if [ ! -e /mnt/backup ]; then mkdir -p /mnt/backup fi cd / /sbin/btrfs subvolume snapshot / "/mnt/backup/backup_${NOW}"Монтирование
Подтом может быть смонтирован в месте, отличном от того, где он был создан, или пользователи могут не монтировать их вообще. Например, пользователь может создать файловую систему Btrfs в /mnt/btrfs и создать подтома /mnt/btrfs/home и /mnt/btrfs/portage. Затем подтома могут быть смонтированы в /home и /usr/portage, при этом исходный верхний уровень подтома оставлен не примонтированным. Это приводит к конфигурации, в которой относительные пути подтомов от верхнего уровня подтома отличаются от их фактического пути.
Чтобы смонтировать подтом, выполните следующую команду, где <rel-path> - это относительный путь подтома от подтома верхнего уровня, который можно получить через команду subvolume list:
root #mount -o subvol=<rel-path> <device> <mountpoint>
Аналогично, можно обновить колонку filesystem, чтобы смонтировать подтома Btrfs следующим образом:
Файл /etc/fstabМонтирование подтомов
<device> <mountpoint> btrfs subvol=<rel-path> 0 2Устранение проблем
Using with VM disk images
When using Btrfs with virtual machine disk images, it is best to disable copy-on-write on the disk images in order to speed up IO performance. This can only be performed on files that are newly created. It also possible to disable CoW on all files created within a certain directory. For example, using the chattr command:
root #chattr +C /var/lib/libvirt/images
Очистка кэша свободного места
Можно очистить кэш свободного места Btrfs путем монтирования файловой системы с помощью параметра монтирования clear_cache. Например:
root #mount -o clear_cache /path/to/device /path/to/mountpoint
Btrfs захват памяти (дискового кеша)
При использовании некоторых специальных способностей Btrfs (таких как создание множества --reflink копий или создание безумного количества снимков) много памяти можно съесть и не освободить достаточно быстро от кеша индексного дескриптора ядра. Эта проблема может быть не обнаружена, поскольку память, предназначенная для кеша диска, может быть не видна в традиционных утилитах мониторинга системы. Утилита slabtop (доступная как часть пакета sys-process/procps) была специально создана для определения того, сколько памяти потребляют объекты ядра:
Если кэш индексного дескриптора потребляет слишком много памяти, ядру можно вручную указать на сброс кэша путем передачи целочисленного значения с помощью команды echo в файл /proc/sys/vm/drop_caches[9].
Для безопасности и чтобы помочь ядру определить максимальный объем освобождаемой памяти, обязательно запустите sync перед запуском echo команд как показано ниже:
В большинстве случаев, пользователям Btrfs, вероятно, потребуется echo 2, чтобы просто восстановить объекты slab (dentries и btrfs_inodes):
root #echo 2 > /proc/sys/vm/drop_caches
Чтобы очистить весь дисковый кэш (объекты slab и кэш страниц), используйте echo 3:
root #echo 3 > /proc/sys/vm/drop_caches
ПредупреждениеХотя приведенные выше команды являются неразрушающими (при условии завершения выполнения команды sync перед их запуском), они могут серьезно, но временно замедлить работу системы, пока ядро опять загружает в память только необходимые элементы. Дважды подумайте, прежде чем запускать вышеуказанные команды на системах под большой нагрузкой!
Более подробную информацию о slab ядра можно найти в этой записи блога dedoimedo.
Не удается смонтировать btrfs, при монтировании возвращается: неизвестный тип файловой системы 'btrfs'
Оригинальное решение Тима на Stack Exchange вдохновило на следующий способ - сборка ядра вручную, вместо использования genkernel:
#cd /usr/src/linux
#make menuconfig
#make && make modules_install
#cp arch/x86_64/boot/bzImage /boot
#mv /boot/bzImage /boot/whatever_kernel_filename
#genkernel --install initramfs
Корневая файловая система Btrfs не загружается
Genkernel's initramfs, созданная с помощью приведенной ниже команды, не загружает btrfs:
root #genkernel --btrfs initramfs
Компилируйте поддержку btrfs в ядре, а не как модуль, или используйте genkernel-next или Dracut для генерации initramfs.
Смотрите также
- Btrfs snapshots - Скрипт, который создает моментальные снимки при изменении файлов.
- Btrfs/System Root Guide - Использование файловой системы btrfs, как коллекции подтомов, в том числе, в качестве корневой файловой системы.
- Btrfs native system root guide - Альтернативное руководство по использованию подтома в файловой системе btrfs в качестве корневой файловой системы.
- ext4 - Файловая система по умолчанию для большинства дистрибутивов Linux.
- Samba shadow copies - Использование Samba для предоставления теневых копий как 'предыдущих версий' клиентам Windows.
- Snapper - Программа командной строки, способная управлять снимками файловой системы Btrfs.
- ZFS - Файловая система, которая имеет много общего с Btrfs, но имеет проблемы с лицензированием.
Внешние ресурсы
Ссылки
- ↑ man page for btrfs-filesystem(8), Btrfs wiki. Retrieved on 6th February, 2017.
- ↑ https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=f51d2b59120ff364a5e612a594ed358767e1cd09
- ↑ https://btrfs.wiki.kernel.org/index.php/Compression#How_can_I_determine_compressed_size_of_a_file.3F
- ↑ Article mentioning that parity RAID code has multiple serious data-loss bugs, Btrfs wiki. Retrieved on January 1st, 2017.
- ↑ Michael Larabel, Btrfs RAID56 "Mostly OK", Phoronix. July 8, 2017.
- ↑ btrfs: scrub: Fix RAID56 recovery race condition, source commit, April 18th 2017.
- ↑ GIT PULL Btrfs from Chris Mason, Linux kernel mailinglist, May 9th 2017.
- ↑ 8.08.1 Section explaining the differences between subvolumes and logical volumes in LVM, Btrfs wiki. Retrieved on January 1st, 2017.
- ↑ Documentation for /proc/sys/vm/*, Kernel.org. Retrieved on January 1st, 2017.
wiki.gentoo.org