Оптимизация запросов в Microsoft SQL Server. Оптимизация запросов ms sql
Оптимизация запросов для Microsoft SQL Server
Аудитория: Администраторы и разработчики баз данных для Microsoft SQL Server
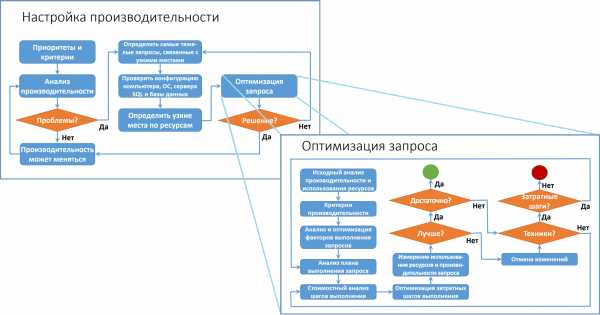
Длительность: 2 дня.Модули:
- Архитектура СУБД (Database Engine) в Microsoft SQL Server
- Методология оптимизации
- Инструменты для анализа SQL-запросов
- Анализ выполнения SQL-запросов
- Оптимизация SQL-запросов
- Анализ и проектирование индексов
- Решения по обеспечению производительности
Библиография:
- Expert performance indexing for SQL Server 2012. Jason Strate, Ted Krueger
- Inside the SQL Server Query Optimizer. Benjamin Nevarez
- Microsoft SQL Server 2012 Performance Tuning Cookbook. Ritesh Shah, Bihag Thaker
- Optimizing Fill-factors for SQL Server. Ken Lassesen
- Performance Tuning with SQL Server Dynamic Management Views. Louis Davidson and Tim Ford
- Plan Caching and Recompilation in SQL Server 2012. Greg Low
- SQL Server DMVs in Action. Better querie
minyurov.com
Оптимизация SQL-запросов - Блог ITVDN
Все мы знаем простую формулу: быстрый сайт = счастливые пользователи, высокая оценка Google-статистики и увеличение количества переходов. Возможно, Вам и кажется, что Ваш сайт работает настолько быстро, насколько ему позволяет быть быстрым WordPress – Вы же видели те списки лучших практик настройки сервера, улучшения производительности кода и так далее – но всё же, разве это предел?
Используя динамические базы данных сервисов типа WordPress, в конечном итоге перед Вами предстанет проблема: запросы к базе замедляют работу сайта.
В рамках этого поста я постараюсь научить Вас определять проблемные места, понимать их причину и предложу некоторые быстрые решения и другие программные подходы для ускорения работы. В качестве примера мы будем использовать действующие примеры работы с базой, замеченные на одном из сайтов.
Идентификация
Первый шаг на пути повышения производительности - это обнаружение проблемных SQL-запросов. И на сцену выходит Query Monitor – по-настоящему незаменимый плагин для мониторинга работы запросов. Особенность его в том, что плагин показывает детальную информацию о каждом запросе, позволяя к тому же отфильтровать их, исходя из порождающего участка кода (включается подсветка дублированных запросов).
Если же по какой-то причине Вы не желаете устанавливать отладочный плагин, вы можете в качестве опции включить MySQL Slow Query Log, логирующий все запросы, требующее длительное время для выполнения. К тому же конфигурация и настройка места логирования относительно проста. Так как это серверное дополнение, падение производительности будет заметно в меньшей мере, чем если бы вместе с отладочным плагином непосредственно на сайте. Однако по мере отсутствия необходимости, MySQL Slow Query Log стоит отключать.
Понимание
Как только вы находите затратный по времени запрос, который было бы неплохо улучшить, встает следующий вопрос: почему он работает медленно? К примеру, во время разработки одного сайта был обнаружен запрос, работающий целых 8 секунд!
Для поддержки магазина плагинов мы использовали WooCommerce и кастомизированную версию WooCommerce Software Subscriptions плагина. Задача приведенного выше запроса была получить все подписки пользователя, оперируя его идентификационным номером. WooCommerce обладает своеобразной комплексной моделью данных, при использовании которой наблюдалось следующее: хотя запрос и хранится как пользовательские пост-типы, идентификатор пользователя хранится в пост-мета данных, а не в post_author, как должно было бы быть. Также было найдено несколько связок с пользовательскими таблицами, созданными плагином. Итак, как же нам уберечь себя от подобных ошибок?
MyS
itvdn.com
Оптимизация SQL-запросов
- 1. Оптимизация SQL-запросов Мастер-класс в компании «ТиЭс Софт»
sql - Оптимизация запроса MS-SQL
Я изо всех сил пытаюсь выполнить один запрос MS-sql, который я должен выполнить для создания отчета в нашей ERP-системе.
Надеюсь, вы можете помочь мне с этим запросом.
Вот запрос:
"Оригинальная версия":
SELECT artikel.artikelnummer, artikel.bezeichnung, SUM(positionen.anzahl), artikel.Einheit FROM artikel, auftrag, positionen INNER JOIN auftrag AS auftrag1 ON (auftrag1.auftrag = positionen.auftrag) INNER JOIN artikel AS artikel1 ON (positionen.artikel = artikel1.artikel) WHERE artikel.warengruppe = 2 OR artikel.warengruppe = 1234 OR artikel.warengruppe = 1235 OR artikel.warengruppe = 1236 OR artikel.warengruppe = 1237 OR artikel.warengruppe = 1239 OR artikel.warengruppe = 1240 OR artikel.warengruppe = 2139 AND auftrag.lieferscheinnr IS NOT NULL GROUP BY artikel.artikelnummer, artikel.bezeichnung,artikel.Einheit"Переведенная версия":
SELECT article.articlenr, article.description, SUM(positions.amount), article.unit FROM article, order, positions INNER JOIN order AS order1 ON (order1.order = positions.order) INNER JOIN article AS article1 ON (positions.article = article1.article) WHERE article.materialgroup = 2 OR article.materialgroup = 1234 OR article.materialgroup = 1235 OR article.materialgroup = 1236 OR article.materialgroup = 1237 OR article.materialgroup = 1239 OR article.materialgroup = 1240 OR article.materialgroup = 2139 AND order.dordernr IS NOT NULL GROUP BY article.articlenr, article.description,article.unitТеперь проблема в том, что таблицы "auftrag" содержат 160 000, "artikel" 155.000 и позиционируют 570 000 записей.
Я прерываю запрос после 1 часа работы. Итак, мой вопрос в том, как я могу оптимизировать запрос?
Моя проблема в том, что я не могу изменить ER-модель.
Заранее благодарю вас за помощь. Надеюсь, вы поймете мой дерьмовый английский. ;)
Оптимизация запросов в Microsoft SQL Server
- Home
- Documents
- Оптимизация запросов в Microsoft SQL Server
Published on04-Jan-2016
View68
Download0
DESCRIPTION
Оптимизация запросов в Microsoft SQL Server. Дмитрий Костылев Начальник отдела разработки системного ПО ОАО « Нордеа Банк » SQL Server MVP 2009-2011. Содержание. Основные понятия Инструменты, поиск «плохих запросов» Анализ плана выполнения - PowerPoint PPT Presentation
Transcript
Конференция по разработке прикладных приложений www.msdevcon.ru 1 Оптимизация запросов в Microsoft SQL Server Дмитрий Костылев Начальник отдела разработки системного ПО ОАО «Нордеа Банк» SQL Server MVP 2009-2011 www.msdevcon.ru 2 Содержание Основные понятия Инструменты, поиск «плохих запросов» Анализ плана выполнения Причины снижения производительности Способы оптимизации запросов Техника написания "быстрых" запросов Табличные переменные и временные таблицы www.msdevcon.ru 3 Основные понятия Оптимизатор План выполнения www.msdevcon.ru Основные понятия: оптимизатор план выполнения Статистика Рекомпиляция Оптимизатор – компилирует запросы. В SQL Server запрос компилируется непосредственно перед первым выполнением. При создании процедуры компиляция не происходит. План выполнения – скомпилированный запрос, в отличии от «обычного» кода его достаточно легко «увидеть» и проанализировать Статистика – информация о распределении значений в полях таблицы Рекомпиляция – повторная компиляция запроса, уже находящегося в процедурном кэше 4 Пример плана выполнения select * from Client c cross apply ( select COUNT_BIG(*) as Cnt from Orders o where o.ClientID = c.ID and o.Status = 'A' ) cn where Status = 'D' www.msdevcon.ru Основные понятия Оптимизатор План выполнения «Процедурный кэш» Статистика Рекомпиляция Логические чтения www.msdevcon.ru Основные понятия: оптимизатор план выполнения Статистика Рекомпиляция Оптимизатор – компилирует запросы. В SQL Server запрос компилируется непосредственно перед первым выполнением. При создании процедуры компиляция не происходит. План выполнения – скомпилированный запрос, в отличии от «обычного» кода его достаточно легко «увидеть» и проанализировать Статистика – информация о распределении значений в полях таблицы Рекомпиляция – повторная компиляция запроса, уже находящегося в процедурном кэше 6 Логические чтения ID Name 1 Иванов 2 Петров 3 Сидоров Клиенты Заказы ID ClientID 1 1 2 3 3 2 4 1 5 2 6 3 www.msdevcon.ru Основные понятия Оптимизатор План выполнения «Процедурный кэш» Статистика Рекомпиляция Логические чтения Прослушивание параметров www.msdevcon.ru Основные понятия: оптимизатор план выполнения Статистика Рекомпиляция Оптимизатор – компилирует запросы. В SQL Server запрос компилируется непосредственно перед первым выполнением. При создании процедуры компиляция не происходит. План выполнения – скомпилированный запрос, в отличии от «обычного» кода его достаточно легко «увидеть» и проанализировать Статистика – информация о распределении значений в полях таблицы Рекомпиляция – повторная компиляция запроса, уже находящегося в процедурном кэше 8 Инструменты SQL Server Management Studio (SSMS) Profiler Динамические системные представления (DMV) www.msdevcon.ru Статистика 9 План выполнения запроса Читаем слева направо и сверху вниз Поток данных – справа налево и снизу вверх www.msdevcon.ru 10 Причины снижения производительности Изменились данные Устарела статистика Недостаточно ресурсов для поиска лучшего плана выполнения Процедура запущена с «плохими» параметрами www.msdevcon.ru 11 Способы оптимизации Изменение структур (создание и изменение индексов и статистик) Подсказки оптимизатору (hints): Уровня запроса Табличные Типы соединений Plan Guides Изменение логики запроса, использование промежуточных наборов Удаление хинтов www.msdevcon.ru Просмотреть хинты запросов Изменение логики запроса – «техника написания быстрых запросов» 12 Техника написания быстрых запросов Все возможные вычисления делать предварительно Не изменять проиндексированные поля, если по ним желателен поиск Скажи нет неявным преобразованиям! Использовать INNER JOIN если только не нужен OUTER Порядок таблиц в запросе – сначала «меньшие потоки данных» Универсальные запросы работают всегда одинаково плохо Борьба с прослушивание параметров www.msdevcon.ru Табличные переменные и временные таблицы Разное использование статистики Для временных таблиц сохраняются все правила «обычных» По табличным переменным не строится статистика, следствия: Нет перекомпиляции запросов после изменения данных в таблице Предполагается, что будет выбираться одна строка за одно обращение к таблице Можно использовать подсказку recompile www.msdevcon.ru Итоги Быстродействие конкретных запросов зависит от выбранного оптимизатором плана выполнения Главным образом на выбор «правильного» плана выполнения влияет статистика Хорошая оптимизация запроса заключается в том, чтобы оптимизацией занимался сам сервер www.msdevcon.ru 15 Обратная связь Ваше мнение очень важно для нас. Пожалуйста, оцените доклад, заполните анкету и сдайте ее при выходе из зала Спасибо! www.msdevcon.ru 16 Вопросы DB804 Дмитрий Костылев [email protected] www.sql.ru/blogs/decolores начальник отдела разработки системного ПО Вы сможете задать вопросы докладчику в зоне «Спроси эксперта» в течение часа после завершения этого доклада www.msdevcon.ru 17 www.msdevcon.ru 18
docslide.net
есть ли инструменты оптимизации запросов для SQL Server? MS SQL Server
Существуют ли какие-либо инструменты для оптимизации запросов для SQL Server 2005 и выше?
Я искал и ничего не нашел.
Если этот вопрос был повторен, прежде чем вы сможете закрыть его, но я не видел ничего подобного
Лучший инструмент, который я когда-либо использовал для оптимизации запросов в MS SQL Server, на сегодняшний день – это вариант «Включить фактический план выполнения» в Microsoft SQL Server Management Studio. Он отображает подробную информацию о пути выполнения, выполняемом сервером при выполнении запроса. (Обратите внимание, что это работает лучше всего, когда в таблицах есть данные. Конечно, без хорошей тестовой информации любая оптимизация в любом случае является чисто теоретической).
Это в основном дает вам три очень важные вещи:
- Он сообщает вам, какие шаги занимают больше времени обработки и что они делают на этом этапе.
- Он сообщает вам, какие шаги переносят большинство данных на следующий шаг, в том числе сколько записей, что помогает идентифицировать места, где вы можете быть более конкретными относительно данных, которые вы хотите, и исключать ненужные записи.
- Это дает вам представление о внутренней работе SQL Server и о том, что он делает с вашими запросами. Эти знания помогут вам значительно оптимизировать вещи с течением времени.
В SSMS – Инструменты | Советник по настройке ядра базы данных – не работает в версиях Express.
Один из лучших оптимизаторов запросов – это просто запуск запроса в SQL Management Studio, а затем проверка плана запроса. Это даст вам подсказки относительно того, какие индексы он использует (или не использует), и как вы можете изменить запрос, чтобы воспользоваться преимуществами этих.
Один очень хороший инструмент и теперь бесплатный для использования – Plan Explorer из SentryOne: https://sentryone.com/plan-explorer
(у них также есть много других программ оптимизации, таких как специальное программное обеспечение Azure и т. д.),
Как прокомментировал Джон Сондерс, лучшим инструментом в вашем распоряжении является ваш собственный ум. Следуя комментарию bernd_k, вот несколько советов по ужесточению этого инструмента.
- SQL Server 2008 Query Performance Tuning Distilled Distilled
- Профессиональный внутренний SQL Server 2008 и устранение неполадок
- Глубокие погружения в SQL Server MVP
Также это хороший инструмент для мониторинга и оптимизации запросов:
Монитор Sql от Red Gate
sqlserver.bilee.com
Помощь оптимизации SQL-запроса MS SQL Server
Если у вас есть SQL Server 2005 или выше, вы можете попробовать следующее:
DECLARE @tempTable TABLE (Empresa VARCHAR(100), IDCuenta INT, Año INT, Periodo INT, ReferenciaOrden INT, Saldo MONEY) INSERT INTO @tempTable (Empresa, IDCuenta, Año, Periodo, ReferenciaOrden, Saldo) SELECT Empresa, IDCuenta, Año, Periodo, ReferenciaOrden, SUM(Saldo) AS Saldo FROM ( SELECT Empresa, IDCuenta, Año, Periodo, ReferenciaOrden, Saldo FROM dbo.GP_ContabilidadTrxActivas WHERE FechaTransacción <= GETDATE() UNION ALL SELECT Empresa, IDCuenta, Año, Periodo, ReferenciaOrden, Saldo FROM dbo.GP_ContabilidadTrxHistoricas WHERE FechaTransacción <= GETDATE() ) AS Base GROUP BY Empresa, IDCuenta, Año, Periodo, ReferenciaOrden SELECT Empresa, IDCuenta, Año, Periodo, Saldo , ( SELECT SUM(Saldo) FROM @tempTable AS BaseInt WHERE BaseInt.IDCuenta = BaseTotal.IDCuenta AND BaseInt.Empresa = BaseTotal.Empresa AND BaseInt.ReferenciaOrden <= BaseTotal.ReferenciaOrden ) AS SaldoAcumulado FROM @tempTable AS BaseTotalА также может быть FechaTransacción индекс, содержащий поле FechaTransacción . Потому что вы фильтруете таблицы им.
Во-первых, видя, что «INCLUDE» как часть вашего индекса смутил меня, так как я никогда не видел этого, я заглянул в него и нашел отличное объяснение / ответ в этом посте . Важно отметить, что INCLUDE должен быть на полях, которые НЕ являются частью таких вещей, как группа. Ваш запрос DEFINITELY использует столбцы как часть группы и ДОЛЖЕН быть частью обычного индекса покрытия для оптимизации запросов.
Во-вторых, что, вероятно, убивает ваше время, так это то, что вы выполняете коррелированный запрос для своего столбца Saldo для каждой возвращенной записи в базовом запросе, тем самым убивая производительность, выполняемую каждый раз многократно. Я бы реструктурировал ваш запрос, чтобы иметь основное предложение FROM, поскольку эти два запроса запускают ONCE EACH и присоединяются к ним на столбцах соответственно. Похоже, что для каждого элемента более глубокого уровня вам также требуется общая сумма агрегации на уровне родителя. Например, все продажи в пределах данного региона составляют один столбец, но также включают общее количество для сравнения с областью ENTIRE. Возможно, я ошибаюсь, но это то, что кажется.
Итак, я бы просто создал ваш индекс как следующие ключи для каждой текущей и истории транзакций. Первые 3 столбца – это, в частности, этот порядок, чтобы соответствовать вашим агрегатам более высокого уровня, чтобы оптимизировать этот TOO без перехода к гранулярному уровню Ano, Periodo, FechaTransaccion.
(Empresa, IdCuenta, ReferenciaOrden, Ano, Periodo, FechaTransaccion) включают (saldo)
SELECT BaseTotal.Empresa, BaseTotal.IDCuenta, BaseTotal.Año, BaseTotal.Periodo, BaseTotal.Saldo, SUM( BaseInt.Saldo ) as OrdenSaldo FROM ( SELECT Empresa, IDCuenta, ReferenciaOrden, Año, Periodo, SUM(Saldo) As Saldo FROM ( SELECT Empresa, IDCuenta, ReferenciaOrden, Año, Periodo, SUM(Saldo) As Saldo FROM dbo.GP_ContabilidadTrxActivas WHERE FechaTransacción <= GETDATE() GROUP BY Empresa, IDCuenta, ReferenciaOrden, Año, Periodo UNION ALL SELECT Empresa, IDCuenta, Año, Periodo, ReferenciaOrden, SUM(Saldo) As Saldo FROM dbo.GP_ContabilidadTrxHistoricas WHERE FechaTransacción <= GETDATE() GROUP BY Empresa, IDCuenta, ReferenciaOrden, Año, Periodo ) As Base GROUP BY Empresa, IDCuenta, ReferenciaOrden, Año, Periodo ) As BaseTotal JOIN ( SELECT Empresa, IDCuenta, ReferenciaOrden, SUM(Saldo) As Saldo FROM ( SELECT Empresa, IDCuenta, ReferenciaOrden, SUM(Saldo) As Saldo FROM dbo.GP_ContabilidadTrxActivas WHERE FechaTransacción <= GETDATE() GROUP BY Empresa, IDCuenta, ReferenciaOrden UNION ALL SELECT Empresa, IDCuenta, ReferenciaOrden, SUM(Saldo) As Saldo FROM dbo.GP_ContabilidadTrxHistoricas WHERE FechaTransacción <= GETDATE() GROUP BY Empresa, IDCuenta, ReferenciaOrden ) As Base GROUP BY Empresa, IDCuenta, ReferenciaOrden ) As BaseInt ON BaseTotal.Empresa = BaseInt.Empresa AND BaseTotal.IDCuenta = BaseInt.IDCuenta AND BaseInt.ReferenciaOrden <= BaseTotal.ReferenciaOrden GROUP BY BaseTotal.Empresa, BaseTotal.IDCuenta, BaseTotal.Año, BaseTotal.Periodo, BaseTotal.Saldo, ORDER BY BaseTotal.Empresa, BaseTotal.IDCuenta, BaseTotal.Año, BaseTotal.PeriodoВы фильтруете по дате, я бы предложил вам создать ваши индексы, подобные этому
CREATE NONCLUSTERED INDEX IX_ReferenciaOrden ON dbo.GP_ContabilidadTrxHistoricas (FechaTransacción)Если это вам не поможет, попробуйте добавить столбцы, как в разделе GROUP BY. Таким образом, индекс сортируется так же, как это требуется GROUp BY
CREATE NONCLUSTERED INDEX IX_ReferenciaOrden ON dbo.GP_ContabilidadTrxHistoricas (FechaTransacción, Empresa, IDCuenta, Año, Periodo,ReferenciaOrden)Если вы все еще считаете, что это медленно, создайте индекс покрытия с помощью столбцов из предложения select, таким образом, кластеризованный индекс не должен быть доступен вообще
CREATE NONCLUSTERED INDEX IX_ReferenciaOrden ON dbo.GP_ContabilidadTrxHistoricas (FechaTransacción, Empresa, IDCuenta, Año, Periodo,ReferenciaOrden) INCLUDE(Saldo)Вы также можете попробовать переформатировать запрос с помощью CTE
sqlserver.bilee.com