Ускорение и оптимизация настроек PostgreSQL для 1С. Оптимизация postgresql
Оптимизация PostgreSQL под сервер 1С:Предприятия
На данный момент производительность PostgreSQL в связке с сервером 1С:Предприятия в сравнении с тем же MS SQL оставляет желать лучшего. Эта статья продолжение попыток добиться достойной производительности на PostgreSQL. Хотя на данный момент у меня не получилось добиться производительности сопоставимой MS SQL, но думаю в недалеком будущем эта проблема будет решена.
Далее в статье перечислены основные параметы и особенности, на которые следует обратить внимание при оптимизации PostgreSQL.
Основные параметры PostgreSQL.
shared_buffers
Объём совместно используемой памяти, выделяемой PostgreSQL для кэширования данных, определяется числом страниц shared_buffers по 8 килобайт каждая. Следует учитывать, что операционная система сама кэширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память. Размер shared_buffers зависит от многих факторов, для начала можно принять следующие значения:
- 8–16 Мб – Обычный настольный компьютер с 512 Мб и небольшой базой данных,
- 80–160 Мб – Небольшой сервер, предназначенный для обслуживания базы данных с объёмом оперативной памяти 1 Гб и базой данных около 10 Гб,
- 400 Мб – Сервер с несколькими процессорами, с объёмом памяти в 8 Гб и базой данных занимающей свыше 100 Гб обслуживающий несколько сотен активных соединений одновременно.
work_mem
Под каждый запрос выделяется ограниченный объём памяти. Этот объём используется для сортировки, объединения и других подобных операций. При превышении этого объёма сервер начинает использовать временные файлы на диске, что может существенно снизить производительность. Оценить необходимое значение для work_mem можно разделив объём доступной памяти (физическая память минус объём занятый под другие программы и под совместно используемые страницы shared_buffers) на максимальное число одновременно используемых активных соединений.
maintenance_work_mem
Эта память используется для выполнения операций по сбору статистики ANALYZE, сборке мусора VACUUM, создания индексов CREATE INDEX и добавления внешних ключей. Размер памяти выделяемой под эти операции должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size
PostgreSQL в своих планах опирается на кэширование файлов, осуществляемое операционной системой. Этот параметр соответствует максимальному размеру объекта, который может поместиться в системный кэш. Это значение используется только для оценки. effective_cache_size можно установить в ½ - 2/3 от объёма имеющейся в наличии оперативной памяти, если вся она отдана в распоряжение PostgreSQL.
ВНИМАНИЕ! Следующие параметры могут существенно увеличить производительность работы PostgreSQL. Однако их рекомендуется использовать только если имеются надежные ИБП и программное обеспечение, завершающее работу системы при низком заряде батарей.
fsync
Данный параметр отвечает за сброс данных из кэша на диск при завершении транзакций. Если установить в этом параметре значение off, то данные не будут записываться на дисковые накопители сразу после завершения операций. Это может существенно повысить скорость операций insert и update, но есть риск повредить базу, если произойдет сбой (неожиданное отключение питания, сбой ОС, сбой дисковой подсистемы).
Отрицательное влияние включенного fsync можно уменьшить отключив его и положившись на надежность вашего оборудования. Или правильно подобрав параметр wal_sync_method - метод, который используется для принудительной записи данных на диск.
Возможные значения:
- open_datasync – запись данных методом open() с параметром O_DSYNC,
- fdatasync – вызов метода fdatasync() после каждого commit,
- fsync_writethrough – вызывать fsync() после каждого commit игнорирую параллельные процессы,
- fsync – вызов fsync() после каждого commit,
- open_sync – запись данных методом open() с параметром O_SYNC.
ПРИМЕЧАНИЕ! Не все методы доступны на определенных платформах. Выбор метода зависит от операционной системы под управлением, которой работает PostgreSQL.
В состав PostgreSQL входит утилита pg_test_fsync, с помощью которой можно определить оптимальное значение параметра wal_sync_method.
Она выполняет серию дисковых тестов с использованием различных методов синхронизации. В результате этого теста получаются оценки производительности дисковой системы, по которым можно определить оптимальный метод синхронизации для данной операционной системы.
Я решил провести вышеуказанный тест на своем рабочем компьютере, имеющем следующие характеристики:
- CPU: Intel Core i3-3220 @ 3.30GHz x 2
- RAM: 4GB
- HDD: Seagate ST3320418AS 320GB
Тест на Windows:
- ОС: Windows 7 Максимальная x64
- ФС: NTFS
- СУБД: PostgreSQL 9.4.2-1.1C x64
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | C:\PROGRA~1\POSTGR~1\9.4.2-1.1C\bin>pg_test_fsync 5 seconds per test O_DIRECT supported on this platform for open_datasync and open_sync. Compare file sync methods using one 8kB write: (in wal_sync_method preference order, except fdatasync is Linux's default) open_datasync 48817.440 ops/sec 20 usecs/op fdatasync n/a fsync 79.688 ops/sec 12549 usecs/op fsync_writethrough 80.072 ops/sec 12489 usecs/op open_sync n/a Compare file sync methods using two 8kB writes: (in wal_sync_method preference order, except fdatasync is Linux's default) open_datasync 24713.634 ops/sec 40 usecs/op fdatasync n/a fsync 78.690 ops/sec 12708 usecs/op fsync_writethrough 79.073 ops/sec 12646 usecs/op open_sync n/a Compare open_sync with different write sizes: (This is designed to compare the cost of writing 16kB in different write open_sync sizes.) 1 * 16kB open_sync write n/a 2 * 8kB open_sync writes n/a 4 * 4kB open_sync writes n/a 8 * 2kB open_sync writes n/a 16 * 1kB open_sync writes n/a Test if fsync on non-write file descriptor is honored: (If the times are similar, fsync() can sync data written on a different descriptor.) write, fsync, close 76.493 ops/sec 13073 usecs/op write, close, fsync 77.676 ops/sec 12874 usecs/op Non-Sync'ed 8kB writes: write 1800.319 ops/sec 555 usecs/op |
По результатам теста мы видим, что для Windows оптимальным решением будет использование open_datasync.
Тест на Linux:
- ОС: Debian 8.6 Jessie
- Ядро: x86_64 Linux 3.16.0-4-amd64
- ФС: ext4
- СУБД: PostgreSQL 9.4.2-1.1C amd64
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | /usr/lib/postgresql/9.4/bin# ./pg_test_fsync 5 seconds per test O_DIRECT supported on this platform for open_datasync and open_sync. Compare file sync methods using one 8kB write: (in wal_sync_method preference order, except fdatasync is Linux's default) open_datasync 80.215 ops/sec 12467 usecs/op fdatasync 80.349 ops/sec 12446 usecs/op fsync 39.384 ops/sec 25391 usecs/op fsync_writethrough n/a open_sync 40.013 ops/sec 24992 usecs/op Compare file sync methods using two 8kB writes: (in wal_sync_method preference order, except fdatasync is Linux's default) open_datasync 40.033 ops/sec 24980 usecs/op fdatasync 77.264 ops/sec 12943 usecs/op fsync 36.325 ops/sec 27529 usecs/op fsync_writethrough n/a open_sync 19.659 ops/sec 50866 usecs/op Compare open_sync with different write sizes: (This is designed to compare the cost of writing 16kB in different write open_sync sizes.) 1 * 16kB open_sync write 38.697 ops/sec 25842 usecs/op 2 * 8kB open_sync writes 17.356 ops/sec 57616 usecs/op 4 * 4kB open_sync writes 8.996 ops/sec 111156 usecs/op 8 * 2kB open_sync writes 4.552 ops/sec 219686 usecs/op 16 * 1kB open_sync writes 2.218 ops/sec 450930 usecs/op Test if fsync on non-write file descriptor is honored: (If the times are similar, fsync() can sync data written on a different descriptor.) write, fsync, close 34.341 ops/sec 29120 usecs/op write, close, fsync 35.753 ops/sec 27970 usecs/op Non-Sync'ed 8kB writes: write 484193.516 ops/sec 2 usecs/op |
По результатам теста мы видим, что наилучшую скорость выдают методы fdatasync и open_datasync. Так же можно заметить, что на же оборудовании Linux выдал скорость записи почти в половину больше, чем на Windows.
Следует учитывать, что в данных тестах использовалась дисковая система, состоящая из одного диска. При использовании RAID массива с большим количеством дисков картина может быть другой.
wal_buffers
Количество памяти используемое в SHARED MEMORY для ведения транзакционных логов. При доступной памяти 1-4 Гб рекомендуется устанавливать 256-1024 Кб. Этот параметр стоит увеличивать в системах с большим количеством модификаций таблиц базы данных.
checkpoint_segments
Oпределяет количество сегментов (каждый по 16 МБ) лога транзакций между контрольными точками. Для баз данных с множеством модифицирующих данные транзакций рекомендуется увеличение этого параметра. Критерием достаточности количества сегментов является отсутствие в логе предупреждений (warning) о том, что контрольные точки происходят слишком часто.
full_page_writes
Включение этого параметра гарантирует корректное восстановление, ценой увеличения записываемых данных в журнал транзакций. Отключение этого параметра ускоряет работу, но может привести к повреждению базы данных в случае системного сбоя или отключения питания.
synchronous_commit
Включает/выключает синхронную запись в лог-файлы после каждой транзакции. Включение синхронной записи защищает от возможной потери данных. Но, накладывает ограничение на пропускную способность сервера. Вы можете отключить синхронную запись, если вам необходимо обеспечить более высокую производительность по количеству транзакций. А потенциально низкая возможность потери небольшого количества изменений при крахе системы не критична. Для отключения синхронной записи установите значение off в этом параметре.
Еще одним способом увеличения производительности работы PostgreSQL является перенос журнала транзакций (pg_xlog) на другой диск. Выделение для журнала транзакций отдельного дискового ресурса позволяет получить получить при этом существенный выигрыш в производительности 10%-12% для нагруженных OLTP систем.
В Linux это делается с помощью создания символьной ссылки на новое положение каталога с журналом транзакций.
В Windows можно использовать для этих целей утилиту Junction. Для этого надо:
- Остановить PostgreSQL.
- Сделать бэкап C:\Program Files\PostgreSQL\X.X.X\data\pg_xlog.
- Скопировать C:\Program Files\PostgreSQL\X.X.X\data\pg_xlog в D:\pg_xlog и удалить C:\Program Files\PostgreSQL\X.X.X\data\pg_xlog.
- Распаковать программу Junction в C:\Program Files\PostgreSQL\X.X.X\data.
- Открыть окно CMD, перейти в C:\Program Files\PostgreSQL\X.X.X\data и выполнить junction -s pg_xlog D:\pg_xlog.
- Установить права на папку D:\pg_xlog пользователю postgres.
- Запустить PostgreSQL.Где X.X.X - версия используемой PostgreSQL.
Особенности и ограничения в 1С:Предприятие при работе с PostgreSQL.
Использование конструкции ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ.
В СУБД PostgreSQL реализована только частичная поддержка FULL OUTER JOIN (ERROR: “FULL JOIN is only supported with mergejoinable join conditions”). Для реализации полной поддержки FULL OUTER JOIN при работе 1С:Предприятия 8 с PostgreSQL подобный запрос трансформируется в другую форму с эквивалентным результатом, однако эффективность использования конструкции ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ снижается.
В связи с этим не рекомендуется использовать ПОЛНОЕ ВНЕШНЕЕ СОЕДИНЕНИЕ при работе с PostgreSQL. В большинстве случаев без использования этой конструкции можно обойтись, переписав исходный запрос.
Оптимизация использования виртуальной таблицы СрезПоследних при работе с PostgreSQL.
Проблема: При работе с PostgreSQL использование соединения с виртуальной таблицей СрезПоследних может приводить к существенному снижению производительности. Из-за ошибки оптимизатора может быть выбран неоптимальный план выполнения запроса.
Решение: Если в запросе используется соединение с виртуальной таблицей языка запросов 1С:Предприятия СрезПоследних и запрос работает с неудовлетворительной производительностью, то рекомендуется вынести обращение к виртуальной таблице в отдельный запрос с сохранением результатов во временной таблице.
Решение проблемы с зависанием PostgreSQL.
При выполнения некоторых регламентных операций (Закрытие месяца, Расчет себестоимости и т.п.), где используются сложные запросы с большим количеством соединений больших таблиц, возможно существенное увеличение времени выполнения операции. В основном, эти проблемы связаны с работой оптимизатора PostgreSQL и отсутствием актуальной статистики по таблицам, участвующим в запросе.
Варианты решения проблемы:
- Увеличить количество записей, просматриваемых при сборе статистики по таблицам. Большие значения могут повысить время выполнения команды ANALYZE, но улучшат построение плана запроса:
- Файл postgresql.conf - default_statistics_target = 1000 -10000.
- Отключение оптимизатору возможности использования NESTED LOOP при выборе плана выполнения запроса в конфигурации PostgreSQL:
- Файл postgresql.conf - enable_nestloop = off.
- Отрицательным эффектом этого способа является возможное замедление некоторых запросов, поскольку при их выполении будут использоваться другие, более затратные, методы соединения (HASH JOIN).
- Отключение оптимизатору возможности изменения порядка соединений таблиц в запросе:
- Файл postgresql.conf - join_collapse_limit=1.
- Следует использовать этот метод, если вы уверены в правильности порядка соединений таблиц в проблемном запросе.
- Изменение параметров настройки оптимизатора:
- Файл postgresql.conf:
- seq_page_cost = 0.1
- random_page_cost = 0.4
- cpu_operator_cost = 0.00025
- Файл postgresql.conf:
- Использование версии PostgreSQL 9.1.2-1.1.C и выше, в которой реализован независимый от AUTOVACUUM сбор статистики, на основе информации об изменении данных в таблице. По умолчанию включен сбор статистики только для временных таблиц и во многих ситуациях этого достаточно. При возникновении проблем с производительностью выполнения регламентных операций, можно включить сбор статистики для всех или отдельных проблемных таблиц изменив значение параметра конфигурации PostgreSQL (файл postgresql.conf) online_analyze.table_type = "temporary" на online_analyze.table_type = "all".
После изменения этих параметров, следует оценить возможное влияние этих изменений на работу системы и выбрать наиболее приемлимый вариант для ваших задач.
Послесловие.
Ко всему вышеперечисленному можно так же добавить:
- Необходимость использования управляемых блокировок при разработке прикладного решения. Если же у вас типовая конфигурация, то по возможности ее так же необходимо переводить на управляемые блокировки.
- Рекомендацию реализовать для PostgreSQL кэширование на SSD-накопитель. Сделать это можно с помощью Flashcache или Bcache. Подробнее вопрос организации системы кэширования я рассмотрю в другой статье.
- Довольно удобный веб-сервис для начальной настройки PostgreSQL. Его порекомендовал мне товарищ Vasiliy P. Melnik. Несмотря на то, что интерфейс на английском, он простой и интуитивно понятный. Думаю каждый желающий сможет с ним разобраться.
Статья обновлена 8 октября 2016 года. Добавлены сравнительные тесты
nixway.org
Оптимизация настроек PostgreSQL (postgresql.conf) | материализация идей
Здесь будут настройки для PostgreSQL, работающей в виртуальной машине ESXi 6.5.
Ресурсы выделенные для ВМ:
процессор — 8 vCPU;
память — 48 GB;
диск для ОС — 50 GB на LUN аппаратном RAID1 из SAS HDD;
диск для БД — 170 GB на программном RAID1 из SSD
диск для логов — 100 GB на программном RAID1 из SSD
Для редактирования настроек выполним команду:
mcedit /var/lib/pgsql/9.6/data/postgresql.confЗакомментированные параметры, которые будем изменять необходимо активировать.
Процессор
autovacuum_max_workers = 4
autovacuum_max_workers = NCores/4..2 но не меньше 4
Количество процессов автовакуума. Общее правило — чем больше write-запросов, тем больше процессов. На read-only базе данных достаточно одного процесса.
ssl = off
Выключение шифрования. Для защищенных ЦОД’ов шифрование бессмысленно, но приводит к увеличению загрузки CPU
Память
shared_buffers = 12GB
shared_buffers = RAM/4
Количество памяти, выделенной PgSQL для совместного кеша страниц. Эта память разделяется между всеми процессами PgSQL. Операционная система сама кеширует данные, поэтому нет необходимости отводить под кэш всю наличную оперативную память.
temp_buffers = 256MB
Максимальное количество страниц для временных таблиц. Т.е. это верхний лимит размера временных таблиц в каждой сессии.
work_mem = 64MB
work_mem = RAM/32..64 или 32MB..128MB
Лимит памяти для обработки одного запроса. Эта память индивидуальна для каждой сессии. Теоретически, максимально потребная память равна max_connections * work_mem, на практике такого не встречается потому что большая часть сессий почти всегда висит в ожидании. Это рекомендательное значение используется оптимайзером: он пытается предугадать размер необходимой памяти для запроса, и, если это значение больше work_mem, то указывает экзекьютору сразу создать временную таблицу. work_mem не является в полном смысле лимитом: оптимайзер может и промахнуться, и запрос займёт больше памяти, возможно в разы. Это значение можно уменьшать, следя за количеством создаваемых временных файлов:
maintenance_work_mem = 2GB
maintenance_work_mem = RAM/16..32 или work_mem * 4 или 256MB..4GB
Лимит памяти для обслуживающих задач, например по сбору статистики (ANALYZE), сборке мусора (VACUUM), создания индексов (CREATE INDEX) и добавления внешних ключей. Размер выделяемой под эти операции памяти должен быть сравним с физическим размером самого большого индекса на диске.
effective_cache_size = 36GB
effective_cache_size = RAM — shared_buffers
Оценка размера кеша файловой системы. Увеличение параметра увеличивает склонность системы выбирать IndexScan планы. И это хорошо.
Диски
effective_io_concurrency = 5
Оценочное значение одновременных запросов к дисковой системе, которые она может обслужить единовременно. Для одиночного диска = 1, для RAID — 2 или больше.
random_page_cost = 1.3
random_page_cost = 1.5-2.0 для RAID, 1.1-1.3 для SSD
Стоимость чтения рандомной страницы (по-умолчанию 4). Чем меньше seek time дисковой системы тем меньше (но > 1.0) должен быть этот параметр. Излишне большое значение параметра увеличивает склонность PgSQL к выбору планов с сканированием всей таблицы (PgSQL считает, что дешевле последовательно читать всю таблицу, чем рандомно индекс). И это плохо.
autovacuum = on
Включение автовакуума.
autovacuum_naptime = 20s
Время сна процесса автовакуума. Слишком большая величина будет приводить к тому, что таблицы не будут успевать вакуумиться и, как следствие, вырастет bloat и размер таблиц и индексов. Малая величина приведет к бесполезному нагреванию.
bgwriter_delay = 20ms
Время сна между циклами записи на диск фонового процесса записи. Данный процесс ответственен за синхронизацию страниц, расположенных в shared_buffers с диском. Слишком большое значение этого параметра приведет к возрастанию нагрузки на checkpoint процесс и процессы, обслуживающие сессии (backend). Малое значение приведет к полной загрузке одного из ядер.
bgwriter_lru_multiplier = 4.0
bgwriter_lru_maxpages = 400
Параметры, управляющие интенсивностью записи фонового процесса записи. За один цикл bgwriter записывает не больше, чем было записано в прошлый цикл, умноженное на bgwriter_lru_multiplier, но не больше чем bgwriter_lru_maxpages.
synchronous_commit = off
Выключение синхронизации с диском в момент коммита. Создает риск потери последних нескольких транзакций (в течении 0.5-1 секунды), но гарантирует целостность базы данных, в цепочке коммитов гарантированно отсутствуют пропуски. Но значительно увеличивает производительность.
wal_keep_segments = 256
wal_keep_segments = 32..256
Максимальное количество сегментов WAL между checkpoint. Слишком частые checkpoint приводят к значительной нагрузке на дисковую подсистему по записи. Каждый сегмент имеет размер 16MB
wal_buffers = 16MB
Объём разделяемой памяти, который будет использоваться для буферизации данных WAL, ещё не записанных на диск. Значение по умолчанию, равное -1, задаёт размер, равный 1/32 (около 3%) от shared_buffers, но не меньше, чем 64 КБ и не больше, чем размер одного сегмента WAL (обычно 16 МБ). Это значение можно задать вручную, если выбираемое автоматически слишком мало или велико, но при этом любое положительное число меньше 32 КБ будет восприниматься как 32 КБ. Этот параметр можно задать только при запуске сервера.
Содержимое буферов WAL записывается на диск при фиксировании каждой транзакции, так что очень большие значения вряд ли принесут значительную пользу. Однако значение как минимум в несколько мегабайт может увеличить быстродействие при записи на нагруженном сервере, когда сразу множество клиентов фиксируют транзакции. Автонастройка, действующая при значении по умолчанию (-1), в большинстве случаев выбирает разумные значения.
default_statistics_target = 1000
Устанавливает целевое ограничение статистики по умолчанию, распространяющееся на столбцы, для которых командой ALTER TABLE SET STATISTICS не заданы отдельные ограничения. Чем больше установленное значение, тем больше времени требуется для выполнения ANALYZE, но тем выше может быть качество оценок планировщика. Значение этого параметра по умолчанию — 100.
checkpoint_completion_target = 0.9
Степень «размазывания» checkpoint’a. Скорость записи во время checkpoint’а регулируется так, что бы время checkpoint’а было равно времени, прошедшему с прошлого, умноженному на checkpoint_completion_target.
min_wal_size = 4G max_wal_size = 8G
min_wal_size = 512MB .. 4Gmax_wal_size = 2 * min_wal_size
Минимальное и максимальный объем WAL файлов. Аналогично checkpoint_segments
fsync = on
Выключение параметра приводит к росту производительности, но появляется значительный риск потери всех данных при внезапном выключении питания. Внимание: если RAID имеет кеш и находиться в режиме write-back, проверьте наличие и функциональность батарейки кеша RAID контроллера! Иначе данные записанные в кеш RAID могут быть потеряны при выключении питания, и, как следствие, PgSQL не гарантирует целостность данных.
row_security = off
Отключение контроля разрешения уровня записи
enable_nestloop = off
Включает или отключает использование планировщиком планов соединения с вложенными циклами. Полностью исключить вложенные циклы невозможно, но при выключении этого параметра планировщик не будет использовать данный метод, если можно применить другие. По умолчанию этот параметр имеет значение on.
Блокировки
max_locks_per_transaction = 256
Максимальное число блокировок индексов/таблиц в одной транзакции
Настройки под платформу 1С
standard_conforming_strings = off
Разрешить использовать символ \ для экранирования
escape_string_warning = off
Не выдавать предупреждение о использовании символа \ для экранирования
Настройка безопасности
Сделаем так, чтобы сервер PostgreSQL был виден только для сервера 1С: Предприятие, установленного на этой же машине.
listen_addresses = ‘localhost’
Если сервер 1С: Предприятие установлен на другой машине или существует необходимость подключиться подключиться к серверу СУБД с помощью оснастки PGAdmin, то вместо localhost нужно указать адрес этой машины.
Хранение базы данных
PostgreSQL как и почти любая СУБД критична к дисковой подсистеме, поэтому для повышения быстродействия СУБД разместим систему PostgreSQL, логи и сами базы на разные диски.
Останавливаем сервер
systemctl stop postgresql-9.6Переносим логи на созданный RAID1 из 120GB SSD:
mv /var/lib/pgsql/9.6/data/pg_xlog /raid120 mv /var/lib/pgsql/9.6/data/pg_clog /raid120 mv /var/lib/pgsql/9.6/data/pg_log /raid120Создаем символьные ссылки:
ln -s /raid120/pg_xlog /var/lib/pgsql/9.6/data/pg_xlog ln -s /raid120/pg_clog /var/lib/pgsql/9.6/data/pg_clog ln -s /raid120/pg_log /var/lib/pgsql/9.6/data/pg_logТак же перенесем каталог с базами:
mv /var/lib/pgsql/9.6/data/base /raid200и создадим символьную ссылку:
ln -s /raid200/base /var/lib/pgsql/9.6/data/baseзапустим сервер и проверим его статус
i-fast.ru
performance - Оптимизация PostgreSQL для быстрого тестирования
Во-первых, всегда используйте последнюю версию PostgreSQL. Улучшения производительности всегда наступают, поэтому вы, вероятно, тратите свое время, если настраиваете старую версию. Например, PostgreSQL 9.2 значительно улучшает скорость TRUNCATE и, конечно же, добавляет только индексирование. Всегда следует соблюдать даже незначительные выпуски; см. в разделе политики .
Этикет
НЕ помещайте табличное пространство в RAMdisk или другое не долговременное хранилище.
Если вы потеряете табличное пространство, вся база данных может быть повреждена и сложна в использовании без существенной работы. Для этого очень мало преимуществ по сравнению с использованием таблиц UNLOGGED и в любом случае с большим количеством ОЗУ для кеша.
Если вам действительно нужна система на основе ramdisk, initdb новый кластер в ramdisk initdb с новым экземпляром PostgreSQL в ramdisk, поэтому у вас есть полностью одноразовый экземпляр PostgreSQL.
Конфигурация сервера PostgreSQL
При тестировании вы можете настроить сервер для не долговечной, но более быстрой работы.
Это одно из единственно приемлемых применений для параметра fsync=off в PostgreSQL. Этот параметр в значительной степени говорит PostgreSQL о том, что он не беспокоится о заказанной записи или какой-либо другой неприятной информации, защищающей целостность данных и безопасности при сбое, давая ему разрешение полностью уничтожать ваши данные, если вы потеряете питание или сбой ОС.
Излишне говорить, что вы никогда не должны включать fsync=off в производство, если вы не используете Pg в качестве временной базы данных для данных, которые вы можете повторно генерировать из других источников. Если и только если вы делаете, чтобы отключить fsync, вы можете отключить full_page_writes, так как это уже не так хорошо. Помните, что fsync=off и full_page_writes применяются на уровне кластера, поэтому они влияют на все базы данных в вашем экземпляре PostgreSQL.
Для использования в целях производства вы можете использовать synchronous_commit=off и установить commit_delay, так как вы получите много преимуществ, таких как fsync=off без риска гибели данных. У вас есть небольшое окно с потерей последних данных, если вы активируете асинхронное комментирование, но это оно.
Если у вас есть возможность слегка изменить DDL, вы также можете использовать таблицы UNLOGGED в Pg 9.1+, чтобы полностью исключить ведение журнала WAL и получить реальное ускорение скорости за счет стрижки таблиц, если сервер выйдет из строя. Не существует опции конфигурации, чтобы сделать все таблицы незаписанными, она должна быть установлена во время CREATE TABLE. В дополнение к тому, чтобы быть хорошим для тестирования, это удобно, если у вас есть таблицы, заполненные сгенерированными или несущественными данными в базе данных, которые в остальном содержат вещи, которые вам нужны для безопасности.
Проверьте свои журналы и посмотрите, есть ли предупреждения о слишком большом количестве контрольных точек. Если да, вы должны увеличить checkpoint_segments. Вы также можете настроить свою контрольную точку_completion_target, чтобы сгладить записи.
Настройте shared_buffers, чтобы соответствовать вашей рабочей нагрузке. Это зависит от ОС, зависит от того, что еще происходит с вашей машиной, и требует некоторых проб и ошибок. По умолчанию они крайне консервативны. Возможно, вам потребуется увеличить ограничение максимальной общей памяти ОС, если вы увеличите shared_buffers на PostgreSQL 9.2 и ниже; 9.3 и выше изменили способ использования разделяемой памяти, чтобы избежать этого.
Если вы используете только пару подключений, которые выполняют большую работу, увеличьте work_mem, чтобы дать им больше оперативной памяти для сортировки и т.д. Остерегайтесь того, что слишком высокий параметр work_mem может привести к нарушению -memory, потому что он не сортируется для каждого соединения, поэтому один запрос может иметь много вложенных ролей. Вам действительно нужно увеличить work_mem, если вы можете увидеть сортировку, разливающуюся на диск в EXPLAIN, или войти в систему с параметром log_temp_files (рекомендуется), но более высокое значение может также позволить Pg выбрать более разумные планы.
Как сказал еще один плакат, целесообразно поместить xlog и основные таблицы/индексы на отдельные жесткие диски, если это возможно. Отдельные разделы довольно бессмысленны, вам действительно нужны отдельные диски. Это разделение имеет гораздо меньшую выгоду, если вы работаете с fsync=off и почти нет, если используете таблицы UNLOGGED.
Наконец, настройте свои запросы. Убедитесь, что ваши random_page_cost и seq_page_cost отражают производительность вашей системы, убедитесь, что ваш effective_cache_size верен и т.д. Используйте EXPLAIN (BUFFERS, ANALYZE) для просмотра отдельных планов запросов и включите модуль auto_explain, чтобы сообщать обо всех медленных запросах. Вы часто можете улучшить производительность запросов, просто создав соответствующий индекс или изменив параметры затрат.
AFAIK нет способа установить всю базу данных или кластер как UNLOGGED. Было бы интересно уметь это делать. Рассмотрите вопрос о списке рассылки PostgreSQL.
Настройка хост-системы
Там есть какая-то настройка, которую вы можете сделать и на уровне операционной системы. Главное, что вы, возможно, захотите сделать, - убедить операционную систему не скрывать записи на диск агрессивно, так как вам действительно все равно, когда/если они попадают на диск.
В Linux вы можете управлять этим с помощью подсистемы виртуальной памяти dirty_*, например dirty_writeback_centisecs.
Единственная проблема с настройкой параметров обратной записи, которая должна быть слишком слабой, заключается в том, что сброс какой-либо другой программы может привести к потере всех накопленных буферов PostgreSQL, вызывая большие киоски, а все блокирует запись. Вы можете облегчить это, запустив PostgreSQL в другой файловой системе, но некоторые флеши могут быть уровнями уровня на уровне устройства или уровня хоста, а не на уровне файловой системы, поэтому вы не можете полагаться на это.
Эта настройка действительно требует игры с настройками, чтобы увидеть, что лучше всего подходит для вашей рабочей нагрузки.
В более новых ядрах вы можете убедиться, что vm.zone_reclaim_mode установлено на ноль, так как это может вызвать серьезные проблемы с производительностью в системах NUMA (большинство систем в наши дни) из-за взаимодействия с тем, как PostgreSQL управляет shared_buffers.
Настройка запросов и рабочей нагрузки
Это вещи, для которых требуются изменения кода; они могут вас не устраивать. Некоторые из них могут быть применены.
Если вы не планируете работу над большими транзакциями, запустите. Многие небольшие транзакции стоят дорого, поэтому вы должны периодически делиться материалами, когда это возможно и практично. Если вы используете async commit, это менее важно, но все же рекомендуется.
По возможности используйте временные таблицы. Они не генерируют WAL-трафик, поэтому они намного быстрее для вставок и обновлений. Иногда стоит засыпать кучу данных в временную таблицу, манипулируя ею, но вам нужно, а затем INSERT INTO ... SELECT ... скопировать ее в финальную таблицу. Обратите внимание, что временные таблицы относятся к сеансу; если ваш сеанс заканчивается или вы теряете соединение, тогда временная таблица исчезает, и никакое другое соединение не может видеть содержимое таблицы (ов) временной сессии сеанса.
Если вы используете PostgreSQL 9.1 или новее, вы можете использовать таблицы UNLOGGED для данных, которые вы можете позволить себе потерять, например состояние сеанса. Они видны на разных сеансах и сохраняются между соединениями. Они усекаются, если сервер отключается нечисто, поэтому они не могут использоваться ни для чего, что вы не можете воссоздать, но они отлично подходят для кэшей, материализованных представлений, таблиц состояний и т.д.
В общем случае не DELETE FROM blah;. Вместо этого используйте TRUNCATE TABLE blah;; это намного быстрее, когда вы сбрасываете все строки в таблице. Усекайте многие таблицы одним вызовом TRUNCATE, если сможете. Там оговорка, если вы делаете много TRUNCATES маленьких таблиц снова и снова, хотя; см. Скорость усечения Postgresql
Если у вас нет индексов для внешних ключей, DELETE с участием первичных ключей, на которые ссылаются эти внешние ключи, будет ужасно медленным. Не забудьте создать такие индексы, если вы когда-либо ожидали DELETE из ссылочной таблицы (таблиц). Индексы не требуются для TRUNCATE.
Не создавайте индексы, которые вам не нужны. Каждый индекс имеет стоимость обслуживания. Попытайтесь использовать минимальный набор индексов и позволить сканирование растровых индексов сочетать их, а не поддерживать слишком много огромных, дорогостоящих многоколоночных индексов. Если требуются индексы, сначала попробуйте заполнить таблицу, а затем создайте индексы в конце.
Оборудование
Наличие достаточного количества ОЗУ для хранения всей базы данных - огромная победа, если вы можете управлять ею.
Если у вас недостаточно ОЗУ, тем быстрее вы сможете получить лучшее хранилище. Даже дешевый SSD делает огромную разницу в ржавчине. Не доверяйте дешевым SSD для производства, хотя они часто не являются аварийными и могут съесть ваши данные.
Обучение
Книга Грега Смита, Высокая производительность PostgreSQL 9.0 остается актуальной, несмотря на несколько более старую версию. Это должно быть полезной ссылкой.
Присоединитесь к списку рассылки PostgreSQL и следуйте за ним.
Чтение:
qaru.site
PostgreSQL : Документация: 9.6: 36.13. Информация для оптимизации операторов : Компания Postgres Professional
36.13. Информация для оптимизации операторов
Определение оператора в PostgreSQL может включать различные дополнительные предложения, которые сообщают системе полезные сведения о поведении оператора. Старайтесь задавать эти предложения при возможности, так как они могут значительно ускорить выполнение запросов, использующих данный оператор. Но если вы задаёте их, убедитесь, что они корректны! Неправильное применение предложений оптимизации может привести к замедлению запросов, неочевидным ошибочным результатам и другим неприятностям. Если вы не уверены в правильности предложения оптимизации, лучше вовсе не использовать его; единственным последствием будет то, что запросы будут работать медленнее, чем могли бы.
В будущих версиях PostgreSQL могут быть добавлены и другие предложения. Здесь описываются те, что поддерживаются версией 9.6.10.
Предложение COMMUTATOR, если представлено, задаёт оператор, коммутирующий для определяемого. Оператор A является коммутирующим для оператора B, если (x A y) равняется (y B x) для всех возможных значений x, y. Заметьте, что B также будет коммутирующим для A. Например, операторы < и > для конкретного типа данных обычно являются коммутирующими друг для друга, а оператор + — коммутирующий для себя. Но традиционный оператор - коммутирующего не имеет.
Тип левого операнда оператора должен совпадать с типом правого операнда коммутирующего для него оператора, и наоборот. Поэтому имя коммутирующего оператора — это всё, что PostgreSQL должен знать, чтобы найти коммутатор, и всё, что нужно указать в предложении COMMUTATOR.
Информация о коммутирующих операторах крайне важна для операторов, которые будут применяться в индексах и условиях соединения, так как, используя её, оптимизатор запросов может «переворачивать» такие выражения и получать формы, необходимые для разных типов планов. Например, рассмотрим запрос с предложением WHERE tab1.x = tab2.y, где tab1.x и tab2.y имеют пользовательский тип, и предположим, что у нас есть индекс по столбцу tab2.y. Оптимизатор сможет задействовать сканирование по индексу, только если ему удастся перевернуть выражение tab2.y = tab1.x, так как механизм сканирования по индексу ожидает, что индексируемый столбец находится слева от оператора. PostgreSQL сам по себе не будет полагать, что такое преобразование возможно — это должен определить создатель оператора =, добавив информацию о коммутирующем операторе.
Когда вы определяете оператор, коммутирующий сам для себя, вы делаете именно это. Если же вы определяете пару коммутирующих операторов, возникает небольшое затруднение: как оператор, определяемый первым, может ссылаться на другой, ещё не определённый? Есть два решения этой проблемы:
Во-первых, можно опустить предложение COMMUTATOR для первого оператора, который вы определяете, а затем добавить его в определении второго. Так как PostgreSQL знает, что коммутирующие операторы связаны парами, встречая второе определение, он автоматически возвращается к первому и добавляет в него недостающее предложение COMMUTATOR.
Во-вторых, можно добавить предложение COMMUTATOR в оба определения. Когда PostgreSQL обрабатывает первое определение и видит, что COMMUTATOR ссылается на несуществующий оператор, в системном каталоге создаётся фиктивная запись для этого оператора. В этой фиктивной записи актуальны будут только имя оператора, типы левого и правого операндов, а также тип результата, так как это всё, что PostgreSQL может определить в этот момент. Запись первого оператора будет связана с этой фиктивной записью. Затем, когда вы определите второй оператор, система внесёт в эту фиктивную запись дополнительную информацию из второго определения. Если вы попытаетесь применить фиктивный оператор, прежде чем он будет полностью определён, вы просто получите сообщение об ошибке.
Предложение NEGATOR, если присутствует, задаёт оператор, обратный к определяемому. Оператор A является обратным к оператору B, если они оба возвращают булевский результат и (x A y) равняется NOT (x B y) для всех возможных x, y. Заметьте, что B так же является обратным к A. Например, операторы < и >= составляют пару обратных друг к другу для большинства типов данных. Никакой оператор не может быть обратным к себе же.
В отличие от коммутирующих операторов, два унарных оператора вполне могут быть обратными к друг другу; это будет означать, что (A x) равняется NOT (B x) для всех x (и для правых унарных операторов аналогично).
У оператора, обратного данному, типы левого и/или правого операнда должны соответствовать типам данного оператора, так же как и с предложением COMMUTATOR; отличие только в том, что имя оператора задаётся в предложении NEGATOR.
Указание обратного оператора очень полезно для оптимизатора запросов, так как это позволяет упростить выражение вида NOT (x = y) до x <> y. Такие выражения не так редки, как может показаться, так как операции NOT могут добавляться автоматически в результате реорганизаций выражений.
Пару обратных операторов можно определить теми же способами, что были описаны ранее для пары коммутирующих.
Предложение RESTRICT, если представлено, определяет функцию оценки избирательности ограничения для оператора. (Заметьте, что в нём задаётся имя функции, а не оператора.) Предложения RESTRICT имеют смысл только для бинарных операторов, возвращающих boolean. Идея оценки избирательности ограничения заключается в том, чтобы определить, какой процент строк в таблице будет удовлетворять условию WHERE вида:
column OP constantдля текущего оператора и определённого значения константы. Это помогает оптимизатору примерно определить, сколько строк будет исключено предложениями WHERE такого вида. (ВЫ спросите, а что если константа находится слева? Ну, собственно для таких случаев и задаётся COMMUTATOR...)
Разработка новых функций оценки избирательности ограничения выходит за рамки данной главы, но обычно можно использовать один из стандартных системных оценщиков для большинства дополнительных операторов. Стандартные оценщики ограничений следующие:
| eqsel для = |
| neqsel для <> |
| scalarltsel для < или <= |
| scalargtsel для > или >= |
Может показаться немного странным, что выбраны именно эти категории, но если подумать, это имеет смысл. Оператор = обычно оставляет только небольшой процент строк в таблице, а <> отбрасывает то же количество. Оператор < оставляет процент, зависящий от того, в какой диапазон значений определённого столбца таблицы попадает заданная константа (информация об этих диапазонах собирается командой ANALYZE и предоставляется оценщику избирательности). Оператор <= оставляет чуть больший процент, чем <, при сравнении с той же константой, но они настолько близки, что различать их не имеет смысла, так как это не даст лучшего результата, чем просто угадывание. Подобные замечания применимы и к операторам > и >=.
Часто вы можете обойтись функциями eqsel и neqsel для операторов с очень высокой или низкой избирательностью, даже если это не операторы собственно равенства или неравенства. Например, геометрические операторы приблизительного равенства используют eqsel в предположении, что соответствующие (равные) элементы будут составлять только небольшой процент от всех записей таблицы.
Функции scalarltsel и scalargtsel можно использовать для сравнений с типами данных, которые могут быть каким-либо осмысленным образом преобразованы в числовые скалярные значения для сравнения диапазонов. Если возможно, добавьте свой тип данных в число тех, что понимает функция convert_to_scalar() в src/backend/utils/adt/selfuncs.c. (Когда-нибудь эта функция должна быть заменена специализированными функциями, которые будут устанавливаться для конкретных типов в определённом столбце системного каталога pg_type; но сейчас это не так.) Если вы этого не сделаете, всё будет работать, но оценки оптимизатора будут не так хороши, как могли бы быть.
Для геометрических операторов разработаны дополнительные функции оценки избирательности в src/backend/utils/adt/geo_selfuncs.c: areasel, positionsel и contsel. На момент написания документации это просто заглушки, но вы, тем не менее, вполне можете использовать (или ещё лучше, доработать) их.
Предложение JOIN, если представлено, определяет функцию оценки избирательности соединения для оператора. (Заметьте, что в нём задаётся имя функции, а не оператора.) Предложения JOIN имеют смысл только для бинарных операторов, возвращающих boolean. Идея оценки избирательности соединения заключается в том, чтобы угадать, какой процент строк в паре таблиц будет удовлетворять условию WHERE следующего вида:
table1.column1 OP table2.column2для текущего оператора. Как и RESTRICT, это предложение очень помогает оптимизатору, позволяя ему выяснить, какой из возможных вариантов соединения скорее всего окажется выгоднее.
Как и ранее, в этой главе мы не будем пытаться рассказать, как написать функцию оценивания избирательности соединения, а просто отметим, что вы можете использовать один из подходящих стандартных оценщиков:
| eqjoinsel для = |
| neqjoinsel для <> |
| scalarltjoinsel для < или <= |
| scalargtjoinsel для > или >= |
| areajoinsel для сравнений областей в плоскости |
| positionjoinsel для сравнения положений в плоскости |
| contjoinsel для проверки на включение в плоскости |
Предложение HASHES, если присутствует, говорит системе, что для соединений с применением этого оператора допустимо использовать метод соединения по хешу. HASHES имеет смысл только для бинарного оператора, который возвращает boolean, и на практике этот оператор должен выражать равенство значений некоторого типа данных или пары типов данных.
Соединение по хешу базируется на том предположении, что оператор соединения возвращает истину только для таких пар значений слева и справа, для которых получается одинаковый хеш. Если два значения оказываются в разных ячейках хеша, операция соединения никогда не будет сравнивать их, неявно подразумевая, что результат оператора соединения в этом случае должен быть ложным. Поэтому не имеет никакого смысла указывать HASHES для операторов, которые не представляют какую-любо форму равенства. В большинстве случаев практический смысл в поддержке хеширования есть только для операторов, принимающих один тип данных с обеих сторон. Однако иногда возможно разработать хеш-функции, совместимые сразу с несколькими типами данных; то есть, функции, которые будут выдавать одинаковые хеш-коды для «равных» значений, несмотря на то, что эти значения будут представлены по-разному. Например, довольно легко функции с такой особенностью реализуются для хеширования целых чисел различного размера.
Чтобы оператор соединения имел характеристику HASHES, он должен входить в семейство операторов индексирования по хешу. Это требование откладывается, когда оператор только создаётся, ведь нужное семейство операторов, разумеется, ещё не может существовать. Но при попытке использовать такой оператор для соединения по хешу, возникнет ошибка во время выполнения, если такого семейства не окажется. Системе необходимо знать семейство операторов, чтобы найти функции для хеширования типа(ов) входных данных оператора. Конечно, вы должны также определить подходящие функции хеширования, прежде чем сможете создать семейство операторов.
При подготовке функции хеширования обязательно позаботьтесь о том, чтобы она всегда выдавала нужный результат, вне зависимости от особенностей машинной архитектуры. Например, если ваш тип данных представлен в структуре, в которой есть незначащие дополняющие биты, нельзя просто передать всю структуру функции hash_any. (Это возможно, только если все ваши операторы и функции гарантированно очищают незначащие биты, что является рекомендуемой стратегией.) В качестве другого примера можно привести типы с плавающей точкой в стандарте IEEE, в которых отрицательный ноль и положительный ноль — различные значения (отличаются на уровне битов), но при сравнении они считаются равными. Если значение с плавающей точкой может содержать отрицательный ноль, требуются дополнительные действия, чтобы для него выдавался тот же хеш, что и для положительного нуля.
Оператор соединения по хешу должен иметь коммутирующий (это может быть тот же оператор, если у него два операнда одного типа, либо связанный оператор равенства, в противном случае), относящийся к тому же семейству операторов. В случае его отсутствия, при попытке использования оператора возможны ошибки планировщика. Также желательно (хотя это строго не требуется), чтобы в семействе операторов хеширования, поддерживающем несколько типов данных, определялись операторы равенства для всех комбинаций этих типов данных; это способствует лучшей оптимизации.
Примечание
Функция, реализующая оператор соединения по хешу, должна быть постоянной (IMMUTABLE) или стабильной (STABLE). Если эта функция изменчивая (VOLATILE), система никогда не будет применять этот оператор для соединения по хешу.
Примечание
Если оператор соединения по хешу реализуется строгой функцией (STRICT), эта функция также должна быть полной: то есть она должна возвращать true или false, но не NULL, для любых двух аргументов, отличных от NULL. Если это правило не соблюдается, оптимизация операций IN с хешем может приводить к неверным результатам. (В частности, выражение IN может вернуть false, когда правильным ответом, согласно стандарту, должен быть NULL, либо выдать ошибку с сообщением о том, что оно не готов к результату NULL.)
Предложение MERGES, если присутствует, говорит системе, что для соединений с применением этого оператора допустимо использовать метод соединения слиянием. MERGES имеет смысл только для бинарного оператора, который возвращает boolean, и на практике этот оператор должен выражать равенство значений некоторого типа данных или пары типов данных.
Идея объединения слиянием заключается в упорядочивании таблиц слева и справа и затем параллельном сканировании их. Поэтому оба типа данных должны поддерживать сортировку в полном объёме, а оператор соединения должен давать положительный результат только для пар значений, оказавшихся в «одном месте» при определённом порядке сортировки. На практике это означает, что оператор соединения должен работать как проверка на равенство. Но при этом возможно объединить слиянием два различных типа данных, если они совместимы логически. Например, оператор проверки равенства smallint и integer может применяться для соединений слиянием; понадобятся только операторы сортировки, приводящие оба типа данных в логически совместимые последовательности.
Чтобы оператор соединения имел характеристику MERGES, он должен являться членом семейства операторов индекса btree, реализующим равенство. Это требование откладывается, когда оператор только создаётся, ведь нужное семейство операторов, разумеется, ещё не может существовать. Но этот оператор не будет фактически применяться для соединений слиянием, пока не будет найдено соответствующее семейство операторов. Таким образом, флаг MERGES только подсказывает планировщику, что стоит обратиться к соответствующему семейству.
Оператор соединения слиянием должен иметь коммутирующий (это может быть тот же оператор, если у него два операнда одного типа, либо связанный оператор равенства, в противном случае), относящийся к тому же семейству операторов. В случае его отсутствия, при попытке использования оператора возможны ошибки планировщика. Также желательно (хотя это строго не требуется), чтобы в семействе операторов btree, поддерживающем несколько типов данных, определялись операторы равенства для всех комбинаций этих типов данных; это способствует лучшей оптимизации.
Примечание
Функция, реализующая оператор соединения слиянием, должна быть постоянной (IMMUTABLE) или стабильной (STABLE). Если эта функция изменчивая (VOLATILE), система никогда не будет применять этот оператор для соединения слиянием.
postgrespro.ru
Оптимизация PostgreSQL. Журнал транзакций и контрольные точки
Журнал транзакций PostgreSQL работает следующим образом: все изменения в файлах данных (в которых находятся таблицы и индексы) производятся только после того, как они были занесены в журнал транзакций, при этом записи в журнале должны быть гарантированно записаны на диск.
В этом случае нет необходимости сбрасывать на диск изменения данных при каждом успешном завершении транзакции: в случае сбоя БД может быть восстановлена по записям в журнале. Таким образом, данные из буферов сбрасываются на диск при проходе контрольной точки: либо при заполнении нескольких (параметр checkpoint_segments, по умолчанию 3) сегментов журнала транзакций, либо через определённый интервал времени (параметр checkpoint_timeout, измеряется в секундах, по умолчанию 300).
Изменение этих параметров прямо не повлияет на скорость чтения, но может принести большую пользу при активной модификации/добавлении данных в базе.
fsync
Данный параметр отвечает за сброс данных из кэша на диск при завершении транзакций.
Наиболее радикальное из возможных решений — выставить значение off параметру fsync. При этом записи в журнале транзакций не будут принудительно сбрасываться на диск, что даст большой прирост скорости записи. Учтите: вы жертвуете надёжностью, в случае сбоя целостность базы будет нарушена, и её придётся восстанавливать из резервной копии!
Использовать этот параметр рекомендуется лишь в том случае, если вы всецело доверяете своему серверу и своему источнику бесперебойного питания. Ну или если данные в базе не представляют для вас особой ценности. Для Windows – крайне не рекомендуется.
synchronous_commit
Параметр synchronous_commit определяет нужно ли ждать WAL записи на диск перед возвратом успешного завершения транзакции для подключенного клиента. По умолчанию и для безопасности данный параметр установлен в on (включен).
При выключении данного параметра (off) может существовать задержка между моментом, когда клиенту будет сообщенно об успехе транзакции и когда та самая транзакция действительно гарантированно и безопасно записана на диск (максимальная задержка – wal_writer_delay * 3).
В отличие от fsync, отключение этого параметра не создает риск краха базы данных: данные могут быть потеряны (последний набор транзакций), но базу данных не придется восстанавливать после сбоя из бэкапа. Так что synchronous_commit может быть полезной альтернативой, когда производительность важнее, чем точная уверенность в согласовании данных.
commit_delay и commit_siblings
commit_delay (в микросекундах, 0 по умолчанию) и commit_siblings (5 по умолчанию) определяют задержку между попаданием записи в буфер журнала транзакций и сбросом её на диск. Если при успешном завершении транзакции активно не менее commit_siblings транзакций, то запись будет задержана на время commit_delay. Если за это время завершится другая транзакция, то их изменения будут сброшены на диск вместе, при помощи одного системного вызова. Эти параметры позволят ускорить работу, если параллельно выполняется много мелких транзакций.
wal_sync_method
Метод, который используется для принудительной записи данных на диск. Если fsync=off, то этот параметр не используется. Возможные значения:
- open_datasync — запись данных методом open() с параметром O_DSYNC;
- fdatasync — вызов метода fdatasync() после каждого commit;
- fsync_writethrough — вызов fsync() после каждого commit, игнорируя параллельные процессы;
- fsync — вызов fsync() после каждого commit;
- open_sync — запись данных методом open() с параметром O_SYNC;
Не все эти методы доступны на разных ОС. По умолчанию устанавливается первый, который доступен для системы.
full_page_writes
Установите данный параметр в off, если fsync=off. Иначе, когда этот параметр on, PostgreSQL записывает содержимое каждой записи в журнал транзакций при первой модификации таблицы. Это необходимо, поскольку данные могут записаться лишь частично, если в ходе процесса <<упала>> ОС. Это приведет к тому, что на диске окажутся новые данные смешанные со старыми.
Строкового уровня записи в журнал транзакций может быть недостаточно, чтобы полностью восстановить данные после падения системы. full_page_writes гарантирует корректное восстановление, ценой увеличения записываемых данных в журнал транзакций (Единственный способ снижения объема записи в журнал транзакций заключается в увеличении checkpoint_interval).
wal_buffers
Количество памяти используемое в SHARED MEMORY для ведения транзакционных логов. Стоит увеличить буфер до 256–512 кБ, что позволит лучше работать с большими транзакциями.
Например, при доступной памяти 1–4 ГБ рекомендуется устанавливать 256–1024 КБ.
www.oslogic.ru
Ускорение и оптимизация настроек PostgreSQL для 1С » Администрирование » FAQ » HelpF.pro
По умолчанию PostgreSQL настроен таким образом, чтобы расходовать минимальное количество ресурсов для работы с небольшими базами до 4 Gb на не очень производительных серверах. То есть, если дело касается систем посерьезней, то вы столкнетесь с большими потерями производительности базы данных лишь потому, что дефолтные настройки могут в корне не соответствовать производительности вашего северного оборудования. Настройки выделения ресурсов оперативной памяти RAM для работы PostgreSQL хранятся в файле postgresql.conf.
Доступен как из папки, куда установлен PostgreSQL / Data, так и из pgAdmin:
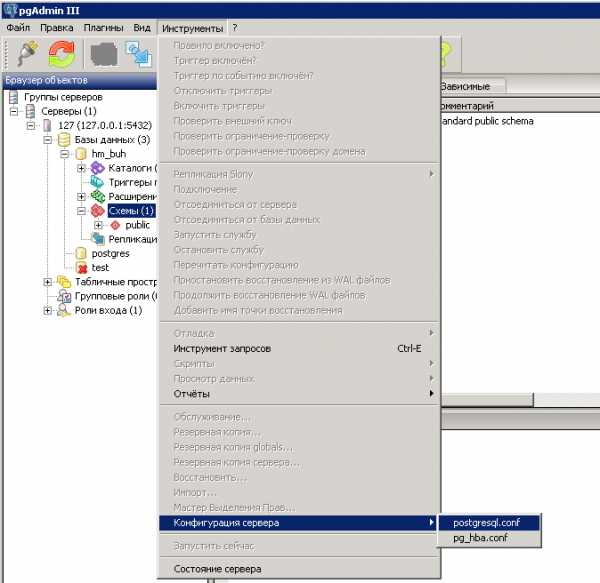
В общем на начальном этапе при возникновении трудностей и замедления работы БД, заметной для глаз пользователей достаточно увеличить три параметра:
shared_buffers
Это размер памяти, разделяемой между процессами PostgreSQL, отвечающими за выполнения активных операций. Максимально-допустимое значение этого параметра – 25% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 64-128 Mb (8192-16384).
temp_buffers
Это размер буфера под временные объекты (временные таблицы). Среднее значение 2-4% всего количества RAM
Например, при 1-2 Gb RAM на сервере, достаточно указать в этом параметре значение 32-64 Mb.
work_mem
Это размер памяти, используемый для сортировки и кэширования таблиц.
При 1-2 Gb RAM на сервере, рекомендуемое значение 32-64 Mb.
Для вступления новых значений в силу, потребуется перезапуск службы, поэтому лучше делать во вне рабочее время.
Еще два важных параметра это maintenance_work_mem (для операций VACUUM, CREATE INDEX и других) и max_stack_depth
Примеры оптимальных настроек:
Hardware:
- CPU: E3-1240 v3 @ 3.40GHz
- RAM: 32Gb 1600Mhz
- Диски: Plextor M6Pro
postgresql.conf:
- shared_buffers = 8GB
- work_mem = 128MB
- maintenance_work_mem = 2GB
- fsync = on
- synchronous_commit = off
- wal_sync_method = fdatasync
- checkpoint_segments = 64
- seq_page_cost = 1.0
- random_page_cost = 6.0
- cpu_tuple_cost = 0.01
- cpu_index_tuple_cost = 0.0005
- cpu_operator_cost = 0.0025
- effective_cache_size = 24GB
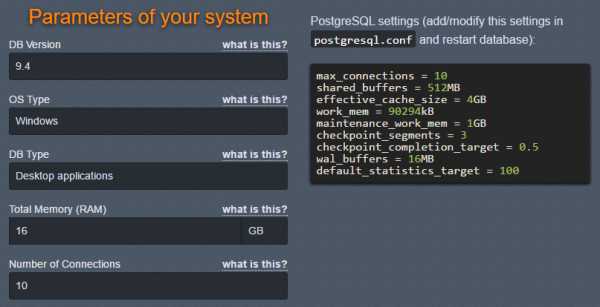
Вариант настроек от pgtune:
Полезные запросы:
Блокировки БД по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Вывести все таблицы, размером больше 10 Мб
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ and pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) like ‘%MB%’;Определение размеров таблиц в базе данных PostgreSQL
Код SQL SELECT tableName, pg_size_pretty(pg_total_relation_size(CAST(tablename as text))) as size from pg_tables where tableName not like ‘sql_%’ order by size;Пользователи блокирующие конкретную таблицу
Код SQL select a.usename, t.relname, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid inner join pg_stat_all_tables t on t.relid=l.relation where t.relname = ‘tablename’; Код SQL select relation::regclass, mode, a.usename, granted, pid from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not mode = ‘AccessShareLock’ and relation is not null;Запросы с эксклюзивными блокировками
Код SQL select a.usename, a.current_query, mode from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where mode ilike ‘%exclusive%’;Количество блокировок по пользователям
Код SQL select a.usename, count(l.pid) from pg_locks l inner join pg_stat_activity a on a.procpid = l.pid where not(mode = ‘AccessShareLock’) group by a.usename;Количество подключений по пользователям
Код SQL select count(usename), usename from pg_stat_activity group by usename order by count(usename) desc;helpf.pro
PostgreSQL : Документация: 9.5: 35.13. Информация для оптимизации операторов : Компания Postgres Professional
35.13. Информация для оптимизации операторов
Определение оператора в PostgreSQL может включать различные дополнительные предложения, которые сообщают системе полезные сведения о поведении оператора. Старайтесь задавать эти предложения при возможности, так как они могут значительно ускорить выполнение запросов, использующих данный оператор. Но если вы задаёте их, убедитесь, что они корректны! Неправильное применение предложений оптимизации может привести к замедлению запросов, неочевидным ошибочным результатам и другим неприятностям. Если вы не уверены в правильности предложения оптимизации, лучше вовсе не использовать его; единственным последствием будет то, что запросы будут работать медленнее, чем могли бы.
В будущих версиях PostgreSQL могут быть добавлены и другие предложения. Здесь описываются те, что поддерживаются версией 9.5.14.
Предложение COMMUTATOR, если представлено, задаёт оператор, коммутирующий для определяемого. Оператор A является коммутирующим для оператора B, если (x A y) равняется (y B x) для всех возможных значений x, y. Заметьте, что B также будет коммутирующим для A. Например, операторы < и > для конкретного типа данных обычно являются коммутирующими друг для друга, а оператор + — коммутирующий для себя. Но традиционный оператор - коммутирующего не имеет.
Тип левого операнда оператора должен совпадать с типом правого операнда коммутирующего для него оператора, и наоборот. Поэтому имя коммутирующего оператора — это всё, что PostgreSQL должен знать, чтобы найти коммутатор, и всё, что нужно указать в предложении COMMUTATOR.
Информация о коммутирующих операторах крайне важна для операторов, которые будут применяться в индексах и условиях соединения, так как, используя её, оптимизатор запросов может «переворачивать» такие выражения и получать формы, необходимые для разных типов планов. Например, рассмотрим запрос с предложением WHERE tab1.x = tab2.y, где tab1.x и tab2.y имеют пользовательский тип, и предположим, что у нас есть индекс по столбцу tab2.y. Оптимизатор сможет задействовать сканирование по индексу, только если ему удастся перевернуть выражение tab2.y = tab1.x, так как механизм сканирования по индексу ожидает, что индексируемый столбец находится слева от оператора. PostgreSQL сам по себе не будет полагать, что такое преобразование возможно — это должен определить создатель оператора =, добавив информацию о коммутирующем операторе.
Когда вы определяете оператор, коммутирующий сам для себя, вы делаете именно это. Если же вы определяете пару коммутирующих операторов, возникает небольшое затруднение: как оператор, определяемый первым, может ссылаться на другой, ещё не определённый? Есть два решения этой проблемы:
Во-первых, можно опустить предложение COMMUTATOR для первого оператора, который вы определяете, а затем добавить его в определении второго. Так как PostgreSQL знает, что коммутирующие операторы связаны парами, встречая второе определение, он автоматически возвращается к первому и добавляет в него недостающее предложение COMMUTATOR.
Во-вторых, можно добавить предложение COMMUTATOR в оба определения. Когда PostgreSQL обрабатывает первое определение и видит, что COMMUTATOR ссылается на несуществующий оператор, в системном каталоге создаётся фиктивная запись для этого оператора. В этой фиктивной записи актуальны будут только имя оператора, типы левого и правого операндов, а также тип результата, так как это всё, что PostgreSQL может определить в этот момент. Запись первого оператора будет связана с этой фиктивной записью. Затем, когда вы определите второй оператор, система внесёт в эту фиктивную запись дополнительную информацию из второго определения. Если вы попытаетесь применить фиктивный оператор, прежде чем он будет полностью определён, вы просто получите сообщение об ошибке.
Предложение NEGATOR, если присутствует, задаёт оператор, обратный к определяемому. Оператор A является обратным к оператору B, если они оба возвращают булевский результат и (x A y) равняется NOT (x B y) для всех возможных x, y. Заметьте, что B так же является обратным к A. Например, операторы < и >= составляют пару обратных друг к другу для большинства типов данных. Никакой оператор не может быть обратным к себе же.
В отличие от коммутирующих операторов, два унарных оператора вполне могут быть обратными к друг другу; это будет означать, что (A x) равняется NOT (B x) для всех x (и для правых унарных операторов аналогично).
У оператора, обратного данному, типы левого и/или правого операнда должны соответствовать типам данного оператора, так же как и с предложением COMMUTATOR; отличие только в том, что имя оператора задаётся в предложении NEGATOR.
Указание обратного оператора очень полезно для оптимизатора запросов, так как это позволяет упростить выражение вида NOT (x = y) до x <> y. Такие выражения не так редки, как может показаться, так как операции NOT могут добавляться автоматически в результате реорганизаций выражений.
Пару обратных операторов можно определить теми же способами, что были описаны ранее для пары коммутирующих.
Предложение RESTRICT, если представлено, определяет функцию оценки избирательности ограничения для оператора. (Заметьте, что в нём задаётся имя функции, а не оператора.) Предложения RESTRICT имеют смысл только для бинарных операторов, возвращающих boolean. Идея оценки избирательности ограничения заключается в том, чтобы определить, какой процент строк в таблице будет удовлетворять условию WHERE вида:
column OP constantдля текущего оператора и определённого значения константы. Это помогает оптимизатору примерно определить, сколько строк будет исключено предложениями WHERE такого вида. (ВЫ спросите, а что если константа находится слева? Ну, собственно для таких случаев и задаётся COMMUTATOR...)
Разработка новых функций оценки избирательности ограничения выходит за рамки данной главы, но обычно можно использовать один из стандартных системных оценщиков для большинства дополнительных операторов. Стандартные оценщики ограничений следующие:
| eqsel для = |
| neqsel для <> |
| scalarltsel для < или <= |
| scalargtsel для > или >= |
Может показаться немного странным, что выбраны именно эти категории, но если подумать, это имеет смысл. Оператор = обычно оставляет только небольшой процент строк в таблице, а <> отбрасывает то же количество. Оператор < оставляет процент, зависящий от того, в какой диапазон значений определённого столбца таблицы попадает заданная константа (информация об этих диапазонах собирается командой ANALYZE и предоставляется оценщику избирательности). Оператор <= оставляет чуть больший процент, чем <, при сравнении с той же константой, но они настолько близки, что различать их не имеет смысла, так как это не даст лучшего результата, чем просто угадывание. Подобные замечания применимы и к операторам > и >=.
Часто вы можете обойтись функциями eqsel и neqsel для операторов с очень высокой или низкой избирательностью, даже если это не операторы собственно равенства или неравенства. Например, геометрические операторы приблизительного равенства используют eqsel в предположении, что соответствующие (равные) элементы будут составлять только небольшой процент от всех записей таблицы.
Функции scalarltsel и scalargtsel можно использовать для сравнений с типами данных, которые могут быть каким-либо осмысленным образом преобразованы в числовые скалярные значения для сравнения диапазонов. Если возможно, добавьте свой тип данных в число тех, что понимает функция convert_to_scalar() в src/backend/utils/adt/selfuncs.c. (Когда-нибудь эта функция должна быть заменена специализированными функциями, которые будут устанавливаться для конкретных типов в определённом столбце системного каталога pg_type; но сейчас это не так.) Если вы этого не сделаете, всё будет работать, но оценки оптимизатора будут не так хороши, как могли бы быть.
Для геометрических операторов разработаны дополнительные функции оценки избирательности в src/backend/utils/adt/geo_selfuncs.c: areasel, positionsel и contsel. На момент написания документации это просто заглушки, но вы, тем не менее, вполне можете использовать (или ещё лучше, доработать) их.
Предложение JOIN, если представлено, определяет функцию оценки избирательности соединения для оператора. (Заметьте, что в нём задаётся имя функции, а не оператора.) Предложения JOIN имеют смысл только для бинарных операторов, возвращающих boolean. Идея оценки избирательности соединения заключается в том, чтобы угадать, какой процент строк в паре таблиц будет удовлетворять условию WHERE следующего вида:
table1.column1 OP table2.column2для текущего оператора. Как и RESTRICT, это предложение очень помогает оптимизатору, позволяя ему выяснить, какой из возможных вариантов соединения скорее всего окажется выгоднее.
Как и ранее, в этой главе мы не будем пытаться рассказать, как написать функцию оценивания избирательности соединения, а просто отметим, что вы можете использовать один из подходящих стандартных оценщиков:
| eqjoinsel для = |
| neqjoinsel для <> |
| scalarltjoinsel для < или <= |
| scalargtjoinsel для > или >= |
| areajoinsel для сравнений областей в плоскости |
| positionjoinsel для сравнения положений в плоскости |
| contjoinsel для проверки на включение в плоскости |
Предложение HASHES, если присутствует, говорит системе, что для соединений с применением этого оператора допустимо использовать метод соединения по хешу. HASHES имеет смысл только для бинарного оператора, который возвращает boolean, и на практике этот оператор должен выражать равенство значений некоторого типа данных или пары типов данных.
Соединение по хешу базируется на том предположении, что оператор соединения возвращает истину только для таких пар значений слева и справа, для которых получается одинаковый хеш. Если два значения оказываются в разных ячейках хеша, операция соединения никогда не будет сравнивать их, неявно подразумевая, что результат оператора соединения в этом случае должен быть ложным. Поэтому не имеет никакого смысла указывать HASHES для операторов, которые не представляют какую-любо форму равенства. В большинстве случаев практический смысл в поддержке хеширования есть только для операторов, принимающих один тип данных с обеих сторон. Однако иногда возможно разработать хеш-функции, совместимые сразу с несколькими типами данных; то есть, функции, которые будут выдавать одинаковые хеш-коды для «равных» значений, несмотря на то, что эти значения будут представлены по-разному. Например, довольно легко функции с такой особенностью реализуются для хеширования целых чисел различного размера.
Чтобы оператор соединения имел характеристику HASHES, он должен входить в семейство операторов индексирования по хешу. Это требование откладывается, когда оператор только создаётся, ведь нужное семейство операторов, разумеется, ещё не может существовать. Но при попытке использовать такой оператор для соединения по хешу, возникнет ошибка во время выполнения, если такого семейства не окажется. Системе необходимо знать семейство операторов, чтобы найти функции для хеширования типа(ов) входных данных оператора. Конечно, вы должны также определить подходящие функции хеширования, прежде чем сможете создать семейство операторов.
При подготовке функции хеширования обязательно позаботьтесь о том, чтобы она всегда выдавала нужный результат, вне зависимости от особенностей машинной архитектуры. Например, если ваш тип данных представлен в структуре, в которой есть незначащие дополняющие биты, нельзя просто передать всю структуру функции hash_any. (Это возможно, только если все ваши операторы и функции гарантированно очищают незначащие биты, что является рекомендуемой стратегией.) В качестве другого примера можно привести типы с плавающей точкой в стандарте IEEE, в которых отрицательный ноль и положительный ноль — различные значения (отличаются на уровне битов), но при сравнении они считаются равными. Если значение с плавающей точкой может содержать отрицательный ноль, требуются дополнительные действия, чтобы для него выдавался тот же хеш, что и для положительного нуля.
Оператор соединения по хешу должен иметь коммутирующий (это может быть тот же оператор, если у него два операнда одного типа, либо связанный оператор равенства, в противном случае), относящийся к тому же семейству операторов. В случае его отсутствия, при попытке использования оператора возможны ошибки планировщика. Также желательно (хотя это строго не требуется), чтобы в семействе операторов хеширования, поддерживающем несколько типов данных, определялись операторы равенства для всех комбинаций этих типов данных; это способствует лучшей оптимизации.
Примечание
Функция, реализующая оператор соединения по хешу, должна быть постоянной (IMMUTABLE) или стабильной (STABLE). Если эта функция изменчивая (VOLATILE), система никогда не будет применять этот оператор для соединения по хешу.
Примечание
Если оператор соединения по хешу реализуется строгой функцией (STRICT), эта функция также должна быть полной: то есть она должна возвращать true или false, но не NULL, для любых двух аргументов, отличных от NULL. Если это правило не соблюдается, оптимизация операций IN с хешем может приводить к неверным результатам. (В частности, выражение IN может вернуть false, когда правильным ответом, согласно стандарту, должен быть NULL, либо выдать ошибку с сообщением о том, что оно не готов к результату NULL.)
Предложение MERGES, если присутствует, говорит системе, что для соединений с применением этого оператора допустимо использовать метод соединения слиянием. MERGES имеет смысл только для бинарного оператора, который возвращает boolean, и на практике этот оператор должен выражать равенство значений некоторого типа данных или пары типов данных.
Идея объединения слиянием заключается в упорядочивании таблиц слева и справа и затем параллельном сканировании их. Поэтому оба типа данных должны поддерживать сортировку в полном объёме, а оператор соединения должен давать положительный результат только для пар значений, оказавшихся в «одном месте» при определённом порядке сортировки. На практике это означает, что оператор соединения должен работать как проверка на равенство. Но при этом возможно объединить слиянием два различных типа данных, если они совместимы логически. Например, оператор проверки равенства smallint и integer может применяться для соединений слиянием; понадобятся только операторы сортировки, приводящие оба типа данных в логически совместимые последовательности.
Чтобы оператор соединения имел характеристику MERGES, он должен являться членом семейства операторов индекса btree, реализующим равенство. Это требование откладывается, когда оператор только создаётся, ведь нужное семейство операторов, разумеется, ещё не может существовать. Но этот оператор не будет фактически применяться для соединений слиянием, пока не будет найдено соответствующее семейство операторов. Таким образом, флаг MERGES только подсказывает планировщику, что стоит обратиться к соответствующему семейству.
Оператор соединения слиянием должен иметь коммутирующий (это может быть тот же оператор, если у него два операнда одного типа, либо связанный оператор равенства, в противном случае), относящийся к тому же семейству операторов. В случае его отсутствия, при попытке использования оператора возможны ошибки планировщика. Также желательно (хотя это строго не требуется), чтобы в семействе операторов btree, поддерживающем несколько типов данных, определялись операторы равенства для всех комбинаций этих типов данных; это способствует лучшей оптимизации.
Примечание
Функция, реализующая оператор соединения слиянием, должна быть постоянной (IMMUTABLE) или стабильной (STABLE). Если эта функция изменчивая (VOLATILE), система никогда не будет применять этот оператор для соединения слиянием.
postgrespro.ru