Настройки PostgreSQL для работы с 1С:Предприятием. Оптимизация 1с postgresql
Тюнинг PostgreSQL 9.4.2-1.1C для 1С:Предприятия 8.3: рельаный опыт настройки
28 сентября 2016 ВК Tw Fb
Как только размер файловой базы данных 1С:Предприятие одного из наших клиентов достиг размера в 32Гб (да, 32Гб), в следствии чего всё постепенно начало тормозить, а потом и встало намертво, наши клиенты попросили нас решить эту проблемы. SSD Enterprise класса ненадолго подсластил пилюлю, но через некоторое время всё вернулось в исходную точку. Ну что ж, тут и к бабке не ходи – переходим на SQL версию БД.
Поскольку мы ярые пользователи Windows, доступно нам только два варианта СУБД – это MSSql и PostgreSQL. Первый хорош до безумия, но стоимость не порадовала. А ещё больше не порадовала новость о дополнительных лицензиях 1С для работы с MSSQL. Поэтому PostgreSQL.
Подробная инструкция с видео доступна здесь. В этой статье мы пройдёмся по ключевым моментам.
Не забываем про резервное копирование баз данных 1С!
Исходные данные:
- ОС Windows Server 2008R2,
- Intel Core i7-2600K 3.40GHz,
- 32Gb RAM,
- Intel SSD DC3700 100Gb (только под БД, ОС на отдельном SSD),
- от 10 до 20 пользователей в БД ежедневно,
- обмен с 5 узлами распределённой БД в фоне.
Зловеще, не правда ли? Приступим.
1. Установка PostgreSQL и pgAdmin.
Никаких откровений по поводу того, откуда качать PostgreSQL не будет — это наш любимый сайт https://releases.1c.ru, раздел «Технологические дистрибутивы». Скачиваем, ставим. Не забываем установить MICROSOFT VISUAL C++ 2010 RUNTIME LIBRARIES WITH SERVICE PACK 1, который идёт в архиве с дистрибутивом. Сами попались на это: не установили, испытали много боли.
Ставим всё на далее, далее, кроме следующих моментов. Устанавливаем, как сервис (галочка) и задаём параметры учётной записи Windows, не PostgreSQL.
Инициализируем кластер базы данных (галочка). А вот здесь задаём параметры учётной записи для PostgreSQL! Важно: у Вас должна быть запущена служба «Secondary Logon» (или на локализированных ОС: «Вторичный вход в систему»). Кодировка UTF8 — это тоже важно!
Дальше ничего интересного. Далее…
pgAdmin в этой сборке староват. Идём на https://www.postgresql.org/ftp/pgadmin3/release/. На момент написания статьи самая свежая версия 1.22.1. Качаем её, ставим. Заходим.
На процессе установки оснастки «Администрирование серверов 1С Предприятия» не будем останавливаться. Это совсем другая тема. Да и сложного там ничего нет.
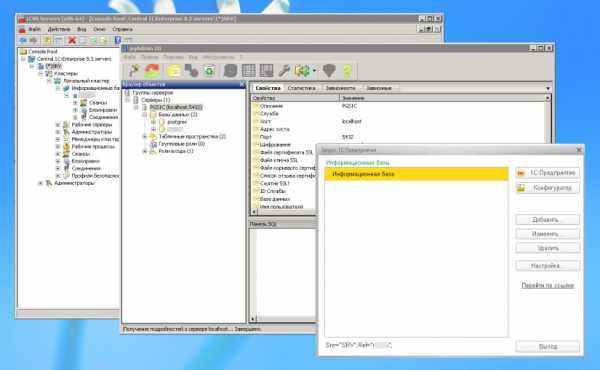
Создаём SQL БД в этой оснастке, проверяем в pgAdmin — БД там появиться, если всё указано верно.
2. Тюнинг PostgreSQL 9.4.2.
Дальше вбиваем себе в голову следующее: перед любым сохранением новых настроек, делайте резервные копии файлов:
- pg_hba.conf
- postgresql.conf
- pgpass.conf
которые лежат здесь:
C:\Program Files\PostgreSQL\9.4.2-1.1C\dataЕсли Вы ошибётесь хоть в одной букве, после обновления конфигурации PostgreSQL не запуститься. Выяснить что же стало причиной будет сложно, даже смотря в журналы Windows. Поэтому не меняйте много параметров сразу и делайте резервные копии.
Для правки конфига есть удобный инструмент, доступный прямо из главного окна pgAdmin. Вот он:
Что мы здесь меняем:
- shared_buffers — Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Делим доступную ОЗУ на 4. В нашем случае это 8Gb.
- effective_cache_size — Оценка размера кэша файловой системы. Считается так: ОЗУ — shared_buffers. В нашем случае это 32Gb — 8Gb = 24Gb. Но лично я оставляю этот параметр ещё ниже, где-то 20Gb — всё-таки ОЗУ нужна не только для PostgreSQL.
- random_page_cost = 1.5 — 2.0 для RAID, 1.1 — 1.3 для SSD. Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
- temp_buffers = 256Mb. Максимальное количество страниц для временных таблиц. То есть это верхний лимит размера временных таблиц в каждой сессии.
- work_mem — Считается так: ОЗУ / 32..64 — в нашем случае получается 1Gb. Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании.
- bgwrite_delay — 20ms. Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
- synchronous_commit — off. ОПАСНО! Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
Это далеко не всё, что удалось узнать из Интернета и статей на https://its.1c.ru. НО! Даже этих настроек хватит, чтобы видимо ускорить работу 1С:Предприятие на PostgreSQL.
В этом конкретном случае после перехода на PostgreSQL пользователи стали жаловаться, что 1С начала тормозить ещё сильнее, чем в файловом варианте. Но после этого тюнинга база «полетела». Теперь все наслаждаются быстрой работой. Однако есть и свои минусы в виде блокировок. Останавливаться на это мы не планируем, будем копать дальше и выкладывать полезные изменения конфигурации PostgreSQL сюда.
Если с базой данных возникли какие-то проблемы, возможно, Вам поможет внутреннее или внешнее тестирование.
Базы данных 1С можно публиковать на веб-серверах!
try2fixkb.ru
Настройки PostgreSQL для работы с 1С:Предприятием. – RDB IT Support
Общие положения
В документе описывается настройка PostgreSQL версий 9.2-9.4 на максимальную производительность для платформы 1С. Предполагается, что сервер, используемый для PostgreSQL является достаточно производительным и имеет приблизительно:
- 4 - 512 Gb RAM
- 2 - 256 CPU cores
- RAID 0-1 или SSD
Данный документ подразумевает хотя бы поверхностное знакомство с архитектурой PgSQL. Приведенные в документе параметры являются приблизительными и стартовыми для тонкой настройки.
Настройки сервера для PostgreSQL
- Рекомендуется отключать HyperThreading. Для программ типа систем управления базами данных от него скорее вред чем польза.
- Также рекомендуется отключать Energy Saving, поскольку в противном случае могут непредсказуемо вырастать задержки ответов БД.
- Надо запретить своппинг разделяемой памяти SYSV/posix (FreeBSD: kern.ipc.shm_use_phys=1)
Обозначения
- RAM - объем оперативной памяти сервера. Если сервер используется не только для PostgreSQL, то надо уменьшить эту величину на объем занятой памяти.
- NCores - суммарное число ядер на всех CPU сервера
- max_connections - максимальное число коннектов (или сессий) к PgSQL. Задается в конфигурационном файле.
- WAL - Write Ahead Log, опережающий лог действий с таблицами и индексами. Основная задача - целостность и отказоустойчивость базы данных при одновременном росте производительности.
- checkpoint - точка восстановления база данных. Все WAL данные, записанные до checkpoint становятся не нужны.
- X..Y - диапазон значений от X до Y включительно
Параметры производительности
shared_buffers = RAM/4
Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL.
temp_buffers = 256MB
Максимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
select maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например вакуум, автовакуум или создания индексов.
effective_cache_size = RAM - shared_buffers
Оценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
effective_io_concurrency = 2
Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID - 2 или больше.
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD
Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
autovacuum = on
Включение автовакуума. Не выключайте его!
autovacuum_max_workers = NCores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило - чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
autovacuum_naptime = 20s
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чемbgwriter_lru_maxpages.
synchronous_commit = off
Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
checkpoint_segments = 32..256 < 9.5
Максимальное количество сегментов WAL между checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
checkpoint_completion_target = 0.5..0.9
Степень "размазывания" checkpoint'a. Скорость записи во время checkpoint'а регулируется так, что бы время checkpoint'а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_target.
min_wal_size = 512MB .. 4G > =9.5max_wal_size = 2 * min_wal_size > =9.5
Минимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
ssl = off
Выключение шифрования. Для защищенных ЦОД'ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
commit_delay = 1000
commit_siblings = 5
Групповой коммит нескольких транзакций. Имеет смысл включать, если темп транзакций превосходит 1000 TPS. Иначе эффекта не имеет.
temp_tablespaces = 'NAME_OF_TABLESPACE'
Дисковое пространство для временных таблиц/индексов. Помещение временных таблиц/индексов на отдельные диски может увеличить производительность. Предварительно надо создать tablespace командой CREATE TABLESPACE. Если характеристики дисков отличаются от основных дисков, то следует в команде указать соответствующий random_page_cost. См. статью.
row_security = off >= 9.5
Отключение контроля разрешения уровня записи
max_files_per_process = 1000 (default)
Максимальное количество открытых файлов на один процесс PostreSQL. Один файл это как минимум либо индекс либо таблица, но таблица/может состоять из нескольких файлов. Если PostgreSQL упирается в этот лимит, он начинает открывать/закрывать файлы, что может сказываться на производительности. Диагностировать проблему под Linux можно с помощью команды lsof.
Параметры для платформы 1С:Предприятия
standard_conforming_strings = off
Разрешить использовать символ \ для экранирования
escape_string_warning = off
Не выдавать предупреждение о использовании символа \ для экранирования
max_locks_per_transaction = 256
Максимальное число блокировок индексов/таблиц в одной транзакции
max_connections = 500..1000
Количество одновременных коннектов/сессий
Параметры
support.rdb24.com
РЕШЕНИЕ ПРОБЛЕМЫ С ЗАВИСАНИЕМ POSTGRESQL. | Gilev.ru
При выполнения некоторых регламентных операций (Закрытие месяца, Расчет себестоимости и т.п.), где используются сложные запросы с большим количеством соединений больших таблиц, возможно существенное увеличение времени выполнения операции. В основном, эти проблемы связаны с работой оптимизатора PostgreSQL и отсутствием актуальной статистики по таблицам, участвующим в запросе.
Варианты решения проблемы:
- Увеличить количество записей, просматриваемых при сборе статистики по таблицам. Большие значения могут повысить время выполнения команды ANALYZE, но улучшат построение плана запроса:
- Файл postgresql.conf — default_statistics_target = 1000 -10000.
- Отключение оптимизатору возможности использования NESTED LOOP при выборе плана выполнения запроса в конфигурации PostgreSQL:
- Файл postgresql.conf — enable_nestloop = off.
- Отрицательным эффектом этого способа является возможное замедление некоторых запросов, поскольку при их выполении будут использоваться другие, более затратные, методы соединения (HASH JOIN).
- Отключение оптимизатору возможности изменения порядка соединений таблиц в запросе:
- Файл postgresql.conf — join_collapse_limit=1.
- Следует использовать этот метод, если вы уверены в правильности порядка соединений таблиц в проблемном запросе.
- Изменение параметров настройки оптимизатора:
- Файл postgresql.conf:
- seq_page_cost = 0.1
- random_page_cost = 0.4
- cpu_operator_cost = 0.00025
- Файл postgresql.conf:
- Использование версии PostgreSQL 9.1.2-1.1.C и выше, в которой реализован независимый от AUTOVACUUM сбор статистики, на основе информации об изменении данных в таблице. По умолчанию включен сбор статистики только для временных таблиц и во многих ситуациях этого достаточно. При возникновении проблем с производительностью выполнения регламентных операций, можно включить сбор статистики для всех или отдельных проблемных таблиц изменив значение параметра конфигурации PostgreSQL (файл postgresql.conf) online_analyze.table_type = "temporary" на online_analyze.table_type = "all".
После изменения этих параметров, следует оценить возможное влияние этих изменений на работу системы и выбрать наиболее приемлемый вариант для ваших задач.
Запись опубликована автором admin в рубрике postgresql, Администрирование, производительность, тюнинг. Добавьте в закладки постоянную ссылку.www.gilev.ru
1С 8.3 : Ускорение и оптимизация настроек PostgreSQL для 1С » Администрирование » FAQ 1С 8.3 : » HelpF.pro
По умолчанию PostgreSQL настроен таким образом, чтобы расходовать минимальное количество ресурсов для работы с небольшими базами до 4 Gb на не очень производительных серверах. То есть, если дело касается систем посерьезней, то вы столкнетесь с большими потерями производительности базы данных лишь потому, что дефолтные настройки могут в корне не соответствовать производительности вашего северного оборудования. Настройки выделения ресурсов оперативной памяти RAM для работы PostgreSQL хранятся в файле postgresql.conf.
Доступен как из папки, куда установлен PostgreSQL / Data, так и из pgAdmin:

В общем на начальном этапе при возникновении трудностей и замедления работы БД, заметной для глаз пользователей достаточно увеличить три параметра:
shared_buffers
Это размер памяти, разделяемой между процессами PostgreSQL, отвечающими за выполнения активных операций. Максимально-допустимое значение этого параметра – 25% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 64-128 Mb (8192-16384).
temp_buffers
Это размер буфера под временные объекты (временные таблицы). Среднее значение 2-4% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 32-64 Mb.
work_mem
Это размер памяти, используемый для сортировки и кэширования таблиц.
При 1-2 Gb RAM на сервере, рекомендуемое значение 32-64 Mb.
Для вступления новых значений в силу, потребуется перезапуск службы, поэтому лучше делать во вне рабочее время.
Еще два важных параметра это maintenance_work_mem (для операций VACUUM, CREATE INDEX и других) и max_stack_depth
Примеры оптимальных настроек:
Hardware:
- CPU: E3-1240 v3 @ 3.40GHz
- RAM: 32Gb 1600Mhz
- Диски: Plextor M6Pro
postgresql.conf:
- shared_buffers = 8GB
- work_mem = 128MB
- maintenance_work_mem = 2GB
- fsync = on
- synchronous_commit = off
- wal_sync_method = fdatasync
- checkpoint_segments = 64
- seq_page_cost = 1.0
- random_page_cost = 6.0
- cpu_tuple_cost = 0.01
- cpu_index_tuple_cost = 0.0005
- cpu_operator_cost = 0.0025
- effective_cache_size = 24GB
Вариант настроек от pgtune:
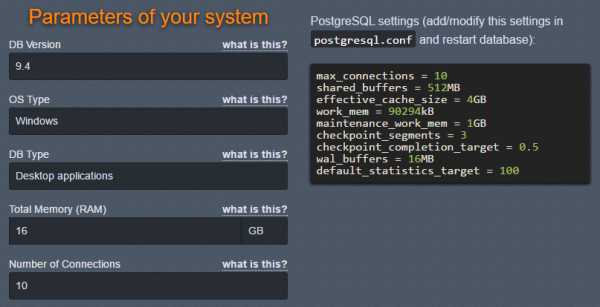
Полезные запросы:
Блокировки БД по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Вывести все таблицы, размером больше 10 Мб
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ and pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) like ‘%MB%’;Определение размеров таблиц в базе данных PostgreSQL
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ order by size;Пользователи блокирующие конкретную таблицу
Код SQL select a.usename, t.relname, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid inner join pg_stat_all_tables t on t.relid=l.relation where t.relname = ‘tablename’; Код SQL select relation::regclass, mode, a.usename, granted, pid from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not mode = ‘AccessShareLock’ and relation is not null;Запросы с эксклюзивными блокировками
Код SQL select a.usename, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where mode ilike ‘%exclusive%’;Количество блокировок по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Количество подключений по пользователям
Код SQL select count(usename), usename from pg_stat_activity group by usename order by count(usename) desc;helpf.pro
Настройка postgresql.conf под 1С - Василий
#В сети уже есть большое количество статей о настройке Postgresql под 1С,#но я решил собрать для себя все в одном месте. Итак поехали…
#Секция — Расположение файлов FILE LOCATIONS
#data_directory = ‘ConfigDir’#hba_file = ‘ConfigDir/pg_hba.conf’#ident_file = ‘ConfigDir/pg_ident.conf’#external_pid_file = ‘(none)’
#Секция — Подключение и аутентификация CONNECTIONS AND AUTHENTICATION
listen_addresses = ‘*’#port = 5432#max_connections = 100#superuser_reserved_connections = 3#unix_socket_directory = »#unix_socket_group = »#unix_socket_permissions = 0777#bonjour_name = »#authentication_timeout = 1min#ssl = off#ssl_ciphers = ‘ALL:!ADH:!LOW:!EXP:!MD5:@STRENGTH’#ssl_renegotiation_limit = 512MB#password_encryption = on#db_user_namespace = off#krb_server_keyfile = »#krb_srvname = ‘postgres’#krb_caseins_users = off#tcp_keepalives_idle = 0#tcp_keepalives_interval = 0#tcp_keepalives_count = 0
#Секция — Использование ресурсов RESOURCE USAGE
shared_buffers = 512MB#Так как данные умеет кешировать не только postgresql, но и операционная система, то считаю,#что нет необходимости выделять под postgresql всю имеющуюся оперативную память
temp_buffers = 32MB#Тут указываем буфер под временные данные, т.к. они временные то много и не надо 🙂
#max_prepared_transactions = 0#В 1с данный параметр не используется
work_mem = 256MB#Количество выделяемой памяти под каждый запрос,#при превышении этого значения сервер использует временные файлы на диске,#что замедляет работу
maintenance_work_mem = 512MB#Данная память используется для операций сбора статистики, очистки мусора#и создания индексов(ANALYZE,VACUUM,CREATE INDEX)#Рекомендуют ставить значение большее чем work_mem
#max_stack_depth = 2MB#max_files_per_process = 1000#shared_preload_libraries = »#vacuum_cost_delay = 0ms#vacuum_cost_page_hit = 1#vacuum_cost_page_miss = 10#vacuum_cost_page_dirty = 20#vacuum_cost_limit = 200#bgwriter_delay = 200ms#bgwriter_lru_maxpages = 100#bgwriter_lru_multiplier = 2.0#effective_io_concurrency = 1#bgwriter_delay = 200ms#bgwriter_lru_maxpages = 100#bgwriter_lru_multiplier = 2.0#effective_io_concurrency = 1
#Секция — Журнал транзакций WRITE AHEAD LOG
fsync = on#Данный параметр влияет на то будет ли сбрасываться кеш на диск, если у Вас нет ИБП,#или стоит Винда, то данный параметр рекомендуют включить
#synchronous_commit = on#wal_sync_method = fsync#Метод который будет использоваться при сбросе даных на диск,#не все методы могут поддерживаться вашим сервером#open_datasync – запись данных методом open() с параметром O_DSYNC#fdatasync – вызов метода fdatasync() после каждого commit#fsync_writethrough – вызывать fsync() после каждого commit игнорирую паралельные процессы#fsync – вызов fsync() после каждого commit#open_sync – запись данных методом open() с параметром O_SYNC
full_page_writes = on#Если fsync у нас off, то данный параметр рекомендутся установить в off
wal_buffers = 2048kB#Количество памяти для ведения транзакционных логов
#wal_writer_delay = 200ms#commit_delay = 0#commit_siblings = 5#checkpoint_segments = 3#checkpoint_timeout = 5min#checkpoint_completion_target = 0.5#checkpoint_warning = 30s#archive_mode = off#archive_command = »#archive_timeout = 0
#Секция — Настройки запроса QUERY TUNING
#enable_bitmapscan = on#enable_hashagg = on#enable_hashjoin = on#enable_indexscan = on#enable_mergejoin = on#enable_nestloop = on#enable_seqscan = on#enable_sort = on#enable_tidscan = on
#Секция — Планирование запросов Planner Cost Constants
#seq_page_cost = 1.0#random_page_cost = 4.0#cpu_tuple_cost = 0.01#cpu_index_tuple_cost = 0.005#cpu_operator_cost = 0.0025effective_cache_size = 512MB#geqo = on#geqo_threshold = 12#geqo_effort = 5#geqo_pool_size = 0#geqo_generations = 0#geqo_selection_bias = 2.0#default_statistics_target = 100#constraint_exclusion = partition#cursor_tuple_fraction = 0.1#from_collapse_limit = 8#join_collapse_limit = 8
#Секция — Сообщения об ошибках ERROR REPORTING AND LOGGING
#log_destination = ‘stderr’#logging_collector = off#log_directory = ‘pg_log#log_filename = ‘postgresql-%Y-%m-%d_%H%M%S.log’#log_truncate_on_rotation = off#log_rotation_age = 1d#log_rotation_size = 10MB#syslog_facility = ‘LOCAL0’#syslog_ident = ‘postgres’#silent_mode = off#client_min_messages = notice#log_min_messages = warning#log_error_verbosity = default#log_min_error_statement = error#log_min_duration_statement = -1#debug_print_parse = off#debug_print_rewritten = off#debug_print_plan = off#debug_pretty_print = on#log_checkpoints = off#log_connections = off#log_disconnections = off#log_duration = off#log_hostname = off#log_line_prefix = »#log_lock_waits = off#log_statement = ‘none’#log_temp_files = -1#log_timezone = unknown
#Секция — Статистика RUNTIME STATISTICS
#track_activities = on#track_counts = on#track_functions = none#track_activity_query_size = 1024#update_process_title = on#stats_temp_directory = ‘pg_stat_tmp’#log_parser_stats = off#log_planner_stats = off#log_executor_stats = off#log_statement_stats = off
#Секция — Очистка от мусора AUTOVACUUM PARAMETERS
autovacuum = on#включаем автоматическую чистку мусора
#log_autovacuum_min_duration = -1#autovacuum_max_workers = 3autovacuum_naptime = 10min#устанавливаем паузу между запуском очистки, зависит от того как часто у Вас меняются данные
autovacuum_vacuum_threshold = 5000#порог после которого происходит запуск очистки
autovacuum_analyze_threshold = 5000#порог после которого происходит запуск анализа
#autovacuum_vacuum_scale_factor = 0.2#autovacuum_analyze_scale_factor = 0.1#autovacuum_freeze_max_age = 200000000#autovacuum_vacuum_cost_delay = 20ms#autovacuum_vacuum_cost_limit = -1
#Секция — Настройки клиентских подключений CLIENT CONNECTION DEFAULTS
#search_path = ‘»$user»,public’#default_tablespace = »#temp_tablespaces = »#check_function_bodies = on#default_transaction_isolation = ‘read committed’#default_transaction_read_only = off#session_replication_role = ‘origin’#statement_timeout = 0#vacuum_freeze_min_age = 50000000#vacuum_freeze_table_age = 150000000#xmlbinary = ‘base64’#xmloption = ‘content’#datestyle = ‘iso, mdy’#intervalstyle = ‘postgres’#timezone = unknown#timezone_abbreviations = ‘Default’#extra_float_digits = 0#client_encoding = sql_ascii#lc_messages = ‘C’#lc_monetary = ‘C’#lc_numeric = ‘C’#lc_time = ‘C’#default_text_search_config = ‘pg_catalog.simple’#dynamic_library_path = ‘$libdir’#local_preload_libraries = »
#Секция — Управление блокировками LOCK MANAGEMENT
deadlock_timeout = 2s#время жизни взаимных блокировок
max_locks_per_transaction = 600#Количество блокировок в предела транзации, раньше у меня стояло 300, но вылетали ошибки
#Секция — Совместимость VERSION/PLATFORM COMPATIBILITY
#add_missing_from = off#array_nulls = on#backslash_quote = safe_encoding#default_with_oids = off#escape_string_warning = on#regex_flavor = advanced#sql_inheritance = on#standard_conforming_strings = off#synchronize_seqscans = on#transform_null_equals = off
#Секция — Индивидуальные опции CUSTOMIZED OPTIONS
#custom_variable_classes = »
#Если У Вас есть замечания или рекомендации, то буду рад услышать их в комментариях
(Просмотров 2 758, 1 за сегодня)
yavasilek.ru
настройка на Linux CentOS 7 для 1С Предприятие ~ Knowledge Base
Postgres – бесплатная SQL база данных. Начиная с версии 8.3 платформа 1С поддерживает PostgreSQL версий 9.4 и 9.6. Для этого фирмой 1С был выпущен набор патчей для PostgreSQL 9.4.2 и 9.6.1 Эти версии СУБД имеют множество улучшений, прежде всего связанных с надежностью. В данной статье рассмотрен пример offnline установки SQL сервера Postgres для работы с кластером 1С Предприятие. В качестве серверного дистрибутива выбран CentOS 7
Дистрибутивы
В качестве дистрибутива использованы пакеты с официального сайта 1С версии 9.6.7-1.1C. На данный момент не тестировались сборки PostgresPro, которые, как уверяют разработчики, являются улучшенными версиями официальных пакетов компании 1С. Получить их можно по следующей ссылке. В ближайшее время я все же попытаюсь сравнить эти версии и оценить стабильность работы. Так же есть еще один канал – Etersoft
Хочу отметить, что инсталляцию необходимо проводить на ветке 9.6, так как она официально заявлена рабочей. На 10 версии Postgres тестирование не проводилось.
Установка
Сейчас интернет есть даже у холодильника, но я столкнулся с ситуацией, когда на площадке Интернет был только на рабочем месте. Не буду вдаваться в подробности почему и как – по факту. Дело не благородное, но вариантов нет! Если у вас есть выход в Интернет, то данную часть можно пропустить. И так, для установки понадобятся следующие пакеты, которых нет в дистрибутиве Centos 7 minimal – bzip2, libicu, libxslt и tcl. Как это сделать, описано в статье Использование YUM для закачки пакетов
Если все дистрибутивы (качестве дистрибутива использованы пакеты с официального сайта 1С версии 9.6.7-1.1C) скачаны и заброшены на сервер, можно приступить к установке
Распаковка архивов
tar -xvf postgresql_9.6.7_1.1C_x86_64_rpm.tar.bz2 tar -xvf postgresql_9.6.7_1.1C_x86_64_addon_rpm.tar.bz2
|
Установка PostgresSQL
cd postgresql-9.6.7-1.1C_x86_64_rpm yum localinstall -y *.rpm
|
Установка дополнений
cd postgresql-9.6.7-1.1C_x86_64_addon_rpm/ yum localinstall -y *.rpm
|
Инициализация базы данных и запуск Postgres
Переключаемся на пользователя postgres
Запуск инициализации системной базы с указанием кодировки и рабочего каталога
/usr/pgsql-9.6/bin/initdb --locale=ru_RU.UTF-8 -D /var/lib/pgsql/9.6/data/
...
Success. You can now start the database server using:
/usr/pgsql-9.6/bin/pg_ctl -D /var/lib/pgsql/9.6/data/ -l logfile start
|
Запуск сервера Postgres
/usr/pgsql-9.6/bin/pg_ctl -D /var/lib/pgsql/9.6/data/ -l logfile start
server starting
|
Подключение в базе
/usr/pgsql-9.6/bin/psql psql (9.6.7) Type "help" for help.
|
Устанавливаем пароль пользователя postgres
postgres=# ALTER USER postgres WITH PASSWORD 'PGPASSWORD'; ALTER ROLE postgres=# \q
|
Проверка локализации и работоспособности
psql -l
List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+-------------+-------------+----------------------- postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres + | | | | | postgres=CTc/postgres (3 rows)
|
Перезагрузка сервера
Настройка подключения
После перезагрузки запустим вручную и добавим в автозагрузку
service postgresql-9.6 start chkconfig postgresql-9.6 on service postgresql-9.6 status
|
Отроем порт Postgres на фаерволе для подключения или отключим совсем
firewall-cmd --permanent --zone=public --add-port=5432/tcp firewall-cmd --reload
|
Отключение фаервола
systemctl stop firewalld systemctl disable firewalld
|
Отключим SELinux
Отредактируем файл /etc/sysconfig/selinux, присвоив параметру SELINUX флаг disabled:
vi /etc/sysconfig/selinux SELINUX=disabled :wq
|
Настройка файла hosts
Для успешной работы кластера 1С Предприятия на Windows сервере, необходимо отредактировать файл hosts, как на Linux? так и Windows и привести к следующему виду. Тоже не обязательная процедура, но иногда возникают проблемы
vi /etc/hosts 192.168.1.252 1c 1c.domain
|
Для Windows необходимо отредактировать файл c:\Windows\System32\Drivers\etc\hosts
Перезагрузка
Выполним перезагрузку для проверки работоспособности системы
Настройка базы данных в кластере 1С Предприятие
Тут все стандартно – задаем имя сервера, имя базы, логин и пароль сервера Postgres
Если подключение прошло успешно, ПОЗДРАВЛЯЮ!!!, вы все настроили верно ))) Можно загрузить в базу нагрузочный тест Гилева и проверить быстродействие системы без оптимизацииОптимизация настроек Postgresql для сервера 1С Предприятие
Некоторые параметры разъяснены в этой статье. Сохраним резервную копию файла настроек
cp /var/lib/pgsql/9.6/data/postgresql.conf /var/lib/pgsql/9.6/data/postgresql.conf.bak
|
Отредактируем файл /var/lib/pgsql/9.6/data/postgresql.conf и приведем его к виду
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
#---------------------------------------------------------------------- listen_addresses = '*' # what IP address(es) to listen on; dynamic_shared_memory_type = posix # the default is the first option log_destination = 'stderr' # Valid values are combinations of log_rotation_age = 1d # Automatic rotation of logfiles will datestyle = 'iso, dmy' timezone = 'W-SU' lc_messages = 'ru_RU.UTF-8' # locale for system error message lc_monetary = 'ru_RU.UTF-8' # locale for monetary formatting lc_numeric = 'ru_RU.UTF-8' # locale for number formatting lc_time = 'ru_RU.UTF-8' # locale for time formatting default_text_search_config = 'pg_catalog.russian' #---------------------------------------------------------------------- effective_cache_size = '12288MB' work_mem = '32MB' shared_buffers = '12288MB' maintenance_work_mem = '512MB' temp_buffers = '32MB' #temp_tablespaces = 'user_temp' max_files_per_process = '24576' autovacuum_max_workers = '4' autovacuum_analyze_scale_factor = '0.01' autovacuum_vacuum_scale_factor = '0.02' random_page_cost = '1.5' log_statement = 'none' #---------------------------------------------------------------------- log_filename = 'postgresql-%Y-%m-%d.log' log_rotation_size = '0' log_timezone = 'W-SU' log_truncate_on_rotation = 'on' logging_collector = 'on' shared_preload_libraries = 'online_analyze, plantuner, auto_explain' online_analyze.enable = off online_analyze.verbose = off online_analyze.table_type = 'temporary' online_analyze.scale_factor = 0.3 online_analyze.min_interval = 10000 online_analyze.threshold = 500 online_analyze.local_tracking = on cpu_operator_cost = 0.0005 plantuner.fix_empty_table = on
autovacuum_naptime = '20' #autovacuum_analyze_threshold = 20
bgwriter_delay = '10' # ms bgwriter_lru_maxpages = '800' bgwriter_lru_multiplier = '8'
# storage specific effective_io_concurrency = '2' random_page_cost = '2'
checkpoint_completion_target = 0.9 #checkpoint_segments = '128' max_connections = '1000'
synchronous_commit = 'off' commit_delay = '1000'
# 1C specific escape_string_warning = 'off' standard_conforming_strings = 'off' max_locks_per_transaction = '256' #work_mem = 65536
# pgbadger
log_directory = 'pg_log' #log_directory = '/var/log/pgsql' #log_filename = 'postgresql.log' log_min_duration_statement = 0s log_autovacuum_min_duration = 0 log_line_prefix = '%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h ' log_checkpoints = on log_connections = on log_disconnections = on log_lock_waits = on log_temp_files = 0
# backup max_wal_senders = 4 wal_level = hot_standby wal_keep_segments = 1024
|
Конфигурация рассчитана на 32Gb оперативной памяти.
Описание параметров с сайта infostat
При настройке сервера для тестирования я полагался на следующие расчеты:Всего 4Гб ОЗУ. Потребители – ОС Windows, сервер 1С, PostgreSQL и дисковый кэш системы. Я исходил из того что для СУБД можно выделить до 2.5Гб ОЗУ
Значения могут указываться с суффиксами kB, MB, GB (значения в килобайта, мегабайтах или гигабайтах). После изменения значений требуется перезапустить службу PostgreSQL.
shared_buffers – Общий буфер сервера
Размер кэша чтения и записи PostgreSQL, общего для всех подключений. Если данные отсутствуют в кэше, производится чтение с диска (возможно, будут кэшированы ОС)
Если объём буфера недостаточен для хранения часто используемых рабочих данных, то они будут постоянно писаться и читаться из кэша ОС или с диска, что крайне отрицательно скажется на производительности.
Но это не вся память, требуемая для работы, не следует указывать слишком большое значение, иначе не останется памяти как для собственно выполнения запросов клиентов (а чем их больше тем выше потребление памяти), так и для ОС и прочих приложений, например, процесса сервера 1С. Так же сервер полагается и на кэш ОС и старается не держать в своём буфере то что скорее всего закэшировано системой.
Начальные рекомендации:Средний объем данных, доступно 256-512Мб – значения 16-32МбБольшой объем данных, доступно 1-4Гб – значения 64-256Мб или выше.
В тесте использовалось
shared_buffers = 512MB
work_mem – память для сортировки, агрегации данных и т.д.
Выделяется на каждый запрос, возможно по нескольку раз для сложных запросов. Если памяти недостаточно – PostgreSQL будет использовать временные файлы. Если значение слишком большое – может возникнуть перерасход оперативной памяти и ОС начнет использовать файл подкачки с соответствующим падением быстродействия.
Есть рекомендация при расчетах взять объем доступной памяти за вычетом shared_buffers, и поделить на количество одновременно исполняемых запросов. В случае сложных запросов делитель стоит увеличить, т.е. уменьшить результат. Для рассматриваемого случая из расчета 5 активных пользователей (2.5Гб-0.5Гб (shared_buffers))/5=400Мб. В случае если СУБД сочтет запросы достаточно сложными, или появятся дополнительные пользователи, потребуется значение уменьшить.
Для простых запросов достаточно небольших значений – до пары мегабайт, но для сложных запросов (а это типовой сценарий для 1С) потребуется больше. Рекомендация – для памяти 1-4Гб можно использовать значения 32-128Мб. В тесте использовал
work_mem = 128MB
maintenance_work_mem – память для команд сбора мусора, статистики, создания индексов.
Рекомендуется устанавливать значение 50-75% от размера самой большой таблицы или индекса, но чтобы памяти хватило для работы системы и приложений. Рекомендуется устанавливать значения больше чем work_mem. В тесте использовалmaintenance_work_mem = 192MB
temp_buffers – буфер под временные объекты, в основном для временных таблиц.
Можно установить порядка 16 МБ. В тесте использовалtemp_buffers = 32MB
effective_cache_size – примерный объем дискового кэша файловой системы.
Оптимизатор использует это значение при построении плана запроса, для оценки вероятности нахождения данных в кэше (с быстрым случайным доступом) или на медленном диске. В Windows текущий объем памяти, выделенной под кэш, можно посмотреть в
www.kost.su
Настройка и аудит 1С на базе PostgreSQL | Gilev.ru
Ниже указанные настройки не панацея, их надо корректировать с учетом реальных доступных мощностей. Реального количества пользователей и интенсивности (записываемой) ввода информации.При настройках системы также важно насколько профессионален тот, кто настраивает ее.Какую ОС установить:
| если у вас есть свой опытный администратор | у вас нет опыта с линуксом |
autovacuum_max_workers = NCores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило — чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
ssl = off
Выключение шифрования. Для защищенных ЦОД’ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
shared_buffers = RAM/4
Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память.
temp_buffers = 256MBМаксимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
work_mem = RAM/32..64 или 32MB..128MBЛимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
<code><code>maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB</code></code>Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size = RAM - shared_buffersОценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
effective_io_concurrency = 2 (только для Linux систем, не применять для Windows)Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID — 2 или больше.
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для <wbr />SSDСтоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
autovacuum = onВключение автовакуума.
autovacuum_naptime = 20sВремя сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
bgwriter_delay = 20msВремя сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0 bgwriter_lru_maxpages = 400Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чемbgwriter_lru_maxpages.
synchronous_commit = offВыключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
checkpoint_segments = 32..256 < 9.5Максимальное количество сегментов WAL между checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
checkpoint_completion_target = 0.5..0.9
Степень «размазывания» checkpoint’a. Скорость записи во время checkpoint’а регулируется так, что бы время checkpoint’а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_target.
min_wal_size = 512MB .. 4G > =9.5max_wal_size = 2 * min_wal_size > =9.5
Минимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
commit_delay = 1000
commit_siblings = 5
Групповой коммит нескольких транзакций. Имеет смысл включать, если темп транзакций превосходит 1000 TPS. Иначе эффекта не имеет.
temp_tablespaces = ‘NAME_OF_TABLESPACE’
Дисковое пространство для временных таблиц/индексов. Помещение временных таблиц/индексов на отдельные диски может увеличить производительность. Предварительно надо создать tablespace командой CREATE TABLESPACE. Если характеристики дисков отличаются от основных дисков, то следует в команде указать соответствующий random_page_cost. См. статью.
row_security = off >= 9.5
Отключение контроля разрешения уровня записи
max_files_per_process = 1000 (default)
Максимальное количество открытых файлов на один процесс PostreSQL. Один файл это как минимум либо индекс либо таблица, но таблица/может состоять из нескольких файлов. Если PostgreSQL упирается в этот лимит, он начинает открывать/закрывать файлы, что может сказываться на производительности. Диагностировать проблему под Linux можно с помощью команды lsof.
Типовая проблема в Windows
Ошибка СУБД: could not send data to server: No buffer space available (0x00002747/10055)
При использовании операционной системы Windows, максимальное стандартное число временных TCP-портов равно 5000. При попытке установить TCP-соединение через порты, номера которых превышают 5000, выдается сообщение об ошибке. Другими словами, надо увеличить количество доступных портов в реестре, где выберите Parameters (HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters) и добавьте следующий параметр реестра MaxUserPort с типом: DWORD и значением: 65534 (Допустимые значения: 5000-65534)
max_locks_per_transaction = 256
Максимальное число блокировок индексов/таблиц в одной транзакции
max_connections = 500..1000Количество одновременных коннектов/сессий
standard_conforming_strings = offРазрешить использовать символ \ для экранирования
escape_string_warning = offНе выдавать предупреждение о использовании символа \ для экранирования
www.gilev.ru