Правильный robots.txt для wordpress - важнейшие моменты. Файл robots wordpress
Robots.txt для сайта Wordpress! Скачай бесплатно!
Добрый день коллеги! В одной из предыдущих статей я вещал о самостоятельной seo оптимизации сайта и говорил, что это очень большая тема и супер подробно каждый пункт в рамках 1-2 двух статей раскрыть в полной мере невозможно.
Помните такое? Так вот, сегодня я хочу раскрыть по подробнее один из самых важных пунктов внутренней оптимизации веб-ресурса. Сегодня будем говорить о файле robots.txt для сайта WordPress. Прочитав статью от начала и до конца, вы узнаете:
Содержание:
1. Что такое файл robots.txt и для чего он нужен?2. Где находится файл robots.txt и как его создать?3. 8 популярных ошибок, которые допускают начинающие веб-мастера4. Правильный и проверенный robots.txt для сайта WordPress5. Описание значения строк файла robots.txt
Кстати, для тех товарищей кто не хочет разбираться в этом файле со странным названием, а желает просто взять готовый и проверенный вариант для своего интернет-проекта, я дам ссылку на скачивание своего рабочего файла robots.txt для сайта WordPress.
Я использую его с 2013 года на всех своих веб-ресурсах созданных на WP и за все время он отлично себя зарекомендовал. Естественно я стараюсь быть в тренде и при необходимости вношу в него правки с учетом нововведений поисковых систем и seo.
Свой файл я собирал очень долго, брал шаблоны с успешных сайтов, которые находятся в ТОПе, скачивал у блогеров, просил у ребят на seo форумах, а потом все это анализировал, взял самое лучшее из каждого и вот он простой, эффективный, рабочий роботс. Итак, давайте начнём с определения.
Что такое файл robots.txt и для чего он нужен?
Robots.txt – это системный, внутренний файл сайта, созданный в обычном текстовом блокноте, который представляет из себя пошаговую инструкцию для поисковых машин, которые ежедневно посещают и индексирует веб-ресурс.
Каждый web-мастер должен знать значение этого важного элемента внутренней оптимизации и уметь его грамотно настраивать. Наличие данного файла обязательное условия для правильного и качественного seo.
Ещё такой нюанс, если у вашего сайта имеется несколько поддоменов, то у каждого из них, в корневом каталоге на сервере должен быть свой роботс. Кстати, данный файл является дополнением к Sitemaps (карта сайта для ПС), дальше в статье вы узнаете об этом более подробно.
У каждого сайта есть разделы, которые можно индексировать и которые нельзя. В роботсе, как раз таки можно диктовать условия для поисковых роботов, например, сказать им, чтобы они индексировали все страницы сайта с полезным и продающим контентом, но не притрагивались к папкам движка, к системным файлам, к страницам с данными аккаунтов пользователей и т.д.
Ещё в нем можно дать команду поисковой машине, соблюдать определенный промежуток времени между загрузкой файлов и документов с сервера во время индексирования, а также он прекрасно решает проблему наличия дублей (копий контента вашего сайта).
А сейчас, я хочу с вами поделиться небольшим секретом, о котором, кстати, знают не все веб-мастера. Если вы создали и настроили robots.txt, то не думайте, что вы властелин поисковых роботов, знайте и помните, что он позволяет лишь частично управлять индексированием сайта.
Наш отечественный поисковый гигант Яндекс строго и ответственно соблюдает прописанные инструкции и правила, а вот американский товарищ Гугл, не добросовестно к этому относится и в легкую может проиндексировать страницы и разделы на которых стоит запрет, а потом ещё и добавить в поисковую выдачу.
Где находится файл robots.txt и как его создать?
Этот товарищ располагается в корневом каталоге сайта, для наглядности смотрите ниже картинку со скриншотом моего каталога на сервере. Если вы устанавливаете WordPress на хостинге через функцию «Установка приложений», об этом я рассказывал в статье «Как установить WordPress на хостинг? Полное руководство по установке!», то файл роботс создается автоматически по умолчанию в стандартном, не доработанном виде.
Создается он на рабочем столе, с помощью обычного, текстового блокнота, который имеет расширение файла .txt. Кстати, рекомендую использовать прогу Notepad++ для редактирования и создания текстовых файлов, очень удобно.
Закачать на сервер его можно, например, с помощью ftp используя программы Filezilla или Total Commander. Если вы хотите посмотреть, как выглядит данный файл на каком-то сайте или на своем, то наберите в браузере адрес http://имя_сайта/robots.txt.
8 популярных ошибок, которые допускают начинающие веб-мастера
1.Путаница в написании правил. Пожалуй это самая популярная ошибка в рунете.
Неправильный вариант:User-agent: /Disallow: Googlebot
Правильный вариант:User-agent: GooglebotDisallow: /
2. Написание целого списка папок в одном правиле. Некоторые ребята умудряются сделать запрет индексации папок в одной строчке.
Неправильный вариант:Disallow: /wp-admin /wp-login.php /xmlrpc.php /wp-includes
Правильный вариант:Disallow: /wp-adminDisallow: /wp-includesDisallow: /wp-login.phpDisallow: /xmlrpc.php
3. Имя файла роботс большими буквами. Здесь я думаю понятно, всегда пишем название только маленькими буквами.
Неправильный вариант:Robots.txtROBOTS.TXT
Правильный вариант:robots.txt
4. Написание пустой строки в директиве User-agent
Неправильный вариант:User-agent:Disallow:
5. Неправильно написанная ссылка в правиле «Host». Нужно писать линк без указания протокола http:// и без слеша на конце /
Неправильный вариант:User-agent: YandexDisallow: /wp-content/pluginsHost: http://www.ivan-maslov.ru/
Правильный вариант:User-agent: YandexDisallow: /wp-content/pluginsHost: www.ivan-maslov.ru
6. Написание длинной колбасы с перечислением каждого файла. Чтобы этого не случилось, просто закрываем папку от индексации целиком.
Неправильный вариант:User-agent: YandexDisallow: /Brend/Armani.htmlDisallow: /Brend/Chanel.htmlDisallow: /Tur/Thailand.htmlDisallow: /Tur/Vietnam.htmlDisallow: /Tur/Egypt.html
Правильный вариант:User-agent: YandexDisallow: /Brend/Disallow: /Tur/
7. Отсутствие в роботсе правила Disallow. По общепринятому стандарту поисковых систем, данная инструкция является обязательной, если вы не собираетесь ничего запрещать, тогда просто оставьте её пустой. Ок?
Неправильный вариант:User-agent: GooglebotHost: www.ivan-maslov.ru
Правильный вариант:User-agent: GooglebotDisallow:Host: www.ivan-maslov.ru
8. Не указывают слеши в каталогах
Неправильный вариант:User-agent: GooglebotDisallow: ivan
Правильный вариант:User-agent: GooglebotDisallow: /ivan/
Правильный и проверенный robots.txt для сайта WordPress
А сейчас, я предлагаю вам ознакомится содержанием кода файла роботс, разобраться в каждой его директиве. а затем скачать готовый вариант.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /?s=* Disallow: /*?* Disallow: /search* Disallow: */trackback/ Disallow: */*/trackback Disallow: */feed Disallow: */*/feed/*/ Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: /cgi-bin Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /tag Disallow: /category/*/* Allow: /wp-content/uploads Crawl-delay: 5 Host: ivan-maslov.ru Sitemap: http:///sitemap.xml Sitemap: http:///sitemap.xml.gz User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /?s=* Disallow: /*?* Disallow: /search* Disallow: */trackback/ Disallow: */*/trackback Disallow: */feed Disallow: */*/feed/*/ Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: /cgi-bin Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /tag Disallow: /category/*/* Allow: /wp-content/uploads User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /?s=* Disallow: /*?* Disallow: /search* Disallow: */trackback/ Disallow: */*/trackback Disallow: */feed Disallow: */*/feed/*/ Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: /cgi-bin Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /tag Disallow: /category/*/* Allow: /wp-content/uploads User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /?s=* Disallow: /*?* Disallow: /search* Disallow: */trackback/ Disallow: */*/trackback Disallow: */feed Disallow: */*/feed/*/ Disallow: */comments/ Disallow: */comment Disallow: */attachment/* Disallow: */print/ Disallow: *?print=* Disallow: */embed* Disallow: /cgi-bin Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /tag Disallow: /category/*/* Allow: /wp-content/uploads User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/ User-agent: Mediapartners-Google Disallow: User-Agent: YaDirectBot Disallow:Описание значения строк файла robots.txt:
- «User-agent: *» — правила, прописанные ниже будут относится ко всем поисковым системам и их роботам, кроме Яндекса и Google
- «User-agent: Yandex» — правила, прописанные ниже будут относится к поисковому гиганту Яндекс и всем его поисковым роботам (ПР)
- «User-agent: Googlebot» — правила, прописанные ниже будут относится к поисковому гиганту Гугл и всем его ПР
- «User-agent: Mail.Ru» — правила, прописанные ниже будут относится к поисковому гиганту Майл ру и всем его ПР
- «Disallow:» — условие запрещающее индексирование
- «Allow:» — условие разрешающее индексирование
- «*» — звездочка означает допущение абсолютно любой и даже пустой последовательности символов
- «$» — дает возможность делать исключение для определенных файлов и каталогов в правиле
- «Host: vas-domen.ru» — данное правило используется только стариком Яндексом и указывает ему главное зеркало вашего сайта (www.sait.ru или sait.ru)
- «User-agent: Googlebot-Image» — правила, прописанные ниже будут относится конкретно к поисковому боту Гугла, который занимается индексированием изображений
- «User-agent: YandexImages» — правила, прописанные ниже будут относится конкретно к поисковому боту Яндекса, который занимается индексированием изображений
- «User-agent: Mediapartners-Google» — правила, прописанные ниже будут относится конкретно к поисковому боту Гугла, который занимается индексированием страниц и объявлений с рекламой AdSense. Напомню, что мы прописали там «Disallow:» это позволит подбирать более релевантные объявления и избежать ошибок индексирования. Если вы в будущем собираетесь размещать рекламу от Гугла или уже размещаете, то прописывайте такие правила сразу, чтобы на верочку было все ок, а то потом забудете.
- «User-Agent: YaDirectBot» — правила, прописанные ниже будут относится конкретно к поисковому боту Яндекса, который занимается индексированием страниц и объявлений с рекламой Яндекс Директ. В остальном все тоже самое, что писал в предыдущем пункте.
- «Sitemap:» — правило, в котором указывается ссылка на местоположение файла с картой сайта sitemap.xml.
- «Crawl-delay:» — полезное правило, которое снижает нагрузку на сервер, когда ПР очень часто заходят в гости к вашему сайту, здесь мы задаем время в секундах и говорим этим неугомонным товарищам, чтобы сканировали наш веб-ресурс не чаще, чем 1 раз в 5 секунд.
Ну вот мы и рассмотрели значение всех строк, если этой информации вам мало, то дополнительно рекомендую почитать справку Яндекса. Кстати, скачать полностью готовый файл robots.txt для сайта WordPress, можно — здесь. Не забудьте поменять в нём строчки:
ссылку на Sitemap
главное зеркало web-ресурса в директиве «Host:»
После того, как вы сделали все настройки и загрузили свой роботс в корневую папку сайта, обязательно проверьте его на ошибки, если вы скачали мой вариант, то можете не проверять, я уже это сделал, там всё чётко 
Вот на всякий случай парочка классных сервисов для анализа и проверки на ошибки файла robots.txt:
Проверяем robots.txt в инструментах Яндекс Вебмастер: http://webmaster.yandex.ru/robots.xml
Проверяем robots.txt в интсрументах Гугла: https://www.google.com/webmasters/tools/robots-testing-tool?hl=ru
Ну и напоследок, хочу обратить ваше внимание на то, что файл robots.txt для сайта WordPress важное звено в seo оптимизации, между вашим web-ресурсом и поисковыми роботами. С его помощью, вы можете влиять на индексацию сайта. Друзья, помните об этом и используйте свой роботс грамотно, ведь в seo не бывает мелочей.
Остались вопросы — пишите их в комментах, постараюсь ответить в ближайшее время. А какие инструкции используете вы в своем файле robots.txt из выше перечисленных?
Если вам понравилась статья, рекомендуйте её своим друзьям и подписывайтесь на рассылку блога. Увидимся в следующих постах, до связи 😉
С уважением, Иван Маслов
ivan-maslov.ru
Как создать файл robots.txt для wordpress. Настройка robots.txt.
 7.10.2014 // Рита Молчанова
7.10.2014 // Рита Молчанова 
Привет! В данной статье пойдёт речь о том, как создать файл robots.txt для wordpress. Также узнаем, как настроить файл robots.txt.
Это очень важный файл для сайтов и блогов. Он показывает роботам поисковых систем, что и как нужно индексировать на Вашем блоге.
Этот тот самый файл, который нужно настроить одним из первых на блоге. Его отсутствие или пренебрежительное отношение к нему — это одна из главных ошибок блоггеров- новичков.
Как создать файл robots.txt для wordpress.
Файл robots.txt, так же, как и карта сайта sitemap.xml, предназначены для управления индексацией. Первым делом правильно пропишем в файле robots.txt правила для поисковиков. А затем добавим папку с файлом в корневой каталог. Делается это легко на раз два. И тогда робот будет подчиняться Вашим правилам. А именно, он поймет, что ему индексировать, а что не стоит. Вы сами пропишите эти правила. Безусловно, это повлияет на успешное продвижение сайта.
Нужно понимать, что не все файлы, находящиеся на блоге или в корневом каталоге нужно индексировать поисковыми системами. Разберем этот вопрос по- подробней. Корневой каталог это не что иное, как основная папка вашего сайта со всеми файлами, будь то видео аудио и картинки , то есть все до последнего файла, находящегося на Вашем блоге(его содержимое). В зависимости от того какой у Вас хостинг, это будет или httpdocs или public_html. Но суть одна. Запомните это!
Все блоги и сайты на wordpress имеют папки и файлы, обусловленные самим движком. Кто не знает что такое движок, поясняю. Движок- это конструктор хоста или хостинга. Или по другому, это система управления хостингом. Вот пример. Система управления хостингом TimeWeb — есть WordpRess. Другими словами -это огромный конструктор без которого Вы не сможете работать на хостинге. Конструкторы или движки бывают разные, но WordPress наиболее известный и популярный.
Идем дальше. В каталоге есть папки wp-admin и wp-includes, которые не несут никакой ценности и для читателей и поисковых систем. Они нужны для работы самого конструктора. Их не нужно индексировать.
Поисковые роботы, зайдя на Ваш сайт будут индексировать все подряд.
Поэтому им нужно указать, что индексировать, а что не нужно. Теперь понимаете, для чего нам нужен файл robots.txt. А как запретить роботам индексацию, иначе поисковые роботы, зайдя на ваш ресурс, будут индексировать все, что попадется на их пути.
Дело в том, что лимит есть и у поисковых систем. Оставив без внимания настройку файла robots.txt Вы рискуете обрасти дублированным контентом и быть не проиндексированными там где это необходимо. Поисковики этого очень не любят и как следствие наложение фильтра на Ваш сайт или АГС. То есть Ваш сайт попадает в черный список неблагонадежных из за нерадивого хозяина.
Где появляются дубли страниц? Дублями страниц в wordpress в основном выступают рубрики, архивы и метки. Если их не закрывать от индекса, тогда их расплодится очень много и со стремительной скоростью. Чтобы этого не случилось для движка wordpress существует плагин поисковой оптимизации All In One SEO Pack. Он при правильной его настройке предотвращает все неприятности связанные с этим явлением как дубли.
Еще очень Важно!!! Если Вы добавляете в корень сайта (каталог) папки с файлами, в которых много внешних ссылок или скриптов, тогда нужно не забывать их обязательно закрывать от индексации в файле robots.txt. Читем дальше, как это сделать легко и просто.
Настройка robots.txt
Robots.txt это обычный файл txt он составляется в обычной программе блокнот или в текстовом редакторе notepad++ и включает несколько важных директив. Первая самая важная User-agent. Это попросту говоря обращение к поисковому роботу. Чтобы обратиться ко всем поисковым роботам, которые будут заходить к вам на блог необходимо в самом начале документа прописать эту фразу :
User-agent: *
Далее идет директива, без которой не может обходится ни один файл robots.txt и она прописывается так: Disallow.
Директива Disallow это значит запретить, а директива Allow:/ разрешить
И так наш документ имеет такой вид:
Disallow:Добавим к Disallow правый слэш «/»:
И документ выглядит так:
User-agent: *Disallow: /
Это означает запрет всем поисковым системам индексировать Ваш сайт.
Но весь сайт запрещать индексировать не нужно, иначе, зачем нам такой сайт.
Поэтому внимательно прописываем запрет только тех папок, которые индексировать мы не хотим. Например, папка wp-admin
Тогда прописываем следующее:
User-agent: *Disallow: /wp-admin
Друзья, я Вас долго не буду мучить и дам Вам правильный файл robots.txt для wordpress, рекомендуемый разработчиками. Но сначала дочитайте статью до конца.
А сейчас рассмотрим еще очень важную директиву Host. Эта директива Host -предназначена только для поисковика Яндекс. Дело в том, что это правило придумал сам Яндекс. Поисковая система Яндекс имеет большой вес в русскоязычном интернете и это явилось важным фактором или капризом. Но это должно выполняться и все без возражений и обсуждений.
Также Яндекс требует выделить отдельный блок для себя и выглядит он так:
User-agent: Yandex
Уясните это к сведению), что во избежание неправильной индексации блога или сайта, директива Host прописывается для Яндекса.
Она указывает на основное зеркало ресурса, то есть адрес по которому будет доступен Ваш сайт:

Другие поисковики не понимают директиву Host!
И так для Яндекса этот блок в файле robots.txt должен выглядеть так:
User-agent: Yandex Disallow: Host: www.sait.ru или User-agent: Yandex Disallow: Host: sait.ruРассмотрим последнюю директиву, которую включает правильный robots.txt для wordpress. Она имеет знакомое название, sitemap.
Это не что иное, как карта сайта для роботов или sitemap.xml У меня по этому поводу есть статья. Читать Sitemap.xml — создаём карту сайта для роботов.
Эта важная директива Sitemap, которая указывает роботам на место, где расположена карта Вашего сайта. Она прописывается отдельно от предыдущих директив один раз. Ее понимают все поисковые роботы без исключения и такой главный робот как Google. Это выглядит так:
Sitemap: http://ваш сайт.ru/sitemap.xml или в моем в моем случае Sitemap: http://ritabk.ru/sitemap.xml или http://ritabk.ru/sitemap.xml.gz
Мы тут рассмотрели основные директивы, которые нужно использовать в правильном robots.txt
Пример правильного файла robots.txt. У меня это так:
User-agent: *Allow: /Disallow: /jexrDisallow: /cgi-binDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /wp-admin/Disallow: /wp-includes/Disallow: /feed/Disallow: */feedDisallow: /trackbackDisallow: */trackbackDisallow: /category/*/*Disallow: */commentsUser-agent: YandexDisallow: /cgi-binDisallow: /wp-content/pluginsDisallow: /wp-content/cacheDisallow: /wp-content/themesDisallow: /wp-admin/Disallow: /wp-includes/Disallow: /feed/Disallow: */feedDisallow: /trackbackDisallow: */trackbackDisallow: /category/*/*Disallow: */commentsHost: ritabk.ruSitemap: http://ritabk.ru/sitemap.xml
Смело копируйте, только впишите свое доменное имя.
Вот этот пункт, Disallow: /jexr/( который выделен желтым) вставляете если у Вас на блоге установлен плагин (J) ExR
Выводы:
Что необходимо скормить поисковым роботам в первую очередь для индексации- конечно это Ваш уникальный контент. Что Вы получаете?
Ваш блог на wordpress будет правильно и быстро индексироваться. И не одна Ваша статья не останется без внимания. Поисковые роботы не будут тратить время на не нужный контент.
Я изучала и сравнивала множество файлов robots.txt на разных блогах wordpress. Они все примерно одинаковы.
Как проверить и посмотреть, как выглядит robots.txt с другого ресурса, нужно прописать в строке браузера, после доменного имени через слеш (/) файл /robots.txt.
Пример: ritabk.ru/robots.txt
Важно! Имя файла должно быть всегда одинаковым! Это выглядит так:
robots.txt
Это Важно.Никаких заглавных букв не должно быть. А на конце не забывайте писать "s". Смело копируйте файл robots.txt, который я Вам дала выше. Только не забудьте поменять мои данные на свои. И загрузите (robots.txt), в корневой каталог. Я это делаю через программу filezilla. Она проста и удобна. Как пользоваться и загружать файлы в корень сайта. Об этом прочитайте Здесь.
На этом все! Жду отзывы.
C уважением, Рита Молчанова, автор блога ritabk.ru
ritabk.ru
Настраиваем файл robots.txt для WordPress

В этой статье пример оптимального, на мой взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
- Вариант 1: оптимальный код robots.txt для WordPress
- Вариант 2: стандартный robots.txt для WordPress
- Дописываем под себя
- Crawl-delay – таймаут для сумасшедших роботов
- Проверка robots.txt
- Я спросил у Яндекса…
- Заключение
Для начала, вспомним зачем нужен robots.txt — файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).

Вариант 1: оптимальный код robots.txt для WordPress
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Host: site.ru User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Sitemap: http://site.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Host: site.ru
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s=
Sitemap: http://site.ru/sitemap.xml |
Разбор кода:
- В строке User-agent: * мы указываем, что все нижеприведенные правила будут работать для всех поисковых роботов *. Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем имя робота (User-agent: Yandex, User-agent: Googlebot).
- В строке Allow: */uploads мы намеренно разрешаем индексировать ссылки, в которых встречается /uploads. Это правило обязательно, т.к. выше мы запрещаем индексировать ссылки начинающихся с /wp-, а /wp- входит в /wp-content/uploads. Поэтому, чтобы перебить правило Disallow: /wp- нужна строчка Allow: */uploads, ведь по ссылкам типа /wp-content/uploads/… у нас могут лежать картинки, которые должны индексироваться, так же там могут лежать какие-то загруженные файлы, которые незачем скрывать. Allow: может быть “до” или “после” Disallow:.
- Остальные строчки запрещают роботам “ходить” по ссылкам, которые начинаются с:
- Disallow: /cgi-bin – закрывает каталог скриптов на сервере
- Disallow: /feed – закрывает RSS фид блога
- Disallow: /trackback – закрывает уведомления
- Disallow: ?s= или Disallow: *?s= – закрыавет страницы поиска
- Disallow: */page/ – закрывает все виды пагинации
- Правило Sitemap: http://site.ru/sitemap.xml указывает роботу на файл с картой сайта в формате XML. Если у вас на сайте есть такой файл, то пропишите полный путь к нему. Таких файлов может быть несколько, тогда указываем путь к каждому отдельно.
- В строке Host: site.ru мы указываем главное зеркало сайта. Если у сайта существуют зеркала (копии сайта на других доменах), то чтобы Яндекс индексировал всех их одинаково, нужно указывать главное зеркало. Директива Host: понимает только Яндекс, Google не понимает!Из документации Яндекса: «Host — независимая директива и работает в любом месте файла (межсекционная)». Поэтому её ставим наверх или в самый конец файла, через пустую строку.
Это важно: сортировка правил перед обработкой
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: * Allow: */uploads Disallow: /wp-
User-agent: * Allow: */uploads Disallow: /wp- |
будет прочитана как:
User-agent: * Disallow: /wp- Allow: */uploads
User-agent: * Disallow: /wp- Allow: */uploads |
Таким образом, если проверяется ссылка вида: /wp-content/uploads/file.jpg, правило Disallow: /wp- ссылку запретит, а следующее правило Allow: */uploads её разрешит и ссылка будет доступна для сканирования.
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило в robots.txt, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Вариант 2: стандартный robots.txt для WordPress
Не знаю кто как, а я за первый вариант! Потому что он логичнее — не надо полностью дублировать секцию ради того, чтобы указать директиву Host для Яндекса, которая является межсекционной (понимается роботом в любом месте шаблона, без указания к какому роботу она относится). Что касается нестандартной директивы Allow, то она работает для Яндекса и Гугла и если она не откроет папку uploads для других роботов, которые её не понимают, то в 99% ничего опасного это за собой не повлечет. Я пока не заметил что первый robots работает не так как нужно.
Вышеприведенный код немного не корректный. Спасибо комментатору “robots.txt” за указание на некорректность, правда в чем она заключалась пришлось разбираться самому. И вот к чему я пришел (могу ошибаться):
- Некоторые роботы (не Яндекса и Гугла) — не понимают более 2 директив: User-agent: и Disallow:;
- Директиву Яндекса Host: нужно использовать после Disallow:, потому что некоторые роботы (не Яндекса и Гугла), могут не понять её и вообще забраковать robots.txt. Cамому же Яндексу, судя по документации, абсолютно все равно где и как использовать Host:, хоть вообще создавай robots.txt с одной только строчкой Host: www.site.ru, для того, чтобы склеить все зеркала сайта;
3. Sitemap: межсекционная директива для Яндекса и Google и видимо для многих других роботов тоже, поэтому её пишем в конце через пустую строку и она будет работать для всех роботов сразу.
На основе этих поправок, корректный код должен выглядеть так:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Host: site.ru User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Sitemap: http://site.ru/sitemap.xml
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s= Host: site.ru
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/themes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /comments Disallow: */trackback Disallow: */embed Disallow: */feed Disallow: /cgi-bin Disallow: *?s=
Sitemap: http://site.ru/sitemap.xml |
Дописываем под себя
Если вам нужно запретить еще какие-либо страницы или группы страниц, можете внизу добавить правило (директиву) Disallow:. Например, нам нужно закрыть от индексации все записи в категории news, тогда перед Sitemap: добавляем правило:
Оно запретить роботам ходить по подобным ссылками:http://site.ru**/news**http://site.ru**/news**/drugoe-nazvanie/
Если нужно закрыть любые вхождения /news, то пишем:
Закроет:http://site.ru**/news**http://site.ru**/news**/drugoe-nazvanie/http://site.ru/category**/news**letter-nazvanie.html
Более подробно изучить директивы robots.txt вы можете на странице помощи Яндекса (но имейте ввиду, что не все правила, которые описаны там, работают для Google).
Crawl-delay – таймаут для сумасшедших роботов
Яндекс
Когда робот Яндекса сканирует сайт как сумасшедший и это создает излишнюю нагрузку на сервер. Робота можно попросить «поубавить обороты».
Для этого нужно использовать директиву Crawl-delay. Она указывает время в секундах, которое робот должен простаивать (ждать) для сканирования каждой следующей страницы сайта.
Для совместимости с роботами, которые плохо следуют стандарту robots.txt, Crawl-delay нужно указывать в группе (в секции User-Agent) сразу после Disallow и Allow
Робот Яндекса понимает дробные значения, например, 0.5 (пол секунды). Это не гарантирует, что поисковый робот будет заходить на ваш сайт каждые полсекунды, но позволяет ускорить обход сайта.
Примеры:
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 # таймаут в 1.5 секунды User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif Crawl-delay: 2 # таймаут в 2 секунды
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1.5 # таймаут в 1.5 секунды
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-*.gif Crawl-delay: 2 # таймаут в 2 секунды |
Робот Google не понимает директиву Crawl-delay. Таймаут его роботам можно указать в панели вебмастера.
Проверка robots.txt
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
Я спросил у Яндекса…
Задал вопрос в тех. поддержку Яндекса насчет межсекционного использования директив Host и Sitemap:
Вопрос:
Здравствуйте!Пишу статью насчет robots.txt на своем блоге. Хотелось бы получить ответ на такой вопрос (в документации я не нашел однозначного “да”):
Если мне нужно склеить все зеркала и для этого я использую директиву Host в самом начале фала robots.txt:
Host: site.ru User-agent: * Disallow: /asd
Host: site.ru
User-agent: * Disallow: /asd |
Также хотел узнать, обязательно ли директиву Sitemap нужно использовать внутри секции или можно использовать за пределами: например, через пустую строчку, после секции?
User-agent: Yandex Disallow: /asd User-agent: * Disallow: /asd Sitemap: http://site.ru/sitemap.xml
User-agent: Yandex Disallow: /asd
User-agent: * Disallow: /asd
Sitemap: http://site.ru/sitemap.xml |
Поймет ли робот в данном примере директиву Sitemap?
Надеюсь получить от вас ответ, который поставит жирную точку в моих сомнениях.
Спасибо!
Ответ:
Здравствуйте!
Директивы Host и Sitemap являются межсекционными, поэтому будут использоваться роботом вне зависимости от места в файле robots.txt, где они указаны.
—С уважением, Платон ЩукинСлужба поддержки Яндекса
Заключение
Важно помнить, что изменения в robots.txt на уже рабочем сайте будут заметны только спустя несколько месяцев (2-3 месяца).
Ходят слухи, что Google иногда может проигнорировать правила в robots.txt и взять страницу в индекс, если сочтет, что страница ну очень уникальная и полезная и она просто обязана быть в индексе. Однако другие слухи опровергают эту гипотезу тем, что неопытные оптимизаторы могут неправильно указать правила в robots.txt и так закрыть нужные страницы от индексации и оставить ненужные. Я больше склоняюсь ко второму предположению…
Статья на эту тему уже была на блоге wp-info.ru, здесь описан альтернативный вариант кода для файла robots.txt.
Статья взята из открытых источников: https://wp-kama.ru/id_803/pishem-pravilnyiy-robotstxt-dlya-wordpress.html
Похожие статьи:
house-computer.ru
Robots.txt для wordpress: правильный файл
Здравствуйте, дорогие друзья!
Сейчас напишу статью о нашумевшем файле, которого так все боятся молодые владельцы сайтов. И не зря, ведь при неправильном его составлении могут возникнуть плохие последствия.
Тема статьи - файл robots.txt. Мы сегодня разберем от основ его составления до примера моего личного файла, который на данный момент хорошо работает. Материал получился довольно сложный и после первого прочтения у вас может не сложиться впечатление целостной картины, но основную мысль вы должны уловить. Будет много советов и инсайдерской информации, которая поможет сделать индексацию сайта более лучшей.
Перед составлением сайта я настоятельно рекомендую ознакомиться с важнейшими моментами работы файла роботс. Вы должны понимать хотя бы базовые принципы работы роботов поисковых систем, чтобы понимать, что и как стоит закрывать от индексации.
Важная теория
Сначала определение самого файла.
Файл Robots.txt дает понимание поисковых систем о том, что не нужно индексировать на сайте для предотвращение появления дублированного контента. Можно закрыть от индексации целые разделы, отдельные страницы, папки на хостинге и так далее. Все, что только в голову взбредет.
Именно на этот файл в первую очередь обращают внимание поисковые роботы при заходе на сайт, чтобы понять, куда стоит смотреть, а что необходимо игнорировать и не заносить в поисковую базу.
Также данный файл служит для облегчения работы поисковым роботам, чтобы они не индексировали много мусорных страниц. Это создает нагрузку на наш сайт, так как роботы будут долго лазить в процессе индексирования.
Файл Robots.txt размещается в корневом каталоге любого сайта и имеет расширение обычного текстового документа. То есть мы его можем редактировать у себя на компьютере с помощью обычного текстового редактора - блокнота.
Чтобы просмотреть содержимое этого файла на лбом сайта, стоит к доменному имени дописать название файла через правую наклонную черту вот так: имя домена.ру/robots.txt
Очень важно понимать, что для некоторых сайтов файл может различаться, так как может быть сложная структура. Но основная мысль в том, чтобы закрыть страницы, которые генерируются самим движком и создают дублированный контент. Также задача стоит в том, чтобы предотвратить попадание таких страниц в индекс, а не только их содержимого. Если у вас простой сайт на WordPress, то файл вам подойдет.
Также рекомендую во все вникать и постараться разобраться в тонкостях, так как это те моменты, которые постепенно могут губить ресурс.
Далее стоит понять, как поисковые системы относятся к этому файлу, так как в Яндексе и в Google имеются различия в восприятии запретов, которые прописываются в файле robots.
к содержанию ↑Различия в работе для Яндекса и Google
Единственное и пожалуй весомое различие проявляется в том, что Яндекс воспринимает запреты в файле, как некое обязательное правило и довольно хорошо следует всем запретам. Мы ему сказали, что эти страницы в индекс брать не нужно, он и не берет их.
В Google же ситуация совершенно иная. Дело в том, что Google действует по принципу "на зло". Что я имею ввиду? Мы ставим запрет на некоторые служебные страницы. Самой частой такой страницей на которую ставят запрет, является страница, создаваемая ссылкой "Ответить" при включенной функции древовидных комментариев.

Страница по такой ссылке имеет приставку "replytocom". Когда мы ставим запрет на такую страницу, google не может получить доступ к ее содержимому и забирает такой адрес в индекс. В итоге, чем больше комментариев на ресурсе, тем больше и мусорных адресов в индексе, что не есть хорошо.
Конечно же, так как мы закрыли такие адреса от индексации, то содержимое страниц не индексируется и не происходит появление дублированного контента в индекс. Об этом свидетельствует надпись «A description for this result is not available because of this site’s robots.txt».

Переводится это так: «Описание веб-страницы не доступно из-за ограничения в robots.txt».
Как бы ничего страшного. Но страница то попала в индекс, хоть и дублирования не произошло. В общем, это может быть, но можно ведь полностью избавиться от такого мусора.
И тут имеется несколько решений:
- Самый простой вариант - открыть такие адреса для робота google в файле robots, чтобы он смог их просканировать. Тогда он наткнется на мета-тег noindex в исходном коде страницы, который не позволит забрать документ в индекс.

Даем доступ - google сам во всем разбирается. Также на такие страницы добавляется атрибут канонических адресов rel="canonical", который укажет на главный адрес данной страницы, что скажет поисковой системе:
Данный адрес индексировать не нужно, так как имеется главная версия страницы, которую и стоит взять в базу.
В итоге, имеется 2 настройки, которые не позволят забрать мусор в индекс. Но это при условии, что подобные страницы открыты в файле роботс и гугл полностью имеет к ним доступ;
- Более сложный вариант заключается в полном закрытии таких ссылок от поисковых систем, чтобы их даже обнаружить нельзя было. Тут можно использовать различные скрипты и плагины. Хорошая функция имеется в плагине WordPress seo by yoast, которая убирает приставку "replytocom" из ссылок "Ответить".

Также имеются специальные плагины под настройку комментариев, где имеется функция закрытия таких ссылок. Можно и их использовать. Но зачем изобретать колесо? Ведь можно ничего не делать и все будет хорошо и без нашего участия. Главное здесь - открыть доступ, чтобы google смог разобраться во всей ситуации.
Google обязательно найдет такие страницы по внутренним ссылкам (в нашем случае для примера - ссылка "Ответить"). Об этом нам говорит сама справка гугла:
Хотя Google не сканирует и не индексирует содержание страниц, заблокированных в файле robots.txt, URL, обнаруженные на других страницах в Интернете, по-прежнему могут добавляться в индекс. В результате URL страницы, а также другие общедоступные сведения, например текст ссылок на сайт или заголовок из каталога Open Directory Project (www.dmoz.org), могут появиться в результатах поиска Google.
Однако даже если вы запретите поисковым роботам сканировать содержание сайта с помощью файла robots.txt, это не исключает, что Google обнаружит его другими способами и добавит в индекс.
А что дальше? Если доступ открыть, то он наткнется на мета-тег Noindex, запрещающий индексирования страницы, и на атрибут rel="canonical", который укажет на главный адрес страницы. Из последнего роботу гугла будет понятно, что данный документ не является главным и его не стоит брать в индекс. Вот и все дела. Ничего в индекс не попадет и никаких конфликтов с поисковым роботом Google не произойдет. И не придется потом избавляться от мусора в индексе.
Если же доступ будет закрыт, то велика вероятность, а скорее всего 100%, что адреса, найденные по таким ссылкам, googlebot проиндексирует. В этом случае придется от них избавляться, что уже занимает время ни одного дня, недели или даже месяца. Все зависит от количества мусора.
В общем, чтобы не произошло такого, стоит использовать правильный файл без лишних запретов + открытые всех подобных страниц для поисковой системы Google.
Можно конечно же просто закрыть все подобные ссылки скриптами или плагинами и сделать 301 редирект с дублированных страниц на главную, чтобы поискового робота сразу перекидывало на главный адрес, который он и будет индексировать, не обращая внимание на дубли.
Второй вариант является более жестким, так сказать более твердым, так как мы делаем некоторые манипуляции, закрывая весь мусор от поисковиков. Мы нее даем им самим разобраться в сложившейся ситуации. Ни малейшего шанса, что страницы по внутренним ссылкам попадут в индекс.
Лично я так и поступил. У меня все закрыто скриптом и редиректами.
Прежде, чем мы рассмотрим основу правильно файла robots, разберем основные директивы, чтобы на базовом уровне вы понимали, как составляется этот файл и как его можно будет доработать под свои нужды.
к содержанию ↑Основные директивы
Основными директивами файла robots являются:
- User-agent - директива, которая указывает, к какому роботу поисковых систем принадлежат правила, прописанные для запретов и разрешений. Если правила необходимо присвоить ко всем поисковым системам, то после директивы ставится звездочка *, если же стоит прописать правила к определенному роботу, например к Яндексу, то стоит прописать имя робота. В данном случае директива будет прописана так:
User-agent: Yandex
Название других роботов:
- Google — Googlebot;
- Яндекс — Yandex;
- Рамблер — StackRambler;
- Мэйл.ру — Mail.Ru.
- Disallow - директива призвана для запрета от индексации каталогов, страниц и документов. Чтобы запретить какой-то раздел, что после директивы прописать название каталога через правую наклонную черту. Например необходимо закрыть категорию "inter" на сайте, тогда необходимо будет прописать следующим образом:
Disallow: /inter
В этом случае будет запрещен от индексации каталог "inter", а также все, что находится внутри него;
- Allow - директива для разрешения частей сайта к индексации. Если нужно разрешить какую-то часть, то по аналогии с директивой Disallow прописывает название каталога или отдельной страницы. Например, если мне нужно открыть подраздел "pr" внутри каталога "inter", то правило будет прописано следующим образом:
Allow: /inter/pr
Хоть каталог "inter" мы и закрыли в предыдущем случае, подраздел "pr" будет индексироваться и все, что внутри него также будет доступно для поисковых роботов.
- Host - директива призвана, чтобы указать поисковым роботам основное зеркало сайта (с www или без).

Прописывать стоит только к Яндексу. Также необходимо указать главное зеркало сайта в панели веб-мастера Яндекс.

- Sitemap - директива призвана указать путь к карте сайта в формате XML. Стоит прописывать ко всем поисковым роботам. Достаточно указать только к директиве User-agent: *, которая ко всем роботам и действует.

Важно! После каждой директивы обязательно должен быть отступ в виде одного пробела.
Зная основные моменты в работе robots.txt и базовые принципы его составление, можно приступить к его сборке.
к содержанию ↑Составляем правильный файл
Вообще, идеальным вариантом было бы полностью открыть свой сайт к индексации и дать возможность поисковым роботам самим разобраться во всей ситуации. Но их алгоритмы не совершенны и они берут в индекс все, что можно только забрать в поисковую базу. А нам это ни к чему, так как будет куча дублированного контента в рамках сайта и куча мусорных страниц.
Чтобы такого не было, нужно составить такой файл, который будет разрешать к индексации только страницы самих статей, то есть контента и по надобности страницы, если они несут полезную информацию посетителю и поисковым системам.
Из пункта 2 сего материала вам стало понятно, что в файле не должно быть лишних запретов для Google, чтобы в индекс не полетели лишние адреса страниц. Это ни к чему. Яндекс же относится к данному файлу нормально и запреты воспринимает хорошо. Что укажем к запрету, то Яндекс и не будет индексировать.
На основе этого я сделал файл, который открывает весь сайт для поисковой системи Google (кроме служебных директорий самого движка WordPress) и закрывает все страницы дублей от Яндекса, Mail и других поисковиков.
Мой файл имеет довольно большой вид.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /xmlrpc.php Disallow: */author/* Disallow: */feed/ Disallow: */feed Disallow: /?feed= Disallow: */page/* Disallow: */trackback/ Disallow: /search Disallow: */tag/* Disallow: /?wp-subscription-manager* Allow: /wp-content/uploads/ Host: kostyakhmelev.ru User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Allow: /wp-content/uploads/ User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /xmlrpc.php Disallow: */author/* Disallow: */feed/ Disallow: */feed Disallow: /?feed= Disallow: */page/* Disallow: */trackback/ Disallow: /search Disallow: */tag/* Disallow: /?wp-subscription-manager* Allow: /wp-content/uploads/ User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /xmlrpc.php Disallow: /?wp-subscription-manager* Allow: /wp-content/uploads/ Sitemap: http://kostyakhmelev.ru/sitemap.xml Sitemap: http://kostyakhmelev.ru/sitemap.xml.gz User-agent: Mediapartners-Google Disallow: User-agent: YaDirectBot Disallow: User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /xmlrpc.php Disallow: */author/* Disallow: */feed/ Disallow: */feed Disallow: /?feed= Disallow: */page/* Disallow: */trackback/ Disallow: /search Disallow: */tag/* Disallow: /?wp-subscription-manager* Allow: /wp-content/uploads/ Host: kostyakhmelev.ru
User-agent: Googlebot Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Allow: /wp-content/uploads/
User-agent: Mail.Ru Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /xmlrpc.php Disallow: */author/* Disallow: */feed/ Disallow: */feed Disallow: /?feed= Disallow: */page/* Disallow: */trackback/ Disallow: /search Disallow: */tag/* Disallow: /?wp-subscription-manager* Allow: /wp-content/uploads/
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /xmlrpc.php Disallow: /?wp-subscription-manager* Allow: /wp-content/uploads/ Sitemap: http://kostyakhmelev.ru/sitemap.xml Sitemap: http://kostyakhmelev.ru/sitemap.xml.gz
User-agent: Mediapartners-Google Disallow:
User-agent: YaDirectBot Disallow:
User-agent: Googlebot-Image Allow: /wp-content/uploads/
User-agent: YandexImages Allow: /wp-content/uploads/ |
Не забудьте изменить адрес моего домена на свой в директивах Host и Sitemap.
Как видим, файл Robots.txt для wordpress вышел довольно большой. Это связано с тем, что правила я прописал к 3м основным роботам: Яндекс, Google и mail. К первым 2м обязательно нужно сделать. Также и к поисковому роботу mail не помешает, так как в последнее время поисковик довольно неплохо развивается и начинает приводить все больше и больше трафика.
Что касается самого содержимого файла, то для роботов Яндекса, Mail и для дериктивы, работающей со всеми роботами (User-agent: *), правила прописаны одни и те же. Запрет идет для всех основных моментов, связанных с появлением дублей в индексе.
Только к поисковому роботу Google я прописал отдельный вариант, который предполагает открытие всего содержимого сайта, кроме служебных папок самого движка. Почему именно так, я рассказывал выше. Нужно, чтобы Googlebot мог просканировать все страницы по внутренним ссылка и увидеть на них запреты в виде мета-тега robots со значением noindex, а также атрибут rel="canonical", что заставит его оставить дубли в покое.
Если же мы в файле роботс сделаем запрет, то робот не сможет увидеть этих данных (тегов) и, как я говорил ранее "на зло", возьмет адрес в индекс.
Также к каждому роботу я разрешил индексирование изображений (Allow: /wp-content/uploads/).
В конце файла я отдельно прописал разрешение индексации изображений для картиночных роботов Google и Яндекса. Вместе с этим разрешил весь сайт для роботов контекстной рекламы этих же поисковиков.
Интересным моментом является закрытие ссылки, которая создается плагином Subscribe to comments.

Если вы его используете, то в данном файле используйте запрет на ее индексирование, так как поисковый робот ее также обнаружит.
Для этого используется следующая строка:
Disallow: /?wp-subscription-manager*
Используя данный файл вы не будете бояться, что в индексе будет появляться дублированный контент, который образуется самим движком, а точнее его внутренними ссылками на страницах сайта. Яндекс все запреты сочтет за некую догму, а Google наткнется на запреты, когда зайдет на дубли, создаваемые движком.
Как я уже описывал ранее, то более продвинутыми настройками является скрытие таких ссылок, чтобы поисковые роботы даже не смогли их найти. К тому же это не только в 100% мере обезопасит нас сейчас, но и даст нам некую подстраховку на будущее, так как алгоритмы поисковых систем постоянно меняются и возможно, что запреты, которые работают сейчас, не будут работать через некоторое время.
Но тут также. Разработчики движка всегда идут в ногу со временем и учтут все новые изменения в работе ПС в совершенствовании wordpress. Исходя из этого, бояться в ближайшее время ничего не стоит.
В следующих статьях я буду описать процесс избавления от дублей страниц, которые могут появиться на ресурсе, а также способы скрытия опасных ссылок, создаваемых средствами WordPress, если вы все же решите обезопасить себя на все 100%. Мы ведь не знаем, как поведет себя поисковой робот? Может он начнет игнорировать запреты даже при наличии мета-тега Noindex и атрибута rel="canonical". В этом случае спасет скрытие опасных ссылок.
Итак, возможно, статья вышла довольно сложная для первого понимания, так как затронут не только вопрос составления самого файла, но и принципов работы поисковых роботов и того, что стоит сделать в идеале, что страшно, а что нет.
Если у вас имеются какие-то вопросы или неясности, то буду благодарен, если напишите об этом в комментариях, чтобы я как-то изменил данный материал для более отзывчивого восприятия другими пользователями.
На этом закончу этот пост. До скорых встреч!
С уважением, Константин Хмелев!

kostyakhmelev.ru
Правильный файл robots.txt для сайта WordPress

22 Июня 2016

В этой статье мы разберем, как создать правильный файл robots.txt для сайта WordPress. Файл robots.txt дает команды поисковым роботам, какие файлы нужно закрыть для индексации. По сути, с его помощью происходит управление индексированием сайта. В сети много противоречивой информации о том, как правильно настраивать роботс тхт. Давайте попробуем разобраться, зачем вообще нужно запрещать индексировать определенные страницы сайта на WordPress.
Плейлист «Как создать сайт на WordPress»
TimeWeb лучший хостинг для WordPress: домен в подарок, 99 рублей в месяц.Попробуйте, 10 дней бесплатно: РЕГИСТРАЦИЯ ОБЗОР ВИДЕО

Файл robots.txt это первое, что проверяет поисковый робот, попадая на сайт. Его отсутствие может отрицательно сказаться на индексировании. То есть, наличие файла robots.txt на сайте обязательно. Поисковые роботы периодически обходят наш сайт. Если весь сайт открыт для индексации, робот будет обходить все файлы и папки, даже те, которые никак не могут попасть в поиск. Зачем нагружать сайт, замедляя тем самым загрузку страниц? Вопрос риторический, очевидно, лучше запретить индексацию файлов, которые не должны и не могут попасть в поиск, разгрузив тем самым ресурсы нашего хостинга. Более того, такие страницы, как дубли, служебные страницы, системные файлы КЭШа крайне отрицательно влияют на продвижение сайта в поисковых системах. Исключение из индекса лишних страниц принесет только пользу нашему сайту.
Поисковые роботы периодически обходят наш сайт. Если весь сайт открыт для индексации, робот будет обходить все файлы и папки, даже те, которые никак не могут попасть в поиск. Зачем нагружать сайт, замедляя тем самым загрузку страниц? Вопрос риторический, очевидно, лучше запретить индексацию файлов, которые не должны и не могут попасть в поиск, разгрузив тем самым ресурсы нашего хостинга. Более того, такие страницы, как дубли, служебные страницы, системные файлы КЭШа крайне отрицательно влияют на продвижение сайта в поисковых системах. Исключение из индекса лишних страниц принесет только пользу нашему сайту.
Какие файлы и страницы стоит запретить для индексации. Системные папки: нужно запретить индексацию к системным файлам и каталогам, так как в них представлена информация для администратора сайта и ее попадание в индекс крайне не желательно. Страницы авторизации и регистрации: на этих страницах вводятся личные данные пользователей, поэтому индексация не желательна. Страницы поиска: индексация результатов внутреннего поиска на сайте не нужна в индексе поисковых систем, так как это может привести к созданию дублей страниц.
Не правильная настройка robots.txt может кардинально повлиять на работу сайта, поэтому рекомендую прочитать рекомендации на Яндексе и Google. Информация в этих разделах общая и, как обычно, воспринимается трудно. Поэтому и написана эта статья.
Как создать файл robots.txt. Рекомендую использовать плагин All in One SEO Pack (подробный обзор плагина здесь). Нам нужно включить два модуля. Для этого перейдите в административную панель «WordPress» ⇒ «All in One SEO Pack» ⇒ «Управление модулями» и активируйте модули «Robots.txt» и «Редактор файлов». Все, создание файла robots.txt завершено. Осталось добавить необходимые директивы, это делается через модуль «Редактор файлов». В модуле «Robots.txt» можно посмотреть содержимое самого файла.
Давайте разбираться дальше, что нужно добавить в файл robots.txt. Обязательно должны присутствовать три директивы robots.txt для Google, Яндекса и других поисковых систем. Важно. Для каждой поисковой системы актуальны разные директивы. Для Яндекса нужно прописать одни правила, для Google совсем другие. Три основные секции для robots.txt:
User-agent: * User-agent: Yandex User-agent: GooglebotЕще один обязательный атрибут это путь к карте сайта. Особенно Яндекс ругается, если не прописана карта в роботсе. Допустимо расположение в любом месте (как в начале, так и в конце файла). Вот так нужно выводить карту сайта в robots.txt (название сайта замените на ваше):
Sitemap: http://busines-expert.com/sitemap.xmlДиректива host в robots.txt. Для Яндекса нужно указать главное зеркало сайта. Основные зеркала: site.com и www.site.com. Укажите в файле реальный адрес вашего сайта (если он включает www, пропишите их). Host нужно прописать обязательно в директиве только для Яндекса. Вот так нужно выводить host в robots.txt (название сайта замените на ваше):
Host: busines-expert.comТеперь давайте рассмотрим, что обозначают директивы robots.txt. Директива User-agent – имена поисковых роботов, для которых предназначены следующие за ней правила. Директива Disallow – отвечает за запрет индексации файлов. Директива Allow – разрешает индексацию файлов. Sitemap – карта сайта. Host – основное зеркало сайта.
Мы рассмотрели, что должно быть прописано обязательно. Теперь я приведу вам конкретный пример файла robots.txt для WordPress. На данный момент все, что прописано в примере ниже, является актуальным и правильным для всех поисковых систем, в том числе, и для Яндекса с Гуглом.
Правильный файл robots.txt для WordPress
User-agent: * Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php User-agent: Yandex Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */trackback Disallow: */feed Disallow: /*? Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Host: busines-expert.com User-agent: Googlebot Allow: *.css Allow: *.js Allow: /wp-includes/*.js Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-includes/ Disallow: /wp-content/cache Disallow: */trackback Disallow: */feed Disallow: /author/ Disallow: /transfers.js Disallow: /go.php Disallow: /xmlrpc.php Disallow: /*? Sitemap: http://busines-expert.com/sitemap.xmlМожете скопировать и вставить в ваш файл robots.txt этот текст предварительно заменив в host и sitemap адрес моего сайта на ваш.
Как создать файл robots.txt. Рекомендую использовать плагин All in One SEO Pack (подробный обзор плагина здесь). Нам нужно включить два модуля. Для этого перейдите в административную панель «WordPress» ⇒ «All in One SEO Pack» ⇒ «Управление модулями» и активируйте модули «Robots.txt» и «Редактор файлов». Все, создание файла robots.txt завершено. Осталось добавить необходимые директивы, это делается через модуль «Редактор файлов». В модуле «Robots.txt» можно посмотреть содержимое самого файла.
Как узнать адрес файла robots.txt. Адрес файл одинаков для всех сайтов, просто добавьте /robots.txt после адреса вашего сайта. Вот адрес моего роботса: http://busines-expert.com/robots.txt. Замените адрес на ваш, и вы сможете просмотреть содержимое файла robots.txt на вашем сайте.
После настройки файла robots.txt нужно обязательно поверить корректность его работы в популярных поисковых системах Яндекс и Google. Возможно, вы допустили ошибку при указании директив. Чтобы избежать отрицательных последствий, проверьте, правильно ли все отображается в поисковиках.
Как добавить robots.txt в Яндекс. Зайдите в административную панель «Яндекс Вебмастер» ⇒ «Инструменты» ⇒ «Анализ robots.txt». Убедитесь, что загружена актуальная версия файла. Это можно посмотреть в поле под надписью «Текст robots.txt», либо скачать сам файл на компьютер. Если будут ошибки, данный инструмент сообщит об этом, также сообщит, как исправить возможные ошибки. Как добавить robots.txt в Google. Зайдите в административную панель «Google WebMasters» ⇒ «Сканирование» ⇒ «Анализ robots.txt». Внизу в поле напротив названия сайта вставьте «robots.txt» и «нажмите проверить»:
Как добавить robots.txt в Google. Зайдите в административную панель «Google WebMasters» ⇒ «Сканирование» ⇒ «Анализ robots.txt». Внизу в поле напротив названия сайта вставьте «robots.txt» и «нажмите проверить»: Затем, чтобы Google как можно быстрее проверил файл robots.txt, нужно отправьте в Google запрос на обновление. Для этого нажмите «отправить» и напротив цифры 3 также нажмите «отправить»:
Затем, чтобы Google как можно быстрее проверил файл robots.txt, нужно отправьте в Google запрос на обновление. Для этого нажмите «отправить» и напротив цифры 3 также нажмите «отправить»: В ближайшее время Google обновит файл. Если будут ошибки, данный инструмент сообщит об этом, предложив варианты их решения.
В ближайшее время Google обновит файл. Если будут ошибки, данный инструмент сообщит об этом, предложив варианты их решения.
Вот мы и закончили обзор файла robots WordPress. Полезного материала много. Надеюсь, дана статья помогла вам правильно настроить файл robots.txt. Напишите в комментариях, как настраиваете роботс вы, думаю, многим веб-мастерам будет интересна разноплановая информация.
Опубликовано в Как создать сайт. Пошаговая инструкцияСоветую посетить следующие страницы:✓ Как создать и настроить файл sitemap✓ 27 необходимых плагинов для WordPress✓ Разработка и создание дизайна сайта самому✓ Полная настройка WordPress✓ Лучшая капча для сайта WordPress
busines-expert.com
Правильный файл robots.txt для WordPress
robots.txt является файлом, специально предназначенным для поисковых систем. В нем указывается, какие части сайта нужно выдавать в поиске, а какие нет. Важность robots.txt неоценима, так как он позволяет нацелить поисковую систему на попадание нужного контента сайта в выдаче результатов. Например, при запросе в Гугле «купить стиральную машину» конечному покупателю незачем попадать на страницу администрирования магазина. В этом случае несомненно важно будет пользователю перейти сразу в раздел “Стиральные машины”.
Как добавить robots.txt на сайт?
Если Вы используете плагин Clearfy — просто выставьте галочку напротив Создать правильный robots.txt в разделе SEO на странице настроек плагина. Ничего вставлять из этой статьи Вам не нужно, все реализовано в плагине.Добавить файл можно несколькими способами. Наиболее удобный для пользователя — по FTP. Для этого необходимо создать сам файл robots.txt. Затем, воспользовавшись одним из FTP-клиентов (например, FileZilla), загрузить robots.txt в корневую папку сайта (рядом с файлами wp-config.php, wp-settings.php) Следует отметить, что перед загрузкой файла нужно узнать у Вашей хостинг-компании IP-адрес, за которым закреплен Ваш сайт, имя FTP-пользователя и пароль.

После успешной загрузки robots.txt, перейдя по адресу http://sitename.com/robots.txt, Вы сможете посмотреть актуальное состояние файла.
Важным является тот факт, что, изменив файл robots.txt, вы не сразу заметите результаты. Для этого может понадобится от одного до нескольких месяцев (это зависит от поисковой системы). Правильным вариантом является составление корректного файла уже на стадии разработки сайта.
Пример корректного robots.txt
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Host: sitename.com** Вместо sitename.com следует указать название Вашего сайта
Плагины для robots.txt
Для облегчения создания robots.txt в WordPress существуют специальные плагины. Некоторые из них: WordPress Robots.txt File, DL Robots.txt, Yoast SEO.
Рассмотрим создание файла robots.txt на примере одного из самых мощных SEO-плагинов Yoast SEO.
После установки и активации плагина необходимо в админ-панели выбрать пункт SEO->Консоль. На вкладке Возможности перейти в раздел Дополнительные настройки страницы, передвинуть ползунок в состояние Включено и сохранить изменения. В админ-панели появятся несколько дополнительных пунктов. Далее необходимо перейти по пункту SEO->Инструменты, где выбрать Редактор файлов. Далее на странице редактора необходимо нажать на кнопку Создать файл robots.txt, в редакторе вставить вышеописанный код и нажать Сохранить изменения в robots.txt.

Если Вам понравилась статья — поделитесь с друзьями
wpschool.ru
Правильный robots.txt для сайта wordpress, как закрыть ссылки от индексации
Индексация сайта представляет собой процесс, благодаря которому страницы вашего сайта попадают в поисковые системы.
Для того чтобы сайт индексировался хорошо, вам нужно создать правильный файл robots txt и вписать туда необходимые директивы.
Файл можно создать в стандартной программе «Блокнот», которая доступна абсолютно каждому пользователю ПК.
Добавляется файл robots txt в корневую папку сайта. Для того чтобы осуществить это действие, вам потребуется программа FileZilla или же обычный Total Commander при условии наличия FTP соединения. На некоторых хостингах есть возможность непосредственного добавления каких-либо файлов.

Что будет, если файл robots txt неправильно настроен
Чтобы ответить на данный вопрос, давайте представим, что сайт wordpress это офис, в который приходят клиенты. В вашем офисе есть как гостевые комнаты, так и служебные, вход в которые доступен только сотрудникам. На дверях служебных помещений обычно вешается табличка с надписью «вход воспрещен» или «вход только для сотрудников». Таким образом, ваши клиенты будут понимать, что туда им лучше не соваться.
Теперь поговорим о сайте wordpress. Если придерживаться аналогии, то его гостевыми комнатами будут открытые к индексации страницы, а служебными — закрытые к индексации страницы. Клиенты же являются поисковыми роботами, которые посещают сайт и вносят в поисковый индекс определенные страницы.
После небольшого экскурса перейдем непосредственно к последствиям, которые могут возникнуть при неправильной настройке файла роботс. Если вы не впишите запрещающие директивы, то поисковый робот будет индексировать абсолютно все подряд, включая данные панели администратора сайта, тем, скриптов и так далее. Также в выдаче могут появиться страницы-дубли. Поисковый робот может запутаться и случайно проиндексировать одну и ту же страницу несколько раз. Бывают случаи, когда роботы вовсе не индексируют сайт из-за того, что директивы файла индексации неправильно настроены, но чаще всего такое последствие является санкцией, которая возлагается на сайт при продаже ссылок. Чтобы выяснить причину, вам нужно зайти в панель управления, которую предоставляют поисковые системы, которая отказывается индексировать сайт и обратить внимание на какие-либо оповещения.
Настройка robots txt
Запомните, что правильный файл robots txt состоит из 3 компонентов: выбор робота, которому вы задаете директивы; запрет на индексацию; разрешение индексации.
Для того чтобы указать конкретного робота, которому будут адресоваться правила, можно использовать директиву User-agent. Ниже представлены возможные примеры.
- User-agent: * (правила будут распространятся на всех поисковых роботов).
- User-agent: название поискового робота (правила будут распространятся только на тех роботов, которых вы впишете). В большинстве случаев сюда вписывают yandex и googlebot.
Чтобы запретить индексацию определенных разделов на wordpress, вам стоит использовать правильный комплекс директив Disallow. Помимо разделов вы можете также запретить индексировать какую-либо папку или файл. Итак, перейдем к примерам.
- Disallow: (на индексацию нет никаких запретов).
- Disallow: /file.pdf (закрыть файл file.pdf). Таким же образом можете попросить закрыть конкретные папки.
- Disallow: /nazvanie-razdela (закрыть страницы, которые находятся в разделе «nazvanie-razdela»).
- Disallow: */*slovo (закрыть страницы, ссылки на которые включают в себя «slovo»). Звездочки означают любой текст ссылки, который стоит перед или после указанного вами слова. При использовании такой комбинации символов поисковый робот будет считать, что звездочка находится и в конце. Поэтому, если хотите закрыть страницы, ссылки на которые заканчиваются определенным текстом, то вам стоит добавить еще «$» после директивы.
- Disallow: / (закрыть весь сайт).
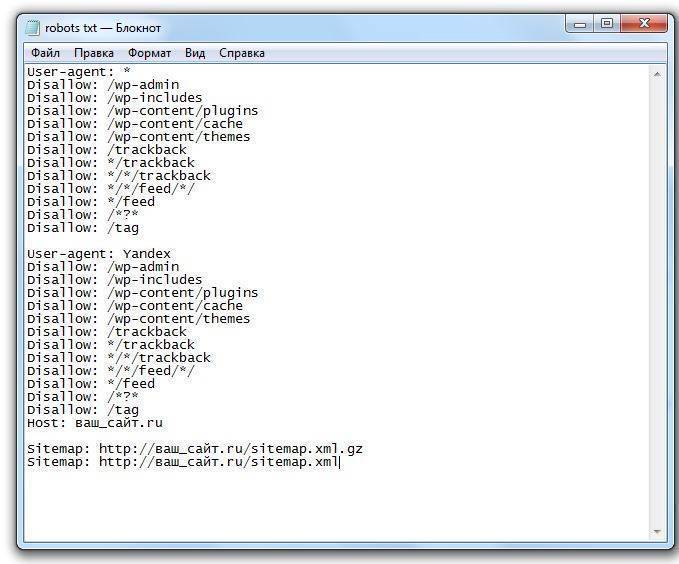 Если же хотите разрешить индексирование конкретных файлов сайта, которые находятся в запрещенных для индексации разделах, то вам поможет директива Allow. Наглядный пример смотрите ниже.
Если же хотите разрешить индексирование конкретных файлов сайта, которые находятся в запрещенных для индексации разделах, то вам поможет директива Allow. Наглядный пример смотрите ниже.
адресуется поисковым роботам Google
User-agent: googlebot
закрыть страницы, которые находятся в разделе «nazvanie-razdela»
Disallow: /nazvanie-razdela
разрешено добавлять в индекс абсолютно все файлы с расширением txt, независимо от раздела сайта
Allow: *.txt$
В случае наличия XML карты сайта вы можете указать текст ее ссылки в директиву Sitemap. Она является неофициальной и поддерживается не всеми поисковыми роботами. Основными же (Yandex, Google, Bing и Yahoo) эта директива поддерживается. Если у сайта есть несколько XML карт, то вы можете указать все, используя ссылки на них. Никаких проблем не должно возникнуть. Основная ваша задача это правильно указать адрес ссылки каждой из них.
Sitemap: сайт.ru/название-карты-сайта.xmlSitemap: сайт.ru/название-карты-сайта1.xml
У многих сайтов вордпресс есть зеркала. Чтобы указать основное, вам потребуется вписать адрес его ссылки в директиву Host. Ее понимают только поисковые роботы системы Yandex. Данную директиву можно вписать как под User-agent, так и в любое другое место роботс тхт. Обратите внимание, что адрес ссылки основного зеркала может содержать www. Если вы забудете его туда вписать, то тогда могут возникнуть проблемы.
Host: основное-зеркало.ru
Теперь, зная директивы, вы можете самостоятельно создать правильный файл роботс под любые поисковые системы. Для этого вам нужно в первую очередь проанализировать структуру сайта вордпресс и решить, что же закрыть от поисковиков, а что открыть. Если же вам лень этим заниматься, то можете использовать пример, который представлен ниже.
Для удобства вам рекомендуется использовать плагин wordpress All in One Seo Pack. Он содержит опцию, благодаря которой можно закрыть индексацию архивов, тегов и страниц поиска. Если у вас нет такого плагина, то вам стоит дописать в robots txt представленные ниже атрибуты после директивы Disallow.
- */20 — отвечает за архивы
- */tag — отвечает за теги
- *?s= — отвечает за страницы поиска
При прописывании директив обратите внимание на то, что все директивы, которые адресуются одному поисковому роботу, нужно прописывать без пробела между строками. В ином же случае вам этот пробел будет необходим.Стоит отметить, что если вы прописали директивы для всех поисковых систем, не нужно их по 10 раз переписывать для каждой отдельно. Это будет лишней тратой времени. Директива User-agent универсальна, поэтому просто вписываете туда звездочку и никаких проблем не должно возникнуть.
Если вам лень прописывать полное название служебных разделов, то можете прописать директиву Disallow: /wp- при условии, что на вашем сайте wordpress нет страниц с таким названием, которые вы бы хотели добавить в индекс. Поэтому будьте внимательны при выборе названия для неслужебных разделов.
При изменении директив файла robots txt вам стоит помнить, что его индексация это не быстрый процесс. Иногда на это требуется не одна неделя. Чтобы проверить статус индексирования этого файла Яндексом, вам нужно перейти в панель вебмастера сервиса Яндекс, выбрать сайт и перейти в раздел «Настройка индексирования». Потом вам нужно будет выбрать «Анализ robots txt».
Чтобы проверить статус индексирования файла в Google, вам нужно перейти в раздел «Сканирование» и выбрать «Инструмент проверки robots txt».
После того как настроите директивы, поисковики должны начать добавлять ваш сайт wordpress в индекс. Стоит отметить, что этот процесс может пойти не так гладко, как вы думаете. Многие вебмастера жалуются на Google из-за того, что он вопреки каким-либо запретам производит индексацию сайта так, как пожелает. Работники Google говорят, что файл роботс является не более, чем рекомендацией.
Даже если прописать запрещающие директивы отдельно для Google, то желаемый результат вы не факт, что получите. К тому же, из-за произвольной индексации роботов Google могут появиться страницы-дубли. Их количество со временем может увеличиться и сайт может попасть под фильтр. Чаще всего это Panda.
Чтобы справиться с этой проблемой, вы можете поставить пароль в панели управления wordpress на конкретный файл или же добавить атрибут noindex в метатеги страниц, на которые желаете наложить запрет индексации. Выглядеть это будет так.
<meta name="robots" content="noindex">
Альтернативой для атрибута noindex является атрибут nofollow. Разница между ними лишь в том, что они по-разному оцениваются поисковыми системами. В случае же с Google вам лучше использовать noindex. Если прислушаться к рекомендации, то вы добьетесь желаемого результата.
В справке сервиса Google можно более детально изучить особенности использования атрибута noindex.
Если вы не хотите вручную создавать роботс для своего wordpress, то можете воспользоваться плагином DL Robots.txt. Его можно установить прямо в панели администратора. Для этого вам нужно будет кликнуть по разделу «Плагины» и выбрать «Добавить новый». Теперь вам останется лишь вписать название и кликнуть «Установить», а затем «Активировать». После этого в панели администратора должна появиться вкладка с названием плагина. Кликнув на нее, вы перейдете в настройки и сможете посмотреть обучающее видео. После проведения настройки вы получите адрес ссылки вашего роботс.

Альтернативами данного плагина wordpress являются PC Robots.txt и iRobots.txt. Они имеют свои особенности, но в целом похожи и являются легкими в настройке. Так что, если первый по каким-либо причинам не будет работать, вы всегда можете воспользоваться последними.
Несколько советов и примечаний
- Помните, что правильный файл роботс wordpress не должен занимать более 32 Кбайта дискового пространства. В противном случае могут возникнуть проблемы и индексацией. Чем меньше вес, тем быстрее обработка.
- Не желательно указывать несколько директив в одной строке.
- Не нужно добавлять в кавычки каждый атрибут директивы, который находится в роботс.
- При отсутствии файла роботс поисковики будут считать, что запрет на индексацию не установлен. Произвольная индексация может привести к фильтрации.
- Стоит отметить, что правильный роботс не должен содержать пробелы в начале каждой строки директивы.
Похожие статьи
wordpresslib.ru