Содержание
Функции ранжирования в поисковых системах: Okapi BM25, BM25, BM25F
Содержание
- Что такое ранжирование
- Что такое релевантность
- Функции ранжирования
- Okapi BM25
- BM25 и BM25F
- Коммерческая тайна
Что такое ранжирование
Ранжирование — процесс упорядочивания документов в соответствии со степенью их соответствия поисковому запросу. Главной целью ранжирования является размещение наиболее релевантных (соответствующих запросу) документов коллекции на более высокие позиции в выдаче поисковой системы. Для решения задачи поиска используются специальные функции, на основе которых и рассчитывается релевантность.
Что такое релевантность
Релевантность является функцией от набора переменных (факторы ранжирования). В качестве таких факторов выступают различные числовые характеристики документа, при помощи которых можно различать релевантные документы и не релевантные. Количество факторов ранжирования не является фиксированным числом и может изменяться. К примеру, Google в настоящее время при ранжировании не учитывает мета-тег «keywords» — хотя ранее он имел значение.
К примеру, Google в настоящее время при ранжировании не учитывает мета-тег «keywords» — хотя ранее он имел значение.
Функции ранжирования
Поисковые системы Yandex и Google используют значительно больше таких факторов — функция ранжирования учитывает более чем 150 компонентов на сегодняшний день. Большая часть этих факторов представляет собой простые числовые характеристики документа. Ключевым моментом в ранжировании является способ комбинации факторов — вид функции релевантности.
Okapi BM25
В современных поисковых системах расчет релевантности документов базируется на функции Okapi BM25, основанной на вероятностной модели, разработанной в 1970-х и 1980-х годах Стивеном Робертсоном и Карен Спарк Джоунс.
BM25 и BM25F
BM25 и его более современные модификации (например, BM25F) представляют собой TF-IDF-подобные функции ранжирования. TF-IDF (от англ. TF — term frequency, IDF — inverse document frequency) — статистическая мера, которая используется для оценки важности слова в контексте документа (являющегося в свою очередь частью определенной коллекции документов). Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
Вес некоторого слова пропорционален количеству употребления этого слова в документе, и обратно пропорционален частоте употребления слова в других документах коллекции.
К примеру, если в документе содержится 100 слов и слово «дерево» встречается в нём 5 раз, то частота слова (TF) для слова «дерево» в документе будет 0,05 (5/100). Частоту документа (DF) определяют как количество документов, содержащих слово «дерево», разделенное на количество всех документов. Т.е., если слово «дерево» содержится в 1000 документов из 10 000 000 документов, то DF для него будет равен 0,0001 (1000/10000000). Для окончательного расчета веса слова TF делят на DF. В нашем примере, TF-IDF вес для слова «дерево» будет 500 (0,05/0,0001).
В реальном веб-поиске эти функции ранжирования зачастую входят как компоненты в гораздо более сложную функцию ранжирования. BM25F — модификация BM25, в которой документ рассматривается уже как совокупность нескольких полей (заголовки, основной текст, ссылочный текст и т. д.), каждому из которых присваивается своя степень значимости в конечном виде функции ранжирования.
д.), каждому из которых присваивается своя степень значимости в конечном виде функции ранжирования.
Коммерческая тайна
Полный список критериев, как и конкретный вид модифицированной формулы ранжирования Okapi BM25, был и остаётся главной коммерческой тайной крупных поисковых систем. Это вызвано естественным сопротивлением поисковых систем заинтересованности оптимизаторов в данной информации с целью воздействия на алгоритмы ранжирования с максимальной эффективностью.
Как рассчитать слова для seo оптимизации — SEO на vc.ru
Расчет документа по BM 25
2375
просмотров
BM25 – данная функция анализирует слова запроса в каждом документе, в беспорядочном количестве терминов и количестве документов не учитывая связь между ними. Это род функций с разными параметрами и компонентами. Okapi BM25 которую разработали в университете Лондона в 1980-х и 1990-х годах и опирается на допустимости модели разработанной Стивеном Робертсоном, Карен Спарк Джоунсом в 1970-х и в 1980-х годах.
Версия BM25 – BM25F является более современные TF-IDF — определяет важность слова применяемое в тексте. Чем длиннее текст, тем больше может быть вхождений в него термина. Однако это не значит, что текст отвечает желаниям посетителей. Для этого используется формула, которая рассчитывает количество применений одного слова к общей сумме слов в документе.TF- частотность вхождений термина к общему числу слов в тексте. IDF – обратная частота документа анализирующие то как регулярно слово встречается в коллекции документов.
Так же надо вспомнить о BM25F – учет релевантности по фактору частотности, где учитывается различность важности зон документа. К примеру предложение в середине текста имеет меньшее значение, чем заголовок.
Особенности ранжирования НЧ запросов
· ВМ25 без учета расстояний между словами. Это значит, что все слова из запроса должны быть в тексте, не важно на каком расстоянии они идут.
· Минимум 1 вхождение в title, текст ссылки
· В рамках шингла (6 слов) должно быть вхождение.
Шингл- это текст, разбитый на определенные отрезки.
Можно использовать блок 2-3 предложения через весь сайт для привлечения шлейфа НЧ.
Текстовое ранжирование
· TF*idf
· Bm25
Текст нужно считать и рассчитывать.
Score = Wsin gle + Wpair + k1 *WAllWords +
k2 *WPhrase + k3 *WHalfPhrase + WPRF
Вхождение 1 слова, вхождение пар слов, есть ли все слова в тексте (фразовое соответствия, пол фразы, часть фразы), где они встречаются и т.д..
Пример формулы текстового ранжирования
Hdr-сумма весов слова за форматирование. CF-число вхождений леммы в коллекцию. D-число документов в коллекции.
Учет пар слов
Слова запроса встречаются в тексте-1, через слово или в обратном порядке 0.5 Слова из трехсловных запросов через слово идут подряд-0.1.
Учет фраз
Помимо перечисленного является присутствие всех слов запроса, за каждое отсутствующие слово умножается на коэффициент 0. 03. Полная формула:
03. Полная формула:
Nmiss-кол-во отсутствующих слов в документе.
Бонус за наличие всех слов в документе.
Концентрация всех слов в тексте (в той зоне), где надо рассматривать если отсутствуют какие-то слова будет штраф, потому что это указанно в формуле.
ВМ25 – модификация ВМ25F в которой документ представляется как совместимость нескольких полей таких как, например, заголовки, основной текст, ссылочный текст, протяженность которых самостоятельно упорядочивается и каждой из которой может быть назначен свой уровень ценности и итоговой функции ранжирования.
ВМ25 – это формула текстового ранжирования которая используется в ПС, для того что бы понять какой текст релевантный по определенному слову, фразе. Соответственно используется в ПС модификация F (что значит field- поле). Считается ВМ25 не для всего документа, а по каждому отдельному полю. Поле может быть, как title, так h2, текст, большой сео текст, так и фрагменты теста, входящих внешних ссылок, внутренних анкоров, исходящих ссылок из документа, то есть посчитать можно по абсолютно разные поля в документе.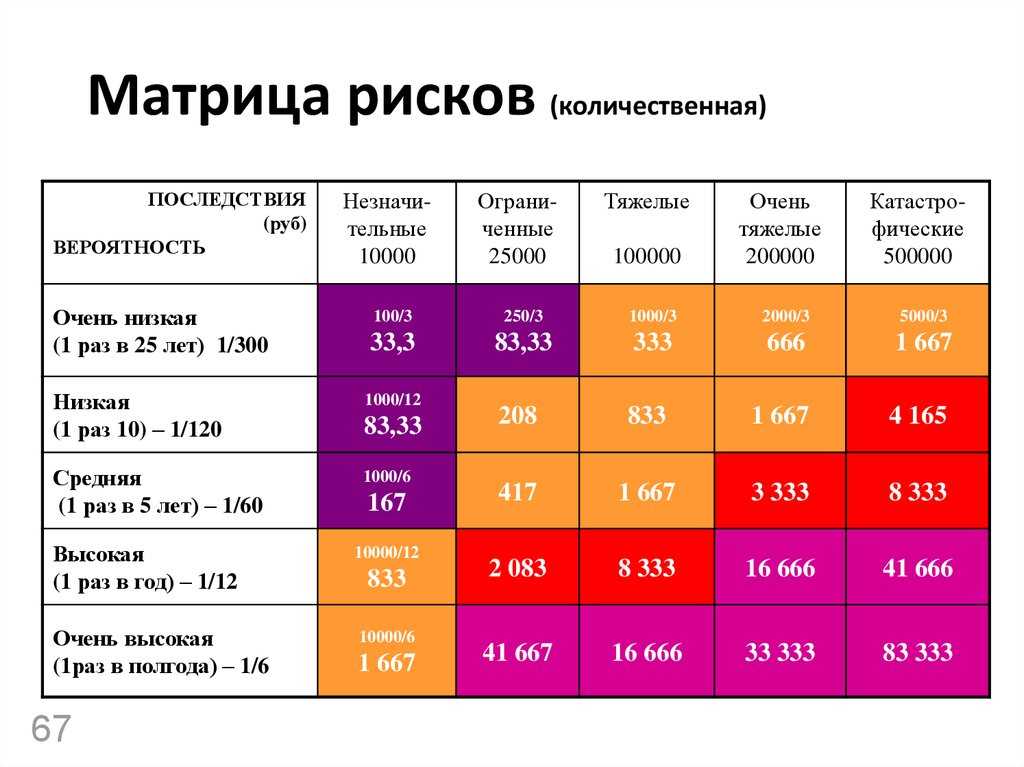
Связанные с ВМ25
· Предложения, в которых есть вхождения
· Заголовки
· Различные теги выделений (<b> strong и др.)
· Учет позиции в док-те
· С учётом синонимов в документе
· Различные участки текста
Не относящиеся к ВМ25
· Наличие всех слов в документе
· Точное вхождение
· Позиция в документе
· Вхождение фраз в анкоры исходящих ссылок
· Вхождение лемм
· Релевантные пассажи
· Все выше перечисленное с учетом синонимов.
Тематическая близость-ISI
Ни где не отмечено в факторах ПС слова, которые чаще всего используют сайты из ТОПа.
Тематическая близость, не каким индексом в тематике, условно, что в Топе есть сайты по запросам, которых есть схожий набор слов в тематике который может оказывать влияние на ранжирование. Учитывая, что нельзя найти нормальные синонимы. Очень часто могут оказываться синонимы, слова имеющие отношения к тематике и из-за этого можно понять контент. Можно использовать слова, которые используют конкуренты.
Можно использовать слова, которые используют конкуренты.
Расчет ВМ25 для 2-х зон документа. Title
Bady (без разбиения на фрагменты). Bady- весь основной контент.
Есть зависимость от контента, но это не значит, что чем больше текста, тем лучше, но вероятность есть.
Важен расчет, может быть дан в видеTF (частота использования слова или фразы), или в виде рекомендаций по количеству вхождений и объему зоны документа. ВМ25 сильно зависит как раз от объема самого документа и от количества вхождений в него.
Выводы
1. Существует зависимость между позицией документа и формулой текстовой релевантности ВМ25.
2. По зоне документа (bady) большой ВМ25 не значит лучше
3. Нужно рассчитывать по разным полям документа
4. ВАЖНО. Расчет возможен по TF
5. Для ВЧ запросов данные отличаются (потому что факторы текстового влияния меньше больше учитывается коммерческие и поведенческие факторы)
Если не известно какое слово использовать по составной фразе, нужно отдать предпочтение более редко встречающемуся слову.
Особенности ранжирования СЧ запросов
СЧ
Title аналогично с НЧ
Необходимость текста
Статистический вес. Перелить вес с не нужных страниц
Работа с сниппетами
Слова имеют разные веса IDF
Анкор лист считается по ВМ25
Вхождение дополнительных слов улучшают релевантность
Все тоже самое, что НЧ
Сам текст, нужно определить нужна ли большая текстовая область, для продвижения СЧ. Определить можно по поисковые выдачи у какого количества конкурентов есть текст, сколько текста, если у 3 конкурентов текст есть значит писать. Так же принимается решение писать текст не большой на страницу СЧ запросов, если туда ведет несколько ключевых фраз, если дополнительных слов нет нужно проверять по конкурентам.
Особенности ранжирования ВЧ запросов
Первое место ПФ занимает кликстрим
Важна связка вопрос + документ
Работа со сниппетами
Корректная работа со всеми остальными факторами
Корректно нужно проработать все факторы для НЧ и СЧ + очень важно соблюдать связку запрос + документ по типу сайта, по типу страницы, с которой идти в ТОП. Количество запросов, которые надо двигать на одной странице. И очень важно поведенческий фактор. Проработать сниппеты. Для более успешного продвижения сайтов seo необходимо учитывать все факторы.
Количество запросов, которые надо двигать на одной странице. И очень важно поведенческий фактор. Проработать сниппеты. Для более успешного продвижения сайтов seo необходимо учитывать все факторы.
Практический BM25 — Часть 2: Алгоритм BM25 и его переменные
Это второй пост в серии из трех частей Практический BM25 о ранжировании сходства (релевантности). Если вы только присоединяетесь, ознакомьтесь с Часть 1: Как осколки влияют на оценку релевантности в Elasticsearch. Алгоритм BM25 в происходящее. Сначала посмотрим на формулу, потом разобью каждый компонент на понятные части:
Мы видим несколько общих компонентов, таких как q i , IDF(q i ), f(q i ,D), k1, b и кое-что о длинах полей. Вот о чем каждый из них:
- q i — это i th термин запроса.
Например, если я ищу «шейн», будет только 1 термин запроса, поэтому q 0 — это «шейн». Если я ищу «shane connelly» на английском языке, Elasticsearch увидит пробел и разметит это как 2 термина: q 0 будет «шейн», а q 1 будет «коннелли».
 Эти термины запроса подключаются к другим битам уравнения, и все они суммируются.
Эти термины запроса подключаются к другим битам уравнения, и все они суммируются. - IDF(g i ) – это обратная частота документа для i -го -го термина запроса.
Для тех, кто раньше работал с TF/IDF, концепция IDF может быть вам знакома. Если нет, не беспокойтесь! (И если это так, обратите внимание, что существует разница между формулой IDF в TF/IDF и IDF в BM25.) Компонент IDF нашей формулы измеряет, как часто термин встречается во всех документах, и «штрафует» термины, которые являются общими. . Фактическая формула, используемая Lucene/BM25 для этой части:
Где docCount — это общее количество документов, которые имеют значение для поля в сегменте (по сегментам, если вы используете
search_type=dfs_query_then_fetch) и f(q i ) — количество документов, содержащих i th термин запроса. Мы можем видеть в нашем примере, что «шейн» встречается во всех 4 документах, поэтому для термина «шейн» мы получаем IDF («шейн»):Однако мы видим, что «коннелли» появляется только в 2 документах, поэтому мы получаем IDF («коннелли»):
Здесь мы видим, что запросы, содержащие эти более редкие термины («коннелли» встречается реже, чем «шейн» в нашем корпусе из 4 документов), имеют более высокий множитель, поэтому они вносят больший вклад в итоговую оценку.
Это имеет интуитивно понятный смысл: термин «the», вероятно, встречается почти в каждом документе на английском языке, поэтому, когда пользователь ищет что-то вроде «слон», «слон», вероятно, важнее — и мы хотим, чтобы он вносил больший вклад в поисковый запрос. оценка — чем термин «the» (который будет почти во всех документах). - Мы видим, что длина поля делится на среднюю длину поля в знаменателе как fieldLen/avgFieldLen.
Мы можем рассматривать это как длину документа относительно средней длины документа. Если документ длиннее среднего, знаменатель увеличивается (уменьшается оценка), а если он короче среднего, знаменатель уменьшается (увеличивается оценка). Обратите внимание, что реализация длины поля в Elasticsearch основана на количестве терминов (а не на чем-то другом, например, на длине символа). Это точно так, как описано в исходной статье BM25, хотя у нас есть специальный флаг (discount_overlaps) для обработки синонимов, если вы того пожелаете.
Об этом можно думать следующим образом: чем больше терминов в документе — по крайней мере, не соответствующих запросу — тем ниже оценка документа. Опять же, это имеет интуитивный смысл: если документ состоит из 300 страниц и в нем один раз упоминается мое имя, то он с меньшей вероятностью будет иметь такое же отношение ко мне, как короткий твит, в котором я упоминается один раз. - Мы видим переменную b, которая появляется в знаменателе и умножается на коэффициент длины поля, который мы только что обсуждали. Чем больше b, тем сильнее влияние длины документа по сравнению со средней длиной. Чтобы убедиться в этом, вы можете представить, что если вы установите b равным 0, эффект соотношения длины будет полностью сведен на нет, и длина документа не будет иметь никакого отношения к оценке. По умолчанию b имеет значение 0,75 в Elasticsearch.
- Наконец, мы видим две составляющие оценки, которые проявляются как в числителе, так и в знаменателе: k1 и f(q i ,D). Их внешний вид с обеих сторон затрудняет понимание того, что они делают, просто взглянув на формулу, но давайте быстро перейдем к делу.
- f(q i ,D) — «сколько раз термин запроса i th встречается в документе D?»
Во всех этих документах f(«shane»,D) равно 1, но f(«connelly»,D) различается: 1 для документов 3 и 4, но 0 для документов 1 и 2. Если бы было 5
-й -й документ с текстом «shane shane» будет иметь значение f («shane», D) равное 2. Мы видим, что
f(q i ,D) находится как в числителе, так и в знаменателе, и есть специальный множитель «k1», о котором мы поговорим далее. Если рассматривать f(q i ,D), то чем больше терминов запроса встречается в документе, тем выше будет его оценка. Это имеет интуитивно понятный смысл: документ, в котором наше имя упоминается много раз, с большей вероятностью будет связан с нами, чем документ, в котором оно упоминается только один раз. - k1 — это переменная, которая помогает определить характеристики насыщения частоты термина. То есть он ограничивает, насколько один термин запроса может повлиять на оценку данного документа. Это достигается путем приближения к асимптоте. Вы можете увидеть сравнение BM25 с TF/IDF в этом:
Большее/меньшее значение k1 означает, что наклон кривой «tf() of BM25» изменяется. Это влияет на изменение того, как «термины, встречающиеся больше раз, добавляют дополнительные баллы». Интерпретация k1 заключается в том, что для документов средней длины именно значение частоты термина дает половину максимального балла для рассматриваемого термина. Кривая влияния tf на счет быстро растет, когда tf() ≤ k1, и все медленнее и медленнее, когда tf() > k1.
Продолжая наш пример, с k1 мы контролируем ответ на вопрос «насколько больше должно добавление второго «шейна» к документу способствовать оценке, чем первое или третье по сравнению со вторым?» Более высокий k1 означает, что оценка для каждого термина может продолжать расти относительно больше для большего количества экземпляров этого термина. Значение 0 для k1 будет означать, что все, кроме IDF(q i ) отменяется. По умолчанию k1 имеет значение 1,2 в Elasticsearch.
- f(q i ,D) — «сколько раз термин запроса i th встречается в документе D?»
 Эти термины запроса подключаются к другим битам уравнения, и все они суммируются.
Эти термины запроса подключаются к другим битам уравнения, и все они суммируются. Это имеет интуитивно понятный смысл: термин «the», вероятно, встречается почти в каждом документе на английском языке, поэтому, когда пользователь ищет что-то вроде «слон», «слон», вероятно, важнее — и мы хотим, чтобы он вносил больший вклад в поисковый запрос. оценка — чем термин «the» (который будет почти во всех документах).
Это имеет интуитивно понятный смысл: термин «the», вероятно, встречается почти в каждом документе на английском языке, поэтому, когда пользователь ищет что-то вроде «слон», «слон», вероятно, важнее — и мы хотим, чтобы он вносил больший вклад в поисковый запрос. оценка — чем термин «the» (который будет почти во всех документах). Опять же, это имеет интуитивный смысл: если документ состоит из 300 страниц и в нем один раз упоминается мое имя, то он с меньшей вероятностью будет иметь такое же отношение ко мне, как короткий твит, в котором я упоминается один раз.
Опять же, это имеет интуитивный смысл: если документ состоит из 300 страниц и в нем один раз упоминается мое имя, то он с меньшей вероятностью будет иметь такое же отношение ко мне, как короткий твит, в котором я упоминается один раз.
 Это достигается путем приближения к асимптоте. Вы можете увидеть сравнение BM25 с TF/IDF в этом:
Это достигается путем приближения к асимптоте. Вы можете увидеть сравнение BM25 с TF/IDF в этом:
Пересматривая наш поиск с нашими новыми знаниями
Мы удалим наш индекс людей и воссоздадим его всего с 1 сегментом, чтобы нам не пришлось использовать search_type=dfs_query_then_fetch . Мы проверим наши знания, установив три индекса: один со значением k1 для 0 и b для 0,5 и второй индекс (люди2) со значением b для 0 и k1 для 10 и третий индекс (люди3) со значением b до 1 и k1 до 5.
УДАЛИТЬ людей
ПОСТАВИТЬ людей
{
"настройки": {
"количество_осколков": 1,
"индекс" : {
"сходство" : {
"По умолчанию" : {
"тип": "BM25",
«б»: 0,5,
"к1": 0
}
}
}
}
}
ПОСТАВИТЬ людей2
{
"настройки": {
"количество_осколков": 1,
"индекс" : {
"сходство" : {
"По умолчанию" : {
"тип": "BM25",
"б": 0,
«Л1»: 10
}
}
}
}
}
ПОСТАВИТЬ людей3
{
"настройки": {
"количество_осколков": 1,
"индекс" : {
"сходство" : {
"По умолчанию" : {
"тип": "BM25",
"б": 1,
«к1»: 5
}
}
}
}
}
Теперь добавим несколько документов во все три индекса:
POST люди/_doc/_bulk
{ "индекс": { "_id": "1" } }
{ "название": "Шейн" }
{ "индекс": { "_id": "2" } }
{ "название": "Шейн Си" }
{ "индекс": { "_id": "3" } }
{ "title": "Шейн П. Коннелли" }
{ "индекс": { "_id": "4" } }
{ "title": "Шейн Коннелли" }
{ "индекс": { "_id": "5" } }
{ "title": "Шейн Шейн Коннелли Коннелли" }
{ "индекс": { "_id": "6" } }
{ "title": "Шейн Шейн Шейн Коннелли Коннелли Коннелли" }
POST люди2/_doc/_bulk
{ "индекс": { "_id": "1" } }
{ "название": "Шейн" }
{ "индекс": { "_id": "2" } }
{ "название": "Шейн Си" }
{ "индекс": { "_id": "3" } }
{ "title": "Шейн П. Коннелли" }
{ "индекс": { "_id": "4" } }
{ "title": "Шейн Коннелли" }
{ "индекс": { "_id": "5" } }
{ "title": "Шейн Шейн Коннелли Коннелли" }
{ "индекс": { "_id": "6" } }
{ "title": "Шейн Шейн Шейн Коннелли Коннелли Коннелли" }
POST люди3/_doc/_bulk
{ "индекс": { "_id": "1" } }
{ "название": "Шейн" }
{ "индекс": { "_id": "2" } }
{ "название": "Шейн Си" }
{ "индекс": { "_id": "3" } }
{ "title": "Шейн П. Коннелли" }
{ "индекс": { "_id": "4" } }
{ "title": "Шейн Коннелли" }
{ "индекс": { "_id": "5" } }
{ "title": "Шейн Шейн Коннелли Коннелли" }
{ "индекс": { "_id": "6" } }
{ "title": "Шейн Шейн Шейн Коннелли Коннелли Коннелли" }
Теперь, когда мы делаем:
ПОЛУЧИТЬ /люди/_поиск
{
"запрос": {
"совпадение": {
"название": "Шейн"
}
}
}
Мы видим у людей, что все документы имеют оценку 0,074107975. Это соответствует нашему пониманию установки k1 на 0: для оценки имеет значение только IDF поискового запроса!
Теперь проверим people2, у которого b = 0 и k1 = 10:
ПОЛУЧИТЬ /people2/_search
{
"запрос": {
"совпадение": {
"название": "Шейн"
}
}
}
Из результатов этого поиска следует сделать вывод о двух вещах.
Во-первых, мы видим, что результаты упорядочены исключительно по количеству появлений «шейн». Документы 1, 2, 3 и 4 получили «шейн» один раз и, таким образом, имеют одинаковую оценку 0,074107975. Документ 5 имеет «шейн» дважды, поэтому имеет более высокий балл (0,13586462) благодаря f («шейн», D5) = 2, а документ 6 снова имеет более высокий балл (0,18812023) благодаря f («шейн», D6) = 3. Это согласуется с нашей интуицией, когда мы устанавливаем b равным 0 в people2: длина — или общее количество терминов в документе — не влияет на оценку; только количество и релевантность совпадающих терминов.
Во-вторых, следует отметить, что разница между этими оценками нелинейна, хотя для этих 6 документов она кажется довольно близкой к линейной.
- Разница в оценке между NO вхождениями из нашего поискового термина и первым — 0,074107975
- Разница в оценке между добавлением секунды нашего поискового термина, а первая — 0,13586462 — 0,074107975 = 0,06117566664596462 — 0,074107975 = 0,06117566664596462 — 0,074107975 = 0,06117666664596462 — 0,074107975 = 0,0617566666645962 — 0,074107975. разница между добавлением третье вхождение нашего поискового запроса, а второе 0,18812023 — 0,13586462 = 0,05225561
0,074107975 довольно близко к 0,061756645, что очень близко к 0,05225561, но они явно уменьшаются. Причина, по которой это выглядит почти как линейных, заключается в том, что k1 велико. По крайней мере, мы можем видеть, что оценка не увеличивается линейно с дополнительными вхождениями — если бы они были, мы ожидали бы увидеть ту же разницу с каждым дополнительным термином. Мы вернемся к этой идее после проверки людей3.
Теперь проверим people3, у которого k1 = 5 и b = 1:
GET /people3/_search
{
"запрос": {
"совпадение": {
"название": "Шейн"
}
}
}
Возвращаем следующие хиты:
"попадания": [
{
"_index": "люди3",
"_тип": "_doc",
"_id": "1",
"_score": 0,16674294,
"_источник": {
"title": "Шейн"
}
},
{
"_index": "люди3",
"_тип": "_doc",
"_id": "6",
"_score": 0,10261105,
"_источник": {
"title": "Шейн Шейн Шейн Коннелли Коннелли Коннелли"
}
},
{
"_index": "люди3",
"_тип": "_doc",
"_id": "2",
"_score": 0,102611035,
"_источник": {
"title": "Шейн Си"
}
},
{
"_index": "люди3",
"_тип": "_doc",
"_id": "4",
"_score": 0,102611035,
"_источник": {
"title": "Шейн Коннелли"
}
},
{
"_index": "люди3",
"_тип": "_doc",
"_id": "5",
"_score": 0,102611035,
"_источник": {
"title": "Шейн Шейн Коннелли Коннелли"
}
},
{
"_index": "люди3",
"_тип": "_doc",
"_id": "3",
"_score": 0,074107975,
"_источник": {
"title": "Шейн П. Коннелли"
}
}
]
Мы можем видеть на примере людей3, что теперь отношение совпадающих терминов («шейн») к несовпадающим — это единственное, что влияет на относительную оценку. Таким образом, такие документы, как документ 3, в котором только 1 термин соответствует из 3 баллов ниже 2, 4, 5 и 6, все из которых соответствуют ровно половине терминов, и все они имеют меньшие баллы, чем документ 1, который точно соответствует документу.
Опять же, мы можем отметить, что существует «большая» разница между документами с наивысшей оценкой и документами с более низкой оценкой для людей2 и людей3. Это благодаря (опять же) большому значению k1. В качестве дополнительного упражнения попробуйте удалить людей2/людей3 и снова установить для них что-то вроде k1 = 0,01, и вы увидите, что оценки между документами с меньшим количеством документов меньше. При b = 0 и k1 = 0,01:
- The score difference between having no occurrences of our search term and the first is 0. 074107975
- The score difference between adding a second occurrence of our search term and the first is 0.074476674 — 0.074107975 = 0.000368699
- The score разница между добавлением третьего вхождения нашего поискового термина и второго составляет 0,07460038 — 0,074476674 = 0,000123706
Таким образом, при k1 = 0,01 мы видим, что влияние оценки каждого дополнительного вхождения падает намного быстрее, чем при k1 = 5 или k1 = 10. 4 9Вхождение 0027-й добавит к счету гораздо меньше, чем 3 -й -й и так далее. Другими словами, при этих меньших значениях k1 показатели термина насыщаются намного быстрее. Как мы и ожидали!
Надеюсь, это поможет увидеть, что эти параметры делают с различными наборами документов. Обладая этими знаниями, мы затем перейдем к тому, как выбрать подходящие b и k1 и как Elasticsearch предоставляет инструменты для понимания оценок и повторения вашего подхода.
Продолжите эту серию: Часть 3: Рекомендации по выбору b и k1 в Elasticsearch
Понимание TF-IDF и BM-25 — KMW Technology
Введение
Эта статья предназначена для специалистов по поиску, которые хотят получить глубокое понимание функций ранжирования TF-IDF и BM25 (также называемых «сходствами» в Lucene). ). Если вы похожи на многих практиков, вы уже знакомы с TF-IDF, но когда вы впервые увидели сложную формулу BM25, вы подумали «может быть, позже». Пришло время, наконец, понять это! Вы, наверное, слышали, что BM25 похож на TF-IDF, но на практике работает лучше. Эта статья покажет вам, как именно BM25 основывается на TF-IDF, какие у него параметры и почему он так эффективен. Если вы предпочитаете пропустить математику и работать с практическими примерами, демонстрирующими поведение BM25, ознакомьтесь с нашей сопутствующей статьей «Понимание оценки на примерах».
Обзор TF-IDF
Давайте рассмотрим TF-IDF, попробовав разработать его с нуля. Представьте, что мы создаем поисковую систему. Предположим, у нас уже есть способ найти документы, которые соответствуют запросу пользователя. Теперь нам нужна функция ранжирования , которая подскажет нам, как упорядочить эти документы. Чем выше оценка документа по этой функции, тем выше мы поместим его в списке результатов, которые мы возвращаем пользователю.
Целью TF-IDF и аналогичных функций ранжирования является вознаграждение релевантность . Допустим, пользователь ищет слово «собаки». Если Документ 1 больше относится к теме собак, чем Документ 2, то мы хотим, чтобы оценка Документа 1 была выше, чем оценка Документа 2, поэтому мы сначала покажем лучший результат, и пользователь будет доволен. Насколько выше должна быть оценка Документа 1? На самом деле это не имеет значения, если порядок оценок соответствует порядку релевантности.
Вы можете быть немного шокированы дерзостью того, что мы пытаемся сделать: мы попытаемся оценить релевантность миллионов или миллиардов документов, используя математическую функцию, ничего не зная о человеке, который делает поиска, причем фактически не читая документы и не понимая, о чем они! Как это возможно?
Мы сделаем простое, но чрезвычайно полезное предположение. Мы предполагаем, что чем больше раз документ содержит термин, тем больше вероятность того, что он будет о этом термине. Другими словами, мы будем использовать частоту термина (TF) , количество вхождений термина в документе, в качестве показателя релевантности. Это единственное предположение открывает нам путь к решению, казалось бы, невозможной проблемы с помощью простой математики. Наше предположение не идеально, и иногда оно идет очень неправильно, но оно работает достаточно часто, чтобы быть полезным. Итак, с этого момента мы будем рассматривать частоту терминов как благо — то, что мы хотим вознаграждать.
TF-IDF: попытка 1
В качестве отправной точки для нашей функции ранжирования давайте сделаем самое простое из возможных. Мы установим оценку документа, равную его частоте терминов. Если мы ищем термин T и оцениваем релевантность документа D, то:
оценка(D, T) = termFrequency(D, T)
Когда запрос содержит несколько терминов, например «собаки и кошки», как мы должны справиться с этим? Должны ли мы попытаться проанализировать взаимосвязь между различными терминами, а затем сложным образом смешать баллы по каждому термину? Не так быстро! Самый простой подход — просто сложить баллы за каждый термин вместе. Так и будем делать, будем надеяться на лучшее. Если у нас есть многотерминальный запрос Q, то мы установим:
score(D, Q) = сумма по всем терминам T в Q score(D, T)
Насколько хорошо работает наша простая функция ранжирования? К сожалению, у него есть некоторые проблемы:
1) Более длинные документы получают несправедливое преимущество перед более короткими, потому что в них больше места для включения большего количества вхождений термина, даже если они могут быть не более релевантными этому термину. Давайте пока проигнорируем эту проблему.
2) Все термины в запросе обрабатываются одинаково, без учета того, какие из них более значимы или важны. Когда мы суммируем баллы за каждый термин вместе, незначительные термины, такие как «и» и «то», которые встречаются очень часто, будут доминировать в объединенном балле. Допустим, вы ищете «слоны и коровы». Возможно, в указателе есть единственный документ, включающий все три термина («слоны», «и», «коровы»), но вместо того, чтобы сначала увидеть этот идеальный результат, вы видите документ, в котором «и» встречается больше всего — может быть, у него 10 000 из них. Это предпочтение слов-заполнителей явно не то, что нам нужно.
TF-IDF: Попытка 2
Чтобы предотвратить доминирование слов-заполнителей, нам нужен способ оценки важности терминов в запросе. Поскольку мы не можем закодировать понимание естественного языка в нашу функцию оценки, мы попытаемся найти прокси для важности. Лучше всего выбрать редкости . Если термин не встречается в большинстве документов корпуса, то всякий раз, когда он встречается, мы предполагаем, что это появление значимо. С другой стороны, если термин встречается в большинстве документов нашего корпуса, то присутствие этого термина в каком-либо конкретном документе теряет свою ценность как показатель релевантности.
Таким образом, высокая частота терминов — это хорошо, но ее достоинства компенсируются высокой частотой документов (DF) — количеством документов, содержащих термин — что мы будем считать плохим явлением.
Чтобы обновить нашу функцию таким образом, чтобы вознаграждать частоту терминов, но снижать частоту документов, мы можем попробовать разделить TF на DF:
score(D, T) = termFrequency(D, T) / docFrequency(T)
Что не так с этим? К сожалению, DF сам по себе ничего нам не говорит. Если DF для термина «слон» равен 100, то является ли термин «слон» редким термином или общепринятым термином? Это зависит от размера корпуса. Если корпус содержит 100 документов, «слон» — обычное явление, если он содержит 100 000 документов, «слон» — редкость.
TF-IDF: попытка 3
Вместо того, чтобы рассматривать DF отдельно, давайте посмотрим на N/DF, где N — размер поискового индекса или корпуса. Обратите внимание, что N/DF является низким для общеупотребительных терминов (100 вхождений слова «слон» в корпусе размером 100 дадут N/DF = 1) и высоким для редких (100 вхождений «слон» в корпусе размером 100 000 будет дают N/DF = 1000). Это именно то, чего мы хотим: совпадения для распространенных терминов должны получать низкие баллы, а совпадения для редких терминов — высокие. Наша улучшенная формула может выглядеть так:
score(D, T) = termFrequency(D, T) * (N / docFrequency(T))
У нас дела обстоят лучше, но давайте подробнее рассмотрим, как ведет себя N/DF. Допустим, у нас есть 100 документов, и в одном из них встречается слово «слон», а в двух — слово «жираф». Оба термина одинаково редки, но значение N/DF для слона будет равно 100, а для жирафа будет вдвое меньше, т.е. 50. Если совпадение для жирафа получит половину оценки соответствия для слона только потому, что частота документирования жирафа на единицу выше, чем у слона ? Штраф за одно дополнительное появление слова в корпусе кажется слишком высоким. Возможно, если у нас есть 100 документов, не должно иметь большого значения, равен ли DF термина 1, 2, 3 или 4 .
TF-IDF: Попытка 4
Как мы видели, когда DF находится в очень низком диапазоне, небольшие различия в DF могут иметь существенное влияние на N/DF и, следовательно, на оценку. Мы могли бы сгладить снижение N/DF, когда DF находится в нижней части своего диапазона. Один из способов сделать это — взять журнал N/DF. Если бы мы захотели, мы могли бы попробовать использовать здесь другую функцию сглаживания, но функция log проста и делает то, что нам нужно. На этой диаграмме сравниваются N/DF и log(N/DF), предполагая, что N=100:
Назовем log(N/DF) обратную частоту документа (IDF) термина. Наша функция ранжирования теперь может быть выражена как TF * IDF или:
score(D, T) = termFrequency(D, T) * log(N / docFrequency(T))
Мы пришли к традиционному определению TF-IDF, и хотя мы сделали несколько смелых допущений, на практике эта функция работает довольно хорошо: она накопила длинный послужной список успешного применения в поисковых системах. Мы закончили или можем сделать еще лучше?
Разработка BM25
Как вы могли догадаться, мы не готовы останавливаться на TF-IDF. В этом разделе мы создадим функцию BM25, которую можно рассматривать как улучшение TF-IDF. Мы сохраним ту же структуру формулы TF * IDF, но заменим компоненты TF и IDF уточнениями этих значений.
Шаг 1: Насыщение сроков
Мы говорили, что TF — это хорошо, и наша формула TF-IDF действительно вознаграждает это. Но если в документе 200 вхождений слова «слон», действительно ли это 9 0003 дважды так же актуален, как и документ, содержащий 100 вхождений? Мы могли бы утверждать, что если слово «слон» встречается достаточно много раз, скажем, 100, документ почти наверняка релевантен, и любые дальнейшие упоминания не увеличивают вероятность релевантности. Иными словами, когда документ насыщен вхождений термина, большее количество вхождений не должно оказывать существенного влияния на оценку. Поэтому нам нужен способ контролировать вклад TF в наш счет. Мы хотели бы, чтобы этот вклад быстро увеличивался, когда TF мал, а затем увеличивался медленнее, приближаясь к пределу, когда TF становится очень большим.
Один из распространенных способов приручить TF — извлечь из него квадратный корень, но это все равно неограниченная величина. Мы хотели бы сделать что-то более изощренное. Мы хотели бы установить ограничение на вклад TF в счет, и мы хотели бы иметь возможность контролировать, насколько быстро вклад приближается к этому пределу. Было бы неплохо, если бы у нас был параметр k , который мог бы управлять формой этой кривой насыщения? Таким образом, мы сможем поэкспериментировать с различными значениями k и посмотреть, что лучше всего подходит для конкретного корпуса.
Для этого мы проделаем трюк. Вместо того, чтобы использовать необработанный TF в нашей формуле ранжирования, мы будем использовать значение:
TF / (TF + k)
Если для k установлено значение 1, будет сгенерирована последовательность 1/2, 2/3, 3/4, 4/5, 5/6 по мере увеличения TF на 1, 2, 3 и т. д. Обратите внимание, как эта последовательность растет быстро в начале, а затем медленнее, приближаясь к 1 с меньшими и меньшими приращениями. Это то, чего мы хотим. Теперь, если мы изменим k на 2, мы получим 1/3, 2/4, 3/5, 4/6, которые растут немного медленнее. Вот график формулы TF/(TF + k) для k = 1, 2, 3, 4:
Этот трюк TF/(TF + k) действительно является основой BM25. Это позволяет нам контролировать вклад TF в счет настраиваемым образом.
Дополнительно: насыщение терминов и многотерминальные запросы
Удачным побочным эффектом использования TF/(TF + k) для учета насыщения терминов является то, что мы в конечном итоге награждаем полные совпадения по сравнению с частичными. Другими словами, мы отдаем предпочтение документам, которые соответствуют большему количеству терминов в многотерминальном запросе, а не документам, которые имеют много совпадений только для одного из терминов.
Предположим, что «кошка» и «собака» имеют одинаковые значения IDF. Если мы ищем «кошка-собака», мы хотели бы, чтобы документ, содержащий по одному экземпляру каждого термина, работал лучше, чем документ, в котором есть два экземпляра «кошка» и ни одного «собака». Если бы мы использовали необработанный TF, они оба получили бы одинаковую оценку. Но давайте сделаем наш улучшенный расчет, предполагая, что k=1. В нашем документе «кошка-собака» «кошка» и «собака» имеют TF = 1, поэтому каждый будет вносить TF/(TF + 1) = 1/2 в оценку, что в сумме составляет 1. В нашем Документ «кошка кошка», «кошка» имеет TF 2, поэтому она будет вносить TF/(TF+1) = 2/3 в оценку. Документ «кошка-собака» выигрывает, потому что «кошка» и «собака» вносят больший вклад, когда каждое встречается один раз, чем «кошка», когда встречается дважды.
Предполагая, что IDF двух терминов одинакова, всегда лучше иметь один экземпляр каждого термина, чем два экземпляра одного из них.
Шаг 2: Длина документа
Теперь давайте вернемся к проблеме, которую мы пропустили при первом создании TF-IDF: длина документа. Если документ оказался очень коротким и в нем один раз встречается слово «слон», это хороший показатель того, что слово «слон» важно для содержимого. Но если документ очень-очень длинный и в нем упоминается слон только один раз, вероятно, документ не о слонах. Поэтому мы хотели бы вознаграждать совпадения в коротких документах и наказывать совпадения в длинных документах. Как мы можем этого добиться?
Во-первых, мы должны решить, что означает для документа быть коротким или длинным. Нам нужна система отсчета, поэтому мы будем использовать сам корпус в качестве нашей системы отсчета. Короткий документ – это документ, который на 90 003 короче, чем в среднем на 90 006 для всего корпуса.
Вернемся к нашему фокусу TF/(TF + k). Конечно, по мере увеличения k значение TF/(TF + k) уменьшается. Чтобы наказать длинные документы, мы можем увеличить k, если документ длиннее среднего, и уменьшить его, если документ короче среднего. Мы добьемся этого, умножив k на отношение дл/адл . Здесь dl — длина документа, а adl — средняя длина документа по всему корпусу.
Когда документ средней длины, dl/adl =1, и наш множитель вообще не влияет на k. Для документа короче среднего мы будем умножать k на значение от 0 до 1, тем самым уменьшая его и увеличивая TF/(TF+k). Для документа, который длиннее среднего, мы будем умножать k на значение больше 1, тем самым увеличивая его и уменьшая TF/(TF+k). Множитель также ставит нас на другую кривую насыщения TF. Более короткие документы будут приближаться к точке насыщения TF быстрее, в то время как более длинные документы будут приближаться к ней более постепенно.
Шаг 3: Параметризация длины документа
В предыдущем разделе мы обновили нашу функцию ранжирования для учета длины документа, но всегда ли это хорошая идея? Насколько большое значение мы должны придавать длине документа в любом конкретном корпусе? Могут ли быть какие-то наборы документов, где длина имеет большое значение, а в каких нет? Мы могли бы рассматривать важность длины документа как второй параметр, с которым мы можем поэкспериментировать.
Мы собираемся добиться этой настраиваемости с помощью другого трюка. Мы добавим новый параметр b в смесь (должно быть между 0 и 1). Вместо умножения k на dl/adl, как мы делали раньше, мы умножим k на следующее значение на основе dl/adl и b:
1 – b + b*dl/adl
Что это делает для нас? Вы можете видеть, что если b равно 1, мы получаем (1 – 1 + 1*dl/adl), и это сводится к множителю, который у нас был раньше, dl/adl. С другой стороны, если b равно 0, все становится равным 1, а длина документа вообще не учитывается. Когда b увеличивается от 0 до 1, множитель быстрее реагирует на изменения в dl/adl. На приведенной ниже диаграмме показано, как ведет себя наш множитель при росте dl/adl, когда b=0,2 по сравнению с b=0,8.
Резюме: Fancy TF
Напомним, что мы работали над изменением термина TF в TF * IDF, чтобы он реагировал на насыщенность терминов и длину документа. Чтобы учесть насыщение терминов, мы ввели прием TF/(TF + k). Чтобы учесть длину документа, мы добавили множитель (1 – b + b*dl/adl). Теперь вместо того, чтобы использовать необработанный TF в нашей функции ранжирования, мы используем эту «причудливую» версию TF:
TF/(TF + k*(1 - b + b*dl/adl))
Отзыв что k — это ручка, которая управляет кривой насыщения термина, а b — это ручка, которая управляет важностью длины документа.
Действительно, это версия TF, используемая в BM25. И поздравляю: если вы дочитали до этого места, теперь вы понимаете все самое интересное о BM25.
Шаг 4: Причудливый или не такой причудливый IDF
Мы еще не закончили, мы должны вернуться к тому, как BM25 обрабатывает частоту документов. Раньше мы определяли IDF как log(N/DF), но BM25 определяет его как:
log((N - DF + .5)/(DF + .5))
В чем разница?
Как вы могли заметить, мы разрабатывали нашу функцию подсчета очков с помощью набора эвристик. Исследователи в области информационного поиска хотели поставить функции ранжирования на более строгую теоретическую основу, чтобы они могли на самом деле доказывать что-то об их поведении, а не просто экспериментировать и надеяться на лучшее. Чтобы вывести теоретически обоснованную версию IDF, исследователи взяли то, что называется весом Робертсона-Спарка-Джонса, сделали упрощающее предположение и получили log (N-DF+0,5)/(DF+0,5). Мы не будем вдаваться в подробности, а просто сосредоточимся на практической значимости этой разновидности IDF. .5 здесь мало что делают, поэтому давайте просто рассмотрим log (N-DF)/DF, который иногда называют «вероятностным IDF». Здесь мы сравниваем нашу ванильную IDF с вероятностной IDF, где N=10.
Вы можете видеть, что вероятностный IDF резко падает для терминов, которые есть в большинстве документов. Это может быть желательно, потому что, если термин действительно существует в 98 % документов, он, вероятно, является стоп-словом, таким как «и» или «или», и он должен иметь гораздо, гораздо меньший вес, чем термин, который очень распространен, например, в 70 % документов. документы, но все еще не совсем вездесущи.
Загвоздка в том, что log (N-DF)/DF отрицателен для терминов, которые находятся более чем в половине корпуса. (Помните, что функция журнала становится отрицательной при значениях от 0 до 1.) Мы не хотим, чтобы отрицательные значения выходили из нашей функции ранжирования, потому что наличие термина запроса в документе никогда не должно учитываться при поиске — оно никогда не должно приводить к ошибке. более низкий балл, чем если бы термин просто отсутствовал. Чтобы предотвратить отрицательные значения, реализация Lucene BM25 добавляет 1 следующим образом:
IDF = log (1 + (N - DF + .5)/(DF + .5))
Эта 1 может показаться невинной модификацией, но она полностью меняет поведение формулы! Если мы снова забудем об этих надоедливых .5 и заметим, что добавление 1 равносильно добавлению DF/DF, вы увидите, что формула сводится к ванильной версии IDF, которую мы использовали раньше: log (N/DF).
log (1 + (N - DF + 0,5)/(DF + 0,5)) ≈ log (1 + (N - DF)/DF ) = log (DF/DF + (N - DF)/DF) = log ((DF + N - DF)/DF) = журнал (N/DF)
Таким образом, хотя кажется, что BM25 использует причудливую версию IDF, на практике (как реализовано в Lucene) в основном используется та же старая версия IDF, которая используется в традиционных TF/IDF, без ускоренного снижения для высоких значений DF. .
Обналичивание
Мы готовы извлечь выгоду из нашего нового понимания, взглянув на результат объяснения запроса Lucene. Вы увидите что-то вроде этого:
«оценка (частота = 3,0), произведение:» «idf, рассчитанный как log (1 + (N — n + 0,5) / (n + 0,5)) из:» «tf, вычисляется как freq / (freq + k1 * (1 — b + b * dl / avgdl)) из:»
Наконец-то мы готовы понять эту абракадабру. Вы можете видеть, что Lucene использует продукт TF*IDF, где TF и IDF имеют свои специальные определения BM25. Нижняя буква n здесь означает DF. Термин IDF — это якобы причудливая версия, которая оказывается такой же, как и традиционная IDF, N/n.
Термин TF основан на нашем трюке с насыщением: частота/(частота + k). Использование k1 вместо k в выводе объяснения историческое — это происходит из того времени, когда в формуле было более одного k. То, что мы называем необработанным TF, обозначается как частота здесь.
Мы видим, что k1 умножается на коэффициент, который наказывает длину документа выше среднего, но вознаграждает длину документа ниже среднего: (1-b + b *dl/avgdl). То, что мы называли adl, здесь обозначено как avgdl .
И, конечно же, мы видим, что есть параметры, для которых по умолчанию установлено значение k=1,2 и b = 0,75 в Lucene. Вам, вероятно, не нужно будет настраивать их, но вы можете, если хотите.
Таким образом, простой TF-IDF вознаграждает за частоту терминов и штрафует за частоту документов. BM25 выходит за рамки этого, чтобы учитывать длину документа и насыщенность частоты терминов.
Стоит отметить, что до того, как Lucene представила BM25 в качестве функции ранжирования по умолчанию в версии 6, она реализовала TF-IDF с помощью так называемой функции практической оценки, которая представляла собой набор улучшений (включая «координат» и нормализацию длины поля). это сделало TF-IDF более похожим на BM25. Таким образом, разница в поведении, которую можно было бы наблюдать, когда Lucene переключилась на BM25, была, вероятно, менее существенной, чем если бы Lucene все время использовала чистый TF-IDF.