Оптимизация PL / SQL запросов. Pl sql оптимизация запросов
oracle - Как оптимизировать запрос с помощью PL/SQL Developer?
У меня есть запрос ~ 53 строк кода, и мне нужно его оптимизировать. У меня есть инструмент PL/SQL Developer 7.0 и как его использовать для оптимизации?
Я попытался использовать Explain Plan, но мне ничего не сказано. Я также добавил столбцы времени и времени, но нет ничего интересного, сначала пустое и второе всегда в одно и то же время.
Я попытался использовать тестовое окно, но есть процедура, для которой требуется вставка переменной, и поскольку мой запрос выбирает многие строки, я не могу его использовать.
Итак, вопрос в том, как я могу оптимизировать SQL-запрос с помощью PL/SQL Developer? Где я должен искать, чтобы получить время выполнения запроса для каждого подзапроса? Может быть, есть несколько гидов, но на данный момент я нашел только документацию, но мне не было полезно передо мной? Для моих текущих знаний невозможно оптимизировать такой большой запрос без каких-либо инструментов.
Запрос, требующий оптимизации:
select count(PRODUCT_NUMBER) from (select W.SUID, I.SUID, W.PRODUCT_NUMBER, MI.ML_NUMBER, I.TITLE_TRANSLIT, I.COUNTRIES, QTY.REMAINS, QTY.ACQ_PRICE_USD, QTY.REMAINS * QTY.ACQ_PRICE_USD as TOTAL from (select UID_WARE, QTY as REMAINS, ACQ_PRICE_USD from (select UID_WARE, PRODUCT_NUMBER, NVL(sum(QTY_ON_STOCK), 0) - NVL(sum(ADD_IN_QTY), 0) + NVL(sum(ADD_OUT_QTY), 0) as QTY, ACQ_PRICE_USD as ACQ_PRICE_USD from (select SI.UID_WARE, W.PRODUCT_NUMBER, count(distinct STK.SUID) as QTY_ON_STOCK, sum(case when 1 = 1 then DECODE('' , SM.UID_SOURCE_LOCATION, SM.QTY, 0) else 0 end) as ADD_OUT_QTY, sum(case when 1 = 1 then DECODE('' , SM.UID_DEST_LOCATION, SM.QTY, 0) else 0 end) as ADD_IN_QTY, ROUND(ACQ.PRICE_USD, 2) as ACQ_PRICE_USD from STOCK_MOVEMENTS SM join STOCK_ITEMS SI on SM.UID_STOCK_ITEM = SI.SUID left outer join (select PR.UID_STOCK_ITEM, DECODE(NVL(CR.RATE, 0), 0, 0, PR.PRICE / CR.RATE) as PRICE_USD from MV_STOCK_ACQ_PRICES PR, CURRENCY_RATES CR where PR.PRICE_DATE = CR.RATE_DATE and PR.UID_CURRENCY = CR.UID_CURRENCY) ACQ on ACQ.UID_STOCK_ITEM = SI.SUID join WARES W on W.SUID = SI.UID_WARE left outer join (select distinct STK.SUID, STK.QTY_REMAINS from STOCK_ITEMS STK where STK.UID_STOCK_LOCATION != 'MS-STL-SALED' ) STK on STK.SUID = SI.SUID where 1 = 1 group by SI.UID_WARE, W.PRODUCT_NUMBER, ACQ.PRICE_USD ) T group by T.UID_WARE, T.PRODUCT_NUMBER, ACQ_PRICE_USD)) QTY join WARES W on W.SUID = QTY.UID_WARE join INVENTORY I on I.SUID = W.UID_ISSUE join MAP_INFO MI on MI.SUID = I.SUID where REMAINS != 0 and w.UID_SECTION in ('MS-SEC-BOOKS', 'MS-SEC-MAPS'))Оптимизация запросов
Доступ к данным в СУБД предоставляется через запросы. Вес клиент-серверные базы данных практически полностью поддерживают язык запросов SQL (но каждый со своими отклонениями и ограничениями), который был разработан и принят еще в 1992 году. Именно этот язык до сих пор является основой любого приложения, использующего СУБД.
Некоторые программисты считают, что запросы SQL работают одинаково в любой СУБД. Это большая ошибка. Действительно, существует стандарт SQL, и запросы, написанные на нем, воспринимаются в большинстве систем одинаково. Но их обработка будет происходить совершенно по-разному.
Максимальные проблемы во время переноса приложения могут принести расширения языка SQL. Так, например, в SQL Server используется Transact-SQL, а в Oracle - PL/SQL, и их операторы совершенно несовместимы.
Но даже если вы переведете синтаксис с одного языка на другой, проблем будет очень много. Это связано с различными архитектурами оптимизаторов запросов, разницей в блокировках и т. д. Если код программы при смене СУБД требует незначительных изменений, то запросы SQL нужно переписывать полностью и с самого начала. Не стоит пытаться исправить их или оптимизировать. Писать надо изначально для определенной СУБД
Несмотря на большие различия между базами данных разных производителей, есть и общие стороны. Например, большинство СУБД обрабатывают запросы в такой последовательности:
1. Разбор запроса.
2. Оптимизация.
3. Генерация плана выполнения. 4 Выполнение запроса.
Это всего лишь общий план выполнения, а для каждой конкретной СУБД количество шагов может отличаться. Перед выполнением осуществляется несколько подготовительных операций, которые отнимают достаточно много времени. После выполнения запроса использованный план будет сохранен в специальном буфере. При следующем запуске сервер получит эти данные из буфера и сразу же начнет выполнение без лишних затрат на подготовку.
Теперь посмотрим на два запроса:
SELECT * FROM TableName WHERE ColumnName = 10 и
SELECT * FROM TableName WHERE ColumnName = 20Оба запроса выбирают все данные из одной и той же таблицы. Только на первый запрос отобразятся строки, в которых колонка ColumnName содержит значение 10, а на второй - строки, где эта же колонка содержит значение 20. На первый взгляд запросы очень похожи и должны выполнятся одинаково. На самом деле оптимизатор воспринимает такие запросы разными и будет осуществлять подготовительные шаги в обоих случаях, несмотря на схожесть.
Чтобы этого не было, нужно использовать в запросах переменные:
SELECT * FROM TableName WHERE ColumnName = paramlТеперь, выполняя запрос, достаточно передать серверу значение неременной paraml, тогда запросы будут восприниматься оптимизатором как одинаковые и лишней обработки не будет.
Буфер для хранения планов выполнения не бесконечен, поэтому в нем хранятся данные только о последних запросах (количество зависит от размера буфера). Если какой-то запрос выполняется часто, то в нем обязательно нужно использовать переменные, потому что это значительно повышает производительность. Попробуйте дважды выполнить один и тот же запрос и посмотреть на скорость выполнения. Вторичное выполнение произойдет намного быстрее и может быть даже незаметным на глаз.
Если запрос выполняется редко, то можно не обращать внимания на оптимизацию. Как мы уже знаем, незачем оптимизировать то, что и так работает быстро и выполняется редко. Эффект от минимизации в данном случае будет минимален.
Часто выполняемые задачи должны работать максимально быстро. Даже если запрос выполняется с приемлемой для клиента скоростью, тысяча таких запросов создадут ощутимую нагрузку на сервер, и он сразу же станет узким звеном в вашей системе.
В большинстве приложений баз данных присутствуют какие-либо возможности для построения отчетов. Запросы на языке SQL для их формирования могут выполняться очень долго, хотя сами отчеты делают очень редко (например, месячный, квартальный или годовой отчет). Из-за этого программисты мало внимания уделяют оптимизации. Но в действительности отчетность может формироваться несколько раз подряд. После первой попытки очень часто в данные вносятся изменения, и формирование повторяется снова. Таким образом, даже редко выполняемые, но очень медленные запросы нужно постараться оптимизировать хотя бы с помощью использования параметров.
При написании запросов старайтесь как можно меньше использовать операторы SELECT, особенно вложенные в секцию WHERE. Для повышения производительности иногда помогает вынос лишнего SELECT в секцию FROM Но иногда бывает и наоборот, быстрее выполняется запрос, в котором SELECT вынесен из FROM в тело WHERE.
Допустим, что из базы данных необходимо выбрать всех людей, которые работают на данный момент. Для всех работающих в колонке Status устанавливается код, который можно получить из справочника состояний. Посмотрите на первый вариант запроса:
SELECT *FROM tbPerson р
WHERE р idStatus = (SELECT [Keyl] FROM tbStatus WHERE sName = 'Работает') Вам не обязательно полностью понимать суть этого запроса. Главное здесь в том, что в секции WHERE выполняется подзапрос. Он будет генерироваться для каждой строки в таблице tbPerson, что может стать большой нагрузкой для сервера.
Теперь разберем, как можно вынести запрос SELECT в секцию FROM. Это можно сделать следующим образом:
(SELECT [Keyl] FROM tbStatus WHERE sName = 'Работает') s WHERE p.idStatus = s Keyl
Данные примеры слишком просты и могут выполняться одинаково по времени, с точностью до секунды. Но при более разветвленной структуре и сложном запросе можно сравнить работу и увидеть наиболее предпочтительный вариант для определенной СУБД (напоминаю, что разные базы данных могут обрабатывать запросы по-разному).
В большинстве случаев каждый оператор SELECT отрицательно влияет на скорость работы, поэтому в предыдущем примере нужно избавиться от него с помощью такой записи:
SELECT *FROM tbPerson p. tbStatus s WHERE p.idStatus = s.Keyl AND s.sName = 'Работает'
В более сложных примерах программисты не видят возможности решения задачи с помощью одного запроса, хотя она существует. Допустим, что у нас есть таблица А с полями:
в Kod - число, принимает значения 1 или 2; в Fami 1 - фамилия; в Fi rstName - имя;• Otch - отчество.
В этой таблице хранится список данных о сотрудниках Для каждого сотрудника выделены две записи с кодом 1 и с кодом 0. Записи с кодом 1 могут быть связаны с таблицей Info, в которой будет храниться полная информация о сотрудниках. Нам надо получить все записи с кодом 0, для которых существует связь между таблицами А и Info. Такую задачу чаще всего решают, используя двойной запрос:
Существует и более простой способ решения: SELECT i2.*
FROM Info il. A. Info i2 WHERE il.Kod = 1 AND il.Fami1 = A.Famil AND il.Famil = i2.Famil AND i2.Kod = 0Здесь в запросе мы дважды ссылаемся на одну и ту же таблицу Info и строим связь Info-A-Info. На первый взгляд связь получается сложной, но при наличии правильно настроенных индексов этот пример будет работать в несколько раз быстрее, чем с использованием подзапросов SELECT.
Для ускорения работы можно разбить один запрос на несколько. Например, для SQL Server предыдущий пример можно видоизменить так:
Declare @id int SELECT @id = [id] FROM tbStatusWHERE sName = 'Работает'
SELECT * FROM tbPerson p WHERE p.idStatus = @idВ этом примере мы сначала объявляем переменную @id. Затем в ней сохраняем значение идентификатора, а потом уже ищем соответствующие строки в таблице tbPerson.
Как видите, одну и ту же задачу можно решить разными способами. Некоторые из них могут повысить производительность в несколько раз.
Как мы уже говорили, при написании программы вы должны полностью изучить систему, в которой программируете. Это справедливо и для баз данных. Вы должны четко представлять себе систему, ее преимущества и недостатки. Невозможно сформулировать универсальные методы написания эффективного кода, которые работали бы везде. Изучайте, экспериментируйте, анализируйте, и только тогда вы сможете получить максимальный эффект от доступных ресурсов.
⇐2.12. Оптимизация в базах данных || Оглавление || 2.12.2. Оптимизация СУБД⇒
www.delphiplus.org
sql - Оптимизация запросов PL/SQL
Избегайте функций TRIM в предложениях WHERE и JOIN → TRIM (A.SHORT_DESC) = TRIM (var1)
Просто создание индексов в столбцах JOIN, WHERE и GROUP не означает, что ваш запрос всегда будет быстро возвращать ваши требуемые результаты. Оптимизатор запросов, который выбирает правильный индекс для запроса, дает вам оптимальную производительность, но оптимизатор запросов может предложить только оптимальный план запроса, используя правильные индексы КОГДА вы помогаете ему, написав хороший синтаксис запросов.
Использование любого типа функции (системы или пользователя) в предложениях WHERE или JOIN может значительно снизить производительность запросов, поскольку эта практика создает препятствия в работе оптимизатора запросов при правильном выборе индекса. Одним из распространенных примеров являются функции TRIM, которые обычно используются разработчиками в предложении WHERE.
USE AdventureWorks GO SELECT pr.ProductID,pr.Name,pr.ProductNumber,wo.* fROM Production.WorkOrder wo INNER JOIN Production.Product pr ON PR.ProductID = wo.ProductID WHERE LTRIM(RTRIM(pr.name)) = 'HL Mountain Handlebars' GO SELECT pr.ProductID,pr.Name,pr.ProductNumber,wo.* fROM Production.WorkOrder wo INNER JOIN Production.Product pr ON PR.ProductID = wo.ProductID WHERE pr.name = 'HL Mountain Handlebars' 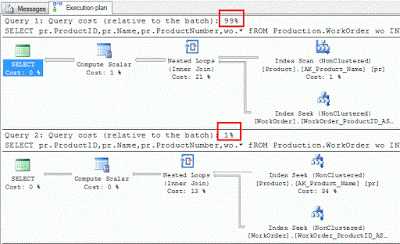
Хотя результаты обоих запросов одинаковы, но первый запрос занимает почти 99% от общего времени выполнения. Это огромное различие заключается только в том, что эти триммерные функции, поэтому на производственных базах данных мы должны избегать этих TRIM и других функций как в предложениях JOIN, так и WHERE.
Взято из блога AASIM ABDULLAH
Итак, что вы могли/должны были сделать, это запустить обновление ваших данных, чтобы обрезать его раз и навсегда, и начать обрезать его при его добавлении в таблицу, поэтому никакие новые данные никогда не потребуют обрезки. Или, если это по какой-то причине невозможно, найдите функциональные индексы, как это сделал Морис Ривз в комментариях.
qaru.site
sql - Оптимизация PL / SQL запросов
Избегайте TRIM функций в ГДЕ и ПРИСОЕДИНЯЙТЕСЬ положение -> TRIM (A.SHORT_DESC) = TRIM (var1)
Только при создании индексов JOIN, WHERE и п GROUP столбцов не означает, что ваш запрос всегда будет возвращать ваши необходимые результаты быстро. Это оптимизатор запросов, который выбирает надлежащий индекс для запроса, чтобы дать вам оптимальную производительность, но оптимизатор запросов может предложить только оптимальный план запроса с помощью соответствующих индексов, когда ваши которые помогают, написав хороший синтаксис запроса.
Используя любой тип функции (или системы определяется пользователем) в том, где или РЕГИСТРИРУЙТЕСЬ положение может существенно снизить производительность запросов , так как эта практика создают препятствия в запросе оптимизатор работы правильного выбора индекса. Один общий пример TRIM функции, которые обычно используются разработчиками в ИНЕКЕ.
USE AdventureWorks GO SELECT pr.ProductID,pr.Name,pr.ProductNumber,wo.* fROM Production.WorkOrder wo INNER JOIN Production.Product pr ON PR.ProductID = wo.ProductID WHERE LTRIM(RTRIM(pr.name)) = 'HL Mountain Handlebars' GO SELECT pr.ProductID,pr.Name,pr.ProductNumber,wo.* fROM Production.WorkOrder wo INNER JOIN Production.Product pr ON PR.ProductID = wo.ProductID WHERE pr.name = 'HL Mountain Handlebars'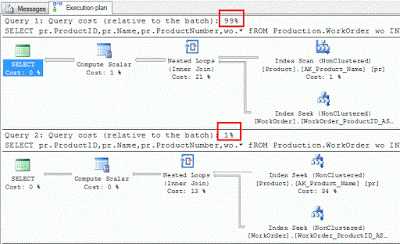
Хотя выходы обоих запросов одинаковы, но первый запрос занял почти 99% от общего времени выполнения. Это огромная разница только из-за эти аккуратные функции так на производственных базах данных мы должны избегать этого TRIM и других функций в обоих JOIN и WHERE положений.
Взятые из Aasim АБДУЛЛА блога
Так что вы можете / должны сделать, это запустить обновление на данных, чтобы обрезать его раз и навсегда, и начать Triming его в то время как его добавления в таблицу, так что новые данные не будут когда-либо требуют обрезки. Или, если это по каким-то причинам не представляется возможным, обратите внимание на функциональные основе индексов, как предложено Морисом Ривзом в комментариях.
coredump.su
Оптимизация PL SQL
Вопрос: Несколько слов об оптимизации БД TecDoc Transbase, сконвертированной в MySQL
Очень часто я слышу вопросы об оптимизации базы данных TecDoc Transbase в MySQL, мол почему так много весит база сконвертировання в MySQL (TecDoc-14Гб=MySQL-50Гб), а как там обстоит дело с индексами, конвертируются ли они при помощи вашего скрипта.Сразу отмечу: Transbase (на которой стоит TecDoc) это не MySQL, и способ организации данных, индексирование у него отличается от способа хранения данных в MySQL. А отсюда и все различия.
Второе, это то что TecDoc это не такая себе "серебряная пуля" или "панацея от всех болезней", его тоже разрабатывают люди, и в нем тоже есть ошибки: ошибки в кросах, ошибки в программе, ошибки в базе. ТекДок не универсален (как и все в этом сером мире :) ), многое в нем заложено на будущее, многое используется не очень редко или вообще не используется.
А посему база ТекДок в том виде, в котором она есть и конвертируется требует оптимизации под задачи клиента(Можно конечно заюзать базу так как она есть, купить выделенный сервер, залить 50-ти гиговую базу, написать свою оболочку и радоватся жизни, но смысл? )
Перед использованием базы данных ТекДок в своем приложении (инет магазине) клиент а соответственно разработчик, которого он нанимает, должны задать себе ряд вопросов:
1) что собой будет представлять проект: интернет магазин, оф-лайновый стол заказов, каталог запчастей2) для кого проект предназначен (категория потребителей: авто-мастера, розничные покупатели, оптовики, менеджеры продаж....)3) определение границ проекта4) График выполнения работ5) ВАЖНО! БЮДЖЕТ! (это пожалуй один из самых важных вопросов)6) Планы на будущее (т.е планируется развитие проекта, или нет)
А коль тема у нас оптимизация, расмотрим пример на таблице артикулов TOF_ARTICLESВ "сыром" виде эта таблица занимает 736,127Кб (в МБ переведете сами)
Простой поиск по аритикулу в этой "сырой" таблице выполняется достаточно долго как для веб-приложения - 19.20 сек. Как видим, даже для локальной машини такие показатели не подходят.
Давайте попытаемся немного оптимизировать эту таблицу.
Исходя из ее структуры, видим, что в поле ART_ARTICLE_NR хранятся сами артикули, и их мы будем искать очень часто, а значит это поле нужно сделать индексным.
Еще у нас есть поле ART_CTM - выясняем, что поле это не используется ТекДоком и заложено на будущее для оптимизации поиска или как бытует мнение на форумах для оптимизации поиска (возможно). Удаляем это поле из базы данных.
После этих нескольких нехитрых действий, получаем следующую картину
Как видим, база данных с индексами уже занимает 129,366 Кб, что практически на 600 мб меньше. И это только после 2-х простых действий.
Соответственно и запрос выполняется намного быстрее, сотые доли секунды
Картинки можно посмотреть здесь
Вот, так вот на примере только одной таблицы TOF_ARTICLES мы увидели как нужно "доводить до ума" нашу базу TecDoc
forundex.ru