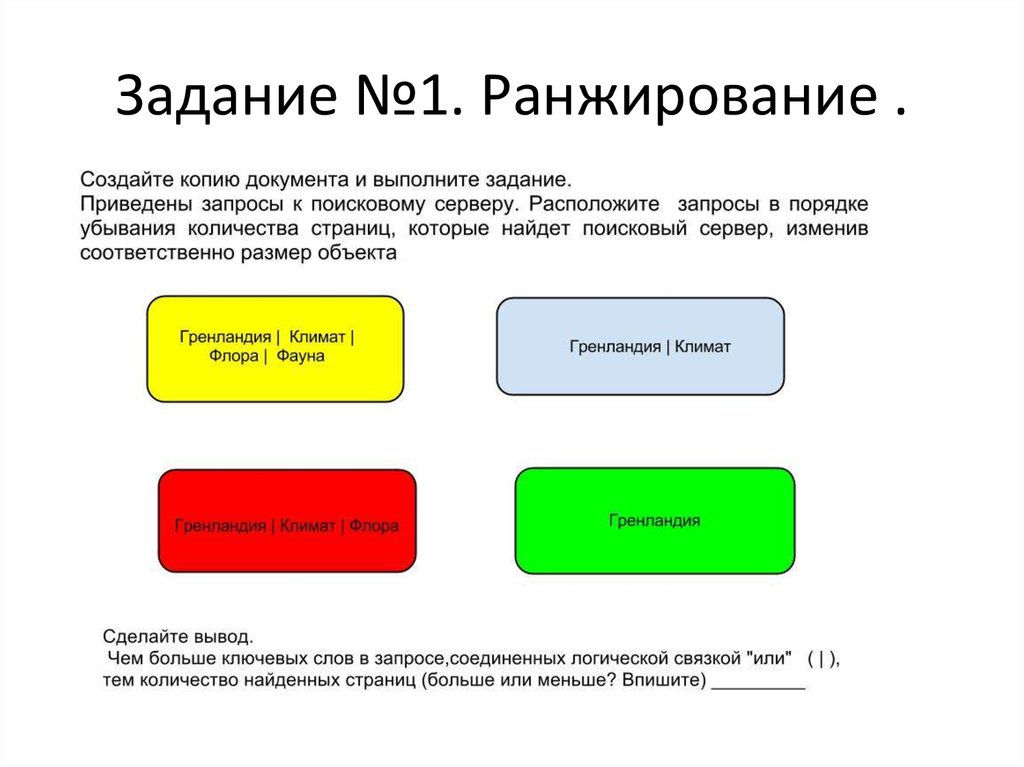
Содержание
Ранжирование текстов по похожести на опорные тексты при помощи модели TF-IDF в реализации GENSM / Хабр
Бывает так, что критерии поиска текстов слишком сложны, чтобы обойтись регулярными выражениями. В таких случаях на помощь приходит ML. Если из списка текстов выбрать самый подходящий для нас, можно выяснить похожесть всех остальных текстов на этот. Похожесть(similarity) это численная мера, чем выше – тем более текст похож, поэтому при сортировке по убыванию по этому параметру мы увидим наиболее подходящие нам тексты из выборки.
В качестве примера возьмем любой набор текстов. Здесь http://study.mokoron.com/ можно скачать небольшое csv с твитами. В реальной работе это могут быть разного рода комментарии, ответы от техподдержки, запросы пользователей. Так или иначе, импортировав все нужные библиотеки, загрузим в pandas наш список текстов и взглянем на первые из них:
import pandas as pd import re from gensim import corpora,models,similarities from gensim.utils import tokenize df = pd.а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
Результат выполнения выглядит так:
Этого иногда бывает достаточно, но даже если нет, такую предварительную работу всегда стоит проводить для облегчения фильтрации. Если мы точно знаем, что в тексте встретятся слова «бумажный носитель», но нам точно не подойдет «платежный документ», мы добавим «бума.*носит» и «платежн.*документ» и в дальнейшем отфильтруем их так, как нам надо.
Для непосредственного поиска похожих текстов стоит использовать реализацию doc2bow из библиотеки genism, поскольку помимо нужных нам моделей она предоставляет множество других полезных функций, например токенизацию со встроенной лемматизацией, что может быть полезно в случае, если предварительно обученные модели для лемматизации использовать нельзя.
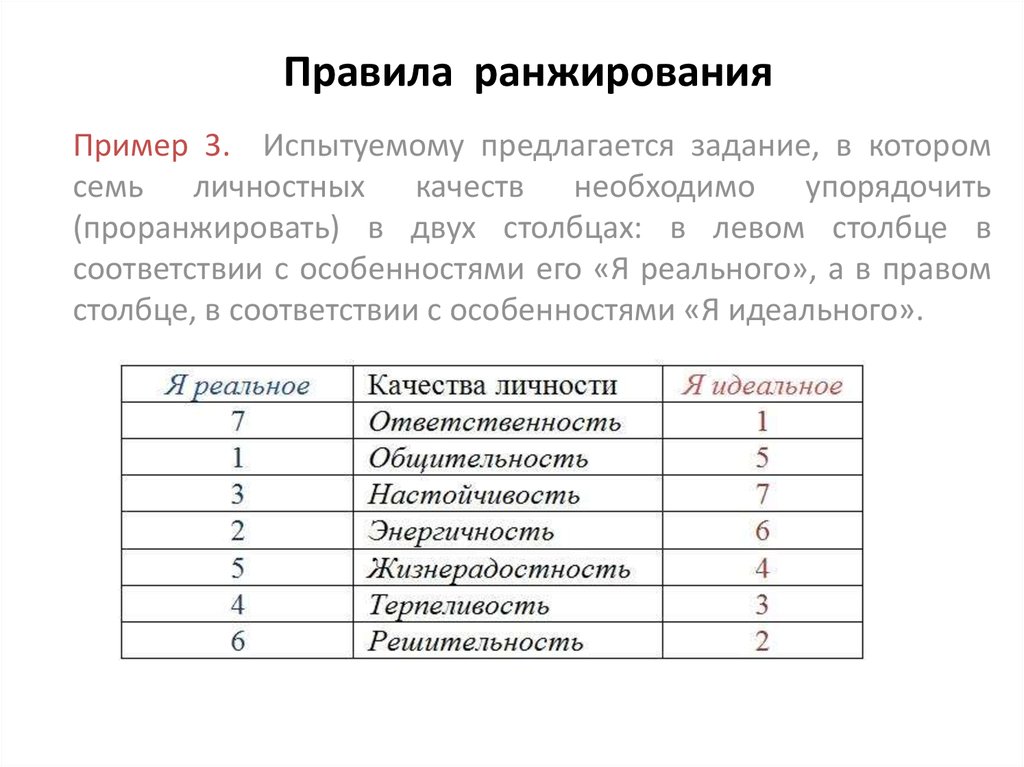
Первым делом выделим тексты, по которым будет проводиться сравнение, далее называя их «опорные тексты». Скорее всего, после первого этапа поисков этот список расширится, поскольку модель предложит дополнительные варианты подходящих текстов. В качестве примера просто возьмем первые 5 твитов, главное помнить, что эти тексты так же должны быть в общем наборе.
texts_to_compare = list(df.head(5)["text"]) ['@first_timee хоть я и школота, но поверь, у нас то же самое :D общество профилирующий предмет типа)', 'Да, все-таки он немного похож на него. Но мой мальчик все равно лучше:D', 'RT @KatiaCheh: Ну ты идиотка) я испугалась за тебя!!!', 'RT @digger2912: "Кто то в углу сидит и погибает от голода, а мы ещё 2 порции взяли, хотя уже и так жрать не хотим" :DD http://t.co/GqG6iuE2…', '@irina_dyshkant Вот что значит страшилка :D\nНо блин,посмотрев все части,у тебя создастся ощущение,что авторы курили что-то :D']Теперь токенизируем все тексты в нашем датасете. На этом этапе осуществляется обработка текстов, который можно провести множеством способов при помощи множества библиотек.
 а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
а-яА-Я] означает «любой символ, который не является русской буквой». Вообще для создания регулярных выражений удобно использовать сайт regex. Метод str.count библиотеки pandas применяет регулярное выражение массово на весь датасет, выдавая количество найденных регулярок. Флаг re.IGNORECASE это часть конфигурации библиотеки регулярных выражений regex, заставляющая ее искать вне зависимости от того, заглавные в тексте буквы или строчные.
 Самые распространённые способы включают в себя:
Самые распространённые способы включают в себя:Удаление стоп слов, таких как «а», «и», «но» и прочее. Обычно для этого используются заранее собранные словари. Можно выполнить библиотекой NLTK
Понижение регистра слов до строчных. Большинство библиотек и чистый python сам по себе могут это делать. Некоторые, могут еще и удалить диакритические знаки, например gensim.
Лемматизация, то есть приведение слова к словарной форме. Сложность этого действия зависит от языка, для русского языка этот процесс не прост и требует специальных библиотек. pymystem3 подойдет, но важно всегда контролировать качество.
Стемминг, или обрезка слов до корня. Это более экстремальный вариант лемматизации, который «чайник» может превратить в «чай». Выполняется если потеря смысла не страшна. Подходящая библиотека pymorphy и написанные под нее скрипты для русского языка в духе Стеммера Портера.
def tokenize_in_df(strin):
try:
return list(tokenize(strin,lowercase=True, deacc=True,))
except:
return ""
df["tokens"] = df["text"]. apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
 apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
apply(tokenize_in_df)
df.head(5)["tokens"].values
array([list(['first_timee', 'хоть', 'я', 'и', 'школота', 'но', 'поверь', 'у', 'нас', 'то', 'же', 'самое', 'd', 'общество', 'профилирующии', 'предмет', 'типа']),
list(['да', 'все', 'таки', 'он', 'немного', 'похож', 'на', 'него', 'но', 'мои', 'мальчик', 'все', 'равно', 'лучше', 'd']),
list(['rt', 'katiacheh', 'ну', 'ты', 'идиотка', 'я', 'испугалась', 'за', 'тебя']),
list(['rt', 'digger', 'кто', 'то', 'в', 'углу', 'сидит', 'и', 'погибает', 'от', 'голода', 'а', 'мы', 'еще', 'порции', 'взяли', 'хотя', 'уже', 'и', 'так', 'жрать', 'не', 'хотим', 'dd', 'http', 't', 'co', 'gqg', 'iue']),
list(['irina_dyshkant', 'вот', 'что', 'значит', 'страшилка', 'd', 'но', 'блин', 'посмотрев', 'все', 'части', 'у', 'тебя', 'создастся', 'ощущение', 'что', 'авторы', 'курили', 'что', 'то', 'd'])],
dtype=object)
В нашем примере мы применили только приведение к строчным буквам и удаление ударений в параметрах функции gensim. tokenize: lowercase=True, deacc=True.
tokenize: lowercase=True, deacc=True.
Создадим словарь слов, которые есть во всем нашем наборе текстов:
dictionary = corpora.Dictionary(df["tokens"])
feature_cnt = len(dictionary.token2id)
dictionary.token2id
{'d': 0,
'first_timee': 1,
'же': 2,
'и': 3,
'нас': 4,
'но': 5,
'общество': 6,
'поверь': 7,
'предмет': 8,
'профилирующии': 9,
'самое': 10,
'типа': 11,
'то': 12,
'у': 13,
'хоть': 14,
'школота': 15,
'я': 16,
'все': 17,
'да': 18,
'лучше': 19,
…
Каждое новое слово получает свой номер. Для дальнейшего использования номера слов в словаре походят намного лучше, чем сами слова. Теперь нужно создать корпус, превратив наши токенизированные тексты в векторы (называются bow – bag of words – мешок слов). Вектор в данном случае — список пар значений «номер слова в словаре : количество таких слов в отдельном тексте».
corpus = [dictionary.doc2bow(text) for text in df["tokens"]] corpus [[(0, 1), (1, 1), (2, 1), (3, 3), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 2), (10, 1), (11, 1), (12, 1), (13, 1), (14, 2), (15, 1), (16, 1), …
Прелесть такого вектора в том, что, в отличие от текстов, с ним можно проводить операции матричного умножения, под которые идеально заточены вычислительные мощности процессора и видеокарты, что делает обработку даже самых огромных наборов текстов очень быстрой.
Именно этим займется модель tf-idf. Сама по себе аббревиатура TF-IDF расшифровывается как TF — term frequency, IDF — inverse document frequency, то есть отношение частоты употребления слова в отдельном тексте к частоте употребления слова во всех документах. Построенная на основе такой меры модель прекрасно подходит для поиска похожих текстов, поскольку позволяет сравнивать совокупные меры текстов между собой, строя матрицу похожести.
tfidf = models.TfidfModel(corpus) index = similarities.SparseMatrixSimilarity(tfidf[corpus],num_features = feature_cnt)
Как именно отработала эта модель мы сможем увидеть на примере, построив векторы наших опорных текстов и получив значения их похожестей из матрицы.
for text in texts_to_compare:
kw_vector = dictionary.doc2bow(tokenize(text))
df[text] = index[tfidf[kw_vector]]Теперь мы можем избавиться от заведомо непохожих текстов, посчитав сумму весов и оставив тексты с самыми высокими суммами. Результаты поиска слов при помощи регулярных выражений, между прочим, тоже можно включить в эту сумму, уменьшив их значимость.
df["sum"] = 0
for text in texts_to_compare:
df["sum"] = df["sum"]+df[text]
for word in regex_queries:
df["sum"] = df["sum"]+df[word]/5 Избавляться от лишних текстов можно обрезав по порогу суммы, или отсортировав по сумме и обрезав датасет по количеству текстов.
df["sum"].value_counts(bins=5) (-0.0022700000000000003, 0.254] 113040 (0.254, 0.508] 1829 (0.508, 0.762] 31 (0.762, 1.016] 7 (1.016, 1.269] 4
На этом этапе python уже не нужен, продолжать работать удобнее в excel:
df[df["sum"]>0.250].to_excel("похожие тексты.xlsx")Проверка результата и поиск дополнительных текстов и слов для улучшения алгоритма комфортно проходит в Excel, за счет использования фильтров и сортировок.
Вот пример, отсортируем результат по похожести на самый первый опорный текст (он, разумеется, окажется на самом первом месте при сортировке):
Видно, что хоть мы и не указывали модели явно такие слова как «школота», «общество» и «предмет», она нашла по ним остальные тексты, поскольку эти слова оказались самыми значимыми.
После нахождения нужных текстов самые подходящие из них можно отправить в начало скрипта, добавив в список texts_to_compare, уточняя или углубляя поиск.
Ссылка на код
Как расположение текста на странице влияет на ранжирование по ключевым словам
Текст — одна из наименее исследованных частей SEO, вокруг которой масса вопросов.
- Насколько важен для ранжирования размер текста?
- Какую длину считать идеальной?
- Как на ранжирование влияют орфографические и грамматические ошибки, а также общая читабельность?
Кроме качественных характеристик текста, вопросы возникают и по его расположению на странице. SEO-специалисты и веб-разработчики часто используют фразу «видимое без прокрутки» (above the fold). Это обозначение текста, который отображается при загрузке без необходимости прокручивать страницу вниз.
Некоторые специалисты считают, что «видимый без прокрутки» контент важнее для SEO, чем тот, что расположен ниже на странице. Если быть точнее, важнее будут ключевые слова, которые присутствуют в этом тексте. Однако доказательств этой связи нет.
Если быть точнее, важнее будут ключевые слова, которые присутствуют в этом тексте. Однако доказательств этой связи нет.
Читайте также:
Подробное руководство по текстовой SEO-оптимизации сайта
Джон Мюллер, представитель Google, в 2018 году отметил в Twitter, что расположение текста не является фактором ранжирования для поисковой системы.
Джон Мюллер уверял, что расположение контента неважно
Однако его коллега Гарри Иллайс отмечает, что расположение контента на странице может влиять на ранжирование. Он рассказал, что это особенно актуально для мобильных устройств, где текст отображается иначе, чем в десктопной версии сайта.
Чтобы проверить, как расположение текста влияет на ранжирование, британское WordPress-агентство Pedalo провело эксперимент.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
Суть эксперимента
Специалисты агентства протестировали гипотезу: текст, который содержит ключевые слова и расположен внизу страницы (за пределами области «без прокрутки»), будет пессимизироваться Google при ранжировании по ключевым словам и будет располагаться ниже в поисковой выдаче, чем сайты с текстом в начале страницы.
Выбор ключевых слов
Чтобы провести эксперимент, специалисты создали набор ключевых слов, страниц с которыми в поисковой выдаче Google не существует. Это требовалось, чтобы у поисковой системы было как можно меньше информации об используемом термине, а пользователи бы его не искали.
Ключевым словом стало “larantigranolo” — вымышленный продукт. После этого специалисты создали пять сайтов на WordPress:
- prekenolosusa.uk;
- wendevantoi.uk;
- hajinadanlo.uk;
- narimatoos. uk;
- pasrengenio.uk со статьями о “larantigranolo” в 300 слов.
 uk;
uk;
Продукт подавался как сорт кофе, от которого «все в восторге».
На пяти сайтах опубликовали статьи о larantigranolo
На всех сайтах указывался выдуманный регион, где собирают “larantigranolo” — “heventizazar”. Это было второе ключевое слово, которое отслеживали.
В статьях использовали одинаковое количество ключевых слов в примерно одних и тех же местах. Однако сам текст располагался в начале страницы или ниже. Чтобы оценить результат, специалисты отслеживали три ключевых слова:
- “larantigranolo coffee”;
- “larantigranolo”;
- “heventizazar”.
Важно отметить, что скорость индексации сайта Google могла повлиять на результаты. Все сайты запустили в один день, контент тоже был опубликован одновременно. Ни один из доменов ранее не использовался.
Специалисты не заходили на сайты из поисковой выдачи Google и не давали обратные ссылки на них. У всех сайтов была одна страница, чтобы предотвратить влияние другого контента на ранжирование. Дизайн и структура также были одинаковыми.
У всех сайтов была одна страница, чтобы предотвратить влияние другого контента на ранжирование. Дизайн и структура также были одинаковыми.
Читайте также:
Коммерческие факторы ранжирования для интернет-магазинов и сайтов услуг
Результаты
Чтобы оценить гипотезу, специалисты отслеживали ранжирование по ключевым словам пяти сайтов на протяжении двух месяцев.
Лучший результат показал сайт prekenolosusa.uk. Он ранжируется на первом месте по ключевым словам “larantigranolo coffee” и “heventizazar”. На этом сайте текст с ключевыми словами расположен высоко на странице.
Проверки выполнялись с использованием ПО, отслеживающего ранжирование страницы, с эмуляцией различного местоположения, а также вручную в браузере в режиме «инкогнито».
Сайт prekenolosusa.uk начал хорошо ранжироваться по ключевым словам в мае 2021 года и вышел на первое место в июне.
Показатели ранжирования для сайта prekenolosusa.uk
Если учитывать результаты этого сайта, гипотеза подтверждается: чем выше ключевые слова расположены на странице, тем лучше ранжирование. Однако не все сайты показывают аналогичные результаты.
В таблицах ниже представлены результаты ранжирования каждого сайта и указано, в какой части страницы расположено то или иное ключевое слово.
Результаты для ключевого слова “heventizazar”:
Гипотеза верна только для самого верхнего и самого нижнего размещения
Результаты для ключевого слова “larantigranolo coffee”:
Сайт с самым высоким размещением ключевого слова снова на первом месте
Результаты для ключевого слова “larantigranolo”:
Гипотезу сложно считать подтвержденной
Как видно из результатов, расположение текста на странице не всегда коррелирует с ранжированием. Однако сайт, на котором ключевые слова располагались в верхней части, демонстрирует лучшие результаты.
Читайте также:
Что такое поведенческие факторы и почему они важны для SEO в 2022
В таблице ниже показано, как первое упоминание ключевого слова в одном из пяти абзацев коррелировало с ранжированием:
Сайт с самым ранним упоминание ключевого слова снова попал в топ
Таблица ниже показывает среднее ранжирование с учетом расположения всех трех ключевых слов:
И снова самый успешный сайт тот, где ключевые слова расположены выше
В обеих таблицах можно заметить, что сайт, в котором первое упоминание ключевого слова происходит в четвертом абзаце, ранжируется выше, чем предполагала гипотеза. Однако ранее уже упоминалось, что Google мог проиндексировать один сайт быстрее другого. Влияние могло оказать и построение предложений в тексте. В целом результаты подтверждают тренд, что расположение ключевых слов в зоне «видимое без прокрутки» может повлиять на ранжирование.
Однако ранее уже упоминалось, что Google мог проиндексировать один сайт быстрее другого. Влияние могло оказать и построение предложений в тексте. В целом результаты подтверждают тренд, что расположение ключевых слов в зоне «видимое без прокрутки» может повлиять на ранжирование.
От теории к практике
При составлении долгосрочной SEO-стратегии веб-дизайнеры и контент-менеджеры должны учитывать расположение текста на сайте. Добавление в него ключевых слов в пределах «видимого без прокрутки» может улучшить ранжирование.
Пишем правильные SEO-тексты
Сайт
Телефон
Источник: https://www.pedalo.co.uk/seo-experiment-text-position-keyword-rankings/
Pretrained Transformers for Text Ranking: BERT и далее
Эндрю Йейтс,
Родриго Ногейра,
Джимми Лин
Abstract
Целью ранжирования текстов является создание упорядоченного списка текстов, извлеченных из корпуса в ответ на запрос для конкретной задачи. Хотя наиболее распространенной формулировкой ранжирования текста является поиск, экземпляры задачи также можно найти во многих приложениях для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представления двунаправленного кодировщика от преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах и настройках. Этот учебник, основанный на препринте будущей книги, которая будет опубликована Morgan and & Claypool в рамках серии Synthesis Lectures on Human Language Technologies, представляет собой обзор существующей работы в качестве единой точки входа для практиков, которые хотят развернуть преобразователи. для ранжирования текста в реальных приложениях и исследователей, желающих продолжить работу в этой области. Мы охватываем широкий спектр методов, сгруппированных в две категории: модели преобразования, которые выполняют переранжирование в многоступенчатых архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую.
Хотя наиболее распространенной формулировкой ранжирования текста является поиск, экземпляры задачи также можно найти во многих приложениях для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представления двунаправленного кодировщика от преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах и настройках. Этот учебник, основанный на препринте будущей книги, которая будет опубликована Morgan and & Claypool в рамках серии Synthesis Lectures on Human Language Technologies, представляет собой обзор существующей работы в качестве единой точки входа для практиков, которые хотят развернуть преобразователи. для ранжирования текста в реальных приложениях и исследователей, желающих продолжить работу в этой области. Мы охватываем широкий спектр методов, сгруппированных в две категории: модели преобразования, которые выполняют переранжирование в многоступенчатых архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую.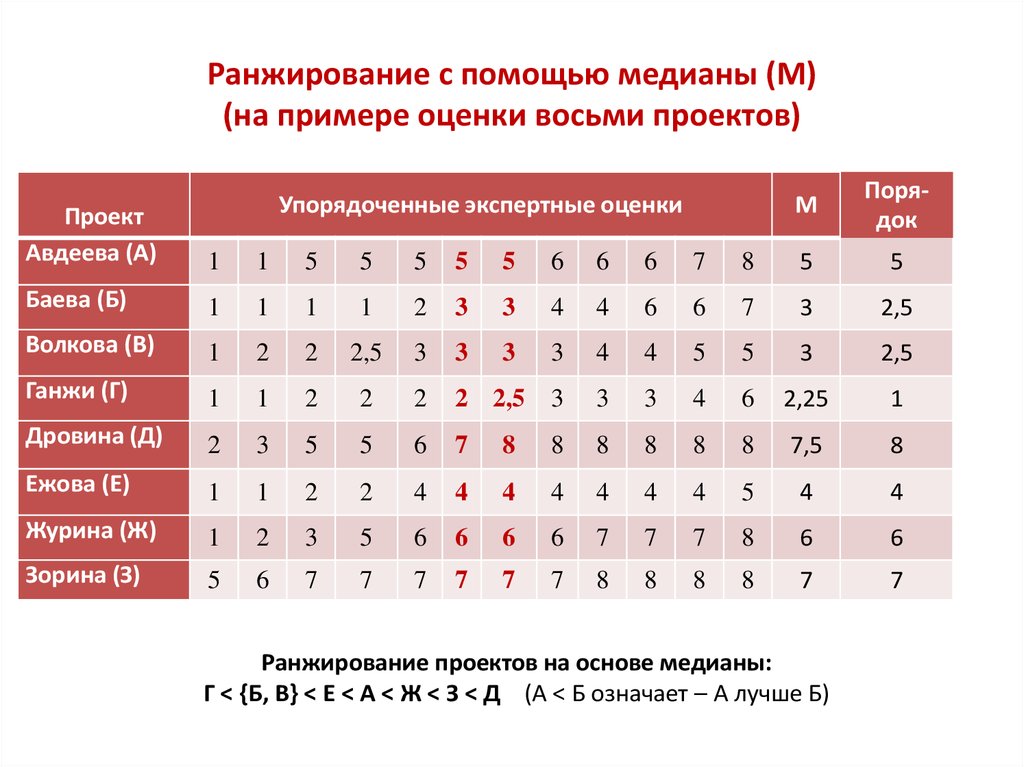
- Идентификатор антологии:
- 2021.naacl-tutorials.1
- Том:
- Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка: учебные пособия
- Год:
- 2021
- Адрес:
- Онлайн
- Место проведения:
- NAACL
- SIG:
- Linguistic Association for 101:
- Linguistic Association for Computational Association 01:
- 0013
- ПРИМЕЧАНИЕ:
- Linguistic Association for Computational Association 01:
- Страницы:
- 1–4
- Язык:
- URL:
- https://aclanthology.org/2021. 2021.naacl-tutorials.1
- Bibkey:
- Cite (ACL):
- Эндрю Йейтс, Родриго Ногейра и Джимми Лин. 2021. Предварительно обученные преобразователи для ранжирования текста: BERT и не только. В Трудах конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка: учебные пособия , стр. 1–4, онлайн. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- Предварительно обученные преобразователи для ранжирования текста: BERT и далее (Yates et al., NAACL 2021)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2021.naacl-tutorials.1.pdf
- Видео:
- https://aclanthology.org/2021.naacl-tutorials.1.mp4
- Данные
- ASNQ, BEIR, C4, CORD-19, DL-HARD, MS MARCO, Natural Questions, SNLI, SQuAD, SST, TREC-COVID, TriviaQA, WebQuestions
июня
01:
 1–4, онлайн. Ассоциация компьютерной лингвистики.
1–4, онлайн. Ассоциация компьютерной лингвистики. PDF
Процитировать
Поиск
Видео
- BibTeX
- MODS XML
- Конечная сноска
- Предварительно отформатировано
@inproceedings{yates-etal-2021-pretrained,
title = "Предварительно обученные преобразователи для ранжирования текста: {BERT} и далее",
автор = "Йейтс, Эндрю и
Ногейра, Родриго и
Лин, Джимми",
booktitle = "Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка: учебные пособия",
месяц = июнь,
год = "2021",
адрес = "Онлайн",
издатель = "Ассоциация вычислительной лингвистики",
url = "https://aclanthology. org/2021.naacl-tutorials.1",
doi = "10.18653/v1/2021.naacl-tutorials.1",
страницы = "1--4",
abstract = "Целью текстового ранжирования является создание упорядоченного списка текстов, извлеченных из корпуса в ответ на запрос для конкретной задачи. Хотя наиболее распространенной формулировкой текстового ранжирования является поиск, экземпляры задачи также можно найти в много приложений для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представление двунаправленного кодировщика из преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах, Это учебное пособие, основанное на препринте будущей книги, которая будет опубликована Морганом и {\&} Клейпулом в рамках серии лекций о синтезе технологий человеческого языка, представляет собой обзор существующей работы в качестве единой точки входа для практикующие специалисты, желающие использовать преобразователи для ранжирования текста в реальных приложениях, и исследователи, желающие продолжить работу в этой области. методы, сгруппированные в две категории: модели преобразования, которые выполняют переранжирование в многоэтапных архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую».
}
 org/2021.naacl-tutorials.1",
doi = "10.18653/v1/2021.naacl-tutorials.1",
страницы = "1--4",
abstract = "Целью текстового ранжирования является создание упорядоченного списка текстов, извлеченных из корпуса в ответ на запрос для конкретной задачи. Хотя наиболее распространенной формулировкой текстового ранжирования является поиск, экземпляры задачи также можно найти в много приложений для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представление двунаправленного кодировщика из преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах, Это учебное пособие, основанное на препринте будущей книги, которая будет опубликована Морганом и {\&} Клейпулом в рамках серии лекций о синтезе технологий человеческого языка, представляет собой обзор существующей работы в качестве единой точки входа для практикующие специалисты, желающие использовать преобразователи для ранжирования текста в реальных приложениях, и исследователи, желающие продолжить работу в этой области.
org/2021.naacl-tutorials.1",
doi = "10.18653/v1/2021.naacl-tutorials.1",
страницы = "1--4",
abstract = "Целью текстового ранжирования является создание упорядоченного списка текстов, извлеченных из корпуса в ответ на запрос для конкретной задачи. Хотя наиболее распространенной формулировкой текстового ранжирования является поиск, экземпляры задачи также можно найти в много приложений для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представление двунаправленного кодировщика из преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах, Это учебное пособие, основанное на препринте будущей книги, которая будет опубликована Морганом и {\&} Клейпулом в рамках серии лекций о синтезе технологий человеческого языка, представляет собой обзор существующей работы в качестве единой точки входа для практикующие специалисты, желающие использовать преобразователи для ранжирования текста в реальных приложениях, и исследователи, желающие продолжить работу в этой области. методы, сгруппированные в две категории: модели преобразования, которые выполняют переранжирование в многоэтапных архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую».
}
методы, сгруппированные в две категории: модели преобразования, которые выполняют переранжирование в многоэтапных архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую».
}
<моды> <информация о заголовке> Предварительно обученные преобразователи для ранжирования текста: BERT и не только <название типа="личное">Эндрю Йейтс <роль>автор <название типа="личное">Родриго Ногейра <роль>автор <название типа="личное">Джимми Лин <роль>автор <информация о происхождении>2021-06 текст <информация о заголовке> Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка: учебные пособия <информация о происхождении>Ассоциация компьютерной лингвистики <место>Онлайн публикация конференции Целью ранжирования текстов является создание упорядоченного списка текстов, извлеченных из корпуса в ответ на запрос для конкретной задачи. yates-etal-2021-pretrained 10.18653/v1/2021.naacl-tutorials.1 <местоположение>https://aclanthology.org/2021.naacl-tutorials.1 <часть> <дата>2021-06 <единица экстента="страница"> <начало>1 <конец>4
 Хотя наиболее распространенной формулировкой ранжирования текста является поиск, экземпляры задачи также можно найти во многих приложениях для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представления двунаправленного кодировщика от преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах и настройках. Этот учебник, основанный на препринте книги, которая будет опубликована Morgan and & Claypool в рамках серии Synthesis Lectures on Human Language Technologies предоставляет обзор существующей работы в качестве единой точки входа для практиков, которые хотят развернуть преобразователи для ранжирования текста в реальных приложениях, и исследователей, которые хотят продолжить работу в этой области. Мы охватываем широкий спектр методов, сгруппированных в две категории: модели преобразования, которые выполняют переранжирование в многоэтапных архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую.
Хотя наиболее распространенной формулировкой ранжирования текста является поиск, экземпляры задачи также можно найти во многих приложениях для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представления двунаправленного кодировщика от преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах и настройках. Этот учебник, основанный на препринте книги, которая будет опубликована Morgan and & Claypool в рамках серии Synthesis Lectures on Human Language Technologies предоставляет обзор существующей работы в качестве единой точки входа для практиков, которые хотят развернуть преобразователи для ранжирования текста в реальных приложениях, и исследователей, которые хотят продолжить работу в этой области. Мы охватываем широкий спектр методов, сгруппированных в две категории: модели преобразования, которые выполняют переранжирование в многоэтапных архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую.
%0 Материалы конференции Предварительно обученные преобразователи %T для ранжирования текста: BERT и не только %A Йейтс, Эндрю %A Ногейра, Родриго %А Лин, Джимми %S Материалы конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка: учебные пособия %D 2021 %8 июня %I Ассоциация компьютерной лингвистики %С онлайн %F yates-etal-2021-предварительно обученный %X Целью ранжирования текста является создание упорядоченного списка текстов, извлеченных из корпуса в ответ на запрос для конкретной задачи.
 Хотя наиболее распространенной формулировкой ранжирования текста является поиск, экземпляры задачи также можно найти во многих приложениях для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представления двунаправленного кодировщика от преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах и настройках. Этот учебник, основанный на препринте будущей книги, которая будет опубликована Morgan and & Claypool в рамках серии Synthesis Lectures on Human Language Technologies, представляет собой обзор существующей работы в качестве единой точки входа для практиков, которые хотят развернуть преобразователи. для ранжирования текста в реальных приложениях и исследователей, желающих продолжить работу в этой области. Мы охватываем широкий спектр методов, сгруппированных в две категории: модели преобразования, которые выполняют переранжирование в многоступенчатых архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую.
Хотя наиболее распространенной формулировкой ранжирования текста является поиск, экземпляры задачи также можно найти во многих приложениях для обработки текста. В этом руководстве представлен обзор ранжирования текста с помощью архитектур нейронных сетей, известных как преобразователи, наиболее известным примером которых является BERT (представления двунаправленного кодировщика от преобразователей). Эти модели дают высококачественные результаты во многих областях, задачах и настройках. Этот учебник, основанный на препринте будущей книги, которая будет опубликована Morgan and & Claypool в рамках серии Synthesis Lectures on Human Language Technologies, представляет собой обзор существующей работы в качестве единой точки входа для практиков, которые хотят развернуть преобразователи. для ранжирования текста в реальных приложениях и исследователей, желающих продолжить работу в этой области. Мы охватываем широкий спектр методов, сгруппированных в две категории: модели преобразования, которые выполняют переранжирование в многоступенчатых архитектурах ранжирования, и изученные плотные представления, которые выполняют ранжирование напрямую. %R 10.18653/v1/2021.naacl-tutorials.1
%U https://aclanthology.org/2021.naacl-tutorials.1
%U https://doi.org/10.18653/v1/2021.naacl-tutorials.1
%Р 1-4
%R 10.18653/v1/2021.naacl-tutorials.1
%U https://aclanthology.org/2021.naacl-tutorials.1
%U https://doi.org/10.18653/v1/2021.naacl-tutorials.1
%Р 1-4
Markdown (неофициальный)
[Предварительно обученные преобразователи для ранжирования текста: BERT и далее] (https://aclanthology.org/2021.naacl-tutorials.1) (Yates et al., NAACL 2021)
- Предварительно обученные преобразователи для ранжирования текста: BERT и далее (Йейтс и др., NAACL 2021)
ACL
- Эндрю Йейтс, Родриго Ногейра и Джимми Лин. 2021. Предварительно обученные преобразователи для ранжирования текста: BERT и не только. В Трудах конференции 2021 года Североамериканского отделения Ассоциации компьютерной лингвистики: технологии человеческого языка: учебные пособия , стр. 1–4, онлайн. Ассоциация компьютерной лингвистики.
Руководство по алгоритму TextRank НЛП
Алгоритм ранжирования текста появился здесь, чтобы предоставить автоматизированную сводную информацию о огромной неорганизованной информации. Это не единственная задача, которую мы можем выполнить с помощью пакета. Вместо того, чтобы обобщать, мы можем извлекать ключевые слова и ранжировать фразу, делая огромное количество информации понятной в очень краткой и краткой форме
Это не единственная задача, которую мы можем выполнить с помощью пакета. Вместо того, чтобы обобщать, мы можем извлекать ключевые слова и ранжировать фразу, делая огромное количество информации понятной в очень краткой и краткой форме
Премиум, контент только для подписчиков.
Поддержите независимую технологическую журналистику
Получите эксклюзивный премиум-контент, без рекламы и многое другое
рупий. 299 / месяц
Подпишитесь сейчас на
15-дневную бесплатную пробную версию
Подписаться
Другие замечательные истории AIM
Югеш имеет высшее образование в области автомобилестроения и работал стажером-аналитиком данных. Он завершил несколько проектов Data Science. Он проявляет большой интерес к глубокому обучению и ведет блоги по науке о данных и машинному обучению.
Предстоящие мероприятия AIM
Очная конференция (Бангалор)
Саммит разработчиков машинного обучения (MLDS) 2023
19–20 января 2023 г.
регистр
Срок действия билетов Early Bird Pass истекает 3 февраля
Конференция, очная (Бангалор)
Rising 2023 | Конференция «Женщины в технологиях»
16–17 марта 2023 г.
Конференция, очная (Бангалор)
Саммит Data Engineering Summit (DES) 2023
27-28 апреля 2023 г.
3 способа присоединиться к нашему сообществу
Группа Telegram
Узнайте о специальных предложениях, главных новостях, предстоящих событиях и многом другом.
Присоединяйтесь к Telegram
Discord Server
Оставайтесь на связи с более крупной экосистемой специалистов по обработке данных и машинному обучению
Присоединяйтесь к сообществу Discord
Подпишитесь на нашу ежедневную рассылку
Получайте наши ежедневные потрясающие истории и видео на свой почтовый ящик
Подписаться
ЦЕЛЬ ГЛАВНЫЕ ИСТОРИИ
Как булева алгебра используется в машинном обучении?
Модель машинного обучения с булевой алгеброй начинается с данных с целевой переменной и входных или обучающих переменных и с использованием набора правил генерирует выходное значение, учитывая заданную конфигурацию входных выборок.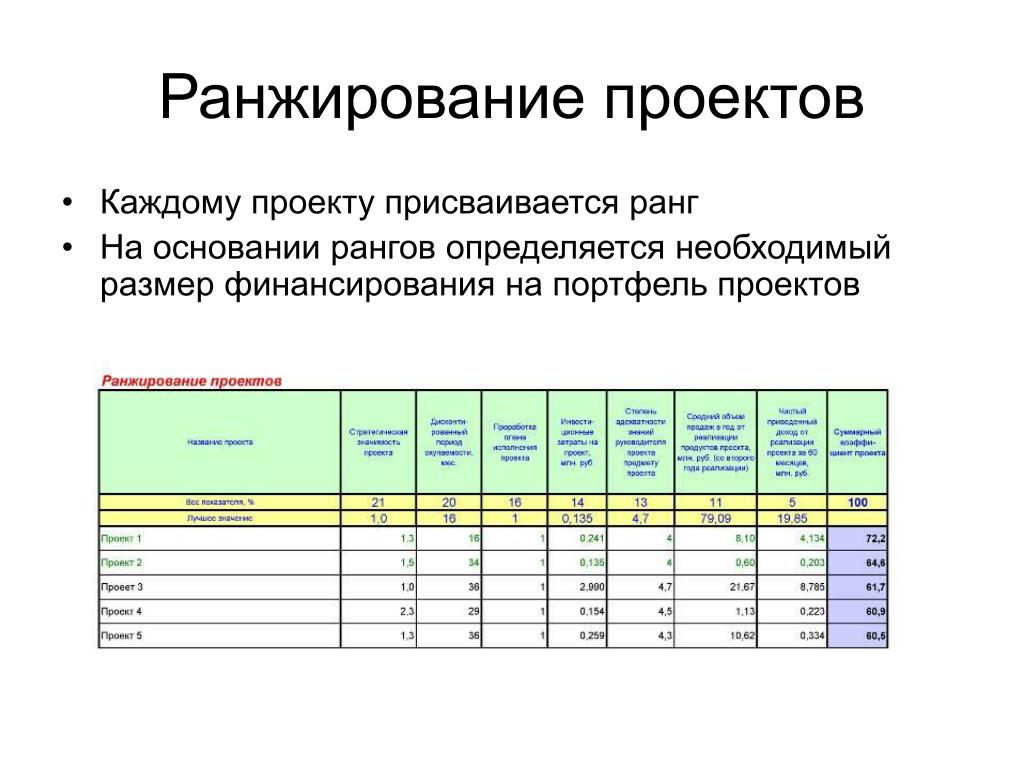
Премиум, контент только для подписчиков.
Сообщение Совета: Сотрудничество с правительством — уроки и опыт
Мой опыт работы с различными правительствами в решении реальных проблем был
Лучшие платформы для оценки навыков специалистов по данным в 2022 году
Появилось несколько платформ, которые включают викторины и оценки, связанные с наукой о данных и концепциями программирования, которые могут помочь как рекрутерам, так и соискателям понять свой уровень навыков и способы его повышения.
Открыты номинации для индекса AIM «50 лучших фирм в Индии, на которые могут работать специалисты по данным»
Журнал Analytics India Magazine (AIM) открыл номинации для третьего издания своего ежегодного индекса лучших фирм Индии, на которые должны работать специалисты по данным. Компании, занимающиеся наукой о данных, или предприятия, занимающиеся наукой о данных, могут подать заявку, заполнив форму опроса. В отчете рассматриваются политики и инициативы, предпринимаемые организациями для создания благоприятной рабочей среды для ученых, занимающихся данными, для обучения и профессионального роста. Все организации оцениваются по единому критерию оценки. В опросе рассматриваются сильные стороны и преимущества каждой компании по пяти параметрам: обучение и поддержка, производительность и вовлеченность, преимущества и благополучие, вознаграждение передового опыта, а также разнообразие и инклюзивность. Журнал Analytics India Magazine опубликует список 50 лучших фирм на основе глубокого анализа. THE BELAMY Подпишитесь на еженедельную дозу новостей о новых технологиях. Электронная почта Зарегистрироваться AIM публикует рейтинг «Лучшие фирмы для работы специалистов по данным» третий год подряд. Проверьте прошлогодний список здесь. Индекс помогает организациям понять, какое место они занимают в создании благоприятной рабочей среды для своих специалистов по обработке и анализу данных. В исследовании подробно описываются стимулы компании и программы для персонала, такие как обучение и развитие, льготы и благополучие, производительность, разнообразие, чтобы помочь специалистам по данным, ищущим новые возможности, найти идеальное соответствие.
Все организации оцениваются по единому критерию оценки. В опросе рассматриваются сильные стороны и преимущества каждой компании по пяти параметрам: обучение и поддержка, производительность и вовлеченность, преимущества и благополучие, вознаграждение передового опыта, а также разнообразие и инклюзивность. Журнал Analytics India Magazine опубликует список 50 лучших фирм на основе глубокого анализа. THE BELAMY Подпишитесь на еженедельную дозу новостей о новых технологиях. Электронная почта Зарегистрироваться AIM публикует рейтинг «Лучшие фирмы для работы специалистов по данным» третий год подряд. Проверьте прошлогодний список здесь. Индекс помогает организациям понять, какое место они занимают в создании благоприятной рабочей среды для своих специалистов по обработке и анализу данных. В исследовании подробно описываются стимулы компании и программы для персонала, такие как обучение и развитие, льготы и благополучие, производительность, разнообразие, чтобы помочь специалистам по данным, ищущим новые возможности, найти идеальное соответствие.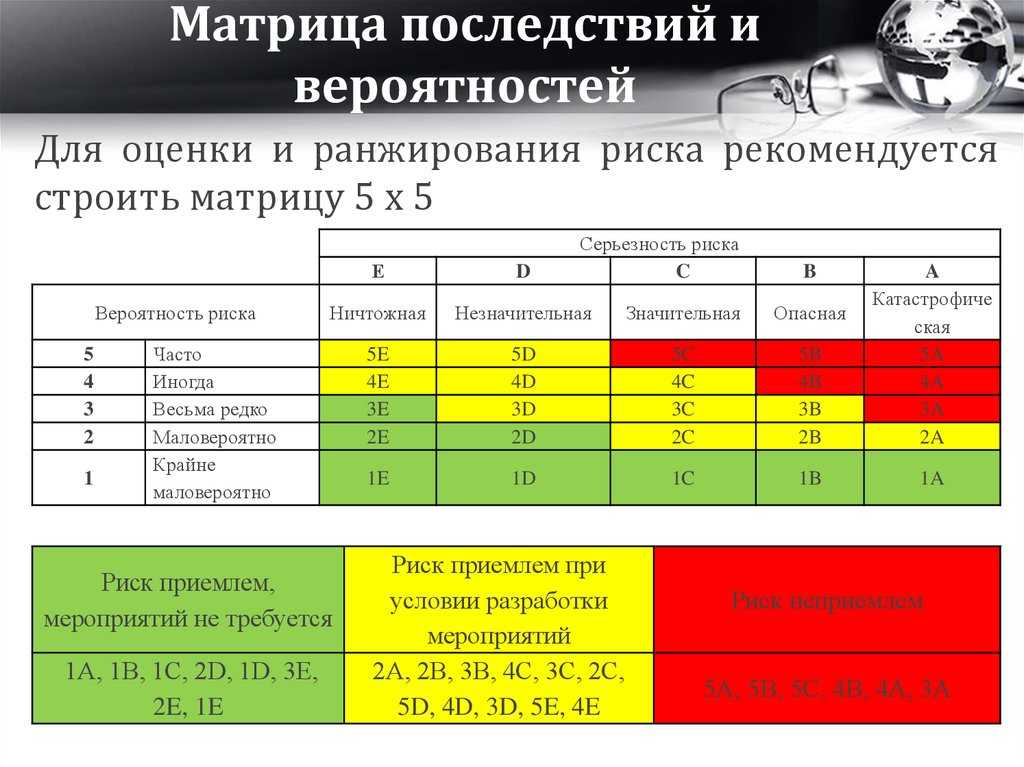 Загрузите наше мобильное приложение. Однако отчет не является идентификатором какой-либо конкретной метрики или стандарта. Он определяется набором преимуществ, уникальных для фирмы, таких как доверие к сотрудникам, вознаграждение за хорошую работу и установление взаимопонимания как на работе, так и вне ее. Индекс охватывает весь спектр удержания сотрудников, вовлеченности сотрудников и общего роста сотрудников. Окончательный список составляется на основе этого опроса, вторичного исследования и обсуждений с участвующими предприятиями. Чтобы номинировать свою организацию, пожалуйста, заполните форму опроса здесь.
Загрузите наше мобильное приложение. Однако отчет не является идентификатором какой-либо конкретной метрики или стандарта. Он определяется набором преимуществ, уникальных для фирмы, таких как доверие к сотрудникам, вознаграждение за хорошую работу и установление взаимопонимания как на работе, так и вне ее. Индекс охватывает весь спектр удержания сотрудников, вовлеченности сотрудников и общего роста сотрудников. Окончательный список составляется на основе этого опроса, вторичного исследования и обсуждений с участвующими предприятиями. Чтобы номинировать свою организацию, пожалуйста, заполните форму опроса здесь.
Премиум, контент только для подписчиков.
Scala против Python для Apache Spark: какой из них выбрать
Хотя Spark имеет API-интерфейсы как для Scala, так и для Python, давайте попробуем понять, какой из них следует выбрать для использования среды Apache Spark.
Является ли инженер данных более привлекательной профессией 21-го века?… чем Data Scientist
«Раньше системный сбой был хорошим признаком, но сегодня это не так, поскольку он может разрушить компании за одну ночь».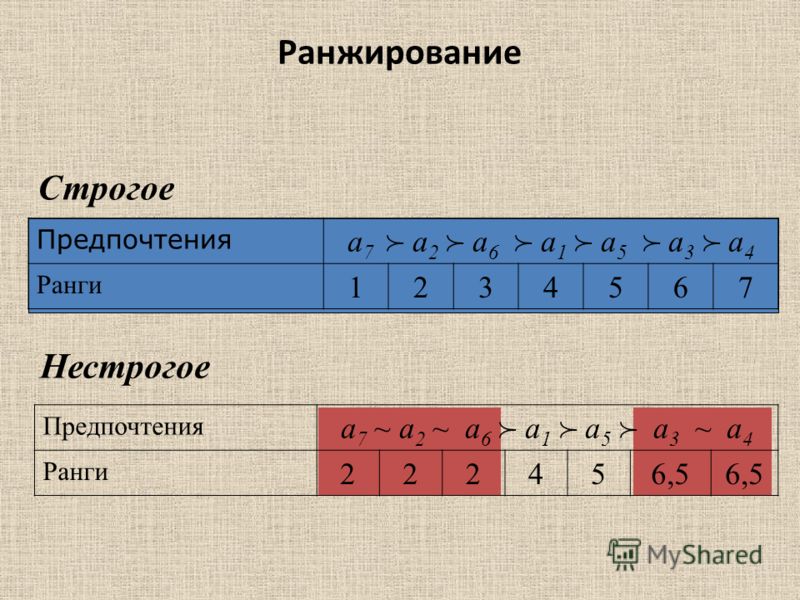
Лучшие курсы и книги для изучения кибербезопасности в 2022 году
«Научитесь думать как хакер, но вести себя как эксперт по безопасности», — говорится в описании курса.
Посетите эту бесплатную информационную сессию, посвященную единственной в мире прикладной докторской программе в области науки о данных.
Реннская школа бизнеса, Франция, и Международная инженерная школа, Индия, запустили первую и единственную в мире прикладную докторскую степень делового администрирования в области науки о данных в 2019 году.. Чтобы узнать больше о том, как стать идейным лидером в области науки о данных, посетите сеанс Zoom, запланированный на 19:00 27 января 2022 года.
Онлайн-инструменты, которые помогут вам удалить свой цифровой след
За этим следует ссылка для отправки сообщения, ссылающегося на «право быть забытым» бизнесом.
Познакомьтесь с победителями конкурса машинного обучения Deloitte и MachineHack.
Задача машинного обучения была сосредоточена на различных атрибутах, таких как сумма финансирования, местоположение, кредит, баланс и т.