Каковы наилучшие методы оптимизации производительности SQL Server? Sql оптимизация
Советы по оптимизации SQL запросов
Другие статьи по оптимизации SQL
1. Ни каких подзапросов, только JOINКак я уже писал ранее, если выборка 1 к 1 или надо что-то просуммировать, то ни каких подзапросов, только join.Стоит заметить, что в большинстве случаев оптимизатор сможет развернуть подзапрос в join, но это может случиться не всегда.
2. Выбор IN или EXISTS ?На самом деле это сложный выбор и правильное решение можно получить только опытным путем.Я дам только несколько советов:* Если в основной выборке много строк, а в подзапросе мало, то ваш выбор IN. Т.к. в этом случае запрос в in выполнится один раз и сразу ограничит большую основную таблицу.* Если в подзапросе сложный запрос, а в основной выборке относительно мало строк, то ваш выбор EXISTS. В этом случае сложный запрос выполнится не так часто.* Если и там и там сложно, то это повод изменить логику на джойны.
3. Не забывайте про индексыСовет для совсем новичков: вешайте индексы на столбцы по которым джойните таблицы.
4. По возможности не используйте OR.Проведите тесты, возможно UNION выглядит не так элегантно, за то запрос может выполнится значительно быстрей. Причина в том, что в случае OR индексы почти не используются в join.
5. По возможности не используйте WITH в oracle. Значительно облегчает жизнь, если запрос в with необходимо использовать несколько раз ( с хинтом materialize ) в основной выборке или если число строк в подзапросе не значительно.Во всех других случаях необходимо использовать прямые подзапросы в from или взаранее подготовленную таблицу с нужными индексами и данными из WITH.Причина плохой работы WITH в том, что при его джойне не используются ни какие индексы и если данных в нем много, то все встанет. Вторая причина в том, что оптимизатору сложно определить сколько данных нам вернет with и оптимизатор не может построить правильный план запроса.В большинстве случаев WITH без +materialize все равно будет развернут в основной запрос.
6. Не делайте километровых запросовЧасто в web обратная проблема - это много мелких запросов в цикле и их советуют объединить в один большой. Но тут есть свои ограничения, если у вас запрос множество раз обернутый в from, то внутреннюю(ие) части надо вынести в отдельную выборку, заполнить временную таблицу, навесить индексы, а потом использовать ее в основной выборке. Скорость работы будет значительно выше (в первую очередь из-за сложности построения оптимального плана на большом числе сочетаний таблиц)
7. Используйте KEEP взамен корреляционных подзапросов.В ORACLE есть очень полезные аналитические функции, которые упростят ваши запросы. Один из них - это KEEP.KEEP позволит сделать вам сортировку или группировку основной выборки без дополнительно запроса.Пример: отобрать контрагента для номенклатуры, который раньше остальных был к ней подвязан. У одной номенклатуры может быть несколько поставщиков.
SELECT n.ID, MIN(c.ID) KEEP (DENSE_RANK FIRST ORDER BY c.date ASC) as cnt_id FROM nmcl n, cnt c WHERE n.cnt_id = c.id GROUP BY n.ID При обычном бы подходе пришлось бы делать корреляционный подзапрос для каждой номенклатуры с выбором минимальной даты. Но не злоупотребляйте большим числом аналитических функций, особенно если они имеют разные сортировки. Каждая разная сортировка - это новое сканирование окна.9. Direct Path ReadУстановка этой настройки (настройкой или параллельным запросом) - чтение данных напрямую в PGA, минуя буферный кэш. Что укоряет последующие этапы запроса, т.к. не используется UNDO и защелки совместного доступа.
10. Direct IOИспользование прямой записи/чтения с диска без использования буфера файловой системы (файловая система конкретно для СУБД). * В случае чтения преимущество в использовании буферного кэша БД, замен кэша ФС (кэш бд лучше заточен на работу с sql)* В случае записи, прямая запись гарантирует, что данные не потеряются в буфере ФС в случае выключения электричества (для redolog всегда использует fsync, в не зависимости от типа ФС)
11. Оптимизация параллельных запросов12. Оценка стоимости запроса и построение правильного плана13. Оптимизация работы секционированных таблиц14. Индексный поиск15. Оптимизация запросов вставки16. Ускорение pl/sql циклов17. И другое...
blog.skahin.ru
Как оптимизировать SQL запросы с целью уменьшения нагрузки на сервер? 15 советов
Порыскав на досуге по тырнету, удивился, что специальных статей-руководств по оптимизации SQL-запросов нет. Перелистав различную информацию и книги, я постараюсь дать некоторое руководство к действию, которое поможет научиться писать правильные запросы. 
OPTIMIZE TABLE `table1`, `table2`…
Не стоит забывать, что во время выполнения оптимизации, доступ к таблице блокируется.
Перестройка данных в таблице. После частых изменений в таблице, данная команда может повысить производительность работы с данными. Она перестраивает их в таблице и сортирует по определённому полю.
ALTER TABLE `table1` ORDER BY `id`
Тип данных. Лучше не индексировать поля, имеющие строковый тип, особенно поля типа TEXT. Для таблиц, данные которых часто изменяются, желательно избегать использования полей типа VARCHAR и BLOB, так как данный тип создаёт динамическую длину строки, тем самым увеличивая время доступа к данным. При этом советуют использовать поле VARCHAR вместо TEXT, так как с ним работа происходит быстрее.
NOT NULL и поле по умолчанию. Лучше всего помечать поля как NOT NULL, так как они немного экономят место и исключают лишние проверки. При этом стоит задавать значение полей по умолчанию и новые данные вставлять только в том случае, если они от него отличаются. Это ускорит добавление данных и снизит время на анализ таблиц. И стоит помнить, что типы полей BLOB и TEXT не могут содержать значения по умолчанию.
Постоянное соединение с сервером БД. Позволяет избежать потерь времени на повторное соединение. Однако стоит помнить, что у сервера может быть ограничение на количество соединений, и в том случае, если посещаемость сайта очень высокая, то постоянное соединение может сыграть злую шутку.
Разделение данных. Длинные не ключевые поля советуют выделить в отдельную таблицу в том случае, если по исходной таблице происходит постоянная выборка данных и которая часто изменяется. Данный метод позволит сократить размер изменяемой части таблицы, что приведёт к сокращению поиска информации. Особенно это актуально в тех случаях, когда часть информации в таблице предназначена только для чтения, а другая часть - не только для чтения, но и для модификации (не забываем, что при записи информации блокируется вся таблица). Яркий пример - счётчик посещений.Есть таблица (имя first) с полями id, content, shows. Первое ключевое с auto_increment, второе - текстовое, а третье числовое - считает количество показов. Каждый раз загружая страницу, к последнему полю прибавляется +1. Отделим последнее поле во вторую таблицу. Итак, первая таблица (first) будет с полями id, content, а вторая (second) с полями shows и first_id. Первое поле понятно, второе думаю тоже - отсыл к ключевому полю id из первой таблицы. Теперь постоянные обновления будут происходить во второй таблице. При этом изменять количество посещений лучше не программно, а через запрос:
UPDATE second SET shows=shows+1 WHERE first_id=нужный_ид
А выборка будет происходить усложнённым запросом, но одним, двух не нужно:
SELECT first.id, first.content, second.first_id, second.shows FROM second INNER JOIN first ON (first.id = second.first_id)
Стоит помнить, что всё это не актуально для сайтов с малой посещаемостью и малым количеством информации.
Имена полей, по которым происходит связывание, к примеру, двух таблиц, желательно, чтобы имели одинаковое название. Тогда одновременное получение информации из разных таблиц через один запрос будет происходить быстрее. Например, из предыдущего пункта желательно, чтобы во второй таблице поле имело имя не first_id, а просто id, аналогично первой таблице. Однако при одинаковом имени становится внешне не очень наглядно что, куда и как. Поэтому совет на любителя.
Требовать меньше данных. При возможности избегать запросов типа:
SELECT * FROM `table1`
Запрос не эффективен, так как скорее всего возвращает больше данных, чем необходимо для работы. Вариантом лучше будет конструкция:
SELECT id, name FROM table1 ORDER BY id LIMIT 25
Тут же сделаю добавление о желательности использования LIMIT. Данная команда ограничивает количество строк, возвращаемых запросом. То есть запрос становится "легче" и производительнее. Если стоит LIMIT 10, то после получения десяти строк запрос прерывается. Если в запросе применяется сортировка ORDER BY, то она происходит не по всей таблице, а только по выборке. Если использовать LIMIT совместно с DISTINCT, то запрос прервётся после того, как будет найдено указанное количество уникальных строк.Если использовать LIMIT 0, то возвращено будет пустое значение (иногда нужно для определения типа поля или просто проверки работы запроса).
Ограничить использование DISTINCT. Эта команда исключает повторяющиеся строки в результате. Команда требует повышенного времени обработки. Лучше всего комбинировать с LIMIT.Есть маленькая хитрость. Если необходимо просмотреть две таблицы на тему соответствия, то приведённая команда остановится сразу же, как только будет найдено первое соответствие.
SELECT DISTINCT table1.content FROM table1, table2 WHERE table1.content = table2.content
Ограничить использование SELECT для постоянно изменяющихся таблиц.
Команда LOAD DATA INFILE позволяет быстро загружать большой объём данных из текстового файла.
Хранение изображений в БД нежелательно. Лучше их хранить в папке на сервере, а в базе сохранять полный путь к ним. Дело в том, что веб-сервер лучше кэширует графические файлы, чем содержимое базы, что значит, что при последующем обращении к изображению, оно будет отображаться быстрее.
Максимально число запросов при генерации страницы, как мне думается, должно быть не более 20 (+- 5 запросов). При этом оно не должно зависеть от переменных параметров.
shublog.ru
Оптимизация производительности в СУБД Microsoft SQL server
Цель данной работы состоит в описании методов настройки сервера таким образом, чтобы добиться максимальной производительности СУБД MS SQL Server с сохранением уже имеющегося функционала.
Введение
Настройка SQL-кода с точки зрения оптимизации производительности на практике начинается уже после того, как основной функционал БД разработан, и большая часть логических ошибок устранена. Пользователей (в широком смысле этого слова) устраивает, что делает приложение. Они хотят, чтобы то же самое делалось быстрее.
Как правило, молодые специалисты достаточно хорошо знают стандарты языка SQL и теорию реляционных баз данных. Они умеют проектировать хорошо нормализованные базы данных и строить достаточно сложные многотабличные запросы, возвращающие правильные результаты. К сожалению, на практике эти запросы работают непозволительно долго для системы on-line на больших таблицах (десятки и сотни тысяч строк) и/или в условиях работы большого числа (десятков и сотен) пользователей, выполняющих однотипные операции.
Цель данной работы состоит в описании методов настройки сервера таким образом, чтобы добиться максимальной производительности СУБД MS SQL Server с сохранением уже имеющегося функционала.
«Самый важный момент, о котором необходимо помнить при настройке производительности, состоит в том, что вам никогда не удастся познать всю подноготную данного вопроса. Если вы являетесь среднестатистическим разработчиком SQL Server, тогда хорошо, если вам известно хотя бы 20% всей информации. К счастью, к этой теме, несомненно, применим принцип “20/80” (знание 20% теории позволяет решить 80% практических вопросов)» [2].
Данная работа может быть интересна преподавателям курсов изучения многопользовательских SQL-ориентированных СУБД, а также администраторам и разработчикам баз данных (особенно на этапе сопровождения продукта).
Задача оптимизации производительности в MS SQL Server
Теоретически разработчик принимается за настройку производительности SQL-кода:
- При разработке функционала БД, который априорно определен как «жизненно важный» и при этом достаточно сложный (потенциально «тяжелым» для СУБД). К сожалению, после внедрения не так уж редко выясняется, что:
- «жизненно важный» код на самом деле не такой уж «жизненно важный», выполняется не так часто, как предполагалось, и пользователи вполне готовы подождать результата лишнюю секунду/минуту. Тем временем другие пользователи при выполнении совершенно других операций постоянно жалуются, что «все работает медленно или не работает вообще».
- запросы, выполняющиеся за миллисекунды на таблицах с десятками и сотнями записей, работают недопустимо долго (десятки минут), когда число записей достигают миллиона-другого...
- Нагрузочное тестирование показало недостаточную производительность с точки зрения некоторых заранее выбранных количественных показателей. Однако, принимая решения на этом этапе, следует учитывать, что:
- возможно, выбранные показатели на самом деле не являются адекватными показателями производительности системы;
- скорость выполнения многотабличного запроса зависит не столько от абсолютного размера используемых в нем таблиц, сколько от отношения их размеров, а также от конкретных данных, прогнозировать и генерировать которые на этапе тестирования порой слишком сложно, слишком долго, слишком дорого или вообще невозможно.
- Система уже внедрена и работает, с точки зрения конечного пользователя, недостаточно быстро.
На практике по-настоящему серьезные проблемы возникают именно на последней стадии, когда разработчик может получить максимум информации о том, что действительно нуждается в оптимизации, и минимум времени для того, чтобы эту настройку выполнить.
Собственно настройку SQL можно условно разделить на следующие этапы:
- Идентификация и анализ запросов, которые являются причинами недостаточно высокой производительности;
- Составление оптимального плана выполнения для запросов, определенных на предыдущем этапе;
- Внесение изменений в запрос или структуру базы данных так, чтобы получить оптимальный план выполнения.
Мониторинг производительности в MS SQL Server
Перед тем, как приступать к настройке, необходимо выяснить, что именно в такой настройке нуждается. На что тратятся ресурсы сервера? Какие хранимые процедуры нужно оптимизировать в первую очередь? Врачи говорят, что гораздо проще лечить конкретный орган, чем человека в целом. Проводя аналогию, администратору приходится иметь дело с работой сервера как единым процессом.
Этот этап, как правило, является наиболее трудоемким при решении проблем связанных с производительностью. Он практически не поддается формализации. Иногда на решение задачи диагностики уходят дни или даже недели, тогда как собственно разработка и реализация необходимых изменений в коде может занять всего несколько минут.
SQL Server предоставляет набор разнообразных средств для предупреждения, обнаружения и оценки быстродействия медленно выполняющихся запросов. Возможности этих средств варьируются от пассивных (выполняется измерение реальной производительности, позволяющее следить, что и с какой скоростью выполняется) до более активных (позволяющих создать «регулятор» запросов, который будет автоматически уничтожать запросы, работающие дольше установленного вами времени).
Мы рассмотрим некоторые из них.
Трассировка выполнения процессов
Инструмент SQL Server Profiler по праву называют «спасательным средством» администратора и специалиста по сопровождению. Невозможно оценить исключительную важность этого инструментального средства при решении проблем быстродействия и не только. Именно SQL Server Profiler позволяет составить представление, что же «на самом деле» происходит на сервере. Однако настраивать трассировку следует так, чтобы она возвращала только необходимый минимум сведений. Нужно помнить о том, что SQL Server Profiler также необходимо пространство для аудита системы, и поэтому у системы могут появиться дополнительные накладные расходы, независимо от того, откуда был запущен SQL Server Profiler. Чем больше будет объем трассировочных сведений, тем больше увеличится нагрузка на систему.
В результате работы с SQL Server Profiler может быть составлен «черный список» запросов, выполняющихся недопустимо долго. Поскольку следует учитывать, что один и тот же параметризованный запрос может запускаться с разными параметрами, гораздо проще анализировать трассировки, представляющие собой вызовы хранимых процедур (и это нужно иметь в виду при разработке архитектуры БД!). Трассировку удобно сохранить в виде таблицы, которую затем можно обработать с помощью агрегатных запросов, с целью поставить в соответствие каждой процедуре количественное значение некоторого критерия, выбранного для сравнения процедур с точки зрения даваемой ими нагрузки на сервер. Такими критериями могут быть:
- Максимальное зафиксированное время выполнения процедуры (самый «неудачный» с точки зрения производительности запуск).
- Суммарное время выполнения всех вызовов процедуры.
- Среднее время выполнения процедуры (суммарное время выполнения всех вызовов процедуры, отнесенное к числу вызовов).
Оперативный мониторинг процессов, занимающих ресурсы сервера
Нагрузка на сервер, как правило, является непостоянной в течение дня. Если с помощью SQL Server Profiler удалось обнаружить, что процедуры выполняются существенно дольше «среднестатистического» времени, или (что вероятнее) пользователи жалуются, что «два часа назад все работало нормально, а сейчас очень медленно», возникает необходимость оперативно выяснить, какие процессы занимают ресурсы сервера именно сейчас, а также какие именно ресурсы являются конфликтными.
- Процессорное время (в этом случае нагрузка сервера максимальна, остальные процедуры выполняются, но медленнее обычного, так как на их «долю» ресурсов остается недостаточно).
- Таблица/страница/строка, заблокированная в рамках транзакции (в этом случае процессы, обратившиеся конфликтным ресурсам, стоят в очереди и ожидают освобождения; загрузка сервера при этом может быть обычной или даже меньше обычного).
SQL Server имеет встроенное средство для мониторинга процессов. На рис. 1 показан монитор активности от SQL Server 2005 [5].
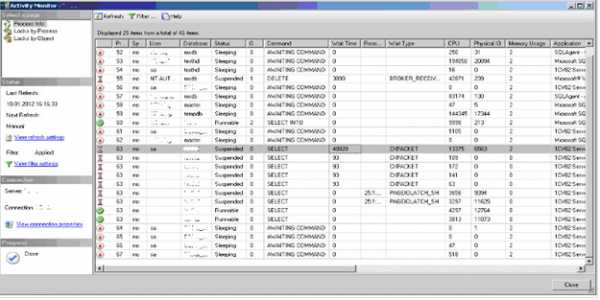 Рисунок 1. Мониторинг процессов.
Рисунок 1. Мониторинг процессов.К сожалению, администратору этот инструмент зачастую недоступен: в «час пик», если в базе работают сотни пользователей, на сбор данных с его помощью требуются десятки минут, что, разумеется, недопустимо. Тем же недостатком в различной степени страдают разнообразные системные хранимые процедуры служебной базы данных master.
В этом случае, как правило, используются самостоятельно разработанные запросы к системным таблицам master.dbo.sysprocess и master.dbo.syslocks, названия которых говорят сами за себя. Ниже (рис.2) приведен пример запроса, используемого одним из авторов при сопровождении БД именно в таких целях.
Наконец, можно узнать последнюю SQL-команду, которую отдал серверу интересующий нас процесс по его уникальному номеру spid с помощью специальной процедуры DBCC INPUTBUFFER (Spid).
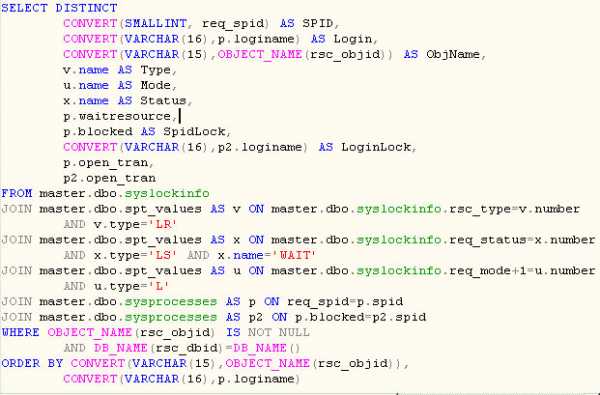 Рисунок 2. Запрос для просмотра текущих процессов, ожидающих заблокированный ресурс.
Рисунок 2. Запрос для просмотра текущих процессов, ожидающих заблокированный ресурс.Оптимизация SQL-кода
Так или иначе, разработчик получает список хранимых процедур, нуждающихся в оптимизации, и примеры их вызовов, выполняющиеся недостаточно быстро. Также он знает (или хотя бы предполагает, что знает) причину «медленной» работы:
- Ожидание ресурса, заблокированного в рамках транзакции, запущенной другим процессом;
- Неоптимальный план выполнения хранимой процедуры.
Работа по устранению каждой из этих причин имеет свою специфику.
Минимизация блокировок в системе
Задача минимизации блокировок в системе сложна в первую очередь потому, что приходится рассматривать различные сочетания вызовов процедур, выполняемых параллельно.
В реальной базе данных блокировки неизбежны. Рассмотрим базу данных торговой компании, реализующую учет товара на складе. Если несколько менеджеров параллельно запускают транзакции, которые в том числе бронируют для клиента товар А, блокировок и ожидания ресурсов не избежать: несколько процессов действительно должны последовательно изменить одну и ту же строку.
Поэтому, выясняя, подлежит ли блокировка устранению, рекомендуется ответить на следующие вопросы:
- Может ли объект блокировки (как правило, это таблица) быть конфликтным ресурсом? В каждой базе данных есть таблицы, по которым блокировки не должны возникать никогда.
- Какая часть таблицы (таблица/страница/строка) является конфликтным ресурсом? За очень редким исключением справедливо утверждение: «право на существование» имеет только блокировка по значению первичного ключа.
- Какие две параллельно выполняющиеся процедуры привели к возникновению блокировки? Имеют ли они общий конфликтный ресурс исходя из их функционального назначения?
- Если блокировка подлежит устранению – кто «виноват» в ее возникновении: процесс, неправильно заблокировавший ресурс, или процесс, неправильно к ресурсу обратившийся?
При написании запросов на изменение и удаление строк в таблице (операторы UPDATE и DELETE) в рамках транзакции следует помнить: эти операции должны выполняться только по первичному ключу! В противном случае сервер заблокирует таблицу целиком.
При написании запросов на выборку следует учитывать назначение полей таблицы, к которым выполняется обращение, а также назначение самого запроса. Возможно, что логика работы приложения допускает построение этого запроса с опциями, разрешающими чтение неподтвержденных данных (NOLOCK) или только незаблокированных строк (READPAST). Например, директор торговой сети периодически формирует и просматривает отчет о выполнении менеджерами планов по валовой прибыли за текущий месяц. При этом менеджеры активно совершают сделки, на сервере постоянно открыто несколько транзакций, проводящих или удаляющих соответствующие документы. Директору вовсе не нужно дожидаться, пока ему отдадут все ресурсы в монопольный доступ. Незавершенные транзакции можно просто не учитывать – они не могут серьезно изменить картину в целом.
Если процессы, вызывающие блокировку, обращаются к одной и той же строке, но к разным полям, то имеет смысл разбить таблицу на несколько, связанных друг с другом по схеме «один к одному».
Для исключения взаимоблокировок следует неукоснительно соблюдать один и тот же порядок опроса конфликтных ресурсов, при этом, по возможности, занимать ресурс, являющийся наиболее часто используемым, как можно ближе к концу транзакции.
Во время транзакции не должно осуществляться никакого интерактивного общения с пользователем (запрос параметров и т.п.), если есть хоть малейшая возможность этого избежать.
Транзакции должны быть настолько короткими, насколько это возможно для обеспечения целостности данных. Точно также уровень изоляции транзакции должен быть наименьшим из возможных.
Выбор индекса
Индексы являются очень мощным средством увеличения производительности сервера.
Разработчики склонны к крайностям при работе с индексами: либо не использовать их вовсе, либо создавать «на все случаи жизни».
Индексы должны создаваться для столбцов, которые будут часто использоваться в параметре WHERE либо, в меньшей степени, в параметре ORDER BY.
Однако, чем больше индексов в таблице, тем медленнее будут производиться операции вставки. С технической точки зрения каждый дополнительный индекс сказывается и на обновлении существующей информации, но в этом случае проблема не является столь глобальной, поскольку изменениям должны будут подвергнуться только те индексы, для которых модифицируемый столбец выступает в качестве части ключа.
Таким образом, если база данных организована так, что большая часть времени посвящена выполнению операторов SELECT, а изменения вносятся сравнительно редко, то чем больше индексов, тем лучше. В противном случае нужно ограничиться индексами только для наиболее часто используемых столбцов. Большую помощь в их определении может оказать мастер настройки индексов – специальный инструмент MS SQL Server, предназначенный для исследования рабочей нагрузки и поиска оптимального варианта внесения изменений в индексы.
Стратегическая денормализация
Иногда следование стандартным и, казалось бы, универсальным правилам, может навредить. На вопрос, в чем мы выигрываем, нормализуя базу данных, 90% вчерашних студентов бойко отвечают: «Обеспечивается целостность, устраняется избыточность и повышается быстродействие». При этом следующий вопрос о том, в чем же мы при этом проигрываем, приводит большинство в тупик. Далеко не все отдают себе отчет, что в хорошо нормализованной базе данных производительность повышается только при выполнении простых операций изменения данных, тогда как производительность запросов на выборку (а также в некоторых сложных случаях использования операторов DELETE, UPDATE и INSERT... SELECT) в лучшем случае не хуже, чем в слабо нормализованной базе данных. Часто добавление в таблицу всего лишь одного столбца может устранить необходимость в сложных объединениях, либо даже позволяет отказаться от объединений, включающих несколько таблиц, за счет чего время выполнения запроса уменьшается с нескольких минут до нескольких секунд.
Конечно, подобно большинству рассмотренных вопросов, данный вопрос имеет и оборотную сторону. Все имеющиеся в БД случаи денормализации существенно затрудняют жизнь разработчикам. Вначале требуется четко определить, чего именно планируется достичь, проверить, принесет ли денормализация желаемый эффект, а также оценить последствия возможного нарушения целостности данных (это особенно важно, если БД сопровождают несколько разработчиков). Если есть хоть малейшие сомнения – следует вернуться к стандартному способу работы с данными.
Правильная организация хранимых процедур
Реализация множественных решений
Примером может послужить поисковый запрос, допускающий множество параметров, но не требующий наличия всех. Вполне можно написать собственную хранимую процедуру, чтобы она просто запускала единственный запрос, независимо от того, сколько в действительности было задано параметров – достаточно универсальный подход. С точки зрения разработки – это громадная экономия времени, однако, если взглянуть на вещи с точки зрения оптимального быстродействия, такой подход убийственен. Более чем вероятно, что каждый раз при запуске вашей хранимой процедуры, сервер будет обращаться к нескольким абсолютно не нужным таблицам!
В такой ситуации можно поступить следующим образом: добавить в код несколько выражений IF . . . ELSE для проверки условий. Это уже может дать заметный эффект. Однако есть еще одна тонкость. Запуская такую процедуру с некоторым фиксированным набором параметров и исключая из недостижимых при данном вызове блоков IF . . . ELSE запросы на выборку, можно обнаружить, что время выполнения увеличивается иногда на порядок! Казалось бы, в чем причина? Ведь исключенные запросы все равно не запускались! К сожалению, SQL Server при составлении плана выполнения хранимой процедуры «не знает», что наши условия взаимоисключающие. Он исходит из худшего случая – что все операторы SELECT (а также INSERT, UPDATE и DELETE) будут выполняться последовательно. Алгоритмические конструкции (IF … ELSE, WHILE, GOTO) игнорируются. Поэтому с точки зрения быстродействия желательно, чтобы внутри блоков IF . . . ELSE помещались не запросы, а вызовы хранимых процедур, в каждой из которых содержится запрос для работы с каждым определенным набором параметров (вызов вложенной хранимой процедуры также игнорируется при составлении плана).
Данная проблема возникает во множестве написанных сценариев. Разработчики – тоже люди, и, как правило, они привыкли иметь дело с объектно-ориентированными языками и развитыми технологиями повторного использования кода. Можно представить, как они отнесутся (и относятся!) к идее написать кучу практически идентичных запросов, чтобы в зависимости от заданных параметров учесть все возможные нюансы применения. Однако этот случай, когда результат, достигаемый таким «возмутительным» образом, говорит сам за себя, и его невозможно достичь никаким другим способом. «По этому поводу я хочу сказать, что в любой работе случаются рутинные моменты, а иначе все давно уже стали бы разработчиками программного обеспечения. Иногда вам стоит, скрипнув зубами, все же проделать эту работу ради получения конечного результата» [2].
Минимальное использование курсоров и циклов
Программисты, работавшие на языках программирования высокого уровня, иногда широко используют курсоры. К сожалению, в среде SQL Server справедливо утверждение: все, что работает с использованием курсора, работает крайне медленно.
На самом деле многое, что, казалось бы, требует применения курсоров, может быть выполнено при помощи набора операций. Иногда искомое решение гораздо менее очевидно, чем цикл, но, как правило, оно вполне осуществимо. Ключевой момент здесь состоит в том, что, избавляясь от курсоров, где это только возможно, вы обеспечиваете грандиозный прирост производительности и одновременно упрощаете программный код [2].
Хорошей альтернативой курсорам с точки зрения производительности являются временные таблицы и табличные переменные. Начальный запрос создает рабочий набор данных. Затем запускается другой процесс, который и производит обработку этих данных.
На практике нужно помнить – операторы INSERT, UPDATE и DELETE – циклы сами по себе, и именно для выполнения таких и только таких циклов разрабатывался SQL Server. Один запрос на UPDATE (даже многотабличный, с вложенными JOIN), модифицирующий сразу 1000 строк выполняется в разы быстрее 1000 запросов, модифицирующих по одной строке.
Для выполнения рекурсивных запросов совсем отказаться от циклов невозможно. В этом случае рекомендуется использовать CTE (common table expression – общие табличные приложения), доступные, начиная с SQL Server 2005.
Заключение
В данной работе были рассмотрены цели и этапы настройки производительности СУБД MS SQL. Представлен обзор основных встроенных в СУБД инструментов мониторинга процессов. Собраны и систематизированы наиболее универсальные приемы оптимизации SQL-кода таким образом, чтобы можно было достичь максимальной производительности в условиях коммерческой базы данных.
novainfo.ru
optimization - Каковы наилучшие методы оптимизации производительности SQL Server?
Применить правильную индексацию в столбцах таблицы в базе данных
- Убедитесь, что в каждой таблице базы данных есть первичный ключ.
Это обеспечит, чтобы каждая таблица создавала кластерный индекс (и, следовательно, соответствующие страницы таблицы физически сортируются на диске в соответствии с полем первичного ключа). Таким образом, любая операция извлечения данных из таблицы с использованием первичного ключа или любая операция сортировки в поле первичного ключа или любой диапазон значений первичного ключа, указанных в предложении where, будут очень быстро извлекать данные из таблицы.
-
Создайте некластеризованные индексы в столбцах
Часто используется в критериях поиска.
Используется для соединения с другими таблицами.
Используется как поля внешнего ключа.
Высокая избирательность (столбец, который возвращает низкий процент (0-5%) строк из общего количества строк на определенное значение).
Используется в предложении ORDER BY.
Не используйте "SELECT *" в SQL-запросе
Необязательные столбцы могут быть извлечены, что добавит затраты на время поиска данных. Механизм базы данных не может использовать преимущество "Covered Index" и, следовательно, запрос выполняется медленно.
Пример:
SELECT Cash, Age, Amount FROM Investments;Вместо:
SELECT * FROM Investments;Попытайтесь избежать предложения HAVING в операторах Select
Предложение HAVING используется для фильтрации строк после выбора всех строк и используется как фильтр. Старайтесь не использовать предложение HAVING для любых других целей.
Пример:
SELECT Name, count (Name) FROM Investments WHERE Name!= ‘Test’ AND Name!= ‘Value’ GROUP BY Name;Вместо:
SELECT Name, count (Name) FROM Investments GROUP BY Name HAVING Name!= ‘Test’ AND Name!= ‘Value’ ;Попробуйте минимизировать количество блоков вспомогательных запросов в запросе
Иногда у нас может быть несколько подзапросов в нашем основном запросе. Мы должны попытаться свести к минимуму количество блоков вспомогательных запросов в нашем запросе.
Пример:
SELECT Amount FROM Investments WHERE (Cash, Fixed) = (SELECT MAX (Cash), MAX (Fixed) FROM Retirements) AND Goal = 1;Вместо:
SELECT Amount FROM Investments WHERE Cash = (SELECT MAX (Cash) FROM Retirements) AND Fixed = (SELECT MAX (Fixed) FROM Retirements) AND Goal = 1;Избегайте ненужных столбцов в списке SELECT и ненужных таблиц в условиях соединения
Выбор ненужных столбцов в запросе Select добавляет служебные данные к фактическому запросу, особенно если ненужные столбцы имеют типы LOB. Включение ненужных таблиц в условия соединения заставляет механизм базы данных извлекать и извлекать ненужные данные и увеличивает время выполнения запроса.
Не используйте агрегат COUNT() в подзапросе, чтобы выполнить проверку существования
Когда вы используете COUNT(), SQL Server не знает, что вы делаете проверку существования. Он подсчитывает все соответствующие значения, либо путем сканирования таблицы, либо путем сканирования самого маленького некластеризованного индекса. Когда вы используете EXISTS, SQL Server знает, что вы выполняете проверку существования. Когда он находит первое совпадающее значение, он возвращает TRUE и перестает смотреть.
Попробуйте избежать соединения между двумя типами столбцов
При объединении двух столбцов разных типов данных один из столбцов должен быть преобразован в тип другого. Столбец, тип которого ниже, тот, который преобразован. Если вы присоединяетесь к таблицам с несовместимыми типами, один из них может использовать индекс, но оптимизатор запросов не может выбрать индекс для столбца, который он преобразует.
Попробуйте не использовать COUNT (*) для получения количества записей в таблице
Чтобы получить общее количество строк в таблице, мы обычно используем следующий оператор Select:
SELECT COUNT(*) FROM [dbo].[PercentageForGoal]Этот запрос выполнит полное сканирование таблицы, чтобы получить количество строк. Следующий запрос не требует полного сканирования таблицы. (Обратите внимание, что это может не дать вам 100% отличных результатов всегда, но это удобно, только если вам не нужен идеальный счет.)
SELECT rows FROM sysindexes WHERE id = OBJECT_ID('[dbo].[PercentageForGoal]') AND indid< 2Попробуйте использовать операторы типа EXISTS, IN и JOINS соответственно в вашем запросе
- Обычно IN имеет наименьшую производительность.
- IN эффективен, только когда большинство критериев фильтра для выбора помещаются в подзапрос инструкции SQL.
- EXISTS эффективен, когда большинство критериев фильтра для выбора находится в основном запросе оператора SQL.
Попробуйте избежать динамического SQL
Если это действительно необходимо, старайтесь избегать использования динамического SQL, потому что: Динамический SQL трудно отлаживать и устранять неполадки. Если пользователь предоставляет вход для динамического SQL, тогда есть вероятность атаки SQL-инъекций.
Старайтесь избегать использования временных таблиц
Если это действительно необходимо, старайтесь избегать использования временных таблиц. Скорее используйте переменные таблицы. В 99% случаев переменные таблицы хранятся в памяти, следовательно, это намного быстрее. Временные таблицы находятся в базе данных TempDb. Таким образом, работа на временных таблицах требует взаимодействия между базами данных и, следовательно, будет медленнее.
Вместо поиска LIKE используйте полнотекстовый поиск для поиска текстовых данных
Полнотекстовые поисковые запросы всегда превосходят LIKE-запросы. Полнотекстовый поиск позволит вам реализовать сложные критерии поиска, которые не могут быть реализованы с помощью поиска LIKE, например, поиск по одному слову или фразе (и, возможно, ранжирование набора результатов), поиск по слову или фразе, близкой к другой слово или фразу, или поиск синонимов формы определенного слова. Реализация полнотекстового поиска проще реализовать, чем поиск LIKE (особенно в случае сложных требований к поиску).
Попробуйте использовать UNION для реализации операции "ИЛИ"
Не пытайтесь использовать "ИЛИ" в запросе. Вместо этого используйте "UNION", чтобы объединить результирующий набор из двух выделенных запросов. Это улучшит производительность запросов. Лучше использовать UNION ALL, если не требуется выдающийся результат. UNION ALL быстрее, чем UNION, поскольку ему не нужно сортировать результирующий набор, чтобы узнать отличительные значения.
Реализовать ленивую стратегию загрузки для больших объектов
Храните столбцы большого объекта (например, VARCHAR (MAX), изображение, текст и т.д.) в другой таблице, чем основная таблица, и поместите ссылку на большой объект в основной таблице. Извлеките все основные данные таблицы в запросе, и если требуется большой объект для загрузки, извлеките большие данные объекта из таблицы больших объектов только тогда, когда это необходимо.
Внедрить следующие рекомендации в пользовательских функциях
Не вызывать функции повторно в своих хранимых процедурах, триггерах, функциях и партиях. Например, вам может потребоваться длина строковой переменной во многих местах вашей процедуры, но не называть функцию LEN всякий раз, когда это необходимо; вместо этого вызовите функцию LEN один раз и сохраните результат в переменной для последующего использования.
Внедрить следующие рекомендации в триггерах
- Старайтесь избегать использования триггеров. Запуск триггера и выполнение инициирующего события - дорогостоящий процесс.
- Никогда не используйте триггеры, которые могут быть реализованы с использованием ограничений.
- Не используйте один и тот же триггер для различных событий запуска (Insert, Update и Delete).
- Не используйте транзакционный код внутри триггера. Триггер всегда работает внутри транзакционной области кода, запускающего триггер.
qaru.site
SQL Query Советы или оптимизации запросов
Вот несколько советов SQL, которые могут сэкономить время и неприятностей с SQL таблицы работы, отчеты команд SQL ...
В идеале, вы хотите, чтобы получить наилучшие результаты при написании запросов SQL, сводя к минимуму количество ошибок и получении максимальной производительности запросов, когда это необходимо. Вот небольшой список запросов советов, которые могут помочь вам в вашем SQL запросов работы и которые могут оптимизированного SQL для лучшей производительности.
SQL Учебник Советы:
SQL SELECT Совет 1
SQL SELECT только столбцы, которые необходимы, избегать использования SELECT *. Во-первых, для каждого столбца, что вам не нужно каждый SQL Server выполняет дополнительную работу, чтобы восстановить и вернуть их клиенту, а второй объем данных, которыми обмениваются между приростами клиентом и SQL Server ненужным. Справка: SQL SELECT Заявление стр.
SQL SELECT Совет 2
SQL SELECT только строки необходимо. Чем меньше извлекаемых строк, тем быстрее SQL-запрос будет выполняться.
SQL SELECT Совет 3
Чернослив SQL SELECT списки. Каждый столбец, который выбран потребляет ресурсы для обработки. Есть несколько областей, которые могут быть рассмотрены с целью определить, если выбора столбца действительно необходимо.
Пример:
WHERE (COL8 = ‘X’)
Если SQL SELECT содержит предикат, где столбец равен одному значению, что столбец не должны быть извлечены для каждой строки, значение всегда будет 'X'.
SQL-таблица Подсказка 4
При создании новой таблицы всегда создают уникальный кластерный индекс принадлежит ему, возможно, это числовой тип.
SQL JOIN Tip 5
использование SQL JOIN вместо подзапросов. Как программист, подзапросы то, что вы можете захотеть использовать и злоупотребления. Подзапросы, как показано ниже, может быть очень полезным:
SELECT a.id, (SELECT MAX(created) FROM posts WHERE author_id = a.id) AS latest_post FROM authors a
Хотя подзапросов полезны, они часто могут быть заменены на соединение, которое, безусловно, быстрее выполнить.
SELECT a.id, MAX(p.created) AS latest_post FROM authors a INNER JOIN posts p ON (a.id = p.author_id) GROUP BY a.id
SQL или наконечник
В следующем примере используется оператор OR, чтобы получить результат:
SELECT * FROM a, b WHERE a.p = b.q OR a.x = b.y;
Оператор UNION позволяет объединить наборов результатов 2 или более запросов на выборку. Следующий пример возвращает тот же результат, что приведенный выше запрос получает, но это будет быстрее
SELECT * FROM a, b WHERE a.p = b.qUNIONSELECT * FROM a, b WHERE a.x = b.y;
SQL кластерного индекса Подсказка
Держите ваш кластерный индекс мал. Одна вещь, которую нужно учитывать при определении того, где поместить ваш кластерный индекс, насколько велика ключ для этого индекса будет. Проблема здесь заключается в том, что ключ к кластерному индексу также используется в качестве ключа для каждого, не кластерный индекс в таблице. Так что если у вас есть большой кластерный индекс по таблице с приличным количеством строк, размер может выдуть значительно. В случае, когда нет кластерный индекс на столе, это может быть так же плохо, потому что он будет использовать указатель строки, которая 8 байт на строку.
SQL Оптимизация Подсказка
8. Избегайте курсоров. Немного не слишком задумываясь. Курсоры менее исполнительский, потому что каждый оператор FETCH выполняется эквивалентно другому SQL SELECT Заявление выполнения, возвращает одну строку. Оптимизатор не может оптимизировать CURSOR заявление, вместо того, чтобы оптимизировать запросы в пределах каждого выполнения цикла курсора, что нежелательно. Учитывая, что большинство операторов, курсор может быть переписан с использованием набора логики, они, как правило, следует избегать.
SQL Компьютер Столбцы Подсказка
9. Используйте вычисляемые столбцы Вычисляемые столбцы получены из других столбцов в таблице. Путем создания и индексирования вычисляемый столбец, вы можете превратить то, что иначе было бы отсканировать в этапе поиска. Например, если вам нужно вычислить SalesPrice и вы имели количество и столбец UnitPrice, умножая их в SQL инлайн приведет сканирование таблицы, как это умноженное две колонки вместе для каждой отдельной строки. Создать вычисляемый столбец под названием SalesPrice, то индекс, и оптимизатор запросов не будет больше не нужно, чтобы получить UnitPrice и количество данных и сделать расчет - это уже сделано.
SQL Подсказка
10. Сопоставление по шаблону: всегда есть противный LIKE и не нравится, но Postgres поддерживает регулярные выражения тоже.
SQL Совет: ORDER BY
11. ПОРЯДОК С ИСПОЛЬЗОВАНИЕМ: позволяет указать произвольную функцию сортировки. Не совсем уверен, как использовать это еще? Вы также можете делать такие вещи, как ORDER BY col1 + col2, что круто.
SELECT col1, col2 FROM table_testORDER BY col1 + col2;
Добавить эту страницу в закладки
beginner-sql-tutorial.com
Оптимизация запросов SQL
Введение………………………………….……………………......……………….…......3
1. Краткая история языка SQL……………………….…….....................................…....5
2. Основные определения и состав языка SQL…….……....................................…….10
2.1. Основные определения языка SQL…………………………........………….……..10
2.2.Состав языка SQL……………………………………….…............…………….…..11
3. Основные команды языка SQL....................................................................................13
3.1. Запросы в языке SQL…………………………………....................……………......17
3.1.1. Создание запроса. Что такое зарос........................................................................17
3.1.2. Где применяются запросы….…………………………..…………………...........17
Заключение………………………...……………............……………….…………..…...18
Глоссарий………………………………………………………………………………...20
Список использованных источников…….…………..........………….…...………........22
Приложение А Архитектура СУБД: однозвенная, двухзвенная, трехзвенная ……...23
Базами данных (БД) называют электронные хранилища информации, доступ к которым осуществляется с одного или нескольких компьютеров. Обычно БД создается для хранения и доступа к данным, содержащим сведения о некоторой предметной области, т.е. некоторой области человеческой деятельности или области реального мира.
В настоящее время термины база данных и система управления базами данных используются исключительно как относящиеся к компьютерам.
Системы управления базами данных (СУБД) – это программные средства, предназначенные для создания, наполнения, обновления и удаления баз данных. Различают три основных вида СУБД: промышленные универсального назначения, промышленные специального назначения и разрабатываемые для конкретного заказчика. Специализированные СУБД создаются для управления базами данных конкретного назначения – банковские, бухгалтерские, и т.д. Универсальные СУБД достаточно сложны, требуют специальных знаний от пользователя, но не имеют строго очерченных рамок применения. Заказные СУБД требуют существенных затрат, а их подготовка к работе и отладка занимают значительный период времени (от нескольких месяцев до нескольких лет).
По своей архитектуре СУБД делятся на одно-, двух-, и трехзвенные, которые представлены в Приложении А.
В зависимости от местоположения отдельных частей СУБД различают локальные и сетевые СУБД.
Все части локальной СУБД размещаются на компьютере пользователя базы данных. Чтобы с одной и той же БД одновременно могло работать несколько пользователей, каждый пользовательский компьютер должен иметь свою копию локальной БД. Существенной проблемой СУБД такого типа является синхронизация копий данных, именно поэтому для решения задач, требующих совместной работы нескольких пользователей, локальные СУБД фактически не применяются.
К сетевым относятся файл-серверные, клиент-серверные и распределенные СУБД. Непременным атрибутом этих систем является сеть, обеспечивающая аппаратную связь компьютеров и делающая возможной корпоративную работу множества пользователей с одними и теми же данными.
В файл-серверных СУБД все данные обычно размещаются в одном или нескольких каталогах достаточно мощной машины, специально выделенной для этих целей и постоянно подключенной к сети. Такой компьютер называется файл-сервером — отсюда название СУБД. Безусловным достоинством СУБД этого типа является относительная простота ее создания и обслуживания — фактически все сводится лишь к развертыванию локальной сети и установке на подключенных к ней компьютерах сетевых операционных систем. По счастью, Delphi «умеет» использовать сетевые средства самой популярной в мире ОС — Windows для создания соответствующих клиентских мест, то есть специального программного обеспечения компьютеров пользователей. Нетрудно заметить, что между локальными и файл-серверными вариантами СУБД нет особых различий, так как в них все части собственно СУБД (кроме данных) находятся на компьютере клиента. По архитектуре они обычно являются однозвенными, но в некоторых случаях могут использовать сервер приложений. Недостатком файл-серверных систем является значительная нагрузка на сеть.[1]
Язык SQL, предназначенный для взаимодействия с базами данных, появился в середине 70-х гг. (первые публикации датируются 1974 г.) и был разработан в компании IBM в рамках проекта экспериментальной реляционной СУБД System R. Исходное название языка SEQUEL (Structured English Query Language) только частично отражало суть этого языка. Язык был ориентирован главным образом на удобную и понятную пользователям формулировку запросов к реляционным БД. Но, в действительности, он почти с самого начала являлся полным языком БД, обеспечивающим помимо средств формулирования запросов и манипулирования БД следующие возможности:
· средства определения и манипулирования схемой БД;
· средства определения ограничений целостности и триггеров;
· средства определения представлений БД;
· средства определения структур физического уровня, поддерживающих эффективное выполнение запросов;
· средства авторизации доступа к отношениям и их полям;
· средства определения точек сохранения транзакции, и выполнения фиксации и откатов транзакций. [2]
В языке отсутствовали средства явной синхронизации доступа к объектам БД со стороны параллельно выполняемых транзакций: с самого начала предполагалось, что необходимую синхронизацию неявно выполняет СУБД.
В настоящее время язык SQL реализован во всех коммерческих реляционных СУБД и почти во всех СУБД, которые изначально основывались не на реляционном подходе. Все компании-производители провозглашают соответствие своей реализации стандарту SQL, и на самом деле реализованные диалекты SQL очень близки. Этого удалось добиться не сразу.
Наиболее близки к System R были две системы компании IBM – SQL/DS и DB2. Разработчики обеих систем использовали опыт проекта System R, а СУБД SQL/DS напрямую основывалась на программном коде System R. Отсюда предельная близость диалектов SQL, реализованных в этих системах, к SQL System R. Из SQL System R были удалены только те части, которые были недостаточно проработаны (например, точки сохранения) или реализация которых вызывала слишком большие технические трудности (например, ограничения целостности и триггеры).
Другой подход применялся в таких системах, как Oracle, Informix и Sybase. Несмотря на различие в способах разработки систем, реализация SQL везде происходила «снизу вверх». В первых выпущенных на рынок версиях этих систем использовалось ограниченное подмножество SQL System R. В частности, в первой известной реализации SQL в СУБД Oracle в операторах выборки не допускалось использование вложенных подзапросов и отсутствовала возможность формулировки запросов с соединениями нескольких отношений.
Несмотря на эти ограничения и на очень слабую, на первых порах, эффективность СУБД, ориентация компаний на поддержку разных аппаратных платформ и заинтересованность пользователей в переходе к реляционным системам позволили компаниям добиться коммерческого успеха и приступить к совершенствованию своих реализаций. В текущих версиях Oracle, Informix, Sybase и Microsoft SQL Server поддерживаются достаточно мощные диалекты SQL, хотя реализация иногда вызывает сомнения.
Деятельность по стандартизации языка SQL началась практически одновременно с появлением его первых коммерческих реализаций. В 1982 г. комитету по базам данных Американского национального института стандартов (ANSI) было поручено разработать спецификацию стандартного языка реляционных баз данных. Первый документ из числа имеющихся у автора проектов стандарта датирован октябрем 1985 г. и является уже не первым проектом стандарта ANSI. Стандарт был принят ANSI в 1986 г., а в 1987 г. одобрен Международной организацией по стандартизации (ISO). Этот стандарт принято называть SQL/86.
В качестве основы стандарта нельзя было использовать SQL System R. Во-первых, этот вариант языка не был должным образом технически проработан. Во-вторых, его слишком сложно было бы реализовать (кто знает, как бы сложилась судьба SQL, если бы все идеи проекта System R были реализованы полностью). Поэтому за основу был взят диалект языка SQL, сложившийся в IBM к началу 1980-х гг. В сущности, этот диалект представлял собой технически проработанное подмножество SQL System R.
К 1989 г. стандарт SQL/86 был несколько расширен, и был подготовлен и принят следующий стандарт, получивший название ANSI/ISO SQL/89. В результате SQL/89 во многих частях имеет чрезвычайно общий характер и допускает очень широкое толкование. В этом стандарте полностью отсутствуют такие важные разделы, как манипулирование схемой БД и динамический SQL. Многие важные аспекты языка в соответствии со стандартом определяются в реализации.
Наиболее важными достижениями стандарта SQL/89 являются четкая стандартизация синтаксиса и семантики операторов выборки данных и манипулирования данными и фиксация средств ограничения целостности БД. Были специфицированы средства определения первичного и внешних ключей отношений и так называемых проверочных ограничений целостности, которые представляют собой подмножество немедленно проверяемых ограничений целостности SQL System R. Средства определения внешних ключей позволяют легко формулировать требования так называемой ссылочной целостности БД. Это распространенное в реляционных БД требование можно было сформулировать и на основе общего механизма ограничений целостности SQL System R, но формулировка на основе понятия внешнего ключа более проста и понятна.[3]
mirznanii.com
Часть 1. Зачем нужны индексы?
Одним из ключевых показателей производительности базы данных является скорость выполнения запросов. При разработке и поддержке высоконагружаемых приложений данный фактор принимает первостепенное значение. Когда в таблицах базы данных содержатся десятки миллионов записей, которые востребованы каждую секунду, обеспечение быстрого выполнения запросов к базе становится весьма тяжелой задачей для разработчика. Данную проблему невозможно решить только наращиваем характеристик серверного оборудования.
В качестве наиболее эффективных решений для повышения производительности базы данных отмечают следующие:
1) Создание репликаций базы данных
2) Шардинг базы данных
3) Индексирование таблиц базы данных с целью оптимизации запросов
В этой статье будет рассмотрен последний способ, как один из наиболее эффективных и простых способов. Также индексирование – это первый шаг, на который идет разработчик при оптимизации базы данных.
Итак, разберемся, что такое индекс, и какие типы индексов мы можем создавать при разработке баз данных.
Индексы создаются для таблицы и, по сути, являются копией этой таблицы. Различие состоит в том, что индекс может включать не все столбцы исходной таблицы, а лишь те которые указал разработчик. Рассмотрим пример. У нас есть таблица Stuffs, которая содержит 10 колонок и упорядоченный индекс IDX_StuffsSalary с ключом Salary, который содержит только два столбца из таблицы Stuffs:
| Таблица Staffs | |
| Id | Int |
| Name | Nvarchar(50) |
| Surname | Nvarchar(50) |
| Salary | Int |
| Address | Nvarchar(50) |
| Telephone | Nvarchar(50) |
| Job | Nvarchar(50) |
| Photo | image |
| Индекс IDX_StaffsSalary | |
| Salary | Int |
| Name | Nvarchar(50) |
Как это работает и в чем тут оптимизация? Допустим, есть следующий запрос:
SELECT Name FROM Stuffs WHERE Salary > 400 AND Salary < 1000
Если бы не было индекса, данный запрос работал бы только с основной таблицей, и происходило бы следующее: для проверки значения колонки Salary из базы будет извлекаться вся строковая запись, то есть значения всех колонок таблицы. В случае наличия индекса, механизм SQL Server вообще не будет обращаться к таблице Staffs, работая полностью с данными в индексе, так как индекс содержит все, необходимые для выполнения запроса, данные. Таким образом, вместо извлечения на каждой итерации десяти колонок – извлекается только две. Поскольку индекс уже отсортирован по его ключу – полю Salary, запрос выполнится еще быстрее, за счет прохождения меньшего количества строк. Когда в таблице миллионы записей, прирост производительности колоссальный.
Стоит отметить, что на синтаксис запросов индексы никак не влияют. Разработчики точно также пишут запросы к таблицам базы, а оптимизатор SQL Server сам ищет нужные индексы, среди созданных, и пытается с помощью них оптимизировать запрос.
Однако есть у индексов и свои подводные камни. Они позволяют оптимизировать и существенно ускорить операции выборки данных, но при этом отрицательно сказываются на производительности запросов по вставке и удалению данных. Так как любые изменения в данных главной таблицы должны автоматически применяться для всех ее индексов. Если для таблицы создано четыре индекса, то простая операция вставки новой строки будет выполняться пять раз. Один раз – вставка в главную таблицу и по одному разу для каждого индекса. Таким образом, время выполнения запроса INSERT увеличится в четыре раза. Аналогично обстоит дело с операцией DELETE.
Стоит отметить, что, как правило, операции выборки данных выполняются гораздо чаще, чем операции вставки и удаления, поэтому в большинстве случаев создание индексов себя оправдывает.
Столбы в индексе могут быть двух типов:
1) Столбцы в ключе индекса
2) Столбы, включенные в индекс
В ключ индекса вносятся столбцы, по которым будет проводиться фильтрация, группировка или сортировка в запросе. А включенные столбцы – это столбы, значения которых возвращается запросом, но с ними не производиться никаких действий.
В зависимости от общего числа столбцов в индексе, индексы делятся на кластеризованные и некластеризованные индексы.
Кластеризованный индекс – это индекс, в который входят все столбцы исходной таблицы (в качестве ключа или включенного столбца). По сути, кластеризованный индекс является копией исходной таблицы. Оптимизация при создании такого индекса достигается за счет упорядочивания данных в индексе по ключу. Кластеризованные индексы рекомендуется создавать для первичного ключа и внешних ключей базовой таблицы.
Некластеризованный индекс – это индекс, в который включена только часть столбцов базовой таблицы. Пример такого индекса приведен выше.
В следующей статье мы научимся правильно создавать индексы для максимальной оптимизации наших баз данных.
djekmusic.blogspot.com