Оптимизация Windows — мифы и реальность (часть 2). Оптимизация подавления ack
Увеличение пропускной способности сетей 802.11n за счёт усовершенствования протокола MAC. Часть 2
A-MPDU
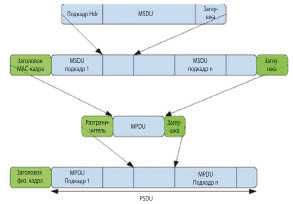
Кванты данных MAC-протокола в конце процесса его работы аккумулируются в единственном кванте данных A-MPDU. Этот процесс отображён на рисунке 6. К каждому подкадру добавляется ограничитель (в начале подкадра) и заглушка для выравнивания по 32-битной границе в конце. Ограничитель содержит длину кванта MPDU, сигнатуру и код циклического контроля. Целью введения ограничителя является предоставление возможности приёмнику выделения отдельного кванта из агрегата, даже если один из предыдущих ограничителей принят с ошибкой. Все MPDU в агрегате должны относиться к одной категории и иметь один адресат. Полная длина этого агрегата ограничивается числом 8, 16, 32 или 64 Кбайт в зависимости от возможностей приёмника. Поскольку агрегат передаётся как единое целое на физическом уровне, то настройка приёмника осуществляется только один раз, в начале процесса передачи. В то же время в процессе передачи условия приёма могут существенно измениться, что приведёт к возникновению ошибок. Следовательно, максимальная длина агрегата ограничивается также максимальным временем когерентности канала связи. Ещё одним ограничением является максимальное число агрегируемых квантов MPDU, равное 64, что связано ограничением на время поступления подтверждения блочной передачи. И, наконец, последним ограничением является максимальное количество кадров в очереди передатчика, т.к. инкапсуляция и агрегирование MPDU осуществляется сетевым интерфейсом.
| Рис. 6. Агрегация A-MPDU |
Двухуровневая агрегация
Двухуровневая агрегация предполагает использование обоих видов слияния кадров — A-MSDU и A-MPDU (см. рис. 7). Поддержка этого вида слияния является опциональной и должна декларироваться на этапе, предшествующем установлению связи. Этот тип агрегации полезен в таких исключительных случаях, когда должна быть передана последовательность MSDU малого размера. В данном случае при использовании только A-MPDU предел в 64 объединяемых кванта приводит к тому, что существенная доля пропускной способности остаётся незадействованной. Аналогичная ситуация возникает при использовании пакетов пользовательских данных большого размера для повышения скорости передачи.
| Рис. 7. Двухуровневая агрегация |
 |
Описанные способы агрегации данных протокола отличаются возможными способами их реализации. Агрегация A-MSDU может быть выполнена хост-системой, позволяющей ожидать поступления требуемого числа квантов MSDU. В противоположность этому механизму агрегация квантов MPDU выполняется собственно сетевым интерфейсом, что ограничивает период ожидания квантов MPDU ёмкостью его буфера очередей пакетов. При этом агрегаты A-MSDU упаковываются в одиночный MPDU с одним-единственным номером в очереди. Если при передаче MPDU возникает ошибка, эту передачу требуется повторить заново. С другой стороны, поскольку в агрегате A-MPDU каждый квант MPDU имеет свой уникальный код-ограничитель, при возникновении ошибок требуется повторная передача только ошибочных квантов. И, наконец, агрегация A-MSDU намного эффективнее A-MPDU, т.к. в процессе последней к каждому субкадру добавляется полный заголовок MPDU.
Механизм блочного подтверждения
Этот механизм, впервые введённый в стандарте 802.11e, в версии 802.11n был изменён и доработан.
Безусловное блочное подтверждение
Первым усовершенствованием стало исключение запроса подтверждения приёма блока (BAR). Этот запрос был исключён, т.к. генерация кадра подтверждения является стандартной реакцией на получение пакета A-MPDU. Последовательность обмена при блочной передаче показана на рисунке 8а. Это уменьшило избыточность передаваемых данных и устранило один из возможных источников ошибок, связанный с вероятностью ошибочного приёма блочного подтверждения BA. В стандарте 802.11n возможна передача множества агрегатов A-MPDU с подтверждением единственным кадром BA. В этом случае все, кроме последнего, агрегаты A-MPDU посылаются в приёмник с установленной политикой блочного подтверждения, и их приём только фиксируется в статусе приёма на принимающей стороне. Последний же агрегат посылается с признаком нормального подтверждения, что вызывает генерацию и посылку блочного подтверждения, содержащего статус всех принятых с момента посылки предыдущего блочного подтверждения агрегатов. Альтернативой этому методу является посылка всех агрегатов с признаком политики блочного подтверждения и специального запроса BAR. Эти варианты показаны на рисунках 8б и 8в.
| Рис. 8. Формирование блочного подтверждения |
Сжатие блочного подтверждения
Обнаружилось, что фрагментация и агрегация кадров плохо сочетаются друг с другом. Целью фрагментации является улучшение надёжности передачи в зашумлённом канале за счёт разбиения длинного кадра на мелкие фрагменты. Это увеличивает вероятность правильного приёма каждого фрагмента и уменьшает накладные расходы на повторные передачи. В то же время при хороших условиях передачи кадры малого размера объединяются для уменьшения доли служебной информации в общем потоке данных. Естественно, что в стандарте 802.11n фрагментация квантов MSDU, являющихся частью агрегата A-MPDU, была запрещена. В результате в кадре блочного подтверждения на каждый квант MPDU оказалось достаточно отвести всего 1 бит. Таким образом, длину такого сжатого сигнала блочного подтверждения оказалось возможным сократить всего до 64 бит по сравнению с 1024 битами несжатого пакета BA. Соответственно, он занимает меньше места в памяти приёмника, требует меньшего времени для передачи и может быть передан более помехоустойчивым методом модуляции.
Блочное подтверждение промежуточных состояний
Система блочных подтверждений стандарта 802.11n требует, чтобы получатель обеспечил хранение статуса всех принятых квантов MPDU за время всех сессий блочного обмена. Поскольку кадр блочного подтверждения должен быть немедленно сгенерирован и передан в ответ на поступивший запрос блочного подтверждения, это представляет определённую проблему с точки зрения компромисса между занимаемой памятью и скоростью доступа к требуемым данным. В стандарте 802.11n эта проблема решается за счёт возможности хранить информацию только о немногих последних блочных передачах. Это обеспечивается за счёт перекладывания задачи хранения информации на передающую сторону, которая ищет необходимые данные до того, как они будут отменены (и перезаписаны) на принимающей стороне. Если соответствующая строка в массиве подтверждений в приёмнике должна быть перезаписана к моменту поступления запроса на блочное подтверждение, приёмник должен немедленно сгенерировать кадр BA со всеми битами, сброшенными в 0. Это вызывает повторную передачу всех квантов MPDU. Типичным сценарием, в котором используется подобный механизм, является передача одного или более агрегатов A-MPDU и получение ответа в виде блочного подтверждения в ходе единственного периода TxOP, как показано на рисунке 8.
Протокол обратной передачи
В некоторых приложениях, например, при реализации протоколов FTP и HTTP, трафик становится существенно асимметричным, т.е. объём данных, передаваемых в одном направлении, существенно превосходит объём данных, передаваемых в обратном. Однако при этом скорости передачи в обоих направлениях чётко связаны, причём скорость передачи в прямом направлении определяется задержкой передачи в обратном. В нормальном режиме работы это означает, что получатель должен получить режим благоприятной передачи TxOP и передавать кадры подтверждения приёма. При этом появляются две проблемы: во-первых, возникает задержка в передаче сигнала подтверждения и, во-вторых, возможности режима TxOP в обратном направлении используются крайне неэффективно. Обе эти проблемы в стандарте 802.1n решаются за счёт введения т.н. протокола обратной передачи RDP (Reverse Direction Protocol). Он позволяет организовать двунаправленный режим наибольшего благоприятствования, суть которого заключается в том, что TxOP предоставляет в пользование часть возможностей другой станции. Этот метод реализуется двумя способами — например, передатчик в прямом направлении может выделить время своему соседу для передачи его кадра подтверждения в конце собственной сессии TxOP, либо приёмник, получив в своё распоряжение TxOP, после получения ожидаемого сигнала подтверждения завершает эту сессию. Такое усовершенствование правил доступа к среде передачи требует очень малого количества управляющих сигналов, но экспериментальная проверка показала, что оно способно увеличить общую пропускную способность среды на 40%.
Управление и использование особенностей устройств физического уровня
И, наконец, необходимо отметить, что на MAC-уровне должно быть запущено несколько процессов, позволяющих должным образом использовать те усовершенствования, которые были введены в стандарте для физического уровня передачи.
Первым делом (и это наиболее важно) следует получить управляющую матрицу, которая используется при формировании передающего луча. В процессе формирования оптимальной диаграммы направленности передатчика он инициирует процедуру установления связи, в процессе которой приёмник должен рассчитать и как можно быстрее отправить передатчику информацию о состоянии канала связи. При формировании оптимальной антенной конфигурации приёмника он должен отправить запрос на передачу, что позволит оптимальным образом настроить канал связи. В дополнение к этому должны быть скомпенсированы все рассогласования в аналоговой части приёмного и передающего устройств. Передатчик запоминает полученную информацию и использует её при дальнейших обменах данными.
В стандарте 802.11n предусмотрено 77 различных вариантов конфигурации канала передачи, отличающихся количеством потоков данных, схемой модуляции, скоростью передачи и полосой пропускания каналов. Из этого многообразия для конкретного канала выбирается ограниченный набор схем, базирующийся на возможностях приёмника и передатчика. Блок управления доступом к среде должен попытаться выбрать наилучший вариант для конкретного кадра и передать его системе управления на физический уровень. Такой выбор не является чем-то неизменным и должен корректироваться в соответствии с изменяющимися условиями. До принятия стандарта 802.11n выбор скорости передачи являлся задачей исключительно передающей стороны, в то время как в новом стандарте появился новый протокол выбора конфигурации (MCS feedback protocol), позволяющий передатчику запросить информацию у приёмника до принятия решения о выборе оптимальной скорости передачи.
Помимо этого, система управления доступом к среде должна правильно выбрать тип и степень агрегации, которые будут использоваться в процессе обмена данными. В значительной мере такой выбор определяется компромиссом между возникающими при агрегации задержками в процессе передачи, однако длина кадра определяется ещё и текущими условиями передачи.
И, наконец, система управления доступом должна обеспечивать обратную совместимость с устройствами, поддерживающими прежние версии стандарта. При этом устройства с шириной канала 20 МГц должны нормально работать в сети совместно с устройствами нового стандарта. Для этого MAC-протокол был дополнен функциями, обеспечивающими оптимизацию скорости передачи при наличии в радиусе действия устройств старых версий и устройств с различным уровнем поддержки нового стандарта.
Заключение
На этом мы закончим рассмотрение модификаций MAC-уровня в стандарте 802.11n. Как уже отмечалось ранее, скорости, доступные устройствам ранних версий стандарта 802.11a/b/g в новой версии увеличились более чем на порядок. Это стало возможным за счёт использования одновременно нескольких каналов передачи данных через несколько антенн, расширения полосы частот и т.д. Для того чтобы превратить это ускорение в увеличение скорости передачи пользовательских данных, был существенно доработан протокол управления доступом к среде (MAC-протокол). Целью при этой доработке стало уменьшение непроизводительных расходов на передачу служебной информации. Основными методами достижения этой цели стали различные способы агрегации данных, блочной передачи и подтверждения и оптимизация двунаправленной передачи в неравноправных сетевых протоколах. Помимо этого в протокол были добавлены механизмы, поддерживающие корректную и оптимальную работу новых функций физического уровня. При реализации всех этих усовершенствований максимальная скорость передачи, на физическом уровне достигающая 600 Мбит/с, на MAC-уровне поднялась до 375 Мбит/с. Фактически это означает, что современные беспроводные сети обеспечивают ту же скорость передачи данных, что и проводные сети класса 1 Гбит. С распространением нового стандарта становится всё более близкой замена проводных сетей Ethernet-стандарта беспроводными.
www.russianelectronics.ru
Bursting, Compression, Fast Frames, Concatenation
Практически во всех выпускаемых ныне беспроводных адаптерах стандарта 802.11g можно встретить суффиксы "super G", "turbo", "plus" и т.д. Причем суффиксами дело обычно не ограничиваются. Производители (точнее их маркетологи) красочно рисуют на коробках цифры 108, а некоторые — аж 125 Мбит/сек.
125 — звучит заманчиво. Неужели беспроводные адаптеры работают быстрее старого доброго Fast Ethernet по проводам? Может ну их… в баню, эти "древние" Fast Ethernet адаптеры? Выкидываем надоевшие кабели и да здравствует радиоезернет? :)
Но, как говорится, семь раз отмерь, один — отрежь. Что в нашем случае означает, что не мешало бы поподробнее узнать, что же это за такие загадочные технологии, как они работают и какие на самом деле скорости обеспечивают (и самое главное — при каких условиях). Другими словами, не забываем анекдот про физиков и из сферических коней в вакууме. А так же делаем скидку маркетологам на то, что для них важнее всего — продать решения своей компании.
Различных вариантов "разгона" стандартного 802.11g существует довольно много. Точнее — у каждого производителя чипов оно свое (по крайней мере — называется по-разному). К сожалению, не все производители объясняют, что именно представляют из себя их технологии. Информацию по технологиям мне удалось найти лишь у компании Atheros и Texas Instruments. Но наиболее информативный ресурс оказался у Atheros — у них даже есть отдельный сайт, посвященный их технологиям Super G и Super AG.
Собственно, бОльшая часть статьи — это компиляция информации с сайтов Atheros и Texas Instruments и по мелочи — из других источников.
Переходим непосредственно к технологиям.
Для начала посмотрим на "чистый" 802.11g. Максимальная пропускная способность в этом режиме — 54 Мбит/сек. Думаю, большинство читателей знает, как перевести мегабиты в мегабайты? Правильно — делим мегабиты на восемь и получаем скорость 6.75 Мбайт/сек.
Но внимательные читатели (кто смотрит в статьях не только предисловие и выводы, а иногда пробегается, хотя бы одним глазом, по диаграммам замера скоростей) знают, что в обычном 802.11g режиме скоростей более ~25 Мбит мы не получали. Так это же только половина от 54 Мбит! Куда делась вторая половина? Куда — это тема отдельной статьи, отмечу лишь, что на пользовательские данные действительно приходится примерно половина (в лучшем случае) пропускной способности канала.
Это первая плохая новость. Есть и вторая. Радиоволны (собственно, с помощью них и передается информация в беспроводных сетях) передаются во все стороны от источника сигнала (рассматриваем общий случай). Т.е. передающего слышат все. Эти "все" могут принимать данные или не принимать, это не важно. Главное — они не могут в этот момент что-либо передавать на той же частоте. Точнее говоря, попытаться то они могут, но сигналы обоих источников наложатся друг на друга, в результате чего информационная составляющая будет искажена и потеряна. Другими словами, в беспроводных сетях одновременно может передавать только один источник из нескольких, работающих на одной и той же частоте. Т.е. принцип рации — сначала говорим, потом молчим и слушаем.
Таким образом, щедро выделенные нам ~25 Мбит делятся на всех участников беспроводной сети. Если количество клиентов составляет 5 хостов, то в момент интенсивной передачи данных с каждого, на одного придется канал пропускной способностью примерно 5 Мбит (а на самом деле даже чуть меньше).
Есть и третья плохая новость. Вторая "плохая новость" насчет "5 Мбит на 5 хостов" верна лишь в случае Ad Hoc сети, т.е. без точки доступа. Если брать более общий случай с точкой доступа, то эти жалкие 5 мбит придется поделить еще на два. Ведь в Infrastructure режиме беспроводной сети (с участием точки доступа) любой обмен с клиентами проходит через точку доступа. А она сначала должна принять данные, а потом ретранслировать их к получателю. В результате получаем по 2 с хвостиком мегабита на брата.
Теперь вернемся к цифрам 108 и 125, которые так любят крупным шрифтом рисовать на коробках производители. Ну, вы уже все поняли, да? :)
Смело делим на два (про сферического коня чуть позже). Получаем максимум 60мбит в случае одного клиента и соответственно в n-цать раз меньше, в случае N клиентов.
Для тех, кому надо было лишь выяснить, пора ли выкидывать провода или "еще погодить", дальнейшую часть статьи можно не читать. Ответ — выкидывать пока рано. Как минимум, надо дождаться WiMAX.
Теперь перейдем к более детальному рассмотрению рассмотрению технологий увеличения пропускной способности беспроводных сетей по сравнению со стандартным 802.11g режимом.
Полагаю, у всех производителей все их плюсы, турбо и т.д. представляют собой то же самое, что и у Atheros с TI, но с другим названием. Но детали реализаций могут различаться, поэтому не факт, что технологии различных производителей совместимы друг с другом.
Технология Atheros для 802.11g носит название Super G (есть еще одна — Super AG, это тоже самое, но для стандарта 802.11a, т.е. для сетей на 5 ГГц). Atheros Super G позволяет увеличить пропускную способность до 108 Мбит/сек. И, как честно заявляет Atheros, для пользователя скорость может достигать 60 Мбит.
Увеличение производительности достигается несколькими способами:
Atheros Super G / Super AG технологии:
| Технология | Краткое описание | Плюсы |
| Bursting |
|
|
| Compression |
|
|
| Fast Frames |
|
|
| Dynamic Turbo |
|
|
У себя на сайте Atheros приводит красочную диаграмму, показывающую влияния различных технологий на скорость передачи данных:
рис.1, влияние различных технологий на производительность беспроводной связиВ базовом режиме 802.11g или 802.11a, в котором все расширенные технологии отключены, можно получить скорость до 22 Мбит (чистых, т.е. доступных пользователю). Добавляя технологии, которые возможно будут в будущем стандарте 802.11e (Bursting, Fast Frames, Compression), можно увеличить скорость до 40 Мбит включительно. Активируя Dynamic Turbo режим, т.е. задействуя два канала под передачу данных, можно довести скорость до теоретического максимума в 60 Мбит.
Разумеется, приведенные цифры — это лишь максимально возможная скорость в данном режиме работы (тот самый сферический конь в вакууме). В реальности все будет зависеть от таких условий, как удаленность клиента от точки доступа, количество одновременно работающих клиентов, радиообстановка в месте, где расположена беспроводная сеть и так далее.
У Texas Instruments технологии повышения производительности носят название G-Plus. Часть из них похожа на технологии Atheros, часть — присуще только TI.
Texas Instruments G-Plus технологии:
| Технология | Краткое описание | Плюсы |
| Frame Concatenation |
|
|
| Packet Bursting |
|
|
Подробно остановимся на каждой из перечисленных технологий — bursting, compression, fast frames, dynamic turbo. Примечательно то, что все четыре технологии работают независимо друг от друга, тем самым добиваясь максимально возможной производительности одновременно несколькими способами.
1. Bursting.
Frame Bursting — технология, заложенная в предварительный вариант стандарта 802.11e QoS. Frame Bursting позволяет увеличивать пропускную способность линка при обмене (точка-точка) между 802.11a, b или g устройствами за счет уменьшения накладных расходов, возникающих при передаче данных в беспроводных сетях. Причем хорошие результаты достигаются как в гомогенных (однородных), так и в смешанных беспроводных сетях.
На рисунке 2 приведен пример стандартной передачи (without bursting).
рис.2, стандартный режим 802.11a/b/gВ режиме стандартной передачи данных мы наблюдаем процесс передачи двух кадров (frame1 и frame2) во времени от источника Source к получателю Destination. Процесс передачи данных поделен на временные интервалы (по оси X — ось времени). Так как в любой момент времени передавать может лишь один источник, то каждая станция слушает эфир в течении времени DIFS (Distributed InterFrame Space), если она не услышала передачи другой станции, значит эфир свободен, можно передавать кадр. После передачи кадра (frame1), станция-передатчик ждет подтверждения об успешном приеме от получателя. Получатель обязан отослать подтверждение (ack), которое он отсылает практически сразу, после ожидания короткого промежутка времени SIFS — Short InterFrame Space (если подтверждения не было, то получатель считает, что кадр не был принят и должен перепослать его заново). После получения подтверждения передатчик опять обязан выждать интервал времени DIFS и только потом (если эфир по-прежнему свободен) начать отсылку второго кадра frame2. И так далее.
Таким образом, кадры ожидания DIFS отнимают достаточно существенную часть пропускной способности беспроводной сети.
Теперь посмотрим на картину передачи при использовании технологии Frame Bursting:
рис.3, задействование Frame BurstingВ этом режиме (рисунок 3), источник и получатель монопольно [по очереди] занимают канал под свою передачу. После передачи кадра frame1 и получения подтверждения об успешном приеме оного, передатчик не ждет положенный интервал времени DIFS. Передатчик выжидает лишь короткий временной интервал SIFS, после чего передает второй кадр данных и так далее. Тем самым, передатчик не дает возможности начать передачу другим станциям — им приходится ожидать окончания общего периода такой burst-передачи.
Разумеется, общий интервал передачи данных в таком режиме ограничен (а то передача нескольких гигабайтов данных полностью бы парализовала работу остальных клиентов той же беспроводной сети). Но удаление интервала DIFS позволяет за тот же период времени передать существенно бОльшее количество данных, тем самым экономя пропускную способность канала, т.е. увеличивая общую скорость передачи данных.
Atheros заявляет, что все ее продукты данную технологию поддерживают. Но очевидно, что устройства других производителей, в которых эта технология не встроена, могут и не понять такой "разрывной" режим работы. Поэтому, если подтверждение на посланный в начале burst-режима пакет не получено получателем, передатчик отключает bursting и переходит в базовый режим работы.
Реализация Bursting у TI аналогична технологии Atheros. TI приводит следующую картинку, иллюстрирующую работу их технологии (рис 4):
рис.4, Frame Bursting от Texas InstumentsTI тоже удаляют "длинный" временной фрейм ожидания, тем самым сокращая накладные расходу на передачу.
Информация о совместимости burst-технологий в реализациях от TI и Atheros на сайтах обеих компний отсутствует.
Подобная "bursing" технология, вероятно, присутствует и у других производителей. Но Atheros пошла дальше и расширила ее до "dynamic bursting". По ее заверениям, эта технология особенно эффектна в сетях с количеством работающих беспроводных клиентов больше единицы.
К примеру, в беспроводной сети две станции, одна расположена близко к точке доступа, другая удалена от нее. Разумеется, дальний клиент работает с точкой доступа на более низкой скорости (из-за расстояния). Поэтому для передачи данных определенного размера (для ближайшего клиента) ему потребуется больше времени, чем ближайшему — для приема этих данных. В этом случае активация bursting для дальней станции позволит ей сократить время передачи порции данных и, как ни странно, это же позволит ближайшей станции еще быстрее эти данные принять (так как она меньше будет ожидать на линии освобождения эфира). Интервалы, на которые клиенты могут занять эфир "burst"-передачей, также зависят от удаленности (точнее, скорости работы) клиентов. Ближайший клиент получит грант на более длинную burst-передачу, так как за единицу времени он передает больше данных (и быстрее освободит эфир).
Atheros Compression technology.
Вторая технология от Atheros, расширяющая стандарт 802.11 — аппаратная компрессия данных. Она встроена во все 802.11a,b,g чипсеты компании. Используемый алгоритм — Lempel Ziv. Этот же алгоритм используется в архиваторах gzip, pkzip, winzip. Данные "на лету" упаковываются перед пересылкой и распаковываются на принимающей стороне.
К сожалению, данные предварительно не анализируются, а сжимаются все кадры подряд. Тем самым, выигрыш достигается не всегда — например, пересылка уже упакованного файла может увеличить размер передаваемых по беспроводной сети данных.
С другой стороны, хорошо подверженные компрессии данные будут переданы кадрами меньшего размера, тем самым передатчик займет меньше эфирного времени на свою передачу. Это время может быть использовано для работы других беспроводных клиентов.
Atheros Fast Frames.
Технология Fast Frames предлагает слияние двух кадров в один, большего размера. Тем самым, мы избавляемся от служебной информации (в заголовке второго пакета — остается лишь один заголовок нового кадра) и временных пауз ожидания между кадрами:
рис.5, обычная передача данных рис.6, Fast Frames активнаПричем размер полученного кадра-фрейма может достигать 3000 байт, что в два раза больше максимального размера кадра стандартного ethernet-пакета. Таким образом, даже если идет поток данных из проводной сети с пакетами максимального (1500 байт) размера, технология Fast Frames все равно будет работать, объединяя каждые два ethernet-пакета в один бОльшего размера. Как только FastFrames-алгоритм будет согласован между точкой доступа и станцией, все дальнейшие пересылки данных между этими двумя устройствами будут происходить с использованием таких, увеличенных вплоть до 3000 байт, кадров.
С учетом того, что Fast Frames может работать совместно с Frame Bursting, мы получаем очень неплохие результаты по скорости передачи. Кстати говоря, как заявляет Atheros, большинство производителей, реализовавших в своих чипах технологию Frame Bursting, тем не менее, не поддерживают Fast Frames. У Atheros тут все впорядке — их продукты держат и то и другое.
Технология Fast Frames — тоже часть черновой версии стандарта 802.11e. Тем не менее, ее совместимость с продуктами других производителей не гарантируется. С другой стороны, технология работает в рамках стандартных временных интервалов (в отличии от Frame Bursting, которая монопольно занимает полосу на некоторое время). Именно поэтому Fast Frames лучше вписывается в беспроводные сети, где используется оборудования различных производителей.
Texas Instruments Frame Concatenation
Технология Frame Concatenation, реализованная в продуктах компании Texas Instruments, использует те же принципы, что и Fast Frames у Atheros.
Но TI пошли дальше. У них объединению подвергаются два и более кадров (рисунок 7):
рис.7, технология Frame ConcatenationТем самым, они выигрывают на удалении служебной информации и межкадровых интервалов ожидания от одного и более кадров. TI заявляет, что их технология Frame Concatenation будет работать с любыми 802.11b/b+/g продуктами от TI и (!)других производителей. Не совсем ясно, что они имели ввиду под другими производителями, если у последних поддержка этой технологии не будет реализована… Возможо имелась ввиду работа с кадрами, размер которых не превышал стандартного (1500 байт) размера.
В технологию Frame Concatenation заложен алгоритм, позволяющий упаковывать в мега-кадры не все пакеты подряд. Например, если в очереди отправки на заданное направление находится лишь один кадр, то он будет отослан незамедлительно. Другими словами, сливаться будут лишь те кадры, у которых одинаковый адрес получателя (destination address, в данном случае имеется ввиду MAC адрес получателя). Причем, алгоритм действует только на unicast-пакеты — широковещательные (multicast), а так же служебные пакеты отсылаются без изменений.
На данный момент, максимальный размер Concatenation-пакета может достигать 4096 байт (что косвенно говорит о том, что эта технология не совместима с подобной же технологией от Atheros).
Заключение.
Как видно, производители не дожидаются официального объявления стандартов (в данном случае 802.11e), а интегрируют новые технологии в свои продукты. В результате, с одной стороны, достигаются неплохие результаты в виде увеличения скорости, с другой — технологии различных производителей часто оказываются несовместимы друг с другом.
Не рассмотренной осталась технология агрегирования каналов у Atheros (Dynamic Turbo). Про нее — во второй части статьи.
А если к тому времени найдутся документы, описывающие реализации super/plus/etc технологий у других производителей беспроводных решений (или мне подскажут ссылки них в форуме (ссылка чуть ниже)), то обзор этих технологий также будет добавлен во вторую часть статьи.
www.ixbt.com
SG TCP Optimizer: масштабная настройка интернета
 Начинающим пользователям крайне сложно, а в некоторых случаях просто невозможно выполнить настройку интернета в ручном варианте. Это непосильная задача для новичков. По этой причине были разработаны специальные помощники, которые помогут произвести все необходимые действия.
Начинающим пользователям крайне сложно, а в некоторых случаях просто невозможно выполнить настройку интернета в ручном варианте. Это непосильная задача для новичков. По этой причине были разработаны специальные помощники, которые помогут произвести все необходимые действия.
С помощью подходящих программных продуктов можно устранить самые разные проблемы, с которыми пользователи могут сталкиваться при работе с персональным компьютером. Есть отдельная категория утилит, которые направлены на то, чтобы быстро и корректно провести настройку интернета.
Всемирная сеть – это океан возможностей для каждого юзера. Все пользователи просто не представляют свою жизнь без интернета. В нем можно просматривать сайты с различным информационным наполнением. Так что доступ к сети должен быть открыт и работать сеть должна наиболее качественно.
Но помогают софты такого направления только в том случае, если проблема возникла не по причине провайдера и никак не связана с роутером. В таком случае можно будет установить софт, чтобы выполнить оптимизацию интернет-настроек, а также попробовать внести некоторые исправления в подключение.
С этой задачей непременно справится сервис под названием SG TCP Optimizer. Это бесплатное приложение используется с целью восстановления всех наиболее важных настроек, которые необходимы для использования возможностей интернета в полной мере.
Особенности программы-оптимизатора
С интернетом все прекрасно ровно до тех пор, пока он реально есть. Но если он вдруг пропадает, то это уже настоящая трагедия. При этом пользователи совершают попытки устранить проблемы с помощью обращения к провайдеру.
Если проблема не в его компетенции, то можно будет попробовать проверить роутер. После работы с данным элементом может оказаться, что трудности с интернетом возникли также не по причине его неполадок. Если все было испробовано, а проблема все равно не устранена, то нужно проверить настройки соединения.
Чаще всего проблемы возникают потому, что операционная система просто перестает распознавать подключения. Так что нужно будет попробовать самые разные методики, дабы ОС снова смогла видеть» сеть. В возможностях SG TCP Optimizer не только устранить неполадки, но и улучшить качество связи.
Благодаря компактному сервису можно выполнить работу по устранению самых разных неполадок, которые только могут возникать в сети. Возможен вариант не только автоматического восстановления самых важных параметров утилита направляет свои действия на прочие параметры, которые влияют на производительность сетевой подсистемы.
Важно то, что благодаря данному приложению удаляется производить все необходимые действия как автоматически, так и в ручном режиме. Причем, и тот и тот вариант является качественно реализуемым и эффективным.Уникальные возможности современного помощника
Утилита позволяет автоматически восстановить сетевые настройки операционной системы. В этом процессе участвуют многочисленные параметры, которые предстоит подкорректировать. Приложение наполнено многочисленными полезными функциями, которые при правильном использовании помогут в улучшении параметров производительности сети.
В ходе функционирования утилита проводит много действий разного направления. Можно будет попробовать выполнить быстрый сброс настроек. При необходимости можно вернуть прежние параметры функционирования или сохранить новые из файла. Также присутствуют готовые профили оптимизированных настроек.
Любые параметры сети можно настраивать по собственному усмотрению. Данная утилита предполагает выполнение работы в ручном варианте или переключение на работу в авто. Пользователям предлагается огромное количество самых разных инструментов, которые можно использовать для улучшения работоспособности сети.
Утилита эта является особенной и даже незаменимой в некоторых ситуациях. Тонкая настройка возможна благодаря этому программному обеспечению. Но есть и один важный момент: все подряд корректировать не нужно. В противном случае пользователю придется в дальнейшем бороться с последствиями. Стоит ли нарушать работу сетевой подсистемы аппарата?
Наиболее востребованная опция: сброс настроек
Для большинства пользователей именно эта функция относится к числу самых часто используемых. Именно с ее помощью юзеры могут организовать более быстрый возврат системы к тому состоянию, когда все настройки будут находиться в нормальном состоянии, чтобы обеспечить подключение к сети.
Важен один момент: утилита не нуждается в проведении установки на устройство. Достаточно лишь будет скачать архив, а затем непосредственно из него выполнять запуск данного помощника.
Сервис относится к числу наиболее востребованных приложений по многим причинам. В загруженном архиве пользователи смогут обнаружить две версии софта. Есть программа с интерфейсом, который полностью на английском языке. Также есть вариант использования программы в частичном переводе на русский язык.
Для реализации первостепенной задачи пользователям необходимо будет разобраться с предложенным интерфейсом на английском языке. Именно в этом варианте утилита является более нормально функционирующей, поскольку перевод на русский в другой версии совсем «слабенький» и далеко не качественный.
Как только запуск выбранного объекта будет реализован, то по умолчанию будет произведена загрузка сетевых настроек. Теперь можно будет перейти во вкладку с общими настройками сети. Далее уже попробуем возобновить доступ к сети.
Осуществить возврат интернета можно в разделе под названием «Windows Default». В данном открывшемся пункте потребуется кликнуть по кнопке «Apply changes». Данная манипуляций приводит к тому, что все настройки соединения сразу же будут устанавливаться.
По идее, уже после этого можно будет попробовать посмотреть, появился доступ в сеть или нет. В обязательном порядке производим перезагрузку персонального компьютера, поскольку этого требует данный софт. Только после этого можно проверить, насколько эффективная данная методика.
Если все же результат оказался отрицательным, то не стоит ждать чуда, а нужно приступить к реализации иного метода. Предполагает он проведение сброса настроек в отношении Winsock и TCP/IP. Реализуется это несложно: нужно лишь перейти в меню программы, а после в нем открыть пункт «File».
В нем попробуем выполнить сброс сетевых настроек. Уже после этого доступ во всемирную сеть должен быть обеспечен наверняка. Так что эта методика работает практически всегда.
Корректировка параметров. Более мощные настройки
Пользователи при знакомстве с этой утилитой могут переходить в различные вкладки. Если нужно открыть раздел с более сложными параметрами, то для этого предусмотрена вторая вкладка.
Можно воспользоваться теми параметрами, которые будут загружены в автоматическом режиме. Также предусмотрено наличие многих параметров. Отличие от первой вкладки в том, что в этом разделе предлагается работать с гораздо большим набором опций.
Но при этом нужно быть настолько внимательным при работе с предложенными настройками, поскольку некорректное их использование грозит крайне негативными последствиями. Во избежание этого пользователям необходимо будет внимательно изучать все параметры, а только после этого уже рассматривать целесообразность внесения изменений.Дополнительные возможности
Также пользователям предлагается использовать в работе и многие другие настройки. Для этого предусмотрено наличие специальных полезных утилит, а также встроенных калькуляторов. Такого рода «полезности» непременно принесут пользу при правильном их использовании.
Именно два рассматриваемых раздела направлены на то, чтобы максимально правильно подобрать сетевые настройки, которые будут наиболее правильными. На вкладке «BDP» находится уникальный калькулятор, который разработчики приложения встроили в собственный программный продукт.
Он нужен с той целью, чтобы вести строгий подсчет пропускной способности канала. Он контролирует заданные параметры, которые указаны в протоколе. Более простыми словами можно описать значение: скоростью интернета.
Если задать правильный параметр, то есть поставить его на максимум, то пользователь получит максимально возможный пакет. Также можно будет перейти во вкладку «MTU/Задержка». Как только данный раздел будет открыт, то перед юзером моментально покажется набор с разнообразными инструментами.
В дальнейшем все предоставленные элементы можно смело применять с той целью, дабы установить наибольшее значение в отношении размера блока данных, параметров задержки и прочее. Если пользователь не понимает о чем идет речь, то не стоит вообще пытаться что-либо в этих вкладках корректировать.
Очень интересно создатели приложения организовали рабочее пространство. В верхней части размещены настройки. Центральная часть отведена для проведения работы. Данная область занимает наибольшее пространство. Внизу установлены кнопки управления всеми основными функциями.
Последняя вкладка. Окончательные настройки
Пользователям также может пригодиться предложенная опция по внесению правок в реестр. Это можно попробовать сделать непосредственно через интерфейс программы. В общем, переходим в настройки, а затем в открывшемся окне можно попробовать установить наиболее приемлемый вариант задержки.
Юзерам требуется проводить все манипуляции правильно. Выставляется максимальная задержка именно в миллисекундах. Также для дальнейшего удобства указывается список сайтов, предназначенных непосредственно для тестирования соединения. Далее уже выполняем активацию параметра редактора реестра.
Только после этого можно будет вносить любые правки в ветки системного реестра. Это очень важный аспект, поскольку именно он отвечает за работу сети. Так что пользователям нужно перейти в крайний раздел, который предусмотрен в данной утилите.
Данная вкладка является немного ограниченным вариантом интерфейса системного реестра. Ограниченность проявляется в том, что собраны исключительно те ветки, которые отвечают за работу сетевой подсистемы используемого гаджета.
Если пользователям смущают некоторые термины, то не стоит этого бояться. Принцип работы идентичен тому, как производятся все действия в отношении обычного реестра. Так что те юзеры, которым ранее приходилось работать с обычным вариантом, непременно, справятся и с прочими вариациями.
Пользователь может вносить коррективы в доступные опции по созданию базовых типов строк. Пользователи могут сколько угодно редактировать существующие ветки. Но при этом необходимо учитывать то, что при работе в реестре не выполняется создание и сохранение резервной копии в отношении всех текущих параметров.
Это значит, что при проведении неграмотной работы пользователям грозят сбои в отношении соединения с интернетом. Так что изменять параметры просто так не нужно. Делать это категорически не стоит.Завершающий этап в работе с утилитой
Теперь уже, если пользователь уверен в том, что он настроил все параметры грамотно, то можно приступать к сохранению полученного результата. Некоторые данные будут сохраняться в автоматическом режиме. Это касается изменений в реестре и сброса настроек. То есть, как только пользователь произведет какие-либо манипуляции, то они будут моментально зафиксированы.
А вот с параметрами более продвинутого уровня дело обстоит немного сложнее. Трудностей нет, но при этом нужно выполнить несколько действий. Предполагается нажатие на кнопку «Применить». После пользователь увидит список всех тех настроек, которые нужно сохранить для дальнейшего обеспечения связи с интернетом.
Напротив каждого параметра указывается два значения. В обязательном порядке покажется прежнее значение, а также только что установленный юзером вариант. Также будет продемонстрирован тот путь, который обеспечит выход к ключам реестра.
Реальная оценка программы
Как и у любого другого софта, у SG TCP Optimizer есть достоинства и недостатки. Важно оценить данные параметры, чтобы понимать то, как именно функционирует софт. Юзерам следует рассмотреть все положительные, а также негативные моменты.
К сильным сторонам нужно отнести возможность быстрого сброса настроек в тот момент, когда обнаружена «пропажа» интернета. Также можно будет применять те параметры, которые считаются наиболее оптимизированными.
Утилита максимально автоматизирована, что в значительной степени снижает риск введения неверных данных. Можно даже не выполнять корректировку некоторых параметров, поскольку представлен вариант работы с теми настройками, которые установлены по умолчанию.
Ручная оптимизация предполагает проведение некоторых манипуляций, направленных на улучшение качества связи с интернетом. Так что это крайне важный спектр действий, которые следовало бы реализовать каждому пользователю.
Среди недостатков отмечено наличие интерфейса, который полностью указывается на английском языке. Также настройки в некоторых моментах новичкам могут показаться достаточно сложными в реализации. В большей степени утилита ориентирована на пользователей профессионального уровня.
bezwindowsa.ru
Оптимизация Windows — мифы и реальность (часть 2)
Что же такое оптимизация?
Прежде чем углубляться в рассуждения, определимся с терминами.
Толковый словарь дает следующие определения слова «оптимизация»:
- Оптимизация — нахождение наибольшего или наименьшего значения какой-либо функции.
- Оптимизация — выбор наилучшего (оптимального) варианта из множества возможных.
Первое определение сразу отбрасываем, поскольку речь идет не о математических функциях. На втором стоит остановиться подробнее. Вариантов изменения настроек ОС действительно множество, сценариев использования компьютеров тоже множество. Как определить, какой из вариантов настроек оптимален? И для чего он оптимален?
Еще один термин — скорость работы системы. Он также весьма многогранен.
С одной стороны, операционная система имеет множество функций, скорость выполнения которых может иметь весьма существенное значение, а может практически не оказывать влияния на другие процессы. Причем какая-то функция может быть важной для одного класса задач, но практически не влиять на работу задач другого класса, и наоборот. Например, скорость работы диспетчера памяти может заметно влиять на работу современных игр, но не сказываться на работе обозревателей интернета или архиватора. Скорость дисковых операций имеет большое значение при обработке видеофайлов или рисунков большого размера, но практически не влияет на набор и редактирование текста, фоновую проверку правописания в Word и на скорость пересчета таблиц Excel.
С другой стороны, собственно операционная система должна работать как можно более прозрачно и незаметно, оставляя как можно больше системных ресурсов прикладным программам, ради которых люди и прибегают к помощи компьютеров.
Проведем небольшой эксперимент: запустим какую-нибудь программу, активно использующую процессор, например архиватор, и посмотрим в диспетчере задач, какую часть процессорного времени она будет использовать (для чистоты эксперимента желательно взять компьютер с одним одноядерным процессором без гиперпоточности либо отключить гиперпоточность и многоядерность).
Скорее всего программа будет использовать 97-99 процентов вычислительной мощности процессора. На первый взгляд все нормально: на свои нужды Windows использует считанные единицы процентов или даже меньше одного процента.
Рис. 1. Запущен архиваторНемного усложним эксперимент и включим в диспетчере задач показ времени ядра.
Картина становится не такой радужной: оказывается, ядро системы работает и отнимает заметную долю ресурсов процессора — в данном случае около 10-20 процентов.
Рис. 2. Включаем показ времени ядраКазалось бы, вот он, резерв повышения производительности! Ведь очевидно, что, оптимизировав работу системы, можно увеличить скорость работы программы чуть ли не на те же самые 10-20 процентов! В идеале, конечно.
На самом деле этот вывод оказывается ложным. Та доля времени, которая отдается ядру, почти целиком используется опять же для нужд того самого архиватора, в частности на операции чтения с диска и записи на него, ведь эти операции выполняет не сама программа, а ОС по указаниям программы. Так что хоть в это «красное» время и исполняется код ядра системы, этот код обслуживает запросы архиватора.
Скорее всего, в этом месте у читателя сходу возникнет полувозражение-полувопрос. Но ведь в это время все же работает код ядра — наверняка можно оптимизировать его работу так, чтобы оно требовало меньше процессорного времени? Что-нибудь подкрутить, что-нибудь подстроить, что-то ненужное отключить?..
Увы, сколько-нибудь заметных улучшений добиться не удастся. Прежде всего потому, что львиная доля этого «красного» времени ядра уходит на работу с железом. Проверить это проще простого: возьмите носитель с невысокой скоростью обмена, скажем, переключив контроллер диска в режим PIO. Автор не рекомендует проводить такие эксперименты на основном жестком диске из-за возможности заметного снижения скорости работы. Поэтому для эксперимента был выбран контроллер PCMCIA с модулем флеш-памяти, работающий именно в режиме программного ввода-вывода.
Рис. 3. Тот же компьютер, те же данные, но очень медленный дискКак видим, доля времени ядра значительно увеличилась, соответственно, скорость работы архиватора сильно упала. Произошло это потому, что почти все ресурсы процессора тратятся на работу с медленным устройством.
Так что первоначальный вывод оказался правильным: на свои нужды ОС тратит лишь небольшую долю ресурсов современного компьютера. Впрочем, внимательный человек давно и сам мог бы сделать такой вывод, если бы вдумался в результаты сравнения производительности последних версий Windows — они различаются буквально на единицы процентов.
Есть ли в системе резервы для ускорения работы?
Каждый раз при выходе новой Windows можно услышать многочисленные возмущения очередными «свистелками» и «финтифлюшками», добавленными разработчиками. Априори подразумевается, что все эти изменения ухудшают работу системы.
Отчасти, конечно, это верно. Вопрос заключается только в том, насколько велико это ухудшение и ухудшение ли это вообще.
С одной стороны, на отображение улучшенных элементов интерфейса действительно тратится больше ресурсов процессора и памяти. Хотя и не всегда: например, включенный (в большинстве случаев) по умолчанию аэро-интерфейс в Висте и Windows 7 снижает нагрузку на процессор за счет переноса значительной части работы по формированию изображения на видеоадаптер. С другой стороны — и ресурсов этих стало гораздо больше, так что доля, «отъедаемая» ОС, практически не изменилась. С третьей… но об этом чуть позже.
Итак, ОС тратит на свои нужды некоторую долю ресурсов, в первую очередь это процессор и память. Обсуждение использования памяти в эту статью точно не влезет, так что отложим его на будущее и остановимся на процессоре. Как можно увидеть из приведенных выше рисунков, собственно ОС на свои собственные нужды в этом примере тратит единицы процентов.
Вернемся в прошлое. Незадолго до выхода Windows XP Майкл Фортин, долгое время руководивший в «Майкрософт» группой, отвечавшей за производительность системы, составил для бета-тестеров весьма любопытный документ о том, как его группа работала и какие результаты получила (выжимки из него можно найти в http://forum.ixbt.com/topic.cgi?id=67:1#22). Внутренняя оценка изменений производительности звучала так: «разница между Win2K и Windows XP временами мала, около одного процента, временами велика, 5-10 процентов или около того».
Из этого следует достаточно очевидный вывод, что сколько-нибудь заметного увеличения скорости работы при помощи твикинга и «оптимизаций» получить не удастся.
Предположим, что система отнимает на свои нужды пять процентов времени процессора (обычно эта величина все же меньше), значит, работающему в это время процессу достается 95%. Допустим, мы улучшим систему вдвое (конечно, это фантастика, но давайте все-таки предположим такую возможность), так что она отнимет только 2,5 процента времени ЦП, а приложению достанется уже 97,5 процента. Скорость работы приложения увеличится на (97,5−95)⁄95=2,6 процента, то есть прирост получится отнюдь не фантастическим и практически незаметным на глаз.
Так что утверждать, что какие-то мелкие изменения способны увеличить скорость работы на десятки процентов, может только весьма наивный или сверх меры оптимистичный человек.
Но ведь, опять же скажете вы, в интернете можно найти кучу советов по улучшению тех или иных характеристик — что они дают? Как вы, уже, наверное, поняли, у меня не возникло ни малейшего желания заниматься экспериментальным опровержением всех этих идей: пусть их доказывает тот, кто делает такие утверждения. Но вопрос Майклу Фортину я все же задал, ведь у его группы ресурсов намного больше, чем у любого человека. Ответ звучал так: «Я опросил часть нашей команды [напомню, она называется Windows performance team, то есть группа производительности Windows] и сам немного удивился. Оказалось, большинство из них обсуждало подобные рекомендации и коллективный вывод был таков: много шума из ничего. За одним-единственным исключением: совет удалять программы, которые не используются, — полезен».
Теперь о третьей стороне «свистелок»
Если нельзя добиться сколько-нибудь значительного прироста скорости работы ОС, то что же остается? Один из путей — увеличить производительность компьютера. Это самый надежный, самый дорогой, но не всегда эффективный метод. Помните старую шутку: замените в своем компьютере Pentium 100 на Pentium 200, и он начнет простаивать вдвое быстрее? Во многих случаях повышение скорости компьютера давно уже не увеличивает скорость выполнения работы человеком, сидящим за этим компьютером. Невозможно набрать текст в редакторе или ввести числа в электронную таблицу быстрее только из-за того, что в компьютере прибавилось оперативной памяти или у нового процессора выше частота.
Конечно, какие-то задачи могут эффективно использовать всё более мощные компьютеры, но отнюдь не все. И вот тут на первый план выходит совсем другой критерий — эффективность и производительность труда человека, сидящего за компьютером. И на взгляд автора, оптимизировать следует именно эту сторону, то есть не скорость работы компьютера, а скорость работы за компьютером. В конце концов, ведь компьютер для человека, а не наоборот.
Возьмем, к примеру, ту характеристику, которую можно реально улучшить некоторыми приемами: время загрузки. Если вы программист, пишете драйвер низкого уровня и при его отладке вам приходится перезагружаться каждые пять-десять минут — конечно, время загрузки для вас критично. Но для обычного пользователя, который загружает компьютер один раз в день, утром, этот параметр уже далеко не так важен. А если используется гибернация и компьютер перезагружается раз в пару недель, то время загрузки уже почти не имеет значения.
Проведем простенький расчет: допустим, вам удалось сократить время загрузки с одной минуты до 30 секунд. Казалось бы, результат весьма неплох. Но перед этим вы полдня провели, читая разные форумы, сравнивая и анализируя полученную информацию, решая, что именно следует предпринять. Итого для экономии 30 секунд на каждой перезагрузке потрачено 4 часа (14400 секунд). Нетрудно подсчитать, что эти затраты оправдаются через 480 перезагрузок, и только после этого (при загрузке раз в день — примерно через полтора года) вы начнете получать выгоду. Причем не исключено, что за эти полтора года вы купите новый компьютер или переустановите систему, и затраты на «оптимизацию» окажутся просто впустую потраченным временем. В лучшем случае вы получите косвенную выгоду за счет дополнительно приобретенных знаний, но право же, эти знания можно было приобрести и другим, более легким путем.
Но возможность увеличить скорость загрузки никто и не отрицал. А вот оценить полезный эффект от изменения настроек не удалось, насколько известно автору, еще никому. Впрочем, можно привести наглядный пример. Сравнительно недавно в форуме (и еще минимум в двух других) с целью «обсуждения системных служб Windows 7, их оптимизации и методов контроля изменения производительности (скорость загрузки ОС и т. д.) при оптимизации» была создана тема. И хотя участнику сразу говорили (на разных форумах), что проку от этого нет, он, однако, не поверил и решил перепроверить всё сам. В итоге появилась на свет статья, в которой человек после личной проверки пришел к тем же самым результатам. Остается надеяться, что гонорар за статью хотя бы частично окупил потраченное время.
И в заключение приведем несколько критериев, по которым можно определить качество работы составителей многочисленных советов по оптимизации.
Если вы видите совет установить некое значение в параметре SecondLevelDataCache, вспомните, что этот параметр перестал использоваться начиная с Win2000 SP1. Утверждения, что параметр DisablePagingExecutive увеличивает скорость работы системы, неверны: он увеличивает скорость отклика системы за счет некоторого снижения производительности в целом. Рекомендация установить число ядер в настройках Msconfig для ускорения загрузки в лучшем случае бесполезна, ведь система и так по умолчанию использует все ядра. Зато уже были примеры, когда человек, сменив двухъядерный процессор на четырехъядерный и забыв восстановить исходное значение настройки, недоумевал, куда же делись два добавленных ядра.
Заключение
Заниматься изучением и внедрением в жизнь различных советов по оптимизации Windows — значит в лучшем случае тратить время впустую, а в худшем — заботливо раскладывать на будущее грабли для себя, любимого.
Вместе с тем, изменение системы для своего удобства, комфорта, привычных условий работы — не только допустимо, но и рекомендуется. Ибо даже если какие-то рекомендации и будут иметь результатом небольшое снижение производительности системы в целом, это с лихвой компенсируется тем, что вы сами сможете сделать больше за тот же период времени.
www.ixbt.com
железо и софт (ч.1)ФШ1 Школа фотографии
«Меня самого и, судя по частым вопросам, многих обрабатывающих фотографов, раздражает медлительность Lightroom’а. Удобный, особенно для пакетной обработки, конвертер, но именно при выполнении этой задачи оказывается, что скорость работы намного ниже, чем хотелось бы. Практика же показала, что ускорить эту программу можно, и для этого есть 3 подхода: ускорение «железа», ускорение софта и ускорение себя» – рассказывает Денис.
.
ЖЕЛЕЗО
«Lightroom достаточно требователен к мощности компьютера. И если вы обрабатываете на устаревшей или предназначенной для офисной работы машине, то она наверняка соображает медленнее вас. А должно быть наоборот: на любое действие «железо» должно отзываться мгновенно. Во всяком случае, быстрее, чем вы перейдете к следующему действию.
Вкладывать деньги в дорогой компьютер смысла нет, потому что не все его компоненты важны при работе в Lightroom. Разберемся, что все-таки имеет значение:
- Процессор. С каждым сдвигом полузнка, с каждым увеличением фотографии, Lr заставляет процессор просчитывать оригинальный RAW-файл и делать из него превью. На слабом процессоре это приведет к длительным «подвисаниям» программы, задержкам в отображении изменений в модуле Develop и к медленному переключению между фотографиями. Быстрый процессор позволит этого избежать, так же он значительно ускорит процессы импорта и экспорта фотографий. Поэтому при выборе конфигурации компьютера для Lr – особое внимание уделите мощному процессору.
- Оперативная память. Если ее в вашей системе слишком много, то Lr быстрее работать не станет. Зато если ее недостаточно, вы почувствуете разницу. Сегодня разумно иметь не меньше 16Гб оперативной памяти.
- SSD vs HDD накопители. Судя по тестам, разницы при экспорте, импорте и переключении между кадрами при использовании SSD или HDD накопителей почти нет, потому что все эти задачи загружают процессор, а не накопитель. Читайте статью – и покупайте исходя из бюджета. Но вы почувствуете, насколько быстрее запускается Lr и пролистываются фотографии в библиотеке при использовании SSD – увеличение скорости заключается в ускорении всей системы, а не процесса работы в Lr.
- Монитор большей диагонали. Технически работу не ускоряет, даже наоборот: большее разрешение монитора требует больших превью, что нагружает процессор. Но работать с большим монитором удобнее и быстрее, т.к. вам не нужно будет постоянно увеличивать мелкие детали, а боковые панели на мешают обзору и при этом постоянно находятся под рукой.
Идеальная ситуация с компьютером выглядит так: конфигурация собирается под конкретную камеру и не требует изменений, пока вы ее не поменяете. Купили 5dmk3 – к нему новый компьютер, и вопрос апгрейда закрыт на ближайшие 3-4 года. Когда появится новое поколение 5dmk4, с новым разрешением матрицы, – прийдется сделать апгрейд. В общем, закладывайте в бюджет новой камеры и новый системный блок».
СОФТ
«Во многих аспектах Lightroom, действительно, медлителен, поэтому для ускорения работы – легче избегать «слабых» мест программы:
- Первое – это медленный просмотр, а точнее загрузка при просмотре, фотографий. Отбор нескольких тысяч кадров, с задержкой даже в 1 секунду, способен отбить самое творческое настроение надолго. Как отбирать кадры в Lightroom быстрее? Не отбирать их в Lightroom! Установите Photo Mechanic и сортируйте фотографии там. RAW-картинки в PM листаются мгновенно. PM позволяет помечать картинки тэгами, цветными метками и оценками (от одной до пяти звезд), причем эти рейтинги при импорте в Lightroom сохраняются.
- Второе: нужно разобраться, как работает Lightroom во время обработки. Каждый сдвиг ползунка в модуле Develop приводит к следующему: RAW-файл заново конвертируется в превью, которое и отображается на экране. Т.е. каждая операция приводит к мини-экспорту картинки с новой настройкой. Процесс происходит немного быстрее, если уменьшить размер превью (Catalog Settings -> File Handling -> Standart Preview Size и Preview Quality). Понятно, что при уменьшении превью упадет детализация картинки на мониторе, но для работы с цветом и контрастом – это не самый важный параметр.
- Довольно простой трюк, который стал возможен с появлением Lr5 – это использование Smart Previews. Lightroom сообщает о них следующее: «Смарт-превью обычно намного меньше оригинальных фотографий, но они позволяют Вам продолжить работу даже когда оригиналы недоступны». На деле, Smart Previews – это уменьшенные, примерно в четыре раза, версии оригинальных «равов» (что-то вроде sRaw), операции с которыми проходят значительно быстрее. Lightroom просчитывает каждый сдвиг ползунка уже не для огромного «рава», а для меньшего smart preview. Все, что нужно сделать – это сгенерировать smart previews для всей обрабатываемой съемки и «потерять» папку с оригиналами (достаточно в название папки добавить один символ). Когда коррекция картинок будет закончена, нужно указать путь к папке с источниками или восстановить её первоначальное расположение и название. Так как смарт превью все же занимают место на диске, после окончания обработки – не забудьте их удалить. Смотрите видео об использовании Smart Previews:
Кроме этих хитростей, работу ускоряет правильная последовательность использования закладок. Вычислительная сложность подавления шума и, скажем, изменения экспозиции сильно отличается, поэтому сложные операции лучше делать в конце.
- Раздел Detail в модуле Develop. Лучше делать в самом конце, потому что он очень сложен для вычислений. Попробуйте на одну съемку добавить даже немного резкости и слегка прибрать шум, а на второй – ничего в detail не трогать. Вы увидите, что в первом случае, во время переключения между фотографиями вы увидите ощутимую и раздражающую задержку, во время которой ползунки становятся неактивными и работа «замирает». НИЧЕГО в закладке Detail не трогаем до самого экспорта.
- Также довольно сильно загружают работу инструменты локальной коррекции, кадрирование и коррекция искажений объектива. Таким образом, старайтесь сначала сделать работу с цветом и контрастом, а потом уже браться за кисть, Spot removal tool и кадрирование. Если все перечисленные инструменты невыносимо подвешивают работу, попробуйте все-таки сделать трюк с Smart Previews.
- Что делать, если со Spot removal tool вам нужно работать действительно много, и делаете вы это в Lr? Кто-то рекомендует начать работу с этого инструмента, но это не совсем хорошо, ведь так вы «подвесите» все остальные ползунки. Лучше закончить работу с цветом, экспортировать jpeg и импортировать их обратно в Lightroom. На jpeg-картинках Spot removal tool работает молниеносно по сравнению с RAW.
- Экспорт занимает много времени? Ускоряем процесс, экспортируя в несколько потоков, – это сильнее загружает все ядра процессора. Выделите четверть фотографий, отправьте экспортироваться, потом еще четверть и так далее. Можно поэкспериментировать с количеством, но даже два потока – значительно ускоряют экспорт.
- Выключите все ненужные программы, закройте вкладки в браузере – все это занимает оперативную память и «ест» ресурсы процессора».
В следующем материале читайте, как ускорить работу Lightroom с помощью ваших рук, и записывайтесь на курс «Основы постобработки».
fsh1.by
Центр компетенции по решениям RAD / Оптимизация соединений в сотовых сетях
Е.А. ЕРОШКИН,
ООО "Телеинком"
Журнал "Телеком/Сети и средства связи", спецвыпуск "Сети доступа" 1-2007
Уровень проникновения сотовой связи в России превысил 100%, и, как наглядное тому подтверждение, все чаще встречаются абоненты, имеющие два сотовых телефона разных операторов. Очевидно, что при таком насыщении рынка дальнейшее увеличение прибыльности сотовых операторов возможно за счет предоставления новых услуг и за счет сокращения внутренних издержек, в том числе сокращения издержек на развитие и эксплуатацию сети.
Затраты на подключение базовых станций - одна из наиболее значительных составляющих обуславливающих высокую стоимость построения и эксплуатации сети сотовой связи. Это справедливо для всех владельцев сотовых сетей, как имеющих собственные каналы связи, так и арендующих выделенные линии у местного оператора связи. Доля этих затрат высока как при построении выделенного сегмента транспортной сети для услуг 3G, так и при интеграции нескольких поколений мобильной связи на одной платформе.
Поскольку стоимость подключения базовых станций оказывает столь большое влияние, как на капиталовложения, так и на эксплуатационные расходы сотовой сети, операторам мобильной связи приходится заново анализировать свой подход к этому вопросу, прежде чем принимать решение о дальнейших капиталовложениях в развитие сети. Задача усложняется необходимостью поддерживать одновременно несколько различных сотовых стандартов и осуществлять подключения через различные типы транспортных сетей. Кроме этого целый ряд вопросов возникает в связи с миграцией от сотовых сетей 2G, основанных на коммутации каналов (TDM) к сетям 3G, использующим технологии коммутации пакетов (на первом этапе - АТМ, в перспективе -Gigabit Ethernet/IP/MPLS). Операторам мобильной связи приходится учитывать и возросшие требования к пропускной способности, и сложности, обусловленные конвергенцией голоса и данных.
Невозможно предложить единую схему или готовое решение для подключения базовых станций, оптимальное для всех операторов. В этом уравнении слишком много неизвестных: типы радиоинтерфейсов, сетевые технологии, набор доступных услуг, планы модернизации сетей, а также финансовые ограничения и ожидаемый экономический эффект. Поэтому мобильным операторам имеет смысл выбирать наиболее гибкий вариант из различных решений подключения базовых станций. В частности, необходимо учитывать быструю эволюцию сотовых стандартов и развитие новых транспортных технологий на основе коммутации пакетов. Эти два аспекта заставляют операторов особенно внимательно подходить к выбору решений, которые должны прослужить многие годы.
Компания RAD предлагает операторам сотовой связи широкий спектр продуктов, поддерживающих сегодняшние и завтрашние протоколы, технологии и интерфейсы для подключения базовых станций. На их основе можно построить наиболее эффективное и экономичное решение для любого сценария модернизации сети. Условно эти продукты можно разделить на три категории по типу приложений: оптимизация голосовых каналов между узлами коммутации, оптимизация пропускной способности для А-bis и A-ter интерфейсов и оптимизация подключения базовых станций.
Оптимизация голосовых каналов МЕЖДУ узлами коммутации
Соединения между узлами коммутации (Mobile Switching Centers, MSC), а, именно, каналы A и E - еще одна составляющая, вносящая весомый вклад в стоимость эксплуатации сотовой сети. Уменьшение числа этих соединений означает немедленную экономию средств. Поскольку между узлами коммутации голосовой трафик передается в потоках Е1 с использованием кодека G711 (64 кб/с на каждый голосовой канал), то при его компрессии можно существенно сократить количество межузловых каналов. Наиболее простым решением этой задачи является линейка устройств Vmux-2100 и Vmux-110 компании RAD. Данные устройства реализуют сжатие голоса, передаваемого по сети, с помощью стандартных алгоритмов.
Шлюз-концентратор голоса RAD Vmux-2100 использует мощные алгоритмы компрессии голоса, позволяющие сократить расходы на выделенные линии и повысить эффективность использования IP- и TDM-сетей. Vmux-2100 сжимает до 16 полных каналов Е1 (496 телефонных соединения) в один канал Е1 (Vmux-110 сжимает один поток Е1), последовательное или IP-подключение, что позволяет корпоративным пользователям, операторам мобильной связи и поставщикам услуг экономить средства за счет аренды меньшего числа выделенных линий для передачи своего голосового трафика. Типовые приложения Vmux-2100 включают передачу голоса по спутниковым каналам, соединение базовых станций сотовых сетей, международный транспорт трафика голоса, местный радиодоступ и организацию телефонной связи в сельских районах. Устройства Vmux могут быть использованы, в частности, в узкополосных приложениях -везде, где существуют ограничения пропускной способности канала для голосового трафика, при передаче по любой транспортной среде (например, TDM или спутниковому каналу IP).
Пример использования шлюзов семейства Vmux представлен на рисунке 1.
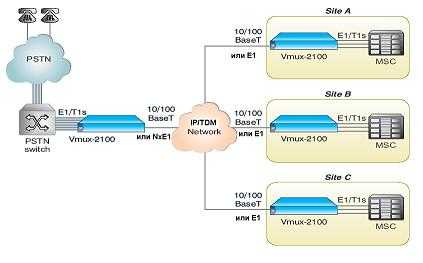
Рис. 1. Оптимизация подключения узлов коммутации
В устройствах Vmux-2100 применяются алгоритмы сжатия голоса С.723.1, С.729А и С.711, обладающие оптимальным соотношением цена/эффективность. Vmux-2100 обеспечивает высокое качество передачи голоса при рекордно высокой степени сжатия при передаче по каналам TDM или сетям IP. Определение голосовой активности и подавление пауз позволяют Vmux-2100 динамически распределять пропускную способность для телефонных разговоров и передачи факсов, что дает эффективное использование пропускной способности при меньшем числе линий связи. Сигнализация при этом передается "прозрачно".
Поддержка технологии TDMoIP позволяет оптимизировать пропускную способность и предлагает реалистичную стратегию миграции к решениям на основе IP. Наличие отдельных портов TDM и Ethernet для соединения с магистральной сетью позволяет использовать для передачи одновременно сети TDM и IP. Благодаря меньшему количеству служебной информации в потоке по сравнению с системами на основе VoIP устройство Vmux увеличивает на 60% пропускную способность канала (по сравнению с VoIP) для дополнительной передачи голоса или данных, что чрезвычайно важно при работе по дорогостоящим или низкоскоростным каналам.
В том случае, когда необходимо скомпрессировать большое количество потоков целесообразно использовать высокопроизводительную платформу сжатия голоса операторского класса Gmux-2000. Шлюз-концентратор голоса Gmux-2000 - это платформа операторского класса для крупных решений со сжатием голоса. В нем использована та же технология TDMoIP, те же алгоритмы сжатия голоса и развитые функции обработки голоса, что и в других шлюзах-концентраторах голоса RAD, а именно, Vmux-2100 и Vmux-110. Gmux-2000 полностью совместим с этими устройствами. Платформа Gmux-2000 для передачи голоса построена на основе шасси высотой 6U, оснащенного специализированными модулями сжатия голоса VC. Каждый модуль сжатия голоса поддерживает до 16 каналов E1, которые сжимаются в два канала E1, или же, весь голосовой трафик собирается в канал STM-1. На одном шасси Gmux -2000 может быть установлено до семи модулей VC, если шасси оснащено одним или двумя модулями STM-1, то число модулей VС уменьшается до шести или пяти, соответственно. Таким образом, емкость Gmux-2000 составляет до 112 потоков Е1. Пример решения с использованием Gmux-2000 представлен на рисунке 2.
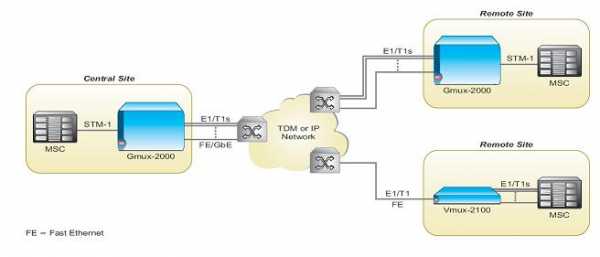
Рис. 2. Передача голоса между MSC с использованием Gmux-2000
ОПТИМИЗАЦИЯ ПРОПУСКНОЙ СПОСОБНОСТИ ДЛЯ A BIS И A-TER ИНТЕРФЕЙСОВ
Система базовых станций (Base Station System, BSS) в любой существующей сети GSM состоит из большого числа базовых станций (BTS) и контроллеров базовых станций (BSC) соединенных по протоколам A-bis и A-ter. Технологии сжатия голоса позволяют сотовым операторам резко сократить потребность в пропускной способности на участке сети между контроллерами базовых станций (BSC) и центрами коммутации мобильной сети (MSC), а также между MSC и на участке от MSC и обычной телефонной сетью. На участке между базовыми станциями (BTS) и BSC голосовой трафик уже передается в сжатом виде, поэтому дальнейшее сжатие не рекомендуется. Однако применение технологий оптимизации к протокольному интерфейсу A-bis (инкапсулированному трафику, передаваемому между BTS и BSC) позволяет получить значительный выигрыш в пропускной способности, приводящий к экономии средств.
В таких соединениях голос передается уже с компрессией Half Rate (НR) или Full Rate (FR) по 8 (8 Кбит/с) или по 4 (16 Кбит/с) каналам в одном временном интервале потока Е1. Ввиду этой особенности оптимизация таких соединений возможна только за счет исключения пауз и неиспользуемых кадров, что позволяет использовать каналы доступа более эффективно и уменьшить требования к пропускной способности выделенных линий, спутниковых и УКВ - каналов. Устройства RAD Vmux-400/420 представляют собой уникальное решение для снижения расходов на передачу голоса, позволяющее сэкономить 50% и более пропускной способности.
Оптимизирующие шлюзы Vmux-400/420 - автономные устройства, дополняющие семейство RAD Vmux для компрессии голоса и позволяющее операторам сотовой связи сократить расходы на подключение своих базовых станций. Vmux-400/420 оптимизируют работу интерфейса A-bis (BTS-BSC), в то время как эффективная работа интерфейсов A (BSC-MSC) и Е (MSC-MSC) обеспечивается далее магистральным шлюзом сжатия голоса Vmux-2100. Благодаря комплексному применению устройств Vmux, предназначенных для сжатия голоса и оптимизации пропускной способности, оператор получает возможность снизить расходы на эксплуатацию сети при одновременном расширении сетевой инфраструктуры и внедрении новых услуг без дополнительных затрат. На рисунке 3. изображен пример оптимизации каналов с помощью шлюзов Vmux-400/420.
Шлюзы Vmux-400/420 для протоколов GSM A-bis и A-ter используют алгоритмы подавления пауз для оптимизации использования пропускной способности и повышения эффективности работы сети. Vmux-420 может обслуживать четыре, восемь либо двенадцать голосовых каналов El A-bis/A-ter, подключенных по магистральным каналам Е1 или сетям Ethernet 10/100 Мбит/с. Это позволяет использовать его в сочетании с меньшими устройствами Vmux-400 (обслуживает два канала) в качестве удаленного высокопроизводительного шлюза, с полным резервированием, для оптимизации трафика A-bis/A-ter. Или же, это устройство может работать как центральный оптимизирующий шлюз GSM A-bis/A-ter.
Vmux-400/420 обеспечивают оптимизацию пропускной способности в 3 раза, а также снижают требуемое число портов Е1 в 2 раза. Это особенно существенно в удаленных и сельских районах, где отсутствует развитая наземная инфраструктура связи и сотовые операторы часто вынуждены подключать базовые станции по спутниковым каналам связи. С другой стороны, в районах со сложившейся городской застройкой, где все существующие наземные линии оказываются в данный момент заняты, для быстрого внедрения услуг могут использоваться радиоканалы УКВ-диапазона. В этих ситуациях применение Vmux-400/420 особенно выгодно, позволяя передать максимальный объем трафика в ограниченной полосе пропускания имеющихся каналов. Более того, ввиду высокой стоимости спутниковых и УКВ-каналов
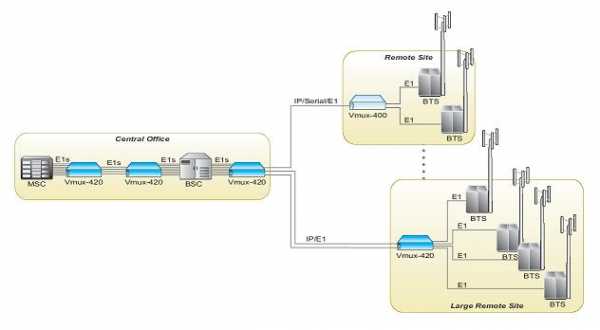
Рис. 3. Vmux-420 и Vmux-400 оптимизируют пропускную способность соединения BTS и BSC (A-bis) в топологии "точка-многоточка" и пропускную способность соединения BSC и MSC (A-ter) Vmux-400/420 окупаются в очень короткие сроки.
Vmux-400/420 поддерживает передачу оптимизированных данных, трафика GPRS и EDGE по многочисленным временным интервалам, а также стандартную оптимизацию трафика GSM A-ter и кодек AMR со скоростями от 4.75 до 12.2 Кбит/c. Vmux-400/420 разработаны в соответствии с действующими стандартами и совместим с коммутационным оборудованием основных производителей, включая Alcatel, Ericsson, Siemens, Huawei, Nokia и Motorola, что облегчает построение сетей на оборудовании различных производителей.
Оптимизация подключения БАЗОВЫХ станций
Переход к третьему поколению сотовых сетей влечет за собой появление целой гаммы широкополосных мобильных услуг. В этой сложной ситуации операторам мобильной связи необходимо выбрать наиболее эффективную технологию для подключения базовых станций, обеспечивающую наиболее экономичные решения. Сегодня этот вопрос становится особенно актуальным, поскольку услуги 3G начинают набирать обороты и необходимо расширять существующие сети, чтобы справиться с растущими объемами трафика. Соглашение 3GPP (3rd Generation Partnership Project) принимает в качестве предпочтительной технологии для подключения базовых станций технологию ATM. Ее основные достоинства состоят в гарантированном качестве услуг (QoS) и дифференцированном подходе к трафику, чувствительному к задержкам, (например, голос, видео в реальном времени) и нечувствительному к ним (доступ в Интернет, потоковое видео, и т.п.)
Агрегация трафика позволяет сократить как капиталовложения, так и текущие затраты на эксплуатацию сети. Экономия достигается благодаря уменьшению числа соединений в сети и возможности использовать более высокоскоростные и менее дорогие порты в ядре сети. Агрегаторы трафика АСЕ-3400 и АСЕ-3402 специально разработаны с учетом перспективы быстрого роста трафика, связанного с широким развертыванием услуг 3G. Устройства объединяют трафик каналов E1/T1/J1, что обеспечивает наиболее эффективное распределение ресурсов опорной сети и предоставление различных услуг 3G. Развитые возможности АСЕ-3400 и АСЕ-3402 в части формирования и планирования трафика позволяют операторам планировать суммарную нагрузку сети выше номинальной пропускной способности (overbooking) чтобы оптимизировать использование сети, сохранить имеющиеся сетевые ресурсы и уменьшить число выделенных каналов связи, необходимых для обеспечения работы сети. На рис. 4. проиллюстрировано приложение агрегации трафика.
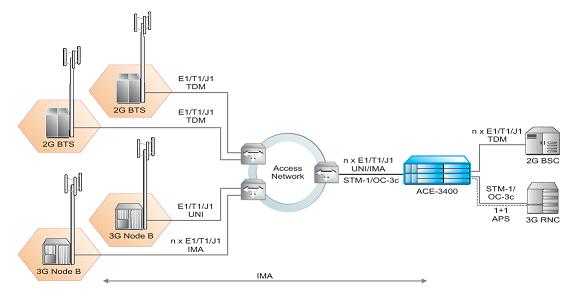
Рис. 4. Агрегация трафика на уровне контролера с использованием АСЕ-3400
Учитывая высокую первоначальную стоимость услуг UMTS далеко не все пользователи немедленно готовы перейти на технологии 3G. В реальности, по некоторым оценкам, пройдет не менее трех лет, прежде чем большинство абонентов обзаведется телефонами с поддержкой 3G. Из-за такого постепенного перехода получается, что на начальных этапах внедрения 3G для базовых станций UMTS Node B потребуется полоса пропускания, меньшая, чем E1/T1/J1. Объединение нескольких каналов ATM со скоростями Fractional E1/T1/J1 на одном сетевом интерфейсе может значительно снизить расходы на подключение базовых станций. Впоследствии, по мере роста популярности услуг 3G, требования к полосе пропускания будут увеличиваться и потребуют перехода к более высокоскоростным каналам связи. Устройства АСЕ-3100 и АСЕ-3200 позволяют собрать трафик интерфейсов Fractional Е1Я1/Л UNI нескольких каналов АТМ с инверсным мультиплексированием (IMA) или эмулируемых каналов TDM E1/T1/J1 (CES) в одно высокоскоростное соединение STM-1/ОС-Зс или IMA.
По мере роста популярности услуг 3G следует ожидать значительного роста трафика базовых станций. Поскольку сегодня расходы на передачу этого трафика составляют наибольшую часть эксплуатационных расходов сотовых операторов, то завтра традиционные способы подключения на основе выделенных линий окажутся коммерчески несостоятельными. В перспективе все сотовые сети будут целиком и полностью базироваться на технологиях коммутации пакетов (PSN) однако на сегодняшний день ситуация такова, что и базовые станции (Node В) и контроллеры (RNC) представляют собой АТМ-устройства.
Чтобы облегчить соединение Node B и RNC по недорогой сетевой инфраструктуре PSN, в продуктах семейства АСЕ-ЗхОО реализована технология сквозной псевдопроводной эмуляции ATM (PWE3). Она обеспечивает передачу трафика ATM (E1/T1/J1 UNI или STM-1 UNI поверх сетей PSN (Ethernet/MPLS/IP).
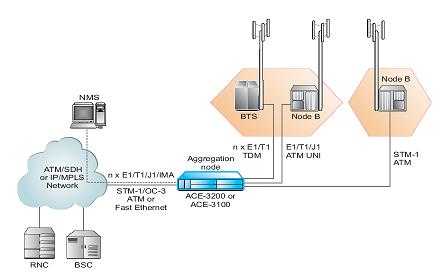
Рис. 5. Эмуляция услуг TDM и АТМ
На рисунке 5 изображен фрагмент сотовой сети с эмуляцией TDM и ATM для подключения различных типов BTS.
Таким образом, использование Vmux-2100/110, Vmux-400/420, ACE-3400/3402, АСЕ-3200/3100 позволяет оптимизировать транспортные каналы на различных участках сотовых сетей, что в результате дает сокращение издержек на эксплуатацию и развитие сетевой инфраструктуры. Причем сокращение затрат может быть очень существенным. Рассмотрим вариант соединения двух MSC посредством 8-ми потоков Е1 (Рис.6.) При средней стоимости аренды канала Е1 в месяц - 4000$, аренда 8 каналов Е1 в месяц составит 32000$.
Рис. 6. Затраты на аренду 8-ми потоков Е1
При использовании шлюза Vmux-2100 количество арендованных каналов можно сократить до одного потока Е1 сохранив при этом пропускную способность 8-ми каналов Е1. Таким образом, ежемесячные расходы снизятся до 4000$, то есть экономия будет составлять 28000$ в месяц (Рис.7).
Рис. 7. Подключение MSC через один поток Е1
При таком положении дел оборудование полностью окупится за два месяца. При меньшей стоимости аренды каналов срок окупаемости увеличится, но, тем не менее, будет рекордно коротким.
По материалам компании RAD DATA Communications
rad-russia.pro