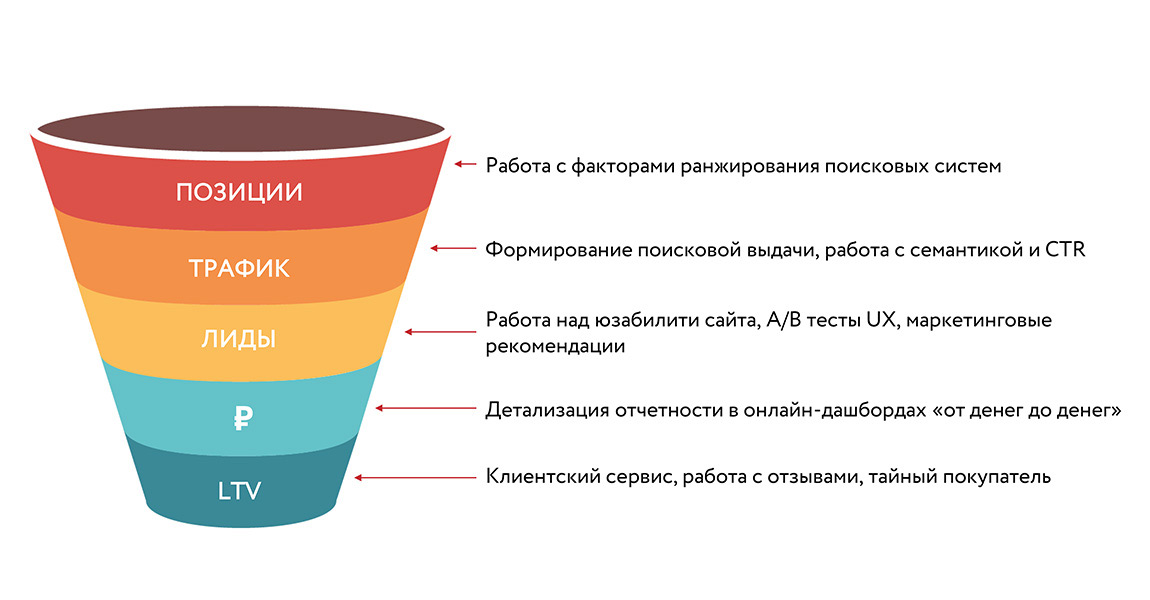
Содержание
Автороцентричное ранжирование. Доклад Яндекса о поиске релевантной аудитории для авторов Дзена / Хабр
Важнее всего для сервиса Яндекс.Дзен — развивать и поддерживать платформу, которая соединяет аудитории с авторами. Чтобы быть привлекательной платформой для хороших авторов, Дзен должен уметь находить релевантную аудиторию для каналов, пишущих на любые темы, в том числе на самые узкие. Руководитель группы счастья авторов Борис Шарчилев рассказал про автороцентричное ранжирование, которое подбирает для авторов наиболее релевантных пользователей. Из доклада можно узнать о том, чем такой подход отличается от подбора релевантных айтемов — более популярного в рекомендательных системах.
Балансируя пользователецентричное и автороцентричное ранжирование, мы можем добиваться правильного соотношения счастья пользователей и счастья авторов.
— Коллеги, всем привет. Меня зовут Боря. Я занимаюсь качеством ранжирования в Дзене. Я уверен, что это один из самых интересных сервисов Яндекса, у нас очень крутое машинное обучение, и в следующие 17 минут я вас в этом постараюсь убедить.
Я уверен, что это один из самых интересных сервисов Яндекса, у нас очень крутое машинное обучение, и в следующие 17 минут я вас в этом постараюсь убедить.
Что такое Дзен? Если совсем просто, Дзен — это сервис персональных рекомендаций. Мы стараемся рекомендовать пользователям релевантный им контент, основываясь на том, что мы знаем об интересах этих пользователей. Наша высокоуровневая цель — чтобы пользователи хотели в Дзене проводить время. И что очень важно — чтобы они об этом времени не жалели.
Примерно так выглядит наша основная форма потребления контента. Это бесконечная лента рекомендаций. И тут видно, что мы, в принципе, стараемся рекомендовать очень материалы на очень разные темы. Тут есть разные тематики: что-то про бизнес, что-то про юмор, даже что-то про фэнтези. То есть в ленте можно найти как познавательные и образовательные статьи, так и более развлекательные. И, разумеется, персонализация. Лента Дзена у всех выглядит по-разному — в зависимости от того, что пользователю интересно. Плюс, конечно, немного рекламы.
Плюс, конечно, немного рекламы.
Очень важный момент. В самом начале, когда мы только появились, мы были, по сути, агрегатором контента из интернета. То есть мы обходили существующие сайты, брали с них контент, и показывали его пользователю в зависимости от интересов. Сейчас ситуация иная. Сейчас Дзен — это целая блогерская платформа, на которой каждый человек может завести свой канал, будь то какой-нибудь известный блогер или начинающий автор, которому есть о чем рассказать. Новые авторы видят вот такой приятный приветственный экран, в котором мы рассказываем о сервисе — что Дзен сам будет подбирать аудиторию, а от него требуется только писать хорошие материалы.
Сейчас на платформу приходится более половины общего трафика в Дзене. И этот показатель будет только расти. Мы понимаем, что ранжировать уже имеющийся контент контент могут все. Разумеется, мы сделаем это лучше всех. Но уникальный контент есть далеко не у всех, и мы верим, что именно в этом будет наше конкурентное преимущество.
Важно понимать, что Дзен уже очень большой. По данным Яндекс.Радара, на конец прошлого года у нас число дневных читателей примерно 10–12 млн в день, число читателей в месяц примерно 35 млн в день, и даже по некоторым данным, из того же Яндекс.Радара, мы в прошлом году впервые обошли по аудитории Яндекс.Новости. Это значит, что мы на полном серьезе делаем интернет, у нас задачи очень серьезные, их много, и мы очень ждем вашей помощи.
Поговорим про детали того, как это работает, и обсудим то, чем же у нас можно заниматься стажеру, чем можно помочь нашему сервису.
Общая схема рекомендаций у нас устроена примерно так. Все начинается с нашей большой базы документов, из которой мы выбираем материалы для рекомендаций. Она состоит из десятков миллионов документов. Причем эта база постоянно пополняется — ежедневно в нее поступает около миллиона новых документов. В идеале мы бы хотели применить весь наш аппарат машинного обучения ко всем этим десяткам миллионов документов персонально для каждого пользователя, и выбрать ему самое-самое релевантное. Но, к сожалению, на практике так сделать не получается, потому что Дзен — это сервис, который работает в реальном времени. У нас есть очень жесткие гарантии на то, насколько быстро мы готовы отвечать, поэтому из практических соображений мы вынуждены на первом этапе сужать базу из десятков миллионов документов до тысяч потенциальных рекомендаций, которые мы можем уже полностью отранжировать нашей моделью и выбрать из них самые релевантные. Этот этап сужения базы с десятков миллионов примерно до тысяч у нас называется отбором кандидатов или легким ранжированием.
Но, к сожалению, на практике так сделать не получается, потому что Дзен — это сервис, который работает в реальном времени. У нас есть очень жесткие гарантии на то, насколько быстро мы готовы отвечать, поэтому из практических соображений мы вынуждены на первом этапе сужать базу из десятков миллионов документов до тысяч потенциальных рекомендаций, которые мы можем уже полностью отранжировать нашей моделью и выбрать из них самые релевантные. Этот этап сужения базы с десятков миллионов примерно до тысяч у нас называется отбором кандидатов или легким ранжированием.
Когда у нас есть этот набор, мы применяем к нему нашу сложную большую модель машинного обучения, которая на верхнем уровне представляет из себя градиентный бустинг. Тут все без сюрпризов, но факторы у нас очень разнообразные — от каких-то простых, которые характеризуют, например, то, насколько пользователю релевантен данный домен, источник, насколько он часто на него заходит, кликает, оставляет фидбек, лайки и дизлайки. Так и более сложные факторы, которые основаны, например, на нейросетевых признаках. Мы обрабатываем текст статьи, мы обрабатываем картинки, другие источники данных, и используем такие композитные признаки тоже. Все это схема довольно сложная, в деталях рассказать не успею.
Мы обрабатываем текст статьи, мы обрабатываем картинки, другие источники данных, и используем такие композитные признаки тоже. Все это схема довольно сложная, в деталях рассказать не успею.
После того, как мы отранжировали наши 2 тыс. кандидатов, мы отбираем из них топ. Размер топа зависит от того, сколько нам надо порекомендовать материалов. Это всегда определяется по-разному. И таким образом мы формируем итоговую выдачу.
Так выглядит схема на высоком уровне. Теперь давайте поговорим о том, какие же компоненты всего этого процесса нам интересно улучшать.
Оказывается, что нам интересно заниматься примерно всем. Задач очень много. Мы хотим увеличивать скорость доставки данных для ранжирования: чем более свежие у нас данные, тем более релевантные мы делаем рекомендации. Хочется ускорять время работы сервиса: чем быстрее работаем, тем лучше пользовательский экспириенс. Мы хотим повышать надежность сервиса.
Нам важно улучшать ранжирование. То есть нам нужно применять и новые модели машинного обучения, и улучшать наши текущие модели в других странах. Мы рекомендуемся не только в России, но и во многих других странах мира.
Мы рекомендуемся не только в России, но и во многих других странах мира.
Также мы хотим учитывать региональность и рекомендовать людям контент, который относится к их региону.
И очень важно — нам надо развивать нашу авторскую платформу. Это наше будущее, нам надо в нее вкладываться. Задач тут тоже очень много. В частности, нам надо уметь находить и бустить качественный контент. Нам важно показывать хорошие материалы, а не треш. Нам нужно уметь ранжировать новые форматы контента. У нас есть не только статьи, но и короткие видео, и посты, которые пользователи смотрят прямо в ленте. Все эти форматы нужно уметь ранжировать.
И очень важный момент, о котором я хочу поговорить немного подробнее в более технических деталях — нам важно уметь для каждого автора находить релевантную ему аудиторию, даже если речь идет о довольно нишевых авторах и темах. Давайте поговорим подробнее, в чем же здесь проблема и как мы ее решаем.
Давайте рассмотрим это на примере.
Мы выбираем, предположим, из двух карточек, которые мы хотим показать пользователю.
Так устроен мир и так устроен человек, что есть нечто более среднепопулярное, где вероятность клика в среднем процентов 20, а есть что-то более нишевое, например статьи про науку или про космос.
Если мы просто ранжируем карточки по вероятности клика, то, разумеется более кликабельный и более простой контент будет собирать очень большое количество показов, а даже очень хорошая статья про науку — нет. Конечно, нам такого не хочется. Мы хотим находить заинтересованную аудиторию даже для нишевых каналов.
Почему это хочется делать? На самом деле, здесь есть две причины. Первая — продуктовая. То есть мы хотим, чтобы Дзен был некоторым срезом интернета. Чтобы всё, что пользователь может найти и чем он интересуется в большом интернете, было представлено в Дзене. И чтобы он получал то, что ему интересно.
У научных каналов есть своя аудитория. Но есть такой нюанс. Если любителям науки показать науку и популярный контент, они на него кликнут с большей вероятностью, чем на науку. Но если им показать только науку, они на науку тоже кликнут, и даже ничуть об этом не пожалеют. Вопрос в том, как находить таких людей и как показывать контент, ориентируясь не на пользователя, а на автора.
Но если им показать только науку, они на науку тоже кликнут, и даже ничуть об этом не пожалеют. Вопрос в том, как находить таких людей и как показывать контент, ориентируясь не на пользователя, а на автора.
Как же это делать? Обычная формула ранжирования, которая предсказывает вероятность кликов, нам здесь не поможет, потому что в среднем более нишевые статьи будут проигрывать. Но можно пойти другим путем — выделить некоторую квоту, и в ней более или менее равномерно дать показы авторам, дать им своего рода минимальную гарантию. Так делать можно, и это сделает авторов немного счастливее, но, к сожалению, это сделает менее счастливыми наших пользователей. Пользователи будут меньше кликать, больше расстраиваться и уходить. Мы этого, конечно, не хотим.
Как здесь быть?
Мы долго думали и придумали новую концепцию. Мы назвали ее автороцентричным ранжированием или показами для автора.
Какова наша цель в обычном ранжировании, которое мы называем пользователецентричным? Найти материал, который наиболее релевантен пользователю. Мы отвечаем на вопрос, что показать пользователю.
Мы отвечаем на вопрос, что показать пользователю.
В автороцентричном ранжировании мы как бы переворачиваем постановку задачи и говорим, что мы хотим показать данного автора, и вопрос в том, кому его показать, кому он наиболее релевантен. Отсюда и разница в метриках. В первом случае нас больше интересуют пользовательские метрики, то есть интегральные клики, интегральное время в Дзене и так далее. Во втором случае нас интересуют так называемые авторские метрики. Например, мы измеряем то, насколько хорошо живется в Дзене, например, bottom 10% авторов. Если им живется достаточно хорошо, то и все остальные тоже счастливы.
Как же мы это делаем? Предположим, что у нас есть обычная формула ранжирования. Для простоты предположим, что она предсказывает вероятность клика пользователя на данный айтем, на данную карточку. Что мы сделаем? Давайте теперь для каждой статьи зафиксируем ее и применим нашу модель для этой статьи, в идеале — ко всем пользователям, на практике — к какому-то семплу пользователей. И построим распределение наших scores, то есть оценок вероятности кликнуть на статью, для каждой статьи по пользователям. Теперь для каждой статьи у нас есть такое распределение, как на графике (слайд выше — прим. ред.). После этого отранжируем статьи для пользователя и выберем топ не просто по вероятности клика, а по перцентили, в которую данный пользователь попадает для данной статьи. То есть мы оценим вероятность клика, посмотрим, куда пользователь попадает в этом распределении, и отранжируем по этой величине.
И построим распределение наших scores, то есть оценок вероятности кликнуть на статью, для каждой статьи по пользователям. Теперь для каждой статьи у нас есть такое распределение, как на графике (слайд выше — прим. ред.). После этого отранжируем статьи для пользователя и выберем топ не просто по вероятности клика, а по перцентили, в которую данный пользователь попадает для данной статьи. То есть мы оценим вероятность клика, посмотрим, куда пользователь попадает в этом распределении, и отранжируем по этой величине.
Вот у нас те же две карточки, одна из них более кликабельна, 20%, другая — менее, 1%. Теперь, если взять конкретного пользователя, возможна такая ситуация, что у него на более популярную карточку вероятность клика больше, чем на менее популярную, скажем, 10% против 3%. Но так как в среднем вероятность клика на популярную карточку 20%, а у пользователя 10%, то он в среднем менее релевантен данной публикации, чем средний пользователь Дзена. А в другой ситуации наоборот: у него вероятность клика 3%, но в среднем у статьи 1%. Поэтому он является более релевантной для статьи аудиторией в среднем, чем остальные пользователи Дзена. Поэтому ключевой инсайт здесь в том, что даже если вероятность клика на статью меньше, с помощью такого фреймворка мы имеем шанс показать менее популярную статью, если пользователь входит в наиболее доверенное ядро для данной публикации.
Поэтому он является более релевантной для статьи аудиторией в среднем, чем остальные пользователи Дзена. Поэтому ключевой инсайт здесь в том, что даже если вероятность клика на статью меньше, с помощью такого фреймворка мы имеем шанс показать менее популярную статью, если пользователь входит в наиболее доверенное ядро для данной публикации.
Если пользователи приходят к нам более или менее равномерно, то данный score, по которому мы ранжируем, то есть перцентиль, в который попадает каждый пользователь, будет распределена равномерно по пользователям. Это значит, что если все статьи ранжировать таким образом, то все они соберут более-менее одинаковое количество показов. Не будет выбросов в десятки миллионов показов против 10 показов у каких-нибудь менее релевантных карточек. Таким образом, балансируя пользователецентричное и автороцентричное ранжирование, мы можем добиваться того соотношения счастья пользователей и счастья авторов, которое мы считаем правильным.
Пару слов о том, как мы это реализовываем в продакшене. Нам нужно посмотреть на наши логи и из них посчитать данное распределение для каждой статьи. Важное ограничение: нам нужно уметь это делать, во-первых, быстро, во-вторых, в потоковом режиме. То есть в идеале для того, чтобы обновить оценку распределения по новым данным, нам нужно иметь в памяти не все предыдущие данные, а только текущую оценку. Такая система масштабируется, такая схема работает. В идеале нам нужно уметь это делать на маленьких данных. Если у какой-нибудь статьи всего 300 показов, то нам нужно уметь за такое количество наблюдений адекватно оценить распределение.
Нам нужно посмотреть на наши логи и из них посчитать данное распределение для каждой статьи. Важное ограничение: нам нужно уметь это делать, во-первых, быстро, во-вторых, в потоковом режиме. То есть в идеале для того, чтобы обновить оценку распределения по новым данным, нам нужно иметь в памяти не все предыдущие данные, а только текущую оценку. Такая система масштабируется, такая схема работает. В идеале нам нужно уметь это делать на маленьких данных. Если у какой-нибудь статьи всего 300 показов, то нам нужно уметь за такое количество наблюдений адекватно оценить распределение.
Мы провели эксперименты и обнаружили, что такие распределения scores на удивление хорошо приближаются к лог-нормальным распределениям. То есть это эмпирическое наблюдение. А раз так, то мы вместо того, чтобы оценивать не параметрически всю гистограмму распределения, можем оценить только два параметра данного распределения. Причем мы можем это делать в потоке, используя только текущую оценку параметров и новые наблюдения. Такая схема получается очень быстрой и работает очень хорошо. Сейчас она у нас находится в продакшене.
Такая схема получается очень быстрой и работает очень хорошо. Сейчас она у нас находится в продакшене.
Результаты тоже получаются хорошими. Мы сильно растим счастье обделенных вниманием хороших авторов в Дзене и при этом не просаживаем общие пользовательские метрики. То есть бизнес-задача полностью достигается.
Я сейчас показал один из примеров задач, которыми у нас можно заниматься. Разумеется, этих задач много, и с каждой из них нам нужна ваша помощь. Очень надеемся, что вы захотите у нас работать. Напоследок скажу пару слов о том, чего же мы ждем от стажеров и чего мы от них не ждем. От стажера мы ждем самого главного — умения писать код. У нас в сервисе нет дата-саентистов в чистом виде. У нас все — ML-инженеры, они должны уметь делать полный цикл задач. Они должны уметь и имплементировать свое решение в продакшен, и применять ML. То есть мы ожидаем, что вы умеете писать код на базовом уровне, понимаете подходы, знаете алгоритмы, структуры данных, основы машинного обучения.
Чего мы не ждем от стажеров? В первую очередь, мы не ждем глубокого знания каких-то языков или фреймворков. То есть если вы не знаете, как работают корутины в Python — ничего страшного, мы вас всему научим. И мы не ждем от вас большого опыта. Мы ждем от вас знаний, желания работать. Если нет опыта — ничего страшного. Всему научим, и все будет хорошо. Спасибо!
Нововведения в алгоритм ранжирования Яндекса.
2014 год — нововведения в алгоритм ранжирования Яндекса
По информации от компании «Яндекс», с начала 2014 года система не будет учитывать ссылки, по которым ранее определялось ранжирование сайтов по коммерческим запросам. Для информационных запросов ссылки будут работать по прежней схеме. Первоначально новый алгоритм запустят только для Москвы (как ожидается, это должно произойти в первой половине 2014 года), при положительных результатах его действие распространится и на остальные регионы.
Цель
Задача «Яндекса» — как можно быстрее и точнее ответить на вопрос пользователя, поэтому поисковик стремится предложить в поисковой выдаче только сайты с качественным и актуальным контентом без технических ошибок с удобной навигацией, то есть ресурсы, рассчитанные на людей. Новый алгоритм призван бороться с псевдооптимизацией сайтов, «благодаря» которой делается упор лишь на закупку коммерческих ссылок, а качественное развитие ресурса игнорируется.
Новый алгоритм призван бороться с псевдооптимизацией сайтов, «благодаря» которой делается упор лишь на закупку коммерческих ссылок, а качественное развитие ресурса игнорируется.
Действие
В настоящее время в формуле ранжирования «Яндекса» участвует около 800 факторов, из которых порядка 50 — «ссылочные». Их отмена приведёт к тому, что влияние оставшихся 750 усилится (это плюс). А так же к тому, что продвижение сайтов будет стоить дороже, так как работы над «поведенческими» и «внутренними» факторами ранжирования станут более трудоёмкими (это минус).
Сегодня добросовестные участники seo–рынка именно так и работают — в их системе изначально заложена проработка всех факторов ранжирования без упора на «ссылочные». Поэтому после введения нового алгоритма коллапса ожидать не нужно, произойдёт усиление позиций сильных за счёт того, что рынок очистится от слабых агентств.
Результат
Как именно изменится поисковая выдача, сегодня точно не сможет ответить никто, возможно, и сам «Яндекс».
Мы рискнём дать следующий прогноз:
- После введения нового алгоритма сайты с большой ссылочной массой могут либо сразу потерять в позициях, либо какое–то время сохранять своё положение в выдаче. Но в любом случае им придётся бороться за место в ТОП–10 с ресурсами, не имеющими такой ссылочной массы, то есть владельцам нужно будет в кратчайшие сроки адаптировать свой сайт к новым требованиям;
- Сайты наших клиентов могут незначительно просесть сразу после смены алгоритма, однако это будет временная утрата позиций, так как мы готовы к такому развитию событий. Новый алгоритм открывает новые возможности для укрепления и роста позиций в выдаче в первую очередь потому, что снизится конкуренция со стороны ресурсов, которые рассчитывали лишь на закупку ссылок.
Новость об изменении алгоритма продвижения не явилась неожиданной для участников рынка, поэтому те, кто был с самого начала заинтересован в долговременной работе в этой сфере, имели возможность подготовиться к изменениям, усилив в своих стратегиях продвижения вес «нессылочных» факторов.
Кто проиграет?
Среди очевидных проигравших окажутся ссылочные биржи — им придётся либо уйти с рынка, или реорганизовать свою деятельность. Но больше всех потеряют те владельцы сайтов, которые делали упор исключительно на покупку ссылок. Они неизбежно уступят позиции своим дальновидным конкурентам, которые не экономили на развитии собственных ресурсов.
Что делать?
Наше агентство всегда работало именно над развитием контента, функционала и юзабилити клиентских сайтов, поэтому действия «Яндекс» не стали для нас неожиданностью. В этом направлении нами уже созданы и протестированы уникальные программы адаптации ресурсов к новым требованиям, поэтому мы уверенно смотрим в будущее и можем со всей ответственностью предложить нашим клиентам услуги эффективного продвижения сайтов в полном соответствии с новыми правилами «Яндекс».
Поделиться
PRANK: предсказание движения на основе ранжирования | от команды самоуправляемых автомобилей Яндекса | Группа самостоятельного вождения Яндекса
Предсказание траекторий других движущихся объектов в пробках имеет решающее значение для безопасного и комфортного вождения. Безопасность и комфорт пассажира в беспилотном автомобиле зависят от того, насколько хорошо он сможет решить задачу прогнозирования движения. Различия в возможных траекториях движения любого данного объекта почти бесконечны. И именно это делает эту проблему такой сложной. Эта крайняя степень вариативности вызвана, с одной стороны, неопределенностью намерения объекта: повернет ли он вправо или влево, или продолжит движение по тому же пути? А с другой стороны, еще более осложняется неопределенностью того, как это намерение может реализоваться: если повернуть направо, какую полосу оно выберет?
Безопасность и комфорт пассажира в беспилотном автомобиле зависят от того, насколько хорошо он сможет решить задачу прогнозирования движения. Различия в возможных траекториях движения любого данного объекта почти бесконечны. И именно это делает эту проблему такой сложной. Эта крайняя степень вариативности вызвана, с одной стороны, неопределенностью намерения объекта: повернет ли он вправо или влево, или продолжит движение по тому же пути? А с другой стороны, еще более осложняется неопределенностью того, как это намерение может реализоваться: если повернуть направо, какую полосу оно выберет?
К проблеме прогнозирования движения при самостоятельном вождении обычно подходят с двух сторон: предсказание намерения объекта или предсказание его будущей траектории. Подходы, основанные на намерениях, предоставляют полезную информацию системе планирования движения беспилотного транспортного средства, но они не указывают, какие именно траектории может выбрать объект. Поэтому подходы такого типа часто полностью игнорируются в пользу методов прогнозирования траектории движения или используются в сочетании с этими методами.
Методы прогнозирования траекторий движения могут предсказывать либо наиболее вероятные будущие траектории объекта, либо распределение вероятности по возможным траекториям объекта, либо набор распределений по местоположению объекта в каждый момент времени. Несмотря на то, что эти методы потенциально могут отразить сложную природу будущего прогнозирования движения, стоимость сложных процедур обучения и логического вывода, задействованных в этом процессе, очень высока. И наоборот, относительно простая генеративная модель хорошо фиксирует часто встречающиеся модели движения, такие как движение вперед или плавные повороты, но не так хорошо работает в сложных сценариях.
Команда Яндекса, занимающаяся беспилотным вождением, стремится разработать эффективный в вычислительном отношении метод, который сможет преодолеть эти ограничения и прогнозировать сложные маневры с небольшими затратами.
Основная идея: метод подсчета очков
Один из разработанных нами подходов к предсказанию будущей траектории называется PRANK, что означает «Предсказание движения на основе ранжирования». Мы опубликовали статью с кратким изложением нашего метода на NeurIPS 2020. Ключевая идея этого метода заключается в том, что вместо того, чтобы синтезировать прогнозы нейронной сети с нуля, мы можем выбирать их из очень большого набора возможных траекторий движения, которые наблюдались система восприятия, работающая на нашем флоте. Этот подход имеет несколько преимуществ по сравнению с традиционным генеративным моделированием:
Мы опубликовали статью с кратким изложением нашего метода на NeurIPS 2020. Ключевая идея этого метода заключается в том, что вместо того, чтобы синтезировать прогнозы нейронной сети с нуля, мы можем выбирать их из очень большого набора возможных траекторий движения, которые наблюдались система восприятия, работающая на нашем флоте. Этот подход имеет несколько преимуществ по сравнению с традиционным генеративным моделированием:
- Траектории, которые мы предсказываем, на самом деле следовали некоторым реальным автомобилям, поэтому наши предсказания имеют тенденцию быть физически правдоподобными;
- Наш набор траекторий содержит множество сложных маневров, которые может выбрать модель;
- Общепризнано, что оценка решения часто в вычислительном отношении проще, чем его создание, поэтому наша нейронная сеть может решать более легкую задачу и, следовательно, может лучше обучаться.
Несколько качественных примеров выполнения PRANK можно увидеть на следующих изображениях. На этих изображениях мы показываем траектории из набора траекторий с прозрачностью, представляющей их апостериорные вероятности. Красный и синий цвета используются для отображения различных режимов в соответствии с нашей моделью, а зеленая линия показывает траекторию наземной истины. Можно видеть, что PRANK может успешно фиксировать мультимодальные апостериорные распределения, где моды создаются неопределенностью в желаемом направлении движения или запланированной скорости в этом направлении.
На этих изображениях мы показываем траектории из набора траекторий с прозрачностью, представляющей их апостериорные вероятности. Красный и синий цвета используются для отображения различных режимов в соответствии с нашей моделью, а зеленая линия показывает траекторию наземной истины. Можно видеть, что PRANK может успешно фиксировать мультимодальные апостериорные распределения, где моды создаются неопределенностью в желаемом направлении движения или запланированной скорости в этом направлении.
Левый: неопределенность между возможным разворотом и левым поворотом, с большим количеством различий в том, как будет реализован маневр. Справа: оставаться в медленной полосе или перестраиваться в полосу с большим пространством. Слева: уступать дорогу пешеходу или пытаться идти первым. Посередине: уступить машине или идти первым. Справа: остановка на желтом и попытка проехать перед красным.
Что касается вычислительной эффективности, мы структурируем нашу нейронную сеть таким образом (заимствованным из компьютерного зрения и НЛП), что выбор правильной траектории из миллионов кандидатов может быть выполнен за миллисекунды с использованием методов приближенного поиска ближайших соседей.
PRANK может производить прогнозы для 50 объектов с частотой 10 Гц, при этом большая часть времени тратится на компоненты метода, не зависящие от PRANK, такие как кодирование сцен и растеризация признаков.
Чтобы сравнить эффективность PRANK с другими методами, мы оценили его на общедоступном вызове Argoverse, созданном нашими коллегами из Argo AI. Что касается метрик ошибок смещения, на момент публикации исследовательской статьи наш метод входил в тройку лучших из ста записей в этом наборе данных. И это несмотря на использование довольно простого растрового представления сцены, в отличие от других записей с наивысшими оценками, которые используют более сложное векторное описание сцены.
Как и любая технология, PRANK имеет место для совершенствования, и мы продолжаем делать его прогнозы все более точными и надежными, а также изучаем более сложные методы представления сцены и процедуры вывода. Тем временем наш парк из более чем сотни автомобилей всегда в пути, прокладывая новые траектории для PRANK 24/7 в очень плотном трафике Москвы.
Прогнозирование оказалось важной частью беспилотного конвейера для любого типа транспортного средства — будь то автомобиль или робот-доставщик — который делит дорогу с людьми. PRANK уже реализован в наших автомобилях, помогая им безопасно ориентироваться в сложном городском потоке и обеспечивать плавные и приятные поездки без постороннего человека за рулем для наших клиентов роботакси в Иннополисе. Мы верим, что наш будущий метод прогнозирования движения обеспечит безопасную и удобную транспортную систему в каждом из наших текущих мест тестирования и за его пределами.
Written and published by Yulia Shveyko
Ukraine war: Russians kept in the dark by internet search
Published
Related Topics
- Russia-Ukraine war
Адам Робинсон, Ольга Робинсон и Кайлин Девлин
BBC Monitoring
Во многих местах поиск в Интернете является воротами в более широкий мир информации, но в России он является частью системы, которая помогает заманивать людей в ловушку альтернативная реальность.
Вскоре после того, как 20 человек были убиты в результате ракетного обстрела Россией украинского города Кременчуг в июне, Лев Гершензон, бывший менеджер российской технологической компании Яндекс, ввел название города в поисковую систему, чтобы узнать больше.
Результаты, которые он получил, потрясли его.
«Источники, занимавшие верхние строчки страницы, были странными и малоизвестными», — сказал он Би-би-си. «Был один блог неизвестного автора, который утверждал, что информация о жертвах была фальшивой».
Кремль жестко контролирует средства массовой информации страны, особенно телевидение, которое прославляет вторжение России в Украину как освободительную миссию и отвергает сообщения о зверствах как фальшивку.
Интернет в России долгое время был основным пространством для альтернативных источников информации, но после начала войны в феврале Кремль начал наступление на независимые интернет-СМИ.
По оценкам Роскомсвободы, борца за цифровые права, за первые шесть месяцев конфликта в России было заблокировано около 7000 веб-сайтов, включая сайты крупных независимых СМИ и правозащитных групп.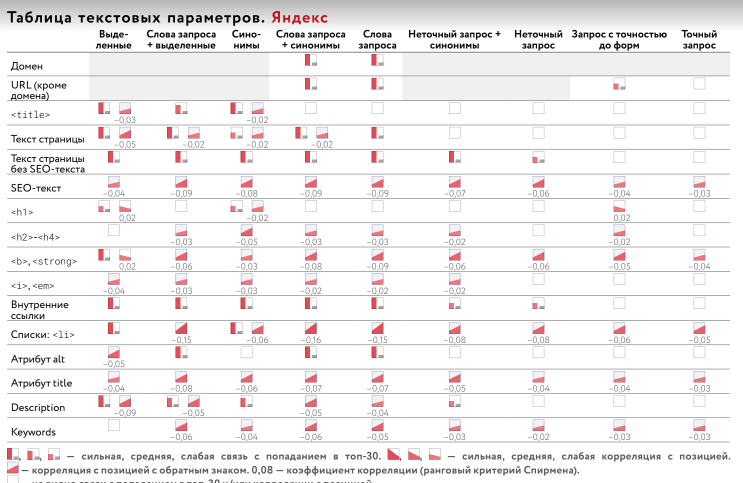
Наш эксперимент
Би-би-си Мониторинг хотела выяснить, что люди в России видят, когда ищут в Интернете сейчас.
Мы использовали виртуальную частную сеть (VPN), поэтому могло показаться, что мы ищем в Интернете из России.
В период с июня по октябрь мы провели десятки поисков в ведущих поисковых системах России — Яндексе и Google — по ключевым словам, связанным с войной на Украине.
Яндекс — одна из больших звезд отечественной технологической сцены в России. Он управляет крупнейшей поисковой системой страны и позиционирует себя как независимая от властей.
Согласно собственной статистике компании, она обрабатывает около 60% поисковых запросов в России, при этом на долю Google приходится около 35%.
С самого начала войны «Яндекс» подвергался критике за прокремлевский уклон сайтов и статей, размещенных на его новостном агрегаторе «Яндекс Новости». В сентябре он продал «Яндекс.Новости» связанному с Кремлем владельцу социальной сети «ВКонтакте».
Но Яндекс сохраняет контроль над своей общей поисковой системой, и здесь результаты эксперимента BBC Monitoring раскрывают альтернативную реальность, в которой доминирует российская пропаганда войны.
Никаких упоминаний о зверствах
Одной из тем, которые искали, была Буча, украинский город, где российские войска убили сотни мирных жителей, прежде чем они отступили в начале апреля.
Смерти потрясли мир, но в России многие, похоже, верят версии государственных СМИ, что их инсценировала Украина.
Подпись к изображению,
Результаты Яндекса об убийствах мирных жителей в Буче, как будто базирующихся в России (слева), содержат сообщения в блогах, отрицающие вину России, в то время как результаты Google в Великобритании говорят о доказательствах зверств
Когда мы искали Буча на Яндексе — используя VPN, как будто базирующийся в России, и печатая по-русски — верхняя страница результатов выглядела так, будто убийств никогда не было.
Три из девяти лучших результатов были анонимными сообщениями в блогах, отрицающими причастность российских войск. Остальные шесть не содержали независимых сообщений о событиях.
Обнаружение массовых захоронений в октябре в городе Лиман, после того, как он был отбит у российских войск, также нашло отражение в Яндексе с прокремлевской точки зрения. Несколько прокремлевских новостей, обвиняющих в гибели украинских «нацистов», попали в первую десятку результатов.
Источник изображения, LiveJournal
Подпись к изображению,
Типичный прокремлевский пост в блоге с высоким рейтингом в результатах поиска Яндекса, отрицающий, что российские военные убивали мирных жителей в Буче результаты сильно смещены в сторону нарратива Кремля.
Четыре из девяти результатов на первой странице связаны с прокремлевскими новостными агентствами, и ни один с независимыми СМИ.
Отрывки независимых репортажей лишь изредка появлялись в результатах поиска Яндекса со ссылками на статьи Википедии или YouTube.
На просьбу BBC прокомментировать, Яндекс сказал, что его поиск в России «отображает контент, [который] доступен в Интернете, за исключением сайтов, которые заблокированы регулятором [медиа]». Он отрицал какое-либо «человеческое вмешательство» в результаты рейтинга.
Image caption,
Результаты Яндекса в России (слева) и Google в Великобритании (справа) охватывают массовые захоронения в Лимане, но в отчетах Яндекса эксгумация тел названа «осквернением»
Так что же произойдет, если вы переходите с Яндекса на вторую по величине поисковую систему России, Google?
Поиск в поисковой системе американской компании с нашим VPN, настроенным на российскую локацию, и набор текста на русском языке по-прежнему выдавали прокремлевские СМИ, но смешанные с некоторыми независимыми и западными источниками.
Еще больше независимых источников появилось, когда мы искали в Google с настроенным VPN, как будто мы были в Великобритании, хотя все еще печатали на русском языке.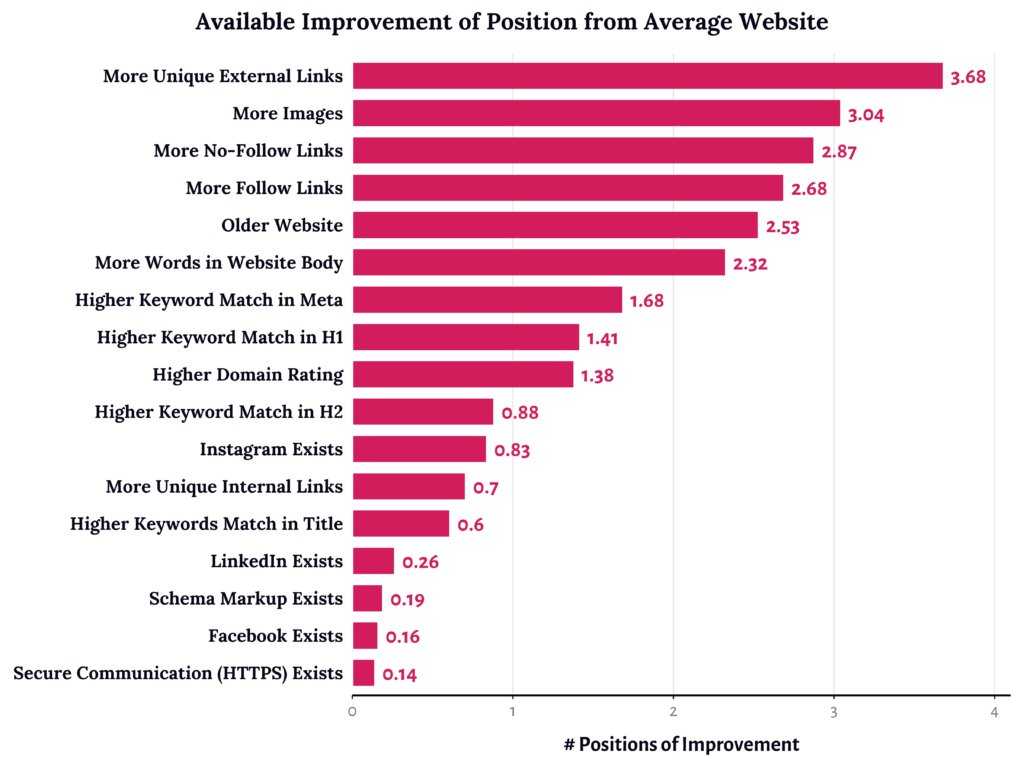 Было много результатов, охватывающих либо гибель мирных жителей, либо войну.
Было много результатов, охватывающих либо гибель мирных жителей, либо войну.
Google сообщил BBC, что его поиск «отражает контент, доступный в открытой сети», а его алгоритм обучен «заметно отображать высококачественную информацию из надежных источников».
Очистка результатов
Так почему же результаты поиска Яндекса так сильно отличаются от результатов поиска Google?
Несколько специалистов, с которыми поговорила Би-би-си, заявили, что маловероятно, чтобы внутри Яндекса происходили крупномасштабные манипуляции, поскольку это было бы слишком сложно сделать.
Одна из возможностей состоит в том, что результаты компании просто искажены репрессиями Кремля в отношении независимых сообщений о вторжении.
Потому что тысячи сайтов были заблокированы российским регулятором СМИ , огромные объемы информации не отображаются в результатах поиска Яндекса.
Подпись к изображению,
В результатах поиска Яндекса по слову «Украина», как будто базирующемся в России (слева), преобладали прокремлевские СМИ и не содержались независимые источники СМИ, в то время как в результатах поиска Google, как если бы они базировались в Великобритании (справа), отображались только западные репортажи
«Они [власти] могут полностью очистить результаты», — сказал Би-би-си Алексей Сокирко, бывший разработчик Яндекса.
В то же время Кремль вкладывает значительные средства в создание веб-контента, отражающего его собственное мировоззрение, добавил он.
Эксперты по поиску Гвидо Амполлини и Михаил Орлов из маркетинговой компании GA Agency говорят, что это также может исказить результаты, которые пользователи увидят в Яндексе, поскольку алгоритм поисковой системы может вознаграждать прокремлевские материалы более высоким рейтингом и понижать рейтинг альтернативных взглядов. .
Искусственный веб-трафик
Может ли использование VPN помочь россиянам узнать больше о войне на их родном языке?
Если они используют Яндекс, чтобы найти эту информацию, то не обязательно.
При поиске на его движке с VPN, настроенным на Великобританию и использующим русский язык, появился странный независимый источник, но прокремлевские источники по-прежнему преобладали.
Г-н Амполлини и г-н Орлов говорят, что прокремлевский контент выглядит тщательно подобранным, чтобы алгоритм ранжировал его выше.
И с одним малоизвестным новостным сайтом, который занимал видное место в результатах, они также обнаружили признаки возможного манипулирования веб-трафиком.
Было обнаружено большое количество потенциально искусственных ссылок на сайт с внешних веб-сайтов — распространенный метод повышения рейтинга сайта в поиске.
Источник изображения, МАРИНА МОИСЕЕНКО
Подпись к изображению,
В результате авиаударов российской авиации по украинским городам погибло много мирных жителей
Наконец, Яндекс может учитывать тот факт, что российские пользователи сами выбирают прокремлевский контент.
Специалист по поиску Ник Бойл из агентства цифрового маркетинга The Audit Lab рассказал Би-би-си, что, в отличие от Google, Яндекс учитывает поведение пользователей.
Это означает, например, что на рейтинг веб-сайта в поиске может влиять количество его посещений. Google говорит, что это не относится к его поисковой системе.
Команда агентства GA предположила, что многие русские нажимают на контент, который положительно изображает их армию, что побуждает алгоритм Яндекса вознаграждать его более высоким рейтингом.