советы по оптимизации базы данных SQL только для чтения. Оптимизация ms sql базы
MS SQL Server. Оптимизация работы
Предисловие
Платформа 1С:Предприятие 8.x поддерживает работу с несколькими СУБД. Самым используемым является продукт компании Microsoft. В статье будут рассмотрены распространенные причины неоптимальной работы SQL-сервера и пути их решения на примере MS SQL Server 2008.Для каждой проблемы будет краткое описание и видеоурок по настройке СУБД для оптимизации работы. Для более подробного описания тех или иных настроек следует обратиться к справочному руководству.
По опыту, самыми распространенными причинами неоптимальной работы SQL-сервера являются:
- Неактуальная статистика о распределении значений и индексов в таблице базы данных.
- Устаревание процедурного КЭШа планов запросов.
- Высокая фрагментация индексов таблиц.
- Периодическая необходимость в перестроении всех индексов таблиц.
Обновление статистик
MS SQL, как и другие современные СУБД, имеют механизм оптимизации запросов к базе данных на основе собранной статистики распределения значений в таблицах и индексах. Оптимизатор SQL, анализируя собранную статистику, выбирает наиболее эффективный план запроса, исключая нерациональные выборки данных.
Достаточно интенсивная работа с базой данных снижает актуальность собранной статистики что не позволяет оптимизатору создавать оптимальные запросы к БД. Поэтому необходимо проводить обновление статистик. Делается это с помощью следующей команды:
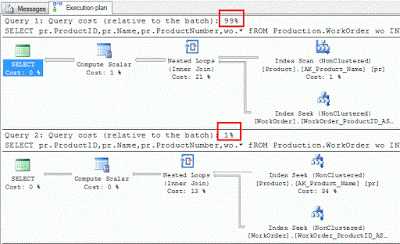
exec sp_msforeachtable N'UPDATE STATISTICS ? WITH FULLSCAN' Наибольшее влияние статистики распределения данных на производительность СУБД можно увидеть с применением вложенных запросов. Если платформа 1С:Предприятие 8.x сформирует запрос к SQL-базе многоуровневой вложенности, плюс к этому еще и соединением двух вложенных запросов, то можно утверждать, что скорость его работы напрямую зависит от актуального состояния собранной статистики. Для поддержки статистик в актуальном состоянии рекомендуется создать регламентное задание, которое будет производить обновление статистик в указанное время. Поскольку данный процесс не блокирует таблицы БД, то его можно запускать практически в любое время. Ниже на видео демонстрируется настройка плана обслуживания по обновлению статистик средствами СУБД MS SQL Server 2008.Очистка процедурного КЭШа
SQL-оптимизатор кэширует используемые планы запросов для увеличения быстродействия. Но стоит учитывать, что обновление статистик распределение данных БД может привести к неверным действиям оптимизатора поскольку кэш будет учитывать устаревшую статистику. Поэтому следует очистить процедурный кэш. В дальнейшем, уже на основе обновленной статистики, оптимизатором SQL будет создан новый процедурный кэш. Очистка процедурного кэша осуществляется следующей командой:
Таким образом, частота очистки процедурного кэша совпадает с частотой обновления статистики распределения данных в таблицах и индексах БД.
Дефрагментация индексов
Интенсивная работа с базой данных приводит к снижению эффективности использования индексов из-за фрагментации. Поэтому рекомендуется регулярно проводить дефрагментацию индексов. Если необходимо провести дефрагментацию для всех таблиц некоторой базы, то можно использовать следующую команду:
sp_msforeachtable N'DBCC INDEXDEFRAG ([ИМЯ БАЗЫ ДАННЫХ], ''?'')' Запуск процесса дефрагментации индексов не блокирует таблицы, что позволяет запускать в любое время. Однако стоит учитывать увеличение нагрузки на сервер СУБД. Рекомендуется проводить дефрагментацию не реже одного раза в неделю. Ниже представлено видео по настройке регламентной операции дефрагментации индексов для существующего плана обслуживания.Дефрагментацию можно настроить как для всей базы, так и для отдельной таблицы, если был проведен анализ нагрузок.
Реиндексация таблиц
Наиболее существенный прирост производительности можно получить за счет полного перестроения индексов. Реиндексацию рекомендуется выполнять регулярно. Стоит учитывать, что процедура проведения реиндексации таблиц БД блокирует. Чтобы работа пользователей не была остановлена, лучше всего проводить данную операцию вне рабочего времени. SQL-команда на запуск процесса перестроения индекса следующая:
sp_msforeachtable N'DBCC DBREINDEX (''?'')'Ниже вы можете посмотреть видео по добавлению к существующему плану обслуживания задачи реиндексации таблиц БД.
После проведения реиндексации таблиц, выполнять дефрагментацию индексов нет необходимости.
Выводы
Выполнение рассмотренных регламентных операций позволит существенно повысить производительность сервера СУБД. Для контроля работы SQL-сервера рекомендуется просматривать журнал событий, где можно посмотреть статистику работы плана обслуживания по указанному расписанию.
 В конечном счете, все рассмотренные регламентные задачи позволят поддерживать SQL-сервер в эффективном, стабильном состоянии.
В конечном счете, все рассмотренные регламентные задачи позволят поддерживать SQL-сервер в эффективном, стабильном состоянии. devel1c.blogspot.com
советы по оптимизации базы данных SQL только для чтения MS SQL Server
У меня есть база данных SQL Server среднего размера, в которой есть актуарные данные. Все варианты использования для него – это запросы только для чтения. Есть ли какая-то специальная оптимизация, которую я должен рассмотреть, учитывая данный сценарий? Или я должен просто придерживаться обычных правил оптимизации базы данных?
Одна из стратегий заключается в том, чтобы добавить файловую группу readonly в вашу базу данных и разместить ваши таблицы только для чтения. Готовая файловая группа позволяет SQL Server делать ряд оптимизаций, включая такие вещи, как устранение всех блокировок.
В дополнение к стандартной оптимизации БД:
- Убедитесь, что все таблицы и индексы имеют нулевую фрагментацию
- Подумайте о добавлении индексов, которых можно было бы избежать в противном случае из-за чрезмерных затрат на обновление
Если он доступен только для чтения, одна вещь, которую вы можете сделать, это поместить индексы практически во все, что может помочь (разрешить пространство). Обычно добавление индекса – это компромисс между ударом производительности и записью производительности для чтения. Если вы избавитесь от писем, это уже не компромисс.
Когда вы загружаете базу данных, вы хотите удалить все / большинство индексов, выполните загрузку, а затем верните индексы в таблицы.
Я не уверен, что вы считаете «нормальными правилами», но вот некоторые предложения.
-
Если вы на 100% уверены, что он доступен только для чтения, вы можете установить уровень изоляции транзакции READ_UNCOMMITTED . Это самая быстрая возможная настройка чтения, но это приведет к фантомным чтениям и грязным чтениям, если вы пишете таблицы.
-
Если у вас есть представления, используйте индексированные представления (создайте для них кластеризованные индексы). Поскольку они никогда не будут обновляться, штраф за исполнение отменяется.
-
Взгляните на эту статью .
В базе данных:
- Денормализовать его.
- При необходимости используйте больше индексов.
- Составьте некоторые данные, если они вам нужны в отчетах.
В программе:
- Используйте уровень готовности READ UNCOMMITTED.
- Используйте autocommits для избежания длительных транзакций.
Для таблицы только для чтения рассмотрите возможность изменения индексов для использования коэффициента заполнения 100%.
Это увеличит количество данных на каждой странице данных. Больше данных на страницу, меньше страниц для чтения, меньше ввода-вывода, что повышает производительность.
Мне нравится этот параметр, потому что он повышает производительность без изменений кода или изменений таблицы.
- Денормализовать данные.
- Примените соответствующие индексы.
- Предварительно рассчитайте агрегации.
- Реализовать базу данных на чередующемся диске.
- Я никогда не видел этого, но если бы вы могли каким-то образом загрузить всю память в память (RAM-диск ???), это было бы очень быстро, не так ли?
Для настройки производительности есть несколько вещей, которые вы можете сделать. Работает Denormailzation. Соответствующие кластерные индексы зависят от того, как будут запрашиваться данные. Я не рекомендую использовать подсказку nolock. Я бы использовал уровень изоляции моментальных снимков.
Также важно, как ваша база данных размещается на дисках. Для производительности только для чтения я бы рекомендовал Raid 10 с отдельными mdf и ldf на изолированные шпиндели. Обычно для производственной базы данных для Raid 5 и Raid 1 для журналов должно быть Raid 5. Убедитесь, что у вас есть файл tempdb для каждого процессора, используемый для сортировки, хороший начальный размер – 5 ГБ данных и 1 ГБ журнала для каждого процессора. Также убедитесь, что вы запускаете свои запросы или procs через showplan, чтобы оптимизировать их, а также, возможно. Убедитесь, что в настройках сервера включен параллелизм.
Кроме того, если у вас есть время и пространство для оптимальной производительности, я бы точно определял, где данные живут на дисках, создавая группы файлов и помещая их на полностью отдельные тома, которые являются изолированными дисками в каждом томе.
sqlserver.bilee.com
Оптимизация платформы SQL Server
Эта документация перемещена в архив и не поддерживается.
Хотя установка SQL Server по умолчанию предоставляет полнофункциональную систему управления реляционной базой данных, оптимизация после установки может значительно увеличить производительность и уменьшить число узких мест. Вкратце, оптимизация после установки на уровне платформы SQL Server состоит в следующем:
- Файлы данных и журналов TempDB должны быть размещены на собственных выделенных томах — временные файлы данных отделяются от временных файлов журналов.
- Количество файлов данных TempDB должно совпадать с числом ядер ЦП на сервере.
- Файлы данных и журналов для всех баз данных должны располагаться на отдельных выделенных томах.
- Размеры файлов данных и журналов, а также параметры автоматического роста должны быть предварительно настроены. Например, для файлов данных можно задать начальный размер 25 ГБ, для файлов журналов — 10 ГБ, а для фактора роста — 5 ГБ.
- Флаг трассировки T1118 должен быть установлен, чтобы уменьшить число конфликтов и добиться максимального параллелизма.
- Выделение памяти для SQL Server должно быть предварительно настроено вместо использования динамического управления памятью по умолчанию.
Более подробные пошаговые инструкции для выполнения этих рекомендаций можно найти в разделе "Оптимизация производительности базы данных" руководства по оптимизации производительности BizTalk Server. В этом разделе представлены всеобъемлющие и по большей части универсальные рекомендации по SQL Server. Диаграмма примера конфигурации хранилища данных представлена в следующей таблице.
| Data_Sys | Файлы данных MASTER, MODEL и MSDB | 1 | 10 | 64 КБ | 2 ГБ | 1 ГБ |
| Logs_Sys | Файлы журналов MASTER, MODEL и MSDB | 2 | 10 | 4 КБ | 2 ГБ | 1 ГБ |
| Data_TempDb | Данные TempDB (x число ядер ЦП) | 3 | 20 | 64 КБ | 5 ГБ | 1 ГБ |
| Logs_TempDb | Журнал TempDB | 4 | 20 | 4 КБ | 5 ГБ | 1 ГБ |
| Data_ASPersistence1 | Файлы данных сохраняемости | 5 | 20 | 64 КБ | 10 ГБ | 5 ГБ |
| Logs_ASPersistence1 | Файлы журналов сохраняемости | 6 | 20 | 4 КБ | 10 ГБ | 5 ГБ |
| Data_ASMonitoring1 | Файлы данных наблюдения | 7 | 100 | 64 КБ | 25 ГБ | 10 ГБ |
| Logs_ASMonitoring1 | Файлы журналов наблюдения | 8 | 25 | 4 КБ | 25 ГБ | 5 ГБ |
| Data_CustomDBs | Файлы данных пользовательской базы данных | 9 | Custom | 64 КБ | Настраиваемый | 5 ГБ |
| Logs_CustomDBs | Файлы журналов пользовательской базы данных | 10 | Настраиваемый | 4 КБ | Настраиваемый | 5 ГБ |
2011-12-05
msdn.microsoft.com
Оптимизируем базу на MSSQL: определяем фрагментацию индексов
Оптимизируем базу на MSSQL: определяем фрагментацию индексов
Ничто так не "убивает" базу, как "плохое" индексирование (С)
Создать правильные индексы - это только половина дела. Нужно еще и правильно ими управлять.
В процессе работы с базой, особенно, если данные в ней довольно часто модифицируются/добавляются/удаляются, со временем индексы приходят в некоторую "негодность". Увеличивается их "фрагментарность", ухудшается их влияние на скорость исполнения запросов к БД.Оптимальным считается, когда уровень фрагментации индекса не превышает 10%, но для поддержания такого показателя необходимо проводить периодическую их дефрагментацию и реорганизацию.(подробнее про реорганизацию и дефрагментацию)
Основным инструментом в процессе управления фрагментацией индексов выступает функция sys.dm_db_index_physical_stats (подробнее)
Для определения списка индексов с уровнем фрагментарности выше оптимальных 10% в своей работе я воспользовалась вот таким запросом:
DECLARE @db_name varchar(50) = N'db_name', @table_name varchar(250) = N'db_name.dbo.tbl_name'SELECT IndStat.database_id, IndStat.object_id, QUOTENAME(s.name) + '.' + QUOTENAME(o.name) AS [object_name], IndStat.index_id, QUOTENAME(i.name) AS index_name, IndStat.avg_fragmentation_in_percent, IndStat.partition_number, (SELECT count (*) FROM sys.partitions p WHERE p.object_id = IndStat.object_id AND p.index_id = IndStat.index_id) AS partition_count FROM sys.dm_db_index_physical_stats (DB_ID(@db_name), OBJECT_ID(@table_name), NULL, NULL , 'LIMITED') AS IndStat INNER JOIN sys.objects AS o ON (IndStat.object_id = o.object_id) INNER JOIN sys.schemas AS s ON s.schema_id = o.schema_id INNER JOIN sys.indexes i ON (i.object_id = IndStat.object_id AND i.index_id = IndStat.index_id)WHERE IndStat.avg_fragmentation_in_percent > 10 AND IndStat.index_id > 0
Если указать @table_name = NULL, тогда мы получим данные по всем таблицам указанной базы. Если указать и @db_name = NULL - получим информацию по всем таблицам всех баз.Естественно, для выполнения этого запроса нужно обладать некоторыми правами:
- CONTROL на специфический объект БД.
- VIEW DATABASE STATE для получения информации обо всех объектах определенной БД (@object_id = NULL).
- VIEW SERVER STATE - для получения информации обо всех базах сервера (@database_id = NULL).
Так же перед использованием желательно обновить статистику БД.
Вышеприведенный запрос дает только справочную информацию. Но на основании функции sys.dm_db_index_physical_stats можно построить скрипт или хранимую процедуру, которая будет не только определять список индексов, нуждающихся в перестройке, но и будет сама проводить эту операцию.Один из вариантов такого скрипта приведен ниже (проводит реорганизацию или перестройку(оффлайн) индексов таблиц текущей базы в зависимости от степени фрагментации):
USE [DATABASE]; GOSET NOCOUNT ON;DECLARE @objectid int;DECLARE @indexid int;DECLARE @partitioncount bigint;DECLARE @schemaname nvarchar(130);DECLARE @objectname nvarchar(130);DECLARE @indexname nvarchar(130);DECLARE @partitionnum bigint;DECLARE @partitions bigint;DECLARE @frag float;DECLARE @command nvarchar(4000);DECLARE @dbid smallint;
-- Выбираем индексы с уровнем фрагментации выше 10%-- Определяем текущую БД
SET @dbid = DB_ID();SELECT [object_id] AS objectid, index_id AS indexid, partition_number AS partitionnum, avg_fragmentation_in_percent AS frag, page_countINTO #work_to_doFROM sys.dm_db_index_physical_stats (@dbid, NULL, NULL , NULL, N'LIMITED')WHERE avg_fragmentation_in_percent > 10.0 AND index_id > 0 -- игнорируем heapAND page_count > 25; -- игнорируем маленькие таблицы
-- объявляем курсор для списка обрабатываемых partitionDECLARE partitions CURSOR FOR SELECT objectid,indexid, partitionnum,frag FROM #work_to_do;
OPEN partitions;
-- цикл по partitionWHILE (1=1)BEGINFETCH NEXTFROM partitionsINTO @objectid, @indexid, @partitionnum, @frag;IF @@FETCH_STATUS 0 BREAK;SELECT @objectname = QUOTENAME(o.name), @schemaname = QUOTENAME(s.name)FROM sys.objects AS oJOIN sys.schemas AS s ON s.schema_id = o.schema_idWHERE o.object_id = @objectid;
SELECT @indexname = QUOTENAME(name)FROM sys.indexesWHERE object_id = @objectid AND index_id = @indexid;SELECT @partitioncount = count (*)FROM sys.partitionsWHERE object_id = @objectid AND index_id = @indexid;
-- 30% считаем пределом для определения типа обновления индекса.IF @frag 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REORGANIZE';IF @frag >= 30.0 SET @command = N'ALTER INDEX ' + @indexname + N' ON ' + @schemaname + N'.' + @objectname + N' REBUILD';IF @partitioncount > 1 SET @command = @command + N' PARTITION=' + CAST(@partitionnum AS nvarchar(10));
EXEC (@command);PRINT N'Выполнено: ' + @command;END;
CLOSE partitions;DEALLOCATE partitions;
-- удаляем временную таблицуDROP TABLE #work_to_do;GO
Еще посмотреть примеры скриптов/хранимок можно тут или вот тут.
Операцию по устранению дефрагментации индексов рекомендуется проводить регулярно (например, раз в неделю/месяц - в зависимости от величины операций модификации над хранимыми данными). Индексы, за состоянием которых не следят, могут очень существенно "просадить" производительность БД при исполнении запросов.
community.terrasoft.ru
НОУ ИНТУИТ | Оптимизация работы серверов баз данных Microsoft SQL Server 2005
Форма обучения:
дистанционная
Стоимость самостоятельного обучения:
бесплатно
Доступ:
свободный
Документ об окончании:
Уровень:
Специалист
Длительность:
17:53:00
Выпускников:
112
Качество курса:
4.49 | 4.15
В курсе дается исчерпывающее объяснение вопросов извлечения и анализа данных, в том числе, данных из удаленных источников, посвящена доступу к SQL Server через интернет, приводится подробное описание некоторых функциональных возможностей, которые делают SQL Server вполне комплексным решением. Среди этих функций - средства выполнения транзакций, аудита, создания отчетов и уведомлений, а также новые функции, такие, как улучшенная поддержка XML.
В курсе рассказывается о том, как извлечь данные, хранящиеся в базе данных; описывается использование агрегатных функций для превращения данных в информацию путем подсчета итогов и анализа, проектирование баз данных, извлекающих данные с максимально возможной скоростью, предоставление пользователям гибких механизмов просмотра данных, связывание данных из других источников и соединение с сервером SQL Server через интернет. Изучаются дополнительные функциональные возможности: использование транзакций для проверки целостности данных, хранение информации о событиях, происшедших в вашей среде, проектирование отчетов при помощи служб составления отчетов Reporting Services и обновление приложений при изменении данных через службы уведомлений Notification Services.
Теги: .net, ADF, BID, microsoft word, oracle, READ COMMITTED, sql, xml, базы данных, безопасность, вложенная транзакция, кластеризованные индексы, монопольная блокировка, некластеризованные индексы, оптимизатор запросов, поиск, приложения, протоколы, процедуры, разделяемая блокировка, серверы, сортировка, статистика, уровень изоляции, форматы, элементыПредварительные курсы
2 часа 30 минут
-
Вычисление агрегатов Прочитав эту лекцию, вы сможете: использовать в приложениях агрегатные функции для возвращения итоговых и других сводных результатов данных, использовать эти функции для повышения производительности и расширения функций приложений, использовать агрегатные функции CLR (общеязыковой среды выполнения) для выполнения специализированных вычислений-
Повышение производительности запроса Прочитав эту лекцию, вы сможете: генерировать планы запросов, Читать планы запросов, разрабатывать базы данных в соответствии с планируемым способом использования данных, применять кластеризованные и некластеризованные индексы, индексировать столбцы XML, индексировать представления, выполнять дефрагментацию индексов, использовать Помощник по настройке ядра СУБД-
Динамическое построение запросов Прочитав эту лекцию, вы сможете: создавать запросы при помощи Конструктора запросов SQL Server Management Studio, извлекать информацию о базе данных из системных таблиц базы данных, динамически создавать простые запросы на основе пользовательского ввода, форматировать пользовательский ввод и фильтровать сложные динамические запросы, выполнять синтаксический анализ и переформатировать данные для использования в фильтре, защитить базу данных от атак типа "SQL-injection", использовать процедуру sp_executeSql для передачи запроса-
Работа с данными из удаленных источников Прочитав эту лекцию, вы сможете: устанавливать нерегламентированные соединения с различными источниками данных при помощи T-SQL, настроить связанный сервер при помощи T-SQL, настроить связанный сервер через интерфейс Microsoft SQL Server Management Studio, обновить данные на удаленном источнике данных-
Чтение данных SQL Server через интернет Прочитав эту лекцию, вы сможете: безопасно подключиться к серверу SQL Server из внешней сети с использованием протокола передачи данных TCP/IP, безопасно подключиться к серверу SQL Server из внешней сети с использованием протокола передачи данных HTTP, безопасным способом обратиться к данным, хранящимся в базе данных SQL Server с удаленного компьютера, не демонстрируя пользователям внешней сети SQL Server-
Хранение архивных данных Прочитав эту лекции, вы сможете: Создавать и использовать моментальные снимки базы данных, разрабатывать эффективные таблицы хроники для вывода итогов по архивным данным, создавать и использовать индексированные представления для вывода итогов по архивным данным, создавать столбцы и таблицы аудита для отслеживания изменений в данных, использовать таблицы аудита для восстановления потерянных данных-
Введение в службы Reporting Services Прочитав эту лекцию, вы сможете: разобраться в системе создания отчета с точки зрения решения для технологии и бизнеса, разобраться в архитектуре служб Reporting Services, создать основной отчет с рядом дополнительных функций, добавить в отчет сводную информацию, настроить фильтр для данных отчета, создать в отчете возможности интерактивной настройки фильтрации и сортировки, добавить в отчет программный код-
Введение в службы Notification Services Прочитав эту лекцию, вы сможете: понимать приложения уведомления как технологию, понимать приложения уведомлений как бизнес-решения, понимать архитектуру служб Notification Services, создать и развернуть основное приложение уведомлений-
www.intuit.ru
Оптимизация приложений на базе SQL Server
Published on06-Feb-2016
View53
Download0
DESCRIPTION
DAT305. Старший консультант. [email protected]. Оптимизация приложений на базе SQL Server. Дмитрий Артемов. - PowerPoint PPT Presentation
Transcript
Оптимизация приложений на базе SQL Server DAT305 Оптимизация приложений на базе SQL Server Дмитрий Артемов Старший консультант [email protected] Analyzing Oracle wait events is the most important performance tuning task you’ll perform when troubleshooting a slow-running query. When a query is running slow, it usually means that there are excessive waits of one type or another Зачем я здесь? Вторая из двух презентаций, в которых я постараюсь дать сводную картину инструментария, доступного в SQL Server 2008 R2 для анализа ситуации, выявления проблем и оптимизации инфраструктуры и приложения (кода и индексной схемы) План Введение – DMV/DMF Указатели оптимизатору, польза и вред Кеширование запросов\повторное использование планов Как правильное кодирование позволяет оптимизировать использование кеша - параметризация Оптимизация индексной схемы (кластерный \ некластерный \ фильтрованный) Все ли индексы нам нужны и от каких можно избавиться Средства поиска проблемного кода Интерпретация результатов от DMV Введение – DMV/DMF DMV/DMF – системные представления/функции, позволяющие заглянуть внутрь SQL Server SQL Server 2008 R2 + SP1: 141 штука Не все описаны в OFFLINE документации SQL Server 2012 : 174 штуки Именованы по подистемам: dm_db/os/io/exec…* В этой части мы будем в первую очередь рассматривать DM_EXEC_*, DM_TRAN_*, DM_DB_*,… Первая презентация рассматривала DM_OS_*, DM_IO_*,… Указатели оптимизатору: польза и вред При использовании указателей нужно тщательно тестировать Часто обновление статистики снимает необходимость использования указателя Однако, если оптимизатор настойчиво ошибается в построении плана, можно зафиксировать план указателем Некоторые указатели фиксируют структуру плана (например FAST n требует обязательного использования LOOP JOIN) Часто полезным оказывается RECOMPILE для устранения проблем с параметризацией Иногда указание HASH JOIN существенно повышает производительность Явное указание MAXDOP поможет ускорению тяжелых запросов Ккеширование, планы, память Кеширование запросов Кеширование обеспечивает повторное использование планов Снижается загрузка процессора Повышается скорость исполнения запросов Интенсивные компиляции могут «уложить» даже мощный сервер SQL Server управляет очередью компиляций через три шлюза DBCC MemoryStatus: Small/Medium/Big Gateway Нужно _очень_ постараться, чтобы забить шлюзы, но это возможно Кеширование запросов sys.dm_exec_cached_plans – полный список планов в кеше refcounts, usecounts – индикация повторного использования планов size_in_bytes – размер плана в кеше plan_handle – ссылка на план sys.dm_exec_query_plan(plan_handle) query_plan – план в формате XML Статистика по выполненным запросам sys.dm_exec_query_stats – на уровне команд sys.dm_exec_procedure_stats – на уровне процедур Накопленная с момента старта сервера При вытеснении плана из кеша информация теряется SQL Server 2008 R2 SP1 получил доп. информацию total_rows, last_rows, min_rows and max_rows Полезно знать различия в выдаче, возможно потребуется RECOMPILE Представления позволяют найти проблемные запросы sys.dm_exec_query_stats Накопленная статистика исполнения по индивидуальным запросам/планам query_hash, query_plan_hash – хеш запроса/плана. Позволяет группировать сходные планы/запросы 11 Статистика по выполненным запросам Сортировка по total_worker_time,total_physical_reads, total_logical_writes, total_logical_reads, возможно поделенные на execution_count, выделяет тяжелые запросы (total_elapsed_time - total_worker_time) позволит определить запросы, которые долго ожидали выполнения Если речь идет о процедуре, то sql_handle и plan_handle одинаковы для запроса и процедуры С помощью statement_start_offset и statement_end_offset можно вычленить текст запроса plan_generation_num позволяет определить число рекомпиляций запроса query_hash, query_plan_hash – хеши запроса и плана позволяют группировать похожие планы и запросы Хеш запроса рассчитывается при компиляции, пробелы, */полный список полей, (не) квалифицированное имя объекта не влияют на хеш Запросы, имеющие одинаковый хеш запроса, но разные значения хеш плана, могут нуждаться в параметризации Планы запросов sys.dm_exec_query_plan (plan_handle) – выводит план запроса в XML Сохраняем с расширением .sqlplan и можем исследовать Иногда текст массивного запроса не попадает в план целиком и нужно добавить выборку из sys.dm_exec_sql_text для получения текста запроса В плане можно найти значения параметров, с которыми план компилировался При первой компиляции Планы нужно как-то смотреть В порядке удобства SQL Sentry Plan Explorer – бесплатная утилита (http://www.sqlsentry.net) XML Notepad – бесплатная утилита (http://msdn.microsoft.com/xml) SQL Server Management Studio Почувствуйте разницу Управление памятью Давление на память может быть внешним и внутренним Внешнее давление – от процессов в системе SQL Server может начать сокращение используемой памяти (если нет настройки Lock pages in memory) Внутреннее – результат завышенных требований от компонентов внутри SQL Server Компоненты, требующих выделения больших страниц (за рамками Buffer pool) Запросы, требующие слишком много памяти SQL Server начинает перераспределять память между компонентами кеша Управление памятью По мере необходимости компоненты управления памятью балансируют объемом для оптимизации работы сервера Уведомление → Менеджер памяти → Memory clerk → Clock hand Если мы видим, что какая-то «стрелка» постоянно движется, нужно искать причины Типов кеша существует несколько: CACHESTORE_OBJCP - triggers,stored procs, functions the CACHESTORE_OBJCP is used to cache the object compile plan. CACHESTORE_SQLCP - Adhoc and prepared sql will be used as queries to be stores in the SQLCP cachestore. CACHESTORE_PHDR - created for views and contains parsing and algebrized tree (so during query optimization). CACHESTORE_XPROC - used by system Xprocs. Xprocs are predefined sps like sp_executesql, sp_cursor*, sp_Trace*. CACHESTORE_TEMPTABLES - store temp objects (local temp table, global temp table, table variable) CACHESTORE_CLRPROC - SQLCLR procedure cache CACHESTORE_EVENTS - used to store event notifications for Service Broker purposes CACHESTORE_CURSORS - Local TSQL cursors, Global TSQL cursor, and API cursors to be stored in this cachestore USERSTORE_TOKENPERM - This cache is used to store all login/user tokens as well as respective permission and access caches. USERSTORE_OBJPERM - An instance of this cache is created for each database and an additional one for server objects Сервер управляет памятью сам и делает это динамически (в пределах установленных лимитов) Кеш процедур: (75% памяти от 0 до 4 Гб) + (10% памяти от 4 до 64 Гб) + (5% памяти более 64 Гб) Потребление памяти sys.dm_exec_query_resource_semaphore Общая информация по потреблению памяти: выделение, ожидание,… sys.dm_exec_query_memory_grants Выделение памяти для текущих запросов Помогает найти запросы с чрезмерными требованиями или оценить ситуацию с нехваткой памяти ideal_memory_kb column – «идеальное» требование к памяти на основе оценки выдачи записей requested_memory_kb – запрошенный объем памяти, по достижении максимума может снижаться Если requested_memory_kb > used_memory_kb, возможно это план с завышенным самомнением Используйте plan_handle, sql_handle, чтобы найти _его_ Содержимое буфера sys.dm_os_buffer_descriptors Показывает все страницы, находящиеся в памяти database_id file_id page_id page_level allocation_unit_id На современном сервере хранит миллионы дескрипторов Любопытным можно посмотреть на динамику, оценить особенности буферизации… Очистка памяти DBCC FREEPROCCACHE [ ( { plan_handle | sql_handle | pool_name } ) ] – удаляет все или указанные планы из кеша FREESESSIONCACHE – очищает кеш с данными о соединениях распределенных запросов FREESYSTEMCACHE ( 'ALL' [, pool_name ] ) – принудительно удаляет неиспользуемые элементы из кеша FLUSHPROCINDB (db_id) – удаляет планы, относящиеся к определенной БД Транзакции Транзакции sys.dm_tran_locks request_status – поиск ожиданий sys.dm_tran_session_transactions Session_id - связка sys.dm_tran_database_transactions Транзакции по всем БД сервера (database_id) database_transaction_log_* - анализ использования журнала транзакций sys.dm_tran_current_transaction Транзакции в сессии. Если не используется snapshot isolation, нам не нужно sys.dm_tran_active_transactions Используя связку через session_id можно найти, кто застрял на исполнении, а там и до плана/текста недалеко Индексы Краткое вступление Кластерный, некластерный, фильтрованный,… Кластерный ключ - узкий, уникальный, статичный, монотонно возрастающий Кластерный индекс – вещь нужная Дефрагментация таблицы Секционирование Поиск Особенно по диапазону, но и точечный хорошо работает Стабильность некластерных индексов при расщеплении страниц Индексы sys.dm_db_index_operational_stats (db_id, object_id, index_id, partition_number) Операционная информация по индексам: вставки, сканирование, ожидания, блокировки По мере заполнения/очистки кеша информация по индексам может появляться/исчезать Индексы sys.dm_db_index_usage_stats Включает только то, что хоть раз было использовано с момента рестарта сервера Выдает информацию по всем индексам всех БД (фильтр по database_id = …) Не понимает секционирования Включает некластеризованную таблицу как индекс (index_id = 0) Насколько полезен индекс user_seeks + user_scans + user_lookups VS user_updates User_lookups – для кластерного индекса (отслеживает Bookmark lookup’ы) Индексы sys.dm_db_index_physical_stats Физическое состояние индексов: количество записей, фрагментация на всех уровнях, различные уровни детализации Способна выдавать информацию на уровне сервера (все БД), отдельной БД, отдельной таблицы, отдельного индекса, отдельной секции По умолчанию используется режим DEFAULT=NULL=LIMITED Листовой уровень индекса не сканируется Для некластеризованных таблиц информация берется из PFS & IAM страниц, страницы данных не сканируются Часть полей выходного набора = NULL SAMPLED – сканируется 1% страниц Если таблица имеет менее 10 000 страниц используется режим DETAILED DETAILED – полное сканирование На больших таблицах – долго и затратно Лирическое отступление Индексы и использование GUID Примерно на порядок медленнее вставки и на порядок больше IO По сравнению с индексированием по «нормальным» типам (например INT, BIGINT) Фрагментация 99.9(9)% - нарастает очень быстро Дефрагментация не имеет смысла Тут же возвращается За счет уплотнения страниц резко возрастает число расщеплений и производительность падает очень сильно Использование секционирования позволяет поддерживать производительность на желаемом уровне Размер секции нужно подбирать (зависит от объема данных, не числа записей) Производительность держится даже без использования кластерного индекса Лирическое отступление Индексы и производительность Факт Индексы повышают скорость выборки Индексы снижают скорость модификаций Вопрос А на сколько снижается скорость вставки? Ответ В нашем тесте, на таблице из 45 полей было построено 33 индекса Производительность вставки упала вдвое (всего вставили 1 000 000 000 записей) Тестируйте ваш подход!! Дефрагментация Если индекс есть, все просто – REBUILD / REORGANIZE там, где нужно/полезно Некластеризованная таблица Если только вставки, то фрагментация может быть и так невелика CREATE / DROP Clustered index – фрагментация частично возвращается ALTER TABLE REBUILD – вообще непонятно что происходит Не все однозначно Лучше все-таки иметь кластерный индекс Отсутствующие индексы sys.dm_db_missing_index_* Каждый раз, когда оптимизатор создает план и видит, что наличие того или иного индекса может улучшить производительность, он помещает в план раздел По данным которого можно спланировать оптимизацию индексной схемы Отсутствующие индексы По счастью, не нужно разбирать план sys.dm_db_missing_index_details sys.dm_db_missing_index_group_stats sys.dm_db_missing_index_groups Позволяют найти наиболее полезные индексы и построить команду CREATE INDEX Missing index details equality_columns, inequality_columns, included_columns, statement Missing index group stats avg_total_user_cost * avg_user_impact * (user_seeks + user_scans) Отсутствующие индексы Нужно помнить о некоторых ограничениях Не предназначена для тонкой настройки конфигурации индексирования. Не может собирать статистику более чем о 500 группах отсутствующих индексов. Не указывает порядок использования столбцов в индексе. Для запросов, содержащих только предикаты неравенства, возвращает менее точные сведения о стоимости. Сообщает только о столбцах включения для некоторых запросов, поэтому ключевые столбцы индекса необходимо выбрать вручную. Возвращает только необработанные сведения о столбцах, для которых индексы могут отсутствовать. Не предлагает отфильтрованные индексы. Может возвращать различные стоимости для одной группы отсутствующих индексов, которая несколько раз встречается в отчете инструкции XML Showplan. Не рассматривает тривиальные планы запросов. Отсутствующие индексы Действительно, следует критически походить к предложениям и не строить слепо все, что предложено В основном следует строить наиболее полезные индексы Часто предлагается очень длинный список INCLUDE полей За построенными индексами нужно следить средствами sys.dm_db_index_usage/operational_stats Полезно именовать их особым образом Все вместе Как быть Найти ожидания Найти запросы, которые страдают от этих ожиданий Определить причину страдания Получить дополнительную информацию Найти пути обхода/устранения Протестировать Найти ожидания … Спасибо! Я готов ответить на ваши вопросы Пожалуйста, не забудьте заполнить форму с оценкой
docslide.net