продвижение блога и заработок в интернете. Оптимизация базы данных
Оптимизация базы данных блога | Заметки вебмастера
 Здравствуйте, дорогие друзья!
Здравствуйте, дорогие друзья!
Рад Вас видеть снова на своём ресурсе!
Сегодня моя статья будет посвящена одной важной теме.
Информация, представленная здесь, обязательно будет полезна всем вебмастерам, которые нацелены на результат и постоянно трудятся над своими блогами, постоянно внедряя различные улучшения.
Вы когда-нибудь слышали о японской философии кайдзен? Она подразумевает постоянное непрекращающееся улучшение в любой сфере деятельности. Создание и развитие своего сайта, блога или любого другого интернет — ресурса не исключение.
Если Вы с этим согласны, то читайте дальше, и я расскажу о том отрицательном моменте, который неизбежно возникнет в процессе подобной деятельности.
Постоянное улучшение ресурса и негативные последствия
Рано или поздно у каждого начинающего вебмастера, после создания своего личного блога и его наполнения появляется ощущение, что что-то не в порядке. Сами статьи, какие — то куцые, дизайн не продуман, цветовая схема не та.
Начинают появляться мысли об улучшении ресурса, обновлении и исправлении различных недочётов. И вот вебмастера приступают к этой бурной деятельности, но не все знают, что каждое изменение или редактирование записывается в базу данных блога!
Например, при редактировании любой уже написанной статьи, сохраняется несколько её вариантов. В базе данных Вашего блога осуществляется копирование информации. Подобных копий может сохраниться в базе предостаточно.
 В базе данных хранятся также все комментарии, в числе которых одобренные, а также надоедливые спам — комментарии и даже те, которые находятся в корзине.
В базе данных хранятся также все комментарии, в числе которых одобренные, а также надоедливые спам — комментарии и даже те, которые находятся в корзине.
Вот вся эта информация постепенно накапливается и со временем начинает занимать достаточно большой объём в Вашей базе данных (БД). Это негативным образом отражается на скорости загрузки Вашего блога.
Мне лично не нравятся блоги, на которых страницы открываются по пол — часа. Вам, думаю, тоже находиться на таком ресурсе не доставит особого удовольствия.
Да и свободное дисковое пространство на сервере Вашего блога явно ограничено, а для его увеличения нужно оплатить дополнительную услугу хостингу. К чему всё это? Лучше выбрать более эффективный метод.
Wp-optimize – плагин, который Вам поможет
Так вот. Чтобы предотвратить накапливание лишней и ненужной информации в своей базе данных, необходимо время от времени производить оптимизацию базы данных блога.
Этим сегодня и займёмся, а поможет нам в этом плагин WP-optimize. Этот плагин создан специально для подобной оптимизации базы данных блогов, созданных с помощью системы WordPress
Хочу отметить, что данный плагин проверен мною лично. Версия плагина свежая, так как недавно он обновился. WP-optimize также совместим с последней версией системы WordPress 3.9.1.
Я пользуюсь им уже более полугода и ни разу он меня не подводил. Глюков с его стороны тоже не наблюдалось. Одним словом, отличный плагин и здорово помогает в работе по очистке ненужного хлама!
Для того, чтобы им воспользоваться, нужно будет его скачать, установить и активировать. В моей предыдущей статье Вы найдёте для себя информацию о том, как искать и устанавливать плагины.
После установки и активации плагина WP-optimize, в Вашей админпанели слева появится вкладка WP-optimize. Нажмите на неё:
Откроется страница оптимизатора. Интерфейс данной программы достаточно простой и разобраться в нём не составит большого труда.
Все элементы будущей оптимизации представлены на русском языке. Итак, есть вкладка для проведения оптимизации, а также имеются ещё три вкладки: «Таблицы», «Настройки» и «Информация»:
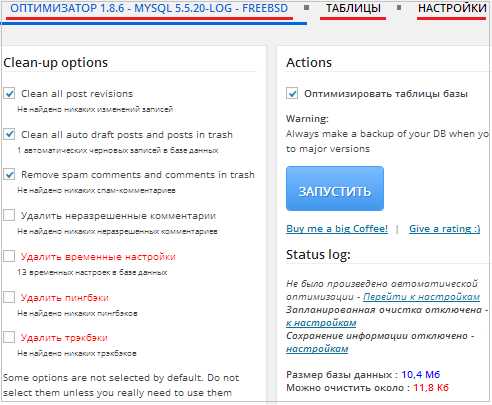
Нажмите на вкладку «Настройки» и откроется окно настроек. Здесь есть две колонки: Общие настройки и настройки автоматической оптимизации:
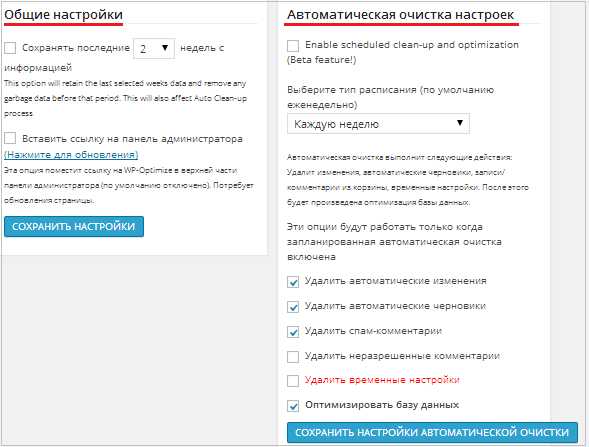
В общих настройках я не ставил метки в пунктах – они там не особо и нужны. Автоматической оптимизацией по расписанию тоже не пользовался, да и не считаю эту опцию необходимой.
Всё дело в том, что после проведения оптимизации базы данных вручную, у меня появляется возможность отключить (деактивировать) плагин WP-optimize и тем самым снизить нагрузку на сервер.
При автоматической очистке базы такая возможность исключается. Но это мой выбор и если Вы думаете иначе, то можете настроить автоматику по расписанию.
Теперь нажмите вкладку «Таблицы» и Вы увидите список всех таблиц базы данных Вашего блога. В колонке «Превышение» красным цветом отмечен объём ненужной информации определённых таблиц, которые нуждаются в оптимизации (нажмите на скрин для увеличения):
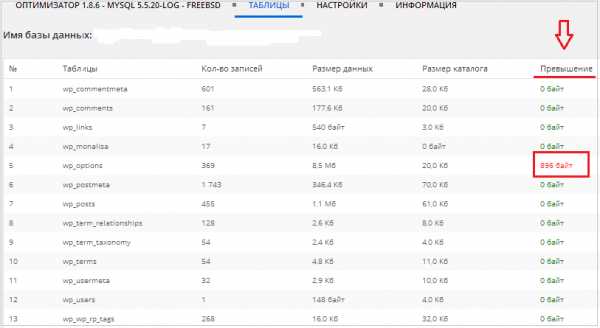
Оптимизация базы данных с помощью плагина Wp-optimize
Ну а теперь приступим непосредственно к самой оптимизации. Перед тем как начать очистку базы данных, я настоятельно рекомендую Вам сделать резервное копирование своей базы данных.
Кроме того, Вам нужно будет просмотреть все спам-комментарии, если у Вас установлен плагин Akismet как способ борьбы со спамом в комментах.
Это связано с тем, что данный плагин иногда отправляет хорошие комментарии в папку «Спам».
Также отсортируйте все неразрешённые комментарии в своей админке. После этого можно приступить к оптимизации.
Перейдите во вкладу «Оптимизатор» и установите метки напротив элементов, нуждающихся в оптимизации. Не забудьте поставить метку в поле «Оптимизировать таблицы базы данных». После чего нужно будет нажать кнопку «Запустить»:
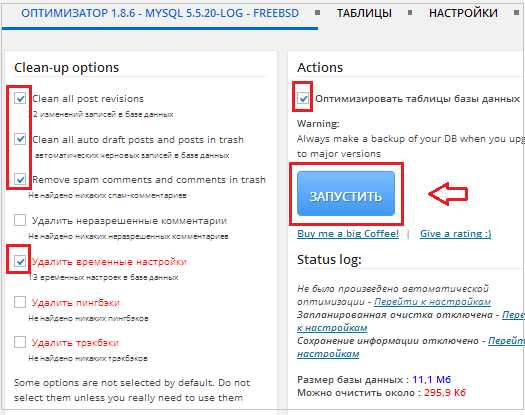
После процесса оптимизации, Ваша база данных очистится от ненужного хлама, а внизу появится информация о том, сколько было высвобождено пространства из Вашей базы:
Кстати, такую операцию по очистке БД, я проделываю после написания каждой статьи, перед тем как сделать резервную копию БД из Php Myadmin. Я советую делать также, если хотите жить и потом не тужить.
Если Вы впервые слышите об очистке баз данных блога, поспешите установить этот плагин и проверить, сколько мусора накопилось там.
А после оптимизации посмотрите, и обрадуйтесь тем десяткам, а может быть и сотням мегабайт свободного пространства на сервере, которое Вы вернули.
Но не всё так безоблачно. Данный плагин удаляет не все старые значения из базы данных. Подробнее об этом можете прочитать в другой моей статье: «Как удалить старые значения из БД».
Да, кстати, ещё об одном моменте. Я уже упоминал об этом ранее, но может Вы забыли. Если Вы чистите БД вручную, а не на автомате, то можете отключить плагин Wp-optimize после проведённой оптимизации.
Для этого просто зайдите в свою админку-> Плагины->Установленные. Найдите Плагин Wp-optimize и нажмите ссылку «Деактивировать»:
Всё, плагин отключен. Нагрузка на сервер уменьшилась.
Для того, чтобы снова начать оптимизацию своей базы данных, просто нажмите ссылку «Активировать».
Ну, вот и всё, друзья! Надеюсь, был полезен. Не забудьте подписаться на рассылку новостей моего блога, чтобы узнавать новую полезную информацию. Пока-пока!
Успехов Вам и Удачи С Уважением,
Другие интересные статьи:
saranchinsergey.ru
Оптимизация базы данных wordpress » Блог Николая Иванова
Маленький человек может сделать многое.
Доброго времени, коллеги!Приветствую Вас у себя на блоге.
Сегодняшняя статья для тех, кто использует WordPress. Она интересна и полезна для всех, потому что, не следя за состоянием базы данных своего сайта, в ней накапливается куча мусора.
Естественно мусор не в прямом смысле, а вся ненужная информация, которая не используется блогом, но оседает в базе.
Многие пользователи не знают, что при публикации новой статьи, Wordpres создает дубль страницу, а при добавлении в пост картинки образуется до десяти дублей изображений различного размера.
Кроме того, когда вы редактируете уже опубликованную статью, то ее копия также остается в базе данных. А о комментариях я вообще молчу. Это и спам в комментариях, и образование дублей, копий и так далее.
Теперь представьте, вы опубликовали 150 статей и получили вдобавок 150 дублей. Если в каждой статье установили по три изображения, то это уже около тысячи дублей.
А если вы неоднократно редактировали пост, внося какие-то изменения, то столько же копий осядет на дисковом пространстве, отведенного вам на хостинге.
Вот это и есть мусор, который раздувает вашу базу данных до огромных размеров. Я тоже был неведом о всех тонкостях WordPress, и однажды получил от техподдержки хостинга письмо о том, что мое дисковое пространство закончилось.
Мне нужно было либо купить дополнительное дисковое пространство, либо перейти на новый тариф с увеличенным объемом. Тогда я стал изучать проблему уменьшения объема базы данных.
Оказывается, можно высвободить достаточно места дискового пространства, если оптимизировать базу данных. Многие предлагают использовать ручные методы удаления дублей постов и изображений, копий редактируемых статей, комментариев.
Но база данных очень капризная вещь. Если не знаешь ее тонкостей, можно потерять сайт в одно касание. Поэтому перед каждым удалением, изменением необходимо делать резервную копию.
Но ведь это затраты во времени как при создании резервной копии, так и при ручной обработке запросов на удаление из базы данных. Поэтому я не касаюсь в этой статье о ручной оптимизации базы данных, вы это сами найдете в интернете, а предлагаю поручить эту тонкую работу плагину.
Звать его WP-Optimize. Несмотря на то, что он на английском языке, сложного в настройках ничего нет. До его использования мое дисковое пространство на хостинге занимало 2000MB, а после работы плагина оно уменьшилось до 870MB.
Сама база данных WordPress имела объем в 37MB, а сократилась до 8,2MB. Для наглядности прилагаю скриншоты. Поэтому мне не пришлось покупать дополнительное дисковое пространство и не переходить на повышенный тариф хостинга.
Как установить плагин я рассказывать не буду, наверное, каждый это умеет. После его активации у вас в консоли панели управления сайтом появится значек плагина.
Жмите на него и переходите на страницу настроек.
Настройка плагина
На этой странице два столбца настроек. Правый–варианты удаления, левый-действия.
Выбираем и ставим галочку для удаления того, что не нужно в нашей базе данных.
- Первая галочка: Удаляем копии всех изменений в ваших постах.
- Вторая галочка: Удаляем все автосохранения измененных статей. Дело в том, что wordpress, пока вы редактируете статью, автоматически ее сохраняет.
- Третья галочка: Удаляем все спам комментарии.
- Четвертая галочка: Удаляем все не одобренные комментарии.
- Строки, отмеченные красным шрифтом не трогаем.
В правом столбце устанавливаем галочку напротив первой строки для начала оптимизации базы даны и жмем на синюю кнопку «Process».
В самом низу этого столбца появиться цифра с объемом вашей оптимизированной базы данных. Сравните ее с той, что была до оптимизации.
Но перед этим не забудьте сделать резервную копию базы данных.
Далее в правом верхнем углу страницы выбираем вкладку «SETTINGS» и переходим к основным настройкам и настройкам автоудаления.
Другими словами вы можете проводить оптимизацию базы вручную, как было рассказано выше, или установить срок проведения оптимизации и поручить это делать плагину автоматически.
В первой строке левого столбца, можно установить срок сохранения последних данных в базе от 2,4,6 и так далее недель. Все остальные данные до этого периода будут удаляться. Выбирайте сами.
Галочка во второй строке покажет в верхней панели управления сайтом ссылку с названием плагина. Она появится после обновления страницы.
Далее, выбираем включение или отключение трекбэков и пингов и сохраняем созданные настройки. Я оставляю эти функции влюченными. Вам,наверное, не терпится спросить, что такое трекбэки и пинги?
Пинг – это автоматический сигнал источнику, которого вы отмечаете у себя в статье открытой ссылкой. Кстати WordPress обладает этой функцией и через указанные в настройках сайты передает пинги.
Получив сигнал о вашей ссылке, источник в ответ размещает обратную безанкорную ссылку на ваш ресурс с названием статьи. Это и есть трекбэк.
В правом столбце отмечаем галочкой автоматическую оптимизацию, устанавливаем график проведения очистки базы данных, далее отмечаем удаление сохраненных редакций статей, удаление автосохранений, удаление спам комментарии.
Затем, ставим галочку на «Optimize database» и если хотите получать на свой еmail сообщения о проведенной оптимизации, то ставьте галочку, указывайте электронную почту и сохраняйте автонастройки.
Все. Забудьте о хламе в базе данных. Сравните объем дискового пространства, занятого на хостинге до и после оптимизации, а также объем базы, и вы будете приятно удивлены.
В следующей статье я начинаю рассказывать об удалении аккаунтов и данных в социальных сетях. Первый пост о том «Как удалить аккаунт в Google».
Это все на сегодня.
Пока.
С вами был Николай Иванов.
НЕ ЗАБУДЬТЕ ОСТАВИТЬ КОММЕНТАРИЙ ИЛИ КЛИКНУТЬ ПО ЛЮБОЙ СОЦКНОПКЕ.Поделиться ссылкой:
Понравилось это:
Нравится Загрузка...
somemoreinfo.ru
Оптимизация производительности модели данных: настройка базы данных | Windows IT Pro/RE
Лучший способ решения проблем с производительностью — просто не допустить их
Оптимизация производительности базы данных SQL Server начинается с выбора корректной конфигурации базы данных и модели данных. Можно повысить быстродействие, дополнив базу данных индексами различных типов и более мощными аппаратными средствами, но полностью ликвидировать недостатки модели данных все равно не удастся. Следствием неудачной конфигурации базы данных или модели данных может стать слишком большое время отклика системы, блокированные или зависшие транзакции, неверные или неточные результаты при подготовке бизнес-отчетов, рассинхронизация данных, несогласованность данных и невозможность составить запрос для извлечения нужных данных. Но неудачная модель данных — не единственная причина таких проблем. Например, медленный отклик системы может быть результатом перегруженности сервера. Неудачное сочетание обновлений транзакции от конфликтующих приложений может привести к зависанию или блокировке. Следует всегда тщательно исследовать причины неполадок. Если не удается обнаружить перегруженный процессор или конфликт между двумя транзакциями, которые пытаются монопольно завладеть одним информационным ресурсом, необходимо внимательно рассмотреть конфигурацию базы данных и модели данных; именно они могут быть причиной неприятностей.
Для построения базы данных, поведение которой будет полностью соответствовать ожиданиям, нужно в первую очередь рассмотреть ее фундамент. Начинать следует с оптимизации операционной системы. Затем требуется настроить конфигурацию базы данных для поддержки корректной модели данных и сохранения их целостности. Заранее продумывая конфигурацию базовых элементов, можно предотвратить многие проблемы производительности и создать условия для повышения общего быстродействия базы данных.
Подготовка среды
Оптимизация производительности SQL Server начинается с операционной системы Windows. SQL Server может работать только в среде Microsoft, поэтому исключительно важное условие успеха — взаимопонимание с системным администратором Windows. Два важнейших параметра сервера базы данных — файловая система и файл подкачки. Для SQL Server следует использовать файловую систему NTFS — она более стабильна и лучше защищена, нежели FAT, хотя считается, что операции записи чуть быстрее выполняются в FAT. При настройке файла подкачки практическое правило для виртуальной памяти — установить статический размер в 1,5 раза больше размера физической памяти. Кроме того, если какой-нибудь компонент сервера, такой как сетевая плата или жесткий диск, переходит в режим ожидания после периода неактивности, то следует запретить переход в режим ожидания (или поручить сделать это системному администратору). Лучше не рисковать необходимостью «холодной» загрузки для активизации элемента компьютера. В многопротокольной среде следует убедиться, что TCP/IP — первый в наборе протоколов. Если сетевые соединения имеют малую пропускную способность, то нужно, чтобы стандартная величина тайм-аута при регистрации превышала время регистрации приложений, использующих базу данных.
В дополнение к оптимизации операционной системы для работы с SQL Server следует повысить отказоустойчивость среды. Для надежности и быстродействия я рекомендую использовать для SQL Server массив RAID. Решение RAID может быть дорогостоящим, но средства, отпущенные на его приобретение, будут потрачены не зря, если продуманно выбрать оптимальный тип RAID для данной среды, определив части базы данных, которые требуется защитить в первую очередь. Объяснения различных типов систем RAID и их преимуществ приведено во врезке «SQL Server на массиве RAID».
Оптимизация производительности SQL Server невозможна без корректной конфигурации базы данных. Для повышения быстродействия базы данных следует отнести основные типы данных, которые предстоит хранить в базе, к отдельным группам файлов. Нужно отделить системные таблицы от пользовательских таблиц, данные от индексов, табличные данные от изображений, текста и n-текста (ntext используется для хранения строк символов Unicode). Применяя эту схему для разделения данных на несколько групп файлов, можно построить чрезвычайно масштабируемую базу данных. Напомню, что масштабируемость — это возможность увеличить число обрабатываемых транзакций без снижения производительности. В малых системах можно собрать все файловые группы на одном диске (за исключением журнала транзакций, который следует всегда хранить на другом диске, отдельно от прочих данных). По мере расширения системы, увеличения числа пользователей и объема данных, можно перемещать различные группы файлов на отдельные диски, тем самым распределяя рабочую нагрузку между несколькими дисками. Благодаря разделению базы данных на несколько групп файлов управление резервным копированием упрощается. Можно использовать группы файлов для резервного копирования очень больших баз данных (very large database, VLDB) во временном окне, отведенном для копирования базы данных. Более подробная информация об использовании групп файлов для резервного копирования приведена в статье Кимберли Трипп «Пока не грянул гром» на сайте www.windowsitpro.ru по адресу http://www.osp.ru/win2000/sql/200309sq477.htm. Группы файлов можно использовать и для горизонтального разделения, которое описано в статье «Возвращение к жизни» по адресу http://www.osp.ru/win2000/sql/admsecrets/401_1.htm (www.windowsitpro.ru). При проектировании высокопроизводительной базы данных группы файлов — полезный инструмент, который поможет избежать возникновения проблем еще до начала работы.
Исходный текст в листинге 1 иллюстрирует мой обычный способ построения базы данных. Каждая группа файлов имеет три имени: имя группы файлов, логическое имя файла и физическое имя файла. Эти имена можно увидеть, открыв любое окно свойств базы данных, а затем выбрав вкладку Data Files. На этой вкладке элементы столбца Filegroup соответствуют PRIMARY и именам групп файлов, которые приведены в первой части листинга 1. Элементы в столбце Location — это имена физических файлов, в которые входит полный путь к месту хранения физического файла на жестком диске. Системные таблицы SQL Server следует поместить в группу PRIMARY, а пользовательские таблицы и индексы — в соответствующие группы файлов, отдельно от системных таблиц SQL Server. Изображения и текстовые данные размещаются в собственной группе файлов, как показано во фрагменте исходного текста с меткой A (листинг 2).
Параметры конфигурирования, следующие за командой CREATE DATABASE, устанавливаются в соответствии со стандартом ANSI SQL-92. Возможно, один или несколько параметров придется изменить в соответствии с требованиями конкретного предприятия. Следует убедиться, что заданные параметры конфигурирования совместимы с конкретной средой.
Целостность — обязательное условие
Следующий шаг в оптимизации производительности базы данных — настроить SQL Server на принудительную целостность ссылок. Например, между таблицами Store и Sale в листинге 2, адаптированном из базы данных pubs, существует отношение зависимости. Продажа (Sale) не может осуществляться без связи со складом (Store). Целостность ссылок означает, что данная бизнес-связь реализуется одним из двух способов. Можно назначить эту задачу приложению вне SQL Server или предоставить SQL Server возможность установить данное правило. На мой взгляд, ведение статических правил, таких как целостность ссылок между Store и Sale, лучше предоставить базе данных. Исходный текст для правила составляется один раз (фрагмент с меткой B в листинге 2). Затем SQL Server применяет правило для всех пользователей базы данных. Если ввести правило с помощью приложения, то оно может исчезнуть из будущих версий этой программы или будет не распознано другими приложениями, которые обращаются к тем же данным. Это может привести к нарушениям целостности ссылок и, возможно, искажению данных.
В дополнение к обеспечению целостности ссылок внутри SQL Server я рекомендую использовать DRI (declarative referential integrity — декларативная целостность ссылок) вместо триггеров или хранимых процедур. DRI — ограничение, а ограничения исполняются более эффективно, чем триггеры или хранимые процедуры, особенно если для передачи данных в базу используются массивные операции загрузки информации.
В листинге 2 показано, как организовать DRI между таблицами Store и Sale. Как отмечалось выше, эти две таблицы адаптированы из базы данных pubs. Я изменила столбцы и вставила параметры, необходимые в хорошо организованной производственной среде, а также добавила несколько столбцов, чтобы проиллюстрировать влияние модели данных на производительность. Оператор CREATE TABLE для таблицы dbo.Store добавляет новый столбец, StorePhoto, в котором содержатся изображения. Следует отметить, что в последней строке оператора CREATE TABLE данные направляются на хранение в группу файлов MyDatabase_data, но связанные с ними изображения будут сохраняться в группе файлов MyDatabase_image.
Внешние ключи. Я всегда задаю ограничения для первичных и внешних ключей отдельно от оператора CREATE TABLE, чтобы иметь возможность управлять именами ограничений. Можно назначить столбец в качестве первичного ключа или внешнего ключа при создании таблицы, но я не делаю этого. Я предпочитаю отдельные операторы ALTER TABLE для ограничений первичных и внешних ключей. При проектировании модели данных приходится постоянно вносить изменения. Поэтому необходимо иметь возможность быстро идентифицировать различные ограничения.
Очевидно, что стандартные имена ограничений, назначаемых SQL Server, являются значимыми. Например, FK__sales__stor_id0AD2A005, имя оригинального ограничения внешнего ключа между Stores и Sales в моем экземпляре базы данных pubs, явно относится к внешнему ключу в таблице Sales, который использует столбец stor_id. Однако из имени ограничения нельзя понять, на какую таблицу производится ссылка. Мое соглашение об именовании, FK_Sale2Store, более краткое, и, хотя в моем имени не содержится информации о столбце, оно говорит о том, что Sale зависит от Store. Кроме того, мне не нужно выполнять запрос, чтобы получить полное имя ограничения. Достаточно следовать стандарту, установленному для имен ограничений внешнего ключа. Имя ограничения любого внешнего ключа будет начинаться с FK_, за которым следует имя зависимой таблицы, номер 2 и, наконец, имя независимой таблицы.
Индексация. SQL Server не строит индекс автоматически для столбцов внешнего ключа (в отличие первичного ключа в таблице). В производственной среде можно использовать столбцы внешнего и первичного ключей для операций слияния. Поэтому при создании новой базы данных следует построить индекс для каждого столбца внешнего ключа в каждой зависимой таблице. Как правило, эти индексы не кластеризованы. В одной из следующих статей я подробнее расскажу о кластеризации, а пока достаточно упомянуть, что кластеризация проводится по столбцу или столбцам, которые предстоит наиболее интенсивно использовать для извлечения данных. Можно даже подождать, пока база данных приблизится или достигнет производственного этапа, прежде чем принимать решение о кластеризации.
Иллюстрация данного подхода к кластеризации — кластеризованный индекс во фрагменте C листинга 2, который был построен для таблицы Sale с использованием StoreCode и SaleID. Отчеты о продажах будут выпускаться ежедневно или ежечасно и сортироваться сначала по магазинам (представленным StoreCode), затем по SaleID. Значения SaleID возрастают в течение дня (SaleID — идентификатор), поэтому они фактически представляют собой последовательные номера записей; как они, так и значения SaleID увеличиваются с каждой новой продажей. Большинство отчетов представляют собой итоговые отчеты с итоговыми данными по отдельным магазинам. StoreCode вместе с SaleID — отличный кандидат на кластеризацию. Благодаря кластерному индексу ускоряется извлечение данных, так как данные уже упорядочены — в данном случае сначала по Store Code, а затем, внутри каждого значения Store Code, по SaleID. Собственно, StoreCode связывает таблицу Sale с таблицей Store. Наличие двух индексов — одного кластерного, одного некластерного, каждый из которых начинается со StoreCode, возможно, избыточно, но в ходе эксплуатации базы данных можно будет увидеть, как SQL Server использует (или не использует) эти индексы. Если SQL Server не задействует некластеризованный индекс, то от него можно смело отказаться. Однако на стадии проектирования рекомендуется построить отдельный индекс для каждого столбца внешнего ключа, даже если поначалу это приведет к избыточности индексов.
Если возможно, следует определить стандартные значения и контрольные ограничения (check constraint задает диапазон значений элементов столбцов) в базе данных, а не на прикладном уровне по той же причине, по которой предпочтительно возложить на базу данных управление целостностью ссылок. Ограничения — объекты базы данных, поэтому они выполняются быстрее и эффективнее, чем программный код во внешнем приложении. Если правила, которые могут быть выражены по умолчанию, и контрольные ограничения статичны — не меняются каждую неделю или каждый месяц, то эти правила можно определить как ограничения столбцов или таблиц. В операторе CREATE TABLE dbo.Sale листинга 2 столбец SaleDate имеет стандартное значение CURRENT_TIMESTAMP. Это правило вряд ли изменится за все время эксплуатации базы данных, поэтому его удобно определить как ограничение столбца. Следующее правило, SalePayTerms, выражено как контрольное ограничение. SalePayTerms не может иметь значение NULL, и первоначально для SalePayTerms определены значения Net 30, Net 60 и On Invoice. Приложение не может изменить этот набор значений. Если нужно добавить значение в набор, то следует изменить данное ограничение столбца. Если предполагается, что набор значений будет часто изменяться, то более удобный способ ввести ограничение — составить просмотровую таблицу условий оплаты покупок, присвоить каждой строке таблицы уникальное значение в качестве идентификатора и сопоставить просмотровую таблицу с dbo.Sale в соотношении «один ко многим» (1:M). Отношение между просмотровой таблицей и dbo.Sale будет зависимым отношением, осуществляемым таким же образом, как отношение между dbo.Store и dbo.Sale.
Оптимизация производительности базы данных — огромная и важная тема, требующая понимания среды базы данных и большого практического опыта. Начинать оптимизацию удобно с изучения модели данных и требований бизнеса. Только после этого можно настроить модель данных на высокую производительность.
Мишель Пуле - Имеет сертификаты MCIS и MCP. Входит в число основателей консалтинговой компании Mount Vernon Data Systems, шт. Колорадо. В университете Дэнвера в качестве адъюнкта преподает программирование и проектирование баз данных. [email protected]
SQL Server на массиве RAID
Мне часто приходится слышать вопросы о повышении отказоустойчивости с помощью дисковых массивов RAID. Следует ли устанавливать SQL Server на устройстве RAID? Ответ — да, если вы можете себе это позволить. RAID — оптимальный способ обеспечить отказоустойчивость, а производственные базы данных, несомненно, предпочтительно размещать в отказоустойчивой среде. Стоимость серверных систем с RAID выше, чем обычных однодисковых серверов из-за дополнительных аппаратных средств и программного обеспечения, необходимого для массива RAID. Широко распространены несколько типов RAID, и у каждого есть своя особая область применения.
В RAID уровня 0 задействован метод расщепления данных, который формирует дисковый раздел, охватывающий несколько жестких дисков; при этом используются преимущества наличия нескольких рабочих головок чтения/записи на многих шпинделях (аналогично методу чередования в Windows NT). RAID уровня 0 — самый быстрый тип RAID, но в отличие от большинства реализаций RAID он не обеспечивает отказоустойчивости. Если один из дисков в массиве RAID 0 отказывает, то все данные теряются. Не следует использовать RAID 0 для хранения важных данных.
RAID 5 — самый распространенный способ реализации отказоустойчивости. Скорость выполнения транзакций чтения данных очень высока, а скорость транзакций записи данных также приемлема по сравнению с другими конфигурациями. Кроме того, RAID 5 обеспечивает хорошую агрегированную скорость пересылки данных. В типичную конфигурацию RAID уровня 5 входит три или более жестких дисков. RAID 5 расщепляет данные и записывает их фрагментами на все диски массива. Избыточность обеспечивается добавлением информации о четности данных, которую контроллер RAID извлекает из данных и которая записывается на все диски массива поочередно с данными. На основе информации о четности контроллер RAID может восстановить данные в случае отказа одного из дисков и потери или порчи сохраненных на нем данных. RAID 5 — наиболее экономичный способ реализации отказоустойчивости. Системные и пользовательские файлы SQL Server рекомендуется хранить на устройствах RAID 5.
В массиве RAID 1 используется зеркалирование (mirroring) — метод, при котором зеркальная копия каждого диска сохраняется на другом диске. Зеркалирование — самая отказоустойчивая конфигурация RAID, но одновременно и самая дорогостоящая из-за необходимости применения дополнительных аппаратных средств и программного обеспечения. SQL Server сохраняет данные последовательно в журналах транзакций и в TempDB, так что эти важные части базы данных хорошо приспособлены для защиты по RAID с уровнем 1. Журнал транзакций и TempDB следует разместить по крайней мере на устройстве RAID 1, даже если финансовые возможности компании не позволяют применить RAID для других частей базы данных.
RAID 10 — комбинация RAID 1 и RAID 0, в которой используются методы зеркалирования и расщепления. Это дорогостоящий, но самый быстрый вариант, который обеспечивает лучшие избыточность и производительность. В RAID 10 зеркалируется два или несколько дисков RAID 0. Если предприятие располагает достаточными средствами, то в целях дополнительной защиты лучше разместить журнал транзакций и TempDB на устройстве RAID 10, а не на RAID 1. Сравнение характеристик различных типов RAID приведено в учебнике по RAID компании Advanced Computer and Network Corporation (http://www.acnc.com/raid.html).
www.osp.ru
Очистка и оптимизация базы данных Word Press / webentrance.ru
Существует исключительно полезный плагин WP Optimize, который является, можно сказать, обязательным в арсенале любого сайтостроителя на движке WordPress, задачей которого является чистка и оптимизация базы данных сайта. Подробнее о базе данных можно почитать здесь.
Содержание:
Факторы, влияющие на утяжеление базы данных
Как известно, вся информация, все действия при работе с сайтом, сохраняются в базе данных. Например, вы сделали изменения в какой-то опубликованной статье, то есть вы редактировали статью и вот эта редакция сохраняется в базе данных. Если вы этих редакций делали очень много, то все они также сохранятся в базе данных.
Или такая опция, как автоматическое сохранение черновиков. Наверное, все обращали внимание, что при редакции какого-то поста идет сохранение в автоматическом режиме. Вот эти автоматические черновики тоже сохраняются в базе данных.
Также сохраняются там спам-комментарии, не сохраненные комментарии. Сохраняются в базе данных и пинк-беки. Пинк это такая часть вызова удаленных процедур. Например, на своем сайте вы сделали ссылку на какой-то сторонний ресурс.
Движок Word Press дает информацию в виде пинга на этот ресурсе. То есть, что ссылка на него создана. Сторонний сайт принимает этот пинг и проверяет, действительно ли создана эта ссылка и возвращает этот пинг обратно на ваш ресурс. Получается пинг-бек.
Только после того, как будет подтверждено создание ссылки, пинг-бек считается завершенным. Вот такие пинг-беки тоже сохраняются в базе данных.
Есть еще ред-бек. Это тот же самый пинг, но только информирующий поисковые системы о том, что на вашем ресурсе создана новая запись.
Все эти действия утяжеляют базу данных ресурса и он начинает медленней загружаться. Поэтому одной из основных задач при администрировании, это постоянно чистить базу данных.
Плагин WP Optimize именно этим и занимается, то есть чистит и выполняет оптимизацию базы данных в автоматическом режиме.
Установка плагина WP Optimize
Заходим в консоль сайта, вкладка Плагины – Добавить новый. Это плагин не зря называется WP, потому что он находится в библиотеке плагинов WordPress.
Вводим плагин WP Optimize в строку поиска и получаем его в выдаче на первом месте.

Кликаем Установить, соглашаемся с установкой и после успешной установки плагин активируем.
Плагин серьезный, поэтому он появляется в консоли сайта. Кликаем по нему и выходим на настройки. Он сразу же дает информацию о размере базы данных и сколько можно удалить из нее лишнего без ущерба для дальнейшей работы.
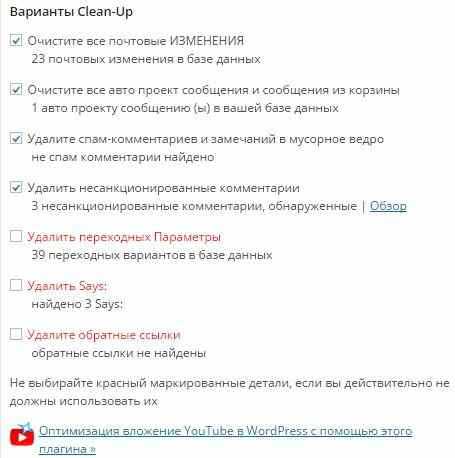
Оптимизация базы данных с плагином WP Optimize
При этом WP Optimize предлагает установить в чекбоксах галочки, напротив которых написано, за что он отвечает и какие изменения будут произведены.
Так, например, предлагается:
- удалить все изменения записей,
- автоматические черновики записей,
- спам-комментарии,
- неразрешенные комментарии,
- временные настройки,
- несвязанные метки сообщений,
- несвязанные ссылки,
- и предлагается оптимизация таблицы базы данных.
Если спуститься ниже, то можно увидеть, что там дается вся информация о базе данных, о размере файлов, которые там находятся и указано, какие базы данных надо оптимизировать. Так же указаны возможности оптимизации.
Если сейчас нажать на кнопку Запустить, то практически мгновенно будет произведена оптимизация базы данных и выдается информация, что было сделано, в частности, сколько освободилось места.
Далее заходим во вкладку Настройки и видим, что существует функция автоматической очистки базы данных. В общих настройках есть опция выбора промежутка времени, в течение которого информация будет сохраняться, например, в течение двух недель.
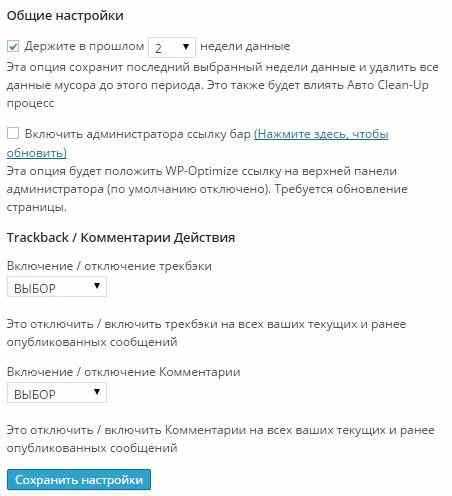
Есть возможность отображать постоянно в панели управления информацию о том, как происходит оптимизация и как изменяются ваши базы данных.
Можно включить запланированную очистку и оптимизация будет происходить через определенный промежуток времени. В нашем случае это будет две недели.
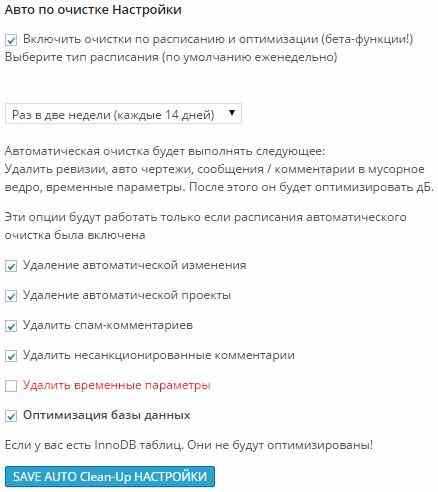
Тут же можно настроить – что нужно удалить. Это опять же автоматические изменения, автоматические черновики и т. д.
Таким образом, плагин WP Optimize выполняет чистку и происходит оптимизация базы данных сайта под управлением WordPress. В результате оптимизации базы данных, они остаются всегда в актуальном состоянии, что позволяет сайту быстрее загружаться.
Другие записи по теме:
webentrance.ru
Оптимизация работы базы данных - Базы данных, знаний и хранилища данных. Big data, СУБД и SQL и noSQL
Индексирование (ср-во ускорения операции поиска записей в табл., поиска, извлеч-я, модифик-ции, сортировки) в инд. Перечисл. знач-я опред. атрибутов с указ. стр. БД, содерж строки, где встреч соотв знач-е. Индексированный файл - основ-й файл, для кот-го созд-ся индексный файл. Индексный ф—ф особ типа, в котор. Кажд. запись сост. из 2 значен.: данн. и указателя номера записи. Данные предоставл. поле, по которому проводилось индексирование, а указатель осущ. связывание с соответствующей записью индексир-го файла. Если ф. большие, то и инд. ф. тоже. Не рекомнд. созд-ть инд. для всех полей, а для перв. ключей, для внешн. Ключей. Осн. преимущ. — значит ускорение процесса выборки или извлечен. данн., осн. недостат. — замедлен процесса обновления дан, т.к. при кажд. добавлен нов. зап. в индексир-ный файл потребуется добавить нов. индексн. файл. Поэт при выб. поля важно знать, кот-й из 2-х показат. важнее: скорость выборки или скор. обработки. В SQL-Create Index.
Особенности технологии хеширования. Хешированием называется технолог. быстрого доступа к храним записи на основе задан значен. некотор. поля. /в отл. от индекс-ния исрольз-тся только 1 хеш-поле). При хешир used некотор ф-ция для определ-я местоположен. любого элем данн. Осн особ-сти хешир: 1. кажд храним запись БД размещ-ся по адресу, кот-й вычисл-ся с пом. спец-й хеш-функции на основе значен. некотор. поля данн. записи. 2. для сохранен. зап в СУБД снач. вычисл-ся хеш-адрес нов. зап., после чего прогр-ма управлен. дисков памятью помещ. эту запись по вычисляемому адресу. 3. для извлечен. нужн. зап. по задан. значен хеш-поля в СУБД снач. выч-ся хеш-адр., затем в прогр. упр-я дисков памятью посыл-ся запрос на извлечен. записи по вычислен адр. Осн. преимущ. хеш-ия закл-ся в быстроте дост. к данным. Минус — сложность выбора подходящ. хеш-функции., возм-сть переполн., недост. наполн. страниц
Сжатие данных на основе различий.
С целью сокращения пространства, необходимого для хранения некоторого набора данных, часто используют технологии сжатия. При этом в результате экономится не только пространство на диске, но и количество дисковых операций ввода-вывода, т. к. доступ к данным меньшего размера требует меньше дисковых операций ввода-вывода. С другой стороны, для распаковки и извлечения сжатых данных требуются некоторые дополнительные манипуляции, но в целом преимущества сокращения операций ввода-вывода могут компенсировать недостатки, связанные с дополнительной обработкой данных.
Технологии сжатия основаны на малой вероятности того, что данные имеют совершенно беспорядочную структуру. Наиболее распространенной является технология сжатия на основе различий, при которой некоторое значение заменяется сведениями о его отличиях от предыдущего значения. Следует отметить, что для реализации такой технологии требуется размещать данные последовательно, поскольку для их распаковки необходимо иметь значение предыдущей величины. Такое сжатие весьма эффективно для данных, к которым необходим последовательный доступ, например для записей в одноуровневом списке. Более того, в таких случаях наряду с данными допускается также сжать и указатели. Дело в том, что если логическая последовательность в файле соответствует физической последовательности размещения данных на диске, то соседние указатели будут незначительно отличаться друг от друга, а значит, сжатие указателей может оказаться весьма полезным и эффективным. Суть сжатие на основе различий заключается в том, чт предусм-ет замену некот значен свед-ми о его отличиях от предыдущ значен.
Иерархическое сжатие. С целью сокращения пространства, необходимого для хранения некоторого набора данных, часто используют технологии сжатия. При этом в результате экономится не только пространство на диске, но и количество дисковых операций ввода-вывода, т. к. доступ к данным меньшего размера требует меньше дисковых операций ввода-вывода. С другой стороны, для распаковки и извлечения сжатых данных требуются некоторые дополнительные манипуляции, но в целом преимущества сокращения операций ввода-вывода могут компенсировать недостатки, связанные с дополнительной обработкой данных.
Иерархическое сжат — кажд. запись разбив-ся на постоян. и перемен., постоян. — кодируемая.
intellect.ml