3.10. Опции, которые контролируют оптимизацию. Gcc уровни оптимизации
Продвинутая оптимизация исполняемого кода с GCC
Под оптимизацией компилируемых программ можно понимать два аспекта. Первый важный аспект - это труд самого разработчика над совершенствованием реализаций алгоритмов в программе. Второй не менее важный - возможности инструментария разработки генерировать более оптимальный исполняемый код. В этом посте речь пойдёт о втором аспекте, поскольку он не требует особых усилий от разработчика и позволяет получать хороший результат прямо здесь и сейчас.
Краткое введение
Преимущественно мы будем говорить об оптимизации программ на языке C для встраиваемых систем на микроконтроллерах, также по умолчанию нашей стратегией будет уменьшение размера программы. Однако применение описанных возможностей этим не ограничивается и будет полезно всем разработчикам, использующим набор инструментов GCC.
Существуют две основных стратегии оптимизации машинного кода:
- Оптимизация размера программы
- Оптимизация скорости выполнения
На практике реальные компиляторы не ограничиваются только этими двумя. Например, GCC позволяет задать следующие стратегии или уровни оптимизации:
- 0 - отсутствие оптимизации и самая быстрая компиляция (по умолчанию)
- 1 - умеренная оптимизация и достаточно быстрая компиляция
- 2 - полная оптимизация по скорости и долгая компиляция
- 3 - более продвинутая полная оптимизация
- s - оптимизация размера кода и данных (не увеличивающая размер оптимизация)
- fast - оптимизация скорости в ущерб строгому следованию стандартам
- g - оптимизация не препятствующая отладке
Мы в праве выбрать любую в зависимости от ограничений и возможностей среды выполнения. С точки зрения компилятора каждая стратегия представлена набором задействованных возможностей кодогенератора, таким образом достаточно изощрённый разработчик может сам скомбинировать нужные ему опции (-fxyz) вместо указания уровня оптимизации (-Ox).
Оптимизация компилятором
Компилятор (cc) превращает файл исходного кода в объектный файл, содержащий секции с машинным кодом функций и данными. Далее мы будем называть каждый такой файл модулем компиляции. Таким образом компилятор осуществляет оптимизацию в пределах модуля.
Существует множество техник улучшения скорости выполнения кода и/или уменьшения его размера при компиляции. Основные из них следующие:
- Исключение недостижимого кода
- Свёртка, объединение и распространение констант
- Выделение общих частей в выражениях
- Полная или частичная развёртка циклов
- Внедрение тела функций в места вызова
- Оптимизация хвостовой рекурсии
Первая техника самая простая: компилятор определяет участки программы, которые в принципе никогда не выполняются, и исключает их из модуля.
Вторая техника посложнее: компилятору придётся проанализировать AST программы, чтобы определить, какие выражения могут быть вычислены ещё на этапе компиляции. Это могут быть не обязательно простые выражения, они могут включать вызов чистых функций (результат которых зависит только от переданных аргументов), объявленных в пределах модуля компиляции, а также встроенных функций компилятора (builtins). Свёртка констант представляет собой замену выражений на константы, а распространение идёт дальше: заменяет заведомо константные переменные в других выражениях вычисленными значениями. Объединение констант это не просто замена одинаковых значений, к примеру, строк, на одно. Компилятор достаточно умён, и если он увидит, что одна строка является частью конца другой строки, он также объединит её с первой. Эти техники оптимизируют как скорость так и размер программы.
Третья техника позволяет уменьшить количество вычислений, путём выделения общих частей выражений в отдельные переменные, вычисляемые только один раз.
Разворачивание циклов ускоряет выполнение, ценой увеличения размера программы. Ускорение осуществляется снижением числа условных и безусловных переходов, которые могут существенно замедлить программу, особенно когда в теле цикла достаточно простая операция. Проще всего развернуть константные циклы, то есть те, что выполняются заведомо известное количество раз. Сложнее обстоит дело с произвольными: здесь в игру вступает так называемая векторизация. Например, когда в цикле происходит итерация по i от 0 до N, компилятор делает предположение, что N может быть больше, скажем, 8 и помещает перед циклом такой же цикл только развёрнутый в 8 раз с итерацией по i через 8. Так компилятор может развернуть цикл несколько раз, например, сначала по 16 шагов, потом по 8, и по 4. В отсутствии информации о реальном выполнении программы эти предположения делаются вслепую.
Техника встраивания позволяет исключить достаточно дорогую операцию вызова функций, внедрением тела функции в места её вызова. Эту оптимизацию наиболее разумно применять в двух случаях:
- Функция статическая (используется только в пределах модуля компиляции)
- Тело функции меньше или сравнимо с операцией её вызова
И наконец, последняя из основных техник позволяет предотвратить вызов функцией самой себя в конце путём безусловного перехода в её начало. Таким образом, хвостовая рекурсия превращается по сути в цикл, к которому может быть применена оптимизация развёртки/векторизации.
Оптимизация линковщиком
Линковщик (ld) объединяет множество модулей компиляции в единый исполняемый файл, путём связывания символов функций и данных разных модулей между собой. Изначально оптимизация не была уделом линковщика, но те времена давно прошли.
Практика разработки показала, что из оптимизированных модулей далеко не всегда получается оптимизированная программа, остаётся ещё множество возможностей дальнейшей оптимизации. Например, функции не могут быть встроены между модулями, или исключены неиспользуемые функции и данные.
Первое время проблема отсутствия оптимизации связывания разработчиками решалась так: в релизе все модули включались в единый исходный файл директивами #include и компилировался уже этот файл. Однако, данный подход применим далеко не во всех случаях, к тому же он не позволяет работать со статическими библиотеками.
В настоящее время линковщики стали намного интеллектуальнее и при некоторой поддержке со стороны компилятора могут производить достаточно изощрённые оптимизации. Но начнём рассмотрение мы с самого простого, а именно, с возможности исключения неиспользуемых функций и констант. Эта возможность связана со способностью линковщика исключать неиспользуемые секции. Так, если заставить компилятор помещать каждую функцию и кусок данных в отдельные секции (с помощью опций -ffunction-sections и -fdata-sections), то линковщик (с опцией --gc-sections) сможет исключить те из них, которые не доступны из программы.
Оптимизация времени связывания
Возможность, носящая название LTO, в GCC реализуется отдельным плагином. Стоит заметить, что нужна соответствующая поддержка со стороны компилятора (включается опцией -flto). Это именно тот тип оптимизаций, который плотно завязан на LTCG. В общих словах это означает, что те оптимизации, которые раньше были доступны только компилятору, теперь могут осуществляться линковщиком, в который загружен соответствующий плагин.
Собирая свой код с -flto, я заметил следующее:
- Компиляция заметно ускорилась вне зависимости от используемых опций оптимизации.
- Линковщик теперь знает о типах переменных и функциях и выдаёт предупреждения, если в разных модулях для общих символов они не совпадают.
Вторая особенность весьма удобна и позволяет избежать неверного использования в некоторых общих случаях.
Но как и с любой достаточно молодой и прогрессивной технологией c LTO не всё так просто, как могло бы быть. С её использованием связаны некоторые проблемы с линковкой, в частности, когда некоторые модули или библиотеки собраны без LTO, могут быть проблемы с нахождением некоторых символов из них.
Мною были опробованы несколько версий GCC для сборки прошивки для устройства на STM32, и получены довольно любопытные результаты:
| Версия arm-none-eabi-gcc | Без LTO | С LTO | ||||||
| text | data | bss | dec | text | data | bss | dec | |
| 4.9.2-10+14~bpo8+1 | 15204 | 17448 | 1364 | 34016 | 13412 | 17448 | 1360 | 32220 |
| 5.4.1 20160919 | 15184 | 17448 | 1364 | 33996 | 13376 | 17444 | 1360 | 32180 |
| 6.3.1 20170215 | 15192 | 17448 | 1360 | 34000 | 13892 | 17444 | 1364 | 32700 |
Компиляция производилась с -Os и опциями -ffunction-sections -fdata-sections для компилятора, а также --gc-sections для линковщика. Но в первом случае без опции -flto, а во втором с ней. В данном конкретном случае GCC 5.4 сгенерировал наиболее оптимальный по размеру код как с LTO так и без.
В результате исследования полученного исполняемого файла утилитой objdump, я сделал следующие выводы:
- Короткие функции были встроены в места вызова, не смотря на расположение в разных модулях и библиотеках
- Функции, вызываемые один раз, также были внедрены в место вызова
- Отладочная информация была окончательно испорчена и польза от неё сведена на нет весьма существенно пострадала
Как было сказано выше, необходимо наличие специального плагина LTO. В GCC предусмотрены специальные обёртки для запуска программ типа nm, ar обеспечивающие загрузку соответствующего плагина. Достаточно просто использовать gcc-nm, gcc-ar вместо них.
Оптимизация, управляемая профилированием
И наконец наиболее продвинутые техники оптимизации PGO. Выше мы сделали оговорку, что во многих случаях компилятор делает выбор в оптимизации исполняемого кода исходя из некоторых общих предположений, которые на практике не всегда могут быть оправданы. Скорректировать эти предположения можно только собрав информацию о реальном выполнении программы. В GCC есть специальные опции -fprofile-generate для компилирования программы с профилированием и -fprofile-use для использования созданного в процессе выполнения профиля на следующем этапе компиляции. Следует учитывать, что скомпилированную для профилирования программу лучше всего запускать с учетом наиболее частого варианта использования, чтобы получить на выходе наиболее оптимальный профиль.
При разработке встраиваемого ПО эта технология оптимизации имеет смысл, если применяются вычислительно-ёмкие алгоритмы типа сжатия, шифрования или кодирования. Но применить её здесь не так тривиально. Во-первых необходимо реализовать кое-какие stub функции для libc, чтобы профилировщик мог записать файл профиля. Во-вторых, дополнительный код профилирования увеличит размер программы и потребление оперативной памяти. Это может стать серьёзным препятствием для запуска её на реальном прототипе устройства, поэтому программу придётся собирать для работы в эмуляторе либо использовать контроллеры с существенно большим объёмом Flash памяти и RAM.
По таблице ниже можно примерно оценить вносимые профилированием накладные расходы:
| Версия arm-none-eabi-gcc | Без PGO | С PGO | ||||||
| text | data | bss | dec | text | data | bss | dec | |
| 5.4.1 20160919 | 13376 | 17444 | 1360 | 32180 | 57576 | 25288 | 14156 | 97020 |
| 6.3.1 20170215 | 13892 | 17444 | 1364 | 32700 | 57608 | 25288 | 14076 | 96972 |
Как видим, они довольно таки велики. Чтобы получить эти данные, мне пришлось выбрать High-density микроконтроллер при сборке, поскольку программа никак не хотела вписываться в имеющуюся оперативную память (20KB).
Выводы
В статье рассмотрены возможности оптимизации, предлагаемые современными версиями GCC. Кроме собственно оптимизаций компилятора, особое внимание уделено оптимизациям линковщика, также затронута тема оптимизации профилированием. На основании полученных данных можно сделать вывод, что оптимизации линковщика весьма полезны в разработке под микроконтроллеры. Профилирование тоже может помочь в генерации наиболее оптимального кода, особенно когда дело касается оптимизации на скорость выполнения. Другая сторона использования продвинутых техник оптимизации: существенное ухудшение возможностей отладки, поэтому можно рекомендовать их применение только для финальной сборки, особенно когда есть соблазн сэкономить на целевом микроконтроллере.
[compiler-construction] Сколько уровней оптимизации GCC существует? [optimization]
Чтобы быть педантичным, существует 8 различных допустимых параметров -O, которые вы можете дать gcc, хотя есть некоторые, которые означают одно и то же.
В оригинальной версии этого ответа было указано 7 вариантов. С тех пор GCC добавила -Og чтобы довести общее количество до 8
На странице руководства :
- -O (То же, что и -O1 )
- -O0 (нет оптимизации, по умолчанию, если не указан уровень оптимизации)
- -O1 (оптимизировать минимально)
- -O2 (оптимизируйте больше)
- -O3 (оптимизируйте еще больше)
- -Ofast (оптимизируйте очень агрессивно до уровня стандартного соответствия)
- -Og (оптимизировать работу отладки. -Og включает оптимизацию, которая не мешает отладке. Это должен быть оптимальный уровень выбора для стандартного цикла редактирования-компиляции-отладки, предлагающий разумный уровень оптимизации при сохранении быстрой компиляции и хорошей отладки опыт.)
- -Os (оптимизация для размера. -Os включает все оптимизации -O2 которые обычно не увеличивают размер кода, а также выполняют дальнейшие оптимизации, предназначенные для уменьшения размера кода. -Os отключает следующие флаги оптимизации: -falign-functions -falign-jumps -falign-loops -falign-labels -freorder-blocks -freorder-blocks-and-partition -fprefetch-loop-arrays -ftree-vect-loop-version )
Также могут быть оптимизированы конкретные платформы, так как примечания @pauldoo, OS X имеет -Oz
Давайте интерпретировать исходный код GCC 5.1, чтобы увидеть, что происходит на -O100 поскольку на man-странице не ясно.
Мы заключим, что:
- что-либо выше -O3 до INT_MAX такое же, как -O3 , но это может легко измениться в будущем, поэтому не полагайтесь на него.
- GCC 5.1 запускает неопределенное поведение, если вы вводите целые числа, превышающие INT_MAX .
- аргумент может иметь только цифры, или он изящно выходит из строя. В частности, это исключает отрицательные целые числа, такие как -O-1
Сосредоточьтесь на подпрограммах
Прежде всего помните, что GCC является только интерфейсом для cpp , as , cc1 , collect2 . Быстрый ./XXX --help говорит, что только collect2 и cc1 принимают -O , поэтому давайте сосредоточимся на них.
А также:
gcc -v -O100 main.c |& grep 100дает:
COLLECT_GCC_OPTIONS='-O100' '-v' '-mtune=generic' '-march=x86-64' /usr/local/libexec/gcc/x86_64-unknown-linux-gnu/5.1.0/cc1 [[noise]] hello_world.c -O100 -o /tmp/ccetECB5.поэтому -O был отправлен как для cc1 и для collect2 .
O в common.opt
common.opt - это формат описания параметров common.opt описанный во внутренней документации и переведенный на C с помощью opth-gen.awk и optc-gen.awk .
Он содержит следующие интересные строки:
O Common JoinedOrMissing Optimization -O<number> Set optimization level to <number> Os Common Optimization Optimize for space rather than speed Ofast Common Optimization Optimize for speed disregarding exact standards compliance Og Common Optimization Optimize for debugging experience rather than speed or sizeкоторый задает все параметры O Обратите внимание, что -O<n> находится в отдельном семействе от других Os , Ofast и Og .
Когда мы создаем, это генерирует файл options.h который содержит:
OPT_O = 139, /* -O */ OPT_Ofast = 140, /* -Ofast */ OPT_Og = 141, /* -Og */ OPT_Os = 142, /* -Os */В качестве бонуса, пока мы используем grepping для \bO\n внутри common.opt мы замечаем строки:
-optimize Common Alias(O)который учит нас, что --optimize (двойной тире, потому что он начинается с -optimize в .opt файле) является недокументированным псевдонимом для -O который может использоваться как --optimize=3 !
Где используется OPT_O
Теперь мы grep:
git grep -E '\bOPT_O\b'который указывает нам на два файла:
Давайте сначала opts.c
opts.c: default_options_optimization
Все opts.c происходят внутри: default_options_optimization .
Мы возвращаем grep, чтобы узнать, кто вызывает эту функцию, и мы видим, что единственный путь к коду:
- main.c:main
- toplev.c:toplev::main
code-examples.net
3.10. Опции, которые контролируют оптимизацию | GCC 7 Documentation
Эти параметры управляют различными видами оптимизации.
Без какой-либо опции оптимизации цель компилятора заключается в уменьшении стоимости компиляции и обеспечении отладки ожидаемых результатов. Заявления независимы: если вы остановите программу с точкой останова между операторами, вы можете затем присвоить новое значение любой переменной или изменить счетчик программ на любой другой оператор в функции и получить точно результаты, ожидаемые от исходного кода.
Включение флагов оптимизации делает попытку компилятора улучшить производительность и / или размер кода за счет времени компиляции и, возможно, возможности отладки программы.
Компилятор выполняет оптимизацию на основе знаний, которые он имеет в программе. Одновременная компиляция нескольких файлов в один выходной файл позволяет компилятору использовать информацию, полученную из всех файлов при компиляции каждого из них.
Не все оптимизации контролируются непосредственно флагом. В этом разделе перечислены только оптимизации, имеющие флаг.
Большинство оптимизаций включаются только в том случае, если в командной строке задан уровень -O . В противном случае они отключены, даже если указаны отдельные флаги оптимизации.
В зависимости от цели и настройки GCC на каждом уровне -O может быть включен несколько иной набор оптимизаций, чем перечисленные здесь. Вы можете вызвать GCC с помощью -Q --help = optimizers, чтобы узнать точный набор оптимизаций, которые включены на каждом уровне. См. Общие параметры , например.
-O -O1Оптимизация. Оптимизация компиляции занимает несколько больше времени, а для большой функции - намного больше памяти.
С -O компилятор пытается уменьшить размер кода и время выполнения, не выполняя никаких оптимизаций, требующих большого времени компиляции.
-O включает следующие флаги оптимизации:
-fauto-inc-dec -fbranch-count-reg -fcombine-stack-adjustments -fcompare-elim -fcprop-registers -fdce -fdefer-pop -fdelayed-branch -fdse -fforward-propagate -fguess-branch-probability -fif-conversion2 -fif-conversion -finline-functions-called-once -fipa-pure-const -fipa-profile -fipa-reference -fmerge-constants -fmove-loop-invariants -freorder-blocks -fshrink-wrap -fshrink-wrap-separate -fsplit-wide-types -fssa-backprop -fssa-phiopt -ftree-bit-ccp -ftree-ccp -ftree-ch -ftree-coalesce-vars -ftree-copy-prop -ftree-dce -ftree-dominator-opts -ftree-dse -ftree-forwprop -ftree-fre -ftree-phiprop -ftree-sink -ftree-slsr -ftree-sra -ftree-pta -ftree-ter -funit-at-a-time-O также включает -fomit-frame-pointer на машинах, где это не мешает отладке.
-O2Оптимизируйте еще больше. GCC выполняет почти все поддерживаемые оптимизации, которые не связаны с компрометацией космической скорости. По сравнению с -O , этот параметр увеличивает как время компиляции, так и производительность сгенерированного кода.
-O2 включает все флаги оптимизации, заданные -O . Он также включает следующие флаги оптимизации:
-fthread-jumps -falign-functions -falign-jumps -falign-loops -falign-labels -fcaller-saves -fcrossjumping -fcse-follow-jumps -fcse-skip-blocks -fdelete-null-pointer-checks -fdevirtualize -fdevirtualize-speculatively -fexpensive-optimizations -fgcse -fgcse-lm -fhoist-adjacent-loads -finline-small-functions -findirect-inlining -fipa-cp -fipa-bit-cp -fipa-vrp -fipa-sra -fipa-icf -fisolate-erroneous-paths-dereference -flra-remat -foptimize-sibling-calls -foptimize-strlen -fpartial-inlining -fpeephole2 -freorder-blocks-algorithm=stc -freorder-blocks-and-partition -freorder-functions -frerun-cse-after-loop -fsched-interblock -fsched-spec -fschedule-insns -fschedule-insns2 -fstore-merging -fstrict-aliasing -fstrict-overflow -ftree-builtin-call-dce -ftree-switch-conversion -ftree-tail-merge -fcode-hoisting -ftree-pre -ftree-vrp -fipa-raОбратите внимание на предупреждение под -fgcse о вызове -O2 для программ, которые используют вычисленные точки доступа.
-O3Оптимизируйте еще больше. -O3 включает все оптимизации, заданные -O2, а также включает -finline-functions , -funswitch-loops , -fpredictive-commoning , -fgcse-after-reload , -ftree-loop- vectorize , -ftree-loop-distribute -патроны , -fsplit-paths -ftree-slp-vectorize , -fvect-cost-model , -free-partial-pre , -fpeel-loops и -fipa-cp-clone .
-O0Сократите время компиляции и сделайте отладку ожидаемыми результатами. Это значение по умолчанию.
-OsОптимизируйте размер. -O разрешает все оптимизации -O2, которые обычно не увеличивают размер кода. Он также выполняет дальнейшую оптимизацию, предназначенную для уменьшения размера кода.
-O отключает следующие флаги оптимизации:
-falign-functions -falign-jumps -falign-loops -falign-labels -freorder-blocks -freorder-blocks-algorithm=stc -freorder-blocks-and-partition -fprefetch-loop-arrays -OfastНе соблюдайте строгое соблюдение стандартов. -Ofast позволяет оптимизировать все -O3 . Он также позволяет оптимизировать, которые недействительны для всех стандартных программ. Он включает -fast-math и Fortran-specific -fno-protect-parens и -fstack-массивы .
-OgОптимизируйте опыт отладки. -Og позволяет оптимизировать, которые не мешают отладке. Это должен быть оптимальный уровень выбора для стандартного цикла редактирования-компиляции-отладки, предлагающий разумный уровень оптимизации при сохранении быстрой компиляции и хорошей отладочной работе.
Если вы используете несколько опций -O , с номерами уровней или без них, последний такой вариант является эффективным.
Опции флага формы -f указывают не зависящие от машины флаги. Большинство флагов имеют как положительные, так и отрицательные формы; отрицательная форма -ffoo есть -fno-foo . В приведенной ниже таблице указана только одна из форм - та, которую вы обычно используете. Вы можете определить другую форму, удалив «нет» или добавив ее.
Следующие параметры управляют определенными оптимизациями. Они либо активируются опциями -O , либо связаны с теми, которые есть. Вы можете использовать следующие флаги в редких случаях, когда требуется «тонкая настройка» оптимизаций.
-fno-defer-popВсегда возвращайте аргументы для каждого вызова функции, как только эта функция возвращается. Для машин, которые должны вызывать аргументы после вызова функции, компилятор обычно позволяет аргументам накапливаться в стеке для нескольких вызовов функций и выводит их все сразу.
Отключено на уровнях -O , -O2 , -O3 , -Os .
-fforward-propagateВыполните проход прямого распространения в RTL. Проход пытается объединить две инструкции и проверяет, можно ли упростить результат. Если активна циклическая развертка, выполняются два прохода, а второй - после разворота цикла.
Эта опция включена по умолчанию на уровнях оптимизации -O , -O2 , -O3 , -Os .
-ffp-contract= style-ffp-contract = off отключает сокращение выражения с плавающей запятой. -ffp-contract = fast
code-examples.net
optimization - Отключить все опции оптимизации в GCC
Уровень оптимизации по умолчанию для компиляции C-программ с использованием GCC -O0. который отключает все оптимизации в соответствии с документацией GCC. например:
gcc -O0 test.cОднако, чтобы проверить, действительно ли -O0 отключить все оптимизации. Я выполнил эту команду:
gcc -Q -O0 --help=optimizersИ здесь я был немного удивлен. У меня включено 50 опций. Затем я проверил аргументы по умолчанию, переданные в gcc, используя это:
gcc -vЯ получил это:
Using built-in specs. COLLECT_GCC=gcc COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/4.8/lto-wrapper Target: x86_64-linux-gnu Configured with: ../src/configure -v --with-pkgversion='Ubuntu 4.8.4- 2ubuntu1~14.04' --with-bugurl=file:///usr/share/doc/gcc-4.8/README.Bugs -- enable-languages=c,c++,java,go,d,fortran,objc,obj-c++ --prefix=/usr -- program-suffix=-4.8 --enable-shared --enable-linker-build-id -- libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --with- gxx-include-dir=/usr/include/c++/4.8 --libdir=/usr/lib --enable-nls --with- sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx- time=yes --enable-gnu-unique-object --disable-libmudflap --enable-plugin -- with-system-zlib --disable-browser-plugin --enable-java-awt=gtk --enable-gtk- cairo --with-java-home=/usr/lib/jvm/java-1.5.0-gcj-4.8-amd64/jre --enable- java-home --with-jvm-root-dir=/usr/lib/jvm/java-1.5.0-gcj-4.8-amd64 --with- jvm-jar-dir=/usr/lib/jvm-exports/java-1.5.0-gcj-4.8-amd64 --with-arch- directory=amd64 --with-ecj-jar=/usr/share/java/eclipse-ecj.jar --enable-objc- gc --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 -- with-multilib-list=m32,m64,mx32 --with-tune=generic --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu Thread model: posix gcc version 4.8.4 (Ubuntu 4.8.4-2ubuntu1~14.04)Итак, я пришел к выводу, что флаг -O0, который я предоставил программе, не был переоценен чем-то другим.
Фактически я пытаюсь реализовать с нуля инструмент, который генерирует случайные последовательности опций оптимизации и сравнивает сгенерированные последовательности с уровнями O0-3 по умолчанию. Также как "acovea". Таким образом, я хотел бы сравнить мои сгенерированные последовательности с уровнем нулевой оптимизации (который должен быть O0)
Можете ли вы объяснить мне, почему 50 опций включены по умолчанию в -O0?
Одна идея, которую я имею в виду, - это скомпилировать с O0 + отключить оптимизацию по умолчанию в O0, используя -fno-OPTIMIZATION_NAME 50 раз. Как вы думаете?
qaru.site
Оптимальные опции для x86 GCC / Блог компании Intel / Хабр
Распространено мнение, что GCC отстает по производительности от других компиляторов. В этой статье мы постараемся разобраться, какие базовые оптимизации GCC компилятора стоит применить для достижения приемлемой производительности.Какие опции в GCC по умолчанию?
(1) По умолчанию в GCC используется уровень оптимизаций “-O0”. Он явно не оптимален с точки зрения производительности и не рекомендуется для компиляции конечного продукта. GCC не распознает архитектуру, на которой запускается компиляция, пока не передана опция ”-march=native”. По умолчанию GCC использует опцию, заданную при его конфигурации. Чтобы узнать конфигурацию GCC, достаточно запустить:| gcc -v «Configured with: [PATH]/configure … --with-arch=corei7 --with-cpu=corei7…» |
| echo «int main {return 0;}» | gcc [OPTIONS] -x c -v -Q – |
| gcc -O2 test.c -march=native |
| gcc -v «Configured with: [PATH]/configure … --with-mfpmath=sse…» |
| gcc -O2 -m32 test.c |
| gcc -O2 -m32 test.c -mfpmath=sse |
32 битный режим или 64 битный?
32 битный режим обычно используется для сокращения объема используемой памяти и как следствие ускорения работы с ней (больше данных помещается в кеш). В 64 битном режиме (по сравнению с 32 битным) количество доступных регистров общего пользования увеличивается с 6 до 14, XMM регистров с 8 до 16. Также все 64 битные архитектуры поддерживают SSE2 расширение, поэтому в 64 битном режиме не надо добавлять опцию “-mfpmath=sse”.Рекомендуется использовать 64 битный режим для счетных задач, а 32 битный режим для мобильных приложений.Как получить максимальную производительность?
Определенного набора опций для получения максимальной проивзодительности не существует, однако в GCC есть много опций, которые стоит попробовать использовать. Ниже представлена таблица с рекомендуемыми опциями и прогнозами прироста для процессоров Intel Atom и 2nd Generation Intel Core i7 относительно опции “-O2”. Прогнозы основаны на среднем геометрическом результатов определенного набора задач, скомпилированных GCC версии 4.7. Также предполагается, что конфигурация компилятора была проведена для x86-64 generic. Прогноз увеличения производительности на мобильных приложениях относительно “-O2” (только в 32 битном режиме, так как он основной для мобильного сегмента):| -m32 -mfpmath=sse | ~5% |
| -m32 -mfpmath=sse -Ofast -flto | ~36% |
| -m32 -mfpmath=sse -Ofast -flto -march=native | ~40% |
| -m32 -mfpmath=sse -Ofast -flto -march=native -funroll-loops | ~43% |
| -m32 -mfpmath=sse | ~4% |
| -m32 -mfpmath=sse -Ofast -flto | ~21% |
| -m32 -mfpmath=sse -Ofast -flto -march=native | ~25% |
| -m32 -mfpmath=sse -Ofast -flto -march=native -funroll-loops | ~24% |
| -m64 -Ofast -flto | ~17% |
| -m64 -Ofast -flto -march=native | ~21% |
| -m64 -Ofast -flto -march=native -funroll-loops | ~22% |
- "-Ofast" аналогично "-O3 -ffast-math" включает более высокий уровень оптимизаций и более агрессивные оптимизации для арифметических вычислений (например, вещественную реассоциацию)
- "-flto" межмодульные оптимизации
- "-m32" 32 битный режим
- "-mfpmath=sse" включает использование XMM регистров в вещественной арифметике (вместо вещественного стека в x87 режиме)
- "-funroll-loops" включает развертывание циклов
habr.com
3. Использование CFLAGS для оптимизации собранных программ
3.1. Для чего все это надо?
Стремление выжать из своего компьютера максимум производительности есть в каждом, ну почти в каждом ;-). Особенно его много в русских линуксоидах Gentoo'шниках ;) Мы попытаемся путем изменения флагов оптимизации ускорить работу приложений нашей системы.
ВНИМАНИЕ: Некоторые флаги могут сделать приложения нестабильными, так что нужно быть аккуратным.
3.2. Оптимизация
Переменная окружения CFLAGS
Для указания параметров оптимизации компилятору GCC, используется переменная окружения CFLAGS. Эта переменная определена в /etc/make.conf, её можно изменить двумя способами:
Отредактировать эту переменную в /etc/make.conf;
Экспортировать ее в окружение (emerge будет использовать эти параметры, но каждый раз выполнять export неудобно):
export CFLAGS='параметры оптимизации'
Уровни оптимизации
Для gcc версий 3.x и выше существует только 5 уровней оптимизации: -O0 (без оптимизации), -O1, -O2 и -O3 (O3 — самый высокий уровень), а так же -Os.
Примечание: Если вы используете несколько -O опций, то только последняя объявленная будет оказывать влияние на процесс компиляции.
-O0
Отключает оптимизацию. Только переменные, объявленные register, сохраняются в регистрах.
-O(-O1)
Включает оптимизацию. Пытается уменьшить размер кода и ускорить работу программы. Соответственно увеличивается время компиляции. При указании -O активируются следующие флаги: -fthread-jumps, -fdefer-pop.
На машинах, у которых есть слоты задержки, включается опция -fdelayed-branch.
На тех машинах, которые способны поддерживать отладку даже без указателя на стек функции, также включается опция -fomit-frame-pointer.
На других машинах могут быть включены и другие флаги.
-O2
Оптимизирует еще больше. GCC выполняет почти все поддерживаемые оптимизации, которые не включают уменьшение времени исполнения за счет увеличения длины кода. Компилятор не выполняет раскрутку циклов или подстановку функций, когда вы указываете -O2. По сравнения с -O, эта опция увеличивает как время компиляции, так и эффективность сгенерированного кода.
-O2 включает все флаги оптимизации наследованные от -O. Также включает следущие флаги оптимизации:
-fforce-mem -foptimize-sibling-calls
-fstrength-reduce -fcse-follow-jumps -fcse-skip-blocks
-frerun-cse-after-loop -frerun-loop-opt -fgcse -fgcse-lm
-fgcse-sm -fgcse-las -fdelete-null-pointer-checks -fexpensive-optimizations
-fregmove -fschedule-insns -fschedule-insns2 -fsched-interblock
-fsched-spec -fcaller-saves -fpeephole2 -freorder-blocks
-fre-order-functions -fstrict-aliasing -funit-at-a-time -falign-functions
-falign-jumps -falign-loops -falign-labels -fcrossjumping
-O3
Оптимизирует еще немного. Включает все оптимизации -O2 и также включает флаг -finline-functions и -fweb.
-Os
Включает оптимизацию по размеру. -Os флаг активирует все флаги оптимизации из -O2, в основном те, которые не увиличивают размер выходного файла. В дальнейшем выполняются оптимизации по уменьшению размера кода.
-Os выключает следущие флаги оптимизации: -falign-functions, -falign-jumps, -falign-loop, -falign-labels, -freorder-blocks, -fprefetch-loop-arrays.
Примечание: Более полное описание флагов -Ox, -fflag смотрите в man gcc
Оптимизация под тип процессора
Не все процессоры одинаковы,поэтому давайте укажем компилятору на наш тип процессора. Для этого есть опции -mtune и -march.Отличие в том,что с опцией -mtune компилятор сделает код,который будет совместим с более младшими моделями процессора,в то время как с -march этого не происходит.Вот список возможных значений для данных опций:
i386
i486
i586
i686
pentium
pentium-mmx
pentiumpro
pentium2
pentium3
pentium4
pentium-m
prescott
nocona
k6
k8
k6-2 (не рекомендуется ставить, из-за багов в компиляторе, заменять на i686)
k6-3
athlon
athlon-tbird
athlon-4
athlon-xp
athlon-mp
athlon64
opteron
winchip-c6
winchip2
c3.
Внимание! pentium-m — это аналог для pentium3. Если процессор в вашем ноутбуке Mobile Intel Pentium 4 — M, то нужно ставить опцию pentium4 или pentium4m (они равнозначны)
Примечание(JohnBat26) (обновлено в 1.5): Если Вы используете компилятор версии 4.2.0 и выше, то вместо указания специфичного типа процессора, можно указывать одно из двух (в параметрах: -march и -mtune):
-
generic: если Вы хотите, чтобы Ваш скомпилированный код запускался на всех процессорах, архитектуры x86;
-
native: если Вы хотите оптимизировать код только для Вашего процессора. В этом случае компилятор будет брать сведения о процессоре путем вызова cpuid ! .
Выбор оптимальных параметров
Для этого есть очень интересная утилита. emerge acovea
Правда существующие профили рассчитаны только на pentium 3/4, и на gcc 3.3/3.4, Но в принципе добавить свою конфигурацию тоже не составляет труда. Также рекомендуется добавить в конфигурацию опции -ftracer и -mfpmath=sse. В некоторых случаях они дают значительный прирост производительности сгенерированного кода.
После чего вызываем утилиту runacovea -config gcc33_pentium3.acovea -bench evobench.c Ждем несколько часов и получаем оптимальные флаги компиляции.
Возможны различные тесты, которые хранятся в каталоге /usr/share/acovea/benchmarks, И различные конфигурации платформы /usr/share/acovea/config, к которым при желании можно добавить свою.
gentoo.theserverside.ru
Об особенностях оптимизации кода в GCC
Сегодня товарищ redp озадачил меня интересным вопросом. Дескать, если современные компиляторы такие умные, то почему GCC не в состоянии преобразовать даже элементарный макрос инверсии байт двойного слова в ассемблерную инструкцию bswap?
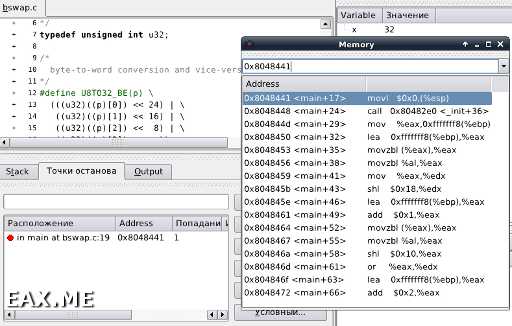
Речь идет о коде вроде этого:
#include <stdio.h>#include <time.h>typedef unsigned int u32;
#define U8TO32_BE(p) \ (((u32)((p)[0]) << 24) | \ ((u32)((p)[1]) << 16) | \ ((u32)((p)[2]) << 8) | \ ((u32)((p)[3]) ))
int main() { u32 x = (u32)time(0); printf("U8TO32_BE(%08x) = %08x\n", x, U8TO32_BE((unsigned char*)&x)); return 0;}
Действительно, как Visual Studio 2008, так и GCC 4.6 не в состоянии распознать в макросе U8TO32_BE простую команду bswap. Конечно, можно воспользоваться ассемблерными вставками или нестандартными расширениями языка типа _byteswap_ulong (не знаю, так ли оно называется в GCC), но эти методы плохи тем, что делают код зависимым от конкретного компилятора или архитектуры процессора.
Я переписал программу следующим образом:
#include <stdio.h>#include <time.h>typedef unsigned int u32;
#define BSWAP32(x) ( \ (((x) & 0xFF) << 24) | \ (((x) & 0xFF00) << 8) | \ (((x) & 0xFF0000) >> 8) | \ (((x) & 0xFF000000) >> 24))
int main() { u32 x = (u32)time(0); printf("BSWAP32(%08x) = %08x\n", x, BSWAP32(x)); return 0;}
И посмотрел ассемблерный код, генерируемый GCC:
/usr/local/bin/gcc46 -O2 -march=i686 -S -c bswap.c
Необходимо указать тип процессора, потому что в i386 команды bswap не было. По умолчанию GCC ничего и никак не оптимизирует, потому флаг оптимизации также необходим. В результате получаем файл bswap.s следующего содержания:
.file "bswap.c" .section .rodata.str1.1,"aMS",@progbits,1.LC0: .string "BSWAP32(%08x) = %08x\n" .section .text.startup,"ax",@progbits .p2align 4,,15 .globl main .type main, @functionmain:.LFB1: .cfi_startproc pushl %ebp .cfi_def_cfa_offset 8 .cfi_offset 5, -8 movl %esp, %ebp .cfi_def_cfa_register 5 andl $-16, %esp subl $16, %esp movl $0, (%esp) call time movl $.LC0, (%esp) movl %eax, %edx bswap %edx movl %eax, 4(%esp) movl %edx, 8(%esp) call printf xorl %eax, %eax leave .cfi_restore 5 .cfi_def_cfa 4, 4 ret .cfi_endproc.LFE1: .size main, .-main .ident "GCC: 4.6.2 20110729 (prerelease)"
Как видите, bswap появился. Что интересно, GCC 4.2 (который вышел в 2008-м году) так не умеет.
Мораль в том, что современные компиляторы хоть и умны, но не настолько, чтобы распознать в серии получения указателей на переменные и обращения к элементам массива простую перестановку байт (еще раз смотрим, что и как делает U8TO32_BE). Чем проще код вы пишите, тем легче компилятору будет его оптимизировать. Например, когда вы пишете цикл, обходящий массив, не нужно извращаться с указателями. Используйте обычные индексы.
PS. А еще, разбираясь с GCC и тем, как он оптимизирует код, я открыл для себя отладчик kgdb (оболочка для gdb). Вполне годная штука, как оказалась. Это к вопросу о недостатке отладочных средств под UNIX.
Дополнение: Вспомнилось мудрая фраза, что преждевременная оптимизация — корень всех зол. Утверждается, что оптимизация с bswap может ускорить алгоритм BLAKE аж на целых 5%. Но простите, а вы уверены, что операция чтения с диска не сводит на нет эту оптимизацию при хэшировании файлов? Не лучше ли сначала получить (1) рабочее, (2) легкое в сопровождении и (3) переносимое приложение, а уже потом заниматься оптимизацией настоящих ее узких мест, если это требуется (вспоминаем правило 80/20)?
Метки: C/C++, Оптимизация, Отладка.
eax.me