Содержание
Выявление алгоритмов ранжирования поисковых систем / Хабр
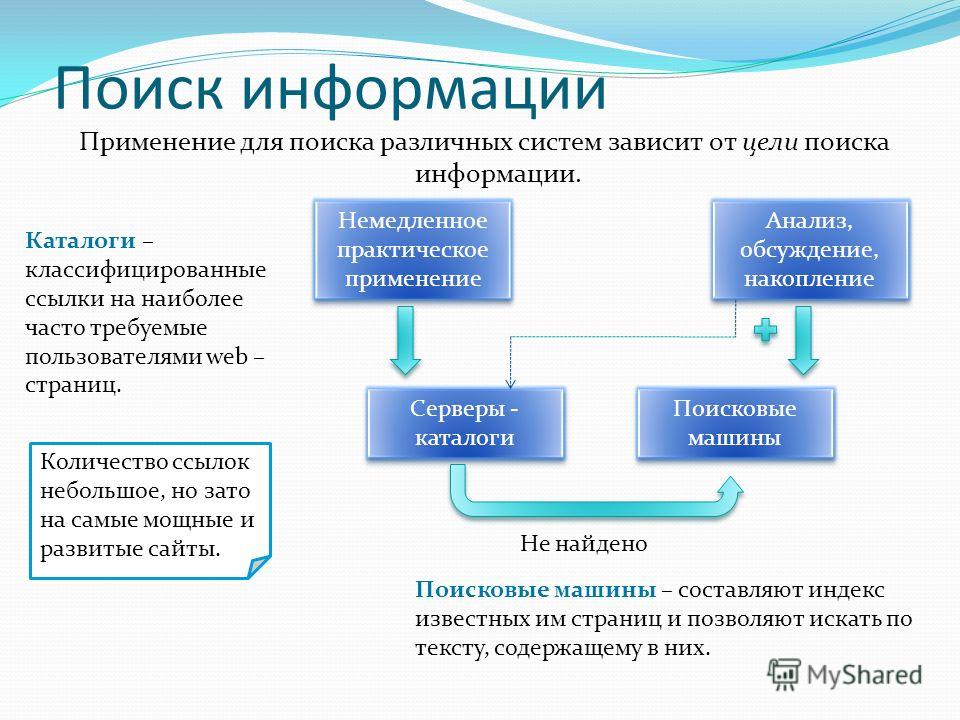
Пища для ума
Когда какое-то время работаешь в сфере SEO, рано или поздно невольно посещают мысли о том, какие же формулы используют поисковики, чтобы поставить сайт в поисковой выдаче выше или ниже. Всем известно, что это все хранится в глубочайшей секретности, а мы, оптимизаторы, знаем только то, что написано в рекомендациях для вебмастеров, и на каких-то ресурсах посвященных продвижению сайтов. А теперь задумайтесь на секунду: что если бы у вас был бы инструмент, который достоверно, с точностью в 80-95% показывал бы, что именно нужно сделать на странице вашего сайта, или на сайте в целом, для того, чтобы по определенному запросу ваш сайт был на первой позиции в выдаче, или на пятой, или просто на первой странице. Мало того, если бы этот инструмент мог бы с такой же точностью определить, на какую позицию выдачи попадете, если выполните те или иные действия. А как только поисковик вводил бы изменения в свою формулу, менял бы важность того или иного фактора, то можно было бы сразу видеть, что конкретно в формуле было изменено. И это только малая доля той информации, которую вы могли бы получить из такого инструмента.
И это только малая доля той информации, которую вы могли бы получить из такого инструмента.
Итак, это не реклама очередного сервиса по продвижению, и это не предоставление конкретной формулы ранжирования сайтов поисковыми системами. Я хочу поделиться своей теорией, на реализацию которой у меня нет ни средств, ни времени, ни достаточных знаний программирования и математики. Но я точно знаю, что даже у тех, у кого все это есть, на реализацию этого может уйти даже не 1 месяц, возможно, 1-1,5 года.
Теория
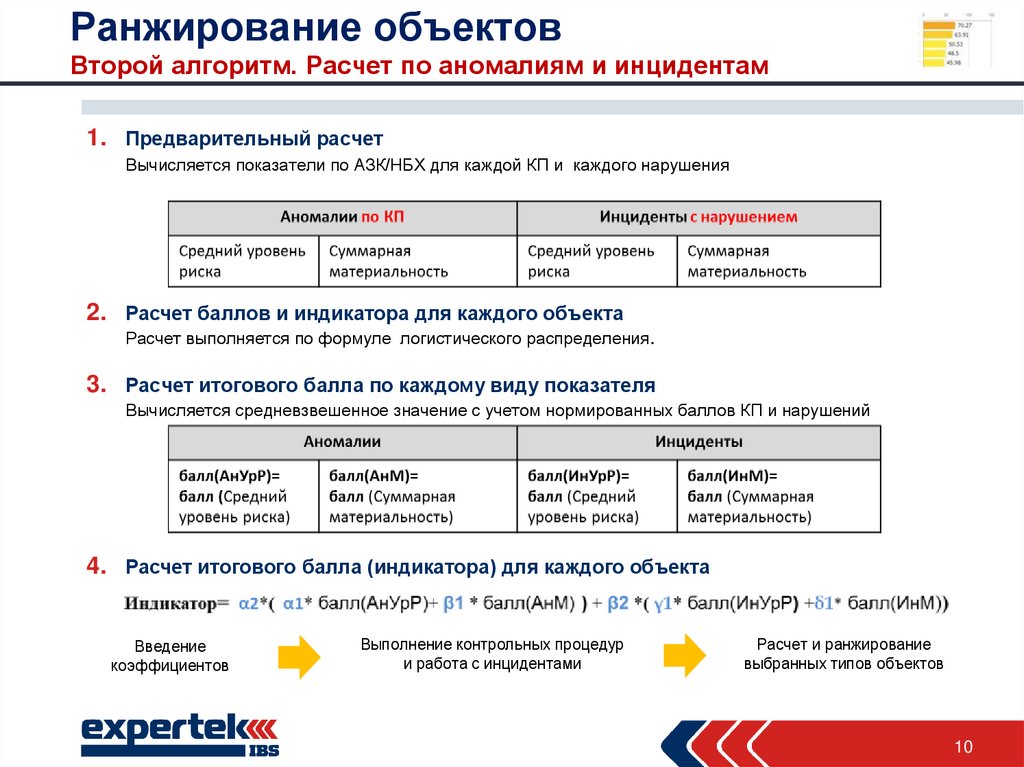
Итак, теория состоит в том, чтобы методом тыка пальцем в небо выяснить, какой фактор влияет на позиции больше или меньше другого фактора. На пальцах это все рассказать очень сложно, поэтому мне пришлось сделать таблицу, которая более менее отобразит то, что я хочу донести.
Посмотрели на таблицу? Теперь к делу. Берем любую ключевую фразу, не важно какую, вводим в поисковик и из выдачи берем первых 10 сайтов, это и будут наши подопытные. Теперь нам нужно сделать следующее: написать код, который будет методом тыка менять значимость у факторов (ЗФ в таблице) ранжирования до тех пор, пока наша программка не расположит сайты таким образом, что бы они точно совпадали с выдачей поисковой системы. То есть мы должны методом тыка повторить алгоритм ранжирования поисковика. Значимость самих факторов мы можем определить только как положительную нейтральную или отрицательную.
Теперь нам нужно сделать следующее: написать код, который будет методом тыка менять значимость у факторов (ЗФ в таблице) ранжирования до тех пор, пока наша программка не расположит сайты таким образом, что бы они точно совпадали с выдачей поисковой системы. То есть мы должны методом тыка повторить алгоритм ранжирования поисковика. Значимость самих факторов мы можем определить только как положительную нейтральную или отрицательную.
Теперь по порядку о таблице и факторах. Условно каждому фактору присваиваем значение от 1 до 800 (примерно). Так как достоверно известно, что у Яндекса, например, факторов ранжирования где-то близко к этому числу. Грубо говоря, у нас максимальное число будет таким, сколько факторов ранжирования нам точно известно. У двух факторов не может быть одинакового числа, то есть у каждого фактора значение уникальное. В таблице для каждого фактора отдельная колоночка, и их очень много, физически мне не удастся на одной картинке все разместить.
Теперь вопрос, как вычислить ранг страницы? Очень просто: для начала простая математика, если фактор положительно влияет, мы к рангу страницы прибавляем ранг фактора, если отрицательно, то прибавляем 0.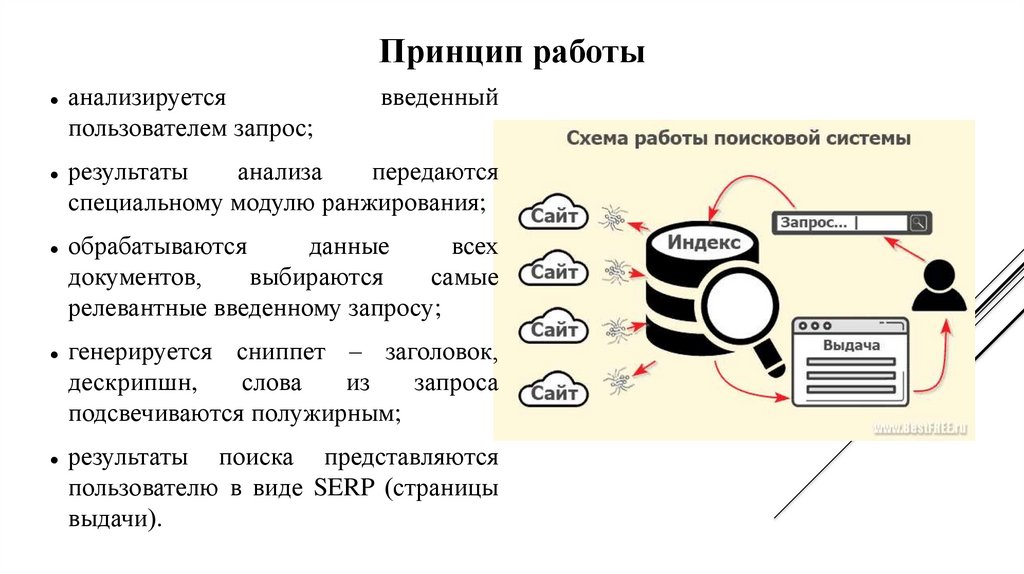 Можно усложнить, сделать 3 варианта и добавить, например, вычитание ранга фактора от ранга страницы, если этот фактор критический, например, грубый спам ключевой фразы.
Можно усложнить, сделать 3 варианта и добавить, например, вычитание ранга фактора от ранга страницы, если этот фактор критический, например, грубый спам ключевой фразы.
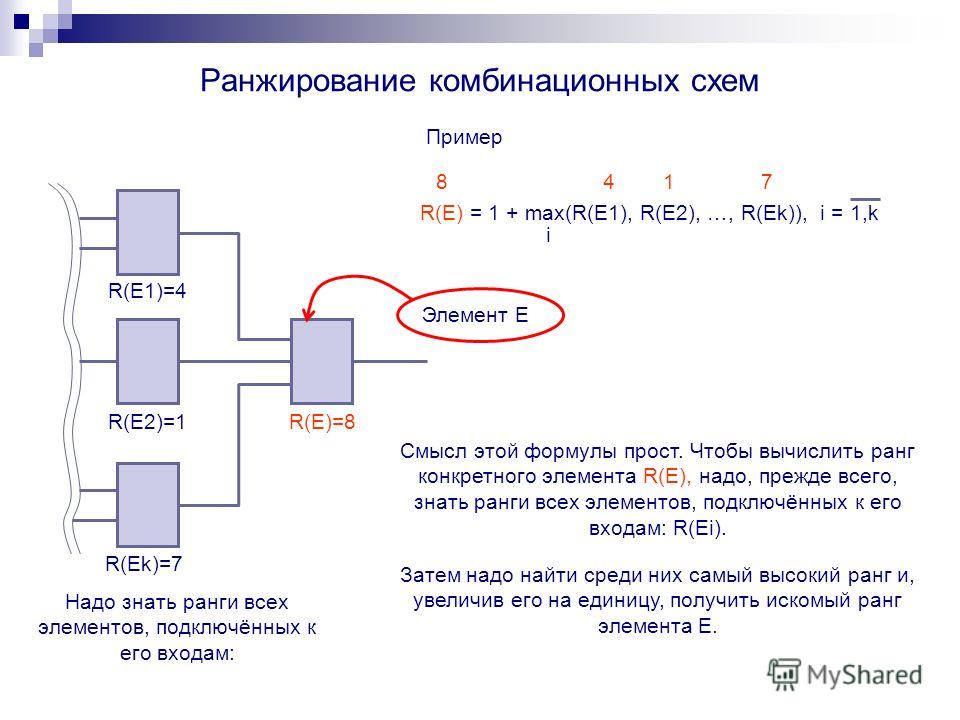
У нас получается примерно такой алгоритм вычисления ранга страницы. Возьмем его за (PR), а фактор возьмем как (F) и тогда:
PR = Берем первый фактор Если F1 положительный, то делать PR + F1, если F1 отрицательный то делать PR — F1, если F1 нейтральный, то не делать ничего, после этого проверяем так же F2, F3, F4 и так далее, пока факторы не кончатся.
А подбор производить таким образом, что бы у каждого фактора попробовать каждое значение ранга. То есть чтобы каждый фактор испробовать в каждом значении.
Вся сложность состоит в том, чтобы учесть все влияющие факторы, вплоть до количества текста на странице и ТИЦа сайта, на котором расположена ссылка на нашу подопытную страницу, и сложность даже не в учете этой информации, а в ее сборе. Потому что вручную собирать всю эту информацию нереально, нужно писать всевозможные парсеры, чтобы наша программка собирала все эти данные автоматически.
Работа очень большая и сложная и требует определенного уровня знаний, но только представьте, какие возможности она откроет после реализации. Я не буду вдаваться во все тонкости вычислений и влияния факторов, не люблю много писанины, мне проще объяснить человеку напрямую.
Сейчас некоторые скажут, что совпадений будет очень много в разных вариациях. Да, будет, но если взять не первую страницу, а, к примеру, первые 50 страниц? Во сколько раз тогда сократится вероятность промаха?
Еще есть сложность в том, что некоторые факторы нам просто негде будет взять, например, мы ни как не сможем учесть поведенческие факторы. Даже если все сайты из выдачи будут под нашим контролем, мы не сможем этого сделать, потому как скорей всего учитываются именно то, как пользователь ведет себя на выдаче, отсюда появляется вторая неизвестная в нашем уравнении, помимо самой позиции.
Что нам даст такой софт после реализации? Нет, точную формулу поисковика он не даст, но точно покажет, какой из факторов влияет на ранжирование сильней, а какой вообще не значительный.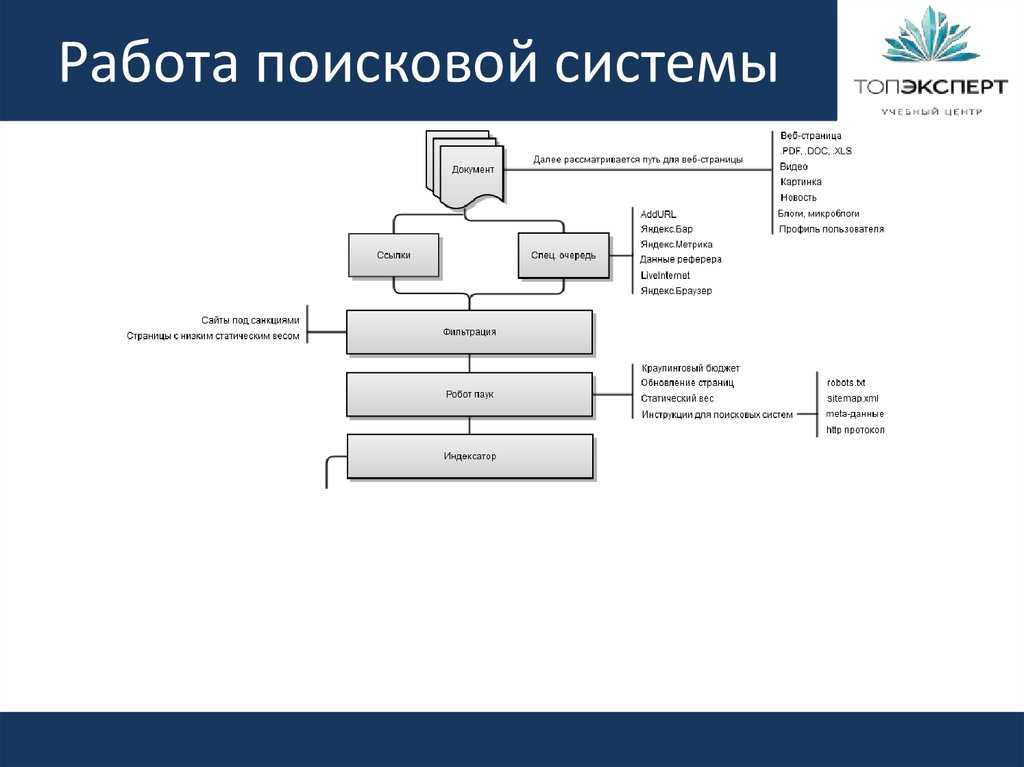 А при продвижении мы сможем в эту формулу подставить страницу своего сайта, со своими параметрами, и еще до того, как начать ее продвижение, увидим, на какой позиции будет страница по определенному запросу после того, как поисковик учтет все изменения.
А при продвижении мы сможем в эту формулу подставить страницу своего сайта, со своими параметрами, и еще до того, как начать ее продвижение, увидим, на какой позиции будет страница по определенному запросу после того, как поисковик учтет все изменения.
В общем, это очень сложная тема, и очень полезная информация для ума, потому как заставляет подумать, хватит, например, мощности одного компьютера на такие вычисления? А если и хватит, то сколько это займет времени к примеру? Если не удовлетворит результат, то формулу как-то можно усложнять, менять, пока не будет 100% точного результата на 100 страницах выдачи. Более того, можно для чистоты эксперимента подключить около 100 различных сайтов и внедрить на них несуществующую ключевую фразу, а потом по этой же ключевой фразе и отследить алгоритм. Вариантов масса. Нужно работать.
| Яндекс | |
| Алгоритмы, анализирующие качество контента | |
Флорида (Florida) Запуск: ноябрь, 2003 г. Особенности:
| Магадан Запуск: май, июль, 2008 г. Особенности:
|
Остин (Austin) Запуск: январь, 2004 г. Особенности:
| АГС-17, АГС-30, АГС-40 Запуск: сентябрь, декабрь, 2009 г., ноябрь, 2012 г. Особенности:
|
Панда (Panda) Запуск: февраль, 2011 г. Особенности:
| Снежинск Запуск: ноябрь, 2009 г. Особенности:
|
Колибри (Hummingbird) Запуск: сентябрь, 2013 г. Особенности:
| Краснодар Запуск: декабрь, 2010 г. Особенности:
|
Пират (Pirate) Запуск: октябрь, 2014 г. Особенности:
| Баден-Баден Запуск: март, 2017 г. Особенности:
|
Фред (Fred) Запуск: март, 2017 г. Особенности:
| |
| Алгоритмы, анализирующие качество ссылок | |
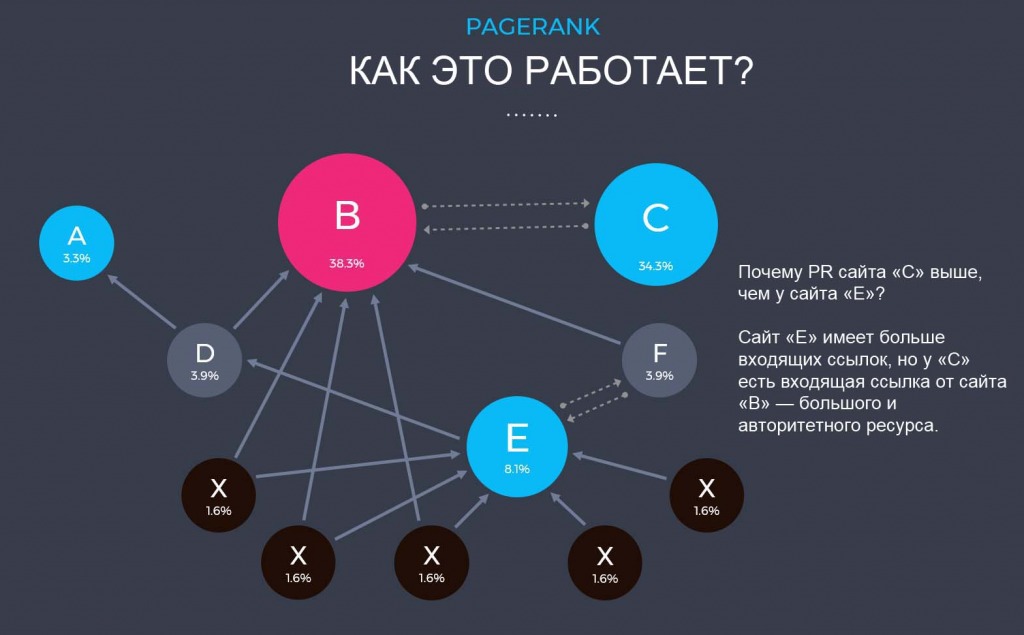
PageRank Запуск: впервые в 1998 г. С тех пор было несколько обновлений. Особенности:
| 8 SP1 Запуск: январь, 2008 г. Особенности:
|
Кассандра (Cassandra) Запуск: апрель, 2003 г. Особенности:
| Обнинск Запуск: сентябрь, 2010 г. Особенности:
|
Хилтоп (Hilltop) Запуск: декабрь, 2010 г. Особенности:
| Минусинск Запуск: май, 2015 г. Особенности:
|
Пингвин (Penguin) Запуск: апрель, 2012 г. Особенности:
| |
| Алгоритмы, анализирующие пригодность сайта для мобильных устройств | |
Mobile friendly Запуск: апрель, 2015 г. Особенности:
| Владивосток Запуск: февраль, 2016 г. Особенности:
|
| Алгоритмы, работающие со сложными и редкими запросами | |
Орион (Orion) Запуск: 2006 г. Особенности:
| Палех Запуск: ноябрь, 2016 г. Особенности:
|
RankBrain Запуск: октябрь, 2015 г. Особенности:
| Королев Запуск: август, 2017 г. Особенности:
|
| Алгоритмы, учитывающие интересы пользователя (персонализация) | |
Персональный поиск Запуск: июнь, 2005 г. Особенности:
| Рейкьявик Запуск: август, 2011 г. Особенности:
|
Search Plus Your World Запуск: январь, 2012 г. Особенности:
| Калининград Запуск: декабрь, 2012 г. Особенности:
|
Дублин Запуск: май, 2013 г. Особенности:
| |
| Алгоритмы, направленные на улучшение качества ранжирования в целом | |
Кофеин (Caffeine) Запуск: июнь, 2010 г. Особенности:
| Находка Запуск: сентябрь, 2008 г. Особенности:
|
| Алгоритмы, отвечающие за региональное ранжирование | |
Опоссум (Possum) Запуск: сентябрь, 2016 г. Особенности:
| Арзамас / Анадырь Запуск: первая версия — апрель, 2009 г.; затем еще несколько версий в июне, августе и сентябре 2009 г. Особенности:
|
Конаково Запуск: декабрь, 2009 г., март 2010 г. Особенности:
| |
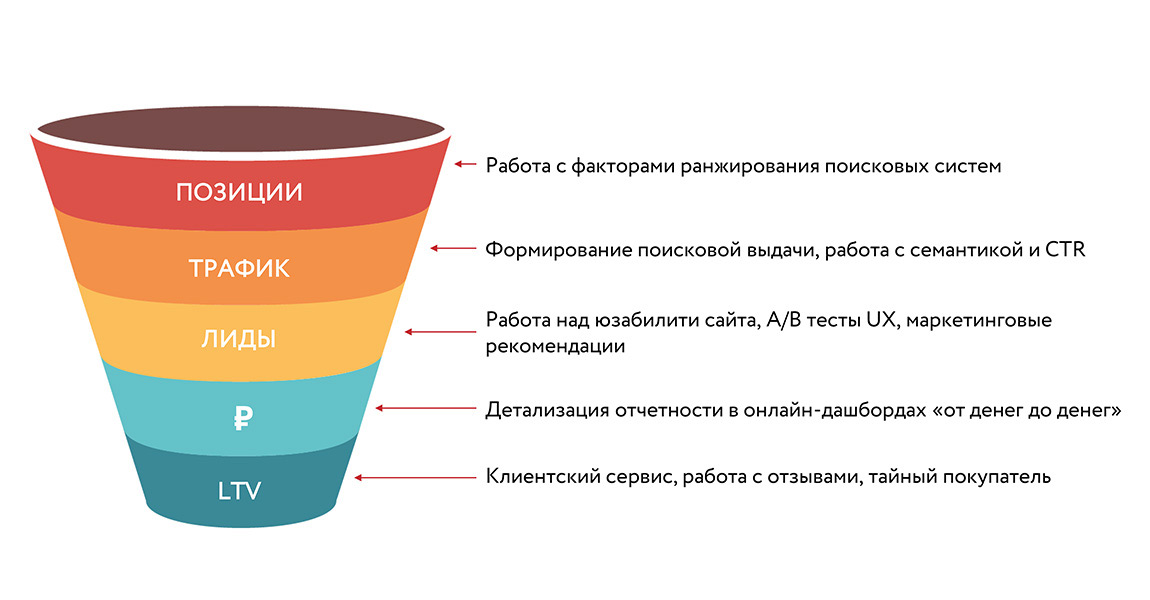
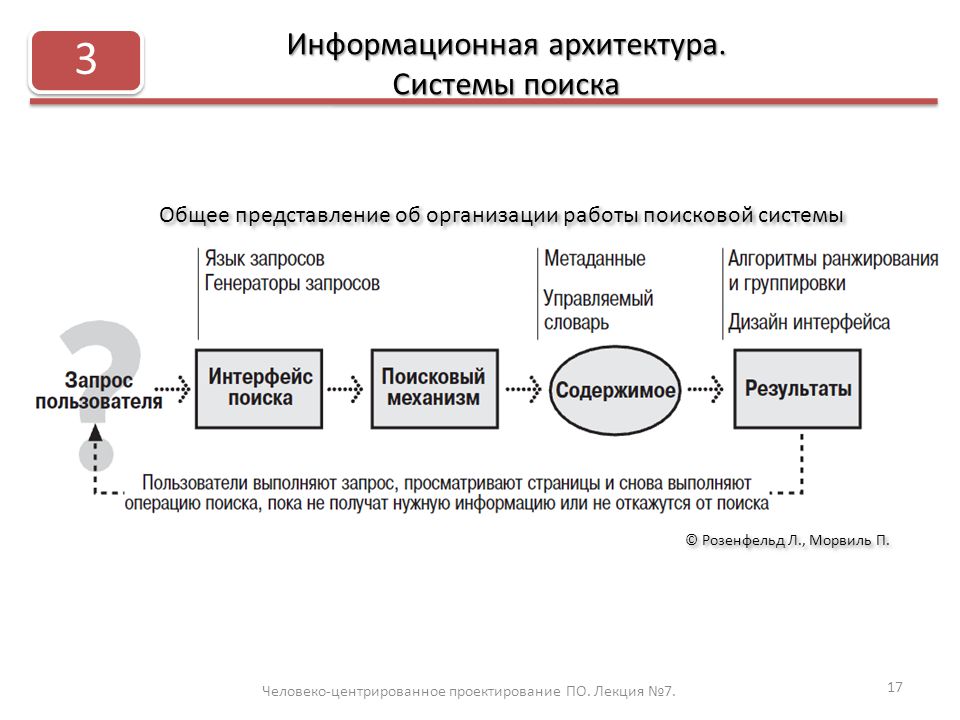
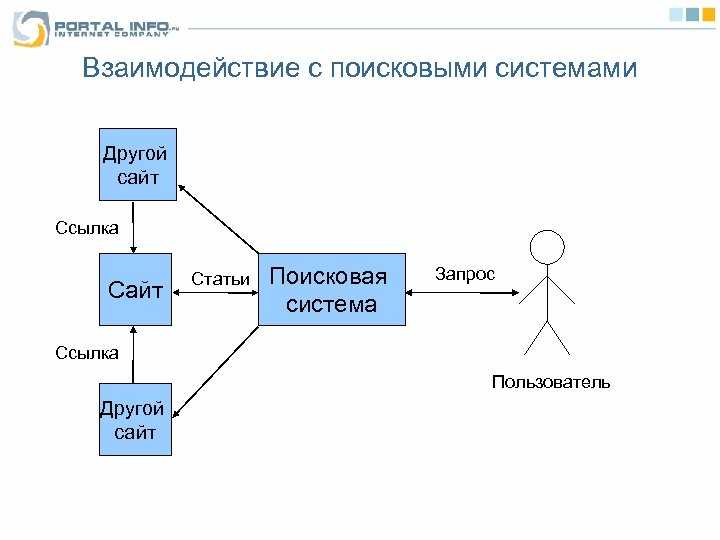
 Чтобы в выдаче оказывались результаты, которые отвечают цели запроса, поисковики используют сложные формулы, учитывающие несколько тысяч сигналов. Механизм ранжирования и фильтрации сайтов на основе содержимых страниц называется алгоритмом.
Чтобы в выдаче оказывались результаты, которые отвечают цели запроса, поисковики используют сложные формулы, учитывающие несколько тысяч сигналов. Механизм ранжирования и фильтрации сайтов на основе содержимых страниц называется алгоритмом.




Как работает алгоритм поиска Google
Билл Видмер
Более 8 лет в качестве цифрового кочевника. Билл путешествует по миру и финансирует его с помощью SEO и контент-маркетинга.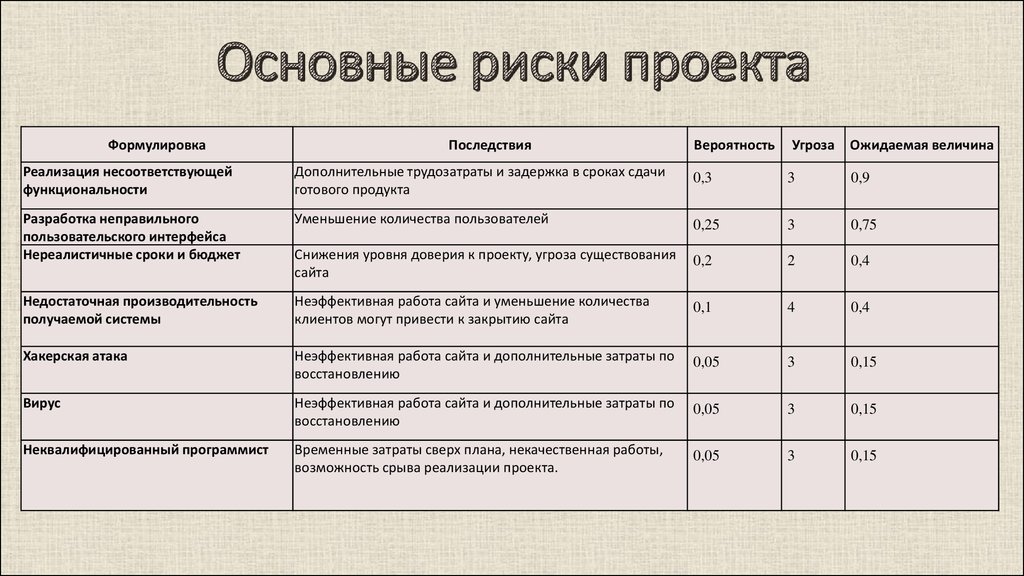
СТАТИЯ СТАТИСТВА
Ежемесячный трафик 2158
Связывание веб -сайтов 125
твиты 43
. содержание. Как правило, чем больше веб-сайтов ссылаются на вас, тем выше ваш рейтинг в Google.
Показывает расчетный месячный поисковый трафик этой статьи по данным Ahrefs. Фактический поисковый трафик (по данным Google Analytics) обычно в 3-5 раз больше.
Сколько раз этой статьей поделились в Твиттере.
Поделитесь этой статьей
Подпишитесь на еженедельные обновления
Подписка по электронной почте
Подпишитесь
Содержание
Алгоритм поиска Google, безусловно, является одной из самых влиятельных технологий, когда-либо созданных. Приблизительно 5,6 миллиарда поисковых запросов Google в день позволяют с уверенностью сказать, что Google оказывает сильное влияние на мир и на ваш бизнес.
Приблизительно 5,6 миллиарда поисковых запросов Google в день позволяют с уверенностью сказать, что Google оказывает сильное влияние на мир и на ваш бизнес.
Но что такое алгоритм поиска Google? Как это работает? И, самое главное, как вы можете получить более высокий рейтинг в Google и получить больше трафика?
Это руководство пытается демистифицировать загадочный алгоритм поиска Google:
- Что такое алгоритм поиска Google?
- Как работает алгоритм поиска Google?
- Каковы факторы ранжирования алгоритма поиска Google?
- Заметка об обновлениях алгоритма Google
- Где найти официальные обновления Google
Что такое алгоритм поиска Google?
Алгоритм поиска Google относится к процессу, который Google использует для ранжирования контента. Он учитывает сотни факторов, включая упоминания ключевых слов, удобство использования и обратные ссылки.
Примечание.
У Google есть несколько поисковых алгоритмов, работающих вместе для получения наилучших результатов. В этой статье мы сосредоточимся в основном на алгоритме (алгоритмах) ранжирования Google, поскольку мы считаем, что большинство людей имеют в виду именно его, когда говорят об алгоритме поиска Google.
В этой статье мы сосредоточимся в основном на алгоритме (алгоритмах) ранжирования Google, поскольку мы считаем, что большинство людей имеют в виду именно его, когда говорят об алгоритме поиска Google.
Как работает алгоритм поиска Google?
Алгоритм Google чрезвычайно сложен, и то, как он работает, не является общедоступной информацией. Считается, что существует более 200 факторов ранжирования, и никто не знает их всех.
Даже если они это сделают, это не будет иметь значения, потому что алгоритм постоянно меняется. Google выпускает обновления своего алгоритма в среднем шесть раз в день. Это до 2000 раз в год.
Тем не менее, Google дает подсказки о том, как вы можете занять высокое место в его результатах.
Каковы факторы ранжирования алгоритма поиска Google?
Когда вы думаете об «алгоритме поиска» — в том, что касается поисковой оптимизации (SEO), — первое, что приходит на ум, вероятно, это факторы ранжирования Google. Другими словами, на что обращает внимание Google, решая, какие страницы ранжировать и в каком порядке?
Другими словами, на что обращает внимание Google, решая, какие страницы ранжировать и в каком порядке?
Если мы посмотрим на страницу Google «Как работает поиск», то увидим, что некоторые из наиболее важных факторов ранжирования Google:
- Обратные ссылки
- Свежесть
- Упоминания ключевых слов
- Пользовательский опыт
- Тематический авторитет
Давайте разберем их.
1. Обратные ссылки
Google хочет отображать страницы, на которых «известные веб-сайты по теме ссылаются на страницу». С точки зрения непрофессионала, он хочет видеть обратные ссылки с авторитетных веб-сайтов (которые также актуальны), указывающие на ваши страницы.
Получение этих ссылок называется линкбилдингом, и, возможно, это одна из самых важных задач, которую вы должны выполнить, чтобы заставить Google доверять вашему веб-сайту и отображать его. С момента его создания в 19 году это был самый важный решающий фактор Google в определении надежности сайта. 96.
96.
Вы можете определить, могут ли ссылки препятствовать ранжированию вашего контента, сравнив профиль обратных ссылок вашей страницы с профилями ваших конкурентов.
Сначала вставьте URL-адрес страницы, которую вы пытаетесь ранжировать, в Site Explorer от Ahrefs, и вы увидите, сколько обратных ссылок и ссылающихся доменов (ссылающихся веб-сайтов) на вашей странице в настоящее время.
Затем перейдите в Проводник ключевых слов Ahrefs и введите основное ключевое слово, на которое вы ориентируетесь для этой страницы. Прокрутить вниз. Вы найдете раздел обзора SERP, где вы можете увидеть, сколько обратных ссылок и ссылающихся доменов есть у ваших конкурентов.
Если вы заметили, что на страницы ваших конкурентов больше обратных ссылок, чем на вашу (как на нашу в приведенном выше примере), это означает, что вам, вероятно, нужно расставить приоритеты в создании ссылок, чтобы ранжировать их выше.
Вот несколько стратегий для начала создания ссылок:
- Гостевой блог
- Создание ссылок
- Создание неработающих ссылок
на вашей веб-странице есть.
 Когда в последний раз он обновлялся?
Когда в последний раз он обновлялся?
Этот фактор имеет большее значение для одних запросов, чем для других. Например, если вы ищете что-то, связанное с новостями, Google обычно ранжирует результаты, опубликованные за последние 24 часа.
Однако, если вы ищете тему, которую не нужно обновлять так часто, свежесть не так сильно влияет на нее. Например, лучшие результаты для «идей для хранения RV» были получены более двух лет назад:
Это потому, что хорошие идеи для хранения RV сегодня в основном такие же, как и два года назад. Так что то, как недавно оно было опубликовано, не имеет большого значения. Подобные руководства — это то, что мы называем «вечнозеленым контентом». То есть контент, который будет полезен долгие годы, не нуждаясь в частых обновлениях.
В целом, при определении важности актуальности ключевых слов, на которые вы ориентируетесь, вы всегда должны анализировать SERP для этого ключевого слова. Похоже, что Google ранжирует свежий контент? Если это так, вам нужно будет часто обновлять статью, чтобы иметь шанс оставаться на вершине.
3. Упоминания ключевых слов
Одной из вещей, о которых заботится Google, является «количество раз, когда ваши поисковые запросы появляются [на странице, которую вы пытаетесь ранжировать]».
В общем, рекомендуется попытаться включить точное ключевое слово на страницу несколько раз в нескольких местах, в том числе:
- Название.
- Хотя бы один подзаголовок.
- URL страницы.
- Вводный абзац.
Тем не менее, мы не считаем, что вам нужно беспокоиться об упоминаниях ключевых слов помимо этого. Это происходит потому, что вы, естественно, упоминаете ключевое слово, на которое ориентируетесь, во всем контенте, когда пишете об этом.
Например, в нашей публикации о вечнозеленом контенте слово «вечнозеленый контент» упоминается 18 раз, и мы не приложили для этого никаких усилий.
Вместо этого обратите больше внимания на убедитесь, что ваша страница соответствует цели поиска и отвечает тому, что ищет ищущий. Другими словами, убедитесь, что вы рассказали все, что могут захотеть узнать пользователи.
Другими словами, убедитесь, что вы рассказали все, что могут захотеть узнать пользователи.
Google подчеркивает важность этого на своей странице «Как работает поиск»:
Только подумайте: когда вы ищете «собаки», вы, вероятно, не хотите, чтобы страница содержала слово «собаки» сотни раз. . Имея это в виду, алгоритмы оценивают, содержит ли страница другой релевантный контент помимо ключевого слова «собаки», например изображения собак, видео или даже список пород .
Один из способов сделать это — использовать инструмент Content Gap от Ahrefs для поиска подтем по заданному ключевому слову, которое вы должны упомянуть на своей странице. Подключите свой сайт к Site Explorer, затем нажмите «Пробел в содержании» слева.
Затем перейдите в Google, найдите ключевое слово, на которое вы ориентируетесь на своей странице, и извлеките первые три-пять URL-адресов ранжирования, которые соответствуют цели вашей страницы (например, если ваша страница является записью в блоге, выберите другой блог посты).
Когда у вас есть URL-адреса ваших конкурентов, подключите их к инструменту, как я сделал на скриншоте ниже, затем нажмите «Показать ключевые слова».
Я сделал это для нашего «Что такое ключевые слова?» гид. На снимке экрана ниже результат показывает, что мы потенциально можем улучшить статью, добавив раздел о том, актуальны ли ключевые слова для SEO.
Кроме того, выполняя этот тип исследования пробелов в контенте, вы также можете найти возможности для дополнительных статей, связанных с той, которую вы сейчас оптимизируете. Я нашел такие ключевые слова, как «лучшие методы поисковой оптимизации ключевых слов» и «что такое исследование ключевых слов», для которых мы потенциально можем писать контент.
Если вы хотите узнать больше о том, как оптимизировать страницу для ключевого слова и где разместить ключевое слово, ознакомьтесь с нашим руководством по поисковой оптимизации на странице.
4. Пользовательский опыт
Google заявляет, что его заботит «удобство страницы для пользователей».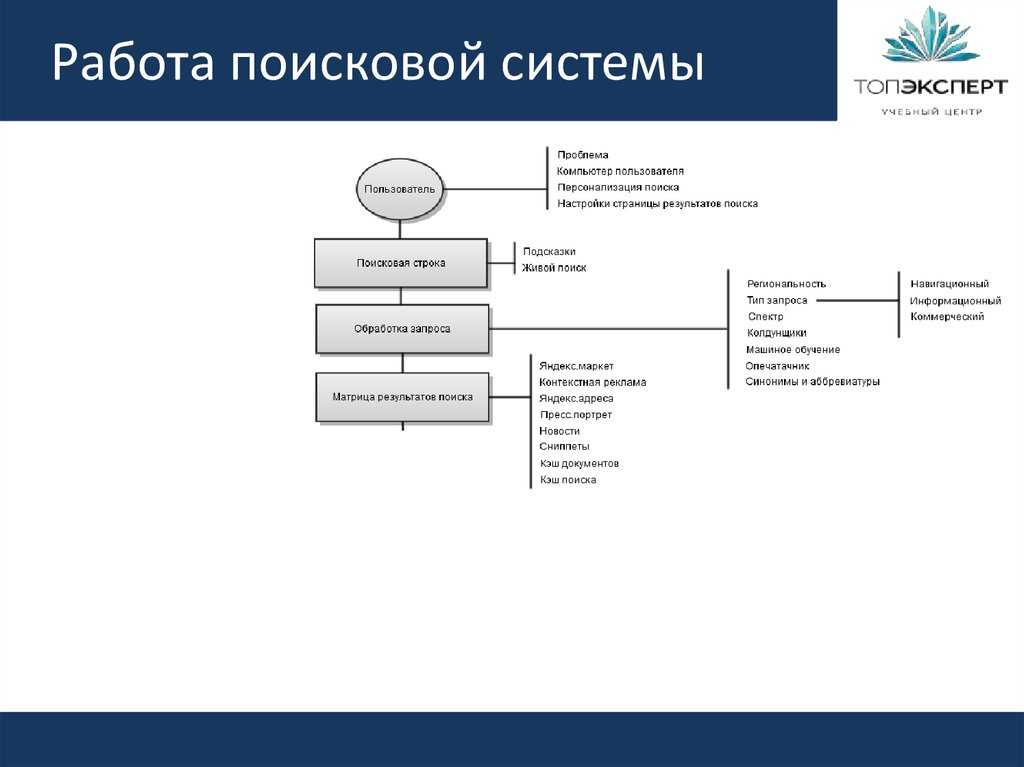 Но что считается «хорошим пользовательским опытом»?
Но что считается «хорошим пользовательским опытом»?
Пользовательский опыт (UX) включает в себя множество различных вещей, в том числе следующие:
- Скорость загрузки страницы (Google рекомендует менее двух секунд)
- Отсутствие навязчивых межстраничных объявлений, таких как реклама или всплывающие окна
- Интуитивно понятная навигация и внутренние ссылки
- Удобство для мобильных устройств
- Дизайн веб-сайта
- Мета-теги (имеющие мета-заголовок и описание, соответствующие поисковому запросу)
- И многое другое
- Лучшее время суток для приема протеина
- Можно ли беременным женщинам протеиновый порошок?
- Откуда берется протеиновый порошок?
- Intrusive Interstitials Update
- Shift to Mobile-First Indexing (Called “Mobilegeddon”)
- RankBrain
- Panda
- Penguin
- Hummingbird
- Pigeon
- Объяснение Google о том, как он ранжирует результаты
- Официальная страница Google в Twitter
- Канал Google Search Central на YouTube оставаться в авангарде того, что Google делает со своим алгоритмом, он также предлагает обычные часы работы под названием Google Search Central. Там такие люди, как Джон Мюллер, старший аналитик тенденций Google для веб-мастеров, ответят на ваши вопросы в прямом эфире.
Заключительные мысли
Алгоритм поиска Google — сложный зверь с множеством движущихся частей, и он постоянно меняется. Но его цель — получить наилучшие результаты для заданного поискового запроса — остается прежней.

Несмотря на множество обновлений Google, основы SEO не сильно изменились с тех пор, как появились поисковые системы. Если вы сосредоточитесь на факторах ранжирования, которые вы узнали из этой статьи, вы сможете занимать высокие позиции в поисковой выдаче.
По существу:
- Создавайте высококачественный, хорошо отформатированный контент, который соответствует цели поиска по вашим ключевым словам.
- Своевременно обновляйте свой контент.
- Убедитесь, что ваш сайт удобен для пользователей.
- Создавайте тематические ссылки.
По словам Google, это то, о чем заботится алгоритм поиска Google.
Готовы погрузиться глубже? Ознакомьтесь с другими статьями в блоге Ahrefs:
- Как повысить рейтинг в Google (6 простых шагов)
- Основы SEO: руководство для начинающих по успешному SEO
- 12 лучших практик SEO, которым должен следовать каждый
Насколько полезен был этот пост?
Количество голосов: 10
Голосов пока нет! Будьте первым, кто оценит этот пост.
Как создать собственный алгоритм ранжирования в поиске с помощью машинного обучения
«Любая достаточно продвинутая технология неотличима от магии». – Артур Кларк (1961)
Эта цитата как нельзя лучше применима к общим поисковым системам и алгоритмам веб-ранжирования.
Подумай об этом.
Вы можете спросить Bing почти о чем угодно, и вы получите 10 лучших результатов из миллиардов веб-страниц в течение нескольких секунд. Если это не магия, то я не знаю что!
Иногда запрос касается малоизвестного хобби. Иногда речь идет о новостном событии, которое вчера никто не мог предсказать.
Иногда даже непонятно, о чем запрос! Все это не имеет значения. Когда пользователи вводят поисковый запрос, они ожидают свои 10 синих ссылок на другой стороне.
Чтобы решить эту сложную проблему масштабируемым и систематическим способом, мы приняли решение в самом начале истории Bing рассматривать веб-ранжирование как проблему машинного обучения.
Еще в 2005 году мы использовали нейронные сети для обеспечения работы нашей поисковой системы, и вы до сих пор можете найти редкие фотографии Сатьи Наделлы, в то время вице-президента по поиску и рекламе, демонстрирующие наши достижения в веб-рейтинге.
В этой статье будет рассмотрена проблема машинного обучения, известная как Learning to Rank. И если вы хотите повеселиться, вы можете выполнить те же шаги, чтобы создать свой собственный алгоритм веб-рейтинга.
Почему машинное обучение?
Стандартное определение машинного обучения выглядит следующим образом:
«Машинное обучение — это наука о том, как заставить компьютеры действовать без явного программирования».
На высоком уровне машинное обучение хорошо выявляет закономерности в данных и делает обобщения на основе (относительно) небольшого набора примеров.
Для веб-рейтинга это означает создание модели, которая будет рассматривать некоторые идеальные результаты поисковой выдачи и определять, какие функции наиболее предсказуемы в отношении релевантности.
Это делает машинное обучение масштабируемым способом создания алгоритма веб-рейтинга. Вам не нужно нанимать экспертов по каждой возможной теме, чтобы тщательно разработать свой алгоритм.
Вместо этого, основываясь на шаблонах, общих для отличного футбольного и бейсбольного сайтов, модель научится определять отличные баскетбольные сайты или даже отличные сайты для спорта, которого еще даже не существует!
Еще одно преимущество рассмотрения веб-рейтинга как проблемы машинного обучения заключается в том, что вы можете использовать десятилетия исследований для систематического решения этой проблемы.
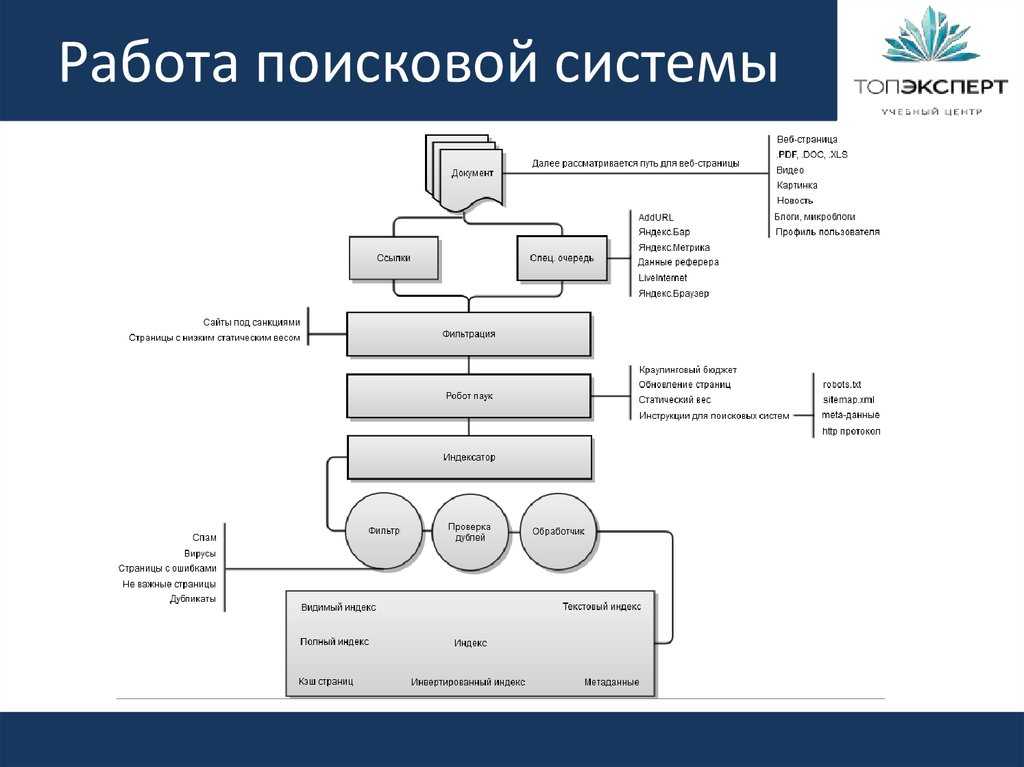
Существует несколько ключевых шагов, практически одинаковых для каждого проекта машинного обучения. На приведенной ниже диаграмме показаны эти шаги в контексте поиска, а в остальной части этой статьи они будут рассмотрены более подробно.
Веб-рейтинг как проблема машинного обучения
1. Определите цель вашего алгоритма
Правильное определение измеримой цели является ключом к успеху любого проекта.
В мире машинного обучения есть поговорка, которая очень хорошо подчеркивает критическую важность определения правильных показателей.«Вы улучшаете только то, что измеряете».
Иногда цель проста: хот-дог или нет?
Даже без каких-либо указаний большинство людей согласятся, увидев различные изображения, независимо от того, изображают они хот-дог или нет.
И ответ на этот вопрос двоичный. Либо это, либо это не хот-дог.
В других случаях все гораздо более субъективно: является ли это идеальной поисковой выдачей для данного запроса?
У каждого будет свое мнение о том, что делает результат релевантным, авторитетным или контекстуальным. Каждый будет расставлять приоритеты и взвешивать эти аспекты по-разному.
Вот где в игру вступают правила рейтинга качества поиска.
В Bing наша идеальная поисковая выдача — это та, которая максимально удовлетворяет пользователей. Команда много думала о том, что это значит и какие результаты нам нужно показать, чтобы сделать наших пользователей счастливыми.
Результат эквивалентен спецификации продукта для нашего алгоритма ранжирования. В этом документе описывается, что является хорошим (или плохим) результатом запроса, и делается попытка устранить субъективность из уравнения.
Дополнительный уровень сложности заключается в том, что качество поиска не является бинарным. Иногда вы получаете идеальные результаты, иногда вы получаете ужасные результаты, но чаще всего вы получаете что-то среднее.
Чтобы уловить эти тонкости, мы просим судей оценить каждый результат по 5-балльной шкале.
Наконец, для запроса и упорядоченного списка рейтинговых результатов вы можете оценить свою поисковую выдачу, используя некоторые классические формулы поиска информации.
Совокупная прибыль со скидкой (DCG) — это каноническая метрика, которая отражает интуицию, заключающуюся в том, что чем выше результат в поисковой выдаче, тем важнее получить его правильно.
2. Соберите некоторые данные
Теперь у нас есть объективное определение качества, шкала для оценки любого данного результата и, соответственно, метрика для оценки любой заданной поисковой выдачи.
Следующим шагом будет сбор данных для обучения нашего алгоритма.Другими словами, мы собираемся собрать набор поисковой выдачи и попросить судей-людей оценить результаты, используя рекомендации.
Мы хотим, чтобы этот набор поисковой выдачи отражал то, что ищет наша широкая пользовательская база. Простой способ сделать это — попробовать некоторые из запросов, которые мы видели в прошлом в Bing.
При этом мы должны убедиться, что в наборе нет нежелательного смещения.
Например, может случиться так, что пользователей Bing на Восточном побережье непропорционально больше, чем в других частях США.
предвзятость, которая будет отражена в алгоритме ранжирования.
Когда у нас есть хороший список поисковой выдачи (как запросов, так и URL-адресов), мы отправляем этот список судьям-людям, которые оценивают их в соответствии с рекомендациями.
После этого у нас есть список пар запрос/URL вместе с их оценкой качества. Этот набор делится на «тренировочный набор» и «тестовый набор», которые соответственно используются для:
- Обучения алгоритма машинного обучения.
- Оцените, насколько хорошо он работает с запросами, с которыми он раньше не сталкивался (но для которых у нас есть оценка качества, позволяющая измерить производительность алгоритма).
Набор для обучения и тестирования помеченных пар «запрос/URL»
3. Определите функции модели
Рейтинги качества поиска основаны на том, что люди видят на странице.
Компьютеры имеют совершенно другое представление этих веб-документов, которое основано на сканировании и индексировании, а также на значительной предварительной обработке.
Это потому, что машины рассуждают с числами, а не непосредственно с текстом, содержащимся на странице (хотя это, конечно, критический ввод).
Следующим шагом построения вашего алгоритма является преобразование документов в «функции».
В этом контексте функция — это определяющая характеристика документа, которую можно использовать для прогнозирования того, насколько он будет релевантным для данного запроса.
Вот несколько примеров.
- Простым признаком может быть количество слов в документе.
- Чуть более продвинутой функцией может быть обнаруженный язык документа (каждый язык представлен другим номером).
- Еще более сложной функцией может быть оценка документа на основе графа ссылок. Очевидно, что это потребует большого объема предварительной обработки!
- У вас могут быть даже синтетические функции, такие как квадрат длины документа, умноженный на логарифм количества исходящих ссылок. Небо это предел!
Подготовка веб-данных для машинного обучения
Было бы заманчиво смешать все сразу, но слишком большое количество функций может значительно увеличить время, необходимое для обучения модели, и повлиять на ее окончательную производительность.
В зависимости от сложности данной функции надежное предварительное вычисление может быть дорогостоящим.
Некоторые функции неизбежно будут иметь незначительный вес в окончательной модели в том смысле, что они так или иначе не помогают прогнозировать качество.
Некоторые функции могут даже иметь отрицательный вес, что означает, что они в какой-то мере предсказывают нерелевантность!
Кстати, запросы также будут иметь свои особенности. Поскольку мы пытаемся оценить качество результатов поиска по заданному запросу, важно, чтобы наш алгоритм учится на обоих.
4. Тренируйте свой алгоритм ранжирования
Здесь все сводится воедино. Каждый документ в указателе представлен сотнями функций. У нас есть набор запросов и URL-адресов, а также их оценки качества.
Целью алгоритма ранжирования является максимизация рейтинга этих поисковой выдачи с использованием только функций документа (и запроса).
Интуитивно мы можем захотеть построить модель, которая предсказывает рейтинг каждой пары запрос/URL, также известную как «точечный» подход. Оказывается, это сложная проблема, и это не совсем то, что нам нужно.
Нас не особенно волнует точный рейтинг каждого отдельного результата. Что нас действительно волнует, так это то, что результаты правильно упорядочены в порядке убывания рейтинга.
Достойным показателем, который фиксирует это понятие правильного порядка, является количество инверсий в вашем рейтинге, количество раз, когда результат с более низким рейтингом появляется над результатом с более высоким рейтингом. Подход известен как «парный», и мы также называем эти инверсии «парными ошибками».
Пример парной ошибки
Не все парные ошибки одинаковы. Поскольку мы используем DCG в качестве оценочной функции, очень важно, чтобы алгоритм выдавал правильные результаты.
Таким образом, парная ошибка в позициях 1 и 2 намного серьезнее, чем ошибка в позициях 9 и 10, при прочих равных условиях. Наш алгоритм должен учитывать этот потенциальный выигрыш (или убыток) в DCG для каждой из пар результатов.
Процесс «обучения» модели машинного обучения, как правило, итеративный (и полностью автоматизированный). На каждом шаге модель настраивает вес каждого признака в том направлении, в котором ожидается максимальное уменьшение ошибки.
После каждого шага алгоритм повторно измеряет рейтинг всех результатов поисковой выдачи (на основе известных рейтингов пары URL/запрос), чтобы оценить, как он работает. Промыть и повторить.
В зависимости от того, сколько данных вы используете для обучения модели, для достижения удовлетворительного результата могут потребоваться часы, а может и дни. Но в конечном итоге модели потребуется меньше секунды, чтобы вернуть 10 синих ссылок, которые, по ее прогнозам, являются лучшими.
Конкретный алгоритм, который мы используем в Bing, называется LambdaMART, это усиленный ансамбль деревьев решений. Это преемник RankNet, первой нейронной сети, используемой общей поисковой системой для ранжирования результатов.
5. Оцените, насколько хорошо вы справились.
Теперь у нас есть алгоритм ранжирования, готовый к испытаниям. Помните, что мы сохранили некоторые помеченные данные, которые не использовались для обучения модели машинного обучения.
Первое, что мы собираемся сделать, это измерить производительность нашего алгоритма на этом «тестовом наборе».
Если мы хорошо поработали, производительность нашего алгоритма на тестовом наборе должна быть сравнима с его производительностью на обучающем наборе. Иногда это не так. Основной риск заключается в том, что мы называем «переоснащением», что означает, что мы чрезмерно оптимизировали нашу модель для поисковой выдачи в обучающем наборе.
Давайте представим карикатурный сценарий, в котором алгоритм жестко запрограммирует лучшие результаты для каждого запроса. Тогда он будет отлично работать на тренировочном наборе, для которого он знает, каковы наилучшие результаты.
С другой стороны, на тестовом наборе, для которого у него нет такой информации, он бы провалился.
А вот и поворот…
Даже если наш алгоритм работает очень хорошо при измерении DCG, этого недостаточно.
Помните, что наша цель — максимальное удовлетворение пользователей. Все началось с руководств, которые фиксируют то, что мы думает, что удовлетворяет пользователей.
4
4
4
4
4 , в частности, стал более важным для Google за последние несколько лет. Летом 2021 года Google выпустил крупное обновление. Из-за этого сейчас важнее пройти тест Google Core Web Vitals (CWV), который по сути является тестом скорости.
Вы можете проверить свой CWV и узнать, как повысить производительность вашего сайта, подключив свой сайт к аудиту сайта Ahrefs и нажав на вкладку «Отчет о производительности». Вам нужно включить сканирование CWV в настройках. (Вы увидите уведомление об этом в верхней части отчета, как показано ниже.)
Вам нужно включить сканирование CWV в настройках. (Вы увидите уведомление об этом в верхней части отчета, как показано ниже.)
После того, как вы разрешили CWV с помощью Google API, запустите новое сканирование своего сайта. Когда это будет сделано, вы получите отчет, показывающий страницы, которые нуждаются в улучшении, и страницы с ошибками.
Чтобы просмотреть эти страницы, щелкните число рядом с «Требуется улучшение» или «Плохо». Он покажет вам, какие страницы не проходят оценку Lighthouse Score или производительность CrUX. (Это показатели скорости страницы, которые являются частью отчета CWV.)
Если вы хотите узнать больше о том, как оптимизировать свой сайт для удобства пользователей, следуйте нашему руководству по аудиту веб-сайта.
5. Тематический авторитет
Google хочет отображать «сайты, которые многие пользователи оценивают по схожим запросам». Это означает сайты, которые имеют дополнительные, value контент о запросах, релевантных искомому.
Хотя Google не уточняет, что подразумевается под «пользователями, кажется, ценят», мы можем с уверенностью предположить, что тематические обратные ссылки являются его частью. Таким образом, помимо создания большого количества связанного контента, вам также необходимо получать ссылки с тематических сайтов.
Например, если вы хотите занять место в рейтинге «лучший протеиновый порошок», Google может с большей вероятностью ранжировать вас, если люди также заходят на ваш сайт за контентом по следующим темам:
Помимо контента по этим темам, вы также должны стремиться получить актуальные обратные ссылки на них.
Наличие большого количества связанного контента и контекстно релевантных ссылок может показать Google (и его пользователям), что вы являетесь авторитетом в этой теме, и может помочь вам занять более высокое место в результатах поиска.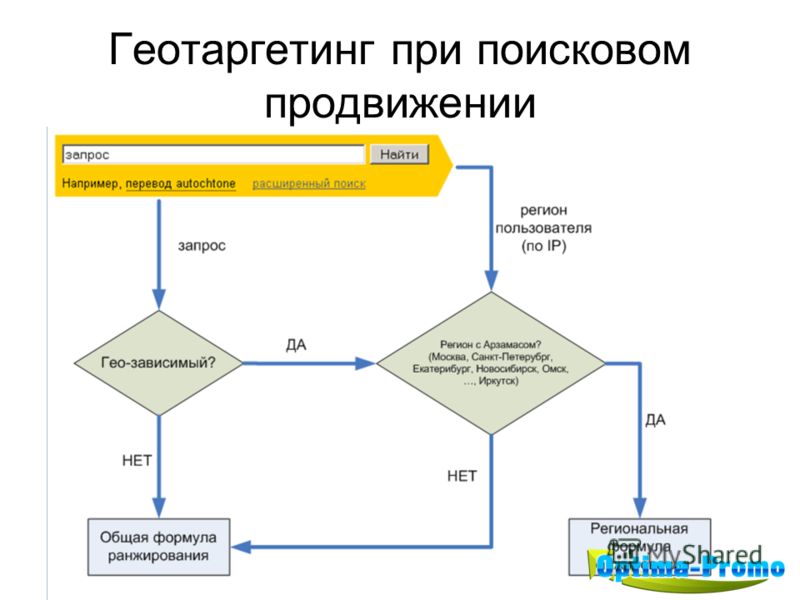 Конечно, мы предполагаем, что вы также оптимизируете другие факторы ранжирования.
Конечно, мы предполагаем, что вы также оптимизируете другие факторы ранжирования.
Готовы исключить этот фактор ранжирования из своего списка? Начните создавать центры контента для SEO.
Заметка об обновлениях алгоритма Google
Google обновляет свой алгоритм почти каждый день и выпускает крупные обновления два-три раза в год, которые могут оказать довольно сильное влияние на рейтинг.
Другими словами, все меняется. Важно быть в курсе факторов ранжирования Google, чтобы не отставать в поисковой выдаче из-за штрафа Google или изменения цели поиска.
Some of the major Google updates include these:
Of конечно, это не обширный список. Более полный список обновлений алгоритма Google и других распространенных терминов SEO см. в нашем глоссарии SEO.
в нашем глоссарии SEO.
Где найти официальные обновления Google
У Google есть несколько каналов, которые публикуют общедоступные обновления об изменениях в своем алгоритме, и у него есть масса официальной общедоступной документации о том, как работает его алгоритм.
Вот несколько отличных источников, чтобы быть в курсе того, что Google делает:


 В мире машинного обучения есть поговорка, которая очень хорошо подчеркивает критическую важность определения правильных показателей.
В мире машинного обучения есть поговорка, которая очень хорошо подчеркивает критическую важность определения правильных показателей.
 Следующим шагом будет сбор данных для обучения нашего алгоритма.
Следующим шагом будет сбор данных для обучения нашего алгоритма.